
Feeds
The Drop Times: Drupal GovCon 2024: LaunchDarkly and Drupal: A Solid Combo For A/B Testing
Reproducible Builds: Reproducible Builds in August 2024
Welcome to the August 2024 report from the Reproducible Builds project!
Our reports attempt to outline what we’ve been up to over the past month, highlighting news items from elsewhere in tech where they are related. As ever, if you are interested in contributing to the project, please visit our Contribute page on our website.
Table of contents:
- LWN: The history, status, and plans for reproducible builds
- Intermediate Autotools build artifacts removed from PostgreSQL distribution tarballs
- Distribution news
- Mailing list news
- diffoscope
- Website updates
- Upstream patches
- Reproducibility testing framework
The free software newspaper of record, Linux Weekly News, published an in-depth article based on Holger Levsen’s talk, Reproducible Builds: The First Eleven Years which was presented at the recent DebConf24 conference in Busan, South Korea.
Titled The history, status, and plans for reproducible builds and written by Jake Edge, LWN’s article not only summarises Holger’s talk and clarifies its message but it links to external information as well. Holger’s original talk can also be watched on the DebConf24 webpage (direct .webm link and his HTML slides are available also). There are also a significant number of comments on LWN’s page as well.
Holger Levsen also headed a scheduled discussion session at DebConf24 on Preserving *other* build artifacts addressing a topic where a number of Debian packages are (or would like to) produce results that are neither the .deb files, the build logs nor the logs of CI tests. This is an issue for reproducible builds as this “4th type” of build artifact are typically shipped within the binary .deb packages, and are invariably non-deterministic; thus making the .deb files unreproducible. (A direct .webm link and HTML slides are available).
Peter Eisentraut wrote a detailed blog post on the subject of “The new PostgreSQL 17 make dist”. Like many projects, the PostgreSQL database has previously pre-built parts of its GNU Autotools build system: “the reason for this is a mix of convenience and traditional practice”. Peter astutely notes that this arrangement in the build system is “quite tricky” as:
You need to carefully maintain the different states of “clean source code”, “partially built source code”, and “fully built source code”, and the commands to transition between them.
However, Peter goes on to mention that:
… a lot more attention is nowadays paid to the software supply chain. There are security and legal reasons for this. When users install software, they want to know where it came from, and they want to be sure that they got the right thing, not some fake version or some version of dubious legal provenance.
And cites the XZ Utils backdoor as a reason to care about transparent and reproducible ways of distributing and communicating a source tarball and provenance. Because of this, intermediate build artifacts are now henceforth essentially disallowed from PostgreSQL distribution tarballs.
Distribution newsIn Debian this month, 30 reviews of Debian packages were added, 17 were updated and 10 were removed this month adding to our knowledge about identified issues. One issue type was added by Chris Lamb, too. […]
In addition, an issue was filed to update the Salsa CI pipeline (used by 1,000s of Debian packages) to no longer test for reproducibility with reprotest’s build_path variation. Holger Levsen provided a rationale for this change in the issue, which has already been made to the tests being performed by tests.reproducible-builds.org.
In Arch Linux this month, Jelle van der Waa published a short blog post on the topic of Investigating creating reproducible images with mkosi, motivated by the desire to make it possible for anyone to “re-recreate the official Arch cloud image bit-by-bit identical on their own machine as per [the] reproducible builds definition.” In addition, Jelle filed a patch for pacman, the Arch Linux package manager, to respect the SOURCE_DATE_EPOCH environment variable when installing a package.
In openSUSE news, Bernhard M. Wiedemann published another report for that distribution.
In Android news, the IzzyOnDroid project added 49 new rebuilder recipes and now features 256 total reproducible applications representing 21% of the total offerings in the repository. IzzyOnDroid is “an F-Droid style repository for Android apps[:] applications in this repository are official binaries built by the original application developers, taken from their resp. repositories (mostly GitHub).”
From our mailing list this month:
-
Bernhard M. Wiedemann posted a brief message to the list with some helpful information regarding nondeterminism within Rust binaries, positing the use of the codegen-units = 16 default and resulting in a bug being filed in the Rust issue tracker. […]
-
Bernhard also wrote to the list, following up to a thread in November 2023, on attempts to make the LibreOffice suite of office applications build reproducibly. In the thread from this month, Bernhard could announce that the four patches previously mentioned have landed in LibreOffice upstream.
-
Fay Stegerman linked the mailing list to a thread she made on the Signal issue tracker regarding whether “device-specific binaries [can] ever be considered meaningfully reproducible”. In particular: “the whole part about ‘allow[ing] multiple third parties to come to a consensus on a “correct” result’ breaks down completely when ‘correct’ is device-specific and not something everyone can agree on.” […]
-
Developer kpcyrd posted an update for source code indexing project, whatsrc.org. Announcing that it now importing packages from live-bootstrap (“a usable Linux system [that is] created with only human-auditable, and wherever possible, human-written, source code”) into its database of provenance data.
-
Lastly, Mechtilde Stehmann posted an update to an earlier thread about how Java builds are not reproducible on the armhf architecture, enquiring how they might gain temporary access to such a machine in order to perform some deeper testing. […]
diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb released versions 274, 275, 276 and 277, uploaded these to Debian, and made the following changes as well:
-
New features:
- Strip ANSI escapes—usually colour codes—from the output of the Procyon Java decompiler. […]
- Factor out a method for stripping ANSI escapes. […]
- Append output from dumppdf(1) in more cases, avoiding situations where we fallback to a binary diff. […]
- Add support for versions of Perl’s IO::Compress::Zip version 2.212. […]
-
Bug fixes:
- Also catch RuntimeError exceptions when importing the PyPDF library so that it, or, crucially, its transitive dependencies, cannot not cause diffoscope to traceback at runtime and build time. […]
- Do not call marshal.load(…) of precompiled Python bytecode as it, alas, inherently unsafe. Replace for now with a brief summary of the code section of .pyc. […][…]
- Don’t include excessive debug output when calling dumppdf(1). […]
-
Testsuite-related changes:
- Don’t bother to check version number in test_python.py: the fixture for this test is fixed. […][…]
- Update test_zip text fixtures and definitions to support new changes to the Perl IO::Compress library. […]
In addition, Mattia Rizzolo updated the available architectures for a number of test dependencies […] and Sergei Trofimovich fixed an issue to avoid diffoscope crashing when hashing directory symlinks […] and Vagrant Cascadian proposed GNU Guix updates for diffoscope versions [275 and 276 and [277.
There were a rather substantial number of improvements made to our website this month, including:
-
Alba Herrerias:
- Substantially extend the guidance on the Contribute page. […]
-
Chris Lamb:
-
Fay Stegerman:
- Add IzzyOnDroid (IoD) to the Projects page. […]
-
hulkoba:
- Considerably overhaul the History page in the documentation, linking strip-nondeterminism and SOURCE_DATE_EPOCH […], fixing the test statistics link […], adjusting the Google Summer of Code application link […], a link to a Debian bug […], and removed a dead link to the debhelper utility […].
- Use the jekyll-sitemap plugin to create a sitemap for the website. […]
- Use raw HTML to avoid a literal { .lead } directive appearing in the page. […]
- Fix a number of issues on the Virtual machine drivers page, such as keeping the Gitian info, linking (and then removing) an issue on the Bitcoin issue tracker […] and fixing a link to the Bazel website […].
- Address a broken footnote link on the Timestamps page. […]
- Unify the style on the Commandments of Reproducible Builds page in order to match other documentation entries. […]
- Add a table of contents to the main Documentation page. […]
- Avoid a number of so-called “here” links on the Variations in the build environment page. […]
- Fix a link to the man2html patch on the SOURCE_DATE_EPOCH documentation page. […]
- Fix a link to sources.debian.org on the Randomness page. […]
-
kpcyrd:
- Fix a typo on the Variations in the build environment page. […]
-
Mattia Rizzolo:
-
Pol Dellaiera:
- Fix the DoI for their thesis on the Publications page. […]
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Bernhard M. Wiedemann:
- agama-integration-tests (uses a random TCP-port number in .lock file)
- ca-certificates-mozilla:ca-certificates-mozilla-prebuilt
- cosmic (hash order issue)
- openSUSE (meta-issue to test reproducibility in the openSUSE Build Service)
- pop-launcher (parallelism-related issue)
- post (toolchain-issue, avoiding Rust parallelism)
- rpm-config-SUSE (date-related issue)
- rust (Rust toolchain issue)
- weblate (build gets stuck)
-
Chris Lamb:
-
James Addison:
- #1064782 forwarded and merged in bind9-doc
- #1066083 forwarded and merged in gnome-maps
The Reproducible Builds project operates a comprehensive testing framework running primarily at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility. In August, a number of changes were made by Holger Levsen, including:
- Temporarily install the openssl-provider-legacy package for the Debian unstable environments for running diffoscope due to Debian bug #1078944. […][…][…][…]
- Mark Debian armhf architecture nodes as being down due to proxy down. […][…]
- Detect proxy failures. […][…][…]
- Run the index-buildinfo for the builtin-pho script with the -q switch. […]
- Disable all Arch Linux reproducible jobs. […]
In addition, Mattia Rizzolo updated the website configuration to install the ruby-jekyll-sitemap package as it is now used in the website […], Roland Clobus updated the script to build Debian ‘live’ images to treat openQA issues as warnings […], and Vagrant Cascadian marked the cbxi4b node as down […].
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC: #reproducible-builds on irc.oftc.net.
-
Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list: rb-general@lists.reproducible-builds.org
-
Twitter: @ReproBuilds
Real Python: Quiz: Lists vs Tuples in Python
Challenge yourself with this quiz to evaluate and deepen your understanding of Python lists and tuples. You’ll explore key concepts, such as how to create and manipulate these data types, while also learning best practices for using them efficiently in your code.
You can take this quiz after reading the Lists vs Tuples in Python tutorial.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
joshics.in: Why Drupal is the Ultimate CMS for Your Business: Flexibility, Security, and Scalability
When it comes to choosing a Content Management System (CMS) or framework, the options can be overwhelming. WordPress, Joomla, Squarespace, and many others each have their own strengths. However, there's one CMS that stands out among the rest for its power, flexibility, and scalability: Drupal. Here’s why Drupal should be at the top of your list.
Unmatched FlexibilityDrupal is known for its modular architecture, which allows developers to create highly customised solutions. Unlike WordPress and Squarespace that offer limited customisation out of the box, Drupal’s framework enables you to build virtually any type of website, from simple blogs to complex enterprise-level applications. Joomla also offers flexibility, but Drupal surpasses it with its extensive range of modules and themes.
Robust SecuritySecurity is a critical concern for any website owner. While WordPress is often targeted due to its vast user base, and Joomla has had its share of vulnerabilities, Drupal boasts one of the most secure CMS frameworks available. With a dedicated security team that actively works to identify and patch vulnerabilities, Drupal ensures that your site is well-protected against common cyber threats.
ScalabilityOne of the most compelling reasons to choose Drupal is its ability to scale. Whether you're running a small business website or a high-traffic enterprise portal, Drupal can handle your needs. Major websites like NASA trust Drupal to manage their vast amount of content and traffic demands. While WordPress can also scale, it may require significant customisation and optimisations, which come naturally to Drupal.
Active Community SupportDrupal has a large and active community of developers, designers, and contributors who constantly improve the platform. While WordPress boasts the largest community, Drupal’s community-driven approach means you benefit from a wide range of modules, themes, and plugins that can extend the functionality of your site. Joomla also has a strong community, but Drupal’s focus on high-quality, enterprise-level solutions sets it apart.
SEO-FriendlyHaving a website that ranks well on search engines is crucial. Drupal offers extensive SEO capabilities right out of the box, comparable to those of WordPress, which is often praised for its SEO plugins. From clean URLs to meta tags and mobile optimisation, Drupal provides the tools you need to ensure your site is easily discoverable by search engines. This built-in SEO functionality means you can focus more on your content and less on technical tweaks.
Cost-Effective in the Long RunWhile initial development costs for a Drupal site might be higher compared to simpler platforms like WordPress or Squarespace, the long-term benefits make it a cost-effective choice. Its robust architecture reduces the need for frequent redesigns or overhauls, ensuring you get a higher return on investment over time.
Integrated Digital EcosystemFor businesses looking to integrate their website with other digital tools and platforms, Drupal offers seamless integration capabilities. Whether it’s CRM systems, marketing automation tools, or e-commerce platforms, Drupal can easily connect with your existing digital ecosystem, streamlining your operations and enhancing user experience.
if you're looking for a CMS that offers unparalleled flexibility, robust security, scalability, active community support, SEO-friendliness, and long-term cost-effectiveness, Drupal is an excellent choice. Make the smart move and consider Drupal for your next project.
Drupal Drupal CMS Drupal Planet Add new commentHynek Schlawack: Production-ready Python Docker Containers with uv
Starting with 0.3.0, Astral’s uv brought many great features, including support for cross-platform lock files uv.lock. Together with subsequent fixes, it has become Python’s finest workflow tool for my (non-scientific) use cases. Here’s how I build production-ready containers, as fast as possible.
Jonathan Dowland: loading (unintended consequences?)
For their 30th anniversary (ish; the Covid pandemic pushed the date out a bit) British electronic music duo Orbital released the compilation 30 something. The track list mostly looks like a best hits list, which — given their prior compilation celebrating 20 years looks much the same — would appear superfluous. However, they’ve rearranged and re-recorded all their songs for 30, to reflect their live arrangements. The reworkings are sufficiently distinct from the original versions (in some cases I prefer them) and elevate the release. The couple of new tracks are also fun, and many of the remixes on the second disc are worth a listen too.
{kind=link}
But what I actually sat down to write about was the cover artwork. They often have designs which riff on the notion of a circle (given their name) and the 30-something art (both for the album and single takes from it) adapts a “loading” spinner-like device from computing (I suppose it mostly closely resembles the spinner from macOS).
A possibly unintended effect of the pattern occurs when you view it on a display which is adjusting its brightness, such as if you’re listening to it on a phone, the screen is off, and you pick it up. The brightest part of the spinner is visible first, and the rest fade into visibility in sequence. The first time you see this is unexpected and very cool. (I've tried to recreate it in the picture below, but I don't think it's worked.)
Although I've suffixed the titled of this post unintended consequences?, It's quite possible this was deliberate.
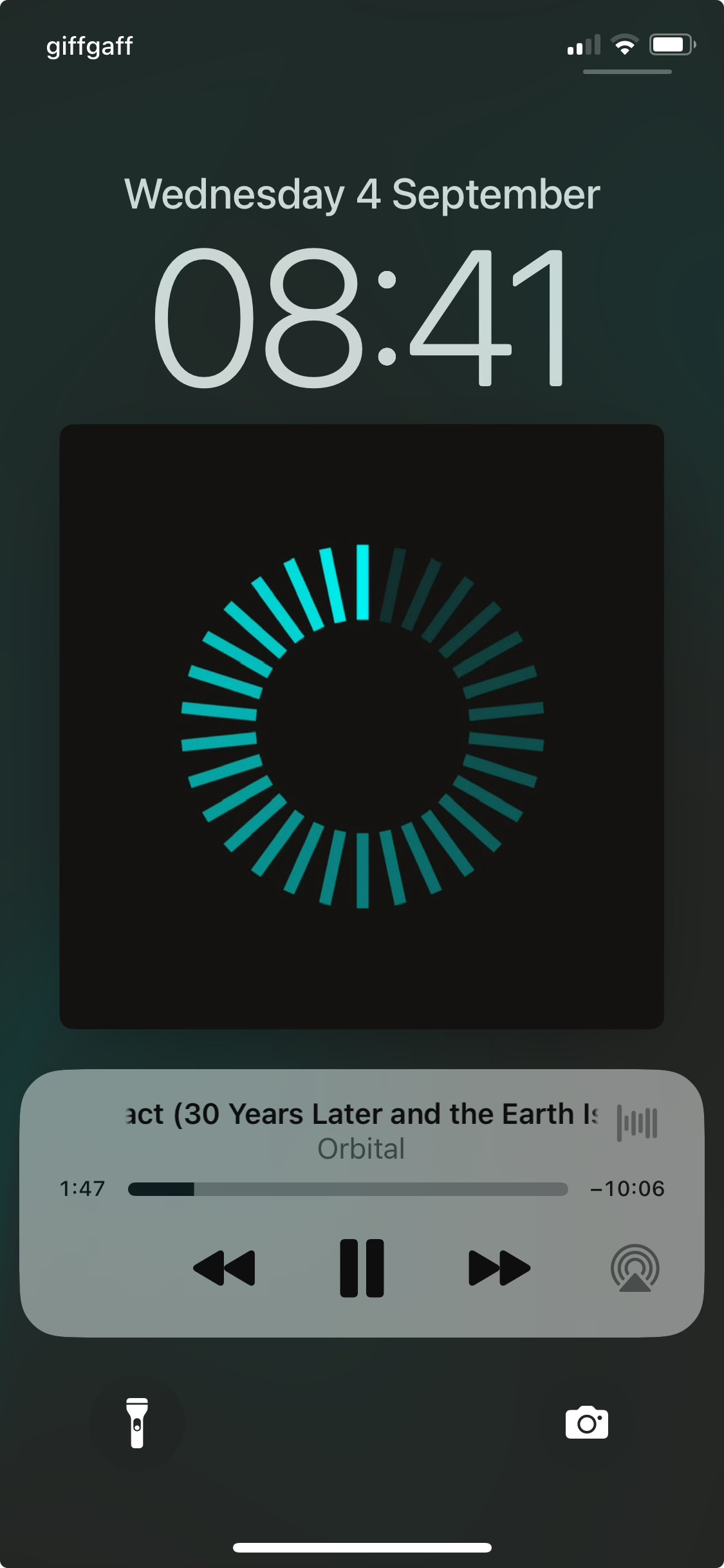{kind=link}
I’ve got the pattern on a t-shirt and my kids love to call out “Daddy’s loading!” In my convalescence it’s taken on a special sort of resonance because at times I’ve felt I’m in a holding state: waiting for an appointment to be made; waiting a polite interval before chasing an appointment; waiting for treatment to start after attending an appointment. Thankfully I’m at the end of that now, I hope.
Promet Source: DotNetNuke vs Drupal for Large Government Agencies
Talk Python to Me: #476: Unified Python packaging with uv
Dirk Eddelbuettel: RcppCNPy 0.2.13 on CRAN: Micro Bugfix
Another (again somewhat minor) maintenance release of the RcppCNPy package arrived on CRAN earlier today.
RcppCNPy provides R with read and write access to NumPy files thanks to the cnpy library by Carl Rogers along with Rcpp for the glue to R.
A change in the most recent Rcpp appears to cause void functions wrapper via Rcpp Modules to return NULL, as opposed to being silent. That tickles discrepancy between the current output and the saved (reference) output of one test file, leading CRAN to display a NOTE which we were asked to take care of. Done here in this release—and now that we know we will also look into restoring the prior Rcpp behaviour. Other small changes involved standard maintenance for continuous integration and updates to files README.md and DESCRIPTION. More details are below.
Changes in version 0.2.13 (2024-09-03)A test script was updated to account for the fact that it now returns a few instances of NULL under current Rcpp.
Small package maintenance updates have been made to the README and DESCRIPTION files as well as to the continuous integration setup.
CRANberries also provides a diffstat report for the latest release. As always, feedback is welcome and the best place to start a discussion may be the GitHub issue tickets page.
If you like this or other open-source work I do, you can now sponsor me at GitHub.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
Brightness controls for all your displays
Whoops, it's already been months since I last blogged. I've been actively involved with Plasma and especially its power management service PowerDevil for over a year now. I'm still learning about how everything fits together.
Turns out though that a little bit of involvement imbues you with just enough knowledge and confidence to review other people's changes as well, so that they can get merged into the next release without sitting in limbo forever. Your favorite weekly blogger for example, Nate Graham, is a force of nature when it comes to responding to proposed changes and finding a way to get them accepted in one form or another. But it doesn't have to take many years of KDE development experience to provide helpful feedback.
Otfen we simply need another pair of eyes trying to understand the inner workings of a proposed feature or fix. If two people think hard about an issue and agree on a solution, chances are good that things are indeed changing for the better. Three or more, even better. I do take pride in my own code, but just as much in pushing excellent improvements like these past the finish line:
- Fabian Arndt's support for Lenovo laptops' battery conservation mode (Plasma 6.1)
- Natalie Clarius's feature to block apps from inhibiting sleep and screen locking (6.2)
- Christoph Wolk's improvements to usability for the Power Management settings page (6.2, one among many of the sort)
- Nate's changes to show the current power profile in addition to the battery charge (6.2)
- Xaver Hugl's push to allow software brightness adjustments not just for HDR displays (6.1), but indeed for any display without hardware brightness controls (6.2)
In turn, responsible developers will review your own changes so we can merge them with confidence. Xaver, Natalie and Nate invested time into getting my big feature merged for Plasma 6.2, which you've already read about:
Per-display Brightness Controls
This was really just a follow-up project to the display support developments mentioned in the last blog post. I felt it had to be done, and it lined up nicely with what KWin's been up to recently.
So how hard could it be to add another slider to your applet? Turns out there are indeed a few challenges.
In KDE, we like to include new features early on and tweak them over time. As opposed to, say, the GNOME community, which tends to discuss them for a loooong time in an attempt to merge the perfect solution on the first try. Both approaches have advantages and drawbacks. Our main drawback is harder to change imperfect code, because it's easy to break functionality for users that already rely on them.
Every piece of code has a set of assumptions embedded into it. When those assumptions don't make sense for the next, improved, hopefully perfect solution (definitely perfect this time around!) then we have to find ways to change our thinking. The code is updated to reflect a more useful set of assumptions, ideally without breaking anyone's apps and desktop. This process is called "refactoring" in software development.
But let's be specific: What assumptions am I actually talking about?
There is one brightness slider for your only displayThis one's obvious. You can use more than just one display at a time. However, our previous code only used to let you read one brightness value, and set one brightness value. For which screen? Well... how about the code just picks something arbitrarily. If you have a laptop with an internal screen, we use that one. If you have no internal screen, but your external monitor supports DDC/CI for brightness controls, we use that one instead.
What's that, you have multiple external monitors that all support DDC/CI? We'll set the same value for all of them! Even if the first one counts from 0 to 100 and the second one from 0 to 10.000! Surely that will work.
No it won't. We only got lucky that most monitors count from 0 to 100.
The solution here is to require all software to treat each display differently. We'll start watching for monitors being connected and disconnected. We tell all the related software about it. Instead of a single set-brightness and a single get-brightness operation, we have one of these per display. When the lower layers require this extra information, software higher up in the stack (for example, a brightness applet) is forced to make better choices about the user experience in each particular case. For example, presenting multiple brightness sliders in the UI.
A popup indicator shows the new brightness when it changesSo this raises new questions. With only one display, we can indicate any brightness change by showing you the new brightness on a percentage bar:
Now you press the "Increase Brightness" key on your keyboard, and multiple monitors are connected. This OSD popup shows up on... your active screen? But did the brightness only change for your active screen, or for all of them? Which monitor is this one popup representing?
Ideally, we'd show a different popup on each screen, with the name of the respective monitor:
That's a good idea! But Plasma's OSD component doesn't have a notion of different popups being shown at the same time on different monitors. It may even take further changes to ask KWin, Plasma's compositor component, about that. What we did for Plasma 6.2 was to provide Plasma's OSD component with all the information it needs to do this eventually. But we haven't implemented our favorite UI yet, instead we hit the 6.2 deadline and pack multiple percentages into a single popup:
That's good enough for now, not the prettiest but always clear. If you only use or adjust one screen, you'll get the original fancy percentage bar you know and love.
The applet can do its own brightness adjustment calculationsYou can increase or decrease brightness by scrolling on the icon of the "Brightness and Color" applet with your mouse wheel or touchpad. Sounds easy to implement: read the brightness for each display, add or subtract a certain percentage, set the brightness again for the same display.
Nope, not that easy.
For starters, we handle brightness key presses in the background service. You'd expect the "Increase Brightness" key to behave the same as scrolling up with your mouse wheel, right? So let's not implement the same thing in two different places. The applet has to say goodbye to its own calculations, and instead we add an interface to background service that the applet can use.
Then again, the background service never had to deal with high-resolution touchpad scrolling. It's so high-resolution that each individual scroll event might be smaller than the number of brightness steps on your screen. The applet contained code to add up all of these tiny changes so that many scroll events taken together will at least make your screen change by one step.
Now the service provides this functionality instead, but it adds up the tiny changes for each screen separately. Not only that, it allows you to keep scrolling even if one of your displays has already hit maximum brightness. When you scroll back afterwards, both displays don't just count down from 100% equally, but the original brightness difference between both screens is preserved. Scroll up and down to your heart's content without messing up your preferred setup.
Dimming will turn down the brightness, then restore the original value laterSimple! Yes? No. As you may guess, we now need to store the original brightness for each display separately so we can restore it later.
But that's not enough: What if you unplug your external screen while it's dimmed? And then you move your mouse pointer again, so the dimming goes away. Your monitor, however, was not there for getting its brightness restored to the original value. Next time you plug it in, it starts out with the dimmed lower brightness as a new baseline, Plasma will gladly dim even further next time.
Full disclosure, this was already an issue in past releases of Plasma and is still an issue. Supporting multiple monitors just makes it more visible. More work is needed to make this scenario bullet-proof as well. We'll have to see if a small and safe enough fix can still be made for Plasma 6.2, or if we'll have to wait until later to address this more comprehensively.
Anyway, these kind of assumptions are what eat up a good amount of development time, as opposed to just adding new functionality. Hopefully users will find the new brightness controls worthwhile.
So let's get to the good newsYour donations allowed KDE e.V. to approve a travel cost subsidy in order to meet other KDE contributors in person and scheme the next steps toward world domination. You know what's coming, I'm going to:
Akademy is starting in just about two days from now! Thank you all for allowing events like this to happen, I'll try to make it count. And while not everyone can get to Germany in person, keep in mind that it's a hybrid conference and especially the weekend talks are always worth watching online. You can still sign up and join the live chat, or take a last-minute weekend trip to Würzburg if you're in the area, or just watch the videos shortly afterwards (I assume they'll go up on the PeerTube Akademy channel).
I'm particularly curious about the outcome of the KDE Goals vote for the upcoming two years, given that I co-drafted a goal proposal this time around. Whether or not it got elected, I haven't forgotten about my promise of working on mouse gesture support on Plasma/Wayland. Somewhat late due to the aforementioned display work taking longer. Other interesting things are starting to happen as well on my end. I'll have to be mindful not to stretch myself too thinly.
Thanks everyone for being kind. I'll be keeping an eye out for your bug reports when the Plasma 6.2 Beta gets released to adventurous testers in just over a week from today.
Discuss this post on KDE Discuss.
Samuel Henrique: DebConf24 was fun!: Security, curl, wcurl, Debian's quality
DebConf24 was fun!
A playlist of all of my talks, with subtitles (en, pt-br) and chapters is available on YouTube.
OverviewDebConf24 was held in Busan, South Korea, between Sunday July 28th to Sunday August 4th 2024.
As usual for DebConfs, I had a great time meeting my friends, but also met new people and got to learn a bit about the interesting things they're working on.
I ended up getting too excited during the talk submission stage of the conference and as a result I presented 5 different activities (3 talks, 1 BoF and 1 lightning talk).
Since I was too busy with the presentations, I did not have a lot of time to actually hang out with folks, or even to go out in the city, I guess I've learned my lesson for next time.
The main purpose of this post is to write about all of the things I presented at the conference. I did want to list some of the interesting talks I've watched, but that I would not be able to be fair as I'm sure I would miss some.
You can get the schedule and the recordings of any talks from the conference's website: https://debconf24.debconf.org/schedule/
wcurl Lightning TalkThe most fun of my presentations, during the second-to-last day of the conference, I've asked for help from Sergio Durigan Junior <sergiodj> to setup an URL containing a whitespace and redirecting that to wcurl's manpage.
I then did a little demo to showcase why me (and a lot others) struggle with downloading things with curl, and how wcurl solves that.
Fixing CVEs on Debian: Everything you probably know alreadyI've always felt like DebConf was missing security-related talks, so I decided to do something about it and presented a few of the things I've learned when fixing CVEs for Debian.
This is an area where we don't get a lot of new contributors, I'm trying to change that, and this talk can be used to introduce newcomers to it.
The secret sauce of DebianDebian is not very vocal about all of the nice things it has regarding quality-assurance, testing, or CI, even though it's at the state-of-the-art for a lot of things.
This talk is an initial step towards making people aware of the cool things happening behind the scenes. Ideally we should have it well-documented somewhere.
"I use Debian BTW": fzf, tmux, zoxide and friendsOne of my earliest good memories of Debian was when it started coming with a colored PS1 by default, I still remember the feeling of relief whenever I jumped into a Debian server and didn't have to deal with a black and white PS1.
There's still a lot of room for Debian to ship better defaults, and I think some of them can actually happen.
This talk is a bit of a silly one where I'm just making people aware of the existence of a few Golang/Rust CLI tools, and also some dotfiles configurations that should probably be the default.
curlThe curl project does such a great job with their security advisories that it will likely never receive the amount of praise it deserves, but I did my best at mentioning it throughout my CVEs talk.
Maybe I will write more extensively about this someday, but in case I don't:
There's no other project which always consistently mentions the exact range of commits that are affected by a given CVE.
Forget about whether the versions are EOL, curl doesn't have LTS releases, yet they do such a great job at clearly documenting their CVEs that I would take that over having LTS releases anytime (that's for curl at least, I acknowledge some types of projects have a different need for LTS releases).
Not only that, but they are also always careful about explaining alternative mitigations such as configuration changes, build flags that defuse the exploitation, or parameters that you should not use.
Just like we tend to do every time we meet, me and the other Debian curl maintainers spent the first 2 or 3 days of the conference talking about how we wanted to eventually meet up to discuss the package.
It was going to be informal, maybe during the Cheese and Wine party, but then I've realized we should make it part of the official schedule, which would also give us the recordings for later.
And so the "curl maintainers BoF" happened, where we spoke about HTTP3, GnutTLS, wcurl and other things.
wcurlRight after that BoF, Daniel Stenberg asked if we were interested in having wcurl adopted into curl, which we definitely were, so wcurl is now part of the curl project.
Daniel was also kind enough to design a logo for the project, which makes me especially happy because I can stop with my own approach at a logo (which I had to redo every few days):
And here is the new logo:
Much better, I would say :)
curl SwagDebConf24 was my chance at forwarding some curl swag items to the other curl maintainers, so both Sergio Durigan Junior <sergiodj> and Carlos Henrique Lima Melara <charles> got the curl-up t-shirt and the very cool curl PCB coaster, both gifted by Daniel Stenberg.
Unfortunately I didn't have any of that for DebConf attendees, but I did drop loads of curl stickers at the stickers table, they were gone very quickly.
For the futureI used to think the most humbling experience you could have as someone who presented a talk was to have to watch it yourself, you notice a lot of mistakes and you instantly think about things that should be done differently.
It turns out the most humbling thing to do is actually to write subtitles for your talks, I noticed every single mistake, often multiple times.
So after spending more than 30 hours writing the subtitles for both English and Brazilian Portuguese for my talks, I feel like it's going to be much easier to avoid committing the same mistakes again. After some time you stop feeling shame about those mistakes and you're just left with feelings of annoyance, and at that point it becomes easier to consciously avoid them.
I am collecting a list of things I wish I had done differently on all of those talks, so if I end up presenting any one of them again, it will be an improved version.
PyCoder’s Weekly: Issue #645 (Sept. 3, 2024)
#645 – SEPTEMBER 3, 2024
View in Browser »
This course covers two problems from introductory astronomy to help you play with some Python libraries. You’ll use NumPy, Matplotlib, and pandas to find planet conjunctions, and graph the best viewing times for a star.
REAL PYTHON course
Talk Python to Me interviews Seth Michael Larson and they talk about this year’s Python Language Summit. Learn all about what happened at the closed door session for core developers inside PyCon.
KENNEDY & LARSON podcast
With CodeRabbit, solve your indentation issues and security concerns. CodeRabbit doesn’t just point out issues; it suggests fixes and explains the reasoning behind the suggestion. Elevate code quality with AI-powered, context-aware reviews and 1-click fixes. Sign up for free today →
CODERABBIT sponsor
This is a plain language guide to every built-in function in Python, paired with a simple example that shows each function in action.
MATT LAYMAN
In this video course, you’ll learn how to sort Python dictionaries. By the end, you’ll be able to sort by key, value, or even nested attributes. But you won’t stop there—you’ll also measure the performance of variations when sorting and compare different key-value data structures.
REAL PYTHON course
The Template Method Pattern is when a base class is used to implement a series of steps, and subclasses can override one or more of those steps to customize the process. This article shows an example usage in Python and why you might want to implement it.
LANCE GOYKE
Experience the power of Edge AI—delivering lightning-fast, real-time processing where it matters. Optimize your applications with low latency, high efficiency, and unparalleled accuracy. Push performance beyond limits with Intel’s OpenVINO toolkit.
INTEL CORPORATION sponsor
The asyncio.gather() function allows you to run multiple co-routines concurrently. There are times when you want to control just how much concurrency you have though and this post shows you how to use a semaphore to do just that.
JASON BROWNLEE
Spreadsheets are a fascinating tool: you can both store and structure data, and include formulas that run computations on the contents of a sheet. James has written a spreadsheet engine, and this post talks about how it is done.
JAMES G
In version 24.2, pip learns to use system certificates by default, receives a handful of optimizations, and deprecates legacy (setup.py develop) editable installations. This article covers the changes and why they’ve been made.
RICHARD SI
Nate has been working on the CPython compiler, applying memory hardening guidelines recommended by OpenSSF’s Memory Safety Special Interest Group. This blog post talks about what was applied and how it should improve CPython.
NATE OHLSON
This is a comparison chart of the most common host providers that support Python serverless functions. It compares what features are supported, pricing, runtime limits, and more.
HAROLD MARTIN
A weird historical first in baseball recently reminded James about how often as programmers we map our data assuming a one-to-one relationship, and how often that’s a bad choice.
JAMES BENNETT
It has been a year since Mike joined the PSF as the Safety & Security Engineer for PyPI. This blog post talks about all the things he’s been involved with.
MIKE FIELDER
Official Python Developers Survey 2023 Results by Python Software Foundation and JetBrains: more than 25k responses from almost 200 countries.
JETBRAINS.COM
This article covers some of the lesser used parts of the Python standard library, including Deque, defaultdict, UserDict, and more.
TRICKSTER DEV
PYPI.ORG • Shared by Alex Towell
anacondacode: Execute Python Directly From Excel pare: Deploy Python Lambdas Alongside Your Web App django-admin-action-forms: Forms for Django Admin PromptMage Simplifies Managing LLM WorkflowsPROMPTMAGE.IO • Shared by Tobias Sterbak
Events EARL 2024 September 4 to September 6, 2024
DATACOVE.CO.UK
September 4, 2024
REALPYTHON.COM
September 5 to September 7, 2024
PYCON.EE
September 5, 2024
MEETUP.COM
September 5, 2024
SYPY.ORG
September 7, 2024
MEETUP.COM
Happy Pythoning!
This was PyCoder’s Weekly Issue #645.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
GSoC Final Update
This is my last update about my GSoC project (Python bindings for KDE Frameworks).
These weeks have been quieter than usual because I’ve been on vacation, but there are still some new things to share.
I published a mini tutorial on how to generate Python bindings using the new CMake module.
People have started to test the Python bindings and some building issues have been reported (which is good, because that means people have interest in them). Unfortunately I’m going to have less time to contribute as I start university next week, but I’m sure you’ll see me!
Many thanks to Carl (my mentor) and everyone who reviewed my merge requests!
FSF Events: Free Software Directory meeting on IRC: Friday, September 6, starting at 12:00 EDT (16:00 UTC)
FSF Blogs: August GNU Spotlight with Amin Bandali
August GNU Spotlight with Amin Bandali
Specbee: Why we switched from GA4 to Matomo and How to set up Matomo in Drupal
Mike Driscoll: ANN: JupyterLab 101 Kickstarter
My latest Python book is now available for pre-order on Kickstarter.
JupyterLab 101 mockupJupyterLab, the latest iteration of the Jupyter Notebook, is a versatile tool for sharing code in an easily understandable format.
Hundreds of thousands of people around the world use Jupyter Notebooks or variations of the Notebook architecture for any or all of the following:
- teaching
- presentations
- learning a computer language
- numerical simulations
- statistical modeling
- data visualization
- machine learning
- and much more!
Jupyter Notebooks can be emailed, put on GitHub, or run online. You may also add HTML, images, Markdown, videos, LaTeX, and custom MIME types to your Notebooks. Finally, Jupyter Notebooks support big data integration.
JupyterLab 101 will get you up to speed on the newest user interface for Jupyter Notebooks and the other tools that JupyterLab supports. You now have a tabbed interface that you can use to edit multiple Notebooks, open terminals in your browser, create a Python REPL, and more. JupyterLab also includes a debugger utility to help you figure out your coding issues.
Rest assured, JupyterLab supports all the same programming languages as Jupyter Notebook. The main difference lies in the user interface, which this guide will help you navigate effectively and efficiently.
After reading JupyterLab 101, you will be an expert in JupyterLab and produce quality Notebooks quickly!
What You’ll LearnIn this book, you will learn how about the following:
- Installation and setup of JupyterLab
- The JupyterLab user interface
- Creating a Notebook
- Markdown in Notebooks
- Menus in JupyterLab
- Launching Other Applications (console, terminal, text files, etc)
- Distributing and Exporting Notebooks
- Debugging in JupyterLab
- Testing your notebooks
As a backer of this Kickstarter, you have some choices to make. You can receive one or more of the following, depending on which level you choose when backing the project:
- An early copy of JupyterLab 101 + all updates including the final version (ALL BACKERS)
- A signed paperback copy (If you choose the appropriate perk)
- Get all by Python courses hosted on Teach Me Python or another site (If you choose the appropriate perk)
- T-shirt with the book cover (If you choose the appropriate perk)
Get the book on Kickstarter today!
The post ANN: JupyterLab 101 Kickstarter appeared first on Mouse Vs Python.
Real Python: Using Pydantic to Simplify Python Data Validation
Pydantic is a powerful data validation and settings management library for Python, engineered to enhance the robustness and reliability of your codebase. From basic tasks, such as checking whether a variable is an integer, to more complex tasks, like ensuring highly-nested dictionary keys and values have the correct data types, Pydantic can handle just about any data validation scenario with minimal boilerplate code.
In this video course, you’ll learn how to:
- Work with data schemas with Pydantic’s BaseModel
- Write custom validators for complex use cases
- Validate function arguments with Pydantic’s @validate_call
- Manage settings and configure applications with pydantic-settings
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Django Weblog: Django security releases issued: 5.1.1, 5.0.9, and 4.2.16
In accordance with our security release policy, the Django team is issuing releases for Django 5.1.1, Django 5.0.9, and Django 4.2.16. These releases address the security issues detailed below. We encourage all users of Django to upgrade as soon as possible.
CVE-2024-45230: Potential denial-of-service vulnerability in django.utils.html.urlize()urlize and urlizetrunc were subject to a potential denial-of-service attack via very large inputs with a specific sequence of characters.
Thanks to MProgrammer for the report.
This issue has severity "moderate" according to the Django security policy.
CVE-2024-45231: Potential user email enumeration via response status on password resetDue to unhandled email sending failures, the django.contrib.auth.forms.PasswordResetForm class allowed remote attackers to enumerate user emails by issuing password reset requests and observing the outcomes.
To mitigate this risk, exceptions occurring during password reset email sending are now handled and logged using the django.contrib.auth logger.
Thanks to Thibaut Spriet for the report.
This issue has severity "low" according to the Django security policy.
Affected supported versions- Django main branch
- Django 5.1
- Django 5.0
- Django 4.2
Patches to resolve the issue have been applied to Django's main, 5.1, 5.0, and 4.2 branches. The patches may be obtained from the following changesets.
CVE-2024-45230: Potential denial-of-service vulnerability in django.utils.html.urlize()- On the main branch
- On the 5.1 branch
- On the 5.0 branch
- On the 4.2 branch
- On the main branch
- On the 5.1 branch
- On the 5.0 branch
- On the 4.2 branch
- Django 5.1.1 (download Django 5.1.1 | 5.1.1 checksums)
- Django 5.0.9 (download Django 5.0.9 | 5.0.9 checksums)
- Django 4.2.16 (download Django 4.2.16 | 4.2.16 checksums)
The PGP key ID used for this release is Natalia Bidart: 2EE82A8D9470983E
General notes regarding security reportingAs always, we ask that potential security issues be reported via private email to security@djangoproject.com, and not via Django's Trac instance, nor via the Django Forum, nor via the django-developers list. Please see our security policies for further information.
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Research
- Give Your Input on the State of Open Source Survey
- Open Data and Open Source AI: Charting a course to get more of both
- The Open Source Initiative and the Eclipse Foundation to Collaborate on Shaping Open Source AI (OSAI) Public Policy
- ClearlyDefined v2.0 adds support for LicenseRefs
- ClearlyDefined at SOSS Fusion 2024: a collaborative solution to Open Source license compliance