
Feeds
Maui Release Briefing #6
Today, we bring you a report on the brand-new release of the Maui Project.
We are excited to announce the latest release of MauiKit version 4.0.0, our comprehensive user interface toolkit specifically designed for convergent interfaces, the complying frameworks, and an in-house developed set of convergent applications.
Built on the solid foundations of Qt Quick Controls, QML, and the power and stability of C++, MauiKit empowers developers to create adaptable and seamless user interfaces across a range of devices, and with this release, we have finally migrated to Qt6 and made available the documentation for the frameworks.
Join us on this journey as we unveil the potential of MauiKit 4 for building convergent interfaces, and finally discover the possibilities offered by the enhanced Maui App stack.
CommunityTo follow the Maui Project’s development or to just say hi, you can join us on our Telegram group @mauiproject
We are present on X and Mastodon:
Thanks to the KDE contributors who have helped to translate the Maui Apps and Frameworks!
Downloads & SourcesYou can get the stable release packages [APKs, AppImage, TARs] directly from the KDE downloads server at https://download.kde.org/stable/maui/
All of the Maui repositories have the newly released branches and tags. You can get the sources right from the Maui group: https://invent.kde.org/maui
Qt6With this version bump the Maui team has finalized the migration over to Qt6, which implies more stability and better performance coming from Qt upgraded QQC engine; but also means that some features have been removed or did not make the cut and still need more time to be brought back in posterior releases.
MauiKit 4 Frameworks & AppsCurrently, there are over 10 frameworks, with two new ones recently introduced. They all, for the most part, have been fully documented, and although, the KDE doxygen agent has some minor issues when publishing some parts, you can find the documentation online at https://api.kde.org/mauikit/ (and if you find missing parts, confusing bits, or overall sections to improve – you can open a ticket at any of the framework repos and it shall be fixed shortly after)
fav filemanager and music player. minimal modern & convergent @maui_project
Maui Apps 4.0 coming out soon. pic.twitter.com/OVLM2HWv6v
A script element has been removed to ensure Planet works properly. Please find it in the original post.
Core & OthersMauiKit Core controls also include the Mauikit Style, which along with the core controls has been revised and improved in the migration. New features have been introduced and some minor changes in the API have been made.
A good way to test the new changes made visually is via the MauiDemo application, when building MauiKit from the source, just add the -DBUILD_DEMO=ON flag and then launch it as MauiDemo4
All of the other frameworks have also been fully ported and reviewed, and some features are absent – for example, for ImageTools the image editor is missing for Android due to KQuickImageEditor problems.
Comic book support is missing in MauiKit-Documents, due to a big pending refactoring.
Finally, TextEditor new backend rendering engine migration is yet to be started.
Most of these pending issues will be tackled in the next releases bit by bit.
More details can be found in the previous blog posts:
Archiver & Git
MauiKit-Archiver is a new framework, and it was created to share components and code between different applications that were duplicating the same code: Index, Arca, and Shelf.
The same goes for MauiKit-Git, which will help unify the code base for implementations made in Index, Bonsai, and Strike, so all of those apps can benefit from a single cohesive and curated code base in the form of a framework.
Archiver is pending to be documented, and Git is pending to be finished for its first stable release.
I have now finished porting all the Maui Apps and MauiKit frameworks to Qt6.
Vvave music player mini mode is back.@maui_project @Nitrux_NX pic.twitter.com/Mal3RU87O2
A script element has been removed to ensure Planet works properly. Please find it in the original post.
Known Issues- MauiKit-Documents comic book support is stalled until the next release due to heavy refactoring under Android.
- MauiKit-ImageTools under Android does not include the image editor, since KQuickImageEditor is not working correctly under Android
- Clip is not working under Android due to issues with the libavformat not finding openssl.so when packaging the APK, this is still under review
- MauiKit-Git is still being worked on, and due to this Bonsai is not included on this stable release as it is being ported over to MauiKit-Git
@maui_project looking good. after the port to qt6 the next goal is to put out a stable version of Maui Shell with a tight integration to the app ecosystem and the HIG #mauikit pic.twitter.com/BkR9ecTzMT
— Camilo Higuita (@cmhiguita) May 6, 2024A script element has been removed to ensure Planet works properly. Please find it in the original post.
Maui ShellAlthough Maui Shell has been ported over to Qt6 and is working with the latest MauiKit4, a lot of pending issues are still present and being worked on. The next release will be dedicated fully on Maui Shell and all of its subprojects, such as Maui Settings, Maui Core, CaskServer, etc.
That’s it for now. Until the next blog post, that will be a bit closer to the 4.0.1 stable release.
Release scheduleThe post Maui Release Briefing #6 appeared first on MauiKit — #UIFramework.
Wim Leers: XB week 15: docs & DX
Monday August 19, 2024 definitely was a milestone:
- I had the satisfaction of being able to remove the TwoTerribleTextareasWidget that I introduced two months ago, because the Experience Builder (XB) UI now is sufficiently developed to be able to place a component and populate its props using static prop sources — by now this terrible hack was now doing more harm than good, so: good riddance! :D
- a huge sigh of relief was heard emanating from Ghent, Belgium because finally comprehensive docs for the XB data model were published, and ADR #2 was published to capture the initial back-end decisions, but is expected to be superseded
(an ADR or Architecture Decision Record can be a way to unambiguously capture current choices, knowing it will be superseded).
Those docs define all XB terminology (such as “static prop sources” in that first bullet above), which enables more precise communication. Contributing to XB becomes simpler thanks to those docs 1, as does observing from a distance — with reviews to ensure accuracy & clarity from Simon “siramsay” Ramsay, Dave “longwave” Long, Ted “tedbow” Bowman, Feliksas “f.mazeikis” Mazeikis and of course, crucially, Alex “effulgentsia” Bronstein, whose proposed abstract data model it is that XB makes concrete.
While we’ll continue to iterate fast, it now is a hard requirement that every MR updates affected docs. That’s why several updates already have been committed.
Docs to come for other aspects!
Missed a prior week? See all posts tagged Experience Builder.
Goal: make it possible to follow high-level progress by reading ~5 minutes/week. I hope this empowers more people to contribute when their unique skills can best be put to use!
For more detail, join the #experience-builder Slack channel. Check out the pinned items at the top!
For a huge DX leap forward for both those working on XB itself as well as those working on the Starshot Demo Design System (spearheaded by Kristen Pol): Felix’ MR to auto-create/update Component config entities for all discovered Single-Directory Components (SDCs) landed — if they meet the minimum criteria.
For example, each SDC prop must have a title defined, because otherwise XB would be forced to expose machine names, like I mentioned at the start of last week’s update. So: XB requires SDCs to have rich enough metadata to be able to generate a good UX.
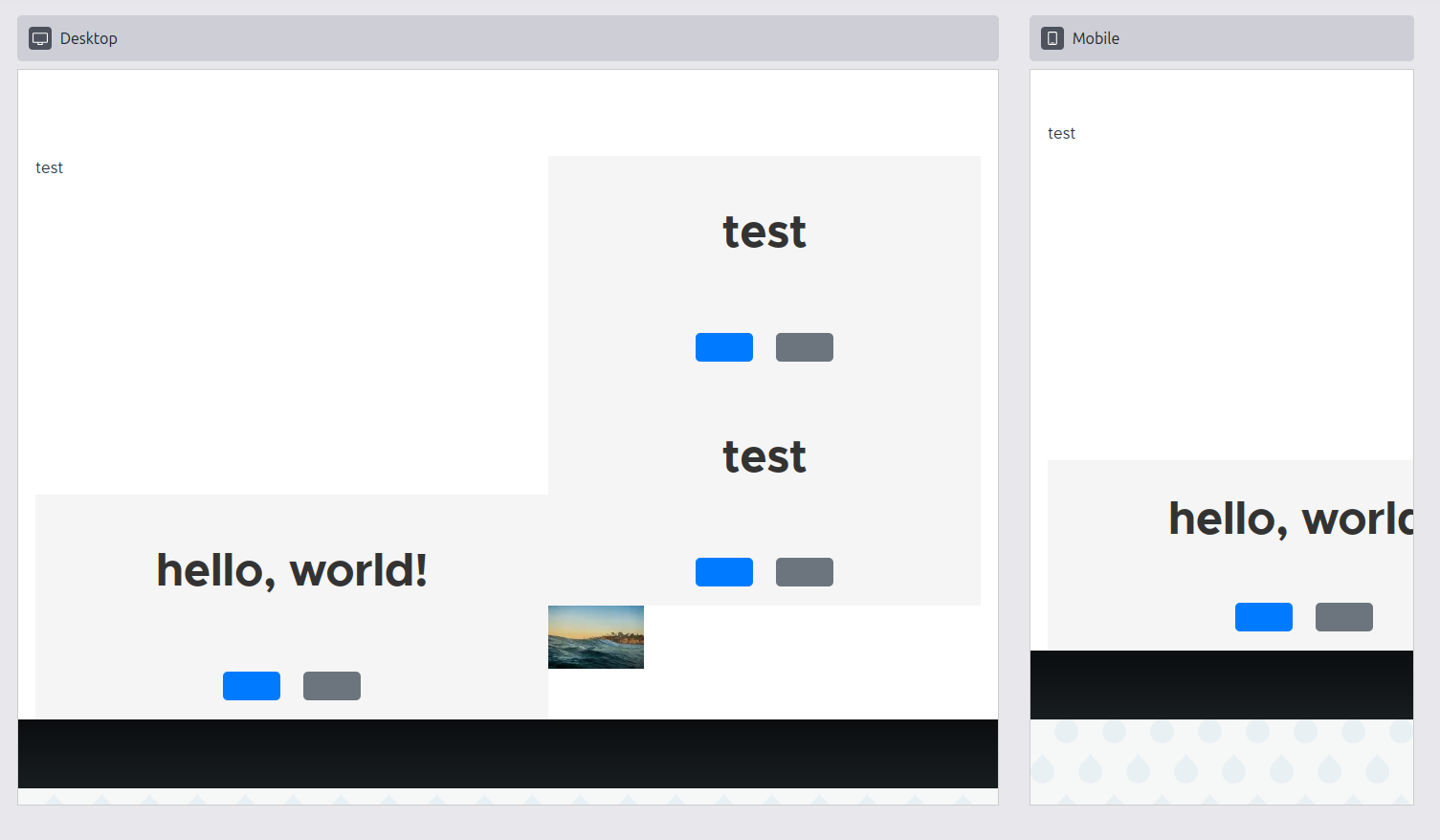
That also allowed Omkar “omkar-pd” Deshpande to remove the awkward-but-necessary-at-the-time add/edit form we’d added months ago. When installing the demo_design_system theme, you’ll see something like:
{kind=link}
Issue #3464025, image by me.
Ted helped the back end race ahead of the front end: while we don’t have designs for it yet (nor capacity to build it before DrupalCon if they would suddenly exist), there now is an HTTP API to get a list of viable candidate field properties that are able to correctly populate a particular component prop. These are what in the current XB terminology are called dynamic prop sources 2 3.
The preview in the XB UI has been loading component CSS/JS for a while, but thanks to Dave & Ted it now also loads the default theme’s global CSS/JS.
More accurate previews, including for example the Olivero font stack, background and footer showing up.{kind=link}
Issue #3468106, image by Dave. Small(ish) but noteworthy
- Ted proved via a test that both symmetric and asymmetric translations work correctly in the current data model/field type implementation
- Bálint “balintbrews” Kléri & Ben “bnjmnm” Mullins fixed the component props form showing the wrong values
- Now that component trees started working (since last week), Jesse “jessebaker” Baker discovered that it is not actually possible to drag and drop a nested component :D Harumi “hooroomoo” Jang quickly squashed that bug!
- Felix and I were able to narrow down why images with spaces in the filename were being refused to be rendered by the SDC subsystem: Drupal core’s File entity type stores a file stream wrapper URI like public://cat and dog.jpg and considers that a valid URL … but it’s not! URIs cannot contain spaces — that should be encoded as public://cat%20and%20dog.jpg to be valid.
SDC is right, the >10 year old PrimitiveTypeConstraintValidator is wrong! This is being added to the increasingly long list of low-level bugs in Drupal core that went unnoticed for over a decade, so we worked around it for now. - Utkarsh “utkarsh_33” fixed a bug where the name/label of a component instance was lost.
- Finally, a hilarious one to end with: at some point, we set up the “canvas” to be to 10,000x10,000 pixels. Unfortunately, this means that people trying XB have sometimes gotten lost :D
So Jesse reduced it to a mere 3500x3500 pixels, for now that’s sufficient, later we’ll compute this dynamically.
Week 15 was August 19–25, 2024.
-
Yes, that’s the third time I’m linking to docs/data-model.md. It’s that important! ↩︎
-
Dynamic Prop Sources are similar to Drupal’s tokens, but are more precise, and support more than only strings, because SDC props often require more complex shapes than just strings. ↩︎
-
This is the shape matching from ~3 months ago made available to the client side. ↩︎
{kind=link}
{kind=link}
The Drop Times: Starshot at Barcelona: 10 Sessions on Drupal CMS You Shouldn't Miss
Real Python: Python News Roundup: September 2024
As the autumn leaves start to fall, signaling the transition to cooler weather, the Python community has warmed up to a series of noteworthy developments. Last month, a new maintenance release of Python 3.12.5 was introduced, reinforcing the language’s ongoing commitment to stability and security.
On a parallel note, Python continues its reign as the top programming language according to IEEE Spectrum’s annual rankings. This sentiment is echoed by the Python Developers Survey 2023 results, which reveal intriguing trends and preferences within the community.
Looking ahead, PEP 750 has proposed the addition of tag strings in Python 3.14, inspired by JavaScript’s tagged template literals. This feature aims to enhance string processing, offering developers more control and expressiveness.
Furthermore, EuroSciPy 2024 recently concluded in Poland after successfully fostering cross-disciplinary collaboration and learning. The event featured insightful talks and hands-on tutorials, spotlighting innovative tools and libraries that are advancing scientific computing with Python.
Let’s dive into the most significant Python news from the past month!
Python 3.12.5 ReleasedEarly last month, Python 3.12.5 was released as the fifth maintenance update for the 3.12 series. Since the previous patch update in June, this release packs over 250 bug fixes, performance improvements, and documentation enhancements.
Here are the most important highlights:
- Standard Library: Many modules in the standard library received crucial updates, such as fixes for crashes in ssl when the main interpreter restarts, and various corrections for error-handling mechanisms.
- Core Python: The core Python runtime has several enhancements, including improvements to dictionary watchers, error messages, and fixes for edge-case crashes involving f-strings and multithreading.
- Security: Key security improvements include the addition of missing audit events for interactive Python use and socket connection authentication within a fallback implementation on platforms such as Windows, where Unix inter-process communication is unavailable.
- Tests: New test cases have been added and bug fixes have been applied to prevent random memory leaks during testing.
- Documentation: Python documentation has been updated to remove discrepancies and clarify edge cases in multithreaded queues.
Additionally, Python 3.12.5 comes equipped with pip 24.2 by default, bringing a slew of significant improvements to enhance security, efficiency, and functionality. One of the most notable upgrades is that pip now defaults to using system certificates, bolstering security measures when managing and installing third-party packages.
Read the full article at https://realpython.com/python-news-september-2024/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
PyCharm: How to Use Jupyter Notebooks in PyCharm
PyCharm is one of the most well-known data science tools, offering excellent out-of-the-box support for Python, SQL, and other languages. PyCharm also provides integrations for Databricks, Hugging Face and many other important tools. All these features allow you to write good code and work with your data and projects faster.
PyCharm Professional’s support for Jupyter notebooks combines the interactive nature of Jupyter notebooks with PyCharm’s superior code quality and data-related features. This blog post will explore how PyCharm’s Jupyter support can significantly boost your productivity.
Watch this video to get a comprehensive overview of using Jupyter notebooks in PyCharm and learn how you can speed up your data workflows.
Speed up data analysis Get acquainted with your dataWhen you start working on your project, it is extremely important to understand what data you have, including information about the size of your dataset, any problems with it, and its patterns. For this purpose, your pandas and Polars DataFrames can be rendered in Jupyter outputs in Excel-like tables. The tables are fully interactive, so you can easily sort one or multiple columns and browse and view your data, you can choose how many rows will be shown in a table and perform many other operations.
The table also provides some important information for example:
- You can find the the size of a table in its header.
- You can find the data type symbols in the column headers.
- You can also use JetBrains AI Assistant to get information about your DataFrame by clicking on the icon.
After getting acquainted with your data, you need to clean it. This an important step, but it is also extremely time consuming because there are all sorts of problems you could find, including missing values, outliers, inconsistencies in data types, and so on. Indeed, according to the State of Developer Ecosystem 2023 report, nearly 50% of Data Professionals dedicate 30% of their time or more to data preparation. Fortunately, PyCharm offers a variety of features that streamline the data-cleaning process.
Some insights are already available in the column headers.
First, we can easily spot the amount of missing data for each column because it is highlighted in red. Also, we may be able to see at a glance whether some of our columns have outliers. For example, in the bath column, the maximum value is significantly higher than the ninety-fifth percentile. Therefore, we can expect that this column has at least one outlier and requires our attention.
Additionally, you might suspect there’s an issue with the data if the data type does not match the expected one. For example, the header of the total_sqft column below is marked with the symbol, which in PyCharm indicates that the column contains the Object data type. The most appropriate data type for a column like total_sqft would likely be float or integer, however, so we may expect there to be inconsistencies in the data types within the column, which could affect data processing and analysis. After sorting, we notice one possible reason for the discrepancy: the use of text in data and ranges instead of numerical values.
So, our suspicion that the column had data-type inconsistencies was proven correct. As this example shows, small details in the table header can provide important information about your data and alert you to issues that need to be addressed, so it’s always worth checking.You can also use no-code visualizations to gather information about whether your data needs to be cleaned. Simply click on the icon in the top-left corner of the table. There are many available visualization options, including histograms, that can be used to see where the peaks of the distribution are, whether the distribution is skewed or symmetrical, and whether there are any outliers.
Of course, you can use code to gather information about your dataset and fix any problems you’ve identified. However, the mentioned low-code features often provide valuable insights about your data and can help you work with it much faster.
Code faster Code completion and quick documentationA significant portion of a data professional’s job involves writing code. Fortunately, PyCharm is well known for its features that allow you to write code significantly faster. For example, local ML-powered full line code completion can provide suggestions for entire lines of code.
Another useful feature is quick documentation, which appears when you hover the cursor over your code. This allows you to gather information about functions and other code elements without having to leave the IDE.
RefactoringsOf course, working with code and data is an interactive process, and you may often decide to make some changes in your code – for example, to rename a variable. Going through the whole file or, in some cases, the entire project, would be cumbersome and time consuming. We can use PyCharm’s refactoring capabilities to rename a variable, introduce a constant, and make many other changes in your code. For example, in this case, I want to rename the DataFrame to make it shorter. I simply use the the Rename refactoring to make the necessary changes.
PyCharm offers a vast number of different refactoring options. To dive deeper into this functionality, watch this video.
Fix problemsIt is practically impossible to write code without there being any mistakes or typos. PyCharm has a vast array of features that allow you to spot and address issues faster. You will notice the Inspection widget in the top-right corner if it finds any problems.
For example, I forgot to import a library in my project and made several typos in the doc so let’s take a look how PyCharm can help here.
First of all, the problem with the library import:
Additionally, with Jupyter traceback, you can see the line where the error occurred and get a link to the code. This makes the bug-fixing process much easier. Here, I have a typo in line 3. I can easily navigate to it by clicking on the blue text.
Additionally if you would like to get more information and suggestion how to fix the problem, you can use JetBrains AI Assistant by clicking on Explain with AI.
Of course, that is just the tip of the iceberg. We recommend reading the documentation to better understand all the features PyCharm offers to help you maintain code quality.
Navigate easilyFor the majority of cases, data science work involves a lot of experimentation, with the journey from start to finish rarely resembling a straight line.
During this experimentation process, you have to go back and forth between different parts of your project and between cells in order to find the best solution for a given problem. Therefore, it is essential for you to be able to navigate smoothly through your project and files. Let’s take a look at how PyCharm can help in this respect.
First of all, you can use the classic CMD+F (Mac) or CTRL+F (Windows) shortcut for searching in your notebook. This basic search functionality offers some additional filters like Match Case or Regex.
You can use Markdown cells to structure the document and navigate it easily.
If you would like to highlight some cells so you can come back to them later, you can mark them with #TODO or #FIXME, and they will be made available for you to dissect in a dedicated window.
Or you can use tags to highlight some cells so you’ll be able to spot them more easily.
In some cases, you may need to see the most recently executed cell; in this case, you can simply use the Go To option.
Save your workBecause teamwork is essential for data professionals, you need tooling that makes sharing the results of your work easy. One popular solution is Git, which PyCharm supports with features like notebook versioning and version comparison using the Diff view. You can find an in-depth overview of the functionality in this tutorial.
Another useful feature is Local History, which automatically saves your progress and allows you to revert to previous steps with just a few clicks.
Use the full power of AI AssistantJetBrains AI Assistant helps you automate repetitive tasks, optimize your code, and enhance your productivity. In Jupyter notebooks, it also offers several unique features in addition to those that are available in any JetBrains tool.
Click the icon to get insights regarding your data. You can also ask additional questions regarding the dataset or ask AI Assistant to do something – for example, “write some code that solves the missing data problem”.
AI data visualizationPressing the icon will suggest some useful visualizations for your data. AI Assistant will generate the proper code in the chat section for your data.
AI cellAI Assistant can create a cell based on a prompt. You can simply ask it to create a visualization or do something else with your code or data, and it will generate the code that you requested.
DebuggerPyCharm offers advanced debugging capabilities to enhance your experience in Jupyter notebooks. The integrated Jupyter debugger allows you to set breakpoints, inspect variables, and evaluate expressions directly within your notebooks. This powerful tool helps you step through your code cell by cell, making it easier to identify and fix issues as they arise. Read our blog post on how you can debug a Jupyter notebook in PyCharm for a real-life example.
Get started with PyCharm ProfessionalPyCharm’s Jupyter support enhances your data science workflows by combining the interactive aspects of Jupyter notebooks with advanced IDE features. It accelerates data analysis with interactive tables and AI assistance, improves coding efficiency with code completion and refactoring, and simplifies error detection and navigation. PyCharm’s seamless Git integration and powerful debugging tools further boost productivity, making it essential for data professionals.
Download PyCharm Professional to try it out for yourself! Get an extended trial today and experience the difference PyCharm Professional can make in your data science endeavors.Use the promo code “PyCharmNotebooks” at checkout to activate your free 60-day subscription to PyCharm Professional. The free subscription is available for individual users only.
Activate your 60-day trialExplore our official documentation to fully unlock PyCharm’s potential for your projects.
qtatech.com blog: Utiliser les API REST de Drupal pour Intégrer des Applications Tiers
Integrating third-party applications with Drupal using REST APIs offers significant flexibility and extensibility, enabling developers to create interoperable and efficient solutions. This article explores the technical aspects of this integration, providing practical examples to guide developers.
Mike Driscoll: Adding Terminal Effects with Python
The Python programming language has thousands of wonderful third-party packages available on the Python Package Index. One of those packages is TerminalTextEffects (TTE), a terminal visual effects engine.
Here are the features that TerminalTextEffects provides, according to their documentation:
- Xterm 256 / RGB hex color support
- Complex character movement via Paths, Waypoints, and motion easing, with support for quadratic/cubic bezier curves.
- Complex animations via Scenes with symbol/color changes, layers, easing, and Path synced progression.
- Variable stop/step color gradient generation.
- Path/Scene state event handling changes with custom callback support and many pre-defined actions.
- Effect customization exposed through a typed effect configuration dataclass that is automatically handled as CLI arguments.
- Runs inline, preserving terminal state and workflow.
Note: This package may be somewhat slow in Windows Terminal, but it should work fine in other terminals.
Let’s spend a few moments learning how to use this neat package
InstallationThe first step to using any new package is to install it. You can use pip or pipx to install TerminalTextEffects. Here is the typical command you would run in your terminal:
python -m pip install terminaltexteffectsNow that you have TerminalTextEffects installed, you can start using it!
UsageLet’s look at how you can use TerminalTextEffects to make your text look neat in the terminal. Open up your favorite Python IDE and create a new file file with the following contents:
from terminaltexteffects.effects.effect_slide import Slide text = ("PYTHON" * 10 + "\n") * 10 effect = Slide(text) effect.effect_config.merge = True with effect.terminal_output() as terminal: for frame in effect: terminal.print(frame)This code will cause the string, “Python” to appear one hundred times with ten strings concatenated and ten rows. You use a Slide effect to make the text slide into view. TerminalTextEffects will also style the text too.
When you run this code, you should see something like the following:
TerminalTextEffects has many different built-in effects that you can use as well. For example, you can use Beams to make the output even more interesting. For this example, you will use the Zen of Python text along with the Beams effects:
from terminaltexteffects.effects.effect_beams import Beams TEXT = """ The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those! """ effect = Beams(TEXT) with effect.terminal_output() as terminal: for frame in effect: terminal.print(frame)Now try running this code. You should see something like this:
That looks pretty neat! You can see a whole bunch of other effects you can apply on the package’s Showroom page.
Wrapping UpTerminalTextEffects provides lots of neat ways to jazz up your text-based user interfaces with Python. According to the documentation, you should be able to use TerminalTextEffects in other TUI libraries, such as Textual or Asciimatics, although it doesn’t specifically state how to do that. Even if you do not do that, you could use TerminalTextEffects with the Rich package to create a really interesting application in your terminal.
Links
The post Adding Terminal Effects with Python appeared first on Mouse Vs Python.
1xINTERNET blog: Hands-on AI application ideation workshop
We recently hosted an AI Ideation workshop for over 60 participants, guiding them through the hands-on process of creating AI applications and sparking creative ideas to improve their work. Read more about the experience and the innovative solutions participants developed!
Python Bytes: #400 Celebrating episode 400
Zato Blog: Service-oriented API task scheduling
An integral part of Zato, its scalable, service-oriented scheduler makes it is possible to execute high-level API integration processes as background tasks. The scheduler runs periodic jobs which in turn trigger services and services are what is used to integrate systems.
Integration processIn this article we will check how to use the scheduler with three kinds of jobs, one-time, interval-based and Cron-style ones.
What we want to achieve is a sample yet fairly common use-case:
- Periodically consult a remote REST endpoint for new data
- Store data found in Redis
- Push data found as an e-mail attachment
Instead of, or in addition to, Redis or e-mail, we could use SQL and SMS, or MongoDB and AMQP or anything else - Redis and e-mail are just example technologies frequently used in data synchronisation processes that we use to highlight the workings of the scheduler.
No matter the input and output channels, the scheduler works always the same - a definition of a job is created and the job's underlying service is invoked according to the schedule. It is then up to the service to perform all the actions required in a given integration process.
Python codeOur integration service will read as below:
# -*- coding: utf-8 -*- # Zato from zato.common.api import SMTPMessage from zato.server.service import Service class SyncData(Service): name = 'api.scheduler.sync' def handle(self): # Which REST outgoing connection to use rest_out_name = 'My Data Source' # Which SMTP connection to send an email through smtp_out_name = 'My SMTP' # Who the recipient of the email will be smtp_to = 'hello@example.com' # Who to put on CC smtp_cc = 'hello.cc@example.com' # Now, let's get the new data from a remote endpoint .. # .. get a REST connection by name .. rest_conn = self.out.plain_http[rest_out_name].conn # .. download newest data .. data = rest_conn.get(self.cid).text # .. construct a new e-mail message .. message = SMTPMessage() message.subject = 'New data' message.body = 'Check attached data' # .. add recipients .. message.to = smtp_to message.cc = smtp_cc # .. attach the new data to the message .. message.attach('my.data.txt', data) # .. get an SMTP connection by name .. smtp_conn = self.email.smtp[smtp_out_name].conn # .. send the e-mail message with newest data .. smtp_conn.send(message) # .. and now store the data in Redis. self.kvdb.conn.set('newest.data', data)Now, we just need to make it run periodically in background.
Mind the timezoneIn the next steps, we will use the Zato Dashboard to configure new jobs for the scheduler.
Keep it mind that any date and time that you enter in web-admin is always interepreted to be in your web-admin user's timezone and this applies to the scheduler too - by default the timezone is UTC. You can change it by clicking Settings and picking the right timezone to make sure that the scheduled jobs run as expected.
It does not matter what timezone your Zato servers are in - they may be in different ones than the user that is configuring the jobs.
Endpoint definitionsFirst, let's use web-admin to define the endpoints that the service uses. Note that Redis does not need an explicit declaration because it is always available under "self.kvdb" in each service.
- Configuring outgoing REST APIs
- Configuring SMTP e-mail
Now, we can move on to the actual scheduler jobs.
Three types of jobsTo cover different integration needs, three types of jobs are available:
- One-time - fires once only at a specific date and time and then never runs again
- Interval-based - for periodic processes, can use any combination of weeks, days, hours, minutes and seconds for the interval
- Cron-style - similar to interval-based but uses the syntax of Cron for its configuration
Select one-time if the job should not be repeated after it runs once.
Interval-basedSelect interval-based if the job should be repeated periodically. Note that such a job will by default run indefinitely but you can also specify after how many times it should stop, letting you to express concepts such as "Execute once per hour but for the next seven days".
Cron-styleSelect cron-style if you are already familiar with the syntax of Cron or if you have some Cron tasks that you would like to migrate to Zato.
Running jobs manuallyAt times, it is convenient to run a job on demand, no matter what its schedule is and regardless of what type a particular job is. Web-admin lets you always execute a job directly. Simply find the job in the listing, click "Execute" and it will run immediately.
Extra contextIt is very often useful to provide additional context data to a service that the scheduler runs - to achieve it, simply enter any arbitrary value in the "Extra" field when creating or an editing a job in web-admin.
Afterwards, that information will be available as self.request.raw_request in the service's handle method.
ReusabilityThere is nothing else required - all is done and the service will run in accordance with a job's schedule.
Yet, before concluding, observe that our integration service is completely reusable - there is nothing scheduler-specific in it despite the fact that we currently run it from the scheduler.
We could now invoke the service from command line. Or we could mount it on a REST, AMQP, WebSocket or trigger it from any other channel - exactly the same Python code will run in exactly the same fashion, without any new programming effort needed.
More resources➤ Python API integration tutorial
➤ What is an integration platform?
➤ Python Integration platform as a Service (iPaaS)
➤ What is an Enterprise Service Bus (ESB)? What is SOA?
Python Morsels: Commenting in Python
Python's comments start with an octothorpe character.
Table of contents
- Writing a comment in Python
- Inline comments in Python
- Best practices for commenting in Python
- Comment as needed, but not too much
We have a Python program that prints out Hello!, pauses for a second, and then prints Goodbye! on the same line:
from time import sleep print("Hello!", end="", flush=True) sleep(1) # ANSI code to clear current line print("\r\033[K", end="") print("Goodbye!")It prints Hello!:
~ $ python3 hello.py Hello!And then one second later it overwrites Hello! with Goodbye!:
~ $ python3 hello.py Goodbye!It does this using an ANSI escape code (that \033[K string).
The line above the print call in our code is called a comment:
# ANSI code to clear current line print("\r\033[K", end="")Python's comments all start with the # character.
I call this character an octothorpe, though it goes by many names. Some of the more common names for # are hashmark, number sign, and pound sign.
You can write a comment in Python by putting an octothorpe character (#) at the beginning of a line, and then writing your comment. The comment stops at the end of the line, meaning the next line is code... unless you write another octothorpe character!
Here we've written more details and added an additional line to note that this code doesn't yet work on Windows:
# ANSI code to clear current line: \r moves to beginning, \033[K erases to end. # Note: This will not work on Windows without code to enable ANSI escape codes. print("\r\033[K", end="")This is sometimes called a block comment because it's a way to write a block of text that represents a comment.
Unlike some programming languages, Python has no multiline comment syntax. If you think you've seen a multiline comment, it may have been a docstring or a multiline string. More on that in multiline comments in Python.
Inline comments in PythonComments don't need to be …
Read the full article: https://www.pythonmorsels.com/commenting-in-python/Oliver Davies' daily list: Avoiding primitive obsession
Something interesting that Dave Liddament and I discussed was the use of value objects in application code.
Instead of using a primitive type, such as string, you can create a new value object for a specific type of string, such as an EmailAddress or, in my side project, a LicenceKey.
Both are strings, but using value objects of specific types can make the code more readable and its intent clearer.
A value object can contain additional logic, such as validation to execute an ensure the value object is valid, such as making sure a string is not empty, is a specific length or only contains valid characters.
This an approach that I'm going to use more going forward.
I also found a lighting talk by Dave at a PHPSW meetup where he explains this further and, of course, you can listen to the podcast episode after it's been released.
KPhotoAlbum went to Akademy!
After years and years of working together on KPhotoAlbum, a considerable part of the devs team (Johannes and me ;-) finally met in person, at Akademy in Würzburg!
It was a very nice and pleasureable meeting, with lots of information around KDE, e.g. community goals, where we stand with Qt 5 and 6 and where we want to go, programming, sustainability and so on. Throughoutly nice and friendly people (esp. the two of us of course ;-), which whom one could have nice and productive conversations. If you can, go to Akademy – it's worth it!
Also, we hopefully again could emphasize – in person – the importance a Qt6/KF6 port of Marble for KPhotoAlbum and also KGeoTag. We now actively work on porting KPA to QT6/KF6, but we need Marble to be able to finally release it. But we're confident everything will work out.
Hopefully, this won't be the last time we meet!
Armin Ronacher: Multiversion Python Thoughts
Now that uv is rapidly advancing I have started to dive back into making multi-version imports for Python work. The goal here is to enable multiple resolutions from the solver in uv so that two incompatible versions of a library can be installed and used simultaniously.
Simplified speaking it should be possible for a library to depend on both pydantic 1.x and 2.x simultaniously.
I have not made it work yet, but I have I think found all of the pieces that stand in the way. This post mostly exists to share how it could be done with the least amount of changes to Python.
Basic OperationPython's import system places modules in a module cache. This cache is exposed via sys.modules. Every module that is imported is placed in that container prior to initialization. The key is the import path of the module. This in some ways presents the first issue.
Note on Terms for Packages, Modules and DistributionsPython's terms for packages are super confusing. Here is what I will use in this article:
- foo.py: this is a python “module”. It gets registered in sys.modules as 'foo' and has an attribute __name__ set to 'foo'.
- foo/__init__.py: declares also a Python “module” named 'foo' but it is simultaniously a “package”. Unlike a normal module it also has two extra attributes: __path__ which is set to ['./foo'] so that sub modules can be found and it has an attribute __package__ which is also set to 'foo' which marks it as package.
- Additionally on PyPI one can register things. These things were called packages at one point and are now mostly called "projects". Within Python however they are not called Projects but “distribution packages”. For instance this is what you see when you try to use the importlib.metadata API. For now I will just call this a “distribution”.
Note that a distribution can ship both modules and multiple at once. You could have a package called whatever and it reports a foo.py file and a bar/baz.py file which in turn would make foo and bar.baz be importable.
Say you have two Python distributions both of which provide the same toplevel package. In that case they are going to clash in sys.modules. As there is actually relationship of the distribution name to the entry in sys.modules this is a problem that does not just exist with multi version imports but it's one that does not happen all that much.
So let's say we have two distributions: foo@1.0.0 and foo@2.0.0. Both expose a toplevel module called foo which is a true Python package with a single __init__.py file. The installer would already fail to place these because one fully overrides the other.
So step 1 would be to place these modules in different places. So where they normally would be in site-packages, in this case we might want to not have these packages there. That solves us the file system clashes.
So we might place them in some extra cache that looks like this:
.venv/ multi-version-packages/ foo@1.0.0/ foo/ __init__.py foo@2.0.0/ foo/ __init__.pyNow that package is entirely non-importable since nothing looks at multi-version-packages. We will need a custom import hook to get them imported. That import hook will also need to change the name of what's stored in sys.modules.
So instead of registering foo as sys.modules['foo'] we might want to try to register it as sys.modules['foo@1.0.0'] and sys.modules['foo@2.0.0'] instead. There is however a catch and that is this very common pattern:
import sys def import_module(name): __import__(name) return sys.modules[name]That poses a bit of a problem because someone is probably going to call this as import_module('foo') and now we would not find the entry in sys.modules.
This means that in addition to the new entries in sys.modules we would also need to register some proxies that “redirect” us to the real names. These proxies however would need to know if they point to 1.0.0 or 2.0.0.
MetadataSo let's deal with this problem first. How do we know if we need 1.0.0 or 2.0.0? The answer is most likely a package's dependenices. Instead of allowing a package to depend simultaniously on two different versions of the same dependency we can start with a much simpler problem and say that each package can only depend on one version. So that means if I have a myapp package it would have to pick between foo@1.0.0 or foo@2.0.0. However if it were to depended on another package (say slow-package) that one could depend on a different version of foo than myapp:
myapp v0.1.0 ├── foo v2.0.0 └── slow-package v0.1.0 └── foo v1.0.0In that case when someone tries to import foo we would be consulting the package metadata of the calling package to figure out which version is attempted.
There are two challenges with this today and they come from the history of Python:
- the import hook does not (always) know which module triggered the import
- python modules do not know their distribution package
Let's look at these in detail.
Import ContextThe goal is that when slow_package/__init__.py imports foo we get foo@1.0.0 version, when myapp/__init__.py improts foo we get the foo@2.0.0 version. What is needed for this to work is that the import system understands not just what is imported, but who is importing. In some sense Python has that. That's because __import__ (which is the entry point to the import machinery) gets the module globals. Here is what an import statement roughly maps to:
# highlevel import from foo import bar # under the hood _rv = __import__('foo', globals(), locals(), ['bar']) bar = _rv.barThe name of the package that is importing can be retrieved by inspecting the globals(). So in theory for instance the import system could utilize this information. globals()['__name__'] would tell us slow_package vs myapp. There however is a catch and that is that the import name is not the distribution name. The PyPI package could be called mycompany-myapp and it exports a python package just called myapp. This happens very commonly in all kinds of ways. For instance on PyPI one installs Scikit-learn but the python package installed is sklearn.
There is however another problem and that is interpreter internals and C/Rust extensions. We have already established that Python packages will pass globals and locals when they import. But what do C extensions do? The most common internal import API is called PyImport_ImportModule and only takes a module name. Is this a problem? Do C extensions even import stuff? Yes they do. Here is an example from pygame:
MODINIT_DEFINE (color) { PyObject *colordict; colordict = PyImport_ImportModule ("pygame.colordict"); if (colordict) { PyObject *_dict = PyModule_GetDict (colordict); PyObject *colors = PyDict_GetItemString (_dict, "THECOLORS"); /* TODO */ } else { MODINIT_ERROR; } /* snip */ }And that makes sense. A sufficiently large python package will have inter dependencies between the stuff written in C and Python. It's also complicated by the fact that the C module does initialize a module, but it does not have a natural module scope. The way the C extension initializes the module is with the PyModule_Create API:
static struct PyModuleDef module_def = { PyModuleDef_HEAD_INIT, "foo", /* name of module */ NULL, -1, SpamMethods }; PyMODINIT_FUNC PyInit_foo(void) { return PyModule_Create(&module_def); }So both the name of the module created as well as the name of what is imported is entirely hardcoded. A C extension does not “know” what the intended name is, it must know this on its own.
In some sense this is already a bit of a disconnect beween the Python and C world. Python for instance has relative imports (from .foo import bar). This is implemented by inspecting the globals. There is however no API to do these relative imports on the C layer.
The only workaround I know right now would be to perform stack walking. That way one would try to isolate the shared library that triggered the import to understand which module it comes from. An alternative would be to carry the current C extension module that is active on the interpreter state, but that would most likely be quite expensive.
The goal would be to find out which .so/.dylib file triggered the import. Stack walking is a rather expensive operation and it can be incredibly brittle but there might not be a perfect way around it. Ideally Python would at any point know which c extension module is active.
Distributions from ModulesSo let's say that we have the calling python module figured out: now we need to figure out the associated PyPI distribution name. Unfortunately such a mapping does not exist at all. Ideally when a sys.module entry is created, we either record a special attribute there (say __distribution__) which carries the name of the PyPI distribution name so we can call importlib.metadata.distribution(__distribution__).requires to get the requirements or we have some other API to map it.
In the absence of that, how could we get it? There is an expensive way to get a reverse mapping (importlib.metadata.packages_distributions) but unfortunately it has some limitations:
- it's very slow
- it has situations where it does not manage to reveal the distribution for a package
- it can reveal more than one distribution for a package
Because of namespace packages in particular it can return more than one distribution that provides a package such as foo (eg: foo-bar provides foo.bar and foo-baz provides foo.baz. In that case it will just return both foo-bar and foo-baz for foo).
The solution here might just be that installers like uv start materializing the distribution name onto the modules in one way or another.
Putting it TogetherThe end to end solution might be this:
- install multi-version packages outside of site-packages
- materialize a __distribution__ field onto modules or provide an API that maps import names to their PyPI distribution name so that meta data (requirements) can be discovered.
- patch __import__ to resolve packages to their fully-qualified, multi
version name based on who imports it
- via globals() for python code
- via stack-walking for C extensions (unless a better option is found)
- register proxy entries in sys.modules that have a dynamic __getattr__ which redirects to the fully qualified names if necessary. This would allow someone to access sys.modules['foo'] and automatically proxy it to foo@1.0.0 or foo@2.0.0 respectively.
There are lots of holes with this approach unfortunately. That's in parts because people patch around in sys.modules. Interestingly enough sys.modules can be manipulated but it can't be replaced. This might make it possible to replace that dictionary with some more magical dictionary in future versions of Python potentially.
Thorsten Alteholz: My Debian Activities in August 2024
This month I accepted 441 and rejected 15 packages. The overall number of packages that got accepted was 442.
I am ashamed of some occurrences that happened this month and I apologize for this. Unfortunately I have no idea how to prevent this in the future without becoming a solo entertainer.
Debian LTSThis was my hundred-twenty-second month that I did some work for the Debian LTS initiative, started by Raphael Hertzog at Freexian.
- [#1073518] bookworm-pu: cups 2.4.2-3+deb12u6 has been closed
- [#1074439] bookworm-pu: cups 2.4.2-3+deb12u7 has been closed
- [#1073519] bullseye-pu: cups 2.3.3op2-3+deb11u7 has been closed
- [#1074438] bullseye-pu: cups 2.3.3op2-3+deb11u8 has been closed
Unfortunately Bullseye was not handed over to LTS in August. So I only prepared new packages of asterisk, libvirt and tinyproxy and will upload them next month.
Last but not least I did a week of FD this month.
Debian ELTSThis month was the seventy-third ELTS month. During my allocated time I uploaded or worked on:
- [ELA-1160-1]tiff security update for two CVEs in Jessie and Stretch. The Buster upload was already done before. This upload fixed a segmentation fault and a memory leak
- [ELA-1161-1]libvirt security update for six CVEs to fix issues related to use-after-free, an off-by-one, a null pointer dereference, a badly handled mutex, a privilege escalation and breaking out of the sVirt confinement. In this case only Jessie and Stretch needed an update.
- [ELA-1166-1]frr security update for one CVEs in Buster to fix a missing length check.
I also did a week of FD.
Debian PrintingThis month I uploaded …
- … gutenprint to fix a gcc14 issue
- … ipp-usb to fix a /usr-merge issue
This work is generously funded by Freexian!
Debian AstroThis month I uploaded a new upstream or bugfix version of:
- … libinovasdk to better add udev rules
- … indi-playerone to fix dependencies
- … libsbig to fix a /usr-move issue
The following packages have been prepared by the GSoC student Nathan:
- … libosmo-netif
- … osmo-bts
- … libosmo-sccp
- … libosmo-abis
- … osmo-hlr
- … osmo-mgw
- … osmo-bsc
- … osmo-iuh
- … osmo-ggsn
- … osmo-msc
- … osmo-sgsn
It was so much fun working with Nathan. Unfortunately GSoC is over now, but Nathan will continue working in Debian and become a Debian Maintainer.
miscThis month I uploaded new upstream or bugfix versions of:
- … mpb to fix a gcc14 issue
- … httperf to fix a gcc14 issue
- … pkcs11-proxy to fix a gcc14 issue
- … meep-mpi-default to fix some bugs
- … gnucobol3 to upload a new upstream version
- … bibclean to fix a gcc14 issue
- … apcupsd to upload from experimental to unstable
- … rplay to fix a gcc14 issue
- … scheme48 to remove some debug stuff
- … gnupg-pksc11-scd to fix an FTBFS with assuan 3
I also filed an RM bug against meep-openmpi. As Adrian made me ware, this package is no longer needed.
stow @ Savannah: GNU Stow 2.4.1 released
Stow 2.4.1 has been released. This release contains some minor bug-fixes -- specifically, fixing the --dotfiles option to work correctly with ignore lists, allowing options in .stowrc with spaces, and avoiding a spurious warning on Perl >= 5.40. There were also some clean-ups and improvements, mostly internal and not visible to users. Read details of what's new: http://git.savannah.gnu.org/cgit/stow.git/tree/NEWS
Dima Kogan: GNU Make: details regarding intermediate files
Suppose I have this Makefile:
a: b touch $@ b: touch $@ # A common chain of build steps %-GENERATED.c: %-generate touch $@ %.o: %.c touch $@ %.so: %-GENERATED.o touch $@ xxx-GENERATED.o: CFLAGS += adsf # Imitates .d files created with "gcc -MMD". Does not exist on the initial build ifneq ($(wildcard xxx.so),) xxx-GENERATED.o: xxx-GENERATED.c endifThis is all very simple build-system stuff. Let's see how it works:
$ rm -rf a b xxx-GENERATED.c xxx-GENERATED.o xxx.so [start from a clean slate] $ touch xxx-generate xxx.h [Files that would be available in a project exist; xxx-generate is some tool] [that would generate xxx-GENERATED.c ] $ touch a ["a" exists but the file "b" it depends on does not] $ make a xxx.so touch b touch a touch xxx-GENERATED.c touch xxx-GENERATED.o touch xxx.so rm xxx-GENERATED.c [It built everything, but then deleted xxx-GENERATED.c] $ make a xxx.so remake: 'a' is up to date. touch xxx-GENERATED.c touch xxx-GENERATED.o touch xxx.so [It knew to not rebuild "a", but the missing xxx-GENERATED.c caused it to] [re-build stuff ]Well that's not good. What if we add .SECONDARY: to the end of the Makefile to mark everything as a secondary file?
$ rm -rf a b xxx-GENERATED.c xxx-GENERATED.o xxx.so $ touch xxx-generate xxx.h $ touch a $ make a xxx.so remake: 'a' is up to date. touch xxx-GENERATED.c touch xxx-GENERATED.o touch xxx.so [It didn't bother rebuilding "a" even though its prerequisites "b" doesn't] [exist. But it didn't delete the xxx-GENERATED.c at least ] $ make a xxx.so remake: 'a' is up to date. remake: 'xxx.so' is up to date. [It knew to not rebuild anything. Great.]So it doesn't work right with or without .SECONDARY:, but it's much closer with it. The solution is to mark everything as not an intermediate file. mrbuild cannot do this without a bleeding-edge version of GNU Make, but users of mrbuild can do this by explicitly mentioning specific files in rules. This would suffice:
___dummy___: file1 file2Detailed notes are in a commit in mrbuild (mrbuild 1.13) and in a post to LKML by Masahiro Yamada.
Antonio Terceiro: gotcha: using ccache in Debian package builds
Before I upload packages to Debian, I always do a full build from source under sbuild. This ensures that the package can build from source on a clean environment, implying that the set of build dependencies is complete.
But when iterating on a non-trivial package locally, I will usually build the package directly on my Debian testing system, and I want to take advantage of ccache to cache native (C/C++) code compilation to speed things up. In Debian, the easiest way to enable ccache is to add /usr/lib/ccache to your $PATH. I do this by doing something similar to the following in my ~/.bashrc:
export PATH=/usr/lib/ccache:$PATHI noticed, however, that my Debian package builds were not using the cache. When building the same small package manually using make, the cache was used, but not when the build was wrapped with dpkg-buildpackage.
I tracked it down to the fact that in compatibility level 13+, debhelper will set $HOME to a temporary directory. For what's it worth, I think that's a good thing: you don't want package builds reaching for your home directory as that makes it harder to make builds reproducible, among other things.
This behavior, however, breaks ccache. The default cache directory is $HOME/.ccache, but that only gets resolved when ccache is actually used. So we end up starting with an empty cache on each build, get a 100% cache miss rate, and still pay for the overhead of populating the cache.
The fix is to explicitly set $CCACHE_DIR upfront, so that by the time $HOME gets overriden, it doesn't matter anymore for ccache. I did this in my ~/.bashrc:
export CCACHE_DIR=$HOME/.ccacheThis way, $HOME will be expanded right there when the shell starts, and by the time ccache is called, it will use the persistent cache in my home directory when though $HOME will then point to a temporary directory.
The Drop Times: Drupal.org Gets a Makeover with New Fonts
Jacob Adams: Linux's Bedtime Routine
How does Linux move from an awake machine to a hibernating one? How does it then manage to restore all state? These questions led me to read way too much C in trying to figure out how this particular hardware/software boundary is navigated.
This investigation will be split into a few parts, with the first one going from invocation of hibernation to synchronizing all filesystems to disk.
This article has been written using Linux version 6.9.9, the source of which can be found in many places, but can be navigated easily through the Bootlin Elixir Cross-Referencer:
https://elixir.bootlin.com/linux/v6.9.9/source
Each code snippet will begin with a link to the above giving the file path and the line number of the beginning of the snippet.
A Starting Point for Investigation: /sys/power/state and /sys/power/diskThese two system files exist to allow debugging of hibernation, and thus control the exact state used directly. Writing specific values to the state file controls the exact sleep mode used and disk controls the specific hibernation mode1.
This is extremely handy as an entry point to understand how these systems work, since we can just follow what happens when they are written to.
Show and Store FunctionsThese two files are defined using the power_attr macro:
#define power_attr(_name) \ static struct kobj_attribute _name##_attr = { \ .attr = { \ .name = __stringify(_name), \ .mode = 0644, \ }, \ .show = _name##_show, \ .store = _name##_store, \ }show is called on reads and store on writes.
state_show is a little boring for our purposes, as it just prints all the available sleep states.
/* * state - control system sleep states. * * show() returns available sleep state labels, which may be "mem", "standby", * "freeze" and "disk" (hibernation). * See Documentation/admin-guide/pm/sleep-states.rst for a description of * what they mean. * * store() accepts one of those strings, translates it into the proper * enumerated value, and initiates a suspend transition. */ static ssize_t state_show(struct kobject *kobj, struct kobj_attribute *attr, char *buf) { char *s = buf; #ifdef CONFIG_SUSPEND suspend_state_t i; for (i = PM_SUSPEND_MIN; i < PM_SUSPEND_MAX; i++) if (pm_states[i]) s += sprintf(s,"%s ", pm_states[i]); #endif if (hibernation_available()) s += sprintf(s, "disk "); if (s != buf) /* convert the last space to a newline */ *(s-1) = '\n'; return (s - buf); }state_store, however, provides our entry point. If the string “disk” is written to the state file, it calls hibernate(). This is our entry point.
static ssize_t state_store(struct kobject *kobj, struct kobj_attribute *attr, const char *buf, size_t n) { suspend_state_t state; int error; error = pm_autosleep_lock(); if (error) return error; if (pm_autosleep_state() > PM_SUSPEND_ON) { error = -EBUSY; goto out; } state = decode_state(buf, n); if (state < PM_SUSPEND_MAX) { if (state == PM_SUSPEND_MEM) state = mem_sleep_current; error = pm_suspend(state); } else if (state == PM_SUSPEND_MAX) { error = hibernate(); } else { error = -EINVAL; } out: pm_autosleep_unlock(); return error ? error : n; } static suspend_state_t decode_state(const char *buf, size_t n) { #ifdef CONFIG_SUSPEND suspend_state_t state; #endif char *p; int len; p = memchr(buf, '\n', n); len = p ? p - buf : n; /* Check hibernation first. */ if (len == 4 && str_has_prefix(buf, "disk")) return PM_SUSPEND_MAX; #ifdef CONFIG_SUSPEND for (state = PM_SUSPEND_MIN; state < PM_SUSPEND_MAX; state++) { const char *label = pm_states[state]; if (label && len == strlen(label) && !strncmp(buf, label, len)) return state; } #endif return PM_SUSPEND_ON; }Could we have figured this out just via function names? Sure, but this way we know for sure that nothing else is happening before this function is called.
AutosleepOur first detour is into the autosleep system. When checking the state above, you may notice that the kernel grabs the pm_autosleep_lock before checking the current state.
autosleep is a mechanism originally from Android that sends the entire system to either suspend or hibernate whenever it is not actively working on anything.
This is not enabled for most desktop configurations, since it’s primarily for mobile systems and inverts the standard suspend and hibernate interactions.
This system is implemented as a workqueue2 that checks the current number of wakeup events, processes and drivers that need to run3, and if there aren’t any, then the system is put into the autosleep state, typically suspend. However, it could be hibernate if configured that way via /sys/power/autosleep in a similar manner to using /sys/power/state to manually enable hibernation.
static ssize_t autosleep_store(struct kobject *kobj, struct kobj_attribute *attr, const char *buf, size_t n) { suspend_state_t state = decode_state(buf, n); int error; if (state == PM_SUSPEND_ON && strcmp(buf, "off") && strcmp(buf, "off\n")) return -EINVAL; if (state == PM_SUSPEND_MEM) state = mem_sleep_current; error = pm_autosleep_set_state(state); return error ? error : n; } power_attr(autosleep); #endif /* CONFIG_PM_AUTOSLEEP */ static DEFINE_MUTEX(autosleep_lock); static struct wakeup_source *autosleep_ws; static void try_to_suspend(struct work_struct *work) { unsigned int initial_count, final_count; if (!pm_get_wakeup_count(&initial_count, true)) goto out; mutex_lock(&autosleep_lock); if (!pm_save_wakeup_count(initial_count) || system_state != SYSTEM_RUNNING) { mutex_unlock(&autosleep_lock); goto out; } if (autosleep_state == PM_SUSPEND_ON) { mutex_unlock(&autosleep_lock); return; } if (autosleep_state >= PM_SUSPEND_MAX) hibernate(); else pm_suspend(autosleep_state); mutex_unlock(&autosleep_lock); if (!pm_get_wakeup_count(&final_count, false)) goto out; /* * If the wakeup occurred for an unknown reason, wait to prevent the * system from trying to suspend and waking up in a tight loop. */ if (final_count == initial_count) schedule_timeout_uninterruptible(HZ / 2); out: queue_up_suspend_work(); } static DECLARE_WORK(suspend_work, try_to_suspend); void queue_up_suspend_work(void) { if (autosleep_state > PM_SUSPEND_ON) queue_work(autosleep_wq, &suspend_work); } The Steps of Hibernation Hibernation Kernel ConfigIt’s important to note that most of the hibernate-specific functions below do nothing unless you’ve defined CONFIG_HIBERNATION in your Kconfig4. As an example, hibernate itself is defined as the following if CONFIG_HIBERNATE is not set.
static inline int hibernate(void) { return -ENOSYS; } Check if Hibernation is AvailableWe begin by confirming that we actually can perform hibernation, via the hibernation_available function.
if (!hibernation_available()) { pm_pr_dbg("Hibernation not available.\n"); return -EPERM; } bool hibernation_available(void) { return nohibernate == 0 && !security_locked_down(LOCKDOWN_HIBERNATION) && !secretmem_active() && !cxl_mem_active(); }nohibernate is controlled by the kernel command line, it’s set via either nohibernate or hibernate=no.
security_locked_down is a hook for Linux Security Modules to prevent hibernation. This is used to prevent hibernating to an unencrypted storage device, as specified in the manual page kernel_lockdown(7). Interestingly, either level of lockdown, integrity or confidentiality, locks down hibernation because with the ability to hibernate you can extract bascially anything from memory and even reboot into a modified kernel image.
secretmem_active checks whether there is any active use of memfd_secret, and if so it prevents hibernation. memfd_secret returns a file descriptor that can be mapped into a process but is specifically unmapped from the kernel’s memory space. Hibernating with memory that not even the kernel is supposed to access would expose that memory to whoever could access the hibernation image. This particular feature of secret memory was apparently controversial, though not as controversial as performance concerns around fragmentation when unmapping kernel memory (which did not end up being a real problem).
cxl_mem_active just checks whether any CXL memory is active. A full explanation is provided in the commit introducing this check but there’s also a shortened explanation from cxl_mem_probe that sets the relevant flag when initializing a CXL memory device.
* The kernel may be operating out of CXL memory on this device, * there is no spec defined way to determine whether this device * preserves contents over suspend, and there is no simple way * to arrange for the suspend image to avoid CXL memory which * would setup a circular dependency between PCI resume and save * state restoration. Check CompressionThe next check is for whether compression support is enabled, and if so whether the requested algorithm is enabled.
/* * Query for the compression algorithm support if compression is enabled. */ if (!nocompress) { strscpy(hib_comp_algo, hibernate_compressor, sizeof(hib_comp_algo)); if (crypto_has_comp(hib_comp_algo, 0, 0) != 1) { pr_err("%s compression is not available\n", hib_comp_algo); return -EOPNOTSUPP; } }The nocompress flag is set via the hibernate command line parameter, setting hibernate=nocompress.
If compression is enabled, then hibernate_compressor is copied to hib_comp_algo. This synchronizes the current requested compression setting (hibernate_compressor) with the current compression setting (hib_comp_algo).
Both values are character arrays of size CRYPTO_MAX_ALG_NAME (128 in this kernel).
static char hibernate_compressor[CRYPTO_MAX_ALG_NAME] = CONFIG_HIBERNATION_DEF_COMP; /* * Compression/decompression algorithm to be used while saving/loading * image to/from disk. This would later be used in 'kernel/power/swap.c' * to allocate comp streams. */ char hib_comp_algo[CRYPTO_MAX_ALG_NAME];hibernate_compressor defaults to lzo if that algorithm is enabled, otherwise to lz4 if enabled5. It can be overwritten using the hibernate.compressor setting to either lzo or lz4.
choice prompt "Default compressor" default HIBERNATION_COMP_LZO depends on HIBERNATION config HIBERNATION_COMP_LZO bool "lzo" depends on CRYPTO_LZO config HIBERNATION_COMP_LZ4 bool "lz4" depends on CRYPTO_LZ4 endchoice config HIBERNATION_DEF_COMP string default "lzo" if HIBERNATION_COMP_LZO default "lz4" if HIBERNATION_COMP_LZ4 help Default compressor to be used for hibernation. static const char * const comp_alg_enabled[] = { #if IS_ENABLED(CONFIG_CRYPTO_LZO) COMPRESSION_ALGO_LZO, #endif #if IS_ENABLED(CONFIG_CRYPTO_LZ4) COMPRESSION_ALGO_LZ4, #endif }; static int hibernate_compressor_param_set(const char *compressor, const struct kernel_param *kp) { unsigned int sleep_flags; int index, ret; sleep_flags = lock_system_sleep(); index = sysfs_match_string(comp_alg_enabled, compressor); if (index >= 0) { ret = param_set_copystring(comp_alg_enabled[index], kp); if (!ret) strscpy(hib_comp_algo, comp_alg_enabled[index], sizeof(hib_comp_algo)); } else { ret = index; } unlock_system_sleep(sleep_flags); if (ret) pr_debug("Cannot set specified compressor %s\n", compressor); return ret; } static const struct kernel_param_ops hibernate_compressor_param_ops = { .set = hibernate_compressor_param_set, .get = param_get_string, }; static struct kparam_string hibernate_compressor_param_string = { .maxlen = sizeof(hibernate_compressor), .string = hibernate_compressor, };We then check whether the requested algorithm is supported via crypto_has_comp. If not, we bail out of the whole operation with EOPNOTSUPP.
As part of crypto_has_comp we perform any needed initialization of the algorithm, loading kernel modules and running initialization code as needed6.
Grab LocksThe next step is to grab the sleep and hibernation locks via lock_system_sleep and hibernate_acquire.
sleep_flags = lock_system_sleep(); /* The snapshot device should not be opened while we're running */ if (!hibernate_acquire()) { error = -EBUSY; goto Unlock; }First, lock_system_sleep marks the current thread as not freezable, which will be important later7. It then grabs the system_transistion_mutex, which locks taking snapshots or modifying how they are taken, resuming from a hibernation image, entering any suspend state, or rebooting.
The GFP MaskThe kernel also issues a warning if the gfp mask is changed via either pm_restore_gfp_mask or pm_restrict_gfp_mask without holding the system_transistion_mutex.
GFP flags tell the kernel how it is permitted to handle a request for memory.
* GFP flags are commonly used throughout Linux to indicate how memory * should be allocated. The GFP acronym stands for get_free_pages(), * the underlying memory allocation function. Not every GFP flag is * supported by every function which may allocate memory.In the case of hibernation specifically we care about the IO and FS flags, which are reclaim operators, ways the system is permitted to attempt to free up memory in order to satisfy a specific request for memory.
* Reclaim modifiers * ----------------- * Please note that all the following flags are only applicable to sleepable * allocations (e.g. %GFP_NOWAIT and %GFP_ATOMIC will ignore them). * * %__GFP_IO can start physical IO. * * %__GFP_FS can call down to the low-level FS. Clearing the flag avoids the * allocator recursing into the filesystem which might already be holding * locks.gfp_allowed_mask sets which flags are permitted to be set at the current time.
As the comment below outlines, preventing these flags from being set avoids situations where the kernel needs to do I/O to allocate memory (e.g. read/writing swap8) but the devices it needs to read/write to/from are not currently available.
/* * The following functions are used by the suspend/hibernate code to temporarily * change gfp_allowed_mask in order to avoid using I/O during memory allocations * while devices are suspended. To avoid races with the suspend/hibernate code, * they should always be called with system_transition_mutex held * (gfp_allowed_mask also should only be modified with system_transition_mutex * held, unless the suspend/hibernate code is guaranteed not to run in parallel * with that modification). */ static gfp_t saved_gfp_mask; void pm_restore_gfp_mask(void) { WARN_ON(!mutex_is_locked(&system_transition_mutex)); if (saved_gfp_mask) { gfp_allowed_mask = saved_gfp_mask; saved_gfp_mask = 0; } } void pm_restrict_gfp_mask(void) { WARN_ON(!mutex_is_locked(&system_transition_mutex)); WARN_ON(saved_gfp_mask); saved_gfp_mask = gfp_allowed_mask; gfp_allowed_mask &= ~(__GFP_IO | __GFP_FS); } Sleep FlagsAfter grabbing the system_transition_mutex the kernel then returns and captures the previous state of the threads flags in sleep_flags. This is used later to remove PF_NOFREEZE if it wasn’t previously set on the current thread.
unsigned int lock_system_sleep(void) { unsigned int flags = current->flags; current->flags |= PF_NOFREEZE; mutex_lock(&system_transition_mutex); return flags; } EXPORT_SYMBOL_GPL(lock_system_sleep); #define PF_NOFREEZE 0x00008000 /* This thread should not be frozen */Then we grab the hibernate-specific semaphore to ensure no one can open a snapshot or resume from it while we perform hibernation. Additionally this lock is used to prevent hibernate_quiet_exec, which is used by the nvdimm driver to active its firmware with all processes and devices frozen, ensuring it is the only thing running at that time9.
bool hibernate_acquire(void) { return atomic_add_unless(&hibernate_atomic, -1, 0); } Prepare ConsoleThe kernel next calls pm_prepare_console. This function only does anything if CONFIG_VT_CONSOLE_SLEEP has been set.
This prepares the virtual terminal for a suspend state, switching away to a console used only for the suspend state if needed.
void pm_prepare_console(void) { if (!pm_vt_switch()) return; orig_fgconsole = vt_move_to_console(SUSPEND_CONSOLE, 1); if (orig_fgconsole < 0) return; orig_kmsg = vt_kmsg_redirect(SUSPEND_CONSOLE); return; }The first thing is to check whether we actually need to switch the VT
/* * There are three cases when a VT switch on suspend/resume are required: * 1) no driver has indicated a requirement one way or another, so preserve * the old behavior * 2) console suspend is disabled, we want to see debug messages across * suspend/resume * 3) any registered driver indicates it needs a VT switch * * If none of these conditions is present, meaning we have at least one driver * that doesn't need the switch, and none that do, we can avoid it to make * resume look a little prettier (and suspend too, but that's usually hidden, * e.g. when closing the lid on a laptop). */ static bool pm_vt_switch(void) { struct pm_vt_switch *entry; bool ret = true; mutex_lock(&vt_switch_mutex); if (list_empty(&pm_vt_switch_list)) goto out; if (!console_suspend_enabled) goto out; list_for_each_entry(entry, &pm_vt_switch_list, head) { if (entry->required) goto out; } ret = false; out: mutex_unlock(&vt_switch_mutex); return ret; }There is an explanation of the conditions under which a switch is performed in the comment above the function, but we’ll also walk through the steps here.
Firstly we grab the vt_switch_mutex to ensure nothing will modify the list while we’re looking at it.
We then examine the pm_vt_switch_list. This list is used to indicate the drivers that require a switch during suspend. They register this requirement, or the lack thereof, via pm_vt_switch_required.
/** * pm_vt_switch_required - indicate VT switch at suspend requirements * @dev: device * @required: if true, caller needs VT switch at suspend/resume time * * The different console drivers may or may not require VT switches across * suspend/resume, depending on how they handle restoring video state and * what may be running. * * Drivers can indicate support for switchless suspend/resume, which can * save time and flicker, by using this routine and passing 'false' as * the argument. If any loaded driver needs VT switching, or the * no_console_suspend argument has been passed on the command line, VT * switches will occur. */ void pm_vt_switch_required(struct device *dev, bool required)Next, we check console_suspend_enabled. This is set to false by the kernel parameter no_console_suspend, but defaults to true.
Finally, if there are any entries in the pm_vt_switch_list, then we check to see if any of them require a VT switch.
Only if none of these conditions apply, then we return false.
If a VT switch is in fact required, then we move first the currently active virtual terminal/console10 (vt_move_to_console) and then the current location of kernel messages (vt_kmsg_redirect) to the SUSPEND_CONSOLE. The SUSPEND_CONSOLE is the last entry in the list of possible consoles, and appears to just be a black hole to throw away messages.
#define SUSPEND_CONSOLE (MAX_NR_CONSOLES-1)Interestingly, these are separate functions because you can use TIOCL_SETKMSGREDIRECT (an ioctl11) to send kernel messages to a specific virtual terminal, but by default its the same as the currently active console.
The locations of the previously active console and the previous kernel messages location are stored in orig_fgconsole and orig_kmsg, to restore the state of the console and kernel messages after the machine wakes up again. Interestingly, this means orig_fgconsole also ends up storing any errors, so has to be checked to ensure it’s not less than zero before we try to do anything with the kernel messages on both suspend and resume.
drivers/tty/vt/vt_ioctl.c:1268
/* Perform a kernel triggered VT switch for suspend/resume */ static int disable_vt_switch; int vt_move_to_console(unsigned int vt, int alloc) { int prev; console_lock(); /* Graphics mode - up to X */ if (disable_vt_switch) { console_unlock(); return 0; } prev = fg_console; if (alloc && vc_allocate(vt)) { /* we can't have a free VC for now. Too bad, * we don't want to mess the screen for now. */ console_unlock(); return -ENOSPC; } if (set_console(vt)) { /* * We're unable to switch to the SUSPEND_CONSOLE. * Let the calling function know so it can decide * what to do. */ console_unlock(); return -EIO; } console_unlock(); if (vt_waitactive(vt + 1)) { pr_debug("Suspend: Can't switch VCs."); return -EINTR; } return prev; }Unlike most other locking functions we’ve seen so far, console_lock needs to be careful to ensure nothing else is panicking and needs to dump to the console before grabbing the semaphore for the console and setting a couple flags.
PanicsPanics are tracked via an atomic integer set to the id of the processor currently panicking.
/** * console_lock - block the console subsystem from printing * * Acquires a lock which guarantees that no consoles will * be in or enter their write() callback. * * Can sleep, returns nothing. */ void console_lock(void) { might_sleep(); /* On panic, the console_lock must be left to the panic cpu. */ while (other_cpu_in_panic()) msleep(1000); down_console_sem(); console_locked = 1; console_may_schedule = 1; } EXPORT_SYMBOL(console_lock); /* * Return true if a panic is in progress on a remote CPU. * * On true, the local CPU should immediately release any printing resources * that may be needed by the panic CPU. */ bool other_cpu_in_panic(void) { return (panic_in_progress() && !this_cpu_in_panic()); } static bool panic_in_progress(void) { return unlikely(atomic_read(&panic_cpu) != PANIC_CPU_INVALID); } /* Return true if a panic is in progress on the current CPU. */ bool this_cpu_in_panic(void) { /* * We can use raw_smp_processor_id() here because it is impossible for * the task to be migrated to the panic_cpu, or away from it. If * panic_cpu has already been set, and we're not currently executing on * that CPU, then we never will be. */ return unlikely(atomic_read(&panic_cpu) == raw_smp_processor_id()); }console_locked is a debug value, used to indicate that the lock should be held, and our first indication that this whole virtual terminal system is more complex than might initially be expected.
/* * This is used for debugging the mess that is the VT code by * keeping track if we have the console semaphore held. It's * definitely not the perfect debug tool (we don't know if _WE_ * hold it and are racing, but it helps tracking those weird code * paths in the console code where we end up in places I want * locked without the console semaphore held). */ static int console_locked;console_may_schedule is used to see if we are permitted to sleep and schedule other work while we hold this lock. As we’ll see later, the virtual terminal subsystem is not re-entrant, so there’s all sorts of hacks in here to ensure we don’t leave important code sections that can’t be safely resumed.
Disable VT SwitchAs the comment below lays out, when another program is handling graphical display anyway, there’s no need to do any of this, so the kernel provides a switch to turn the whole thing off. Interestingly, this appears to only be used by three drivers, so the specific hardware support required must not be particularly common.
drivers/gpu/drm/omapdrm/dss drivers/video/fbdev/geode drivers/video/fbdev/omap2drivers/tty/vt/vt_ioctl.c:1308
/* * Normally during a suspend, we allocate a new console and switch to it. * When we resume, we switch back to the original console. This switch * can be slow, so on systems where the framebuffer can handle restoration * of video registers anyways, there's little point in doing the console * switch. This function allows you to disable it by passing it '0'. */ void pm_set_vt_switch(int do_switch) { console_lock(); disable_vt_switch = !do_switch; console_unlock(); } EXPORT_SYMBOL(pm_set_vt_switch);The rest of the vt_switch_console function is pretty normal, however, simply allocating space if needed to create the requested virtual terminal and then setting the current virtual terminal via set_console.
Virtual Terminal Set ConsoleWith set_console, we begin (as if we haven’t been already) to enter the madness that is the virtual terminal subsystem. As mentioned previously, modifications to its state must be made very carefully, as other stuff happening at the same time could create complete messes.
All this to say, calling set_console does not actually perform any work to change the state of the current console. Instead it indicates what changes it wants and then schedules that work.
int set_console(int nr) { struct vc_data *vc = vc_cons[fg_console].d; if (!vc_cons_allocated(nr) || vt_dont_switch || (vc->vt_mode.mode == VT_AUTO && vc->vc_mode == KD_GRAPHICS)) { /* * Console switch will fail in console_callback() or * change_console() so there is no point scheduling * the callback * * Existing set_console() users don't check the return * value so this shouldn't break anything */ return -EINVAL; } want_console = nr; schedule_console_callback(); return 0; }The check for vc->vc_mode == KD_GRAPHICS is where most end-user graphical desktops will bail out of this change, as they’re in graphics mode and don’t need to switch away to the suspend console.
vt_dont_switch is a flag used by the ioctls11 VT_LOCKSWITCH and VT_UNLOCKSWITCH to prevent the system from switching virtual terminal devices when the user has explicitly locked it.
VT_AUTO is a flag indicating that automatic virtual terminal switching is enabled12, and thus deliberate switching to a suspend terminal is not required.
However, if you do run your machine from a virtual terminal, then we indicate to the system that we want to change to the requested virtual terminal via the want_console variable and schedule a callback via schedule_console_callback.
void schedule_console_callback(void) { schedule_work(&console_work); }console_work is a workqueue2 that will execute the given task asynchronously.
Console Callback /* * This is the console switching callback. * * Doing console switching in a process context allows * us to do the switches asynchronously (needed when we want * to switch due to a keyboard interrupt). Synchronization * with other console code and prevention of re-entrancy is * ensured with console_lock. */ static void console_callback(struct work_struct *ignored) { console_lock(); if (want_console >= 0) { if (want_console != fg_console && vc_cons_allocated(want_console)) { hide_cursor(vc_cons[fg_console].d); change_console(vc_cons[want_console].d); /* we only changed when the console had already been allocated - a new console is not created in an interrupt routine */ } want_console = -1; } ...console_callback first looks to see if there is a console change wanted via want_console and then changes to it if it’s not the current console and has been allocated already. We do first remove any cursor state with hide_cursor.
static void hide_cursor(struct vc_data *vc) { if (vc_is_sel(vc)) clear_selection(); vc->vc_sw->con_cursor(vc, false); hide_softcursor(vc); }A full dive into the tty driver is a task for another time, but this should give a general sense of how this system interacts with hibernation.
Notify Power Management Call Chain pm_notifier_call_chain_robust(PM_HIBERNATION_PREPARE, PM_POST_HIBERNATION)This will call a chain of power management callbacks, passing first PM_HIBERNATION_PREPARE and then PM_POST_HIBERNATION on startup or on error with another callback.
int pm_notifier_call_chain_robust(unsigned long val_up, unsigned long val_down) { int ret; ret = blocking_notifier_call_chain_robust(&pm_chain_head, val_up, val_down, NULL); return notifier_to_errno(ret); }The power management notifier is a blocking notifier chain, which means it has the following properties.
* Blocking notifier chains: Chain callbacks run in process context. * Callouts are allowed to block.The callback chain is a linked list with each entry containing a priority and a function to call. The function technically takes in a data value, but it is always NULL for the power management chain.
struct notifier_block; typedef int (*notifier_fn_t)(struct notifier_block *nb, unsigned long action, void *data); struct notifier_block { notifier_fn_t notifier_call; struct notifier_block __rcu *next; int priority; };The head of the linked list is protected by a read-write semaphore.
struct blocking_notifier_head { struct rw_semaphore rwsem; struct notifier_block __rcu *head; };Because it is prioritized, appending to the list requires walking it until an item with lower13 priority is found to insert the current item before.
/* * Blocking notifier chain routines. All access to the chain is * synchronized by an rwsem. */ static int __blocking_notifier_chain_register(struct blocking_notifier_head *nh, struct notifier_block *n, bool unique_priority) { int ret; /* * This code gets used during boot-up, when task switching is * not yet working and interrupts must remain disabled. At * such times we must not call down_write(). */ if (unlikely(system_state == SYSTEM_BOOTING)) return notifier_chain_register(&nh->head, n, unique_priority); down_write(&nh->rwsem); ret = notifier_chain_register(&nh->head, n, unique_priority); up_write(&nh->rwsem); return ret; } /* * Notifier chain core routines. The exported routines below * are layered on top of these, with appropriate locking added. */ static int notifier_chain_register(struct notifier_block **nl, struct notifier_block *n, bool unique_priority) { while ((*nl) != NULL) { if (unlikely((*nl) == n)) { WARN(1, "notifier callback %ps already registered", n->notifier_call); return -EEXIST; } if (n->priority > (*nl)->priority) break; if (n->priority == (*nl)->priority && unique_priority) return -EBUSY; nl = &((*nl)->next); } n->next = *nl; rcu_assign_pointer(*nl, n); trace_notifier_register((void *)n->notifier_call); return 0; }Each callback can return one of a series of options.
#define NOTIFY_DONE 0x0000 /* Don't care */ #define NOTIFY_OK 0x0001 /* Suits me */ #define NOTIFY_STOP_MASK 0x8000 /* Don't call further */ #define NOTIFY_BAD (NOTIFY_STOP_MASK|0x0002) /* Bad/Veto action */When notifying the chain, if a function returns STOP or BAD then the previous parts of the chain are called again with PM_POST_HIBERNATION14 and an error is returned.
/** * notifier_call_chain_robust - Inform the registered notifiers about an event * and rollback on error. * @nl: Pointer to head of the blocking notifier chain * @val_up: Value passed unmodified to the notifier function * @val_down: Value passed unmodified to the notifier function when recovering * from an error on @val_up * @v: Pointer passed unmodified to the notifier function * * NOTE: It is important the @nl chain doesn't change between the two * invocations of notifier_call_chain() such that we visit the * exact same notifier callbacks; this rules out any RCU usage. * * Return: the return value of the @val_up call. */ static int notifier_call_chain_robust(struct notifier_block **nl, unsigned long val_up, unsigned long val_down, void *v) { int ret, nr = 0; ret = notifier_call_chain(nl, val_up, v, -1, &nr); if (ret & NOTIFY_STOP_MASK) notifier_call_chain(nl, val_down, v, nr-1, NULL); return ret; }Each of these callbacks tends to be quite driver-specific, so we’ll cease discussion of this here.
Sync FilesystemsThe next step is to ensure all filesystems have been synchronized to disk.
This is performed via a simple helper function that times how long the full synchronize operation, ksys_sync takes.
void ksys_sync_helper(void) { ktime_t start; long elapsed_msecs; start = ktime_get(); ksys_sync(); elapsed_msecs = ktime_to_ms(ktime_sub(ktime_get(), start)); pr_info("Filesystems sync: %ld.%03ld seconds\n", elapsed_msecs / MSEC_PER_SEC, elapsed_msecs % MSEC_PER_SEC); } EXPORT_SYMBOL_GPL(ksys_sync_helper);ksys_sync wakes and instructs a set of flusher threads to write out every filesystem, first their inodes15, then the full filesystem, and then finally all block devices, to ensure all pages are written out to disk.
/* * Sync everything. We start by waking flusher threads so that most of * writeback runs on all devices in parallel. Then we sync all inodes reliably * which effectively also waits for all flusher threads to finish doing * writeback. At this point all data is on disk so metadata should be stable * and we tell filesystems to sync their metadata via ->sync_fs() calls. * Finally, we writeout all block devices because some filesystems (e.g. ext2) * just write metadata (such as inodes or bitmaps) to block device page cache * and do not sync it on their own in ->sync_fs(). */ void ksys_sync(void) { int nowait = 0, wait = 1; wakeup_flusher_threads(WB_REASON_SYNC); iterate_supers(sync_inodes_one_sb, NULL); iterate_supers(sync_fs_one_sb, &nowait); iterate_supers(sync_fs_one_sb, &wait); sync_bdevs(false); sync_bdevs(true); if (unlikely(laptop_mode)) laptop_sync_completion(); }It follows an interesting pattern of using iterate_supers to run both sync_inodes_one_sb and then sync_fs_one_sb on each known filesystem16. It also calls both sync_fs_one_sb and sync_bdevs twice, first without waiting for any operations to complete and then again waiting for completion17.
When laptop_mode is enabled the system runs additional filesystem synchronization operations after the specified delay without any writes.
/* * Flag that puts the machine in "laptop mode". Doubles as a timeout in jiffies: * a full sync is triggered after this time elapses without any disk activity. */ int laptop_mode; EXPORT_SYMBOL(laptop_mode);However, when running a filesystem synchronization operation, the system will add an additional timer to schedule more writes after the laptop_mode delay. We don’t want the state of the system to change at all while performing hibernation, so we cancel those timers.
/* * We're in laptop mode and we've just synced. The sync's writes will have * caused another writeback to be scheduled by laptop_io_completion. * Nothing needs to be written back anymore, so we unschedule the writeback. */ void laptop_sync_completion(void) { struct backing_dev_info *bdi; rcu_read_lock(); list_for_each_entry_rcu(bdi, &bdi_list, bdi_list) del_timer(&bdi->laptop_mode_wb_timer); rcu_read_unlock(); }As a side note, the ksys_sync function is simply called when the system call sync is used.
SYSCALL_DEFINE0(sync) { ksys_sync(); return 0; } The End of PreparationWith that the system has finished preparations for hibernation. This is a somewhat arbitrary cutoff, but next the system will begin a full freeze of userspace to then dump memory out to an image and finally to perform hibernation. All this will be covered in future articles!
-
Hibernation modes are outside of scope for this article, see the previous article for a high-level description of the different types of hibernation. ↩
-
Workqueues are a mechanism for running asynchronous tasks. A full description of them is a task for another time, but the kernel documentation on them is available here: https://www.kernel.org/doc/html/v6.9/core-api/workqueue.html ↩ ↩2
-
This is a bit of an oversimplification, but since this isn’t the main focus of this article this description has been kept to a higher level. ↩
-
Kconfig is Linux’s build configuration system that sets many different macros to enable/disable various features. ↩
-
Kconfig defaults to the first default found ↩
-
Including checking whether the algorithm is larval? Which appears to indicate that it requires additional setup, but is an interesting choice of name for such a state. ↩
-
Specifically when we get to process freezing, which we’ll get to in the next article in this series. ↩
-
Swap space is outside the scope of this article, but in short it is a buffer on disk that the kernel uses to store memory not current in use to free up space for other things. See Swap Management for more details. ↩
-
The code for this is lengthy and tangential, thus it has not been included here. If you’re curious about the details of this, see kernel/power/hibernate.c:858 for the details of hibernate_quiet_exec, and drivers/nvdimm/core.c:451 for how it is used in nvdimm. ↩
-
Annoyingly this code appears to use the terms “console” and “virtual terminal” interchangeably. ↩
-
ioctls are special device-specific I/O operations that permit performing actions outside of the standard file interactions of read/write/seek/etc. ↩ ↩2
-
I’m not entirely clear on how this flag works, this subsystem is particularly complex. ↩
-
In this case a higher number is higher priority. ↩
-
Or whatever the caller passes as val_down, but in this case we’re specifically looking at how this is used in hibernation. ↩
-
An inode refers to a particular file or directory within the filesystem. See Wikipedia for more details. ↩
-
Each active filesystem is registed with the kernel through a structure known as a superblock, which contains references to all the inodes contained within the filesystem, as well as function pointers to perform the various required operations, like sync. ↩
-
I’m including minimal code in this section, as I’m not looking to deep dive into the filesystem code at this time. ↩
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Research
- Highlights from the Digital Public Goods Alliance Annual Members Meeting 2024
- Give Your Input on the State of Open Source Survey
- Open Data and Open Source AI: Charting a course to get more of both
- The Open Source Initiative and the Eclipse Foundation to Collaborate on Shaping Open Source AI (OSAI) Public Policy
- ClearlyDefined v2.0 adds support for LicenseRefs