
FLOSS Project Planets
Lullabot: Drupal 11: What’s New and What’s Next
Drupal 11 was released on August 2nd, 2024. A lot has changed since Drupal 10, and a lot of preliminary work has been done that will help with Drupal Starshot. Besides improvements made to CKEditor integration, a revamp of the Field UI, performance improvements, and revisions for taxonomy terms, several big changes have been included to help the ambitious site builder.
Tag1 Consulting: Migrating Your Data from D7 to D10: Migrating taxonomy vocabularies and D7 field collections into D10 paragraphs
In the previous article, we began migrating configuration from Drupal 7 example site to our Drupal 10 instance, specifically content types. In today's article, we will continue with two more D7 entities: taxonomy vocabularies and field collections. The latter will be imported as Paragraphs in Drupal 10. Along the way, we will review the content model and the migration plan. This will help us determine what parts of the migration should be automated and what can be performed manually.
Read more mauricio Wed, 08/07/2024 - 06:50Python Software Foundation: Security Developer-in-Residence role extended thanks to Alpha-Omega
We are excited to announce the continuation of Seth Larson’s work in the Security Developer-in-Residence role through the end of 2024 thanks to continued support from Alpha-Omega. (This six month extension is intended to align the renewal period for this role with the calendar year going forward).
The first year of the Security Developer-in-Residence initiative has been a success, seeing multiple improvements to the Python ecosystem's security posture. These improvements include authorizing the PSF as a CVE Numbering Authority, migrating the CPython release process to an isolated hosted build platform, and generating comprehensive Software Bill-of-Materials documents for CPython artifacts.
Open source software security continues to evolve, this year saw new regulations for software security like the EU Cyber Resiliency Act (CRA) and evolving threats to open source like the backdoor of xz-utils.
The PSF is looking forward to continuing our investment in the security of the Python ecosystem and everyone who depends on Python software. For the remainder of 2024, priorities for Security Developer-in-Residence role include:
- Formalization of the Python Security Response Team (PSRT) and processes for handling vulnerability reports and fixes.
- Developing a strategy for Software Bill-of-Materials documents and Python packages.
- Completing the migration of the CPython release process and generation of SBOM documents for the macOS installer.
- Continued engagement with the Python community promoting security best-practices and standards.
For updates on these and other projects, check out Seth’s blog.
The PSF is a non-profit whose mission is to promote, protect, and advance the Python programming language, and to support and facilitate the growth of a diverse and international community of Python programmers. The PSF supports the Python community using corporate sponsorships, grants, and donations. Are you interested in sponsoring or donating to the PSF so it can continue supporting Python and its community? Check out our sponsorship program, donate directly here, or contact our team!
Drupal life hack's: Extended Review of Backward Compatibility Questions When Upgrading to Drupal 11
Drupal Starshot blog: Introducing Drupal Starshot's product strategy
This blog has been re-posted and edited with permission from Dries Buytaert's blog.
Drupal Starshot aims to attract mid-market marketers by offering out-of-the-box marketing best practices, user-friendly tools, AI-driven site building features, all while maintaining the many advantages of Drupal Core.
I'm excited to share the first version of Drupal Starshot's product strategy, a document that aims to guide the development and marketing of Drupal Starshot. To read it, download the full Drupal Starshot strategy document as a PDF (8 MB).
This strategy document is the result of a collaborative effort among the Drupal Starshot leadership team, the Drupal Starshot Advisory Council, and the Drupal Core Committers. We also tested it with marketers who provided feedback and validation.
Drupal Starshot and Drupal CoreDrupal Starshot is the temporary name for an initiative that extends the capabilities of Drupal Core. Drupal Starshot aims to broaden Drupal's appeal to marketers and a wider range of project budgets. Our ultimate goal is to increase Drupal's adoption, solidify Drupal's position as a leading CMS, and champion an Open Web.
For more context, please watch my DrupalCon Portland keynote.
It's important to note that Drupal Starshot and Drupal Core will have separate, yet complementary, product strategies. Drupal Starshot will focus on empowering marketers and expanding Drupal's presence in the mid-market, while Drupal Core will prioritize the needs of developers and more technical users. I'll write more about the Drupal Core product strategy in a future blog post once we have finalized it. Together, these two strategies will form a comprehensive vision for Drupal as a product.
Why a product strategy?By defining our goals, target audience and necessary features, we can more effectively guide contributors and ensure that everyone is working towards a common vision. This product strategy will serve as a foundation for our development roadmap, our marketing efforts, enabling Drupal Certified Partners, and more.
Drupal Starshot product strategy TL;DRFor the detailed product strategy, please read the full Drupal Starshot strategy document (8 MB, PDF). Below is a summary.
Drupal Starshot aims to be the gold standard for marketers that want to build great digital experiences.
We'd like to expand Drupal's reach by focusing on two strategic shifts:
- Prioritizing Drupal for content creators, marketers, web managers, and web designers so they can independently build websites. A key goal is to empower these marketing professionals to build and manage their websites independently without relying on developers or having to use the command line or an IDE.
- Extending Drupal's presence in the mid-market segment, targeting projects with total budgets between $30,000 and $120,000 USD (€25,000 to €100,000).
Drupal Starshot will differentiate itself from competitors by providing:
- A thoughtfully designed platform for marketers, balancing ease of use with flexibility. It includes smart defaults, best practices for common marketing tasks, marketing-focused editorial tools, and helpful learning resources.
- A growth-oriented approach. Start simple with Drupal Starshot's user-friendly tools, and unlock advanced features as your site grows or you gain expertise. With sophisticated content modeling, efficient content reuse across channels, and robust integrations with other leading marketing technologies, ambitious marketers won't face the limitations of other CMSs and will have the flexibility to scale their site as needed.
- AI-assisted site building tools to simplify complex tasks, making Drupal accessible to a wider range of users.
- Drupal's existing competitive advantages such as extensibility, scalability, security, accessibility, multilingual support, and more.
In the past, we used the term ambitious site builders to describe Drupal's target audience. Although this term doesn't appear in the product strategy document, it remains relevant.
While the strategy document is publicly available, it is primarily an internal guide. It outlines our plans but doesn't dictate our marketing language. Our product strategy's language purposly aligns with terms used by our target users, based on persona research and interviews.
To me, "ambitious site builders" includes all Drupal users, from those working with Drupal Core (more technically skilled) to those working with Drupal Starshot (less technical). Both groups are ambitious, with Drupal Starshot specifically targeting "ambitious marketers" or "ambitious no-code developers".
Give feedbackThe product strategy is a living document, and we value input. We invite you to share your thoughts, suggestions, and questions in the product strategy feedback issue within the Drupal Starshot issue queue.
Get involvedThere are many opportunities to get involved with Drupal Starshot, whether you're a marketer, developer, designer, writer, project manager, or simply passionate about the future of Drupal. To learn more about how you can contribute to Drupal Starshot, visit https://drupal.org/starshot.
Thank youI'd like to thank the Drupal Starshot leadership team, the Drupal Starshot Advisory Council, and the Drupal Core Committers for their input on the strategy. I'm also grateful for the marketers who provided feedback on our strategy, helping us refine our approach.
File attachments: starshot-strategy-1920w.jpg{kind=link}
Django Weblog: Django 5.1 released
The Django team is happy to announce the release of Django 5.1.
The release notes showcase a kaleidoscope of improvements. A few highlights are:
- Easier guardrails for authentication: the new and shiny LoginRequiredMiddleware, when added to MIDDLEWARE, enforces authentication for all views by default.
- A more inclusive framework: Django 5.1 includes several accessibility enhancements, such as improved screen reader support in the admin interface, more semantic HTML elements, and better association of help text and labels with form fieldsets.
- The second oldest ticket fixed in this release provides the long awaited querystring template tag, which greatly simplifies the handling of query strings when building URLs in templates.
(If you are curious about the oldest ticket fixed in this release, check out Ticket #10743.)
You can get Django 5.1 from our downloads page or from the Python Package Index. The PGP key ID used for this release is Natalia Bidart: 2EE82A8D9470983E.
With the release of Django 5.1, Django 5.0 has reached the end of mainstream support. The final minor bug fix release, 5.0.8, was issued yesterday. Django 5.0 will receive security and data loss fixes until April 2025. All users are encouraged to upgrade before then to continue receiving fixes for security issues.
See the downloads page for a table of supported versions and the future release schedule.
Jamie McClelland: Who ate my RAM?
One of our newest servers, with a hefty 256GB of RAM, recently began killing processes via the oomkiller.
According to free, only half of the RAM was in use (125GB). About 4GB was free, with the remainer used by the file cache.
I’m used to seeing unexpected “free RAM” numbers like this and have been assured that the kernel is simply not wasting RAM. If it’s not needed, use it to cache files to save on disk I/O. That make sense.
However… why is the oomkiller being called instead of flushing the file cache?
I came up with all kinds of amazing and wrong theories: maybe the RAM is fragmented (is that even a thing?!?), maybe there is a spike in RAM and the kernel can’t flush the cache quickly enough (I really don’t think that’s a thing). Maybe our kvm-manager has a weird bug (nope, but that didn’t stop me from opening a spurious bug report).
I learned lots of cool things, like the oomkiller report includes a table of the memory in use by each process (via the rss column) - and you have to muliply that number by 4096 because it’s in 4K pages.
That’s how I discovered that the oomkiller was killing off processes with only half the memory in use.
I also learned that lsof sometimes lists the same open file multiple times, which made me think a bunch of files were being opened repeatedly causing a memory problem, but really it amounted to nothing.
That last thing I learned, courtesy of an askubuntu post is that the /dev filesystem is allocated by default exactly half the RAM on the system. What a coincidence! That is exactly how much RAM is useable on the server.
And, on the server in question, that filesystem is full. What?!? Normally, that filesystem should be using 0 bytes because it’s not a real filesystem. But in our case a process created a 127GB file there - it was only stopped because the file system filled up.
Real Python: Quiz: Asynchronous Iterators and Iterables in Python
Test your understanding of how to create and use Python async iterators and iterables in the context of asynchronous code.
You can take this quiz after reading the Asynchronous Iterators and Iterables in Python tutorial.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Qt Creator 14.0.1 released
We are happy to announce the release of Qt Creator 14.0.1!
mark.ie: Sponsorship slot available for Drupal contribution credits
I have a small window of time available if you'd like to get credits for sponsoring Drupal contributions.
roose.digital: Let your Drupal website perform actions without the need for programming
Python Insider: Python 3.12.5 released
I'm pleased to announce the release of Python 3.12.5:
https://www.python.org/downloads/release/python-3125/
Python 3.12 is the newest major release of the Python programming language, and it contains many new features and optimizations. 3.12.5 is the latest maintenance release, containing more than 250 bugfixes, build improvements and documentation changes since 3.12.4.
This version of Python 3.12 also comes with pip 24.2 by default. However, due to an incompatibility with older macOS versions, macOS 10.9 through 10.12 will downgrade their version of pip to 24.1.2 during the installation process (in the Install Certificates step). See the installer ReadMe and the pip issue on the matter for more information. Versions of macOS older than 10.13 haven’t been supported by Apple since 2019, and maintaining support for them is becoming increasingly difficult. While this release of 3.12 still supports them, it is likely that we will be forced to drop support for macOS 10.12 and older in a future 3.12 release. (Python 3.13 has already dropped support for them.)
Major new features of the 3.12 series, compared to 3.11 New features
- More flexible f-string parsing, allowing many things previously disallowed (PEP 701).
- Support for the buffer protocol in Python code (PEP 688).
- A new debugging/profiling API (PEP 669).
- Support for isolated subinterpreters with separate Global Interpreter Locks (PEP 684).
- Even more improved error messages. More exceptions potentially caused by typos now make suggestions to the user.
- Support for the Linux perf profiler to report Python function names in traces.
- Many large and small performance improvements (like PEP 709 and support for the BOLT binary optimizer), delivering an estimated 5% overall performance improvement.
- New type annotation syntax for generic classes (PEP 695).
- New override decorator for methods (PEP 698).
- The deprecated wstr and wstr_length members of the C implementation of unicode objects were removed, per PEP 623.
- In the unittest module, a number of long deprecated methods and classes were removed. (They had been deprecated since Python 3.1 or 3.2).
- The deprecated smtpd and distutils modules have been removed (see PEP 594 and PEP 632. The setuptools package continues to provide the distutils module.
- A number of other old, broken and deprecated functions, classes and methods have been removed.
- Invalid backslash escape sequences in strings now warn with SyntaxWarning instead of DeprecationWarning, making them more visible. (They will become syntax errors in the future.)
- The internal representation of integers has changed in preparation for performance enhancements. (This should not affect most users as it is an internal detail, but it may cause problems for Cython-generated code.)
For more details on the changes to Python 3.12, see What’s new in Python 3.12.
More resources- Online Documentation.
- PEP 693, the Python 3.12 Release Schedule.
- Report bugs via GitHub Issues.
- Help fund Python directly or via GitHub Sponsors, and support the Python community.
Thanks to all of the many volunteers who help make Python Development and these releases possible! Please consider supporting our efforts by volunteering yourself or through organization contributions to the Python Software Foundation.
Your release team,
Thomas Wouters
Łukasz Langa
Ned Deily
Steve Dower
Drupal.org blog: The Bounty program: Starshot edition
With all the news and activities happening around Starshot, you may have missed this, but the Drupal Association has launched the Starshot Contribution Credits. This consists of credits granted to a series contributions, in particular:
-
contributions to any modules, themes, etc that are designated as part of Starshot,
-
50 credits per week for each FTE (full time employee) equivalent dedicated to starshot,
-
1 credit per $100 invested for financial contributions and finally,
-
Special credit bounties for individual issues of exceptional importance.
You can read more about the contribution bonuses https://www.drupal.org/about/starshot/contribution-credit
The last point, special credit bounties, opens the door to a contribution coming from the Bounty Program.
What are we trying to do?Given the success of the previous phase, we thought it was the moment to announce a few new issues that would carry extra credits, supporting the Starshot initiative. These issues are targeted at improvements to Drupal core that would reduce the number of contrib modules required in Starshot.
These are the issues that the period involved have identified:
-
Improve the linking experience in CKEditor 5. Why? Because this integration provides a critical site feature and improves the editorial experience in a significant way.
-
Fixed maximum number of field values, but use «add more» similar to when cardinality «unlimited» is used. This is a great UX improvement for Drupal that makes forms much more usable where fields have a set cardinality.
-
Views handler loading should respect configuration. Fixing this bug will enable more flexible configuration of Views.
-
Configurable views filters to allow for different widgets. Once the bug above is fixed, we can provide a UI for selecting the views handler, supporting more robust filtering options.
And, as in the previous edition, the reward will be 50 credits for contributing to resolving these issues (5x the standard credit amount). Sounds good?
While these issues are not good candidates for a user or organization's first time contribution, they are a great opportunity for more senior contributors to have an impact.
Special thanks to: Tim Lehnen, Pamela Barone, Gábor Hojtsy, Nathaniel Catchpole and everyone that I am missing in and out of the core team for their help and support in identifying candidate issues for these bounties.
The Bounty program started as a proof of concept to validate that we can help align the goals of the Drupal Association and Drupal itself, with the goals of individuals, companies, and the rest of the community, and hence, accelerate Drupal Innovation.
You may remember that this started during my tenure with the Drupal Association, and although my contract and direct involvement reached to an end at the beginning of the year, I committed myself, even before I left, to continuing the work I started with the Drupal Association, but especially with Drupal as a project, and the community. That’s why I’m still committed to helping run and coordinating this and other innovation programs, and that’s why I’m running as well for the Board of Directors (more on this soon).
Thomas Lange: Download Debian
It's just a very tiny difference, but hopefully a big step forward for our users. Our main download web page (which still uses the URL https://www.debian.org/distrib/) now has the title "Download Debian". Hopefully this will improve the results in the search engines.
A brief history of this web page in time- 1998: The title "Distribution" was added
- 2002: Title changed to "Getting Debian"
- 2024: Finally changed to "Download Debian"
Here are the screenshots of these three versions.
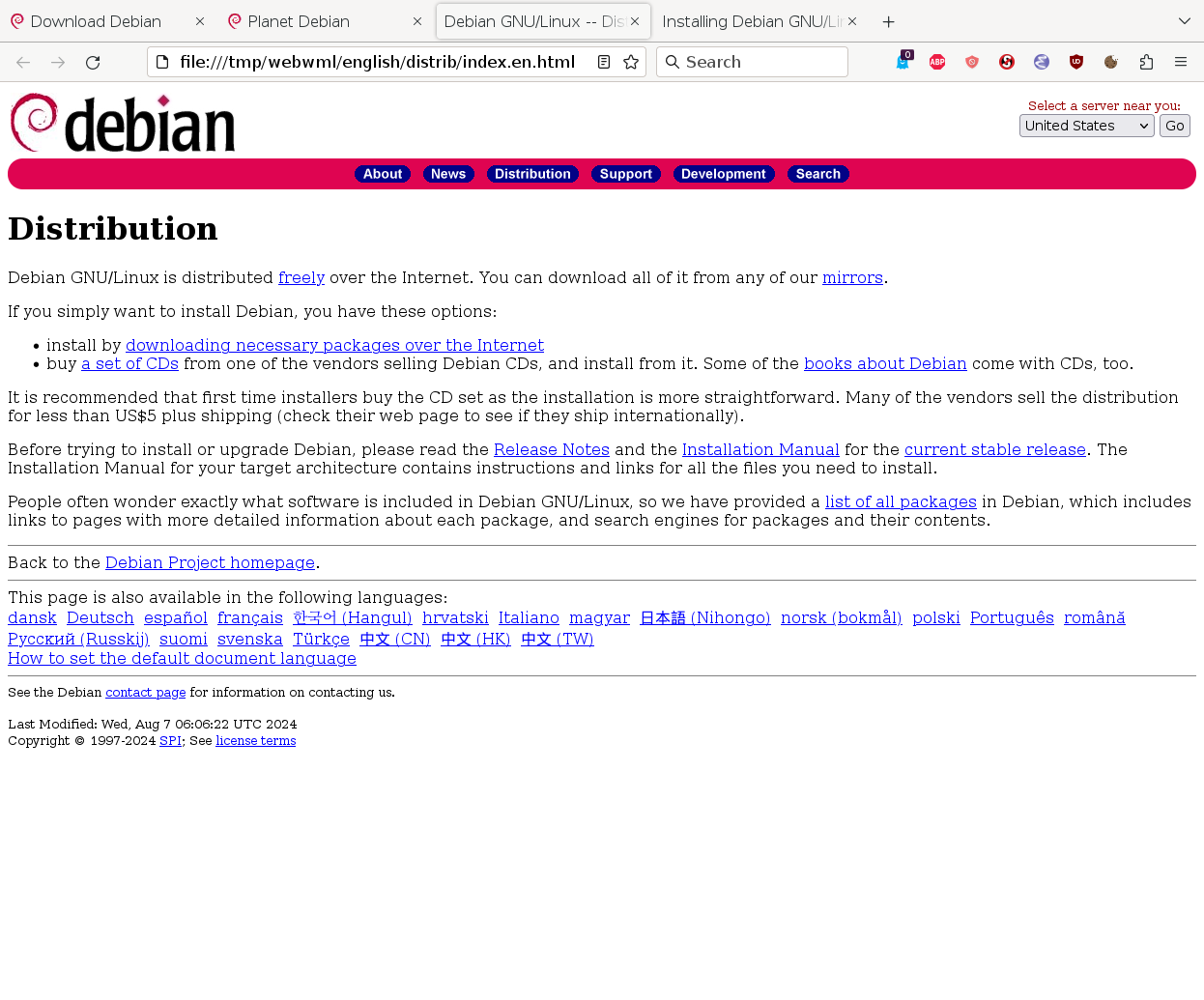{kind=link}
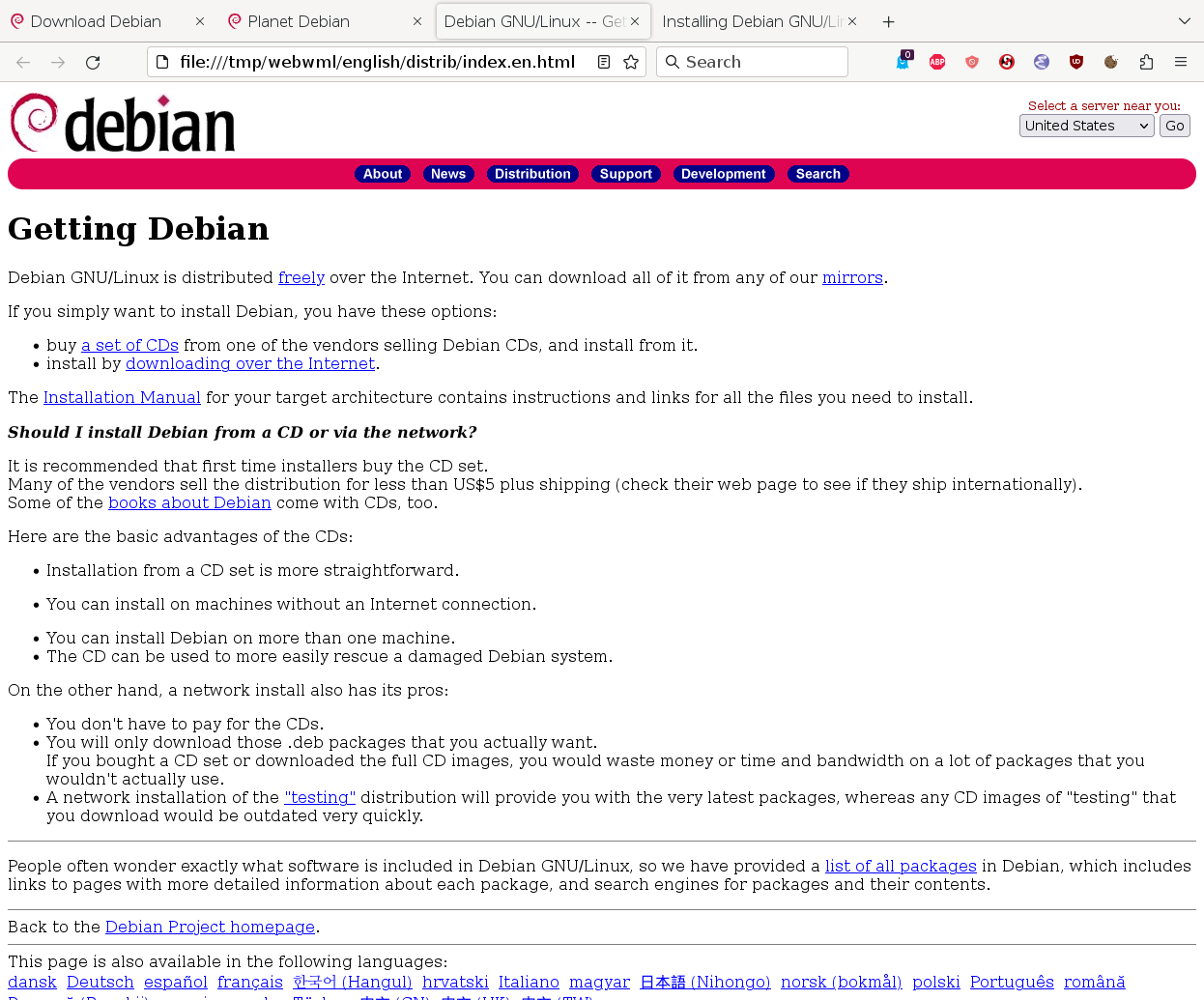{kind=link}
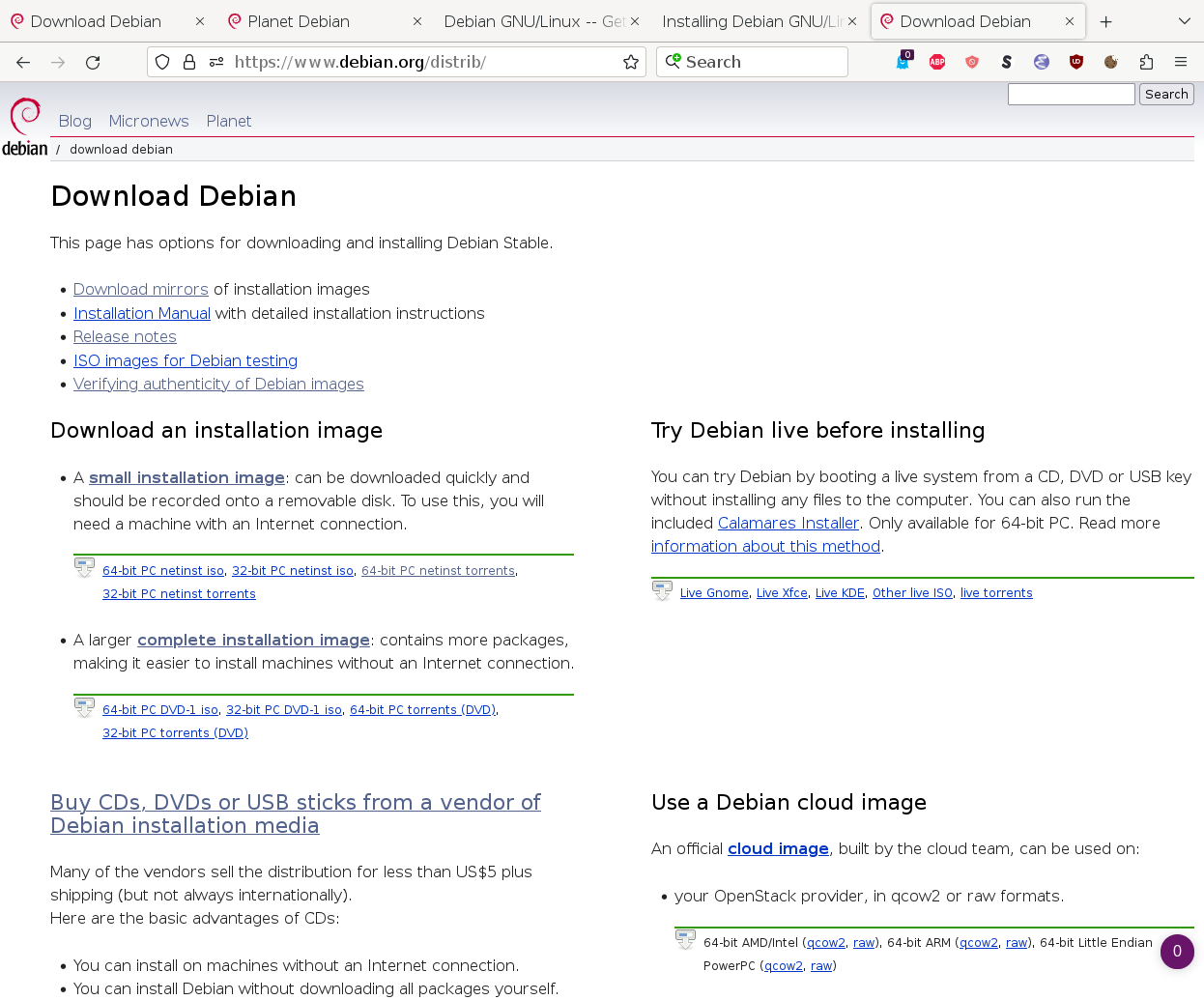{kind=link}
I like that we had a selection menu on the top right corner to select a mirror for downloading in the past.
A few days ago I've also removed the info "Internal ISDN cards are unfortunately not supported." from the netinst subpage. Things are moving forward, but slowly.
Sahil Dhiman: Banks With Own ASN in India
Most banks are behind CDNs and DDoS mitigation providers nowadays, though they still hold their own IP space. Was interested in this, so compiled a list from BGP.Tools and Hurricane Electric BGP Toolkit.
- AS24055 Deutsche Bank AG-India Internet AS
- AS38468 ASN for Yes Bank
- AS45644 SBI-EMS-NET-IN
- AS59194 Central Bank of India
- AS17436 ICICIBANK Ltd, Banking, Mumbai
- AS131283 HDFC Bank House
- AS132440 Unity Small Finance Bank Pvt. Ltd.
- AS132946 Ujjivan Small Finance Bank Ltd
- AS132989 Sangli Urban Co-operative Bank Ltd
- AS133640 Indian Overseas Bank
- AS133657 IndusInd Bank Ltd
- AS134909 The South Indian Bank Ltd
- AS135086 Axis Bank Limited
- AS135745 UCO Bank
- AS135819 Chaitanya Godavari Grameena Bank
- AS136252 The Bank of Baroda Limited
- AS136324 IDBI Bank Ltd
- AS136622 Equitas Small Finance Bank Ltd
- AS136707 The Kalupur Commercial Co-operative Bank Limited
- AS136680 Bank of Maharashtra
- AS137104 India Post Payments Bank Limited
- AS137108 Bank of India
- AS137130 Punjab National Bank
- AS137662 IDFC Bank Ltd
- AS137670 Canara Bank
- AS138318 The Visakhapatnam Cooperative Bank Ltd
- AS140156 Karnataka Gramin Bank
- AS141222 Telangana State Coorperative Apex Bank Ltd
- AS141561 Punjab and Sind Bank
- AS146870 TJSB Sahakari Bank Ltd
- AS149202 The Jammu And Kashmir Bank Pvt Ltd
- AS149528 Indian Bank
- AS149603 Suryoday Small Finance Bank Limited
- AS150029 The Karnataka Bank Ltd
- AS151172 CSB Bank Ltd
- AS151692 Small Industries Development Bank of India
Other noteable mentions:
- AS141857 National Bank for Agriculture and Rural Development
- AS151773 Reserve Bank Information Technology Pvt Ltd
Let me know if I’m missing someone. Many thanks to Saswata Sarkar for helping with the list.
Drupal.org blog: Updated window for Drupal.org login flow deployment
The Drupal Association engineering team is preparing to switch over to our new single sign-on solution for user login. This is an important step in our work to upgrade Drupal.org, and in the future will give you the ability to use your Drupal.org identity in new ways.
This switchover was previously scheduled for Thursday, 25 July, but unfortunately we had to roll-back that attempt. After pausing for a week to avoid disrupting the Drupal 11 release window, we are ready to try again.
The switch-over is scheduled for:
-
Thursday 8 August - from 9am to 1pm Pacific (16:00-20:00 UTC).
During this window you will not be able to update your Drupal.org profile, and during portions of this window you may not be able to login to Drupal.org, and may not be able to access related services which use your Drupal identity, such as git.drupalcode.org.
Below you'll find the details from our original blog post about how the login experience will look different:
If you are an existing userWhen you click to login or create an account you will be redirected to: accounts.drupal.org
You will log in with your existing Drupal.org username or email and your current password, and your two factor authentication code if you have TFA enabled.
Once you log in, you will have to change your password.
If you have Two Factor Authentication enabled, you will also have to set up a new seed.
After that, you'll be taken back to Drupal.org as normal. You should be directed back to the path you came from.
If you are creating a new accountWhen you click 'create account' on Drupal.org you will be taken to the new account creation page:
After you complete the basic information, you will be taken to the Drupal.org welcome page to fill out the rest of your user profile.
If you need to change your account informationThe majority of your account information will continue to live in your Drupal.org profile, however, some basic account information will now be stored and updated in the Drupal.org SSO system.
When you click to edit your first and last name, username, password, email address, or enable two factor authentication you'll be taken to the account page:
Setting up Two Factor AuthenticationThis account settings page is also where you can change your Two Factor Authentication settings. You can use the 'Account Security' tab in the sidebar to navigate to the Two Factor setup process:
If you need to reset your passwordIf you have forgotten your password, you can reset your password from the login page:
You will receive a password reset email from noreply@drupal.org allowing you to change your password.
If you encounter any issues with your account, please contact us at help@drupal.org
We want to thank two of our partners for supporting this project.
Cloud-IAM is our SSO partner. Cloud-IAM is a privacy centric provider of hosted solutions for Keycloak, an open source identity management service. They are enthusiastic supporters of the Drupal community, and would like to offer any site owners and agencies who are looking for their own identity and access management service 10% off, with promo code: DRUPAL10.
Our implementation partner on this project was Tag1Consulting. Tag1Consulting is a global team of Drupal experts working with clients from non-profits to the Fortune 500, and is one of the top contributors to Drupal. They have been the Drupal Association's infrastructure partner for many years.
Matt Layman: An Opinionated Introduction to CI/CD
ImageX: Exploring the Drupal 11 Release: New Features and Major Enhancements
Authored by Nadiia Nykolaichuk.
Drupal 11.0.0 has been successfully released as a new major Drupal version which is very exciting news for everyone using Drupal or thinking about making the switch! This flexible, accessible, powerful, integration-ready, and secure CMS has transformed even more on the way from Drupal 10 to Drupal 11.
Dries Buytaert: Introducing Drupal Starshot's product strategy
I'm excited to share the first version of Drupal Starshot's product strategy, a document that aims to guide the development and marketing of Drupal Starshot. To read it, download the full Drupal Starshot strategy document as a PDF (8 MB).
This strategy document is the result of a collaborative effort among the Drupal Starshot leadership team, the Drupal Starshot Advisory Council, and the Drupal Core Committers. We also tested it with marketers who provided feedback and validation.
Drupal Starshot and Drupal CoreDrupal Starshot is the temporary codename for an initiative that extends the capabilities of Drupal Core. Drupal Starshot aims to broaden Drupal's appeal to marketers and a wider range of project budgets. Our ultimate goal is to increase Drupal's adoption, solidify Drupal's position as a leading CMS, and champion an Open Web.
For more context, please watch my DrupalCon Portland keynote.
It's important to note that Drupal Starshot and Drupal Core will have separate yet complementary product strategies. Drupal Starshot will focus on empowering marketers and expanding Drupal's presence in the mid-market, while Drupal Core will prioritize the needs of developers and more technical users. I'll write more about the Drupal Core product strategy in a future blog post once we have finalized it. Together, these two strategies will form a comprehensive vision for Drupal as a product.
Why a product strategy?By defining our goals, target audience and necessary features, we can more effectively guide contributors and ensure that everyone is working towards a common vision. This product strategy will serve as a foundation for our development roadmap, our marketing efforts, enabling Drupal Certified Partners, and more.
Drupal Starshot product strategy TL;DRFor the detailed product strategy, please read the full Drupal Starshot strategy document (8 MB, PDF). Below is just a summary.
Drupal Starshot aims to be the gold standard for marketers that want to build great digital experiences.
We'd like to expand Drupal's reach by focusing on two strategic shifts:
- Prioritizing Drupal for content creators, marketers, web managers, and web designers so they can independently build websites. A key goal is to empower these marketing professionals to build and manage their websites independently without relying on developers or having to use the command line or an IDE.
- Extending Drupal's presence in the mid-market segment, targeting projects with total budgets between $30,000 and $120,000 USD (€25,000 to €100,000).
Drupal Starshot will differentiate itself from competitors by providing:
- A thoughtfully designed platform for marketers, balancing ease of use with flexibility. It includes smart defaults, best practices for common marketing tasks, marketing-focused editorial tools, and helpful learning resources.
- A growth-oriented approach. Start simple with Drupal Starshot's user-friendly tools, and unlock advanced features as your site grows or you gain expertise. With sophisticated content modeling, efficient content reuse across channels, and robust integrations with other leading marketing technologies, ambitious marketers won't face the limitations of other CMSs and will have the flexibility to scale their site as needed.
- AI-assisted site building tools to simplify complex tasks, making Drupal accessible to a wider range of users.
- Drupal's existing competitive advantages such as extensibility, scalability, security, accessibility, multilingual support, and more.
The product strategy is a living document, and we value input. We invite you to share your thoughts, suggestions, and questions in the product strategy feedback issue within the Drupal Starshot issue queue.
Get involvedThere are many opportunities to get involved with Drupal Starshot, whether you're a marketer, developer, designer, writer, project manager, or simply passionate about the future of Drupal. To learn more about how you can contribute to Drupal Starshot, visit https://drupal.org/starshot.
Thank youI'd like to thank the Drupal Starshot leadership team, the Drupal Starshot Advisory Council, and the Drupal Core Committers for their input on the strategy. I'm also grateful for the marketers who provided feedback on our strategy, helping us refine our approach.
PyCoder’s Weekly: Issue #641 (Aug. 6, 2024)
#641 – AUGUST 6, 2024
View in Browser »
This post is Bite Code’s monthly summary, but the lead story happened just days ago. In line with a 7 year old deprecation, setuptools finally removed the ability to call its test command. Many packages promptly broke. The following day the change was undone.
BITE CODE!
In this step-by-step tutorial, you’ll learn how to create an installable Django app. You’ll cover everything you need to know, from extracting your app from a Django project to turning it into a package that’s available on PyPI and installable through pip.
REAL PYTHON
Let Judoscale solve your scaling issues. We support Django, Flask, and FastAPI, and we also autoscale your Celery and RQ task queues. Traffic spike? Scaled up. Quiet night? Scaled down. Work queue backlog? No problem →
JUDOSCALE sponsor
Talk Python interviews David Lord, the lead maintainer of the Pallets open source organization which is responsible for Flask, Jinja, and Click. They talk about the latest for the org and Flask.
TALK PYTHON podcast
Scouring an open source project’s issues can lead to an open source contribution, but there is often an overwhelming amount of issues to sift through. In this article, Stefanie shares her tips for navigating an open source project’s issue tracker to find something to work on.
STEFANIE MOLIN • Shared by Stefanie Molin
In this tutorial, you’ll learn how to read and write JSON-encoded data in Python. You’ll begin with practical examples that show how to use Python’s built-in “json” module and then move on to learn how to serialize and deserialize custom data.
REAL PYTHON
Testing an application that reads files from a disk can be complicated. It may depend on the machine, require special access, or be frustratingly slow. This course shows you how to simulate a text file using Python to simplify testing.
REAL PYTHON course
This is a description of how Joshua uses Python in a package-centric way to organize his approach to data analyses. This is a system he has evolved while working on his computational biology Ph.D. and working in industry.
JOSHUA COOK • Shared by Joshua Cook
In this tutorial, you’ll learn about the main tools for string formatting in Python, as well as their strengths and weaknesses. These tools include f-strings, the .format() method, and the modulo operator.
REAL PYTHON
Python’s json.tool command-line interface pretty prints your JSON. Have you ever wondered why it is in json.tool instead of the module directly? This article explains the history behind this module.
TREY HUNNER
Recently, the PSF board was alerted to a flaw in the bylaws that could expose the foundation to unbounded financial liability. As such, a board driven change has been instituted.
PYTHON SOFTWARE FOUNDATION
This opinion piece outlines why the culture of rapid delivery has eroded quality engineering. It talks about how we got where we are and what should be done instead.
PAO RAMEN
The git log command has arguments you can use to examine just part of a commit. This article shows you how to trace the changes to a single Python function.
JOËL PERRAS
This post introduces you to the new tea-tasting project that lets you do statistical analysis on your A/B tests.
EVGENY IVANOV
August 7, 2024
REALPYTHON.COM
August 8 to August 9, 2024
MEETUP.COM
August 9 to August 11, 2024
PYTHONNORDESTE.ORG
August 10 to August 11, 2024
NOKIDBEHIND.ORG
August 10, 2024
MEETUP.COM
August 10, 2024
MEETUP.COM
Happy Pythoning!
This was PyCoder’s Weekly Issue #641.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
- mark.ie: My LocalGov Drupal contributions for week-ending November 22nd, 2024
- ImageX: Instantly Enhance Your Website with Drupal Recipes for Exciting Features
- FSF Events: Free Software Directory meeting on IRC: Friday, November 22, starting at 12:00 EST (17:00 UTC)
- Metadrop: Artisan Drupal SDC theme: What you need to know
- Django Weblog: 2024 Django Developers Survey
FLOSS Research
- Give Your Input on the State of Open Source Survey
- Open Data and Open Source AI: Charting a course to get more of both
- The Open Source Initiative and the Eclipse Foundation to Collaborate on Shaping Open Source AI (OSAI) Public Policy
- ClearlyDefined v2.0 adds support for LicenseRefs
- ClearlyDefined at SOSS Fusion 2024: a collaborative solution to Open Source license compliance