
FLOSS Project Planets
Bastian Venthur: Investigating the popularity of Python build backends over time (II)
Last year, I analyzed the popularity of build backends used in pyproject.toml files over time. This post is the update for 2024.
AnalysisLike last year, I’m using Tom Forbes’ fantastic dataset containing information about every file within every release uploaded to PyPI. To get the current dataset, I followed the same process as in last year’s analysis, so I won’t repeat all the details here. Instead, I’ll highlight the main steps:
- Download the parquet files from the dataset
- Use DuckDB to query the parquet files, extracting the project name, upload date, the pyproject.toml file, and its hash for each upload
- Download each pyproject.toml file and extract the build backend. To avoid redundant downloads, I stored a mapping of the file hash and their respective build backend
Downloading all the parquet files took roughly a week due to GitHub’s rate limiting. Tom suggested leveraging the Git v2 protocol to fetch the data directly. This approach could bypass rate limiting and complete the download of all pyproject.toml files in just 20 minutes(!). However, I couldn’t find sufficient documentation that would help me to implement this method, so this will have to wait until next year’s analysis.
Once all the data is downloaded, I perform some preprocessing:
- Grouped the top 4 build backends by their absolute number of uploads and categorized the remaining ones as “other”
- Binned upload dates into quarters to reduce clutter in the resulting graphs
I modified the plots a bit from last year to make them easier to read. Most notably, I binned the data into quarters to make the plots less noisy, and secondly, I stopped stacking the relative distribution plots to make the percentages directly readable.
The first plot shows the absolute number of uploads (in thousands) by quarter and build backend.
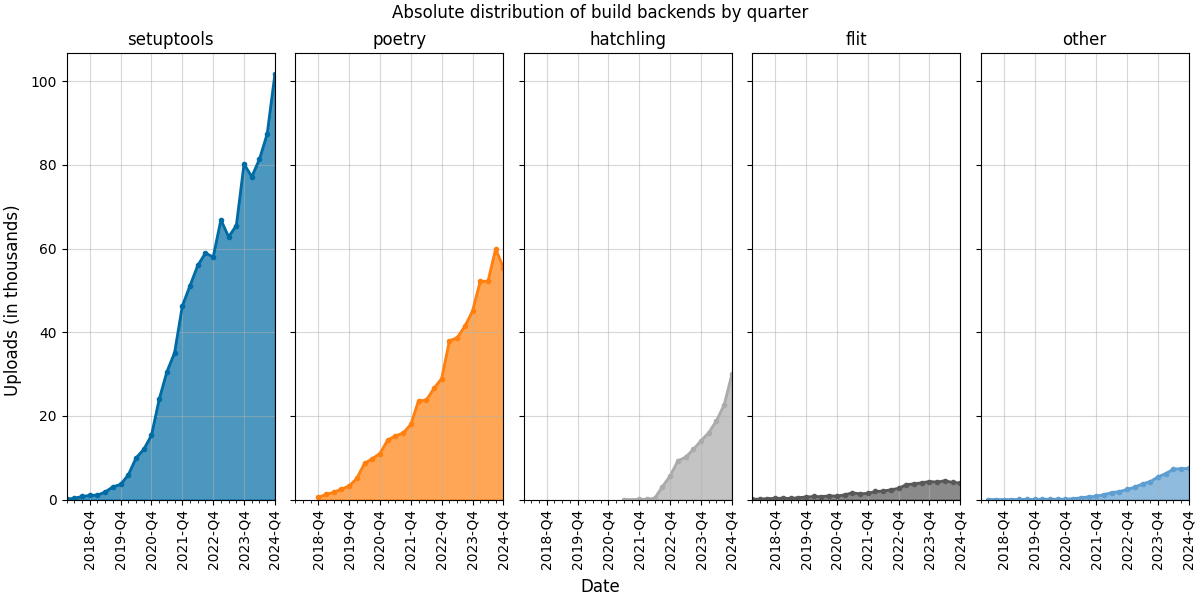{kind=link}
The second plot shows the relative distribution of build backends by quarter.
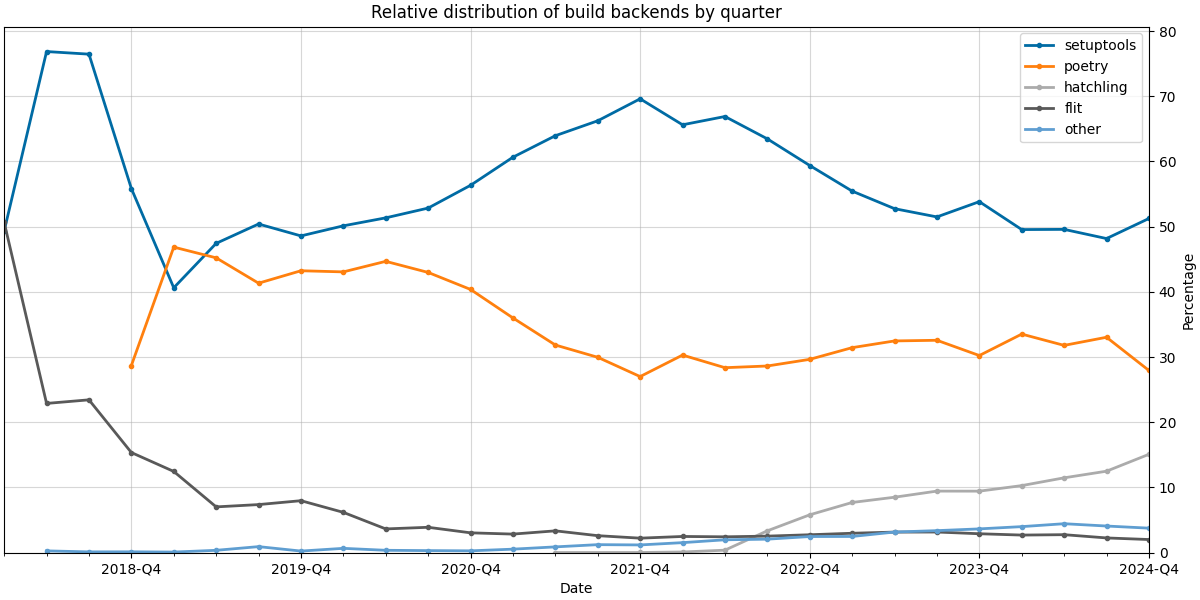{kind=link}
In 2024, we observe that:
- Setuptools continues to grow in absolute numbers and remains around the 50% mark in relative distribution
- Poetry maintains a 30% relative distribution, but the trend has been declining since 2024-Q3. Preliminary data for 2025-Q1 (not shown here) supports this, suggesting that Poetry might be surpassed by Hatch in 2025, which showed a remarkable growth last year.
- Flit is the only build backend in this analysis whose absolute and relative numbers decreased in 2024. With a 5% relative distribution, it underlines the dominance of Setuptools, Poetry, and Hatch over the remaining build backends.
The script for downloading and analyzing the data is available in my GitHub repository. If someone has insights or examples on implementing the Git v2 protocol to download the pyproject.toml file given the repository URL and its hash, I’d love to hear from you!
This Week in KDE Apps: Usability improvements, new features, and updated apps
Welcome to a new issue of "This Week in KDE Apps"! Every week we cover as much as possible of what's happening in the world of KDE apps.
This week we look at the usability improvements landing in Alligator, Dolphin, and Itinerary; new features for KMyMoney, Tokodon and NeoChat; and updated versions of Amarok and Skrooge.
Alligator RSS feed readerYou can now mark one feed or all feeds as read (Mark Penner, 25.04.0. Link), and save the settings when the application is suspended (Mark Penner, 24.12.3. Link).
Amarok Rediscover your musicAmarok 3.2.1 is out with a more complete Qt6 support and some small UI bug fixes. You can find the full announcement on Amarok's development Squad blog.
Note that this version is still marked as experimental.
Arianna EBook readerArianna will once again remember the current reading progress of your books with the new backend. (Ryan Zeigler. 25.04.0. Link)
It is now possible to add multiple books in your library at the same time. (Onuralp SEZER, 25.04.0. Link)
Dolphin Manage your filesDolphin now visually elides the middle portion of long file names rather than the end. So rather than Family Gathering 2….jpg you might see Family Gath…ng 2018.jpg. Depending on your naming schemes, this might be a good or a bad change for you, so sorry in advance if it affects you negatively, but on average it should be an improvement (Nate Graham, 25.04.0. Link 1).
The right-click context menu in the Trash had the "Restore" action right next to the "Delete" action, which made it easy to accidentally click the opposite of what you wanted leading to data loss. This week Nate moved the "Delete" action to the very end of the menu so this no longer happens. Also the "Restore" wording was changed to "Restore to Former Location" for clarity (Nate Graham, 25.04.0. Link 1).
Felix fixed a regression in Dolphin 24.12.0 on X11 which caused the keyboard focus to move to the Places or Terminal panels when Dolphin is minimized and then unminimized (Felix Ernst, 24.12.2. Link).
KDE Itinerary Digital travel assistantThe Itinerary team improved travel document extractors for Bilkom and PKP PDF tickets (Grzegorz Mu, 24.12.2. Link 1 and link 2), International Trenitalia ticket barcodes (Volker Krause, 25.04.0. Link), and the Danish language support for Booking.com (Volker Krause, 24.12.3. Link).
The team also switched the querying public transport information feature from Deutsche Bahn to a new API after the previous one was disabled. This unfortunately results in the loss of some previously available trip information (Volker Krause, 24.12.2. Link).
Note that this same issue affects KTrip and for the same reason.
Keysmith Two-factor code generator for Plasma Mobile and DesktopIt's now possible to import accounts via otpauth:// URIs in QR codes (Jack Hill, 25.04.0. Link).
KDE Connect Seamless connection of your devicesThe list of devices in the sidebar is now properly scrollable (Christoph Wolk, 25.04.0. Link).
Kdenlive Video editorThe scaling algorithm has been improved and now, when you zoom, individual pixels without blur are clearly displayed (Jean-Baptiste Mardelle, 24.04.0. Link).
Note that this change is currently only available on Linux.
KMyMoney Personal finance manager based on double-entry bookkeepingThomas added a new feature that shows paid out dividends in investment reports and in the calculation of returns (Thomas Baumgart. Link), and Ralf added a column showing the annualized return in the investment performance reports (Ralf Habacker Link).
LabPlot Interactive Data Visualization and AnalysisIsrael made it possible for LabPlot to read the value generated by a formula from a cell instead of the formula text iself when importing data from Excel files (Israel Galadima. Link).
Merkuro Mail Read and write emailsThe email lists in Merkuro Mail now supports selecting multiple emails at once, dragging and dropping and keyboard navigation (Carl Schwan, 25.04.0. Link 1 and link 2).
It's also now possible to move or copy emails to another folder manually.
NeoChat Chat on MatrixJoshua implemented requests for user data erasure (Joshua Goins, 25.04.0. Link) and Carl fixed the bug that stopped the context menu froma appearing in the maximized image preview (Carl Schwan, 24.12.3. Link).
Skrooge Single-entry bookkeeping for home useThe Skrooge Team announced the release of version 25.1.0 of its Personal Finances Manager. This is the first version ported to Kf6/Qt6. You can find the full announcement here.
Tokodon Browse the FediverseJoshua improved the compatibility with GoToSocial servers even more (Joshua Goins, 25.04.0. Link) and also made it possible to share an account handle via a QR code (Joshua Goins, 25.04.0. Link).
Meanwhile Carl ported the remaining menus from Tokodon to the new convergent alternative (Carl Schwan, 25.04.0. Link).
PackagingWe updated the Craft packages to use Qt 6.8.1 and KDE Frameworks 6.10.0.
…And Everything ElseThis blog only covers the tip of the iceberg! If you’re hungry for more, check out Nate's blog about Plasma and be sure not to miss his This Week in Plasma series, where every Saturday he covers all the work being put into KDE's Plasma desktop environment.
For a complete overview of what's going on, visit KDE's Planet, where you can find all KDE news unfiltered directly from our contributors.
Get InvolvedThe KDE organization has become important in the world, and your time and contributions have helped us get there. As we grow, we're going to need your support for KDE to become sustainable.
You can help KDE by becoming an active community member and getting involved. Each contributor makes a huge difference in KDE — you are not a number or a cog in a machine! You don’t have to be a programmer either. There are many things you can do: you can help hunt and confirm bugs, even maybe solve them; contribute designs for wallpapers, web pages, icons and app interfaces; translate messages and menu items into your own language; promote KDE in your local community; and a ton more things.
You can also help us by donating. Any monetary contribution, however small, will help us cover operational costs, salaries, travel expenses for contributors and in general just keep KDE bringing Free Software to the world.
To get your application mentioned here, please ping us in invent or in Matrix.
kcursorgen and SVG cursors
In the latest Plasma 6.3 Beta, you will find a new executable named kcursorgen in /usr/bin. It can convert an SVG cursor theme to the XCursor format, in any sizes you like. Although this tool is intended for internal use in future Plasma versions, there are a few tricks you can play now with it and an SVG cursor theme.
(Unfortunately, the only theme with the support that I know, besides Breeze, is Catppuccin. I have this little script that might help you convert more cursor themes.)
Requirements- The qt6-svg library.
- The xcursorgen command, usually found in xorg-xcursorgen package.
You should be able to set any cursor size with SVG cursors, right? Well, not at the moment, because:
- Only those apps using the Wayland cursor shape protocol would be using SVG cursors. Other apps still use the XCursor format, with a limited list of sizes.
- Plasma's cursor setting UI hasn't been updated to allow arbitrary sizes.
But we can do it manually with kcursorgen. Take Breeze for example:
Step 1: Make a copy of the themeFirst, copy the cursor theme to your home directory. And let's change the directory name, so the original one is not overriden:
mkdir -p ~/.local/share/icons cp -r /usr/share/icons/breeze_cursors ~/.local/share/icons/breeze_cursors.myThen open ~/.local/share/icons/breeze_cursors.my/index.theme in the editor. Change the name in Name[_insert your locale_]= so you can tell it from the original in the cursor settings.
Step 2: Regenerate the XCursor filesFor example, if we want a size 36 cursor, and the display scale is 250%:
cd ~/.local/share/icons/breeze_cursors.my rm -r cursors/ kcursorgen --svg-theme-to-xcursor --svg-dir=cursors_scalable --xcursor-dir=cursors --sizes=36 --scales=1,2.5,3Some Wayland apps don't support fractional scaling, so they will round the scale up. So we need to include both 2.5 and 3 in the scale list.
The above command generates XCursor at size 36, 90 and 108. Note that the max size of the original Breeze theme is 72, so this is something not possible with the original theme.
(kcursorgen also adds paddings when necessary, to satisfy alignment requirements of some apps / toolkits. E.g., GTK3 requires cursor image sizes to be multiple of 3 when the display scale is 3. So please use --sizes=36 --scales=1,2.5,3, not --sizes=36,90,108 --scales=1, because only the former would consider alignments.)
Then you can go to systemsettings - cursor themes, select your new theme, and choose size 36 in the dropdown.
(Yes, you can have HUGE cursors without shaking. Size 240.)
Trick 2: Workaround for the huge cursor problem in GTK4As explained before, Breeze theme triggers a bug in GTK4 when global scaling is used, resulting in huge cursors. It's because Breeze's "nominal size" (24) is different from the image size (32).
We can work around this problem by changing the nominal size to 32.
Step 1 is same as above. Then we modify the metadata:
cd ~/.local/share/icons/breeze_cursors.my find cursors_scalable/ -name 'metadata.json' -exec sed -i 's/"nominal_size": 24/"nominal_size": 32/g' '{}' \; rm -r cursors/ kcursorgen --svg-theme-to-xcursor --svg-dir=cursors_scalable --xcursor-dir=cursors --sizes=32 --scales=1,1.5,2,2.5,3Then you can go to systemsettings - cursor themes, select your new theme, and choose size 32 in the dropdown. Cursors in GTK4 apps should be fixed now.
Extra idea: (For distro maintainers) reduce cursor theme package size to 1/10It might be possible to only package the index.theme file and cursors_scalable directory for the Breeze cursor theme (and other SVG cursors themes), then in an postinstall script, use kcursorgen to generate the cursors directory on the user's machine.
This would greatly reduce the package size. And also you can generate more sizes without worrying about blown package size.
But the fact that kcursorgen is in the breeze package might make some dependency problems. I have an standalone Python script that does the same. (But it requires Python and PySide6.)
Sahil Dhiman: Prosody Certificate Management With Nginx and Certbot
I have a self-hosted XMPP chat server through Prosody. Earlier, I struggled with certificate renewal and generation for Prosody because I have Nginx (and a bunch of other services) running on the same server which binds to Port 80. Due to this, Certbot wasn’t able to auto-renew (through HTTP validation) for domains managed by Prosody.
Now, I have cobbled together a solution to keep both Nginx and Prosody happy. This is how I did it:
- Expose /.well-known/acme-challenge through Nginx for Prosody domain. Nginx config looked like this:
- Run certbot to get certificates for <PROSODY.DOMAIN>.
- To use those in Prosody, add a cron entry for root user:
Explanation from Prosody docs:
Certificates and their keys are copied to /etc/prosody/certs (can be changed with the certificates option) and then it signals Prosody to reload itself. –root lets prosodyctl write to paths that may not be writable by the prosody user, as is common with /etc/prosody.
- Certbot now manages auto-renewal as well, and we’re all set.
Interview on Tech Over Tea about fundraising, money, and design
I recently sat down with Brodie Robertson again to appear on his Tech Over Tea show, this time on the subject of KDE’s recent fundraising, the role of money in open-source in general, and also design (I can never resist talking about this). If these topics interest you, check it out!
Amarok 3.2.1 released
The Amarok Development Squad is happy to announce the immediate availability of Amarok 3.2.1, the first bugfix release for Amarok 3.2 "Punkadiddle"!
3.2.1 features fixes for some small UI bugs, improvements for file transfers to MTP devices, and some compilation fixes for different combinations of Qt6 versions and compilers, enabling easier testing of Qt6 builds. Additionally, it is now theoretically possible to enable last.fm and gpodder.net support in a Qt6 build. However, this requires Qt6 support in liblastfm and libmygpo-qt; a functionality that is not yet included in the most recent released versions of the libraries.
Changes since 3.2.0 CHANGES:- Support gpodder and lastfm on Qt6 builds
- Limit maximum current track font size more when context view is narrow
- Fix displaying settings button for Internet services
- Enable Wikipedia context applet on Qt6 builds
- Don't crash when copying multiple files to MTP device (BR 467616)
- Avoid unnecessarily flooding MTP devices with storage capacity queries
- Compilation fixes for various compiler + Qt6 version combinations
In addition to source code, Amarok is available for installation from many distributions' package repositories, which are likely to get updated to 3.2.1 soon, as well as the flatpak available on flathub.
Packager sectionYou can find the tarball package on download.kde.org and it has been signed with Tuomas Nurmi's GPG key.
Andrew Cater: 20250111 Release media testing for Debian 12.9
We're part way through the testing of release media. RattusRattus, Isy, Sledge, smcv and Helen in Cambridge, a new tester Blew in Manchester, another new tester MerCury[m] and also highvoltage in South Africa.
Everything is going well so far and we're chasing through the test schedule.
Sorry not to be there in Cambridgeshire with friends - but the room is fairly small and busy :)
[UPDATE/EDIT - at 20250111 1701 - we're pretty much complete on the testing]
Real Python: Python's urllib.request for HTTP Requests
If you’re looking to make HTTP requests in Python using the built-in urllib.request module, then this tutorial is for you. urllib.request lets you perform HTTP operations without having to add external dependencies.
This tutorial covers how to execute GET and POST requests, handle HTTP responses, and even manage character encodings. You’ll also learn how to handle common errors and differentiate between urllib.request and the requests library.
By the end of this tutorial, you’ll understand that:
- urllib is part of Python’s standard library.
- urllib is used to make HTTP requests.
- You can open a URL with urllib by importing urlopen and calling it with the target URL.
- To send a POST request using urllib, you pass data to urlopen() or a Request object.
- The requests package offers a higher-level interface with intuitive syntax.
- urllib3 is different from the built-in urllib module.
In this tutorial, you’ll learn how to make basic HTTP requests, how to deal with character encodings of HTTP messages, and how to solve some common errors when using urllib.request. Finally, you’ll explore why both urllib and the requests library exist and when to use one or the other.
If you’ve heard of HTTP requests, including GET and POST, then you’re probably ready for this tutorial. Also, you should’ve already used Python to read and write to files, ideally with a context manager, at least once.
Learn More: Click here to join 290,000+ Python developers on the Real Python Newsletter and get new Python tutorials and news that will make you a more effective Pythonista.
Basic HTTP GET Requests With urllib.requestBefore diving into the deep end of what an HTTP request is and how it works, you’re going to get your feet wet by making a basic GET request to a sample URL. You’ll also make a GET request to a mock REST API for some JSON data. In case you’re wondering about POST Requests, you’ll be covering them later in the tutorial, once you have some more knowledge of urllib.request.
Beware: Depending on your exact setup, you may find that some of these examples don’t work. If so, skip ahead to the section on common urllib.request errors for troubleshooting.
If you’re running into a problem that’s not covered there, be sure to comment below with a precise and reproducible example.
To get started, you’ll make a request to www.example.com, and the server will return an HTTP message. Ensure that you’re using Python 3 or above, and then use the urlopen() function from urllib.request:
Python >>> from urllib.request import urlopen >>> with urlopen("https://www.example.com") as response: ... body = response.read() ... >>> body[:15] b'<!doctype html>' Copied!In this example, you import urlopen() from urllib.request. Using the context manager with, you make a request and receive a response with urlopen(). Then you read the body of the response and close the response object. With that, you display the first fifteen positions of the body, noting that it looks like an HTML document.
There you are! You’ve successfully made a request, and you received a response. By inspecting the content, you can tell that it’s likely an HTML document. Note that the printed output of the body is preceded by b. This indicates a bytes literal, which you may need to decode. Later in the tutorial, you’ll learn how to turn bytes into a string, write them to a file, or parse them into a dictionary.
The process is only slightly different if you want to make calls to REST APIs to get JSON data. In the following example, you’ll make a request to {JSON} Placeholder for some fake to-do data:
Python >>> from urllib.request import urlopen >>> import json >>> url = "https://jsonplaceholder.typicode.com/todos/1" >>> with urlopen(url) as response: ... body = response.read() ... >>> todo_item = json.loads(body) >>> todo_item {'userId': 1, 'id': 1, 'title': 'delectus aut autem', 'completed': False} Copied!In this example, you’re doing pretty much the same as in the previous example. But in this one, you import urllib.request and json, using the json.loads() function with body to decode and parse the returned JSON bytes into a Python dictionary. Voila!
If you’re lucky enough to be using error-free endpoints, such as the ones in these examples, then maybe the above is all that you need from urllib.request. Then again, you may find that it’s not enough.
Now, before doing some urllib.request troubleshooting, you’ll first gain an understanding of the underlying structure of HTTP messages and learn how urllib.request handles them. This understanding will provide a solid foundation for troubleshooting many different kinds of issues.
The Nuts and Bolts of HTTP MessagesTo understand some of the issues that you may encounter when using urllib.request, you’ll need to examine how a response is represented by urllib.request. To do that, you’ll benefit from a high-level overview of what an HTTP message is, which is what you’ll get in this section.
Before the high-level overview, a quick note on reference sources. If you want to get into the technical weeds, the Internet Engineering Task Force (IETF) has an extensive set of Request for Comments (RFC) documents. These documents end up becoming the actual specifications for things like HTTP messages. RFC 7230, part 1: Message Syntax and Routing, for example, is all about the HTTP message.
If you’re looking for some reference material that’s a bit easier to digest than RFCs, then the Mozilla Developer Network (MDN) has a great range of reference articles. For example, their article on HTTP messages, while still technical, is a lot more digestible.
Now that you know about these essential sources of reference information, in the next section you’ll get a beginner-friendly overview of HTTP messages.
Understanding What an HTTP Message Is Read the full article at https://realpython.com/urllib-request/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Real Python: Python's pathlib Module: Taming the File System
Python’s pathlib module helps streamline your work with file and directory paths. Instead of relying on traditional string-based path handling, you can use the Path object, which provides a cross-platform way to read, write, move, and delete files.
pathlib also brings together functionality previously spread across other libraries like os, glob, and shutil, making file operations more straightforward. Plus, it includes built-in methods for reading and writing text or binary files, ensuring a clean and Pythonic approach to handling file tasks.
By the end of this tutorial, you’ll understand that:
- pathlib provides an object-oriented interface for managing file and directory paths in Python.
- You can instantiate Path objects using class methods like .cwd(), .home(), or by passing strings to Path.
- pathlib allows you to read, write, move, and delete files efficiently using methods.
- To get a list of file paths in a directory, you can use .iterdir(), .glob(), or .rglob().
- You can use pathlib to check if a path corresponds to a file by calling the .is_file() method on a Path object.
You’ll also explore a bunch of code examples in this tutorial, which you can use for your everyday file operations. For example, you’ll dive into counting files, finding the most recently modified file in a directory, and creating unique filenames.
It’s great that pathlib offers so many methods and properties, but they can be hard to remember on the fly. That’s where a cheat sheet can come in handy. To get yours, click the link below:
Free Download: Click here to claim your pathlib cheat sheet so you can tame the file system with Python.
The Problem With Representing Paths as StringsWith Python’s pathlib, you can save yourself some headaches. Its flexible Path class paves the way for intuitive semantics. Before you have a closer look at the class, take a moment to see how Python developers had to deal with paths before pathlib was around.
Traditionally, Python has represented file paths using regular text strings. However, since paths are more than plain strings, important functionality was spread all around the standard library, including in libraries like os, glob, and shutil.
As an example, the following code block moves files into a subfolder:
Python import glob import os import shutil for file_name in glob.glob("*.txt"): new_path = os.path.join("archive", file_name) shutil.move(file_name, new_path) Copied!You need three import statements in order to move all the text files to an archive directory.
Python’s pathlib provides a Path class that works the same way on different operating systems. Instead of importing different modules such as glob, os, and shutil, you can perform the same tasks by using pathlib alone:
Python from pathlib import Path for file_path in Path.cwd().glob("*.txt"): new_path = Path("archive") / file_path.name file_path.replace(new_path) Copied!Just as in the first example, this code finds all the text files in the current directory and moves them to an archive/ subdirectory. However, with pathlib, you accomplish these tasks with fewer import statements and more straightforward syntax, which you’ll explore in depth in the upcoming sections.
Path Instantiation With Python’s pathlibOne motivation behind pathlib is to represent the file system with dedicated objects instead of strings. Fittingly, the official documentation of pathlib is called pathlib — Object-oriented filesystem paths.
The object-oriented approach is already quite visible when you contrast the pathlib syntax with the old os.path way of doing things. It gets even more obvious when you note that the heart of pathlib is the Path class:
If you’ve never used this module before or just aren’t sure which class is right for your task, Path is most likely what you need. (Source)
In fact, Path is so frequently used that you usually import it directly:
Python >>> from pathlib import Path >>> Path <class 'pathlib.Path'> Copied!Because you’ll mainly be working with the Path class of pathlib, this way of importing Path saves you a few keystrokes in your code. This way, you can work with Path directly, rather than importing pathlib as a module and referring to pathlib.Path.
There are a few different ways of instantiating a Path object. In this section, you’ll explore how to create paths by using class methods, passing in strings, or joining path components.
Using Path Methods Read the full article at https://realpython.com/python-pathlib/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Real Python: Operators and Expressions in Python
Python operators enable you to perform computations by combining objects and operators into expressions. Understanding Python operators is essential for manipulating data effectively.
This tutorial covers arithmetic, comparison, Boolean, identity, membership, bitwise, concatenation, and repetition operators, along with augmented assignment operators. You’ll also learn how to build expressions using these operators and explore operator precedence to understand the order of operations in complex expressions.
By the end of this tutorial, you’ll understand that:
- Arithmetic operators perform mathematical calculations on numeric values.
- Comparison operators evaluate relationships between values, returning Boolean results.
- Boolean operators create compound logical expressions.
- Identity operators determine if two operands refer to the same object.
- Membership operators check for the presence of a value in a container.
- Bitwise operators manipulate data at the binary level.
- Concatenation and repetition operators manipulate sequence data types.
- Augmented assignment operators simplify expressions involving the same variable.
This tutorial provides a comprehensive guide to Python operators, empowering you to create efficient and effective expressions in your code. To get the most out of this tutorial, you should have a basic understanding of Python programming concepts, such as variables, assignments, and built-in data types.
Free Bonus: Click here to download your comprehensive cheat sheet covering the various operators in Python.
Take the Quiz: Test your knowledge with our interactive “Python Operators and Expressions” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Python Operators and ExpressionsTest your understanding of Python operators and expressions.
Getting Started With Operators and ExpressionsIn programming, an operator is usually a symbol or combination of symbols that allows you to perform a specific operation. This operation can act on one or more operands. If the operation involves a single operand, then the operator is unary. If the operator involves two operands, then the operator is binary.
For example, in Python, you can use the minus sign (-) as a unary operator to declare a negative number. You can also use it to subtract two numbers:
Python >>> -273.15 -273.15 >>> 5 - 2 3 Copied!In this code snippet, the minus sign (-) in the first example is a unary operator, and the number 273.15 is the operand. In the second example, the same symbol is a binary operator, and the numbers 5 and 2 are its left and right operands.
Programming languages typically have operators built in as part of their syntax. In many languages, including Python, you can also create your own operator or modify the behavior of existing ones, which is a powerful and advanced feature to have.
In practice, operators provide a quick shortcut for you to manipulate data, perform mathematical calculations, compare values, run Boolean tests, assign values to variables, and more. In Python, an operator may be a symbol, a combination of symbols, or a keyword, depending on the type of operator that you’re dealing with.
For example, you’ve already seen the subtraction operator, which is represented with a single minus sign (-). The equality operator is a double equal sign (==). So, it’s a combination of symbols:
Python >>> 42 == 42 True Copied!In this example, you use the Python equality operator (==) to compare two numbers. As a result, you get True, which is one of Python’s Boolean values.
Speaking of Boolean values, the Boolean or logical operators in Python are keywords rather than signs, as you’ll learn in the section about Boolean operators and expressions. So, instead of the odd signs like ||, &&, and ! that many other programming languages use, Python uses or, and, and not.
Using keywords instead of odd signs is a really cool design decision that’s consistent with the fact that Python loves and encourages code’s readability.
You’ll find several categories or groups of operators in Python. Here’s a quick list of those categories:
- Assignment operators
- Arithmetic operators
- Comparison operators
- Boolean or logical operators
- Identity operators
- Membership operators
- Concatenation and repetition operators
- Bitwise operators
All these types of operators take care of specific types of computations and data-processing tasks. You’ll learn more about these categories throughout this tutorial. However, before jumping into more practical discussions, you need to know that the most elementary goal of an operator is to be part of an expression. Operators by themselves don’t do much:
Python >>> - File "<input>", line 1 - ^ SyntaxError: incomplete input >>> == File "<input>", line 1 == ^^ SyntaxError: incomplete input >>> or File "<input>", line 1 or ^^ SyntaxError: incomplete input Copied!As you can see in this code snippet, if you use an operator without the required operands, then you’ll get a syntax error. So, operators must be part of expressions, which you can build using Python objects as operands.
So, what is an expression anyway? Python has simple and compound statements. A simple statement is a construct that occupies a single logical line, like an assignment statement. A compound statement is a construct that occupies multiple logical lines, such as a for loop or a conditional statement. An expression is a simple statement that produces and returns a value.
Read the full article at https://realpython.com/python-operators-expressions/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Real Python: Inheritance and Composition: A Python OOP Guide
In Python, understanding inheritance and composition is crucial for effective object-oriented programming. Inheritance allows you to model an is a relationship, where a derived class extends the functionality of a base class. Composition, on the other hand, models a has a relationship, where a class contains objects of other classes to build complex structures. Both techniques promote code reuse, but they approach it differently.
You achieve composition in Python by creating classes that contain objects of other classes, allowing you to reuse code through these contained objects. This approach provides flexibility and adaptability, as changes in component classes minimally impact the composite class.
Inheritance in Python is achieved by defining a class that derives from a base class, inheriting its interface and implementation. You can use multiple inheritance to derive a class from more than one base class, but it requires careful handling of method resolution order (MRO).
By the end of this tutorial, you’ll understand that:
- Composition and inheritance in Python model relationships between classes, enabling code reuse in different ways.
- Composition is achieved by creating classes that contain objects of other classes, allowing for flexible designs.
- Inheritance models an is a relationship, allowing derived classes to extend base class functionality.
- Inheritance in Python is achieved by defining classes that derive from base classes, inheriting their interface and implementation.
Exploring the differences between inheritance and composition helps you choose the right approach for designing robust, maintainable Python applications. Understanding how and when to apply each concept is key to leveraging the full power of Python’s object-oriented programming capabilities.
Get Your Code: Click here to get the free sample code that shows you how to use inheritance and composition in Python.
Take the Quiz: Test your knowledge with our interactive “Inheritance and Composition: A Python OOP Guide” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Inheritance and Composition: A Python OOP GuideIn this quiz, you'll test your understanding of inheritance and composition in Python. These are two major concepts in object-oriented programming that help model the relationship between two classes. By working through this quiz, you'll revisit how to use inheritance and composition in Python, model class hierarchies, and use multiple inheritance.
What Are Inheritance and Composition?Inheritance and composition are two major concepts in object-oriented programming that model the relationship between two classes. They drive the design of an application and determine how the application should evolve as new features are added or requirements change.
Both of them enable code reuse, but they do it in different ways.
What’s Inheritance?Inheritance models what’s called an is a relationship. This means that when you have a Derived class that inherits from a Base class, you’ve created a relationship where Derived is a specialized version of Base.
Inheritance is represented using the Unified Modeling Language, or UML, in the following way:
This model represents classes as boxes with the class name on top. It represents the inheritance relationship with an arrow from the derived class pointing to the base class. The word extends is usually added to the arrow.
Note: In an inheritance relationship:
- Classes that inherit from another are called derived classes, subclasses, or subtypes.
- Classes from which other classes are derived are called base classes or super classes.
- A derived class is said to derive, inherit, or extend a base class.
Say you have the base class Animal, and you derive from it to create a Horse class. The inheritance relationship states that Horse is an Animal. This means that Horse inherits the interface and implementation of Animal, and you can use Horse objects to replace Animal objects in the application.
This is known as the Liskov substitution principle. The principle states that if S is a subtype of T, then replacing objects of type T with objects of type S doesn’t change the program’s behavior.
You’ll see in this tutorial why you should always follow the Liskov substitution principle when creating your class hierarchies, and you’ll learn about the problems that you’ll run into if you don’t.
What’s Composition?Composition is a concept that models a has a relationship. It enables creating complex types by combining objects of other types. This means that a class Composite can contain an object of another class Component. This relationship means that a Composite has a Component.
UML represents composition as follows:
The model represents composition through a line that starts with a diamond at the composite class and points to the component class. The composite side can express the cardinality of the relationship. The cardinality indicates the number or the valid range of Component instances that the Composite class will contain.
Read the full article at https://realpython.com/inheritance-composition-python/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Real Python: HTML and CSS for Python Developers
Combining HTML, CSS, and Python equips you to build dynamic, interactive websites. HTML provides the structure, CSS adds styling, and Python can be used to interact with and manipulate the HTML content. By understanding how these technologies work together, you can create visually appealing and functionally robust websites.
This tutorial guides you through the basics of creating HTML files, using CSS for styling, and leveraging Python to manage HTML content programmatically.
By the end of this tutorial, you’ll understand that:
- Python can be used alongside HTML and CSS to create dynamic web content.
- HTML, CSS, and Python are sufficient for developing basic web applications.
- Learning HTML, CSS, and Python simultaneously is feasible and beneficial.
- Learning HTML and CSS first can give you a solid foundation before tackling Python.
- You can mix Python with HTML to automate and enhance web development.
Explore how HTML and CSS can enhance your Python projects, enabling you to create impressive websites and understand web frameworks like Flask and Django more deeply.
You’ll get an introduction to HTML and CSS that you can follow along with. Throughout this tutorial, you’ll build a website with three pages and CSS styling:
While creating the web project, you’ll craft a boilerplate HTML document that you can use in your upcoming web projects. You may find that the source code will come in handy when you’re working on future projects. You can download it here:
Free Bonus: Click here to download the supplemental materials for this tutorial, including a time-saving HTML template file.
After learning the basics of HTML and CSS, you’ll find ideas on how to continue your journey at the end of the tutorial.
Create Your First HTML FileThink of any website that you’ve recently visited. Maybe you read some news, chatted with friends, or watched a video. No matter what kind of website it was, you can bet that its source code has a basic <html> tag at the beginning.
HTML stands for HyperText Markup Language. HTML was created by Tim Berners-Lee, whose name might also ring a bell for you as the inventor of the World Wide Web.
The hypertext part of HTML refers to building connections between different HTML pages. With hyperlinks, you can jump between pages and surf the Web.
You use markup to structure content in a document. In contrast to formatting, the markup defines the meaning of content and not how it looks. In this section, you’ll learn about HTML elements and their roles.
Writing semantic HTML code will make your documents accessible for a wide range of visitors. After all, you want to enable everybody to consume your content, whether they’re visiting your page with a browser or using screen reading tools.
For each HTML element, there’s a standard that defines its intended use. Today, the standards of HTML are defined by the Web Hypertext Application Technology Working Group (WHATWG). The WHATWG plays a similar role for HTML as the Python Steering Council does for Python.
Approximately 95 percent of websites use HTML, so you’ll be hard-pressed to avoid it if you want to do any web development work in Python.
In this section, you’ll start by creating your first HTML file. You’ll learn how to structure your HTML code to make it readable for your browser and for humans.
The HTML DocumentIn this section, you’ll create a basic HTML file. The HTML file will contain the base structure that most websites are built with.
To start things off, create a file named index.html with some text:
HTML index.html Am I HTML already? Copied!Traditionally, the first file of your website is called index.html. You can think of the index.html page as akin to the main.py or app.py file in a Python project.
Note: Unless your server is configured differently, index.html is the file that the server tries to load when you visit the root URL. That’s why you can visit https://www.example.com/ instead of typing the full https://www.example.com/index.html address.
Read the full article at https://realpython.com/html-css-python/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
The Drop is Always Moving: People of the wonderful Drupal community are hosting more than 40 parties on Wednesday to celebrate the launch of Drupal CMS 1.0, quite incredible! Which one will you be at? There is also a global online party to join! https:...
People of the wonderful Drupal community are hosting more than 40 parties on Wednesday to celebrate the launch of Drupal CMS 1.0, quite incredible! Which one will you be at? There is also a global online party to join! https://www.drupal.org/association/blog/join-the-party-help-us-launch-drupal-cms-in-style
This Week in Plasma: Final Plasma 6.3 Features
Welcome to a new issue of "This Week in Plasma"! Every week we cover as much as possible of what's happening in the world of KDE Plasma and its associated apps like Discover, System Monitor, and more.
This week the focus was on landing final Plasma 6.3 features and UI changes… and land them we did! Now it's time to spend the next month exclusively on bug-fixing and polishing.
Notable New FeaturesWhen notifications arrive while "Do Not Disturb" mode is engaged, exiting that mode now shows a single notification informing you of how many you missed, rather than sending them all in a giant unmanageable flood. (Fushan Wen, 6.3.0. Link)
The desktop context menu for symbolic links now includes a "Show Target" menu item, just like one one in Dolphin. (Nate Graham, 6.3.0. Link)
The System Monitor app and widgets are now capable of collecting GPU statistics on FreeBSD. (Henry Hu, 6.3.0. Link)
Notable UI ImprovementsIf you didn't like the change in Plasma 6.2 to use symbolic icons in Kickoff's category sidebar, you can now undo it yourself; we changed the implementation to pull icons from the standard data source, so you can set them to whatever you want using the Menu Editor app. (David Redondo, 6.3.0. Link 1 and link 2)
Reduced the clutter on the Edit Mode toolbar, making its contents more focused and relevant. (Nate Graham, Link 1, link 2, and link 3)
The DrKonqi crash reporter/browser app's main windows now remember their size, maximization state, and (on X11), position on screen. (Nate Graham, 6.3.0. Link)
External web links in Kirigami-based apps such as Discover now show the typical "arrow pointing out of a square" icon to make this more clear. (Carl Schwan and Nate Graham, Frameworks 6.11. Link)
Modernized the UI style of the standalone printer-related apps that are not yet integrated directly into the System Settings page. (Thomas Duckworth, 6.3.0. Link)
All close buttons throughout KDE software are now consistent; we've standardized on the black X. As part of this, we also changed the timeout indicator on Plasma notifications to not be dependent on any particular close button icon appearance, as was the case before. (Nate Graham, Plasma 6.3.0 with Frameworks 6.11. Link 1, link 2, and link 3)
System Settings' Night Light page has moved from the "Colors & Themes" group to the "Display & Monitor" group, which is a more natural and expected place for it. (Kisaragi Hiu, 6.4.0. Link)
In Plasma's Networks widget, there's now a "Configure" button for networks that you've used in the past but aren't currently connected to. (Kai Uwe Broulik, 6.3.0. Link)
Notable Bug FixesPlasma no longer crashes when you switch the desktop from "Folder" containment to "Desktop" containment, and then back. (Marco Martin, 6.3.0. Link)
The session restore "Excluded applications" list you can populate yourself now actually takes effect on Wayland. Also, you now list apps by their desktop file names, which lets the feature work for apps whose executable is ambiguous, such as Flatpak apps. (Harald Sitter, 6.3.0. Link 1 and link 2)
Fixed a bug that could cause full-screen windows being screencasted to freeze under certain circumstances. (Xaver Hugl, 6.3.0. Link)
Made laptops more robust against waking up while the lid is closed. (Xaver Hugl, 6.3.0. Link)
Tooltips for favorited apps in Kicker once again appear as expected, and don't disappear immediately on hover. (Marco Martin, 6.3.0. Link)
Typing text into KRunner that matches a history item but with different capitalization no longer causes the grayed-out auto-completion text to de-sync with the text you already typed. (Nate Graham, 6.3.0. Link)
Plasma no longer unnecessarily shows you an OSD indicating the default audio device when you return from a different TTY. (Kai Uwe Broulik, 6.3.0. Link)
Time zones shown in the Digital Clock widget's popup are once again sorted by time, rather than randomly. (Nate Graham, 6.3.0. Link)
Fixed a visual glitch that could manifest as brief graphical corruption when interacting with pages in the clipboard settings dialog in a certain way. (David Edmundson, 6.3.0. Link)
Fixed a bug in the Wayland session restoration feature that could make it inappropriately restore multiple instances of apps. (Harald Sitter, 6.3.0. Link)
In Discover, app pages and pages with lists of apps are no longer inappropriately horizontally scrollable. (Nate Graham and Ismael Asensio, 6.3.0. Link 1 and link 2)
Fixed an issue in Kirigami.Icon that affected multiple Plasma widgets, whereby an icon from the active icon theme would be mistakenly provided instead of a custom image, in cases where that custom image was referenced from an absolute path and happened to have the same filename as a themed icon. (Marco Martin, Frameworks 6.11. Link)
Fixed a case where some dialogs in Kirigami-based apps such as System Monitor could have overflowing footer buttons in some languages. (Nate Graham, Frameworks 6.11. Link)
Other bug information of note:
- 3 Very high priority Plasma bugs (up from 3 last week). Current list of bugs
- 36 15-minute Plasma bugs (up from 34 last week). Current list of bugs
- At least 138 KDE bugs of all kinds fixed over the past week. Full list of bugs
Reduced the System Monitor app's background CPU usage down to 1-3% with some clever internal restructuring. (Arjen Hiemstra, 6.3.0. Link)
Removed a bunch of unnecessary old "sanity checks" on login that were not actually providing any additional sanity, and could even prevent login under certain circumstances! (David Redondo, 6.3.0. Link)
Improved performance on certain GPUs while Night Light is active; previously it could sometimes be quite poor. (Xaver Hugl, 6.3.0. Link)
It's now possible to pre-authorize apps for remote desktop access, so you don't have to wait for them to pop up an interactive permission dialog. Preliminary documentation can be found here. (Harald Sitter, 6.3.0. Link)
How You Can HelpKDE has become important in the world, and your time and contributions have helped us get there. As we grow, we need your support to keep KDE sustainable.
You can help KDE by becoming an active community member and getting involved somehow. Each contributor makes a huge difference in KDE — you are not a number or a cog in a machine!
You don’t have to be a programmer, either. Many other opportunities exist:
- Triage and confirm bug reports, maybe even identify their root cause
- Contribute designs for wallpapers, icons, and app interfaces
- Design and maintain websites
- Translate user interface text items into your own language
- Promote KDE in your local community
- …And a ton more things!
You can also help us by making a donation! Any monetary contribution — however small — will help us cover operational costs, salaries, travel expenses for contributors, and in general just keep KDE bringing Free Software to the world.
To get a new Plasma feature or a bugfix mentioned here, feel free to push a commit to the relevant merge request on invent.kde.org.
joshics.in: Sustaining Drupal 7 Post-EOL: In-Depth Strategies for Collaboration & Ecosystem Updates
As the long-standing powerhouse supporting numerous websites, Drupal 7 faces fresh challenges with its end-of-life (EOL). For developers and site owners committed to maintaining their investment, a strategic approach involving collaboration and proactive updates is crucial. Here’s an expanded guide on sustaining your Drupal 7 site effectively post-EOL.
Why Continue with Drupal 7?There are several reasons why maintaining Drupal 7 might still be beneficial:
- Stability and Familiarity: For many organizations, Drupal 7 offers a stable and well-understood environment. Teams that have fine-tuned their processes around it may prefer to stick with what works.
- Resource Constraints: Transitioning to Drupal 10 or an alternative can require significant resources—including time, budget, and technical adjustments—that some organizations may not have readily available.
- Security Vulnerabilities: With the cessation of official updates, potential security loopholes pose a higher risk. Proactively monitoring and patching these vulnerabilities becomes critical.
- Module Compatibility: As web standards and technologies evolve, some Drupal 7 modules might fall out of sync with modern requirements, leading to functionality issues.
- Reduced Community Support: With the community shifting focus to newer versions, accessing help and resources could become more difficult.
- Engage with Community Initiatives:
- Find Dedicated Groups: Engage with forums and groups committed to Drupal 7 maintenance. Collaborating with like-minded individuals can provide new solutions and resources.
- Join Working Groups: Participate in specialized working groups focused on Drupal 7. Contribute your insights and leverage shared knowledge to solve common challenges.
- Contribute to Module Maintenance:
- Adopt Key Modules: Identify key modules vital to your site’s operation and dedicate resources to their maintenance. Consider becoming a co-maintainer or collaborating with other developers.
- Develop Custom Patches: For modules with limited external support, develop and share custom patches that address critical issues or improve functionality.
- Share Updates and Insights:
- Create Knowledge Networks: Build a network of professionals managing Drupal 7 sites. Regularly share updates, best practices, and insights on overcoming challenges.
- Host Webinars and Workshops: Organize webinars and workshops to disseminate knowledge and foster collaboration. These platforms can serve as valuable venues for sharing discoveries and learning from peers.
- Monitor Emerging Trends:
- Stay informed about industry trends and find ways to integrate relevant advancements into your Drupal 7 environment. This proactive stance helps keep your site competitive and functional.
- Upgrade Wisely:
- Plan gradual enhancements to the core and modules, ensuring they're aligned with evolving standards. This step-by-step approach can prevent sudden disruptions and maintain site reliability.
- Evaluate Alternatives:
- Regularly assess other platforms and updates. Even if sticking with Drupal 7 for now, knowing your options keeps you prepared for future transitions when resources permit.
Sustaining Drupal 7 post-EOL requires a strategic blend of collaboration, innovation, and vigilance. By actively engaging with the community, committing to module maintenance, and adapting to ecosystem changes, you can extend the life of your Drupal 7 site while planning for the future. This commitment to proactive management ensures your site remains secure, efficient, and ready to meet current demands.
Skrooge 25.1.0 released
This is the first version for Kf6/Qt6.
Changelog- Correction bug 494197: Shortcut for Setting Status to Checked
- Correction bug 494159: Wrong decimal separator in CSV import
- Correction bug 494516: Categories "closed" are not displayed
- Correction bug 494023: Downloading values from yahoo fails HTTP Error 401: Unauthorized
- Correction bug 494077: document History panel and better document viewing transactions modified by an action
- Correction bug 498157: Inconsistent icons in the Pages sidebar
- Correction: Replace yahoo source (not working) by boursorama source
- Correction: More robust copy of tables
- Migration: Support build on qt6/kf6
- Correction: Fix performances issue on qt6 due to QDateTime::fromString
Dirk Eddelbuettel: nanotime 0.3.11 on CRAN: Polish
Another minor update 0.3.11 for our nanotime package is now on CRAN. nanotime relies on the RcppCCTZ package (as well as the RcppDate package for additional C++ operations) and offers efficient high(er) resolution time parsing and formatting up to nanosecond resolution, using the bit64 package for the actual integer64 arithmetic. Initially implemented using the S3 system, it has benefitted greatly from a rigorous refactoring by Leonardo who not only rejigged nanotime internals in S4 but also added new S4 types for periods, intervals and durations.
This release covers two corner case. Michael sent in a PR avoiding a clang warning on complex types. We fixed an issue that surfaced in a downstream package under sanitizier checks: R extends coverage of NA to types such as integer or character which need special treatment in non-R library code as ‘they do not know’. We flagged (character) formatted values after we had called the corresponding CCTZ function but that leaves potentiall ‘undefined’ values (from R’s NA values for int, say, cast to double) so now we flag them, set a transient safe value for the call and inject the (character) representation "NA" after the call in those spots. End result is the same, but without a possibly slap on the wrist from sanitizer checks.
The NEWS snippet below has the full details.
Changes in version 0.3.11 (2025-01-10)Explicit Rcomplex assignment accommodates pickier compilers over newer R struct (Michael Chirico in #135 fixing #134)
When formatting, NA are flagged before CCTZ call to to not trigger santizier, and set to NA after call (Dirk in #136)
Thanks to my CRANberries, there is a diffstat report for this release. More details and examples are at the nanotime page; code, issue tickets etc at the GitHub repository – and all documentation is provided at the nanotime documentation site.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. If you like this or other open-source work I do, you can now sponsor me at GitHub.
Glyph Lefkowitz: The “Active Enum” Pattern
Have you ever written some Python code that looks like this?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18from enum import Enum, auto class SomeNumber(Enum): one = auto() two = auto() three = auto() def behavior(number: SomeNumber) -> int: match number: case SomeNumber.one: print("one!") return 1 case SomeNumber.two: print("two!") return 2 case SomeNumber.three: print("three!") return 3That is to say, have you written code that:
- defined an enum with several members
- associated custom behavior, or custom values, with each member of that enum,
- needed one or more match / case statements (or, if you’ve been programming in Python for more than a few weeks, probably a big if/elif/elif/else tree) to do that association?
In this post, I’d like to submit that this is an antipattern; let’s call it the “passive enum” antipattern.
For those of you having a generally positive experience organizing your discrete values with enums, it may seem odd to call this an “antipattern”, so let me first make something clear: the path to a passive enum is going in the correct direction.
Typically - particularly in legacy code that predates Python 3.4 - one begins with a value that is a bare int constant, or maybe a str with some associated values sitting beside in a few global dicts.
Starting from there, collecting all of your values into an enum at all is a great first step. Having an explicit listing of all valid values and verifying against them is great.
But, it is a mistake to stop there. There are problems with passive enums, too:
- The behavior can be defined somewhere far away from the data, making it difficult to:
- maintain an inventory of everywhere it’s used,
- update all the consumers of the data when the list of enum values changes, and
- learn about the different usages as a consumer of the API
- Logic may be defined procedurally (via if/elif or match) or
declaratively (via e.g. a dict whose keys are your enum and whose values
are the required associated value).
- If it’s defined procedurally, it can be difficult to build tools to interrogate it, because you need to parse the AST of your Python program. So it can be difficult to build interactive tools that look at the associated data without just calling the relevant functions.
- If it’s defined declaratively, it can be difficult for existing tools that do know how to interrogate ASTs (mypy, flake8, Pyright, ruff, et. al.) to make meaningful assertions about it. Does your linter know how to check that a dict whose keys should be every value of your enum is complete?
To refactor this, I would propose a further step towards organizing one’s enum-oriented code: the active enum.
An active enum is one which contains all the logic associated with the first-party provider of the enum itself.
You may recognize this as a more generalized restatement of the object-oriented lens on the principle of “separation of concerns”. The responsibilities of a class ought to be implemented as methods on that class, so that you can send messages to that class via method calls, and it’s up to the class internally to implement things. Enums are no different.
More specifically, you might notice it as a riff on the Active Nothing pattern described in this excellent talk by Sandi Metz, and, yeah, it’s the same thing.
The first refactoring that we can make is, thus, to mechanically move the method from an external function living anywhere, to a method on SomeNumber . At least like this, we present an API to consumers externally that shows that SomeNumber has a behavior method that can be invoked.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18from enum import Enum, auto class SomeNumber(Enum): one = auto() two = auto() three = auto() def behavior(self) -> int: match self: case SomeNumber.one: print("one!") return 1 case SomeNumber.two: print("two!") return 2 case SomeNumber.three: print("three!") return 3However, this still leaves us with a match statement that repeats all the values that we just defined, with no particular guarantee of completeness. To continue the refactoring, what we can do is change the value of the enum itself into a simple dataclass to structurally, by definition, contain all the fields we need:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17from dataclasses import dataclass from enum import Enum from typing import Callable @dataclass(frozen=True) class NumberValue: result: int effect: Callable[[], None] class SomeNumber(Enum): one = NumberValue(1, lambda: print("one!")) two = NumberValue(2, lambda: print("two!")) three = NumberValue(3, lambda: print("three!")) def behavior(self) -> int: self.value.effect() return self.value.resultHere, we give SomeNumber members a value of NumberValue, a dataclass that requires a result: int and an effect: Callable to be constructed. Mypy will properly notice that if x is a SomeNumber, that x will have the type NumberValue and we will get proper type checking on its result (a static value) and effect (some associated behaviors)1.
Note that the implementation of behavior method - still conveniently discoverable for callers, and with its signature unchanged - is now vastly simpler.
But what about... Lookups?You may be noticing that I have hand-waved over something important to many enum users, which is to say, by-value lookup. enum.auto will have generated int values for one, two, and three already, and by transforming those into NumberValue instances, I can no longer do SomeNumber(1).
For the simple, string-enum case, one where you might do class MyEnum: value = “value” so that you can do name lookups via MyEnum("value"), there’s a simple solution: use square brackets instead of round ones. In this case, with no matching strings in sight, SomeNumber["one"] still works.
But, if we want to do integer lookups with our dataclass version here, there’s a simple one-liner that will get them back for you; and, moreover, will let you do lookups on whatever attribute you want:
1by_result = {each.value.result: each for each in SomeNumber} enum.Flag?You can do this with Flag more or less unchanged, but in the same way that you can’t expect all your list[T] behaviors to be defined on T, the lack of a 1-to-1 correspondence between Flag instances and their values makes it more complex and out of scope for this pattern specifically.
3rd-party usage?Sometimes an enum is defined in library L and used in application A, where L provides the data and A provides the behavior. If this is the case, then some amount of version shear is unavoidable; this is a situation where the data and behavior have different vendors, and this means that other means of abstraction are required to keep them in sync. Object-oriented modeling methods are for consolidating the responsibility for maintenance within a single vendor’s scope of responsibility. Once you’re not responsible for the entire model, you can’t do the modeling over all of it, and that is perfectly normal and to be expected.
The goal of the Active Enum pattern is to avoid creating the additional complexity of that shear when it does not serve a purpose, not to ban it entirely.
A Case StudyI was inspired to make this post by a recent refactoring I did from a more obscure and magical2 version of this pattern into the version that I am presenting here, but if I am going to call passive enums an “antipattern” I feel like it behooves me to point at an example outside of my own solo work.
So, for a more realistic example, let’s consider a package that all Python developers will recognize from their day-to-day work, python-hearthstone, the Python library for parsing the data files associated with Blizzard’s popular computerized collectible card game Hearthstone.
As I’m sure you already know, there are a lot of enums in this library, but for one small case study, let’s look a few of the methods in hearthstone.enums.GameType.
GameType has already taken the “step 1” in the direction of an active enum, as I described above: as_bnet is an instancemethod on GameType itself, making it at least easy to see by looking at the class definition what operations it supports. However, in the implementation of that method (among many others) we can see the worst of both worlds:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16class GameType(IntEnum): def as_bnet(self, format: FormatType = FormatType.FT_STANDARD): if self == GameType.GT_RANKED: if format == FormatType.FT_WILD: return BnetGameType.BGT_RANKED_WILD elif format == FormatType.FT_STANDARD: return BnetGameType.BGT_RANKED_STANDARD # ... else: raise ValueError() # ... return { GameType.GT_UNKNOWN: BnetGameType.BGT_UNKNOWN, # ... GameType.GT_BATTLEGROUNDS_DUO_FRIENDLY: BnetGameType.BGT_BATTLEGROUNDS_DUO_FRIENDLY, }[self]We have procedural code mixed with a data lookup table; raise ValueError mixed together with value returns. Overall, it looks like this might be hard to maintain this going forward, or to see what’s going on without a comprehensive understanding of the game being modeled. Of course for most python programmers that understanding can be assumed, but, still.
If GameType were refactored in the manner above3, you’d be able to look at the member definition for GT_RANKED and see a mapping of FormatType to BnetGameType, or GT_BATTLEGROUNDS_DUO_FRIENDLY to see an unconditional value of BGT_BATTLEGROUNDS_DUO_FRIENDLY. Given that this enum has 40 elements, with several renamed or removed, it seems reasonable to expect that more will be added and removed as the game is developed.
ConclusionIf you have large enums that change over time, consider placing the responsibility for the behavior of the values alongside the values directly, and any logic for processing the values as methods of the enum. This will allow you to quickly validate that you have full coverage of any data that is required among all the different members of the enum, and it will allow API clients a convenient surface to discover the capabilities associated with that enum.
AcknowledgmentsThank you to my patrons who are supporting my writing on this blog. If you like what you’ve read here and you’d like to read more of it, or you’d like to support my various open-source endeavors, you can support my work as a sponsor!
-
You can get even fancier than this, defining a typing.Protocol as your enum’s value, but it’s best to keep things simple and use a very simple dataclass container if you can. ↩
-
derogatory ↩
-
I did not submit such a refactoring as a PR before writing this post because I don’t have full context for this library and I do not want to harass the maintainers or burden them with extra changes just to make a rhetorical point. If you do want to try that yourself, please file a bug first and clearly explain how you think it would benefit their project’s maintainability, and make sure that such a PR would be welcome. ↩
Test and Code: pytest plugins - a full season
This episode kicks off a season of pytest plugins.
In this episode:
- Introduction to pytest plugins
- The pytest.org pytest plugin list
- Finding pytest related packages on PyPI
- The Top pytest plugins list on pythontest.com
- Exploring popular plugins
- Learning from plugin examples
Links:
- Top pytest plugins list
- pytest.org plugin list
- Top PyPI Packages
- And links to plugins mentioned in the show can be found at pythontest.com/top-pytest-plugins
Learn pytest
- pytest is the number one test framework for Python.
- Learn the basics super fast with Hello, pytest!
- Then later you can become a pytest expert with The Complete pytest Course
- Both courses are at courses.pythontest.com
Tag1 Consulting: New Critical Security Updates for Drupal 7 Highlight Importance of Drupal 7 Extended Support by Tag1
Starting January 2025, the Drupal Security team will no longer review reported issues or release security updates for Drupal 7 core or contrib modules. To address this, the Drupal Association has authorized Tag1 to be a D7 Extended Support Partner, ensuring your D7 sites stay protected with Tag1's Drupal 7 Extended Support (D7ES). We will continue to monitor for security vulnerabilities and provide updates and support to ensure your site remains safe and secure beyond January 2025.
Hank Fri, 01/10/2025 - 12:29Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
- Bastian Venthur: Investigating the popularity of Python build backends over time (II)
- This Week in KDE Apps: Usability improvements, new features, and updated apps
- kcursorgen and SVG cursors
- Sahil Dhiman: Prosody Certificate Management With Nginx and Certbot
- Interview on Tech Over Tea about fundraising, money, and design