
Planet Debian
François Marier: Blocking comment spammers on an Ikiwiki blog
Despite comments on my ikiwiki blog being fully moderated, spammers have been increasingly posting link spam comments on my blog. While I used to use the blogspam plugin, the underlying service was likely retired circa 2017 and its public repositories are all archived.
It turns out that there is a relatively simple way to drastically reduce the amount of spam submitted to the moderation queue: ban the datacentre IP addresses that spammers are using.
Looking up AS numbersIt all starts by looking at the IP address of a submitted comment:
From there, we can look it up using whois:
$ whois -r 2a0b:7140:1:1:5054:ff:fe66:85c5 % This is the RIPE Database query service. % The objects are in RPSL format. % % The RIPE Database is subject to Terms and Conditions. % See https://docs.db.ripe.net/terms-conditions.html % Note: this output has been filtered. % To receive output for a database update, use the "-B" flag. % Information related to '2a0b:7140:1::/48' % Abuse contact for '2a0b:7140:1::/48' is 'abuse@servinga.com' inet6num: 2a0b:7140:1::/48 netname: EE-SERVINGA-2022083002 descr: servinga.com - Estonia geoloc: 59.4424455 24.7442221 country: EE org: ORG-SG262-RIPE mnt-domains: HANNASKE-MNT admin-c: CL8090-RIPE tech-c: CL8090-RIPE status: ASSIGNED mnt-by: MNT-SERVINGA created: 2020-02-18T11:12:49Z last-modified: 2024-12-04T12:07:26Z source: RIPE % Information related to '2a0b:7140:1::/48AS207408' route6: 2a0b:7140:1::/48 descr: servinga.com - Estonia origin: AS207408 mnt-by: MNT-SERVINGA created: 2020-02-18T11:18:11Z last-modified: 2024-12-11T23:09:19Z source: RIPE % This query was served by the RIPE Database Query Service version 1.114 (SHETLAND)The important bit here is this line:
origin: AS207408which referts to Autonomous System 207408, owned by a hosting company in Germany called Servinga.
Looking up IP blocksAutonomous Systems are essentially organizations to which IPv4 and IPv6 blocks have been allocated.
These allocations can be looked up easily on the command line either using a third-party service:
$ curl -sL https://ip.guide/as207408 | jq .routes.v4 >> servinga $ curl -sL https://ip.guide/as207408 | jq .routes.v6 >> servingaor a local database downloaded from IPtoASN.
This is what I ended up with in the case of Servinga:
[ "45.11.183.0/24", "80.77.25.0/24", "194.76.227.0/24" ] [ "2a0b:7140:1::/48" ] Preventing comment submissionWhile I do want to eliminate this source of spam, I don't want to block these datacentre IP addresses outright since legitimate users could be using these servers as VPN endpoints or crawlers.
I therefore added the following to my Apache config to restrict the CGI endpoint (used only for write operations such as commenting):
<Location /blog.cgi> Include /etc/apache2/spammers.include Options +ExecCGI AddHandler cgi-script .cgi </Location>and then put the following in /etc/apache2/spammers.include:
<RequireAll> Require all granted # https://ipinfo.io/AS207408 Require not ip 46.11.183.0/24 Require not ip 80.77.25.0/24 Require not ip 194.76.227.0/24 Require not ip 2a0b:7140:1::/48 </RequireAll>Finally, I can restart the website and commit my changes:
$ apache2ctl configtest && systemctl restart apache2.service $ git commit -a -m "Ban all IP blocks from Servinga" Future improvementsI will likely automate this process in the future, but at the moment my blog can go for a week without a single spam message (down from dozens every day). It's possible that I've already cut off the worst offenders.
I have published the list I am currently using.
Petter Reinholdtsen: 121 packages in Debian mapped to hardware for automatic recommendation
For some years now, I have been working on a automatic hardware based package recommendation system for Debian and other Linux distributions. The isenkram system I started on back in 2013 now consist of two subsystems, one locating firmware files using the information provided by apt-file, and one matching hardware to packages using information provided by AppStream. The former is very similar to the mechanism implemented in debian-installer to pick the right firmware packages to install. This post is about the latter system. Thanks to steady progress and good help from both other Debian and upstream developers, I am happy to report that the Isenkram system now are able to recommend 121 packages using information provided via AppStream.
The mapping is done using modalias information provided by the kernel, the same information used by udev when creating device files, and the kernel when deciding which kernel modules to load. To get all the modalias identifiers relevant for your machine, you can run the following command on the command line:
find /sys/devices -name modalias -print0 | xargs -0 sort -uThe modalias identifiers can look something like this:
acpi:PNP0000 cpu:type:x86,ven0000fam0006mod003F:feature:,0000,0001,0002,0003,0004,0005,0006,0007,0008,0009,000B,000C,000D,000E,000F,0010,0011,0013,0015,0016,0017,0018,0019,001A,001B,001C,001D,001F,002B,0034,003A,003B,003D,0068,006B,006C,006D,006F,0070,0072,0074,0075,0076,0078,0079,007C,0080,0081,0082,0083,0084,0085,0086,0087,0088,0089,008B,008C,008D,008E,008F,0091,0092,0093,0094,0095,0096,0097,0098,0099,009A,009B,009C,009D,009E,00C0,00C5,00E1,00E3,00EB,00ED,00F0,00F1,00F3,00F5,00F6,00F9,00FA,00FB,00FD,00FF,0100,0101,0102,0103,0111,0120,0121,0123,0125,0127,0128,0129,012A,012C,012D,0140,0160,0161,0165,016C,017B,01C0,01C1,01C2,01C4,01C5,01C6,01F9,024A,025A,025B,025C,025F,0282 dmi:bvnDellInc.:bvr2.18.1:bd08/14/2023:br2.18:svnDellInc.:pnPowerEdgeR730:pvr:rvnDellInc.:rn0H21J3:rvrA09:cvnDellInc.:ct23:cvr:skuSKU=NotProvided pci:v00008086d00008D3Bsv00001028sd00000600bc07sc80i00 platform:serial8250 scsi:t-0x05 usb:v413CpA001d0000dc09dsc00dp00ic09isc00ip00in00The entries above are a selection of the complete set available on a Dell PowerEdge R730 machine I have access to, to give an idea about the various styles of hardware identifiers presented in the modalias format. When looking up relevant packages in a Debian Testing installation on the same R730, I get this list of packages proposed:
% sudo isenkram-lookup firmware-bnx2x firmware-nvidia-graphics firmware-qlogic megactl wsl %The list consist of firmware packages requested by kernel modules, as well packages with program to get the status from the RAID controller and to maintain the LAN console. When the edac-utils package providing tools to check the ECC RAM status will enter testing in a few days, it will also show up as a proposal from isenkram. In addition, once the mfiutil package we uploaded in October get past the NEW processing, it will also propose a tool to configure the RAID controller.
Another example is the trusty old Lenovo Thinkpad X230, which have hardware handled by several packages in the archive. This is running on Debian Stable:
% isenkram-lookup beignet-opencl-icd bluez cheese ethtool firmware-iwlwifi firmware-misc-nonfree fprintd fprintd-demo gkrellm-thinkbat hdapsd libpam-fprintd pidgin-blinklight thinkfan tlp tp-smapi-dkms tpb %Here there proposal consist of software to handle the camera, bluetooth, network card, wifi card, GPU, fan, fingerprint reader and acceleration sensor on the machine.
Here is the complete set of packages currently providing hardware mapping via AppStream in Debian Unstable: air-quality-sensor, alsa-firmware-loaders, antpm, array-info, avarice, avrdude, bmusb-v4l2proxy, brltty, calibre, colorhug-client, concordance-common, consolekit, dahdi-firmware-nonfree, dahdi-linux, edac-utils, eegdev-plugins-free, ekeyd, elogind, firmware-amd-graphics, firmware-ath9k-htc, firmware-atheros, firmware-b43-installer, firmware-b43legacy-installer, firmware-bnx2, firmware-bnx2x, firmware-brcm80211, firmware-carl9170, firmware-cavium, firmware-intel-graphics, firmware-intel-misc, firmware-ipw2x00, firmware-ivtv, firmware-iwlwifi, firmware-libertas, firmware-linux-free, firmware-mediatek, firmware-misc-nonfree, firmware-myricom, firmware-netronome, firmware-netxen, firmware-nvidia-graphics, firmware-qcom-soc, firmware-qlogic, firmware-realtek, firmware-ti-connectivity, fpga-icestorm, g810-led, galileo, garmin-forerunner-tools, gkrellm-thinkbat, goldencheetah, gpsman, gpstrans, gqrx-sdr, i8kutils, imsprog, ledger-wallets-udev, libairspy0, libam7xxx0.1, libbladerf2, libgphoto2-6t64, libhamlib-utils, libm2k0.9.0, libmirisdr4, libnxt, libopenxr1-monado, libosmosdr0, librem5-flash-image, librtlsdr0, libticables2-8, libx52pro0, libykpers-1-1, libyubikey-udev, limesuite, linuxcnc-uspace, lomoco, madwimax, media-player-info, megactl, mixxx, mkgmap, msi-keyboard, mu-editor, mustang-plug, nbc, nitrokey-app, nqc, ola, openfpgaloader, openocd, openrazer-driver-dkms, pcmciautils, pcscd, pidgin-blinklight, ponyprog, printer-driver-splix, python-yubico-tools, python3-btchip, qlcplus, rosegarden, scdaemon, sispmctl, solaar, spectools, sunxi-tools, t2n, thinkfan, tlp, tp-smapi-dkms, trezor, tucnak, ubertooth, usbrelay, uuu, viking, w1retap, wsl, xawtv, xinput-calibrator, xserver-xorg-input-wacom and xtrx-dkms.
In addition to these, there are several with patches pending in the Debian bug tracking system, and even more where no-one wrote patches yet. Good candiates for the latter are packages with udev rules but no AppStream hardware information.
The isenkram system consist of two packages, isenkram-cli with the command line tools, and isenkram with a GUI background process. The latter will listen for dbus events from udev emitted when new hardware become available (like when inserting a USB dongle or discovering a new bluetooth device), look up the modalias entry for this piece of hardware in AppStream (and a hard coded list of mappings from isenkram - currently working hard to move this list to AppStream), and pop up a dialog proposing to install any not already installed packages supporting this hardware. It work very well today when inserting the LEGO Mindstorms RCX, NXT and EV3 controllers. :) If you want to make sure more hardware related packages get recommended, please help out fixing the remaining packages in Debian to provide AppStream metadata with hardware mappings.
As usual, if you use Bitcoin and want to show your support of my activities, please send Bitcoin donations to my address 15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
Petter Reinholdtsen: What is the most supported MIME type in Debian in 2025?
Seven and twelve years ago, I measured what the most supported MIME type in Debian was, first by analysing the desktop files in all packages in the archive, then by analysing the DEP-11 AppStream data set. I guess it is time to repeat the measurement, only for unstable as last time:
Debian Unstable:
count MIME type ----- ----------------------- 63 image/png 63 image/jpeg 57 image/tiff 54 image/gif 51 image/bmp 50 audio/mpeg 48 text/plain 42 audio/x-mp3 40 application/ogg 39 audio/x-wav 39 audio/x-flac 36 audio/x-vorbis+ogg 35 audio/x-mpeg 34 audio/x-mpegurl 34 audio/ogg 33 application/x-ogg 32 audio/mp4 31 audio/x-scpls 31 application/pdf 29 audio/x-ms-wmaThe list was created like this using a sid chroot:
cat /var/lib/apt/lists/*sid*_dep11_Components-amd64.yml.gz | \ zcat | awk '/^ - \S+\/\S+$/ {print $2 }' | sort | \ uniq -c | sort -nr | head -20It is nice to see that the same number of packages now support PNG and JPEG. Last time JPEG had more support than PNG. Most of the MIME types are known to me, but the 'audio/x-scpls' one I have no idea what represent, except it being an audio format. To find the packages claiming support for this format, the appstreamcli command from the appstream package can be used:
% appstreamcli what-provides mediatype audio/x-scpls | grep Package: | sort -u Package: alsaplayer-common Package: amarok Package: audacious Package: brasero Package: celluloid Package: clapper Package: clementine Package: cynthiune.app Package: elisa Package: gtranscribe Package: kaffeine Package: kmplayer Package: kylin-burner Package: lollypop Package: mediaconch-gui Package: mediainfo-gui Package: mplayer-gui Package: mpv Package: mystiq Package: parlatype Package: parole Package: pragha Package: qmmp Package: rhythmbox Package: sayonara Package: shotcut Package: smplayer Package: soundconverter Package: strawberry Package: syncplay Package: vlc %Look like several video and auto tools understand the format. Similarly one can check out the number of packages supporting the STL format commonly used for 3D printing:
% appstreamcli what-provides mediatype model/stl | grep Package: | sort -u Package: cura Package: freecad Package: open3d-viewer %How strange the slic3r and prusa-slicer packages do not support STL. Perhaps just missing package metadata? Luckily the amount of package metadata in Debian is getting better, and hopefully this way of locating relevant packages for any file format will be the preferred one soon.
As usual, if you use Bitcoin and want to show your support of my activities, please send Bitcoin donations to my address 15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
C.J. Collier: Security concerns regarding OpenSSH mac sha1 in Debian
What is HMAC?
HMAC stands for Hash-Based Message Authentication Code. It’s a specific way to use a cryptographic hash function (like SHA-1, SHA-256, etc.) along with a secret key to produce a unique “fingerprint” of some data. This fingerprint allows someone else with the same key to verify that the data hasn’t been tampered with.
How HMAC Works
Keyed Hashing: The core idea is to incorporate the secret key into the hashing process. This is done in a specific way to prevent clever attacks that might try to bypass the security.
Inner and Outer Hashing: HMAC uses two rounds of hashing. First, the message and a modified version of the key are hashed together. Then, the result of that hash, along with another modified version of the key, are hashed again. This two-step process adds an extra layer of protection.
HMAC in OpenSSH
OpenSSH uses HMAC to ensure the integrity of messages sent back and forth during an SSH session. This prevents an attacker from subtly modifying data in transit.
HMAC-SHA1 with OpenSSH: Is it Weak?
SHA-1 itself is considered cryptographically broken. This means that with enough computing power, it’s possible to find collisions (two different messages that produce the same hash). However, HMAC-SHA1 is generally still considered secure for most purposes. This is because exploiting weaknesses in SHA-1 to break HMAC-SHA1 is much more difficult than just finding collisions in SHA-1.
Should you use it?
While HMAC-SHA1 might still be okay for now, it’s best practice to move to stronger alternatives like HMAC-SHA256 or HMAC-SHA512. OpenSSH supports these, and they provide a greater margin of safety against future attacks.
In Summary
HMAC is a powerful tool for ensuring data integrity. Even though SHA-1 has weaknesses, HMAC-SHA1 in OpenSSH is likely still safe for most users. However, to be on the safe side and prepare for the future, switching to HMAC-SHA256 or HMAC-SHA512 is recommended.
Following are instructions for creating dataproc clusters with sha1 mac support removed:
I can appreciate an excess of caution, and I can offer you some code to produce Dataproc instances which do not allow HMAC authentication using sha1.
Place code similar to this in a startup script or an initialization action that you reference when creating a cluster with gcloud dataproc clusters create:
#!/bin/bash # remove mac specification from sshd configuration sed -i -e 's/^macs.*$//' /etc/ssh/sshd_config # place a new mac specification at the end of the service configuration ssh -Q mac | perl -e \ '@mac=grep{ chomp; ! /sha1/ }; print("macs ", join(",",@mac), $/)' >> /etc/ssh/sshd_config # reload the new ssh service configuration systemctl reload ssh.serviceIf this code is hosted on GCS, you can refer to it with
--initialization-actions=CLOUD_STORAGE_URI,[...]or
--metadata startup-script-url=CLOUD_STORAGE_URI,[...] TweetRussell Coker: Systemd Hardening and Sending Mail
A feature of systemd is the ability to reduce the access that daemons have to the system. The restrictions include access to certain directories, system calls, capabilities, and more. The systemd.exec(5) man page describes them all [1]. To see an overview of the security of daemons run “systemd-analyze security” and to get details of one particular daemon run a command like “systemd-analyze security mon.service”.
I created a Debian wiki page for a systemd-analyze security goal [2]. At this time release goals aren’t a serious thing for Debian so this won’t result in release critical bug reports, but it is still something we can aim for.
For a simple daemon (EG BIND, dhcpd, and syslogd) this isn’t difficult to do. It might be difficult to understand the implications of some changes (especially when restricting system calls) but you can do some quick tests. The functionality of such programs has a limited scope and once you get it basically working it’s done.
For some daemons it’s harder. Network-Manager is one of the well known slightly more difficult cases as it could do things like starting a VPN connection. The larger scope and the use of plugins makes it difficult to test the combinations. The systemd restrictions apply to child processes too unlike restrictions by SE Linux and AppArmor which permit a child process to run in a different security context.
The messages when a daemon fails due to systemd restrictions are usually unclear which makes things harder to setup and makes it more important to get it right.
My “mon” package (which I forked upstream as etbe-mon [3] is one of the difficult daemons as local test can involve probing large parts of the system. But I have got that working reasonably well for most cases.
I have a bug report about running mon with Exim [4]. The problem with this is that Exim has a single process model which means that the process doing local delivery can be a child of the process that initially received the message. So the main mon process needs all the access for delivering mail (writing to /home etc). This also means that every other child of mon will get such access including programs that receive untrusted data from the Internet. Most of the extra access needed by Exim is not a problem, but /home access is a potential risk. It also means that more effort is needed when reviewing the access control.
The problem with this Exim design is that it applies to many daemons. Every daemon that sends email or that potentially could send email in some configuration needs extra access to be granted.
Can Exim be configured to have it’s sendmail -T” type operation just write a file in a spool directory for another program to process? Do we need to grant permissions to most of the system just for Exim?
- [1] https://www.freedesktop.org/software/systemd/man/latest/systemd.exec.html
- [2] https://wiki.debian.org/ReleaseGoals/SystemdAnalyzeSecurity
- [3] https://doc.coker.com.au/projects/etbe-mon/
- [4] Debian Bug #1082646
Related posts:
- Systemd Notes A few months ago I gave a lecture about systemd...
- systemd – a Replacement for init etc The systemd projecct is an interesting concept for replacing init...
- Ethernet Interface Naming With Systemd Systemd has a new way of specifying names for Ethernet...
Reproducible Builds (diffoscope): diffoscope 285 released
The diffoscope maintainers are pleased to announce the release of diffoscope version 285. This version includes the following changes:
[ Chris Lamb ] * Validate --css command-line argument. Thanks to Daniel Schmidt @ SRLabs for the report. (Closes: #396) * Prevent XML entity expansion attacks through vulnerable versions of pyexpat. Thanks to Florian Wilkens @ SRLabs for the report. (Closes: #397) * Print a warning if we have disabled XML comparisons due to a potentially vulnerable version of pyexpat. * Remove (unused) logging facility from a few comparators. * Update copyright years.You find out more by visiting the project homepage.
Michael Ablassmeier: sshcont
Due to circumstances:
sshcont: ssh daemon that starts and enters a throwaway docker container for testing
Adnan Hodzic: How I replaced myself with a genAI chatbot using Gemini
Sergio Talens-Oliag: Command line tools to process templates
I’ve always been a fan of template engines that work with text files, mainly to work with static site generators, but also to generate code, configuration files, and other text-based files.
For my own web projects I used to go with Jinja2, as all my projects were written in Python, while for static web sites I used the template engines included with the tools I was using, i.e. Liquid with Jekyll and Go Templates (based on the text/template and the html/template go packages) for Hugo.
When I needed to generate code snippets or configuration files from shell scripts I used to go with sed and/or envsubst, but lately things got complicated and I started to use a command line application called tmpl that uses the Go Template Language with functions from the Sprig library.
tmplI’ve been using my fork of the tmpl program to process templates on CI/CD pipelines (gitlab-ci) to generate configuration files and code snippets because it uses the same syntax used by helm (easier to use by other DevOps already familiar with the format) and the binary is small and can be easily included into the docker images used by the pipeline jobs.
One interesting feature of the tmpl tool is that it can read values from command line arguments and from multiple files in different formats (YAML, JSON, TOML, etc) and merge them into a single object that can be used to render the templates.
There are alternatives to the tmpl tool and I’ve looked at them (i.e. simple ones like go-template-cli or complex ones like gomplate), but I haven’t found one that fits my needs.
For my next project I plan to evaluate a move to a different tool or template format, as tmpl is not being actively maintained (as I said, I’m using my own fork) and it is not included on existing GNU/Linux distributions (I packaged it for Debian and Alpine, but I don’t want to maintain something like that without an active community and I’m not interested in being the upstream myself, as I’m trying to move to Rust instead of Go as the compiled programming language for my projects).
Mini JinjaLooking for alternate tools to process templates on the command line I found the minijinja rust crate, a minimal implementation of the Jinja2 template engine that also includes a small command line utility (minijinja-cli) and I believe I’ll give it a try on the future for various reasons:
- I’m already familiar with the Jinja2 syntax and it is widely used on the industry.
- On my code I can use the original Jinja2 module for Python projects and MiniJinja for Rust programs.
- The included command line utility is small and easy to use, and the binaries distributed by the project are good enough to add them to the docker container images used by CI/CD pipelines.
- As I want to move to Rust I can try to add functionalities to the existing command line client or create my own version of it if they are needed (don’t think so, but who knows).
Dirk Eddelbuettel: RcppFastFloat 0.0.5 on CRAN: New Upstream, Updates
A new minor release of RcppFastFloat just arrived on CRAN. The package wraps fast_float, another nice library by Daniel Lemire. For details, see the arXiv preprint or published paper showing that one can convert character representations of ‘numbers’ into floating point at rates at or exceeding one gigabyte per second.
This release updates the underlying fast_float library version to the current version 7.0.0, and updates a few packaging aspects.
Changes in version 0.0.5 (2025-01-15)No longer set a compilation standard
Updates to continuous integration, badges, URLs, DESCRIPTION
Update to fast_float 7.0.0
Per CRAN Policy comment-out compiler 'diagnostic ignore' instances
Courtesy of my CRANberries, there is also a diffstat report for this release. For questions, suggestions, or issues please use the [issue tracker][issue tickets] at the GitHub repo.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. If you like this or other open-source work I do, you can now sponsor me at GitHub.
Thomas Lange: FAI 6.2.5 and new ISO available
The new years starts with a FAI release. FAI 6.2.5 is available and contains many small improvements. A new feature is that the command fai-cd can now create ISOs for the ARM64 architecture.
The FAIme service uses the newest FAI version and the Debian most recent point release 12.9. The FAI CD images were also updated. The Debian packages of FAI 6.2.5 are available for Debian stable (aka bookworm) via the FAI repository adding this line to sources.list:
deb https://fai-project.org/download bookworm koelnUsing the tool extrepo, you can also add the FAI repository to your host
# extrepo enable faiFAI 6.2.5 will soon be available in Debian testing via the official Debian mirrors.
Dirk Eddelbuettel: RProtoBuf 0.4.23 on CRAN: Mulitple Updates
A new maintenance release 0.4.23 of RProtoBuf arrived on CRAN earlier today, about one year after the previous update. RProtoBuf provides R with bindings for the Google Protocol Buffers (“ProtoBuf”) data encoding and serialization library used and released by Google, and deployed very widely in numerous projects as a language and operating-system agnostic protocol.
This release brings a number of contributed PRs which are truly appreciate. As the package dates back fifteen+ years, some code corners can be crufty which was addressed in several PRs, as were two updates for ongoing changes / new releases of ProtoBuf itself. I also made the usual changes one does to continuous integrations, README badges and URL as well as correcting one issue the checkbashism script complained about.
The following section from the NEWS.Rd file has full details.
Changes in RProtoBuf version 0.4.23 (2022-12-13)More robust tests using toTextFormat() (Xufei Tan in #99 addressing #98)
Various standard packaging updates to CI and badges (Dirk)
Improvements to string construction in error messages (Michael Chirico in #102 and #103)
Accommodate ProtoBuf 26.x and later (Matteo Gianella in #104)
Accommodate ProtoBuf 6.30.9 and later (Lev Kandel in #106)
Correct bashism issues in configure.ac (Dirk)
Thanks to my CRANberries, there is a diff to the previous release. The RProtoBuf page has copies of the (older) package vignette, the ‘quick’ overview vignette, and the pre-print of our JSS paper. Questions, comments etc should go to the GitHub issue tracker off the GitHub repo.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. If you like this or other open-source work I do, you can sponsor me at GitHub.
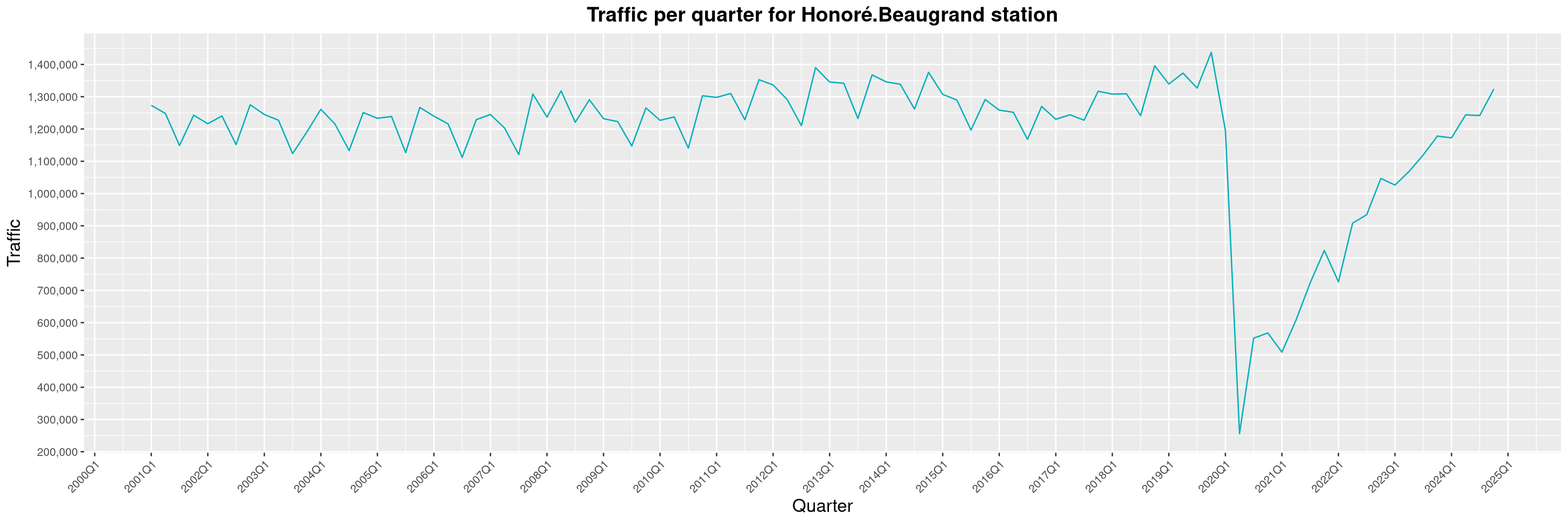
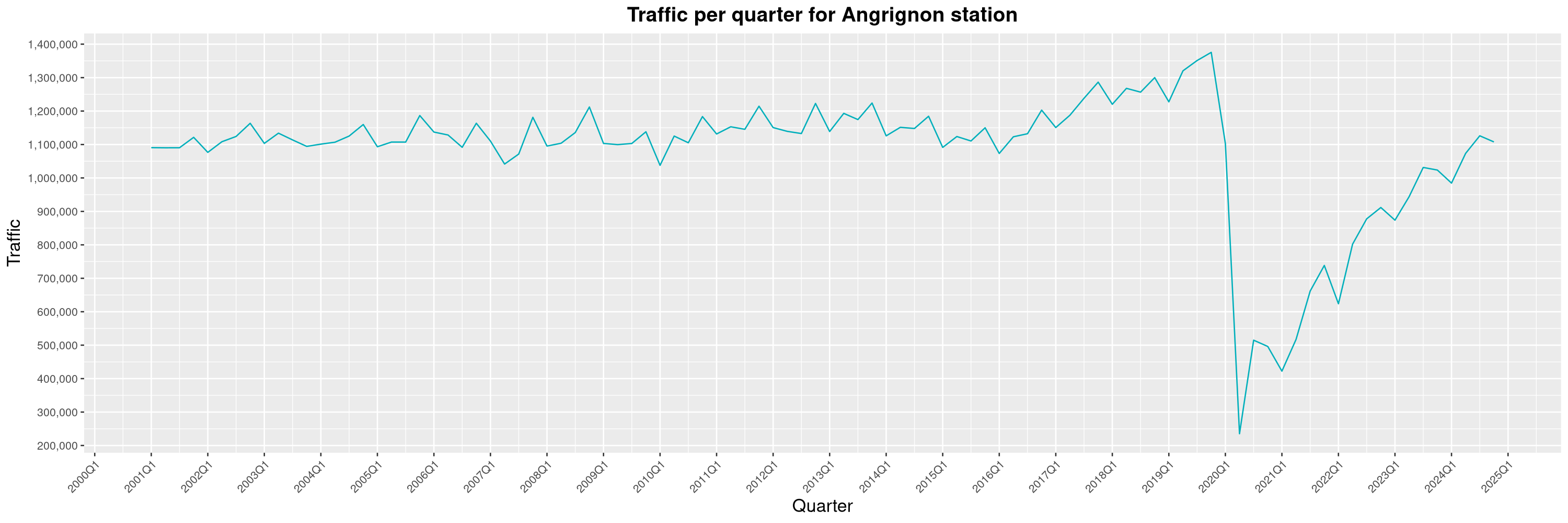
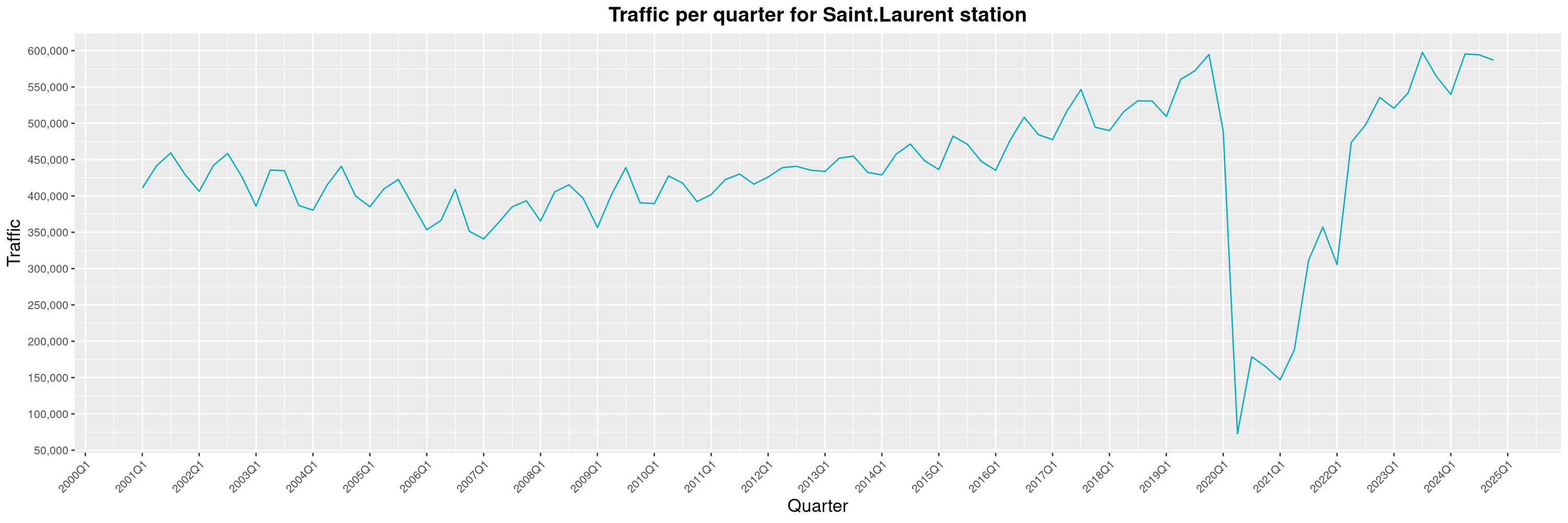
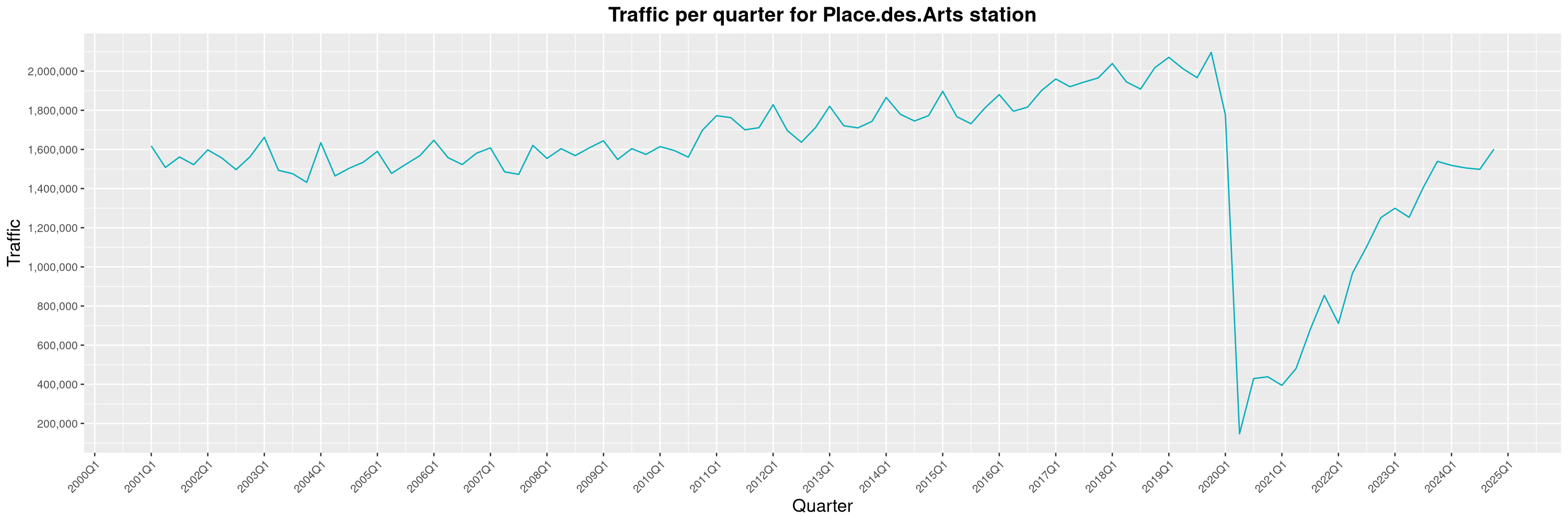
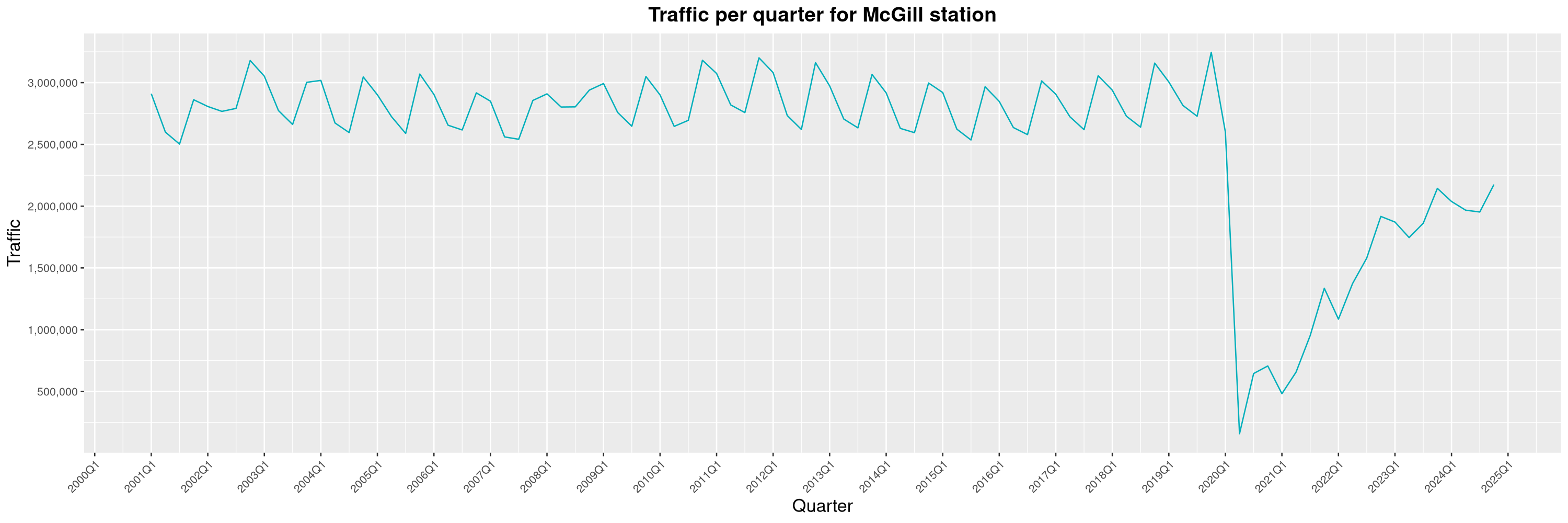
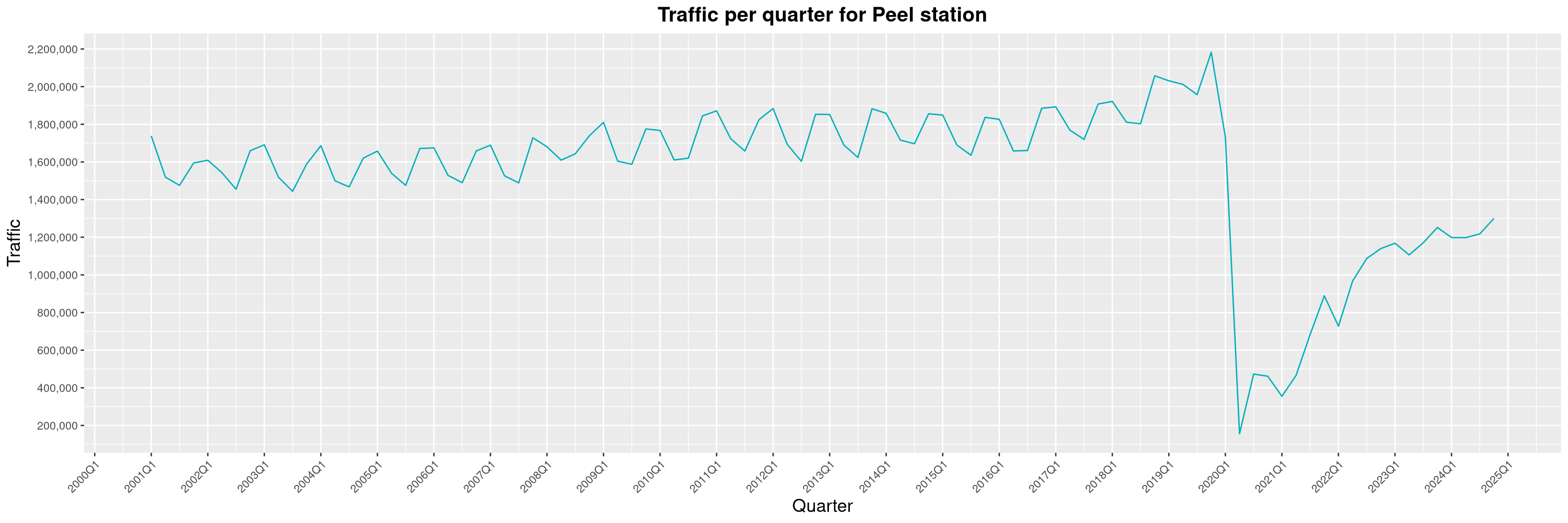
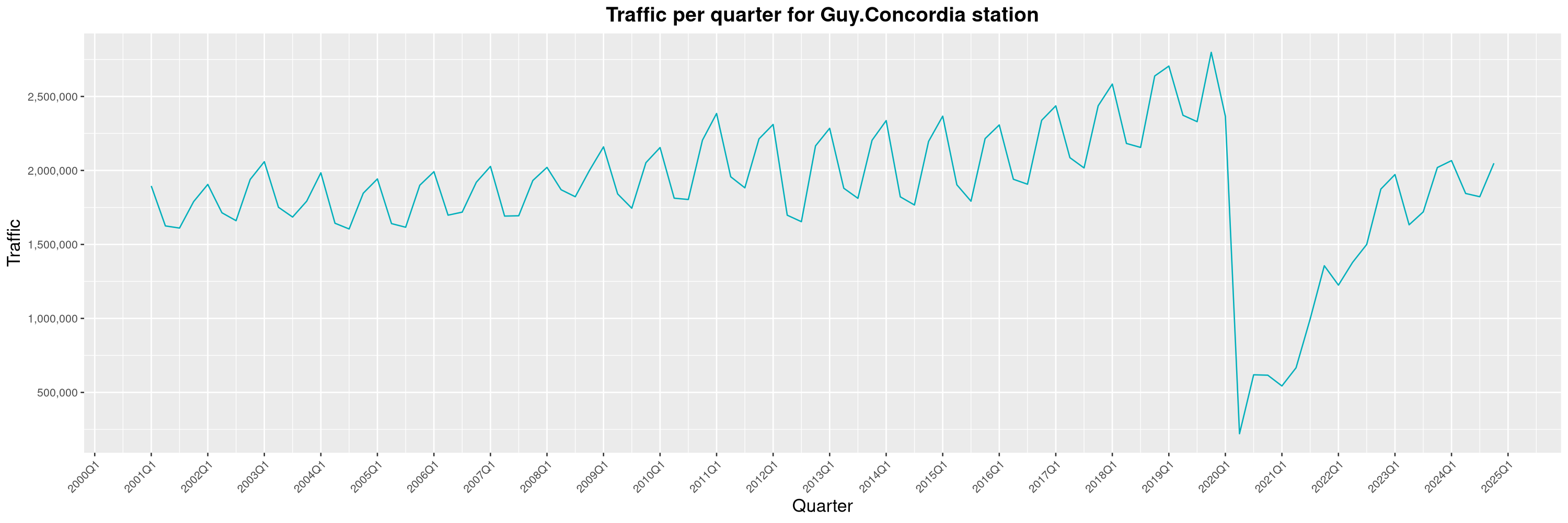
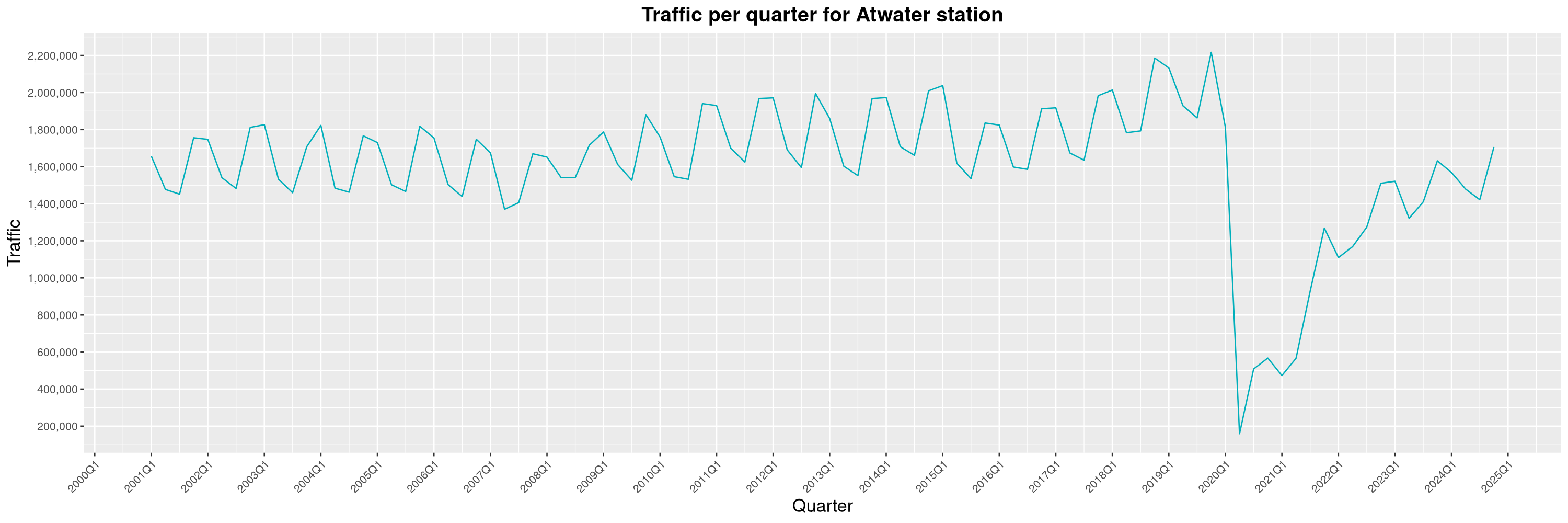
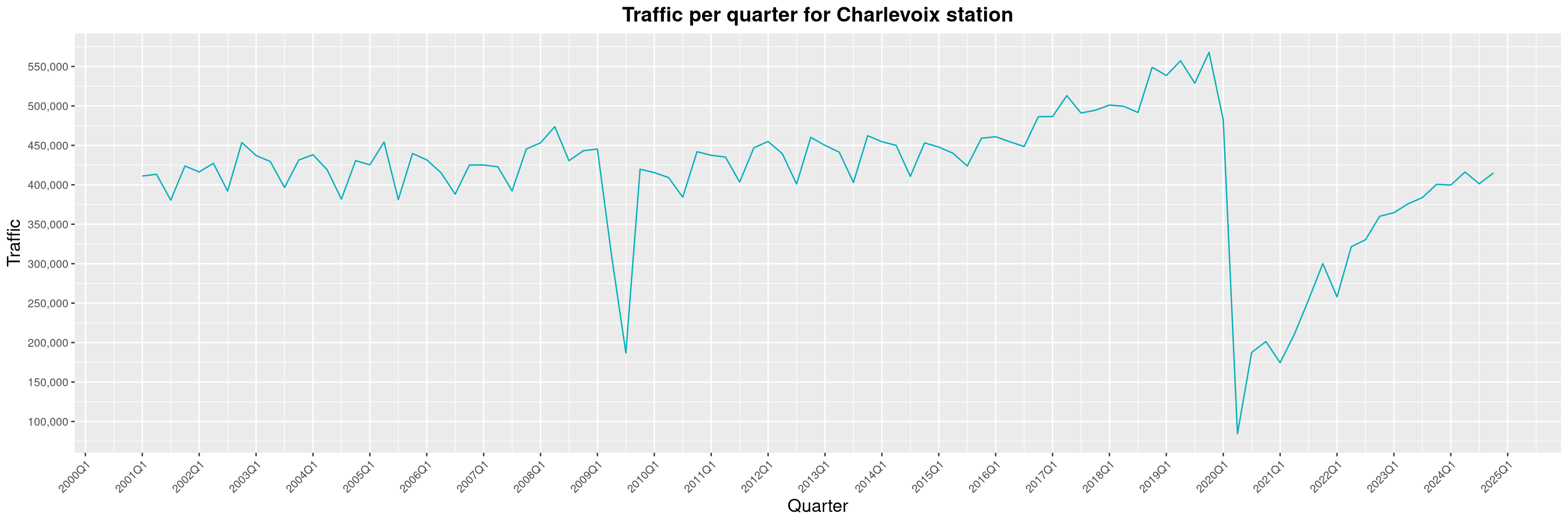
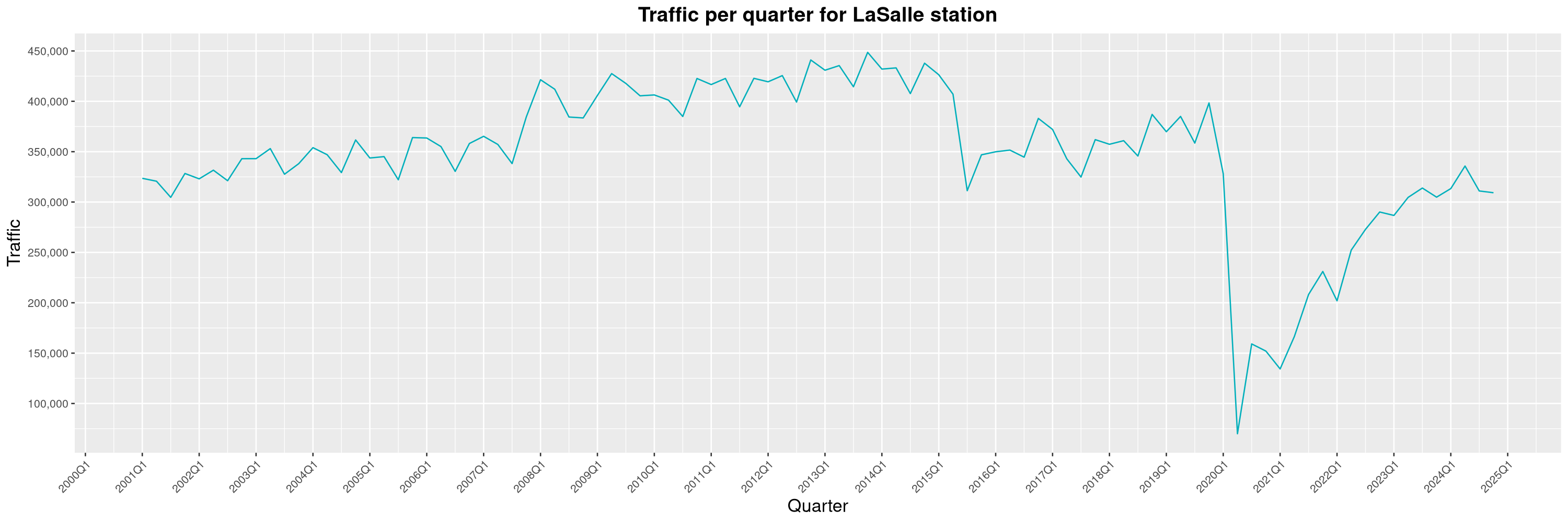
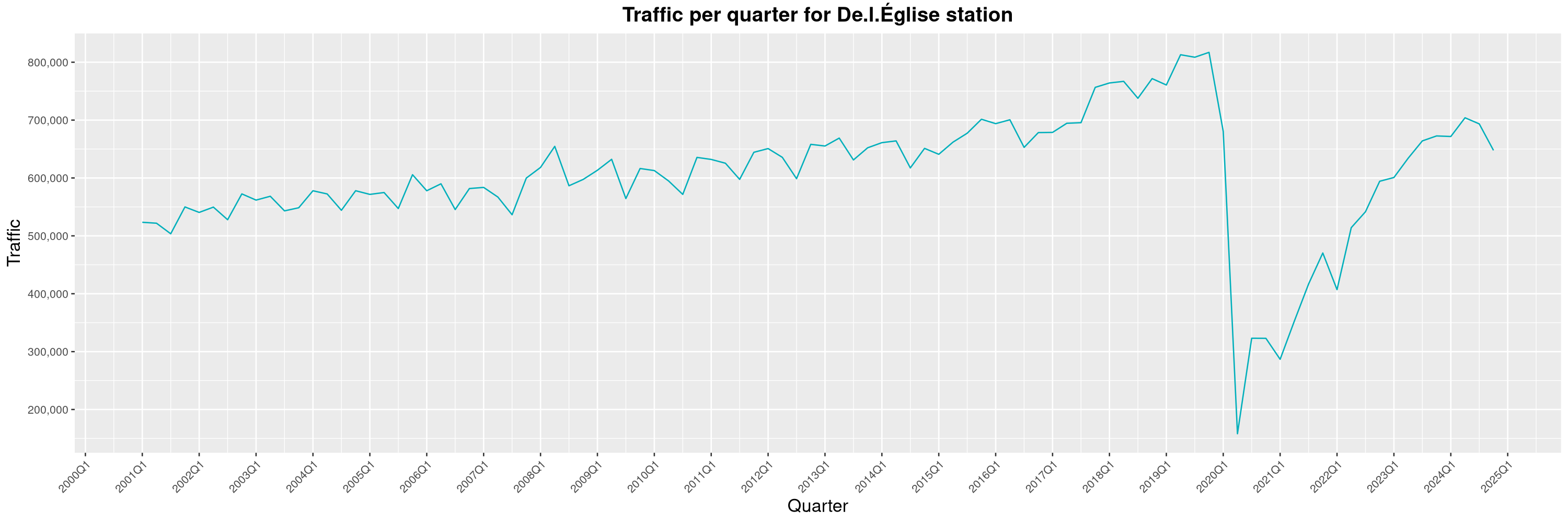
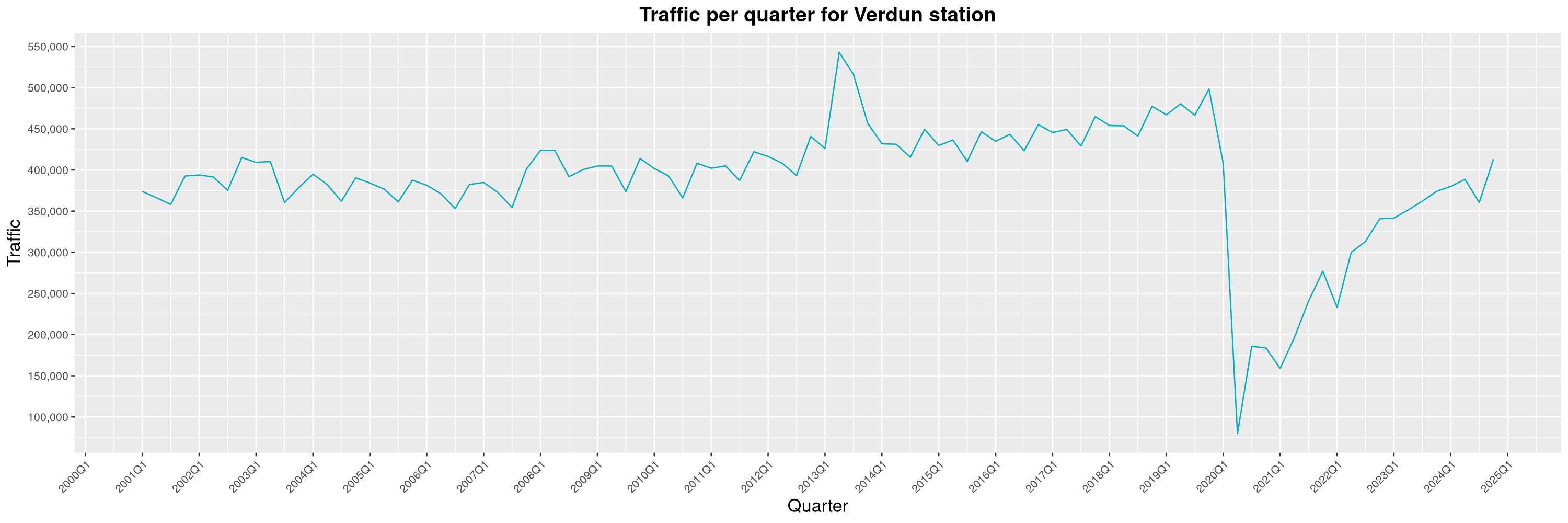
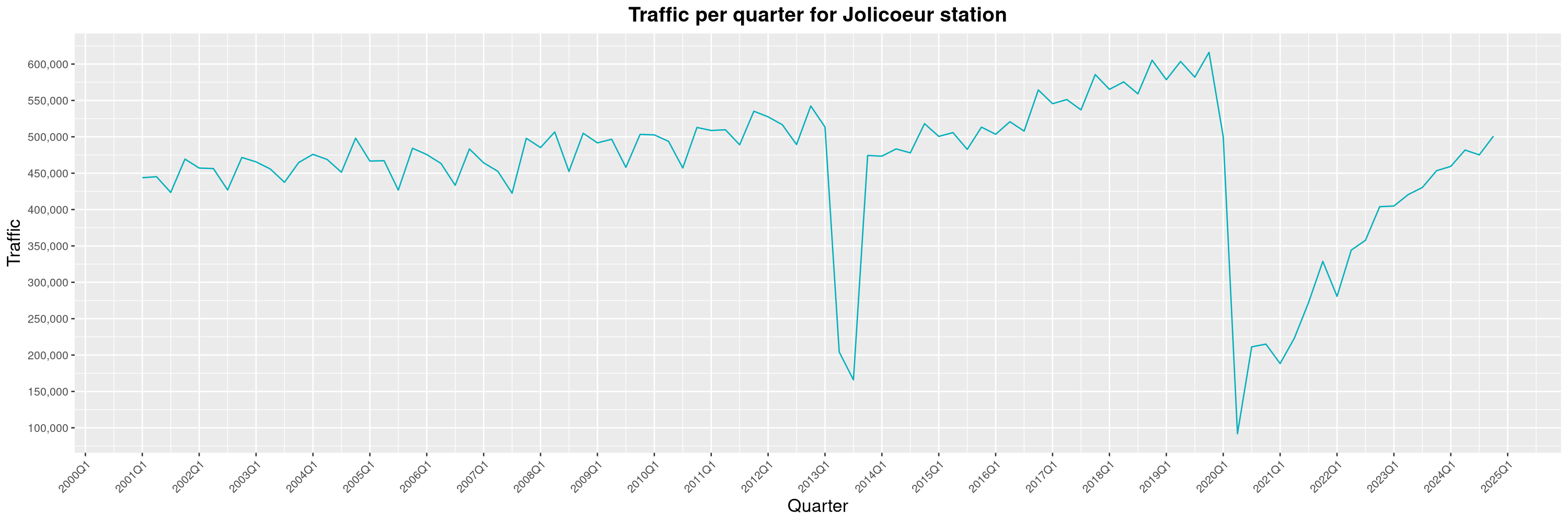
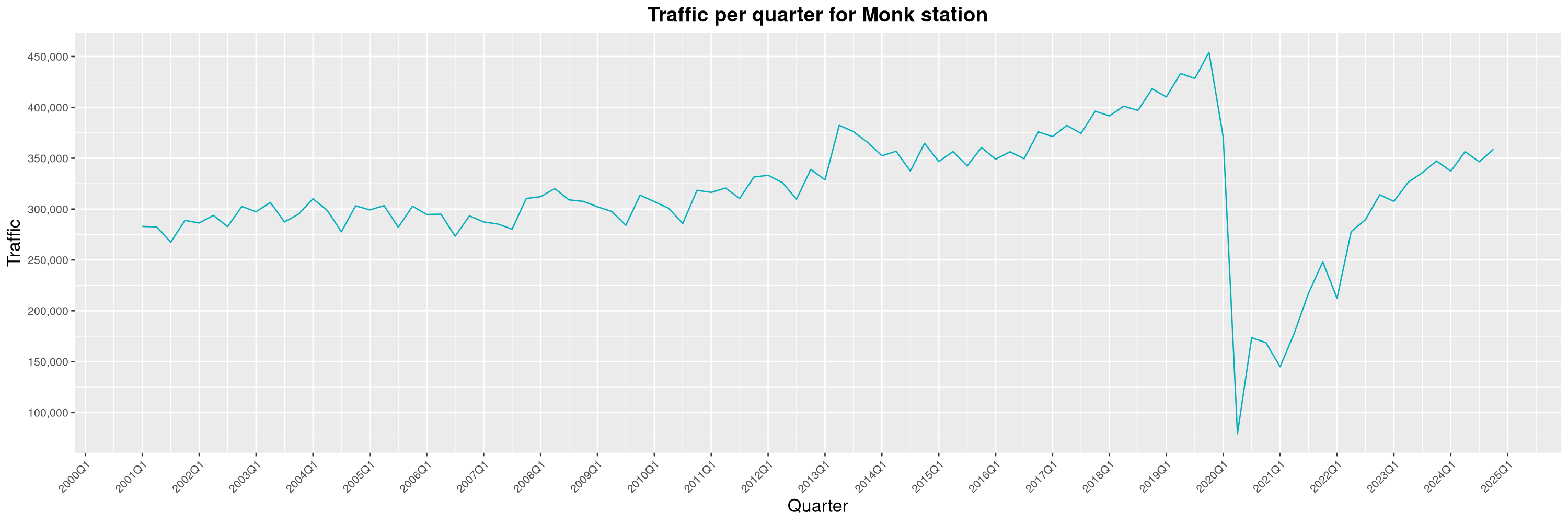
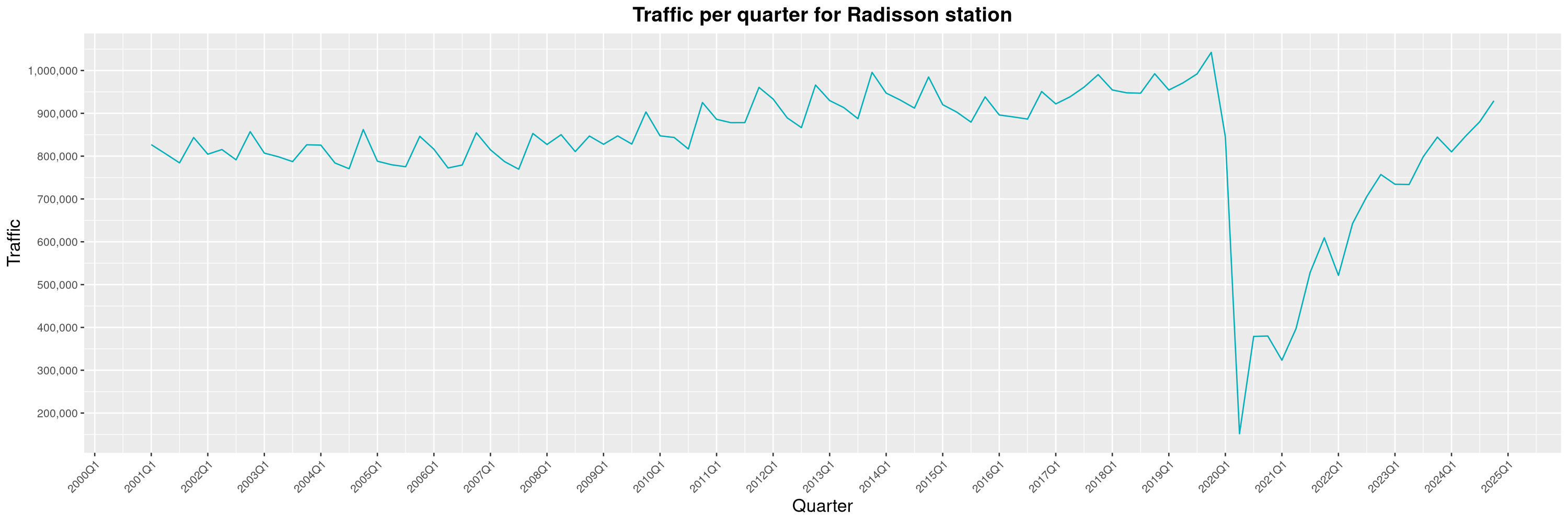
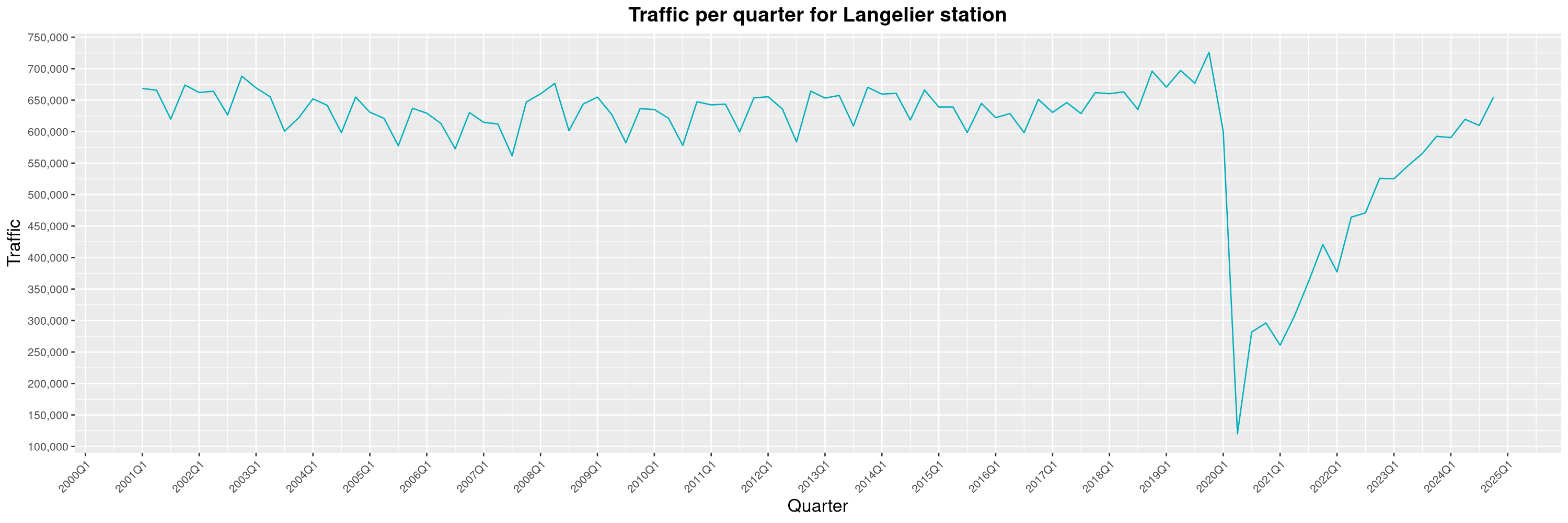
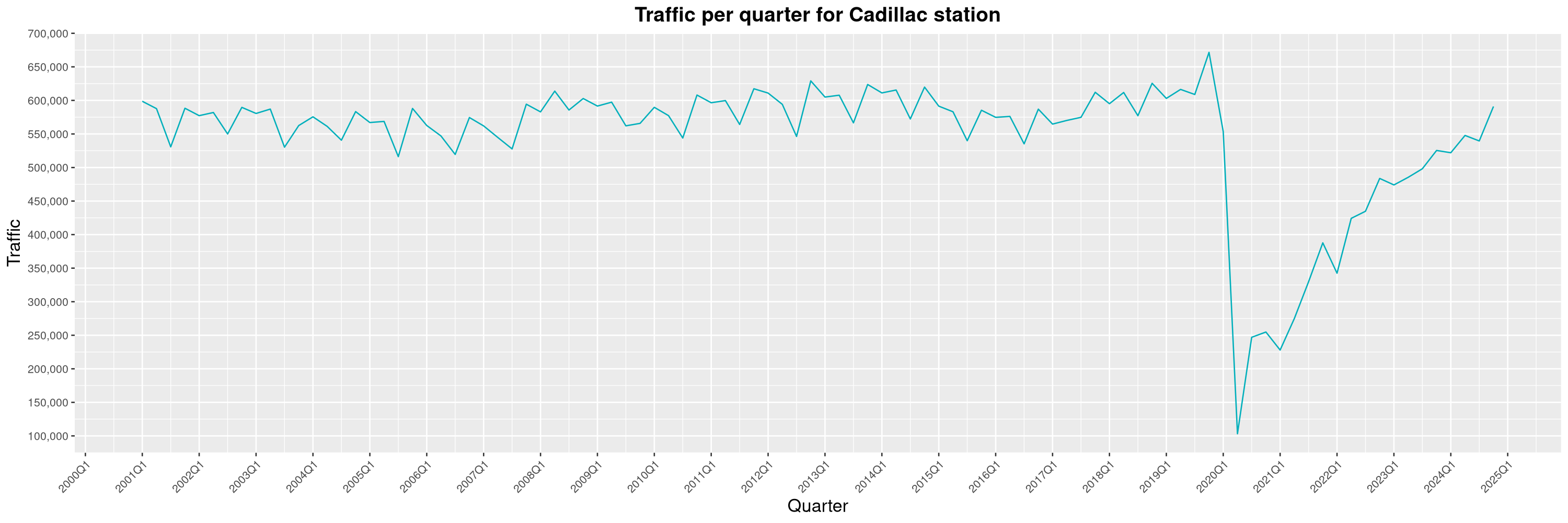
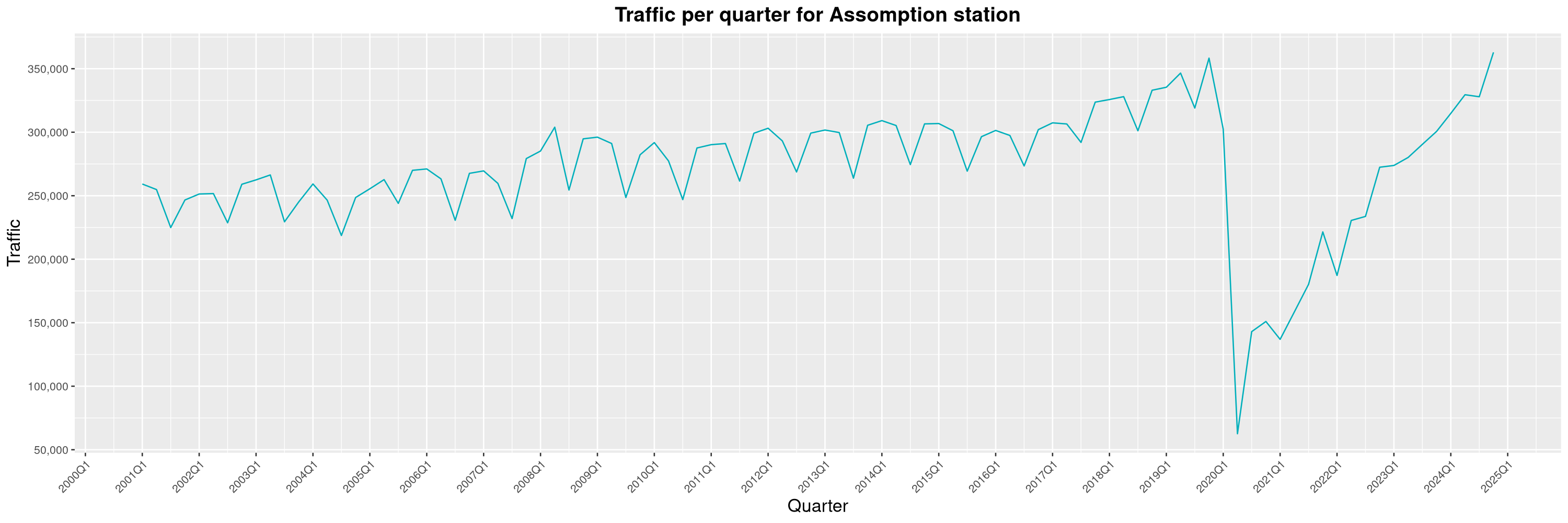
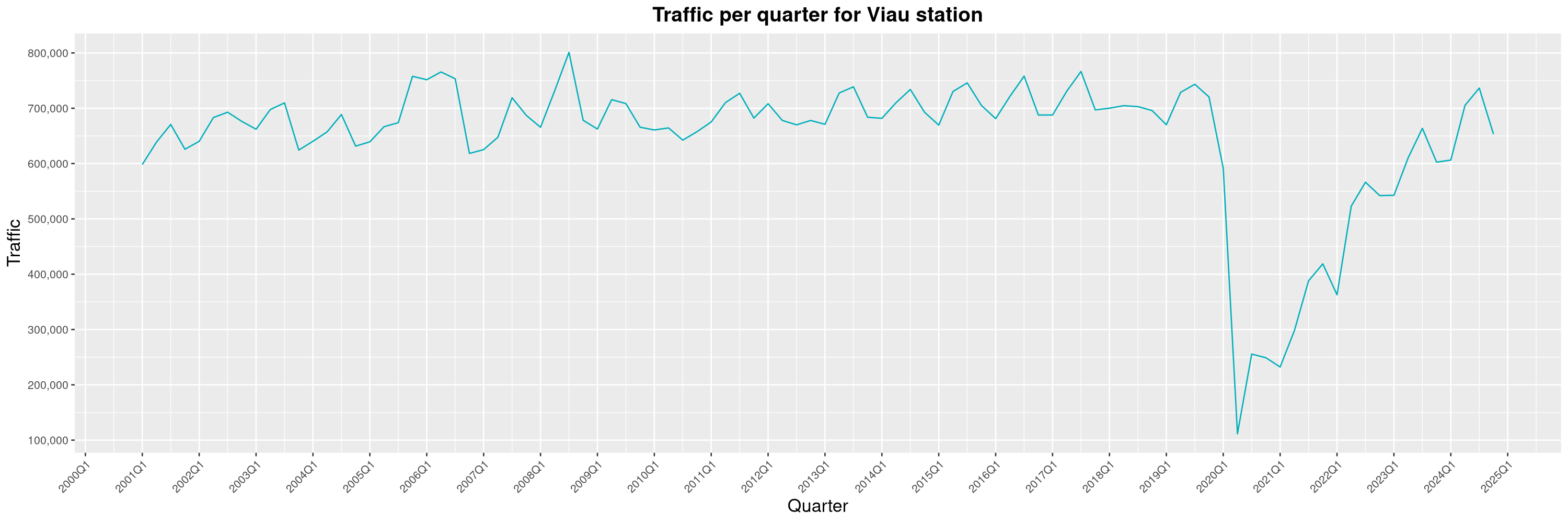
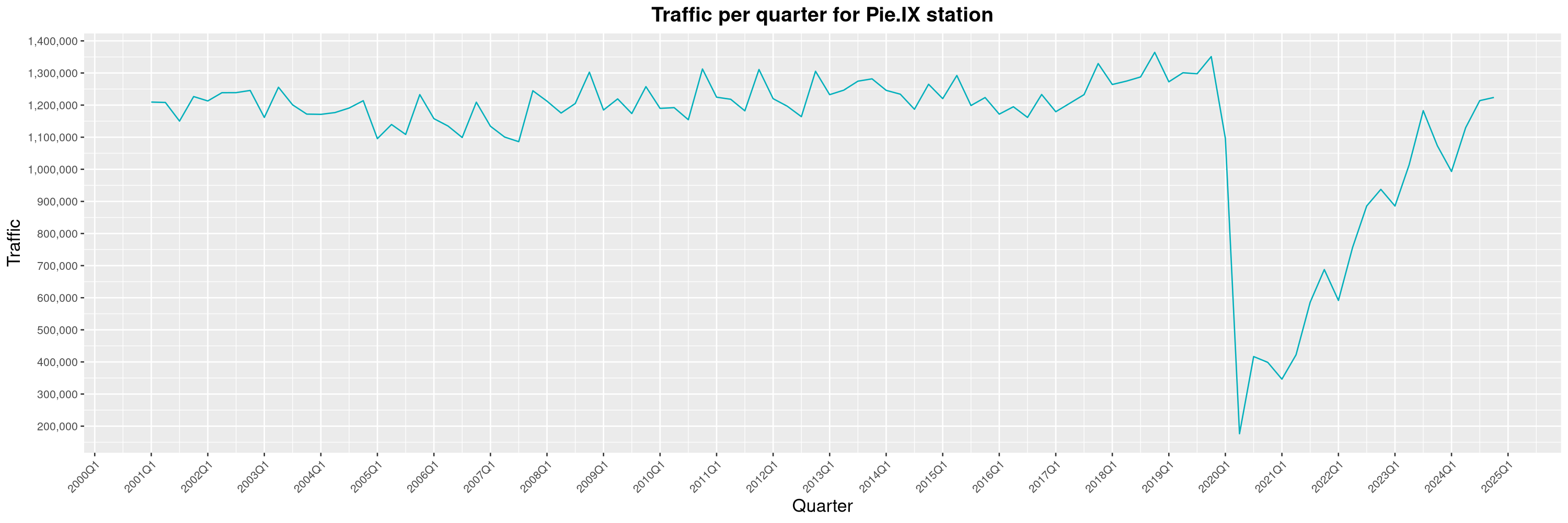
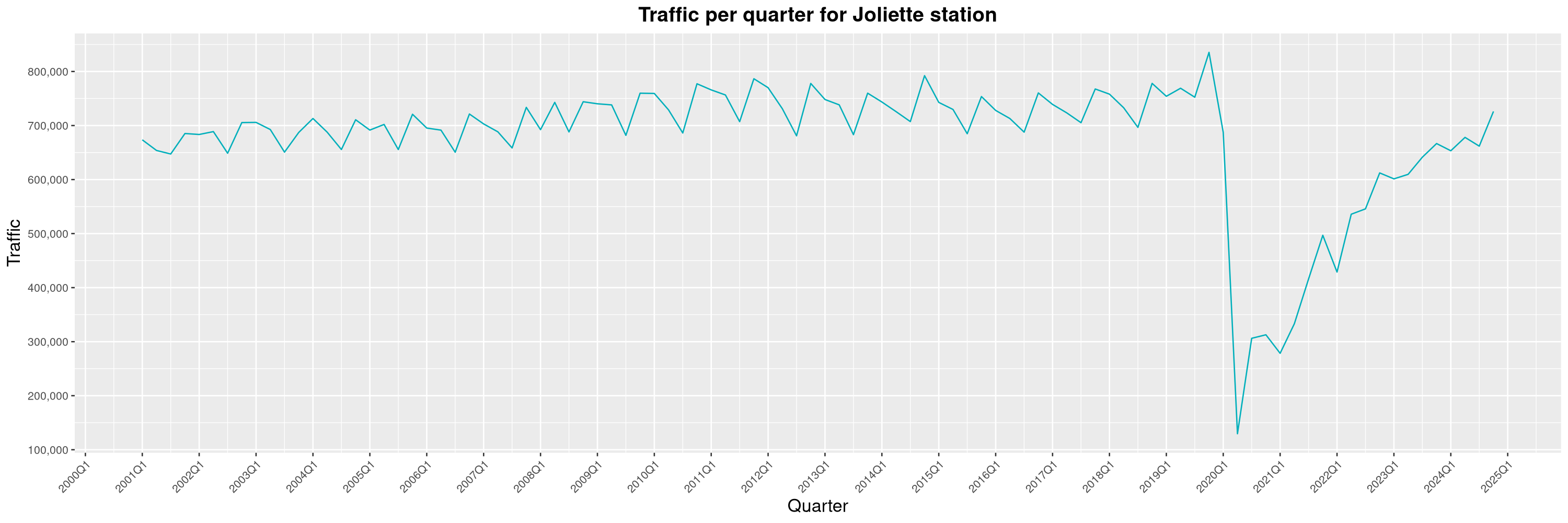
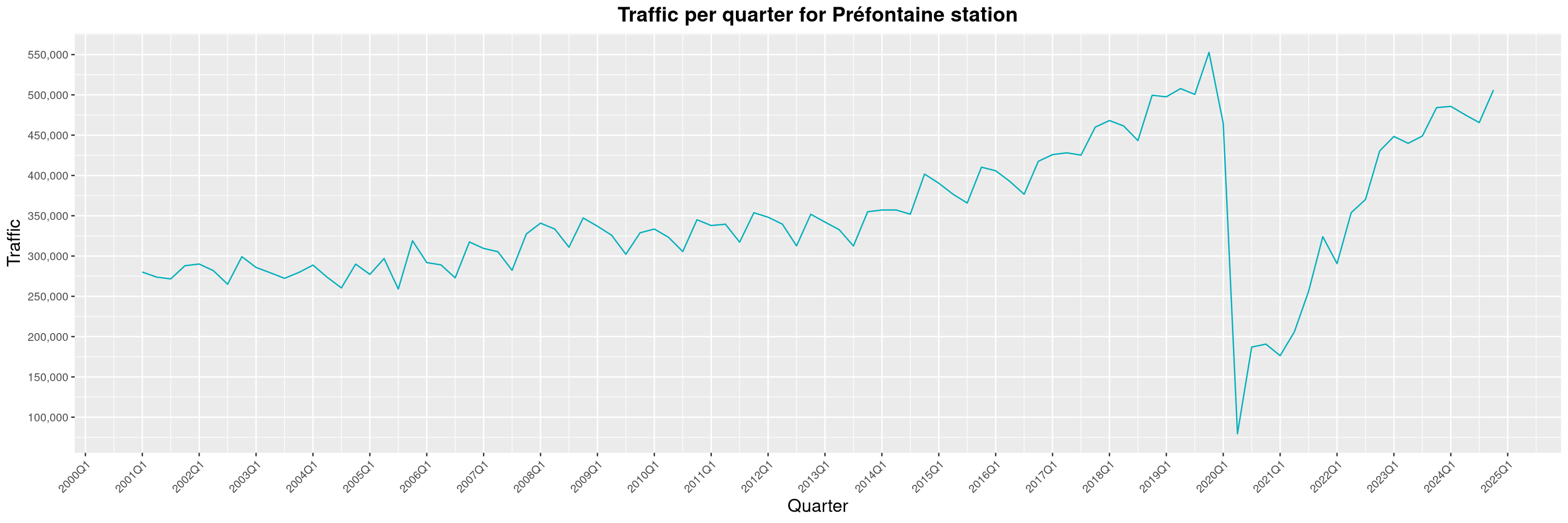
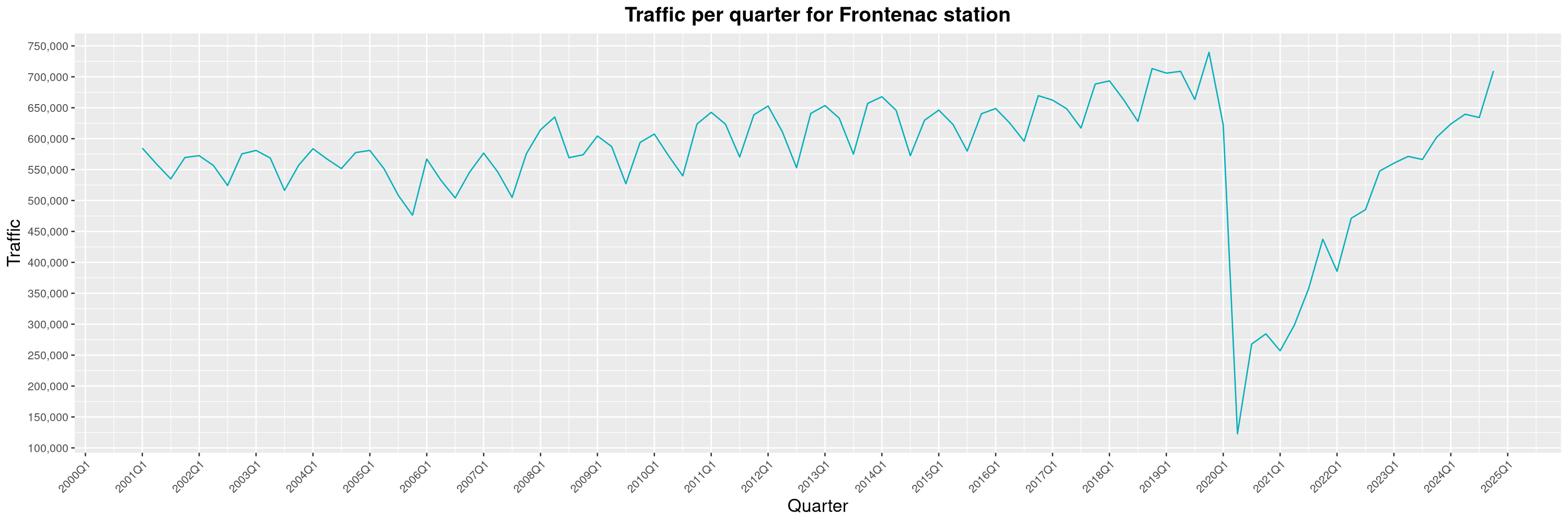
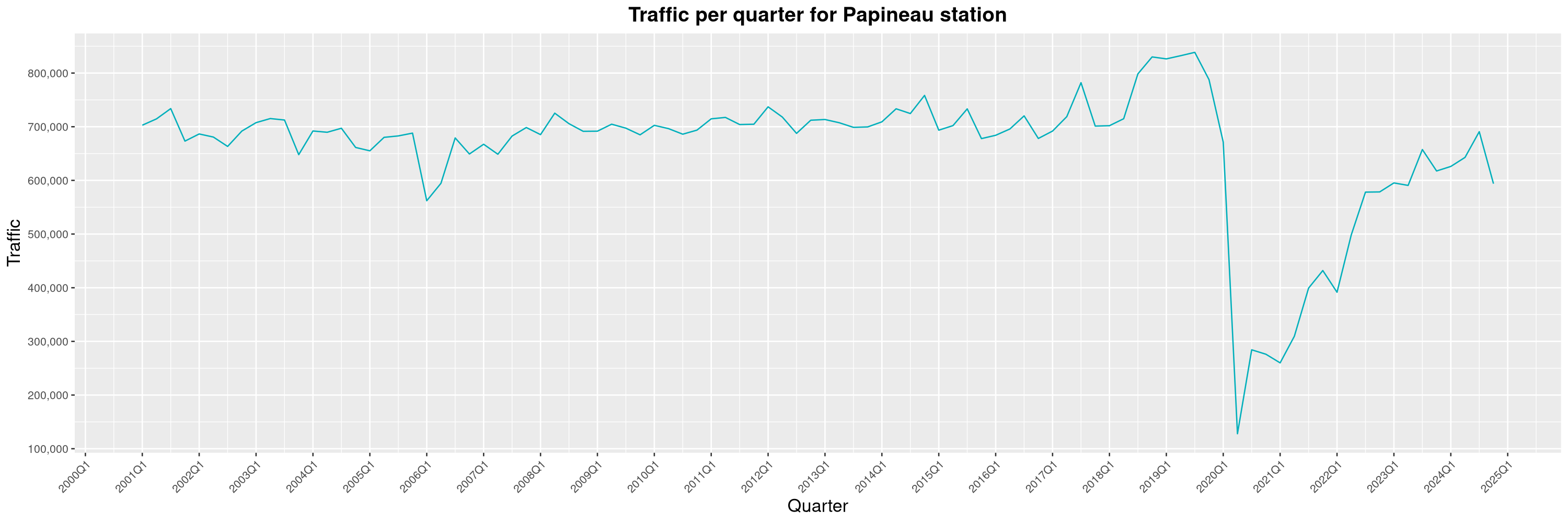
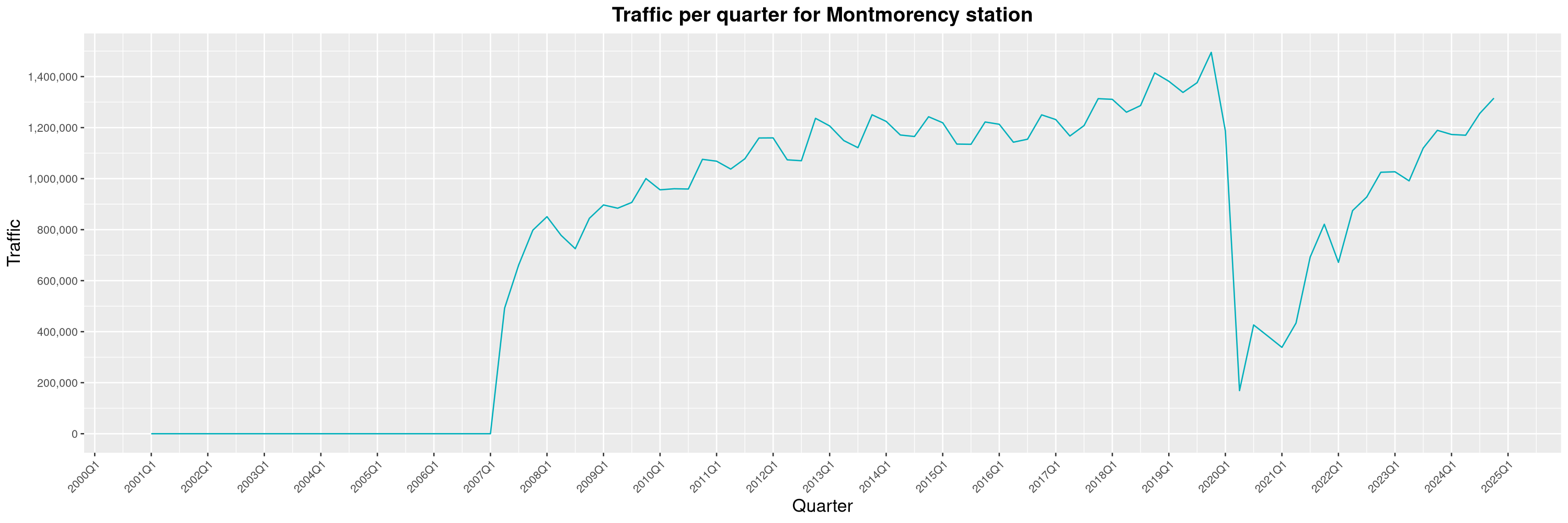
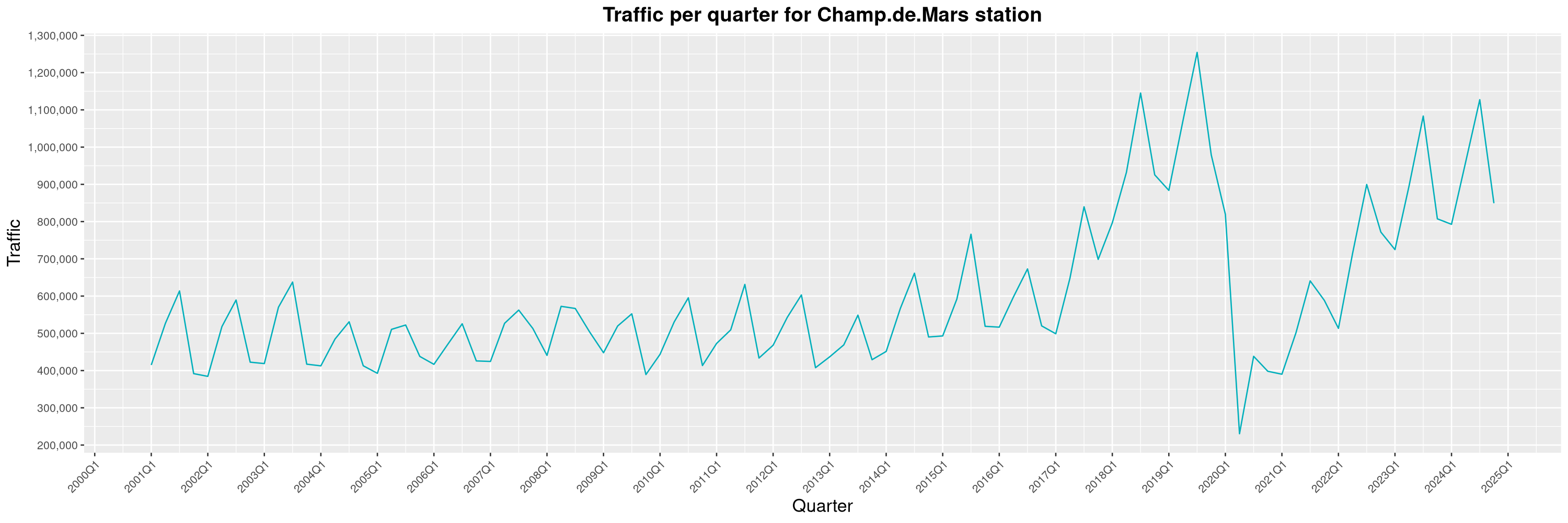
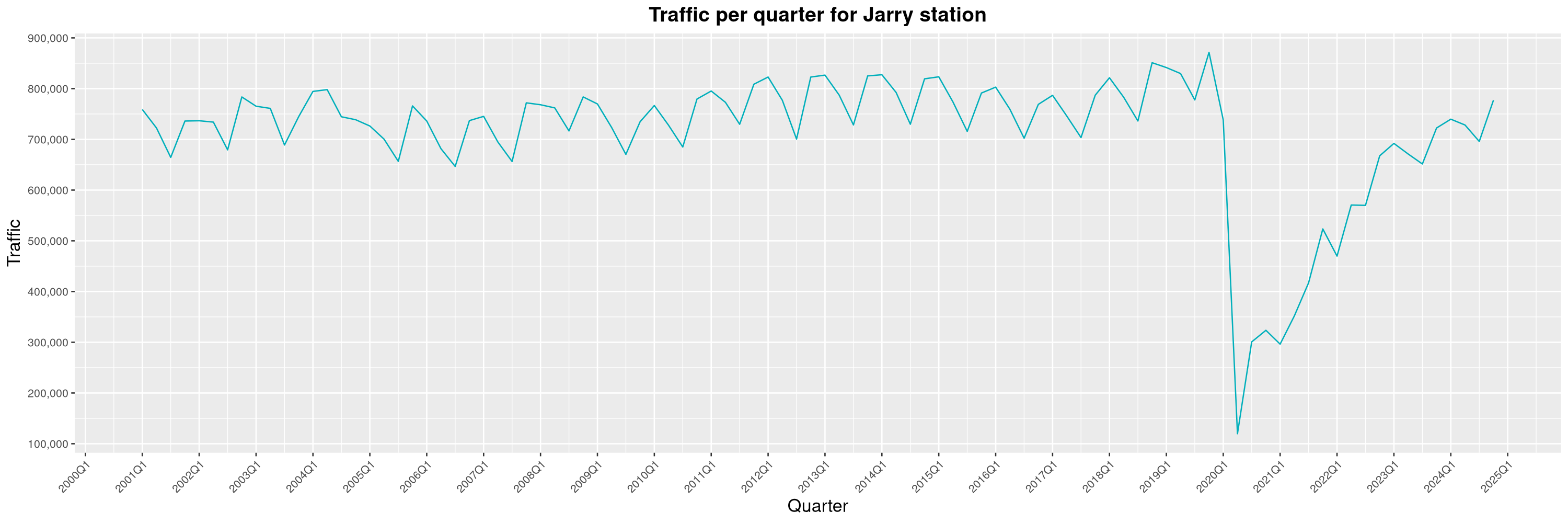
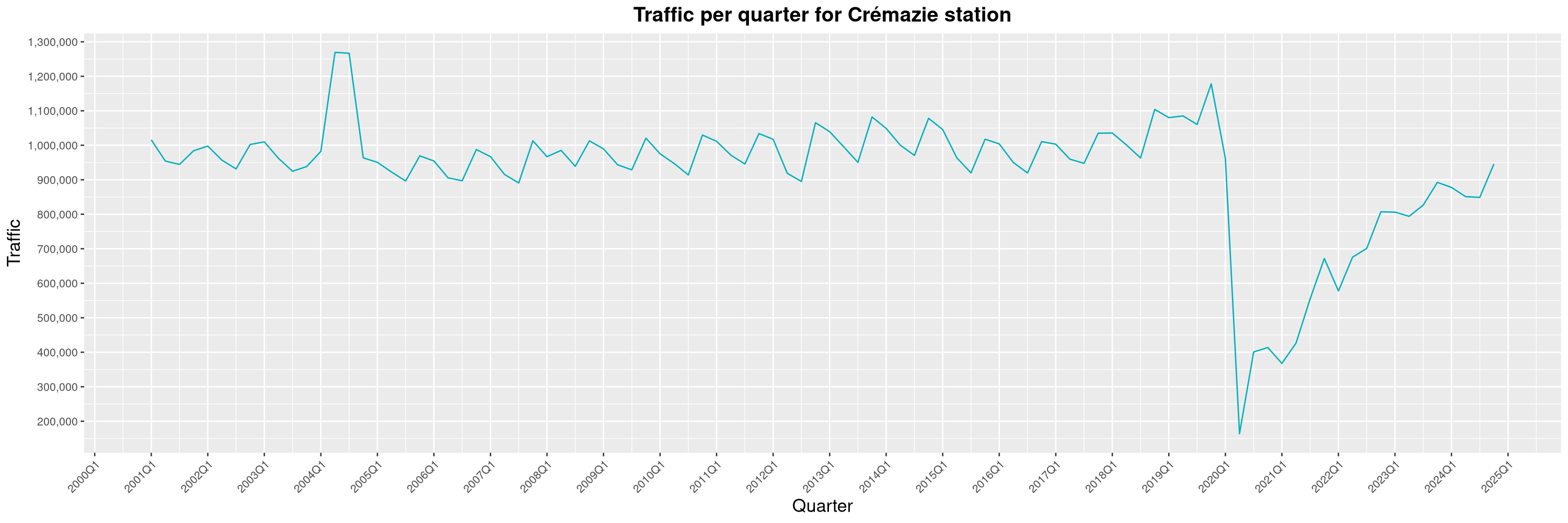
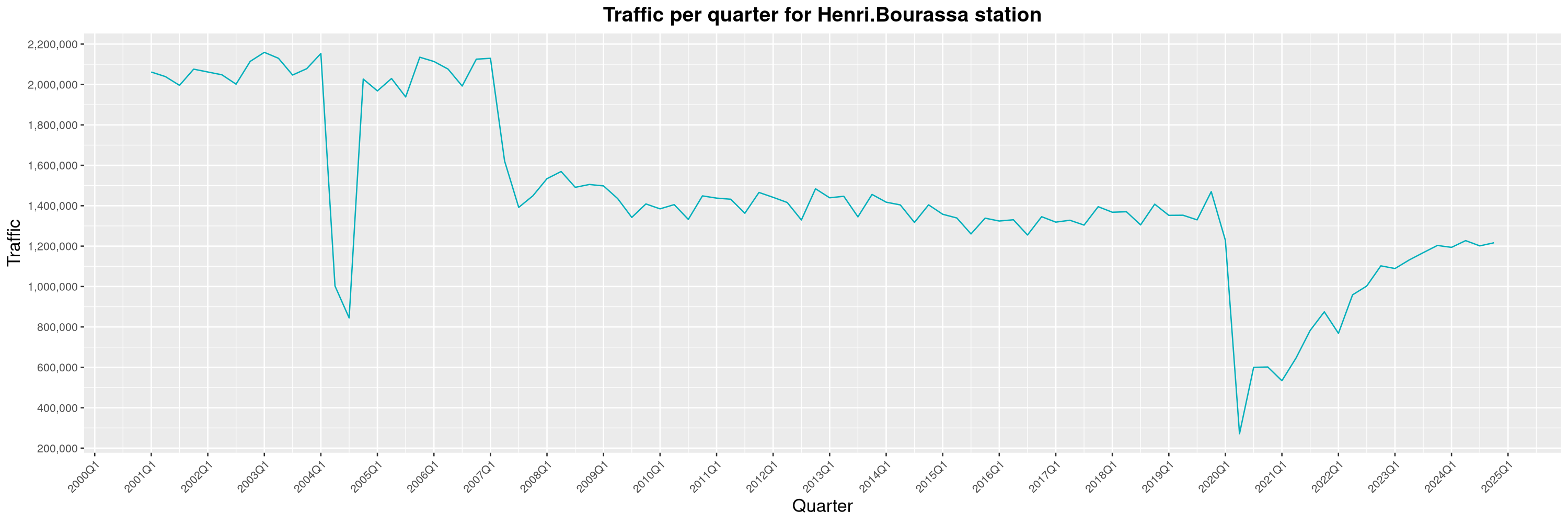
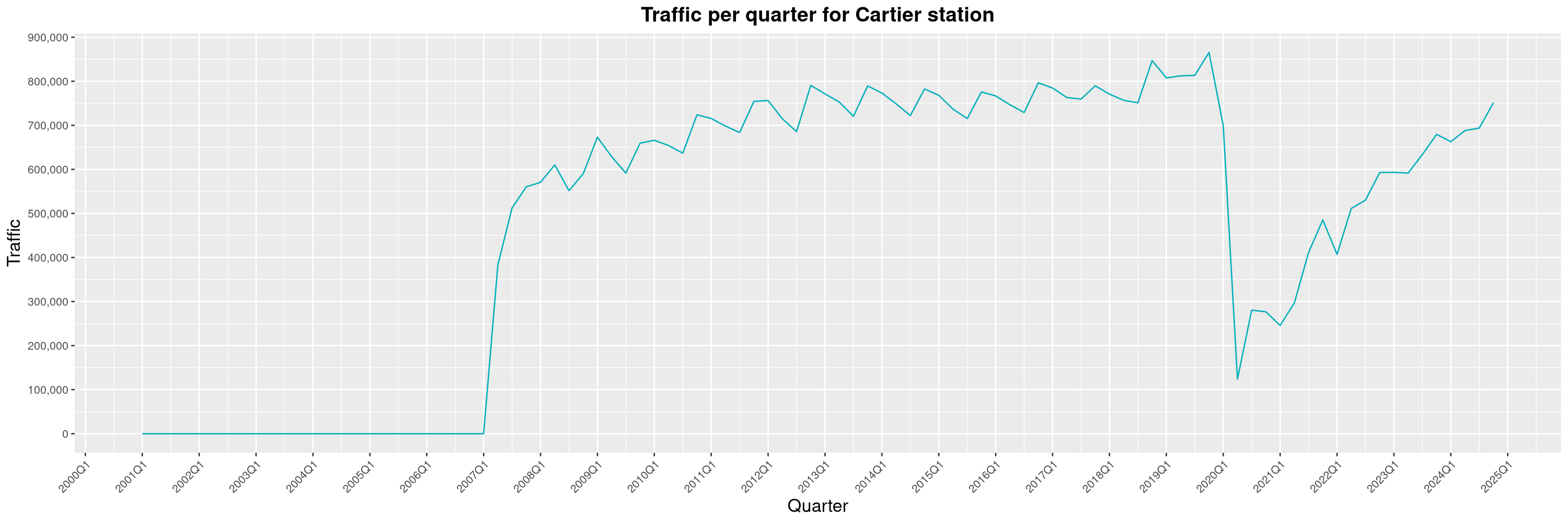
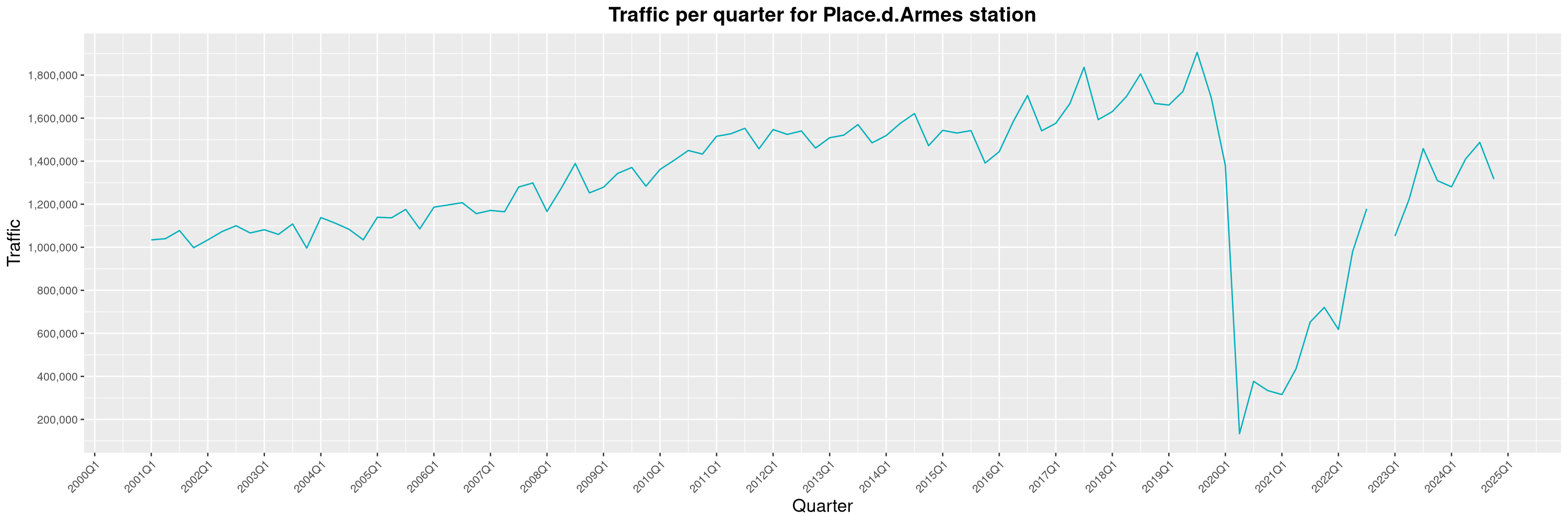
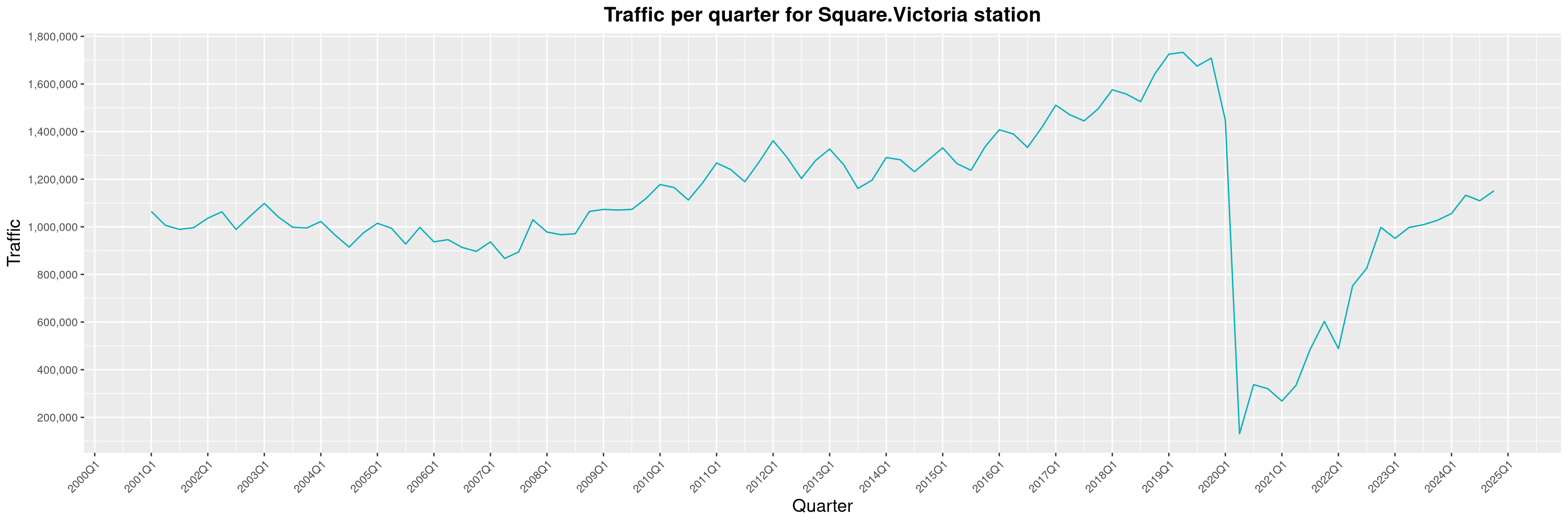
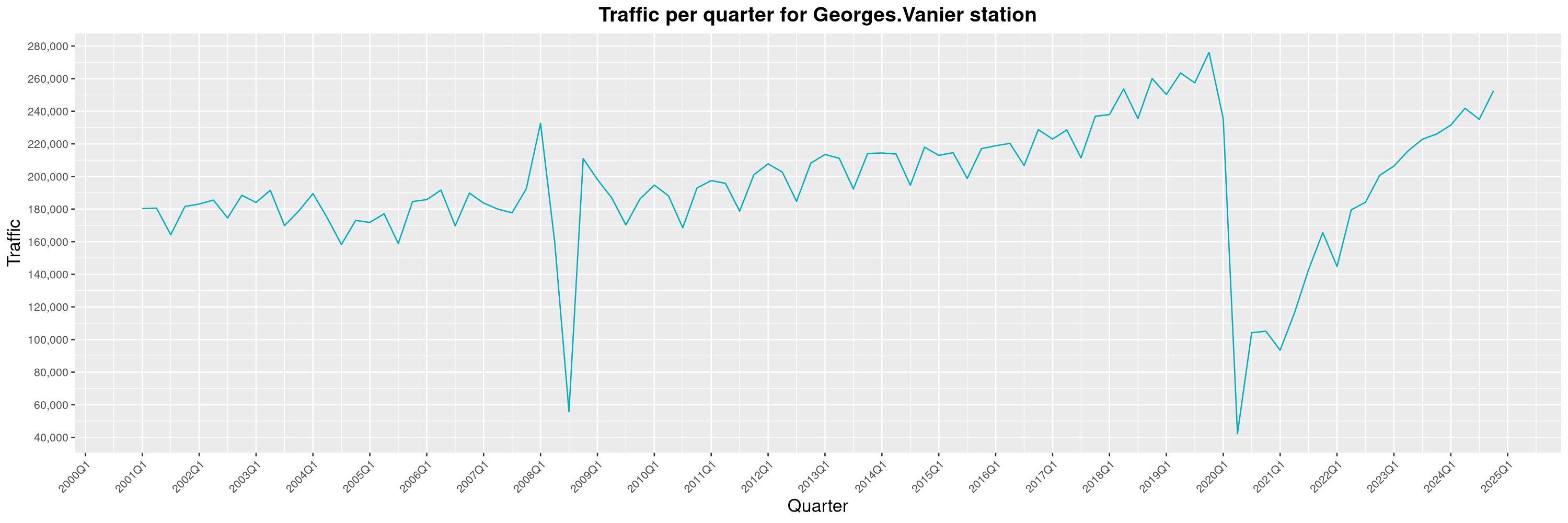
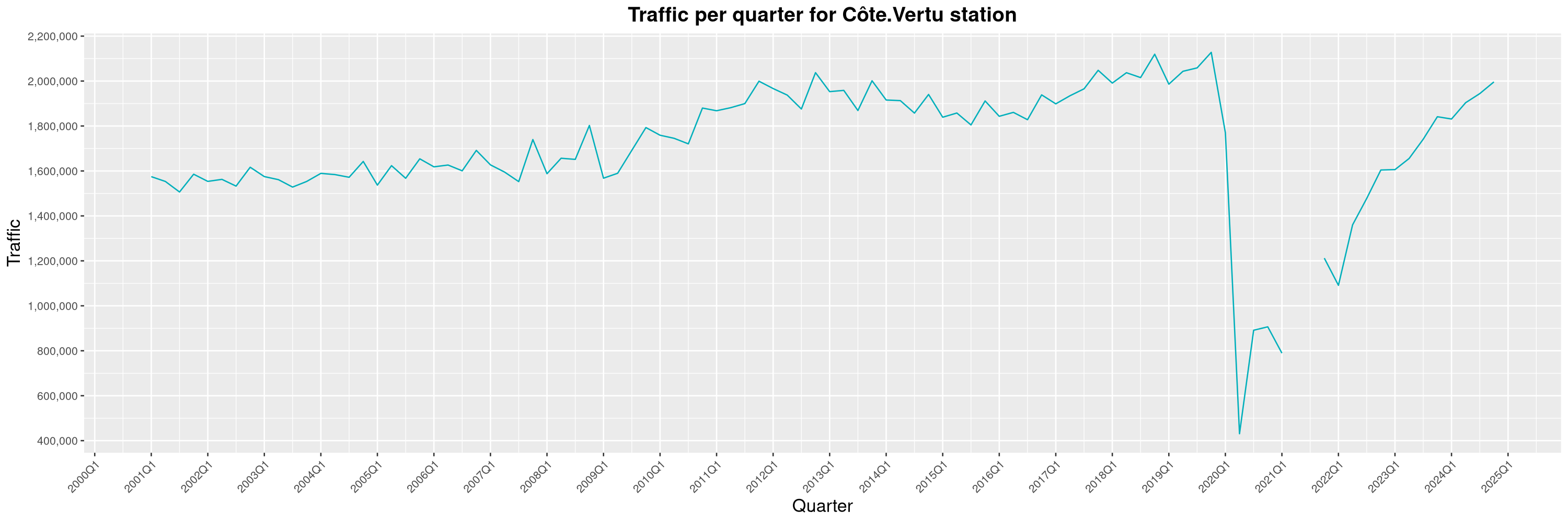
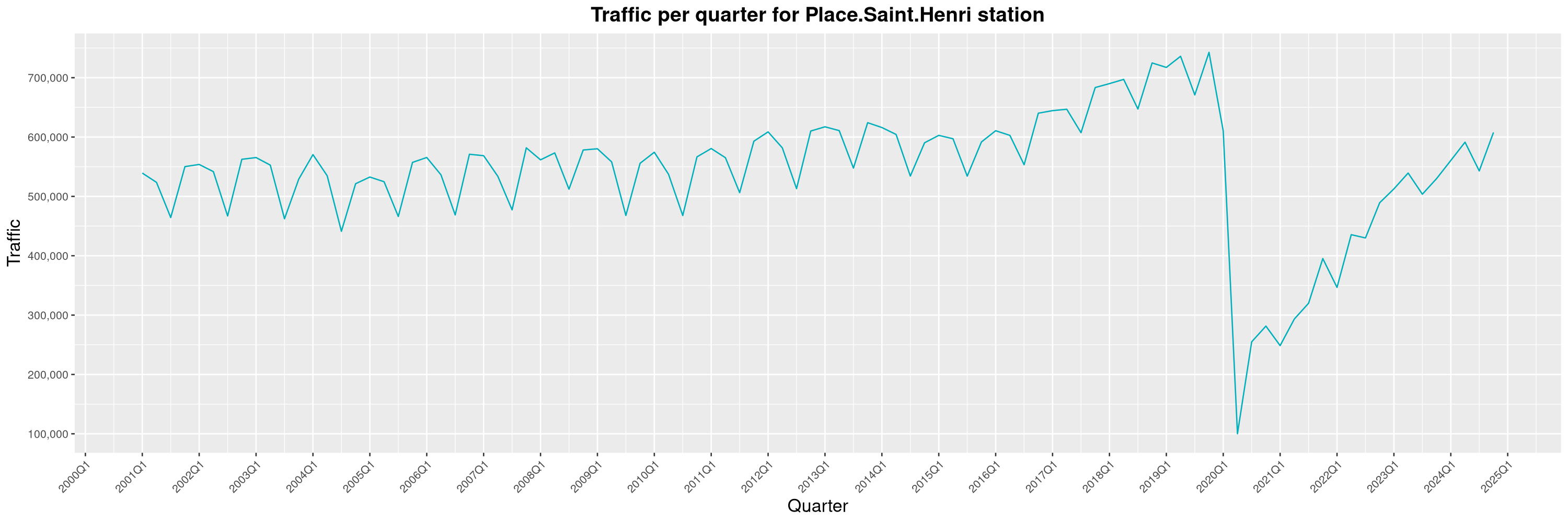
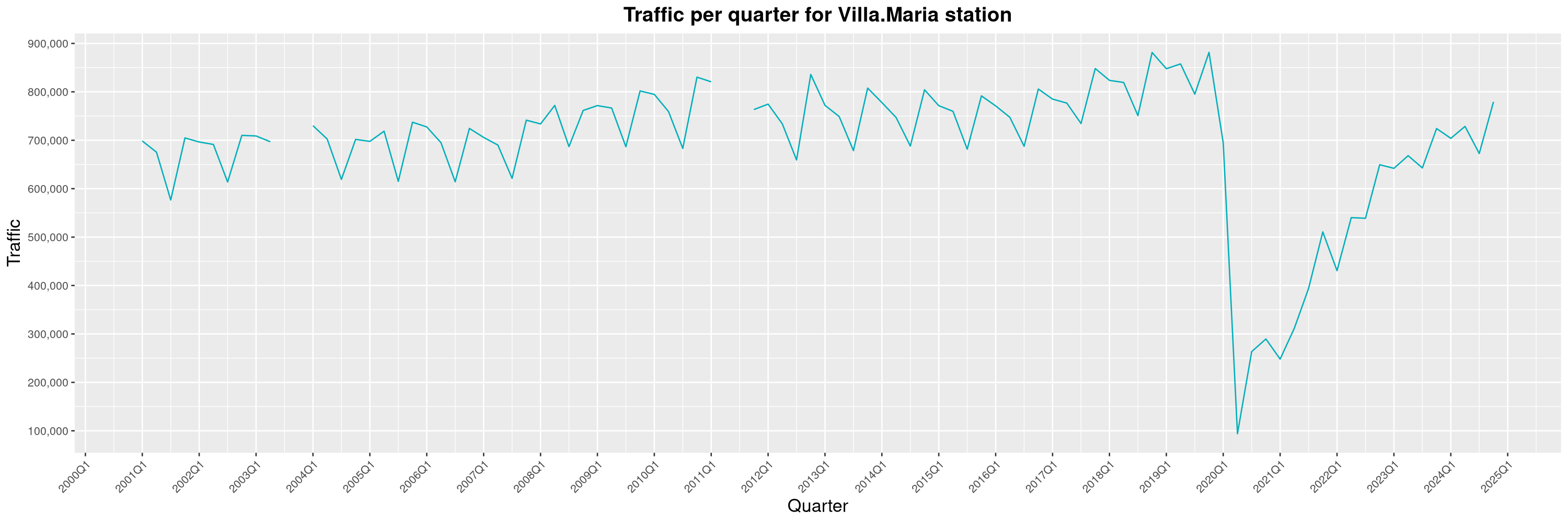
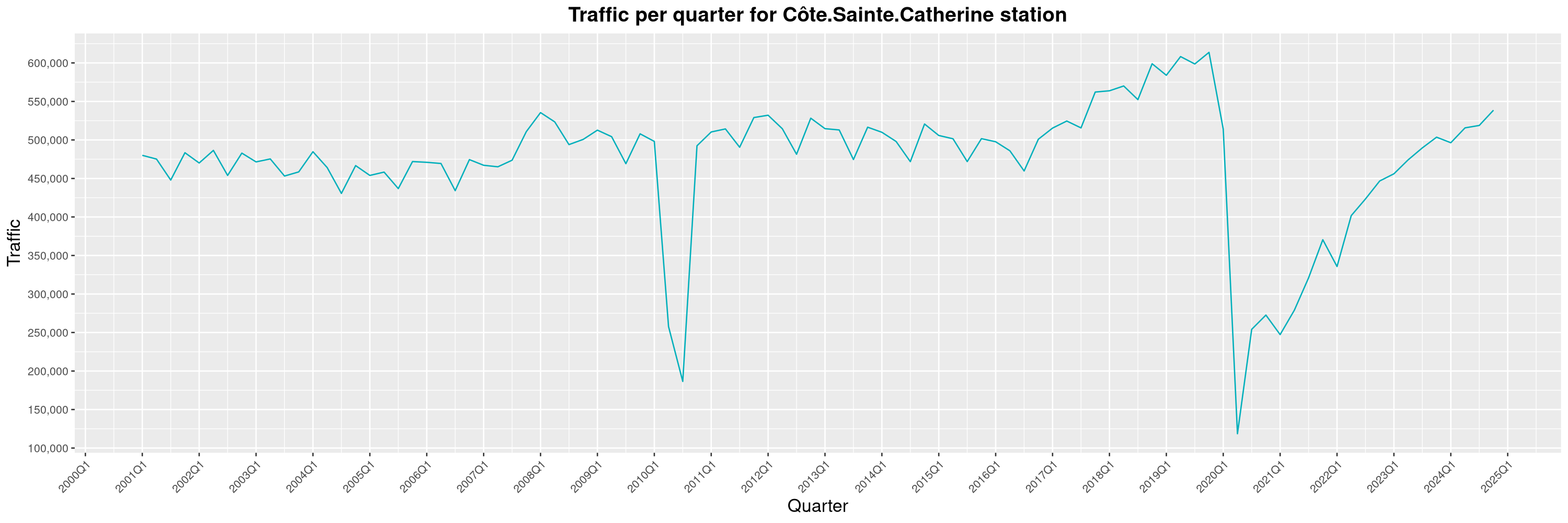
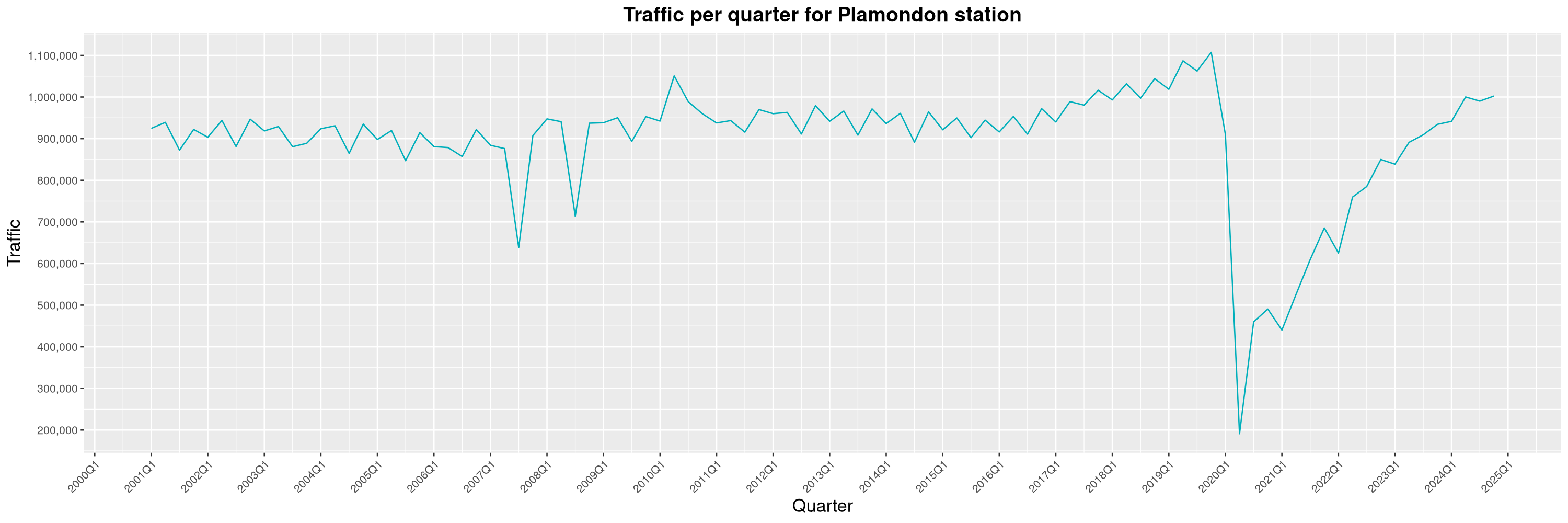
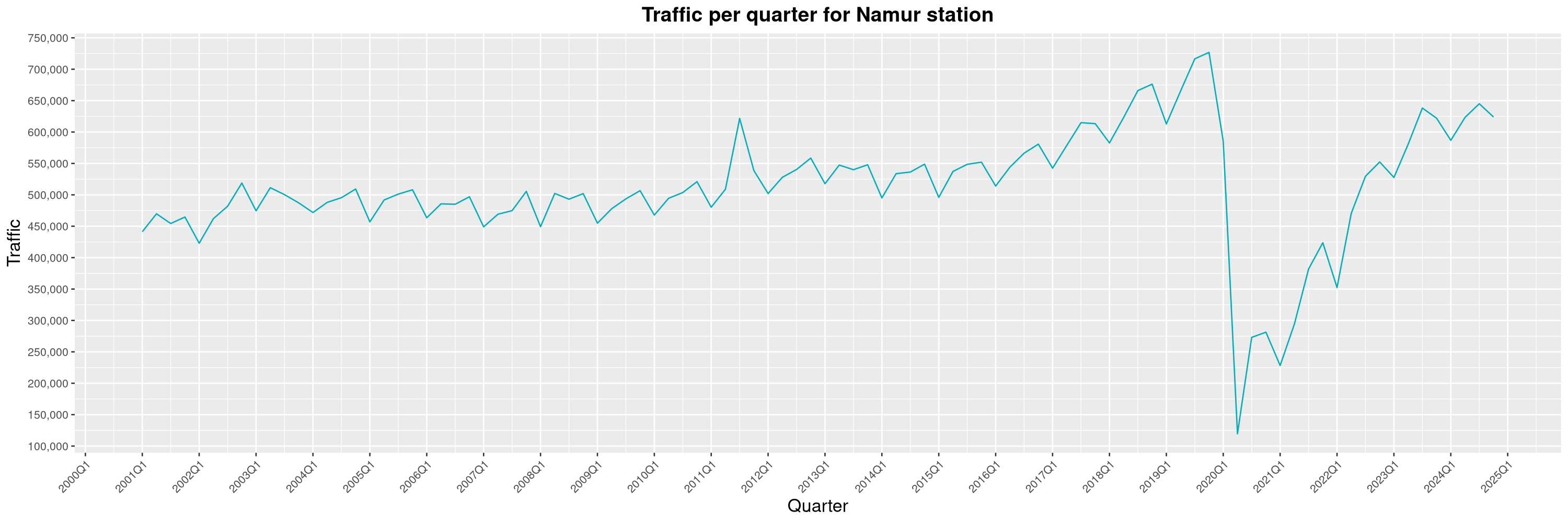
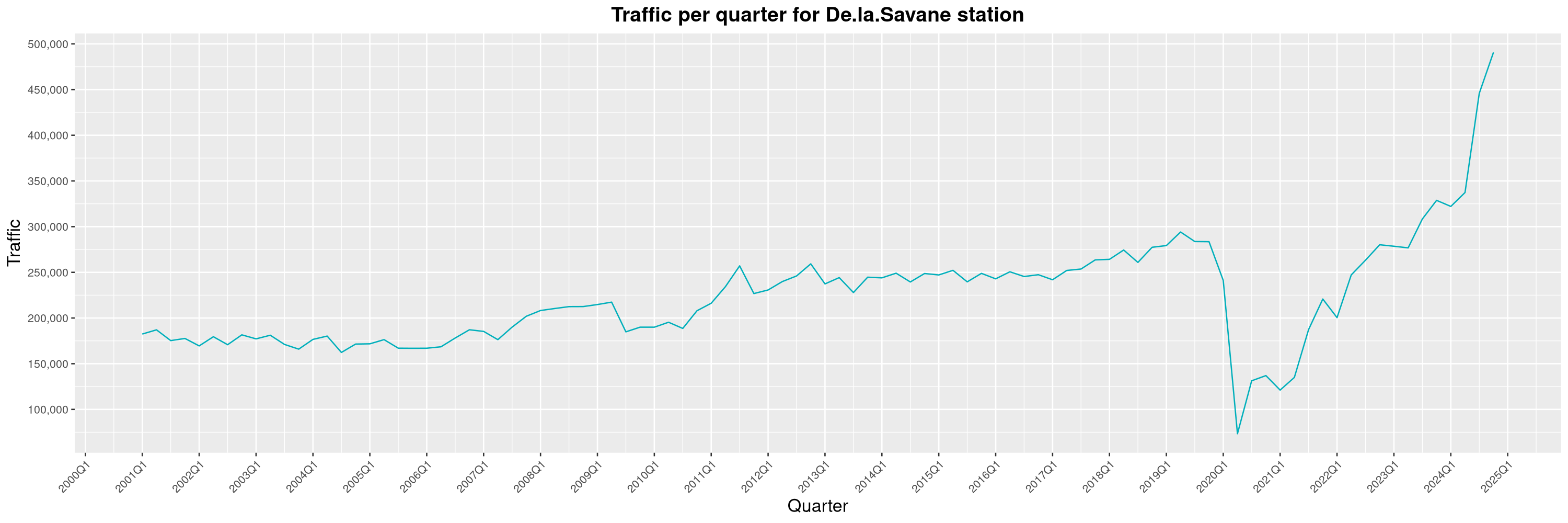
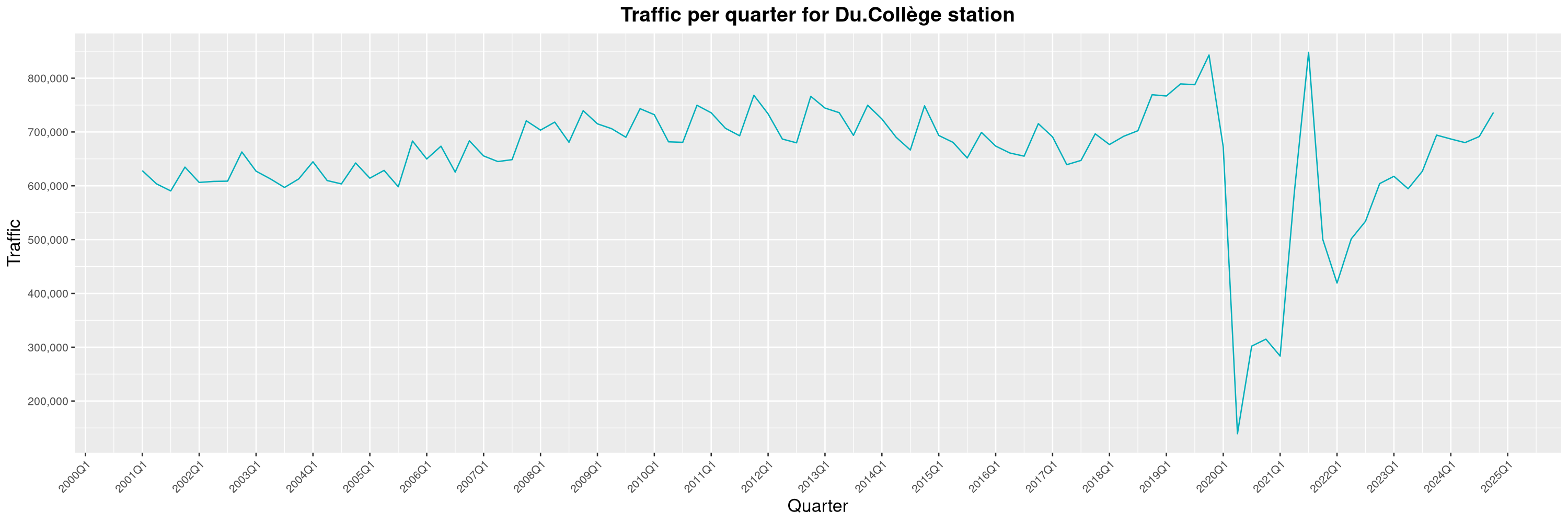
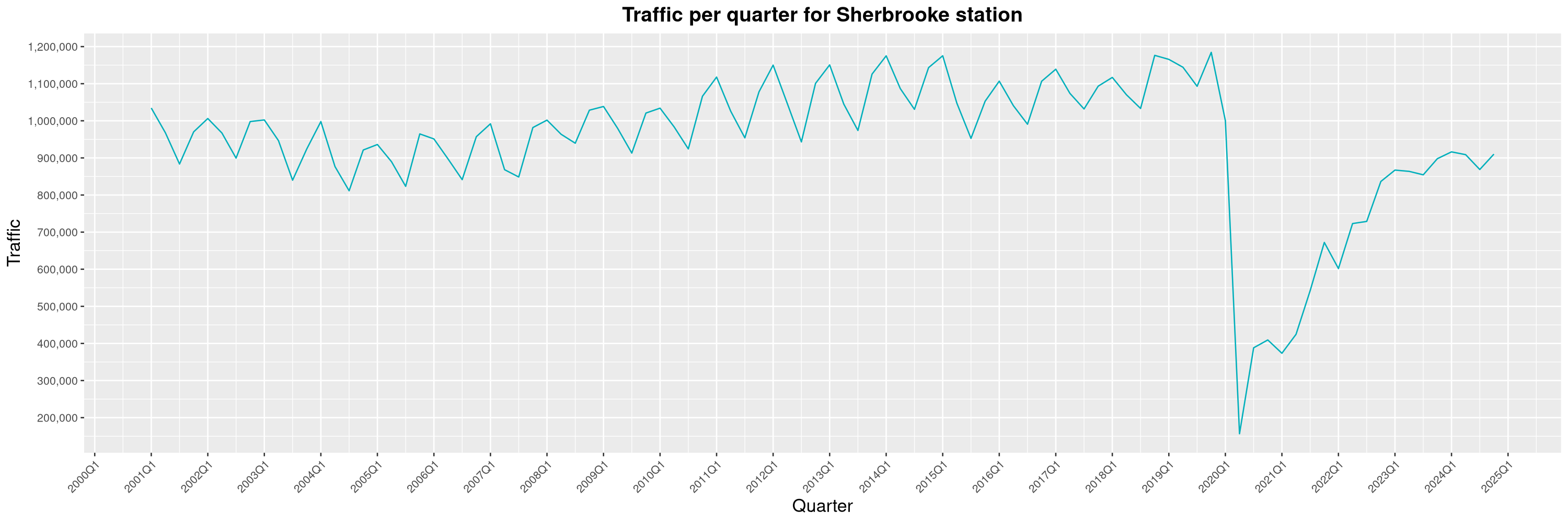
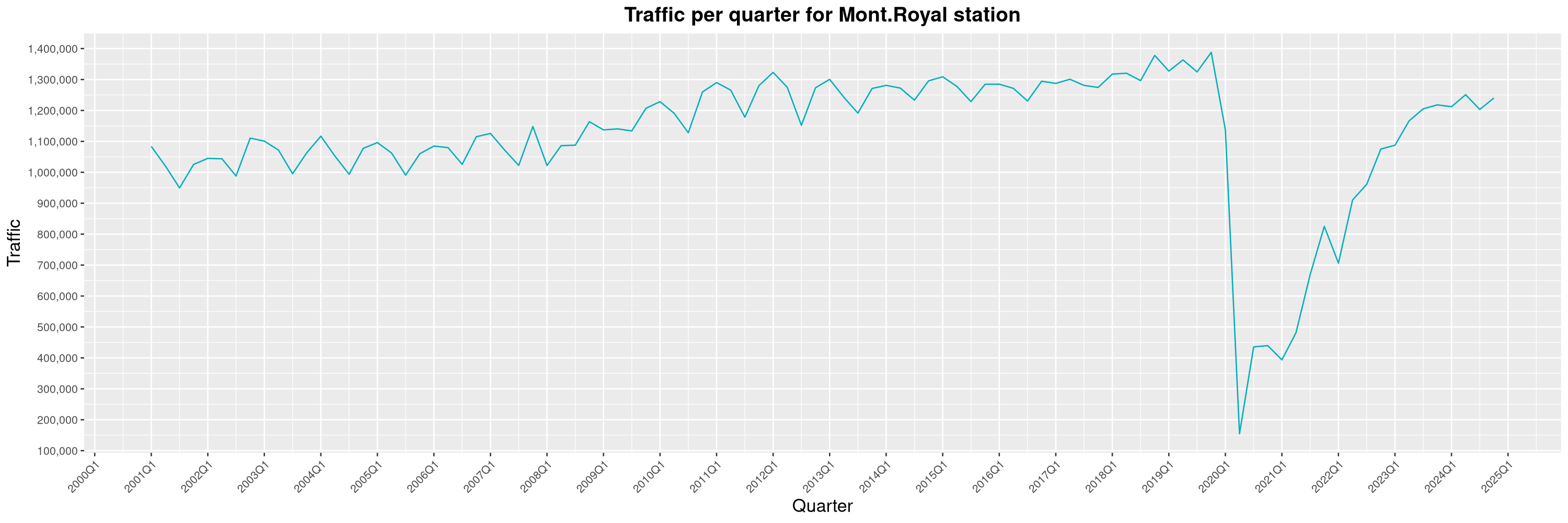
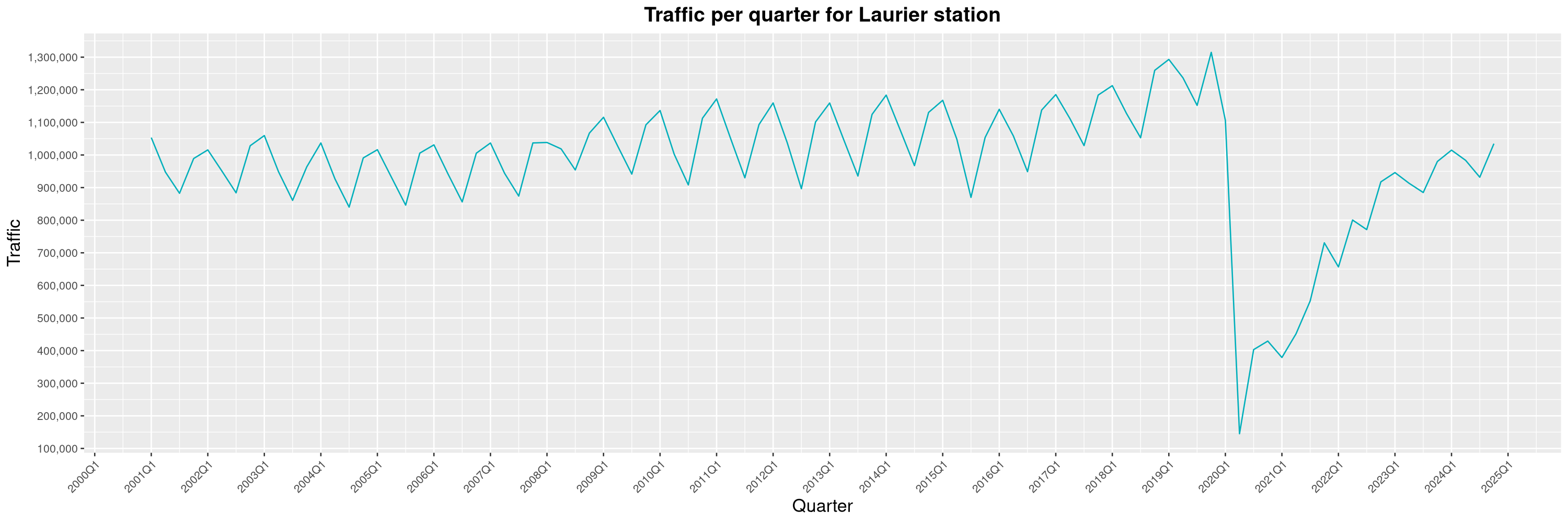
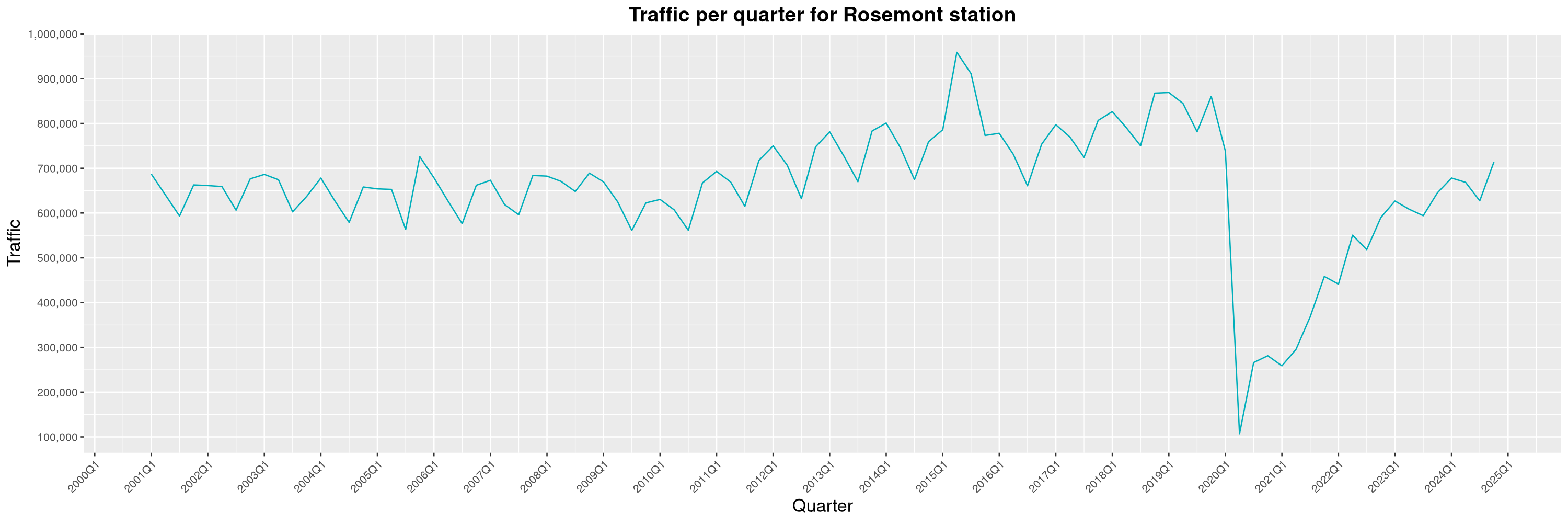
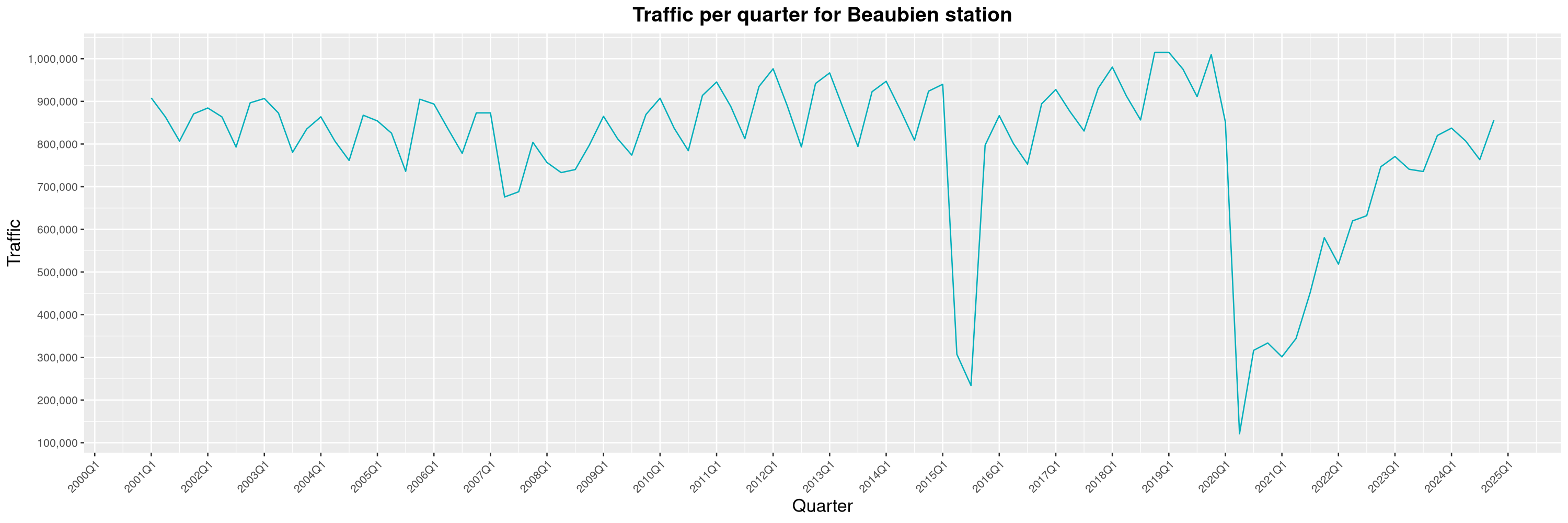
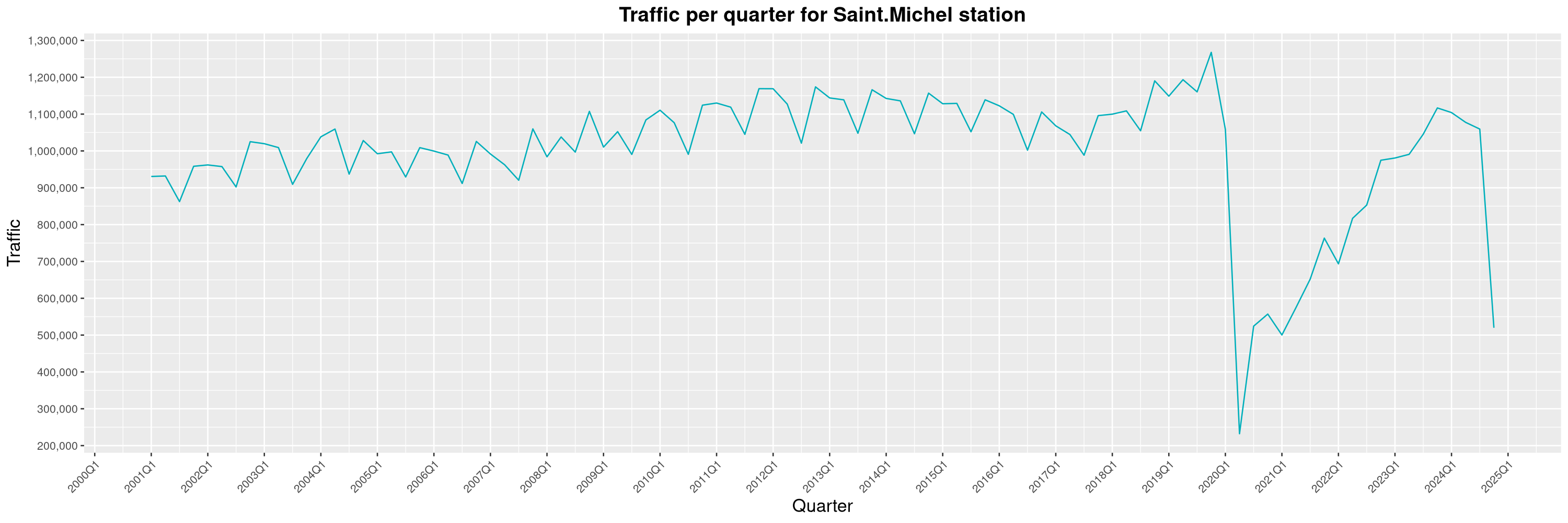
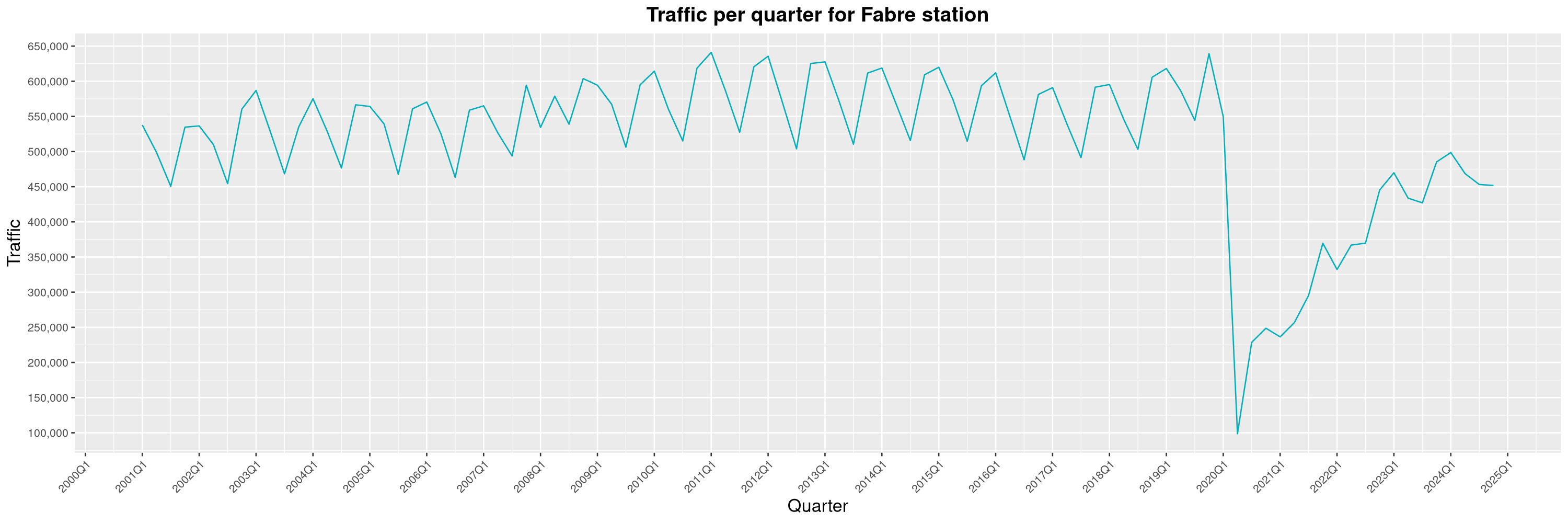
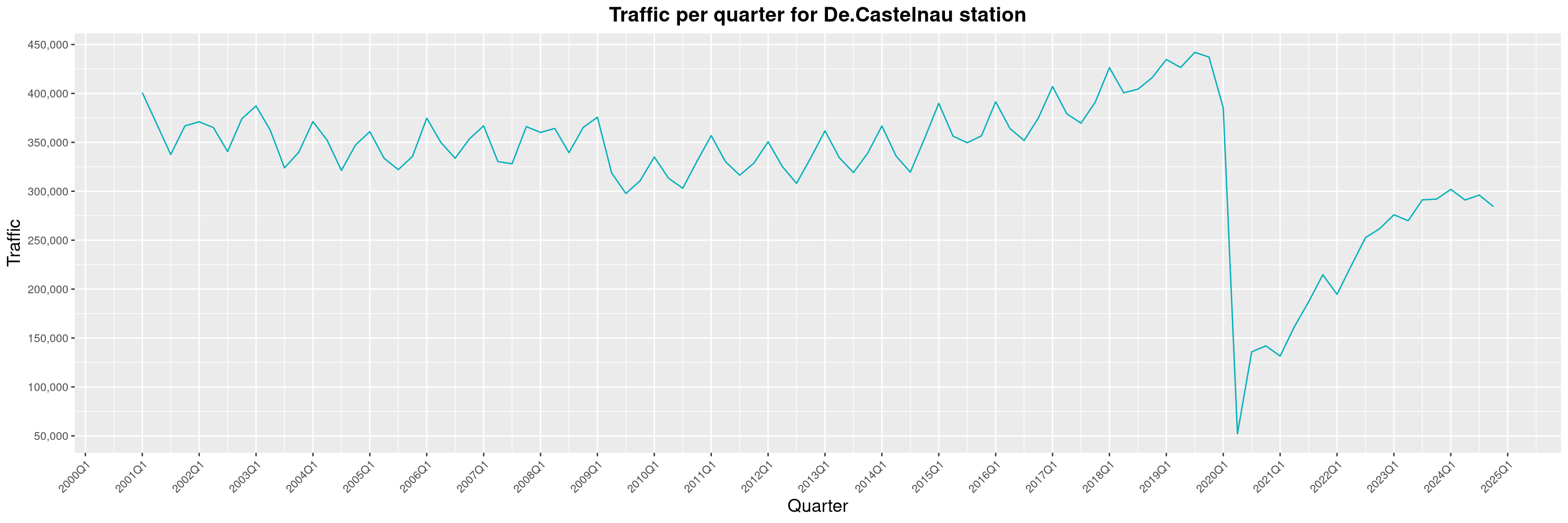
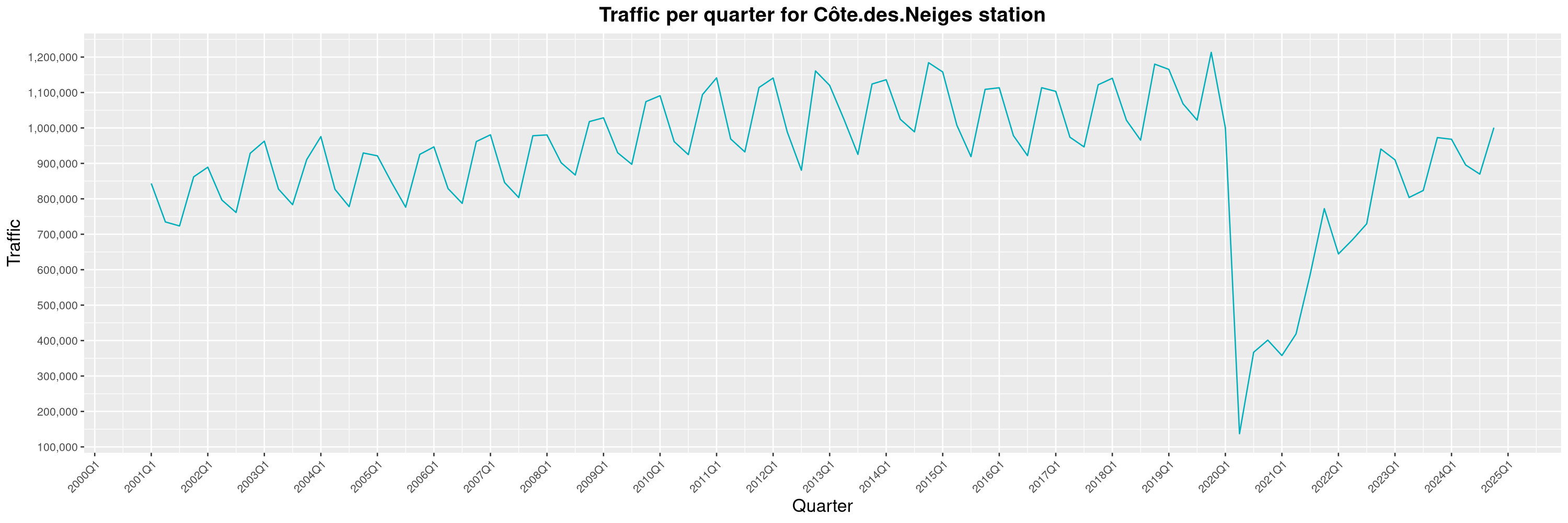
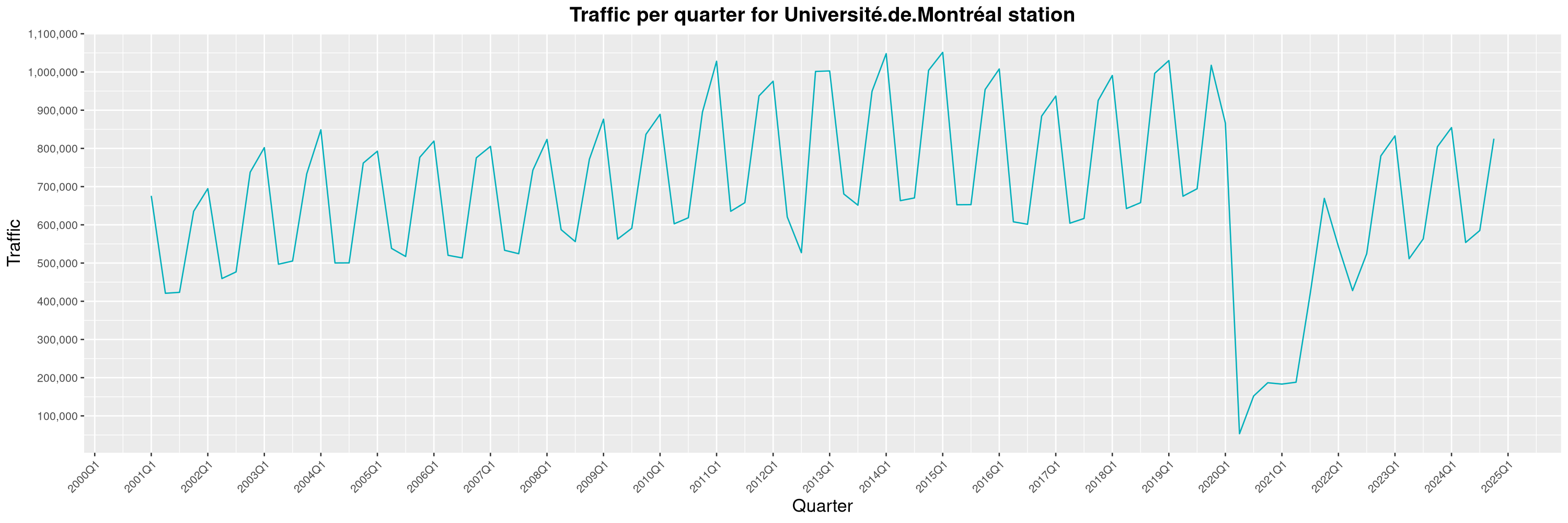
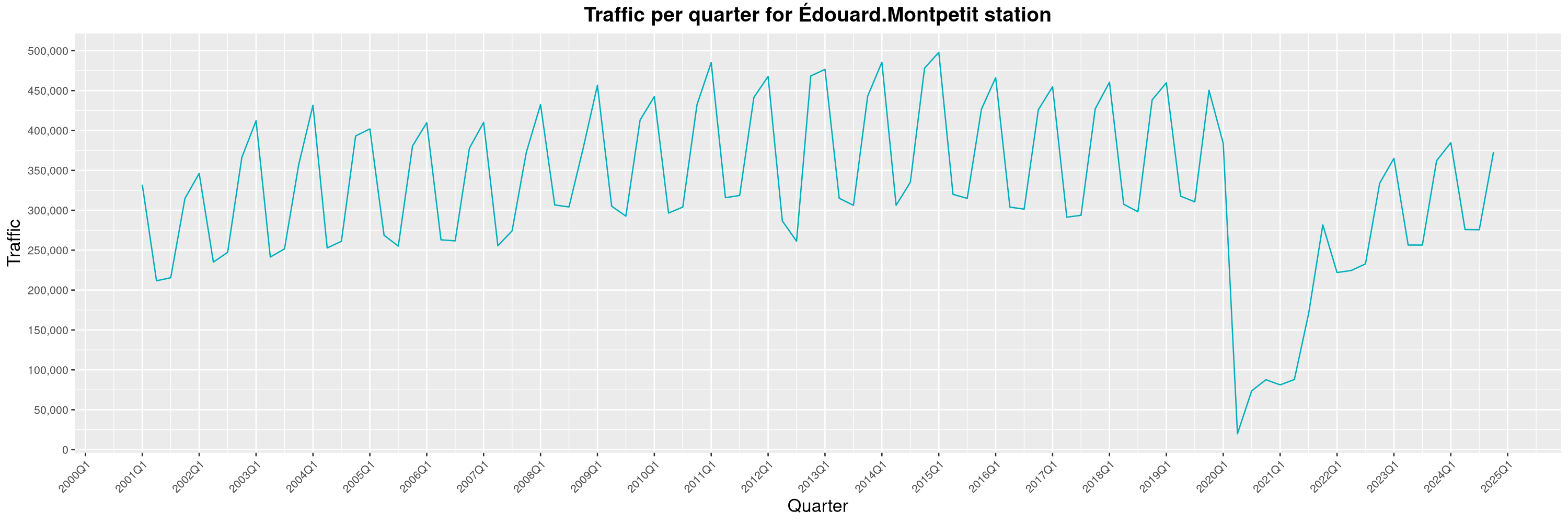
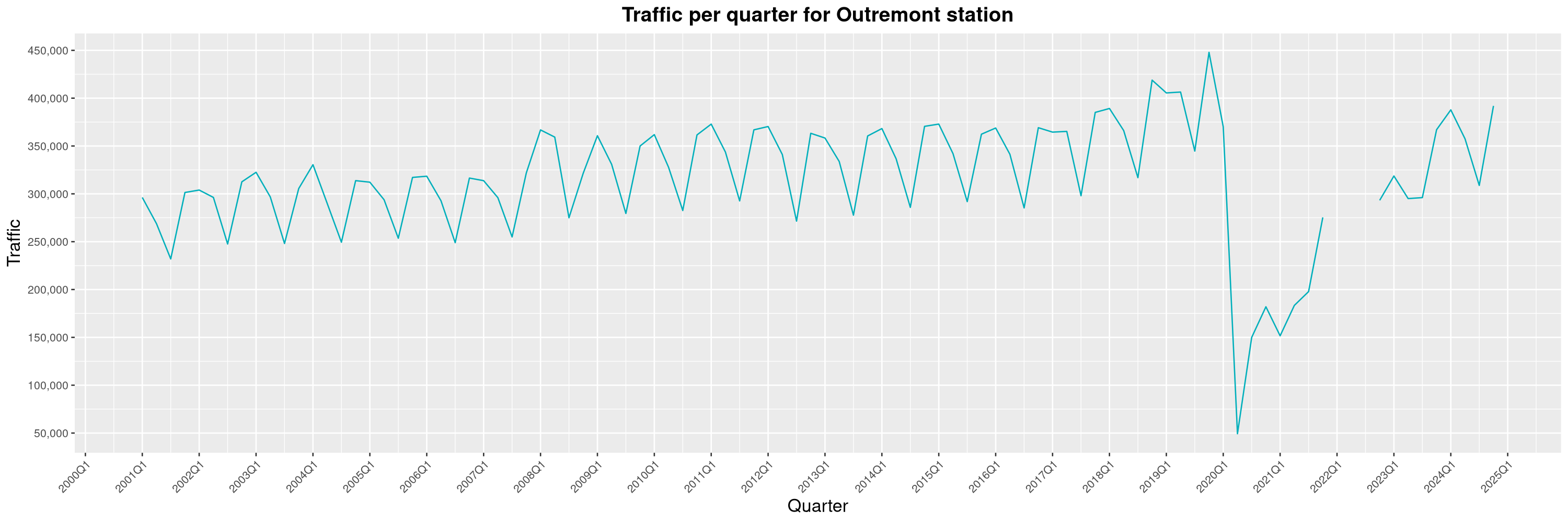
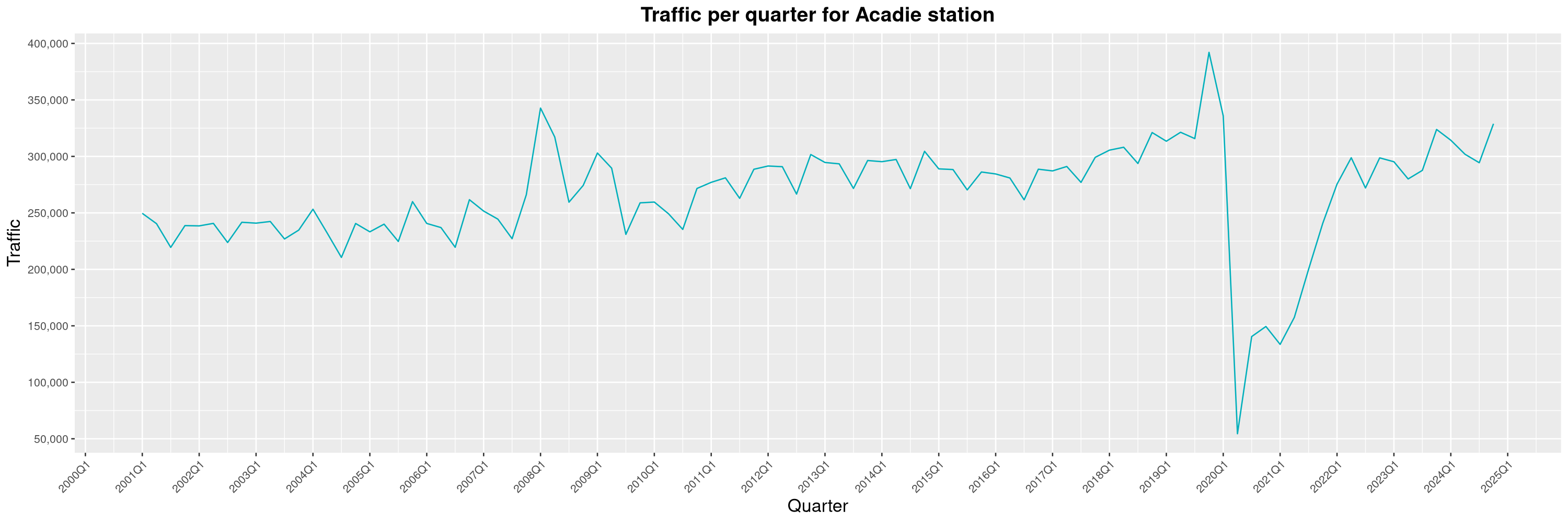
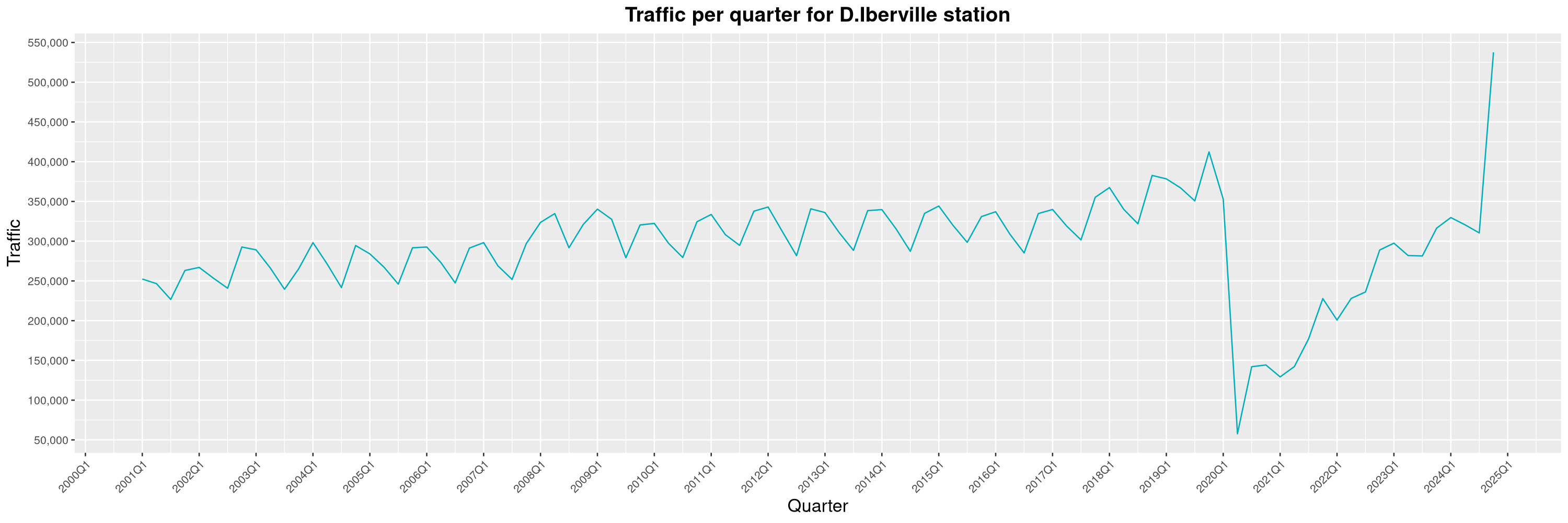
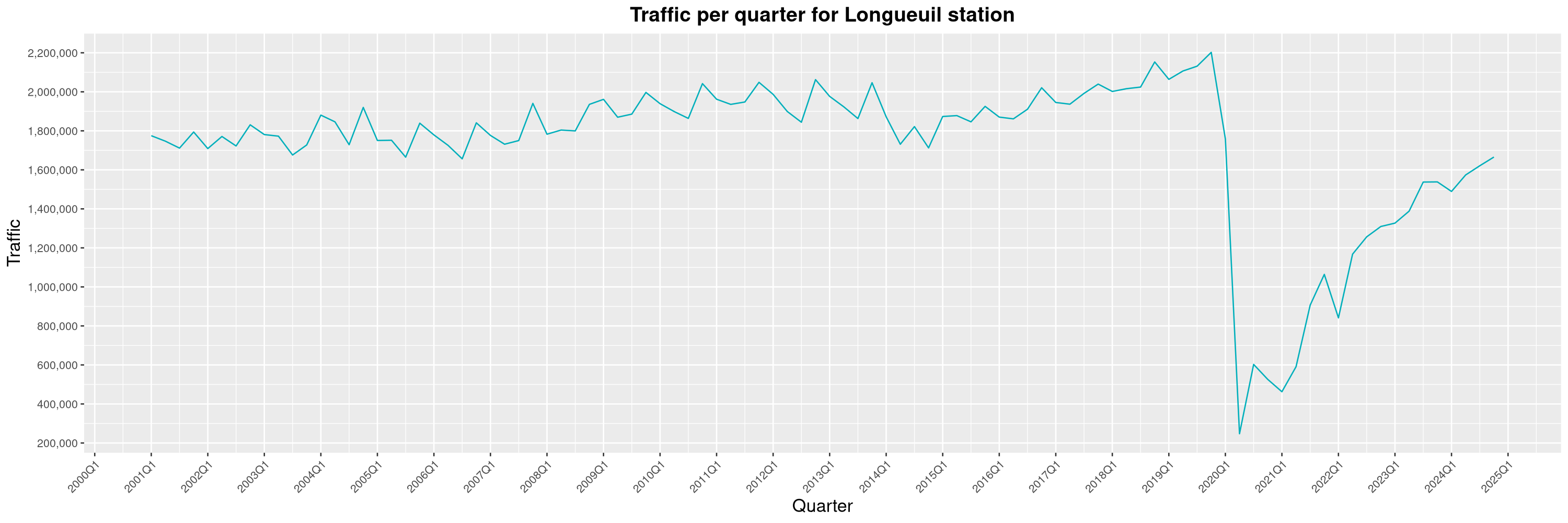
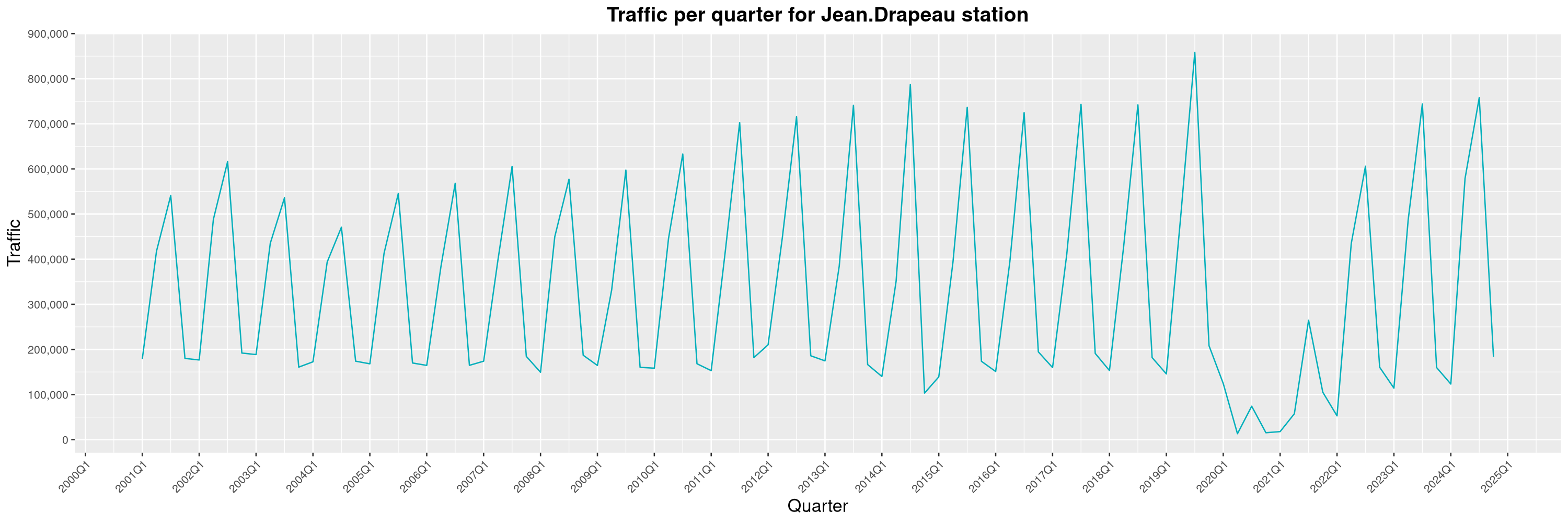
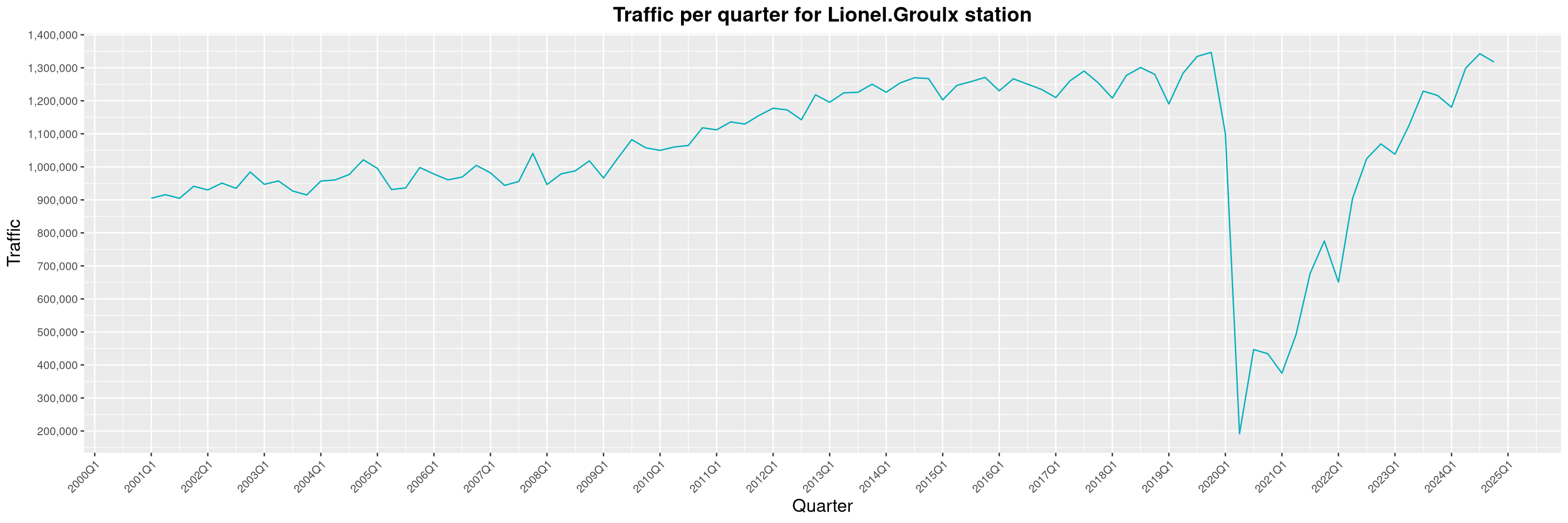
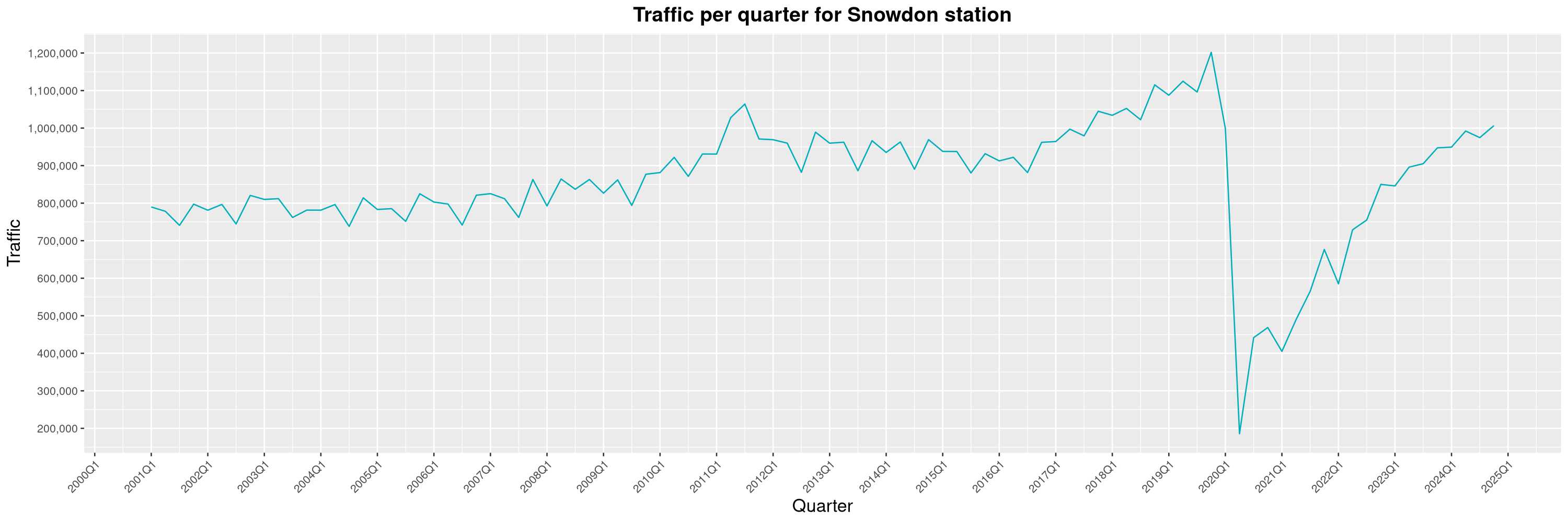
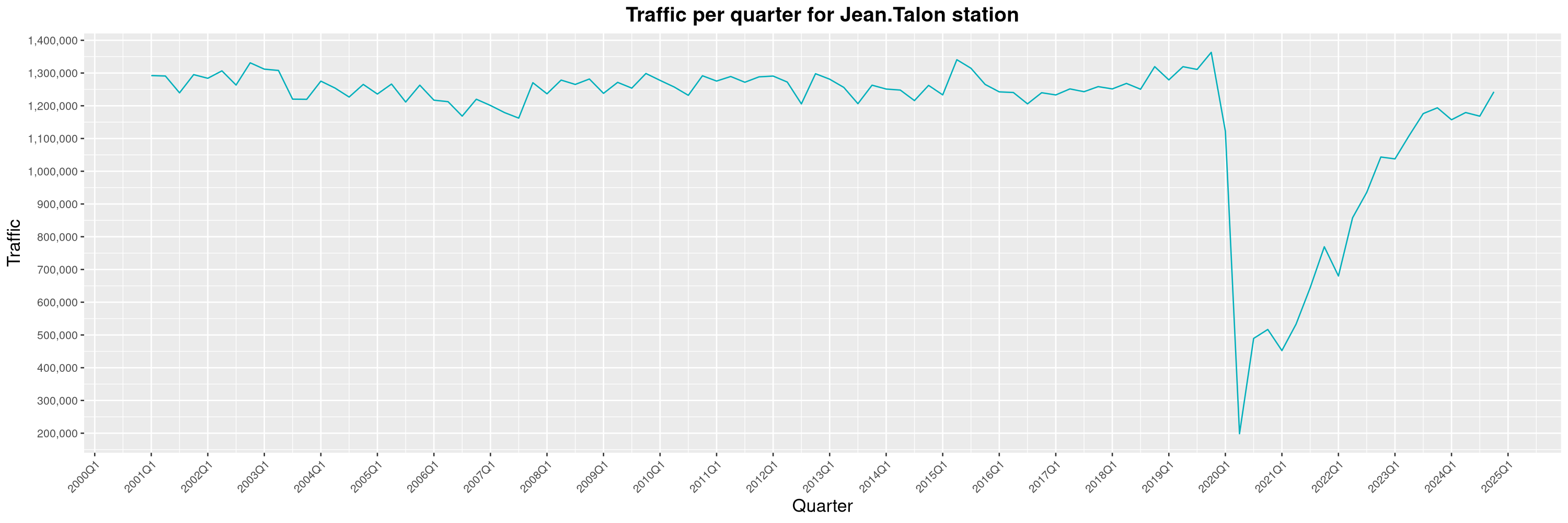
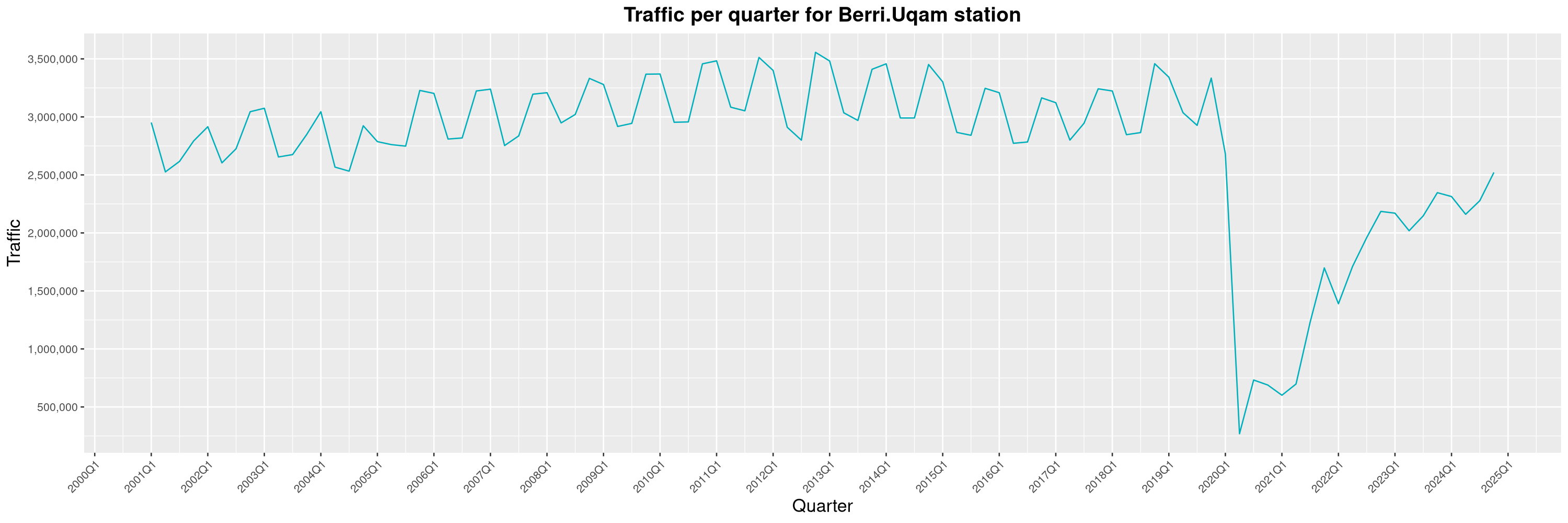
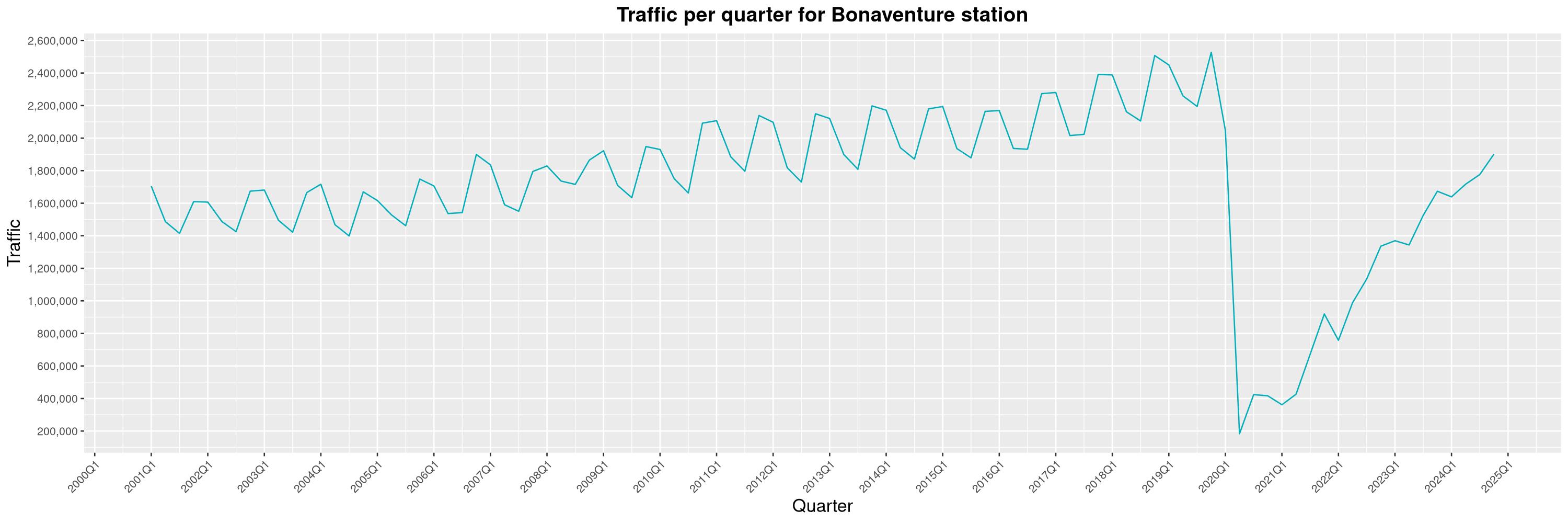
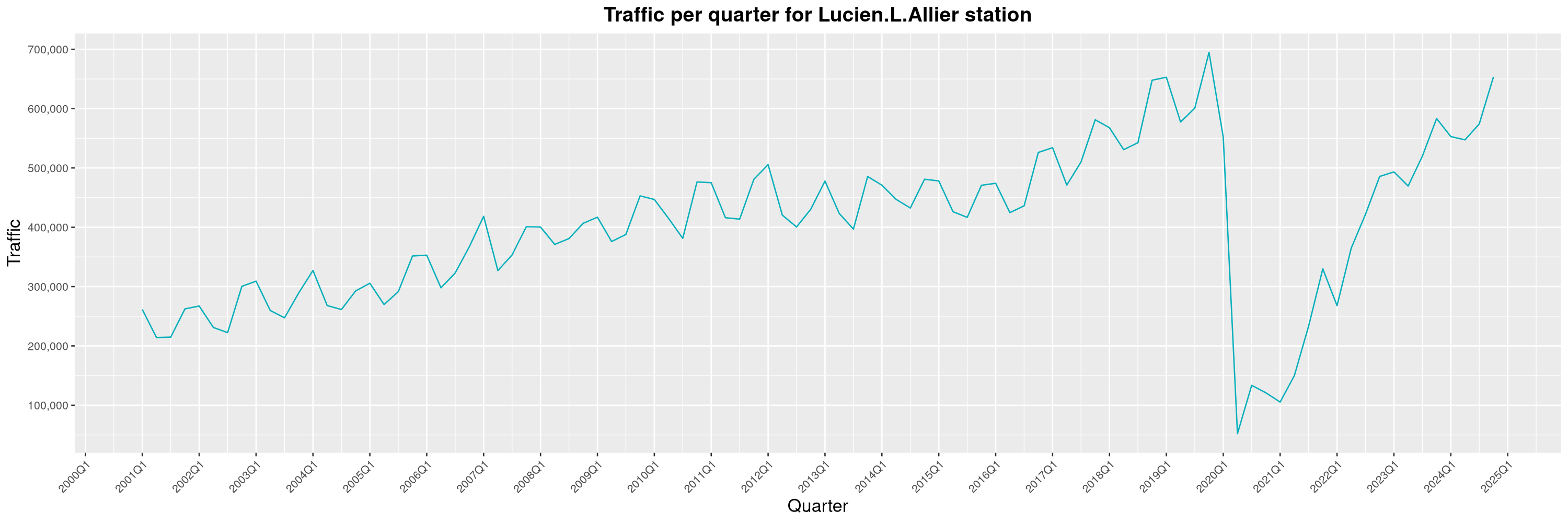
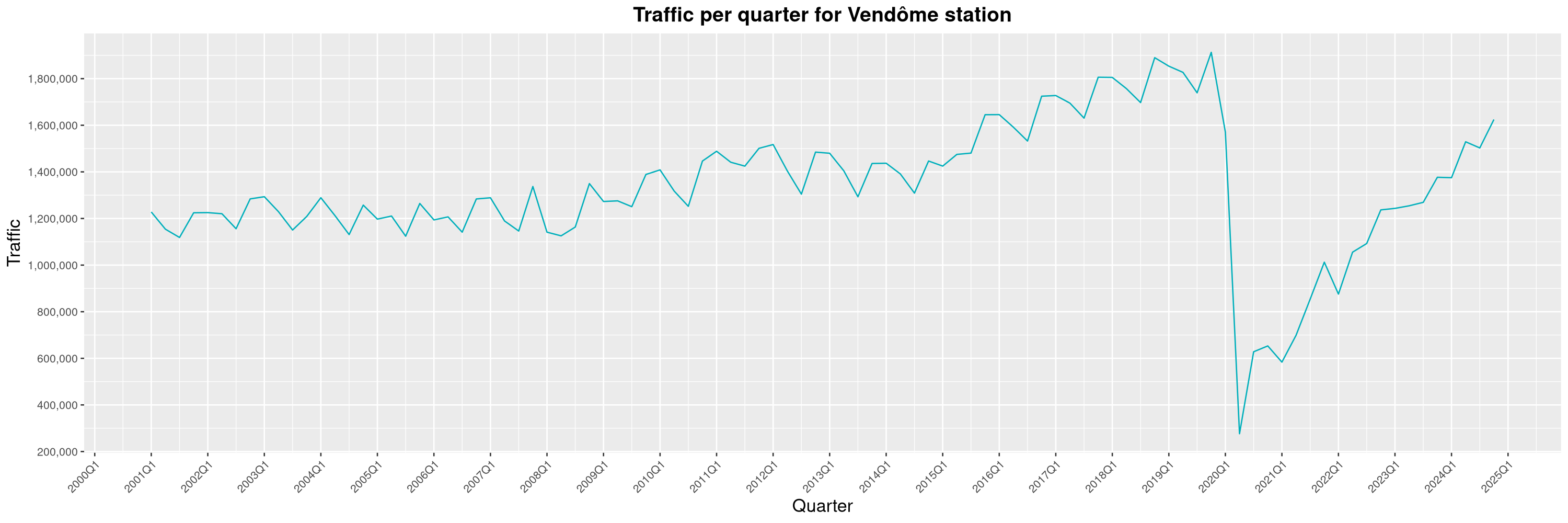
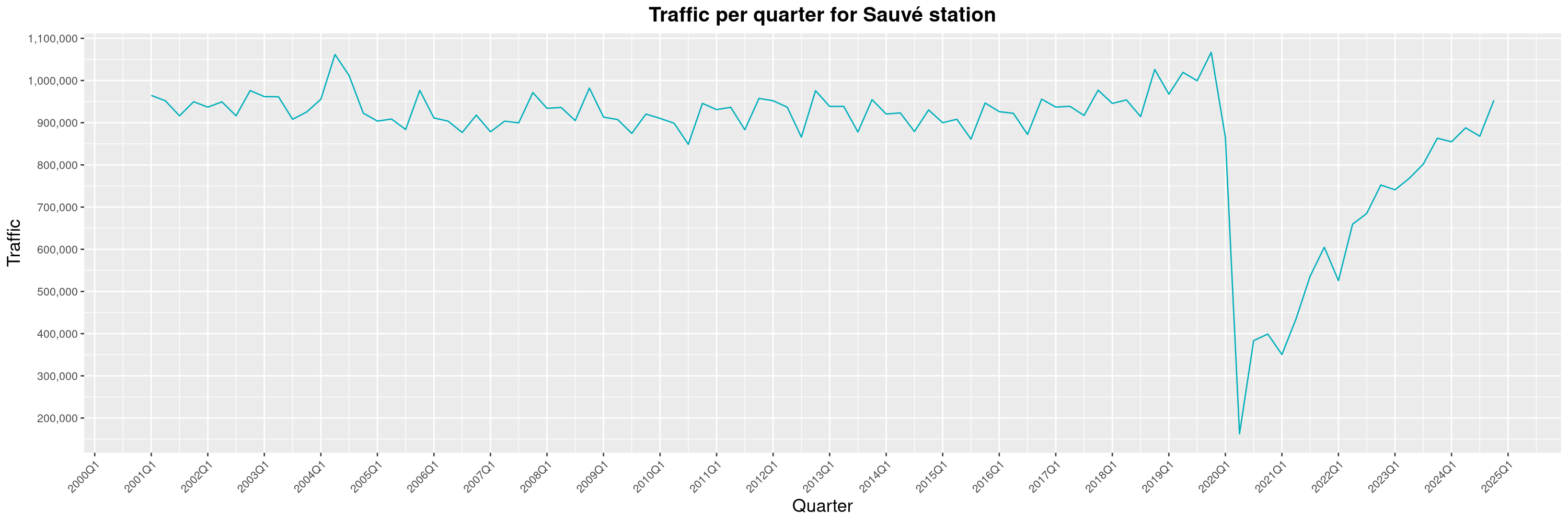
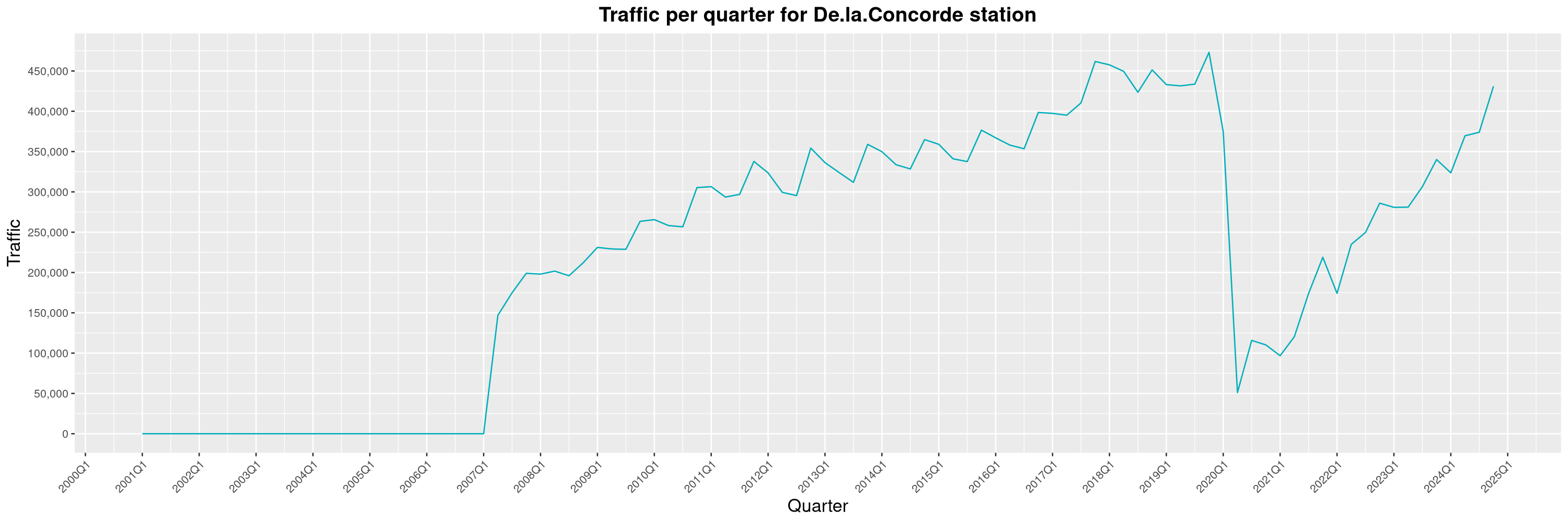
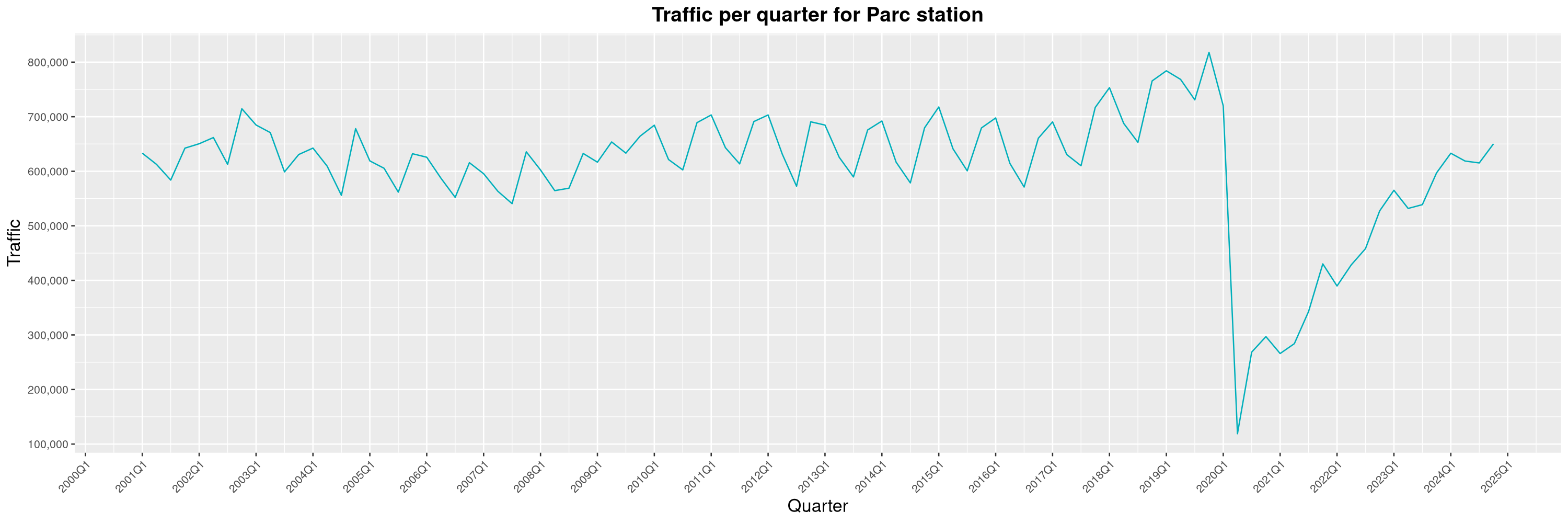
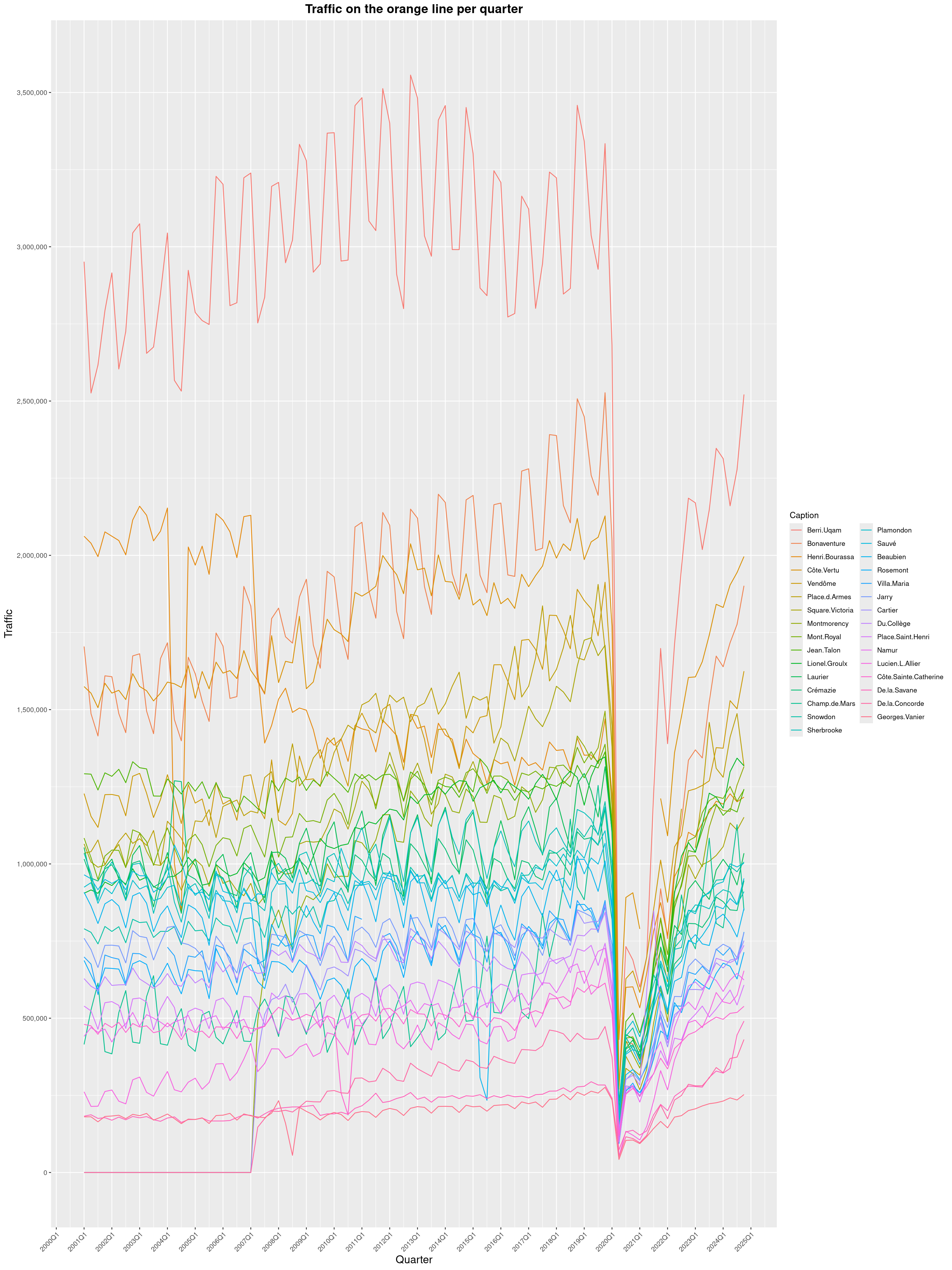
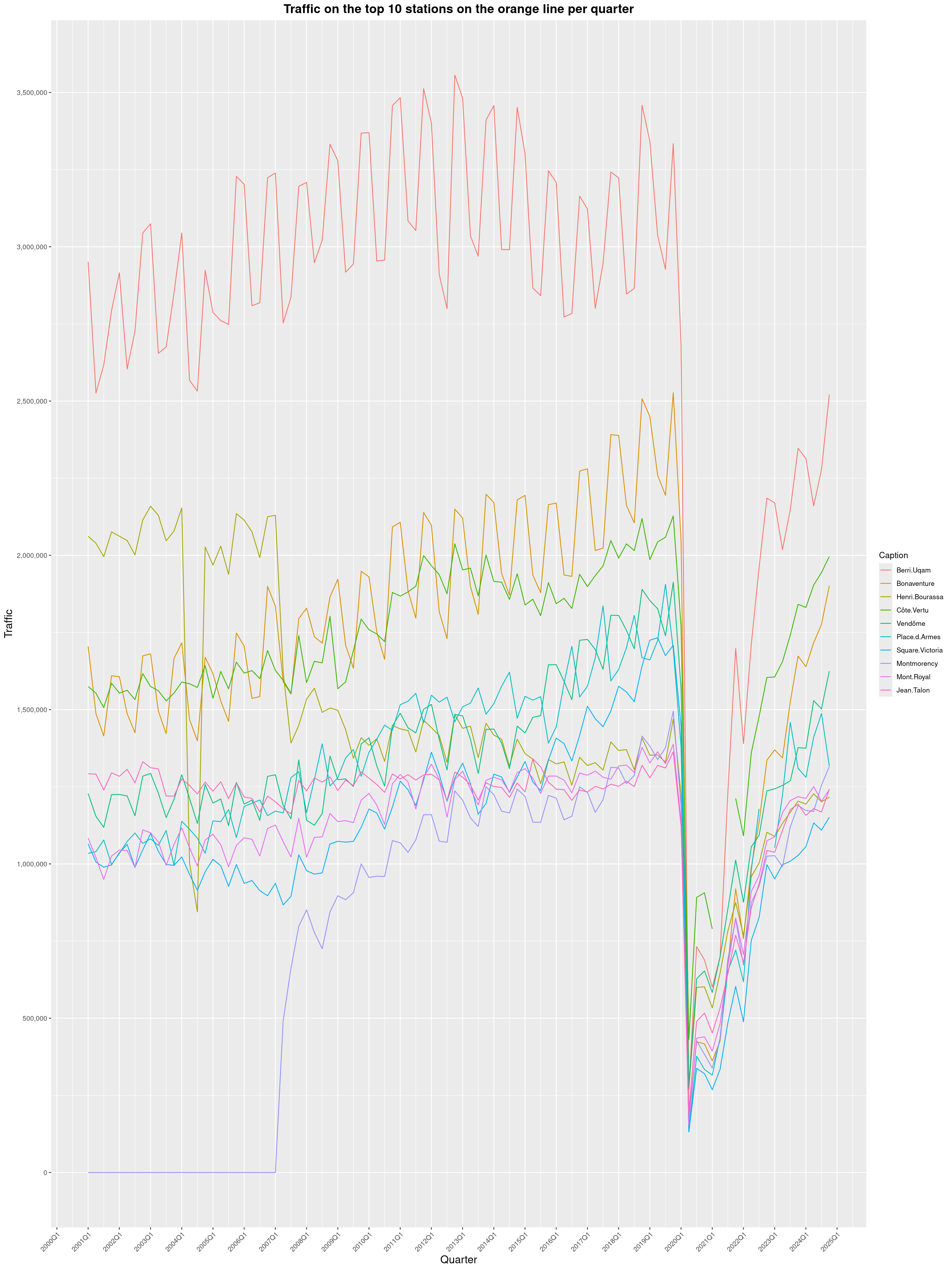
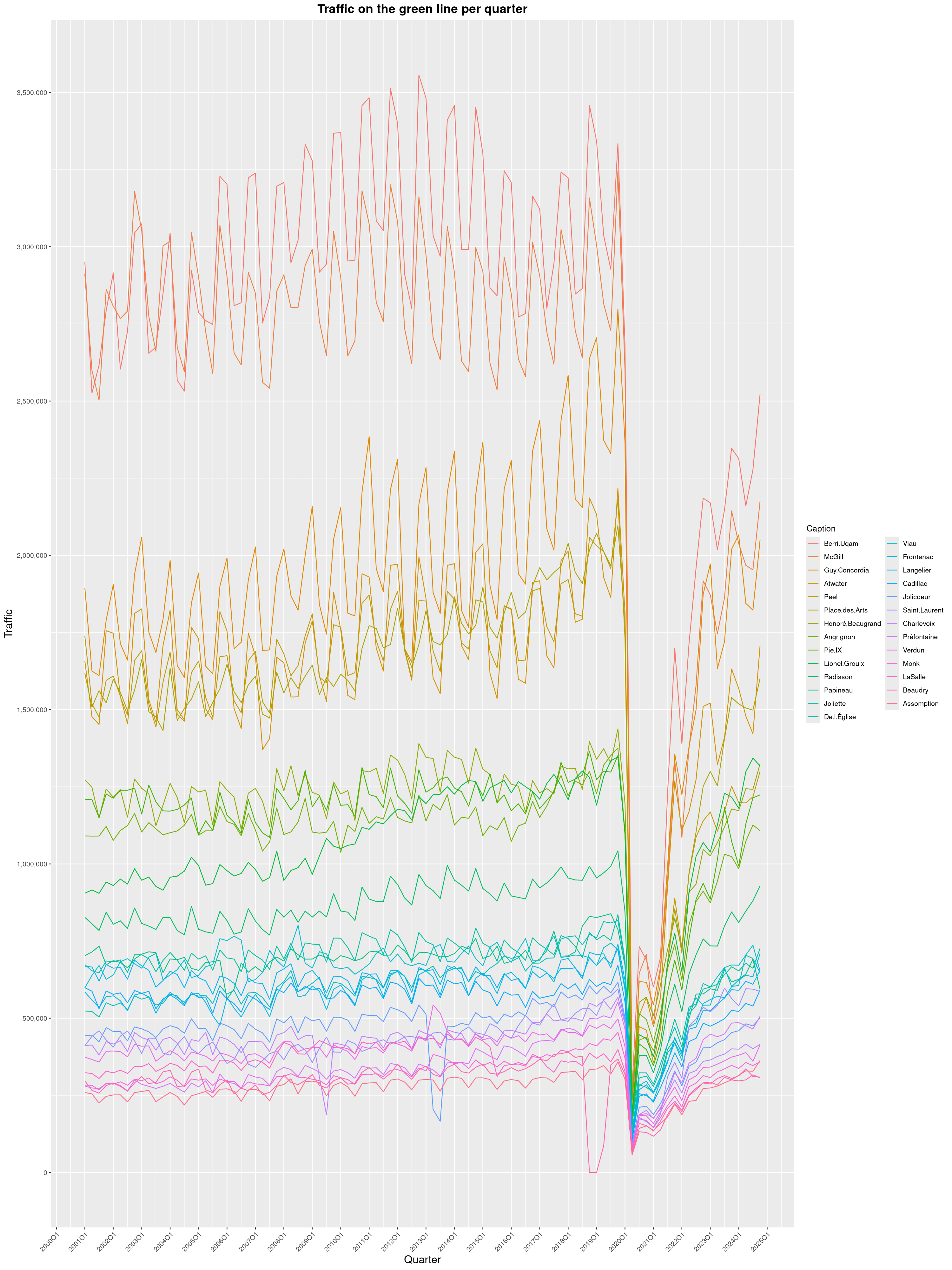
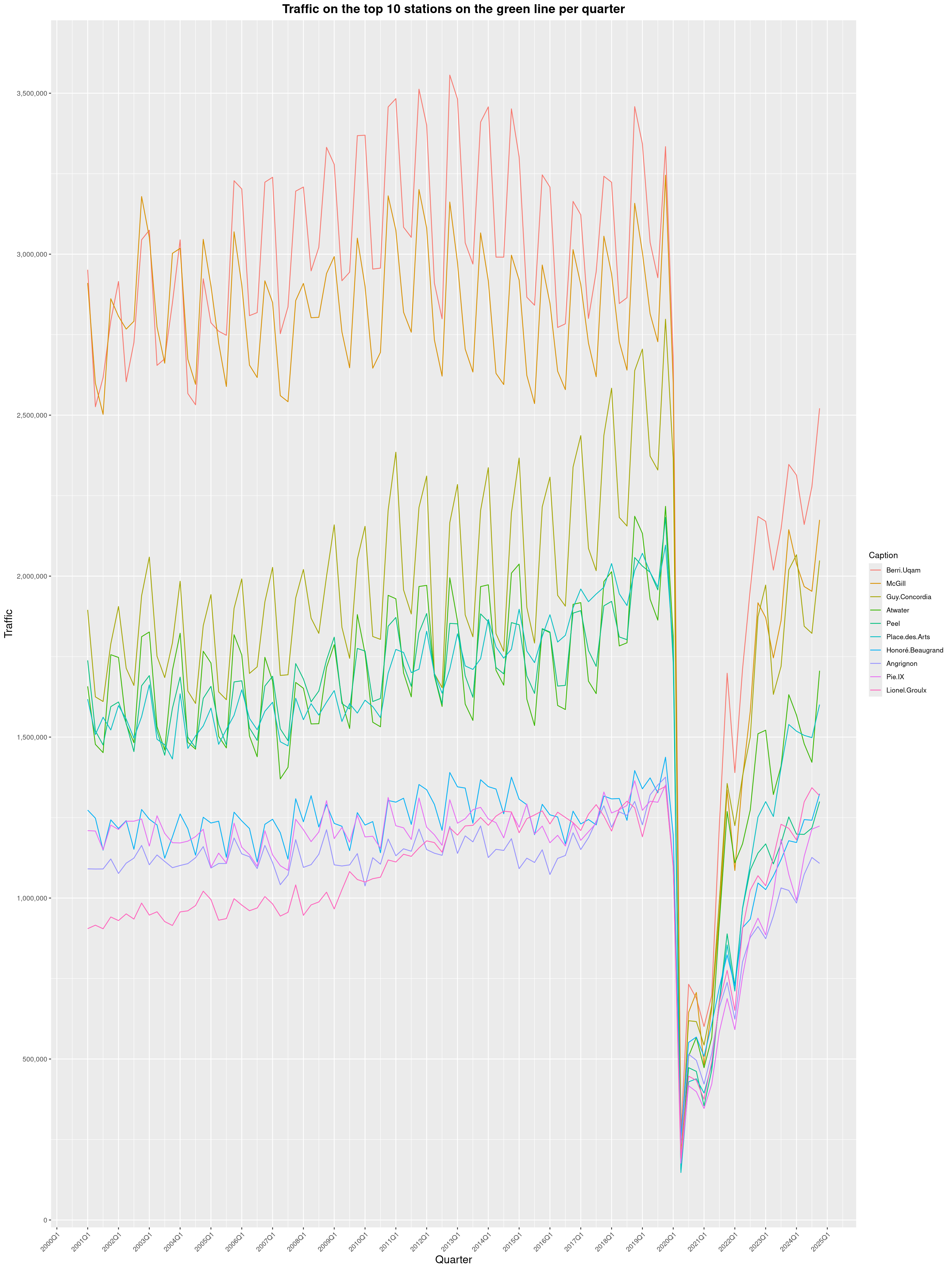
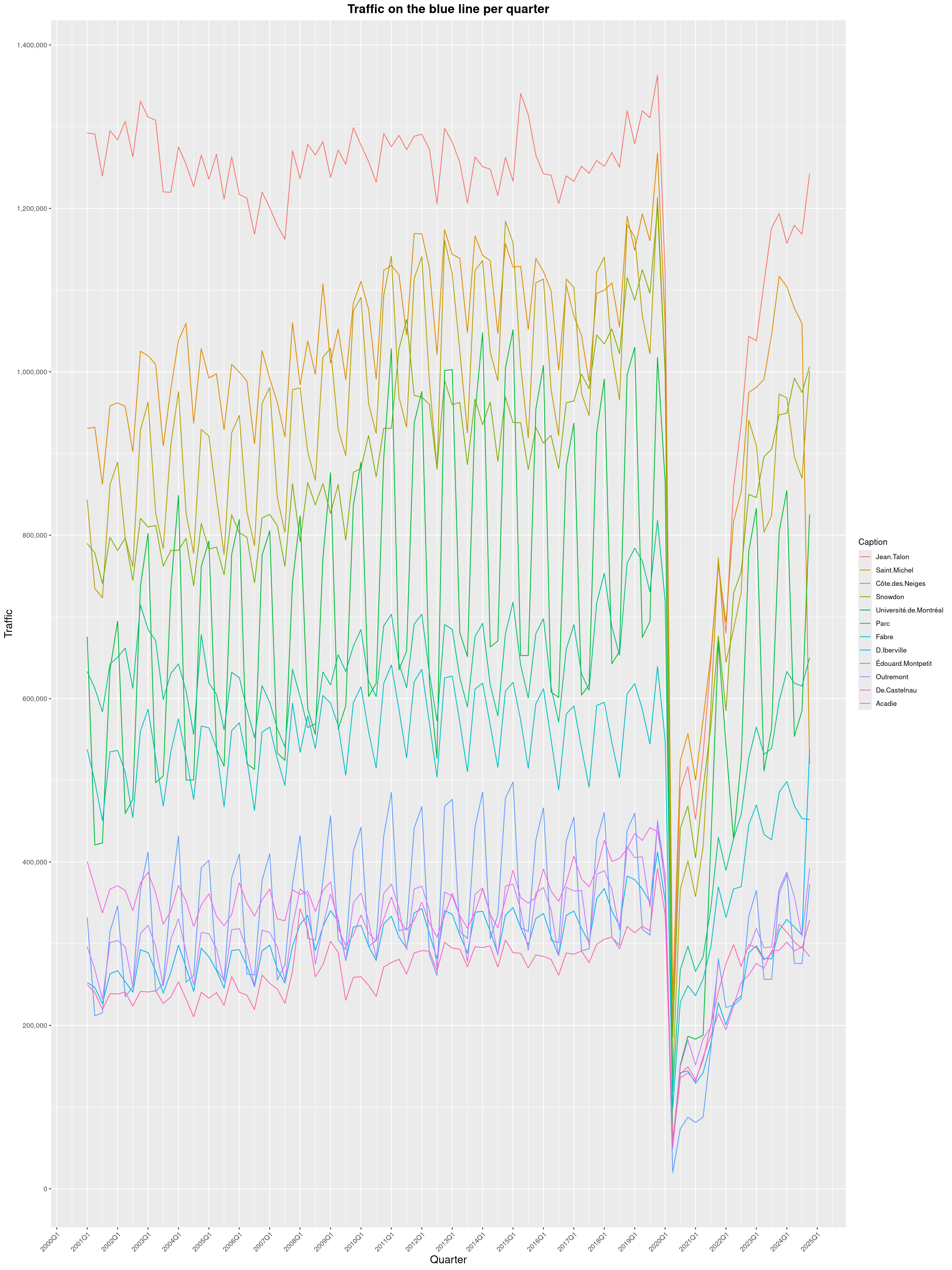
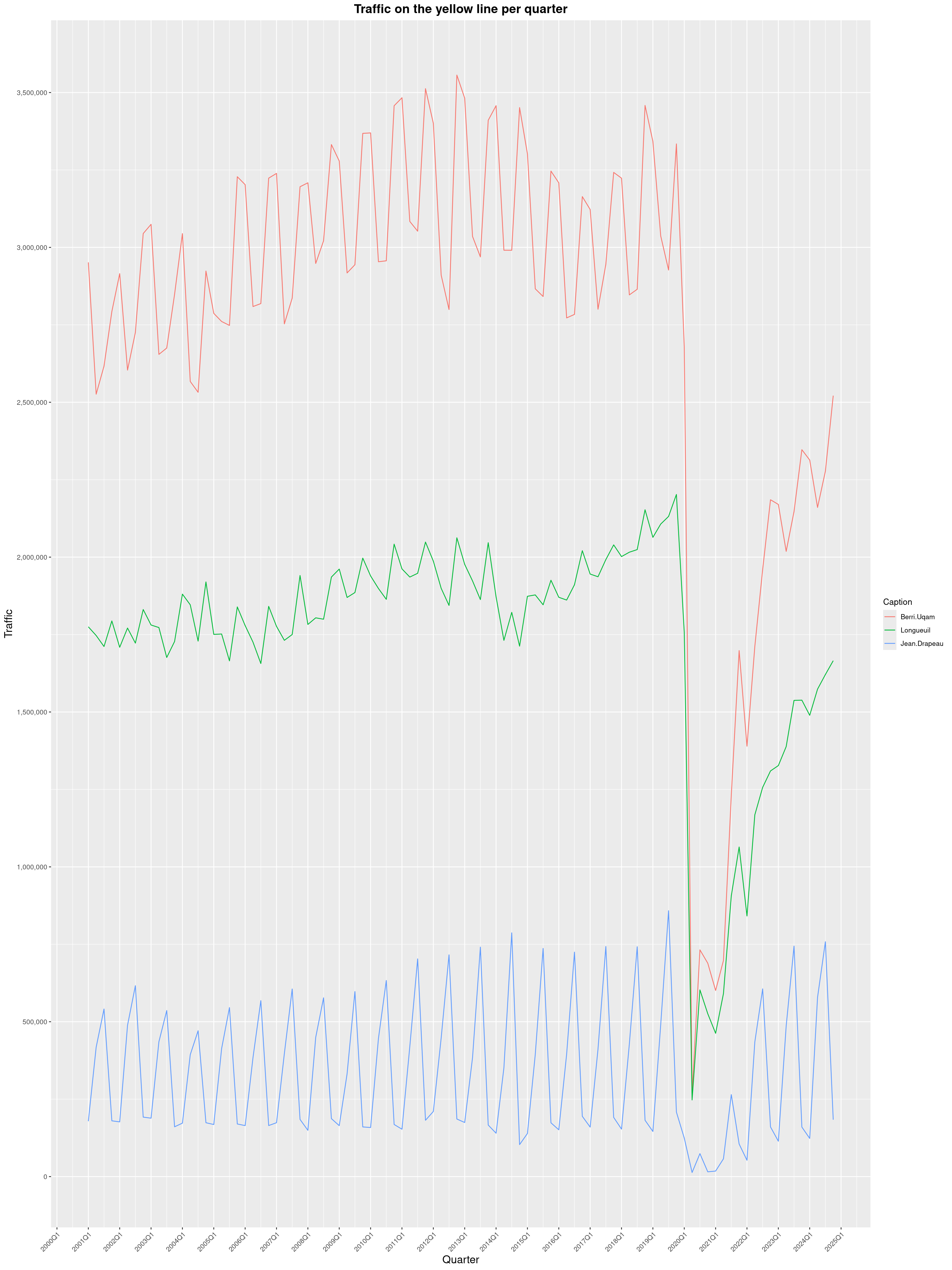
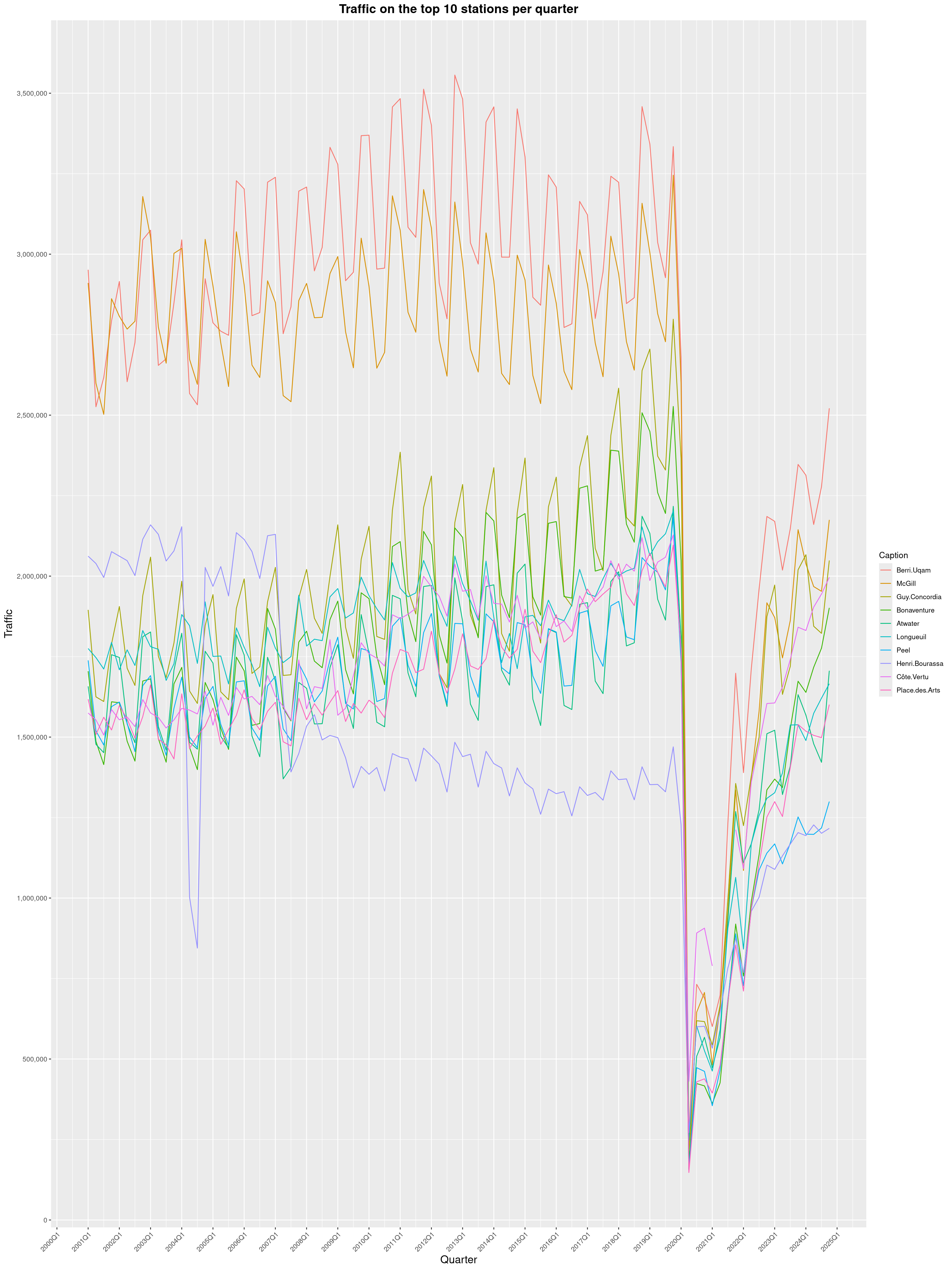
Louis-Philippe Véronneau: Montreal Subway Foot Traffic Data, 2024 edition
Another year of data from Société de Transport de Montréal, Montreal's transit agency!
A few highlights this year:
-
The closure of the Saint-Michel station had a drastic impact on D'Iberville, the station closest to it.
-
The opening of the Royalmount shopping center nearly doubled the traffic of the De La Savane station.
-
The Montreal subway continues to grow, but has not yet recovered from the pandemic. Berri-UQAM station (the largest one) is still below 1 million entries per quarter compared to its pre-pandemic record.
By clicking on a subway station, you'll be redirected to a graph of the station's foot traffic.
Licences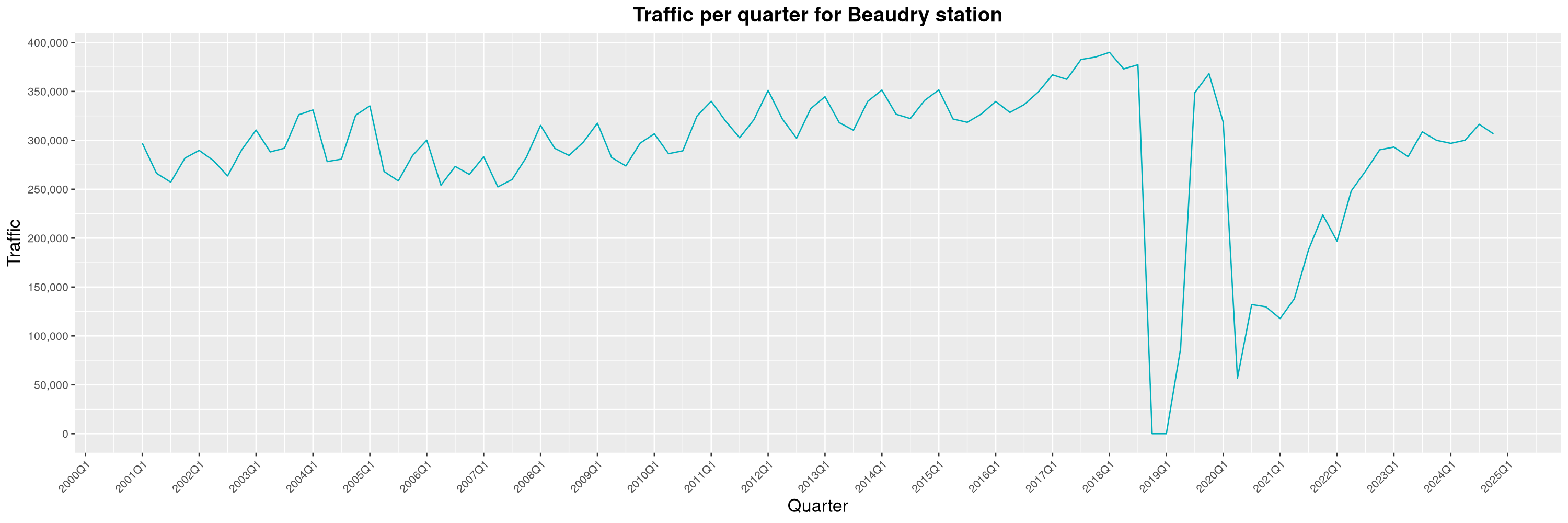{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
-
The subway map displayed on this page, the original dataset and my modified dataset are licenced under CCO 1.0: they are in the public domain.
-
The R code I wrote is licensed under the GPLv3+. It's pretty much the same code as last year. STM apparently changed (again!) the way they are exporting data, and since it's now somewhat sane, I didn't have to rely on a converter script.
Kentaro Hayashi: Stick to boot from 6.11 linux-image
Since Dec 2024, there is a compatibility issue with linux-image 6.12 and nvidia-driver 535.216.03.
#1089513 - nvidia-driver: crash in drm_open_helper on Linux 6.12.3 - Debian Bug report logs
It seems that the upstream was already fixed this issue in newer release, but not available yet on Debian sid.
If you keep installed linux-image-amd64 or linux-headers-amd64, it will be booted from 6.12 by default. Surely it will boot, but it still has the resolution issue. It can't be your daily driver.
Thus workaround is sticking to boot from 6.11 linux-image. As usually older image was listed in "Advanced options for ..." submenu, you need to explicitly choose 6.11 image during booting. In such a case, the changing default boot image is useful. (another option is just purge all 6.12 linux-image, linux-image-amd64 and linux-headers-amd64, but it's out of scope in this article)
See /boot/grub/grub.cfg and collect each menuentry_id_option.
You need to collect the following menuentry id.
- submenu menuentry's id (It might be 'gnulinux-advanced-.....') [1]
- 6.11 kernel's menuentry id which you want to boot by default. (It might be 'gnulinux-6.11.10-amd64-advanced-...') [2]
Then, edit GRUB_DEFAULT entry in /etc/default/grub.
GRUB_DEFAULT should be combination with [1] and [2] which is concatenated with ">"
e.g. NOTE: the actual value might vary on your environment
GRUB_DEFAULT="gnulinux-advanced-2e0e7dd0-7e10-4b58-92f7-518dabb5b547>gnulinux-6.11.10-amd64-advanced-2e0e7dd0-7e10-4b58-92f7-518dabb5b547"After that, update grub entry with sudo update-grub.
Freexian Collaborators: Monthly report about Debian Long Term Support, December 2024 (by Roberto C. Sánchez)
Like each month, have a look at the work funded by Freexian’s Debian LTS offering.
Debian LTS contributorsIn December, 19 contributors have been paid to work on Debian LTS, their reports are available:
- Abhijith PA did 14.0h (out of 14.0h assigned).
- Adrian Bunk did 47.75h (out of 53.0h assigned and 47.0h from previous period), thus carrying over 52.25h to the next month.
- Andrej Shadura did 6.0h (out of 17.0h assigned and -7.0h from previous period after hours given back), thus carrying over 4.0h to the next month.
- Bastien Roucariès did 22.0h (out of 22.0h assigned).
- Ben Hutchings did 15.0h (out of 0.0h assigned and 18.0h from previous period), thus carrying over 3.0h to the next month.
- Chris Lamb did 18.0h (out of 18.0h assigned).
- Daniel Leidert did 23.0h (out of 17.0h assigned and 9.0h from previous period), thus carrying over 3.0h to the next month.
- Emilio Pozuelo Monfort did 32.25h (out of 40.5h assigned and 19.5h from previous period), thus carrying over 27.75h to the next month.
- Guilhem Moulin did 22.5h (out of 9.75h assigned and 12.75h from previous period).
- Jochen Sprickerhof did 2.0h (out of 3.5h assigned and 6.5h from previous period), thus carrying over 8.0h to the next month.
- Lee Garrett did 8.5h (out of 14.75h assigned and 45.25h from previous period), thus carrying over 51.5h to the next month.
- Lucas Kanashiro did 32.0h (out of 10.0h assigned and 54.0h from previous period), thus carrying over 32.0h to the next month.
- Markus Koschany did 40.0h (out of 20.0h assigned and 20.0h from previous period).
- Roberto C. Sánchez did 13.5h (out of 6.75h assigned and 17.25h from previous period), thus carrying over 10.5h to the next month.
- Santiago Ruano Rincón did 18.75h (out of 24.75h assigned and 0.25h from previous period), thus carrying over 6.25h to the next month.
- Sean Whitton did 6.0h (out of 2.0h assigned and 4.0h from previous period).
- Sylvain Beucler did 10.5h (out of 21.5h assigned and 38.5h from previous period), thus carrying over 49.5h to the next month.
- Thorsten Alteholz did 11.0h (out of 11.0h assigned).
- Tobias Frost did 12.0h (out of 12.0h assigned).
In December, we have released 29 DLAs.
The LTS Team has published updates to several notable packages. Contributor Guilhem Moulin published an update of php7.4, a widely-used open source general purpose scripting language, which addressed denial of service, authorization bypass, and information disclosure vulnerabilities. Contributor Lucas Kanashiro published an update of clamav, an antivirus toolkit for Unix and Linux, which addressed denial of service and authorization bypass vulnerabilities. Finally, contributor Tobias Frost published an update of intel-microcode, the microcode for Intel microprocessors, which well help to ensure that processor hardware is protected against several local privilege escalation and local denial of service vulnerabilities.
Beyond our customary LTS package updates, the LTS Team has made contributions to Debian’s stable bookworm release and its experimental section. Notably, contributor Lee Garrett published a stable update of dnsmasq. The LTS update was previously published in November and in December Lee continued working to bring the same fixes (addressing the high profile KeyTrap and NSEC3 vulnerabilities) to the dnsmasq package in Debian bookworm. This package was accepted for inclusion in the Debian 12.9 point release scheduled for January 2025. Addititionally, contributor Sean Whitton provided assistance, via upload sponsorships, to the Debian maintainers of xen. This assistance resulted in two uploads of xen into Debian’s experimental section, which will contribute to the next Debian stable release having a version of xen with better longterm support from the upstream development team.
Thanks to our sponsorsSponsors that joined recently are in bold.
- Platinum sponsors:
- Toshiba Corporation (for 111 months)
- Civil Infrastructure Platform (CIP) (for 79 months)
- VyOS Inc (for 43 months)
- Gold sponsors:
- Roche Diagnostics International AG (for 121 months)
- Akamai - Linode (for 115 months)
- Babiel GmbH (for 105 months)
- Plat’Home (for 104 months)
- University of Oxford (for 61 months)
- Deveryware (for 48 months)
- EDF SA (for 33 months)
- Dataport AöR (for 8 months)
- CERN (for 6 months)
- Silver sponsors:
- Domeneshop AS (for 126 months)
- Nantes Métropole (for 120 months)
- Univention GmbH (for 112 months)
- Université Jean Monnet de St Etienne (for 112 months)
- Ribbon Communications, Inc. (for 106 months)
- Exonet B.V. (for 96 months)
- Leibniz Rechenzentrum (for 90 months)
- Ministère de l’Europe et des Affaires Étrangères (for 74 months)
- Cloudways by DigitalOcean (for 63 months)
- Dinahosting SL (for 61 months)
- Bauer Xcel Media Deutschland KG (for 55 months)
- Platform.sh SAS (for 55 months)
- Moxa Inc. (for 49 months)
- sipgate GmbH (for 47 months)
- OVH US LLC (for 45 months)
- Tilburg University (for 45 months)
- GSI Helmholtzzentrum für Schwerionenforschung GmbH (for 36 months)
- Soliton Systems K.K. (for 33 months)
- THINline s.r.o. (for 9 months)
- Copenhagen Airports A/S (for 3 months)
- Bronze sponsors:
- Evolix (for 126 months)
- Seznam.cz, a.s. (for 126 months)
- Intevation GmbH (for 123 months)
- Linuxhotel GmbH (for 123 months)
- Daevel SARL (for 122 months)
- Bitfolk LTD (for 121 months)
- Megaspace Internet Services GmbH (for 121 months)
- Greenbone AG (for 120 months)
- NUMLOG (for 120 months)
- WinGo AG (for 119 months)
- Entr’ouvert (for 111 months)
- Adfinis AG (for 108 months)
- Laboratoire LEGI - UMR 5519 / CNRS (for 103 months)
- Tesorion (for 103 months)
- GNI MEDIA (for 102 months)
- Bearstech (for 94 months)
- LiHAS (for 94 months)
- Catalyst IT Ltd (for 89 months)
- Supagro (for 84 months)
- Demarcq SAS (for 83 months)
- Université Grenoble Alpes (for 69 months)
- TouchWeb SAS (for 61 months)
- SPiN AG (for 58 months)
- CoreFiling (for 54 months)
- Institut des sciences cognitives Marc Jeannerod (for 49 months)
- Observatoire des Sciences de l’Univers de Grenoble (for 45 months)
- Tem Innovations GmbH (for 40 months)
- WordFinder.pro (for 39 months)
- CNRS DT INSU Résif (for 38 months)
- Alter Way (for 31 months)
- Institut Camille Jordan (for 21 months)
- SOBIS Software GmbH (for 6 months)
Divine Attah-Ohiemi: My 30-Day Outreachy Experience with the Debian Community
Hey everyone! It’s Divine Attah-Ohiemi here, and I’m excited to share what I’ve been up to in my internship with the Debian community. It’s been a month since I began this journey, and if you’re thinking about applying for Outreachy, let me give you a glimpse into my project and the amazing people I get to work with.
So, what’s it like in the Debian community? It’s a fantastic mix of folks from all walks of life—seasoned developers, curious newbies, and everyone in between. What really stands out is how welcoming everyone is. I’m especially thankful to my mentors, Thomas Lange, Carsten Schoenert, and Subin Siby, for their guidance and for always clocking in whenever I have questions. It feels like a big family where you can share your ideas and learn from each other. The commitment to diversity and merit is palpable, making it a great place for anyone eager to jump in and contribute.
Now, onto the project! We’re working on improving the Debian website by switching from WML (Web Meta Language) to Hugo, a modern static site generator. This change doesn’t just make the site faster; it significantly reduces the time it takes to build compared to WML. Plus, it makes it way easier for non-developers to contribute and add pages since the content is built from Markdown files. It’s all about enhancing the experience for both new and existing users.
My role involves developing a proof of concept for this transition. I’m migrating existing pages while ensuring that old links still work, so users won’t run into dead ends. It’s a bit of a juggling act, but knowing that my work is helping to make Debian more accessible is incredibly rewarding.
What gets me most excited is the chance to contribute to a project that’s been around for over 20 years! It’s an honor to be part of something so significant and to help shape its future. How cool is it to know that what I’m doing will impact users around the globe?
In the past month, I’ve learned a bunch of new things. For instance, I’ve been diving into Apache's mod_rewrite to automatically map old multilingual URLs to new ones. This is important since Hugo handles localization differently than WML. I’ve also been figuring out how to set up 301 redirects to prevent dead links, which is crucial for a smooth user experience.
One of the more confusing parts has been using GNU Make to manage Perl scripts for dynamic pages. It’s a bit of a learning curve, but I’m tackling it head-on. Each challenge is a chance to grow, and I’m here for it!
If you’re considering applying to the Debian community through Outreachy, I say go for it! There’s so much to learn and experience, and you’ll be welcomed with open arms. Happy coding, everyone! 🌟
Dirk Eddelbuettel: Rcpp 1.0.14 on CRAN: Regular Semi-Annual Update
The Rcpp Core Team is once again thrilled, pleased, and chuffed (am I doing this right for LinkedIn?) to announce a new release (now at 1.0.14) of the Rcpp package. It arrived on CRAN earlier today, and has since been uploaded to Debian. Windows and macOS builds should appear at CRAN in the next few days, as will builds in different Linux distribution–and of course r2u should catch up tomorrow too. The release was only uploaded yesterday, and as always get flagged because of the grandfathered .Call(symbol) as well as for the url to the Rcpp book (which has remained unchanged for years) ‘failing’. My email reply was promptly dealt with under European morning hours and by the time I got up the submission was in state ‘waiting’ over a single reverse-dependency failure which … is also spurious, appears on some systems and not others, and also not new. Imagine that: nearly 3000 reverse dependencies and only one (spurious) change to worse. Solid testing seems to help. My thanks as always to the CRAN for responding promptly.
This release continues with the six-months January-July cycle started with release 1.0.5 in July 2020. This time we also need a one-off hotfix release 1.0.13-1: we had (accidentally) conditioned an upcoming R change on 4.5.0, but it already came with 4.4.2 so we needed to adjust our code. As a reminder, we do of course make interim snapshot ‘dev’ or ‘rc’ releases available via the Rcpp drat repo as well as the r-universe page and repo and strongly encourage their use and testing—I run my systems with these versions which tend to work just as well, and are also fully tested against all reverse-dependencies.
Rcpp has long established itself as the most popular way of enhancing R with C or C++ code. Right now, 2977 packages on CRAN depend on Rcpp for making analytical code go faster and further. On CRAN, 13.6% of all packages depend (directly) on Rcpp, and 60.8% of all compiled packages do. From the cloud mirror of CRAN (which is but a subset of all CRAN downloads), Rcpp has been downloaded 93.7 million times. The two published papers (also included in the package as preprint vignettes) have, respectively, 1947 (JSS, 2011) and 354 (TAS, 2018) citations, while the the book (Springer useR!, 2013) has another 676.
This release is primarily incremental as usual, generally preserving existing capabilities faithfully while smoothing our corners and / or extending slightly, sometimes in response to changing and tightened demands from CRAN or R standards. The move towards a more standardized approach for the C API of R once again to a few changes; Kevin did once again did most of these PRs. Other contributed PRs include Gábor permitting builds on yet another BSD variant, Simon Guest correcting sourceCpp() to work on read-only files, Marco Colombo correcting a (surprisingly large) number of vignette typos, Iñaki rebuilding some documentation files that tickled (false) alerts, and I took care of a number of other maintenance items along the way.
The full list below details all changes, their respective PRs and, if applicable, issue tickets. Big thanks from all of us to all contributors!
Changes in Rcpp release version 1.0.14 (2025-01-11)Changes in Rcpp API:
Support for user-defined databases has been removed (Kevin in #1314 fixing #1313)
The SET_TYPEOF function and macro is no longer used (Kevin in #1315 fixing #1312)
An errorneous cast to int affecting large return object has been removed (Dirk in #1335 fixing #1334)
Compilation on DragonFlyBSD is now supported (Gábor Csárdi in #1338)
Use read-only VECTOR_PTR and STRING_PTR only with with R 4.5.0 or later (Kevin in #1342 fixing #1341)
Changes in Rcpp Attributes:
Changes in Rcpp Deployment:
One unit tests for arm64 macOS has been adjusted; a macOS continuous integration runner was added (Dirk in #1324)
Authors@R is now used in DESCRIPTION as mandated by CRAN, the Rcpp.package.skeleton() function also creates it (Dirk in #1325 and #1327)
A single datetime format test has been adjusted to match a change in R-devel (Dirk in #1348 fixing #1347)
Changes in Rcpp Documentation:
Thanks to my CRANberries, you can also look at a diff to the previous release Questions, comments etc should go to the rcpp-devel mailing list off the R-Forge page. Bugs reports are welcome at the GitHub issue tracker as well (where one can also search among open or closed issues).
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. If you like this or other open-source work I do, you can sponsor me at GitHub.
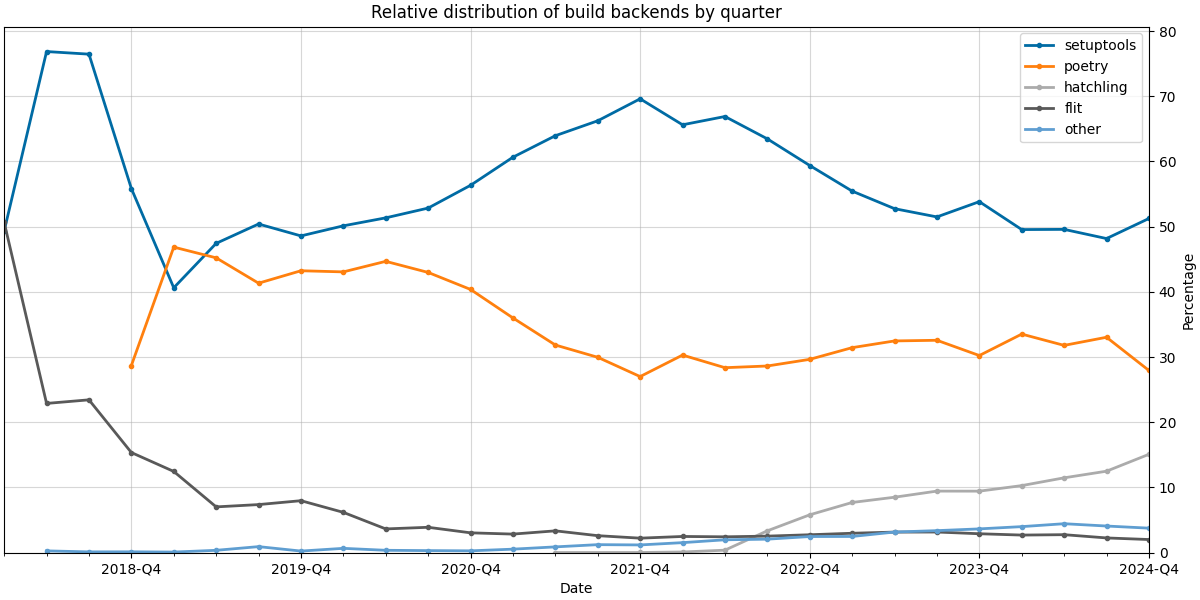
Bastian Venthur: Investigating the popularity of Python build backends over time (II)
Last year, I analyzed the popularity of build backends used in pyproject.toml files over time. This post is the update for 2024.
AnalysisLike last year, I’m using Tom Forbes’ fantastic dataset containing information about every file within every release uploaded to PyPI. To get the current dataset, I followed the same process as in last year’s analysis, so I won’t repeat all the details here. Instead, I’ll highlight the main steps:
- Download the parquet files from the dataset
- Use DuckDB to query the parquet files, extracting the project name, upload date, the pyproject.toml file, and its hash for each upload
- Download each pyproject.toml file and extract the build backend. To avoid redundant downloads, I stored a mapping of the file hash and their respective build backend
Downloading all the parquet files took roughly a week due to GitHub’s rate limiting. Tom suggested leveraging the Git v2 protocol to fetch the data directly. This approach could bypass rate limiting and complete the download of all pyproject.toml files in just 20 minutes(!). However, I couldn’t find sufficient documentation that would help me to implement this method, so this will have to wait until next year’s analysis.
Once all the data is downloaded, I perform some preprocessing:
- Grouped the top 4 build backends by their absolute number of uploads and categorized the remaining ones as “other”
- Binned upload dates into quarters to reduce clutter in the resulting graphs
I modified the plots a bit from last year to make them easier to read. Most notably, I binned the data into quarters to make the plots less noisy, and secondly, I stopped stacking the relative distribution plots to make the percentages directly readable.
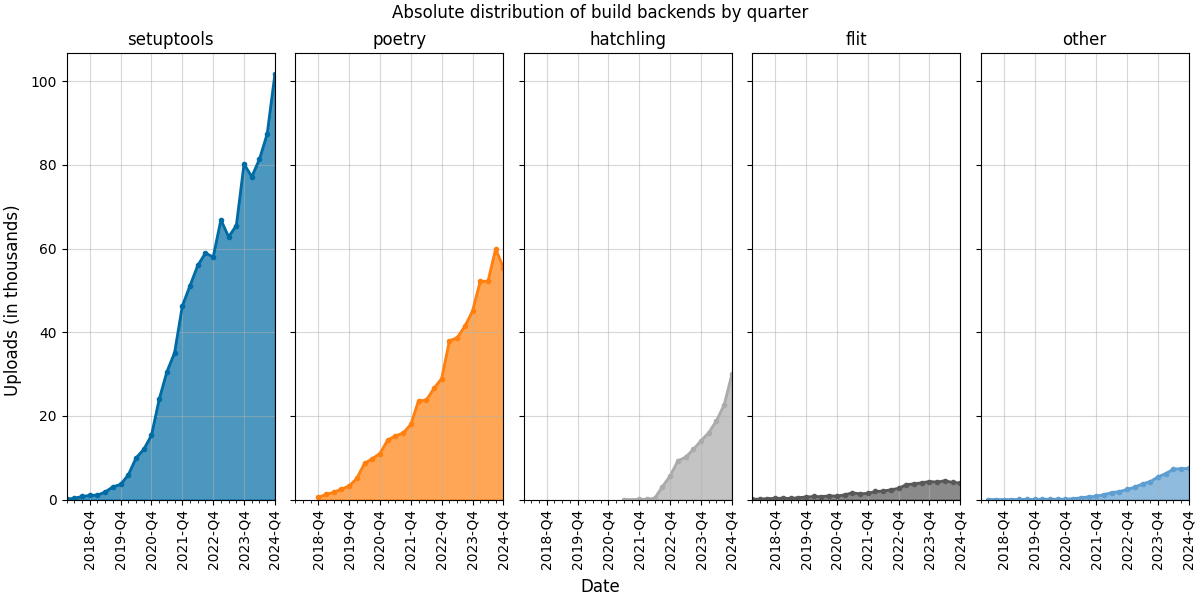
The first plot shows the absolute number of uploads (in thousands) by quarter and build backend.
{kind=link}
The second plot shows the relative distribution of build backends by quarter.
{kind=link}
In 2024, we observe that:
- Setuptools continues to grow in absolute numbers and remains around the 50% mark in relative distribution
- Poetry maintains a 30% relative distribution, but the trend has been declining since 2024-Q3. Preliminary data for 2025-Q1 (not shown here) supports this, suggesting that Poetry might be surpassed by Hatch in 2025, which showed a remarkable growth last year.
- Flit is the only build backend in this analysis whose absolute and relative numbers decreased in 2024. With a 5% relative distribution, it underlines the dominance of Setuptools, Poetry, and Hatch over the remaining build backends.
The script for downloading and analyzing the data is available in my GitHub repository. If someone has insights or examples on implementing the Git v2 protocol to download the pyproject.toml file given the repository URL and its hash, I’d love to hear from you!
Sahil Dhiman: Prosody Certificate Management With Nginx and Certbot
I have a self-hosted XMPP chat server through Prosody. Earlier, I struggled with certificate renewal and generation for Prosody because I have Nginx (and a bunch of other services) running on the same server which binds to Port 80. Due to this, Certbot wasn’t able to auto-renew (through HTTP validation) for domains managed by Prosody.
Now, I have cobbled together a solution to keep both Nginx and Prosody happy. This is how I did it:
- Expose /.well-known/acme-challenge through Nginx for Prosody domain. Nginx config looked like this:
- Run certbot to get certificates for <PROSODY.DOMAIN>.
- To use those in Prosody, add a cron entry for root user:
Explanation from Prosody docs:
Certificates and their keys are copied to /etc/prosody/certs (can be changed with the certificates option) and then it signals Prosody to reload itself. –root lets prosodyctl write to paths that may not be writable by the prosody user, as is common with /etc/prosody.
- Certbot now manages auto-renewal as well, and we’re all set.
Andrew Cater: 20250111 Release media testing for Debian 12.9
We're part way through the testing of release media. RattusRattus, Isy, Sledge, smcv and Helen in Cambridge, a new tester Blew in Manchester, another new tester MerCury[m] and also highvoltage in South Africa.
Everything is going well so far and we're chasing through the test schedule.
Sorry not to be there in Cambridgeshire with friends - but the room is fairly small and busy :)
[UPDATE/EDIT - at 20250111 1701 - we're pretty much complete on the testing]
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects