
FLOSS Project Planets
Plasma 6.1
Plasma 6 hits its stride with version 6.1. While Plasma 6.0 was all about getting the migration to the underlying Qt 6 frameworks correct (and what a massive job that was), 6.1 is where developers start implementing the features that will take you desktop to a new level.
In this release, you will find features that go far beyond subtle changes to themes and tweaks to animations (although there is plenty of those too), as you delve into interacting with desktops on remote machines, become more productive with usability and accessibility enhancements galore, and discover customizations that will even affect the hardware of your computer.
These features and more are being built directly into Plasma's Wayland version natively, avoiding the need for third party software and hacky extensions required by similar solutions implemented in X.
Things will only get more interesting from here. But meanwhile enjoy what will land on your desktop with your next update.
Note: Due to unforeseen circumstances, we have been unable to ship the new wallpaper, "Reef", with this version of Plasma. However, there will be a new wallpaper coming soon in the next 6.2 version.
If you can't wait, you can download "Reef" here.
We apologise for this delay and the inconvenience this may cause.
What's New Access Remote Plasma DesktopsOne of the more spectacular (and useful) features added in Plasma 6.1 is that you can now start up a remote desktop directly from the System Settings app. This means that if you are sysadmin who needs to troubleshoot users' machines, or simply need to work on a Plasma-enabled computer that is out of reach, setting up a connection is just a few clicks away.
Once enabled, you can connect to the remote desktop using a client such as KRDC. You will see the remote machine's Plasma desktop in a window and be able to interact with it from your own computer.
Customization made (more) VisualWe all love customizing our Plasma desktops, don't we? One of the quickest ways to do this is by entering Plasma's Edit Mode (right-click anywhere on the desktop background and select Enter Edit Mode from the menu).
In version 6.1, the visual aspect of Edit Mode has been overhauled and you will now see a slick animation when you activate it. The entire desktop zooms out smoothly, giving you a better overview of what is going on and allowing you to make your changes with ease.
Persistent AppsPlasma 6.1 on Wayland now has a feature that "remembers" what you were doing in your last session like it did under X11. Although this is still work in progress, If you log off and shut down your computer with a dozen open windows, Plasma will now open them for you the next time you power up your desktop, making it faster and easier to get back to what you were doing.
Sync your Keyboard's Colored LEDsIt wouldn't be a new Plasma release without at least one fancy aesthetic customization features. This time, however, we give you the power to reach beyond the screen, all the way onto your keyboard, as you can now synchronize the LED colours of your keys to match the accent colour on your desktop.
The ultimate enhancement for the fashion-conscious user.
Please note that this feature will not work on unsupported keyboards — support for additional keyboards is on the way!
And all this too...-
We have simplified the choices you see when you try to exit Plasma by reducing the number of confusing options. For example, when you press Shutdown, Plasma will only list Shutdown and Cancel, not every single power option.
-
Screen Locking gives you the option of configuring it to behave like a traditional screensaver, as you can choose it not to ask you for a password to unlock it.
-
Two visual accessibility changes make it easier to use the cursor in Plasma 6.1:
-
Shake Cursor makes the cursor grow when you "shake" it. This helps you locate that tiny little arrow on your large, cluttered screens when you lose it among all those windows.
-
Edge Barrier is useful if you have a multi-monitor setup and want to access things on the very edge of your monitor. The "barrier" is a sticky area for your cursor near the edge between screens, and it makes it easier to click on things (if that is what you want to do), rather than having the cursor scooting across to the next display.
-
-
Two major Wayland breakthroughs will greatly improve your Plasma experience:
-
Explicit Sync eliminates flickering and glitches traditionally experienced by NVidia users.
-
Triple Buffering support in Wayland makes animations and screen rendering smoother.
-
Talking Drupal: Talking Drupal #455 - Top 5 uses of AI for Drupal
Today we are talking about AI Tips for Drupal Devs, AI Best Practices, and Drupal Droid with guest Mike Miles. We’ll also cover AI interpolator as our module of the week.
For show notes visit: www.talkingDrupal.com/455
Topics- Top 5 tips
- Idea Generation (Ideation)
- Code Generation
- Debugging
- Content Generation
- Technical Explanations
- How do you suggest people use AI for Ideation
- Is MIT Sloan using AI to help with Drupal Development
- Does that code get directly inserted into your sites
- What are some common pitfalls
- Is your team using AI for debugging
- Any best practices you have found helping when working with AI
- Is MIT Sloan using AI for content generation
- What is an example of how you use AI for technical explanations
- What is your view ont he future of AI in Drupal, do you think AI will replace Drupal developers
- Drupal Droid
- Talking Drupal - Drupal Droid
- Workflows of ai
- AI guidelines
- Using AI as a Development Tool
- Drupal Starshot: Delivering on a promise to Ambitious Site Builders
Michael Miles - mike-miles.com mikemiles86
HostsNic Laflin - nLighteneddevelopment.com nicxvan John Picozzi - epam.com johnpicozzi Randy Fay - rfay
MOTW CorrespondentMartin Anderson-Clutz - mandclu.com mandclu
- Brief description:
- Have you ever wanted to use AI to help populate entity fields that were left blank by Drupal content authors? There’s a module for that.
- Module name/project name:
- Brief history
- How old: created in Sep 2023 by Marcus Johansson of FreelyGive
- Versions available: 1.0.0-rc4
- Maintainership
- Actively maintained, recent release in the past month
- Security coverage - opted in, needs stable release
- Test coverage
- Documentation - User guide
- Number of open issues: 18 open issues, none of which are a bugs
- Usage stats:
- 94 sites
- Module features and usage
- In scientific fields, interpolation is the process of using known data to extrapolate or estimate unknown data points. In a similar way this module helps your Drupal site provide values for fields that didn’t receive input, based on the information that was provided.
- Fundamentally Interpolator AI provides a framework and an API, and then relies on companion modules for processing, either by leveraging third-party services like AI LLMs, or PHP-based scripting.
- There are existing integrations with a variety of AI services, including OpenAI, Dreamstudio, Hugging Face, and more.
- You can add retrievers to help extract and normalize the content you’re processing, for example photos from an external site, and other tools to help normalize and optimize content and media, and optimize any prompts you will be using with AI services.
- You can also extend the workflow capabilities of AI Interpolator, for example using the popular and powerful ECA module that we’ve talked about before on this show.
PyBites: Deploying a FastAPI App as an Azure Function: A Step-by-Step Guide
In this article I will show you how to deploy a FastAPI app as a function in Azure. Prerequisites are that you have an Azure account and have the Azure CLI installed (see here).
Setup AzureFirst you need to login to your Azure account:
az loginIt should show your subscriptions and you select the one you want to use.
Create a resource groupLike this:
az group create --name myResourceGroup --location eastusA resource group is a container that holds related resources for an Azure solution (of course use your own names throughout this guide).
It comes back with the details of the resource group you just created.
Create a storage accountUsing this command:
az storage account create --name storage4pybites --location eastus --resource-group myResourceGroup --sku Standard_LRSNote that for me, to get this working, I had to first make an MS Storage account, which I did in the Azure portal.
The storage account name can only contain lowercase letters and numbers. Also make sure it’s unique enough (e.g. mystorageaccount was already taken).
Upon success it comes back with the details of the storage account you just created.
Create a function appNow, create a function app.
az functionapp create --resource-group myResourceGroup --consumption-plan-location eastus --runtime python --runtime-version 3.11 --functions-version 4 --name pybitesWebhookSample --storage-account storage4pybites --os-type Linux Your Linux function app 'pybitesWebhookSample', that uses a consumption plan has been successfully created but is not active until content is published using Azure Portal or the Functions Core Tools. Application Insights "pybitesWebhookSample" was created for this Function App. You can visit <URL> to view your Application Insights component App settings have been redacted. Use `az webapp/logicapp/functionapp config appsettings list` to view. { ...JSON response... }A bit more what these switches mean:
- --consumption-plan-location is the location of the consumption plan.
- --runtime is the runtime stack of the function app, here Python.
- --runtime-version is the version of the runtime stack, here 3.11 (3.12 was not available at the time of writing).
- --functions-version is the version of the Azure Functions runtime, here 4.
- --name is the name of the function app (same here: make it something unique / descriptive).
- --storage-account is the name of the storage account we created.
- --os-type is the operating system of the function app, here Linux (Windows is the default but did not have the Python runtime, at least for me).
Go to your FastAPI app directory and create a requirements.txt file with your dependencies if not done already:
To demo this from scratch, let’s create a simple FastAPI webhook app (the associated repo is here).
mkdir fastapi_webhook cd fastapi_webhook mkdir webhookFirst, create a requirements.txt file:
fastapi azure-functionsThe azure-functions package is required to run FastAPI on Azure Functions.
Then create an __init__.py file inside the webhook folder with the FastAPI app code:
import azure.functions as func from fastapi import FastAPI app = FastAPI() @app.post("/webhook") async def webhook(payload: dict) -> dict: """ Simple webhook that just returns the payload. Normally you would do something with the payload here. And add some security like secret key validation (HMAC for example). """ return {"status": "ok", "payload": payload} async def main(req: func.HttpRequest, context: func.Context) -> func.HttpResponse: return await func.AsgiMiddleware(app).handle_async(req, context)This took a bit of trial and working to get it working, because it was not evident that I had to use AsgiMiddleware to run FastAPI on Azure Functions. This article helped with that.
Next, create a host.json file in the root of the project for the Azure Functions host:
{ "version": "2.0", "extensions": { "http": { "routePrefix": "" } } }A local.settings.json file for local development:
{ "IsEncrypted": false, "Values": { "AzureWebJobsStorage": "UseDevelopmentStorage=true", "FUNCTIONS_WORKER_RUNTIME": "python" } }And you’ll need a function.json file in the webhook directory that defines the configuration for the Azure Function:
{ "scriptFile": "__init__.py", "bindings": [ { "authLevel": "anonymous", "type": "httpTrigger", "direction": "in", "name": "req", "methods": ["post"] }, { "type": "http", "direction": "out", "name": "$return" } ] }I also included a quick test script in the root of the project:
import sys import requests url = "http://localhost:7071/webhook" if len(sys.argv) < 2 else sys.argv[1] data = {"key": "value"} resp = requests.get(url) print(resp) resp = requests.post(url, json=data) print(resp) print(resp.text)If you run this script, you should see a 404 for the GET request (not implemented) and a 200 for the POST request. For remote testing I can run the script with the live webhook URL (see below).
Run the function locallyTo verify that the function works locally run it with:
func startThen run the test script:
$ python test.py <Response [404]> <Response [200]> {"status":"ok","payload":{"key":"value"}}Awesome!
Deploy it to AzureTime to deploy the function to Azure:
(venv) √ fastapi_webhook (main) $ func azure functionapp publish pybitesWebhookSample Getting site publishing info... [2024-06-17T16:06:08.032Z] Starting the function app deployment... Creating archive for current directory... ... ... Remote build succeeded! [2024-06-17T16:07:35.491Z] Syncing triggers... Functions in pybitesWebhookSample: webhook - [httpTrigger] Invoke url: https://pybiteswebhooksample.azurewebsites.net/webhookLet’s see if it also works on Azure:
$ python test.py https://pybiteswebhooksample.azurewebsites.net/webhook <Response [404]> <Response [200]> {"status":"ok","payload":{"key":"value"}}Cool, it works!
If something goes wrong remotely, you can check the logs:
az webapp log tail --name pybitesWebhookSample --resource-group myResourceGroupAnd when you make changes, you can redeploy with:
func azure functionapp publish pybitesWebhookSampleThat’s it, a FastAPI app running as an Azure Function! I hope this article helps you if you want to do the same. If you have any questions, feel free to reach out to me on X | Fosstodon | LinkedIn -> @bbelderbos.
ADCI Solutions: How to add a live chat to a website using Mercure
Real Python: Ruff: A Modern Python Linter for Error-Free and Maintainable Code
Linting is essential to writing clean and readable code that you can share with others. A linter, like Ruff, is a tool that analyzes your code and looks for errors, stylistic issues, and suspicious constructs. Linting allows you to address issues and improve your code quality before you commit your code and share it with others.
Ruff is a modern linter that’s extremely fast and has a simple interface, making it straightforward to use. It also aims to be a drop-in replacement for many other linting and formatting tools, such as Flake8, isort, and Black. It’s quickly becoming one of the most popular Python linters.
In this tutorial, you’ll learn how to:
- Install Ruff
- Check your Python code for errors
- Automatically fix your linting errors
- Use Ruff to format your code
- Add optional configurations to supercharge your linting
To get the most from this tutorial, you should be familiar with virtual environments, installing third-party modules, and be comfortable with using the terminal.
Ruff cheat sheet: Click here to get access to a free Ruff cheat sheet that summarizes the main Ruff commands you’ll use in this tutorial.
Take the Quiz: Test your knowledge with our interactive “Ruff: A Modern Python Linter” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Ruff: A Modern Python LinterIn this quiz, you'll test your understanding of Ruff, a modern linter for Python. By working through this quiz, you'll revisit why you'd want to use Ruff to check your Python code and how it automatically fixes errors, formats your code, and provides optional configurations to enhance your linting.
Installing RuffNow that you know why linting your code is important and how Ruff is a powerful tool for the job, it’s time to install it. Thankfully, Ruff works out of the box, so no complicated installation instructions or configurations are needed to start using it.
Assuming your project is already set up with a virtual environment, you can install Ruff in the following ways:
Shell $ python -m pip install ruff Copied!In addition to pip, you can also install Ruff with Homebrew if you’re on macOS or Linux:
Shell $ brew install ruff Copied!Conda users can install Ruff using conda-forge:
Shell $ conda install -c conda-forge ruff Copied!If you use Arch, Alpine, or openSUSE Linux, you can also use the official distribution repositories. You’ll find specific instructions on the Ruff installation page of the official documentation.
Additionally, if you’d like Ruff to be available for all your projects, you might want to install Ruff with pipx.
You can check that Ruff installed correctly by using the ruff version command:
Shell $ ruff version ruff 0.4.7 Copied!For the ruff command to appear in your PATH, you may need to close and reopen your terminal application or start a new terminal session.
Linting Your Python CodeWhile linting helps keep your code consistent and error-free, it doesn’t guarantee that your code will be bug-free. Finding the bugs in your code is best handled with a debugger and adequate testing, which won’t be covered in this tutorial. Coming up in the next sections, you’ll learn how to use Ruff to check for errors and speed up your workflow.
Checking for ErrorsThe code below is a simple script called one_ring.py. When you run it, it gets a random Lord of the Rings character name from a tuple and lets you know if that character bore the burden of the One Ring. This code has no real practical use and is just a bit of fun. Regardless of the size of your code base, the steps are going to be the same:
Read the full article at https://realpython.com/ruff-python/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Real Python: Quiz: Ruff: A Modern Python Linter
In this quiz, you’ll test your understanding of Ruff, a modern linter for Python.
By working through this quiz, you’ll revisit why you’d want to use Ruff to check your Python code and how it automatically fixes errors, formats your code, and provides optional configurations to enhance your linting.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Robin Wilson: Accessing Planetary Computer STAC files in DuckDB
Microsoft Planetary Computer is a wonderful archive of geospatial datasets (primarily raster images of various types), provided with a STAC catalog to enable them to be easily searched through an API. That’s fine for normal usage where you want to find a selection of images and access the images themselves, but less useful when you want to do some analysis of the metadata itself.
For that use case, Planetary Computer provide the STAC metadata in bulk, stored as GeoParquet files. Their documentation page explains how to use this with geopandas and do some large-ish scale processing with Dask. I wanted to try this with DuckDB – a newer tool that is excellent at accessing and processing Parquet files, including efficiently accessing files available via HTTP, and only downloading the relevant parts of the file. So, this post explains how I managed to do this – showing various different approaches I tried and how (or if!) each of them worked.
Getting URLsPlanetary Computer URLs are basically just URLs to files on Azure Blob Storage. However, the URLs require signing with a Shared Access Signature (SAS) key. Luckily, there is a Planetary Computer Python module that will use an API to generate the correct keys for us.
In the docs for using the STAC GeoParquet files, they give this code:
catalog = pystac_client.Client.open( "https://planetarycomputer.microsoft.com/api/stac/v1/", modifier=planetary_computer.sign_inplace, ) asset = catalog.get_collection("io-lulc-9-class").assets["geoparquet-items"]This gets a collection, and the geoparquet-items collection-level asset, having used a ‘modifier’ to sign the URLs as they are acquired from the STAC API. The URL is then stored in asset.href.
Using the DuckDB CLI – with HTTP URLsWhen using GeoPandas, the docs show that you can pass a storage_options parameter to the read_parquet method and it will ‘just work’:
df = geopandas.read_parquet( asset.href, storage_options=asset.extra_fields["table:storage_options"] )However, to use the file in DuckDB we need a full URL. The SQL code we’re going to use in DuckDB for a quick test looks like this:
SELECT * FROM <URL> LIMIT 1This just gets the first row of whatever URL is given.
Unfortunately, though, the URL provided by the STAC catalog looks like this:
abfs://items/io-lulc-9-class.parquetIf we try that with DuckDB, we find it doesn’t know how to deal with it. So, we need to convert this to a standard HTTP URL that can be downloaded as if it were just typed into a web browser (or used with cURL or wget). After a bit of playing around, I found I could create a full URL with this Python code:
url = f'https://{asset.extra_fields["table:storage_options"] ["account_name"]}.dfs.core.windows.net/{asset.href[7:]}? {asset.extra_fields["table:storage_options"]["credential"]}'That’s taking the account_name and sticking it in as part of the host part of the UK, then extracting the path from the original URL and adding that, and then finishing with the SAS token (stored as credential in the storage options) as a URL query parameter.
That results in a URL that looks like this (split over multiple lines for readability):
https://pcstacitems.dfs.core.windows.net/items/io-lulc-9-class.parquet ?st=2024-06-14T19%3A04%3A20Z&se=2024-06-15T19%3A49%3A20Z&sp=rl&sv=2024-05-04& sr=c&skoid=9c8ff44a-6a2c-4dfb-b298-1c9212f64d9a &sktid=72f988bf-86f1-41af-91ab-2d7cd011db47&skt=2024-06-15T09%3A00%3A14Z &ske=2024-06-22T09%3A00%3A14Z&sks=b &skv=2024-05-04 &sig=A0e%2BihbAagHmIZ%2Bg8gzH71TavRYQMZiHWJ/Uk9j0Who%3D(note: that specific URL won’t work for you, as the SAS tokens are time-limited).
If we insert that into our DuckDB SQL statement then we find it works (click to enlarge):
{kind=link}
Great! Now let’s try with a different collection on Planetary Computer – in this case the Sentinel 2 collection. We can make the URL in the same way as before, by changing how we define asset:
asset = catalog.get_collection("sentinel-2-l2a").assets["geoparquet-items"]and then using the same query in DuckDB with the new URL. Unfortunately, this time we get an error:
Invalid Input Error: File '<URL>' too small to be a Parquet fileThe problem here is that for larger collections, the STAC metadata is spread out over a series of GeoParquet files inside a folder, and the URL we’ve been given is just to the folder (even though it ends in .parquet). As we’re just using HTTP, there is no way to do things like list the files in a folder, so DuckDB has no way to find out what files are within the folder and start reading them. We need to find another way.
Using the DuckDB CLI – with the Azure extensionConveniently, there is an Azure extension for DuckDB, and it lets you use URLs like 'abfss://⟨my_filesystem⟩/⟨path⟩/⟨my_file⟩.⟨parquet_or_csv⟩'. That’s a slightly different URL scheme to the one we’ve been given (abfss as opposed to abfs), but we can easily sort that.
Looking at the authentication docs though, it seems to require you to specify either a connection string, a service principal or using the ‘Azure Credential Chain’ (which, I think, works with the az command line and various environment variables that you may have set up). We don’t have any of those – they’re all a far broader scope than what we’ve got, which is just a SAS token for a specific file or folder. It looks like the Azure extension doesn’t support this, so we’ll have to look for another way.
Using the DuckDB Python library – with an Azure connectorAs well as the command-line interface, DuckDB can also be used from Python. To set this up, just run pip install duckdb. While you’re at it, you might want to install pandas and the adlfs library for connecting to Azure Storage.
Using this is actually quite simple, first import the libraries:
import duckdb from adlfs.spec import AzureBlobFileSystemthen set up the Azure connection:
a = AzureBlobFileSystem(account_name='pcstacitems', sas_token=asset.extra_fields["table:storage_options"]['credential'])Note how here we’re using the sas_token parameter to provide a SAS token. We could use a different parameter here to provide a connection string or some other credential type. I couldn’t find much real-world use of this sas_token parameter when looking online – so this is probably the key ‘less well documented’ bit to take away from this article.
Continuing, we then connect to DuckDB and ‘register’ this Azure connection:
connection = duckdb.connect() connection.register_filesystem(a)From there, we can run a SQL query like this:
query = connection.sql(f""" SELECT * FROM 'abfs://items/sentinel-2-l2a.parquet/*.parquet' LIMIT 1; """) query.to_df()The call to to_df at the end converts the result into a Pandas DataFrame for easy viewing and manipulation. The results are shown below (click to enlarge):
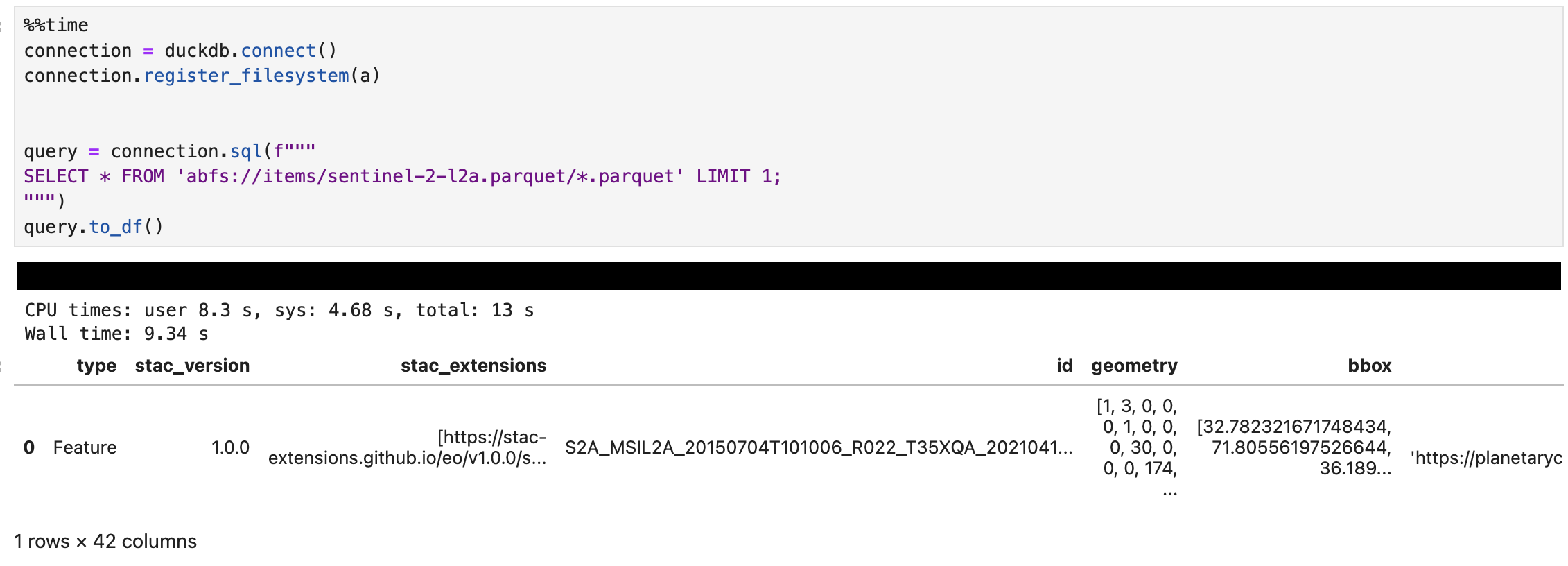{kind=link}
Note that we’re passing a URL of abfs://items/sentinel-2-l2a.parquet/*.parquet – this is the URL from the STAC catalog with /*.parquet added to the end to ensure DuckDB picks up the large number of Parquet files stored there. I’d have thought this would have worked without that, but if I miss that out I get a error saying:
TypeError: int() argument must be a string, a bytes-like object or a real number, not 'NoneType'I suspect this is something to do with how things are passed to the Azure connection that we registered with DuckDB, but I’m not entirely sure. If you do know, then please leave a comment!
A few fun queriesSo, now we’ve got this working, what can we do? Well, we can – fairly efficiently – run queries across all the STAC metadata for Sentinel 2 images. I’ll just give a few examples of queries I’ve run below.
We can find out how many images there are in the collection in total:
SELECT COUNT(*) FROM 'abfs://items/sentinel-2-l2a.parquet/*.parquet'We can do the same for just the images acquired in 2020 – by using a fact we know about how the individual parquet files are named (from the Planetary Computer docs):
SELECT COUNT(*) FROM 'abfs://items/sentinel-2-l2a.parquet/*2020*.parquet'And we can start looking at how many scenes were captured with different amounts of cloud cover:
SELECT COUNT(*) / (SELECT COUNT(*) FROM 'abfs://items/sentinel-2-l2a.parquet/*2020*.parquet'), CASE WHEN "eo:cloud_cover" between 0 and 5 then '0-5%' WHEN "eo:cloud_cover" between 5 and 10 then '5-10%' WHEN "eo:cloud_cover" between 10 and 15 then '10-15%' END AS category FROM 'abfs://items/sentinel-2-l2a.parquet/*2020*.parquet' GROUP BY category,This tells us that 20% of scenes had between 0 and 5% cloud cover (quite a high number, I thought – but then again, I am used to living in the UK!), and around 4-5% in each of the 5-10% and 10-15% categories.
There are plenty of other analyses that you could do with these Parquet files, of course. At some point I might even get around to the task which initially made me look into this: that is, trying to find Landsat and Sentinel 2 scenes that were acquired over the same location at very similar times. I think I’ll leave that for another day though…
Greg Casamento: Keysight laid me off in January!
I think it happened for several reasons:
- Economic - This is what was explained to me, but I am not sure I believe it
- Politics - I think this part is because I expressed my opinions HONESTLY about the direction of the company given that they wanted to make the application into a VSCode plugin.
- Perception - I am 54 years old... so I think that they believed that Objective-C was my one and only talent, it's not... I know many other languages and have many other skills.
Keysight is and will remain a major contributor to GNUstep.
That being said, I recently ran into something rather disturbing at another company. I have been working with a company based out of New Mexico that is interested in space applications. They have been using GNUstep and have been awaiting funding.
The lead of this effort expressed something during a meeting saying "We will work on the GNUstep side of this because there is no reason we should have to pay for any of this." This hit a sour note with me to say the very least. As it turns out he was under the mistaken impression that, because the work was on GNUstep, it was for free... which is WRONG.
I wonder if the same impression was present at Keysight or if other companies believe this. The saying, according to RMS, is "Free as in freedom, not as in beer." If you are a manager at a company who is under the mistaken impression that work on any Free Software or Open Source project is free when your product depends on it, please correct your thinking. Just because it is someone's passion project does NOT mean that they are going to do that work for free and prioritize the things that need to be done for your organization.
All of that being said the positive sides are this:
- More time to code on GNUstep without interruption
- More time to work on my own projects
- Time to rest and relax
The Drop Times: Tech Talks, Brand Strategies, and the Future of Drupal: Highlights from The DropTimes
An enterprise web solution is inherently complex. Its endless integrations with various applications that are added or loaded off as per the changing requirements, multiple front-ends that provide varied and personalised digital experiences, the cultural nuances catered to in its l10n editions, the time-zone differences that are to be taken care of, etc., etc., are the most basic parts that add to the complexity.
Continuous investment, development and deployment are part and parcel of such a solution. Even so, it becomes amiable only if the complexity is masked out in the simplicity of the consumer touch points.
Two separate sets of consumers should be considered there. One is the enterprise consumers, the content creators and marketers, who are the immediate benefactors of the solution. The second, a more prominent set, is the customers to whom the enterprises cater.
Drupal, the platform for building a digital experience, invested heavily in satisfying the end customers. That was what Drupal agencies were doing all these years. They got an exoskeleton on which they built the end-user experiences. But what about the enterprise consumers themselves? Weren’t they the ones who ultimately decided to ditch or continue using the services? How good were their experiences sans the involvement of a hired developer?
The decision to simplify the touch points of enterprise consumers is a development and design decision. These content creators and marketers will benefit the most from the Starshot Initiative. It supports the marketing team by reducing the go-to-market time and eases the content creators by providing the most valuable tools out of the box. A complex solution is now draped in a simple cassock.
The first story I’m sharing today concerns Drupal’s new brand strategy and future directions. The Starshot Initiative manifests this strategy and the direction the project is taking. An interview with Shawn Perritt, Senior Director of Brand & Creative at Acquia, shines a light on this brand refresh. Read Shawn’s conversation with Alka Elizabeth, our sub-editor.
Montreal became the hub for tech talks in the past week. We conducted one-question interviews with three featured speakers at Evolve Drupal Montreal. Kazima Abbas, our sub-editor, spoke with Josh Koenig, co-founder of Pantheon, Joe Kwan, Manager of Web Development at the University of Waterloo, and the formidable Mike Herchel, Senior Front-end Developer at Agileana. Their answers form part of the feature published here.
Kazima also conducted an exclusive interview with Baddý Sonja Breidert, CEO and Co-Founder of 1xINTERNET. The interview focused on the agency’s support for the Starshot Initiative based on its experience with ‘Try Drupal’, which implements a default Drupal deployment for enterprises. It explains why they did not wait or hesitate to offer all-out support for the new initiative.
Alka Elizabeth and Ben Peter Mathew, our community manager, had jointly covered the Starshot Session on ‘Strategic Milestones in Product Definition’ led by Dries Buytaert and Cristina Chumillas on June 7. The report can be read here.
The next two stories are our signature stories, written by our founder and lead, Anoop John, CTO of Zyxware Technologies. From the start, Anoop was vocal about ‘DrupalCollab’, an idea he had been nurturing for years. As part of the initiative, he has published a list of the largest 500+ cities in the world with a sizable population of people tagged ‘Drupal developers’ on LinkedIn. You can read the analysis here. The second story published with this list is, On Using LinkedIn to Analyze the Size of the Drupal Community, an article on the methodology for this analysis using LinkedIn, associated errors and justifications. Based on these stories, Anoop is trying to build momentum to restart local Drupal meetups in as many cities as possible. Also, read his LinkedIn article on the initiative here.
Mautic 5.1 Andromeda Edition was released last week with major updates. Read our report here. We published a quick review of the Drupal Quick Exit Module developed by Oomph Inc. Ben Peter Mathew spoke with Alyssa Varsanyi of Oomph to produce this report.
To ensure brevity, I shall list the rest of the important stories below without much ado.
That is for the week, dear readers. I wish you all a very sacred Eid Ul Adha. Let the festival of sacrifice be a time to ponder the things we are ready to give up for the better common good.
To get timely updates, follow us on LinkedIn, Twitter and Facebook. Also, join us on Drupal Slack at #thedroptimes.
Thanks and regards.
Sincerely,
Sebin A. Jacob,
Editor-in-Chief, The DropTimes
GSoC'24 Okular | Week 2-3 Recap
While working on keystroke events, I realized my improvements to the event.change property were still inconsistent for certain Unicode characters. This led me to delve into code units, code points, graphemes, and other cool Unicode concepts. I found this blog post to be very enlightening.
Here’s an update on my progress over the past two weeks:
MRs merged:- event.change : The change property of the event object now correctly handles Unicode, with adjustments to selStart and selEnd calculations. !MR998
- cursor position and undo/redo fix : Fixed cursor position calculations to account for rejected input text and resolved merging issues with undo/redo commands in text fields. !MR1011
- DocOpen Event implementation : Enabled document-level scripts to access the event object by implementing the DocOpen event. !MR1003
- Executing validation events correctly : Fixed a bug where validation scripts wouldn’t run after KeystrokeCommit scripts in Okular. !MR999
- Widget refresh functions for RadioButton, ListEdit and ComboEdit : Added refresh functions as slots for RadioButton, ListEdit, and ComboEdit widgets, aiding in reset functionality and script updates. !MR1012
- Additional document actions in Poppler : Implemented reading additional document actions (CloseDocument, SaveDocumentStart, SaveDocumentFinish, PrintDocumentStart, PrintDocumentFinish) in the qt5 and qt6 frontends for Poppler. !MR1561 (in Poppler)
- Reset form implementation in qt6 frontend for Okular : Working on the reset form functionality in Okular, currently focusing on qt6 frontend details. !MR1564 (in Poppler)
- Reset form in Okular : Using the Poppler API to reset forms within Okular. !MR1007
- Fixing order of execution of events for text form fields : Addressing the incorrect execution order of certain events (e.g., calculation scripts) and ensuring keystroke commit, validation, and format scripts are evaluated correctly when setting fields via JavaScript. !MR1002
For the coming weeks, my focus will be on implementing reset forms, enhancing keystroking and formatting scripts, and possibly starting on submit forms. Let’s see how it goes.
See you next time. Cheers!
Quansight Labs Blog: How Narwhals and scikit-lego came together to achieve dataframe-agnosticism
Report From KDEPIM Spring Sprint 2024
Like last year, the KDEPIM team convened in Toulouse to hold it’s traditional spring sprint. Unlike last year this time it was late spring, almost made it into summer. This time we’ve been hosted by Étincelle Coworking in one of their spaces. It was fairly nice. Lots of space, comfortable, well situated in the center. I definitely recommend.
The Warm-upSome of the team (namely Carl and Volker) arrived early before the official start. I’m pretty sure Carl made it early to have lunch in the infamous Cake Place™ (at last). Of course a stupid amount of cake slices was involved. And after a short stroll we got to the meeting space we would use the rest of the time.
We started preparing the work board and finished collecting ideas as Dan arrived.
Day 1Once again, we had two types of tasks: discussions and actual hacking. During that first day we mostly focused on the conversations but did some hacking on the side. Since the attendance was a bit low this year, we didn’t go for break out groups and did them all as a single group.
Said discussions covered mostly the following topics:
- Retiring some old software or now unused resources
- Trying to devise plans to remove some duplication of efforts (did you know we have several copies of the time tree parser?)
- Some minor stability issues were discussed to have a plan to solve them
- How to improve the usage of Akonadi on mobile which revolved mostly around some better partial syncing and some tight coupling with widgets at places
- Devising a strategy to have some end to end testing of the supported resources
- How to have better tag support and indexing in Akonadi (which opens the door to really cool features so stay tuned)
- And finally, we spent quite some time discussing how to improve our little PR efforts and how to recruit new contributors
Of course, like last year we’re contrained by the size of the team and so need to use smartly everyone’s time. Again no grand plans, but some of the items we plan to deliver during the year could have very nice consequences. We’ll focus on a better quality of life both for users and contributors.
Day 2We already started some of the technical tasks the previous day, but Sunday was mostly devoted to them. We had a break for a nice brunch of course but still people worked on their branches around it.
As far as technical tasks, we got the following things done already:
- Some obscure and broken feature around notes in KMail has been removed
- KJots notes can now be imported into MarkNotes giving an upgrade path
- Akonadi tag discovery in caldav resources is a thing
- The Akonadi brand should finally not appear anywhere in the applications anymore
- A way to clean up the data coming from retired resources is now in place
But there’s more in the works, namely:
- the completion of the infrastructure for QtQuick based config dialogs
- the switch to KConfigDialogManager where is makes sense (instead of using an old PIM specific legacy system)
- the rewrite of the indexing system (which should improve performance and have instant indexing of payloads)
- the migration agent to apply tag discovery also to old and already existing items
- the move of KMime to KDE Frameworks is getting prepared
- the IMAP resource configuration system is in the works to be able to jump on the QtQuick infrastructure (it’s one of the more complex ones with lots of QtWidgets dependencies)
- the KDAV test suite is being completed for better coverage
The mentioned tasks and all the ones created during the conversations have been added to our Technical Roadmap on Gitlab. The work is still on going for some of them.
What now?The most noticeable is probably one thing we acted on immediately after our discussions. We added milestones in the PIM group. Indeed, it’s probably not always easy for people wanting to join to know which are the bigger on going goals in the KDEPIM team and what to work on to help.
This is now encoded through those milestones. It’s the early days for them so they need to be improved and more tasks added, but at least this gives an idea of what has higher priority for now.
We plan to have a BoF at Akademy 2024 to be announced later when the schedule for the BoFs actually opens. There we’ll plan to focus at discussing the experience of contributors and see how it can be improved. We’ll also present our milestones. We might sign you up on tasks there, don’t hesitate to show up, we want to hear from you.
Last but not leastIf you want to know more or engage with us, please join the KDEPIM matrix channel! Let’s chat further.
Also, I’d like to thank again Étincelle Coworking and KDE e.V. to make this event possible. This wouldn’t be possible without a venue and without at least partial support in the travel expenses.
Finally, if you like such meetings to happen in the future so that we can push forward your favorite software, please consider making a tax-deductible donation to the KDE e.V. foundation.
KDE PIM Sprint 2024 edition
This year again I participated to the KDE PIM Sprint in Toulouse. As always it was really great to meet other KDE contributors and to work together for one weekend. And as you might have seen on my Mastodon account, a lot of food was also involved.
Day 1 (Friday Afternoon)We started our sprint on Thursday with a lunch at the legendary cake place, which I missed last year due to my late arrival.
Picture of some delicious cakes: a piece of cheesecake raspberry and basil, a piece of lemon tart with meringue and a piece of carrot cake)
We then went to the coworking space where we would spend the remaining of this sprint and started working on defining tasks to work on and putting them on real kanban board.
A kanban board with tasks to discuss and to implement
To get a good summary of the specific topics we discussed, I invite you to consult the blog of Kevin.
That day, aside from the high level discussion, I proceeded to port away the IMAP authentification mechanism for Outlook accounts away from the KWallet API to use the more generic QtKeychain API. I also removed a large dependency from libkleo (the KDE library to interact with GPG).
Day 2 (Saturday)On the second day, we were greated by a wonderful breakfast (thanks Kevin).
Picture of croissant, brioche and chocolatine
I worked on moving EventViews (the library that renders the calendar in KOrganizer) and IncidenceEditor (the library that provides the event/todo editor in KOrganizer) to KOrganizer. This will allow to reduce the number of libraries in PIM.
- Remove KOrganizer plugins from kdepim-addons and move them instead to KOrganizer
- Do not use a complex plugin system for handling calendar invitation and instead provide the incidence editor as a binary and call it instead. (MR 1, MR 2 and MR 3)
For lunch, we ended up eating at the excellent Mexican restaurant next to the location of the previous sprint.
I also worked on removing the “Add note” functionality in KMail. This feature allow to store notes to emails following RFC5257. Unfortunatelty this RFC never left the EXPERIMENTAL state and so these notes were only stored in Akonadi and not synchronized with any services.
This allow to remove the relevant widget from the pimcommon library and the Akonadi attribute.
I also started removing another type of notes: the KNotes app which provided sticky notes. This application was not maintained anymore, didn’t work so well with Wayland. If you were using KNotes, to make sure you don’t loose your notes, I added support in Marknote to import notes from KNotes.
Marknote with the context menu to import notes
Finally I worked on removing visible Akonadi branding from some KDE PIM applications. The branding was usually only visible when an issue occurred, which didn’t help with Akonadi reputation.
We ended up working quite late and ordering Pizzas. I personally got one with a lot of cheese (but no photo this time).
Day 3 (Sunday)The final day, we didn’t had any breakfast :( but instead a wonderful brunch.
Aside from eating, I started writing a plugin system for the MimeTreeParser which powers the email viewer in Merkuro and in Kleopatra. In the short term, I want to be able to add Itinerary integration in Merkuro but in the longer term the goal is to bring this email viewer to feature parity with the email viewer from KMail and then replace the KMail email viewer with the one from Merkuro. Aside from removing duplicate code, this will improve the security since the individual email parts are isolated from each other and this will makes it easier for the email view to follow KDE styling as this is just normal QML instead of fake HTML components.
I also merged and rebased some WIP merge requests in Marknote in preparation of a new release soon and reviewed merge requests from the others.
Last but not leastIf you want to know more or engage with us, please join the KDE PIM and the Merkuro matrix channels! Let’s chat further.
Also, I’d like to thank again Étincelle Coworking and KDE e.V. to make this event possible. This wouldn’t be possible without a venue and without at least partial support in the travel expenses.
Finally, if you like such meetings to happen in the future so that we can push forward your favorite software, please consider making a tax-deductible donation to the KDE e.V. foundation.
Ned Batchelder: Math factoid of the day: 62
There are two Archimedean solids with 62 faces:
rhombicosidodecahedron truncated icosidodecahedronThey both have 62 faces because of their roots in the dodecahedron and icosahedron. They have a face for each of the faces, vertices, and edges of either of those polyhedra: 12 + 20 + 30 = 62.
The rhombicosidodecahedron shows up in more places than you might expect for a complex polyhedron. The Zometool building kit uses it for hubs, though the squares are adjusted to rectangles:
Recently one also showed up on Kickstarter: Glint, a rhombicosidodecahedron machined in solid brass. I have one. It’s satisfyingly heavy and precise. Here it is with its little Zome sister:
The rhombicosidodecahedron is very pleasing: nearly round, but with simple polygonal faces roughly equal in size. Who’d have thought a number as seemingly uninteresting as 62 could appear in such serendipitous places?
Zato Blog: Using OAuth in API Integrations
OAuth is often employed in processes requiring permissions to be granted to frontend applications and end users. Yet, what we typically need in API systems integrations is a way to secure connections between the integration middleware and backend systems without a need for any ongoing human interactions.
OAuth can be a good choice for that scenario and this article shows how it can be achieved in Python, with backend systems using REST and HL7 FHIR.
What we would like to haveLet's say we have a typical integration scenario as in the diagram below:
-
External systems and applications invoke the interoperability layer (Zato) which is expected to further invoke a few backend systems, e.g. a REST and HL7 FHIR one so as to return a combined result of backend API invocations. It does not matter what technology the client systems use, i.e. whether they are REST ones or not.
-
The interoperability layer needs to identify itself with the backend systems before it is allowed to invoke them - they need to make sure that it really is Zato and that it accesses only the resources allowed.
-
An OAuth server issues time-based access tokens, which are simple strings, like web browser session cookies, confirming that such and such bearer of the said token is allowed to make such and such requests. Note that the tokens have an explicit expiration time, e.g. they will become invalid after one hour. Also observe that Zato stores the tokens as-is, they are genuinely opaque strings.
-
If a client system invokes the interoperability layer, the layer will obtain a token from the OAuth server and keep it in an internal cache. Next, Zato will invoke the backend systems, bearing the token among other HTTP headers. Each invoked backend system will extract the token from the incoming request and validate it.
How the validation looks like in practices is something that Zato will not be aware of because it treats the token as an opaque string but, in practice, if the token is self-contained (e.g. JWT data) the system may validate it on its own, and if it is not self-contained, the system may invoke an introspection endpoint on the OAuth server to validate the access token from Zato.
Once the validation succeeds, the backend system will reply with the business data and the interoperability layer will combine the results for the calling application's benefit.
In subsequent requests, the same access token will be reused by Zato with the same flow of messages as previously. However, if the cached token expires, Zato will request a new one from the OAuth server - this will be transparent to the calling application - and the flow will resume.
In OAuth terminology, what is described above has specific names, the overall flow of messages between Zato and the OAuth server is called a "Client Credential Flow" and Zato is then considered a "client" from the OAuth server's perspective.
Configuring OAuthFirst, we need to create an OAuth security definition that contains the OAuth server's connection details. In this case, the server is Okta. Note the scopes field - it is a list of permissions ("scopes") that Zato will be able to make use of.
What exactly the list of scopes should look like is something to be coordinated with the people who are responsible for the configuration of the OAuth server. If it is you personally, simply ensure that what is in the the OAuth server and in Zato is in sync.
Calling REST
To invoke REST services, fill out a form as below, pointing the "Security" field to the newly created OAuth definition. This suffices for Zato to understand when and how to obtain new tokens from the underlying OAuth server.
Here is sample code to invoke a backend REST system - note that we merely refer to a connection by its name, without having to think about security at all. It is Zato that knows how to get and use OAuth tokens as required.
# -*- coding: utf-8 -*- # Zato from zato.server.service import Service class GetClientBillingPlan(Service): """ Returns a billing plan for the input client. """ def handle(self): # In a real service, this would be read from input payload = {'client_id': 123} # Get a connection to the server .. conn = self.out.rest['REST Server'].conn # .. invoke it .. response = conn.get(self.cid, payload) # .. and handle the response here. ... Calling HL7 FHIRSimilarly to REST endpoints, to invoke HL7 FHIR servers, fill out a form as below and let the "Security" field point to the OAuth definition just created. This will suffice for Zato to know when and how to use tokens received from the underlying OAuth server.
Here is sample code to invoke a FHIR server system - as with REST servers above, observe that we only refer to a connection by its name and Zato takes care of OAuth.
# -*- coding: utf-8 -*- # Zato from zato.server.service import Service class GetPractitioner(Service): """ Returns a practictioner matching input data. """ def handle(self) -> 'None': # Connection to use conn_name = 'My EHR' # In a real service, this would be read from input practitioner_id = 456 # Get a connection to the server .. with self.out.hl7.fhir[conn_name].conn.client() as client: # Get a reference to a FHIR resource .. practitioners = client.resources('Practitioner') # .. look up the practitioner .. result = practitioners.search(active=True, _id=practitioner_id).get() # .. and handle the response here. ... What about the API clients?One aspect omitted above are the initial API clients - this is on purpose. How they invoke Zato, using what protocols, with what security mechanisms, and how to build responses based on their input data, this is completely independent of how Zato uses OAuth in its own communication with backend systems.
All of these aspects can and will be independent in practice, e.g. clients will use Basic Auth rather than OAuth. Or perhaps the clients will use AMQP, Odoo, SAP, or IBM MQ, without any HTTP, or maybe there will be no explicit API invocations and what we call "clients" will be actually CSV files in a shared directory that your services will be scheduled to periodically pick up. Yet, once more, regardless of what makes the input data available, the backend OAuth mechanism will work independently of it all. ```
➤ API programming screenshots
➤ Python API integration tutorial
➤ More API programming examples in Python
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
- SVG cursors: everything that you need to know about them
- Julien Tayon: Simpler than PySimpleGUI and python tkinter: talking directly to tcl/tk
- ImageX: Integrate Zoom Meetings Seamlessly into Your Drupal Website via Our Developer’s Module
- Julien Tayon: PySimpleGUI : surviving the rug pull of licence part I
- This week in Plasma: 6.2 is nigh