
Feeds
Port Arianna to Foliate-js - GSoC '24
I am Ajay Chauhan (IRC: hisir:matrix.org), currently in my second year of undergraduate studies in Computer Science & Engineering. I'll be working on porting Arianna to Foliate-js for my Google Summer of Code project. I have previously worked on Kdenlive as part of the Season of KDE '24.
I hope to help bring the said feature into reality, but also to sharpen my own development skills through real-world projects, contribute back to the open source community and gain more inner confidence.
What am I working on for this year’s GSoC?Arianna uses epub.js, which is no longer actively maintained. This creates a challenge as the epub.js may not be able to keep up with the evolving standards and new changes. To address this issue, the proposed solution is to port Arianna to the Foliate-js, which is an actively maintained epub renderer and has more features compared to epub.js and is used by the Foliate ebook reader also.
The problem that this project aims to solve is the need for a reliable and up-to-date epub rendering solution for the Arianna ebook reader. By porting Arianna to Foliate-js, the project will ensure that Arianna can continue to provide support for the latest epub standards and features.
My mentors for the project is Carl Schwan, and I appreciate the opportunity to collaborate with and learn from him during this process.
My work done so far Setting up the development environmentFirst step was to setup the dev environment, I used Qt Creator for that, it’s fairly easy to set up the development environment.
Reading through existing codebaseThe journey began with a thorough review of the existing implementation of epub.js (epub-viewer.js) in Arianna. I identified the features and functionalities that needed to be ported to Foliate-js, understanding how epub.js was used in Arianna for rendering, navigation, and user interactions, and the C++ backend code.
Next, I focused on identifying all the places where epub.js was integrated with Qt in Arianna. This involved comparing the existing implementation with Foliate-js's approach to implementing the same features. To document the changes, I prepared a draft merge request.
Familiarised myself with the current Foliate reader implementation of the foliate-js. However, challenging for me to understand the backend architecture and how different components are interconnected within Foliate-js, requiring additional time to fully grasp the codebase.
Implementing changes- Fixing the tricky part of the loading process. I had a hard time wrapping my head around how all the pieces fit together. My mentor helped me in this.
It takes the TOC data from the book and imports it into the app's context drawer. This way, users can easily access and navigate through the book's structure.
Added metadata handling: const metadata = action.payload.book.metadata; if (metadata) { backend.metadata = metadata; root.bookReady(backend.metadata.title); Database.addBook(backend.file, JSON.stringify(metadata)); }Let me break down what this does:
- First, it grabs the metadata from the book that's been loaded.
- If there's metadata, it does a few important things:
- Updates the backend with this new info.
- Tells the app that the book is ready to go, passing along the title.
- Stores all this metadata in the database.
In the following weeks of GSoC, I plan to first to focus on tackling the rendition setup. This is a crucial step - it's what will allow our ebook reader to display the content of ebooks correctly, and also setting the style for the reader. This will involve integrating the Foliate-js rendition module with Arianna's Qt implementation.
Thanks for your reading, stay tuned for updates on my progress via my blog and feel free to connect with me.
Venue maps in Kongress
With Akademy 2024 hosted in a venue with OSM indoor mapping, what happens if we put KDE’s conference companion app Kongress and Itinerary’s train station indoor map view together?
Venue mapsOut of the box we get a multi-floor map, which is already an improvement compared to just showing building outlines on a conventional (outdoor) map. Visually it’s still far off from handmade conference venue maps though.
Indoor venue map in Kongress.This is using vanilla OSM data (via KDE’s raw data tile server), which is following upstream within 24 hours. Any work done on the map data is thus not only benefiting a specific event but all OSM users.
Finding roomsUsing OSM raw data and client-side rendering rather than pre-rendered raster graphics allows for additional ways to interact with the map or browse the data.
Itinerary has a nearby amenity search feature for example. What you are also often looking for at a conference venue are rooms though. We can apply the same concept here, with a few adjustments on which data to display and how to group it.
Room search dialog in Kongress.This is also the foundation for matching room information from the schedule to the map. That’s not implemented yet in the app though, as we’ll need the actual schedule for testing that.
Custom stylesFor a conference in e.g. a university building only a small subset of rooms might be relevant for an event. Custom made venue maps often highlight those somehow, e.g. with different colors.
As our indoor map renderer uses MapCSS stylesheets to control the visual appearance, that’s easy enough to do here as well. And since MapCSS stylesheets can include other files, we also only need a small event-specific addition that then includes the default style.
Even-specific stylesheet highlighting and labeling relevant rooms. Custom contentWhile stylesheet can do a lot, they can’t generate new content on the map. That’s also needed though, as there might be structures that are only there for the event and thus too short-lived to be added to OSM.
This can be solved by applying an OSM changeset file on top of the loaded map data. That’s basically a “diff” for the map data with event-specific additions, changes or removals.
Event-specific additional map content.This way event-specific content becomes part of the map data itself rather than being in an app-specific overlay. We can therefore make use of all the existing infrastructure for the custom content as well, from support for multi-lingual labels to being searchable.
OutlookAnd there’s still more we could do.
Time-dependent elementsSome elements might only be available or applicable for a certain time of the event, or certain rooms might have different purposes on different days.
OSM has a complex mechanism to model time-dependent information, using opening hours expressions. We can parse and interpret those as well, but their use is currently limited to showing actual opening hours for amenities or shops. This is accessible to styles, so we can e.g. gray out currently closed things.
Generalizing this and also allowing to interpret opening hours expression on arbitrary tags in combination with custom styles should not be too far out and give us a really powerful mechanism to model time-dependent features.
RoutingKongress also has our experimental indoor router integrated. For the Akademy venue this works ok-ish (apart from access to the elevator, the map data quality around that isn’t good enough yet).
Indoor map routing in Kongress.An important still missing part here however is the ability to select and customize routing profiles, as routing becomes particularly useful when considering mobility constraints.
Also note that we are only talking about routing here, full navigation is much further away still as we need to have working indoor localization for that as well, which is a much harder problem to solve.
Do we actually need all this?For a comparatively small event like Akademy in a relatively simple two-floor venue, probably not. But think about your first visit at a massive event like FOSDEM, or consider stairs being an insurmountable obstacle. Having support with finding your way around becomes much more important then.
Akademy is a great opportunity to experiment with this though, both from the software and the mapping perspective, and to show what’s possible with the data and technology we already have.
This week in KDE: autoscrolling
You can now turn on the “autoscrolling” feature of the Libinput driver, which lets you scroll on any scrollable view by holding down the middle button of your mouse and moving the whole mouse (Evgeniy Chesnokov, Plasma 6.2.0. Link)
UI ImprovementsWhen zooming into or out of a document in Okular using Ctrl+Scroll, it now zooms into or out of the actual cursor position, not the center of the page (Alexis Murzeau, Okular 24.08.0. Link)
Okular now scales radio buttons and checkboxes to the size of the form fields they inhabit, which looks better for forms that have huge or tiny versions of these (Pratham Gandhi, Okular 24.08.0. Link)
Dolphin now supports the systemwide “disable smooth scrolling” setting (Nathan Misner, Dolphin 24.08.0 Link)
Opening and closing Elisa’s playlist panel is no longer somewhat choppy (Jack Hill, Elisa 24.08. Link)
When quick-tiling two adjacent windows and resizing one, the other will resize too. The location of the split between them is now reset to its default position after all adjacent quick-tiled windows are closed or un-tiled (Erwin Saumweber, Plasma 6.1.2. Link)
.Desktop files in sub-folders below your desktop are now shown as they are on the desktop itself (Alexander Wilms, Plasma 6.2.0. Link)
On System Settings’ Accessibility page, the Open dialog for choosing custom bell sounds now accepts .oga files, and also tells you what types of files it supports (me: Nate Graham, Plasma 6.2.0. Link)
On System Settings Desktop Effects page, “internal” effects are no longer listed at all (even in a hidden-by-default state), which makes it more difficult for people to break their systems by accident, and also fixes an odd interaction whereby clicking the “Defaults” button would reset the default settings of internal effects changed elsewhere. You can still see the internal effects in KWin’s debug console window if needed (Vlad Zahorodnii, Plasma 6.2.0. Link)
Made a bunch of small changes to System Settings pages to align them better with the new human interface guidelines (me: Nate Graham, Plasma 6.2.0. Link 1, link 2, link 3, and link 4)
Improved the legibility of the text in Kirigami.NavigationTabBar buttons, especially on low or medium DPI screens (me: Nate Graham, Frameworks 6.4. Link)
Bug FixesFixed a recent regression that caused the Powerdevil power management daemon to sometimes crash randomly when the system has any monitors connected that support DDC-based brightness control (Jakob Petsovits, Plasma 6.1.2. Link)
On the System Settings’ recently re-done Keyboard page, table columns in the layout table are once again resizable, and also have more sensible default widths now (Wind He, Plasma 6.1.2. Link)
Fixed one source of the recent issue with certain System Settings pages being sometimes broken when opened — this one being the issue where opening the Touchpad or Networks pages would break other ones opened afterwards. We’re still investigating the other issues, which frankly make no sense and shouldn’t be happening. Some of them may be Qt regressions. Investigation is ongoing (Marco Martin, Plasma 6.1.3. Link)
Icons in the new Edit Mode’s toolbar buttons are no longer slightly blurry (Akseli Lahtinen, Plasma 6.1.3. Link)
KWin’s “open new windows under pointer” feature now actually does, and ignores the active screen when that screen differs from the screen with the pointer on it (Xaver Hugl, Plasma 6.1.3. Link)
Fixed multiple recent regressions and longstanding issues with System Monitor widgets displayed on panels (Arjen Hiemstra, Plasma 6.2.0):
- Text in small pie charts overflowing onto the next line awkwardly (link)
- Adjacent pie charts overlapping at certain panel thicknesses (link)
- Graphs not taking enough space on a thick panel (link)
With wide color gamut turned on or an ICC color profile in use, transparent windows are no longer too transparent (Xaver Hugl, Plasma 6.2.0. Link)
Showing and hiding titlebars and frames on a scaled display no longer causes XWayland windows to move diagonally by about 1px every time (Vlad Zahorodnii, Plasma 6.2.0. Link)
Fixed multiple issues and glitches affecting floating panels via a significant code refactor (Marco Martin, Plasma 6.2.0. Link 1, link 2, and link 3)
Fixed a recent Qt regression that caused Plasma to sometimes crash when screens were disconnected (David Edmundson, Qt 6.7.3. Link 1 and link 2)
Fixed a Qt regression that caused web pages rendered by QtWebEngine (most notably in KMail’s HTML message viewer window) to display have blocky, blurry, or pixelated text and graphics (David Edmundson, Qt 6.8.0. Link)
Other bug information of note:
- 3 Very high priority Plasma bugs (down from 4 last week). Current list of bugs
- 31 15-minute Plasma bugs (up from 29 last week). Current list of bugs
- 98 KDE bugs of all kinds fixed over the last week. Full list of bugs
Made the pam_kwallet library able to build with libgcrypt 1.11, restoring its ability to let the system wallet unlock automatically on login again (Daniel Exner, Plasma 6.1.2. Link)
Automation & SystematizationAdded some UI tests to KCalc, ensuring that the recent prominent regression in functionality can’t happen again (Gabriel Barrantes, link)
…And Everything ElseThis blog only covers the tip of the iceberg! If you’re hungry for more, check out https://planet.kde.org, where you can find more news from other KDE contributors.
How You Can HelpAs I mentioned last week, if you use have multiple systems or an adventurous personality, you can really help us out by installing beta versions of Plasma using your distro’s available repos and reporting bugs. Arch, Fedora, and openSUSE Tumbleweed are examples of great distros for this purpose. So please please do try out Plasma beta versions. It truly does help us! Heck, if you’re very adventurous, live on the nightly repos. I’ve been doing this full-time for 5 years with my sole computer and it’s surprisingly stable.
Does that sound too scary? Consider donating today instead! That helps too.
Otherwise, visit https://community.kde.org/Get_Involved to discover other ways to be part of a project that really matters. Each contributor makes a huge difference in KDE; you are not a number or a cog in a machine! You don’t have to already be a programmer, either. I wasn’t when I got started. Try it, you’ll like it! We don’t bite!
Carl Trachte: Graphviz - Editing a DAG Hamilton Graph dot File
Last post featured the DAG Hamilton generated graphviz graph shown below. I'll be dressing this up a little and highlighting some functionality. For the toy example here, the script employed is a bit of overkill. For a bigger workflow, it may come in handy.
{kind=link}
I'll start with the finished products:
1) A Hamilton logo and a would be company logo get added (manual; the Data Inputs Highlighted subtitle is there for later processing when we highlight functionality.)
{kind=link}
2) through 4) are done programmatically (code is shown further down). I saw an example on the Hamilton web pages that used aquamarine as the highlight color; I liked that, so I stuck with it.
2) Data source and data source function highlighted.
{kind=link}
3) Web scraping functions highlighted.
{kind=link}
4) Output nodes highlighted.
{kind=link}
A few observations and notes before we look at configuration and code: I've found the charts to be really helpful in presenting my workflow to users and leadership (full disclosure: my boss liked some initial charts I made; my dream of the PowerPoint to solve all scripter<->customer communication challenges is not yet reality, but for the first time in a long time, I have hope.)
In the web scraping highlighted diagram, you can pretty clearly see that data_with_company node has an input into the commodity_word_counts node. The domain specific rationale from the last blog post is that I don't want to count every "Barrick Gold" company name occurrence as another mention of "Gold" or "gold."
Toy example notwithstanding, in real life, being able to show where something branches critically is a real help. Assumptions about what a script is actually doing versus what it is doing can actually be costly in terms of time and productivity for all parties. Being able to say and show ideas like, "What it's doing over here doesn't carry over to that other mission critical part you're really concerned with; it's only for purposes of the visualization which lies over here on the diagram" or "This node up here representing <the real life thing> is your sole source of input for this script; it is not looking at <other real world thing> at all."
graphviz and diagrams like this have been around for decades - UML, database schema visualizations, etc. What makes this whole DAG Hamilton thing better for me is how easy and accessible it is. I've seen C++ UML diagrams over the years (all respect to the C++ people - it takes a lot of ability, discipline, and effort); my first thought is often, "Oh wow . . . I'm not sure I have what it takes to do that . . . and I'm not sure I'd want to . . ."
Enough rationalization and qualifying - on to the config and the code!
I added the title and logos manually. The assumption that the graphviz dot file output of DAG Hamilton will always be in the format shown would be premature and probably wrong. It's an implementation detail subject to change and not a feature. That said, I needed some features in my graph outputs and I achieved them this one time.
Towards the top of the dot file is where the title goes:
// Dependency Graphdigraph { labelloc="t" label=<<b>Toy Web Scraping Script Run Diagram<BR/>Data Inputs Highlighted</b>> fontsize="36" fontname=Helvetica
labelalloc="t" puts the text at the top of the graph (t for top, I think).
// Dependency Graphdigraph { labelloc="t" label=<<b>Toy Web Scraping Script Run Diagram<BR/>Data Inputs Highlighted</b>> fontsize="36" fontname=Helvetica hamiltonlogo [label="" image="hamiltonlogolarge.png" shape="box", width=0.6, height=0.6, fixedsize=true] companylogo [label="" image="fauxcompanylogo.png" shape="box", width=5.10 height=0.6 fixedsize=true]
The DAG Hamilton logo listed first appears to end up in the upper left part of the diagram most of the time (this is an empirical observation on my part; I don't have a super great handle on the internals of graphviz yet).
Getting the company logo next to it requires a bit more effort. A StackOverflow exchange had a suggestion of connecting it invisibly to an initial node. In this case, that would be the data source. Inputs in DAG Hamilton don't get listed in the graphviz dot file by their names, but rather by the node or nodes they are connected to: _parsed_data_inputs instead of "datafile" like you might expect. I have a preference for listing my input nodes only once (deduplicate_inputs=True is the keyword argument to DAG Hamilton's driver object's display_all_functions method that makes the graph).
The change is about one third of the way down the dot file where the node connection edges start getting listed:
parsed_data -> data_with_wikipedia _parsed_data_inputs [label=<<table border="0"><tr><td>datafile</td><td>str</td></tr></table>> fontname=Helvetica margin=0.15 shape=rectangle style="filled,dashed" fillcolor="#ffffff"] companylogo -> _parsed_data_inputs [style=invis]
DAG Hamilton has a dashed box for script inputs. That's why there is all that extra description inside the square brackets for that node. I manually added the fillcolor="#ffffff" at the end. It's not necessary for the chart (I believe the default fill of white /#ffffff was specified near the top of the file), but it is necessary for the code I wrote to replace the existing color with something else. Otherwise, it does not affect the output.
I think that's it for manual prep.
Onto the code. Both DAG Hamilton and graphviz have API's for customizing the graphviz dot file output. I've opted to approach this with brute force text processing. For my needs, this is the best option. YMMV. In general, text processing any code or configuration tends to be brittle. It worked this time.
# python 3.12
"""Try to edit properties of graphviz output."""
import sys
import re
import itertools
import graphviz
INPUT = 'ts_with_logos_and_colors'
FILLCOLORSTRLEN = 12AQUAMARINE = '7fffd4'COLORLEN = len(AQUAMARINE)
BOLDED = ' penwidth=5'BOLDEDEDGE = ' [penwidth=5]'
NODESTOCOLOR = {'data_source':['_parsed_data_inputs', 'parsed_data'], 'webscraping':['data_with_wikipedia', 'colloquial_company_word_counts', 'data_with_company', 'commodity_word_counts'], 'output':['info_output', 'info_dict_merged', 'wikipedia_report']}
EDGEPAT = r'\b{0:s}\b[ ][-][>][ ]\b{1:s}\b'
TITLEPAT = r'Toy Web Scraping Script Run Diagram[<]BR[/][>]'ENDTITLEPAT = r'</b>>'
# Two tuples as values for edges.EDGENODESTOBOLD = {'data_source':[('_parsed_data_inputs', 'parsed_data')], 'webscraping':[('data_with_wikipedia', 'colloquial_company_word_counts'), ('data_with_wikipedia', 'data_with_company'), ('data_with_wikipedia', 'commodity_word_counts'), ('data_with_company', 'commodity_word_counts')], 'output':[('data_with_company', 'info_output'), ('colloquial_company_word_counts', 'info_dict_merged'), ('commodity_word_counts', 'info_dict_merged'), ('info_dict_merged', 'wikipedia_report'), ('data_with_company', 'info_dict_merged')]}
OUTPUTFILES = {'data_source':'data_source_highlighted', 'webscraping':'web_scraping_functions_highlighted', 'output':'output_functions_highlighted'}
TITLES = {'data_source':'Data Sources and Data Source Functions Highlighted', 'webscraping':'Web Scraping Functions Highlighted', 'output':'Output Functions Highlighted'}
def get_new_source_nodecolor(src, nodex): """ Return new source string for graphviz with selected node colored aquamarine.
src is the original graphviz text source from file.
nodex is the node to have it's color edited. """ # Full word, exact match. wordmatchpat = r'\b' + nodex + r'\b' pat = re.compile(wordmatchpat) # Empty string to hold full output of edited source. src2 = '' match = re.search(pat, src) # nodeidx = src.find(nodex) nodeidx = match.span()[0] print('nodeidx = ', nodeidx) src2 += src[:nodeidx] idxcolor = src[nodeidx:].find('fillcolor') print('idxcolor = ', idxcolor) # fillcolor="#b4d8e4" # 012345678901234567 src2 += src[nodeidx:nodeidx + idxcolor + FILLCOLORSTRLEN] src2 += AQUAMARINE currentposit = nodeidx + idxcolor + FILLCOLORSTRLEN + COLORLEN src2 += src[currentposit:] return src2
def get_new_title(src, title): """ Return new source string for graphviz with new title part of header.
src is the original graphviz text source from file.
title is a string. """ # Empty string to hold full output of edited source. src2 = '' match = re.search(TITLEPAT, src) titleidx = match.span()[1] print('titleidx = ', titleidx) src2 += src[:titleidx] idxendtitle = src[titleidx:].find(ENDTITLEPAT) print('idxendtitle = ', idxendtitle) src2 += title currentposit = titleidx + idxendtitle print('currentposit = ', currentposit) src2 += src[currentposit:] return src2
def get_new_source_penwidth_nodes(src, nodex): """ Return new source string for graphviz with selected node having bolded border.
src is the original graphviz text source from file.
nodex is the node to have its box bolded. """ # Full word, exact match. wordmatchpat = r'\b' + nodex + r'\b' pat = re.compile(wordmatchpat) # Empty string to hold full output of edited source. src2 = '' match = re.search(pat, src) nodeidx = match.span()[0] print('nodeidx = ', nodeidx) src2 += src[:nodeidx] idxbracket = src[nodeidx:].find(']') src2 += src[nodeidx:nodeidx + idxbracket] print('idxbracket = ', idxbracket) src2 += BOLDED src2 += src[nodeidx + idxbracket:] return src2
def get_new_source_penwidth_edges(src, nodepair): """ Return new source string for graphviz with selected node pair having bolded edge.
src is the original graphviz text source from file.
nodepair is the two node tuple to have its edge bolded. """ # Full word, exact match. edgepat = EDGEPAT.format(*nodepair) print(edgepat) pat = re.compile(edgepat) # Empty string to hold full output of edited source. src2 = '' match = re.search(pat, src) edgeidx = match.span()[1] print('edgeidx = ', edgeidx) src2 += src[:edgeidx] src2 += BOLDEDEDGE src2 += src[edgeidx:] return src2
def makehighlightedfuncgraphs(): """ Cycle through functionalities to make specific highlighted functional parts of the workflow output graphs.
Returns dictionary of new filenames. """ with open(INPUT, 'r') as f: src = f.read()
retval = {} for functionality in TITLES: print(functionality) src2 = src retval[functionality] = {'dot':None, 'svg':None, 'png':None} src2 = get_new_title(src, TITLES[functionality]) # list of nodes. to_process = (nodex for nodex in NODESTOCOLOR[functionality]) countergenerator = itertools.count() count = next(countergenerator) print('\nDoing node colors\n') for nodex in to_process: print(nodex) src2 = get_new_source_nodecolor(src2, nodex) count = next(countergenerator) to_process = (nodex for nodex in NODESTOCOLOR[functionality]) countergenerator = itertools.count() count = next(countergenerator) print('\nDoing node bolding\n') for nodex in to_process: print(nodex) src2 = get_new_source_penwidth_nodes(src2, nodex) count = next(countergenerator) print('Bolding edges . . .') to_process = (nodex for nodex in EDGENODESTOBOLD[functionality]) countergenerator = itertools.count() count = next(countergenerator) for nodepair in to_process: print(nodepair) src2 = get_new_source_penwidth_edges(src2, nodepair) count = next(countergenerator) print('Writing output files . . .') outputfile = OUTPUTFILES[functionality] with open(outputfile, 'w') as f: f.write(src2) graphviz.render('dot', 'png', outputfile) graphviz.render('dot', 'svg', outputfile)
makehighlightedfuncgraphs()
Thanks for stopping by.
TestDriven.io: Developing GraphQL APIs in Django with Strawberry
ImageX: The Gems of Drupal 10.3: Exploring What’s New in the Release
Authored by Nadiia Nykolaichuk.
Drupal is ceaselessly evolving, with the best Drupal minds nurturing brilliant ideas and implementing them in the new releases. Six months ago, Drupal 10.2 rolled out with a set of exciting enhancements. Now it’s time to celebrate that Drupal 10.3 has been officially released on June 20.
FSF Blogs: Share free software with your friends and colleagues
Share free software with your friends and colleagues
The Drop is Always Moving: Continuous forward compatibility checking of extensions for Drupal 12, 13, etc using @gitlab CI 😍 https://www.hojtsy.hu/blog/2024-jul-05/continuous-forward-compatibility-checking-extensions-drupal-12-13-etc Get inline and...
Continuous forward compatibility checking of extensions for Drupal 12, 13, etc using @gitlab CI 😍 https://www.hojtsy.hu/blog/2024-jul-05/continuous-forward-compatibility-checking-extensions-drupal-12-13-etc Get inline and ongoing feedback about readiness for upcoming major versions of Drupal as you develop extensions!
Wim Leers: XB week 6: diagrams & meta issues
1.5 week prior, Lee “larowlan” + Jesse fixed a bug in the undo/redo functionality and added the first unit test (#3452895), and added it to CI (where it now runs immediately, no need to wait for composer to run JS unit tests!) Except … the unit tests didn’t actually run — oops! Rectifying that revealed a whole range of new Cypress challenges, which Ben “bnjmnm” worked tirelessly to solve this during the entire 5th week, and it was merged on Wednesday of this week :)
Anybody who has contributed to the drupal.org GitLab CI templates knows how painful this can be!
Missed a prior week? See all posts tagged Experience Builder.
Goal: make it possible to follow high-level progress by reading ~5 minutes/week. I hope this empowers more people to contribute when their unique skills can best be put to use!
For more detail, join the #experience-builder Slack channel. Check out the pinned items at the top!
As alluded to in last week’s update, I’m shifting my focus to coordinating.
That, together with quite a few people being out or preparing for webinars or Drupal Dev Days Burgas means this is an unusually short update — also because I left on vacation on Friday the 21st of June.
Before going on vacation, I wanted to ensure work could continue in my absence because we need to get to the point where Lauri’s vision is accessible in both UX wireframe form (Lauri’s working on that with Acquia UX) and technical diagram form (up to me to get that going). So, since last week:
- Lauri created #3454094: Milestone 0.1.0: Experience Builder Demo. I created #3455753: Milestone 0.2.0: Experience Builder-rendered nodes. Anything that is not necessary for either of those two should not be worked on at this time. They together form “the early phase” — the milestone 0.1.0 has a hard DrupalCon Barcelona 2024 deadline in September, the 0.2.0 does not have a similar firm date.
- As much of 0.2.0 as possible should already be in 0.1.0, which means ideally the back end is ahead of the front end. That’s what #3450586: [META] Early phase back-end work coordination and #3450592: [META] Early phase front-end work coordination. are for. I did a big update to have the next ~10 or so back-end things to build spelled out in detail in concrete issues, with vaguer descriptions for the things that are further out and subject to change anyway.
- Initial diagram of the data model as currently partially implemented and the direction we’ve been going in … followed by a significant expansion of detail. You can see the diagrams on GitLab, in the docs/diagrams directory.
- The JSON-based data storage model is influenced significantly by some of the product requirements, and what those are and their exact purpose has not been very clear. To fix that, I created [later phase] [META] 7. Content type templates — aka “default layouts” — affects the tree+props data model (which updates the data model diagram!) — and Lauri recorded a video with his thinking around this, in which he walks through two diagrams: one for data sources + design system, one that breaks down a concrete content type.
- A lot of discussion happened between Lauri, catch and I on [META] Configuration management: define needed config entity types, which needs a lot more clarity before all config entity types can be implemented.
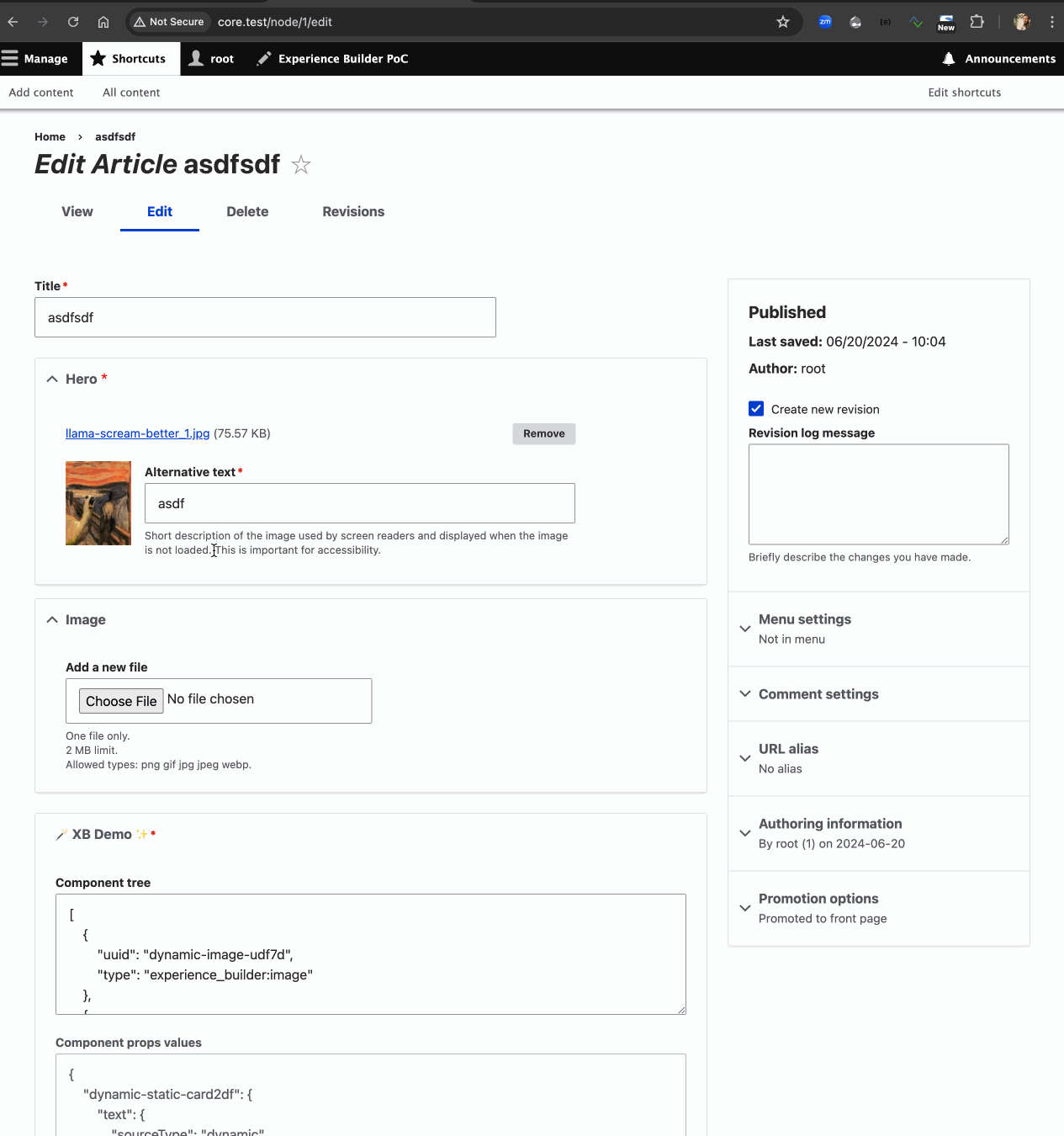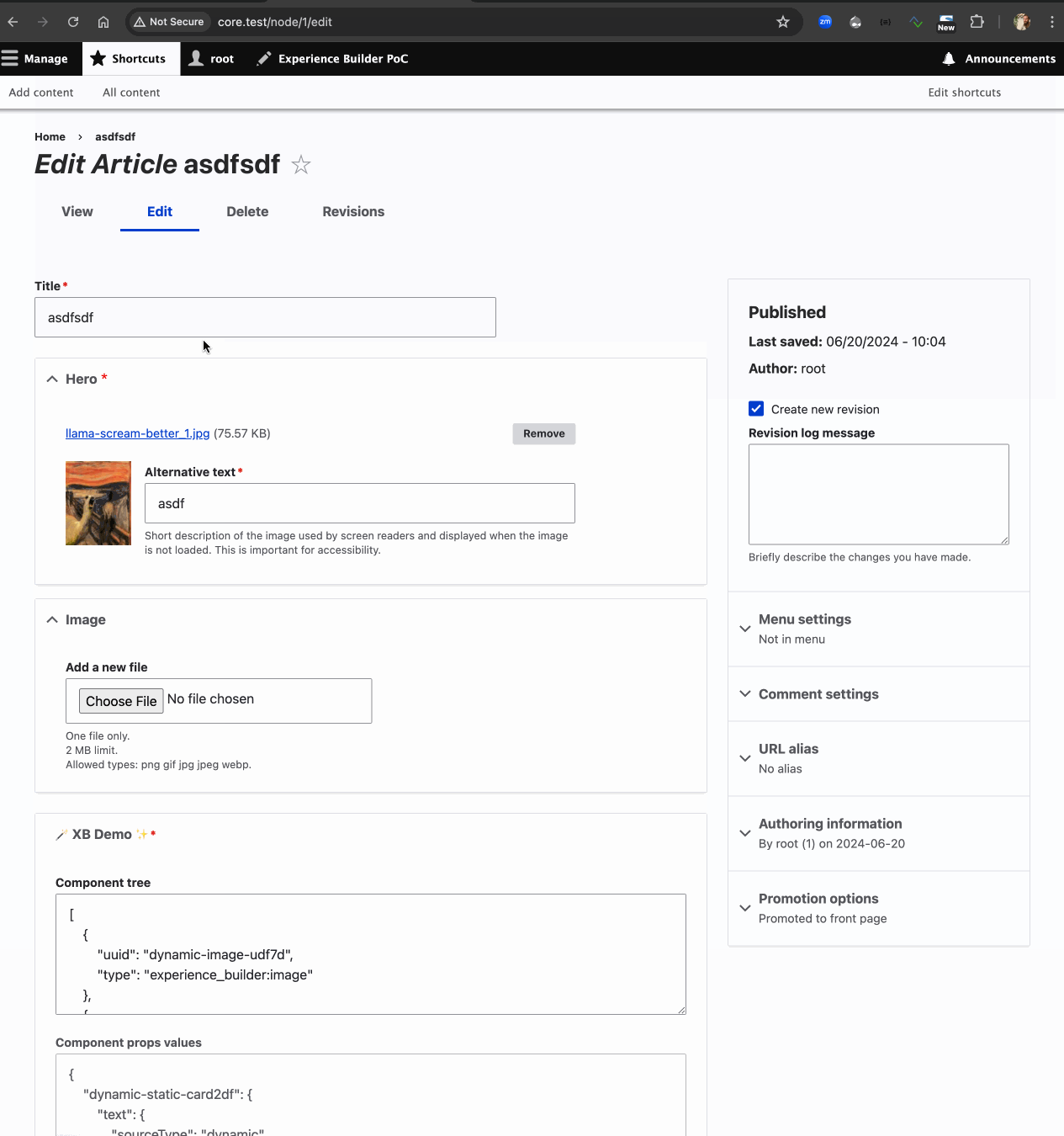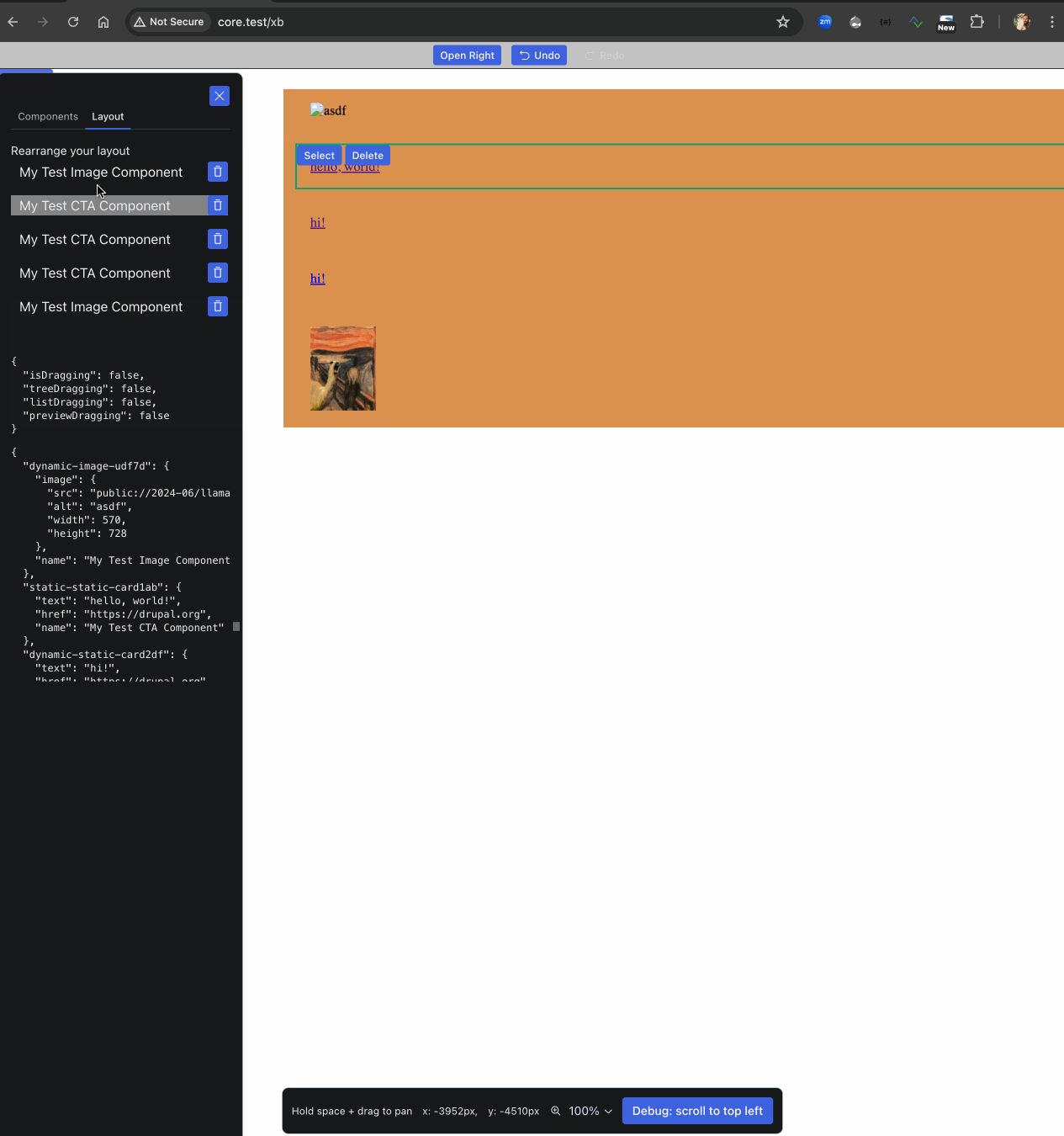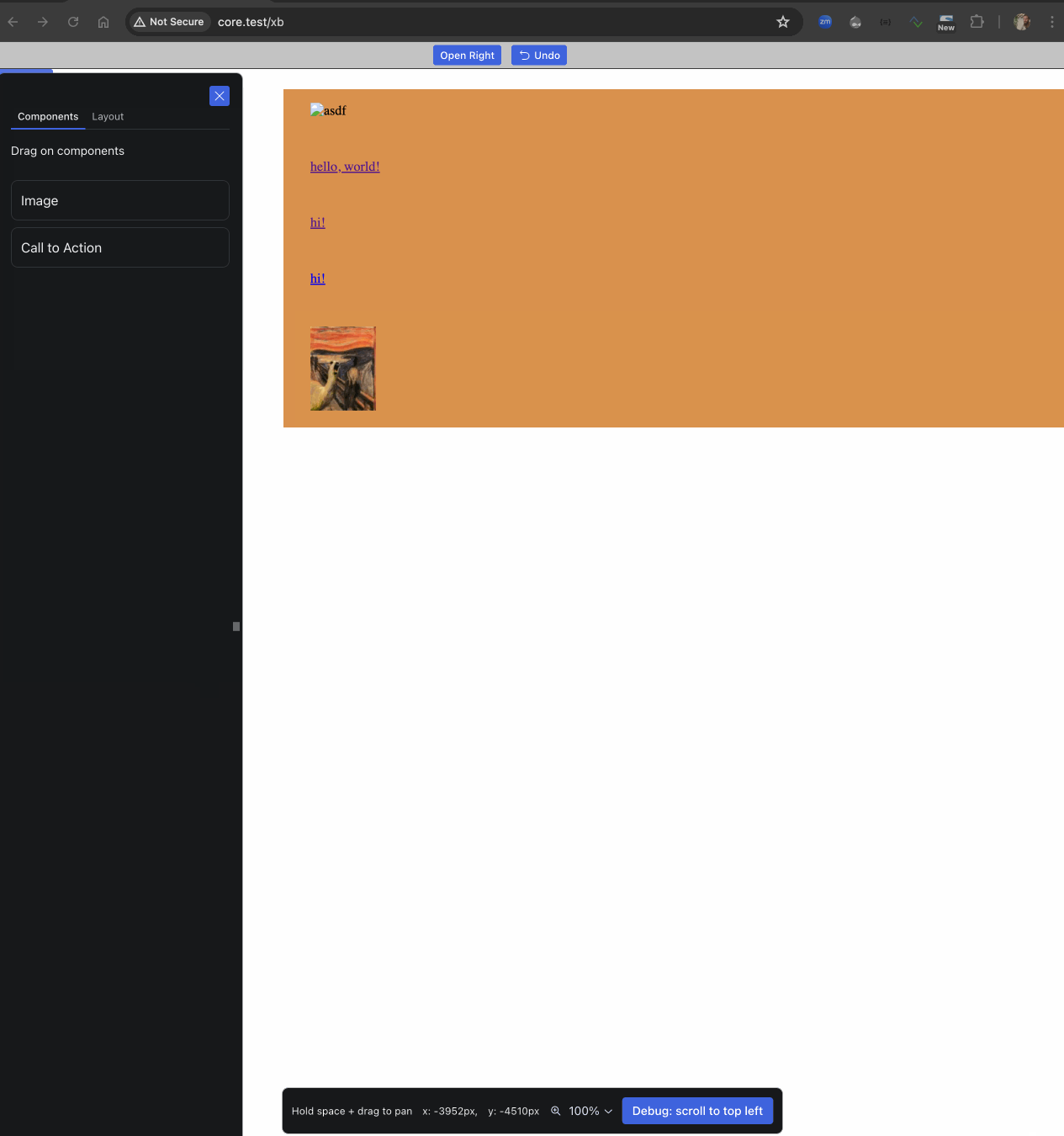
One pretty cool issue landed this week that drives home that second item : #3455898: Connect client & server, with zero changes to client (UI): rough working endpoints that mimic the UI’s mocks — thanks to that, the PoC UI is now optionally populated by the first article node, unless you enable development mode (see ui/README.md), then it uses dummy data not served by Drupal. A small but hacky change but an important pragmatic step in the right direction :) And it unblocks Jesse on next steps on the UI!
Try it yourself locally if you like, but there’s not much you can do yet.
Install the 0.x branch — the “Experience Builder PoC” toolbar item takes you there!
{kind=link}
Weeks 7 and 8 will be special editions: I will have been completely absent during week 7 (plus, it’ll be Drupal Dev Days!), and present only for the last day of week 8. I’ll catch up what happened and do a write-up both for myself as well as all of you!
Thanks to Lauri for reviewing this!
{kind=link}
Gábor Hojtsy: Continuous forward compatibility checking of extensions for Drupal 12, 13, etc
We still keep improving the ecosystem readiness and tooling with each new major Drupal core version. Drupal 11 is to be released in a few weeks on the week of July 29 (so probably the first days of August) and already almost half of the top 200 modules are ready. But we need to keep thinking ahead.
The Project Update Bot (originally built by Ted Bowman at Acquia and since then very actively owned and improved by Björn Brala at SWIS) posted into more than 7600 project issue queues on Drupal.org with merge request suggestions to improve and in many cases solve compatibility with the upcoming major version.
The bot is a clever combination of Upgrade Status and drupal-rector with some custom decision logic. So humans can also run those tools! But what if we automate it even more? What if we help pre-empt forwards incompatible code getting into modules in the first place?
Gábor Hojtsy Fri, 07/05/2024 - 20:34Sahil Dhiman: Atleast Not Written by an AI
I keep on going back and correcting bootload of grammatical and other errors in my posts here. I somewhat feel embarrassed how such mistakes slip through when I was proofreading. Back then it was all good and suddenly this mistake cropped up in my text, which everyone might have already noticed by now. A thought just stuck around that. Those mistakes signify that the text is written by a real human, and humans makes mistakes. :)
PS - Even LanguageTool (non-premium) couldn’t identify those errors.
The Drop Times: Drupal Usage in Government: A Data-Driven Study of CMS Adoption Patterns
Web Review, Week 2024-27
Let’s go for my web review for the week 2024-27.
Online anonymity: study found ‘stable pseudonyms’ created a more civil environment than real user namesTags: tech, internet, anonymity, privacy
There’s clearly an interesting balance between full anonymity and no anonymity at all. This is a path to keep discussions genuine and civil.
Tags: tech, telegram, security, criticism
This organization indeed doesn’t seem healthy. Especially regarding the amount of user data they are responsible of.
Tags: tech, philosophy, ai, machine-learning, gpt, ethics
Makes a strong case about why LLMs are better described as “bullshit machine”. In any case this is a good introduction into bullshit as a philosophical concept. I guess with our current relationship to truth these are products well suited to their context…
https://link.springer.com/article/10.1007/s10676-024-09775-5
Tags: tech, ai, machine-learning, gpt, spam
A new era of spam is on us… this is going to be annoying to filter out.
https://timharek.no/blog/i-received-an-ai-email
Tags: tech, ssh, security
Make sure your OpenSSH server is up to date.
https://www.qualys.com/2024/07/01/cve-2024-6387/regresshion.txt
Tags: tech, unix, posix, system, standard
From the perspective of a given implementation. Still this is a good list of what POSIX 2024 changes. I’m particularly interested to see that per-file-descriptor advisory locks finally made it to the standard. Still some progress to make in this department but it’s a good step already.
https://sortix.org/blog/posix-2024/
Tags: tech, architecture, services, complexity, go, postgresql, databases, react
Nice return on experience of using a simple stack to serve loads of web requests.
https://notes.billmill.org/blog/2024/06/Serving_a_billion_web_requests_with_boring_code.html
Tags: tech, c++, standard
Looks like C++26 is going to be a big deal. The reflection and generation features alone are going to be a game changer. Now if it also gets contracts it’d be really nice.
https://herbsutter.com/2024/07/02/trip-report-summer-iso-c-standards-meeting-st-louis-mo-usa/
Tags: tech, shell, processes
This is too often underestimated. This article shows nice uses of job control.
https://jvns.ca/blog/2024/07/03/reasons-to-use-job-control/
Tags: tech, linux, profiling, debugging, tools
Nice suite of tools. The eBPF based ones look promising.
Tags: tech, programming, python
Obviously very opinionated. Still probably a nice list to pick from when making your own project specific coding guidelines.
https://www.stuartellis.name/articles/python-modern-practices/
Tags: tech, web, css, frontend, maintenance
Interesting approach to structure CSS custom properties. Should help a bit with maintainability.
https://keithjgrant.com/posts/2024/06/a-structured-approach-to-custom-properties/
Tags: tech, programming, asynchronous
Not really Rust specific, this might be an interesting way to structure your code once async gets introduced. Should avoid some of the usual traps.
https://blog.sulami.xyz/posts/sync-core-async-shell/
Tags: tech, hardware, software, performance
As Moore’s law fades away this question is indeed essential. Looks like there will be more pressure on software and algorithms than before (at last one might say, we had decades of waste there). Streamlining hardware architectures will have a role too, we might see simpler cores in greater numbers.
https://www.science.org/doi/10.1126/science.aam9744
Tags: tech, tdd, tests
Starting from a wrong analogy to raise real thinking and questions about TDD.
https://tidyfirst.substack.com/p/tdd-is-not-hill-climbing
Tags: tech, codereview
Good reasons to really make sure your organization practice code reviews.
https://two-wrongs.com/code-reviews-do-find-bugs.html
Tags: tech, quality, productivity
Good reminder that those two aspects are not necessarily competing which each other. In the long run quality improves productivity. In the short term it might as well.
https://www.haskellforall.com/2024/07/quality-and-productivity-are-not.html?m=1
Tags: management, organization, cognition, planning, bias
Very good primer on a widespread and very hard to avoid bias. This is why it’s hard for projects to properly meet deadlines.
https://thedecisionlab.com/biases/planning-fallacy
Tags: tech, team, organization, leadership, management
Interesting tips and actions to help frame the conversation. The goal is to get the team better self-organized and directed.
https://newsletter.canopy.is/p/the-4-keys-to-creating-team-accountability
Bye for now!
mark.ie: My Drupal Core Contributions for week-ending July 5th, 2024
Here's what I've been working on for my Drupal contributions this week. Thanks to Code Enigma for sponsoring the time to work on these.
drunomics: A Journey Towards Sustainability and Team Building
At drunomics GmbH, our dedication to sustainable digital practices is at the heart of everything we do. We see technology as a powerful force for positive change, and our recent team event in Burgas, Bulgaria, emphasized sustainability as the focal point of the event. Here is a glimpse into the vibrant discussions, collaborative learning, and memorable moments that made this event truly special.
Nurturing Sustainability 1. Green UX Design InsightsDuring our event, we immersed ourselves in the principles of Green UX design. Our discussions centered on creating digital experiences that are both user-friendly and environmentally conscious. Here are some of the key insights we shared:
- Optimizing Code for Efficiency: Streamlining scripts and using efficient algorithms not only boosts performance but also cuts down on energy consumption, contributing to a greener web.
- Data Transfer Reduction: Minimizing data transfer is crucial for sustainability. We explored methods like lazy loading, content compression, and efficient caching to create smoother user experiences while reducing our digital carbon footprint.
- Balancing Aesthetics and Sustainability: Green UX is about finding harmony between visual appeal and resource efficiency. Thoughtful use of images, animations, and fonts can achieve this balance effectively.
Our discussions also focused on empowering users to make eco-friendly choices through smart intuitive design:
-
Empowering Users: We brainstormed ways to integrate sustainability into user interactions, such as through informative tool-tips, personalized recommendations, and eco-friendly badges.
- Behavioral Nudges: Subtle prompts within the user experience can encourage eco-friendly behavior, like promoting energy-saving modes, suggesting public transportation options, or highlighting sustainable product choices.
The event was an engaging forum for sharing ideas and fostering dynamic discussions. We challenged assumptions and explored new perspectives on integrating sustainability into our projects. This collaborative approach helped us discover innovative solutions and prepared us to infuse eco-consciousness into every stage of our work.
Real Python: The Real Python Podcast – Episode #211: Python Doesn't Round Numbers the Way You Might Think
Does Python round numbers the same way you learned back in math class? You might be surprised by the default method Python uses and the variety of ways to round numbers in Python. Christopher Trudeau is back on the show this week, bringing another batch of PyCoder's Weekly articles and projects.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
mark.ie: A bash script to install different Drupal profiles the easy way
Over the past few weeks I've been sharing handy ways to set up Drupal for easier Drupal core development. Here's a bash script for installing Drupal and allowing you to choose what profile you want.
The Python Show: Dashboards in Python with Streamlit
This week, I chatted with Channin Nantasenamat about Python and the Streamlit web framework.
Specifically, we chatted about the following topics:
Python packages
Streamlit
Teaching bioinformatics
Differences in data science disciplines
Being a YouTuber
and much more!
Data Professor YouTube Channel
Follow Channin on X / Twitter
Reproducible Builds (diffoscope): diffoscope 272 released
The diffoscope maintainers are pleased to announce the release of diffoscope version 272. This version includes the following changes:
[ Chris Lamb] * Move away from using DSA OpenSSH keys in tests; support has been removed in OpenSSH 9.8p1. (Closes: reproducible-builds/diffoscope#382) * Move to assert_diff helper in test_openssh_pub_key.py * Update copyright years.You find out more by visiting the project homepage.
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects