
Feeds
Qt/.NET — Using QML in a .NET WPF application
Qt/.NET is a proposed toolkit for interoperability between C++ and .NET, including a Qt-based custom native host for managed assemblies, as well as a native-to-managed adapter module that provides higher-level interoperability services such as object life-cycle management, instance method invocation and event notification.
Zero to Mastery: Python Monthly Newsletter 💻🐍
Russ Allbery: Review: Thornhedge
Review: Thornhedge, by T. Kingfisher
Publisher: Tor Copyright: 2023 ISBN: 1-250-24410-2 Format: Kindle Pages: 116Thornhedge is a fantasy novella by T. Kingfisher, the pen name that Ursula Vernon uses for her adult writing. It won the 2024 Hugo Award for best novella. No matter how much my brain wants to misspell the title, it is a story about a hedge, not a Neolithic earthwork.
The fairy was the greenish-tan color of mushroom stems and her skin bruised blue-black, like mushroom flesh. She had a broad, frog-like face and waterweed hair. She was neither beautiful nor made of malice, as many of the Fair Folk are said to be.
There is a princess asleep in a tower, surrounded by a wall of thorns. Toadling's job is to keep anyone from foolishly breaking in. At first, it was a constant struggle and all that she could manage, but with time, the flood of princes slowed to a trickle. A road was built and abandoned. People fled. There was a plague. With any luck, the tower was finally forgotten.
Then a knight shows up. Not a very rich knight, nor a very successful knight. Just a polite and very persistent knight who wants to get into the tower that Toadling does not want him to get into.
As you might have guessed, this is a Sleeping Beauty retelling. As you may have also guessed from the author, or from the cover text that says "not all curses should be broken," this version is a bit different. How and why it departs from the original is a surprise that slowly unfolds over the course of the story, in parallel to a delicate, cautious, and delightfully kind-hearted conversation between the knight and the fairy.
If you have read a T. Kingfisher story before, particularly one of her fractured fairy tales, you know what to expect. Toadling is one of her typical well-meaning, earnest, slightly awkward protagonists who is just trying to do the right thing in a confusing world full of problems and dangers. She's constantly overwhelmed and yet she keeps going, because what else is there to do. Like a lot of Kingfisher's writing, it's a story about quiet courage from someone who doesn't consider herself courageous. One of the twists this time is that the knight is a character from a similar vein: doggedly unwilling to leave any problem alone, but equally determined to try to be kind. The two of them together make for a story with a gentle and rather melancholy tone.
We do, eventually, learn the whole backstory of the tower, the wall of thorns, and Toadling. There is a god, a rather memorable one, who is frustratingly cryptic in the way that gods are. There are monsters who are more loving than most humans. There are humans who turn out to be surprisingly decent when it matters. And, like most of Kingfisher's writing, there is a constant awareness of how complicated the world is, how full it is of people who are just trying to get through each day, and how heavy of burdens people can shoulder when they don't see another way.
This story pulled me right in. It is not horror, although there are a few odd bits like there always are in Kingfisher stories. Your largest risk as a reader is that it might make you cry if stories about earnest people doing their best in overwhelming situations hit you that way. My primary complaint is that there was nowhere near enough ending for me. After everything I learned about the characters, I wanted to spend some time with them outside of the bounds of the story. Kingfisher points the reader in a direction and then leaves the rest to your imagination, and I can see why she chose that story construction, but I wanted more catharsis than I got.
That complaint aside, this is quintessential T. Kingfisher, and I am unsurprised that it won a Hugo. If you've read any of her other fractured fairy tales, or the 2023 Hugo winner for best novel, you know the sort of stories she tells, and you probably know whether you will like this. I am one of the people who like this.
Rating: 8 out of 10
Steve McIntyre: A birthday gift to remember!
Warning: If you're not into meat, you might want to skip the rest of this...
This year, I turned 50. Wow. Lots of friends and family turned up to help me celebrate, with a BBQ (of course!). I was very grateful for a lovely set of gifts from those awesome people, and I have a number of driving experiences to book in the next year or so. I'm going to have so much fun driving silly cars on and off road!
However, the most surprising gift was something totally different - a full-day course of hands-on pork butchery. I was utterly bemused - I've never considered doing anything like this at all, and I'd certainly never talked to friends about like it either. I was shocked, but in a good way!
So, two weekends back Jo and I went over to Empire Farm in Somerset. We stayed nearby so we could be ready on-site early on Sunday morning, and then we joined three other people doing the course. Jo was there to observe, i.e. to watch and take (lots of!) pictures.
I can genuinely say that this was the most fun surprise gift I've ever received! David Coldman, the master butcher working with us, has been in the industry for many years. He was an excellent teacher, showing us everything we needed to know and being very patient with us when we needed it. It was great to hear his philosophy too - he only uses the very best locally-sourced meat and focuses on quality over quantity. He showed us all the different cuts of pork that a butcher will make, and we were encouraged to take everything home - no waste here!
At the beginning of the day, we each started with half a pig. Over the next several hours, we steadily worked our way through a series of cuts with knife and saw, making the remaining pig smaller and smaller as we went.
We finished the day with three sets of meat. First, a stack of vacuum-packed joints, chops and steaks ready for cooking and eating at home. Second: a box of off-cuts that we minced and made into sausages at the end of the day. Finally: a bag of skin and bones. Our friend's dog got some of the bones, and Jo turned a lot of the skin into crackling that we shared with friends at the OMGWTFBBQ the next weekend.
This was an amazing day. Massive thanks to my good friend Chris Walker for suggesting this gift. As I told David on the day: this was the most fun surprise gift I've ever received. Good hands-on teaching in a new craft is an incredible thing to experience, and I can't recommend this course highly enough.
Darren Oh: Starshot ignites Drupal Forge
Matt Layman: Kamal - Building SaaS #200
Reproducible Builds (diffoscope): diffoscope 277 released
The diffoscope maintainers are pleased to announce the release of diffoscope version 277. This version includes the following changes:
[ Sergei Trofimovich ] * Don't crash when attempting to hashing symlinks with targets that point to a directory.You find out more by visiting the project homepage.
PyCharm: PyCharm 2024.2.1: What’s New!
PyCharm 2024.2.1 is here! This release’s key features include initial support for Python 3.13, improvements to the Data View tool window, and enhanced code assistance for Django.
Don’t forget to visit our What’s New page to get all the new updates. Download the latest version from our website, or update your current version through our free Toolbox App.
Download PyCharm 2024.2.1 PyCharm 2024.2.1 key features Data View PROPyCharm now provides two color-scheme options for the table heatmaps in the Data View tool window: the Diverging and Sequential color schemes.
The Diverging color scheme emphasizes variation relative to a norm. It consists of two contrasting colors that deviate from a central value in two opposite directions.
The Sequential color scheme consists of a single color or a range of closely related colors that vary in intensity.
You can apply the heatmap color schemes to the whole table or to each column separately, or you can use coloring only for Boolean values.
Python 3.13PyCharm now recognizes TypeIs syntax, providing proper type inference and code completion for user-defined narrowed functions. As part of Python 3.13 support, the IDE is now also aware of ReadOnly keys in TypedDict and warns you if something is assigned to a ReadOnly member.
Read more Django: Completion for ModelAdmin fields, and more PROGet intelligent code completion, refactoring, and navigation for the fields in ModelAdmin classes. Other productivity enhancements include a warning about newly created apps that have not been added to the INSTALLED_APPS declaration, and the ability to insert an app’s tag into the manage.py console automatically when migrations are made from the Django Structure tool window.
Read our release notes for the full breakdown and more details on all of the features in 2024.2.1. If you encounter any problems, please report them in our issue tracker so we can address them promptly.
Connect with us on X (formerly Twitter) to share your thoughts on PyCharm 2024.2.1. We’re looking forward to hearing them!
Drupal Starshot blog: Drupal Starshot Initiative update for the end of August 2024
Dries Buytaert announced recently that the product name for the result of the Drupal Starshot Initiative will be Drupal CMS. Exciting! Activities on features for Drupal CMS are divided into tracks - a set of deliverables focused to provide valuable solutions for different parts of the product strategy.
Let’s see what’s cooking in the Drupal CMS kitchen as since the announcement of the track leads, quite some work has been done. We are happy to share a brief overview to highlight the progress made!
The Events Track has been busy with transferring the Events recipe to the Drupal CMS and now we’ve got the beginnings of an event system. As with all the Drupal CMS components, the ultimate plan is for each one to be available as its own project, but at the same time all be developed within the same repo.
The Data Privacy / Compliance Track is busy developing a survey for the international audience. We are looking forward to sharing it with the community very soon.
The Trial Experience Track in coordination with the Drupal Association has devised a solution to leverage GitLab Pages. After checking in with the rest of the Drupal CMS team, it was decided the trial codebase would be added to the monolithic repository. You can find more details at the dedicated blog post by Matt Glaman.
The Starshot Demo Design System initiative is supporting the Experience Builder demo next month by providing Drupal-branded components within a design system theme. The team has made excellent progress and needs more help in the next two weeks to test components within Experience Builder. Learn how to get involved!
The SEO Track managed to add Basic SEO recipe to Drupal CMS. This recipe will be applied by default, is idempotent (can be applied multiple times), and sets the simple best practices configuration we feel every site needs. The team is continuing to work to define an advanced SEO recipe that we will propose to be optional that has more tools for optimizing for search engines.
The Advanced Search Track has drafted a proposal for the track. It is being reviewed by the leadership team and the idea is to provide a recipe for at least two different approaches and collect community feedback. We expect this to happen in September so stay tuned!
The Media Management Track is undertaking discovery to gather common practices and new insights that will lead to a proposal for the features and recipes for media in early versions of Drupal CMS. The track will also propose how improvements and innovations could look for media beyond the launch of Drupal CMS. Tony Barker has created a survey as part of the discovery and welcomes the community to provide their thoughts and feelings on media in Drupal using this form.
We are observing the progress each track team is making with excitement and will keep you up to date on upcoming developments!
mark.ie: My LocalGov Drupal contributions for week-ending August 30th, 2024
This week was all about catching up on notifications and open PRs from last week, and creating a mega amount of new PRs.
libtool @ Savannah: libtool-2.5.2 released [beta]
Libtoolers!
The Libtool Team is pleased to announce the release of libtool 2.5.2, a beta release.
This beta release was not planned, but additional testing of a recent bugfix
was requested for distros to have the chance to test it with mass-rebuilds.
The details of this bugfix can be found here:
https://debbugs.gnu.org/cgi/bugreport.cgi?bug=71489
The commit for this bugfix can be found here:
https://git.savannah.gnu.org/cgit/libtool.git/commit/?id=0e1b33332429cd578367bd0ad420c065d5caf0ac
I hope to release the stable in a couple of weeks if testing goes well!
GNU Libtool hides the complexity of using shared libraries behind a
consistent, portable interface. GNU Libtool ships with GNU libltdl, which
hides the complexity of loading dynamic runtime libraries (modules)
behind a consistent, portable interface.
There have been 9 commits by 4 people in the 35 days since 2.5.1.
See the NEWS below for a brief summary.
Thanks to everyone who has contributed!
The following people contributed changes to this release:
Bruno Haible (1)
Ileana Dumitrescu (6)
Sergey Poznyakoff (1)
Tobias Stoeckmann (1)
Ileana
[on behalf of the libtool maintainers]
==================================================================
Here is the GNU libtool home page:
https://gnu.org/s/libtool/
For a summary of changes and contributors, see:
https://git.sv.gnu.org/gitweb/?p=libtool.git;a=shortlog;h=v2.5.2
or run this command from a git-cloned libtool directory:
git shortlog v2.5.1..v2.5.2
Here are the compressed sources:
https://alpha.gnu.org/gnu/libtool/libtool-2.5.2.tar.gz (1.9MB)
https://alpha.gnu.org/gnu/libtool/libtool-2.5.2.tar.xz (1.0MB)
Here are the GPG detached signatures:
https://alpha.gnu.org/gnu/libtool/libtool-2.5.2.tar.gz.sig
https://alpha.gnu.org/gnu/libtool/libtool-2.5.2.tar.xz.sig
Use a mirror for higher download bandwidth:
https://www.gnu.org/order/ftp.html
Here are the SHA1 and SHA256 checksums:
e3384dc0099855942f76ef8a97be94edab6f56de libtool-2.5.2.tar.gz
KSdftFsjbW/3IKQz+c1fYeovUsw6ouX4m6V3Jr2lR5M= libtool-2.5.2.tar.gz
71b7333e80b76510f5dbd14db54d311d577bb716 libtool-2.5.2.tar.xz
e2C09MNk6HhRMNNKmP8Hv6mmFywgxdtwirScaRPkgmM= libtool-2.5.2.tar.xz
Verify the base64 SHA256 checksum with cksum -a sha256 --check
from coreutils-9.2 or OpenBSD's cksum since 2007.
Use a .sig file to verify that the corresponding file (without the
.sig suffix) is intact. First, be sure to download both the .sig file
and the corresponding tarball. Then, run a command like this:
gpg --verify libtool-2.5.2.tar.gz.sig
The signature should match the fingerprint of the following key:
pub rsa4096 2021-09-23 [SC]
FA26 CA78 4BE1 8892 7F22 B99F 6570 EA01 146F 7354
uid Ileana Dumitrescu <ileanadumi95@protonmail.com>
uid Ileana Dumitrescu <ileanadumitrescu95@gmail.com>
If that command fails because you don't have the required public key,
or that public key has expired, try the following commands to retrieve
or refresh it, and then rerun the 'gpg --verify' command.
gpg --locate-external-key ileanadumi95@protonmail.com
gpg --recv-keys 6570EA01146F7354
wget -q -O- 'https://savannah.gnu.org/project/release-gpgkeys.php?group=libtool&download=1' | gpg --import -
As a last resort to find the key, you can try the official GNU
keyring:
wget -q https://ftp.gnu.org/gnu/gnu-keyring.gpg
gpg --keyring gnu-keyring.gpg --verify libtool-2.5.2.tar.gz.sig
This release was bootstrapped with the following tools:
Autoconf 2.72e
Automake 1.17
Gnulib v1.0-563-gd3efdd55f3
NEWS
- Noteworthy changes in release 2.5.2 (2024-08-29) [beta]
** Bug fixes:
- Use shared objects built in source tree instead of the installed
versions for more reliable testing.
- Fix test in bug_62343.at for confirmed Cygwin/Mingw32 where the
incorrect architecture version of a compiler was generating
object files that could not be linked with a library file.
- Fix typos found with codespell.
** Changes in supported systems or compilers:
- Add support for 32-bit mode on FreeBSD/powerpc64.
Enjoy!
The Drop Times: Humility Over Hype: Iztok Smolic's Approach to Leadership and Community
Drupal Association blog: Drupal Association Announces Dropsolid as Partner for Drupal 7 Extended Security Support Provider Program
PORTLAND, Ore., 29 August 2024—The Drupal Association is pleased to announce Dropsolid as a partner for the Drupal 7 Extended Security Support Provider Program. This initiative aims to support Drupal 7 users by carefully selecting providers that deliver extended security support services beyond the 5 January 2025 end-of-life (EOL) date.
The Drupal 7 Extended Security Support Provider Program allows organizations that cannot migrate from Drupal 7 to newer versions by the EOL date to continue using a version of Drupal 7 that is secure and compliant. This program complements the Association’s Drupal 7 Certified Migration Providers Program, which helps organizations find the right partner to transition their sites from Drupal 7 to Drupal 11.
Dropsolid’s Drupal 7 extended support offers Drupal 7 support beyond 5 January 2024, with Enterprise Drupal specialists with a reputation in the community, access to enterprise Drupal 7 developers to continue development, and much more.
“We’re excited that Dropsolid has stepped up and committed to our Drupal 7 Extended Security Support Program,” commented Tim Doyle, CEO of the Drupal Association. “Dropsolid has been a tremendous supporter of Drupal and the Drupal Community, and we’re grateful that they’re including bona fide Drupal 7 support among their offerings.”
As organizations prepare for the transition from Drupal 7, Dropsolid will provide the necessary support to keep their sites secure and operational.
Dominique De Cooman, co-founder and co-CEO of Dropsolid, proudly added: “We are thrilled to qualify for the Drupal 7 Extended Security Support program. Even more so since we're the only European company selected (even though we have offices in US and EU). As an organization of makers contributing towards security of Drupal and Mautic, we want to continue contributing to Drupal as much as possible. It's part of our mission to give Drupal 7 the End of Life it deserves. Beyond EOL support, Dropsolid will continue to deliver robust D7 support at both the code and platform levels. We’re here to back you—past, present, and future.”
More information on Drupal 7 Extended Support from Dropsolid.
About the Drupal AssociationThe Drupal Association is a non-profit organization that fosters and supports the Drupal software project, the community, and its growth. Our mission is to drive innovation and adoption of Drupal as a high-impact digital public good, hand-in-hand with our open source community. Through various initiatives, events, and programs, the Drupal Association helps ensure the ongoing development and success of the Drupal project.
About DropsolidDriven by an open culture and with a passion for open source, Dropsolid shares their knowledge, code, and talent with their clients. Dropsolid designs, builds, hosts, evolves, and creates websites & DXP with results. Equipped with a CMS, marketing automation, personalization, and even AI. Starting from a strong digital strategy with one goal in mind: the best digital experiences for your organization and your customers and stakeholders.
Jonathan Carter: Orphaning bcachefs-tools in Debian
Around a decade ago, I was happy to learn about bcache – a Linux block cache system that implements tiered storage (like a pool of hard disks with SSDs for cache) on Linux. At that stage, ZFS on Linux was nowhere close to where it is today, so any progress on gaining more ZFS features in general Linux systems was very welcome. These days we care a bit less about tiered storage, since any cost benefit in using anything else than nvme tends to quickly evaporate compared to time you eventually lose on it.
In 2015, it was announced that bcache would grow into its own filesystem. This was particularly exciting and it caused quite a buzz in the Linux community, because it brought along with it more features that compare with ZFS (and also btrfs), including built-in compression, built-in encryption, check-summing and RAID implementations.
Unlike ZFS, it didn’t have a dkms module, so if you wanted to test bcachefs back then, you’d have to pull the entire upstream bcachefs kernel source tree and compile it. Not ideal, but for a promise of a new, shiny, full-featured filesystem, it was worth it.
In 2019, it seemed that the time has come for bcachefs to be merged into Linux, so I thought that it’s about time we have the userspace tools (bcachefs-tools) packaged in Debian. Even if the Debian kernel wouldn’t have it yet by the time the bullseye (Debian 11) release happened, it might still have been useful for a future backported kernel or users who roll their own.
By total coincidence, the first git snapshot that I got into Debian (version 0.1+git20190829.aa2a42b) was committed exactly 5 years ago today.
It was quite easy to package it, since it was written in C and shipped with a makefile that just worked, and it made it past NEW into unstable in 19 January 2020, just as I was about to head off to FOSDEM as the pandemic started, but that’s of course a whole other story.
Fast-forwarding towards the end of 2023, version 1.2 shipped with some utilities written in Rust, this caused a little delay, since I wasn’t at all familiar with Rust packaging yet, so I shipped an update that didn’t yet include those utilities, and saw this as an opportunity to learn more about how the Rust eco-system worked and Rust in Debian.
So, back in April the Rust dependencies for bcachefs-tools in Debian didn’t at all match the build requirements. I got some help from the Rust team who says that the common practice is to relax the dependencies of Rust software so that it builds in Debian. So errno, which needed the exact version 0.2, was relaxed so that it could build with version 0.4 in Debian, udev 0.7 was relaxed for 0.8 in Debian, memoffset from 0.8.5 to 0.6.5, paste from 1.0.11 to 1.08 and bindgen from 0.69.9 to 0.66.
I found this a bit disturbing, but it seems that some Rust people have lots of confidence that if something builds, it will run fine. And at least it did build, and the resulting binaries did work, although I’m personally still not very comfortable or confident about this approach (perhaps that might change as I learn more about Rust).
With that in mind, at this point you may wonder how any distribution could sanely package this. The problem is that they can’t. Fedora and other distributions with stable releases take a similar approach to what we’ve done in Debian, while distributions with much more relaxed policies (like Arch) include all the dependencies as they are vendored upstream.
As it stands now, bcachefs-tools is impossible to maintain in Debian stable. While my primary concerns when packaging, are for Debian unstable and the next stable release, I also keep in mind people who have to support these packages long after I stopped caring about them (like Freexian who does LTS support for Debian or Canonical who has long-term Ubuntu support, and probably other organisations that I’ve never even heard of yet). And of course, if bcachfs-tools don’t have any usable stable releases, it doesn’t have any LTS releases either, so anyone who needs to support bcachefs-tools long-term has to carry the support burden on their own, and if they bundle it’s dependencies, then those as well.
I’ll admit that I don’t have any solution for fixing this. I suppose if I were upstream I might look into the possibility of at least supporting a larger range of recent dependencies (usually easy enough if you don’t hop onto the newest features right away) so that distributions with stable releases only need to concern themselves with providing some minimum recent versions, but even if that could work, the upstream author is 100% against any solution other than vendoring all its dependencies with the utility and insisting that it must only be built using these bundled dependencies. I’ve made 6 uploads for this package so far this year, but still I constantly get complaints that it’s out of date and that it’s ancient. If a piece of software is considered so old that it’s useless by the time it’s been published for two or three months, then there’s no way it can survive even a usual stable release cycle, nevermind any kind of long-term support.
With this in mind (not even considering some hostile emails that I recently received from the upstream developer or his public rants on lkml and reddit), I decided to remove bcachefs-tools from Debian completely. Although after discussing this with another DD, I was convinced to orphan it instead, which I have now done. I made an upload to experimental so that it’s still available if someone wants to work on it (without having to go through NEW again), it’s been removed from unstable so that it doesn’t migrate to testing, and the ancient (especially by bcachefs-tools standards) versions that are in stable and oldstable will be removed too, since they are very likely to cause damage with any recent kernel versions that support bcachefs.
And so, my adventure with bcachefs-tools comes to an end. I’d advise that if you consider using bcachefs for any kind of production use in the near future, you first consider how supportable it is long-term, and whether there’s really anyone at all that is succeeding in providing stable support for it.
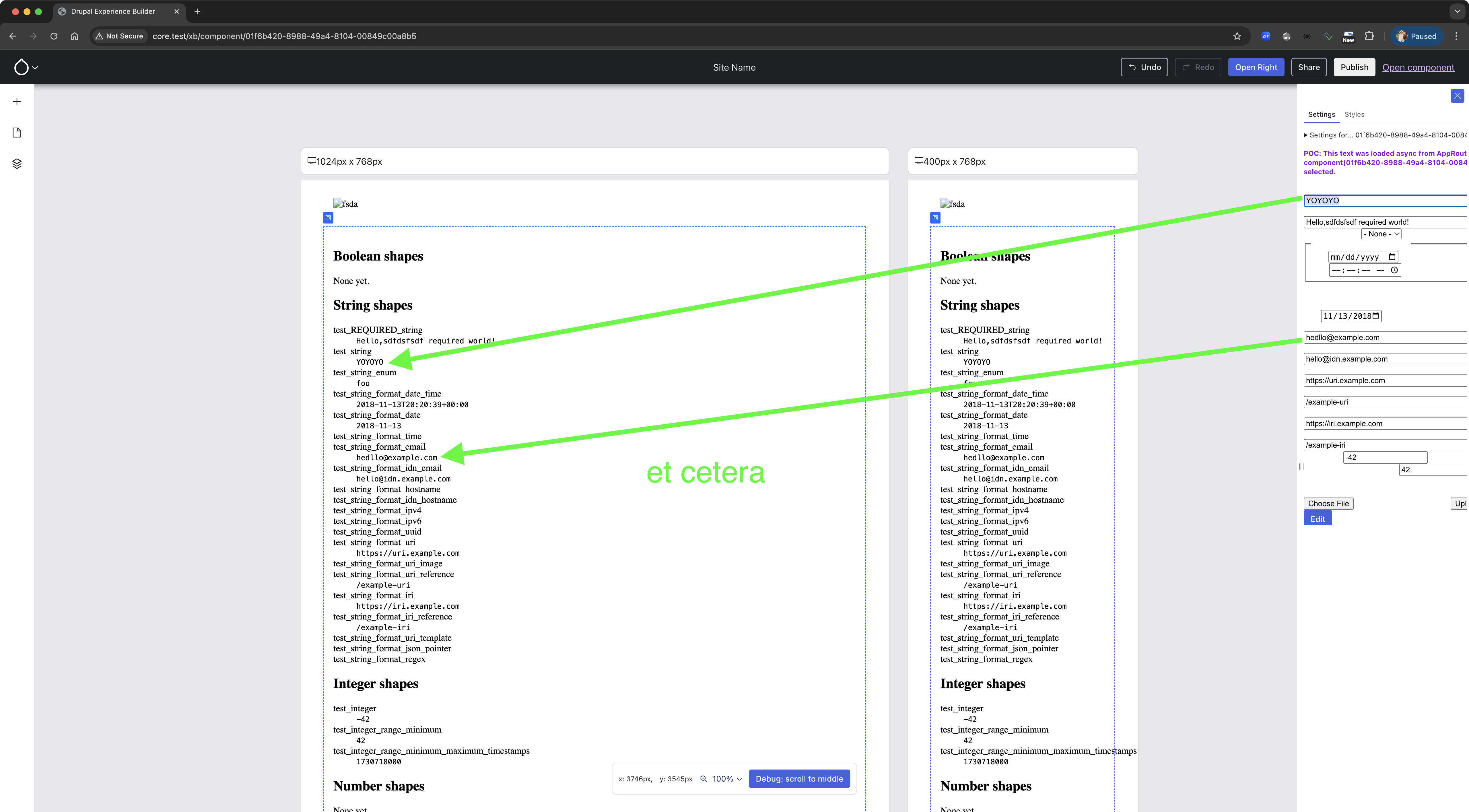
Wim Leers: XB week 13: location, location & OpenAPI
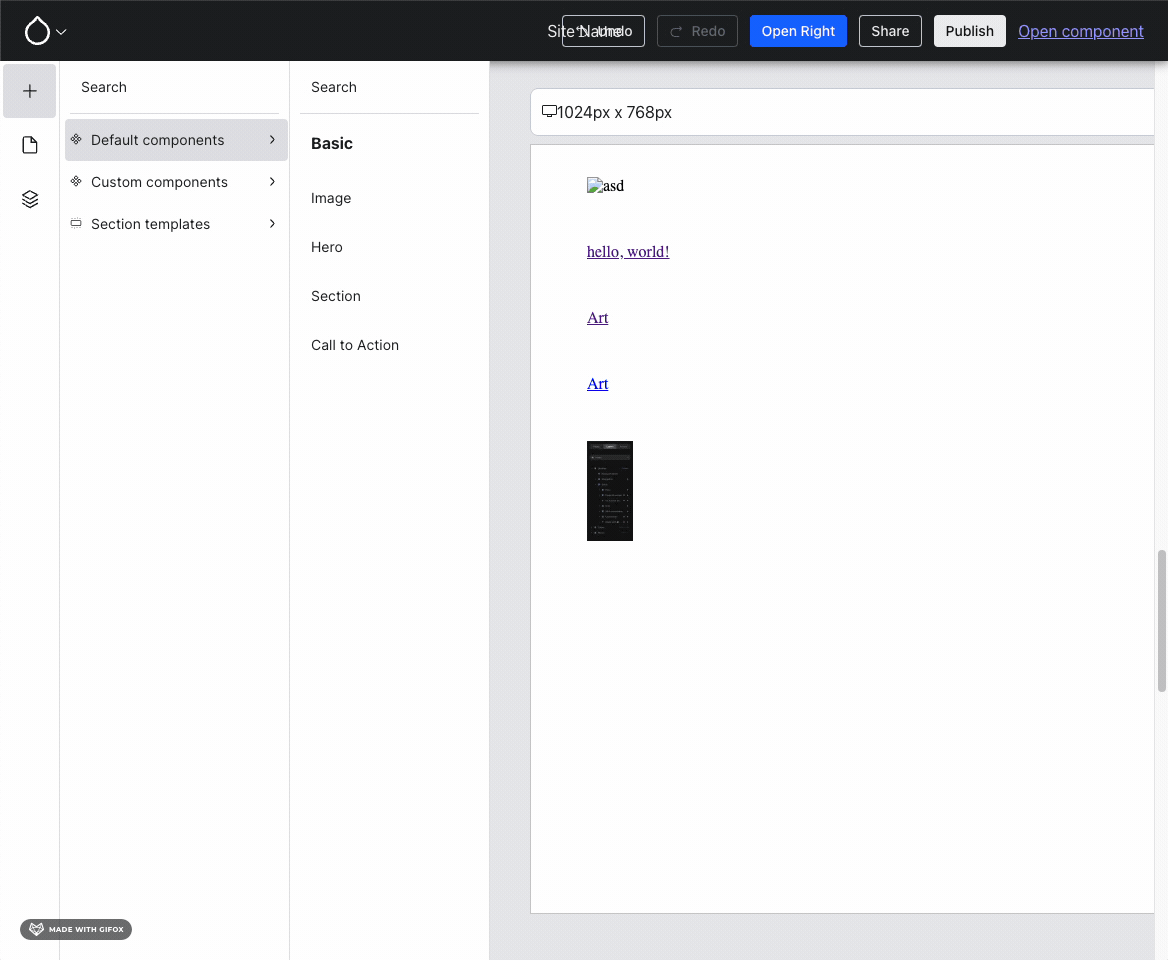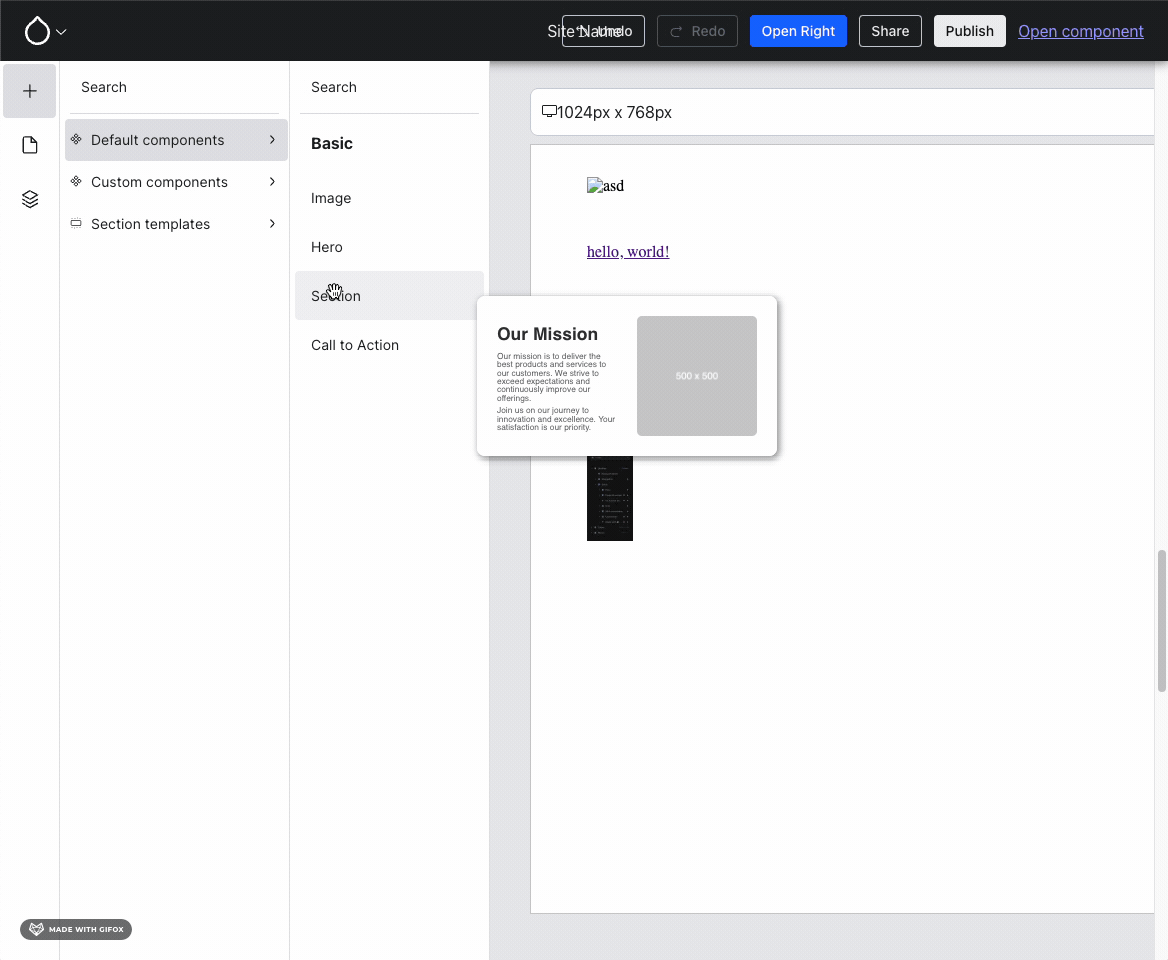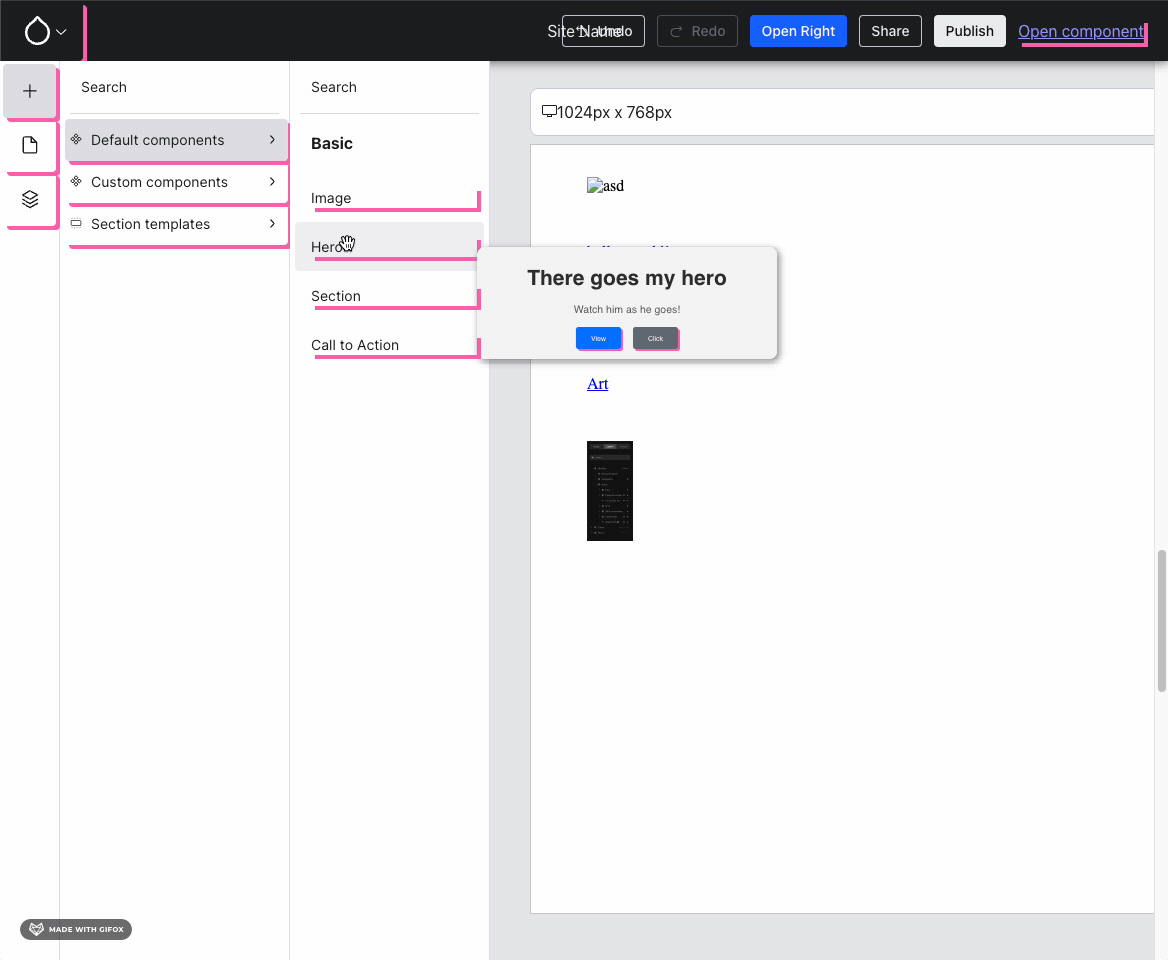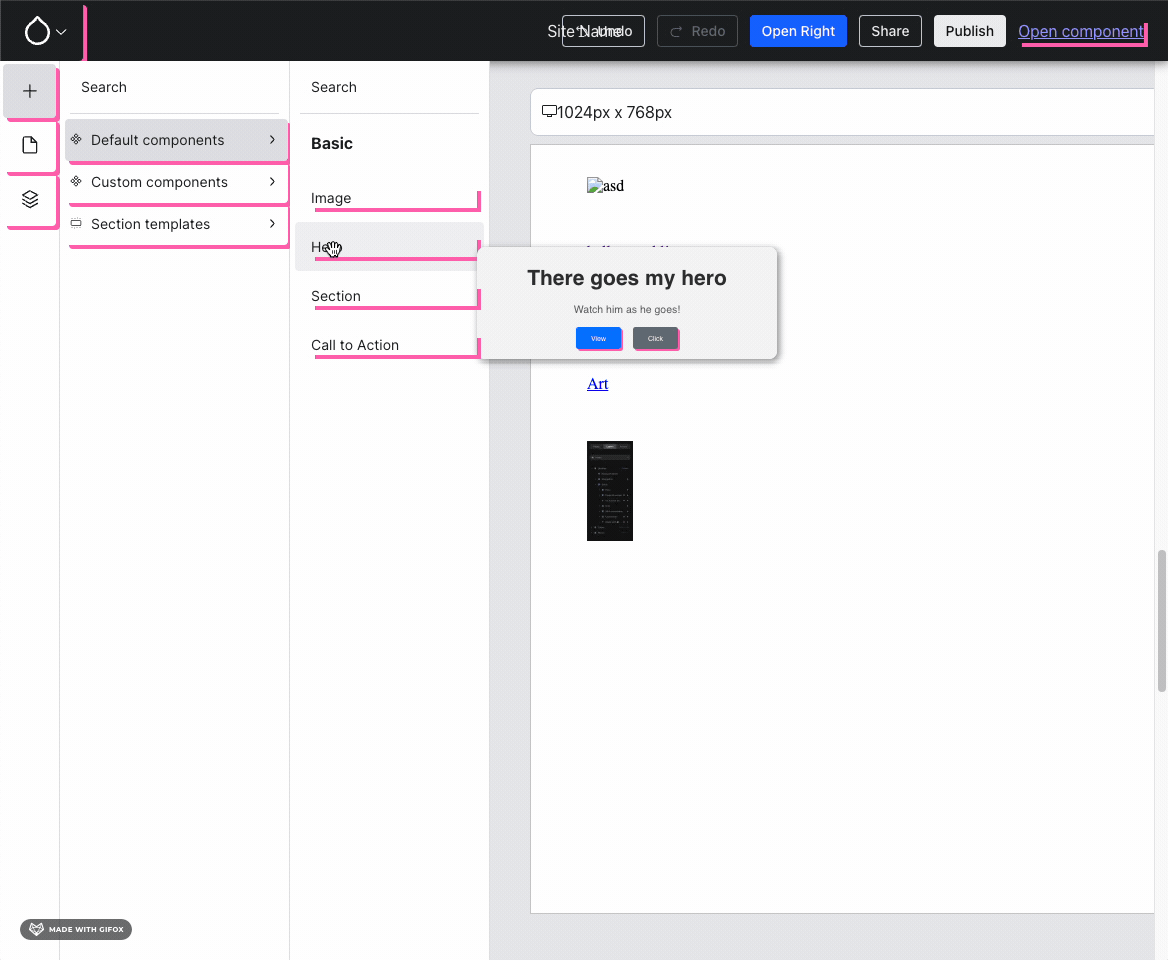
The first prominent leap forward this week was built by Harumi “hooroomoo” Jang: they added the ability to Experience Builder (XB) to first pick the location to add a component to, and then pick the component, rather than only the other way around:
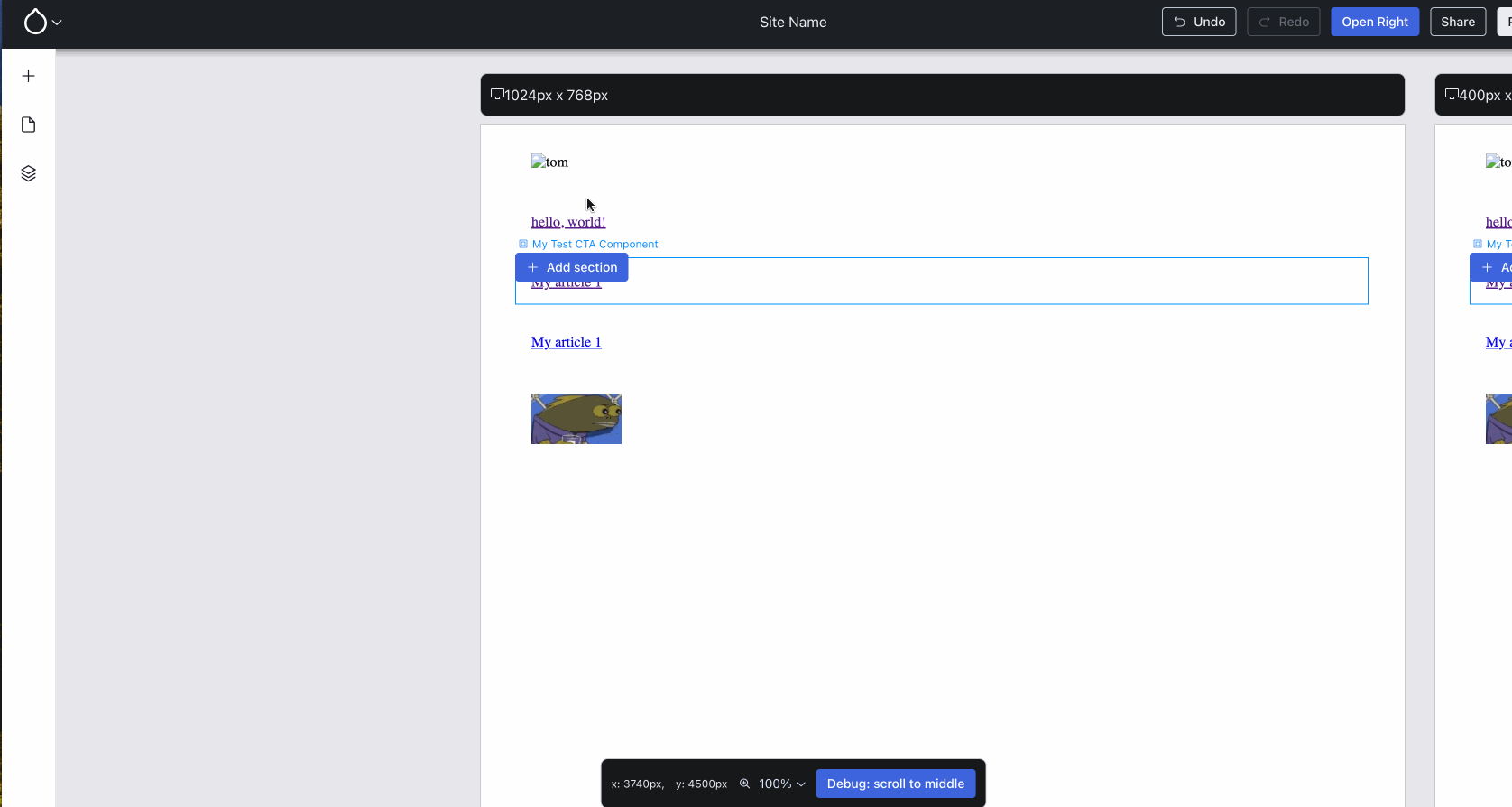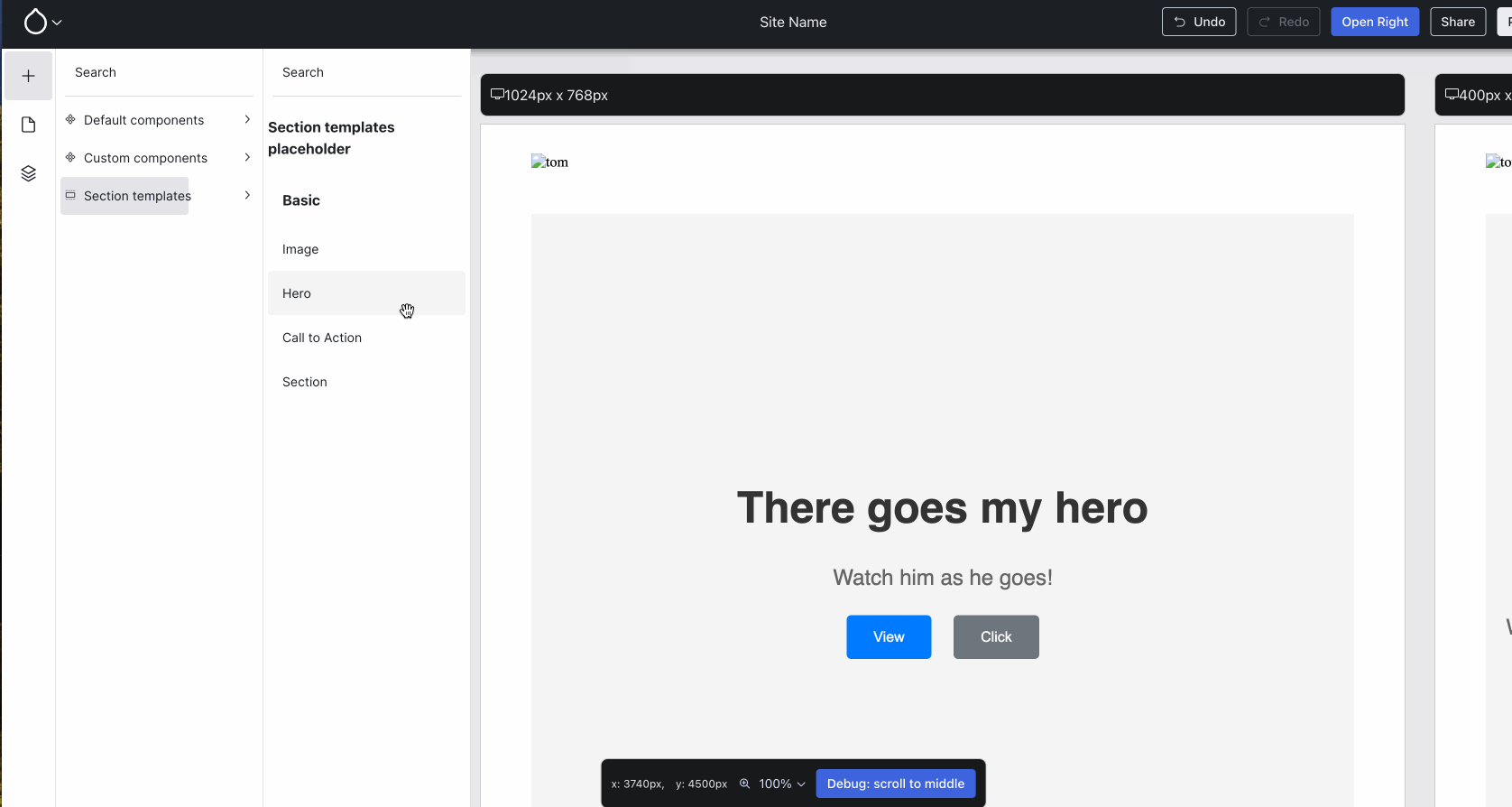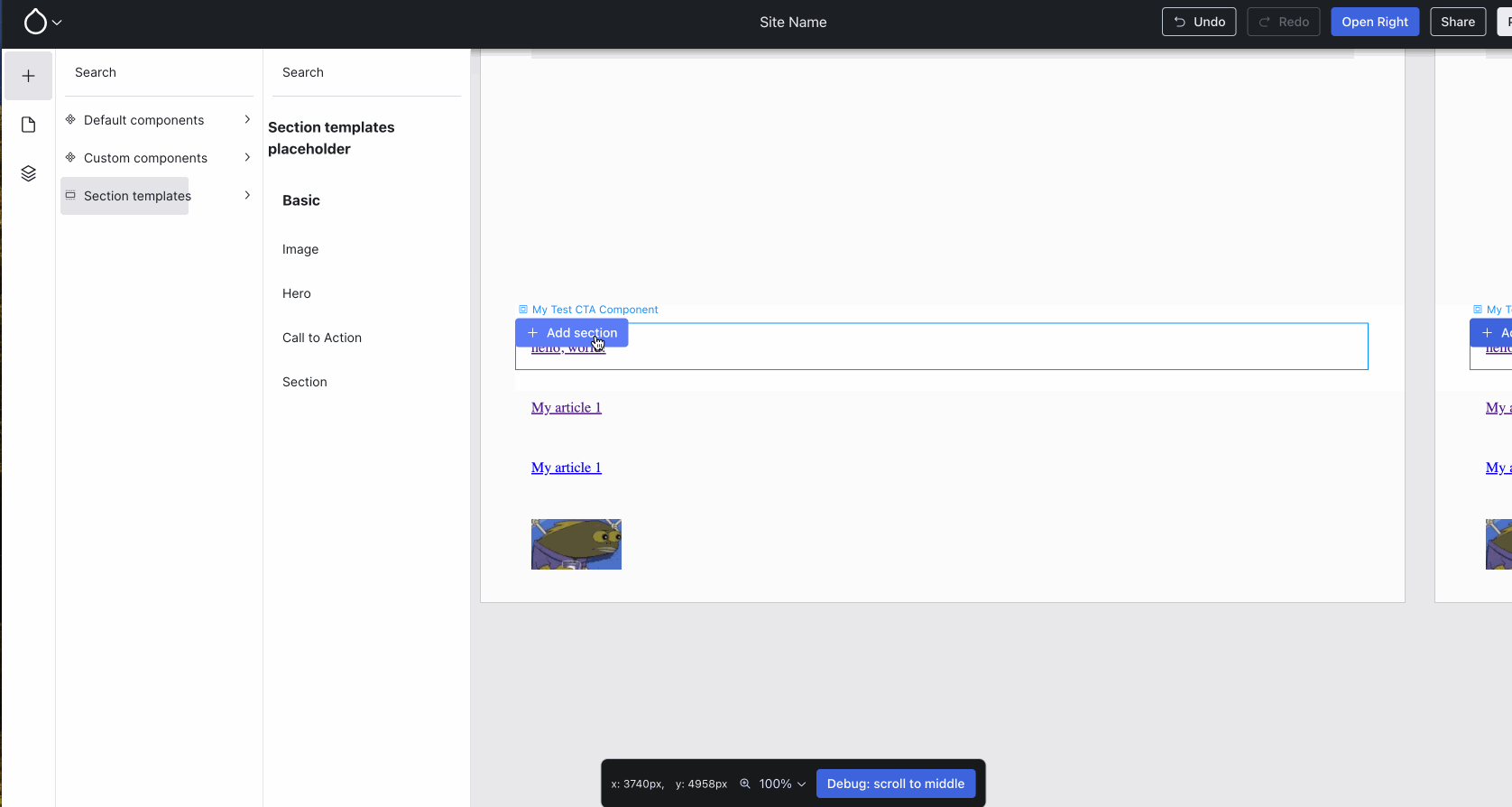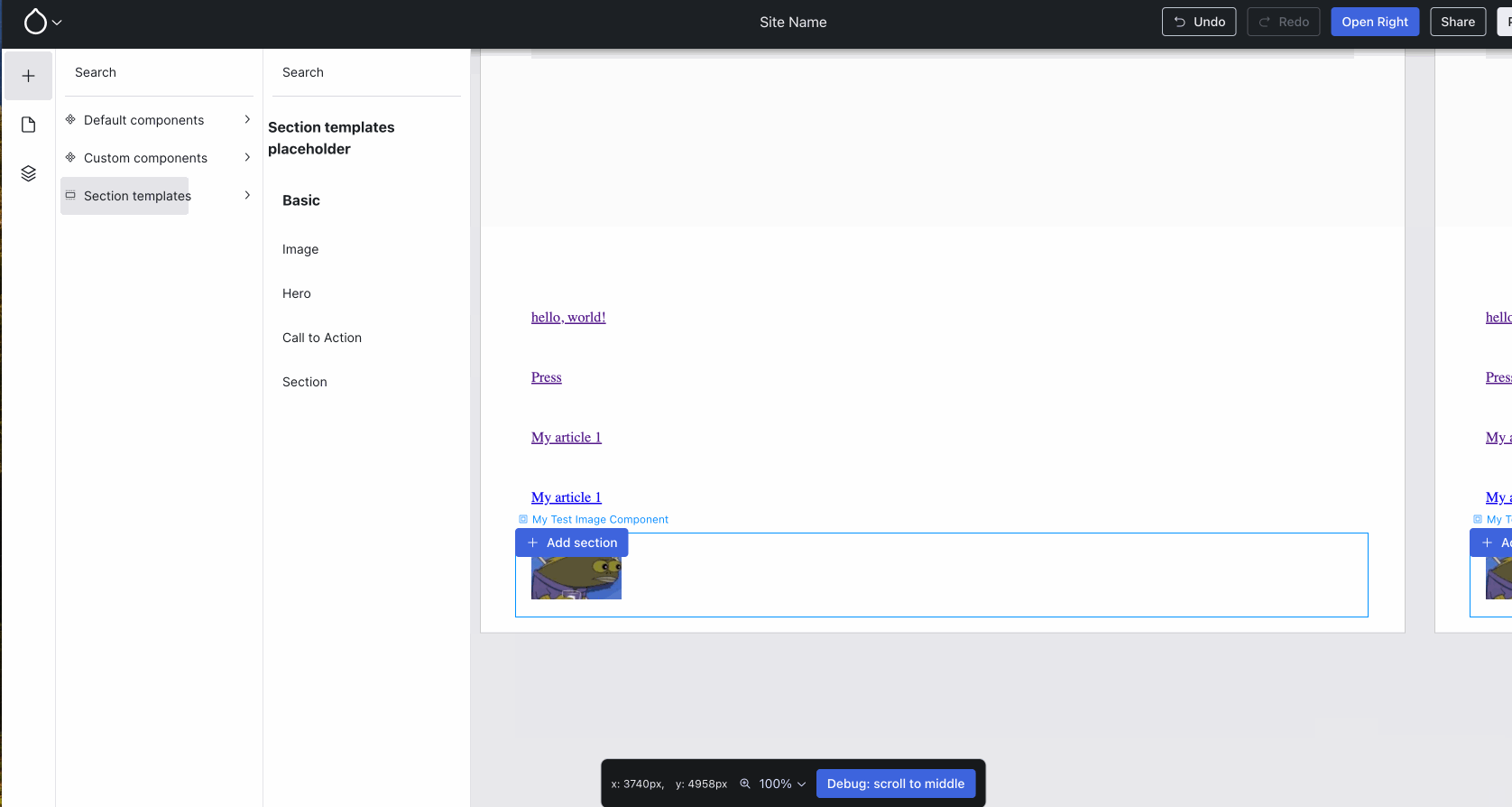
Hovering a section (XB calls top-level components sections) now offers placing another section and triggers the component list form.{kind=link}
Issue #3460952, image by Harumi.
Clearly, it’s important to support both paths towards placing a component!
Great news: this week, Bálint “balintbrews” Kléri joined the team working on XB full-time :) Satisfyingly, he landed an improvement that he started working on as a volunteer contributor: #3458535: Middle click + drag doesn’t work correctly if middle click is inside preview iframe.
Utkarsh “utkarsh_33”, syeda-farheen, Harumi and Jesse “jessebaker” Baker fixed the undo/redo functionality and added end-to-end tests, ensuring that XB cannot regress anymore on that essential functionality.
Ben “bnjmnm” Mullins and I collaborated to overhaul XB’s all-props test-only Single-Directory Component (SDC), whose purpose is solely to exercise the full spectrum of prop shapes (JSON schemas) that SDC can use:
The all-props test-only SDC facilitates testing/developing missing pieces of XB: it makes it easy to see the editing UX that is generated for a particular SDC prop shape.{kind=link}
Issue #3463583, image by Wim.
Last week, we landed component previews, and that was a big leap forward! We firmly believe in rapid iteration, and landing something as soon as it’s at least partially usable, rather than polishing it to perfection — for a mature codebase like Drupal core that makes sense, but not for something that is still in its infancy, like XB. So, unsurprisingly, we found an (obvious) bug: the preview caused styles to bleed:
Notice how pink outlines appear everywhere as soon as the Hero component is previewed — that’s obviously not the intent! :D{kind=link}
Issue #3466303, image by Jesse.
Jesse, Utkarsh and Gaurav “gauravvvv” used shadow DOM to properly encapsulate this.
Missed a prior week? See all posts tagged Experience Builder.
Goal: make it possible to follow high-level progress by reading ~5 minutes/week. I hope this empowers more people to contribute when their unique skills can best be put to use!
For more detail, join the #experience-builder Slack channel. Check out the pinned items at the top!
OpenAPI: constantly keeping front-end and back-end work in syncBack during week 3, Lee “larowlan” Rowlands opened an issue to create an OpenAPI spec for the (then) mock HTTP responses. Back then, the client (React, JS) and server (PHP, Drupal module) were being developed completely independently. Because things were still moving so rapidly back then, some request or response shape was changing almost daily, and nobody had OpenAPI experience … it sadly didn’t become a priority.
then, in the past ~5 or so weeks, having an OpenAPI spec that both the mocks and the actual server responses were validated against would have prevented several problems, and would have boosted productivity.
Thankfully, Philip “pfrilling” Frilling had already gotten significant parts working (and he was able to reuse Lee’s work on the Decoupled Layout Builder API module!). It was not yet mergeable because it didn’t validate the actual server responses yet.
So I started pushing it forward and ran into PHP dependency hell, was able to fix that, and then got us onto OpenAPI 3.1.0 (instead of 3.0.0), enabling XB’s openapi.yml to use patternProperties, without which we actually cannot express all of XB’s response shapes.
Hurray! A whole class of productivity blockers gone! (And Lee was right all along, of course.)
Shape matching woesLast week’s StorablePropShape worked okay, but Ted “tedbow” Bowman’s work on #3446722: Introduce an example set of representative SDC components; transition from “component list” to “component tree” revealed an interesting edge case: JSON object keys are always strings, so 50 is encoded as '50', meaning … the type is changed, and information is lost. Fortunately, Drupal core solved this a decade ago: we (re)discovered Drupal core’s ::storageSettingsFromConfigData(), which was added for precisely this purpose! A simple fix by Utkarsh “utkarsh_33” later, and we were good to go :)
That wasn’t the only problem #3446722 surfaced: we figured out why exactly the JSON schema validation refused to accept a sample value generated by Drupal core’s uri field type … and it turns out that’s simply because that field type indeed generates invalid URIs! We worked around it by swapping the class and overriding the logic to generate valid sample values. 1
In other words: matching the SDC props’ type information (expressed as JSON schema) against Drupal’s Typed Data/Entity/Field/Field Property type information (expressed as DataType plugins + validation constraints) is definitely revealing interesting problems that probably nobody else has been running into :D
P.S.: we set a new record by a significant margin this week: 16 MRs merged!
Week 13 was August 5–11, 2024.
-
We’ll eventually create upstream issues in Drupal core, but first we’re working accumulating a range of these kinds of problems, to identify the best strategy to fix this upstream. We’re now at ten overrides for field type classes, for a variety of reasons — most for missing validation constraints and/or incorrect field property class implementations. ↩︎
- Hovering a section (a top-level component) now offers placing another section and triggers the component list form.
- The all-props test-only SDC facilitates testing/developing missing pieces of XB: it makes it easy to see the editing UX.
- Notice how pink outlines appear everywhere as soon as the Hero component is previewed.
{kind=link}
{kind=link}
{kind=link}
Skynet Technologies USA LLC Blogs: How to maximize WCAG and ADA accessibility for Drupal multi-language sites? – Best Practices!
mark.ie: Placeholders are often a bad UX pattern
When the value of the placeholder is the same as the value you need in the field, it just looks like a disabled field.
Python Software Foundation: Python Developers Survey 2023 Results
We are excited to share the results of the seventh official annual Python Developers Survey. This survey is done yearly as a collaborative effort between the Python Software Foundation and JetBrains. Responses were collected from November 2023 through February 2024. This year, we kept the response period open longer to facilitate as much global representation as possible. More than 25,000 Python developers and enthusiasts from almost 200 countries and regions participated in the survey to reveal the current state of the language and the ecosystem around it.
Check out the survey results!
The survey aims to map the Python landscape and covers the following topics:
- General Python usage
- Purpose for using Python
- Python versions
- Frameworks and Libraries
- Cloud Platforms
- Data science
- Development tools
- Python packaging
- Demographics
We encourage you to check out the methodology and the raw data for this year's Python Developers Survey, as well as those from past years (2022, 2021, 2020, 2019, 2018, and 2017). We would love to hear about what you learn by digging into the numbers! Share your results and comments with us on social media by mentioning JetBrains (LinkedIn, X) and the PSF (Mastodon, LinkedIn, X) using the #pythondevsurvey hashtag. Based on the feedback we received last year, we made adjustments to the 2023 survey- so we welcome suggestions and feedback that could help us improve again for next year!
PyPy: Guest Post: How PortaOne uses PyPy for high-performance processing, connecting over 1B of phone calls every month
The PyPy project is always happy to hear about industrial use and deployments of PyPy. For the GC bug finding task earlier this year, we collaborated with PortaOne and we're super happy that Serhii Titov, head of the QA department at PortaOne, was up to writing this guest post to describe their use and experience with the project.
What does PortaOne do?We at PortaOne Inc. allow telecom operators to launch new services (or provide existing services more efficiently) using our VoIP platform (PortaSIP) and our real-time charging system (PortaBilling), which provides additional features for cloud PBX, such as call transfer, queues, interactive voice response (IVR) and more. At this moment our support team manages several thousand servers with our software installed in 100 countries, through which over 500 telecommunication service providers connect millions of end users every day. The unique thing about PortaOne is that we supply the source code of our product to our customers - something unheard of in the telecom world! Thus we attract "telco innovators", who use our APIs to build around the system and the source code to create unique tweaks of functionality, which produces amazing products.
At the core of PortaSIP is the middle-ware component (the proper name for it is "B2BUA", but that probably does not say much to anyone outside of experts in VoIP), which implements the actual handling of SIP calls, messages, etc. and all added features (for instance, trying to send a call via telco operators through which the cost per minute is lower). It has to be fast (since even a small delay in establishing a call is noticed by a customer), reliable (everyone hates when a call drops or cannot be completed) and yet easily expandable with new functionality. This is why we decided to use Python as opposed to C/C++ or similar programming languages, which are often used in telecom equipment.
The B2BUA component is a batch of similar Python processes that are looped inside a asyncore.dispatcher wrapper. The load balancing between these Python processes is done by our stateless SIP proxy server written in C++. All our sockets are served by this B2BUA. We have our custom client-wrappers around pymysql, redis, cassandra-driver and requests to communicate with external services. Some of the Python processes use cffi wrappers around C-code to improve their performance (examples: an Oracle DB driver, a client to a radius server, a custom C logger).
The I/O operations that block the main thread of the Python processes are processed in sub-threads. We have custom wrappers around threading.Thread and also asyncore.dispatcher. The results of such operations are returned to the main thread.
Improving our performance with PyPyWe started with CPython and then in 2014 switched to PyPy because it was faster. Here's an exact quote from our first testing notes: "PyPy gives significant performance boost, ~50%". Nowadays, after years of changes in all the software involved, PyPy still gives us +50% boost compared to CPython.
Taking care of real time traffic for so many people around the globe is something we're really proud of. I hope the PyPy team can be proud of it as well, as the PyPy product is a part of this solution.
Finding a garbage collector bug: stage 1, the GC hooksHowever our path with PyPy wasn't perfectly smooth. There were very rare cases of crashes on PyPy that we weren't able to catch. That's because to make coredump useful we needed to switch to PyPy with debug, but we cannot let it run in that mode on a production system for an extended period of time, and we did not have any STR (steps-to-reproduce) to make PyPy crash again in our lab. That's why we kept (and still keep) both interpreters installed just in case, and we would switch to CPython if we noticed it happening.
At the time of updating PyPy from 3.5 to 3.6 our QA started noticing those crashes more often, but we still had no luck with STR or collecting proper coredumps with debug symbols. Then it became even worse after our development played with the Garbage Collector's options to increase performance of our middleware component. The crashes started to affect our regular performance testing (controlled by QA manager Yevhenii Bovda). At that point it was decided that we can no longer live like that and so we started an intense investigation.
During the first stage of our investigation (following the best practice of troubleshooting) we narrowed down the issue as much as we could. So, it was not our code, it was definitely somewhere in PyPy. Eventually our SIP software engineer Yevhenii Yatchenko found out that this bug is connected with the use of our custom hooks in the GC. Yevhenii created ticket #4899 and within 2-3 days we got a fix from a member of the PyPy team, in true open-source fashion.
Finding a garbage collector bug: stage 2, the real bugThen came stage 2. In parallel with the previous ticket, Yevhenii created #4900 that we still see failing with coredumps quite often, and they are not connected to GC custom hooks. In a nutshell, it took us dozens of back and forward emails, three Zoom sessions and four versions of a patch to solve the issue. During the last iteration we got a new set of options to try and a new version of the patch. Surprisingly, that helped! What a relief! So, the next logical step was to remove all debug options and run PyPy only with the patch. Unfortunately, it started to fail again and we came to the obvious conclusion that what will help us is not a patch, but one of options we were testing out. At that point we found out that PYPY_GC_MAX_PINNED=0 is a necessary and sufficient condition to solve our issue. This points to another bug in the garbage collector, somehow related to object pinning.
Here's our current state: we have to add PYPY_GC_MAX_PINNED=0, but we do not face the crashes anymore.
Conclusion and next stepsGratitude is extended to Carl for his invaluable assistance in resolving the nasty bugss, because it seems we're the only ones who suffered from the last one and we really did not want to fall back to CPython due to its performance disadvantage.
Serhii Titov, head of the QA department at PortaOne Inc.
P.S. If you are a perfectionist and at this point you have mixed feelings and you are still bothered by the question "But there might still be a bug in the GC, what about that?" - Carl has some ideas about it and he will sort it out (we will help with the testing/verification part).
Six Tips for Maximizing Desktop Screen Potential
Desktop software has many differences from mobile and embedded applications but one of the biggest and most obvious is the screen. How can you take advantage of all that real estate for your application? Here are six considerations for managing the screen in your desktop application.
- Choosing the right GUI framework
Use a flexible GUI framework that easily supports building apps with differing resolutions. The less hand-tweaking you need for your dialogs, graphical assets, and interface across a wide spectrum of resolutions, the better.
- Testing across diverse displays
Make sure you have a wide range of monitors to test your app against. It’s easy to assume everything works perfectly when your app is tested on a uniform configuration provided by IT. However, visual issues may arise when your app runs on smaller, larger, or different monitors.
- Setting clear resolution standards
Set a clear minimum resolution that supports your application’s features effectively. Ensure all dialogs fit on screen, scrollbars function properly, nothing is off-screen. Also, test against ultra-high-resolution monitors (like 4K and 8K) to ensure clarity and usability at high DPI settings. Verify that text is legible, controls are noticeable, and clickable regions are big enough to target accurately.
- Designing for adaptability
Ensure that your application’s user interface is not only scalable but also adaptable. It should reconfigure itself based on the resolution, maintaining a balance between functionality and aesthetics. Dialog boxes should be resizable, and layout managers should dynamically adjust component placement based on the available screen real estate.
- Embracing multi-monitor flexibility
Multi-monitor setups aren’t just for developers anymore. Many people use laptops along with a larger monitor. In fact, a two-screen configuration may be even more popular than single screens. Make sure your application handles this flexibility intelligently by allowing spawning windows or panels that can be moved to the monitor that best works for the user.
- Customizing the user workspace
With features such as dockable toolbars, multiple document interfaces, or floating inspectors, you can allow users to customize their workspace. This is particularly handy for apps like graphic design, audio/video editing, and software development, where distributing a wide variety of tools, dialogs, controls, and views across the entire screen real estate is essential.
Final thoughtsDesigning and testing for multiple screen resolutions and configurations is part of making a great application. As screen technology evolves and user expectations rise, your applications’ ability to harness the full potential of ultra resolution and multi-monitor setups might just set it apart from the crowd. If you’re interested in more tips for building desktop applications, you may want to read our related best practice guide.
About KDAB
If you like this article and want to read similar material, consider subscribing via our RSS feed.
Subscribe to KDAB TV for similar informative short video content.
KDAB provides market leading software consulting and development services and training in Qt, C++ and 3D/OpenGL. Contact us.
The post Six Tips for Maximizing Desktop Screen Potential appeared first on KDAB.
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
FLOSS Research
- Give Your Input on the State of Open Source Survey
- Open Data and Open Source AI: Charting a course to get more of both
- The Open Source Initiative and the Eclipse Foundation to Collaborate on Shaping Open Source AI (OSAI) Public Policy
- ClearlyDefined v2.0 adds support for LicenseRefs
- ClearlyDefined at SOSS Fusion 2024: a collaborative solution to Open Source license compliance