
Feeds
Update from the board of directors
The Chair of the Board of the OSI has acknowledged the resignation offered by Secretary of the Board, Aeva Black. The Chair and the entire Board would like to thank Black for their invaluable contribution to the success of OSI, as well of the entire Open Source Community, and for their service as board member and officer of the Initiative.
Obey the Testing Goat: Progress on the Third Edition of the Book!
In lieu of a formal announcement about the Third Edition, how about a progress update?
Core technology updates: Django + PythonEmbarrassment-Driven Development
One of the main motivations for a third edition was that the 2e is based on Django 1.11, which dropped out of support back in 2017, and that's been a big turnoff for readers for a while, and quite embarrassing really.
So, the plan is to upgrade to Django 5.x, and progress is good -- I've already updated most of the core chapters to Django 4.2, and upgrade Python to 3.12 while I was at it. Django 5 is next, and I'm hoping/assuming it will be a smaller leap that 1->4 was, so that won't be far behind.
New Deployment Technologies: Docker + AnsibleI've always been proud that the book includes several chapters on how to actually deploy our app to production, and make the app live on the actual public Internet. But the deployment process from the first and second editions--broadly speaking, SSH in to your server, hack about to figure out how to get your app deployed manually, and then automate what you did with glorified shellscripts, aka Fabric--was starting to look less and less like what modern deployment looks like, or my experience of it at least.
I uhmmed and ahhed about it for a while, but in the end I decided to go with a deployment process that looks like this:
- Package up our app into a Docker container, and use our tests to confirm it really works
- Use Ansible to automate pushing that container onto a server and running it.
Check out the latest version of the deployment chapters here:
- Chapter 9: Containerization aka Docker
- Chapter 10: Making our App Production-Ready
- Chapter 11: Infrastructure As Code: Automated Deployments With Ansbile
I think I like how it's turned out, a lot of the fiddliness and debugging of deployment/production-readiness can now happen locally (in Docker containers on your own machine), so I think that tightens and speeds up the feedback loop a fair bit.
JavaScriptThe Javascript chapter was another head-scratcher. I wanted to move away from QUnit, and include some more modern/ES6 syntax. In the end, I decided to go with Jasmine, which is old but still popular, but to keep the browser-based test runner, which is a bit of an unconventional choice, but it does mean we can avoid the whole Node.js and node_modules learning curve.
Aside from that, I've wound down the "JavaScript is such a nightmare" jokes, because they're really not fair any more, and were probably never that funny besides.
Check out the new version here:
Some changes of emphasisThe other main changes to the book are going to be around how I talk about some of the tradeoffs involved in the use of mocking, and unit vs integration vs functional/e2e tests. I think the first and second editions were perhaps a little too opinionated on this front (I still cringe to think how defensive I was when I first wrote the Hot Lava chapter, sorry CaseY!!), and my thinking has evolved a lot since I wrote my second book with Bob.
That's still very much on the drawing board though, so you'll have to watch this space for updates on that front.
Anyways, all the latest versions of the 3e chapters are live here on the site, and also as an Early Release on O'Reilly Learning, so do dive in and let me know what you think!
Real Python: Asynchronous Iterators and Iterables in Python
When you write asynchronous code in Python, you’ll likely need to create asynchronous iterators and iterables at some point. Asynchronous iterators are what Python uses to control async for loops, while asynchronous iterables are objects that you can iterate over using async for loops.
Both tools allow you to iterate over awaitable objects without blocking your code. This way, you can perform different tasks asynchronously.
In this tutorial, you’ll:
- Learn what async iterators and iterables are in Python
- Create async generator expressions and generator iterators
- Code async iterators and iterables with the .__aiter__() and .__anext__() methods
- Use async iterators in async loops and comprehensions
To get the most out of this tutorial, you should know the basics of Python’s iterators and iterables. You should also know about Python’s asynchronous features and tools.
Get Your Code: Click here to download the free sample code that you’ll use to learn about asynchronous iterators and iterables in Python.
Take the Quiz: Test your knowledge with our interactive “Asynchronous Iterators and Iterables in Python” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Asynchronous Iterators and Iterables in PythonTake this quiz to test your understanding of how to create and use Python async iterators and iterables in the context of asynchronous code.
Getting to Know Async Iterators and Iterables in PythonIterators and iterables are fundamental components in Python. You’ll use them in almost all your programs where you iterate over data streams using a for loop. Iterators power and control the iteration process, while iterables typically hold data that you want to iterate over.
Python iterators implement the iterator design pattern, which allows you to traverse a container and access its elements. To implement this pattern, iterators need the .__iter__() and .__next__() special methods. Similarly, iterables are typically data containers that implement the .__iter__() method.
Note: To dive deeper into iterators and iterables, check out the Iterators and Iterables in Python: Run Efficient Iterations tutorial.
Python has extended the concept of iterators and iterables to asynchronous programming with the asyncio module and the async and await keywords. In this scenario, asynchronous iterators drive the asynchronous iteration process, mainly powered by async for loops and comprehensions.
Note: In this tutorial, you won’t dive into the intricacies of Python’s asynchronous programming. So, you should be familiar with the related concepts. If you’re not, then you can check out the following tutorials:
In these tutorials, you’ll gain the required background to prepare for exploring asynchronous iterators and iterables in more depth.
In the following sections, you’ll briefly examine the concepts of asynchronous iterators and iterables in Python.
Async IteratorsPython’s documentation defines asynchronous iterators, or async iterators for short, as the following:
An object that implements the .__aiter__() and .__anext__() [special] methods. .__anext__() must return an awaitable object. [An] async for [loop] resolves the awaitables returned by an asynchronous iterator’s .__anext__() method until it raises a StopAsyncIteration exception. (Source)
Similar to regular iterators that must implement .__iter__() and .__next__(), async iterators must implement .__aiter__() and .__anext__(). In regular iterators, the .__iter__() method usually returns the iterator itself. This is also true for async iterators.
To continue with this parallelism, in regular iterators, the .__next__() method must return the next object for the iteration. In async iterators, the .__anext__() method must return the next object, which must be awaitable.
Python defines awaitable objects as described in the quote below:
An object that can be used in an await expression. [It] can be a coroutine or an object with an .__await__() method. (Source)
In practice, a quick way to make an awaitable object in Python is to call an asynchronous function. You define this type of function with the async def keyword construct. This call creates a coroutine object.
Note: You can also create awaitable objects by implementing the .__await__() special method in a custom class. This method must return an iterator that yields control back to the event loop until the awaited result is ready. This topic is beyond the scope of this tutorial.
When the data stream runs out of data, the method must raise a StopAsyncIteration exception to end the asynchronous iteration process.
Here’s an example of an async iterator that allows iterating over a range of numbers asynchronously:
Read the full article at https://realpython.com/python-async-iterators/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
The Drop Times: Introducing Dresktop: Multi-Platform Tool for Drupal Project Management
Lullabot: Drupal 11: What’s New and What’s Next
Drupal 11 was released on August 2nd, 2024. A lot has changed since Drupal 10, and a lot of preliminary work has been done that will help with Drupal Starshot. Besides improvements made to CKEditor integration, a revamp of the Field UI, performance improvements, and revisions for taxonomy terms, several big changes have been included to help the ambitious site builder.
Tag1 Consulting: Migrating Your Data from D7 to D10: Migrating taxonomy vocabularies and D7 field collections into D10 paragraphs
In the previous article, we began migrating configuration from Drupal 7 example site to our Drupal 10 instance, specifically content types. In today's article, we will continue with two more D7 entities: taxonomy vocabularies and field collections. The latter will be imported as Paragraphs in Drupal 10. Along the way, we will review the content model and the migration plan. This will help us determine what parts of the migration should be automated and what can be performed manually.
Read more mauricio Wed, 08/07/2024 - 06:50Python Software Foundation: Security Developer-in-Residence role extended thanks to Alpha-Omega
We are excited to announce the continuation of Seth Larson’s work in the Security Developer-in-Residence role through the end of 2024 thanks to continued support from Alpha-Omega. (This six month extension is intended to align the renewal period for this role with the calendar year going forward).
The first year of the Security Developer-in-Residence initiative has been a success, seeing multiple improvements to the Python ecosystem's security posture. These improvements include authorizing the PSF as a CVE Numbering Authority, migrating the CPython release process to an isolated hosted build platform, and generating comprehensive Software Bill-of-Materials documents for CPython artifacts.
Open source software security continues to evolve, this year saw new regulations for software security like the EU Cyber Resiliency Act (CRA) and evolving threats to open source like the backdoor of xz-utils.
The PSF is looking forward to continuing our investment in the security of the Python ecosystem and everyone who depends on Python software. For the remainder of 2024, priorities for Security Developer-in-Residence role include:
- Formalization of the Python Security Response Team (PSRT) and processes for handling vulnerability reports and fixes.
- Developing a strategy for Software Bill-of-Materials documents and Python packages.
- Completing the migration of the CPython release process and generation of SBOM documents for the macOS installer.
- Continued engagement with the Python community promoting security best-practices and standards.
For updates on these and other projects, check out Seth’s blog.
The PSF is a non-profit whose mission is to promote, protect, and advance the Python programming language, and to support and facilitate the growth of a diverse and international community of Python programmers. The PSF supports the Python community using corporate sponsorships, grants, and donations. Are you interested in sponsoring or donating to the PSF so it can continue supporting Python and its community? Check out our sponsorship program, donate directly here, or contact our team!
Drupal life hack's: Extended Review of Backward Compatibility Questions When Upgrading to Drupal 11
Drupal Starshot blog: Introducing Drupal Starshot's product strategy
This blog has been re-posted and edited with permission from Dries Buytaert's blog.
Drupal Starshot aims to attract mid-market marketers by offering out-of-the-box marketing best practices, user-friendly tools, AI-driven site building features, all while maintaining the many advantages of Drupal Core.
I'm excited to share the first version of Drupal Starshot's product strategy, a document that aims to guide the development and marketing of Drupal Starshot. To read it, download the full Drupal Starshot strategy document as a PDF (8 MB).
This strategy document is the result of a collaborative effort among the Drupal Starshot leadership team, the Drupal Starshot Advisory Council, and the Drupal Core Committers. We also tested it with marketers who provided feedback and validation.
Drupal Starshot and Drupal CoreDrupal Starshot is the temporary name for an initiative that extends the capabilities of Drupal Core. Drupal Starshot aims to broaden Drupal's appeal to marketers and a wider range of project budgets. Our ultimate goal is to increase Drupal's adoption, solidify Drupal's position as a leading CMS, and champion an Open Web.
For more context, please watch my DrupalCon Portland keynote.
It's important to note that Drupal Starshot and Drupal Core will have separate, yet complementary, product strategies. Drupal Starshot will focus on empowering marketers and expanding Drupal's presence in the mid-market, while Drupal Core will prioritize the needs of developers and more technical users. I'll write more about the Drupal Core product strategy in a future blog post once we have finalized it. Together, these two strategies will form a comprehensive vision for Drupal as a product.
Why a product strategy?By defining our goals, target audience and necessary features, we can more effectively guide contributors and ensure that everyone is working towards a common vision. This product strategy will serve as a foundation for our development roadmap, our marketing efforts, enabling Drupal Certified Partners, and more.
Drupal Starshot product strategy TL;DRFor the detailed product strategy, please read the full Drupal Starshot strategy document (8 MB, PDF). Below is a summary.
Drupal Starshot aims to be the gold standard for marketers that want to build great digital experiences.
We'd like to expand Drupal's reach by focusing on two strategic shifts:
- Prioritizing Drupal for content creators, marketers, web managers, and web designers so they can independently build websites. A key goal is to empower these marketing professionals to build and manage their websites independently without relying on developers or having to use the command line or an IDE.
- Extending Drupal's presence in the mid-market segment, targeting projects with total budgets between $30,000 and $120,000 USD (€25,000 to €100,000).
Drupal Starshot will differentiate itself from competitors by providing:
- A thoughtfully designed platform for marketers, balancing ease of use with flexibility. It includes smart defaults, best practices for common marketing tasks, marketing-focused editorial tools, and helpful learning resources.
- A growth-oriented approach. Start simple with Drupal Starshot's user-friendly tools, and unlock advanced features as your site grows or you gain expertise. With sophisticated content modeling, efficient content reuse across channels, and robust integrations with other leading marketing technologies, ambitious marketers won't face the limitations of other CMSs and will have the flexibility to scale their site as needed.
- AI-assisted site building tools to simplify complex tasks, making Drupal accessible to a wider range of users.
- Drupal's existing competitive advantages such as extensibility, scalability, security, accessibility, multilingual support, and more.
In the past, we used the term ambitious site builders to describe Drupal's target audience. Although this term doesn't appear in the product strategy document, it remains relevant.
While the strategy document is publicly available, it is primarily an internal guide. It outlines our plans but doesn't dictate our marketing language. Our product strategy's language purposly aligns with terms used by our target users, based on persona research and interviews.
To me, "ambitious site builders" includes all Drupal users, from those working with Drupal Core (more technically skilled) to those working with Drupal Starshot (less technical). Both groups are ambitious, with Drupal Starshot specifically targeting "ambitious marketers" or "ambitious no-code developers".
Give feedbackThe product strategy is a living document, and we value input. We invite you to share your thoughts, suggestions, and questions in the product strategy feedback issue within the Drupal Starshot issue queue.
Get involvedThere are many opportunities to get involved with Drupal Starshot, whether you're a marketer, developer, designer, writer, project manager, or simply passionate about the future of Drupal. To learn more about how you can contribute to Drupal Starshot, visit https://drupal.org/starshot.
Thank youI'd like to thank the Drupal Starshot leadership team, the Drupal Starshot Advisory Council, and the Drupal Core Committers for their input on the strategy. I'm also grateful for the marketers who provided feedback on our strategy, helping us refine our approach.
File attachments: starshot-strategy-1920w.jpg{kind=link}
Django Weblog: Django 5.1 released
The Django team is happy to announce the release of Django 5.1.
The release notes showcase a kaleidoscope of improvements. A few highlights are:
- Easier guardrails for authentication: the new and shiny LoginRequiredMiddleware, when added to MIDDLEWARE, enforces authentication for all views by default.
- A more inclusive framework: Django 5.1 includes several accessibility enhancements, such as improved screen reader support in the admin interface, more semantic HTML elements, and better association of help text and labels with form fieldsets.
- The second oldest ticket fixed in this release provides the long awaited querystring template tag, which greatly simplifies the handling of query strings when building URLs in templates.
(If you are curious about the oldest ticket fixed in this release, check out Ticket #10743.)
You can get Django 5.1 from our downloads page or from the Python Package Index. The PGP key ID used for this release is Natalia Bidart: 2EE82A8D9470983E.
With the release of Django 5.1, Django 5.0 has reached the end of mainstream support. The final minor bug fix release, 5.0.8, was issued yesterday. Django 5.0 will receive security and data loss fixes until April 2025. All users are encouraged to upgrade before then to continue receiving fixes for security issues.
See the downloads page for a table of supported versions and the future release schedule.
Jean-Pierre Lorre: Voices of the Open Source AI Definition
The Open Source Initiative (OSI) is running a blog series to introduce some of the people who have been actively involved in the Open Source AI Definition (OSAID) co-design process. The co-design methodology allows for the integration of diverging perspectives into one just, cohesive and feasible standard. Support and contribution from a significant and broad group of stakeholders is imperative to the Open Source process and is proven to bring diverse issues to light, deliver swift outputs and garner community buy-in.
This series features the voices of the volunteers who have helped shape and are shaping the Definition.
Meet Jean-Pierre LorreWhat’s your background related to Open Source and AI?
I’ve been using Open Source technologies since the very beginning of my career and have been directly involved in Open Source projects for around 20 years.
I graduated in artificial intelligence engineering in 1985. Since then I have worked in a number of applied AI research structures in fields such as medical image processing, industrial plant supervision, speech recognition and natural language processing. My knowledge covers both symbolic AI methods and techniques and deep learning.
I currently lead a team of around fifteen AI researchers at LINAGORA. LINAGORA is an Open Source company.
What motivated you to join this co-design process to define Open Source AI?
The team I lead is heavily involved in the development of LLM generative models, which we want to distribute under an open license. I realized that the term Open Source AI was not defined and that the definition we had at LINAGORA was not the same as the one adopted by our competitors.
As the OSI is the leading organization for defining Open Source and there was a project underway to define the term Open Source AI, I decided to join it.
Can you describe your experience participating in this process? What did you most enjoy about it and what were some of the challenges you faced?
I participated in two ways: firstly, to provide input for the definition currently being drafted; and secondly, to evaluate LLM models with regard to the definition (I contributed to Bloom, Falcon and Mistral).
For the first item, my main difficulty was keeping up with the meandering discussions, which were very active. I didn’t manage to do so completely, but I was able to appreciate the summaries provided from time to time, which enabled me to follow the overall thread.
The second difficulty concerns the evaluation of the models: the aim of the exercise was to evaluate the consistency of OSAID version 0.8 on models that currently claim to be “Open Source.” Implementing the definition involves looking for information that is sometimes non-existent and sometimes difficult to find.
Why do you think AI should be Open Source?
Artificial intelligence models are expected to play a very important role in our professional lives, but also in our everyday lives. In this respect, the need for transparency is essential to enable people to check the properties of the models. They must also be accessible to as many people as possible, to avoid widening the inequalities between those who have the means to develop them and those who will remain on the sidelines of this innovation. Similarly, they might be adapted for different uses without the need for authorization.
The Open Source approach makes it possible to create a community such as the one created by LINAGORA, OpenLLM-Europe. This is a way for small players to come together to build the critical mass needed not only to develop models but also to disseminate them. Such an approach, which may be compared to that associated with the digital commons, is a guarantee of sovereignty because it allows knowledge and governance to be shared.
In short, they are the fruit of work based on data collected from as many people as possible, so they must remain accessible to as wide an audience as possible.
What do you think is the role of data in Open Source AI?
Data provides the basis for training models. It is therefore the pool of information from which the knowledge displayed by the model and the applications deduced from it will be drawn. In the case of an open model, the dissemination of as many elements as possible to qualify this data is a means of transparency that facilitates the study of the model’s properties; indeed, this data is likely to include cultural bias, gender, ethnic origin, skin color, etc. It is also a means of facilitating the study of the model’s properties. It also makes it easier to modify the model and its outputs.
Has your personal definition of Open Source AI changed along the way? What new perspectives or ideas did you encounter while participating in the co-design process?
Yes, we initially thought that the provision of training data was a sine qua non condition for the design of truly Open Source models. Our basic assumption was that the model may be seen as a work derived from the data and that therefore the license assigned to the data, in particular the non-commercial nature, had an impact on the license of the model. As the discussions progressed, we realized that this condition was very restrictive and severely limited the possibility of developing models.
Our current analysis is that the condition defined in version 0.8 of the OSAID is sufficient to provide the necessary guarantees of transparency for the four freedoms and in particular the freedom to study the model underlying access to data. With regard to the data, it stipulates that “sufficiently detailed information about the data used to train the system, so that a skilled person can recreate a substantially equivalent system using the same or similar data” must be provided. Even if we can agree that this condition seems difficult to satisfy without providing the data sets, other avenues may be envisaged, in particular the provision of synthetic data. This information should make it possible to carry out almost all of the model’s studies.
What do you think the primary benefit will be once there is a clear definition of Open Source AI?
Having such a definition with clear, implementable rules will provide model suppliers with a concrete framework for producing models that comply with the ethics of the Open Source movement.
A collateral effect will be to help sort out the “wheat from the chaff.” In particular, to detect attempts at “Open Source washing.” This definition is therefore a structuring element for a company such as LINAGORA, which wants to build a sustainable business model around the provision of value-added AI services.
It should also be noted that such a definition is necessary for regulations such as the European IA Act, which defines exceptions for Open Source generative models. Such legislative construction cannot be satisfied with a fuzzy basis.
What do you think are the next steps for the community involved in Open Source AI?
The next steps that need to be addressed by the community concern firstly the definition of a certification process that will formalize the conformity of a model; this process may be accompanied by tools to automate it.
In a second phase, it may also be useful to provide templates of AI models that comply with the definition, as well as best practice guides, which would help model designers.
How to get involvedThe OSAID co-design process is open to everyone interested in collaborating. There are many ways to get involved:
- Join the working groups: be part of a team to evaluate various models against the OSAID.
- Join the forum: support and comment on the drafts, record your approval or concerns to new and existing threads.
- Comment on the latest draft: provide feedback on the latest draft document directly.
- Follow the weekly recaps: subscribe to our newsletter and blog to be kept up-to-date.
- Join the town hall meetings: participate in the online public town hall meetings to learn more and ask questions.
- Join the workshops and scheduled conferences: meet the OSI and other participants at in-person events around the world.
Jamie McClelland: Who ate my RAM?
One of our newest servers, with a hefty 256GB of RAM, recently began killing processes via the oomkiller.
According to free, only half of the RAM was in use (125GB). About 4GB was free, with the remainer used by the file cache.
I’m used to seeing unexpected “free RAM” numbers like this and have been assured that the kernel is simply not wasting RAM. If it’s not needed, use it to cache files to save on disk I/O. That make sense.
However… why is the oomkiller being called instead of flushing the file cache?
I came up with all kinds of amazing and wrong theories: maybe the RAM is fragmented (is that even a thing?!?), maybe there is a spike in RAM and the kernel can’t flush the cache quickly enough (I really don’t think that’s a thing). Maybe our kvm-manager has a weird bug (nope, but that didn’t stop me from opening a spurious bug report).
I learned lots of cool things, like the oomkiller report includes a table of the memory in use by each process (via the rss column) - and you have to muliply that number by 4096 because it’s in 4K pages.
That’s how I discovered that the oomkiller was killing off processes with only half the memory in use.
I also learned that lsof sometimes lists the same open file multiple times, which made me think a bunch of files were being opened repeatedly causing a memory problem, but really it amounted to nothing.
That last thing I learned, courtesy of an askubuntu post is that the /dev filesystem is allocated by default exactly half the RAM on the system. What a coincidence! That is exactly how much RAM is useable on the server.
And, on the server in question, that filesystem is full. What?!? Normally, that filesystem should be using 0 bytes because it’s not a real filesystem. But in our case a process created a 127GB file there - it was only stopped because the file system filled up.
Real Python: Quiz: Asynchronous Iterators and Iterables in Python
Test your understanding of how to create and use Python async iterators and iterables in the context of asynchronous code.
You can take this quiz after reading the Asynchronous Iterators and Iterables in Python tutorial.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Qt Creator 14.0.1 released
We are happy to announce the release of Qt Creator 14.0.1!
mark.ie: Sponsorship slot available for Drupal contribution credits
I have a small window of time available if you'd like to get credits for sponsoring Drupal contributions.
roose.digital: Let your Drupal website perform actions without the need for programming
Python Insider: Python 3.12.5 released
I'm pleased to announce the release of Python 3.12.5:
https://www.python.org/downloads/release/python-3125/
Python 3.12 is the newest major release of the Python programming language, and it contains many new features and optimizations. 3.12.5 is the latest maintenance release, containing more than 250 bugfixes, build improvements and documentation changes since 3.12.4.
This version of Python 3.12 also comes with pip 24.2 by default. However, due to an incompatibility with older macOS versions, macOS 10.9 through 10.12 will downgrade their version of pip to 24.1.2 during the installation process (in the Install Certificates step). See the installer ReadMe and the pip issue on the matter for more information. Versions of macOS older than 10.13 haven’t been supported by Apple since 2019, and maintaining support for them is becoming increasingly difficult. While this release of 3.12 still supports them, it is likely that we will be forced to drop support for macOS 10.12 and older in a future 3.12 release. (Python 3.13 has already dropped support for them.)
Major new features of the 3.12 series, compared to 3.11 New features
- More flexible f-string parsing, allowing many things previously disallowed (PEP 701).
- Support for the buffer protocol in Python code (PEP 688).
- A new debugging/profiling API (PEP 669).
- Support for isolated subinterpreters with separate Global Interpreter Locks (PEP 684).
- Even more improved error messages. More exceptions potentially caused by typos now make suggestions to the user.
- Support for the Linux perf profiler to report Python function names in traces.
- Many large and small performance improvements (like PEP 709 and support for the BOLT binary optimizer), delivering an estimated 5% overall performance improvement.
- New type annotation syntax for generic classes (PEP 695).
- New override decorator for methods (PEP 698).
- The deprecated wstr and wstr_length members of the C implementation of unicode objects were removed, per PEP 623.
- In the unittest module, a number of long deprecated methods and classes were removed. (They had been deprecated since Python 3.1 or 3.2).
- The deprecated smtpd and distutils modules have been removed (see PEP 594 and PEP 632. The setuptools package continues to provide the distutils module.
- A number of other old, broken and deprecated functions, classes and methods have been removed.
- Invalid backslash escape sequences in strings now warn with SyntaxWarning instead of DeprecationWarning, making them more visible. (They will become syntax errors in the future.)
- The internal representation of integers has changed in preparation for performance enhancements. (This should not affect most users as it is an internal detail, but it may cause problems for Cython-generated code.)
For more details on the changes to Python 3.12, see What’s new in Python 3.12.
More resources- Online Documentation.
- PEP 693, the Python 3.12 Release Schedule.
- Report bugs via GitHub Issues.
- Help fund Python directly or via GitHub Sponsors, and support the Python community.
Thanks to all of the many volunteers who help make Python Development and these releases possible! Please consider supporting our efforts by volunteering yourself or through organization contributions to the Python Software Foundation.
Your release team,
Thomas Wouters
Łukasz Langa
Ned Deily
Steve Dower
Drupal.org blog: The Bounty program: Starshot edition
With all the news and activities happening around Starshot, you may have missed this, but the Drupal Association has launched the Starshot Contribution Credits. This consists of credits granted to a series contributions, in particular:
-
contributions to any modules, themes, etc that are designated as part of Starshot,
-
50 credits per week for each FTE (full time employee) equivalent dedicated to starshot,
-
1 credit per $100 invested for financial contributions and finally,
-
Special credit bounties for individual issues of exceptional importance.
You can read more about the contribution bonuses https://www.drupal.org/about/starshot/contribution-credit
The last point, special credit bounties, opens the door to a contribution coming from the Bounty Program.
What are we trying to do?Given the success of the previous phase, we thought it was the moment to announce a few new issues that would carry extra credits, supporting the Starshot initiative. These issues are targeted at improvements to Drupal core that would reduce the number of contrib modules required in Starshot.
These are the issues that the period involved have identified:
-
Improve the linking experience in CKEditor 5. Why? Because this integration provides a critical site feature and improves the editorial experience in a significant way.
-
Fixed maximum number of field values, but use «add more» similar to when cardinality «unlimited» is used. This is a great UX improvement for Drupal that makes forms much more usable where fields have a set cardinality.
-
Views handler loading should respect configuration. Fixing this bug will enable more flexible configuration of Views.
-
Configurable views filters to allow for different widgets. Once the bug above is fixed, we can provide a UI for selecting the views handler, supporting more robust filtering options.
And, as in the previous edition, the reward will be 50 credits for contributing to resolving these issues (5x the standard credit amount). Sounds good?
While these issues are not good candidates for a user or organization's first time contribution, they are a great opportunity for more senior contributors to have an impact.
Special thanks to: Tim Lehnen, Pamela Barone, Gábor Hojtsy, Nathaniel Catchpole and everyone that I am missing in and out of the core team for their help and support in identifying candidate issues for these bounties.
The Bounty program started as a proof of concept to validate that we can help align the goals of the Drupal Association and Drupal itself, with the goals of individuals, companies, and the rest of the community, and hence, accelerate Drupal Innovation.
You may remember that this started during my tenure with the Drupal Association, and although my contract and direct involvement reached to an end at the beginning of the year, I committed myself, even before I left, to continuing the work I started with the Drupal Association, but especially with Drupal as a project, and the community. That’s why I’m still committed to helping run and coordinating this and other innovation programs, and that’s why I’m running as well for the Board of Directors (more on this soon).
Thomas Lange: Download Debian
It's just a very tiny difference, but hopefully a big step forward for our users. Our main download web page (which still uses the URL https://www.debian.org/distrib/) now has the title "Download Debian". Hopefully this will improve the results in the search engines.
A brief history of this web page in time- 1998: The title "Distribution" was added
- 2002: Title changed to "Getting Debian"
- 2024: Finally changed to "Download Debian"
Here are the screenshots of these three versions.
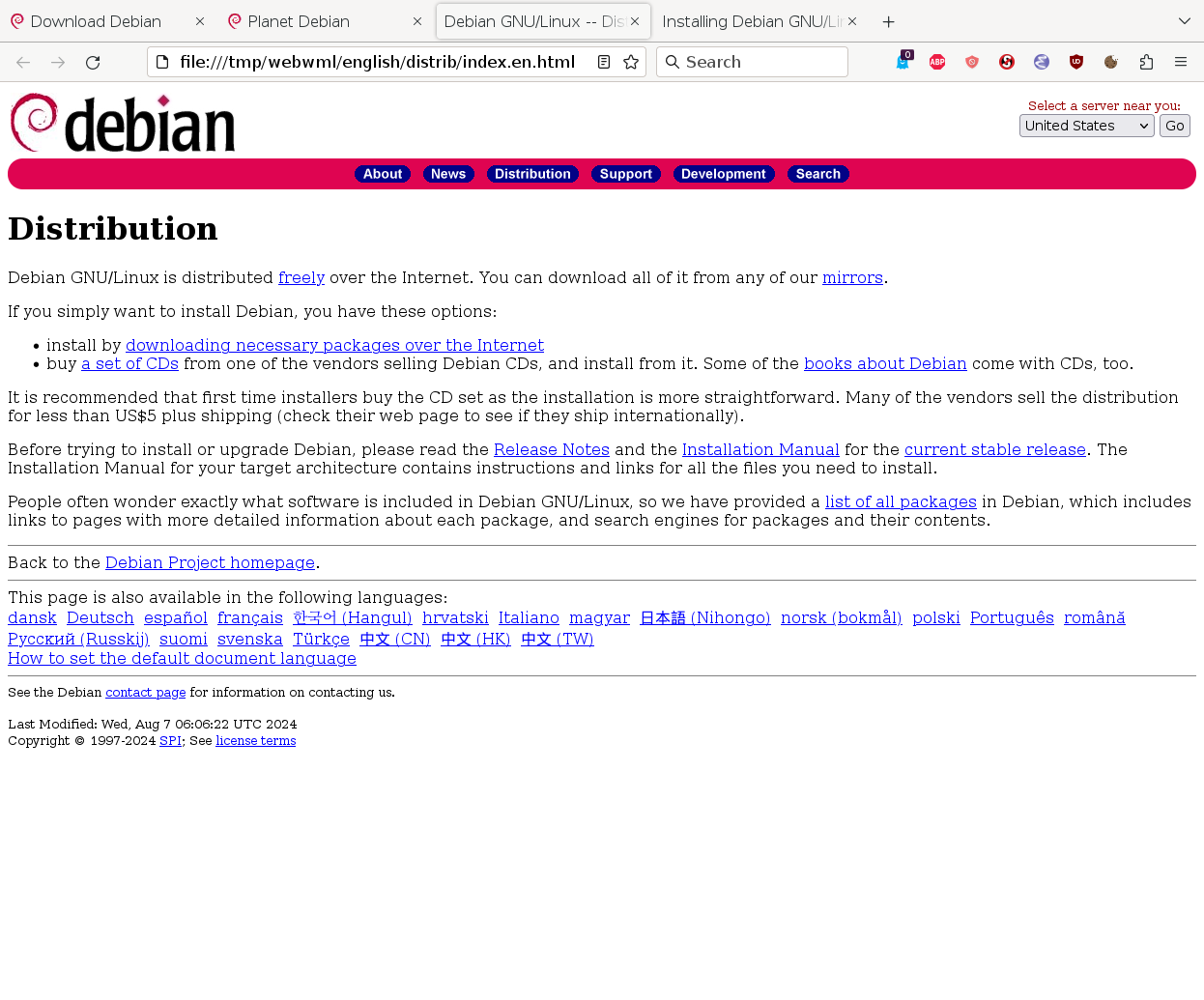{kind=link}
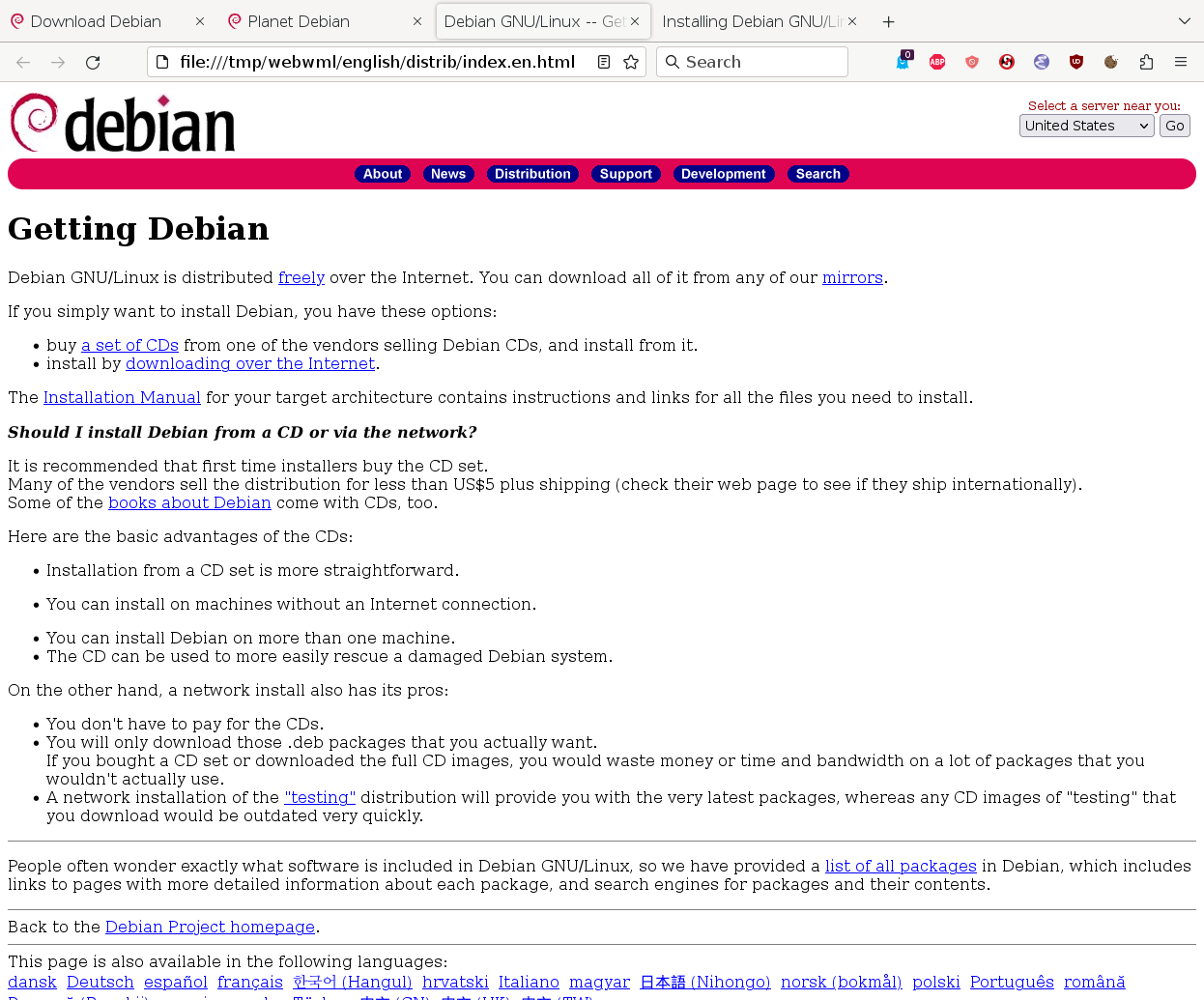{kind=link}
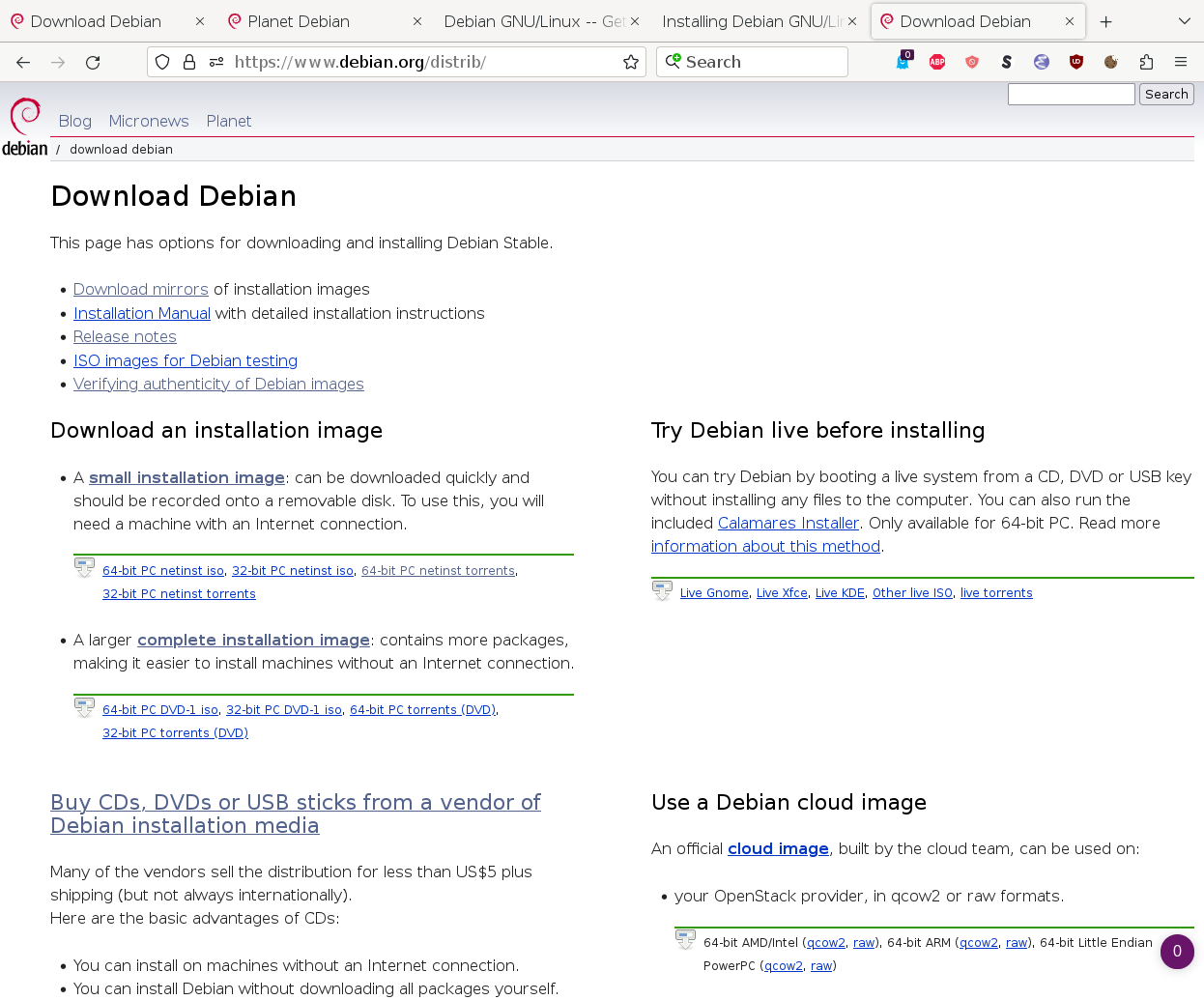{kind=link}
I like that we had a selection menu on the top right corner to select a mirror for downloading in the past.
A few days ago I've also removed the info "Internal ISDN cards are unfortunately not supported." from the netinst subpage. Things are moving forward, but slowly.
Sahil Dhiman: Banks With Own ASN in India
Most banks are behind CDNs and DDoS mitigation providers nowadays, though they still hold their own IP space. Was interested in this, so compiled a list from BGP.Tools and Hurricane Electric BGP Toolkit.
- AS24055 Deutsche Bank AG-India Internet AS
- AS38468 ASN for Yes Bank
- AS45644 SBI-EMS-NET-IN
- AS59194 Central Bank of India
- AS17436 ICICIBANK Ltd, Banking, Mumbai
- AS131283 HDFC Bank House
- AS132440 Unity Small Finance Bank Pvt. Ltd.
- AS132946 Ujjivan Small Finance Bank Ltd
- AS132989 Sangli Urban Co-operative Bank Ltd
- AS133640 Indian Overseas Bank
- AS133657 IndusInd Bank Ltd
- AS134909 The South Indian Bank Ltd
- AS135086 Axis Bank Limited
- AS135745 UCO Bank
- AS135819 Chaitanya Godavari Grameena Bank
- AS136252 The Bank of Baroda Limited
- AS136324 IDBI Bank Ltd
- AS136622 Equitas Small Finance Bank Ltd
- AS136707 The Kalupur Commercial Co-operative Bank Limited
- AS136680 Bank of Maharashtra
- AS137104 India Post Payments Bank Limited
- AS137108 Bank of India
- AS137130 Punjab National Bank
- AS137662 IDFC Bank Ltd
- AS137670 Canara Bank
- AS138318 The Visakhapatnam Cooperative Bank Ltd
- AS140156 Karnataka Gramin Bank
- AS141222 Telangana State Coorperative Apex Bank Ltd
- AS141561 Punjab and Sind Bank
- AS146870 TJSB Sahakari Bank Ltd
- AS149202 The Jammu And Kashmir Bank Pvt Ltd
- AS149528 Indian Bank
- AS149603 Suryoday Small Finance Bank Limited
- AS150029 The Karnataka Bank Ltd
- AS151172 CSB Bank Ltd
- AS151692 Small Industries Development Bank of India
Other noteable mentions:
- AS141857 National Bank for Agriculture and Rural Development
- AS151773 Reserve Bank Information Technology Pvt Ltd
Let me know if I’m missing someone. Many thanks to Saswata Sarkar for helping with the list.
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
FLOSS Research
- Give Your Input on the State of Open Source Survey
- Open Data and Open Source AI: Charting a course to get more of both
- The Open Source Initiative and the Eclipse Foundation to Collaborate on Shaping Open Source AI (OSAI) Public Policy
- ClearlyDefined v2.0 adds support for LicenseRefs
- ClearlyDefined at SOSS Fusion 2024: a collaborative solution to Open Source license compliance