
Planet Debian
Sahil Dhiman: 25, A Quarter of a Century Later
25 the number says well into adulthood. Aviral pointed that I have already passed 33% mark in my life, which does hits different.
I had to keep reminding myself about my upcoming birthday. It didn’t felt like birthday month, week or the day itself.
My writings took a long hiatus starting this past year. The first post came out in May and quite a few people asked about the break. Hiatus had its own reasons, but restarting became harder each passing day afterward. Preparations for DebConf24 helped push DebConf23 (first post this year) out of the door, after which things were more or less back on track on the writing front.
Recently, I have picked the habit of reading monthly magazines. When I was a child, I used to fancy seeing all the magazines on stationary and bookshops and thought of getting many when I’m older. Seems like that was the connection, and now I’m heavily into monthly magazines and order many each month (including Hindi ones). They’re fun short reads and cover a wide spectrum of topics.
Travelling has become the new found love. I got the opportunity to visit a few new cities like Jaipur, Meerut, Seoul and Busan. My first international travel showed me how a society which cares about the people’s overall wellbeing turns out to be. Going in foreign land, expanded the concept of everything for me. It showed the beauty of silence in public places. Also, re-visited Bengaluru, which felt good with its good weather and food.
It has become almost become tradition to attend a few events. Jashn-e-Rekhta, DebConf, New Delhi World Book Fair, IndiaFOSS and FoECon. It’s always great talking to new and old folks, sharing and learning about ideas. It’s hard for an individual to learn, grow and understand the world in a silo. Like I keep on saying about Free Software projects, it’s all about the people, it’s always about the people. Good and interesting people keep the project going and growing. (Side Note - it’s fine if a project goes. Things are not meant to last a perpetuity. Closing and moving on is fine). Similarly, I have been trying to attend Jaipur Literature Festival since a while but failing. Hopefully, I would this time around.
Expanding my Free Software Mirror to India was a big highlight this year. The mirror project now has 3 nodes in India and 1 in Germany, serving almost 3-4 TB of mirror traffic daily. Increasing the number of Software mirrors in India was and still is one of my goals. Hit me up if you want to help or setup one yourself. It’s not that hard now actually, projects that require more mirrors and hosting setup has already been figured out.
One realization I would like to mention was to amplify/support people who’re already doing (a better job) at it, rather than reinventing the wheel. A single person might not be able to change the world, but a bunch of people experimenting and trying to make a difference certainly would.
Writing 25 was felt harder than all previous years. It was a traditional year with much internal growth due to experiencing different perspectives and travelling.
To infinity and beyond!
Dirk Eddelbuettel: qlcal 0.0.13 on CRAN: Small Calendar Update
The thirteenth release of the qlcal package arrivied at CRAN today.
qlcal delivers the calendaring parts of QuantLib. It is provided (for the R package) as a set of included files, so the package is self-contained and does not depend on an external QuantLib library (which can be demanding to build). qlcal covers over sixty country / market calendars and can compute holiday lists, its complement (i.e. business day lists) and much more. Examples are in the README at the repository, the package page, and course at the CRAN package page.
This releases synchronizes qlcal with the QuantLib release 1.36 (made this week) and contains some minor updates to two calendars.
Changes in version 0.0.13 (2024-10-15)Synchronized with QuantLib 1.36 released yesterday
Calendar updates for South Korea and Poland
Courtesy of my CRANberries, there is a diffstat report for this release. See the project page and package documentation for more details, and more examples. If you like this or other open-source work I do, you can sponsor me at GitHub.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
Jonathan Dowland: Arturia Microfreak
{kind=link}
Arturia Microfreak. © CC-BY-SA 4
{kind=link}
I nearly did, but ultimately I didn't buy an Arturia Microfreak.
The Microfreak is a small form factor hybrid synth with a distinctive style. It's priced at the low end of the market and it is overflowing with features. It has a weird 2-octave keyboard which is a stylophone-style capacitive strip rather than weighted keys. It seems to have plenty of controls, but given the amount of features it has, much of that functionality is inevitably buried in menus. The important stuff is front and centre, though. The digital oscillators are routed through an analog filter. The Microfreak gained sampler functionality in a firmware update that surprised and delighted its owners.
I watched a load of videos about the Microfreak, but the above review from musician Stimming stuck in my mind because it made a comparison between the Microfreak and Teenage Engineering's OP-1.
{kind=link}
The Teenage Engineering OP-1.
I'd been lusting after the OP-1 since it appeared in 2011: a pocket-sized1 music making machine with eleven synthesis engines, a sampler, and less conventional features such as an FM radio, a large colour OLED display, and a four track recorder. That last feature in particular was really appealing to me: I loved the idea of having an all-in-one machine to try and compose music. Even then, I was not keen on involving conventional computers in music making.
Of course in many ways it is a very compromised machine. I never did buy a OP-1, and by now they've replaced it with a new model (the OP-1 field) that costs 50% more (but doesn't seem to do 50% more) I'm still not buying one.
Framing the Microfreak in terms of the OP-1 made the penny drop for me. The Microfreak doesn't have the four-track functionality, but almost no synth has: I'm going to have to look at something external to provide that. But it might capture a similar sense of fun; it's something I could use on the sofa, in the spare room, on the train, during lunchbreaks at work, etc.
On the other hand, I don't want to make the same mistake as with the Micron: too much functionality requiring some experience to understand what you want so you can go and find it in the menus. I also didn't get a chance to audition the unusual keyboard: there's only one music store carrying synths left in Newcastle and they didn't have one.
So I didn't buy the Microfreak. Maybe one day in the future once I'm further down the road. Instead, I started to concentrate my search on more fundamental, back-to-basics instruments…
- Big pockets, mind↩
Lukas Märdian: Waiting for a Linux system to be online
{kind=link}
Networking is a complex topic, and there is lots of confusion around the definition of an “online” system. Sometimes the boot process gets delayed up to two minutes, because the system still waits for one or more network interfaces to be ready. Systemd provides the network-online.target that other service units can rely on, if they are deemed to require network connectivity. But what does “online” actually mean in this context, is a link-local IP address enough, do we need a routable gateway and how about DNS name resolution?
The requirements for an “online” network interface depend very much on the services using an interface. For some services it might be good enough to reach their local network segment (e.g. to announce Zeroconf services), while others need to reach domain names (e.g. to mount a NFS share) or reach the global internet to run a web server. On the other hand, the implementation of network-online.target varies, depending on which networking daemon is in use, e.g. systemd-networkd-wait-online.service or NetworkManager-wait-online.service. For Ubuntu, we created a specification that describes what we as a distro expect an “online” system to be. Having a definition in place, we are able to tackle the network-online-ordering issues that got reported over the years and can work out solutions to avoid delayed boot times on Ubuntu systems.
In essence, we want systems to reach the following networking state to be considered online:
- Do not wait for “optional” interfaces to receive network configuration
- Have IPv6 and/or IPv4 “link-local” addresses on every network interface
- Have at least one interface with a globally routable connection
- Have functional domain name resolution on any routable interface
NetworkManager and systemd-networkd are two very common networking daemons used on modern Linux systems. But they originate from different contexts and therefore show different behaviours in certain scenarios, such as wait-online. Luckily, on Ubuntu we already have Netplan as a unification layer on top of those networking daemons, that allows for common network configuration, and can also be used to tweak the wait-online logic.
With the recent release of Netplan v1.1 we introduced initial functionality to tweak the behaviour of the systemd-networkd-wait-online.service, as used on Ubuntu Server systems. When Netplan is used to drive the systemd-networkd backend, it will emit an override configuration file in /run/systemd/system/systemd-networkd-wait-online.service.d/10-netplan.conf, listing the specific non-optional interfaces that should receive link-local IP configuration. In parallel to that, it defines a list of network interfaces that Netplan detected to be potential global connections, and waits for any of those interfaces to reach a globally routable state.
Such override config file might look like this:
[Unit]ConditionPathIsSymbolicLink=/run/systemd/generator/network-online.target.wants/systemd-networkd-wait-online.service
[Service]
ExecStart=
ExecStart=/lib/systemd/systemd-networkd-wait-online -i eth99.43:carrier -i lo:carrier -i eth99.42:carrier -i eth99.44:degraded -i bond0:degraded
ExecStart=/lib/systemd/systemd-networkd-wait-online --any -o routable -i eth99.43 -i eth99.45 -i bond0
In addition to the new features implemented in Netplan, we reached out to upstream systemd, proposing an enhancement to the systemd-networkd-wait-online service, integrating it with systemd-resolved to check for the availability of DNS name resolution. Once this is implemented upstream, we’re able to fully control the systemd-networkd backend on Ubuntu Server systems, to behave consistently and according to the definition of an “online” system that was lined out above.
Future workThe story doesn’t end there, because Ubuntu Desktop systems are using NetworkManager as their networking backend. This daemon provides its very own nm-online utility, utilized by the NetworkManager-wait-online systemd service. It implements a much higher-level approach, looking at the networking daemon in general instead of the individual network interfaces. By default, it considers a system to be online once every “autoconnect” profile got activated (or failed to activate), meaning that either a IPv4 or IPv6 address got assigned.
There are considerable enhancements to be implemented to this tool, for it to be controllable in a fine-granular way similar to systemd-networkd-wait-online, so that it can be instructed to wait for specific networking states on selected interfaces.
A note of cautionMaking a service depend on network-online.target is considered an antipattern in most cases. This is because networking on Linux systems is very dynamic and the systemd target can only ever reflect the networking state at a single point in time. It cannot guarantee this state to be remained over the uptime of your system and has the potentially to delay the boot process considerably. Cables can be unplugged, wireless connectivity can drop, or remote routers can go down at any time, affecting the connectivity state of your local system. Therefore, “instead of wondering what to do about network.target, please just fix your program to be friendly to dynamically changing network configuration.” [source].
Iustin Pop: Optical media lifetime - one data point
Way back (more than 10 years ago) when I was doing DVD-based backups, I knew that normal DVDs/Blu-Rays are no long-term archival solutions, and that if I was real about doing optical media backups, I need to switch to M-Disc. I actually bought a (small stack) of M-Disc Blu-Rays, but never used them.
I then switched to other backups solutions, and forgot about the whole topic. Until, this week, while sorting stuff, I happened upon a set of DVD backups from a range of years, and was very curious whether they are still readable after many years.
And, to my surprise, there were no surprises! Went backward in time, and:
- 2014, TDK DVD+R, fully readable
- 2012, JVC DVD+R and TDK DVD+R, fully readable
- 2010, Verbatim DVD+R, fully readable
- 2009/2008/2007, Verbatim DVD+R, 4 DVDs, fully readable
I also found stack of dual-layer DVD+R from 2012-2014, some for sure Verbatim, and some unmarked (they were intended to be printed on), but likely Verbatim as well. All worked just fine. Just that, even at ~8GiB per disk, backing up raw photo files took way too many disks, even in 2014 😅.
At this point I was happy that all 12+ DVDs I found, ranging from 10 to 14 years, are all good. Then I found a batch of 3 CDs! Here the results were mixed:
- 2003: two TDK “CD-R80”, “Mettalic”, 700MB: fully readable, after 21 years!
- unknown year, likely around 1999-2003, but no later, “Creation” CD-R, 700MB: read errors to the extent I can’t even read the disk signature (isoinfo -d).
I think the takeaway is that for all explicitly selected media - TDK, JVC and Verbatim - they hold for 10-20 years. Valid reads from summer 2003 is mind boggling for me, for (IIRC) organic media - not sure about the “TDK metallic” substrate. And when you just pick whatever (“Creation”), well, the results are mixed.
Note that in all this, it was about CDs and DVDs. I have no idea how Blu-Rays behave, since I don’t think I ever wrote a Blu-Ray. In any case, surprising to me, and makes me rethink a bit my backup options. Sizes from 25 to 100GB Blu-Rays are reasonable for most critical data. And they’re WORM, as opposed to most LTO media, which is re-writable (and to some small extent, prone to accidental wiping).
Now, I should check those M-Disks to see if they can still be written to, after 10 years 😀
Dirk Eddelbuettel: RcppDate 0.0.4: New Upstream Minor
RcppDate wraps the featureful date library written by Howard Hinnant for use with R. This header-only modern C++ library has been in pretty wide-spread use for a while now, and adds to C++11/C++14/C++17 what will be (with minor modifications) the ‘date’ library in C++20.
This release, the first in 3 1/2 years, syncs the code with the recent date 3.0.2 release from a few days ago. It also updates a few packaging details such as URLs, badges or continuous integration.
Changes in version 0.0.4 (2024-10-14)Updated to upstream version 3.0.2 (and adjusting one pragma)
Several small updates to overall packaging and testing
Courtesy of my CRANberries, there is also a diffstat report for the most recent release. More information is available at the repository or the package page.
If you like this or other open-source work I do, you can sponsor me at GitHub.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
Scarlett Gately Moore: Kubuntu 24.10 Released, KDE Snaps at 24.08.2, and I lived to tell you about it!
Sorry my blog updates have been MIA. Let me tell you a story…
As some of you know, 3 months ago I was in a no fault car accident. Thankfully, the only injury was I ended up with a broken arm. ER sends me home in a sling and tells me it was a clean break and it will mend itself in no time. After a week of excruciating pain I went to my follow up doctor appointment, and with my x-rays in hand, the doc tells me it was far from a clean break and needs surgery. So after a week of my shattered bone scraping my nerves and causing pain I have never felt before, I finally go in for surgery! They put in a metal plate with screws to hold the bone in place so it can properly heal. The nerve pain was gone, so I thought I was on the mend. Some time goes by and the swelling still has not subsided, the doctors are not as concerned about this as I am, so I carry on until it becomes really inflamed and developed fever blisters. After no success in reaching the doctors office my husband borrows the neighbors car and rushes me to the ER. Good thing too, I had an infection. So after a 5 day stay in the hospital, they sent us home loaded with antibiotics and trained my husband in wound packing. We did everything right, kept the place immaculate, followed orders with the wound care, took my antibiotics, yet when they ran out there was still no sign of relief, or healing. Went to doctors and they gave me another month supply of antibiotics. Two days after my final dose my arm becomes inflamed again and with extra spectacular levels of pain to go with it. I call the doctor office… They said to come in on my appointment day ( 4 days away ). I asked, “You aren’t concerned with this inflammation?”, to which they replied, “No.”. Ok, maybe I am over reacting and it’s all in my head, I can power through 4 more days. The following morning my husband observed fever blisters and the wound site was clearly not right, so once again off we go to the ER. Well… thankfully we did. I was in Sepsis and could have died… After deliberating with the doctor on the course of action for treatment, the doctor accepted our plea to remove the plate, rather than tighten screws and have me drive 100 miles to hospital everyday for iv antibiotics (Umm I don’t have a car!?) So after another 4 day stay I am released into the world, alive and well. I am happy to report, the swelling is almost gone, the pain is minimal, and I am finally healing nicely. I am still in a sling and I have to be super careful and my arm was not fully knitted. So with that I am bummed to say, no traveling for me, no Ubuntu Summit
I still need help with that car, if it weren’t for our neighbor, this story would have ended much differently.
Despite my tragic few months for my right arm, my left arm has been quite busy. Thankfully I am a lefty! On to my work progress report.
Kubuntu:
Kubuntu 24.10 Oracular Oriole Released With Plasma 6! A big thank you to the Debian KDE/QT team and Rik Mills, could not have done it without you!KDE Snaps:
All release service snaps are done! Save a few problematic ones still WIP.. I have released 24.08.2 which you can find here:
https://snapcraft.io/publisher/kde
I completed the qt6 and KDE frameworks 6 content packs for core24
Snapcraft:
I have a PR in for kde-neon-6 extension core24 support.
That’s all for now. Thanks for stopping by!
Philipp Kern: Touch Notifications for YubiKeys
yubikey-touch-detector (fresh in unstable) solves this issue by providing a way for your desktop environment to signal the user that the device is waiting for a touch. It provides an event feed on a socket that other components can consume. It comes with libnotify support and there are some custom integrations for other environments.
For GNOME and KDE libnotify support should be sufficient, however you still need to turn it on:
$ mkdir -p ~/.config/yubikey-touch-detector $ sed -e 's/^YUBIKEY_TOUCH_DETECTOR_LIBNOTIFY=.*/YUBIKEY_TOUCH_DETECTOR_LIBNOTIFY=true/' \ < /usr/share/doc/yubikey-touch-detector/examples/service.conf.example \ > ~/.config/yubikey-touch-detector/service.conf $ systemctl --user restart yubikey-touch-detectorI would still have preferred a more visible, more modal prompt. I guess that would be an exercise for another time, listening to the socket and presenting a window. But for now, desktop notifications will do for me.
PS: I have not managed to get SSH's no-touch-required to work with YubiKey 4, while it works just fine with a YubiKey 5.
Andy Simpkins: The state of the art
A long time ago a computer was a woman (I think almost exclusively a women, not a man) who was employed to do a lot of repetitive mathematics – typically for accounting and stock / order processing.
Then along came Lyons, who deployed an artificial computer to perform the same task, only with fewer errors in less time. Modern day computing was born – we had entered the age of the Digital Computer.
These computers were large, consumed huge amounts of power but were precise, and gave repeatable, verifiable results.
Over time the huge mainframe digital computers have shrunk in size, increased in performance, and consume far less power – so much so that they often didn’t need the specialist CFC based, refrigerated liquid cooling systems of their bigger mainframe counterparts, only requiring forced air flow, and occasionally just convection cooling. They shrank so far and became cheep enough that the Personal Computer became to be, replacing the mainframe with its time shared resources with a machine per user. Desktop or even portable “laptop” computers were everywhere.
We networked them together, so now we can share information around the office, a few computers were given specialist tasks of being available all the time so we could share documents, or host databases these servers were basically PCs designed to operate 24×7, usually more powerful than their desktop counterparts (or at least with faster storage and networking).
Next we joined these networks together and the internet was born. The dream of a paperless office might actually become realised – we can now send email (and documents) from one organisation (or individual) to another via email. We can make our specialist computers applications available outside just the office and web servers / web apps come of age.
Fast forward a few years and all of a sudden we need huge data-halls filled with “Rack scale” machines augmented with exotic GPUs and NPUs again with refrigerated liquid cooling, all to do the same task that we were doing previously without the magical buzzword that has been named AI; because we all need another dot com bubble or block chain band waggon to jump aboard. Our AI enabled searches take slightly longer, consume magnitudes more power, and best of all the results we are given may or may not be correct….
Progress, less precise answers, taking longer, consuming more power, without any verification and often giving a different result if you repeat your question AND we still need a personal computing device to access this wondrous thing.
Remind me again why we are here?
(time lines and huge swaves of history simply ignored to make an attempted comic point – this is intended to make a point and not be scholarly work)
Andrew Cater: Mini-DebConf Cambridge 20241013 1300
LATE NEWS
I haven't blogged until now: I should have done from Thursday onwards.
It's
a joy to be here in Cambridge at ARM HQ. Lots of people I recognise
from last year here: lots *not* here because this mini-conference is a
month before the next one in Toulouse and many people can't attend both.
Two
days worth of chatting, working on bits and pieces, chatting and
informal meetings was a very good and useful way to build relationships
and let teams find some space for themselves.
Lots of quiet hacking going on - a few loud conversations. A new ARM machine in mini-ITX format - see Steve's blog.
Two
days worth of talks for Saturday and Sunday. For some people, this is a
first time. Lightning talks are particularly good to break down
barriers - three slides and five minutes (and the chance for a bit of
gamesmanship to break the rules creatively).
Longer talks: a
couple from Steve Capper of ARM were particularly helpful to those
interested in upcoming development. A couple of the talks in the
schedule are traditional: if the release team are here, they tell us
what they are doing, for example.
ARM are main sponsors and have
been very generous in giving us conference and facilities space. Fast
network, coffee and interested people - what's not to like :)
Taavi Väänänen: Bulk downloading Wikimedia Commons categories
Wikimedia Commons, the Wikimedia project for freely licensed media files, also contains a bunch of photos by me and photos of me at various events. While I don't think Commons is going away anytime soon, I would still like to have a local copy of those images available on my own storage hardware.
Obviously this requires some way to query for photos you want to download. I'm using Commons categories for this, since that's easy to implement and works for both use cases. The Commons community tends to come up with very specific categories that you can use, and if not, you can usually categorize the files yourself.
thankfully Commons has no such thing as a Conflict of interest (COI) policy
There is almost an existing tool for this: Sam Wilson's mwcli project has support for exporting images one has uploaded to Commons. However I couldn't use that to upload photos of me others have uploaded, plus it's written in PHP and I don't exactly want to deal with the problem of figuring out how to package it in a way I could neatly install it on my NAS.
So I wrote my own tool for it, called comload. It's written in Python because Python is easy to deploy (I can just throw it in a .deb and upload it to my internal repository), and because I did not find a Go library to handle Action API pagination for me. The basic usage is like this:
$ comload --subcats "Taavi Väänänen"This will download any files in Category:Taavi Väänänen and its sub-categories to the current directory. Former image versions, as well as the image description and SDC data, if any, is also included. And it's smart enough to not download any files that are already there on future runs, so you can just throw it in a systemd timer to get any future files. I'd still like it to handle moved files without creating a duplicate copy, but otherwise I'm really happy with the current state.
comload is available from PyPI and from my Git server directly, and is licensed under the GPLv3.
Jonathan Dowland: Code formatting in documents
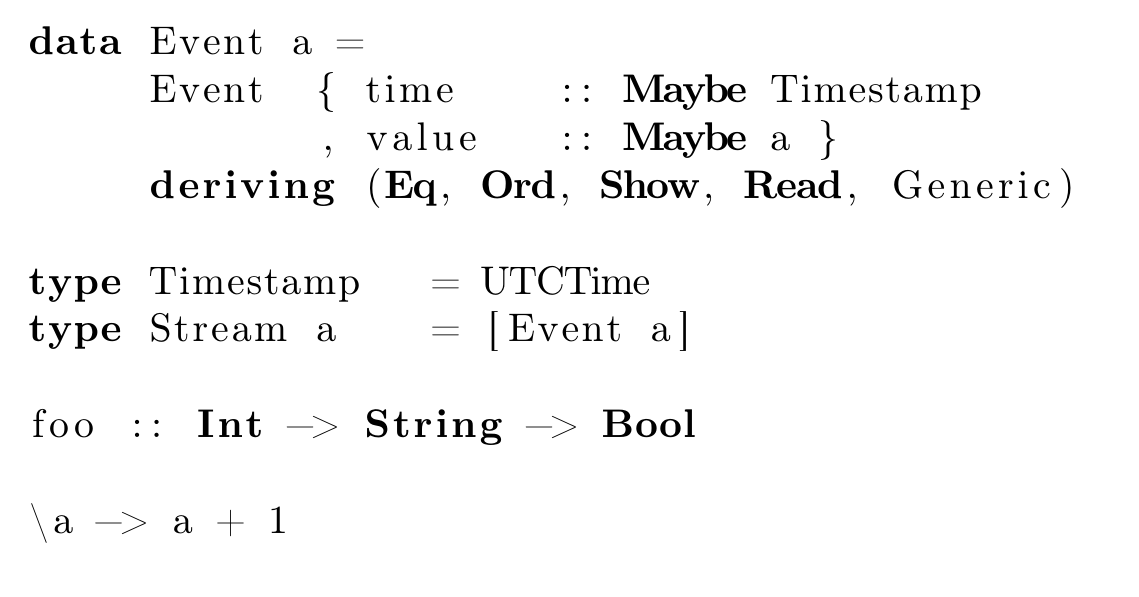
I've been exploring typesetting and formatting code within text documents such as papers, or my thesis. Up until now, I've been using the listings package without thinking much about it. By default, some sample Haskell code processed by listings looks like this (click any of the images to see larger, non-blurry versions):
{kind=link}
It's formatted with a monospaced font, with some keywords highlighted, but not syntactic symbols.
There are several other options for typesetting and formatting code in LaTeX documents. For Haskell in particular, there is the preprocessor lhs2tex, The default output of which looks like this:
{kind=link}
A proportional font, but it's taken pains to preserve vertical alignment, which is syntactically significant for Haskell. It looks a little cluttered to me, and I'm not a fan of nearly everything being italic. Again, symbols aren't differentiated, but it has substituted them for more typographically pleasing alternatives: -> has become →, and \ is now λ.
Another option is perhaps the newest, the LaTeX package minted, which leverages the Python Pygments program. Here's the same code again. It defaults to monospace (the choice of font seems a lot clearer to me than the default for listings), no symbolic substitution, and liberal use of colour:
{kind=link}
An informal survey of the samples so far showed that the minted output was the most popular.
All of these packages can be configured to varying degrees. Here are some examples of what I've achieved with a bit of tweaking
{kind=link}
listings adjusted with colour and some symbols substituted (but sadly not the two together)
{kind=link}
lhs2tex adjusted to be less italic, sans-serif and use some colour
All of this has got me wondering whether there are straightforward empirical answers to some of these questions of style.
Firstly, I'm pretty convinced that symbolic substitution is valuable. When writing Haskell, we write ->, \, /= etc. not because it's most legible, but because it's most practical to type those symbols on the most widely available keyboards and popular keyboard layouts.1 Of the three options listed here, symbolic substitution is possible with listings and lhs2tex, but I haven't figured out if minted can do it (which is really the question: can pygments do it?)
I'm unsure about proportional versus monospaced fonts. We typically use monospaced fonts for editing computer code, but that's at least partly for historical reasons. Vertical alignment is often very important in source code, and it can be easily achieved with monospaced text; it's also sometimes important to have individual characters (., etc.) not be de-emphasised by being smaller than any other character.
lhs2tex, at least, addresses vertical alignment whilst using proportional fonts. I guess the importance of identifying individual significant characters is just as true in a code sample within a larger document as it is within plain source code.
From a (brief) scan of research on this topic, it seems that proportional fonts result in marginally quicker reading times for regular prose. It's not clear whether those results carry over into reading computer code in particular, and the margin is slim in any case. The drawbacks of monospaced text mostly apply when the volume of text is large, which is not the case for the short code snippets I am working with.
I still have a few open questions:
- Is colour useful for formatting code in a PDF document?
- does this open up a can of accessibility worms?
- What should be emphasised (or de-emphasised)
- Why is the minted output most popular: Could the choice of font be key? Aspects of the font other than proportionality (serifs? Size of serifs? etc)
- The Haskell package Data.List.Unicode lets the programmer use a range of unicode symbols in place of ASCII approximations, such as ∈ instead of elem, ≠ instead of /=. Sadly, it's not possible to replace the denotation for an anonymous function, \, with λ this way.↩
Steve McIntyre: Rock 5 ITX
It's been a while since I've posted about arm64 hardware. The last machine I spent my own money on was a SolidRun Macchiatobin, about 7 years ago. It's a small (mini-ITX) board with a 4-core arm64 SoC (4 * Cortex-A72) on it, along with things like a DIMM socket for memory, lots of networking, 3 SATA disk interfaces.
The Macchiatobin was a nice machine compared to many earlier systems, but it took quite a bit of effort to get it working to my liking. I replaced the on-board U-Boot firmware binary with an EDK2 build, and that helped. After a few iterations we got a new build including graphical output on a PCIe graphics card. Now it worked much more like a "normal" x86 computer.
I still have that machine running at home, and it's been a reasonably reliable little build machine for arm development and testing. It's starting to show its age, though - the onboard USB ports no longer work, and so it's no longer useful for doing things like installation testing. :-/
So...
I was involved in a conversation in the #debian-arm IRC channel a few weeks ago, and diederik suggested the Radxa Rock 5 ITX. It's another mini-ITX board, this time using a Rockchip RK3588 CPU. Things have moved on - the CPU is now an 8-core big.LITTLE config: 4*Cortex A76 and 4*Cortex A55. The board has NVMe on-board, 4*SATA, built-in Mali graphics from the CPU, soldered-on memory. Just about everything you need on an SBC for a small low-power desktop, a NAS or whatever. And for about half the price I paid for the Macchiatobin. I hit "buy" on one of the listed websites. :-)
A few days ago, the new board landed. I picked the version with 24GB of RAM and bought the matching heatsink and fan. I set it up in an existing case borrowed from another old machine and tried the Radxa "Debian" build. All looked OK, but I clearly wasn't going to stay with that. Onwards to running a native Debian setup!
I installed an EDK2 build from https://github.com/edk2-porting/edk2-rk3588 onto the onboard SPI flash, then rebooted with a Debian 12.7 (Bookworm) arm64 installer image on a USB stick. How much trouble could this be?
I was shocked! It Just Worked (TM)
I'm running a standard Debian arm64 system. The graphical installer ran just fine. I installed onto the NVMe, adding an Xfce desktop for some simple tests. Everything Just Worked. After many years of fighting with a range of different arm machines (from simple SBCs to desktops and servers), this was without doubt the most straightforward setup I've ever done. Wow!
It's possible to go and spend a lot of money on an Ampere machine, and I've seen them work well too. But for a hobbyist user (or even a smaller business), the Rock 5 ITX is a lovely option. Total cost to me for the board with shipping fees, import duty, etc. was just over £240. That's great value, and I can wholeheartedly recommend this board!
The two things that are missing compared to the Macchiatobin? This is soldered-on memory (but hey, 24G is plenty for me!) It also doesn't have a PCIe slot, but it has sufficient onboard network, video and storage interfaces that I think it will cover most people's needs.
Where's the catch? It seems these are very popular right now, so it can be difficult to find these machines in stock online.
FTAOD, I should also point out: I bought this machine entirely with my own money, for my own use for development and testing. I've had no contact with the Radxa or Rockchip folks at all here, I'm just so happy with this machine that I've felt the need to shout about it! :-)
Here's some pictures...
Freexian Collaborators: Monthly report about Debian Long Term Support, September 2024 (by Roberto C. Sánchez)
Like each month, have a look at the work funded by Freexian’s Debian LTS offering.
Debian LTS contributorsIn September, 18 contributors have been paid to work on Debian LTS, their reports are available:
- Abhijith PA did 7.0h (out of 0.0h assigned and 14.0h from previous period), thus carrying over 7.0h to the next month.
- Adrian Bunk did 51.75h (out of 9.25h assigned and 55.5h from previous period), thus carrying over 13.0h to the next month.
- Arturo Borrero Gonzalez did 10.0h (out of 0.0h assigned and 10.0h from previous period).
- Bastien Roucariès did 20.0h (out of 20.0h assigned).
- Ben Hutchings did 20.0h (out of 12.0h assigned and 12.0h from previous period), thus carrying over 4.0h to the next month.
- Chris Lamb did 18.0h (out of 18.0h assigned).
- Daniel Leidert did 23.0h (out of 26.0h assigned), thus carrying over 3.0h to the next month.
- Emilio Pozuelo Monfort did 23.5h (out of 22.25h assigned and 37.75h from previous period), thus carrying over 36.5h to the next month.
- Guilhem Moulin did 22.25h (out of 20.0h assigned and 2.5h from previous period), thus carrying over 0.25h to the next month.
- Lucas Kanashiro did 10.0h (out of 5.0h assigned and 15.0h from previous period), thus carrying over 10.0h to the next month.
- Markus Koschany did 40.0h (out of 40.0h assigned).
- Ola Lundqvist did 6.5h (out of 14.5h assigned and 9.5h from previous period), thus carrying over 17.5h to the next month.
- Roberto C. Sánchez did 24.75h (out of 21.0h assigned and 3.75h from previous period).
- Santiago Ruano Rincón did 19.0h (out of 19.0h assigned).
- Sean Whitton did 0.75h (out of 4.0h assigned and 2.0h from previous period), thus carrying over 5.25h to the next month.
- Sylvain Beucler did 16.0h (out of 42.0h assigned and 18.0h from previous period), thus carrying over 44.0h to the next month.
- Thorsten Alteholz did 11.0h (out of 11.0h assigned).
- Tobias Frost did 17.0h (out of 7.5h assigned and 9.5h from previous period).
In September, we have released 52 DLAs.
September marked the first full month of Debian 11 bullseye under the responsibility of the LTS Team and the team immediately got to work, publishing more than 4 dozen updates.
Some notable updates include ruby2.7 (denial-of-service, information leak, and remote code execution), git (various arbitrary code execution vulnerabilities), firefox-esr (multiple issues), gnutls28 (information disclosure), thunderbird (multiple issues), cacti (cross site scripting and SQL injection), redis (unauthorized access, denial of service, and remote code execution), mariadb-10.5 (arbitrary code execution), cups (arbitrary code execution).
Several LTS contributors have also contributed package updates which either resulted in a DSA (a Debian Security Announcement, which applies to Debian 12 bookworm) or in an upload that will be published at the next stable point release of Debian 12 bookworm. This list of packages includes cups, cups-filters, booth, nghttp2, puredata, python3.11, sqlite3, and wireshark. This sort of work, contributing fixes to newer Debian releases (and sometimes even to unstable), helps to ensure that upgrades from a release in the LTS phase of its lifecycle to a newer release do not expose users to vulnerabilities which have been closed in the older release.
Looking beyond Debian, LTS contributor Bastien Roucariès has worked with the upstream developers of apache2 to address regressions introduced upstream by some recent vulnerability fixes and he has also reached out to the community regarding a newly discovered security issue in the dompurify package. LTS contributor Santiago Ruano Rincón has undertaken the work of triaging and reproducing nearly 4 dozen CVEs potentially affecting the freeimage package. The upstream development of freeimage appears to be dormant and some of the issues have languished for more than 5 years. It is unclear how much can be done without the aid of upstream, but we will do our best to provide as much help to the community as we can feasibly manage.
Finally, it is sometimes necessary to limit or discontinue support for certain packages. The transition of a release from being under the responsibility of the Debian Security Team to that of the LTS Team is an occasion where we assess any pending decisions in this area and formalize them. Please see the announcement for a complete list of packages which have been designated as unsupported.
Thanks to our sponsorsSponsors that joined recently are in bold.
- Platinum sponsors:
- TOSHIBA (for 108 months)
- Civil Infrastructure Platform (CIP) (for 76 months)
- VyOS Inc (for 40 months)
- Gold sponsors:
- Roche Diagnostics International AG (for 118 months)
- Akamai - Linode (for 112 months)
- Babiel GmbH (for 102 months)
- Plat’Home (for 101 months)
- CINECA (for 76 months)
- University of Oxford (for 58 months)
- Deveryware (for 45 months)
- EDF SA (for 30 months)
- Dataport AöR (for 5 months)
- CERN (for 3 months)
- Silver sponsors:
- Domeneshop AS (for 123 months)
- Nantes Métropole (for 117 months)
- Univention GmbH (for 109 months)
- Université Jean Monnet de St Etienne (for 109 months)
- Ribbon Communications, Inc. (for 103 months)
- Exonet B.V. (for 92 months)
- Leibniz Rechenzentrum (for 87 months)
- Ministère de l’Europe et des Affaires Étrangères (for 70 months)
- Cloudways by DigitalOcean (for 60 months)
- Dinahosting SL (for 58 months)
- Bauer Xcel Media Deutschland KG (for 52 months)
- Platform.sh SAS (for 52 months)
- Moxa Inc. (for 46 months)
- sipgate GmbH (for 44 months)
- OVH US LLC (for 42 months)
- Tilburg University (for 42 months)
- GSI Helmholtzzentrum für Schwerionenforschung GmbH (for 33 months)
- Soliton Systems K.K. (for 30 months)
- THINline s.r.o. (for 6 months)
- Copenhagen Airports A/S
- Bronze sponsors:
- Evolix (for 123 months)
- Seznam.cz, a.s. (for 123 months)
- Intevation GmbH (for 120 months)
- Linuxhotel GmbH (for 120 months)
- Daevel SARL (for 119 months)
- Bitfolk LTD (for 118 months)
- Megaspace Internet Services GmbH (for 118 months)
- Greenbone AG (for 117 months)
- NUMLOG (for 117 months)
- WinGo AG (for 116 months)
- Entr’ouvert (for 107 months)
- Adfinis AG (for 105 months)
- Tesorion (for 100 months)
- GNI MEDIA (for 99 months)
- Laboratoire LEGI - UMR 5519 / CNRS (for 99 months)
- Bearstech (for 91 months)
- LiHAS (for 91 months)
- Catalyst IT Ltd (for 86 months)
- Supagro (for 81 months)
- Demarcq SAS (for 80 months)
- Université Grenoble Alpes (for 66 months)
- TouchWeb SAS (for 58 months)
- SPiN AG (for 55 months)
- CoreFiling (for 51 months)
- Institut des sciences cognitives Marc Jeannerod (for 46 months)
- Observatoire des Sciences de l’Univers de Grenoble (for 42 months)
- Tem Innovations GmbH (for 37 months)
- WordFinder.pro (for 36 months)
- CNRS DT INSU Résif (for 35 months)
- Alter Way (for 28 months)
- Institut Camille Jordan (for 18 months)
- SOBIS Software GmbH (for 3 months)
Reproducible Builds (diffoscope): diffoscope 280 released
The diffoscope maintainers are pleased to announce the release of diffoscope version 280. This version includes the following changes:
[ Chris Lamb ] * Drop Depends on deprecated python3-pkg-resources. (Closes: #1083362)You find out more by visiting the project homepage.
Gunnar Wolf: Started a guide to writing FUSE filesystems in Python
As DebConf22 was coming to an end, in Kosovo, talking with Eeveelweezel they invited me to prepare a talk to give for the Chicago Python User Group. I replied that I’m not really that much of a Python guy… But would think about a topic. Two years passed. I meet Eeveelweezel again for DebConf24 in Busan, South Korea. And the topic came up again. I had thought of some ideas, but none really pleased me. Again, I do write some Python when needed, and I teach using Python, as it’s the language I find my students can best cope with. But delivering a talk to ChiPy?
On the other hand, I have long used a very simplistic and limited filesystem I’ve designed as an implementation project at class: FIUnamFS (for “Facultad de Ingeniería, Universidad Nacional Autónoma de México”: the Engineering Faculty for Mexico’s National University, where I teach. Sorry, the link is in Spanish — but you will find several implementations of it from the students 😉). It is a toy filesystem, with as many bad characteristics you can think of, but easy to specify and implement. It is based on contiguous file allocation, has no support for sub-directories, and is often limited to the size of a 1.44MB floppy disk.
As I give this filesystem as a project to my students (and not as a mere homework), I always ask them to try and provide a good, polished, professional interface, not just the simplistic menu I often get. And I tell them the best possible interface would be if they provide support for FIUnamFS transparently, usable by the user without thinking too much about it. With high probability, that would mean: Use FUSE.
{kind=link}
But, in the six semesters I’ve used this project (with 30-40 students per semester group), only one student has bitten the bullet and presented a FUSE implementation.
Maybe this is because it’s not easy to understand how to build a FUSE-based filesystem from a high-level language such as Python? Yes, I’ve seen several implementation examples and even nice web pages (i.e. the examples shipped with thepython-fuse module Stavros’ passthrough filesystem, Dave Filesystem based upon, and further explaining, Stavros’, and several others) explaining how to provide basic functionality. I found a particularly useful presentation by Matteo Bertozzi presented ~15 years ago at PyCon4… But none of those is IMO followable enough by itself. Also, most of them are very old (maybe the world is telling me something that I refuse to understand?).
And of course, there isn’t a single interface to work from. In Python only, we can find python-fuse, Pyfuse, Fusepy… Where to start from?
…So I setup to try and help.
Over the past couple of weeks, I have been slowly working on my own version, and presenting it as a progressive set of tasks, adding filesystem calls, and being careful to thoroughly document what I write (but… maybe my documentation ends up obfuscating the intent? I hope not — and, read on, I’ve provided some remediation).
I registered a GitLab project for a hand-holding guide to writing FUSE-based filesystems in Python. This is a project where I present several working FUSE filesystem implementations, some of them RAM-based, some passthrough-based, and I intend to add to this also filesystems backed on pseudo-block-devices (for implementations such as my FIUnamFS).
So far, I have added five stepwise pieces, starting from the barest possible empty filesystem, and adding system calls (and functionality) until (so far) either a read-write filesystem in RAM with basicstat() support or a read-only passthrough filesystem.
I think providing fun or useful examples is also a good way to get students to use what I’m teaching, so I’ve added some ideas I’ve had: DNS Filesystem, on-the-fly markdown compiling filesystem, unzip filesystem and uncomment filesystem.
They all provide something that could be seen as useful, in a way that’s easy to teach, in just some tens of lines. And, in case my comments/documentation are too long to read, uncommentfs will happily strip all comments and whitespace automatically! 😉
So… I will be delivering my talk tomorrow (2024.10.10, 18:30 GMT-6) at ChiPy (virtually). I am also presenting this talk virtually at Jornadas Regionales de Software Libre in Santa Fe, Argentina, next week (virtually as well). And also in November, in person, at nerdear.la, that will be held in Mexico City for the first time.
Of course, I will also share this project with my students in the next couple of weeks… And hope it manages to lure them into implementing FUSE in Python. At some point, I shall report!
Freexian Collaborators: Debian Contributions: Packaging Pydantic v2, Reworking of glib2.0 for cross bootstrap, Python archive rebuilds and more! (by Anupa Ann Joseph)
Contributing to Debian is part of Freexian’s mission. This article covers the latest achievements of Freexian and their collaborators. All of this is made possible by organizations subscribing to our Long Term Support contracts and consulting services.
Pydantic v2, by Colin WatsonPydantic is a useful library for validating data in Python using type hints: Freexian uses it in a number of projects, including Debusine. Its Debian packaging had been stalled at 1.10.17 in testing for some time, partly due to needing to make sure everything else could cope with the breaking changes introduced in 2.x, but mostly due to needing to sort out packaging of its new Rust dependencies. Several other people (notably Alexandre Detiste, Andreas Tille, Drew Parsons, and Timo Röhling) had made some good progress on this, but nobody had quite got it over the line and it seemed a bit stuck.
Colin upgraded a few Rust libraries to new upstream versions, packaged rust-jiter, and chased various failures in other packages. This eventually allowed getting current versions of both pydantic-core and pydantic into testing. It should now be much easier for us to stay up to date routinely.
Reworking of glib2.0 for cross bootstrap, by Helmut GrohneSimon McVittie (not affiliated with Freexian) earlier restructured the libglib2.0-dev such that it would absorb more functionality and in particular provide tools for working with .gir files. Those tools practically require being run for their host architecture (practically this means running under qemu-user) which is at odds with the requirements of architecture cross bootstrap. The qemu requirement was expressed in package dependencies and also made people unhappy attempting to use libglib2.0-dev for i386 on amd64 without resorting to qemu. The use of qemu in architecture bootstrap is particularly problematic as it tends to not be ready at the time bootstrapping is needed.
As a result, Simon proposed and implemented the introduction of a libgio-2.0-dev package providing a subset of libglib2.0-dev that does not require qemu. Packages should continue to use libglib2.0-dev in their Build-Depends unless involved in architecture bootstrap. Helmut reviewed and tested the implementation and integrated the necessary changes into rebootstrap. He also prepared a patch for libverto to use the new package and proposed adding forward compatibility to glib2.0.
Helmut continued working on adding cross-exe-wrapper to architecture-properties and implemented autopkgtests later improved by Simon. The cross-exe-wrapper package now provides a generic mechanism to a program on a different architecture by using qemu when needed only. For instance, a dependency on cross-exe-wrapper:i386 provides a i686-linux-gnu-cross-exe-wrapper program that can be used to wrap an ELF executable for the i386 architecture. When installed on amd64 or i386 it will skip installing or running qemu, but for other architectures qemu will be used automatically. This facility can be used to support cross building with targeted use of qemu in cases where running host code is unavoidable as is the case for GObject introspection.
This concludes the joint work with Simon and Niels Thykier on glib2.0 and architecture-properties resolving known architecture bootstrap regressions arising from the glib2.0 refactoring earlier this year.
Analyzing binary package metadata, by Helmut GrohneAs Guillem Jover (not affiliated with Freexian) continues to work on adding metadata tracking to dpkg, the question arises how this affects existing packages. The dedup.debian.net infrastructure provides an easy playground to answer such questions, so Helmut gathered file metadata from all binary packages in unstable and performed an explorative analysis. Some results include:
- binutils-mipsen uses wrong file ownership
- /usr-merge is not the only cause for aliasing problems in Debian.
Guillem also performed a cursory analysis and reported other problem categories such as mismatching directory permissions for directories installed by multiple packages and thus gained a better understanding of what consistency checks dpkg can enforce.
Python archive rebuilds, by Stefano RiveraLast month Stefano started to write some tooling to do large-scale rebuilds in debusine, starting with finding packages that had already started to fail to build from source (FTBFS) due to the removal of setup.py test. This month, Stefano did some more rebuilds, starting with experimental versions of dh-python.
During the Python 3.12 transition, we had added a dependency on python3-setuptools to dh-python, to ease the transition. Python 3.12 removed distutils from the stdlib, but many packages were expecting it to still be available. Setuptools contains a version of distutils, and dh-python was a convenient place to depend on setuptools for most package builds. This dependency was never meant to be permanent. A rebuild without it resulted in mass-filing about 340 bugs (and around 80 more by mistake).
A new feature in Python 3.12, was to have unittest’s test runner exit with a non-zero return code, if no tests were run. We added this feature, to be able to detect tests that are not being discovered, by mistake. We are ignoring this failure, as we wouldn’t want to suddenly cause hundreds of packages to fail to build, if they have no tests. Stefano did a rebuild to see how many packages were affected, and found that around 1000 were. The Debian Python community has not come to a conclusion on how to move forward with this.
As soon as Python 3.13 release candidate 2 was available, Stefano did a rebuild of the Python packages in the archive against it. This was a more complex rebuild than the others, as it had to be done in stages. Many packages need other Python packages at build time, typically to run tests. So transitions like this involve some manual bootstrapping, followed by several rounds of builds. Not all packages could be tested, as not all their dependencies support 3.13 yet. The result was around 100 bugs in packages that need work to support Python 3.13. Many other packages will need additional work to properly support Python 3.13, but being able to build (and run tests) is an important first step.
Miscellaneous contributions-
Carles prepared the update of python-pyaarlo package to a new upstream release.
-
Carles worked on updating python-ring-doorbell to a new upstream release. Unfinished, pending to package a new dependency python3-firebase-messaging RFP #1082958 and its dependency python3-http-ece RFP #1083020.
-
Carles improved po-debconf-manager. Main new feature is that it can open Salsa merge requests. Aiming for a lightning talk in MiniDebConf Toulouse (November) to be functional end to end and get feedback from the wider public for this proof of concept.
-
Carles helped one translator to use po-debconf-manager (added compatibility for bullseye, fixed other issues) and reviewed 17 package templates.
-
Colin upgraded the OpenSSH packaging to 9.9p1.
-
Colin upgraded the various YubiHSM packages to new upstream versions, enabled more tests, fixed yubihsm-shell build failures on some 32-bit architectures, made yubihsm-shell build reproducibly, and fixed yubihsm-connector to apply udev rules to existing devices when the package is installed. As usual, bookworm-backports is up to date with all these changes.
-
Colin fixed quite a bit of fallout from setuptools 72.0.0 removing setup.py test, backported a large upstream patch set to make buildbot work with SQLAlchemy 2.0, and upgraded 25 other Python packages to new upstream versions.
-
Enrico worked with Jakob Haufe to get him up to speed for managing sso.debian.org
-
Raphaël did remove spam entries in the list of teams on tracker.debian.org (see #1080446), and he applied a few external contributions, fixing a rendering issue and replacing the DDPO link with a more useful alternative. He also gave feedback on a couple of merge requests that required more work. As part of the analysis of the underlying problem, he suggested to the ftpmasters (via #1083068) to auto-reject packages having the “too-many-contacts” lintian error, and he raised the severity of #1076048 to serious to actually have that 4 year old bug fixed.
-
Raphaël uploaded zim and hamster-time-tracker to fix issues with Python 3.12 getting rid of setuptools. He also uploaded a new gnome-shell-extension-hamster to cope with the upcoming transition to GNOME 47.
-
Helmut sent seven patches and sponsored one upload for cross build failures.
-
Helmut uploaded a Nagios/Icinga plugin check-smart-attributes for monitoring the health of physical disks.
-
Helmut collaborated on sbuild reviewing and improving a MR for refactoring the unshare backend.
-
Helmut sent a patch fixing coinstallability of gcc-defaults.
-
Helmut continued to monitor the evolution of the /usr-move. With more and more key packages such as libvirt or fuse3 fixed. We’re moving into the boring long-tail of the transition.
-
Helmut proposed updating the meson buildsystem in debhelper to use env2mfile.
-
Helmut continued to update patches maintained in rebootstrap. Due to the work on glib2.0 above, rebootstrap moves a lot further, but still fails for any architecture.
-
Santiago reviewed some Merge Request in Salsa CI, such as: !478, proposed by Otto to extend the information about how to use additional runners in the pipeline and !518, proposed by Ahmed to add support for Ubuntu images, that will help to test how some debian packages, including the complex MariaDB are built on Ubuntu.
Santiago also prepared !545, which will make the reprotest job more consistent with the result seen on reproducible-builds.
-
Santiago worked on different tasks related to DebConf 25. Especially he drafted the fundraising brochure (which is almost ready).
-
Thorsten Alteholz uploaded package libcupsfilter to fix the autopkgtest and a dependency problem of this package. After package splix was abandoned by upstream and OpenPrinting.org adopted its maintenance, Thorsten uploaded their first release.
-
Anupa published posts on the Debian Administrators group in LinkedIn and moderated the group, one of the tasks of the Debian Publicity Team.
-
Anupa helped organize DebUtsav 2024. It had over 100 attendees with hand-on sessions on making initial contributions to Linux Kernel, Debian packaging, submitting documentation to Debian wiki and assisting Debian Installations.
Ben Hutchings: FOSS activity in September 2024
- I continued to attend and soemtimes chair Debian kernel team meetings
- For the Debian firmware-nonfree package:
- I opened the MRs:
- I reviewed the MRs:
- I merged my own MRs:
- !104: Update to linux-support-6.10.6
- !105: nvidia-graphics: Add versioned Breaks on initramfs-tools to avoid bug #1076539
- I uploaded:
- version 20240709-2 to unstable
- version 20240709-2~bpo12+1 to bookworm-backports
- I respnded to bug reports:
- For the kernel-team repository:
- I reviewed and merged the MR !5: git-format-patch-for-debian: Support for sourcehut
- I deleted some obsolete text from the kernel upload checklist
- For the Debian linux package:
- I announced the end of i386 kernel packages
- I opened or updated the MRs:
- !741: Fix most reproducibility issues
- !1182: [x86] ACPI: Enable ACPI_EC_DEBUGFS as module (Closes: #980555)
- !1188: [arm64] udeb: fix duplicated modules
- !1199: [i386] Stop building kernel packages
- !1200: Backport CI support to bullseye
- !1209: Build fixes for rtla
- !1213: Build fixes for objtool and rtla
- !1215: d/rules.real: Try harder to set the locale to C.UTF-8
- !1218: Clean up udeb configuration
- !1219: Remove d/b/genorig.py in favour of uscan
- !1220: [arm64,armhf] udeb: Add all watchdog drivers to kernel-image
- I reviewed the MRs:
- !675: [arm64] drivers/usb/host: Enable USB_XHCI_PCI_RENESAS as module (Closes: #1032671)
- !1732: [x86] linux-cpupower: Add intel-speed-select command (rebased and merged)
- !1038: debian/rules.real: export LANG = C.UTF-8 for sphinx (closed)
- !1041: Add “-b” flag to genorig.py (closed)
- !1065: Enable UBSAN_BOUNDS and UBSAN_SHIFT (closed)
- !1166: [amd64] Enable CRYPTO_DEV_IAA_CRYPTO (merged)
- !1169: [arm64] Add additional kernel with 64k page size
- !1172: debian/config: add DAMON support for debian kernel (merged)
- !1177: powerpc: Explicitly disable CRASH_DUMP on 32-bit” (merged)
- !1178: mm: set CONFIG_ZONE_DEVICE=y on most 64-bit architectures, not only amd64 (merged)
- !1185: riscv64: fix module duplication detected by kernel-wedge starting with version 2.106 (merged)
- !1186: [arm64] udeb: fix duplicated modules (merged)
- !1192: [loong64] enable LBT, KVM and para-virt support (merged)
- !1193: [arm64] Update rk3588 platform support (merged)
- !1195: [arm64] enable Qualcomm X Elite support (merged)
- !1196: [arm64] include modules for Rockchip RK3588 (closed)
- !1198: Revert “Make linux-libc-dev provide all cross packages” (merged)
- !1204: [arm64] Enable drivers for K3-AM642 SoC on SolidRun HummingBoard-T
- !1207: [rt] Update to 6.11-rc5-rt5 (merged)
- !1208: Support some Wi-Fi 7 devices (merged)
- !1211: Set CONFIG_I2C=y on alpha and sparc64 (closed)
- !1214: [loong64] Enable USB EHCI and OHCI host support (merged)
- I merged my own MRs:
- !741: Fix most reproducibility issues
- !1182: [x86] ACPI: Enable ACPI_EC_DEBUGFS as module (Closes: #980555)
- !1188: [arm64] udeb: fix duplicated modules
- !1199: [i386] Stop building kernel packages
- !1200: Backport CI support to bullseye
- !1209: Build fixes for rtla
- !1215: d/rules.real: Try harder to set the locale to C.UTF-8
- !1218: Clean up udeb configuration
- I uploaded:
- linux-6.1 versions 6.1.106-3~deb11u1, 6.1.106-3~deb11u2, and 6.1.106-3~deb11u3 to bullseye-security
- linux version 6.11-1~exp1 to experimental
- I updated the bullseye-security branch to upstream version 5.10.226
- I responded to bug reports:
- #980555: Missing ec_sys module (fixed)
- #1041484: kernel: hpet_acpi_add: no address or irqs in _CRS (forwarded)
- #1071468: linux-image-amd64: mess left when kernel installation fails (grub treats the uninstalled kernel as existing) (closed)
- #1075855: Kernel panic caused by aacraid module prevents normal boot
- #1076555: linux-image-6.9.9-amd64: boot crash RIP: 0010:kmem_cache_alloc (closed)
- #1078997: gretap tunnel with checksum enabled: some packets have zero checksum (closed)
- #1080975: upgrade 6.1.106 to 6.10.6 failed (reassigned)
- #1081195: devscripts: test-patches KeyError: ‘pae’ (confirmed)
- #1082001: linux-image-6.1.0-25-amd64: TOMOYO LSM rejects execveat(AT_EMPTY_PATH) inside chroot (referred upstream)
- #1081546: new “GPU HANG: ecode 12:1:85dffdfb, in Renderer” regression in i915 driver since 6.10 kernel upgrade (more info requested)
- #1081563: Please consider adding the new Xe Graphics driver for Intel GPUs
- #1081310: Wired ethernet connection disabled.
- I sent patches upstream:
- I sent a new response to Proposal: Switch to linear git history
- For the Debian nfs-utils package:
- I reviewed the MRs:
- I closed my own old bug report #711021: mount.nfs timeout for GETPORT is much too short
- For diffoscope:
- I commented on issue #100: Excessive memory use when comparing Linux Debian .dbg packages to report that the issue still exists, and to provide a reproducer
- I commented on issue #342: Gets killed trying to diff very large (~5GB) images which seems like a duplicate of #100
- I opened the MR !145: Draft: Reduce memory usage by revert to using popen() for diff input and output which fixes #100 but needs work to avoid regressions for other cases
- For the Debian nss-wrapper package, I opened MR !4: Replace wrap-and-sort autopkgtest with a CI job
- For the Debian pam-wrapper package, I opened MR !4: Replace wrap-and-sort autopkgtest with a CI job
- For initramfs-tools:
- I opened the MR !136: Fix copy_file again; expand documentation and add tests
- I reviewed the MRs:
- !66: Add boot script 00_mount_efivarfs mounting efivarfs (closed)
- !84: Allow providing UDEV_WAIT and ROUNDTTT times in environment variables (closed)
- !125: hook-functions: Add more modules based on dracut 90kernel-modules (merged)
- !127: Filter net kernel modules by symbol regexp from dracut
- !134: add losetup-rootfs-img script: boot from rootfs image files
- !135: hook-functions: fixes for Qualcomm platforms
- I responded to bug report #1082647: copy_exec: [regression] ignores trailing slash, installs file as directory name (pending)
- For debian-kernel-handbook:
- I responded (belatedly) to Debian tech-ctte bug #1065416: linux-libc-dev claims to provide linux-libc-dev-ARCH-cross, but it doesn’t do that completely
Thorsten Alteholz: My Debian Activities in September 2024
This month I accepted 441 and rejected 29 packages. The overall number of packages that got accepted was 448.
I couldn’t believe my eyes, but this month I really accepted the same number of packages as last month.
Debian LTSThis was my hundred-twenty-third month that I did some work for the Debian LTS initiative, started by Raphael Hertzog at Freexian. During my allocated time I uploaded or worked on:
- [unstable] libcupsfilters security update to fix one CVE related to validation of IPP attributes obtained from remote printers
- [unstable] cups-filters security update to fix two CVEs related to validation of IPP attributes obtained from remote printers
- [unstable] cups security update to fix one CVE related to validation of IPP attributes obtained from remote printers
- [DSA 5778-1] prepared package for cups-filters security update to fix two CVEs related to validation of IPP attributes obtained from remote printers
- [DSA 5779-1] prepared package for cups security update to fix one CVE related to validation of IPP attributes obtained from remote printers
- [DLA 3905-1] cups-filters security update to fix two CVEs related to validation of IPP attributes obtained from remote printers
- [DLA 3904-1] cups security update to fix one CVE related to validation of IPP attributes obtained from remote printers
- [DLA 3905-1] cups-filters security update to fix two CVEs related to validation of IPP attributes obtained from remote printers
Despite the announcement the package libppd in Debian is not affected by the CVEs related to CUPS. By pure chance there is an unrelated package with the same name in Debian. I also answered some question about the CUPS related uploads. Due to the CUPS issues, I postponed my work on other packages to October.
Last but not least I did a week of FD this month and attended the monthly LTS/ELTS meeting.
Debian ELTSThis month was the seventy-fourth ELTS month. During my allocated time I uploaded or worked on:
- [ELA-1186-1]cups-filters security update for two CVEs in Stretch and Buster to fix the IPP attribute related CVEs.
- [ELA-1187-1]cups-filters security update for one CVE in Jessie to fix the IPP attribute related CVEs (the version in Jessie was not affected by the other CVE).
I also started to work on updates for cups in Buster, Stretch and Jessie, but their uploads will happen only in October.
I also did a week of FD and attended the monthly LTS/ELTS meeting.
Debian PrintingThis month I uploaded …
- … libcupsfilters to also fix a dependency and autopkgtest issue besides the security fix mentioned above.
- … splix for a new upstream version. This package is managed now by OpenPrinting.
Last but not least I tried to prepare an update for hplip. Unfortunately this is a nerve-stretching task and I need some more time.
This work is generously funded by Freexian!
Debian MatomoThis month I even found some time to upload packages that are dependencies of Matomo …
This work is generously funded by Freexian!
Debian AstroThis month I uploaded a new upstream or bugfix version of:
- … openvlbi
- … indi-playerone
- … libsbig
- … indi-pentax
- … indi-sbig
- … indi-fishcamp
- … indi-inovaplx
- … libfishcamp
- … libsbig
- … libplayeronecamera
- … libplayerone
- … libahp-gt
- … libahp-xc
Most of the uploads were related to package migration to testing. As some of them are in non-free or contrib, one has to build all binary versions. From my point of view handling packages in non-free or contrib could be very much improved, but well, they are not part of Debian …
Anyway, starting in December there is an Outreachy project that takes care of automatic updates of these packages. So hopefully it will be much easier to keep those package up to date. I will keep you informed.
Debian IoTThis month I uploaded new upstream or bugfix versions of:
- … pywws
This month I did source uploads of all the packages that were prepared last month by Nathan and started the transition. It went rather smooth except for a few packages where the new version did not propagate to the tracker and they got stuck in old failing autopkgtest. Anyway, in the end all packages migrated to testing.
I also uploaded new upstream releases or fixed bugs in:
miscThis month I uploaded new upstream or bugfix versions of:
Most of those uploads were needed to help packages to migrate to testing.
Steinar H. Gunderson: Pimp my SV08
The Sovol SV08 is a 3D printer which is a semi-assembled clone of Voron 2.4, an open-source design. It's not the cheapest of printers, but for what you get, it's extremely good value for money—as long as you can deal with certain, err, quality issues.
Anyway, I have one, and one of the fun things about an open design is that you can switch out things to your liking. (If you just want a tool, buy something else. Bambu P1S, for instance, if you can live with a rather closed ecosystem. It's a bit like an iPhone in that aspect, really.) So I've put together a spreadsheet with some of the more common choices:
It doesn't contain any of the really difficult mods, and it also doesn't cover pure printables. And none of the dreaded macro stuff that people seem to be obsessing over (it's really like being in the 90s with people's mIRC scripts all over again sometimes :-/), except where needed to make hardware work.
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects