
FLOSS Project Planets
PyPy: A Knownbits Abstract Domain for the Toy Optimizer, Correctly
After Max' introduction to abstract interpretation for the toy optimizer in the last post, I want to present a more complicated abstract domain in this post. This abstract domain reasons about the individual bits of a variable in a trace. Every bit can be either "known zero", "known one" or "unknown". The abstract domain is useful for optimizing integer operations, particularly the bitwise operations. The abstract domain follows quite closely the tristate abstract domain of the eBPF verifier in the Linux Kernel, as described by the paper Sound, Precise, and Fast Abstract Interpretation with Tristate Numbers by Harishankar Vishwanathan, Matan Shachnai, Srinivas Narayana, and Santosh Nagarakatte.
The presentation in this post will still be in the context of the toy optimizer. We'll spend a significant part of the post convincing ourselves that the abstract domain transfer functions that we're writing are really correct, using both property-based testing and automated proofs (again using Z3).
PyPy has implemented and merged a more complicated version of the same abstract domain for the "real" PyPy JIT. A more thorough explanation of that real world implementation will follow.
I'd like to thank Max Bernstein and Armin Rigo for lots of great feedback on drafts of this post. The PyPy implementation was mainly done by Nico Rittinghaus and me.
Contents:
- Motivation
- The Knownbits Abstract Domain
- Transfer Functions
- Property-based Tests with Hypothesis
- When are Transfer Functions Correct? How do we test them?
- Implementing Binary Transfer Functions
- Addition and Subtraction
- Proving correctness of the transfer functions with Z3
- Cases where this style of Z3 proof doesn't work
- Making Statements about Precision
- Using the Abstract Domain in the Toy Optimizer for Generalized Constant Folding
- Using the KnownBits Domain for Conditional Peephole Rewrites
- Conclusion
In many programs that do bit-manipulation of integers, some of the bits of the integer variables of the program can be statically known. Here's a simple example:
x = a | 1 ... if x & 1: ... else: ...After the assignment x = a | 1, we know that the lowest bit of x must be 1 (the other bits are unknown) and an optimizer could remove the condition x & 1 by constant-folding it to 1.
Another (more complicated) example is:
assert i & 0b111 == 0 # check that i is a multiple of 8 j = i + 16 assert j & 0b111 == 0This kind of code could e.g. happen in a CPU emulator, where i and j are integers that represent emulated pointers, and the asserts are alignment checks. The first assert implies that the lowest three bits of i must be 0. Adding 16 to such a number produces a result where the lowest three bits are again all 0, therefore the second assert is always true. So we would like a compiler to remove the second assert.
Both of these will optimizations are doable with the help of the knownbits abstract domain that we'll discuss in the rest of the post.
The Knownbits Abstract DomainAn abstract value of the knownbits domain needs to be able to store, for every bit of an integer variable in a program, whether it is known 0, known 1, or unknown. To represent three different states, we need 2 bits, which we will call one and unknown. Here's the encoding:
one unknown knownbit 0 0 0 1 0 1 0 1 ? 1 1 illegalThe unknown bit is set if we don't know the value of the bit ("?"), the one bit is set if the bit is known to be a 1. Since two bits are enough to encode four different states, but we only need three, the combination of a set one bit and a set unknown is not allowed.
We don't just want to encode a single bit, however. Instead, we want to do this for all the bits of an integer variable. Therefore the instances of the abstract domain get two integer fields ones and unknowns, where each pair of corresponding bits encodes the knowledge about the corresponding bit of the integer variable in the program.
We can start implementing a Python class that works like this:
from dataclasses import dataclass @dataclass(eq=False) class KnownBits: ones : int unknowns : int def __post_init__(self): if isinstance(self.ones, int): assert self.is_well_formed() def is_well_formed(self): # a bit cannot be both 1 and unknown return self.ones & self.unknowns == 0 @staticmethod def from_constant(const : int): """ Construct a KnownBits corresponding to a constant, where all bits are known.""" return KnownBits(const, 0) def is_constant(self): """ Check if the KnownBits instance represents a constant. """ # it's a constant if there are no unknowns return self.unknowns == 0We can also add some convenience properties. Sometimes it is easier to work with an integer where all the known bits are set, or one where the positions of all the known zeros have a set bit:
class KnownBits: ... @property def knowns(self): """ return an integer where the known bits are set. """ # the knowns are just the unknowns, inverted return ~self.unknowns @property def zeros(self): """ return an integer where the places that are known zeros have a bit set. """ # it's a 0 if it is known, but not 1 return self.knowns & ~self.onesAlso, for debugging and for writing tests we want a way to print the known bits in a human-readable form, and also to have a way to construct a KnownBits instance from a string. It's not important to understand the details of __str__ or from_str for the rest of the post, so I'm putting them into a fold:
KnownBits from and to string conversions class KnownBits: ... def __repr__(self): if self.is_constant(): return f"KnownBits.from_constant({self.ones})" return f"KnownBits({self.ones}, {self.unknowns})" def __str__(self): res = [] ones, unknowns = self.ones, self.unknowns # construct the string representation right to left while 1: if not ones and not unknowns: break # we leave off the leading known 0s if ones == -1 and not unknowns: # -1 has all bits set in two's complement, so the leading # bits are all 1 res.append('1') res.append("...") break if unknowns == -1: # -1 has all bits set in two's complement, so the leading bits # are all ? assert not ones res.append("?") res.append("...") break if unknowns & 1: res.append('?') elif ones & 1: res.append('1') else: res.append('0') ones >>= 1 unknowns >>= 1 if not res: res.append('0') res.reverse() return "".join(res) @staticmethod def from_str(s): """ Construct a KnownBits instance that from a string. String can start with ...1 to mean that all higher bits are 1, or ...? to mean that all higher bits are unknown. Otherwise it is assumed that the higher bits are all 0. """ ones, unknowns = 0, 0 startindex = 0 if s.startswith("...?"): unknowns = -1 startindex = 4 elif s.startswith("...1"): ones = -1 startindex = 4 for index in range(startindex, len(s)): ones <<= 1 unknowns <<= 1 c = s[index] if c == '1': ones |= 1 elif c == '?': unknowns |= 1 return KnownBits(ones, unknowns) @staticmethod def all_unknown(): """ convenience constructor for the "all bits unknown" abstract value """ return KnownBits.from_str("...?")And here's a pytest-style unit test for str:
def test_str(): assert str(KnownBits.from_constant(0)) == '0' assert str(KnownBits.from_constant(5)) == '101' assert str(KnownBits(5, 0b10)) == '1?1' assert str(KnownBits(~0b1111, 0b10)) == '...100?0' assert str(KnownBits(1, ~0b1)) == '...?1'An instance of KnownBits represents a set of integers, namely those that match the known bits stored in the instance. We can write a method contains that takes a concrete int value and returns True if the value matches the pattern of the known bits:
class KnownBits: ... def contains(self, value : int): """ Check whether the KnownBits instance contains the concrete integer `value`. """ # check whether value matches the bit pattern. in the places where we # know the bits, the value must agree with ones. return value & self.knowns == self.onesand a test:
def test_contains(): k1 = KnownBits.from_str('1?1') assert k1.contains(0b111) assert k1.contains(0b101) assert not k1.contains(0b110) assert not k1.contains(0b011) k2 = KnownBits.from_str('...?1') # all odd numbers for i in range(-101, 100): assert k2.contains(i) == (i & 1) Transfer FunctionsNow that we have implemented the basics of the KnownBits class, we need to start implementing the transfer functions. They are for computing what we know about the results of an operation, given the knownledge we have about the bits of the arguments.
We'll start with a simple unary operation, invert(x) (which is ~x in Python and C syntax), which flips all the bits of at integer. If we know some bits of the arguments, we can compute the corresponding bits of the result. The unknown bits remain unknown.
Here's the code:
class KnownBits: ... def abstract_invert(self): # self.zeros has bits set where the known 0s are in self return KnownBits(self.zeros, self.unknowns)And a unit-test:
def test_invert(): k1 = KnownBits.from_str('01?01?01?') k2 = k1.abstract_invert() assert str(k2) == '...10?10?10?' k1 = KnownBits.from_str('...?') k2 = k1.abstract_invert() assert str(k2) == '...?'Before we continue with further transfer functions, we'll think about correctness of the transfer functions and build up some test infrastructure. To test transfer functions, it's quite important to move being simple example-style unit tests. The state-space for more complicated binary transfer functions is extremely large and it's too easy to do something wrong in a corner case. Therefore we'll look at property-based-test for KnownBits next.
Property-based Tests with HypothesisWe want to do property-based tests of KnownBits, to try make it less likely that we'll get a corner-case in the implementation wrong. We'll use Hypothesis for that.
I can't give a decent introduction to Hypothesis here, but want to give a few hints about the API. Hypothesis is a way to run unit tests with randomly generated input. It provides strategies to describe the data that the test functions expects. Hypothesis provides primitive strategies (for things like integers, strings, floats, etc) and ways to build composite strategies out of the primitive ones.
To be able to write the tests, we need to generate random KnownBits instances, and we also want an int instance that is a member of the KnownBits instance. We generate tuples of (KnownBits, int) together, to ensure this property. We'll ask Hypothesis to generate us a random concrete int as the concrete value, and then we'll also generate a second random int to use as the unknown masks (i.e. which bits of the concrete int we don't know in the KnownBits instance). Here's a function that takes two such ints and builds the tuple:
def build_knownbits_and_contained_number(concrete_value : int, unknowns : int): # to construct a valid KnownBits instance, we need to mask off the unknown # bits ones = concrete_value & ~unknowns return KnownBits(ones, unknowns), concrete_valueWe can turn this function into a hypothesis strategy to generate input data using the strategies.builds function:
from hypothesis import strategies, given, settings ints = strategies.integers() random_knownbits_and_contained_number = strategies.builds( build_knownbits_and_contained_number, ints, ints )One important special case of KnownBits are the constants, which contain only a single concrete value. We'll also generate some of those specifically, and then combine the random_knownbits_and_contained_number strategy with it:
constant_knownbits = strategies.builds( lambda value: (KnownBits.from_constant(value), value), ints ) knownbits_and_contained_number = constant_knownbits | random_knownbits_and_contained_numberNow we can write the first property-based tests, for the KnownBits.contains method:
@given(knownbits_and_contained_number) def test_contains(t): k, n = t assert k.contains(t)The @given decorator is used to tell Hypothesis which strategy to use to generate random data for the test function. Hypothesis will run the test with a number of random examples (100 by default). If it finds an error, it will try to minimize the example needed that demonstrates the problem, to try to make it easier to understand what is going wrong. It also saves all failing cases into an example database and tries them again on subsequent runs.
This test is as much a check for whether we got the strategies right as it is for the logic in KnownBits.contains. Here's an example output of random concrete and abstract values that we are getting here:
110000011001101 ...?0???1 ...1011011 ...1011011 ...1001101110101000010010011111011 ...1001101110101000010010011111011 ...1001101110101000010010011111011 ...100110111010100001?010?1??1??11 1000001101111101001011010011111101000011000111011001011111101 1000001101111101001011010011111101000011000111011001011111101 1000001101111101001011010011111101000011000111011001011111101 1000001101111101001011010011111101000011000111????01?11?????1 1111100000010 1111100000010 1111100000010 ...?11111?00000?? 110110 110110 110110 ...?00?00????11??10 110110 ??0??0 ...100010111011111 ...?100?10111??111? ...1000100000110001 ...?000?00000??000? 110000001110 ...?0?0??000?00?0?0000000?00???0000?????00???000?0?00?01?000?0??1?? 110000001110 ??000000???0 1011011010000001110101001111000010001001011101010010010001000000010101010010001101110101111111010101010010101100110000011110000 1011011010000001110101001111000010001001011101010010010001000000010101010010001101110101111111010101010010101100110000011110000 ...1011010010010100 ...1011010010010100 ...1011111110110011 ...1011111110110011 101000011110110 101000011?10?1? 100101 ?00?0?That looks suitably random, but we might want to bias our random numbers a little bit towards common error values like small constants, powers of two, etc. Like this:
INTEGER_WIDTH = 64 # some small integers ints_special = set(range(100)) # powers of two ints_special = ints_special.union(1 << i for i in range(INTEGER_WIDTH - 2)) # powers of two - 1 ints_special = ints_special.union((1 << i) - 1 for i in range(INTEGER_WIDTH - 2)) # negative versions of what we have so far ints_special = ints_special.union(-x for x in ints_special) # bit-flipped versions of what we have so far ints_special = ints_special.union(~x for x in ints_special) ints_special = list(ints_special) # sort them (because hypothesis simplifies towards earlier elements in the list) ints_special.sort(key=lambda element: (abs(element), element < 0)) ints = strategies.sampled_from(ints_special) | strategies.integers()Now we get data like this:
1110 1110 ...10000000000000000001 ...10000??0??0000??00?1 1 ??0??0000??00?1 1 ? ...10101100 ...10101100 110000000011001010111011111111111111011110010001001100110001011 ...?0?101? 110000000011001010111011111111111111011110010001001100110001011 ??00000000??00?0?0???0??????????????0????00?000?00??00??000?0?? ...1011111111111111111111111111 ...?11?11?? ...1011111111111111111111111111 ...?0?????????????????????????? 0 ...?0?????????????????????????? 101101 101101 111111111111111111111111111111111111111111111 111111111111111111111111111111111111111111111 10111 10111 ...101100 ...1?111011?0 101000 ?001010?0 101000 ?0?000 110010 110010 ...100111 ...100111 1111011010010 1111011010010 ...1000000000000000000000000000000000000 ...1000000000000000000000000000000000000We can also write a test that checks that the somewhat tricky logic in __str__ and from_str is correct, by making sure that the two functions round-trip (ie converting a KnownBits to a string and then back to a KnownBits instance produces the same abstract value).
@given(knownbits_and_contained_number) def test_hypothesis_str_roundtrips(t1): k1, n1 = t1 s = str(k1) k2 = KnownBits.from_str(s) assert k1.ones == k2.ones assert k1.unknowns == k2.unknownsNow let's actually apply this infrastructure to test abstract_invert.
When are Transfer Functions Correct? How do we test them?Abstract values, i.e. instances of KnownBits represent sets of concrete values. We want the transfer functions to compute overapproximations of the concrete values. So if we have an arbitrary abstract value k, with a concrete number n that is a member of the abstract values (i.e. k.contains(n) == True) then the result of the concrete operation op(n) must be a member of the result of the abstract operation k.abstract_op() (i.e. k.abstract_op().contains(op(n)) == True).
Checking the correctness/overapproximation property is a good match for hypothesis. Here's what the test for abstract_invert looks like:
@given(knownbits_and_contained_number) def test_hypothesis_invert(t): k1, n1 = t1 n2 = ~n1 # compute the real result k2 = k1.abstract_invert() # compute the abstract result assert k2.contains(n2) # the abstract result must contain the real resultThis is the only condition needed for abstract_invert to be correct. If abstract_invert fulfils this property for every combination of abstract and concrete value then abstract_invert is correct. Note however, that this test does not actually check whether abstract_invert gives us precise results. A correct (but imprecise) implementation of abstract_invert would simply return a completely unknown result, regardless of what is known about the input KnownBits.
The "proper" CS term for this notion of correctness is called soundness. The correctness condition on the transfer functions is called a Galois connection. I won't go into any mathematical/technical details here, but wanted to at least mention the terms. I found Martin Kellogg's slides to be quite an approachable introduction to the Galois connection and how to show soundness.
Implementing Binary Transfer FunctionsNow we have infrastructure in place for testing transfer functions with random inputs. With that we can start thinking about the more complicated case, that of binary operations. Let's start with the simpler ones, and and or. For and, we can know a 0 bit in the result if either of the input bits are known 0; or we can know a 1 bit in the result if both input bits are known 1. Otherwise the resulting bit is unknown. Let's look at all the combinations:
and input1: 000111??? input2: 01?01?01? result: 00001?0?? class KnownBits: ... def abstract_and(self, other): ones = self.ones & other.ones # known ones knowns = self.zeros | other.zeros | ones return KnownBits(ones, ~knowns)Here's an example unit-test and a property-based test for and:
def test_and(): # test all combinations of 0, 1, ? in one example k1 = KnownBits.from_str('01?01?01?') k2 = KnownBits.from_str('000111???') res = k1.abstract_and(k2) # should be: 0...00001?0?? assert str(res) == "1?0??" @given(knownbits_and_contained_number, knownbits_and_contained_number) def test_hypothesis_and(t1, t2): k1, n1 = t1 k2, n2 = t2 k3 = k1.abstract_and(k2) n3 = n1 & n2 assert k3.contains(n3)To implement or is pretty similar. The result is known 1 where either of the inputs is 1. The result is known 0 where both inputs are known 0, and ? otherwise.
or input1: 000111??? input2: 01?01?01? result: 01?111?1? class KnownBits: ... def abstract_or(self, other): ones = self.ones | other.ones zeros = self.zeros & other.zeros knowns = ones | zeros return KnownBits(ones, ~knowns)Here's an example unit-test and a property-based test for or:
def test_or(): k1 = KnownBits.from_str('01?01?01?') k2 = KnownBits.from_str('000111???') res = k1.abstract_or(k2) # should be: 0...01?111?1? assert str(res) == "1?111?1?" @given(knownbits_and_contained_number, knownbits_and_contained_number) def test_hypothesis_or(t1, t2): k1, n1 = t1 k2, n2 = t2 k3 = k1.abstract_or(k2) n3 = n1 | n2 assert k3.contains(n3)Implementing support for abstract_xor is relatively simple, and left as an exercise :-).
Addition and Subtractioninvert, and, and or are relatively simple transfer functions to write, because they compose over the individual bits of the integers. The arithmetic functions add and sub are significantly harder, because of carries and borrows. Coming up with the formulas for them and gaining an intuitive understanding is quite tricky and involves carefully going through a few examples with pen and paper. When implementing this in PyPy, Nico and I didn't come up with the implementation ourselves, but instead took them from the Tristate Numbers paper. Here's the code, with example tests and hypothesis tests:
class KnownBits: ... def abstract_add(self, other): sum_ones = self.ones + other.ones sum_unknowns = self.unknowns + other.unknowns all_carries = sum_ones + sum_unknowns ones_carries = all_carries ^ sum_ones unknowns = self.unknowns | other.unknowns | ones_carries ones = sum_ones & ~unknowns return KnownBits(ones, unknowns) def abstract_sub(self, other): diff_ones = self.ones - other.ones val_borrows = (diff_ones + self.unknowns) ^ (diff_ones - other.unknowns) unknowns = self.unknowns | other.unknowns | val_borrows ones = diff_ones & ~unknowns return KnownBits(ones, unknowns) def test_add(): k1 = KnownBits.from_str('0?10?10?10') k2 = KnownBits.from_str('0???111000') res = k1.abstract_add(k2) assert str(res) == "?????01?10" def test_sub(): k1 = KnownBits.from_str('0?10?10?10') k2 = KnownBits.from_str('0???111000') res = k1.abstract_sub(k2) assert str(res) == "...?11?10" k1 = KnownBits.from_str( '...1?10?10?10') k2 = KnownBits.from_str('...10000???111000') res = k1.abstract_sub(k2) assert str(res) == "111?????11?10" @given(knownbits_and_contained_number, knownbits_and_contained_number) def test_hypothesis_add(t1, t2): k1, n1 = t1 k2, n2 = t2 k3 = k1.abstract_add(k2) n3 = n1 + n2 assert k3.contains(n3) @given(knownbits_and_contained_number, knownbits_and_contained_number) def test_hypothesis_sub(t1, t2): k1, n1 = t1 k2, n2 = t2 k3 = k1.abstract_sub(k2) n3 = n1 - n2 assert k3.contains(n3)Now we are in a pretty good situation, and have implemented abstract versions for a bunch of important arithmetic and binary functions. What's also surprising is that the implementation of all of the transfer functions is quite efficient. We didn't have to write loops over the individual bits at all, instead we found closed form expressions using primitive operations on the underlying integers ones and unknowns. This means that computing the results of abstract operations is quite efficient, which is important when using the abstract domain in the context of a JIT compiler.
Proving correctness of the transfer functions with Z3As one can probably tell from my recent posts, I've been thinking about compiler correctness a lot. Getting the transfer functions absolutely correct is really crucial, because a bug in them would lead to miscompilation of Python code when the abstract domain is added to the JIT. While the randomized tests are great, it's still entirely possible for them to miss bugs. The state space for the arguments of a binary transfer function is 3**64 * 3**64, and if only a small part of that contains wrong behaviour it would be really unlikely for us to find it with random tests by chance. Therefore I was reluctant to merge the PyPy branch that contained the new abstract domain for a long time.
To increase our confidence in the correctness of the transfer functions further, we can use Z3 to prove their correctness, which gives us much stronger guarantees (not 100%, obviously). In this subsection I will show how to do that.
Here's an attempt to do this manually in the Python repl:
>>>> import z3 >>>> solver = z3.Solver() >>>> # like last blog post, proof by failing to find counterexamples >>>> def prove(cond): assert solver.check(z3.Not(cond)) == z3.unsat >>>> >>>> # let's set up a z3 bitvector variable for an abitrary concrete value >>>> n1 = z3.BitVec('concrete_value', 64) >>>> n1 concrete_value >>>> # due to operator overloading we can manipulate z3 formulas >>>> n2 = ~n1 >>>> n2 ~concrete_value >>>> >>>> # now z3 bitvector variables for the ones and zeros fields >>>> ones = z3.BitVec('abstract_ones', 64) >>>> unknowns = z3.BitVec('abstract_unknowns', 64) >>>> # we construct a KnownBits instance with the z3 variables >>>> k1 = KnownBits(ones, unknowns) >>>> # due to operator overloading we can call the methods on k1: >>>> k2 = k1.abstract_invert() >>>> k2.ones ~abstract_unknowns & ~abstract_ones >>>> k2.unknowns abstract_unknowns >>>> # here's the correctness condition that we want to prove: >>>> k2.contains(n2) ~concrete_value & ~abstract_unknowns == ~abstract_unknowns & ~abstract_ones >>>> # let's try >>>> prove(k2.contains(n2)) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 1, in prove AssertionError >>>> # it doesn't work! let's look at the counterexample to see why: >>>> solver.model() [abstract_unknowns = 0, abstract_ones = 0, concrete_value = 1] >>>> # we can build a KnownBits instance with the values in the >>>> # counterexample: >>>> ~1 # concrete result -2 >>>> counter_example_k1 = KnownBits(0, 0) >>>> counter_example_k1 KnownBits.from_constant(0) >>>> counter_example_k2 = counter_example_k1.abstract_invert() >>>> counter_example_k2 KnownBits.from_constant(-1) >>>> # let's check the failing condition >>>> counter_example_k2.contains(~1) FalseWhat is the problem here? We didn't tell Z3 that n1 was supposed to be a member of k1. We can add this as a precondition to the solver, and then the prove works:
>>>> solver.add(k1.contains(n1)) >>>> prove(k2.contains(n2)) # works!This is super cool! It's really a proof about the actual implementation, because we call the implementation methods directly, and due to the operator overloading that Z3 does we can be sure that we are actually checking a formula that corresponds to the Python code. This eliminates one source of errors in formal methods.
Doing the proof manually on the Python REPL is kind of annoying though, and we also would like to make sure that the proofs are re-done when we change the code. What we would really like to do is writing the proofs as a unit-test that we can run while developing and in CI. Doing this is possible, and the unit tests that really perform proofs look pleasingly similar to the Hypothesis-based ones.
First we need to set up a bit of infrastructure:
INTEGER_WIDTH = 64 def BitVec(name): return z3.BitVec(name, INTEGER_WIDTH) def BitVecVal(val): return z3.BitVecVal(val, INTEGER_WIDTH) def z3_setup_variables(): # instantiate a solver solver = z3.Solver() # a Z3 variable for the first concrete value n1 = BitVec("n1") # a KnownBits instances that uses Z3 variables as its ones and unknowns, # representing the first abstract value k1 = KnownBits(BitVec("n1_ones"), BitVec("n1_unkowns")) # add the precondition to the solver that the concrete value n1 must be a # member of the abstract value k1 solver.add(k1.contains(n1)) # a Z3 variable for the second concrete value n2 = BitVec("n2") # a KnownBits instances for the second abstract value k2 = KnownBits(BitVec("n2_ones"), BitVec("n2_unkowns")) # add the precondition linking n2 and k2 to the solver solver.add(k2.contains(n2)) return solver, k1, n1, k2, n2 def prove(cond, solver): z3res = solver.check(z3.Not(cond)) if z3res != z3.unsat: assert z3res == z3.sat # can't be timeout, we set no timeout # make the model with the counterexample global, to make inspecting the # bug easier when running pytest --pdb global model model = solver.model() print(f"n1={model.eval(n1)}, n2={model.eval(n2)}") counter_example_k1 = KnownBits(model.eval(k1.ones).as_signed_long(), model.eval(k1.unknowns).as_signed_long()) counter_example_k2 = KnownBits(model.eval(k2.ones).as_signed_long(), model.eval(k2.unknowns).as_signed_long()) print(f"k1={counter_example_k1}, k2={counter_example_k2}") print(f"but {cond=} evaluates to {model.eval(cond)}") raise ValueError(solver.model())And then we can write proof-unit-tests like this:
def test_z3_abstract_invert(): solver, k1, n1, _, _ = z3_setup_variables() k2 = k1.abstract_invert() n2 = ~n1 prove(k2.contains(n2), solver) def test_z3_abstract_and(): solver, k1, n1, k2, n2 = z3_setup_variables() k3 = k1.abstract_and(k2) n3 = n1 & n2 prove(k3.contains(n3), solver) def test_z3_abstract_or(): solver, k1, n1, k2, n2 = z3_setup_variables() k3 = k1.abstract_or(k2) n3 = n1 | n2 prove(k3.contains(n3), solver) def test_z3_abstract_add(): solver, k1, n1, k2, n2 = z3_setup_variables() k3 = k1.abstract_add(k2) n3 = n1 + n2 prove(k3.contains(n3), solver) def test_z3_abstract_sub(): solver, k1, n1, k2, n2 = z3_setup_variables() k3 = k1.abstract_sub(k2) n3 = n1 - n2 prove(k3.contains(n3), solver)It's possible to write a bit more Python-metaprogramming-magic and unify the Hypothesis and Z3 tests into the same test definition.1
Cases where this style of Z3 proof doesn't workUnfortunately the approach described in the previous section only works for a very small number of cases. It breaks down as soon as the KnownBits methods that we're calling contain any if conditions (including hidden ones like the short-circuiting and and or in Python). Let's look at an example and implement abstract_eq. eq is supposed to be an operation that compares two integers and returns 0 or 1 if they are different or equal, respectively. Implementing this in knownbits looks like this (with example and hypothesis tests):
class KnownBits: ... def abstract_eq(self, other): # the result is a 0, 1, or ? # if they are both the same constant, they must be equal if self.is_constant() and other.is_constant() and self.ones == other.ones: return KnownBits.from_constant(1) # check whether we have known disagreeing bits, then we know the result # is 0 if self._disagrees(other): return KnownBits.from_constant(0) return KnownBits(0, 1) # an unknown boolean def _disagrees(self, other): # check whether the bits disagree in any place where both are known both_known = self.knowns & other.knowns return self.ones & both_known != other.ones & both_known def test_eq(): k1 = KnownBits.from_str('...?') k2 = KnownBits.from_str('...?') assert str(k1.abstract_eq(k2)) == '?' k1 = KnownBits.from_constant(10) assert str(k1.abstract_eq(k1)) == '1' k1 = KnownBits.from_constant(10) k2 = KnownBits.from_constant(20) assert str(k1.abstract_eq(k2)) == '0' @given(knownbits_and_contained_number, knownbits_and_contained_number) def test_hypothesis_eq(t1, t2): k1, n1 = t1 k2, n2 = t2 k3 = k1.abstract_eq(k2) assert k3.contains(int(n1 == n2))Trying to do the proof in the same style as before breaks:
>>>> k3 = k1.abstract_eq(k2) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "knownbits.py", line 246, in abstract_eq if self._disagrees(other): File "venv/site-packages/z3/z3.py", line 381, in __bool__ raise Z3Exception("Symbolic expressions cannot be cast to concrete Boolean values.") z3.z3types.Z3Exception: Symbolic expressions cannot be cast to concrete Boolean values.We cannot call abstract_eq on a KnownBits with Z3 variables as fields, because once we hit an if statement, the whole approach of relying on the operator overloading breaks down. Z3 doesn't actually parse the Python code or anything advanced like that, we rather build an expression only by running the code and letting the Z3 formulas build up.
To still prove the correctness of abstract_eq we need to manually transform the control flow logic of the function into a Z3 formula that uses the z3.If expression, using a small helper function:
def z3_cond(b, trueval=1, falseval=0): return z3.If(b, BitVecVal(trueval), BitVecVal(falseval)) def z3_abstract_eq(k1, k2): # follow the *logic* of abstract_eq, we can't call it due to the ifs in it case1cond = z3.And(k1.is_constant(), k2.is_constant(), k1.ones == k2.ones) case2cond = k1._disagrees(k2) # ones is 1 in the first case, 0 otherwise ones = z3_cond(case1cond, 1, 0) # in the first two cases, unknowns is 0, 1 otherwise unknowns = z3_cond(z3.Or(case1cond, case2cond), 0, 1) return KnownBits(ones, unknowns) def test_z3_abstract_eq_logic(): solver, k1, n1, k2, n2 = z3_setup_variables() n3 = z3_cond(n1 == n2) # concrete result k3 = z3_abstract_eq(k1, k2) prove(k3.contains(n3), solver)This proof works. It is a lot less satisfying than the previous ones though, because we could have done an error in the manual transcription from Python code to Z3 formulas (there are possibly more heavy-handed approaches where we do this transformation more automatically using e.g. the ast module to analyze the source code, but that's a much more complicated researchy project). To lessen this problem somewhat we can factor out the parts of the logic that don't have any conditions into small helper methods (like _disagrees in this example) and use them in the manual conversion of the code to Z3 formulas.2
The final condition that Z3 checks, btw, is this one:
If(n1 == n2, 1, 0) & ~If(Or(And(n1_unkowns == 0, n2_unkowns == 0, n1_ones == n2_ones), n1_ones & ~n1_unkowns & ~n2_unkowns != n2_ones & ~n1_unkowns & ~n2_unkowns), 0, 1) == If(And(n1_unkowns == 0, n2_unkowns == 0, n1_ones == n2_ones), 1, 0) Making Statements about PrecisionSo far we have only used Z3 to prove statements about correctness, i.e. that our abstract operations overapproximate what can happen with concrete values. While proving this property is essential if we want to avoid miscompilation, correctness alone is not a very strong constraint on the implementation of our abstract transfer functions. We could simply return Knownbits.unknowns() for every abstract_* method and the resulting overapproximation would be correct, but useless in practice.
It's much harder to make statements about whether the transfer functions are maximally precise. There are two aspects of precision I want to discuss in this section, however.
The first aspect is that we would really like it if the transfer functions compute the maximally precise results for singleton sets. If all abstract arguments of an operations are constants, i.e. contain only a single concrete element, then we know that the resulting set also has only a single element. We can prove that all our transfer functions have this property:
def test_z3_prove_constant_folding(): solver, k1, n1, k2, n2 = z3_setup_variables() k3 = k1.abstract_invert() prove(z3.Implies(k1.is_constant(), k3.is_constant()), solver) k3 = k1.abstract_and(k2) prove(z3.Implies(z3.And(k1.is_constant(), k2.is_constant()), k3.is_constant()), solver) k3 = k1.abstract_or(k2) prove(z3.Implies(z3.And(k1.is_constant(), k2.is_constant()), k3.is_constant()), solver) k3 = k1.abstract_sub(k2) prove(z3.Implies(z3.And(k1.is_constant(), k2.is_constant()), k3.is_constant()), solver) k3 = z3_abstract_eq(k1, k2) prove(z3.Implies(z3.And(k1.is_constant(), k2.is_constant()), k3.is_constant()), solver)Proving with Z3 that the transfer functions are maximally precise for non-constant arguments seems to be relatively hard. I tried a few completely rigorous approaches and failed. The paper Sound, Precise, and Fast Abstract Interpretation with Tristate Numbers contains an optimality proof for the transfer functions of addition and subtraction, so we can be certain that they are as precise as is possible.
I still want to show an approach for trying to find concrete examples of abstract values that are less precise than they could be, using a combination of Hypothesis and Z3. The idea is to use hypothesis to pick random abstract values. Then we compute the abstract result using our transfer function. Afterwards we can ask Z3 to find us an abstract result that is better than the one our transfer function produced. If Z3 finds a better abstract result, we have a concrete example of imprecision for our transfer function. Those tests aren't strict proofs, because they rely on generating random abstract values, but they can still be valuable (not for the transfer functions in this blog post, which are all optimal).
Here is what the code looks like (this is a little bit bonus content, I'll not explain the details and can only hope that the comments are somewhat helpful):
@given(random_knownbits_and_contained_number, random_knownbits_and_contained_number) @settings(deadline=None) def test_check_precision(t1, t2): k1, n1 = t1 k2, n2 = t2 # apply transfer function k3 = k1.abstract_add(k2) example_res = n1 + n2 # try to find a better version of k3 with Z3 solver = z3.Solver() solver.set("timeout", 8000) var1 = BitVec('v1') var2 = BitVec('v2') ones = BitVec('ones') unknowns = BitVec('unknowns') better_k3 = KnownBits(ones, unknowns) print(k1, k2, k3) # we're trying to find an example for a better k3, so we use check, without # negation: res = solver.check(z3.And( # better_k3 should be a valid knownbits instance better_k3.is_well_formed(), # it should be better than k3, ie there are known bits in better_k3 # that we don't have in k3 better_k3.knowns & ~k3.knowns != 0, # now encode the correctness condition for better_k3 with a ForAll: # for all concrete values var1 and var2, it must hold that if # var1 is in k1 and var2 is in k2 it follows that var1 + var2 is in # better_k3 z3.ForAll( [var1, var2], z3.Implies( z3.And(k1.contains(var1), k2.contains(var2)), better_k3.contains(var1 + var2))))) # if this query is satisfiable, we have found a better result for the # abstract_add if res == z3.sat: model = solver.model() rk3 = KnownBits(model.eval(ones).as_signed_long(), model.eval(unknowns).as_signed_long()) print("better", rk3) assert 0 if res == z3.unknown: print("timeout")It does not actually fail for abstract_add (nor the other abstract functions). To see the test failing we can add some imprecision to the implementation of abstract_add to see Hypothesis and Z3 find examples of values that are not optimally precise (for example by setting some bits of unknowns in the implementation of abstract_add unconditionally).
Using the Abstract Domain in the Toy Optimizer for Generalized Constant FoldingNow after all this work we can finally actually use the knownbits abstract domain in the toy optimizer. The code for this follows Max' intro post about abstract interpretation quite closely.
For completeness sake, in the fold there's the basic infrastructure classes that make up the IR again (they are identical or at least extremely close to the previous toy posts).
toy infrastructure class Value: def find(self): raise NotImplementedError("abstract") @dataclass(eq=False) class Operation(Value): name : str args : list[Value] forwarded : Optional[Value] = None def find(self) -> Value: op = self while isinstance(op, Operation): next = op.forwarded if next is None: return op op = next return op def arg(self, index): return self.args[index].find() def make_equal_to(self, value : Value): self.find().forwarded = value @dataclass(eq=False) class Constant(Value): value : object def find(self): return self class Block(list): def __getattr__(self, opname): def wraparg(arg): if not isinstance(arg, Value): arg = Constant(arg) return arg def make_op(*args): op = Operation(opname, [wraparg(arg) for arg in args]) self.append(op) return op return make_op def bb_to_str(l : Block, varprefix : str = "var"): def arg_to_str(arg : Value): if isinstance(arg, Constant): return str(arg.value) else: return varnames[arg] varnames = {} res = [] for index, op in enumerate(l): # give the operation a name used while # printing: var = f"{varprefix}{index}" varnames[op] = var arguments = ", ".join( arg_to_str(op.arg(i)) for i in range(len(op.args)) ) strop = f"{var} = {op.name}({arguments})" res.append(strop) return "\n".join(res)Now we can write some first tests, the first one simply checking constant folding:
def test_constfold_two_ops(): bb = Block() var0 = bb.getarg(0) var1 = bb.int_add(5, 4) var2 = bb.int_add(var1, 10) var3 = bb.int_add(var2, var0) opt_bb = simplify(bb) assert bb_to_str(opt_bb, "optvar") == """\ optvar0 = getarg(0) optvar1 = int_add(19, optvar0)"""Calling the transfer functions on constant KnownBits produces a constant results, as we have seen. Therefore "regular" constant folding should hopefully be achieved by optimizing with the KnownBits abstract domain too.
The next two tests are slightly more complicated and can't be optimized by regular constant-folding. They follow the motivating examples from the start of this blog post, a hundred years ago:
def test_constfold_via_knownbits(): bb = Block() var0 = bb.getarg(0) var1 = bb.int_or(var0, 1) var2 = bb.int_and(var1, 1) var3 = bb.dummy(var2) opt_bb = simplify(bb) assert bb_to_str(opt_bb, "optvar") == """\ optvar0 = getarg(0) optvar1 = int_or(optvar0, 1) optvar2 = dummy(1)""" def test_constfold_alignment_check(): bb = Block() var0 = bb.getarg(0) var1 = bb.int_invert(0b111) # mask off the lowest three bits, thus var2 is aligned var2 = bb.int_and(var0, var1) # add 16 to aligned quantity var3 = bb.int_add(var2, 16) # check alignment of result var4 = bb.int_and(var3, 0b111) var5 = bb.int_eq(var4, 0) # var5 should be const-folded to 1 var6 = bb.dummy(var5) opt_bb = simplify(bb) assert bb_to_str(opt_bb, "optvar") == """\ optvar0 = getarg(0) optvar1 = int_and(optvar0, -8) optvar2 = int_add(optvar1, 16) optvar3 = dummy(1)"""Here is simplify to make these tests pass:
def unknown_transfer_functions(*abstract_args): return KnownBits.all_unknown() def simplify(bb: Block) -> Block: abstract_values = {} # dict mapping Operation to KnownBits def knownbits_of(val : Value): if isinstance(val, Constant): return KnownBits.from_constant(val.value) return abstract_values[val] opt_bb = Block() for op in bb: # apply the transfer function on the abstract arguments name_without_prefix = op.name.removeprefix("int_") method_name = f"abstract_{name_without_prefix}" transfer_function = getattr(KnownBits, method_name, unknown_transfer_functions) abstract_args = [knownbits_of(arg.find()) for arg in op.args] abstract_res = abstract_values[op] = transfer_function(*abstract_args) # if the result is a constant, we optimize the operation away and make # it equal to the constant result if abstract_res.is_constant(): op.make_equal_to(Constant(abstract_res.ones)) continue # otherwise emit the op opt_bb.append(op) return opt_bbThe code follows the approach from the previous blog post very closely. The only difference is that we apply the transfer function first, to be able to detect whether the abstract domain can tell us that the result has to always be a constant. This code makes all three tests pass.
Using the KnownBits Domain for Conditional Peephole RewritesSo far we are only using the KnownBits domain to find out that certain operations have to produce a constant. We can also use the KnownBits domain to check whether certain operation rewrites are correct. Let's use one of the examples from the Mining JIT traces for missing optimizations with Z3 post, where Z3 found the inefficiency (x << 4) & -0xf == x << 4 in PyPy JIT traces. We don't have shift operations, but we want to generalize this optimization anyway. The general form of this rewrite is that under some circumstances x & y == x, and we can use the KnownBits domain to detect situations where this must be true.
To understand when x & y == x is true, we can think about individual pairs of bits a and b. If a == 0, then a & b == 0 & b == 0 == a. If b == 1 then a & b == a & 1 == a. So if either a == 0 or b == 1 is true, a & b == a follows. And if either of these conditions is true for all the bits of x and y, we can know that x & y == x.
We can write a method on KnownBits to check for this condition:
class KnownBits: ... def is_and_identity(self, other): """ Return True if n1 & n2 == n1 for any n1 in self and n2 in other. (or, equivalently, return True if n1 | n2 == n2)""" return self.zeros | other.ones == -1Since my reasoning about this feels ripe for errors, let's check that our understanding is correct with Z3:
def test_prove_is_and_identity(): solver, k1, n1, k2, n2 = z3_setup_variables() prove(z3.Implies(k1.is_and_identity(k2), n1 & n2 == n1), solver)Now let's use this in the toy optimizer. Here are two tests for this rewrite:
def test_remove_redundant_and(): bb = Block() var0 = bb.getarg(0) var1 = bb.int_invert(0b1111) # mask off the lowest four bits var2 = bb.int_and(var0, var1) # applying the same mask is not redundant var3 = bb.int_and(var2, var1) var4 = bb.dummy(var3) opt_bb = simplify(bb) assert bb_to_str(opt_bb, "optvar") == """\ optvar0 = getarg(0) optvar1 = int_and(optvar0, -16) optvar2 = dummy(optvar1)""" def test_remove_redundant_and_more_complex(): bb = Block() var0 = bb.getarg(0) var1 = bb.getarg(1) # var2 has bit pattern ???? var2 = bb.int_and(var0, 0b1111) # var3 has bit pattern ...?1111 var3 = bb.int_or(var1, 0b1111) # var4 is just var2 var4 = bb.int_and(var2, var3) var5 = bb.dummy(var4) opt_bb = simplify(bb) assert bb_to_str(opt_bb, "optvar") == """\ optvar0 = getarg(0) optvar1 = getarg(1) optvar2 = int_and(optvar0, 15) optvar3 = int_or(optvar1, 15) optvar4 = dummy(optvar2)"""The first test could also be made to pass by implementing a reassociation optimization that turns (x & c1) & c2 into x & (c1 & c2) and then constant-folds the second and. But here we want to use KnownBits and conditionally rewrite int_and to its first argument. So to make the tests pass, we can change simplify like this:
def simplify(bb: Block) -> Block: abstract_values = {} # dict mapping Operation to KnownBits def knownbits_of(val : Value): ... opt_bb = Block() for op in bb: # apply the transfer function on the abstract arguments name_without_prefix = op.name.removeprefix("int_") method_name = f"abstract_{name_without_prefix}" transfer_function = getattr(KnownBits, method_name, unknown_transfer_functions) abstract_args = [knownbits_of(arg.find()) for arg in op.args] abstract_res = abstract_values[op] = transfer_function(*abstract_args) # if the result is a constant, we optimize the operation away and make # it equal to the constant result if abstract_res.is_constant(): op.make_equal_to(Constant(abstract_res.ones)) continue # <<<< new code # conditionally rewrite int_and(x, y) to x if op.name == "int_and": k1, k2 = abstract_args if k1.is_and_identity(k2): op.make_equal_to(op.arg(0)) continue # >>>> end changes opt_bb.append(op) return opt_bbAnd with that, the new tests pass as well. A real implementation would also check the other argument order, but we leave that out for the sake of brevity.
This rewrite also generalizes the rewrites int_and(0, x) -> 0 and int_and(-1, x) -> x, let's add a test for those:
def test_remove_and_simple(): bb = Block() var0 = bb.getarg(0) var1 = bb.getarg(1) var2 = bb.int_and(0, var0) # == 0 var3 = bb.int_invert(var2) # == -1 var4 = bb.int_and(var1, var3) # == var1 var5 = bb.dummy(var4) opt_bb = simplify(bb) assert bb_to_str(opt_bb, "optvar") == """\ optvar0 = getarg(0) optvar1 = getarg(1) optvar2 = dummy(optvar1)"""This test just passes. And that's it for this post!
ConclusionIn this post we've seen the implementation, testing and proofs about a 'known bits' abstract domain, as well as its use in the toy optimizer to generalize constant folding, and to implement conditional peephole rewrites.
In the next posts I'll write about the real implementation of a knownbits domain in PyPy's JIT, its combination with the existing interval abstract domain, how to deal with gaining informations from conditions in the program, and some lose ends.
Sources:
- Known bits in LLVM
- Tristate numbers for known bits in Linux eBPF
- Sound, Precise, and Fast Abstract Interpretation with Tristate Numbers
- Verifying the Verifier: eBPF Range Analysis Verification
- Bit-Twiddling: Addition with Unknown Bits is a super readable blog post by Dougall J. I've taken the ones and unknowns naming from this post, which I find significantly clearer than value and mask, which the Linux kernel uses.
- Bits, Math and Performance(?), a fantastic blog by Harold Aptroot. There are a lot of relevant posts about known bits, range analysis etc. Harold is also the author of Haroldbot, a website that can be used for bitvector calculations, and also checks bitvector identities.
- Sharpening Constraint Programming approaches for Bit-Vector Theory
- Deriving Abstract Transfer Functions for Analyzing Embedded Software
- Synthesizing Abstract Transformers
-
There's a subtletly about the Z3 proofs that I'm sort of glossing over here. Python integers are of arbitrary width, and the KnownBits code is actually carefully written to work for integers of any size. This property is tested by the Hypothesis tests, which don't limit the sizes of the generated random integers. However, the Z3 proofs only check bitvectors of a fixed bitwidth of 64. There are various ways to deal with this situation. For most "real" compilers, the bitwidth of integers would be fixed anyway. Then the components ones and unknowns of the KnownBits class would use the number of bits the corresponding integer variable has, and the Z3 proofs would use the same width. This is what we do in the PyPy JIT. ↩
-
The less close connection between implementation and proof for abstract_eq is one of the reasons why it makes sense to do unit-testing in addition to proofs. For a more detailed explanation of why both tests and proofs are good to have, see Jeremy Siek's blog post, as well as the Knuth quote. ↩
This week in KDE: Discover and more
It was a big week for Discover, which received multiple UI improvements, performance enhancements, and bug fixes that you’ll find mentioned throughout the text!
There are more features and UI improvements to other components as well, plus a bunch of juicy bug fixes. I’m feeling like we’ve turned the corner on those bugs. No really significant Plasma bugs have been reported in the past week or two, just little ones that are easily squashed. Plasma is really feeling solid these days!
Notable New FeaturesYou can now re-bind the buttons on drawing tablet pens to mouse clicks if you’d like, in addition to the existing feature to bind them to keyboard shortcuts. And the user interface for this is now much better and clearer (Joshua Goins, Plasma 6.2.0. Link):
There’s now an on-by-default sound that plays when you connect or disconnect a screen, to help you figure out whether it was connected successfully — just like we already do for USB devices (Kai Uwe Broulik, Plasma 6.2.0. Link)
Notable UI ImprovementsPlasma’s Task Manager textual-list-style group popup now scales properly (Christoph Wolk, Plasma 6.1.4. Link)
Plasma’s Battery Monitor widget once again stays visible while plugged in and charging but not fully charged yet (me: Nate Graham, Plasma 6.2.0. Link)
Landed a minor redesign of Discover’s app page to better conform to the HIG, including the following changes:
- Better and more consistent margins and padding
- Better and more compact display of the content rating information
- Use underlined links rather than buttons for opening web URLs
- Replace internal separator lines with whitespace
- Move display of distro-packaged apps’ permissions to the bottom
(me: Nate Graham, Plasma 6.2.0. Link 1, link 2, link 3, link 4):
The menu of clipboard items that appears when you press Meta+V now shares its UI with the Plasma Clipboard widget, offering maintenance benefits, a more consistent UI, and better visualization for long text and images (Fushan Wen, Plasma 6.2.0. Link):
In Welcome Center, the pages introducing Overview and Plasma Vaults now have beautiful, rich graphics depicting the features themselves, and like all the others, they respect your system’s active theme settings, too (Oliver Beard, Plasma 6.2.0. Link 1 and link 2):
The frequency with which Discover’s notifier System Tray icon appears now respects the “Notification frequency” setting that you can choose in System Settings, matching the frequency with which system notifications about updates appear (Thomas Duckworth, Plasma 6.2.0. Link)
When you tile a Breeze-themed window to the left or right screen edge, the window’s top-most pixels no longer allow the window to be resized by dragging, breaking Fitts’ Law for those pixels (Vlad Zahorodnii, Plasma 6.2.0. Link)
Plasma’s Activities widget now scales properly and no longer grows too large with a really thick panel (me: Nate Graham, Plasma 6.2.0. Link 1 and link 2)
System Settings’ Night Light page now prevents you from setting manual timings that cause the start and stop transitions to overlap, and shows this visually, too (Ismael Asensio, Plasma 6.2.0. Link)
Made the menu button on System Settings’ Autostart page conform to the HIG (Christoph Wolk, Plasma 6.2.0. Link)
Made the list-remove Breeze icon look like a red X, same as edit-delete-remove. This helps to standardize on the red X symbolism for “remove this abstract thing” that the HIG recommends (me: Nate Graham, Frameworks 6.5. Link):
Notable Bug FixesFixed a somewhat common way that Powerdevil could crash after the system went to sleep due to inactivity (Jakob Petsovits, Plasma 6.1.4. Link)
When Flatpak/sandboxed/portal-using apps request inhibiting sleep, it now actually works! (Jakob Petsovits, Plasma 6.1.4. Link)
When you move a Plasma panel to another screen edge, its widgets no longer inappropriately become interactive until you leave Edit Mode (Marco Martin, Plasma 6.1.4. Link)
Fixed two issues with Plasma’s “Centered” and “Scaled and cropped” wallpaper positioning modes that caused images of certain sizes to be displayed incorrectly with certain screen scales (Marco Martin, Plasma 6.1.4. Link 1 and link 2)
Fixed three Plasma 6 porting regressions in Folder View that caused the widget representation to lose its custom title feature, caused existing labels to remain visible while renaming, and made it impossible to select other items with the keyboard after renaming something (Marco Martin and me: Nate Graham, Plasma 6.1.4. Link 1, link 2, and link 3)
Discover no longer cuts off the first letter of the name of non-SPDX-compatible licenses when it displays them on the app page (me: Nate Graham, Plasma 6.1.4. Link)
When Alt+Tabbing through windows, tab keystrokes no longer leak into XWayland-using apps when using default XWayland app keyboard snooping setting (David Edmundson, Plasma 6.2.0. Link)
Maximized XWayland-using apps no longer leave pixel gaps on the side of the screen with certain fractional scale factors (Xaver Hugl, Plasma 6.2.0. Link)
Fixed a Qt bug that caused many Plasma crashes while performing a variety of everyday activities with multiple screens are connected (David Edmundson, Qt 6.7.4 and 6.8.0. Link)
Other bug information of note:
- 2 Very high priority Plasma bugs (same as last week). Current list of bugs
- 31 15-minute Plasma bugs (same as last week). Current list of bugs
- 130 KDE bugs of all kinds fixed over the last two weeks. Full list of bugs
Made the icon loading code in Discover non-blocking, which speeds up launch time and improves scrolling smoothness (Harald Sitter, Plasma 6.2.0. Link)
The “Ring system bell when modifier keys are used” and “Ring system bell when locking keys are toggled” Sticky Keys features are now implemented on Wayland. This completes the project to gain full Sticky Keys support! (Nicolas Fella, Plasma 6.2.0. Link 1, link 2, and link 3)
KWin no longer chooses an inappropriate default scale factor for really wacky screens that mis-report their physical dimensions badly enough that they say they’re between zero and three millimeters wide or tall (me: Nate Graham, Plasma 6.2.0. Link)
On Wayland, apps that intentionally suppress cursor launch feedback now have more correct activation behaviors (Nicolas Fella, Frameworks 6.5. Link)
Notable in Automation & SystematizationAdded an “All bugs reported by me” link to the homepage on https://bugs.kde.org, so now you can truly see all of your bug reports, not just the open ones (me: Nate Graham, link)
Shortened the messages sent by the bug janitor warning that bugs will be auto-closed soon (Oliver Beard, link)
Adjusted the new bug template to be more accurate about how you fill in version numbers, including recommending using the kinfo command-line tool (me: Nate Graham, link)
…And Everything ElseThis blog only covers the tip of the iceberg! If you’re hungry for more, check out https://planet.kde.org, where you can find more news from other KDE contributors.
How You Can HelpIf you use have multiple systems or an adventurous personality, you can really help us out by installing beta versions of Plasma using your distro’s available repos and reporting bugs. Arch, Fedora, and openSUSE Tumbleweed are examples of great distros for this purpose. So please please do try out Plasma beta versions. It truly does help us! Heck, if you’re very adventurous, live on the nightly repos. I’ve been doing this full-time for 5 years with my sole computer and it’s surprisingly stable.
Does that sound too scary? Consider donating today instead! That helps too.
Otherwise, visit https://community.kde.org/Get_Involved to discover other ways to be part of a project that really matters. Each contributor makes a huge difference in KDE; you are not a number or a cog in a machine! You don’t have to already be a programmer, either. I wasn’t when I got started. Try it, you’ll like it! We don’t bite!
Paul Wise: FLOSS Activities July 2024
This month I didn't have any particular focus. I just worked on issues in my info bubble.
Issues- Unnecessary deps in zlint
- Debian IRC: add an entry message redirecting folks from #debian-ci to #debci
- Respond to queries from folks on Debian and other IRC channels.
All work was done on a volunteer basis.
Twin Cities Drupal Camp: Early Bird Tickets Are Almost Gone!
Now is your last chance to save before regular pricing takes affect. Twin Cities Drupal Camp is coming on September 12-13, 2024, at the University of Minnesota campus in Minneapolis.
Registration includes access to all sessions and events, including the keynote and the unconference. Meals and social events are also part of the deal, free of additional cost.
This Early Bird rate won’t last forever, so do it now.
Posted In Drupal PlanetAkademy 2023 and 2024
Python Morsels: How to make a tuple
Tuples are technically just immutable lists, but by convention we tend to use tuples and lists for quite different purposes.
Table of contents
- Making tuples in Python
- Tuples are like lists, but immutable
- Tuples are all over the place
- The parentheses are optional: it's the commas that make the tuple
- When should you make a tuple?
- Returning multiple values from a function
- Summary
Here's a list named coordinates:
>>> coordinates = [3, 4, 5] >>> type(coordinates) <class 'list'>It's a list because we used square brackets ([...]) to make it.
If we had used parentheses ((...)) instead, we would've made a tuple:
>>> coordinates = (3, 4, 5) >>> type(coordinates) <class 'tuple'> >>> coordinates (3, 4, 5) Tuples are like lists, but immutableLike a list, a tuple …
Read the full article: https://www.pythonmorsels.com/how-to-make-a-tuple/Amarok 3.1 "Tricks of the Light" released!
The Amarok Development Squad is happy to announce the immediate availability of Amarok 3.1 "Tricks of the Light"!
Coming three months after 3.0.0 and two months after the first bugfix release 3.0.1, the main development focus in 3.1 has been getting Qt6 / KDE Frameworks 6 based version closer. We are not quite there yet, but not that far away anymore. And there are some quite nice new features too! Amarok 3.1.0 brings in a refreshed Last.fm integration, which uses more up-to-date account connection mechanisms, and is better at informing users of any Last.fm errors. Similar Artists context applet does a comeback, and there's naturally also a nice bunch of smaller features and bug fixes; this time the oldest fulfilled feature request was filed just under 15 years ago.
Changes since 3.0.1 FEATURES:- Last.fm plugin updated to use token-based authentication method and to notify user of session key errors (BR 414826, BR 327547)
- Reintroducing Last.fm Similar Artists context applet - a new Amarok 3 version
- Remember the previous destination provider when saving playlist (BR 216528)
- Amarok now depends on KDE Frameworks 5.89.
- Cleanup of unused code and various changes that improve Qt6 compatibility but shouldn't affect functionality. (n.b. one won't be able to compile a Qt6 Amarok with 3.1 yet, but perhaps with the eventual 3.2)
- Remove old derelict openDesktop.org integrations from about dialog. This also removes the dependency to Attica framework.
- Disable gapless playback if ReplayGain is active and the following track is not from same album, to avoid volume spikes due to delay in the applying of ReplayGain (BR 299461)
- Small UI and compilation fixes
- Fix saving and restoring playlist queue on quit / restart (BR 338741)
- Fix system tray icon menu reordering
- Fix erroneous apparent zero track progresses on track changes, which caused playcount updates and scrobbles to get skipped (BR 337849, BR 406701)
- Fix 'save playlist' button in playlist controls
- Sort playlist sorting breadcrumb menu by localized names (BR 277146)
- Miscellaneous fixes to saving and loading various playlist file formats, resulting also in improved compatibility with other software (including BR 435779, BR 333745)
- Don't show false reordering visual hints on a sorted playlist (BR 254821)
- Fix multiple instances of web services appearing in Internet menu after saving plugin config.
- Show podcast provider actions for non-empty podcast categories, too (BR 371192)
- Fix threading-related crashes in CoverManager (BR 490147)
In comparison to changes between 2.9 to 3.0, the git repository statistics between 3.0 and 3.1 are somewhat short:
Tuomas Nurmi: 164 commits, +11910, -29957
l10n daemon script: 97 commits, +207075, -237380
Pino Toscano: 13 commits, +1, -11152
However, this is an excellent spot to send a huge thank you out to everyone who has been on board outside the git history; translators, packagers, bug reporters, writers, commenters, and of course: users - music fans all around the world! Happy listening, everyone! You rok!
Getting AmarokIn addition to source code, Amarok is available for installation from many distributions' package repositories, which are likely to update to 3.1.0 soon. A flatpak is currently available on flathub-beta.
Packager sectionYou can find the package on download.kde.org and it has been signed with Tuomas Nurmi's GPG key.
Wim Leers: XB week 10: no field widget left behind
The Cypress front-end testing infrastructure clean-up landed on Monday, so this week we’ve already been seeing increased velocity! Last week, we landed the initial implementation of the primary menu, this week it was improved by Harumi “hooroomoo” Jang:
XB’s primary menu now closes after dropping a dragged component onto the canvas. Issue #3458617, image by Harumi.
{kind=link}
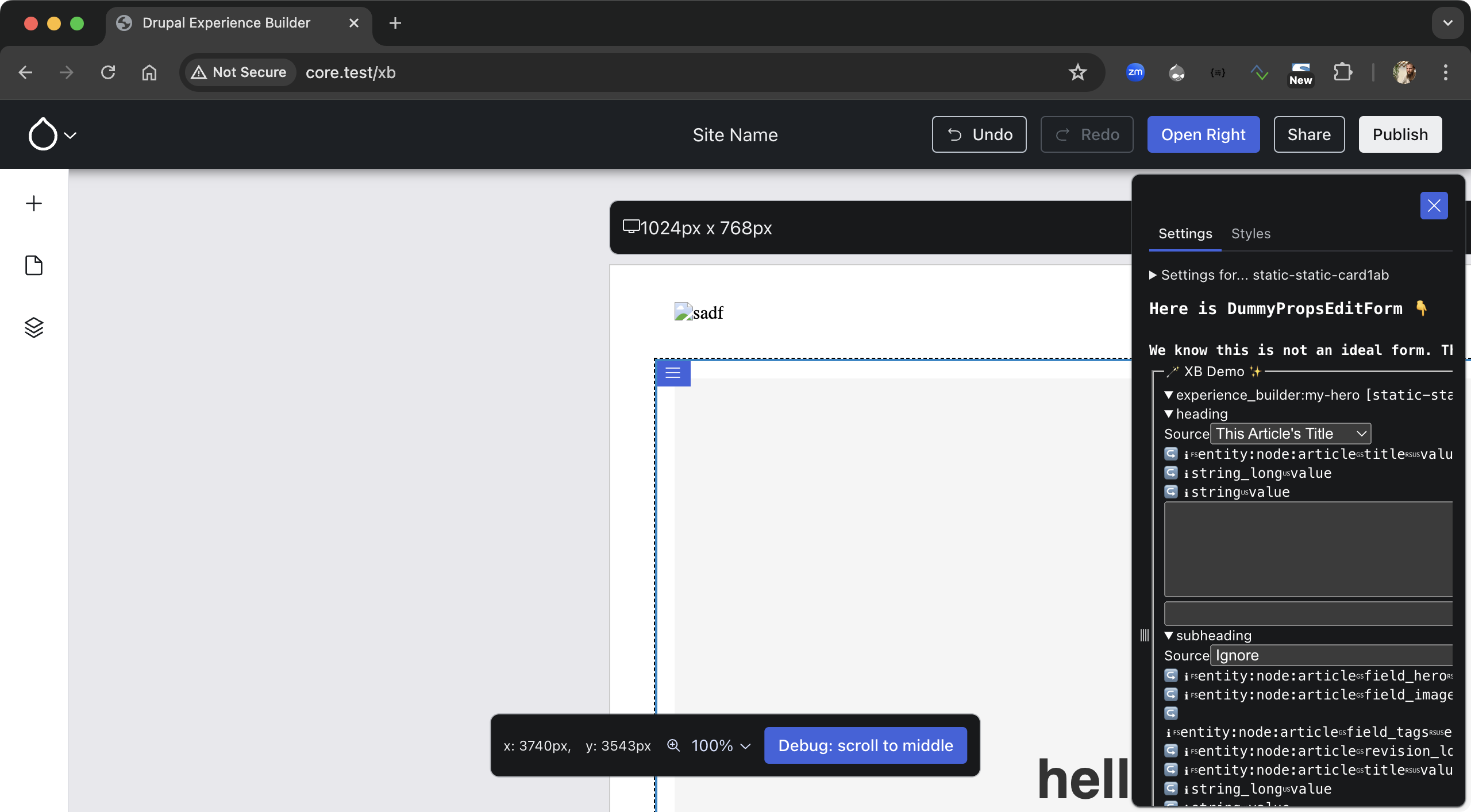
We saw a huge leap forward this week, thanks to Ben “bnjmnm” Mullins! He’s taking an unchanged PHP-based form definition and is rendering it using React and TSX! :O
Why? To prove we can render existing (core/contrib/custom) Field Widgets, because a goal for XB is to keep existing functionality working. Here’s what that looks like:
A React+TSX-rendered Drupal form to edit the props of the selected component. Incredibly ugly, because no CSS/JS is loaded yet, but mostly because the original Drupal form also is incredibly ugly — you’re seeing part of TwoTerribleTextAreasWidget (written by me to get us started)! Expect significant improvements in the coming weeks.
{kind=link}
That screenshot does not do Ben’s monumental work justice. We’re of course already planning to improve that, starting with … no longer using TwoTerribleTextAreasWidget: #3461422: Evolve component instance edit form to become simpler: generate a Field Widget directly. Expect future screenshots and GIFs to be far more convincing :)
This leap also made it became critically important that the Cypress end-to-end tests (tests/src/Cypress/cypress/e2e/xb-general.cy.js) would actually test both the client and server, with the client actually talking to the server. (Until now, xb-general.cy.js was talking to the mock server!) So, Ben also made that happen. (Long overdue ever since the client and server first got connected … 4 weeks ago.)
Back endOn the back-end side, Ben also improved DX and velocity by removing XB’s dependency on the sdc_test module, which was kinda tricky to install (due to it being a test-only module). This simplifies the onboarding/contribution experience, and makes it easier to try the 0.x branch of the XB module too!
Ted “tedbow” Bowman landed the thorough validation for the component tree list: #3456024: Lift most logic out of ComponentTreeItem::preSave() and into a new validation constraint — yay!
What’s cool is that this one validation constraint is being used to validate both an Experience Builder (XB) field instance on a content entity and the default value of the XB field in config (yes, config schema validation at work!). This means slower progress, but means more reliable foundations, because there’s no separate code paths, no distinct semantics. This is crucial to meet the 14. Configuration management and 1.2 Design system (foundations), 45. Content type template variants and many other product requirements.
In other words: it is an important stepping stone towards both #3446722: Introduce an example set of representative SDC components; transition from “component list” to “component tree” and #3455629: [later phase] [META] 7. Content type templates — aka “default layouts” — affects the tree+props data model
Now that that is in, Ted will begin work next on #3460856: Create validation constraint for ComponentTreeStructure, which is a hard blocker for #3446722.
In progressSo many high-impact MRs having landed this week — I’ve simply omitted the smaller ones that are more housekeeping-esque. In closing, there are also some interesting things in progress:
- Lee “larowlan” Rowlands and I met to dive into his draft/proposal MR on #3454519: [META] Support component types other than SDC. Lee provided context for the 5 different parts that his MR consists of and … I liked the direction each one :) We can’t merge as-is, because A) upstream changed quite a bit since then, B) some things we agreed should change. I’ve summarized our conversation, Lee will be extracting MRs for the different pieces :)
- Jesse “jessebaker” Baker and Lee have been making progress on #3453690: [META] Real-time preview: supporting back-end infrastructure
- #3454257: Allow Experience Builder fields to support Asymmetric and Symmetric translations is on the verge of being finished by Ted
- I revived #3450308: Create an Open API spec for the current mock HTTP requests, because that is growing ever more important
… and some notable new issues:
- Lauri created #3461431: Improve client side error handling, where I suggested to use the technique that we used in Acquia Migrate: Accelerate’s React UI, which worked out very well
- by yours truly: #3461499: Introduce new PropShapeInput config entity type — with strong +1 from Lee :)
- by yours truly: #3461490: Document the current JSON-based data model, and describe in an ADR, but will be impacted by the above, so holding off until that lands
- finally: Gauravvvv created #3462074: Option to change the icon for components on the page hierarchy display — which if we end up doing, would require additions to Single-Directory Components’ metadata
I’m pretty confident next week will be more exciting still (well, has been … because I’m a few weeks behind on writing these posts!)
Week 10 was July 15–21, 2024.
{kind=link}
{kind=link}
mark.ie: My Drupal Core Contributions for week-ending August 2nd, 2024
Here's what I've been working on for my Drupal contributions this week. Thanks to Code Enigma for sponsoring the time to work on these.
Bits from Debian: Bits from the DPL
Dear Debian community,
this are my bits from DPL written at my last day at another great DebConf.
DebConf attendanceAt the beginning of July, there was some discussion with the bursary and content team about sponsoring attendees. The discussion continued at DebConf. I do not have much experience with these discussions. My summary is that while there is an honest attempt to be fair to everyone, it did not seem to work for all, and some critical points for future discussion remained. In any case, I'm thankful to the bursary team for doing such a time-draining and tedious job.
Popular packages not yet on Salsa at allOtto Kekäläinen did some interesting investigation about Popular packages not yet on Salsa at all. I think I might provide some more up to date list soon by some UDD query which considers more recent uploads than the trends data soon. For instance wget was meanwhile moved to Salsa (thanks to Noël Köthe for this).
Keep on contacting more teamsI kept on contacting teams in July. Despite I managed to contact way less teams than I was hoping I was able to present some conclusions in the Debian Teams exchange BoF and Slide 16/23 of my Bits from the DPL talk. I intend to do further contacts next months.
Nominating Jeremy Bícha for GNOME Advisory BoardI've nominated Jeremy Bícha to GNOME Advisory Board. Jeremy has volunteered to represent Debian at GUADEC in Denver.
DebCamp / DebConfI attended DebCamp starting from 22 July evening and had a lot of fun with other attendees. As always DebConf is some important event nearly every year for me. I enjoyed Korean food, Korean bath, nature at the costline and other things.
I had a small event without video coverage Creating web galleries including maps from a geo-tagged photo collection. At least two attendees of this workshop confirmed success in creating their own web galleries.
I used DebCamp and DebConf for several discussions. My main focus was on discussions with FTP master team members Luke Faraone, Sean Whitton, and Utkarsh Gupta. I'm really happy that the four of us absolutely agree on some proposed changes to the structure of the FTP master team, as well as changes that might be fruitful for the work of the FTP master team itself and for Debian developers regarding the processing of new packages.
My explicit thanks go to Luke Faraone, who gave a great introduction to FTP master work in their BoF. It was very instructive for the attending developers to understand how the FTP master team checks licenses and copyright and what workflow is used for accepting new packages.
In the first days of DebConf, I talked to representatives of DebConf platinum sponsor WindRiver, who announced the derivative eLxr. I warmly welcome this new derivative and look forward to some great cooperation. I also talked to the representative of our gold sponsor, Microsoft.
My first own event was the Debian Med BoF. I'd like to repeat that it might not only be interesting for people working in medicine and microbiology but always contains some hints how to work together in a team.
As said above I was trying to summarise some first results of my team contacts and got some further input from other teams in the Debian Teams exchange BoF.
Finally, I had my Bits from DPL talk. I received positive responses from attendees as well as from remote participants, which makes me quite happy. For those who were not able to join the events on-site or remotely, the videos of all events will be available on the DebConf site soon. I'd like to repeat the explicit need for some volunteers to join the Lintian team. I'd also like to point out the "Tiny tasks" initiative I'd like to start (see below).
BTW, if someone might happen to solve my quiz for the background images there is a summary page in my slides which might help to assign every slide to some DebConf. I could assume that if you pool your knowledge you can solve more than just the simple ones. Just let me know if you have some solution. You can add numbers to the rows and letters to the columns and send me:
2000/2001: Uv + Wx 2002: not attended 2003: Yz 2004: not attended 2005: 2006: not attended 2007: ... 2024: A1This list provides some additional information for DebConfs I did not attend and when no video stream was available. It also reminds you about the one I uncovered this year and that I used two images from 2001 since I did not have one from 2000. Have fun reassembling good memories.
Tiny tasks: Bug of the dayAs I mentioned in my Bits from DPL talk, I'd like to start a "Tiny tasks" effort within Debian. The first type of tasks will be the Bug of the day initiative. For those who would like to join, please join the corresponding Matrix channel. I'm curious to see how this might work out and am eager to gain some initial experiences with newcomers. I won't be available until next Monday, as I'll start traveling soon and have a family event (which is why I need to leave DebConf today after the formal dinner).
Kind regards from DebConf in Busan Andreas.
Drupal In the News: Drupal launches Drupal 11, the latest version of the Open Source CMS
PORTLAND, Ore., 1 August 2024—Drupal, the most powerful open source content management system for everyone from Fortune 500 enterprise companies to mission-driven nonprofits and entrepreneurial small businesses, is launching the latest upgrade to its popular software.
Drupal 11 continues enhancing the strengths of the platform. It makes structured content, workflows, and content governance more flexible and easier for ambitious builders.
Drupal 11 is designed to empower ambitious site builders to build exceptional websites and to accelerate Drupal's innovation,” says Dries Buytaert, Founder and Project Lead of Drupal. “With Drupal 11, we've made Drupal more intuitive, powerful, and flexible, ensuring it continues to lead in web development and digital experience creation."
This latest version of Drupal brings together code and design for a refreshed CMS navigation experience, with an updated toolbar and a collapsible left-hand menu, all designed to ensure a seamless development experience.
With new Recipes functionality, you can add new features to your website instantly by applying a set of predefined configuration. A recipe can provide anything that can be configured in Drupal, from a simple content type to a full suite of features. You can create your own recipes to share or reuse, or apply recipes created by other Drupal users. Recipes are experimental in this release but already usable and expected to be stable in 11.1.
Single-Directory Components simplify front-end development by consolidating all necessary code into a single directory, making components self-contained and effortlessly reusable.
Drupal’s high performance means it runs fast by default with swift page loading, and Drupal 11 is even faster than previous versions, running up to 50% faster on PHP 8.3.
Accessible for every userDrupal’s core strengths include its accessibility, security, multilingual capabilities, and flexible features.
Thousands of developers worldwide contribute their expertise to ensure that Drupal is continuously pioneering the industry in these strengths. Supported by a global community of domain experts, it offers multilingual support with over 100 languages.
Drupal 11 improves upon these core strengths with various features suitable for developing simple websites or complex web applications.
Accessibility is a key strength of Drupal,” says Tim Doyle, CEO of the Drupal Association. “The Open Web is for everyone, and our continual focus on accessibility, multilingual capabilities, and flexibility is intended to ensure that Drupal is a beacon of inclusiveness in an online world where many try to build walls and barriers to entry.”
With more features coming soonAutomatic Updates and Project Browser are two key features slated for a future release of Drupal 11 and are currently under development as contributed modules.
Drupal’s open source innovation keeps pressing ahead with the release of Drupal 11, including milestone features like Automatic Updates and Project Browser. These features will be key to the success of the new Drupal Starshot project, which will see Drupal become even easier to use for anyone wanting to unleash the power of the world’s leading enterprise CMS.” - Owen Lansbury, Drupal Association Board Chair
Automatic Updates module will apply patch-level updates to Drupal core in a separate, sandboxed copy of your site to keep you up and running without any interruptions. It can detect and report problems at every stage of the update process, so you don't have to discover them after an update is live. It automatically detects database updates and helps you run them during the process.
Project Browser will make it easy for site builders to extend the functionality, look and feel of Drupal. It provides a search interface in the Extend section of the Admin UI to find contributed modules and themes and research their capabilities. Once an extension is selected, instructions are provided on installing it on your site, all without leaving your website.
Next stepsTo start using Drupal 11, visit the Drupal 11 landing page. If you have questions about upgrading to Drupal 11, check out the FAQ page.
To get help onboarding to Drupal 11 or creating a digital experience from the ground up, connect with one of our Drupal Certified Partners located around the world.
About Drupal and the Drupal AssociationDrupal is the open source content management software trusted by millions of people and organizations worldwide. It’s supported by a network of over 10k professionals and over 100 Drupal Certified Partners. The Drupal Association is a nonprofit organization dedicated to accelerating Drupal innovation and supporting the growth of the open source community. This work delivers value to businesses, the digital community, and users of Drupal, in alignment with Drupal’s commitment to the Open Web.
Dries Buytaert: Drupal 11 released
Today is a big day for Drupal as we officially released Drupal 11!
In recent years, we've seen an uptick in innovation in Drupal. Drupal 11 continues this trend with many new and exciting features. You can see an overview of these improvements in the video below:
Drupal 11 has been out for less than six hours, and updating my personal site was my first order of business this morning. I couldn't wait! Dri.es is now running on Drupal 11.
I'm particularly excited about two key features in this release, which I believe are transformative and will likely reshape Drupal in the years ahead:
- Recipes (experimental): This feature allows you to add new features to your website by applying a set of predefined configurations.
- Single-Directory Components: SDCs simplify front-end development by providing a component-based workflow where all necessary code for each component lives in a single, self-contained directory.
These two new features represent a major shift in how developers and site builders will work with Drupal, setting the stage for even greater improvements in future releases. For example, we'll rely heavily on them in Drupal Starshot.
Drupal 11 is the result of contributions from 1,858 individuals across 590 organizations. These numbers show how strong and healthy Drupal is. Community involvement remains one of Drupal's greatest strengths. Thank you to everyone who contributed to Drupal 11!
Dries Buytaert: Sydney Opera House using Drupal
Across its 50-year history, the Sydney Opera House has welcomed musicians, dancers, actors, playwrights, filmmakers, contemporary artists, and thinkers who have both challenged and defined the cultural scene. As a result, the Sydney Opera House draws millions of visitors from around the world each year.
Not only is the Sydney Opera House of incredible cultural importance, it's also an architectural masterpiece. Its unique design makes it one of the most iconic buildings in the world, and has earned it a place as a UNESCO World Heritage Site.
Last year, the Sydney Opera House chose to migrate its website to Drupal. Today, it is running Drupal 10. The decision by such a prestigious institution to relaunch their website on Drupal highlights Drupal's flexibility, security, and ability to manage complex websites.
A couple of weeks ago, during my visit to Australia, I met with the Drupal team at the Sydney Opera House. I was particularly impressed by the team's dedication to using Open Source to expand cultural access and their enthusiasm for collaborating with other arts and cultural organizations. Their focus on innovation, inclusivity, and collaboration perfectly aligns with the core values of Open Source and the Open Web. Drupal is such a great solution for them!
Colin Watson: Free software activity in July 2024
My Debian contributions this month were all sponsored by Freexian.
You can also support my work directly via Liberapay.
OpenSSHAt the start of the month, I uploaded a quick fix (via Salvatore Bonaccorso) for a regression from CVE-2006-5051, found by Qualys; this was because I expected it to take me a bit longer to merge OpenSSH 9.8, which had the full fix.
This turned out to be a good guess: it took me until the last day of the month to get the merge done. OpenSSH 9.8 included some substantial changes to split the server into a listener binary and a per-session binary, which required some corresponding changes in the GSS-API key exchange patch. At this point I was very grateful for the GSS-API integration test contributed by Andreas Hasenack a little while ago, because otherwise I might very easily not have noticed my mistake: this patch adds some entries to the key exchange algorithm proposal, and on the server side I’d accidentally moved that to after the point where the proposal is sent to the client, which of course meant it didn’t work at all. Even with a failing test, it took me quite a while to spot the problem, involving a lot of staring at strace output and comparing debug logs between versions.
There are still some regressions to sort out, including a problem with socket activation, and problems in libssh2 and Twisted due to DSA now being disabled at compile-time.
Speaking of DSA, I wrote a release note for this change, which is now merged.
GCC 14 regressionsI fixed a number of build failures with GCC 14, mostly in my older packages: grub (legacy), imaptool, kali, knews, and vigor.
autopkgtestI contributed a change to allow maintaining Incus container and VM images in parallel. I use both of these regularly (containers are faster, but some tests need full machine isolation), and the build tools previously didn’t handle that very well.
I now have a script that just does this regularly to keep my images up to date (although for now I’m running this with PATH pointing to autopkgtest from git, since my change hasn’t been released yet):
RELEASE=sid autopkgtest-build-incus images:debian/trixie RELEASE=sid autopkgtest-build-incus --vm images:debian/trixie Python teamI fixed dnsdiag’s uninstallability in unstable, and contributed the fix upstream.
I reverted python-tenacity to an earlier version due to regressions in a number of OpenStack packages, including octavia and ironic. (This seems to be due to #486 upstream.)
I fixed a build failure in python3-simpletal due to Python 3.12 removing the old imp module.
I added non-superficial autopkgtests to a number of packages, including httmock, py-macaroon-bakery, python-libnacl, six, and storm.
I switched a number of packages to build using PEP 517 rather than calling setup.py directly, including alembic, constantly, hyperlink, isort, khard, python-cpuinfo, and python3-onelogin-saml2. (Much of this was by working through the missing-prerequisite-for-pyproject-backend Lintian tag, but there’s still lots to do.)
I upgraded frozenlist, ipykernel, isort, langtable, python-exceptiongroup, python-launchpadlib, python-typeguard, pyupgrade, sqlparse, storm, and uncertainties to new upstream versions. In the process, I added myself to Uploaders for isort, since the previous primary uploader has retired.
Other odds and endsI applied a suggestion by Chris Hofstaedtler to create /etc/subuid and /etc/subgid in base-passwd, since the login package is no longer essential.
I fixed a wireless-tools regression due to iproute2 dropping its (/usr)/sbin/ip compatibility symlink.
I applied a suggestion by Petter Reinholdtsen to add AppStream metainfo to pcmciautils.
Real Python: The Real Python Podcast – Episode #215: Fetching Graph Data in Django With Strawberry & Prototype Purgatory
How do you integrate GraphQL into your Python web development? How about quickly building graph-based APIs inside Django's battery-included framework? Christopher Trudeau is back on the show this week, bringing another batch of PyCoder's Weekly articles and projects.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Web Review, Week 2024-31
Let’s go for my web review for the week 2024-31.
Third-party cookies have got to go | W3CTags: tech, browser, privacy, google
Apparently this needs to be spelled out for browser providers to understand this needs to go.
https://www.w3.org/blog/2024/third-party-cookies-have-got-to-go/
Tags: tech, security
Looks like we really get back to the same type of vulnerabilities… it’s only a couple of dozens usual suspects.
https://cwe.mitre.org/top25/archive/2023/2023_stubborn_weaknesses.html
Tags: tech, security, empathy
A very good piece, it’s nice it’s been resurrected. This is a good reminder that the blame and shame of the user for general computing security is plain wrong. It’s we the developers and the UX designers who should be kept on our toes.
https://harihareswara.net/posts/2024/a-story-about-jessica-by-swiftonsecurity/
Tags: tech, ai, trust, marketing
Interesting finding. Looks like the trust is not very high in the general public towards products with AI.
Tags: tech, ai, machine-learning, gpt
This ought to be easier, this should help a bit.
https://github.com/healsdata/ai-training-opt-out
Tags: tech, cpu, amd, performance
Interesting article about what’s coming for the branch predictor in the Zen 5 architecture from AMD.
Tags: tech, linux, kernel, trust, sustainability
Having a bootstrappable build is definitely not an easy feat! It is something necessary to do though for trust and for longevity reasons.
https://lwn.net/SubscriberLink/983340/25f5b1f6b1247079/
Tags: tech, linux, kernel
Looks like a good online reference resource if you need to make your own modules.
https://sysprog21.github.io/lkmpg/
Tags: tech, c++, safety
It’s nice to see progress coming to lifetime checks in C++ compilers.
https://lemire.me/blog/2024/07/26/safer-code-in-c-with-lifetime-bounds/
Tags: tech, databases, storage, filesystem, sqlite, performance
Interesting experiment showing that BLOBs in a database can be a good alternative to individual files on a filesystem in some contexts.
https://sqlite.org/fasterthanfs.html
Tags: tech, tools, internet, networking
This is not said enough but this is indeed a very useful tool. There is a few tricks I didn’t know in this list.
https://martinheinz.dev/blog/113
Tags: tech, python, debugging
Nice little utility for Python programming. Helps to introspect on the spot.
https://igrek51.github.io/wat/
Tags: tech, version-control, git
Oh fancy! I didn’t know this git log parameter. Definitely useful.
https://nerderati.com/tracing-the-evolution-of-a-python-function-with-git-log/
Tags: tech, 3d, shader, graphics
Good collection of techniques to procedurally generating scene assets.
https://cprimozic.net/blog/tools-and-techniques-for-procedural-gamedev/
Tags: tech, graphics, shader, 3d, simulation
Very neat shader for a procedural earth simulation. The breakdown is interesting covering the tricks being used in this shader.
https://davidar.io/post/sim-glsl
Tags: tech, infrastructure, virtualization, security, safety, complexity, cloud
Definitely not as fashionable as the kubernetes craze. This gives very interesting properties that multi-tenant applications can’t really provide. The article is nice as it lays out properly the pros and cons, helps make the choice depending on the context.
https://blog.thinkst.com/2024/07/unfashionably-secure-why-we-use-isolated-vms.html
Tags: tech, engineering, management, product-management
This is an interesting framing of the question. We often talk about the scope, but how thorough are we when handling it? Should we even be that thorough? Might make some of the trade offs more explicit.
https://www.theengineeringmanager.com/growth/scope-how-about-thoroughness/
Tags: tech, management
Interesting concept of task relevant maturity. I should probably take it more into account myself.
https://substack.com/@refactoring/note/c-63277431
Bye for now!
The Drop is Always Moving: Drupal 11 is now available! Check out the announcement video at https://youtu.be/Dw6_fBZ6D5Y
Drupal 11 is now available! Check out the announcement video at https://youtu.be/Dw6_fBZ6D5Y
Drupal Association blog: Drupal launches Drupal 11, the latest version of the Open Source CMS
PORTLAND, Ore., 1 August 2024—Drupal, the most powerful open source content management system for everyone from Fortune 500 enterprise companies to mission-driven nonprofits and entrepreneurial small businesses, is launching the latest upgrade to its popular software.
Drupal 11 continues enhancing the strengths of the platform. It makes structured content, workflows, and content governance more flexible and easier for ambitious builders.
Drupal 11 is designed to empower ambitious site builders to build exceptional websites and to accelerate Drupal's innovation,” says Dries Buytaert, Founder and Project Lead of Drupal. “With Drupal 11, we've made Drupal more intuitive, powerful, and flexible, ensuring it continues to lead in web development and digital experience creation."
This latest version of Drupal brings together code and design for a refreshed CMS navigation experience, with an updated toolbar and a collapsible left-hand menu, all designed to ensure a seamless development experience.
With new Recipes functionality, you can add new features to your website instantly by applying a set of predefined configuration. A recipe can provide anything that can be configured in Drupal, from a simple content type to a full suite of features. You can create your own recipes to share or reuse, or apply recipes created by other Drupal users. Recipes are experimental in this release but already usable and expected to be stable in 11.1.
Single-Directory Components simplify front-end development by consolidating all necessary code into a single directory, making components self-contained and effortlessly reusable.
Drupal’s high performance means it runs fast by default with swift page loading, and Drupal 11 is even faster than previous versions, running up to 50% faster on PHP 8.3.
Accessible for every userDrupal’s core strengths include its accessibility, security, multilingual capabilities, and flexible features.
Thousands of developers worldwide contribute their expertise to ensure that Drupal is continuously pioneering the industry in these strengths. Supported by a global community of domain experts, it offers multilingual support with over 100 languages.
Drupal 11 improves upon these core strengths with various features suitable for developing simple websites or complex web applications.
Accessibility is a key strength of Drupal,” says Tim Doyle, CEO of the Drupal Association. “The Open Web is for everyone, and our continual focus on accessibility, multilingual capabilities, and flexibility is intended to ensure that Drupal is a beacon of inclusiveness in an online world where many try to build walls and barriers to entry.”
With more features coming soonAutomatic Updates and Project Browser are two key features slated for a future release of Drupal 11 and are currently under development as contributed modules.
Drupal’s open source innovation keeps pressing ahead with the release of Drupal 11, including milestone features like Automatic Updates and Project Browser. These features will be key to the success of the new Drupal Starshot project, which will see Drupal become even easier to use for anyone wanting to unleash the power of the world’s leading enterprise CMS.” - Owen Lansbury, Drupal Association Board Chair
Automatic Updates module will apply patch-level updates to Drupal core in a separate, sandboxed copy of your site to keep you up and running without any interruptions. It can detect and report problems at every stage of the update process, so you don't have to discover them after an update is live. It automatically detects database updates and helps you run them during the process.
Project Browser will make it easy for site builders to extend the functionality, look and feel of Drupal. It provides a search interface in the Extend section of the Admin UI to find contributed modules and themes and research their capabilities. Once an extension is selected, instructions are provided on installing it on your site, all without leaving your website.
Next stepsTo start using Drupal 11, visit the Drupal 11 landing page. If you have questions about upgrading to Drupal 11, check out the FAQ page.
To get help onboarding to Drupal 11 or creating a digital experience from the ground up, connect with one of our Drupal Certified Partners located around the world.
About Drupal and the Drupal AssociationDrupal is the open source content management software trusted by millions of people and organizations worldwide. It’s supported by a network of over 10k professionals and over 100 Drupal Certified Partners. The Drupal Association is a nonprofit organization dedicated to accelerating Drupal innovation and supporting the growth of the open source community. This work delivers value to businesses, the digital community, and users of Drupal, in alignment with Drupal’s commitment to the Open Web.
Golems GABB: Security and Speed Optimization in Drupal 11
Improved scalability and functionality are two promises of the anticipated Drupal 11, which is expected to be a dynamic and innovative release. Even before the release of Drupal 10, anticipation was built around Drupal 11 making it one of the most hyped versions in the history of Drupal.
Drupal 11 discussions and plans were already ongoing as Drupal 10 reached its final stages, showing how forward-thinking this community is. This proactive stance shows that Drupal 11 has a stride ahead towards progressiveness.
Yet, as it is not yet known when exactly Drupal 10 will reach its End-of-Life, one should note though that PHP 8.1, one of its dependencies become obsolete by the year 2024. Therefore, PHP versions starting from PHP 8.2 will have to be provided for compatibility purposes for Drupal 11.
Aigars Mahinovs: Debconf 24 photos
Debconf 24 is coming to a close in Busan, South Korea this year.
I thought that last year in India was hot. This year somehow managed to beat that. With 35C and high humidity the 55 km that I managed to walk between the two conference buildings have really put the pressure on. Thankfully the air conditioning in the talk rooms has been great and fresh water has been plentiful. And the korean food has been excellent and very energetic.
Today I will share with you the main group photo:
You can also see it in:
{kind=link}
The rest of my photos from the event will be published next week. That will give me a bit more time to process them correctly and also give all of you a chance to see these pictures with fresh eyes and stir up new memories from the event.
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
- www-zh-cn @ Savannah: Welcome our new member - bingchuanjuzi
- Matt Glaman: Lenient Composer Plugin officially replaces lenient packages endpoint
- libtool @ Savannah: libtool-2.5.4 released [stable]
- Trey Hunner: Python Black Friday & Cyber Monday sales (2024)
- Security advisories: Drupal core - Moderately critical - Gadget chain - SA-CORE-2024-008
FLOSS Research
- Give Your Input on the State of Open Source Survey
- Open Data and Open Source AI: Charting a course to get more of both
- The Open Source Initiative and the Eclipse Foundation to Collaborate on Shaping Open Source AI (OSAI) Public Policy
- ClearlyDefined v2.0 adds support for LicenseRefs
- ClearlyDefined at SOSS Fusion 2024: a collaborative solution to Open Source license compliance