
FLOSS Project Planets
Scarlett Gately Moore: KDE: Snaps 24.12.1 Release, Kubuntu Plasma 5.27.12 Call for testers
I have released more core24 snaps to –edge for your testing pleasure. If you find any bugs please report them at bugs.kde.org and assign them to me. Thanks!
Kdenlive our amazing video editor!
- Moved to core24.
- Fixed icon missing bug https://bugs.kde.org/show_bug.cgi?id=495797
Haruna is a video player that also supports youtube!
Kdevelop is our feature rich development IDE
KDE applications 24.12.1 release https://kde.org/announcements/gear/24.12.1/
New qt6 ports
- lokalize
- isoimagewriter
- parley
- kteatime
- ghostwriter
- ktorrent
- kanagram
- marble
Kubuntu:
We have Plasma 5.27.12 Bugfix release in staging https://launchpad.net/~kubuntu-ppa/+archive/ubuntu/staging-plasma for noble updates, please test! Do NOT do this on a production system. Thanks!
I hate asking but I am unemployable with this broken arm fiasco and 6 hours a day hospital runs for treatment. If you could spare anything it would be appreciated! https://gofund.me/573cc38e
Reproducible Builds: Reproducible Builds in December 2024
Welcome to the December 2024 report from the Reproducible Builds project!
Our monthly reports outline what we’ve been up to over the past month and highlight items of news from elsewhere in the world of software supply-chain security when relevant. As ever, however, if you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website.
Table of contents:
- reproduce.debian.net
- debian-repro-status
- On our mailing list
- “Enhancing the Security of Software Supply Chains”
- diffoscope
- Supply-chain attack in the Solana ecosystem
- Website updates
- Debian changes
- Other development news
- Upstream patches
- Reproducibility testing framework
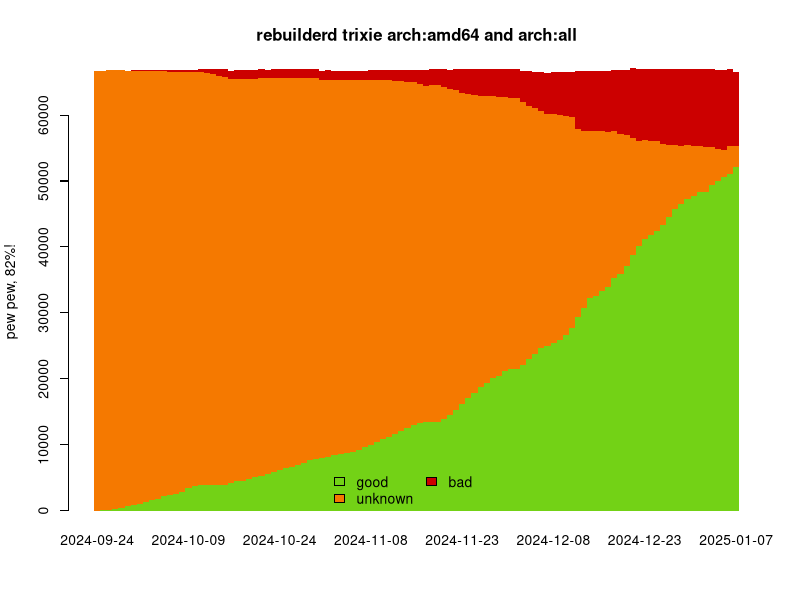
Last month saw the introduction of reproduce.debian.net. Announced at the recent Debian MiniDebConf in Toulouse, reproduce.debian.net is an instance of rebuilderd operated by the Reproducible Builds project. rebuilderd is our server designed monitor the official package repositories of Linux distributions and attempts to reproduce the observed results there.
This month, however, we are pleased to announce that not only does the service now produce graphs, the reproduce.debian.net homepage itself has become a “start page” of sorts, and the amd64.reproduce.debian.net and i386.reproduce.debian.net pages have emerged. The first of these rebuilds the amd64 architecture, naturally, but it also is building Debian packages that are marked with the ‘no architecture’ label, all. The second builder is, however, only rebuilding the i386 architecture.
{kind=link}
Both of these services were also switched to reproduce the Debian trixie distribution instead of unstable, which started with 43% of the archive rebuild with 79.3% reproduced successfully. This is very much a work in progress, and we’ll start reproducing Debian unstable soon.
Our i386 hosts are very kindly sponsored by Infomaniak whilst the amd64 node is sponsored by OSUOSL — thank you! Indeed, we are looking for more workers for more Debian architectures; please contact us if you are able to help.
Reproducible builds developer kpcyrd has published a client program for reproduce.debian.net (see above) that queries the status of the locally installed packages and rates the system with a percentage score. This tool works analogously to arch-repro-status for the Arch Linux Reproducible Builds setup.
The tool was packaged for Debian and is currently available in Debian trixie: it can be installed with apt install debian-repro-status.
On our mailing list this month:
-
Bernhard M. Wiedemann wrote a detailed post on his “long journey towards a bit-reproducible Emacs package.” In his interesting message, Bernhard goes into depth about the tools that they used and the lower-level technical details of, for instance, compatibility with the version for glibc within openSUSE.
-
Shivanand Kunijadar posed a question pertaining to the reproducibility issues with encrypted images. Shivanand explains that they must “use a random IV for encryption with AES CBC. The resulting artifact is not reproducible due to the random IV used.” The message resulted in a handful of replies, hopefully helpful!
-
User Danilo posted an in interesting question related to their attempts in trying to achieve reproducible builds for Threema Desktop 2.0. The question resulted in a number of replies attempting to find the right combination of compiler and linker flags (for example).
-
Longstanding contributor David A. Wheeler wrote to our list announcing the release of the “Census III of Free and Open Source Software: Application Libraries” report written by Frank Nagle, Kate Powell, Richie Zitomer and David himself. As David writes in his message, the report attempts to “answer the question ‘what is the most popular Free and Open Source Software (FOSS)?’”.
-
Lastly, kpcyrd followed-up to a post from September 2024 which mentioned their desire for “someone” to implement “a hashset of allowed module hashes that is generated during the kernel build and then embedded in the kernel image”, thus enabling a deterministic and reproducible build. However, they are now reporting that “somebody implemented the hash-based allow list feature and submitted it to the Linux kernel mailing list”. Like kpcyrd, we hope it gets merged.
Mehdi Keshani of the Delft University of Technology in the Netherlands has published their thesis on “Enhancing the Security of Software Supply Chains: Methods and Practices”. Their introductory summary first begins with an outline of software supply chains and the importance of the Maven ecosystem before outlining the issues that it faces “that threaten its security and effectiveness”. To address these:
First, we propose an automated approach for library reproducibility to enhance library security during the deployment phase. We then develop a scalable call graph generation technique to support various use cases, such as method-level vulnerability analysis and change impact analysis, which help mitigate security challenges within the ecosystem. Utilizing the generated call graphs, we explore the impact of libraries on their users. Finally, through empirical research and mining techniques, we investigate the current state of the Maven ecosystem, identify harmful practices, and propose recommendations to address them.
A PDF of Mehdi’s entire thesis is available to download.
diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made the following changes, including preparing and uploading versions 283 and 284 to Debian:
- Update copyright years. […]
- Update tests to support file 5.46. […][…]
- Simplify tests_quines.py::test_{differences,differences_deb} to simply use assert_diff and not mangle the test fixture. […]
A significant supply-chain attack impacted Solana, an ecosystem for decentralised applications running on a blockchain.
Hackers targeted the @solana/web3.js JavaScript library and embedded malicious code that extracted private keys and drained funds from cryptocurrency wallets. According to some reports, about $160,000 worth of assets were stolen, not including SOL tokens and other crypto assets.
Similar to last month, there was a large number of changes made to our website this month, including:
-
Chris Lamb:
-
Holger Levsen:
- Fixed a number of issues on the 2024 Summit page, including fixing the path to a sponsor logo […] but also added the event documentation from Aspiration […].
- Check and cleanup a presentation formerly linked from the “About” page on the Debian wiki. […]
- Link to reproduce.debian.net on the Involved Projects page. […]
- Fix a number of links on the Talks & Resources page. […][…][…][…]
-
hulkoba:
- Remove the sidebar-type layout and move to a static navigation element. […][…][…][…]
- Create and merge a new Success stories page, which “highlights the success stories of Reproducible Builds, showcasing real-world examples of projects shipping with verifiable, reproducible builds. These stories aim to enhance the technical resilience of the initiative by encouraging community involvement and inspiring new contributions.”. […]
- Further changes to the homepage. […]
- Remove the translation icon from the navigation bar. […]
- Remove unused CSS styles pertaining to the sidebar. […]
- Add sponsors to the global footer. […]
- Add extra space on large screens on the Who page. […]
- Hide the side navigation on small screens on the Documentation pages. […]
There were a significant number of reproducibility-related changes within Debian this month, including:
-
Santiago Vila uploaded version 0.11+nmu4 of the dh-buildinfo package. In this release, the dh_buildinfo becomes a no-op — ie. it no longer does anything beyond warning the developer that the dh-buildinfo package is now obsolete. In his upload, Santiago wrote that “We still want packages to drop their [dependency] on dh-buildinfo, but now they will immediately benefit from this change after a simple rebuild.”
-
Holger Levsen filed Debian bug #1091550 requesting a rebuild of a number of packages that were built with a “very old version” of dpkg.
-
Fay Stegerman contributed to an extensive thread on the debian-devel development mailing list on the topic of “Supporting alternative zlib implementations”. In particular, Fay wrote about her results experimenting whether zlib-ng produces identical results or not.
-
kpcyrd uploaded a new rust-rebuilderd-worker, rust-derp, rust-in-toto and debian-repro-status to Debian, which passed successfully through the so-called NEW queue.
-
Gioele Barabucci filed a number of bugs against the debrebuild component/script of the devscripts package, including:
-
Gioele Barabucci also filed a bug against the dh-r package to report that the Recommends and Suggests fields are missing from rebuilt R packages. At the time of writing, this bug has no patch and needs some help to make over 350 binary packages reproducible.
-
Lastly, 8 reviews of Debian packages were added, 11 were updated and 11 were removed this month adding to our knowledge about identified issues.
In other ecosystem and distribution news:
-
Jan-Benedict Glaw published the 6th NetBSD Reproducibility Report and reported on our mailing list as well.
-
Developer unmush wrote a long post on the GNU Guix blog on the topic of “Adding a fully-bootstrapped Mono” to the distribution.
-
The Glasgow Haskell Compiler (GHC) has released a new version of their compiler. This release introduces a new experimental flag, -fobject-determinism, which enables “deterministic object code generation”.
-
The IzzyOnDroid Android APK repository published an extensive “Review of 2024 and Outlook for 2025” which includes statistics and future plans related to reproducible builds (including having passed the 30% mark this month).
-
The historic Arch Linux reproducibility tests that were hosted at tests.reproducible-builds.org/archlinux now redirect to reproducible.archlinux.org instead. In fact, everything Arch-related has now been removed from the jenkins.debian.net.git repository, as those continuous integration tests have been disabled for some time.
-
reprotest version 0.7.29 was uploaded to Debian unstable by Vagrant Cascadian. It included contributions already covered in previous months as well as new ones from Rebecca N. Palmer, such as:
-
rebuilderd was updated as follows by kpcyrd:
- Lastly, in openSUSE, Bernhard M. Wiedemann published another report for the distribution. There, Bernhard reports about the success of building ‘R-B-OS’, a partial fork of openSUSE with only 100% bit-reproducible packages. This effort was sponsored by the NLNet NGI0 initiative.
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Bernhard M. Wiedemann: cargo-packaging/rusty_v8, cockpit, collectd, deepin-daemon, deepin-file-manager, esbuild, grpc, hyperkitty, icedtea-web, java-atk-wrapper, kdenetwork-filesharing, kicad, kompare, librespeed-cli, lincity-ng, mraa, ollama, opa-fmgui, opencryptoki, opencryptoki, openmpi4:gnu-hpc, openwsman, patterns-microos, portmidi, presage, procps, sad, scons/nst, sendmail, static-initrd, suse-hpc, swtpm, tiny, vtk, xdg-desktop-portal and yast.
-
Chris Lamb:
- #1089011 filed against pyorbital.
- #1089095 filed against python-pbcore.
-
Gioele Barabucci:
-
James Addison:
-
Johannes Schauer Marin Rodrigues:
-
Moritz Schlarb:
-
Roland Clobus:
- #1090981 filed against dictionaries-common.
The Reproducible Builds project operates a comprehensive testing framework running primarily at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility. In November, a number of changes were made by Holger Levsen, including:
-
reproduce.debian.net-related:
- Add a new i386.reproduce.debian.net rebuilder. […][…][…][…][…][…]
- Make a number of updates to the documentation. […][…][…][…][…]
- Run i386.reproduce.debian.net run on a public port to allow external workers. […]
- Add a link to the /api/v0/pkgs/list endpoint. […]
- Add support for a statistics page. […][…][…][…][…][…]
- Limit build logs to 20 MiB and diffoscope output to 10 MiB. […]
- Improve the frontpage. […][…]
- Explain that we’re testing arch:any and arch:all on the amd64 architecture, but only arch:any on i386. […]
-
Misc:
- Remove code for testing Arch Linux, which has moved to reproduce.archlinux.org. […][…]
- Don’t install dstat on Jenkins nodes anymore as its been removed from Debian trixie. […]
- Prepare the infom08-i386 node to become another rebuilder. […]
- Add debug date output for benchmarking the reproducible_pool_buildinfos.sh script. […]
- Install installation-birthday everywhere. […]
- Temporarily disable automatic updates of pool links on buildinfos.debian.net. […]
- Install Recommends by default on Jenkins nodes. […]
- Rename rebuilder_stats.py to rebuilderd_stats.py. […]
- r.d.n/stats: minor formatting changes. […]
- Install files under /etc/cron.d/ with the correct permissions. […]
… and Jochen Sprickerhof made the following changes:
- Always prefer official .buildinfo on buildinfos.debian.net files. […][…][…]
- Add a rebuilder_stats.py scripts. […]
Lastly, Gioele Barabucci also classified packages affected by 1-second offset issue filed as Debian bug #1089088 […][…][…][…], Chris Hofstaedtler updated the URL for Grml’s dpkg.selections file […], Roland Clobus updated the Jenkins log parser to parse warnings from diffoscope […] and Mattia Rizzolo banned a number of bots and crawlers from the service […][…].
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC: #reproducible-builds on irc.oftc.net.
-
Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list: rb-general@lists.reproducible-builds.org
-
Twitter: @ReproBuilds
eGenix.com: Python Meeting Düsseldorf - 2025-01-22
The following text is in German, since we're announcing a regional user group meeting in Düsseldorf, Germany.
Das nächste Python Meeting Düsseldorf findet an folgendem Termin statt:
22.01.2025, 18:00 Uhr
Raum 1, 2.OG im Bürgerhaus Stadtteilzentrum Bilk
Düsseldorfer Arcaden, Bachstr. 145, 40217 Düsseldorf
- Daniel Schmitz:
Maintaining SciPy: Large scale Open Source in practice - Arkadius Schuchhardt:
Erfahrungen mit Reflex - Marc-André Lemburg:
Programming hardware displays the easy way - using MicroPython and LVGL - Jochen Wersdörfer:
Skip the Overhead: Lean Web Development with Django - Klaus Bremer:
Server Side Events (SSE) with htmx and async frameworks
Wir treffen uns um 18:00 Uhr im Bürgerhaus in den Düsseldorfer Arcaden.
Das Bürgerhaus teilt sich den Eingang mit dem Schwimmbad und befindet
sich an der Seite der Tiefgarageneinfahrt der Düsseldorfer Arcaden.
Über dem Eingang steht ein großes "Schwimm’ in Bilk" Logo. Hinter der Tür
direkt links zu den zwei Aufzügen, dann in den 2. Stock hochfahren. Der
Eingang zum Raum 1 liegt direkt links, wenn man aus dem Aufzug kommt.
>>> Eingang in Google Street View
Das Python Meeting Düsseldorf ist eine regelmäßige Veranstaltung in Düsseldorf, die sich an Python Begeisterte aus der Region wendet.
Einen guten Überblick über die Vorträge bietet unser PyDDF YouTube-Kanal, auf dem wir Videos der Vorträge nach den Meetings veröffentlichen.Veranstaltet wird das Meeting von der eGenix.com GmbH, Langenfeld, in Zusammenarbeit mit Clark Consulting & Research, Düsseldorf:
Das Python Meeting Düsseldorf nutzt eine Mischung aus (Lightning) Talks und offener Diskussion.
Vorträge können vorher angemeldet werden, oder auch spontan während des Treffens eingebracht werden. Ein Beamer mit HDMI und FullHD Auflösung steht zur Verfügung.(Lightning) Talk Anmeldung bitte formlos per EMail an info@pyddf.de
KostenbeteiligungDas Python Meeting Düsseldorf wird von Python Nutzern für Python Nutzer veranstaltet.
Da Tagungsraum, Beamer, Internet und Getränke Kosten produzieren, bitten wir die Teilnehmer um einen Beitrag in Höhe von EUR 10,00 inkl. 19% Mwst. Schüler und Studenten zahlen EUR 5,00 inkl. 19% Mwst.
Wir möchten alle Teilnehmer bitten, den Betrag in bar mitzubringen.
AnmeldungDa wir nur 25 Personen in dem angemieteten Raum empfangen können, möchten wir bitten, sich vorher anzumelden.
Meeting Anmeldung bitte per Meetup
Weitere Informationen finden Sie auf der Webseite des Meetings:
https://pyddf.de/
Viel Spaß !
Marc-Andre Lemburg, eGenix.com
The Drop Times: Accessibility Always a Focus in Drupal!
Django Weblog: DSF member of the month - Hiroki Kiyohara
This month marks the start of a new year, and the Django Software Foundation would like to wish you all a very happy new year. New year, new resolutions, but also the start of a new blog post series, with DSF members presented each month through an interview. A great way to learn more about the people behind Django, recognized for their contribution to the DSF mission.
For January 2025, we welcome Hiroki Kiyohara (@hirokiky) as our DSF member of the month! ⭐
Hiroki is the creator and a staff member of DjangoCongress JP. The CFP is still open!
He has done a lot for the Django Japan community which exist for many years and he has been a DSF member since October 2024.
You can learn more about Hiroki by checking out his website or visiting Hiroki’s GitHub Profile.
Let’s spend some time getting to know Hiroki better!
Can you tell us a little about yourself (hobbies, education, etc)My name is Hiroki Kiyohara and I am the CEO of an AI Startup named ZenProducts. I like techno music, cars, drinking and VRChat!
How did you start using Django?I started learning Python around 2010 after reading an essay "How to become a Hacker", which had a big impact on my life. I created a web service using Django, which has been a great project since then.
What other framework do you know and if there is anything you would like to have in Django if you had magical powers?One thing I wanted to include in Django was an asynchronous worker, but it was already discussed as a future plan!
What projects are you working on now?We are developing Shodo (https://shodo.ink/), an AI proofreading service for Japanese texts. The AI we developed in-house (by using transformers lib) and the server are all in Python. Of course we use Django with Async!
Which Django libraries are your favorite (core or 3rd party)?We often use django-storages, DjangoRestFramework and pytest-django
What are the top three things in Django that you like?Admin, Migration and ORM, and the last thing is the community (i.e. you!)
What made you decide to create DjangoCongress JP? Do you have any advice for someone who would like to create a local Django conference?There was PyCon JP, but as Python became more widely used in different areas, there were fewer Django and web talks. So we created a Django-only event so that we could cover in-depth stuff.
I think if there is 1 person to join, you can start your event. Not just a big conference, we can create a community.
Do you have a quote or proverb in Japanese that you personally love?I love 色即是空. It means that form is emptiness. So everything is not an absolute object or form and everything can be changed and something like flow. I also love "The times they are a changin’" by Bob Dylan. Both of them gave us a great perspective on the world.
Is there anything else you’d like to say?I'm very glad to be here, thank you!
Thank you for doing the interview, Hiroki!
Freexian Collaborators: Debian Contributions: Tracker.debian.org updates, Salsa CI improvements, Coinstallable build-essential, Python 3.13 transition, Ruby 3.3 transition and more! (by Anupa Ann Joseph, Stefano Rivera)
Contributing to Debian is part of Freexian’s mission. This article covers the latest achievements of Freexian and their collaborators. All of this is made possible by organizations subscribing to our Long Term Support contracts and consulting services.
Tracker.debian.org updates, by Raphaël HertzogProfiting from end-of-year vacations, Raphaël prepared for tracker.debian.org to be upgraded to Debian 12 bookworm by getting rid of the remnants of python3-django-jsonfield in the code (it was superseded by a Django-native field). Thanks to Philipp Kern from the Debian System Administrators team, the upgrade happened on December 23rd.
Raphaël also improved distro-tracker to better deal with invalid Maintainer fields which recently caused multiples issues in the regular data updates (#1089985, MR 105). While working on this, he filed #1089648 asking dpkg tools to error out early when maintainers make such mistakes.
Finally he provided feedback to multiple issues and merge requests (MR 106, issues #21, #76, #77), there seems to be a surge of interest in distro-tracker lately. It would be nice if those new contributors could stick around and help out with the significant backlog of issues (in the Debian BTS, in Salsa).
Salsa CI improvements, by Santiago Ruano RincónGiven that the Debian buildd network now relies on sbuild using the unshare backend, and that Salsa CI’s reproducibility testing needs to be reworked (#399), Santiago resumed the work for moving the build job to use sbuild. There was some related work a few months ago that was focused on sbuild with the schroot and the sudo backends, but those attempts were stalled for different reasons, including discussions around the convenience of the move (#296). However, using sbuild and unshare avoids all of the drawbacks that have been identified so far. Santiago is preparing two merge requests: !568 to introduce a new build image, and !569 that moves all the extract-source related tasks to the build job. As mentioned in the previous reports, this change will make it possible for more projects to use the pipeline to build the packages (See #195). Additional advantages of this change include a more optimal way to test if a package builds twice in a row: instead of actually building it twice, the Salsa CI pipeline will configure sbuild to check if the clean target of debian/rules correctly restores the source tree, saving some CPU cycles by avoiding one build. Also, the images related to Ubuntu won’t be needed anymore, since the build job will create chroots for different distributions and vendors from a single common build image. This will save space in the container registry. More changes are to come, especially those related to handling projects that customize the pipeline and make use of the extract-source job.
Coinstallable build-essential, by Helmut GrohneBuilding on the gcc-for-host work of last December, a notable patch turning build-essential Multi-Arch: same became feasible. Whilst the change is small, its implications and foundations are not. We still install crossbuild-essential-$ARCH for cross building and due to a britney2 limitation, we cannot have it depend on the host’s C library. As a result, there are workarounds in place for sbuild and pbuilder. In turning build-essential Multi-Arch: same, we may actually express these dependencies directly as we install build-essential:$ARCH instead. The crossbuild-essential-$ARCH packages will continue to be available as transitional dummy packages.
Python 3.13 transition, by Colin Watson and Stefano RiveraBuilding on last month’s work, Colin, Stefano, and other members of the Debian Python team fixed 3.13 compatibility bugs in many more packages, allowing 3.13 to now be a supported but non-default version in testing. The next stage will be to switch to it as the default version, which will start soon. Stefano did some test-rebuilds of packages that only build for the default Python 3 version, to find issues that will block the transition. The default version transition typically shakes out some more issues in applications that (unlike libraries) only test with the default Python version.
Colin also fixed Sphinx 8.0 compatibility issues in many packages, which otherwise threatened to get in the way of this transition.
Ruby 3.3 transition, by Lucas KanashiroThe Debian Ruby team decided to ship Ruby 3.3 in the next Debian release, and Lucas took the lead of the interpreter transition with the assistance of the rest of the team. In order to understand the impact of the new interpreter in the ruby ecosystem, ruby-defaults was uploaded to experimental adding ruby3.3 as an alternative interpreter, and a mass rebuild of reverse dependencies was done here. Initially, a couple of hundred packages were failing to build, after many rounds of rebuilds, adjustments, and many uploads we are down to 30 package build failures, of those, 21 packages were asked to be removed from testing and for the other 9, bugs were filled. All the information to track this transition can be found here. Now, we are waiting for PHP 8.4 to finish to avoid any collision. Once it is done the Ruby 3.3 transition will start in unstable.
Miscellaneous contributions- Enrico Zini redesigned the way nm.debian.org stores historical audit logs and personal data backups.
- Carles Pina submitted a new package (python-firebase-messaging) and prepared updates for python3-ring-doorbell.
- Carles Pina developed further po-debconf-manager: better state transition, fixed bugs, automated assigning translators and reviewers on edit, updating po header files automatically, fixed bugs, etc.
- Carles Pina reviewed, submitted and followed up the debconf templates translation (more than 20 packages) and translated some packages (about 5).
- Santiago continued to work on DebConf 25 organization related tasks, including handling the logo survey and results. Stefano spent time on DebConf 25 too.
- Santiago continued the exploratory work about linux livepatching with Emmanuel Arias. Santiago and Emmanuel found a challenge since kpatch won’t fully support linux in trixie and newer, so they are exploring alternatives such as klp-build.
- Helmut maintained the /usr-move transition filing bugs in e.g. bubblewrap, e2fsprogs, libvpd-2.2-3, and pam-tmpdir and corresponding on related issues such as kexec-tools and live-build. The removal of the usrmerge package unfortunately broke debootstrap and was quickly reverted. Continued fallout is expected and will continue until trixie is released.
- Helmut sent patches for 10 cross build failures and worked with Sandro Knauß on stuck Qt/KDE patches related to cross building.
- Helmut continued to maintain rebootstrap removing the need to build gnu-efi in the process.
- Helmut collaborated with Emanuele Rocca and Jochen Sprickerhof on an interesting adventure in diagnosing why gcc would FTBFS in recent sbuild.
- Helmut proposed supporting build concurrency limits in coreutils’s nproc. As it turns out nproc is not a good place for this functionality.
- Colin worked with Sandro Tosi and Andrej Shadura to finish resolving the multipart vs. python-multipart name conflict, as mentioned last month.
- Colin upgraded 48 Python packages to new upstream versions, fixing four CVEs and a number of compatibility bugs with recent Python versions.
- Colin issued an openssh bookworm update with a number of fixes that had accumulated over the last year, especially fixing GSS-API key exchange which had been quite broken in bookworm.
- Stefano fixed a minor bug in debian-reimbursements that was disallowing combination PDFs containing JAL tickets, encoded in UTF-16.
- Stefano uploaded a stable update to PyPy3 in bookworm, catching up with security issues resolved in cPython.
- Stefano fixed a regression in the eventlet from his Python 3.13 porting patch.
- Stefano continued discussing a forwarded patch (renaming the sysconfigdata module) with cPython upstream, ending in a decision to drop the patch from Debian. This will need some continued work.
- Anupa participated in the Debian Publicity team meeting in December, which discussed the team activities done in 2024 and projects for 2025.
Valhalla's Things: Poor Man Media Server
Tags: madeof:bits
Some time ago I installed minidlna on our media server: it was pretty easy to do, but quite limited in its support for the formats I use most, so I ended up using other solutions such as mounting the directory with sshfs.
Now, doing that from a phone, even a pinephone running debian, may not be as convenient as doing it from the laptop where I already have my ssh key :D and I needed to listed to music from the pinephone.
So, in anger, I decided to configure a web server to serve the files.
I installed lighttpd because I already had a role for this kind of configuration in my ansible directory, and configured it to serve the relevant directory in /etc/lighttpd/conf-available/20-music.conf:
$HTTP["host"] =~ "music.example.org" { server.name = "music.example.org" server.document-root = "/path/to/music" }the domain was already configured in my local dns (since everything is only available to the local network), and I enabled both 20-music.conf and 10-dir-listing.conf.
And. That’s it. It works. I can play my CD rips on a single flac exactly in the same way as I was used to (by ssh-ing to the media server and using alsaplayer).
Then this evening I was talking to normal people1, and they mentioned that they wouldn’t mind being able to skip tracks and fancy things like those :D and I’ve found one possible improvement.
For the directories with the generated single-track ogg files I’ve added some playlists with the command ls *.ogg > playlist.m3u, then in the directory above I’ve run ls */*.m3u > playlist.m3u and that also works.
With vlc I can now open http://music.example.org/band/album/playlist.m3u to listen to an album that I have in ogg, being able to move between tracks, or I can open http://music.example.org/band/playlist.m3u and in the playlist view I can browse between the different albums.
Left as an exercise to the reader2 are writing a bash script to generate all of the playlist.m3u files (and running it via some git hook when the files change) or writing a php script to generate them on the fly.
Update 2025-01-10: another reader3 wrote the php script and has authorized me to post it here.
<?php define("MUSIC_FOLDER", __DIR__); define("ID3v2", false); function dd() { echo "<pre>"; call_user_func_array("var_dump", func_get_args()); die(); } function getinfo($file) { $cmd = 'id3info "' . MUSIC_FOLDER . "/" . $file . '"'; exec($cmd, $output); $res = []; foreach($output as $line) { if (str_starts_with($line, "=== ")) { $key = explode(" ", $line)[1]; $val = end(explode(": ", $line, 2)); $res[$key] = $val; } } if (isset($res['TPE1']) || isset($res['TIT2'])) echo "#EXTINF: , " . ($res['TPE1'] ?? "Unk") . " - " . ($res['TIT2'] ?? "Untl") . "\r\n"; if (isset($res['TALB'])) echo "#EXTALB: " . $res['TALB'] . "\r\n"; } function pathencode($path, $name) { $path = urlencode($path); $path = str_replace("%2F", "/", $path); $name = urlencode($name); if ($path != "") $path = "/" . $path; return $path . "/" . $name; } function serve_playlist($path) { echo "#EXTM3U"; echo "# PATH: $path\n\r"; foreach (glob(MUSIC_FOLDER . "/$path/*") as $filename) { $name = basename($filename); if (is_dir($filename)) { echo pathencode($path, $name) . ".m3u\r\n"; } $t = explode(".", $filename); $ext = array_pop($t); if (in_array($ext, ["mp3", "ogg", "flac", "mp4", "m4a"])) { if (ID3v2) { getinfo($path . "/" . $name); } else { echo "#EXTINF: , " . $path . "/" . $name . "\r\n"; } echo pathencode($path, $name) . "\r\n"; } } die(); } $path = $_SERVER["REQUEST_URI"]; $path = urldecode($path); $path = trim($path, "/"); if (str_ends_with($path, ".m3u")) { $path = str_replace(".m3u", "", $path); serve_playlist($path); } $path = MUSIC_FOLDER . "/" . $path; if (file_exists($path) && is_file($path)) { header('Content-Description: File Transfer'); header('Content-Type: application/octet-stream'); header('Expires: 0'); header('Cache-Control: must-revalidate'); header('Pragma: public'); header('Content-Length: ' . filesize($path)); readfile($path); }It’s php, so I assume no responsability for it :D
KDE Plasma 6.3 Beta Release
Here are the new modules available in the Plasma 6.3 beta:
Spectacle- We have moved our screenshot and screen recording tool to Plasma to better align with the tech it uses
KDE Ships Frameworks 6.10.0
Thursday, 9 January 2025
KDE today announces the release of KDE Frameworks 6.10.0.
KDE Frameworks are 72 addon libraries to Qt which provide a wide variety of commonly needed functionality in mature, peer reviewed and well tested libraries with friendly licensing terms. For an introduction see the KDE Frameworks release announcement.
This release is part of a series of planned monthly releases making improvements available to developers in a quick and predictable manner.
New in this version Baloo- Remove unused member. Commit.
- Create-app-symlinks.py: add cuttlefish (org.kde.iconexplorer). Commit.
- Add new pcmanfm-qt icon. Commit.
- Add open-link-symbolic icon. Commit.
- Add snap package icon. Commit.
- Add symbolic version of preferences-security. Commit.
- Add symbolic version of preferences-desktop-emoticons. Commit.
- Tests: ignore missing index.theme in ScalableTest::test_scalableDuplicates(). Commit.
- Make building docs optional. Commit.
- Add since documentation. Commit.
- ECMAddAndroidApk: add "PACKAGE_NAME" argument. Commit.
- ECMGenerateHeaders: set IWYU export pragma also for helper prefixed headers. Commit.
- Also allow to disable the nasty Android threads workaround via env vars. Commit.
- ECMGenerateHeaders: Set include-what-you-use pragma. Commit.
- Simplify moving QM catalog loading to the main thread. Commit.
- Remove unimplemented methods. Commit.
- Add missing log categories. Commit.
- Fix shortcuts for mac os. Commit.
- Replace BufferFragment by QByteArrayView. Commit.
- Docs(DESIGN): Fix URL to tutorial. Commit.
- Don't install namelink for kquickcontrolsprivate. Commit.
- Port kquickcontrols to ecm_add_qml_module. Commit.
- Fix the documented mailing list address for this project. Commit.
- Update Turkish entities. Commit.
- General.entities "BSD" is not TM. Commit.
- Systemclipboard: Cache mimetypes after retrieval. Commit. Fixes bug #497735
- Dont crash if the compostior doesnt support the shortcut inhibit protocol. Commit. Fixes bug #497457
- Bump PlasmaWaylandProtocols build dependency to 1.15.0 due to 333ba248641023d80ced18012e8cef45bbb71edb. Commit.
- Update holiday_bg_bg: Add namedays. Commit.
- Add context to missing argument warnings in i18n QML calls. Commit.
- Use Qt API to fully override the engine. Commit.
- Avif: color profiles improvements. Commit.
- Update heif.json. Commit.
- HEIF plug-in extended to read AVCI format. Commit.
- Readme updated with some clarification. Commit.
- DDS: enable plugin by default. Commit.
- PSD: Added support to MCH1 and MCH2. Commit.
- XCF: Fix OSS Fuzz issue 42527849. Commit.
- JXR: Fix loss of HDR data on write for format RGBA16FPx16_Premultiplied. Commit.
- DDS: Fix for OSS Fuzz issue 384974505. Commit.
- DDS: improved read/write support. Commit.
- Read / Write test: added NULL device test. Commit.
- DDS: multiple FP improvements. Commit.
- PFM: fix error when loading images with comments. Commit.
- DDS: fix buffer overflow in readCubeMap. Commit.
- Re-added DDS plugin support. Commit. See bug #380956
- Remove unimplemented methods. Commit.
- [kfilefiltercombo] Fix creating 'All supported types' filter. Commit. See bug #497399
- StandardThumbnailJob is internal, header not installed. Commit.
- Expose auto exclusive from AbstractButton to Kirigami.Action. Commit.
- Mnemonic: Emit sequence change also when it gets disabled. Commit.
- ListSectionHeader: set Accessible.role to Heading. Commit.
- Controls/Card: set title as default Accessible.name. Commit. See bug #497971
- FormLayout: Set mnemonic only if buddy is visible and doesn't have one. Commit.
- FormLayout: Activate buddy with ShortcutFocusReason. Commit.
- Qmltest: Avoid Qt module include. Commit.
- SearchDialog: Add emptyHelpfulAction. Commit.
- FormLayout: Make use of animateClick in shortcut activation. Commit.
- Don't overwrite menubar position. Commit.
- Platformtheme: Set Accent color in highlight. Commit.
- Fix documentation referring to not existing Theme.smallSpacing. Commit.
- Ensure sidebar "y" position is only shifted when menubar/header is visible. Commit.
- Remove unimplemented methods. Commit.
- Remove Q_EMIT for non-signal method call. Commit.
- Add trailing comma to enum. Commit.
- Fix compile on macos. Commit.
- NotifyByAndroid: Set CONTEXT_NOT_EXPORTED. Commit.
- Src/mainwindow.cpp fix deprecation warning. Commit.
- Remove unimplemented methods. Commit.
- Fix default shortcuts for mac os. Commit.
- Rewrite Kate::TextBlock::mergeBlock m_cursors merging code. Commit.
- Use one targetBlock->m_lines.insert instead of many targetBlock->m_lines.push_back. Commit.
- Add testNoFlippedRange and testBlockSplitAndMerge to movingrange_test. Commit.
- Preprocess lineEndings before pasting. Commit.
- "Paste From File" feature for Kate to select a file and insert it's contents into the current file. Commit. Fixes bug #496902
- Remove unnecessary multicursor clipboard code. Commit.
- Try to split clipboard text across multiple cursors when pasting. Commit. Fixes bug #497863
- Optimize kill lines for large number of cursors. Commit.
- Fix full line selection behaviour of the C++ versions of the editing commands. Commit.
- Remove not needed include. Commit.
- Ensure content like from document doesn't make the dialog size explode. Commit. Fixes bug #497328
- Store QTextLayout inline. Commit. See bug #483363
- Remove unimplemented methods. Commit.
- KBusyIndicatorWidget: Add member functions to start and stop the spinning animation. Commit.
- Ci: add Alpine/musl job. Commit.
- Fix -Werror=return-type error when building kmessagewidgettest. Commit.
- Add more support for toolbars in dbus interface. Commit.
- Remove checks for quotes on ConnectivityCheckUri. Commit.
- Expose ConnectivityCheck properties. Commit.
- Add QtMultimedia dependency to scanner QML module. Commit.
- Remove errornous QML registration. Commit.
- Register ScanResult to QML. Commit.
- Use DBus instead of kdeconnect-cli executable. Commit.
- [kdeconnect] Port away from org.kde.kdeconnect QML import. Commit.
- AlternativesModel: Return early if there's no input data. Commit.
- Switch: Fix typo. Commit.
- UpdateItem when mnemonic active changes. Commit.
- Make use of animateClick in mnemonics. Commit.
- ToolButton: Remove unused id. Commit.
- [UPowerManager] Also print error message on failure. Commit. See bug #497474
- Add null check for StorageAccess interface in storageAccessFromPath. Commit. Fixes bug #497299. See bug #492578
- Remove unimplemented methods. Commit.
KDE Gear 24.12.1
Over 180 individual programs plus dozens of programmer libraries and feature plugins are released simultaneously as part of KDE Gear.
Today they all get new bugfix source releases with updated translations, including:
- kasts: Retrieve duration from file as soon as it's downloaded (Commit), fixes bug #497448
- konversation: Prevent crash when updating Watched Nicks (Commit, fixes bug #497799)
- telly-skout: Speed up program description update (Commit, fixes bug #497954)
Distro and app store packagers should update their application packages.
- 24.12 release notes for information on tarballs and known issues.
- Package download wiki page
- 24.12.1 source info page
- 24.12.1 full changelog
Plasma Wayland Protocols 1.16.0
Plasma Wayland Protocols 1.16.0 is now available for packaging. It is needed for the forthcoming KDE Frameworks.
URL: https://download.kde.org/stable/plasma-wayland-protocols/
SHA256: da3fbbe3fa5603f9dc9aabe948a6fc8c3b451edd1958138628e96c83649c1f16
Signed by: E0A3EB202F8E57528E13E72FD7574483BB57B18D Jonathan Riddell jr@jriddell.org
Full changelog:
- external-brightness: Allow the client to specify observed brightness
- output management: add a failure reason event
- output device,-management: add a dimming multiplier
- output device/management: add power/performance vs. color accuracy preference
EuroPython Society: Board Report for December 2024
The board has been working tirelessly over the past month to bootstrap the organization of the 2025 conference and lead the Society toward a more sustainable and stable future!
In December, we focused on three main areas:
- Onboarding
- Hiring an Event Manager
- Bootstrapping the 2025 conference
All board members received access to the tools and resources they needed and went through important information in the board wiki to help everyone get started smoothly. We also had 6 board meetings.
Hiring an Event Manager:This was a big priority and an important step for the future of the Society. We reached out to a candidate and we’re excited that they are interested to cooperate with us! We worked together to define their role, gathered resources for them, and drafted the first version of their contract. We are looking forward to working with them soon!
This is a big move toward making the Society’s future more stable and sustainable.
Bootstrapping the 2025 conference:In December, we announced that the 2025 conference is happening in Prague. We also have a new website with a new logo. We defined team responsibilities, launched the Calls for Contributors, and promoted it within the EPS, the local community, and on social media. We reached out to our first co-leads to get things moving and currently we are onboarding our first team members.
Individual reports:Artur- Onboarding new board members - setting up access, sharing resources, setting up the board wiki and documentation
- Wrapping up the GA2024, and publishing missing records for GA2023
- Setting up the new server for EP websites
- Helping with the helpdesk migration
- Setting up new infrastructure for EP2025
- Coordinating the EP2025 conference launch
- Setting up the framework for the Event Manager - responsibilities and the paperwork
- Setting up Project Management tools for the Board/2025 Team.
- Board Meetings
- Finished all tasks and released videos and materials for GA 2023 and GA 2024.
- Went through the board Wiki and onboarded to board resources and tasks.
- Scheduled social media posts regarding the conference announcement and informed the local community about it.
- Updated the team descriptions document and the Calls for Contributors form, then launched the Calls for Contributors. Announced the Calls for Contributors internally and on social media. Delivered a lightning talk announcing the Calls for Contributors on the local meetup.
- Worked on the brand strategy: documented the current state and described personas. Analyzed our media and web presence, attendance data, community voting, and participant feedback. Researched similar-sized conferences for inspiration. Finally, created a 2025 brand proposal for the website and documented everything.
- Met with a CPython core developer to brainstorm ideas for the conference, followed by a meeting with the program co-lead.
- Reviewed previous venue contract discussions and compared the current contract to the previous one.
- Had a call with the event manager, helped define their role in the Wiki, and drafted the first version of the Letter of Engagement.
- Scheduled social media posts for the end of the year.
- Onboarding to the board tasks (getting access, information on the tools used)
- Checked the 2024 GA recording for flare ups
- Updated the helpdesk instance and other infrastructure tasks
- Looked through the old tickets and tried to understand why they are open
- Set up part of the environments for the new teams
- Helped defining the context for the event manager job
- Looked through the old documents and provided cleaned up versions for part of the teams
- Prepared the responses from potential conference organisers for the selection
- Helped onboard the first Co-Leads
- Onboarding to the board resources and tasks
- Helped with the EM responsibilities and scope
- Feedback on the call to actions and co-lead recruitment
- Updated accounting information with info from the SEB accounts
- Board meetings
- Onboarding to the board tasks (getting access, information on the tools used)
- Launched the initial website for 2025
- Prepared call-to-action cards for the website (for CfC and pre-feedback form)
- Discussed the options for the new website/static server/repository structure
- Communicated with the PSF Trademarks Committee for the approval of the new logo variations
- Had a meeting with a CPython core developer to get feedback and explore ideas to improve EuroPython and EuroPython Society
- Discussed ideas for new EuroPython Branding
- Worked on EP Timeline Discussion and facilitation
- Helped to reach previous on-site volunteers for co-lead recruitment
- Board Meetings
- Initial board meeting
- Initiated data updates to local authorities
Dirk Eddelbuettel: RcppGetconf 0.0.4 on CRAN: Updates
A minor package update, the first in over six years, for the RcppGetconf package for reading system configuration — not unlike getconf from the libc library — is now on CRAN
The changes are all minor package maintenance items of keeping URLs, continuous integration, and best practices current. We had two helper scripts use bash in their shebangs, and we just got dinged in one of them. Tedious as this can at times seem, it ensures CRAN packages do in fact compile just about anywhere which is a Good Thing (TM) so we obliged and updated the package with that change—and all the others that had accumulated over six years. No interface or behaviour changes, “just maintenance” as one does at times.
The short list of changes in this release follows:
Changes in inline version 0.0.4 (2025-01-07)Dynamically linked compiled code is now registered in NAMESPACE
The continuous integration setup was update several times
The README was updated with current badges and URLs
The DESCRIPTION file now uses Authors@R
The configure and cleanup scripts use /bin/sh
Courtesy of my CRANberries, there is also a diffstat report of changes relative to the previous release. More about the package is at the local RcppGetconf page and the GitHub repo.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. If you like this or other open-source work I do, you can now sponsor me at GitHub.
PyCharm: Data Cleaning in Data Science
In this Data Science blog post series, we’ve talked about where to get data from and how to explore that data using pandas, but whilst that data is excellent for learning, it’s not similar to what we will term real-world data. Data for learning has often already been cleaned and curated to allow you to learn quickly without needing to venture into the world of data cleaning, but real-world data has problems and is messy. Real-world data needs cleaning before it can give us useful insights, and that’s the subject of this blog post.
Data problems can come from the behaviour of the data itself, the way the data was gathered, or even the way the data was input. Mistakes and oversights can happen at every stage of the journey.
We are specifically talking about data cleaning here rather than data transformation. Data cleaning ensures that conclusions you make from your data can be generalised to the population you define. In contrast, data transformation involves tasks such as converting data formats, normalising data and aggregating data.
Why Is Data Cleaning Important?The first thing we need to understand about datasets is what they represent. Most datasets are a sample representing a wider population, and in working with this sample, you will be able to extrapolate (or generalise) your findings to this population. For example, we used a dataset in the previous two blog posts. This dataset is broadly about house sales, but it only covers a small geographical area, a small period of time and potentially not all houses in that area and period; it is a sample of a larger population.
Your data needs to be a representative sample of the wider population, for example, all house sales in that area over a defined period. To ensure that our data is a representative sample of the wider population, we must first define our population’s boundaries.
As you might imagine, it’s often impractical to work with the entire population, except perhaps census data, so you need to decide where your boundaries are. These boundaries might be geographical, demographical, time-based, action-based (such as transactional) or industry-specific. There are numerous ways to define your population, but to generalise your data reliably, this is something you must do before you clean your data.
In summary, if you’re planning to use your data for any kind of analysis or machine learning, you need to spend time cleaning the data to ensure that you can rely on your insights and generalise them to the real world. Cleaning your data results in more accurate analysis and, when it comes to machine learning, performance improvements, too.
Without cleaning your data, you risk issues such as not being able to generalise your learnings to the wider population reliably, inaccurate summary statistics and incorrect visualisations. If you are using your data to train machine learning models, this can also lead to errors and inaccurate predictions.
Try PyCharm Professional for free
Examples of Data CleaningWe’re going to take a look at five tasks you can use to clean your data. This is not an exhaustive list, but it’s a good place to start when you get your hands on some real-world data.
Deduplicating dataDuplicates are a problem because they can distort your data. Imagine you are plotting a histogram where you’re using the frequency of sale prices. If you have duplicates of the same value, you will end up with a histogram that has an inaccurate pattern based on the prices that are duplicated.
As a side note, when we talk about duplication being a problem in datasets, we are talking about duplication of whole rows, each of which is a single observation. There will be duplicate values in the columns, and we expect this. We’re just talking about duplicate observations.
Fortunately for us, there is a pandas method we can use to help us detect if there are any duplicates in our data. We can use JetBrains AI chat if we need a reminder with a prompt such as:
Code to identify duplicate rows
Here’s the resulting code:
duplicate_rows = df[df.duplicated()] duplicate_rowsThis code assumes that your DataFrame is called df, so make sure to change it to the name of your DataFrame if it is not.
There isn’t any duplicated data in the Ames Housing dataset that we’ve been using, but if you’re keen to try it out, take a look at the CITES Wildlife Trade Database dataset and see if you can find the duplicates using the pandas method above.
Once you have identified duplicates in your dataset, you must remove them to avoid distorting your results. You can get the code for this with JetBrains AI again with a prompt such as:
Code to drop duplicates from my dataframe
The resulting code drops the duplicates, resets the index of your DataFrame and then displays it as a new DataFrame called df_cleaned:
df_cleaned = df.drop_duplicates() df_cleaned.reset_index(drop=True, inplace=True) df_cleanedThere are other pandas functions that you can use for more advanced duplicate management but this is enough to get you started with deduplicating your dataset.
Dealing with implausible valuesImplausible values can occur when data is entered incorrectly or something has gone wrong in the data-gathering process. For our Ames Housing dataset, an implausible value might be a negative SalePrice, or a numerical value for Roof Style.
Spotting implausible values in your dataset relies on a broad approach that includes looking at your summary statistics, checking the data validation rules that were defined by the collector for each column and noting any data points that fall outside of this validation as well as using visualisations to spot patterns and anything that looks like it might be an anomaly.
You will want to deal with implausible values as they can add noise and cause problems with your analysis. However, how you deal with them is somewhat open to interpretation. If you don’t have many implausible values relative to the size of your dataset, you may want to remove the records containing them. For example, if you’ve identified an implausible value in row 214 of your dataset, you can use the pandas drop function to remove that row from your dataset.
Once again, we can get JetBrains AI to generate the code we need with a prompt like:
Code that drops index 214 from #df_cleaned
Note that in PyCharm’s Jupyter notebooks I can prefix words with the # sign to indicate to JetBrains AI Assistant that I am providing additional context and in this case that my DataFrame is called df_cleaned.
The resulting code will remove that observation from your DataFrame, reset the index and display it:
df_cleaned = df_cleaned.drop(index=214) df_cleaned.reset_index(drop=True, inplace=True) df_cleanedAnother popular strategy for dealing with implausible values is to impute them, meaning you replace the value with a different, plausible value based on a defined strategy. One of the most common strategies is to use the median value instead of the implausible value. Since the median is not affected by outliers, it is often chosen by data scientists for this purpose, but equally, the mean or the mode value of your data might be more appropriate in some situations.
Alternatively, if you have domain knowledge about the dataset and how the data was gathered, you can replace the implausible value with one that is more meaningful. If you’re involved in or know of the data-gathering process, this option might be for you.
How you choose to handle implausible values depends on their prevalence in your dataset, how the data was gathered and how you intend to define your population as well as other factors such as your domain knowledge.
Formatting dataYou can often spot formatting problems with your summary statistics or early visualisations you perform to get an idea of the shape of your data. Some examples of inconsistent formatting are numerical values not all being defined to the same decimal place or variations in terms of spelling, such as “first” and “1st”. Incorrect data formatting can also have implications for the memory footprint of your data.
Once you spot formatting issues in your dataset, you need to standardise the values. Depending on the issue you are facing, this normally involves defining your own standard and applying the change. Again, the pandas library has some useful functions here such as round. If you wanted to round the SalePrice column to 2 decimal places, we could ask JetBrains AI for the code:
Code to round #SalePrice to two decimal places
The resulting code will perform the rounding and then print out the first 10 rows so you can check it:
df_cleaned['SalePrice'] = df_cleaned['SalePrice].round(2) df_cleaned.head()As another example, you might have inconsistent spelling – for example, a HouseStyle column that has both “1Story” and “OneStory”, and you’re confident that they mean the same thing. You can use the following prompt to get code for that:
Code to change all instances of #OneStory to #1Story in #HouseStyle
The resulting code does exactly that and replaces all instances of OneStory to 1Story:
df_cleaned[HouseStyle'] = df_cleaned['HouseStyle'].replace('OneStory', '1Story') Addressing outliersOutliers are very common in datasets, but how you address them, if at all, is very context-dependent. One of the easiest ways to spot outliers is with a box plot, which uses the seaborn and matplotlib libraries. I discussed box plots in my previous blog post on exploring data with pandas if you need a quick refresher.
We’ll look at SalePrice in our Ames housing dataset for this box plot. Again, I’ll use JetBrains AI to generate the code for me with a prompt such as:
Code to create a box plot of #SalePrice
Here’s the resulting code that we need to run:
import seaborn as sns import matplotlib.pyplot as plt # Create a box plot for SalePrice plt.figure(figsize=(10, 6)) sns.boxplot(x=df_cleaned['SalePrice']) plt.title('Box Plot of SalePrice') plt.xlabel('SalePrice') plt.show()The box plot tells us that we have a positive skew because the vertical median line inside the blue box is to the left of the centre. A positive skew tells us that we have more house prices at the cheaper end of the scale, which is not surprising. The box plot also tells us visually that we have lots of outliers on the right-hand side. That is a small number of houses that are much more expensive than the median price.
You might accept these outliers as it’s fairly typical to expect a small number of houses with a larger price point than the majority. However, this is all dependent on the population you want to be able to generalise to and the conclusions you want to draw from your data. Putting clear boundaries around what is and what is not part of your population will allow you to make an informed decision about whether outliers in your data are going to be a problem.
For example, if your population consists of people who will not be buying expensive mansions, then perhaps you can delete these outliers. If, on the other hand, your population demographics include those who might reasonably be expected to buy these expensive houses, you might want to keep them as they’re relevant to your population.
I’ve talked about box plots here as ways to spot outliers, but other options such as scatter plots and histograms can quickly show you if you have outliers in your data, so you can make an informed decision on if you need to do anything about them.
Addressing outliers usually falls into two categories – deleting them or using summary statistics less prone to outliers. In the first instance, we need to know exactly which rows they are.
Until now we’ve just been discussing how to identify them visually. There are different ways to determine which observations are and aren’t outliers. One common approach is using a method called the modified Z score. Before we look at how and why it’s modified, the Z-score is defined as:
Z-score = (data point value – mean) / standard deviation
The reason we then modify the Z-score for detecting outlets is that both the mean and the standard deviation are prone to outlier influence by virtue of how they are calculated. The modified Z-score is defined as:
Modified Z-score = (data point value – median) / median absolute deviation
As we learned when we talked about summary statistics, the median is not affected by outliers. The median absolute deviation is the median value of the dataset’s absolute deviations from the median. For example, if your data set contains these values:
1, 2, 2, 2, 3, 3, 3, 5,9
Then your median is 3 as the value in the middle of the dataset. The deviations from your median value of 3 are as follows in the order presented above:
2, 1, 1, 1, 0, 0, 0, 2, 5
When we sort these into ascending order we get:
0, 0, 0, 1, 1, 1, 2, 2, 5
Meaning the median absolute deviation in this example would be 1.
How do we calculate the Modified Z-score for our data set for SalePrice? Let’s give JetBrains AI this prompt:
Given:
Modified Z-score = (data point value – median) / median absolute deviation
Calculate the Modified Z-score for #SalePrice
That results in this code:
import pandas as pd from scipy.stats import median_abs_deviation # Assuming 'data' is your DataFrame and it contains the 'SalePrice' column # Calculate the median for the SalePrice column median_sale_price = data['SalePrice'].median() # Calculate the Median Absolute Deviation (MAD) for the SalePrice column mad_sale_price = median_abs_deviation(data['SalePrice'], scale='normal') # Calculate the Modified Z-scores for the SalePrice column data['Modified_Z_Score'] = (data['SalePrice'] - median_sale_price) / mad_sale_price # Display the first few rows with the Modified Z-scores print(data[['SalePrice', 'Modified_Z_Score']].head())When we install the required packages and run this code, we can see we’re partway through, but now we need to decide what an outlier for our SalePrice is based on the modified Z-score. The general wisdom here is that an outlier is anything >=3 or <=-3 however, it’s worth noting that like most statistical decisions, it can and should be tailored to your dataset.
Let’s pass another prompt over to JetBrains AI so we can further tailor our output:
Just list those that have a #Modified_Z_Score of 3 or above or -3 or below
I’m going to take this snippet of code and replace it with the relevant rows above:
# Filter the rows where the Modified Z-score is 3 or above, or -3 or below outliers = data[(data['Modified_Z_Score'] >= 3) | (data['Modified_Z_Score'] <= -3)] # Print all the filtered rows, showing their index and SalePrice outliers = (outliers[['SalePrice', 'Modified_Z_Score']]) outliersI have modified this code to save the outliers in a new DataFrame called outliers and print them out so I can view them.
Our next step would be to remove these outliers from our DataFrame. Again we can use JetBrains AI to generate the code with a prompt like:
Create a new dataframe without the outliers
data_without_outliers = data.drop(index=outliers.index) # Display the new DataFrame without outliers print(data_without_outliers)Our new DataFrame, data_without_outliers, excludes those values where the SalePrice variable is considered an outlier.
We can update our box plot code to look at the new DataFrame. It still shows our positive skew as we’d expect, but the values considered as outliers have been removed:
import seaborn as sns import matplotlib.pyplot as plt # Create a box plot for SalePrice plt.figure(figsize=(10, 6)) sns.boxplot(x=data_without_outliers['SalePrice']) plt.title('Box Plot of SalePrice') plt.xlabel('SalePrice') plt.show()Before we finish up here, let’s take a look at how many observations were removed from our DataFrame as a percentage because we considered them to be outliers based on SalePrice.
We can use a prompt such as:
Calculate the percentage of observations removed between #data and #data_without_outliers
# Calculate the number of observations in the original and filtered DataFrames original_count = len(data) filtered_count = len(data_without_outliers) # Calculate the number of removed observations removed_count = original_count - filtered_count # Calculate the percentage of observations removed percentage_removed = (removed_count / original_count) * 100 # Display the percentage print(f"Percentage of observations removed: {percentage_removed:.2f}%")PyCharm tells us that 5.67% of observations have been removed.
As I mentioned earlier, if you are keeping your outliers, consider using summary values less prone to being affected by outliers such as the median and interquartile range. You might consider using these measurements to form your conclusions when you’re working with datasets that you know contain outliers that you’ve not removed because they are relevant to the population you’ve defined and the conclusions you want to draw.
Missing valuesThe fastest way to spot missing values in your dataset is with your summary statistics. As a reminder, in your DataFrame, click Show Column Statistics on the right-hand side and then select Compact. Missing values in the columns are shown in red, as you can see here for Lot Frontage in our Ames housing dataset:
There are three kinds of missingness that we have to consider for our data:
- Missing completely at random
- Missing at random
- Missing not at random
Missing completely at random means the data has gone missing entirely by chance and the fact that it is missing has no relationship to other variables in the dataset. This can happen when someone forgets to answer a survey question, for example.
Data that is missing completely at random is rare, but it’s also among the easiest to deal with. If you have a relatively small number of observations missing completely at random, the most common approach is to delete those observations because doing so shouldn’t affect the integrity of your dataset and, thus, the conclusions you hope to draw.
Missing at randomMissing at random has a pattern to it, but we’re able to explain that pattern through other variables we’ve measured. For example, someone didn’t answer a survey question because of how the data was collected.
Consider in our Ames housing dataset again, perhaps the Lot Frontage variable is missing more frequently for houses that are sold by certain real estate agencies. In that case, this missingness could be due to inconsistent data entry practices by some agencies. If true, the fact that the Lot Frontage data is missing is related to how the agency that sold the property gathered the data, which is an observed characteristic, not the Lot Frontage itself.
When you have data missing at random, you will want to understand why that data is missing, which often involves digging into how the data was gathered. Once you understand why the data is missing, you can choose what to do. One of the more common approaches to deal with missing at random is to impute the values. We’ve already touched on this for implausible values, but it’s a valid strategy for missingness too. There are various options you could choose from based on your defined population and the conclusions you want to draw, including using correlated variables such as house size, year built, and sale price in this example. If you understand the pattern behind the missing data, you can often use contextual information to impute the values, which ensures that relationships between data in your dataset are preserved.
Missing not at randomFinally, missing not at random is when the likelihood of missing data is related to unobserved data. That means that the missingness is dependent on the unobserved data.
One last time, let’s return to our Ames housing dataset and the fact that we have missing data in Lot Frontage. One scenario for data missing not at random is when sellers deliberately choose not to report Lot Frontage if they consider it small and thus reporting it might reduce the sale price of their house. If the likelihood of Lot Frontage data being missing depends on the size of the frontage itself (which is unobserved), smaller lot frontages are less likely to be reported, meaning the missingness is directly related to the missing value.
Visualising missingnessWhenever data is missing, you need to establish whether there’s a pattern. If you have a pattern, then you have a problem that you’ll likely have to address before you can generalize your data.
One of the easiest ways to look for patterns is with heat map visualisations. Before we get into the code, let’s exclude variables with no missingness. We can prompt JetBrains AI for this code:
Code to create a new dataframe that contains only columns with missingness
Here’s our code:
# Identify columns with any missing values columns_with_missing = data.columns[data.isnull().any()] # Create a new DataFrame with only columns that have missing values data_with_missingness = data[columns_with_missing] # Display the new DataFrame print(data_with_missingness)Before you run this code, change the final line so we can benefit from PyCharm’s nice DataFrame layout:
data_with_missingnessNow it’s time to create a heatmap; again we will prompt JetBrains AI with code such as:
Create a heatmap of #data_with_missingness that is transposed
Here’s the resulting code:
import seaborn as sns import matplotlib.pyplot as plt # Transpose the data_with_missingness DataFrame transposed_data = data_with_missingness.T # Create a heatmap to visualize missingness plt.figure(figsize=(12, 8)) sns.heatmap(transposed_data.isnull(), cbar=False, yticklabels=True) plt.title('Missing Data Heatmap (Transposed)') plt.xlabel('Instances') plt.ylabel('Features') plt.tight_layout() plt.show()Note that I removed cmap=’viridis’ from the heatmap arguments as I find it hard to view.
This heatmap suggests that there might be a pattern of missingness because the same variables are missing across multiple rows. In one group, we can see that Bsmt Qual, Bsmt Cond, Bsmt Exposure, BsmtFin Type 1 and Bsmt Fin Type 2 are all missing from the same observations. In another group, we can see that Garage Type, Garage Yr Bit, Garage Finish, Garage Qual and Garage Cond are all missing from the same observations.
These variables all relate to basements and garages, but there are other variables related to garages or basements that are not missing. One possible explanation is that different questions were asked about garages and basements in different real estate agencies when the data was gathered, and not all of them recorded as much detail as is in the dataset. Such scenarios are common with data you don’t collect yourself, and you can explore how the data was collected if you need to learn more about missingness in your dataset.
Best Practices for Data CleaningAs I’ve mentioned, defining your population is high on the list of best practices for data cleaning. Know what you want to achieve and how you want to generalise your data before you start cleaning it.
You need to ensure that all your methods are reproducible because reproducibility also speaks to clean data. Situations that are not reproducible can have a significant impact further down the line. For this reason, I recommend keeping your Jupyter notebooks tidy and sequential while taking advantage of the Markdown features to document your decision-making at every step, especially with cleaning.
When cleaning data, you should work incrementally, modifying the DataFrame rather than the original CSV file or database, and ensuring you do it all in reproducible, well-documented code.
SummaryData cleaning is a big topic, and it can have many challenges. The larger the dataset is, the more challenging the cleaning process is. You will need to keep your population in mind to generalise your conclusions more widely while balancing tradeoffs between removing and imputing missing values and understanding why that data is missing in the first place.
You can think of yourself as the voice of the data. You know the journey that the data has been on and how you have maintained data integrity at all stages. You are the best person to document that journey and share it with others.
John Goerzen: Censorship Is Complicated: What Internet History Says about Meta/Facebook
In light of this week’s announcement by Meta (Facebook, Instagram, Threads, etc), I have been pondering this question: Why am I, a person that has long been a staunch advocate of free speech and encryption, leery of sites that talk about being free speech-oriented? And, more to the point, why an I — a person that has been censored by Facebook for mentioning the Open Source social network Mastodon — not cheering a “lighter touch”?
The answers are complicated, and take me back to the early days of social networking. Yes, I mean the 1980s and 1900s.
Before digital communications, there were barriers to reaching a lot of people. Especially money. This led to a sort of self-censorship: it may be legal to write certain things, but would a newspaper publish a letter to the editor containing expletives? Probably not.
As digital communications started to happen, suddenly people could have their own communities. Not just free from the same kinds of monetary pressures, but free from outside oversight (parents, teachers, peers, community, etc.) When you have a community that the majority of people lack the equipment to access — and wouldn’t understand how to access even if they had the equipment — you have a place where self-expression can be unleashed.
And, as J. C. Herz covers in what is now an unintentional history (her book Surfing on the Internet was published in 1995), self-expression WAS unleashed. She enjoyed the wit and expression of everything from odd corners of Usenet to the text-based open world of MOOs and MUDs. She even talks about groups dedicated to insults (flaming) in positive terms.
But as I’ve seen time and again, if there are absolutely no rules, then whenever a group gets big enough — more than a few dozen people, say — there are troublemakers that ruin it for everyone. Maybe it’s trolling, maybe it’s vicious attacks, you name it — it will arrive and it will be poisonous.
I remember the debates within the Debian community about this. Debian is one of the pillars of the Internet today, a nonprofit project with free speech in its DNA. And yet there were inevitably the poisonous people. Debian took too long to learn that allowing those people to run rampant was causing more harm than good, because having a well-worn Delete key and a tolerance for insults became a requirement for being a Debian developer, and that drove away people that had no desire to deal with such things. (I should note that Debian strikes a much better balance today.)
But in reality, there were never absolutely no rules. If you joined a BBS, you used it at the whim of the owner (the “sysop” or system operator). The sysop may be a 16-yr-old running it from their bedroom, or a retired programmer, but in any case they were letting you use their resources for free and they could kick you off for any or no reason at all. So if you caused trouble, or perhaps insulted their cat, you’re banned. But, in all but the smallest towns, there were other options you could try.
On the other hand, sysops enjoyed having people call their BBSs and didn’t want to drive everyone off, so there was a natural balance at play. As networks like Fidonet came into play, a sort of uneasy approach kicked in: don’t be excessively annoying, and don’t be easily annoyed. Like it or not, it seemed to generally work. A BBS that repeatedly failed to deal with troublemakers could risk removal from Fidonet.
On the more institutional Usenet, you generally got access through your university (or, in a few cases, employer). Most universities didn’t really even know they were running a Usenet server, and you were generally left alone. Until you did something that annoyed somebody enough that they tracked down the phone number for your dean, in which case real-world consequences would kick in. A site may face the Usenet Death Penalty — delinking from the network — if they repeatedly failed to prevent malicious content from flowing through their site.
Some BBSs let people from minority communities such as LGBTQ+ thrive in a place of peace from tormentors. A lot of them let people be themselves in a way they couldn’t be “in real life”. And yes, some harbored trolls and flamers.
The point I am trying to make here is that each BBS, or Usenet site, set their own policies about what their own users could do. These had to be harmonized to a certain extent with the global community, but in a certain sense, with BBSs especially, you could just use a different one if you didn’t like what the vibe was at a certain place.
That this free speech ethos survived was never inevitable. There were many attempts to regulate the Internet, and it was thanks to the advocacy of groups like the EFF that we have things like strong encryption and a degree of freedom online.
With the rise of the very large platforms — and here I mean CompuServe and AOL at first, and then Facebook, Twitter, and the like later — the low-friction option of just choosing a different place started to decline. You could participate on a Fidonet forum from any of thousands of BBSs, but you could only participate in an AOL forum from AOL. The same goes for Facebook, Twitter, and so forth. Not only that, but as social media became conceived of as very large sites, it became impossible for a person with enough skill, funds, and time to just start a site themselves. Instead of neading a few thousand dollars of equipment, you’d need tens or hundreds of millions of dollars of equipment and employees.
All that means you can’t really run Facebook as a nonprofit. It is a business. It should be absolutely clear to everyone that Facebook’s mission is not the one they say it is — “[to] give people the power to build community and bring the world closer together.” If that was their goal, they wouldn’t be creating AI users and AI spam and all the rest. Zuck isn’t showing courage; he’s sucking up to Trump and those that will pay the price are those that always do: women and minorities.
The problem with a one-size-fits-all policy is that the world isn’t that kind of place. For instance, I am a pacifist. There is a place for a group where pacifists can hang out with each other, free from the noise of the debate about pacifism. And there is a place for the debate. Forcing everyone that signs up for the conversation to sign up for the debate is harmful. Preventing the debate is often also harmful. One company can’t square this circle.
Beyond that, the fact that we care so much about one company is a problem on two levels. First, it indicates how succeptible people are to misinformation and such. I don’t have much to offer on that point. Secondly, it indicates that we are too centralized.
We have a solution there: Mastodon. Mastodon is a modern, open source, decentralized social network. You can join any instance, easily migrate your account from one server to another, and so forth. You pick an instance that suits you. There are thousands of others you can choose from. Some aggressively defederate with instances known to harbor poisonous people; some don’t.
And, to harken back to the BBS era, if you have some time, some skill, and a few bucks, you can run your own Mastodon instance.
Personally, I still visit Facebook on occasion because some people I care about are mainly there. But it is such a terrible experience that I rarely do. Meta is becoming irrelevant to me. They are on a path to becoming irrelevant to many more as well. Maybe this is the moment to go “shrug, this sucks” and try something better.
Real Python: Image Processing With the Python Pillow Library
Python Pillow allows you to manipulate images and perform basic image processing tasks. As a fork of the Python Imaging Library (PIL), Pillow supports image formats like JPEG, PNG, and more, enabling you to read, edit, and save images. With Python Pillow, you can crop, resize, rotate, and apply filters to images, making it a versatile tool for image manipulation.
Pillow is often used for high-level image processing tasks and exploratory work. While not the fastest library, it offers a gentle learning curve and a comprehensive set of features for basic to intermediate image processing needs. You can enhance its capabilities by integrating it with NumPy for pixel-level manipulations and creating animations.
By the end of this tutorial, you’ll understand that:
- Python Pillow is used for image manipulation and basic image processing.
- Pillow offers reasonable speed for its intended use cases.
- PIL is the original library, while Pillow is its actively maintained fork.
- You read an image in Python Pillow using Image.open() from the PIL module.
- Pillow is used for its ease of use, versatility, and integration with NumPy.
With these insights, you’re ready to dive into the world of image processing with Python Pillow. You’ll use several images in this tutorial, which you can download from the tutorial’s image repository:
Get Images: Click here to get access to the images that you’ll manipulate and process with Pillow.
With these images in hand, you’re now ready to get started with Pillow.
Basic Image Operations With the Python Pillow LibraryThe Python Pillow library is a fork of an older library called PIL. PIL stands for Python Imaging Library, and it’s the original library that enabled Python to deal with images. PIL was discontinued in 2011 and only supports Python 2. To use its developers’ own description, Pillow is the friendly PIL fork that kept the library alive and includes support for Python 3.
There’s more than one module in Python to deal with images and perform image processing. If you want to deal with images directly by manipulating their pixels, then you can use NumPy and SciPy. Other popular libraries for image processing are OpenCV, scikit-image, and Mahotas. Some of these libraries are faster and more powerful than Pillow.
However, Pillow remains an important tool for dealing with images. It provides image processing features that are similar to ones found in image processing software such as Photoshop. Pillow is often the preferred option for high-level image processing tasks that don’t require more advanced image processing expertise. It’s also often used for exploratory work when dealing with images.
Pillow also has the advantage of being widely used by the Python community, and it doesn’t have the same steep learning curve as some of the other image processing libraries.
You’ll need to install the library before you can use it. You can install Pillow using pip within a virtual environment:
Windows PowerShell PS> python -m venv venv PS> .\venv\Scripts\activate (venv) PS> python -m pip install Pillow Copied! Shell $ python -m venv venv $ source venv/bin/activate (venv) $ python -m pip install Pillow Copied!Now that you’ve installed the package, you’re ready to start familiarizing yourself with the Python Pillow library and perform basic manipulations of images.
The Image Module and Image Class in PillowThe main class defined in Pillow is the Image class. When you read an image using Pillow, the image is stored in an object of type Image.
For the code in this section, you’ll need the image file named buildings.jpg (image credit), which you can find in the image repository for this tutorial:
Get Images: Click here to get access to the images that you’ll manipulate and process with Pillow.
You can place this image file in the project folder that you’re working in.
When exploring images with Pillow, it’s best to use an interactive REPL environment. You’ll start by opening the image that you just downloaded:
Python >>> from PIL import Image >>> filename = "buildings.jpg" >>> with Image.open(filename) as img: ... img.load() ... >>> type(img) <class 'PIL.JpegImagePlugin.JpegImageFile'> >>> isinstance(img, Image.Image) True Copied!You might expect to import from Pillow instead of from PIL. You did install Pillow, after all, not PIL. However, Pillow is a fork of the PIL library. Therefore, you’ll still need to use PIL when importing into your code.
You call the open() function to read the image from the file and .load() to read the image into memory so that the file can now be closed. You use a with statement to create a context manager to ensure the file is closed as soon as it’s no longer needed.
Read the full article at https://realpython.com/image-processing-with-the-python-pillow-library/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Sandro Tosi: HOWTO remove Reddit (web) "Recent" list of communities
If you go on reddit.com via browser, on the left column you can see a section called "RECENT" with the list of the last 5 communities recently visited.
If you want to remove them, say for privacy reasons (shared device, etc.), there's no simple way to do so: there's not "X" button next to it, your profile page doesn't offer a way to clear that out. you could clear all the data from the website, but that seems too extreme, no?
Enter Chrome's "Developer Tools"
While on reddit.com open Menu > More Tools > Developers tool, go on the Application tab, Storage > Local storage and select reddit.com; on the center panel you see a list of key-value pairs, look for the key "recent-subreddits-store"; you can see the list of the 5 communities in the JSON below.
If you wanna get rid of the recently viewed communities list, simply delete that key, refresh reddit.com and voila, empty list.
Note: I'm fairly sure i read about this method somewhere, i simply cant remember where, but it's definitely not me who came up with it. I just needed to use it recently and had to back track memories to figure it out again, so it's time to write it down.
Jonathan Wiltshire: Using TPM for Automatic Disk Decryption in Debian 12
These days it’s straightforward to have reasonably secure, automatic decryption of your root filesystem at boot time on Debian 12. Here’s how I did it on an existing system which already had a stock kernel, secure boot enabled, grub2 and an encrypted root filesystem with the passphrase in key slot 0.
There’s no need to switch to systemd-boot for this setup but you will use systemd-cryptenroll to manage the TPM-sealed key. If that offends you, there are other ways of doing this.
CaveatThe parameters I’ll seal a key against in the TPM include a hash of the initial ramdisk. This is essential to prevent an attacker from swapping the image for one which discloses the key. However, it also means the key has to be re-sealed every time the image is rebuilt. This can be frequent, for example when installing/upgrading/removing packages which include a kernel module. You won’t get locked out (as long as you still have a passphrase in another slot), but will need to re-seal the key to restore the automation.
You can also choose not to include this parameter for the seal, but that opens the door to such an attack.
Caution: these are the steps I took on my own system. You may need to adjust them to avoid ending up with a non-booting system.
Check for a usable TPM deviceWe’ll bind the secure boot state, kernel parameters, and other boot measurements to a decryption key. Then, we’ll seal it using the TPM. This prevents the disk being moved to another system, the boot chain being tampered with and various other attacks.
# apt install tpm2-tools # systemd-cryptenroll --tpm2-device list PATH DEVICE DRIVER /dev/tpmrm0 STM0125:00 tpm_tis Clean up older kernels including leftover configurationsI found that previously-removed (but not purged) kernel packages sometimes cause dracut to try installing files to the wrong paths. Identify them with:
# apt install aptitude # aptitude search '~c'Change search to purge or be more selective, this part is an exercise for the reader.
Switch to dracut for initramfs imagesUnless you have a particular requirement for the default initramfs-tools, replace it with dracut and customise:
# mkdir /etc/dracut.conf.d # echo 'add_dracutmodules+=" tpm2-tss crypt "' > /etc/dracut.conf.d/crypt.conf # apt install dracut Remove root device from crypttab, configure grubRemove (or comment) the root device from /etc/crypttab and rebuild the initial ramdisk with dracut -f.
Edit /etc/default/grub and add ‘rd.auto rd.luks=1‘ to GRUB_CMDLINE_LINUX. Re-generate the config with update-grub.
At this point it’s a good idea to sanity-check the initrd contents with lsinitrd. Then, reboot using the new image to ensure there are no issues. This will also have up-to-date TPM measurements ready for the next step.
Identify device and seal a decryption key # lsblk -ip -o NAME,TYPE,MOUNTPOINTS NAME TYPE MOUNTPOINTS /dev/nvme0n1p4 part /boot /dev/nvme0n1p5 part `-/dev/mapper/luks-deff56a9-8f00-4337-b34a-0dcda772e326 crypt |-/dev/mapper/lv-var lvm /var |-/dev/mapper/lv-root lvm / `-/dev/mapper/lv-home lvm /homeIn this example my root filesystem is in a container on /dev/nvme0n1p5. The existing passphrase key is in slot 0.
# systemd-cryptenroll --tpm2-device=auto --tpm2-pcrs=7+8+9+14 /dev/nvme0n1p5 Please enter current passphrase for disk /dev/nvme0n1p5: ******** New TPM2 token enrolled as key slot 1.The PCRs I chose (7, 8, 9 and 14) correspond to the secure boot policy, kernel command line (to prevent init=/bin/bash-style attacks), files read by grub including that crucial initrd measurement, and secure boot MOK certificates and hashes. You could also include PCR 5 for the partition table state, and any others appropriate for your setup.
RebootYou should now be able to reboot and the root device will be unlocked automatically, provided the secure boot measurements remain consistent.
The key slot protected by a passphrase (mine is slot 0) is now your recovery key. Do not remove it!
Please consider supporting my work in Debian and elsewhere through Liberapay.
GNUnet News: libgnunetchat 0.5.2
We are pleased to announce the release of libgnunetchat 0.5.2.
This is a minor new release bringing compatibility with the major changes in latest GNUnet release 0.23.0. A few API updates and fixes are included. Additionally the messaging client applications using libgnunetchat got updated to stay compatible. This release will also require your GNUnet to be at least 0.23.0 because of that.
The GPG key used to sign is: 3D11063C10F98D14BD24D1470B0998EF86F59B6A
Note that due to mirror synchronization, not all links may be functional early after the release. For direct access try http://ftp.gnu.org/gnu/gnunet/
Noteworthy changes in 0.5.2- Implement iteration of tags by chat contact
- Adjust types and API to improve consistency
- Add more test cases and fix some older test cases
- Adjust IV derivation for file encryption/decryption key
A detailed list of changes can be found in the ChangeLog .
Messenger-GTK 0.10.2This minor release will add optional notification sounds and contact filtering via tags. But mostly the release is intended to reflect changes in libgnunetchat 0.5.2.
Download linksKeep in mind the application is still in development. So there may still be major bugs keeping you from getting a reliable connection. But if you encounter such issue, feel free to consult our bug tracker at bugs.gnunet.org .
messenger-cli 0.3.1This release will apply necessary changes to fix build issues with libgnunetchat 0.5.2.
FSF Blogs: Psychological care should grant you freedom and protection
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
- Bastian Venthur: Investigating the popularity of Python build backends over time (II)
- This Week in KDE Apps: Usability improvements, new features, and updated apps
- kcursorgen and SVG cursors
- Sahil Dhiman: Prosody Certificate Management With Nginx and Certbot
- Interview on Tech Over Tea about fundraising, money, and design