
FLOSS Project Planets
FSF Blogs: October GNU Spotlight with Amin Bandali: Seven new GNU releases!
October GNU Spotlight with Amin Bandali: Seven new GNU releases!
Web Review, Week 2024-44
Let’s go for my web review for the week 2024-44.
What You Can Learn from Just Seven Pages by Hannah ArendtTags: tech, philosophy, history, politics
A very precious philosopher from the 20th century. Her texts are still very precious and resonate today. In this piece it’s focusing about tech relevant excerpts, she had plenty to say about today’s politics as well.
https://www.honest-broker.com/p/what-you-can-learn-from-just-seven
Tags: tech, foss, ai, machine-learning
Nice initiative from the OSI. It is timely, such a definition was surely needed. The data information part seems fairly weak though… for sure you could make a system which doesn’t respect the four freedoms that way.
https://opensource.org/ai/open-source-ai-definition
Tags: tech, foss, ai, machine-learning
Like me, you find the Open Source AI Definition weak on the training data information side? You’d be right and there’s a reason for it… it’s probably hiding quite some open washing for the larger models. This is a good explanation of the motives and consequences.
https://tante.cc/2024/10/16/does-open-source-ai-really-exist/
Tags: tech, web, mobile, react, framework, criticism
This is definitely true. As long as web frontends are dominated by large frameworks, the web will always have subpar experience on mobile. And the solution isn’t going to come from the mobile providers too happy to gatekeep their app store.
https://infrequently.org/2024/10/platforms-are-competitions/#fn-failure-on-repeat-2
Tags: tech, matrix, protocols
This is definitely getting there in terms of performance and usability. The mobile clients seem mature enough, just need the desktop clients to catch up before this becomes really something I’d feel confident enough to recommend and push for.
https://matrix.org/blog/2024/10/29/matrix-2.0-is-here/
Tags: tech, unix, posix
It’s nice to see the standard still moves. Some of the additions are definitely welcome.
https://blog.toast.cafe/posix2024-xcu
Tags: tech, time, culture, internationalization
Time management and timezones are definitely complicated. In a way it’s culture colliding with computers and localisation… it can’t be simple.
https://ssoready.com/blog/engineering/truths-programmers-timezones/
Tags: tech, tools, ssh, dns, security
Nice technique for automating the verification of SSH host keys. It’d be nice to see wider adoption.
https://blog.apnic.net/2022/12/02/improving-sshs-security-with-sshfp-dns-records/
Tags: tech, github, ci, security, tools
Definitely an interesting tool. GitHub Actions workflow aren’t easy to setup while ensuring they’re secure, having a tool analyzing them for issues can only help.
https://blog.yossarian.net/2024/10/27/Now-you-can-have-beautiful-clean-workflows
Tags: tech, rust, type-systems, memory
Interesting progress on safe type casting in Rust. This should bring nice zero copy parsing of binary data in some cases.
https://lwn.net/SubscriberLink/994334/5e1f97f08916b494/
Tags: tech, c++, rust, legacy
This is a good view of what you’re getting into with the “rewrite it in Rust” knee-jerk reaction.
https://gaultier.github.io/blog/lessons_learned_from_a_successful_rust_rewrite.html
Tags: tech, postgresql, databases, ai, machine-learning, language
I definitely like the approach of having vectorisation in the RDBMS directly. This is one less moving part, less complexity at the application level to synchronize everything together. In this case it’s a Postgres extension.
https://www.timescale.com/blog/vector-databases-are-the-wrong-abstraction/
Tags: tech, sqlite, databases, tools
Interesting, there’s now an official tool to replicate sqlite databases. It’s still early days, we’ll see which features it’ll get.
Tags: tech, java, spring, profiling
A quick tour of the available tools to profile Spring Boot applications.
https://foojay.io/today/how-to-profile-a-performance-issue-using-spring-boot-profiling-tools/
Tags: tech, git, tools
Yet another Git option I missed. This is definitely useful, I’ll try it out.
https://andrewlock.net/working-with-stacked-branches-in-git-is-easier-with-update-refs/
Tags: tech, python, 3d, webgpu, data-visualization
Looks like a very interesting Python library to build interactive 3d visualizations.
https://docs.pygfx.org/stable/index.html
Tags: tech, 2d, 3d, graphics, mathematics
Ever wondered how to simulate 3D from 2D based primitives? Here is a nice experiment explaining how to approach it.
https://www.charlespetzold.com/blog/2024/09/Rudimentary-3D-on-the-2D-HTML-Canvas.html
Tags: tests, 3d, graphics
A nice list of the techniques used to render shadows in games.
https://30fps.net/pages/videogame-shadows/
Tags: tech, 3d, graphics, shader
Very nice deep dive into a post-processing shader to create a painted scene effect.
https://blog.maximeheckel.com/posts/on-crafting-painterly-shaders/?ck_subscriber_id=2669647738
Tags: tech, craftsmanship, learning, career
Indeed, those are fundamental traits to make sure you learn and make progress on your journey.
https://registerspill.thorstenball.com/p/the-basics
Tags: tech, learning, career, craftsmanship
Another excellent piece from Kent Beck, he’s right that the real differentiator in our profession is about digging deep on topics, seeing them through even if that’s on the side. Curiosity is a key trait.
https://tidyfirst.substack.com/p/background-work
Tags: tech, agile, architecture, history
Good explanation on how the agile movement scaled down about design over time in its literature. It’s probably its biggest failure. The good thing is that the pendulum is starting to swing in the other direction a bit (that’s probably why Beck is now working on a book series on software design).
https://explaining.software/archive/the-death-of-the-architect/
Tags: tech, quality, product-management, project-management
This is accurate in my opinion. Engineering and product teams need to properly negotiate, otherwise quality will suffer.
Tags: tech, project-management, product-management, decision-making
Interesting guidelines idea to help teams manage the priorities themselves. It’s written in the context of a product manager but I think it is lightweight and generic enough to apply in other contexts.
https://productmanagers.substack.com/p/how-to-not-be-a-prioritization-machine
Tags: science, complexity
It’s sometimes extremely difficult to get to the original source of a scientific claim. Our corpus of science is so large and complex now that finding where a claim comes from can be a daunting task.
https://www.youtube.com/watch?v=bgo7rm5Maqg
Tags: science, neuroscience
This is an amazing example of the brain plasticity. It’s also great to have a patch for increased quality of life with a training of only a few weeks.
https://academic.oup.com/cercor/article/34/6/bhae239/7696241?login=false
Bye for now!
Python Engineering at Microsoft: Python in Visual Studio Code – November 2024 Release
We’re excited to announce the November 2024 release of the Python, Pylance and Jupyter extensions for Visual Studio Code!
This release includes the following announcements:
- Generate docstrings with Pylance
- New fold and unfold all docstrings commands
- Import suggestions can now include aliases from user files
- Experimental AI Code Action for implementing abstract classes
- Native REPL variables view
If you’re interested, you can check the full list of improvements in our changelogs for the Python, Jupyter and Pylance extensions.
Generate docstrings with PylanceYou can now more conveniently generate documentation for your Python code with Pylance‘s docstrings template generation feature! You can generate a docstring template for classes or methods by typing """ or ''', pressing kbstyle(Ctrl+Space), or selecting the lightbulb to invoke the Generate Docstring Code Action. The generated docstring includes fields for the function’s description, parameter descriptions, parameter types, return value description, and return type.
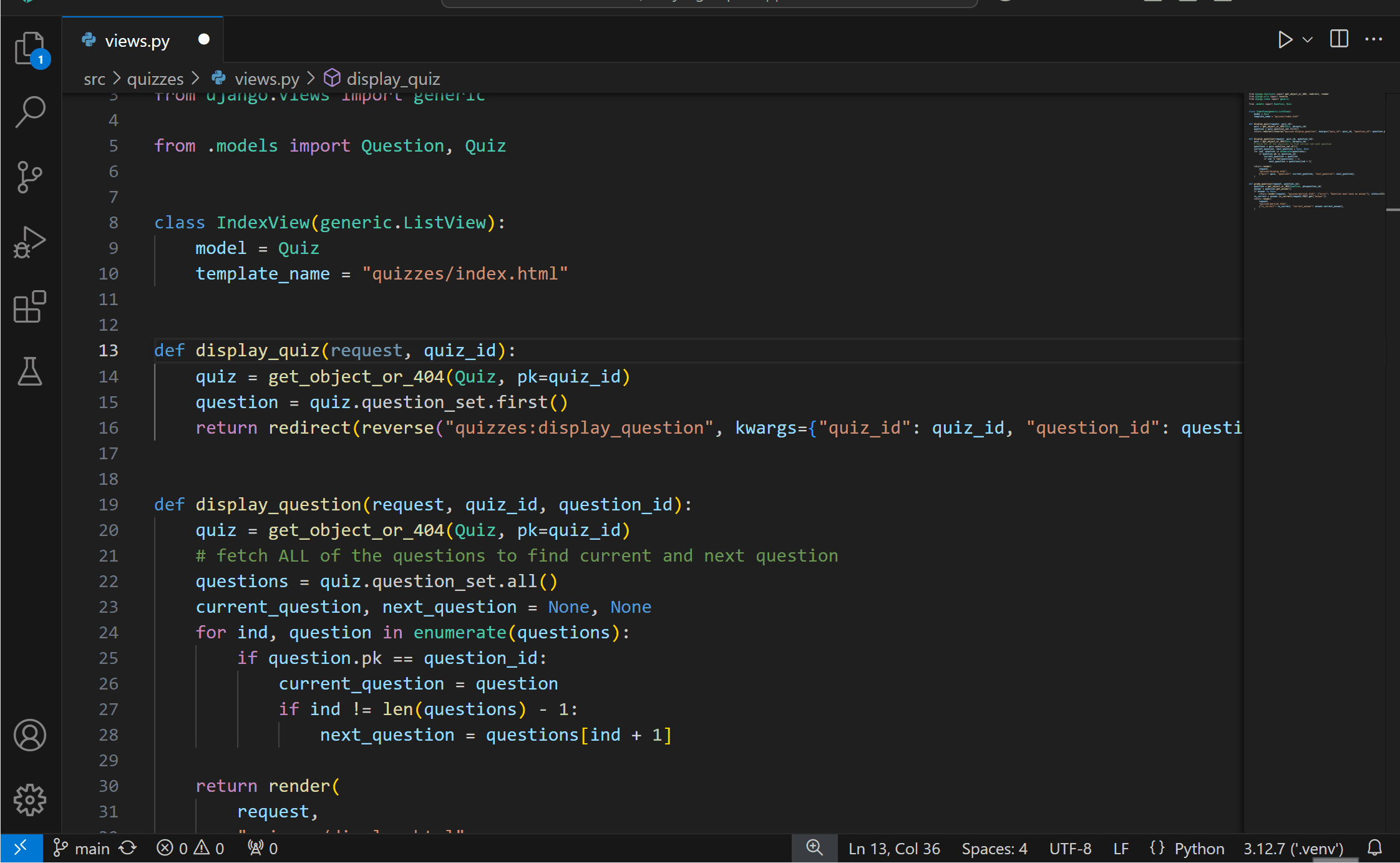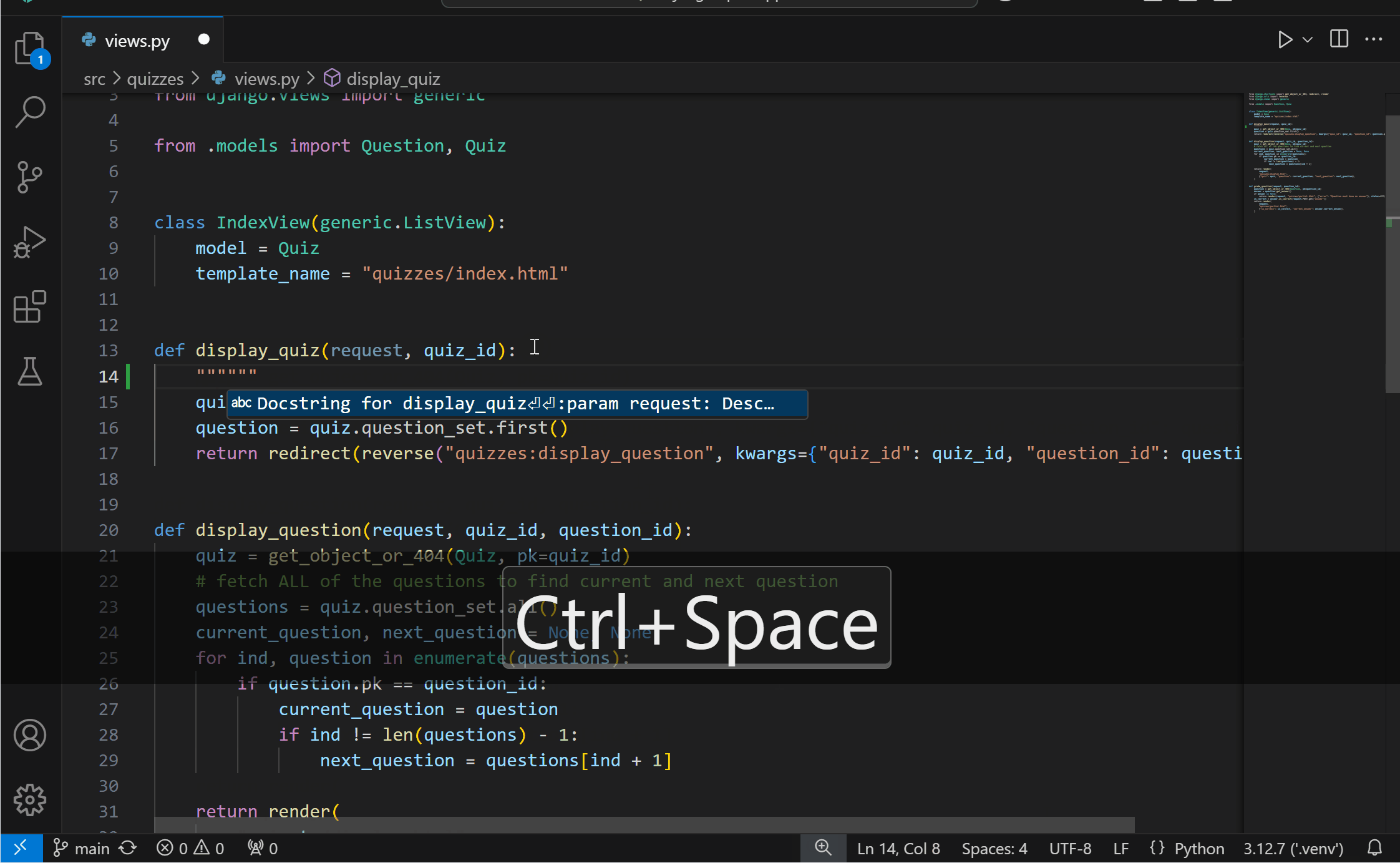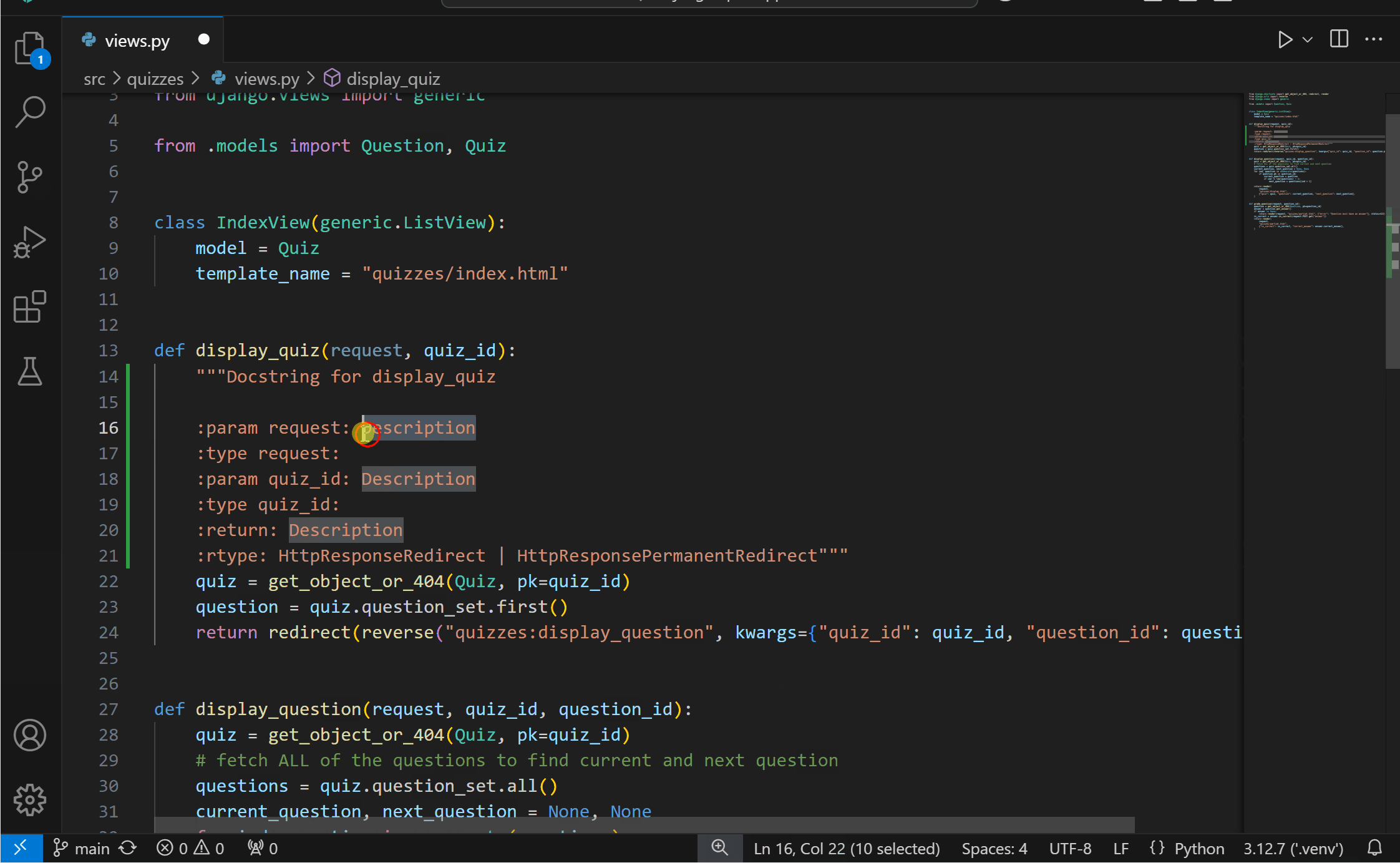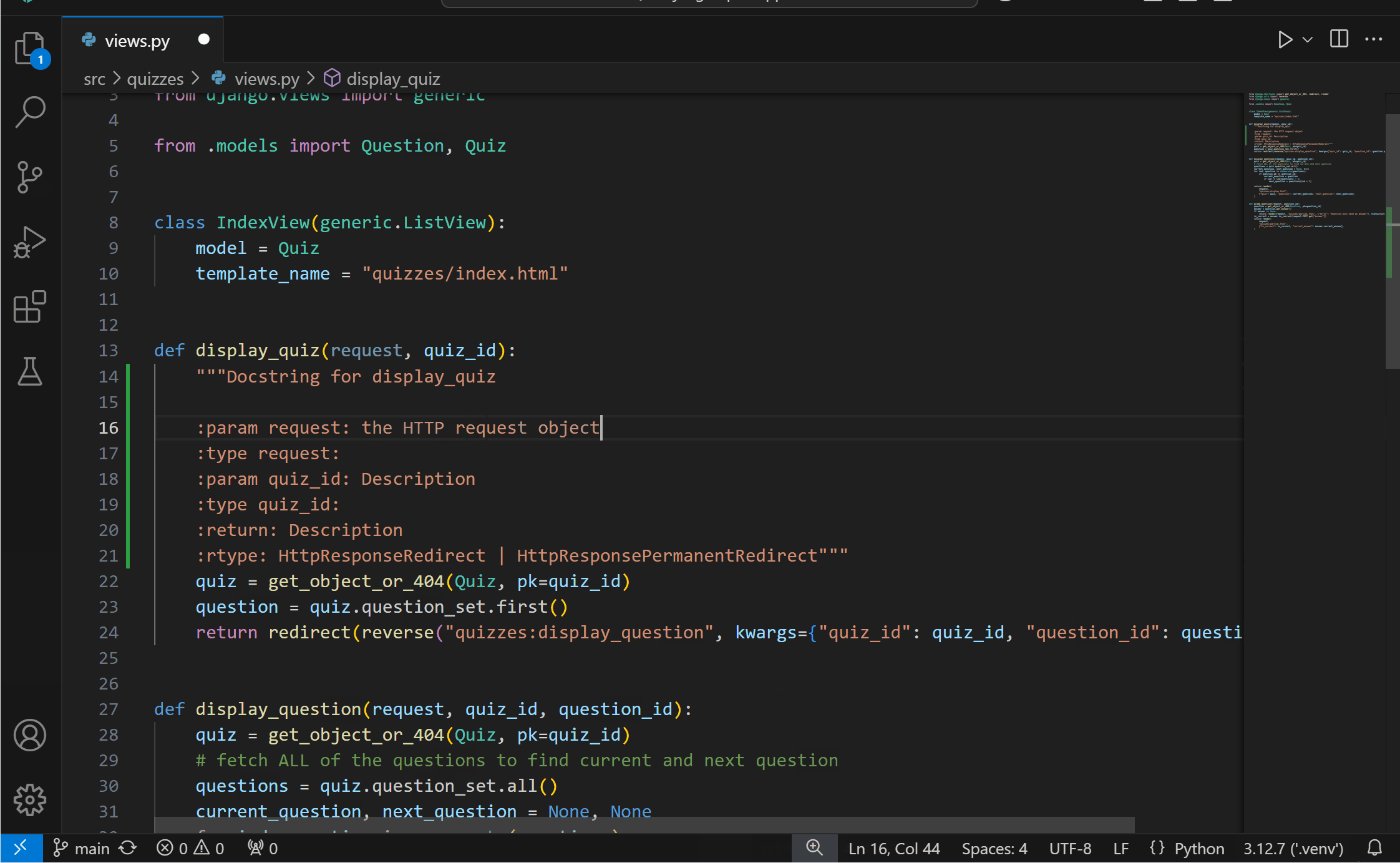{kind=link}
This feature is currently behind an experimental setting, but we look forward to making it the default experience soon. You can try it out today by enabling the python.analysis.supportDocstringTemplate setting.
New fold and unfold all docstrings commandsDocstrings are great for providing context and explanations for your code, but sometimes you might want to fold them to focus on the code itself. You can now more easily do so by folding docstrings with the new Pylance: Fold All Docstrings command, which can also be bound to a keybinding of your choice. To unfold them, use the Pylance: Unfold All Docstrings command.
Import suggestions with aliases from user files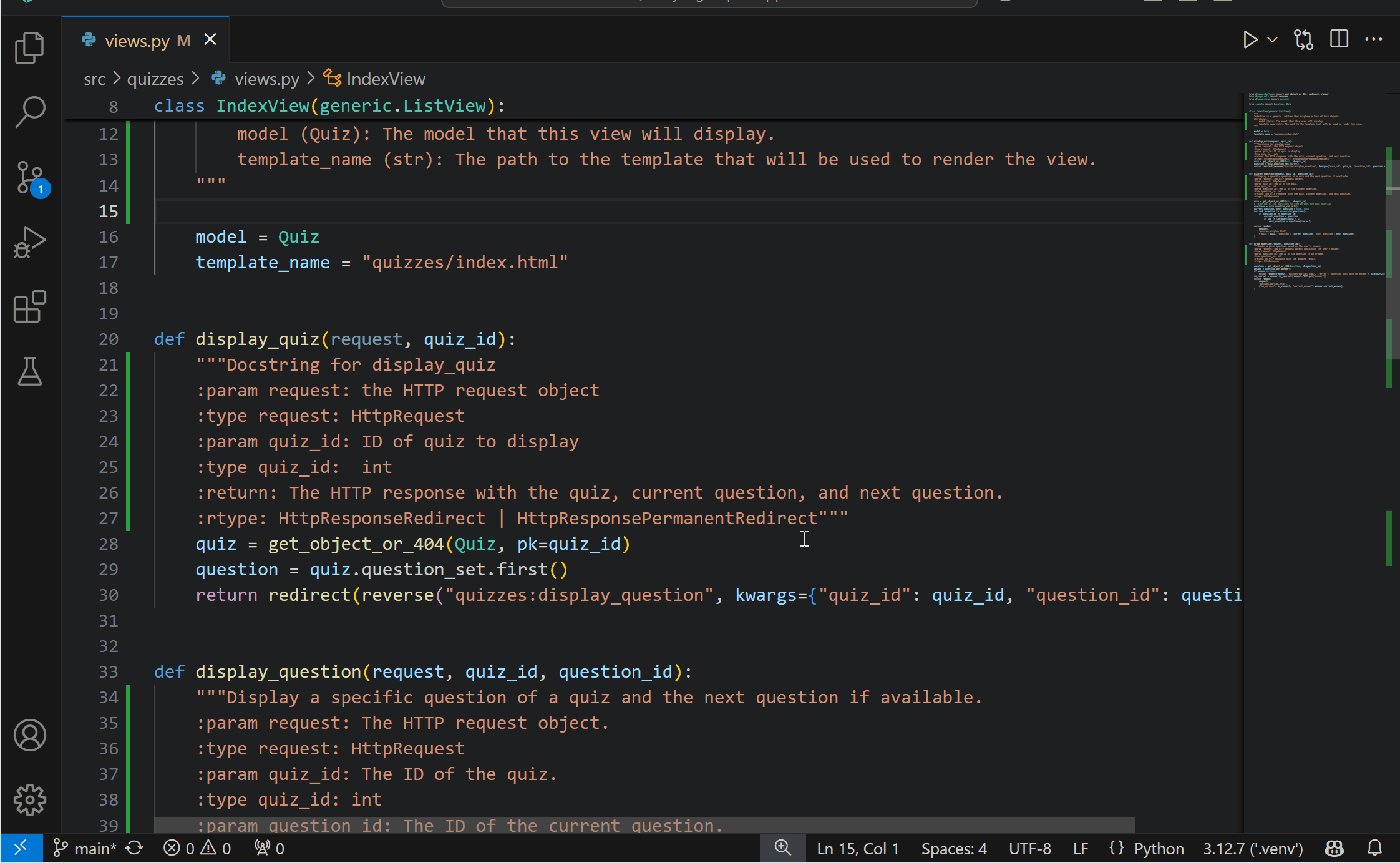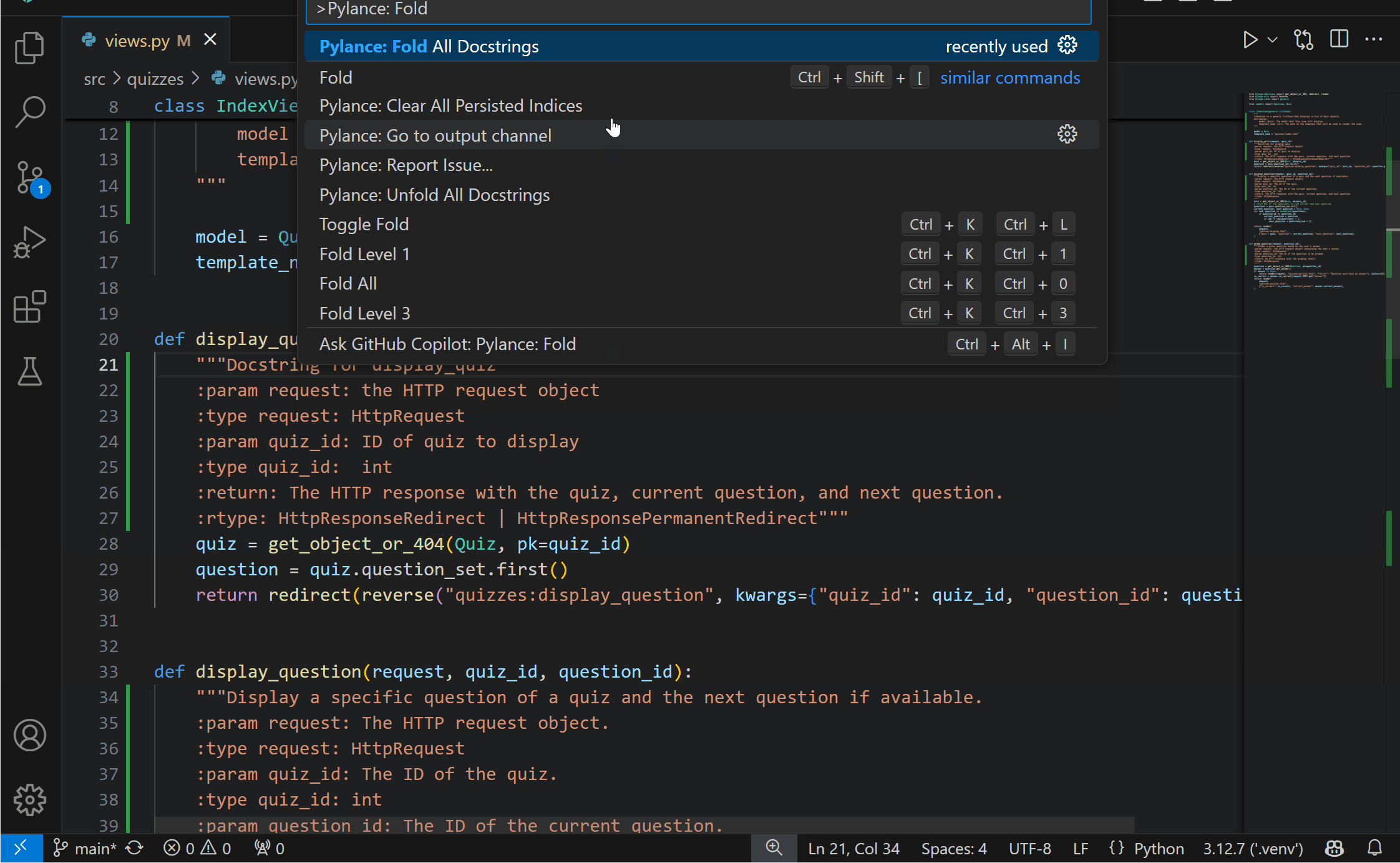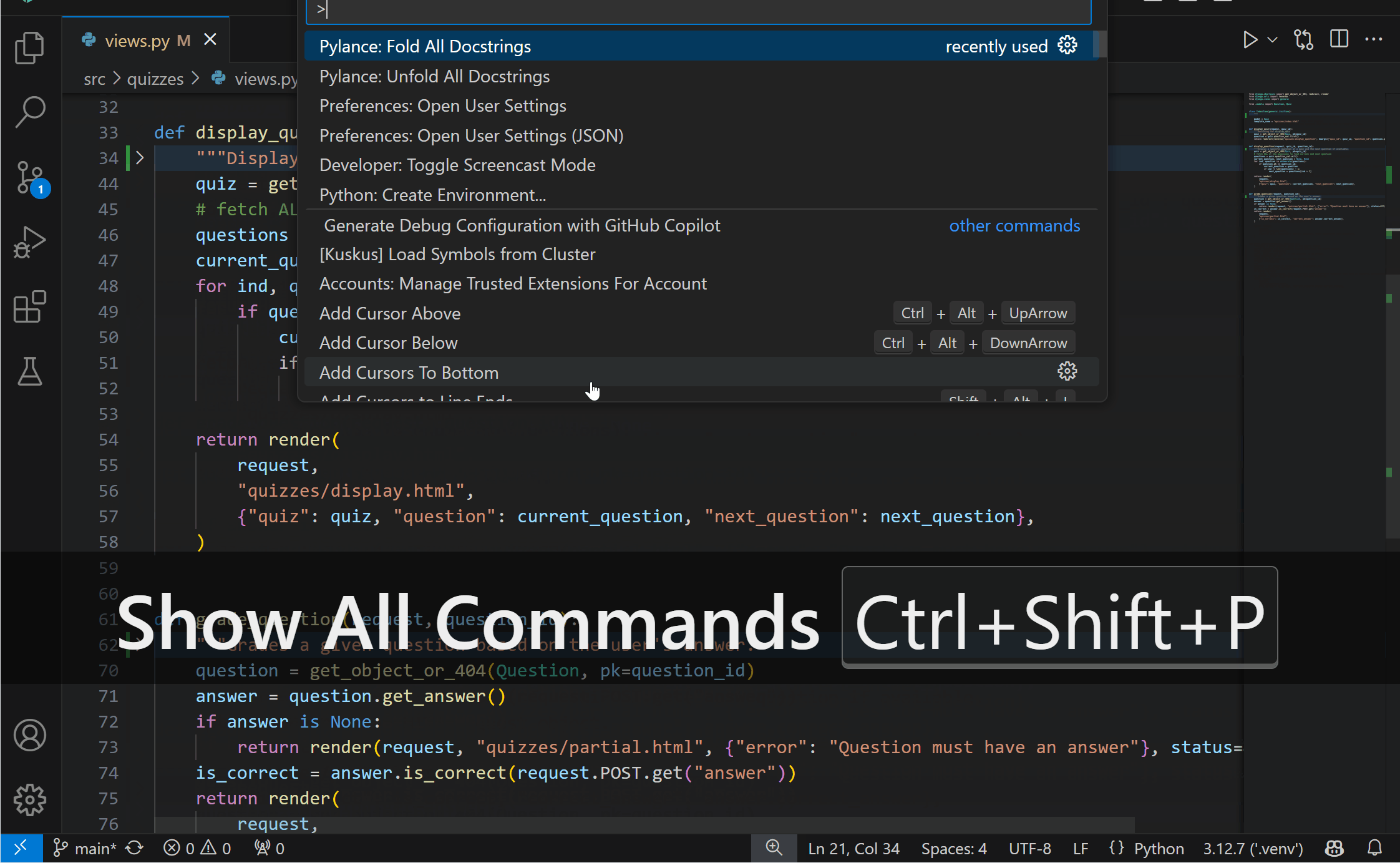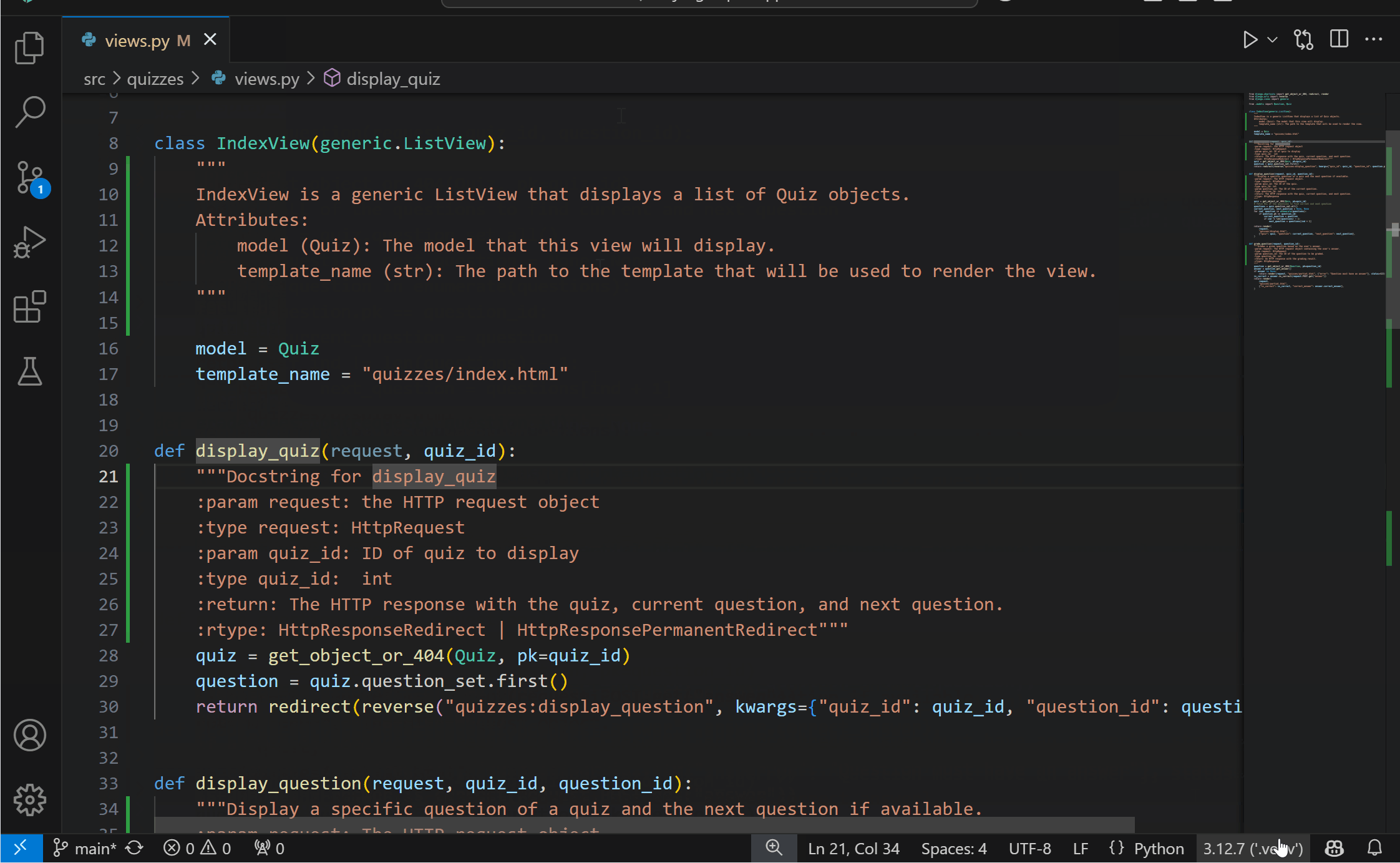{kind=link}
One of Pylance’s most powerful features is its ability to provide auto-import suggestions. By default, Pylance offers the import suggestion from where the symbol is defined, but you might want it to import from a file where the symbol is imported (i.e. aliased). With the new python.analysis.includeAliasesFromUserFiles setting, you can now control whether Pylance includes alias symbols from user files in its auto-import suggestions and in the add import Quick Fix.
Note: Enabling this setting can negatively impact performance, especially in large codebases, as Pylance may need to index more symbols and monitor more files for changes, which can increase resource usage.
Experimental AI Code Action: Implement Abstract ClassesYou can now get the best of both worlds with AI and static analysis with the new experimental Code Action to implement abstract classes! This feature requires both the Pylance and the GitHub Copilot extensions. To try it out, you can select the Implement all inherited abstract classes with Copilot Code Action when defining a class that inherits from an abstract one.
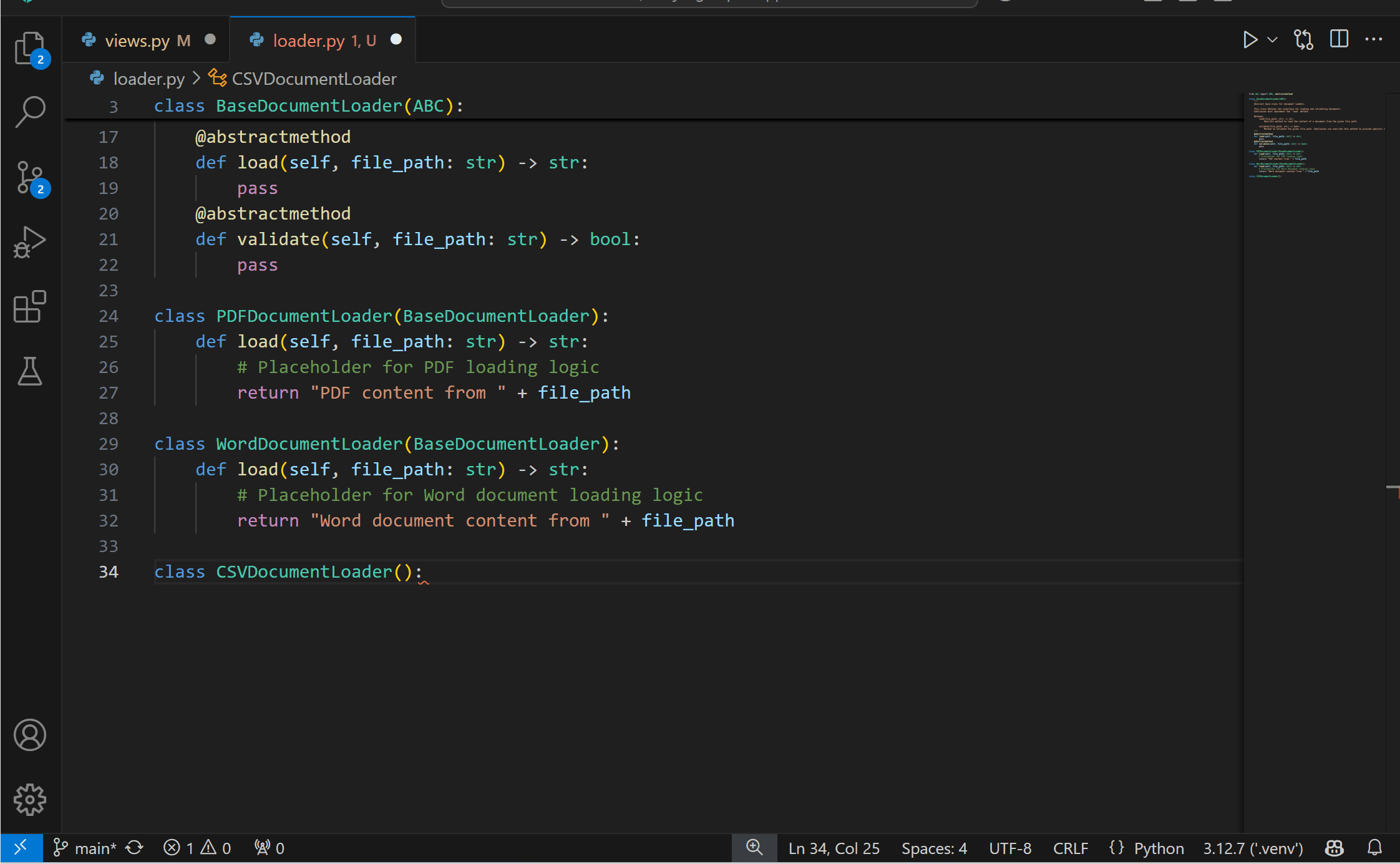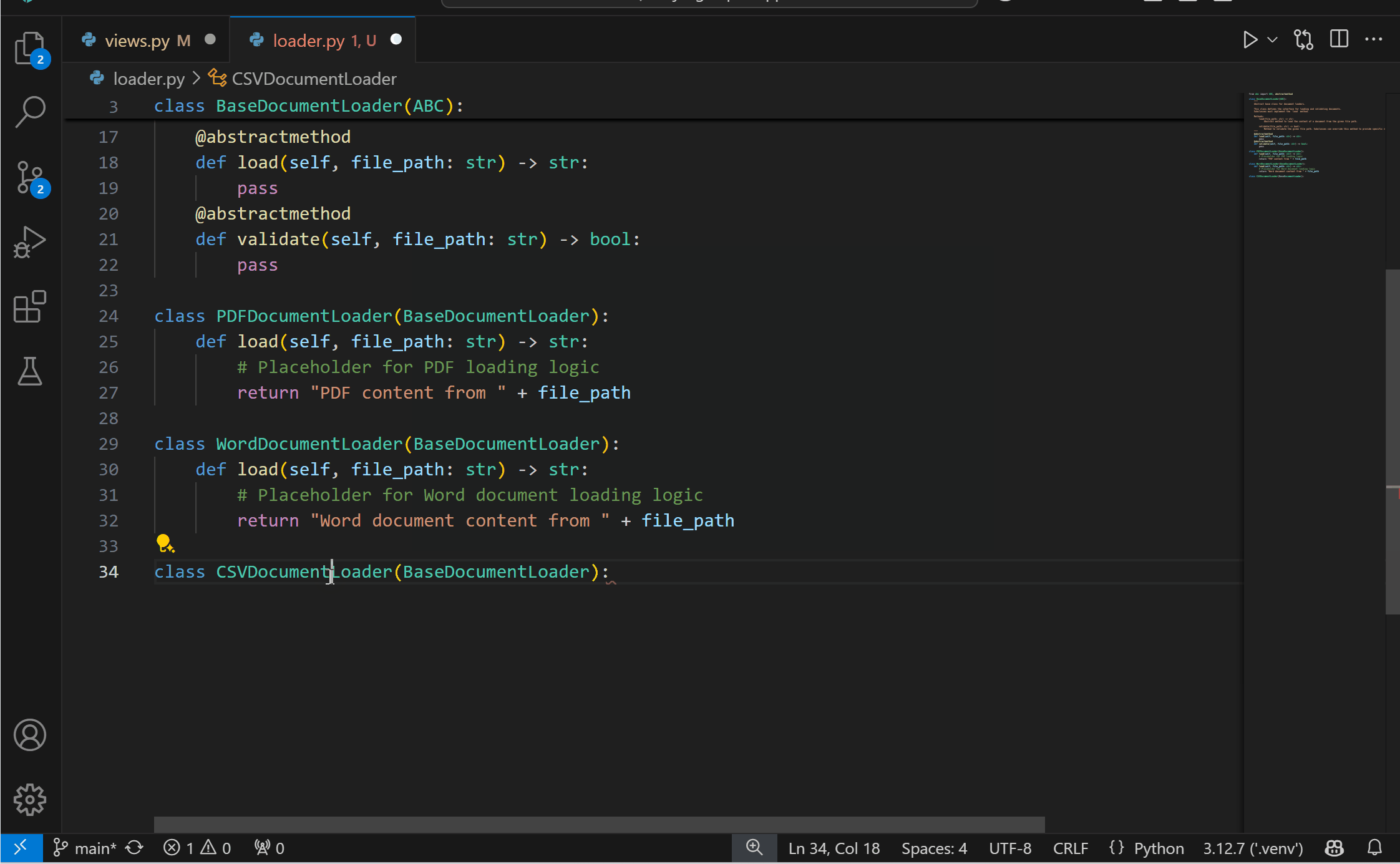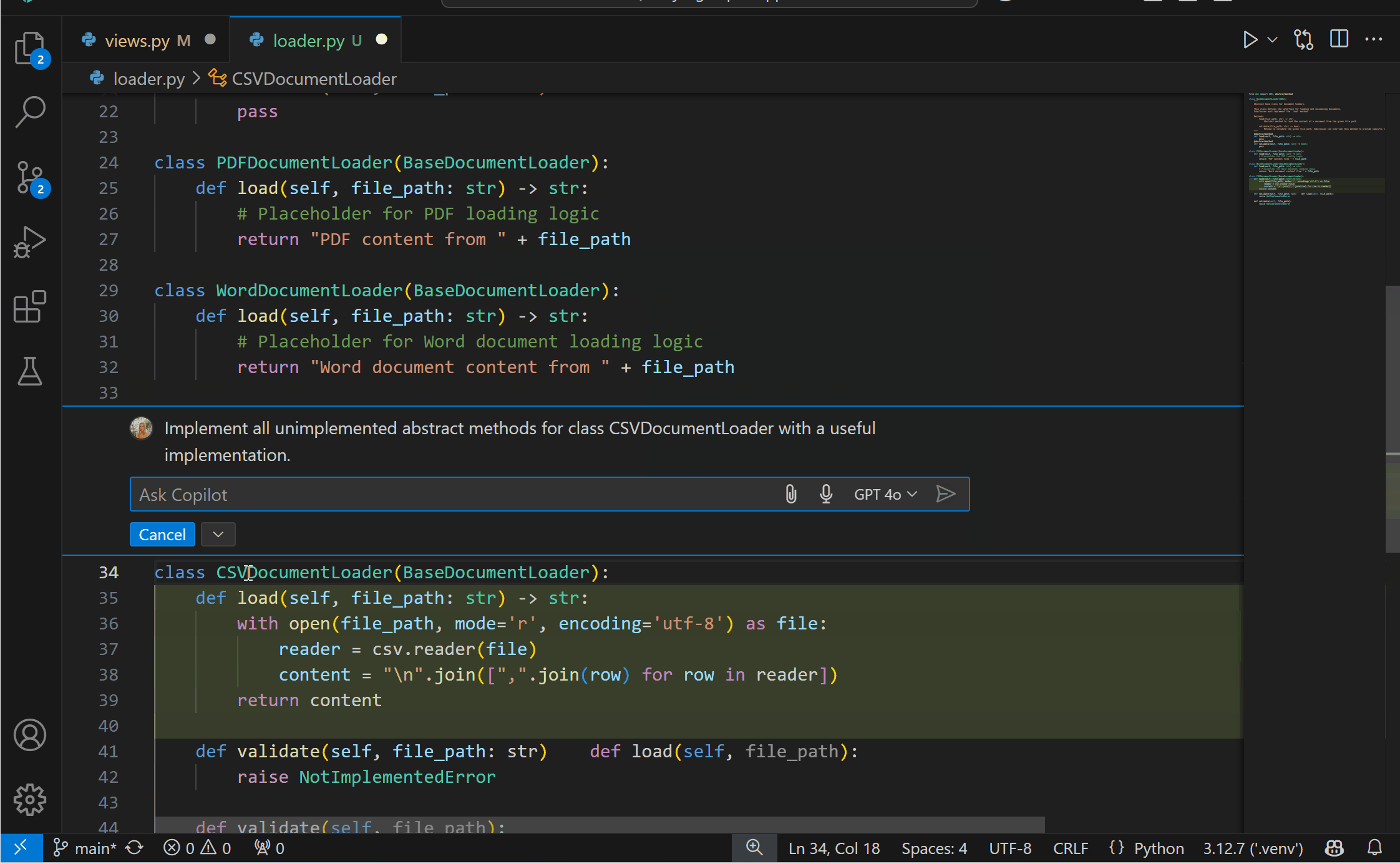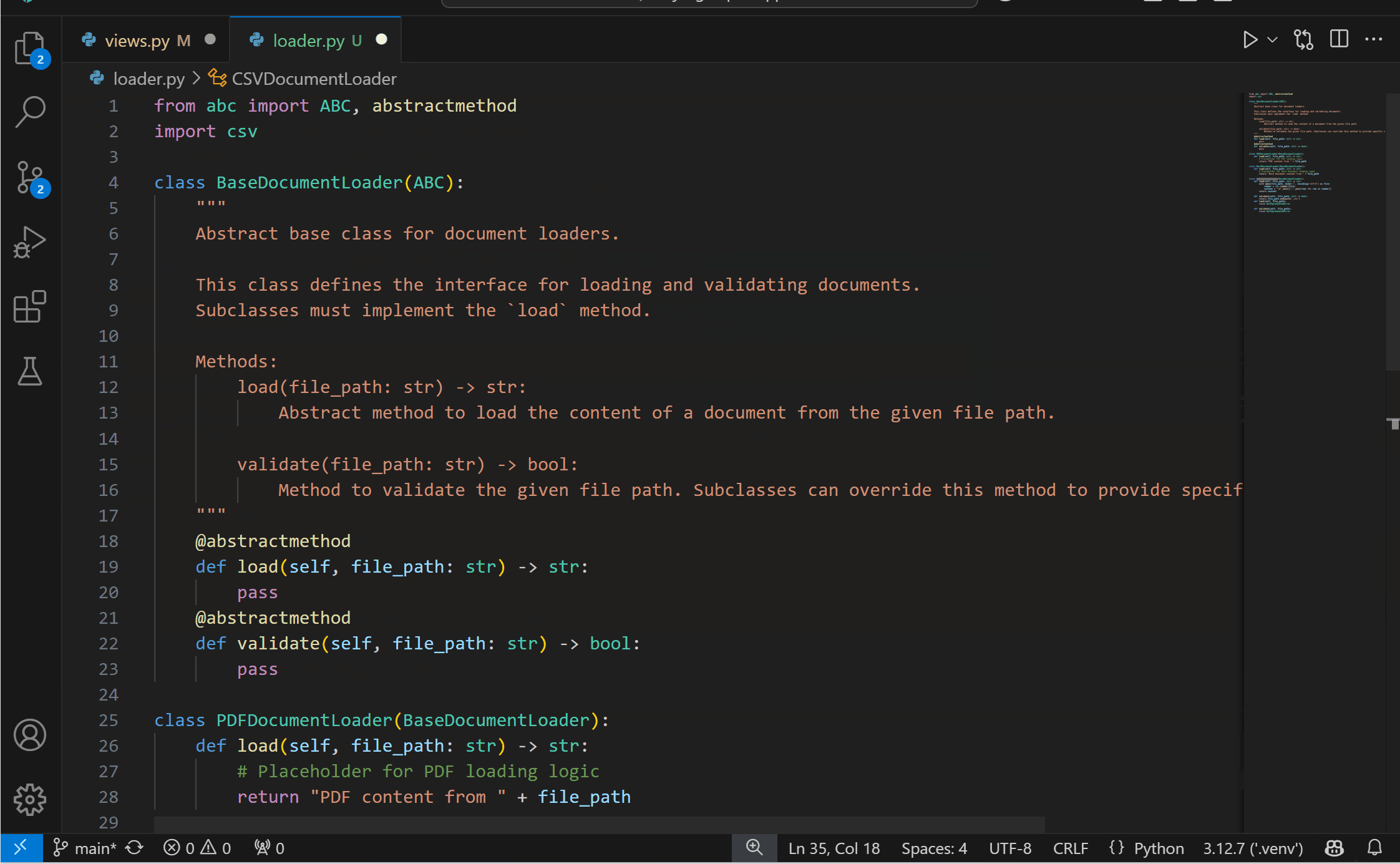{kind=link}
You can disable this feature by setting "python.analysis.aiCodeActions": {"implementAbstractClasses": false} in your User settings.
Native REPL Variables ViewThe Native Python REPL now provides up-to-date variables for the built-in Variables view. This lets you dig into the state of the interpreter as you execute code from files or through the REPL input box.
Upcoming deprecation of Python 3.8 support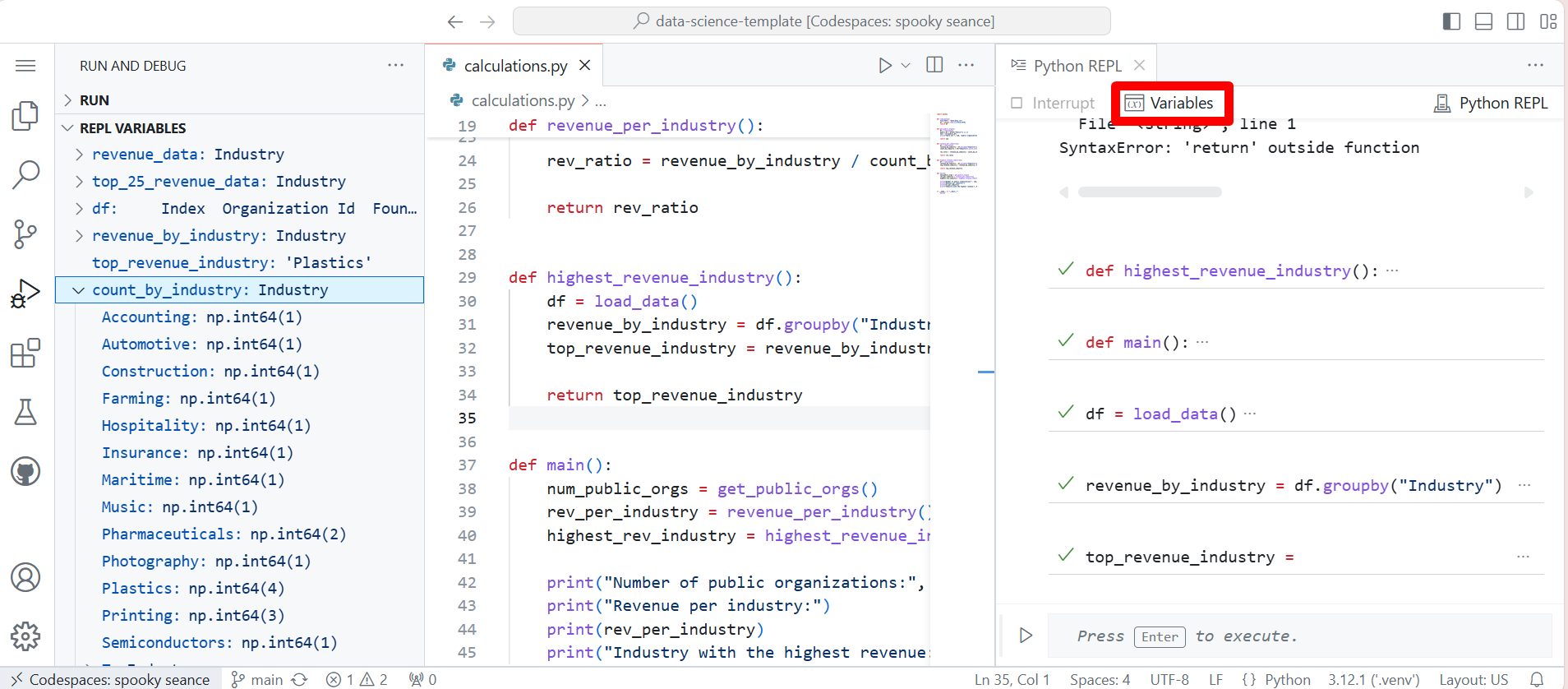{kind=link}
Python 3.8 reached end-of-life (EOL) on 2024-10-07. As such, official support for Python 3.8 in the Python extension will stop in three months, in the February 2025 release of the Python extension. There are no plans to actively remove support for Python 3.8, and so we expect the extension will continue to work unofficially with Python 3.8 for the foreseeable future.
Other Changes and EnhancementsWe have also added small enhancements and fixed issues requested by users that should improve your experience working with Python and Jupyter Notebooks in Visual Studio Code. Some notable changes include:
- There’s a new documentation page on the various ways to run Python code in VS Code.
- Pixi functionality has been restored only when Pixi is available (vscode-python#24310).
- You can now change the type checking mode to strict or standard from the Language Status menu (pylance-release#6080)
We would also like to extend special thanks to this month’s contributors:
- @mnoah1 Add customizable interpreter discovery timeout in vscode-python#24227
- @brokoli777 Refactor code to remove unused JSDoc types in vscode-python#24300
- @T-256 Make python_server.py compatible to Python 3.7 in vscode-python#24252
Note: This doesn’t guarantee full compatibility nor support for Python 3.7 in other parts of the Python extension. The minimum Python version we support is still Python 3.8 until February 2025, when the minimum officially supported version will be Python 3.9.
Try out these new improvements by downloading the Python extension and the Jupyter extension from the Marketplace, or install them directly from the extensions view in Visual Studio Code (Ctrl + Shift + X or ⌘ + ⇧ + X). You can learn more about Python support in Visual Studio Code in the documentation. If you run into any problems or have suggestions, please file an issue on the Python VS Code GitHub page.
The post Python in Visual Studio Code – November 2024 Release appeared first on Python.
mark.ie: Why Your Council Should Consider LocalGov Drupal for Your Website’s CMS
Let’s explore why it’s the CMS of choice for councils across the UK!
Python Software Foundation: PyCon US 2025 Kicks Off: Website, CfP, and Sponsorship Now Open!
Exciting news: the PyCon US 2025 conference website, Call for Proposals, and sponsorship program are open!
To learn more about the location, deadlines, and other details, check out the links below:
- PyCon US 2025 Launch Blog Post
- PyCon US 2025 Website
- Submit Your PyCon US 2025 Proposal on Pretalx
- Sponsorship Application
- PyCon US 2025 Changes Blog Post
We’re very happy to answer any questions you have about PSF sponsorship or PyCon US 2025– please feel free to reach out to us at sponsors@python.org.
On behalf of the PSF and the PyCon US 2025 Team, we look forward to receiving your proposals and seeing you in Pittsburgh next year 🥳 🐍
PyCon: PyCon US 2025 Launches!
We’re super excited to announce that PyCon US 2025 is back in Pittsburgh! If you missed our first time here, please check out our PyCon US 2024 recap and video recordings.
We’re also excited to announce the launch of our conference website, along with Call for Proposals and our sponsorship program!We’re Coming Back to Pittsburgh!We will be hosting PyCon US 2025 again in Pittsburgh, Pennsylvania. We will continue to return in person, with Health and Safety Guidelines in place.PyCon US 2025 will be held at the David L. Lawrence Convention Center in Pittsburgh, Pennsylvania, on the following dates:
- May 14-15, 2025 - Tutorials
- May 15, 2025 - Sponsor Presentations
- May 16-18, 2025 - Main Conference Days—Keynotes, Talks, Charlas, Expo Hall, and more
- May 19-22, 2025 - Sprints
{kind=link}
{kind=link}
Introducing PyCon US Co-Chair, and Future Conference Chair: Jon Banafato!:"Hi folks! I'm Jon, and I've been a Python community organizer for the past decade and change. You may recognize me from my work behind the scenes at PyGotham, volunteering at other Python conferences, or talking shop with other community organizers. I'm excited to be working with Elaine and the rest of the staff, organizers, and volunteers for the next few PyCon US conferences. Feel free to reach out to share your thoughts about the conference, and I look forward to seeing everyone back in Pittsburgh next year!"PyCon US 2025 Website is Live
You can now head over to the PyCon US 2025 website for all the conference details and more information about our sponsorship program.
Our design for this year’s event draws inspiration from the local fare of Pittsburgh infused with pops of colors and dynamic elements that reflect the uniqueness and character of our community.
We’re excited to collaborate with designers Malek Jerbi and Hamza Haj Taieb from Tunisia, whose illustrations and designs brought the PyCon US 2025 website to life. The design is brought together with the coordination of Georgi K and implemented by YupGup.PyCon US Call for Proposals is Now OpenPyCon US 2025’s Call for Proposals is officially open for Talks, Tutorials, Posters, and Charlas! The deadline to submit for all tracks is December 19, 2024, 11:59 PM ET. You can view what time that is for you locally on our CfP countdown.
We need beginner, intermediate, and advanced proposals on all sorts of topics— and beginner, intermediate, and advanced speakers to give said presentations. You don’t need to be a 20-year veteran who has spoken at dozens of conferences. On all fronts, we need all types of people. Our community is comprised of a diverse set of people with unique skill sets, and we want our conference program to be a true reflection of that diversity.
For the new and first-time speakers, be sure to take advantage of the speaker mentorship program where you can be matched with experienced speakers who can help you with crafting your proposal. Check out the info on our Proposal Mentorship Program page.
For more information on where and how to submit your proposal, visit the Proposal Guidelines page on the PyCon US 2025 website.
Hatchery Program - Coming Soon!The PyCon US Hatchery is an effort to establish a path for the introduction of new tracks, summits, and demos at PyCon US. We are still finalizing the details of this program, so please stay tuned for more news about the PyCon US Hatchery 🐣 and start thinking of ideas you might want to contribute!
Sponsorship Has Tremendous ImpactSponsors are what make PyCon US and the Python Software Foundation possible. PyCon US is the main source of revenue for the PSF, the non-profit behind the Python language and the Python Packaging Index (PyPI), and the hub for the Python community.
PyCon US is the largest and longest-running Python gathering globally, with a diverse group of highly engaged attendees, many of whom you won’t find at other conferences. We’re excited to be able to provide our sponsors with opportunities to connect with and support the Python community. You’ll be face-to-face with talented developers, qualified recruits, and potential customers, access a large and diverse audience, as well as elevate your visibility and corporate identity within the Python community.
Check out our full menu of benefits,
What you can expect when you sponsor PyCon US and the PSF:
- Reach - Access to 2500+ attendees interested in your products and services and generate qualified leads.
- Brand strength - Be part of the biggest and most prestigious Python conference in the world and support the nonprofit organization behind the Python language.
- Connections - Networking with attendees in person to create connections and provide detailed information about your products and services.
- Recruiting - Access to qualified job candidates. If you’re hiring, there’s no better place to find Python developers than PyCon US.
- 12 months of benefits - Reach the Python community during PyCon US and beyond, with options for recognition on Python.org, PyPI.org, and more.
If you have any questions about sponsoring PyCon US and the PSF, please contact us at sponsors@python.org.Stay in the LoopAs we get closer to the event, the conference website is where you’ll find details for our call for proposals, registration launch, venue information, and everything PyCon US related! Be sure to subscribe here to the PyCon US Blog, follow @PyCon on Twitter, @pycon@fosstodon.org and @ThePSF@fosstodon.org on Mastodon, the PSF on LinkedIn, and subscribe to PyCon US 2025 News so you won’t miss a thing. Our official hashtag is #PyConUS.
Colin Watson: Free software activity in October 2024
Almost all of my Debian contributions this month were sponsored by Freexian.
You can also support my work directly via Liberapay.
AnsibleI noticed that Ansible had fallen out of Debian testing due to autopkgtest failures. This seemed like a problem worth fixing: in common with many other people, we use Ansible for configuration management at Freexian, and it probably wouldn’t make our sysadmins too happy if they upgraded to trixie after its release and found that Ansible was gone.
The problems here were really just slogging through test failures in both the ansible-core and ansible packages, but their test suites are large and take a while to run so this took some time. I was able to contribute a few small fixes to various upstreams in the process:
- test: Make git archive prefix fit in 32-bit ssize_t (though upstream went for a different approach)
- test: replace more deprecated assertEquals
- Fix import error on Python 3.13
- Make test_start_daemon_with_no_mock less flaky
This should now get back into testing tomorrow.
OpenSSHMartin-Éric Racine reported that ssh-audit didn’t list the ext-info-s feature as being available in Debian’s OpenSSH 9.2 packaging in bookworm, contrary to what OpenSSH upstream said on their specifications page at the time. I spent some time looking into this and realized that upstream was mistakenly saying that implementations of ext-info-c and ext-info-s were added at the same time, while in fact ext-info-s was added rather later. ssh-audit now has clearer output, and the OpenSSH maintainers have corrected their specifications page.
I looked into a report of an ssh failure in certain cases when using GSS-API key exchange (which is a Debian patch). Once again, having integration tests was a huge win here: the affected scenario is quite a fiddly one, but I was able to set it up in the test, and thereby make sure it doesn’t regress in future. It still took me a couple of hours to get all the details right, but in the past this sort of thing took me much longer with a much lower degree of confidence that the fix was correct.
On upstream’s advice, I cherry-picked some key exchange fixes needed for big-endian architectures.
Python teamI packaged python-evalidate, needed for a new upstream version of buildbot.
The Python 3.13 transition rolls on. I fixed problems related to it in htmlmin, humanfriendly, postgresfixture (contributed upstream), pylint, python-asyncssh (contributed upstream), python-oauthlib, python3-simpletal, quodlibet, zope.exceptions, and zope.interface.
A trickier Python 3.13 issue involved the cgi module. Years ago I ported zope.publisher to the multipart module because cgi.FieldStorage was broken in some situations, and as a result I got a recommendation into Python’s “dead batteries” PEP 594. Unfortunately there turns out to be a name conflict between multipart and python-multipart on PyPI; python-multipart upstream has been working to disentangle this, though we still need to work out what to do in Debian. All the same, I needed to fix python-wadllib and multipart seemed like the best fit; I contributed a port upstream and temporarily copied multipart into Debian’s python-wadllib source package to allow its tests to pass. I’ll come back and fix this properly once we sort out the multipart vs. python-multipart packaging.
tzdata moved some timezone definitions to tzdata-legacy, which has broken a number of packages. I added tzdata-legacy build-dependencies to alembic and python-icalendar to deal with this in those packages, though there are still some other instances of this left.
I tracked down an nltk regression that caused build failures in many other packages.
I fixed Rust crate versioning issues in pydantic-core, python-bcrypt, and python-maturin (mostly fixed by Peter Michael Green and Jelmer Vernooij, but it needed a little extra work).
I fixed other build failures in entrypoints, mayavi2, python-pyvmomi (mostly fixed by Alexandre Detiste, but it needed a little extra work), and python-testing.postgresql (ditto).
I fixed python3-simpletal to tolerate future versions of dh-python that will drop their dependency on python3-setuptools.
I fixed broken symlinks in python-treq.
I removed (build-)depends on python3-pkg-resources from alembic, autopep8, buildbot, celery, flufl.enum, flufl.lock, python-public, python-wadllib (contributed upstream), pyvisa, routes, vulture, and zodbpickle (contributed upstream).
I upgraded astroid, asyncpg (fixing a Python 3.13 failure and a build failure), buildbot (noticing an upstream test bug in the process), dnsdiag, frozenlist, netmiko (fixing a Python 3.13 failure), psycopg3, pydantic-settings, pylint, python-asyncssh, python-bleach, python-btrees, python-cytoolz, python-django-pgtrigger, python-django-test-migrations, python-gssapi, python-icalendar, python-json-log-formatter, python-pgbouncer, python-pkginfo, python-plumbum, python-stdlib-list, python-tokenize-rt, python-treq (fixing a Python 3.13 failure), python-typeguard, python-webargs (fixing a build failure), pyupgrade, pyvisa, pyvisa-py (fixing a Python 3.13 failure), toolz, twisted, vulture, waitress (fixing CVE-2024-49768 and CVE-2024-49769), wtf-peewee, wtforms, zodbpickle, zope.exceptions, zope.interface, zope.proxy, zope.security, and zope.testrunner to new upstream versions.
I tried to fix a regression in python-scruffy, but I need testing feedback.
I requested removal of python-testing.mysqld.
Real Python: The Real Python Podcast – Episode #226: PySheets: Spreadsheets in the Browser Using PyScript
What goes into building a spreadsheet application in Python that runs in the browser? How do you make it launch quickly, and where do you store the cells of data? This week on the show, we speak with Chris Laffra about his project, PySheets, and his book "Communication for Engineers."
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
PyCon: Important Changes Ahead: A Commitment to Financial Transparency
PyCon US is the largest and longest-running annual gathering for the community using and developing the open-source Python programming language. It is produced and underwritten by the Python Software Foundation (PSF), the 501(c)(3) nonprofit organization dedicated to advancing and promoting Python and its community.
The PSF is a grant-giving non-profit and the revenue generated by PyCon US is essential to our continued community support and operations. Check out our Mission and our latest Annual Impact Report to get an idea of the scope of work our foundation is responsible for. Many misunderstand or are unaware of this relationship, but the PSF relies on maintaining a strict budget for the operation of PyCon US in order to continue its grants programs and other financial responsibilities.
With this in mind, PyCon US has taken on many expenses in the years following the pandemic, including the losses associated with canceling PyCon US 2020 and the move to PyCon US 2021 online. Additionally, inflation in event costs and lower projected sponsorships have combined to create a significant loss for PyCon US and the PSF in 2024.
Because the PSF is a nonprofit, we keep PyCon US registration costs much lower than comparable technology conferences. Our goal is for PyCon US to remain accessible to the widest group possible. For us to continue to do so and ensure the sustainability of the event, we’ve had to make some changes to the structure of PyCon US. We know that an important piece of making changes to PyCon US is notice and awareness to our wonderful community– and we want to be transparent about the reasons behind them.
Ticket PricesTo continue providing the content, program, and opportunities of PyCon US this year and in the future and to offset these rising costs, we’ve decided to raise ticket prices this year by $50 USD for the Individual and Corporate rates and $25 USD for the Student rate.
New PyCon US 2025 registration prices:
- Corporate: $800 USD
- Individual: $450 USD
- Student: $125 USD
By adjusting ticket prices, we hope to continue delivering a valuable and enriching conference experience while still being financially accessible to our community.
PyCon US OnlinePyCon US moved to online for the first year in 2021 during the pandemic and we’ve been proud to offer the Online attendance option for the past three years since. While we recognize the value that PyCon US Online provides in terms of accessibility, the challenges of delivering a seamless and engaging experience for both in-person and virtual attendees have been significant. From a cost perspective alone, cutting the online event will free up resources that can be put back into the in person and after-conference experience.
PyCon US will record all Talk tracks, Keynotes and Lightning Talks on the main days of the conference (Friday - Sunday) and we plan to publish these recordings very quickly after the sessions take place so those who can’t join us in person can access them while the topics are still current.
We appreciate the enthusiasm and participation of everyone who was part of the PyCon US Online experience and encourage everyone who can to join us in person in Pittsburgh this year. If you are unable to join, we welcome you to subscribe to our PyCon US YouTube channel to receive notifications of new content.
Tutorial RecordingsThe pre-conference tutorials are a valuable part of the PyCon US conference and provide an opportunity for Pythonistas around the world to learn and grow their skills in hands-on sessions.
Tutorial ticket sales are a large source of revenue for PyCon US, but in the past few years, the margin on the tutorials has declined due to rising costs associated with recording these sessions.
Because tutorials are longer than talks and are in an interactive classroom-like setting, they require many resources such as power, better internet connectivity, and catering. Additionally, tutorial instructors are compensated due to the amount of work involved in preparing and providing these sessions.
Since tutorial registration is at an additional cost, we want to prioritize the experience for those attending in person and to do so, we will be removing tutorial recordings this year. The value of the face-to-face learning, discussions, and hands-on engagement that occurs during the tutorials outweighs the benefits of capturing the sessions for later viewing and can’t be replicated in a recorded format. We hope this change will encourage more attendees to participate in the tutorials onsite and engage with the content the instructors work very hard to provide.
Speaker Travel Grant LimitThe support of our community has allowed us to offer generous Travel Grants based on individual needs including travel, accommodation, and conference tickets. The Travel Grant program helps us shape a conference that is diverse on a number of axes from technical to geographic.
However, with decreased Travel Grant funds, PyCon US wants to ensure that we can still spread out our funding to support as many people as possible. Currently, a large part of the Travel Grant budget goes to speakers, and all speakers who are included on the proposal for an accepted talk are automatically eligible for a travel grant. For 2025, there will be a limit of two Travel Grant-funded speakers per accepted proposal across all tracks. We believe this will allow us to spread our funding capacity across our community and welcome as many Pythonistas to PyCon US as we can, while not impacting the quality and diversity of our programming.
Thank you!PyCon US has been around for over 20 years, and we want to ensure it sticks around for many more! We recognize that these changes will impact many folks in a variety of ways, and we hope that our transparency about why these decisions were made will help bring understanding.
By making these changes and being willing to adapt, PyCon US can continue to be a welcoming, community conference, where everyone can meet new people and learn new things, connect with old friends and tell people about their projects. We appreciate our community’s support and understanding regarding these changes. If you have any feedback or questions, please feel free to reach out to the organizing team.
Qt Quick 3D survey - November 2024
The Qt Quick 3D project was first announced and released in 2019. Since then, it has seen numerous enhancements. We have concentrated on boosting performance, introducing new features, and expanding the module's capabilities.
Emergency and weather alerts
I had previously mentioned efforts on bringing public emergency and weather alerts to free software and free infrastructure, which was also my initial motivation to work on push notifications. With that moving forward it’s time to explain a bit more what’s happening there.
FOSS Public Alert ServerAs part of the initial push notification work I had written a simple prototype server which aggregates alerts from about a hundred countries and allows clients to subscribe to be notified about alerts in a given area of interest.
With the push notification client and server parts for KDE released and deployed, that’s now the next thing to tackle.
After teaming up with FOSS Warn (a free alternative to the proprietary emergency and weather alert apps in Germany), who need the same kind of infrastructure there’s now even NLnet funding to turn this into production-ready software.
Work is going to happen in this repository on KDE’s Gitlab instance, and can be followed on this Mastodon account.
Public emergency alert push notification. Common Alerting Protocol (CAP)For this to scale globally we need standardized data models, data formats and protocols. And thankfully those exist in form of OASIS’ Common Alerting Protocol (CAP) since many years and are widely in use.
CAP describes an XML format for alert messages, covering categorization, severity, certainty, urgency, affected area, and multi-lingual descriptions and instructions.
Build on top of that are CAP feeds, which are basically RSS or Atom feeds of CAP alert messages.
There’s also a bunch of national- or agency-specific profiles which for example define additional information elements or specify the use of existing fields more precisely for their use-case.
From a technical point of view none of that is particularly challenging, we already have support for CAP alerts in KWeatherCore for example.
CAP is widespread for internal use in various international, national or sub-national emergency warning systems, for connecting alerting authorities with e.g. media broadcast or mobile network providers. In many countries CAP feeds are also publicly available, which is the interesting part for us here.
CAP WorkshopAfter having gotten in touch with other people working in this area we got invited to the CAP Workshop that happened last week, a rather unassuming name for a three day international conference with national delegations from more than 120 countries, several UN agencies and NGOs like the International Red Cross/Crescent, and quite a bit more formal than what we are used to from other events.
Unfortunately I couldn’t be there in person and only followed this online, but even that provided quite some interesting insights.
- OASIS’ work on extended event codes, which should help with better display and filtering of alerts in client applications.
- Several talks covered the “usability” of alerts, ie. how to word/present warnings so that they are understood by everyone and so that they result in the intended reaction. Much of this is in the hands of the alert issuers, but client software can help here as well, e.g. regarding accessibility (TTS, both visual and audible notifications, translations and understandable language in general, etc).
- Google showed the various places where they integrate alerts in their products: displayed on maps, discoverable via search, location-dependent push notifications, integrated with weather forecasts and in routing before entering an affected area. Can be inspiration for what we could do as well.
- A talk presented work on Mexico’s earthquake early warning system. As earthquakes can’t be predicted this uses the fact that an alert can outrace the shockwave and thus might still reach people further away in time (same as tsunami warnings work, just at a much shorter timescale). Their estimate from a simulation of past earthquakes was 10 seconds making a difference of 10k lives. That’s a level of responsiveness our current CAP feed polling approach is not going to be able to reach, this would need direct listening to the alert radio signals.
- There’s several CAP feeds that aren’t publicly available yet, whenever such a case came up there was push for changing that in the following Q&A session. Good, we need that.
There’s plenty of things to do here. On the software development side there’s getting the server code production ready and deployed, building monitoring tools for that and turning the demo app into a reuable client library and integrating that in places where it makes sense.
Equally important though is finding more CAP feeds and in some cases additional data sets to resolve area codes used in the alerts to geographic polygons. This is something that often needs local knowledge and understanding the local languages. And where there are no CAP feeds yet, nagging your local authorities to change that also helps.
We should soon get a dedicated Matrix channel for coordinating this, and we’ll be at 38C3 and FOSDEM 2025 if you want to talk about this in person.
Nick Coghlan: The origin of venvstacks
There has been a longstanding gap in the Python packaging ecosystem that has somewhat annoyed me, but not enough to do anything about it: we haven't really had a good way to compose multiple layers of Python virtual environments together, allowing large dependencies (like AI and machine learning libraries) to be shared across multiple different application environments without having to install them directly into the base runtime environment.
Utilities for collecting up an entire Python runtime, an application, and all its dependencies into a single deployable artifact have existed since before the turn of the century.
We've had standardised virtual environments (allowing multiple applications to share a base Python runtime and its directly installed third party packages) for almost as long.
We've had zip applications for a long time as well (and other utilities which build on that feature).
We've had tools like wagon which allow us to ship a bundle of prebuilt Python wheel archives and install them on a destination system without needing to download anything else from the internet at installation time.
We've had tools like conda (and more recently uv), which make intelligent use of hard links on local systems to avoid making duplicate copies of completely identical versions of packages.
We've technically had platform specific mechanisms like Linux container images, where the contents of an environment can be built up across multiple container image layers, with the lower layers being shared across multiple image definitions, but have lacked a convenient way to handle the dependency management complications involved in using these tools to share large Python libraries.
But we've never had something which specifically took full advantage of the way Python's import system works to enable robust structural decomposition of Python applications into independently updatable subcomponents (with a granularity larger than single packages).
All of this history meant that I was thoroughly intrigued when a mutual acquaintance introduced me to the creators of the LM Studio personal AI desktop application to discuss a Python packaging problem they had looming on their technical road map: it was clear from user demand and the rate of evolution in the Python AI/ML ecosystem that they needed a way to ship Python AI/ML components directly to their users without having to wait for those capabilities to be made available through native interfaces in other languages (such as Swift, C++, or JavaScript), but it didn't seem obvious to them how they could readily integrate that capability into LM Studio without making the application installation process substantially more complicated for their users.
What started as a consulting contract for a technical proof of concept, and has since turned into a permanent position with the organisation, proved fruitful, and the result is the recently published open source venvstacks utility, which is specifically designed to enable the kind of portable deterministic artifact publishing setup that LM Studio needed, including:
- Base runtime layers (based on python-build-standalone)
- Framework layers (for shipping large dependencies, such as Apple MLX or PyTorch)
- Application layers (including additional unpackaged "launch modules" for app execution)
There are certainly still some technical limitations to be addressed (the dynamic linking problem with layering virtual environments like this is notorious amongst Python packaging experts for a reason), but even in its current form, venvstacks is already capable enough to power the recent inclusion of Apple MLX support in LM Studio.
Russ Allbery: Review: Overdue and Returns
Review: Overdue and Returns, by Mark Lawrence
Publisher: Mark Lawrence Copyright: June 2023 Copyright: February 2024 ASIN: B0C9N51M6Y ASIN: B0CTYNQGBX Format: Kindle Pages: 99Overdue is a stand-alone novelette in the Library Trilogy universe. Returns is a collection of two stories, the novelette "Returns" and the short story "About Pain." All of them together are about the length of a novella, so I'm combining them into a single review.
These are ancillary stories in the same universe as the novels, but not necessarily in the same timeline. (Trying to fit "About Pain" into the novel timeline will give you a headache and I am choosing to read it as author's fan fiction.) I'm guessing they're part of the new fad for releasing short fiction on Amazon to tide readers over and maintain interest between books in a series, a fad about which I have mixed feelings. Given the total lack of publisher metadata in either the stories or on Amazon, I'm assuming they were self-published even though the novels are published by Ace, but I don't know that for certain.
There are spoilers for The Book That Wouldn't Burn, so don't read these before that novel. There are no spoilers for The Book That Broke the World, and I don't think the reading order would matter.
I found all three of these stories irritating and thuddingly trite. "Returns" is probably the best of the lot in terms of quality of storytelling, but I intensely dislike the structural implications of the nature of the book at its center and am therefore hoping that it's non-canonical.
I would not waste your time with these even if you are enjoying the novels.
"Overdue": Three owners of the same bookstore at different points in time have encounters with an albino man named Yute who is on a quest. One of the owners is trying to write a book, one of them is older, depressed, and closed off, and one of them has regular conversations with her sister's ghost. The nature of the relationship between the three is too much of a spoiler, but it involves similar shenanigans as The Book That Wouldn't Burn.
Lawrence uses my least favorite resolution of benign ghost stories. The story tries very hard to sell it as a good thing, but I thought it was cruel and prefer fantasy that rejects both branches of that dilemma. Other than that, it was fine, I guess, although the moral was delivered with all of the subtlety of the last two minutes of a Saturday morning cartoon. (5)
"Returns": Livira returns a book deep inside the library and finds that she can decipher it, which leads her to a story about Yute going on a trip to recover another library book. This had a lot of great Yute lines, plus I always like seeing Livira in exploration mode. The book itself is paradoxical in a causality-destroying way, which is handwaved away as literal magic. I liked this one the best of the three stories, but I hope the world-building of the main series does not go in this direction and I'm a little afraid it might. (6)
"About Pain": A man named Holden runs into a woman named Clovis at the gym while carrying a book titled Catcher that his dog found and that he's returning to the library. I thoroughly enjoy Clovis and was happy to read a few more scenes about her. Other than that, this was fine, I guess, although it is a story designed to deliver a point and that point is one that appears in every discussion of classics and re-reading that has ever happened on the Internet. Also, I know I'm being grumpy, but Lawrence's puns with authors and character names are chapter-epigraph amusing but not short-story-length funny. Yes, yes, his name is Holden, we get it. (5)
Rating: 5 out of 10
Paul Wise: FLOSS Activities October 2024
This month I didn't have any particular focus. I just worked on issues in my info bubble.
Changes- ArchiveBot: improve dashboard filtering
- Debian wiki pages: ArmPorts, Exploits
- FLOSS license needed for ThreadTree
- Features in ThreadTree (1 2 3 4 5), systemd-cron
- Warnings in kraft, python3-pypandoc
All work was done on a volunteer basis.
Taavi Väänänen: Custom domains on the Wikimedia Cloud VPS web proxy
The shared web proxy used on Wikimedia Cloud VPS now has technical support for using arbitrary domains (and not just wmcloud.org subdomains) in proxy names. I think this is a good example of how software slowly evolves over time as new requirements emerge, with each new addition building on top of the previous ones.
According to the edit history on Wikitech, the web proxy service has its origins in 2012, although the current idea where you create a proxy and map it to a specific instance and port was only introduced a a year later. (Before that, it just directly mapped the subdomain to the VPS instance with the same name).
There were some smaller changes in the coming years like the migration to acme-chief for TLS certificate management, but the overall logic stayed very similar until 2020 when the wmcloud.org domain was introduced. That was implemented by adding a config option listing all possible domains, so future domain additions would be as simple as adding the new domain to that list in the configuration.
Then the changes start becoming more frequent:
- In 2022, for my Terraform support project, a bunch of logic, including the list of supported backend domains was moved from the frontend code to the backend. This also made it possible to dynamically change which projects can use which domains suffixes for their proxies.
- Then, early this year, I added support for zones restricted to a single project, because we wanted to use the proxy for the *.svc.toolforge.org Toolforge infrastructure domains instead of coming up with a new system for that use case. This also added suport for using different TLS certificates for different domains so that we would not have to have a single giant certificate with all the names.
- Finally, the last step was to add two new features to the proxy system: support for adding a proxy at the apex of a domain, as well as support for domains that are not managed in Designate (the Cloud VPS/OpenStack auth DNS service). In addition, we needed a bit of config to ensure http-01 challenges get routed to the acme-chief instance.
SystemSeed.com: Video: An Introduction to Human-Centred Design
Watch the recording of 'An Introduction to Human-Centred Design', presented by Elise West at DrupalCon Barcelona 2024
Tamsin Fox-Davies Thu, 10/31/2024 - 22:23{kind=link}
Qt Creator 15 Beta2 released
We are happy to announce the release of Qt Creator 15 Beta2!
John Cook: How hard is constraint programming?
{kind=link}
I’ve been writing code for the Z3 SMT solver for several months now. Here are my findings.
Python is used here as the base language. Python/Z3 feels like a two-layer programming model—declarative code for Z3, imperative code for Python. In this it seems reminiscent of C++/CUDA programming for NVIDIA GPUs—in that case, mixed CPU and GPU imperative code. Either case is a clever combination of methodologies that is surprisingly fluent and versatile, albeit not a perfect blend of seamless conceptual cohesion.
Other comparisons:
- Both have two separate memory spaces (CUDA CPU/GPU memories for one; pure Python variables and Z3 variables for the other).
- Both can be tricky to debug. In earlier days, CUDA had no debugger, so one had to fall back to the trusty “printf” statement (for a while it didn’t even have that!). If the code crashed, you might get no output at all. To my knowledge, Z3 has no dedicated debugger. If the problem being solved comes back as satisfiable, you can print out the discovered model variables, but if satisfiability fails, you get very little information. Like some other novel platforms, something of a “black box.”
- In both cases, programmer productivity can be well-served by developing custom abstractions. I developed a Python class to manage multidimensional arrays of Z3 variables, this was a huge time saver.
There are differences too, of course.
- In Python, “=” is assignment, but in Z3, one only has “==”, logical or numeric equality, not assignment per se. Variables are set once and can’t be changed—sort of a “write-once variables” programming model—as is natural to logic programming.
- Code speed optimization is challenging. Code modifications for Z3 constraints/variables can have extreme and unpredictable runtime effects, so it’s hard to optimize. Z3 is solving an NP-complete problem after all, so runtimes can theoretically increase massively. Speedups can be massive also; one round of changes I made gave 2000X speedup on a test problem. Runtime of CUDA code can be unpredictable to a lesser degree, depending on the PTX and SASS code generation phases and the aggressive code optimizations of the CUDA compiler. However, it seems easier to “see through” CUDA code, down to the metal, to understand expected performance, at least for smaller code fragments. The Z3 solver can output statistics of the solve, but these are hard to actionably interpret for a non-expert.
- Z3 provides many, many algorithmic tuning parameters (“tactics”), though it’s hard to reason about which ones to pick. Autotuners like FastSMT might help. Also there have been some efforts to develop tools to visualize the solve process, this might be of help.
It would be great to see more modern tooling support and development of community best practices to help support Z3 code developers.
The post How hard is constraint programming? first appeared on John D. Cook.Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
- www-zh-cn @ Savannah: Welcome our new member - bingchuanjuzi
- Matt Glaman: Lenient Composer Plugin officially replaces lenient packages endpoint
- libtool @ Savannah: libtool-2.5.4 released [stable]
- Trey Hunner: Python Black Friday & Cyber Monday sales (2024)
- Security advisories: Drupal core - Moderately critical - Gadget chain - SA-CORE-2024-008
FLOSS Research
- Give Your Input on the State of Open Source Survey
- Open Data and Open Source AI: Charting a course to get more of both
- The Open Source Initiative and the Eclipse Foundation to Collaborate on Shaping Open Source AI (OSAI) Public Policy
- ClearlyDefined v2.0 adds support for LicenseRefs
- ClearlyDefined at SOSS Fusion 2024: a collaborative solution to Open Source license compliance