
Feeds
1xINTERNET blog: 1xINTERNET at Drupal Developer Days Burgas 2024
At 1xINTERNET, we proudly sponsored and spread our knowledge at Drupal Developer Days in Burgas 2024. Discover the insights we shared this year!
May and June in KDE PIM
Here's our bi-monthly update from KDE's personal information management applications team. This report covers progress made in the months of May and June 2024.
Since the last report 38 people have contributed over 1500 changes to KDE PIM code base.
PIM SprintLet's start with the biggest event of the last two months: the PIM sprint!
The team met in Toulouse for a weekend of discussions, hacking and French pastries. You can read reports from Kevin, Carl, Dan and Volker on their blogs to get all the nitty gritty.
In this report, we will cover the biggest topics that were discussed and worked on during the sprint.
MilestonesWe have decided to plan and track our work in milestones. Milestones should represent a concrete goal with clear definitions of what we understand as done, and be achievable within a reasonable time frame. Each milestone is then split into smaller bite-sized tasks that can be worked on independently.
This will help us prioritize important work, make our progress more visible and, most importantly, make it easier for people to get excited about what we are working on. New contributors will also be able to pick up a well-defined task and start contributing to PIM.
You can see the milestones on our Gitlab board - if anything there catches your eye and you would like to help, reach out to us on the #kontact:kde.org Matrix channel!
This report, as well as future ones will try to focus on the current milestones and their progress, hopefully making them more exciting to read :)
Retiring KJots and KNotesWe have decided to retire the KJots and KNotes applications. These applications have not seen any support or development in many years and are not in a state that we feel comfortable shipping to our users. With the introduction of Marknote, KDE can now offer a modern, well-maintained note-taking application that we can recommend users to migrate to. The latest release of Marknote has gained support for importing notes from KJots and KNotes, so no notes will be lost.
Polished Tag SupportTags were introduced into KDE PIM many, many years ago, but they have never reached their full potential. We have decided to change that and make tags a first-class citizen in our applications. The first step is making sure that tags are actually usable, so we started by implementing automatic extraction of tags from events and todos and syncing them into local iCal calendars and remote DAV calendars. Thanks to this, you can now sync tags between KOrganizer and NextCloud, for example.
Moving Protocol Implementations to KDE Framworks
We have libraries in KDE PIM that implement various standards and protocols. By moving them to KDE Frameworks we make them independent from KDE PIM and thus available to anyone who wants to use them. In the past we have moved KCalendarCore (iCal support library) and KContacts (vCard support library) to Frameworks. We are now working on moving KMime (email/RFC822 support library) and KIMAP (IMAP protocol implementations) to Frameworks as well.
This is helping cleanup KMime. KMime APIs is now in many places const correct to avoid the risk of modifying a message when reading it, proper CamelCase headers are now generated like for all the KDE Frameworks. Finally, parsing a MIME file is now up to 10 times faster on typical emails.
Other Improvements and Fixes ItineraryOur travel assistant app Itinerary gained support for the public transport routing service Transitous, got a new import staging area and can now create new entries directly from OSM elements. For more details see its own summary blog post.
Merkuro
"Snow flurry" fixed the start of the week math for locales that use Sunday as the first day of the week. They also fixed the navigation of the basic mode for the month view and week view (which are used on mobile).
Claudio continued working on the Merkuro Mail application and added a progress bar in the sidebar which appears when a background job is running.
The settings dialogs have been ported to the new KirigamiAddons.ConfigurationView which fixes some issues on mobile.
Get InvolvedIf you would like to get involved in KDE PIM, check our milestones board and pick a task! And don't forget to join us in the #kontact:kde.org Matrix channel or the kde-pim mailing list!
Arturo Borrero González: Wikimedia Toolforge: migrating Kubernetes from PodSecurityPolicy to Kyverno
Christian David, CC BY-SA 4.0, via Wikimedia Commons
{kind=link}
This post was originally published in the Wikimedia Tech blog, authored by Arturo Borrero Gonzalez.
Summary: this article shares the experience and learnings of migrating away from Kubernetes PodSecurityPolicy into Kyverno in the Wikimedia Toolforge platform.
Wikimedia Toolforge is a Platform-as-a-Service, built with Kubernetes, and maintained by the Wikimedia Cloud Services team (WMCS). It is completely free and open, and we welcome anyone to use it to build and host tools (bots, webservices, scheduled jobs, etc) in support of Wikimedia projects.
We provide a set of platform-specific services, command line interfaces, and shortcuts to help in the task of setting up webservices, jobs, and stuff like building container images, or using databases. Using these interfaces makes the underlying Kubernetes system pretty much invisible to users. We also allow direct access to the Kubernetes API, and some advanced users do directly interact with it.
Each account has a Kubernetes namespace where they can freely deploy their workloads. We have a number of controls in place to ensure performance, stability, and fairness of the system, including quotas, RBAC permissions, and up until recently PodSecurityPolicies (PSP). At the time of this writing, we had around 3.500 Toolforge tool accounts in the system. We early adopted PSP in 2019 as a way to make sure Pods had the correct runtime configuration. We needed Pods to stay within the safe boundaries of a set of pre-defined parameters. Back when we adopted PSP there was already the option to use 3rd party agents, like OpenPolicyAgent Gatekeeper, but we decided not to invest in them, and went with a native, built-in mechanism instead.
In 2021 it was announced that the PSP mechanism would be deprecated, and removed in Kubernetes 1.25. Even though we had been warned years in advance, we did not prioritize the migration of PSP until we were in Kubernetes 1.24, and blocked, unable to upgrade forward without taking actions.
The WMCS team explored different alternatives for this migration, but eventually we decided to go with Kyverno as a replacement for PSP. And so with that decision it began the journey described in this blog post.
First, we needed a source code refactor for one of the key components of our Toolforge Kubernetes: maintain-kubeusers. This custom piece of software that we built in-house, contains the logic to fetch accounts from LDAP and do the necessary instrumentation on Kubernetes to accommodate each one: create namespace, RBAC, quota, a kubeconfig file, etc. With the refactor, we introduced a proper reconciliation loop, in a way that the software would have a notion of what needs to be done for each account, what would be missing, what to delete, upgrade, and so on. This would allow us to easily deploy new resources for each account, or iterate on their definitions.
The initial version of the refactor had a number of problems, though. For one, the new version of maintain-kubeusers was doing more filesystem interaction than the previous version, resulting in a slow reconciliation loop over all the accounts. We used NFS as the underlying storage system for Toolforge, and it could be very slow because of reasons beyond this blog post. This was corrected in the next few days after the initial refactor rollout. A side note with an implementation detail: we stored a configmap on each account namespace with the state of each resource. Storing more state on this configmap was our solution to avoid additional NFS latency.
I initially estimated this refactor would take me a week to complete, but unfortunately it took me around three weeks instead. Previous to the refactor, there were several manual steps and cleanups required to be done when updating the definition of a resource. The process is now automated, more robust, performant, efficient and clean. So in my opinion it was worth it, even if it took more time than expected.
Then, we worked on the Kyverno policies themselves. Because we had a very particular PSP setting, in order to ease the transition, we tried to replicate their semantics on a 1:1 basis as much as possible. This involved things like transparent mutation of Pod resources, then validation. Additionally, we had one different PSP definition for each account, so we decided to create one different Kyverno namespaced policy resource for each account namespace — remember, we had 3.5k accounts.
We created a Kyverno policy template that we would then render and inject for each account.
For developing and testing all this, maintain-kubeusers and the Kyverno bits, we had a project called lima-kilo, which was a local Kubernetes setup replicating production Toolforge. This was used by each engineer in their laptop as a common development environment.
We had planned the migration from PSP to Kyverno policies in stages, like this:
- update our internal template generators to make Pod security settings explicit
- introduce Kyverno policies in Audit mode
- see how the cluster would behave with them, and if we had any offending resources reported by the new policies, and correct them
- modify Kyverno policies and set them in Enforce mode
- drop PSP
In stage 1, we updated things like the toolforge-jobs-framework and tools-webservice.
In stage 2, when we deployed the 3.5k Kyverno policy resources, our production cluster died almost immediately. Surprise. All the monitoring went red, the Kubernetes apiserver became irresponsibe, and we were unable to perform any administrative actions in the Kubernetes control plane, or even the underlying virtual machines. All Toolforge users were impacted. This was a full scale outage that required the energy of the whole WMCS team to recover from. We temporarily disabled Kyverno until we could learn what had occurred.
This incident happened despite having tested before in lima-kilo and in another pre-production cluster we had, called Toolsbeta. But we had not tested that many policy resources. Clearly, this was something scale-related. After the incident, I went on and created 3.5k Kyverno policy resources on lima-kilo, and indeed I was able to reproduce the outage. We took a number of measures, corrected a few errors in our infrastructure, reached out to the Kyverno upstream developers, asking for advice, and at the end we did the following to accommodate the setup to our needs:
- corrected the external HAproxy kubernetes apiserver health checks, from checking just for open TCP ports, to actually checking the /healthz HTTP endpoint, which more accurately reflected the health of each k8s apiserver.
- having a more realistic development environment. In lima-kilo, we created a couple of helper scripts to create/delete 4000 policy resources, each on a different namespace.
- greatly over-provisioned memory in the Kubernetes control plane servers. This is, bigger memory in the base virtual machine hosting the control plane. Scaling the memory headroom of the apiserver would prevent it from running out of memory, and therefore crashing the whole system. We went from 8GB RAM per virtual machine to 32GB. In our cluster, a single apiserver pod could eat 7GB of memory on a normal day, so having 8GB on the base virtual machine was clearly not enough. I also sent a patch proposal to Kyverno upstream documentation suggesting they clarify the additional memory pressure on the apiserver.
- corrected resource requests and limits of Kyverno, to more accurately describe our actual usage.
- increased the number of replicas of the Kyverno admission controller to 7, so admission requests could be handled more timely by Kyverno.
I have to admit, I was briefly tempted to drop Kyverno, and even stop pursuing using an external policy agent entirely, and write our own custom admission controller out of concerns over performance of this architecture. However, after applying all the measures listed above, the system became very stable, so we decided to move forward. The second attempt at deploying it all went through just fine. No outage this time 🙂
When we were in stage 4 we detected another bug. We had been following the Kubernetes upstream documentation for setting securityContext to the right values. In particular, we were enforcing the procMount to be set to the default value, which per the docs it was ‘DefaultProcMount’. However, that string is the name of the internal variable in the source code, whereas the actual default value is the string ‘Default’. This caused pods to be rightfully rejected by Kyverno while we figured the problem. I sent a patch upstream to fix this problem.
We finally had everything in place, reached stage 5, and we were able to disable PSP. We unloaded the PSP controller from the kubernetes apiserver, and deleted every individual PSP definition. Everything was very smooth in this last step of the migration.
This whole PSP project, including the maintain-kubeusers refactor, the outage, and all the different migration stages took roughly three months to complete.
For me there are a number of valuable reasons to learn from this project. For one, the scale is something to consider, and test, when evaluating a new architecture or software component. Not doing so can lead to service outages, or unexpectedly poor performances. This is in the first chapter of the SRE handbook, but we got a reminder the hard way 🙂
This post was originally published in the Wikimedia Tech blog, authored by Arturo Borrero Gonzalez.
KDE Gear 24.05.2
Over 180 individual programs plus dozens of programmer libraries and feature plugins are released simultaneously as part of KDE Gear.
Today they all get new bugfix source releases with updated translations, including:
- kdepim-runtime: Fix a memory leak in the EWS resource (Commit, fixes bug #486861)
- kio-gdrive: Fix "This file does not exist" after clicking on a folder (Commit, fixes bug #487021)
- partitionmanager: Fix a crash caused by clicking the remove mount point button (Commit, fixes bug #432103)
Distro and app store packagers should update their application packages.
- 24.05 release notes for information on tarballs and known issues.
- Package download wiki page
- 24.05.2 source info page
- 24.05.2 full changelog
Keychain Development Update: Yubikey Support
Following my latest post about Keychain, here is a new development update. Yubikey and Key Files are now supported, which allows you to requires a YubiKey to open a password database but also to save it.
Saving and editing groups also now works.
And I now started working on the database creation process. The UI is ready but I still need to bind it to the backend.
Thanks to everyone who send me encouragement messages and also to Laurent who did a lot of cleanups in the codebase.
See you in the next development update.
Drupal Association blog: Navigating the Future 6 Months out from Drupal 7 Support Ending: Options for Your Drupal 7 Site
With Drupal 7’s (D7) end-of-life (EOL) in 6 months on January 5, 2025, organizations relying on D7 face critical decisions regarding the future of their websites. This article will help guide you through the paths you can take: migrating to modern Drupal, leveraging extended long-term support options, or staying on unsupported Drupal 7.
Update to Modern DrupalTransitioning from Drupal 7 to a newer version is crucial in future-proofing your digital presence. These versions embrace modern PHP standards, object-oriented programming, and Symfony components, providing a powerful foundation for your website. This upgrade allows you to access advanced features, enhanced performance, and ensures ongoing support and security updates.
Why Migrate to the Latest Versions?Modernization: Drupal 10 offers cutting-edge features and performance improvements, and an easy upgrade path to Drupal 11, releasing very soon.
Security: Continuous security updates protect your site from vulnerabilities.
Flexibility: Adopt contemporary coding standards and best practices.
Future-Proofing: Ensure compatibility with future updates and maintain a seamless digital experience.
Additionally, the upcoming release of Starshot, slated before the end of 2024, promises even more enhancements and features that will elevate your website's capabilities. By migrating now, your organization can seamlessly integrate these future advancements.
Migrating to newer versions can involve navigating significant architectural changes, and may require extensive modifications to custom modules and themes. However, tools like Drupal Rector and Retrofit on our DIY migration resources page can help make this process easier. The benefits of modernization, enhanced security, and future-proofing outweigh the initial investment in time, resources, and budget.
But you don’t have to do it yourself. There are a number of Drupal Certified Partners who can assist organizations in planning and implementing their migration.
Find the qualified company that is best for you: Certified Migration Partners.
Extended Security Support for Drupal 7To address the challenges of using unsupported software, the Drupal Association has established a program for supporting site owners who won't be able to migrate before the end of life date. The D7 Extended Security Support Program identifies existing Drupal Certified Partners who meet stringent standards and who the Drupal Association feels confident recommending.
With the end of support, the Drupal Security Team will no longer be involved in supporting Drupal 7. The Drupal Association recognizes that some site owners will not be in a position to migrate their site or need more time to do so. For many of these site owners, paying for extended support would be a good option.
Recognizing that the Drupal Security Team would not be officially involved in any such service, the Drupal Association created rigorous standards before certifying companies under this program. Some of these requirements include:
- Being a Drupal Certified Partner at the Gold tier or higher
- Employing a core security team member
- Experience in providing security and compatibility fixes
- History of reporting 2 or more CVEs and creating fixes for the same
- Willingness to enter in a service level agreement to ensure standards are being met
Find the company that will work best for you: D7 Extended Security Support Partners
Stay on Unsupported Drupal 7When Drupal 7 reaches its EOL, it will no longer receive new security updates, fixes, or official support from the Drupal community. While this option might seem cost-effective and leverages your team's stability and familiarity with Drupal 7, it comes with significant risks.
Without updates, your site will be vulnerable to new security exploits and non-compliance with standards such as FedRAMP, PCI-DSS, and HIPAA. Over time, tools and utilities supporting your Drupal 7 site may become incompatible with new versions of dependencies like PHP, and finding developers skilled in outdated technology could become increasingly difficult.
The Drupal Association does not recommend this option.
ConclusionOrganizations must carefully weigh their options as Drupal 7 approaches its EOL to ensure continued security, compliance, and compatibility. Embracing Drupal 10 and the upcoming Drupal 11 and Starshot release will position your organization for long-term success with access to the latest features, security updates, and a vibrant support community..
Greg Casamento: What Apple has forgotten...
When NeXT still existed and the black hardware was a thing, Steve Jobs made the announcement that OPENSTEP would be created and that the object model, not the operating system and not the hardware, was the important thing.
This is a concept that Apple has forgotten. With it's push towards Apple Silicon and a walled-garden, Apple has committed itself to the same pitfall that NeXT fell into. NeXT lacked the infrastructure to handle OPENSTEP running on multiple kinds of hardware, but the object model on different OSes was successful... this is evident in OPENSTEP1.1 for Solaris and OPENSTEP for NT.
GNUstep attempts to reach the same goal, but provides the APIs that are available with Cocoa. The object model IS the important thing and this is why GNUstep is so important. It breaks the walled garden and makes it possible for users to run their apps and tools on other operating systems. GNUstep HASN'T forgotten and we believe this is a core concept that Apple has left behind.
Samuel Henrique: Debian's curl now supports HTTP3
Starting with curl 8.0.0-2, you can now use HTTP3.
curl --http3-only https://example.comOr, if you would like to try it out in a container:
podman run debian:unstable apt install --update -y curl && curl --http3-only https://example.com(in case you haven't noticed, apt now has the --update option for the upgrade and install commands, although not available on stable yet)
Availability- Debian unstable - Since 2024-07-02
- Debian testing - Coming up between the second and third week of July 2024 (estimate if no issues are spotted).
- Debian 12/bookworm backports - As soon as the package gets to Debian testing, I'll upload it to bookworm.
- Debian 12/bookworm - Due to the mechanisms we have in place to make sure Debian stable is in fact stable, we will never be able to ship this in the regular repository. Users can make use of the backports repositories instead.
- Debian derivatives - Rolling releases will get it by the time it's on Debian testing (e.g.: Kali Linux). Stable derivatives only in their next major release.
HTTP3 is fresh new, well... not really, but at least fresh enough that I'm not aware of any other Linux distribution supporting it on curl, the reason is likely two-fold:
- OpenSSL is not there yet
OpenSSL still doesn't have proper HTTP3 support, and given that OpenSSL is so widely used, almost every curl distributor/packager will build curl with it and thus changing the TLS backend to something else is risky.
Unfortunately, proper support for the OpenSSL libcurl is unlikely to come anytime before the end of this year, the OpenSSL performance is not good enough yet as of version 3.3.
Daniel Stenberg has written about the state of this multiple times, most recently at HTTP/3 in curl mid 2024, if you're interested, I suggest reading through his other posts as well.
Some might have noticed that nginx does support HTTP3 through OpenSSL, although when you look closely, it's not exactly perfect:
An SSL library that provides QUIC support is recommended to build nginx, such as BoringSSL, LibreSSL, or QuicTLS. Otherwise, the OpenSSL compatibility layer will be used that does not support early data.
As you can see, they don't recommend using OpenSSL, and when doing so, you don't get complete support.
- HTTP3 support for GnuTLS/nghttp3/ngtcp2 is recent
The non-experimental support arrived back in October 2023, and so that's when I started seriously planning for this.
curl has been working on HTTP3 support for years, and so it did support other TLS backends before that, but out of them, the one most feasible for a distribution to ship would be GnuTLS, which gets HTTP3 support through ngctp2 and nghttp3.
The Debian curl package has historically shipped at least two variants of libcurl, an OpenSSL and a GnuTLS one.
The OpenSSL libcurl can't support HTTP3 for the reasons explained above, but the GnuTLS libcurl can (with ngtcp2 and nghtp3).
Debian packages can choose which version of libcurl to link against (without having to modify any upstream source code). Debian's "git" package being a famous example of a package that links against the GnuTLS libcurl.
Enabling HTTP3 on curl was done in three steps:
- Make sure all required dependencies fulfill the minimum requirements.
- Enable HTTP3 for GnuTLS libcurl.
- Change the libcurl used by the curl CLI, from OpenSSL to GnuTLS.
curl's HTTP3 support requires a somewhat recent version of nghttp3 and updating that required a transition (due to the SONAME bump), while we've also had months of freeze for transitions due to the time_t transition.
After the dependencies were in place, enabling HTTP3 for the GnuTLS libcurl was straightforward.
Then, for the last part, we had to switch the TLS backend used by the curl CLI. Doing the swap is also quite easy on the packaging level, but we have to consider the chances of this change breaking our users' environments.
Ensuring there are no breakagesThe first thing to consider regarding breakages is that this change is not going to be pushed directly to the current Debian stable releases, it will be present in the next stable release (13/trixie) but the current one will stick to the version that's already shipped.
Secondly, we have to consider the risk of losing the ability to use certain parameters from the curl CLI which could be limited to the OpenSSL backend. During curl-up 2024, the curl developers pointed out the existence of a page that lists the TLS related options and the backends they work with.
Analysing that page, ignoring all of the options that are suffixed with "BLOB" (only pertinent to the library, not the CLI), the only one left which is attention worthy is CURLOPT_ECH.
This experimental feature requires a special build of OpenSSL, as ECH is not yet supported in OpenSSL releases. In contrast ECH is supported by the latest BoringSSL and wolfSSL releases.
As it turns out, Encrypted Client Hello is experimental and it's not supported by the vanilla OpenSSL.
This was enough of an investigation for me to go ahead with the change. Noting that even in the worst case scenario (we find a horrible regression), we can rollback without having affected a single stable release.
Now that the package is on Debian unstable, the CI tests (autopkgtest) of every package that depends on curl is currently running, the results are compared against the migration-reference (in this case, the curl CLI with OpenSSL, before the change).
If everything goes right, curl with HTTP3 support will migrate to Debian testing in around 5 days. If we spot any issues, we'll have to solve them first and it's going to be hard to predict how long it takes, although it's fair to expect less than a month.
FeedbackFeel free to join the Matrix room for the Debian curl maintainers:
https://matrix.to/#/#debian-curl-maintainers:matrix.org
We have historically spoken Portuguese in the room but we'll switch to English
in case anyone joins.
It took us a bit longer than expected to be able to enable HTTP3, nonetheless it's still early enough to be excited about.
A lot of people were crucial to make this happen.
I should recognize in the first place, obviously, the curl developers and the developers of the supporting libraries: GnuTLS, nghttp3, ngtcp2. Participating in the curl-up 2024 conference helped me get motivated to push this through, besides becoming aware of the right documentation to research for impact.
On the Debian side, Sakirnth Nagarasa <sakirnth> was responsible for updating and taking care of the transition for nghttp3 and ngtcp2.
Also on the Debian side, I've got loads of help and support from the co-maintainers of the curl package: Sergio Durigan Junior <sergiodj> and Carlos Henrique Lima Melara <charles>.
Mike Gabriel: Polis - a FLOSS Tool for Civic Participation -- Initial Evaluation and Adaptation (episode 2/5)
Here comes the 2nd article of the 5-episode blog post series written by Guido Berhörster, member of staff at my company Fre(i)e Software GmbH.
Enjoy also this read on Guido's work on Polis,
Mike
- Introduction
- Initial evaluation and adaptation (this article)
- Issues extending Polis and adjusting our goals
- Creating (a) new frontend(s) for Polis
- Current status and roadmap
The Polis code base consists of a number of components, the administration and participation interfaces, a common web backend, and a statistics processing server. Both frontends and the backend are written in a mixture of JavaScript and TypeScript, only the statistics processing server is written in Clojure.
In case of self hosting the preferred method of deployment is via Docker containers using Docker Compose or any other orchestrator. The participation frontend for conversations can either be used as a standalone web page or be embedded via an iframe.
For our planned use case we initially defined the following goals:
- custom branding and the integration into different content management systems (CMS)
- better support for mobile devices
- mandatory authentication and support for a broader range of authentication methods, including self-hosted solutions and DigiD
- support for alternative email sending services
- GDPR compliance
After a preliminary evaluation of our own and consulting with Policy Lab UK who were also evaluating and testing Polis and had already made a range of improvements related to self-hosting as well as bug fixes and modernization changes we decided to take their work as a base for our adaptations with the intent of submitting generally useful changes back to the Polis project.
Subsequently, a number of changes were implemented, including the removal of hardcoded domain names, the elimination of unnecessary cookies and third-party requests, support for an alternative email sending service, and the option of disabling Facebook and X integration.
For the branding our approach was to add an option allowing websites which are embedding conversations in an iframe to load an alternative stylesheet for overriding the native Polis branding. For this to be practical we intended to use CSS custom properties for defining branding-related styles such as colors and fonts. That approach turned out to be problematic because although the Polis participation frontend stylesheet is generated via SCSS and some of the colors are parameterized, however, they are not used consistently throughout the SCSS stylesheets, unfortunately. In addition the frontend templates contain a large amount of hardcoded style attributes. While we succeeded in implementing user-defined stylesheets, it took a disproportionate amount of development resources to parameterize all used colors and fonts via CSS custom properties aggravated by the fact that the SCSS and template files are huge and contain many unused rules and code.
Ian Jackson: derive-deftly is nearing 1.x - call for review/testing
derive-deftly, the template-based derive-macro facility for Rust, has been a great success.
It’s coming up to time to declare a stable 1.x version. If you’d like to try it out, and have final comments / observations, now is the time.
Introduction to derive-deftlyHave you ever wished that you could that could write a new derive macro without having to mess with procedural macros?
You can!
derive-deftly lets you write a #[derive] macro, using a template syntax which looks a lot like macro_rules!:
use derive_deftly::{define_derive_deftly, Deftly}; define_derive_deftly! { ListVariants: impl $ttype { fn list_variants() -> Vec<&'static str> { vec![ $( stringify!( $vname ) , ) ] } } } #[derive(Deftly)] #[derive_deftly(ListVariants)] enum Enum { UnitVariant, StructVariant { a: u8, b: u16 }, TupleVariant(u8, u16), } assert_eq!( Enum::list_variants(), ["UnitVariant", "StructVariant", "TupleVariant"], );Statusderive-deftly has a wide range of features, which can be used to easily write sophisticated and reliable derive macros. We’ve been using it in Arti, the Tor Project’s reimplementation of Tor in Rust, and we’ve found it very useful.
There is comprehensive reference documentation, and more discursive User Guide for a more gentle introduction. Naturally, everything is fully tested.
Historyderive-deftly started out as a Tor Hackweek project. It used to be called derive-adhoc. But we renamed it because we found that many of the most interesting use cases were really not very ad-hoc at all.
Over the past months we’ve been ticking off our “1.0 blocker” tickets. We’ve taken the opportunity to improve syntax, terminology, and semantics. We hope we have now made the last breaking changes.
Plans - call for review/testingIn the near future, we plan to declare version 1.0. After 1.x, we intend to make breaking changes very rarely.
So, right now, we’d like last-minute feedback. Are there any wrinkles that need to be sorted out? Please file tickets or MRs on our gitlab. Ideally, anything which might imply breaking changes would be submitted on or before the 13th of August.
In the medium to long term, we have many ideas for how to make derive-deftly even more convenient, and even more powerful. But we are going to proceed cautiously, because we don’t want to introduce bad syntax or bad features, which will require difficult decisions in the future about forward compatibility.
comments
Highlights from AI_dev Paris
On June 19-20, the Linux Foundation hosted AI_dev: Open Source GenAI & ML Summit Europe 2024. This event brought together developers exploring the complex world of Open Source generative AI and Machine Learning. Central to this event is the conviction that Open Source drives innovation in AI. Please find below some highlights from AI_dev Paris and how they are aligned with OSI’s work on the Open Source AI Definition.
Keynote: Welcome & Opening RemarksIbrahim Haddad, Executive Director of the LF AI & Data Foundation, provided an overview of the major challenges in Open Source AI, which include:
- Lack of a common understanding of openness in AI
- Open Source software licenses used on non-software assets
- Diverse restrictions including the use of Acceptable Use Policies
- Lack of understanding of licenses and implications in the context of AI models
- Incomplete release of model components
To address some of these challenges, Haddad introduced the Model Openness Framework (MOF) and announced the official launch of the Model Openness Tool (MOT) at the conference.
Introducing the Model Openness Framework: Achieving Completeness and Openness in a Confusing Generative AI LandscapeAnni Lai, Matt White, and Cailean Osborne delved into the Model Openness Framework, a comprehensive system for evaluating and classifying the completeness and openness of Machine Learning models. This framework assesses which components of the model development lifecycle are publicly released and under what licenses, ensuring an objective evaluation. Matt White, Executive Director of the Pytorch Foundation and author of the MOF white paper, went on to demonstrate the Model Openness Tool, which evaluates each model across 3 classes: Open Science (Class I), Open Tooling (Class II), and Open Model (Class III).
Model Openness Tool: launched at the Linux Foundation’s AI_dev Paris conference The Open Source AI dilemma: Crafting a clear definition for Open Source AIOfer Hermoni, founder of the LF AI & Data Foundation, continued examining the Model Openness Framework and explained how this framework and its list of components serve as the basis for OSI’s Open Source AI Definition (OSAID). The OSAID evaluates each component on the four fundamental freedoms of Open Source:
- To use the system for any purpose and without having to ask for permission
- To study how the system works and inspect its components
- To modify the system for any purpose, including to change its output
- To share the system for others to use with or without modifications, for any purpose
Lea Gimpel and Daniel Brumund from the Digital Public Goods Alliance (DPGA) emphasized the importance of democratizing AI through digital public goods, including Open Source software, open AI models, open data, open standards, and open content. Lea highlighted that, while open data is desirable, it is not conditional. She supported the OSI’s Open Source AI Definition, as it helps the DPGA navigate legal uncertainties around data sharing and broadens the pool of potential solutions that can be recognized, marketed, and made available as digital public goods, thereby offering more opportunities to positively impact people’s lives.
ConclusionIt was clear throughout this conference that the work to create a standard Open Source AI Definition that upholds the fundamental freedoms of Open Source is vital for addressing some of the key challenges in AI and ML development and democratization. The OSI appreciates Linux Foundation’s collaboration toward this goal and its commitment to host another successful event to facilitate these important discussions.
Drupal Association blog: Introducing Ripple Makers: our revamped Individual Membership program!
Fellow Drupalists!
We have exciting news. As a way to express our appreciation for our community, the Drupal Association is pleased to announce some changes to the Individual Membership program, now called Ripple Makers!
Our goal is to increase communication and transparency, and create more opportunities for engagement.
The Drupal Association is a United States incorporated 501(c)3 nonprofit organization. Donations to Ripple Makers are tax deductible, where applicable. We raise funding primarily through event registration, event sponsorship, the Drupal Certified Partner program, some grants, and individual contributions. We do not have a for profit parent corporation telling us what to do, nor do we ever charge to download Drupal. In fact, it is our mission to ensure that it will always be free.
Drupal has given members of our community opportunities beyond just a career. The values adopted by open source communities create innovation, collaboration, and creation across the globe. Drupal itself is recognized as a Digital Public Good. Drupal is a lever for change and makes a difference preserving the integrity of the internet.
At the heart of the Ripple Makers transformation is a commitment to fostering deeper connections with each and every member of our community, recognizing the invaluable role that sustaining donors play in advancing our shared mission and impact. By revamping our sustaining donors club to be more inclusive and communicative, we aim to create a culture of belonging where every donor feels valued, heard, and empowered to make a difference.
Ripple Makers is your chance to give back—and to celebrate the Drupal community and the open source ecosystem that helps it thrive. We invite you to make a monthly donation in support of the Drupal Association.
Sahil Dhiman: RTI to NPL Regarding Their NTP Infrastructure
I became interested in Network Time Protocol (NTP) last year after learning how fundamental this protocol is to the functioning of the global Internet. NTP helps synchronize clocks on devices over the Internet, which is essential for secure browsing, timestamping, keeping everyone in sync or just checking what time it is. Computers usually have a hardware real-time clock (RTC) but that deviates over time, so an occasional sync over NTP is required to keep the time accurate. Many network and IoT devices don’t have hardware RTC so have even more reliance on NTP.
Accurate time keeping starts with reference clocks like atomic clocks, GPS etc. Multiple government standard agencies host these reference clocks, which are regarded as Stratum 0. Stratum 1 servers are known as primary servers, and directly connect to Stratum 0 clocks for time. Stratum 1 servers then distribute time to Stratum 2 and further down the hierarchy. Computers typically connects to one or more Stratum 1/2/3… servers to get their time.
Someone has to host these public Stratum 1,2,3… NTP servers. That’s what NTP pool, a global effort by volunteers does. They provide NTP servers for the public to use. As of today, there are 4700+ servers in the pool which are free to use for anyone.
Now let’s come to the reason for writing this post. Indian Computer Emergency Response Team (CERT-In) in April 2022 released a set of cybersecurity directions which set the alarm bells ringing. Internet Society (and almost everyone else) wrote about it.
And then there was this specific section about NTP:
All service providers, intermediaries, data centres, body corporate and Government organisations shall connect to the Network Time Protocol (NTP) Server of National Informatics Centre (NIC) or National Physical Laboratory (NPL) or with NTP servers traceable to these NTP servers, for synchronisation of all their ICT systems clocks. Entities having ICT infrastructure spanning multiple geographies may also use accurate and standard time source other than NPL and NIC, however it is to be ensured that their time source shall not deviate from NPL and NIC.
CSIR-National Physical Laboratory (NPL) is the official timekeeper for India and hosts the only public Stratum 1 clock in India, according to NTP pool website. So I was naturally curious to know what kind of infrastructure they’re running for NTP. India has a Right to Information (RTI) Act which, like the Freedom of Information Act (FOIA) in the United States, gives citizens rights to request information from governmental entities, to which they have to respond in under 30 days. So last year, I filed two sets of RTI (one after the first reply came) inquiring about NPL’s public NTP server setup.
The first RTI had some generic questions:
First RTI. Click to enlarge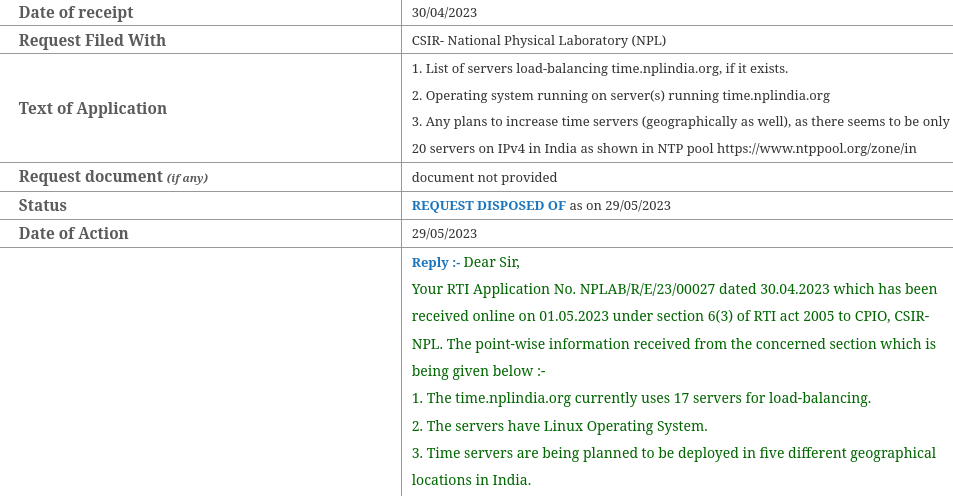{kind=link}
This gave a vague idea about the setup, so I sat down and came with some specific questions in the next RTI.
Second RTI. Click to enlarge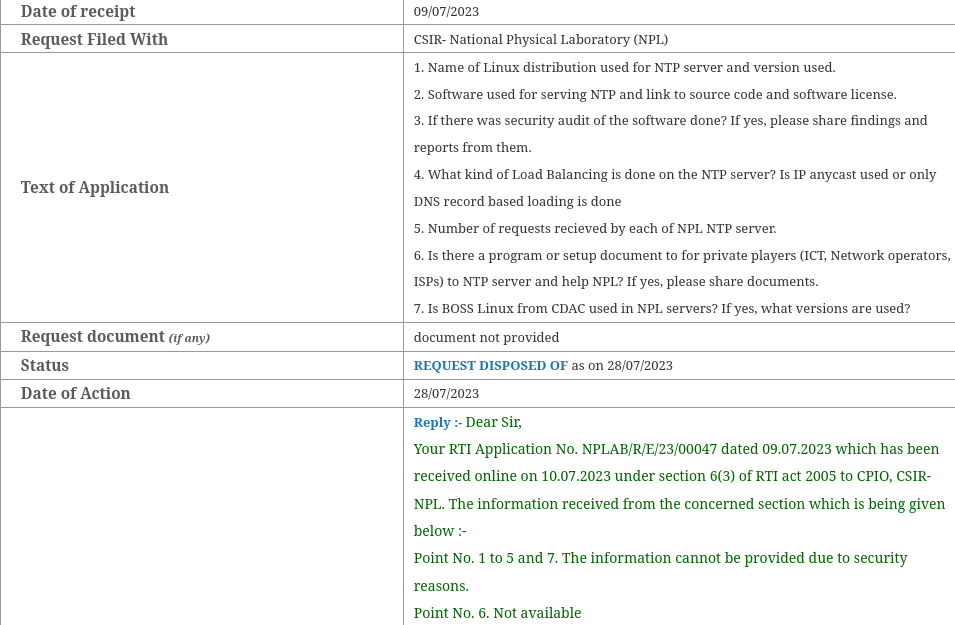{kind=link}
Feel free to make your conclusions from it now. Bear in mind these were filled last year so things might have changed. Do let me know if you have more information about it.
Real Python: Working With JSON Data in Python
Since its introduction, JSON has rapidly emerged as the predominant standard for the exchange of information. Whether you want to transfer data with an API or store information in a document database, it’s likely you’ll encounter JSON. Fortunately, Python provides robust tools to facilitate this process and help you manage JSON data efficiently.
In this tutorial, you’ll learn how to:
- Understand the JSON syntax
- Convert Python data to JSON
- Deserialize JSON to Python
- Write and read JSON files
- Validate JSON syntax
- Prettify JSON in the terminal
- Minify JSON with Python
While JSON is the most common format for data distribution, it’s not the only option for such tasks. Both XML and YAML serve similar purposes. If you’re interested in how the formats differ, then you can check out the tutorial on how to serialize your data with Python.
Free Bonus: Click here to download the free sample code that shows you how to work with JSON data in Python.
Take the Quiz: Test your knowledge with our interactive “Working With JSON Data in Python” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Working With JSON Data in PythonIn this quiz, you'll test your understanding of working with JSON in Python. JSON has become the de facto standard for information exchange, and Python provides easy-to-use tools to handle JSON data.
Introducing JSONThe acronym JSON stands for JavaScript Object Notation. As the name suggests, JSON originated from JavaScript. However, JSON has transcended its origins to become language-agnostic and is now recognized as the standard for data interchange.
The popularity of JSON can be attributed to native support by the JavaScript language, resulting in excellent parsing performance in web browsers. On top of that, JSON’s straightforward syntax allows both humans and computers to read and write JSON data effortlessly.
To get a first impression of JSON, have a look at this example code:
JSON hello_world.json { "greeting": "Hello, world!" } Copied!You’ll learn more about the JSON syntax later in this tutorial. For now, recognize that the JSON format is text-based. In other words, you can create JSON files using the code editor of your choice. Once you set the file extension to .json, most code editors display your JSON data with syntax highlighting out of the box:
The screenshot above shows how VS Code displays JSON data using the Bearded color theme. You’ll have a closer look at the syntax of the JSON format next!
Examining JSON SyntaxIn the previous section, you got a first impression of how JSON data looks. And as a Python developer, the JSON structure probably reminds you of common Python data structures, like a dictionary that contains a string as a key and a value. If you understand the syntax of a dictionary in Python, you already know the general syntax of a JSON object.
Note: Later in this tutorial, you’ll learn that you’re free to use lists and other data types at the top level of a JSON document.
The similarity between Python dictionaries and JSON objects is no surprise. One idea behind establishing JSON as the go-to data interchange format was to make working with JSON as convenient as possible, independently of which programming language you use:
[A collection of key-value pairs and arrays] are universal data structures. Virtually all modern programming languages support them in one form or another. It makes sense that a data format that is interchangeable with programming languages is also based on these structures. (Source)
To explore the JSON syntax further, create a new file named hello_frieda.json and add a more complex JSON structure as the content of the file:
JSON hello_frieda.json 1{ 2 "name": "Frieda", 3 "isDog": true, 4 "hobbies": ["eating", "sleeping", "barking"], 5 "age": 8, 6 "address": { 7 "work": null, 8 "home": ["Berlin", "Germany"] 9 }, 10 "friends": [ 11 { 12 "name": "Philipp", 13 "hobbies": ["eating", "sleeping", "reading"] 14 }, 15 { 16 "name": "Mitch", 17 "hobbies": ["running", "snacking"] 18 } 19 ] 20} Copied!In the code above, you see data about a dog named Frieda, which is formatted as JSON. The top-level value is a JSON object. Just like Python dictionaries, you wrap JSON objects inside curly braces ({}).
In line 1, you start the JSON object with an opening curly brace ({), and then you close the object at the end of line 20 with a closing curly brace (}).
Note: Although whitespace doesn’t matter in JSON, it’s customary for JSON documents to be formatted with two or four spaces to indicate indentation. If the file size of the JSON document is important, then you may consider minifying the JSON file by removing the whitespace. You’ll learn more about minifying JSON data later in the tutorial.
Inside the JSON object, you can define zero, one, or more key-value pairs. If you add multiple key-value pairs, then you must separate them with a comma (,).
Read the full article at https://realpython.com/python-json/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Lullabot: Responsive HTML Tables: Presenting Data in an Accessible Way
Long gone are the days of using HTML tables for page layouts. That time almost seems shrouded in myth. One of the (many) reasons tables fell out of use was the advent of responsive design to meet the needs of different contexts and screen sizes. Tables are rigid. Their presence naturally hampers the responsiveness of a website to conform to a smaller screen size.
But tables are still useful. In some cases, they are necessary.
Real Python: Quiz: Python's Magic Methods: Leverage Their Power in Your Classes
In this quiz, you’ll test your understanding of Python’s Magic Methods.
By working through this quiz, you’ll revisit the concept of magic methods in Python, how they work, and how you can use them to customize the behavior of your classes.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
The Drop Times: Transforming Drupal Site Building: Lauri Timmanee on Experience Builder and Starshot Initiative
Samuel Henrique: Announcing wcurl: a curl wrapper to download files
Whenever you need to download files through the terminal and don't feel like using wget:
wcurl example.com/filename.txtManpage:
https://manpages.debian.org/unstable/curl/wcurl.1.en.html
- Debian unstable - Since 2024-07-02
- Debian testing - Coming up between the second and third week of July 2024.
- Debian 12/bookworm backports - As soon as the package gets to Debian testing, I'll upload it to bookworm.
- Debian 12/bookworm - Depends on whether Debian's release team will approve it, it could be available in the next point release.
- Debian derivatives - Rolling releases will get it by the time it's on Debian testing (e.g.: Kali Linux). Stable derivatives only in their next major release.
If you don't want to wait for the package update to arrive, you can always copy
the script and place it in your /usr/bin, the code is here:
https://github.com/Debian/wcurl/blob/main/wcurl
https://salsa.debian.org/debian/wcurl/-/blob/main/wcurl?ref_type=heads
Starting with curl version 8.8.0-2, the Debian's curl package now ships a wcurl executable.
wcurl is the solution for those who just need to download files without having to remember curl's parameters for things like automatically naming the files.
Some people, myself included, would fall back to using wget whenever there was a need to download a file. Sometimes even installing wget just for that usecase. After all, it's easier to remember "apt install wget" rather than "curl -L -O -C - ...".
wcurl consists of a simple shell script that provides sane defaults for the curl invocation, for when the use case is to just download files.
By default, wcurl will:
- Encode whitespaces in URLs;
- Download multiple URLs in parallel;
- Follow redirects;
- Automatically choose a filename as output;
- Perform retries;
- Resume from broken/interrupted downloads.
- Set the downloaded file timestamp to the value provided by the server, if available;
Example, to download a single file:
wcurl example.com/filename.txtIf you ever need to set a custom flag, you can make use of the -o/--opts wcurl option, anything set there will be passed to the curl invocation. Just beware that if you need to set any custom flags, it's likely you will be better served by calling curl directly. The -o/--opts options are there to allow for some flexibility in unforeseen circumstances.
The need for wcurlI've always felt a bit ashamed of not remembering curl's parameters for downloading a file and automatically naming it, having resorted to wget most of the times this was needed (even installing wget when it wasn't there, just for this). I've spoken to a few other experienced people I know and confirmed what could be obvious to others: a lot of people struggle with this.
Recently, the curl project released the results of 2024's curl survey, which also showed this is as a much needed feature, just look at some of the answers:
Q: Which curl command line option do you think needs improvement and how?-O, I really want wget like functionality where I don't have to specify the name
Downloading a file (like wget) could be improved - with automatic naming of the file
downloading files - wget is much cleaner
I wish the default behaviour when GETting a binary was to drop it on disk. That's the only reason 'wget foo.tgz" is still ingrained in my muscle memory .
Maybe have a way to download without specifying something in -o (the only reason i used wget still)
--remote-time should be default
--remote-name-all could really use a short flag
Q: If you miss support for something, tell us what!"Write the data to the file named in the URL (or in redirects if I'm feeling daring), and timestamp the file to the last-modified-date". This is the main reason I'm still using wget.
I can finally feel less bad about falling back to wget due to not remembering the parameters I want.
Idealization vs. realityI don't believe curl will ever change its default behavior in such a way that would accommodate this need, as that would have a side-effect of breaking things which expect the current behavior (the blast radius is literally the solar system).
This means a new executable needs to be shipped side-by-side with curl, an opportunity to start fresh and work with a more focused use case (to download files).
Ideally, this new executable would be maintained by the curl project, make use of libcurl under-the-hood, and be available everywhere. Nobody wants to worry if their systems have the tool or not, it should always be there.
Given I'm just a Debian Developer, with not as much free time as I wish, I've decided to write a simple shell script wrapper calling the curl CLI under-the-hood.
wcurl will come installed with the curl package from now on, and I will check with the release team about shipping it on the current Debian stable as well. Shipping wcurl in other distros will be up to them (Debian-derivatives should pick it up automatically, though).
We've tried to make it easy for anyone to ship this by using the curl license, keeping the script POSIX-compliant, and shipping a manpage.
Maybe if there's enough interest across distributions, someone might sign up for implementing this in upstream curl and increase its reach. I would be happy with the curl project reusing the wcurl name when that happens. It's unlikely that wcurl would be shipped by curl upstream as it is, assuming they would prefer a solution that uses libcurl direclty (more similar to curl the CLI, to maintain).
In the worst case, wcurl becomes a Debian-specific tool that only a few people are aware of, in the best case, it becomes the new go-to CLI tool for simply downloading files. I would be happy if at least someone other than me finds it useful.
Naming is hardWhen I started working on it, I was calling the new executable "curld" (stands for "curl download"), but then when discussing this in one of our weekly calls in the Debian Brasília community, it was mentioned that this could be confused for a daemon.
We then settled for the name "wcurl", which doesn't really stand for anything, but it's very easy to remember.
You know... "it's that wget alternative for when you want to use curl instead" :)
FeedbackI'm hosting the code on Github and Debian's GitLab instance, feel free to open an issue to provide feedback.
https://salsa.debian.org/debian/wcurl
https://github.com/Debian/wcurl
We also have a Matrix room for the Debian curl maintainers:
https://matrix.to/#/#debian-curl-maintainers:matrix.org
We have historically spoken Portuguese in the room but we'll switch to
English in case anyone joins.
The idea for wcurl came a few days before the curl-up conference 2024. I've been thinking a lot about developer productivity in the terminal lately, different tools and better defaults. Before curl-up, I was also thinking about packaging improvements for the curl package. I don't remember what exactly happened, but I likely had to download something and felt a bit ashamed of maintaining curl and not remembering the parameters to download files the way I wanted.
I first discussed this idea in the conference, where I asked the participants about it and there were no concerns raised, and some people said I should give it a go. Participating in curl-up was a really great experience and I'm thankful for the interactions I've had there.
On the Debian side, I've got reviews of the code and manpage by Sergio Durigan Junior <sergiodj>, Guilherme Puida Moreira <puida> and Carlos Henrique Lima Melara <charles>. Sergio ended up rewriting the tool to be POSIX-compliant (my version was written in bash), so he takes all the credit for the portability.
Calamares & some Distro Notes
Calamares is an indepdendent Linux distro-installer, and we just released Calamares 3.3.7. There’s a couple of known issues that need tracking down, but it is a slow process – one entirely dependent on how much time volunteers are able and willing to put into careful bug reporting (and reproduction) and then dealing with code to fix them. Anyway, here’s some semi-coherent notes about Calamares and distro’s and issues and things.
Installing KubuntuI recently had to install an “emergency PC” for my mom, and picked Kubuntu – fairly arbitrarily, I must say. The install-Kubuntu icon does not look like Calamares, and first comes up with some other selection dialog in a different style, so I was pleasantly surprised to see it using Calamares after that.
It picked up Dutch from geo-location, which was fine. Less fine is that the Dutch translations aren’t complete. I’m pretty sure I could fix that.
Installation was straightforward, although I always pick “erase whole disk” and click through nearly all of the defaults. No complicated installs for me, and it worked without a hitch.
Mom didn’t need the emergency PC after all, so now I do have a spare low-end desktop machine with Kubuntu. I might turn it into a try-real-installs box for a while.
Building Calamares on KDE NeonKDE Neon was a CI target for Calamares for a long time, but I switched it off in March 2024. Dependencies were a mess at the time, and the automatic CI builds were failing every night. Other distro’s didn’t have that struggle, so I put more CI weight on Fedora.
I did keep one of my desktop machines installed with KDE Neon, as a gaming machine. At least I can see what Plasma 6 is supposed to be like, as a reference for when we land it in FreeBSD. Untangling the package mess to return it to a development machine was just too much of a hassle.
At some point I removed Qt5 – and everything that depended on it – and then reinstalled some bits and did a pkcon update and whatever and the machine finally ended up in a workable state for development again, but don’t ask me exactly what I did and don’t talk to me about the upgrade experience.
Building Calamares on FreeBSDIt’s possible, just probably not very useful. Clang spits out mountains of warnings, which I occasionally try to address.
Not all of the warnings are all that useful – when dealing with command-line arguments, for instance. The relationship between argc and argv (conventional names for parameters) in main() is clear, but there’s nothing in the type of either to express that, so you get warnings like this one:
src/libcalamares/geoip/test_geoip.cpp:37:45: warning: unsafe buffer access [-Wunsafe-buffer-usage] 37 | QString selector = argc == 3 ? QString( argv[ 2 ] ) : QString(); Building Calamares on EndeavourOSThe live-ISO for EndeavourOS is one of my favorites. I don’t know why they ship an ISO with git in the live-image, but it means that I trivially have a system with a working Calamares configuration, which I can update with the latest version:
git clone http://github.com/calamares/calamares cd calamares sudo ./ci/deps-endeavouros.sh sudo pacman -Scc export CMAKE_ARGS="-DWITH_QT6=ON -DCMAKE_BUILD_TYPE=Debug" export BUILDDIR=build ./ci/build.shI have a VM with the live-ISO, but also two virtual disks attached. By doing the checkout and package download on one of the disks, and doing test-installs to the other, this is by far the easiest and most pleasant develop-and-test setup I have right now.
And the wallpaper is pretty nice, too.
Gaël Varoquaux: Skrub 0.2.0: tabular learning made easy
We just released skrub 0.2.0. This release markedly simplifies learning on complex dataframes.
model = tabular_learner(‘classifier’) Simple, yet solid default baselineThe highlight of the release is the tabular_learner function, which facilitates creating pipelines that readily perform machine learning on dataframes, adding preprocessing to a scikit-learn compatible learner. The function packs defaults and heuristics to transform all forms of dataframes to a representation that is well suited to a learner, and it can adapt these transformation: tabular_learner(HistGradientBoostingClassifier()) encodes categories differently than tabular_learner(LogisticRegression()).
The heuristics are tuned based on much benchmarking and experience shows that they give good tradeoffs. The default tabular_learner(‘classifier’) is often a strong baseline.
The benefit are visible in a really simple example:
>>> # First retrieve data >>> from skrub.datasets import fetch_employee_salaries >>> dataset = fetch_employee_salaries() >>> df = dataset.X >>> y = dataset.y >>> # The dataframe is a quite rich and complex dataframe, with various columns >>> dfWe can then easily build a learner that applies readily to this dataframe, without any transformation:
>>> from skrub import tabular_learner >>> learner = tabular_learner('regressor') >>> # The resulting learner can apply all the machine-learning conveniences (eg cross-validation) directly on the dataframe >>> from sklearn.model_selection import cross_val_score >>> cross_val_score(learner, df, y) array([0.89370447, 0.89279068, 0.92282557, 0.92319094, 0.92162666]) transformer = TableVectorizer() Making encoding complex dataframes easyBehind the hood, the work is done by the skrub.TableVectorizer(), a scikit-learn compatible transformer that facilitates combining multiple transformations on the different columns of a dataframe. The TableVectorizer is not new in the 0.2.0 release, but we have completely revamped its internals to cover really well edge cases. Indeed, one challenge is to make sure that nothing different or strange happens at test time. Actually, enforcing consistency between train-time and test-time transformation is the real value of skrub compared to using pandas or polars to do transformation.
Increasing support of polars Short-term goal of optimized support for pandas and polarsWe have implemented a new mechanism for supporting both pandas and polars. It has not been applied on all the codebase, hence the support is still imperfect. However, we are seeing increasing support for polars in skrub, and our goal in the short term is to provide rock-solid polar support.
Try skrub out! It’s still young, but in mind opinion, it provides a lot of value to tabular learning.
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Research
- The Open Source Initiative joins CMU in launching Open Forum for AI: A human-centered approach to AI development
- Open Source AI Definition – Weekly update July 15
- Mer Joyce: voices of the Open Source AI Definition
- Beyond SPDX: expanding licenses identified by ClearlyDefined
- Highlights from AI_dev Paris