
Feeds
FSF Blogs: The FSF is turning 39! Join us in celebrating almost 40 years of fighting for software freedom
The FSF is turning 39! Join us in celebrating almost 40 years of fighting for software freedom
Python Engineering at Microsoft: Python in Visual Studio Code – October 2024 Release
We’re excited to announce the October 2024 release of the Python and Jupyter extensions for Visual Studio Code!
This release includes the following announcements:
- Run Python tests with coverage
- Default Python problem matcher
- Python language server mode
If you’re interested, you can check the full list of improvements in our changelogs for the Python, Jupyter and Pylance extensions.
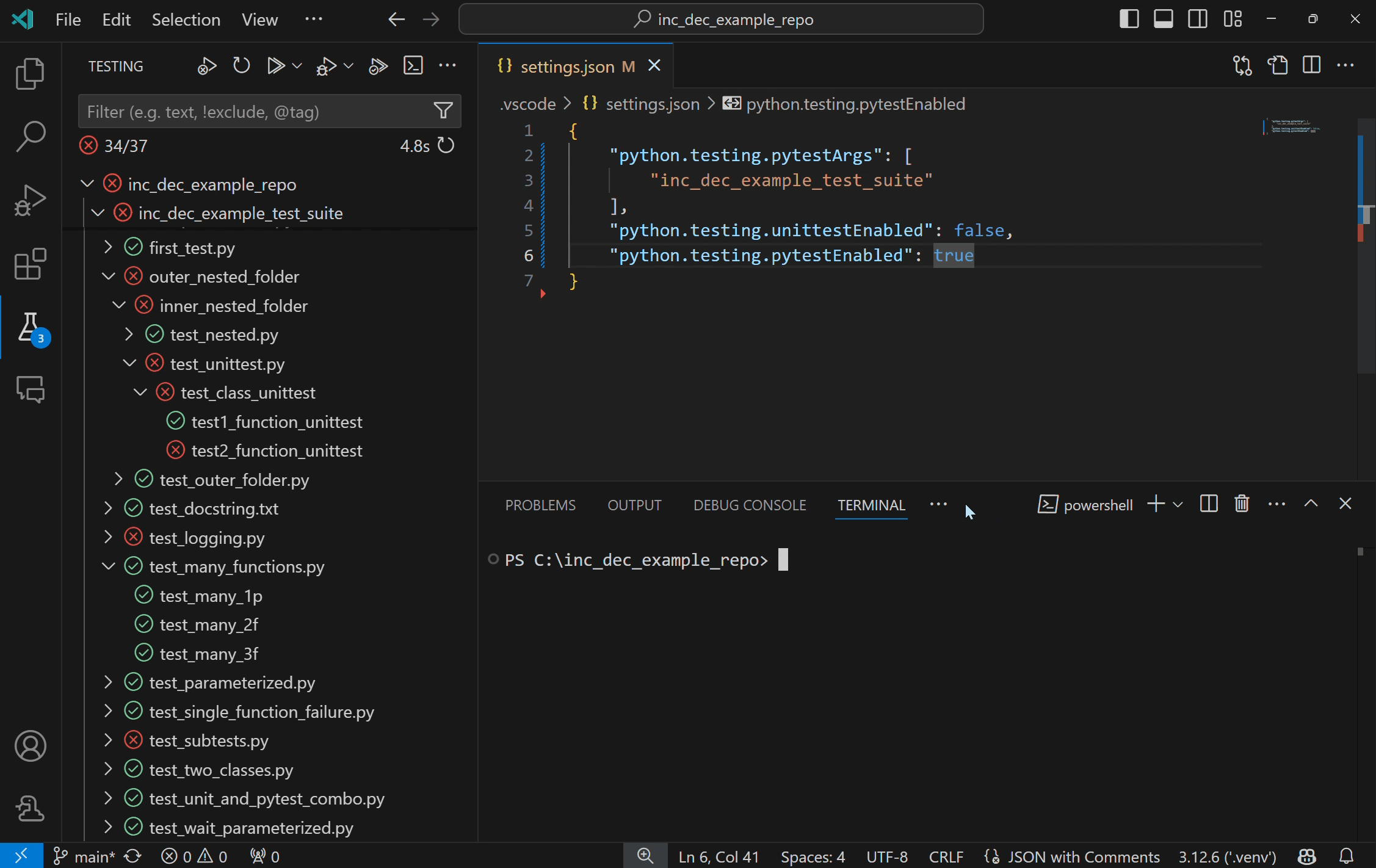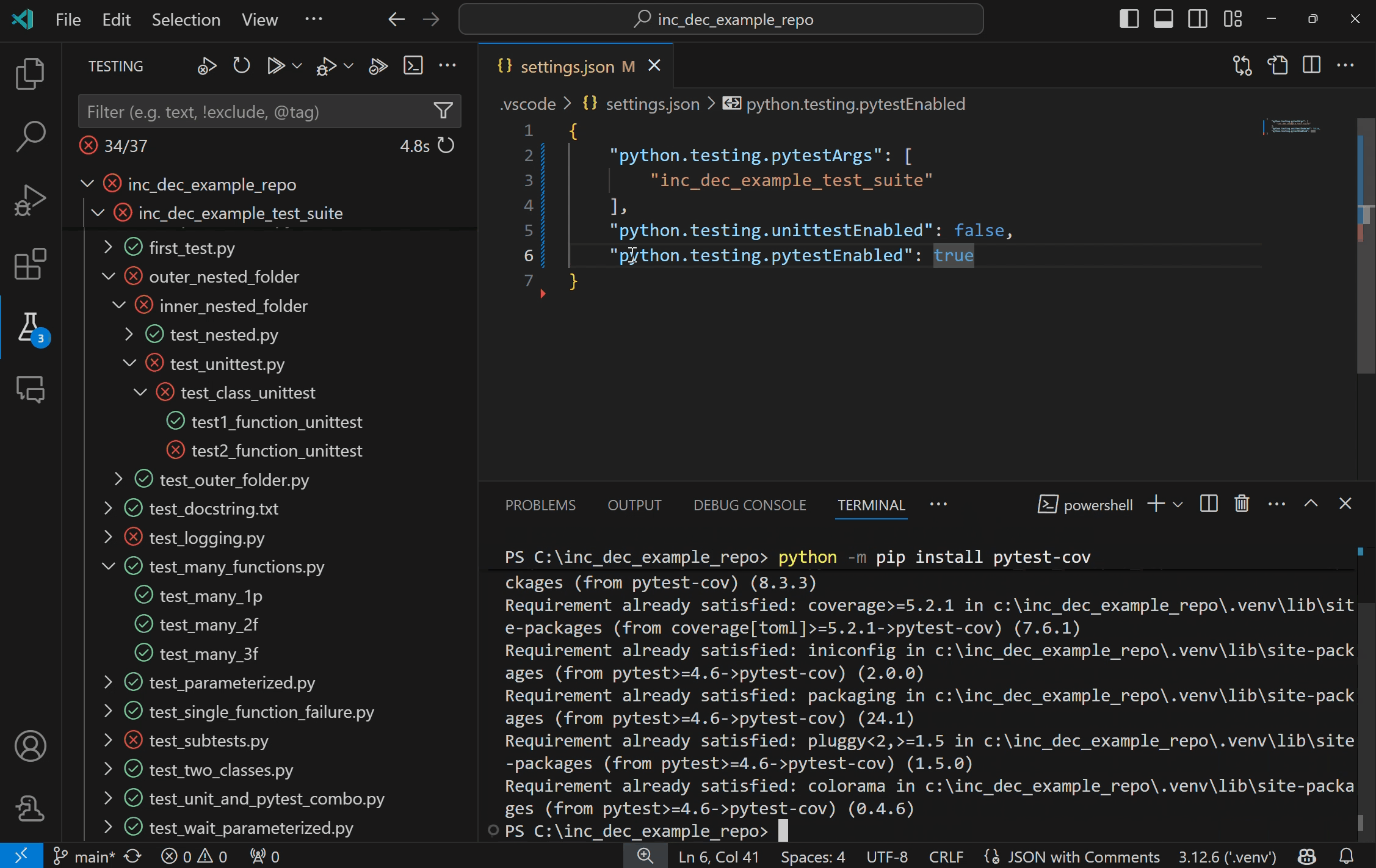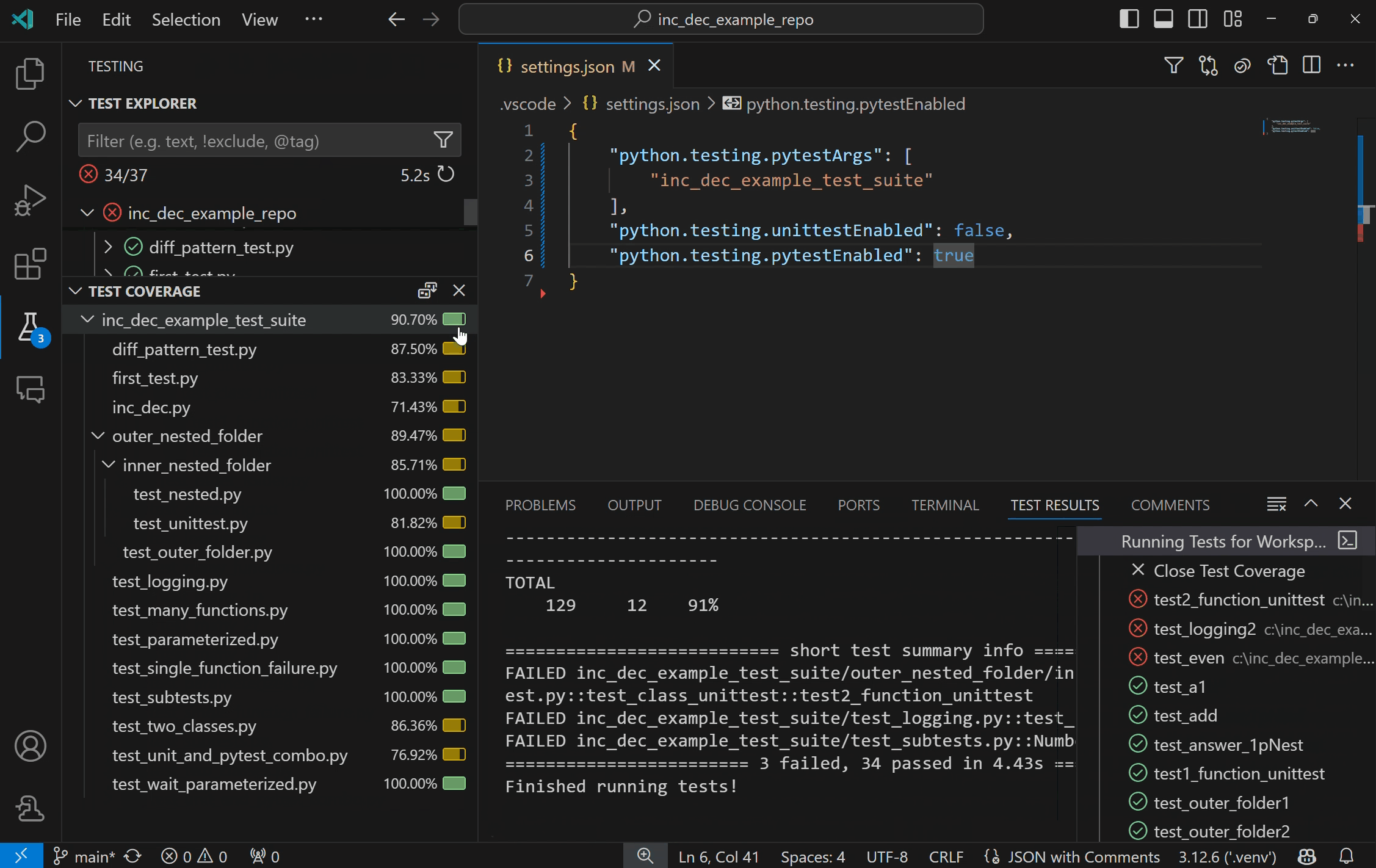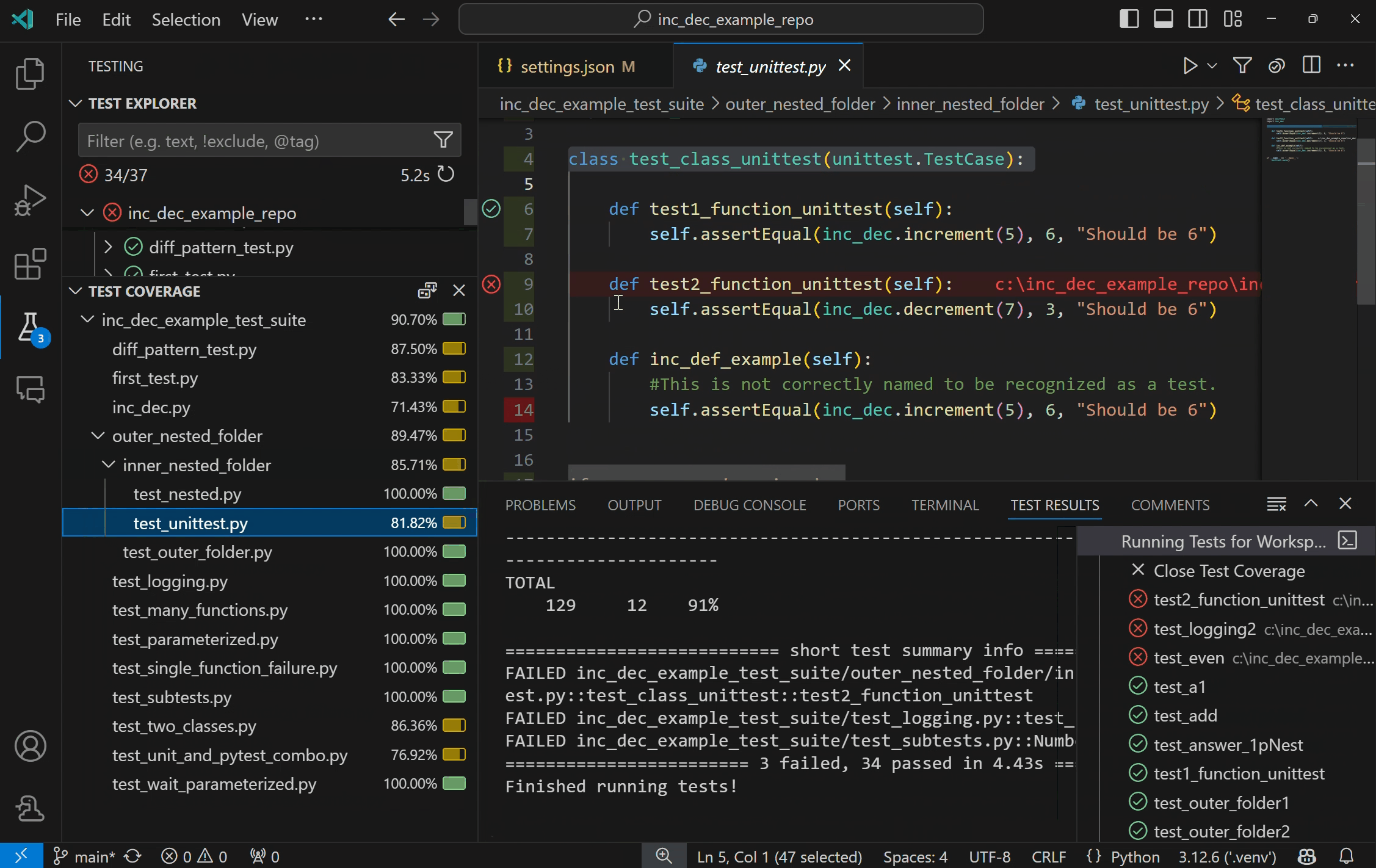
Run Python tests with coverageYou can now run Python tests with coverage in VS Code! Test coverage is a measure of how much of your code is covered by your tests, which can help you identify areas of your code that are not being fully tested.
To run tests with coverage enabled, select the coverage run icon in the Test Explorer or the “Run with coverage” option from any menu you normally trigger test runs from. The Python extension will run coverage using the pytest-cov plugin if you are using pytest, or with coverage.py for unittest.
Note: Before running tests with coverage, make sure to install the correct testing coverage package for your project.
Once the coverage run is complete, lines will be highlighted in the editor for line level coverage. Test coverage results will appear as a “Test Coverage” sub-tab in the Test Explorer, which you can also navigate to with Testing: Focus on Test Coverage View in Command Palette (F1)). On this panel you can view line coverage metrics for each file and folder in your workspace.
{kind=link}
For more information on running Python tests with coverage, see our Python test coverage documentation. For general information on test coverage, see VS Code’s Test Coverage documentation.
Default Python problem matcherWe are excited to announce support for one of our longest request features: there is now a default Python problem matcher! Aiming to simplifying issue tracking in your Python code and offering more contextual feedback, a problem matcher scans the task’s output for errors and warnings and displays them in the Problems panel, enhancing your development workflow. To integrate it, add "problemMatcher": "$python" to your tasks in task.json.
Below is an example of a task.json file that uses the default problem matcher for Python:
{ "version": "2.0.0", "tasks": [ { "label": "Run Python", "type": "shell", "command": "${command:python.interpreterPath}", "args": [ "${file}" ], "problemMatcher": "$python" } ] }For more information on tasks and problem matchers, visit VS Code’s Tasks documentation.
Pylance language server modeThere’s a new setting python.analysis.languageServerMode that enables you to choose between our current IntelliSense experience or a lightweight one that is optimized for performance. If you don’t require the full breadth of IntelliSense capabilities and prefer Pylance to be as resource-friendly as possible, you can set python.analysis.languageServerMode to light. Otherwise, to continue with the experience you have with Pylance today, you can leave out the setting entirely or explicitly set it to default .
This new functionality overrides the default values of the following settings:
Setting light mode default mode “python.analysis.exclude” [“**”] [] “python.analysis.useLibraryCodeForTypes” false true “python.analysis.enablePytestSupport” false true “python.analysis.indexing” false trueThe settings above can still be changed individually to override the default values.
Shell integration in Python terminal REPLThe Python extension now includes a python.terminal.shellIntegration.enabled setting to enable a better terminal experience on MacOS and Linux machines. When enabled, this setting runs a PYTHONSTARTUP script before you launch the Python REPL in the terminal (for example, by typing and entering python), allowing you to leverage terminal shell integrations such as command decorations, re-run command and run recent commands.
Other Changes and Enhancements{kind=link}
We have also added small enhancements and fixed issues requested by users that should improve your experience working with Python and Jupyter Notebooks in Visual Studio Code. Some notable changes include:
- Experimental Implement Abstract Classes with Copilot Code Action available for GitHub Copilot users using Pylance. Enable by adding "python.analysis.aiCodeActions": {"implementAbstractClasses": true} in your User settings.json
- Fixed duplicate Python executable code when sending code to the Terminal REPL by using executeCommand rather than sendText for the activation command in @vscode#23929
We would also like to extend special thanks to this month’s contributors:
- @edgarrmondragon Add uv.lock to file associations in vscode-python#23991
- @vishrutss Remove redundant @typescript-eslint/no-explicit-any suppression in vscode-python#24091
Try out these new improvements by downloading the Python extension and the Jupyter extension from the Marketplace, or install them directly from the extensions view in Visual Studio Code (Ctrl + Shift + X or ⌘ + ⇧ + X). You can learn more about Python support in Visual Studio Code in the documentation. If you run into any problems or have suggestions, please file an issue on the Python VS Code GitHub page.
The post Python in Visual Studio Code – October 2024 Release appeared first on Python.
Promet Source: DUSWDS: Your Agency's USWDS-Aligned CMS Solution
Web Review, Week 2024-40
Let’s go for my web review for the week 2024-40.
W3C 30th anniversary clipTags: tech, web, history
Excellent clip for the W3C 30th anniversary. Shows the big milestones and evolution of the WWW.
https://www.youtube.com/watch?v=0TfUBuIZkmQ
Tags: tech, foss, map
An excellent service to provide. Let’s hope it stays sustainable, the risk is commercial leeches not giving back a dime. Be responsible, sponsor it if you use it commercially.
Tags: tech, freebsd, laptop
Unexpected but definitely welcome. Let’s wish them luck in this endeavor.
Tags: tech, copyright, public-domain, commons
Putting things in the public domain voluntarily is indeed more difficult than it should be. The best tool we got is CC0, but it still raises (probably unwarranted) concerns for software.
Tags: tech, patents
Always happy to see a patent troll bite the dust.
https://blog.cloudflare.com/patent-troll-sable-pays-up/
Tags: tech, mozilla, advertisement, surveillance
Mozilla is clearly loosing its way, this is sad to watch. I guess the forks which remove the online advertising measures will become more popular.
https://blog.mozilla.org/en/mozilla/improving-online-advertising/
Tags: tech, microsoft, ai, machine-learning, surveillance, privacy
They’re trying a come back… of course they added layers of security to pretend it’s all solved and shiny. They totally ignore the social implications or if something like this even needs to be done. At least one can remove it… for now…
Tags: tech, ai, machine-learning, gpt, cognition, neuroscience, philosophy, mathematics, logic, research
This is a short article summarizing a research paper at the surface level. It is clearly the last nail in the coffin for the generative AI grand marketing claims. Of course, I recommend reading the actual research paper (link at the end) but if you prefer this very short form, here it is. It’s clearly time to go back to the initial goals of the AI field: understanding cognition. The latest industrial trends tend to confuse too much the map with the territory.
https://www.ru.nl/en/research/research-news/dont-believe-the-hype-agi-is-far-from-inevitable
Tags: tech, ai, machine-learning, gpt, energy, ecology
If you run the number, we actually can’t afford this kind of generative AI arm race. It’s completely unsustainable both for training and during use…
https://wimvanderbauwhede.codeberg.page/articles/the-insatiable-hunger-of-openai/
Tags: tech, ai, machine-learning, fake, fake-news
Maybe extrapolating a bit more than it should. Still this leads to worrying uses of AI generated images.
https://machinesociety.ai/p/new-ai-trick-synthetic-human-memories
Tags: tech, ai, machine-learning, ethics
Good article about the ethical implications of using AI in systems. I like the distinction about assistive vs automated. It’s not perfect as it underestimates the “asleep at the steering wheel” effects, but this is a good starting point.
https://jacobian.org/2024/oct/1/ethical-public-sector-ai/
Tags: tech, ai, machine-learning, copilot, productivity
Unsurprisingly the productivity gains announced for coding assistants have been greatly exaggerated. There might be cases of strong gains but it’s still unclear in which niches this is going to happen.
Tags: tech, ai, machine-learning, copilot, marketing, criticism
Or why we shouldn’t trust marketing survey… they definitely confuse perception and actual results. Worse they do it on purpose.
https://ideatrash.net/2024/09/lies-damn-lies-and-surveys-about-ai.html
Tags: tech, ai, machine-learning, copilot, productivity
How shocking! This was all hype? Not surprised since we’ve seen the referenced papers before, but put all together it makes things really clear.
https://garymarcus.substack.com/p/sorry-genai-is-not-going-to-10x-computer
Tags: tech, ai, machine-learning, gpt, business
The arm race is still on-going at a furious pace. Still wondering how messy it will be when this bubble bursts.
https://www.theverge.com/2024/10/3/24261160/elon-musk-xai-recruiting-party-openai-dev-day-sam-altman
Tags: tech, ai, machine-learning, gpt, marketing, criticism
I definitely agree with this. I’m sick of the grand claims around what is essentially a parlor trick. Could we tone down the marketing enough so that we can properly think about making useful products again?
https://www.ontestautomation.com/i-am-tired-of-ai/
Tags: tech, ai, machine-learning, gpt, research
OK, this paper picked my curiosity. The limitations of the experiments makes me wonder if some threshold effects aren’t ignored. Still this is a good indication that the question is worth pursuing further.
https://arxiv.org/abs/2410.01201
Tags: tech, social-media, scam, ai, machine-learning
Doxxing will get easier and easier. Con men are likely paying attention.
https://docs.google.com/document/d/1iWCqmaOUKhKjcKSktIwC3NNANoFP7vPsRvcbOIup_BA/mobilebasic
Tags: tech, automotive, security
More details about the KIA security issue. Clearly securing the embedded systems is not worth much if it is then all exposed via unsafe web services.
https://samcurry.net/hacking-kia
Tags: tech, linux, security
This one is definitely a bad one. Looks like CUPS is a weak part of the ecosystem, especially when coupled with zeroconf. I wouldn’t be surprised to see macOS being affected too.
https://www.evilsocket.net/2024/09/26/Attacking-UNIX-systems-via-CUPS-Part-I/
Tags: tests, crdt, collaborative
This could be a game changer to collaborative editing. Clearly a good competitor to CRDTs, should make it easier to build such features without a central server.
https://arxiv.org/abs/2409.14252
Tags: tech, distributed, reliability
Interesting point. You likely need to be careful with fallback modes especially in distributed systems. They might bring even more issues when the system is already under stress.
https://a-nickels-worth.dev/posts/modesharm/
Tags: tech, c++, programming, safety, performance
If you still needed to be convinced you need to use std::array and std::span, here is the proof.
https://pvs-studio.com/en/blog/posts/cpp/1164/
Tags: tech, c++, rust, metaprogramming
Interesting comparison of the different choices made in Rust and the upcoming C++26 for code generation. It’s fascinating how they managed to have such facilities in Rust while having no introspection. C++ going the opposite direction will have a very different feel both in term of use or of implementation.
https://brevzin.github.io/c++/2024/09/30/annotations/
Tags: tech, multithreading, performance, system
Nice results. Interesting implementation too. I wonder if some of it will make its way to the glibc or musl.
Tags: tech, web, frontend, htmx
As it gets more adoption people are figuring out ways to use htmx properly and not abuse what should be niche features.
https://unplannedobsolescence.com/blog/less-htmx-is-more/
Tags: tech, web, frontend, html, htmx
Interesting proposals, let’s see how far they go. They could bring most of the benefits of htmx and similar straight in HTML.
https://alexanderpetros.com/triptych/
Tags: tech, foss, project-management
We keep saying they’re not the same. This article does a good job highlighting the differences and explaining why you need both.
https://harihareswara.net/posts/2024/changelogs-and-release-notes/
Tags: tech, product-management
Good idea on how product managers should behave to facilitate requirements handling. I wish more of them would do this.
https://kevinyien.com/blog/bs.html
Tags: tech, energy, ecology, economics
Interesting analysis… I wonder if and how Jevons paradox will get in the way though.
https://www.sustainabilitybynumbers.com/p/electrification-energy-efficiency
Bye for now!
Real Python: Quiz: Iterators and Iterables in Python: Run Efficient Iterations
In this quiz, you’ll test your understanding of Python’s Iterators and Iterables.
By working through this quiz, you’ll revisit how to create and work with iterators and iterables, understand the differences between them, and review how to use generator functions and the yield statement.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
KDE e.V. and Kdenlive team are looking for contractors
KDE e.V., the non-profit organization supporting the KDE community, and the Kdenlive team are looking for proactive contractors to implement some features in the Kdenlive video editor. Two positions are currently open:
-
OpenTimelineIO integration: this will require implementing a C++ module in Kdenlive to allow importing and exporting using this open standard, to allow exchanging project files with other applications. Please see the job ad for more details about this contracting opportunity.
-
Audiowaveform integration: this will require rewriting the code used to generate and display the audio waveforms in Kdenlive using the audiowaveform library. This should bring faster and more precise waveforms in the timeline. Please see the job ad for more details about this contracting opportunity. We are looking forward to your application.
QCoro 0.11.0 Release Announcement
A long over-due release which has accumulated a bunch of bugfixes but also some fancy new features…read on!
As always, big thanks to everyone who reported issues and contributed to QCoro. Your help is much appreciated!
QCoro::LazyTask<T>The biggest new features in this release is the brand-new QCoro::LazyTask<T>. It’s a new return type that you can use for your coroutines. It differs from QCoro::Task<T> in that, as the name suggest, the coroutine is evaluated lazily. What that means is when you call a coroutine that returns LazyTask, it will return imediately without executing the body of the coroutine. The body will be executed only once you co_await on the returned LazyTask object.
This is different from the behavior of QCoro::Task<T>, which is eager, meaning that it will start executing the body immediately when called (like a regular function call).
QCoro::LazyTask<int> myWorker() { qDebug() << "Starting worker"; co_return 42; } QCoro::Task<> mainCoroutine() { qDebug() << "Creating worker"; const auto task = myWorker(); qDebug() << "Awaiting on worker"; const auto result = co_await task; // do something with the result }This will result in the following output:
mainCoroutine(): Creating worker mainCoroutine(): Awaiting on worker myWorker(): Starting workerIf myWorker() were a QCoro::Task<T> as we know it, the output would look like this:
mainCoroutine(): Creating worker myWorker(): Starting worker mainCoroutine(): Awaiting on workerThe fact that the body of a QCoro::LazyTask<T> coroutine is only executed when co_awaited has one very important implication: it must not be used for Qt slots, Q_INVOKABLEs or, in general, for any coroutine that may be executed directly by the Qt event loop. The reason is, that the Qt event loop is not aware of coroutines (or QCoro), so it will never co_await on the returned QCoro::LazyTask object - which means that the code inside the coroutine would never get executed. This is the reason why the good old QCoro::Task<T> is an eager coroutine - to ensure the body of the coroutine gets executed even when called from the Qt event loop and not co_awaited.
For more details, see the documentation of QCoro::LazyTask<T>.
Defined Semantics for Awaiting Default-Constructed and Moved-From TasksThis is something that wasn’t clearely defined until now (both in the docs and in the code), which is what happens when you try to co_await on a default-constructed QCoro::Task<T> (or QCoro::LazyTask<T>):
co_await QCoro::Task<>(); // will hang indefinitely!Previously this would trigger a Q_ASSERT in debug build and most likely a crash in production build. Starting with QCoro 0.11, awaiting such task will print a qWarning() and will hang indefinitely.
The same applies to awaiting a moved-from task, which is identical to a default-constructed task:
QCoro::LazyTask<int> task = myTask(); handleTask(std::move(task)); co_await task; // will hang indefinitely!` Compiler SupportWe have dropped official support for older compilers. Since QCoro 0.11, the officially supported compilers are:
- GCC >= 11
- Clang >= 15
- MSVC >= 19.40 (Visual Studio 17 2022)
- AppleClang >= 15 (Xcode 15.2)
QCoro might still compile or work with older versions of those compilers, but we no longer test it and do not guarantee that it will work correctly.
The reason is that coroutine implementation in older versions of GCC and clang were buggy and behaved differently than they do in newer versions, so making sure that QCoro behaves correctly across wide range of compilers was getting more difficult as we implemented more and more complex and advanced features.
Other Features and ChangesA coroutine-friendly version of QFuture::takeResult() is now available in the form of QCoroFuture::takeResult() when building QCoro against Qt 6 (#217).
QCoro::waitFor(QCoro::Task<T>) no longer requires that the task return type T is default-constructible (#223, Joey Richey)
Bugfixes- Suppress Clang error when building against Android NDK <= 25 (#204, Daniel Vrátil)
- Fixed missing QtGui dependency in QCoroQuick module (#209, Andreas Sturmlechner)
- Fixed QCoroIODevice::write() always returning 0 instead of bytes written (#211, Daniel Vrátil)
- Fixed unchecked std::optional access in QCoroIODevice::write
- Fixed awaiting on signal emission with qCoro() would resume the awaiter in the sender’s thread context (#213, Daniel Vrátil)
- Fixed build wilth clang 18 due to missing #include <exception> (#220, Micah Terhaar)
- Fixed crash when QNetworkAccessManager is destroyed from a coroutine awaiting on a network reply (#231, Daniel Vrátil)
If you enjoy using QCoro, consider supporting its development on GitHub Sponsors or buy me a coffee on Ko-fi (after all, more coffee means more code, right?).
Golems GABB: Drupal integrations with Popular Cloud Services: AWS vs MS Azure vs GCP
Welcome to the world of cloud integration, where popular cloud services such as AWS, Azure, and GCP are the keys to a Drupal site's success.
Imagine that you've finished your Drupal website. It turned out fantastic, but the basic options are not enough for you. So you can't wait to unleash its full potential. This is where cloud services come into play. They are your site's superhero assistants.
Today, our Drupal team plans to look at the benefits of these cloud services and how AWS, Azure, and GCP can take your Drupal website to a new performance, scalability, and security. Get ready to revolutionize your online presence and, of course, leave your competitors behind.
ImageX: Under the Barcelona Sun: A Recap of Our Team’s Journey at DrupalCon Europe 2024
Authored by Nadiia Nykolaichuk.
Bits from Debian: Debian welcomes Freexian as our newest partner!
We are excited to announce and welcome Freexian into Debian Partners.
Freexian specializes in Free Software with a particular focus on Debian GNU/Linux. Freexian can assist with consulting, training, technical support, packaging, or software development on projects involving use or development of Free software.
All of Freexian's employees and partners are well-known contributors in the Free Software community, a choice that is integral to Freexian's business model.
About the Debian Partners ProgramThe Debian Partners Program was created to recognize companies and organizations that help and provide continuous support to the project with services, finances, equipment, vendor support, and a slew of other technical and non-technical services.
Partners provide critical assistance, help, and support which has advanced and continues to further our work in providing the 'Universal Operating System' to the world.
Thank you Freexian!
obsidian.md to-do list calendar subscription
Seth Michael Larson: EuroPython 2024 talks about security
Published 2024-10-04 by Seth Larson
Reading time: minutes
EuroPython 2024 which occurred back in July 2024 has published the talk recordings to YouTube earlier this week. I've been under the weather for most of this week, but have had a chance to listen to a few of the security-related talks in-between resting.
Counting down for Cyber Resilience Act: Updates and expectationsThis talk was delivered by Python Software Foundation Executive Director Deb Nicholson and and Board Member Cheuk Ting Ho. The Cyber Resilience Act (CRA) is coming, and it'll affect more software than just the software written in the EU. Deb and Cheuk describe the recent developments in the CRA like the creation of a new entity called the "Open Source Steward" and how open source foundations and maintainers are preparing for the CRA.
For the rest of this year and next year I am focusing on getting the Python ecosystem ready for software security regulations like the CRA and SSDF from the United States.
Starting with improving the Software Bill-of-Materials (SBOM) story for Python, because this is required by both (and likely, future) regulations. Knowing what software you are running is an important first step towards being able to secure that same software.
To collaborate with other open source foundations and projects on this work, I've joined the Open Regulatory Compliance Working Group hosted by the Eclipse Foundation.
Towards licensing standardization in Python packagingThis talk was given by Karolina Surma and it detailed all the work that goes into researching, writing, and having a Python packaging standard accepted (spoiler: it's a lot!). Karolina is working on PEP 639 which is for adopting the SPDX licensing expression and identifier standards in Python as they are the current state of the art for modeling complex licensing situations accurately for machine (and human) consumption.
This work is very important for Software Bill-of-Materials, as they require accurate license information in this exact format. Thanks to Karolina, C.A.M. Gerlach, and many others for working for years on this PEP, it will be useful to so many uers once adopted!
The Update Framework (TUF) joins PyPIThis talk was given by Kairo de Araujo and Lukas Pühringer and it detailed the history and current status of The Update Framework (TUF) integration into the Python Package Index.
TUF provides better integrity guarantees for software repositories like PyPI like making it more difficult to "compel" the index to serve the incorrect artifacts and to make a compromise of PyPI easier to roll-back and be certain that files hadn't been modified. For a full history and latest status, you can view PEP 458 and the top-level GitHub issue for Warehouse.
I was around for the original key-signing ceremony for the PyPI TUF root keys which was live-streamed back in October 2020. Time flies, huh.
Writing Python like it's Rust: more robust code with type hintsThis talk was given by Jakub Beránek about using type hints for more robust Python code. Having written a case-study on urllib3's adoption of type hints to find defects that testing and other tooling missed I highly recommend type hints for Python code as well:
Accelerating Python with Rust: The PyO3 RevolutionThis talk was given by Roshan R Chandar about using PyO3 and Rust in Python modules.
Automatic Trusted Publishing with PyPIThis talk was given by Facundo Tuesca on using Trusted Publishing for authenticating with PyPI to publish packages.
Zero Trust APIs with PythonThis talk was given by Jose Haro Peralta on how to design and implement secure web APIs using Python, data validation with Pydantic, and testing your APIs using tooling for detecting common security defects.
Best practices for securely consuming open source in PythonThis talk was given by Cira Carey which highlights many of today's threats targetting open source consumers. Users should be aware of these when selecting projects to download and install.
Thanks for reading! ♡ Did you find this article helpful and want more content like it?
Get notified of new posts by subscribing to the RSS feed or the email newsletter.
This work is licensed under CC BY-SA 4.0
Trey Hunner: Switching from virtualenvwrapper to direnv, Starship, and uv
Earlier this week I considered whether I should finally switch away from virtualenvwrapper to using local .venv managed by direnv.
I’ve never seriously used direnv, but I’ve been hearing Jeff and Hynek talk about their use of direnv for a while.
After a few days, I’ve finally stumbled into a setup that works great for me. I’d like to note the basics of this setup as well as some fancy additions that are specific to my own use case.
My old virtualenvwrapper workflowFirst, I’d like to note my old workflow that I’m trying to roughly recreate:
- I type mkvenv3 <project_name> to create a new virtual environment for the current project directory and activate it
- I type workon <project_name> when I want to workon that project: this activates the correct virtual environment and changes to the project directory
The initial setup I thought of allows me to:
- Run echo layout python > .envrc && direnv allow to create a virtual environment for the current project and activate it
- Change directories into the project directory to automatically activate the virtual environment
The more complex setup I eventually settled on allows me to:
- Run venv <project_name> to create a virtual environment for the current project and activate it
- Run workon <project_name> to change directories into the project (which automatically activates the virtual environment)
First, I installed direnv and added this to my ~/.zshrc file:
1 eval "$(direnv hook zsh)"Then whenever I wanted to create a virtual environment for a new project I created a .envrc file in that directory, which looked like this:
1 layout pythonThen I ran direnv allow to allow, as direnv instructed me to, to allow the new virtual environment to be automatically created and activated.
That’s pretty much it.
Unfortunately, I did not like this initial setup.
No shell prompt?The first problem was that the virtual environment’s prompt didn’t show up in my shell prompt. This is due to a direnv not allowing modification of the PS1 shell prompt. That means I’d need to modify my shell configuration to show the correct virtual environment name myself.
So I added this to my ~/.zshrc file to show the virtual environment name at the beginning of my prompt:
1 2 3 4 5 6 7 # Add direnv-activated venv to prompt show_virtual_env() { if [[ -n "$VIRTUAL_ENV_PROMPT" && -n "$DIRENV_DIR" ]]; then echo "($(basename $VIRTUAL_ENV_PROMPT)) " fi } PS1='$(show_virtual_env)'$PS1 Wrong virtual environment directoryThe next problem was that the virtual environment was placed in .direnv/python3.12. I wanted each virtual environment to be in a .venv directory instead.
To do that, I made a .config/direnv/direnvrc file that customized the python layout:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 layout_python() { if [[ -d ".venv" ]]; then VIRTUAL_ENV="$(pwd)/.venv" fi if [[ -z $VIRTUAL_ENV || ! -d $VIRTUAL_ENV ]]; then log_status "No virtual environment exists. Executing \`python -m venv .venv\`." python -m venv .venv VIRTUAL_ENV="$(pwd)/.venv" fi # Activate the virtual environment . $VIRTUAL_ENV/bin/activate } Loading, unloading, loading, unloading…I also didn’t like the loading and unloading messages that showed up each time I changed directories. I removed those by clearing the DIRENV_LOG_FORMAT variable in my ~/.zshrc configuration:
1 export DIRENV_LOG_FORMAT= The more advanced setupI don’t like it when all my virtual environment prompts show up as .venv. I want ever prompt to be the name of the actual project… which is usually the directory name.
I also really wanted to be able to type venv to create a new virtual environment, activate it, and create the .envrc file for my automatically.
Additionally, I thought it would be really handy if I could type workon <project_name> to change directories to a specific project.
I made two aliases in my ~/.zshrc configuration for all of this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 venv() { local venv_name=${1:-$(basename "$PWD")} local projects_file="$HOME/.projects" # Check if .envrc already exists if [ -f .envrc ]; then echo "Error: .envrc already exists" >&2 return 1 fi # Create venv if ! python3 -m venv --prompt "$venv_name"; then echo "Error: Failed to create venv" >&2 return 1 fi # Create .envrc echo "layout python" > .envrc # Append project name and directory to projects file echo "${venv_name} = ${PWD}" >> $projects_file # Allow direnv to immediately activate the virtual environment direnv allow } workon() { local project_name="$1" local projects_file="$HOME/.projects" local project_dir # Check for projects config file if [[ ! -f "$projects_file" ]]; then echo "Error: $projects_file not found" >&2 return 1 fi # Get the project directory for the given project name project_dir=$(grep -E "^$project_name\s*=" "$projects_file" | sed 's/^[^=]*=\s*//') # Ensure a project directory was found if [[ -z "$project_dir" ]]; then echo "Error: Project '$project_name' not found in $projects_file" >&2 return 1 fi # Ensure the project directory exists if [[ ! -d "$project_dir" ]]; then echo "Error: Directory $project_dir does not exist" >&2 return 1 fi # Change directories cd "$project_dir" }Now I can type this to create a .venv virtual environment in my current directory, which has a prompt named after the current directory, activate it, and create a .envrc file which will automatically activate that virtual environment (thanks to that ~/.config/direnv/direnvrc file) whenever I change into that directory:
1 $ venvIf I wanted to customized the prompt name for the virtual environment, I could do this:
1 $ venv my_projectWhen I wanted to start working on that project later, I can either change into that directory or if I’m feeling lazy I can simply type:
1 $ workon my_projectThat reads from my ~/.projects file to look up the project directory to switch to.
Switching to uvI also decided to try using uv for all of this, since it’s faster at creating virtual environments. One benefit of uv is that it tries to select the correct Python version for the project, if it sees a version noted in a pyproject.toml file.
Another benefit of using uv, is that I should also be able to update the venv to use a specific version of Python with something like --python 3.12.
Here are the updated shell aliases for the ~/.zshrc for uv:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 venv() { local venv_name local dir_name=$(basename "$PWD") # If there are no arguments or the last argument starts with a dash, use dir_name if [ $# -eq 0 ] || [[ "${!#}" == -* ]]; then venv_name="$dir_name" else venv_name="${!#}" set -- "${@:1:$#-1}" fi # Check if .envrc already exists if [ -f .envrc ]; then echo "Error: .envrc already exists" >&2 return 1 fi # Create venv using uv with all passed arguments if ! uv venv --seed --prompt "$@" "$venv_name"; then echo "Error: Failed to create venv" >&2 return 1 fi # Create .envrc echo "layout python" > .envrc # Append to ~/.projects echo "${venv_name} = ${PWD}" >> ~/.projects # Allow direnv to immediately activate the virtual environment direnv allow } Switching to starshipI also decided to try out using Starship to customize my shell this week.
I added this to my ~/.zshrc:
1 eval "$(starship init zsh)"And removed this, which is no longer needed since Starship will be managing the shell for me:
1 2 3 4 5 6 7 # Add direnv-activated venv to prompt show_virtual_env() { if [[ -n "$VIRTUAL_ENV_PROMPT" && -n "$DIRENV_DIR" ]]; then echo "($(basename $VIRTUAL_ENV_PROMPT)) " fi } PS1='$(show_virtual_env)'$PS1I also switched my python layout for direnv to just set the $VIRTUAL_ENV variable and add the $VIRTUAL_ENV/bin directory to my PATH, since the $VIRTUAL_ENV_PROMPT variable isn’t needed for Starship to pick up the prompt:
1 2 3 4 5 layout_python() { VIRTUAL_ENV="$(pwd)/.venv" PATH_add "$VIRTUAL_ENV/bin" export VIRTUAL_ENV }I also made a very boring Starship configuration in ~/.config/starship.toml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 format = """ $python\ $directory\ $git_branch\ $git_state\ $character""" add_newline = false [python] format = '([(\($virtualenv\) )]($style))' style = "bright-black" [directory] style = "bright-blue" [character] success_symbol = "[\\$](black)" error_symbol = "[\\$](bright-red)" vimcmd_symbol = "[❮](green)" [git_branch] format = "[$symbol$branch]($style) " style = "bright-purple" [git_state] format = '\([$state( $progress_current/$progress_total)]($style)\) ' style = "purple" [cmd_duration.disabled]I setup such a boring configuration because when I’m teaching, I don’t want my students to be confused or distracted by a prompt that has considerably more information in it than their default prompt may have.
The biggest downside of switching to Starship has been my own earworm-oriented brain. As I update my Starship configuration files, I’ve repeatedly heard David Bowie singing “I’m a Starmaaan”. 🎶
Ground control to major TOMLAfter all of that, I realized that I could additionally use different Starship configurations for different directories by putting a STARSHIP_CONFIG variable in specific layouts. After that realization, I made my configuration even more vanilla and made some alternative configurations in my ~/.config/direnv/direnvrc file:
1 2 3 4 5 6 7 8 9 10 11 12 layout_python() { VIRTUAL_ENV="$(pwd)/.venv" PATH_add "$VIRTUAL_ENV/bin" export VIRTUAL_ENV export STARSHIP_CONFIG=/home/trey/.config/starship/python.toml } layout_git() { export STARSHIP_CONFIG=/home/trey/.config/starship/git.toml }Those other two configuration files are fancier, as I have no concern about them distracting my students since I’ll never be within those directories while teaching.
You can find those files in my dotfiles repository.
The necessary toolsSo I replaced virtualenvwrapper with direnv, uv, and Starship. Though direnv was is doing most of the important work here. The use of uv and Starship were just bonuses.
I am also hoping to eventually replace my pipx use with uv and once uv supports adding python3.x commands to my PATH, I may replace my use of pyenv with uv as well.
Thanks to all who participated in my Mastodon thread as I fumbled through discovering this setup.
KStars v3.7.3 is Released
KStars v3.7.3 is released on 2024.10.03 for Windows, MacOS & Linux. It's a bi-monthly bug-fix release with a couple of exciting features.
Extension InterfaceEd Lee contributed the Extension Interface for KStars.
Extensions are small programs that can be added to interact with KStars/Ekos/INDI in order to provide extra functions and features. Extensions are separate from KStars. They are not provided as part of this software. Only a means to call them is provided for convenience. Make sure that you understand the requirements and risks of using an extension.
Three extensions are ready for release:
- FireCapture launcher (FC_launcher): disconnects the current primary camera INDI driver and launches FireCapture. Upon close restarts the INDI driver.
- KStars Backup (KS_backup): provides a GUI for the archiving and restoration of KStars/INDI (and optionally others) configuration directories to/from .tar.gz archives/
- Sirial_EEA: provides live stacking of the preview job from the Capture Module and displays it auto-stretched in the Ekos preview window.
Each extension must have a companion configuration file also located in the extensions directory, named the same as the executable with the addition of a .conf eg: an extension named example must also have a configuration file named example.conf A configuration file is a plain text file that provides configuration settings to the extension program and usage information to the user. A configuration file is only valid if it contains a line starting with: minimum_kstars_version=x.y.z The x.y.z is the minimum release of KStars that the extension is designed/tested against. This value is checked against the current KStars KSTARS_VERSION macro defined in version.h and must be equal or lower for the extension to be considered valid. The extension should also check that this minimum_kstars_version string matches what it expects.
Optionally each extension can also provide an icon file for display in the Extension drop down list. Again the naming should match the extension executable with a valid file extension (.jpg, .bmp, .gif, .png or .svg) and be placed in the same extensions directory. A default icon is used for any extension that does not provide it's own icon.
Several new DBus functions/signals are added to enable general extension use and for a specific upcoming extension.Multi-Target SchedulerWolfgang Reissenberger continued the development of multi-camera acquisition and now scheduling with many exciting updates!
Multi-Camera SchedulingWith this new release it is possible to create and run schedules for two or more optical trains in parallel within the same KStars instance. All mount related events like slewing, dithering, alignment and meridian flip are synchronized, i.e. capturing on all optical trains takes these events into account.
Lead and follower jobsIf you want to run capturing on multiple optical trains in parallel, you need to decide, which of the optical trains is the lead job, which defines the target and the scheduling criteria. All other optical trains will be follower jobs, for which only the capture sequence to be used is relevant.
Job SynchronizationEkos ensures that no mount motion happens while one of the optical trains is capturing to avoid star trails.
In case of dithering, the capture module decides what to do as soon as dithering is requested, depending on the setup of the lead job. If the remaining capture time of a follower train is more than 50% of the lead job exposure time, capturing of the follower train is stopped and restarted after dithering. If the remaining capture time is less than 50%, the Capture module waits for the follower to finish its capture.
For the meridian flip and re-alignment: both are controlled by the lead job. All running follower capturing sequences are stopped and restarted after a successful completion of the respective action.
Recommendations
- The lead job should have the longest exposure times, especially if dithering is used.
- If you use re-focusing, consider to not suspend guiding during focusing, since the other optical train might capture in parallel.
- Configure the same optical train in the Align module that you use in the lead job. This is important if you use the re-alignment check option of the scheduler.
Hy Murveit introduced an experimental Multi-Star parameter. In the original (conservative) multi-star guiding implementation, although many stars contributed to the computed guiding drift computation, there still was one more important star that anchored the scheme.
With this change, all the guide stars contribute equally to the guiding calculations. This removes the risk that an unfortunate selection of a double star for the more-important main guide star would degrade performance.
Improvements & Bug fixesmark.ie: My LocalGov Drupal contributions for week-ending October 4th, 2024
This week, I spent my time mostly looking at issues tagged with "Editor Experience".
Members Newsletter – October 2024
We’re pleased to announce that Release Candidate 1 of the Open Source AI Definition has been confirmed and published! If you’d like to add your name to the list of endorsers published online, please let us know.
We traveled four continents presenting to diverse audiences and soliciting feedback on the draft definition: Deep Learning Indaba in Dakar, Senegal; IndiaFOSS in Bangalore, India; Open Source Summit EU in Vienna, Austria; and Nerdearla in Buenos Aires, Argentina.
The work continues this month as we continue to seek input at the Data in OSAI in Paris, France; at OCX in Mainz, Germany; and during our weekly town hall meetings. And, finally, we’ll be in Raleigh, North Carolina, at the end of the month for All Things Open, where we plan to present the Open Source AI Definition version 1.0!
My thanks to everyone who is contributing to this community-led process. Please continue to let your voice be heard.
Stefano Maffulli
Executive Director, OSI
I hold weekly office hours on Fridays with OSI members: book time if you want to chat about OSI’s activities, if you want to volunteer or have suggestions.
News from the OSI The Open Source AI Definition RC1 is available for commentsThe Open Source AI Definition first Release Candidate has been published and collaboration continues.
Other highlights:
- Co-designing the OSAID: a highlight from Nerdearla
- A Journey toward defining Open Source AI: presentation at Open Source Summit Europe
- Copyright law makes a case for requiring data information rather than open datasets for Open Source AI
- Data Transparency in Open Source AI: Protecting Sensitive Datasets
- Is “Open Source” ever hyphenated?
- Jordan Maris joins OSI
Article from Mark Surman at The New Stack
Other highlights:
- Elastic founder on returning to open source four years after going proprietary (TechCrunch)
- Europe’s Tech Future Hinges on Open Source AI (The New Stack)
- How big new AI regulatory pushes could affect open source (Tech Brew)
- Does Open Source Software Still Matter? (Datanami)
- AI2’s new model aims to be open and powerful yet cost effective (VentureBeat)
- Is that LLM Actually “Open Source”? We need to talk Open-Washing in AI Governance (HackerNoon)
- AI Models From Google, Meta, Others May Not Be Truly ‘Open Source’ (PCMag)
- What’s Behind Elastic’s Unexpected Return to Open Source? (The New Stack)
The Open Policy Alliance reaches 100 members on LinkedIn.
Other newsNews from OSI affiliates:
- The Eclipse Foundation Launches the Open Regulatory Compliance Working Group to Help Open Source Participants Navigate Global Regulations
- LPI and OSI Unite to Professionalize the Global Linux and Open Source Ecosystem
- Apache Software Foundation Initiatives to Fuel the Next 25 Years of Open Source Innovation
- Open source orgs strengthen alliance against patent trolls
- Open Source Foundations Considered Helpful
- Solving the Maker-Taker problem
News from OpenSource.net:
- OpenSource.Net turns one with a redesign
- Beyond the binary: The nuances of Open Source innovation
- Steady in a shifting Open Source world: FreeBSD’s enduring stability
Tidelift’s 2024 State of the Open Source Maintainer Report
More than 400 maintainers responded and shared details about their work.
The State of Open Source Survey
In collaboration with the Eclipse Foundation and Open Source Initiative (OSI).
JobsLead OSI’s public policy agenda and education.
Bloomberg is seeking a Technical Architect to join their OSPO team.
EventsUpcoming events:
- Hacktoberfest (October – Online)
- SOSS Fusion (October 22-23, 2024 – Atlanta)
- Open Community Experience (October 22-24, 2024 – Mainz)
- All Things Open (October 27-29 – Raleigh)
- Nerdearla Mexico (November 7-9, 2024 – Mexico City)
- SeaGL (November 8-9, 2024 – Seattle)
- OpenForum Academy Symposium (November, 13-14, 2024 – Boston)
CFPs:
- FOSDEM 2025 call for devrooms (February 1-2, 2024 – Brussels)
- Consul Conference (February, 4-6, 2025 – Las Palmas de Gran Canaria)
- SCALE 22x (March 6-9, 2025 – Pasadena)
- Mercado Libre
- FerretDB
- Word Unscrambler
Interested in sponsoring, or partnering with, the OSI? Please see our Sponsorship Prospectus and our Annual Report. We also have a dedicated prospectus for the Deep Dive: Defining Open Source AI. Please contact the OSI to find out more about how your company can promote open source development, communities and software.
Support OSI by becoming a member!Let’s build a world where knowledge is freely shared, ideas are nurtured, and innovation knows no bounds!
Co-designing the OSAID: a highlight from Nerdearla
At the 10th anniversary of Nerdearla, one of the largest Open Source conferences in Latin America, Mer Joyce, Co-Design Facilitator of the Open Source AI Definition (OSAID), delivered a key presentation titled “Defining Open Source AI”. Held in Buenos Aires from September 24-28, 2024, this major event brought together 12,000 in-person participants and over 30,000 virtual attendees, with more than 200 speakers from 20 countries. Organized as a free-to-attend event, Nerdearla 2024 exemplified the spirit of Open Source collaboration by providing a platform for developers, enthusiasts, and thought leaders to share knowledge and foster community engagement.
Why is a definition so important?Mer Joyce took the stage at Nerdearla to present “Defining Open Source AI”. Mer’s presentation focused on the organization’s ongoing work to establish a global Open Source AI Definition (OSAID). She emphasized the importance of co-designing this definition through a collaborative, inclusive process that ensures input from stakeholders across industries and continents.
Her talk underscored the significance of defining Open Source AI in the context of increasing AI regulations from governments in the EU, the U.S., and beyond. In her view, defining OSAI is essential for combating “open-washing”—where companies falsely market their AI systems as Open Source while imposing restrictive licenses—and for promoting true openness, transparency, and innovation in the AI space.
A global and inclusive processMer Joyce highlighted the co-design process for the Open Source AI Definition, which has been truly global in scope. Workshops, talks, and activities were held on five continents, including Africa, Europe, Asia, North, and South America, with participants from over 35 countries. These in-person and virtual sessions ensured that voices from a wide range of backgrounds—especially those from underrepresented regions—contributed to shaping the OSAID.
The four freedomsThe core of the OSAID rests on the “Four Freedoms” of Open Source AI:
- Use the system for any purpose and without having to ask for permission.
- Study how the system works and inspect its components.
- Modify the system for any purpose, including to change its output.
- Share the system for others to use with or without modifications, for any purpose.
Four working groups were formed with the intention of identifying what components must be open in order for an AI system to be used, studied, modified, and shared. The working groups focused on Bloom, OpenCV, Llama 2, and Pythia, four systems with different approaches to OSAI.
Each working group voted on the required components and evaluated legal frameworks and legal documents for each component. Subsequently, each working group proceeded to publish a recommendation report.
The end result is the OSAID with a comprehensive definition checklist encompassing a total of 17 components. As part of the validation process, more working groups are being formed to evaluate how well other AI systems align with the definition.
Nerdearla: a platform for open innovationMer Joyce’s presentation at Nerdearla exemplified the broader theme of the conference—creating a more open and collaborative future for technology. As one of the largest Open Source conferences in Latin America, Nerdearla serves as a vital hub for fostering innovation across the Open Source community. By bringing together experts like Mer Joyce to discuss pivotal issues such as AI transparency and openness, the event highlights the importance of defining shared standards for emerging technologies.
Moving forward: the future of the OSAIDThe OSAID is currently in its final stages of development, with version 1.0 expected to be launched at the All Things Open conference in October 2024. The OSI invites individuals and organizations to endorse the OSAID ahead of its official release. This endorsement signifies support for a global definition that aims to ensure AI systems are open, transparent, and aligned with the values of the Open Source movement.
To get involved, participants are encouraged to attend weekly town halls, contribute feedback, and participate in the public review process. Consider endorsing the OSAID to become a part of the movement to define and promote truly Open Source AI systems.
Real Python: Quiz: Python import: Advanced Techniques and Tips
In this quiz, you’ll test your understanding of Python’s import statement and related topics.
By working through this quiz, you’ll revisit how to use modules in your scripts and import modules dynamically at runtime.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
August/September in KDE Itinerary
A lot has happened again around KDE Itinerary since the previous summary post two month ago: A new two-level trip/timeline view, extended public transport location search, a new website and more public transport data coverage to name just a few things.
New Features Per-trip timelineThe probably biggest change is the replacement of the single combined timeline view that Itinerary had since its beginning with a two-level view consisting of a list of trips and a per-trip timeline view.
Trip list view.Work on prerequisites for this has been featured in the past two summary blog posts already, such as the more explicit trip grouping controls and the staging area for about to be imported data.
Per-trip actions.As trip grouping has become more relevant with this, there’s now multiple ways to explicitly control this:
- Merge two adjacent trips.
- Split an existing trip.
- Select which trip newly added content belongs to.
Another visually very noticeable change are the new transport icons by Andy Betts, replacing the previously used incoherent mix of different icon styles.
Breeze icons for modes of transport. Extended location searchThe location picker for public transport searches can now also search for addresses instead of just stop names. Whether a result is a stop or an address can be distinguished by an icon, and more information about location results are shown when available (such as city, state/region and/or country), to help with identifying different places with the same name.
Searching for public transport stops and addresses.Address search is only supported with the Transitous backend so far.
Another new way of getting to a location for a public transport search is via geo: URIs passed from other applications, which Itinerary can now handle on Linux and on Android.
Infrastructure Work New WebsiteThanks to work by Carl on allowing to customize the automatically generated apps.kde.org pages, Itinerary now has a much nicer website, reusing some of the great content created for the KDE for Travelers page.
TransitousThe work on Transitous and MOTIS would deserve its own post, so this is just scratching the surface here, focusing on changes most impactful for Itinerary users.
- New base schedule coverage in France, Latvia, Lithuania, Montenegro, Poland, Serbia, Turkey and USA.
- New real-time data coverage in Croatia and Germany.
- Support for via routing, transfer time settings and GTFS shapes in MOTIS (which yet has to be made available to our clients though).
- Upgraded hardware thanks to an SSD donation, which should improve routing performance.
The foundational work around explicit trip management in the past months has also cleared the path for synchronizing trips over Matrix. As mentioned in a previous post the work on this has now started.
Synchronization increases the requirements on precise change tracking and change notification, and it adds another path how data can change. The current implementation has been a bit sloppy in that regard, and improvements for this have already been integrated. This should fix timeline entries not updating correctly after an edit or receiving public transport data updates.
Fixes & Improvements Travel document extractor- New or improved extractors for BlablaBus, booking.com, DB, Entur, Eurostar, Eventim, Flixbus, Italo, Koleo, MAV, Reisnordland ferries, Reservix, SNCB, SNCF, Sunnycars, United Airlines and VDV e-tickets.
- Support for importing Deutsche Bahn journey sharing links.
All of this has been made possible thanks to your travel document donations!
Public transport data- Added access to BLS (Basel, Switzerland) and KVB (Cologne, Germany) public transport data.
- Fixed access to BVG (Berlin, Germany) and ZVV (Zürich, Switzerland) public transport data.
- Fixed missing intermediate stops in French long-distance trains, caused by incomplete data reported by ÖBB.
- Migrated to a new train coach layout API in Germany, increasing the coverage for regional and local trains as well as increasing the level of detail for vehicle feature information such as the quantity rather than just the presence of bike or wheelchair spaces.
- Improve data merging when location names are provided in localized and ASCII-transliterated forms.
- Improved display of semi-transparent logos in dark mode in element info dialog.
- Avoid element info dialog resizes during logo or image loading.
- Show bus station quay numbers on the map.
- Fix some combo boxes not opening correctly in mobile mode.
- Use the more compact seat display from the timeline view also on details pages.
- Fix particularly long URLs not being detected as such during importing.
- Allow to create events in any OSM building.
- Fix showing arrival/departure times for disembark-only intermediate stops.
- Android’s dark mode is now respected automatically.
- Allow editing flight boarding groups.
- Show per-day sections in public transport journey search results.
Feedback and travel document samples are very much welcome, as are all other forms of contributions. Feel free to join us in the KDE Itinerary Matrix channel.
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
FLOSS Research
- Give Your Input on the State of Open Source Survey
- Open Data and Open Source AI: Charting a course to get more of both
- The Open Source Initiative and the Eclipse Foundation to Collaborate on Shaping Open Source AI (OSAI) Public Policy
- ClearlyDefined v2.0 adds support for LicenseRefs
- ClearlyDefined at SOSS Fusion 2024: a collaborative solution to Open Source license compliance