
Feeds
TechBeamers Python: How Do You Filter a List in Python?
In this tutorial, we’ll explain different methods to filter a list in Python with the help of multiple examples. You’ll learn to use the Python filter() function, list comprehension, and also use Python for loop to select elements from the list. Filter a List in Python With the Help of Examples As we know there […]
The post How Do You Filter a List in Python? appeared first on TechBeamers.
Real Python: What Are Python Raw Strings?
If you’ve ever come across a standard string literal prefixed with either the lowercase letter r or the uppercase letter R, then you’ve encountered a Python raw string:
Python >>> r"This is a raw string" 'This is a raw string' Copied!Although a raw string looks and behaves mostly the same as a normal string literal, there’s an important difference in how Python interprets some of its characters, which you’ll explore in this tutorial.
Notice that there’s nothing special about the resulting string object. Whether you declare your literal value using a prefix or not, you’ll always end up with a regular Python str object.
Other prefixes available at your fingertips, which you can use and sometimes even mix together in your Python string literals, include:
- b: Bytes literal
- f: Formatted string literal
- u: Legacy Unicode string literal (PEP 414)
Out of those, you might be most familiar with f-strings, which let you evaluate expressions inside string literals. Raw strings aren’t as popular as f-strings, but they do have their own uses that can improve your code’s readability.
Creating a string of characters is often one of the first skills that you learn when studying a new programming language. The Python Basics book and learning path cover this topic right at the beginning. With Python, you can define string literals in your source code by delimiting the text with either single quotes (') or double quotes ("):
Python >>> david = 'She said "I love you" to me.' >>> alice = "Oh, that's wonderful to hear!" Copied!Having such a choice can help you avoid a syntax error when your text includes one of those delimiting characters (' or "). For example, if you need to represent an apostrophe in a string, then you can enclose your text in double quotes. Alternatively, you can use multiline strings to mix both types of delimiters in the text.
You may use triple quotes (''' or """) to declare a multiline string literal that can accommodate a longer piece of text, such as an excerpt from the Zen of Python:
Python >>> poem = """ ... Beautiful is better than ugly. ... Explicit is better than implicit. ... Simple is better than complex. ... Complex is better than complicated. ... """ Copied!Multiline string literals can optionally act as docstrings, a useful form of code documentation in Python. Docstrings can include bare-bones test cases known as doctests, as well.
Regardless of the delimiter type of your choice, you can always prepend a prefix to your string literal. Just make sure there’s no space between the prefix letters and the opening quote.
When you use the letter r as the prefix, you’ll turn the corresponding string literal into a raw string counterpart. So, what are Python raw strings exactly?
Free Bonus: Click here to download a cheatsheet that shows you the most useful Python escape character sequences.
Take the Quiz: Test your knowledge with our interactive “Python Raw Strings” quiz. Upon completion you will receive a score so you can track your learning progress over time:
In Short: Python Raw Strings Ignore Escape Character SequencesIn some cases, defining a string through the raw string literal will produce precisely the same result as using the standard string literal in Python:
Python >>> r"I love you" == "I love you" True Copied!Here, both literals represent string objects that share a common value: the text I love you. Even though the first literal comes with a prefix, it has no effect on the outcome, so both strings compare as equal.
To observe the real difference between raw and standard string literals in Python, consider a different example depicting a date formatted as a string:
Python >>> r"10\25\1991" == "10\25\1991" False Copied!This time, the comparison turns out to be false even though the two string literals look visually similar. Unlike before, the resulting string objects no longer contain the same sequence of characters. The raw string’s prefix (r) changes the meaning of special character sequences that begin with a backslash (\) inside the literal.
Note: To understand how Python interprets the above string, head over to the final section of this tutorial, where you’ll cover the most common types of escape sequences in Python.
Read the full article at https://realpython.com/python-raw-strings/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Tag1 Consulting: Unraveling the Extract, Transform, Load (ETL) Data Migration Process: A Deep Dive on Load
In this episode of Tag1 Team Talks, our team of Drupal experts delve into the essential "Load" phase of the ETL (Extract, Transform, Load) process in Drupal migrations.
Read more janez Wed, 01/24/2024 - 05:37Ned Batchelder: You (probably) don’t need to learn C
On Mastodon I wrote that I was tired of people saying, “you should learn C so you can understand how a computer really works.” I got a lot of replies which did not change my mind, but helped me understand more how abstractions are inescapable in computers.
People made a number of claims. C was important because syscalls are defined in terms of C semantics (they are not). They said it was good for exploring limited-resource computers like Arduinos, but most people don’t program for those. They said it was important because C is more performant, but Python programs often offload the compute-intensive work to libraries other people have written, and these days that work is often on a GPU. Someone said you need it to debug with strace, then someone said they use strace all the time and don’t know C. Someone even said C was good because it explains why NUL isn’t allowed in filenames, but who tries to do that, and why learn a language just for that trivia?
I’m all for learning C if it will be useful for the job at hand, but you can write lots of great software without knowing C.
A few people repeated the idea that C teaches you how code “really” executes. But C is an abstract model of a computer, and modern CPUs do all kinds of things that C doesn’t show you or explain. Pipelining, cache misses, branch prediction, speculative execution, multiple cores, even virtual memory are all completely invisible to C programs.
C is an abstraction of how a computer works, and chip makers work hard to implement that abstraction, but they do it on top of much more complicated machinery.
C is far removed from modern computer architectures: there have been 50 years of innovation since it was created in the 1970’s. The gap between C’s model and modern hardware is the root cause of famous vulnerabilities like Meltdown and Spectre, as explained in C is Not a Low-level Language.
C can teach you useful things, like how memory is a huge array of bytes, but you can also learn that without writing C programs. People say, C teaches you about memory allocation. Yes it does, but you can learn what that means as a concept without learning a programming language. And besides, what will Python or Ruby developers do with that knowledge other than appreciate that their languages do that work for them and they no longer have to think about it?
Pointers came up a lot in the Mastodon replies. Pointers underpin concepts in higher-level languages, but you can explain those concepts as references instead, and skip pointer arithmetic, aliasing, and null pointers completely.
A question I asked a number of people: what mistakes are JavaScript/Ruby/Python developers making if they don’t know these things (C, syscalls, pointers)?”. I didn’t get strong answers.
We work in an enormous tower of abstractions. I write programs in Python, which provides me abstractions that C (its underlying implementation language) does not. C provides an abstract model of memory and CPU execution which the computer implements on top of other mechanisms (microcode and virtual memory). When I made a wire-wrapped computer, I could pretend the signal travelled through wires instantaneously. For other hardware designers, that abstraction breaks down and they need to consider the speed electricity travels. Sometimes you need to go one level deeper in the abstraction stack to understand what’s going on. Everyone has to find the right layer to work at.
When you no longer have problems at that layer, that’s when you can stop caring about that layer. I don’t think there’s a universal level of knowledge that people need or is sufficient.
“like jam or bootlaces” made another excellent point:
There’s a big difference between “everyone should know this” and “someone should know this” that seems to get glossed over in these kinds of discussions.
C can teach you many useful and interesting things. It will make you a better programmer, just as learning any new-to-you language will because it broadens your perspective. Some kinds of programming need C, though other languages like Rust are ably filling that role now too. C doesn’t teach you how a computer really works. It teaches you a common abstraction of how computers work.
Find a level of abstraction that works for what you need to do. When you have trouble there, look beneath that abstraction. You won’t be seeing how things really work, you’ll be seeing a lower-level abstraction that could be helpful. Sometimes what you need will be an abstraction one level up. Is your Python loop too slow? Perhaps you need a C loop. Or perhaps you need numpy array operations.
You (probably) don’t need to learn C.
Thomas Lange: FAI 6.2 released
After more than one a year, a new minor FAI version is available, but it includes some interesting new features.
Here a the items from the NEWS file:
fai (6.2) unstable; urgency=low
- fai-cd can now create live images
- Use systemd during installation
- New feature: run FAI inside a screen or tmux session
- fai-diskimage: do not use compression of qemu-img which is slow instead provide .qcow2.zst, add option -C
- fai-kvm: add support for booting from USB storage
- new tool mk-data-partition adds a data partition to an ISO
- easy installation of packages from /pkgs/<CLASS> directories
- new helper functions for creating custom list of disks
- new method detect:// for FAI_CONFIG_SRC
In the past the command fai-cd was only used for creating installation ISOs, that could be used from CD or USB stick. Now it possible to create a live ISO. Therefore you create your live chroot environment using 'fai dirinstall' and then convert it to a bootable live ISO using fai-cd. See man fai-cd(8) for an example.
Years ago I had the idea to use the remaining disk space on an USB stick after copying an ISO onto it. I've blogged about this recently:
https://blog.fai-project.org/posts/extending-iso-images/
The new FAI version includes the tool mk-data-partition for adding a data partition to the ISO itself or to an USB stick.
FAI detects this data partition, mounts it to /media/data and can then use various configurations from it. You may want to copy your own set of .deb packages or your whole FAI config space to this partition. FAI now automatically searches this partition for usable FAI configuration data and packages. FAI will install all packages from pkgs/<CLASSNAME> if the equivalent class is defined. Setting FAI_CONFIG_SRC=detect:// now looks into the data partition for the subdirectory 'config' and uses this as the config space. So it's now possible to modify an existing ISO (that is read-only) and make changes to the config space. If there's no config directory in the data partition FAI uses the default location on the ISO.
The tool fai-kvm, which starts virtual machines can now boot an ISO not only as CD but also as USB stick.
Sometimes users want to adjust the list of disks before the partitioning is startet. Therefore FAI provides several new functions including
- smallestdisk()
- largestdisk()
- matchdisks()
You can select individual disks by their model name or even the serial number.
Two new FAI flags were added (tmux and screen) that make it easy to run FAI inside a tmux or screen session.
And finally FAI uses systemd. Yeah!This technical change was waiting since 2015 in a merge request from Moritz 'Morty' Strübe, that would enable using systemd during the installation. Before FAI still was using old-style SYSV init scripts and did not started systemd. I didn't tried to apply the patch, because I was afraid that it would need much time to make it work. But then in may 2023 Juri Grabowski just gave it a try at MiniDebConf Hamburg, and voilà it just works! Many, many thanks to Moritz and Juri for their bravery.
The whole changelog can be found at https://tracker.debian.org/media/packages/f/fai/changelog-6.2
New ISOs for FAI are also available including an example of a Xfce desktop live ISO: https://fai-project.org/fai-cd/
The FAIme service for creating customized installation ISOs will get its update later.
The new packages are available for bookworm by adding this line to your sources.list:
deb https://fai-project.org/download bookworm koeln
IslandT: How to search multiple lines with Python?
Often you will want to search for words or phrase in the entire paragraph and here is the python regular expression code which will do that.
pattern = re.compile(r'^\w+ (\w+) (\w+)', re.M)We use the re.M flag which will search the entire paragraph for the match words.
Now let us try out the program above…
gad = pattern.findall("hello mr Islandt\nhello mr gadgets") print(gad)…which will then display the following outcome
[('mr', 'Islandt'), ('mr', 'gadgets')]Explanation :
The program above will look for two words in the first line and keeps them under a tuple and when the program meets the new line character it continues the search in the second line and return another tuple, both of the tuple will include inside a list. Using re.M flag the search will go on for multiple lines as long as there are more matches out there!
PyBites: Exploring the Role of Static Methods in Python: A Functional Perspective
Python’s versatility in supporting different programming paradigms, including procedural, object-oriented, and functional programming, opens up a rich landscape for software design and development.
Among these paradigms, the use of static methods in Python, particularly in an object-oriented context, has been a topic of debate.
This article delves into the role and implications of static methods in Python, weighing them against a more functional approach that leverages modules and functional programming principles.
The Nature of Static Methods in Python Definition and Usage:Static methods in Python are defined within a class using the @staticmethod decorator.
Unlike regular methods, they do not require an instance (self) or class (cls) reference.
They are typically used for utility functions that logically belong to a class but are independent of class instances.
Example in Practice:Consider this code example from Django:
# django/db/backends/oracle/operations.py class DatabaseOperations(BaseDatabaseOperations): ... other methods and attributes ... @staticmethod def convert_empty_string(value, expression, connection): return "" if value is None else value @staticmethod def convert_empty_bytes(value, expression, connection): return b"" if value is None else valueHere, convert_empty_string and convert_empty_bytes are static due to their utility nature and specific association with the DatabaseOperations class.
The Case for Modules and Functional Programming Embracing Python’s Module System:Python’s module system allows for effective namespace management and code organization.
Namespaces are one honking great idea — let’s do more of those!
The Zen of Python, by Tim PetersFunctions, including those that could be static methods, can be organized in modules, making them reusable and easily accessible.
Functional Programming Advantages:- Quick Development: Functional programming emphasizes simplicity and stateless operations, leading to concise and readable code.
- Code Resilience: Pure functions (functions that do not alter external state) enhance predictability and testability. Related: 10 Tips to Write Better Functions in Python
- Separation of Concerns: Using functions and modules promotes a clean separation of data representation (classes) and behavior (functions).
- Abstraction with Classes: Use classes for data representation, encapsulating state and behavior that are closely related. See also our When to Use Classes article.
- Functional Constructs: Utilize functional concepts like higher-order functions, immutability, and pure functions for business logic and data manipulation.
- Factories and Observers: Implement design patterns like factory and observer for creating objects and managing state changes, respectively (shout-out to Brandon Rhodes’ awesome great design patterns guide!)
The decision to use static methods, standalone functions, or a functional programming approach in Python depends on several factors:
- Relevance: Is the function logically part of a class’s responsibilities?
- Reusability: Would the function be more versatile as a standalone module function?
- Simplicity: Can the use of regular functions simplify the class structure and align with the Single Responsibility Principle? Related article: Tips for clean code in Python.
Ultimately, the choice lies in finding the right balance that aligns with the application’s architecture, maintainability, and the development team’s expertise.
Python, with its multi-paradigm capabilities , offers the flexibility to adopt a style that best suits the project’s needs.
Fun Fact: Static Methods Were an AccidentGuido added static methods as an accident! He originally meant to add class methods instead.
I think the reason is that a module at best acts as a class where every method is a *static* method, but implicitly so. Ad we all know how limited static methods are. (They’re basically an accident — back in the Python 2.2 days when I was inventing new-style classes and descriptors, I meant to implement class methods but at first I didn’t understand them and accidentally implemented static methods first. Then it was too late to remove them and only provide class methods.)
Guido van Rossum, see the discussion thread here, and thanks Will for pointing me to this. Call to ActionWhat’s your approach to using static methods in Python?
Do you favor a more functional style, or do you find static methods indispensable in certain scenarios?
Share your thoughts and experiences in our community …
eGenix.com: eGenix Antispam Bot for Telegram 0.6.0 GA
eGenix has long been running a local user group meeting in Düsseldorf called Python Meeting Düsseldorf and we are using a Telegram group for most of our communication.
In the early days, the group worked well and we only had few spammers joining it, which we could well handle manually.
More recently, this has changed dramatically. We are seeing between 2-5 spam signups per day, often at night. Furthermore, the signups accounts are not always easy to spot as spammers, since they often come with profile images, descriptions, etc.
With the bot, we now have a more flexible way of dealing with the problem.
Please see our project page for details and download links.
Features
- Low impact mode of operation: the bot tries to keep noise in the group to a minimum
- Several challenge mechanisms to choose from, more can be added as needed
- Flexible and easy to use configuration
- Only needs a few MB of RAM, so can easily be put into a container or run on a Raspberry Pi
- Can handle quite a bit of load due to the async implementation
- Works with Python 3.9+
- MIT open source licensed
The 0.6.0 release fixes a few bugs and adds more features:
- Upgraded to pyrogram 2.0.106, which fixes a weird error we have been getting recently with the old version 1.4.16 (see pyrogram/pyrogram#1347)
- Catch weird error from Telegram when deleting conversations; this seems to sometimes fail, probably due to a glitch on their side
- Made the math and char entry challenges a little harder
- Added new DictItemChallenge
It has been battle-tested in production for several years already
and is proving to be a really useful tool to help with Telegram group
administration.
More Information
For more information on the eGenix.com Python products, licensing and download instructions, please write to sales@egenix.com.
Enjoy !
Marc-Andre Lemburg, eGenix.com
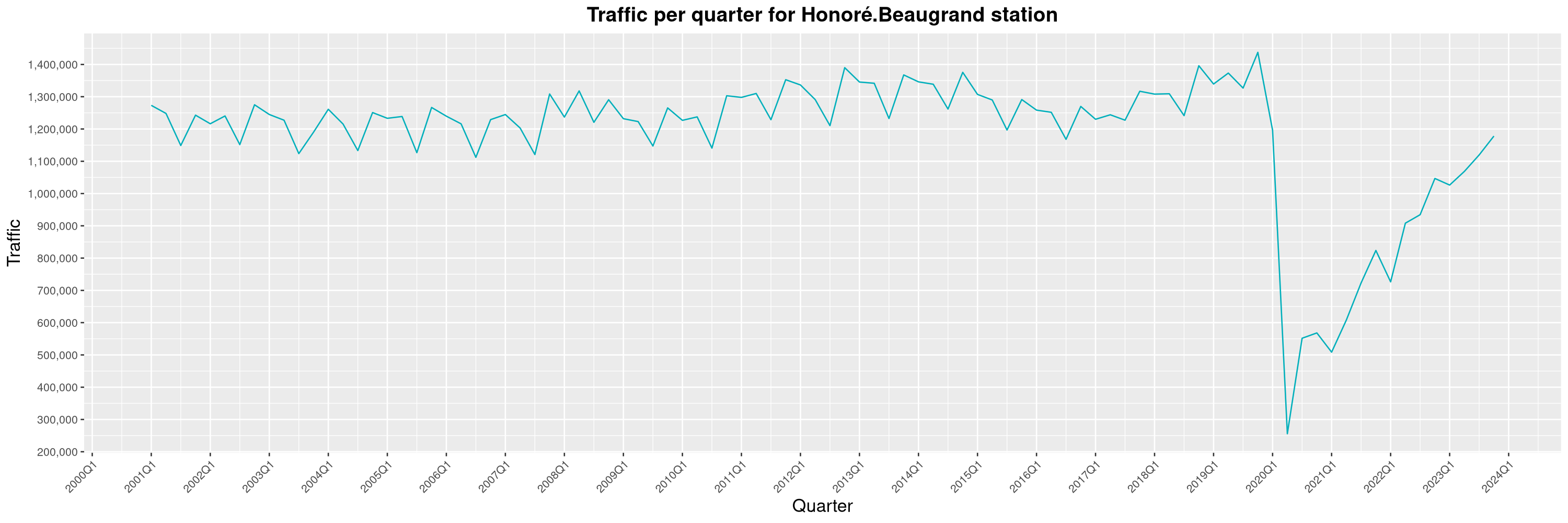
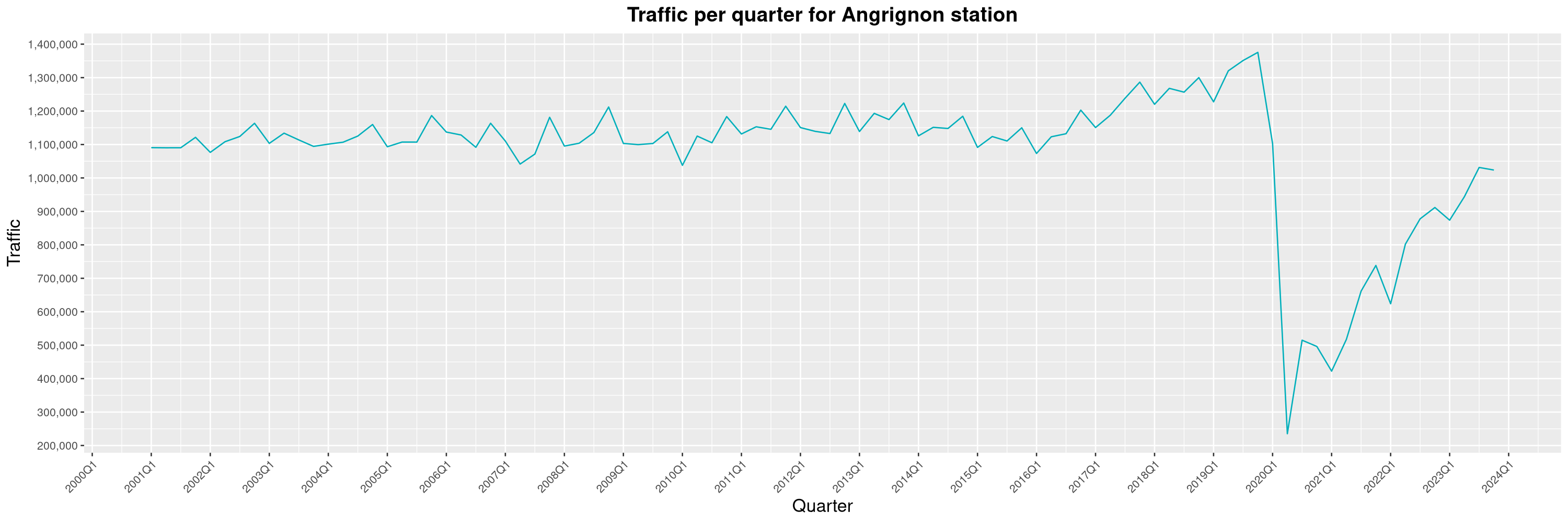
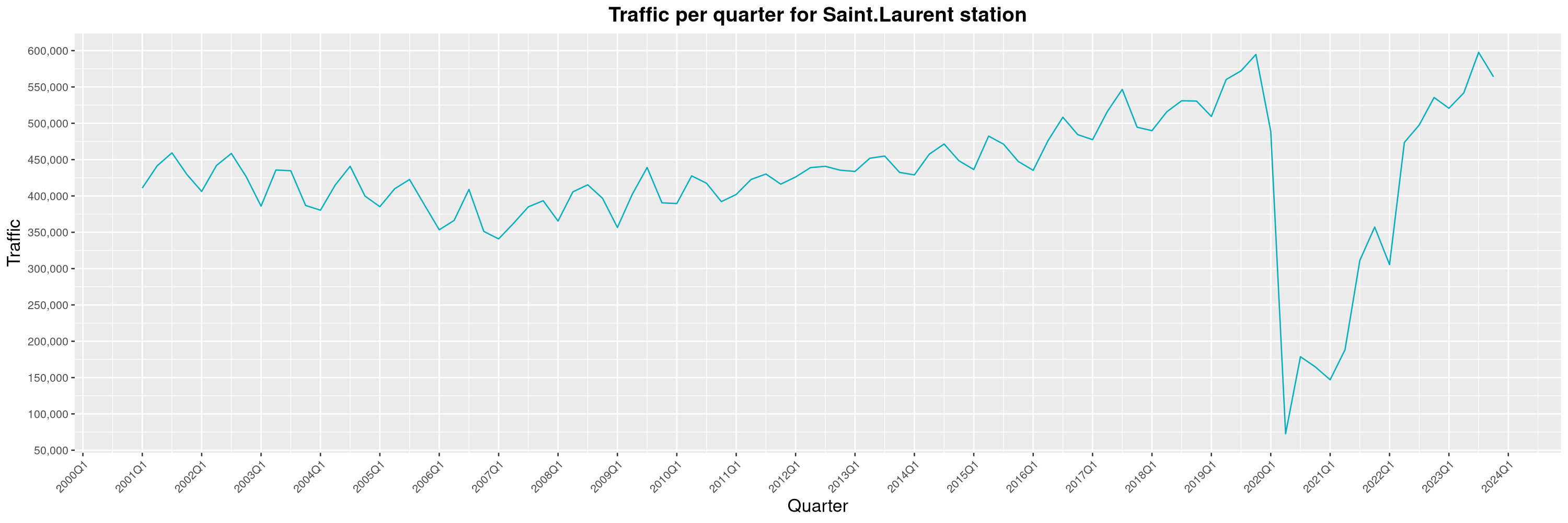
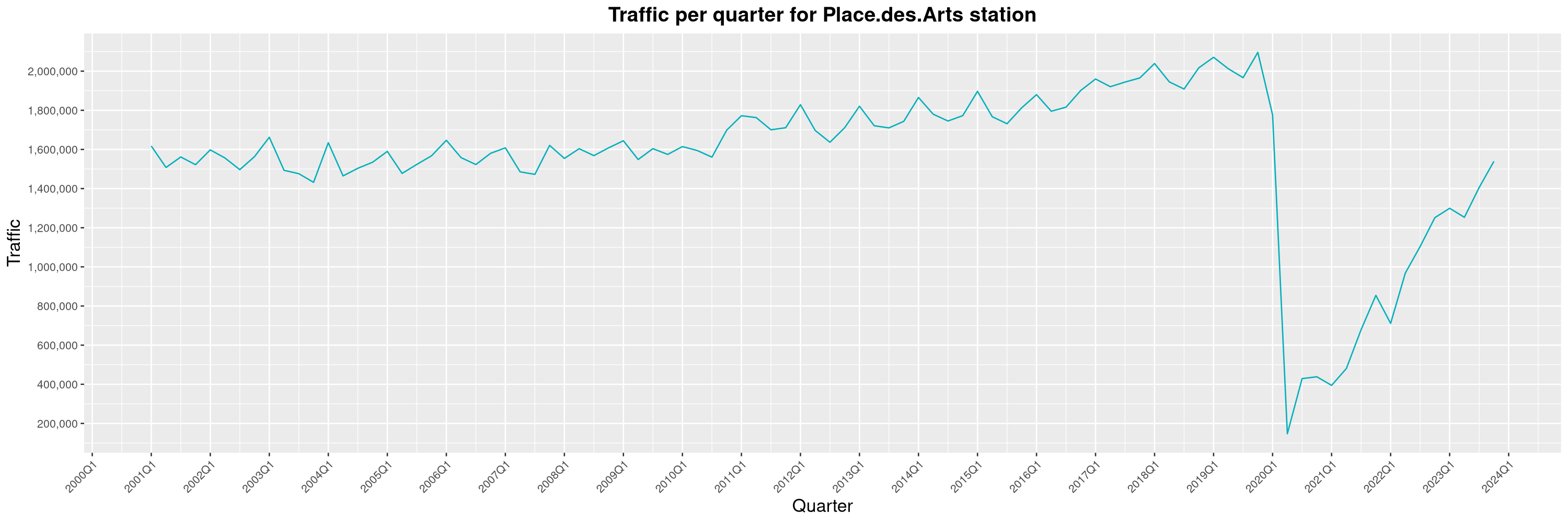
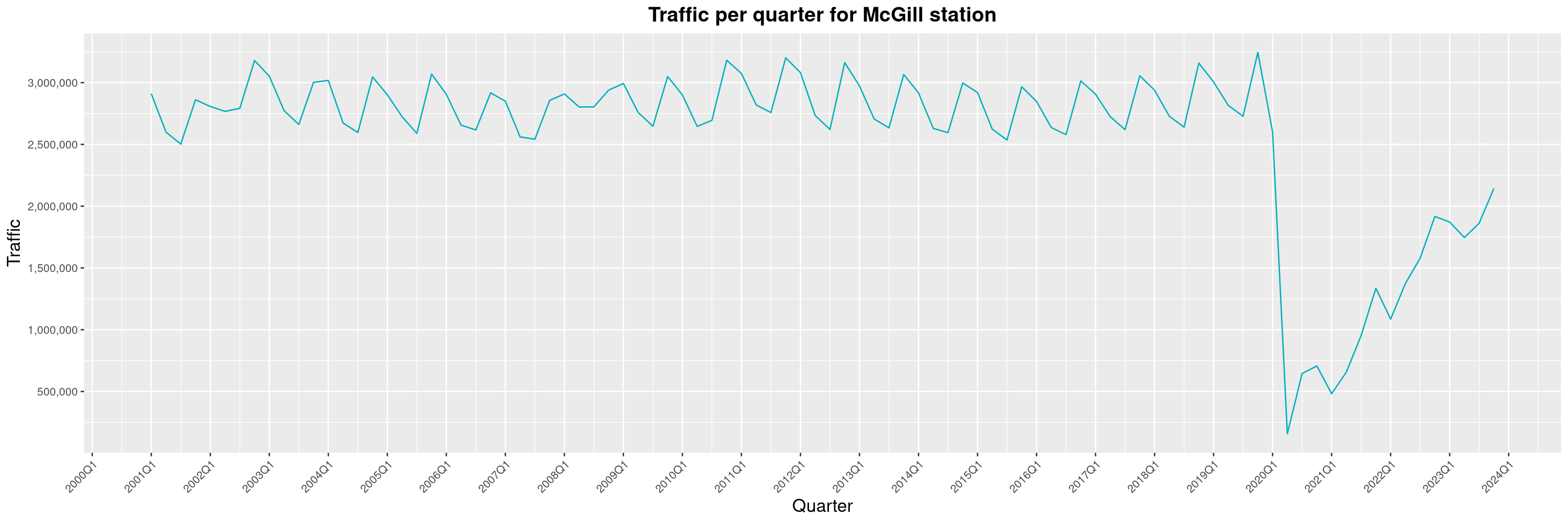
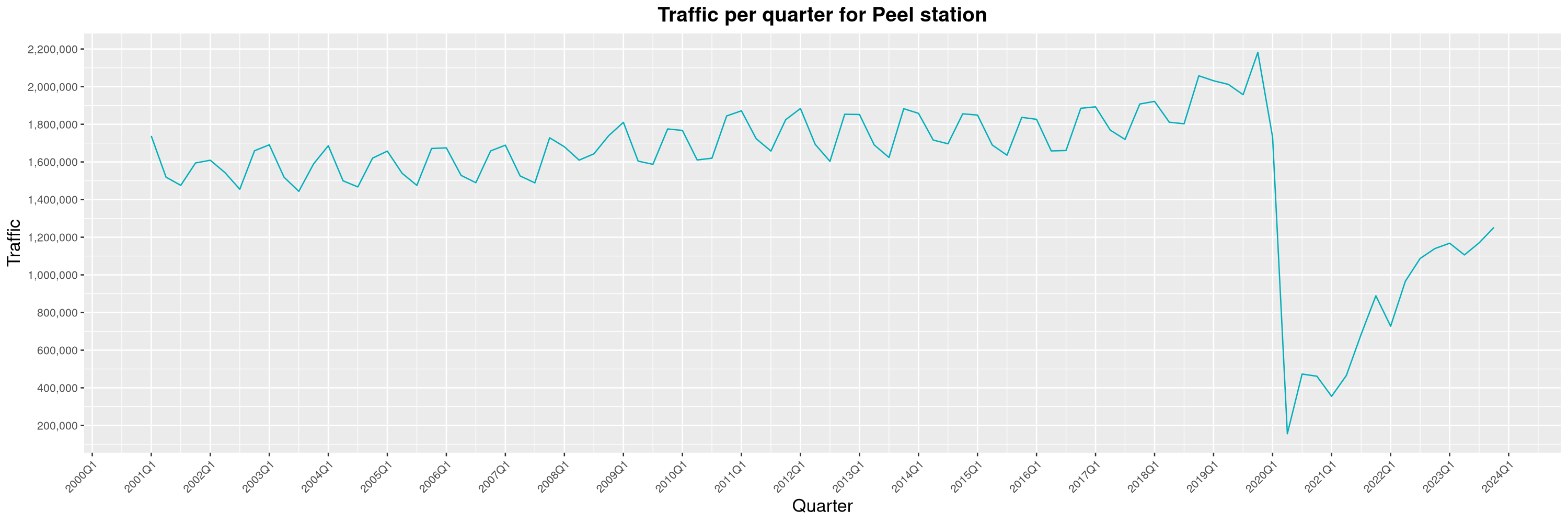
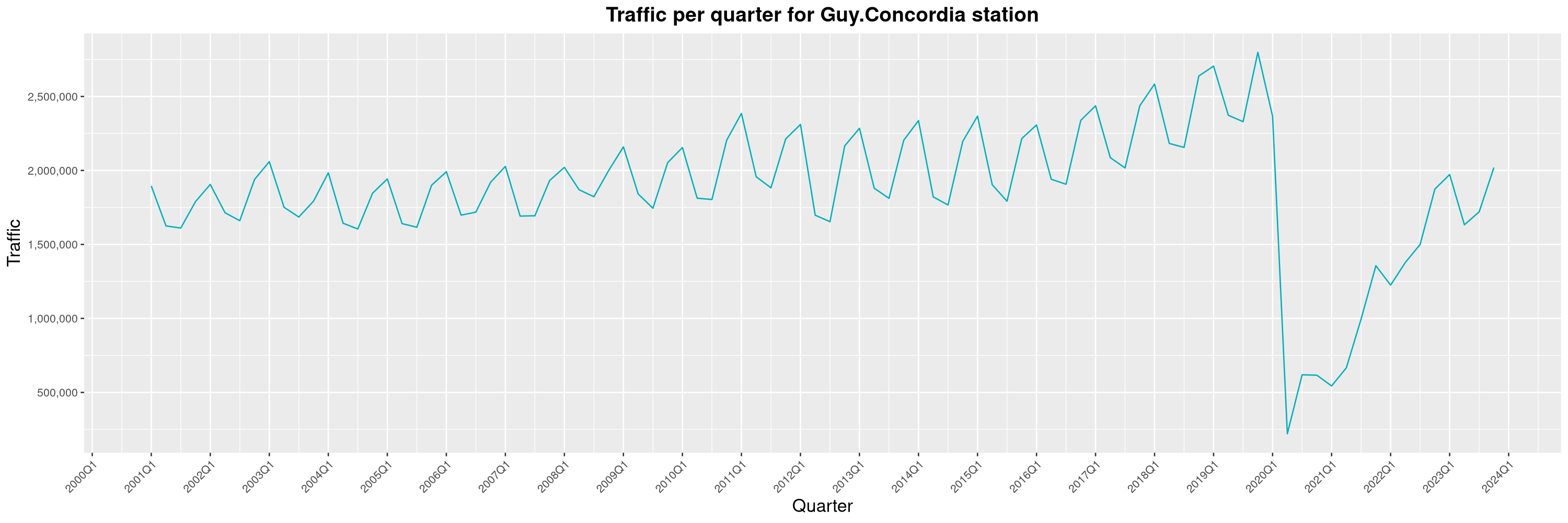
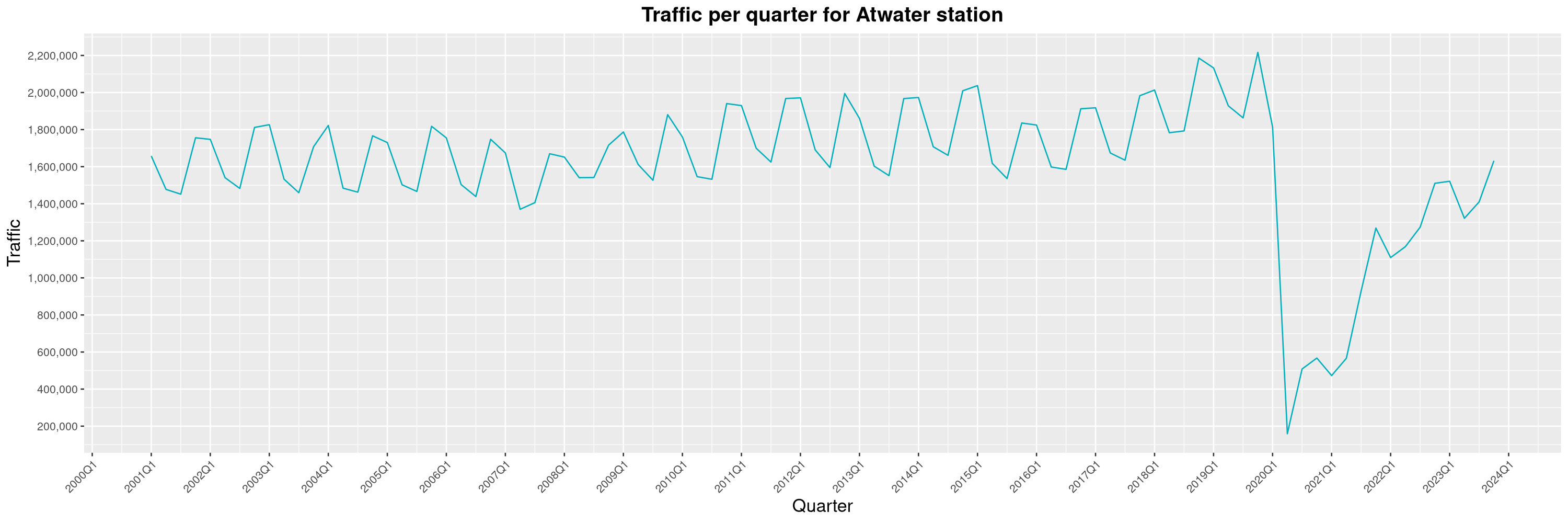
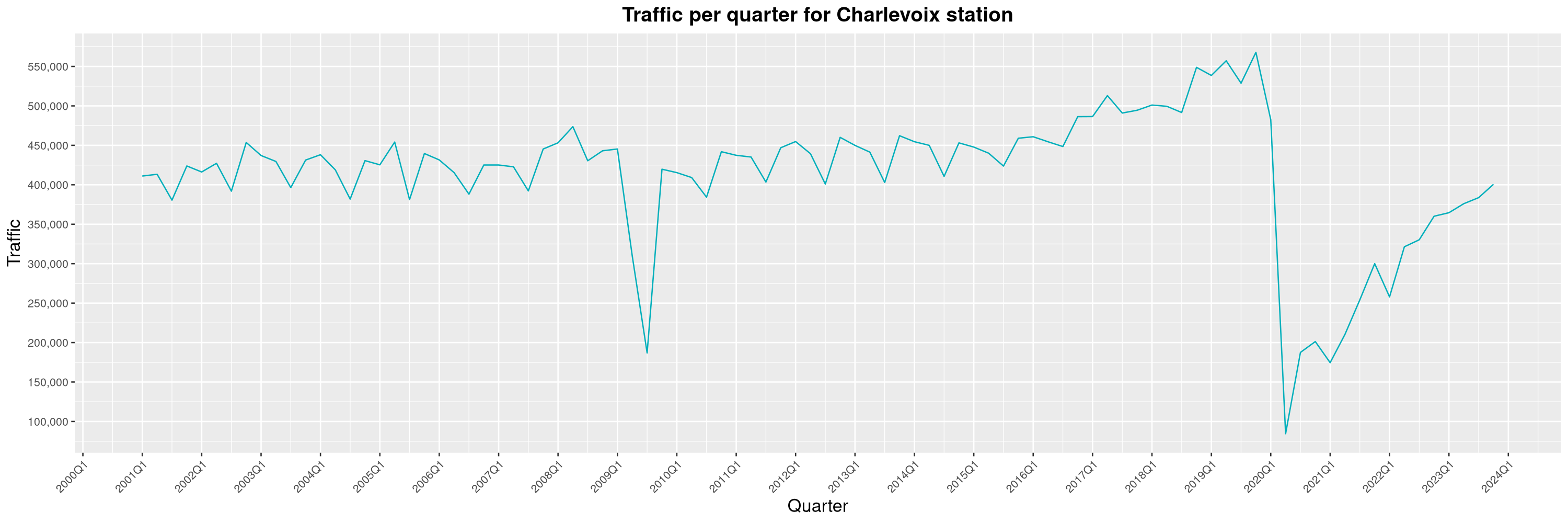
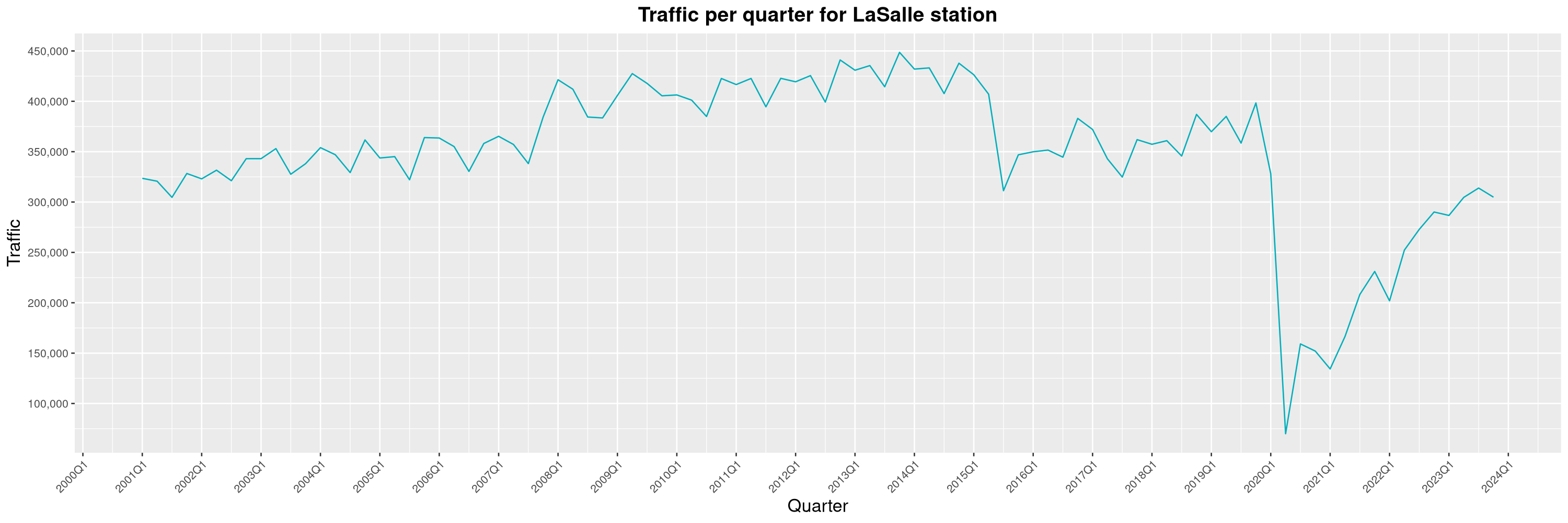
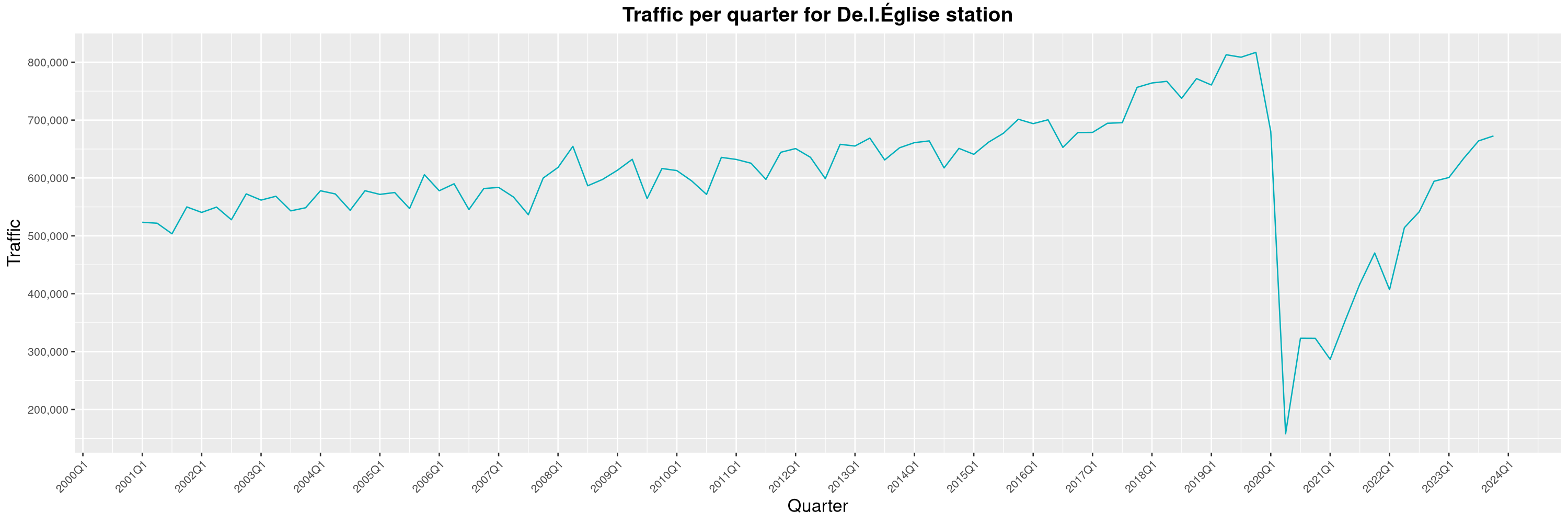
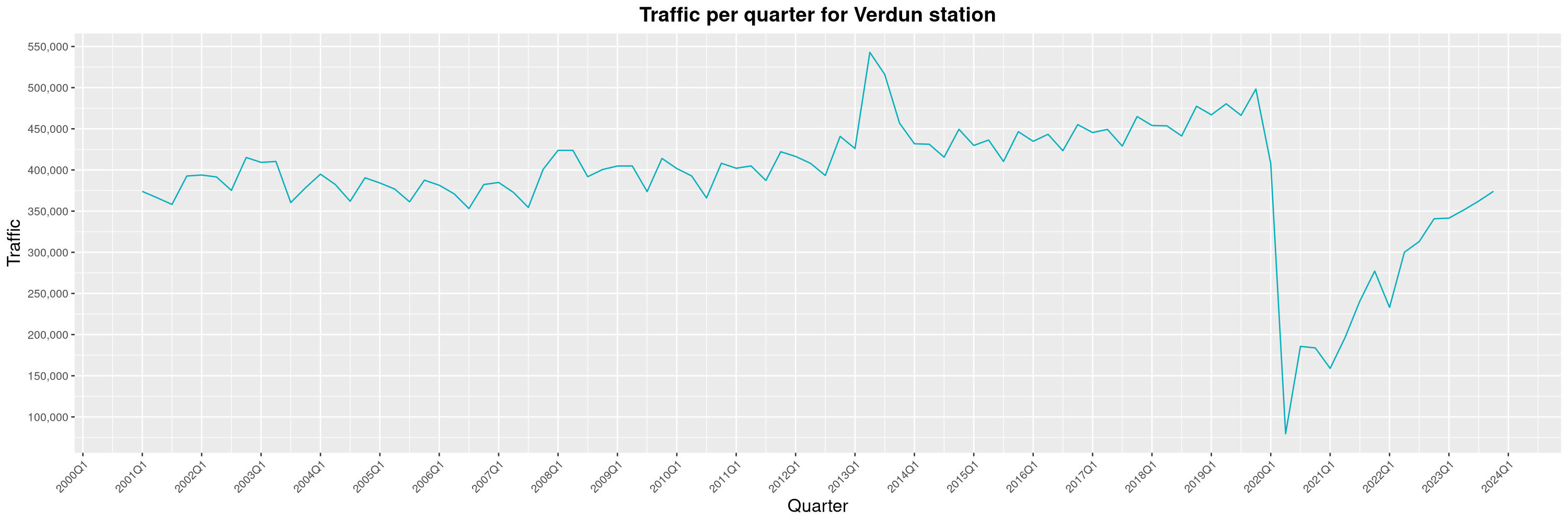
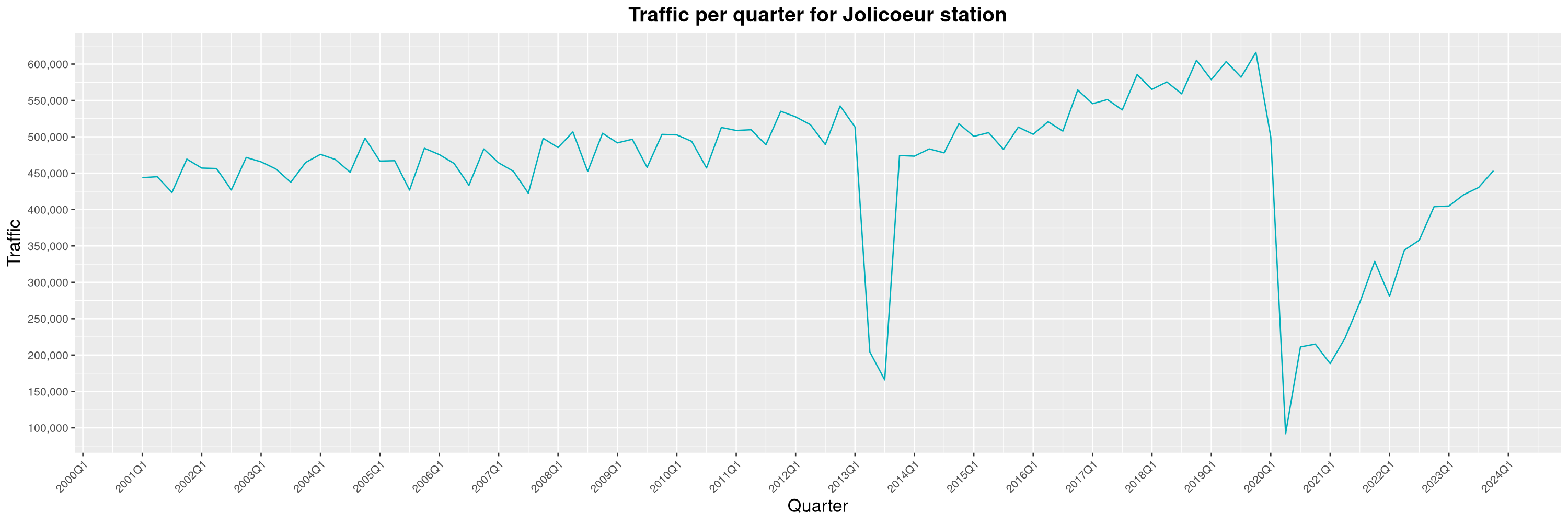
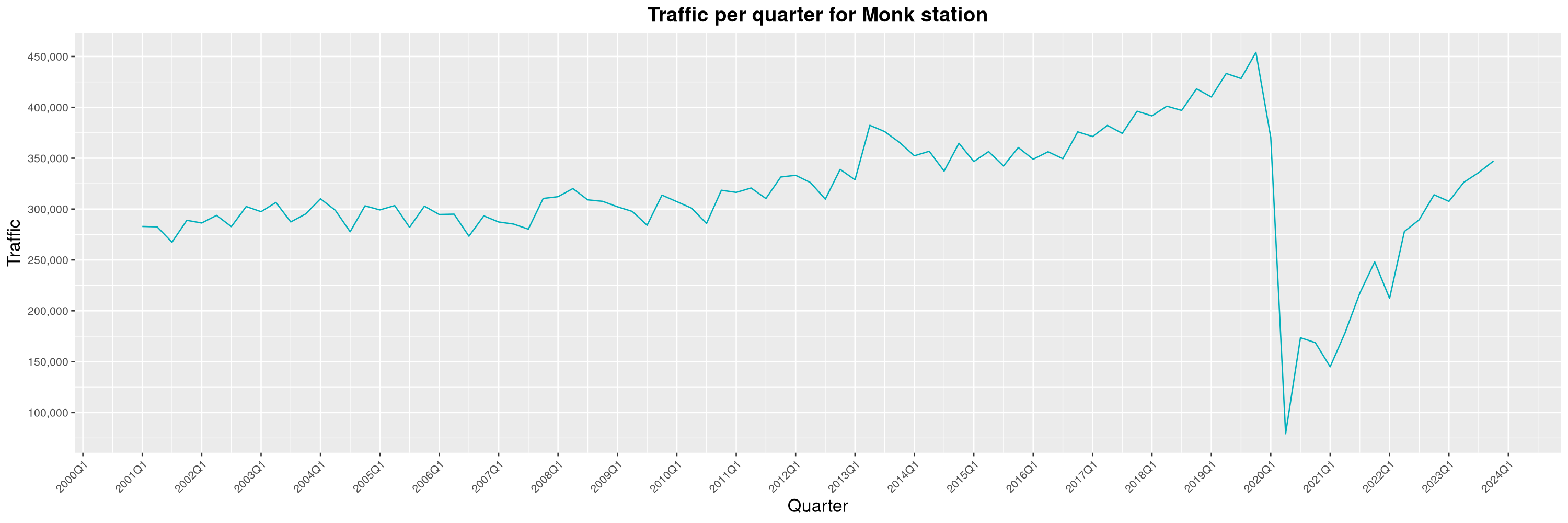
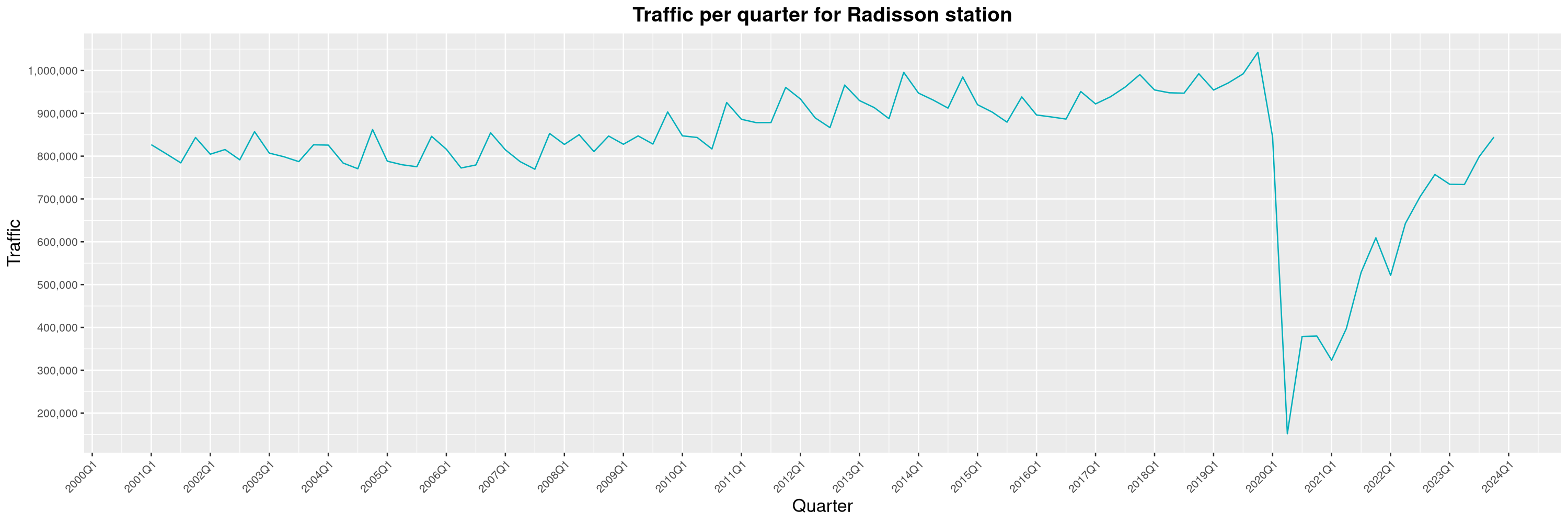
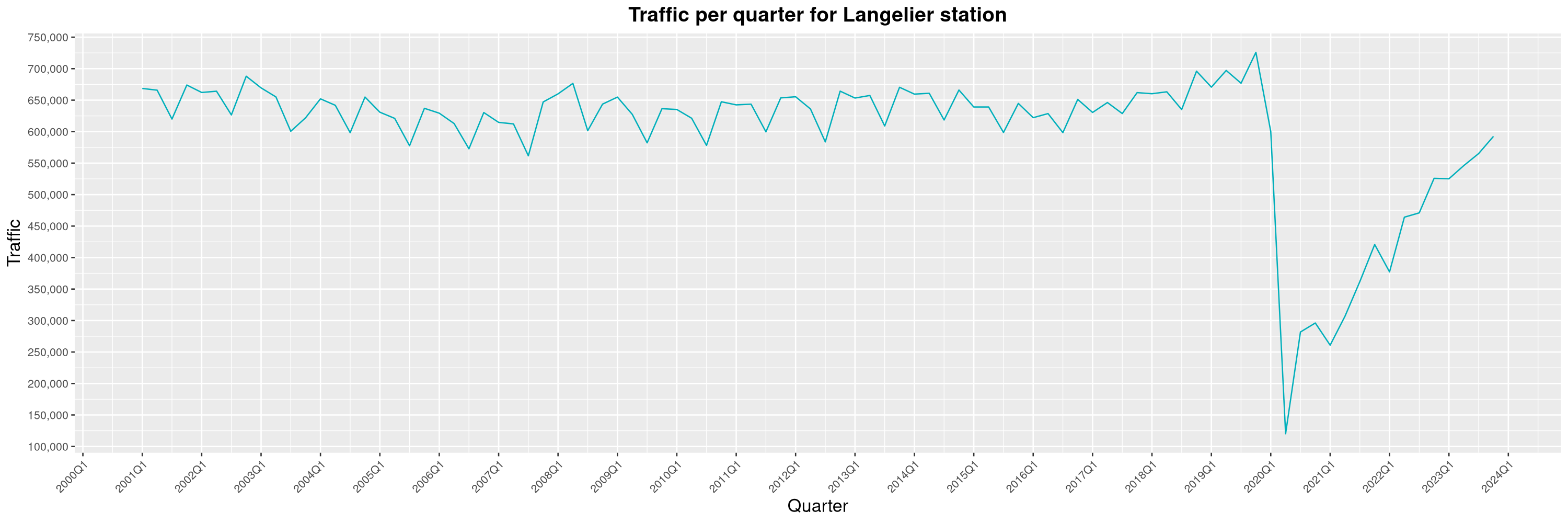
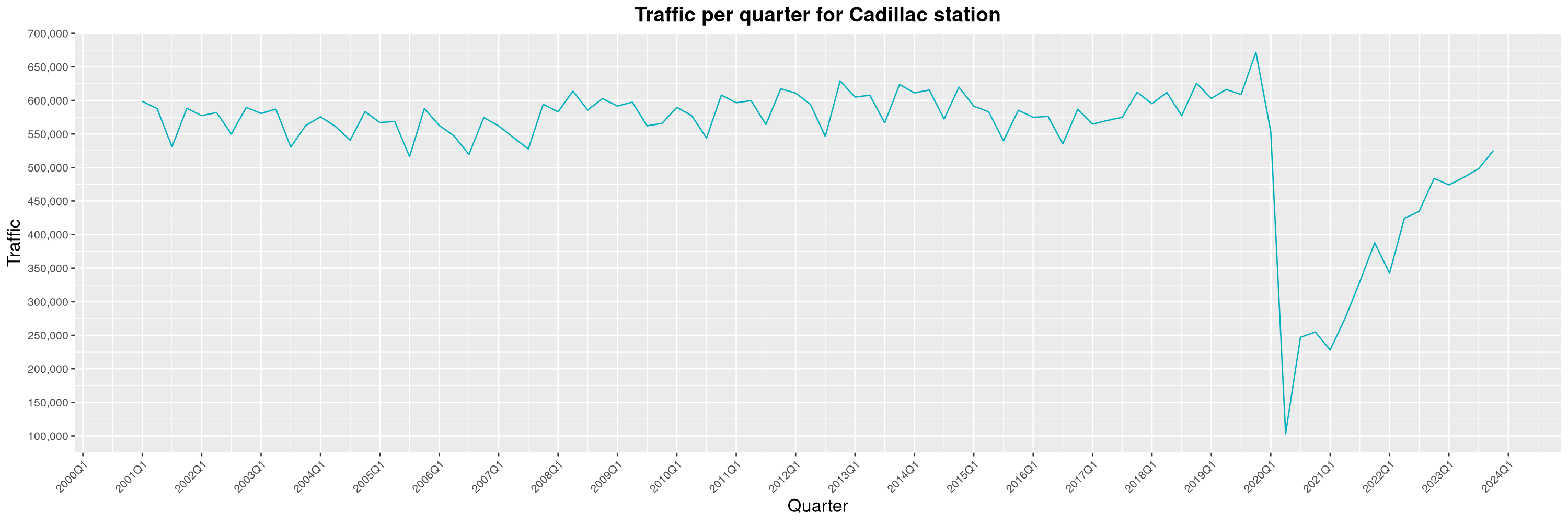
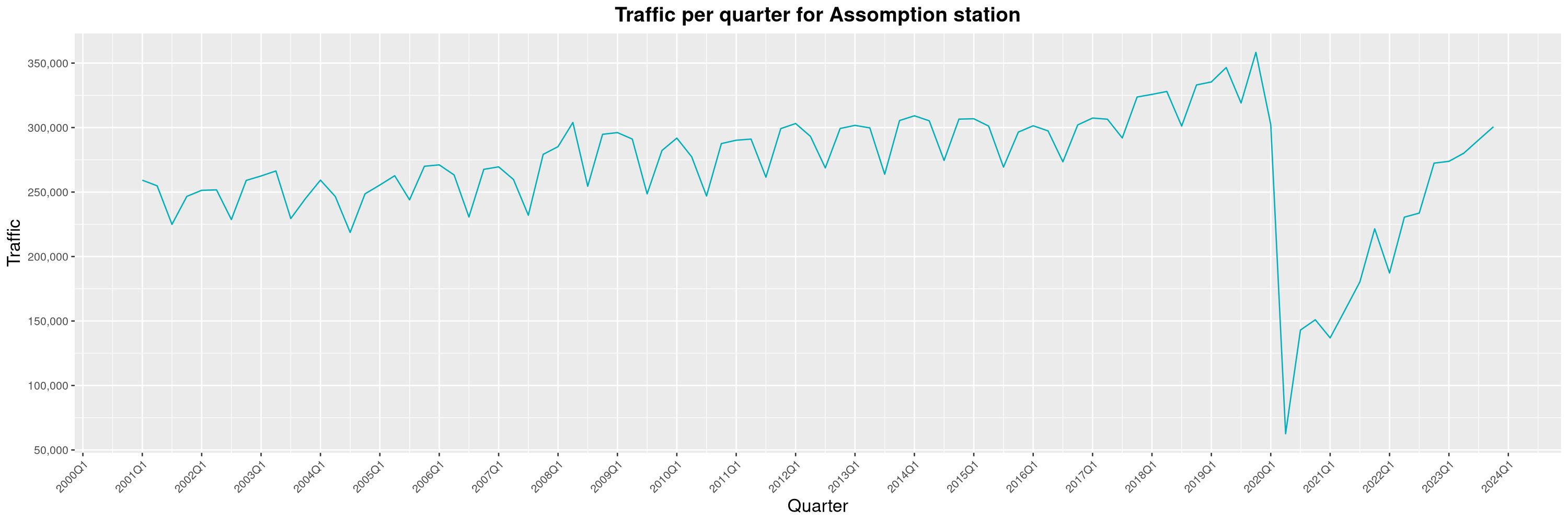
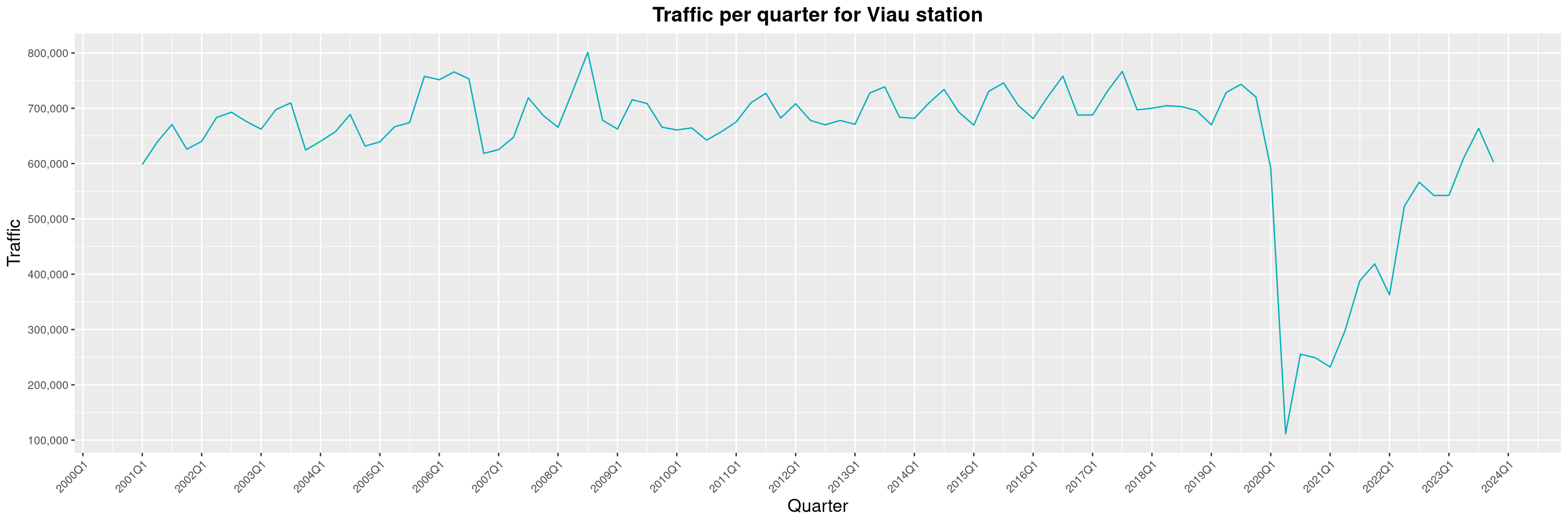
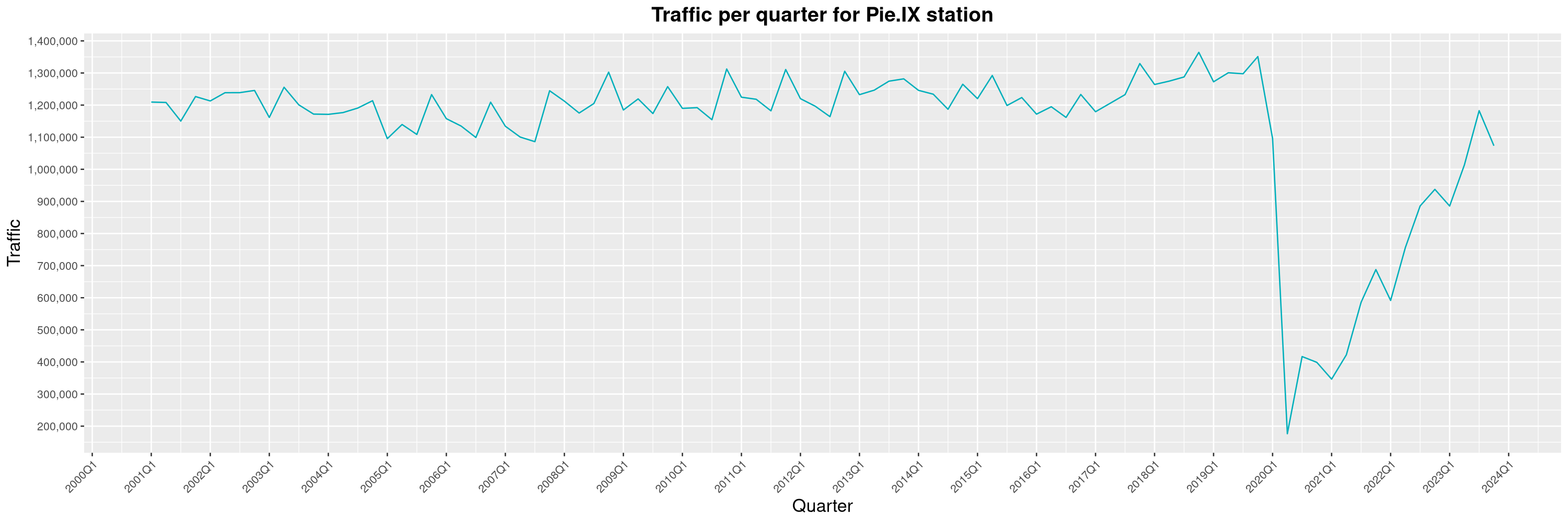
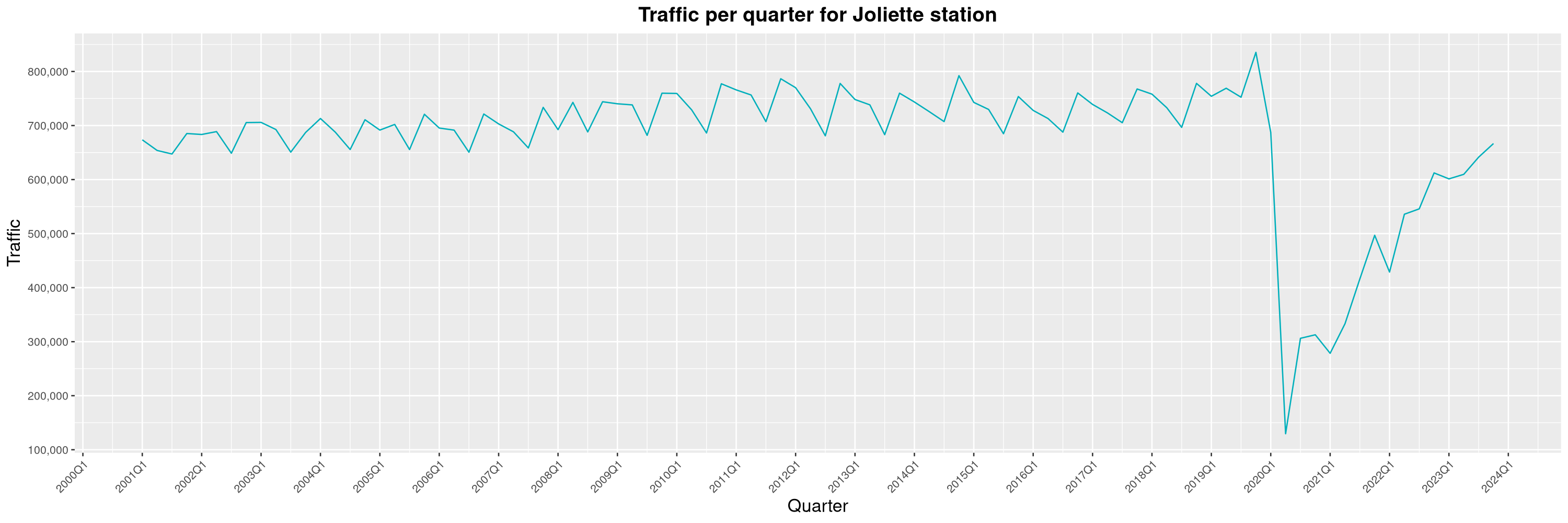
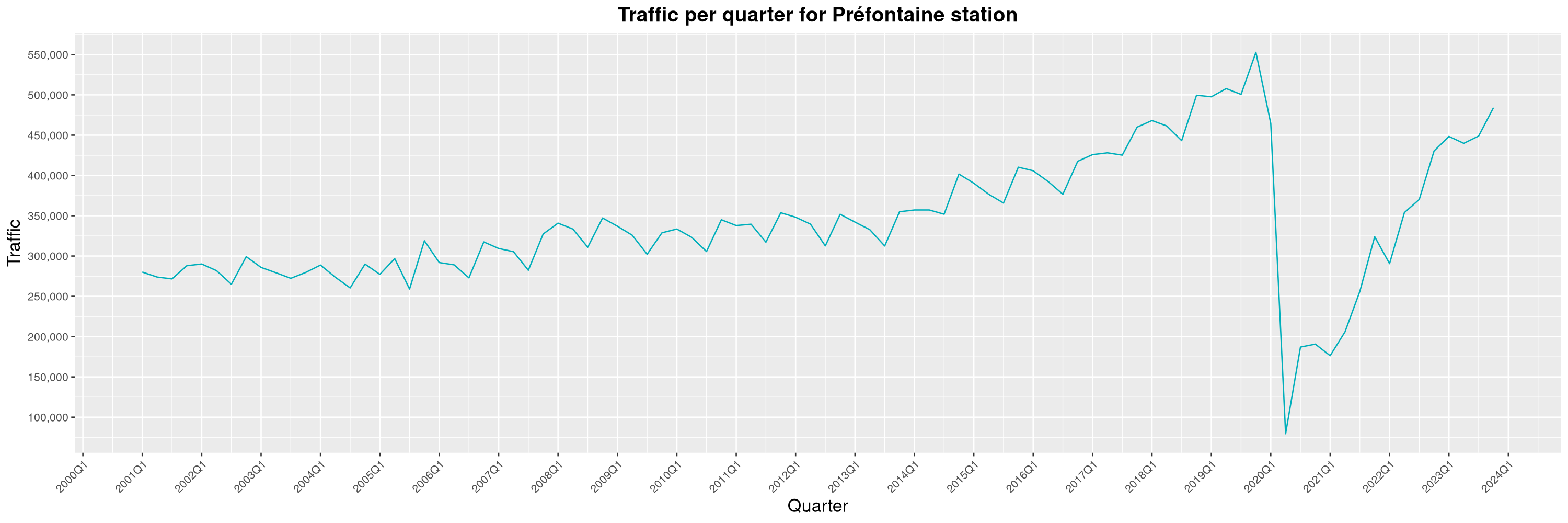
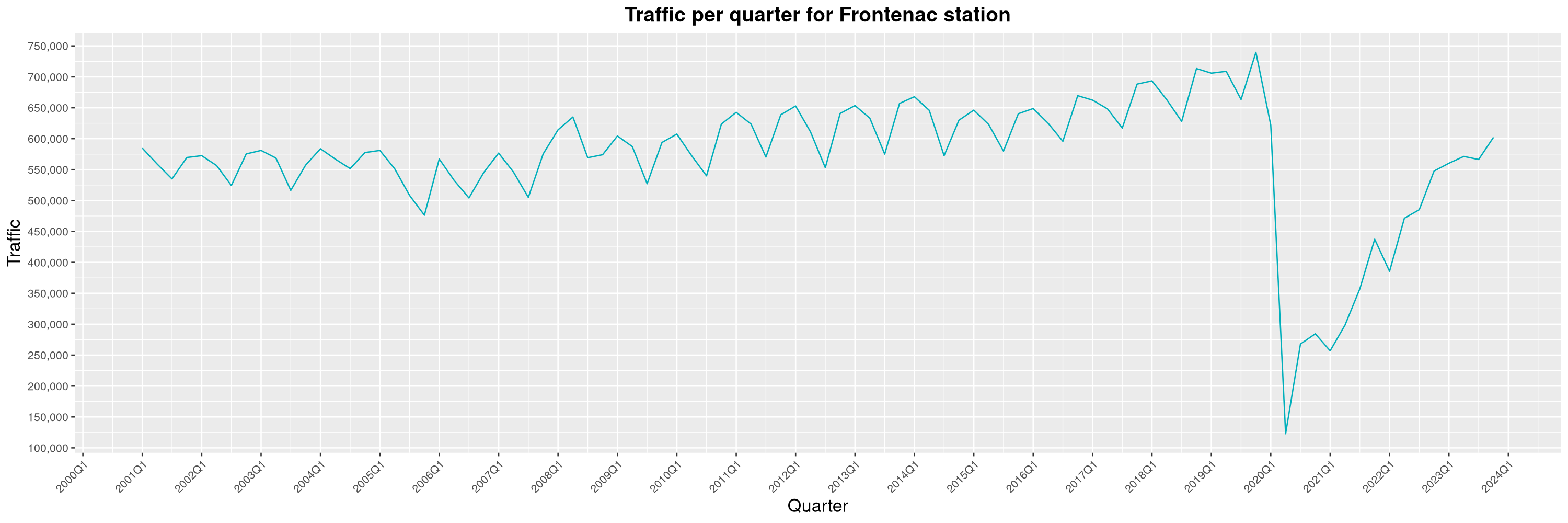
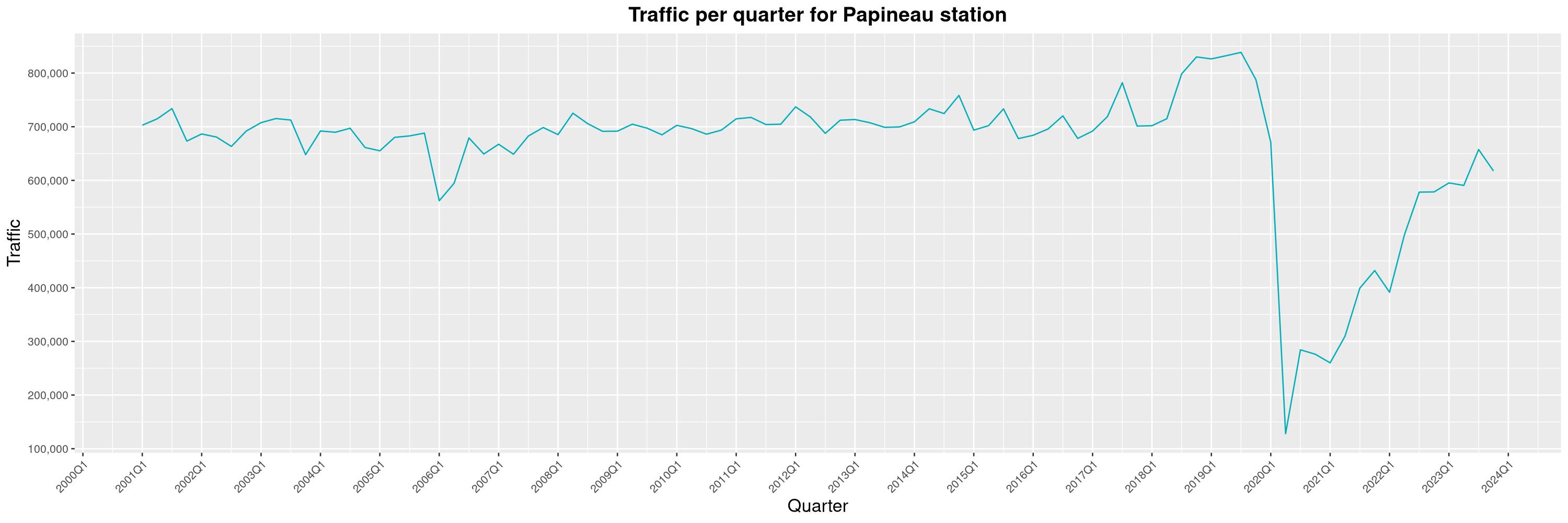
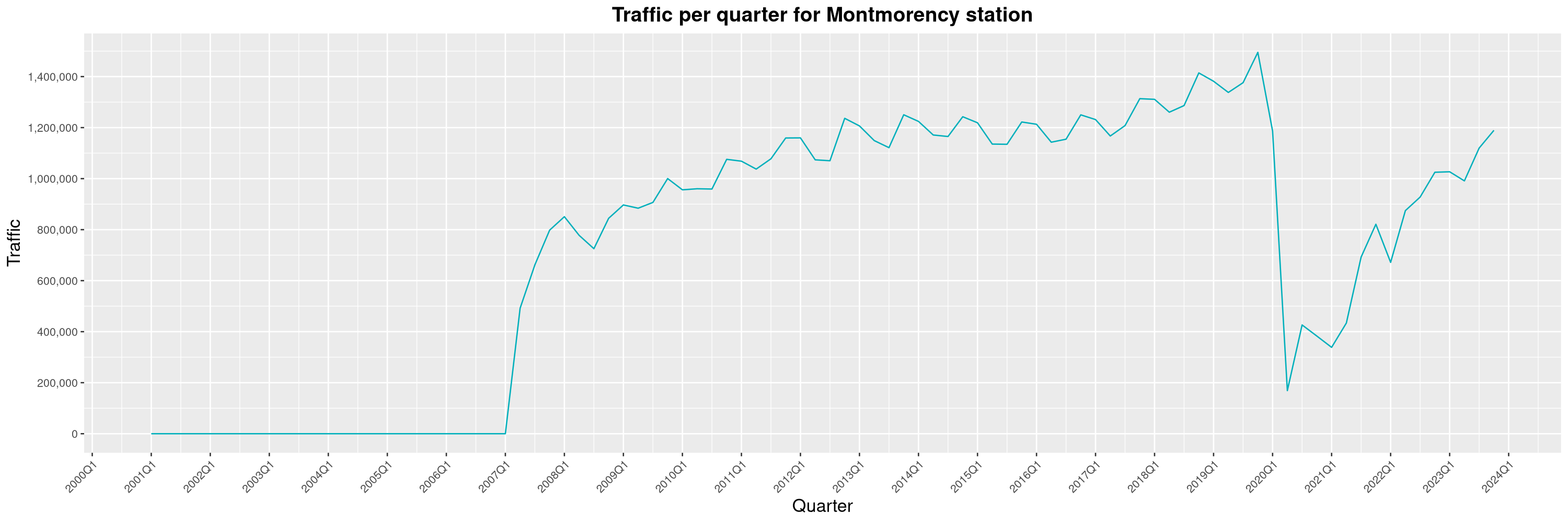
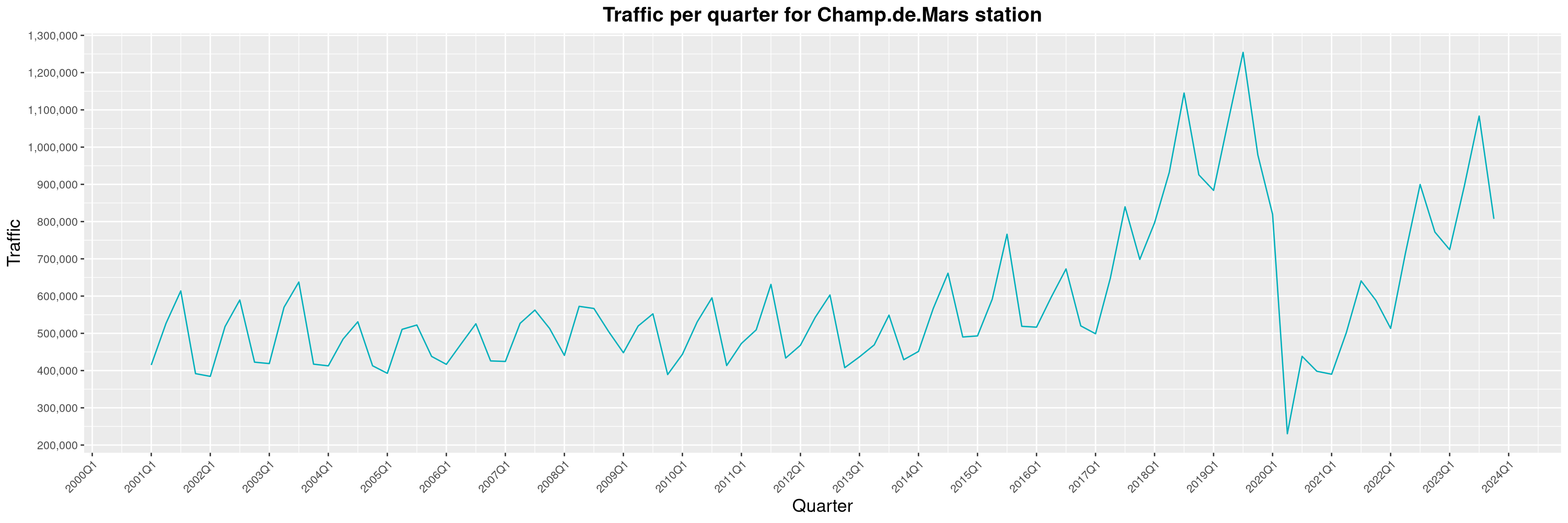
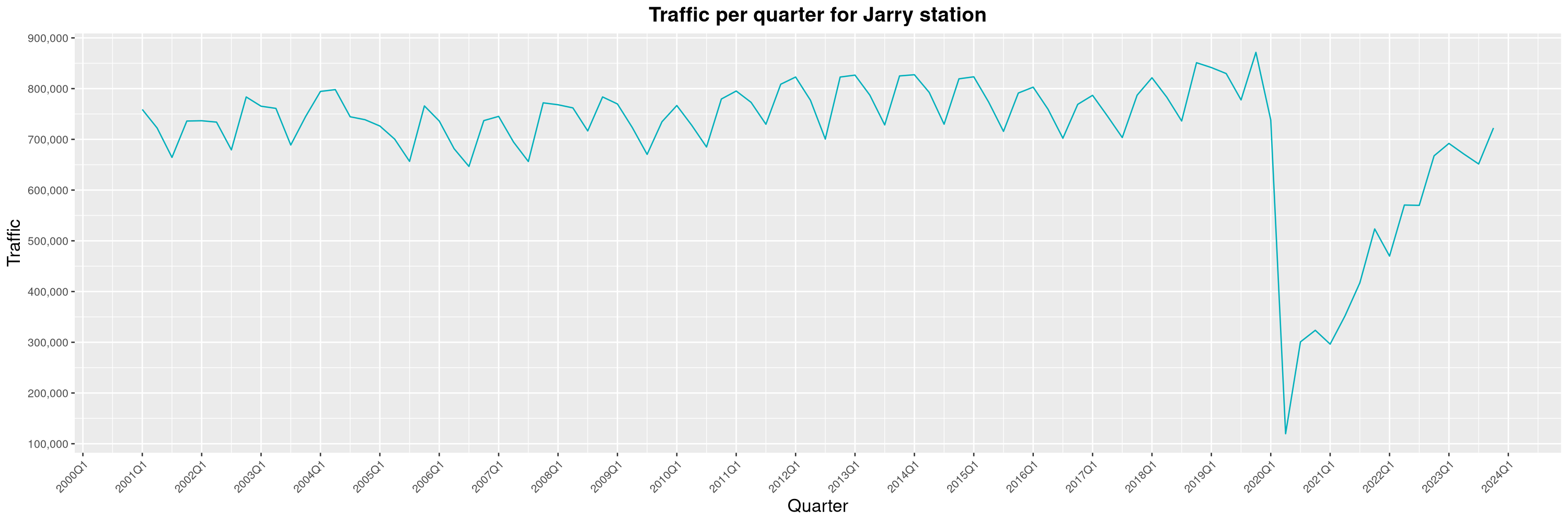
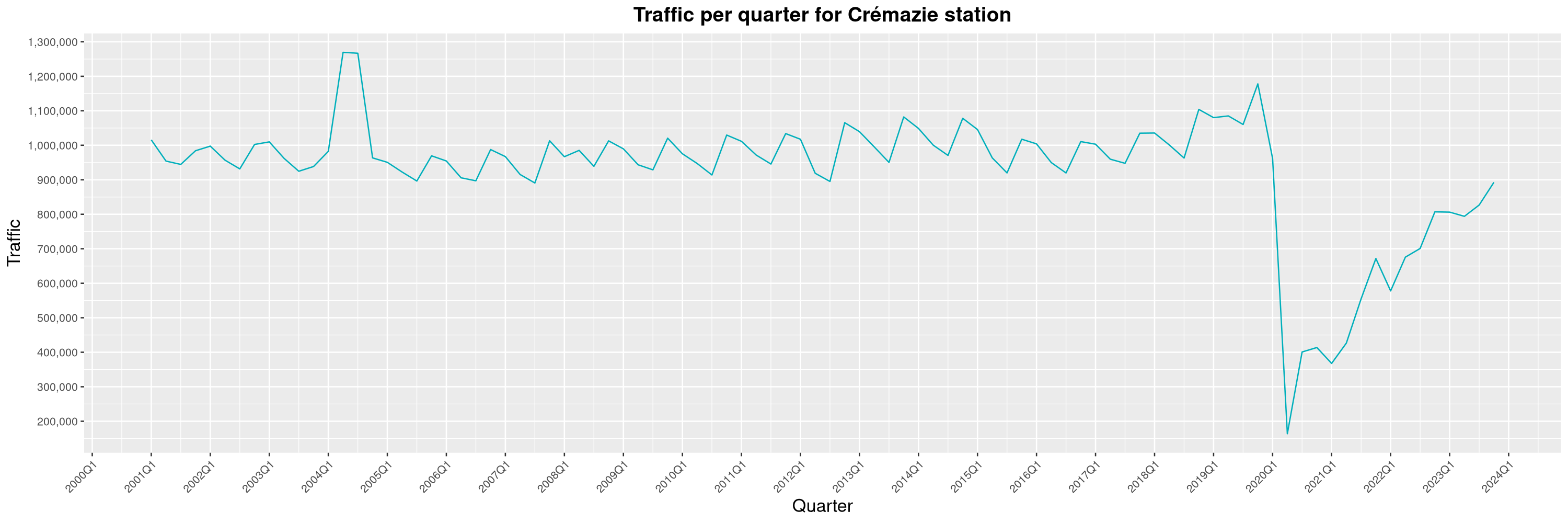
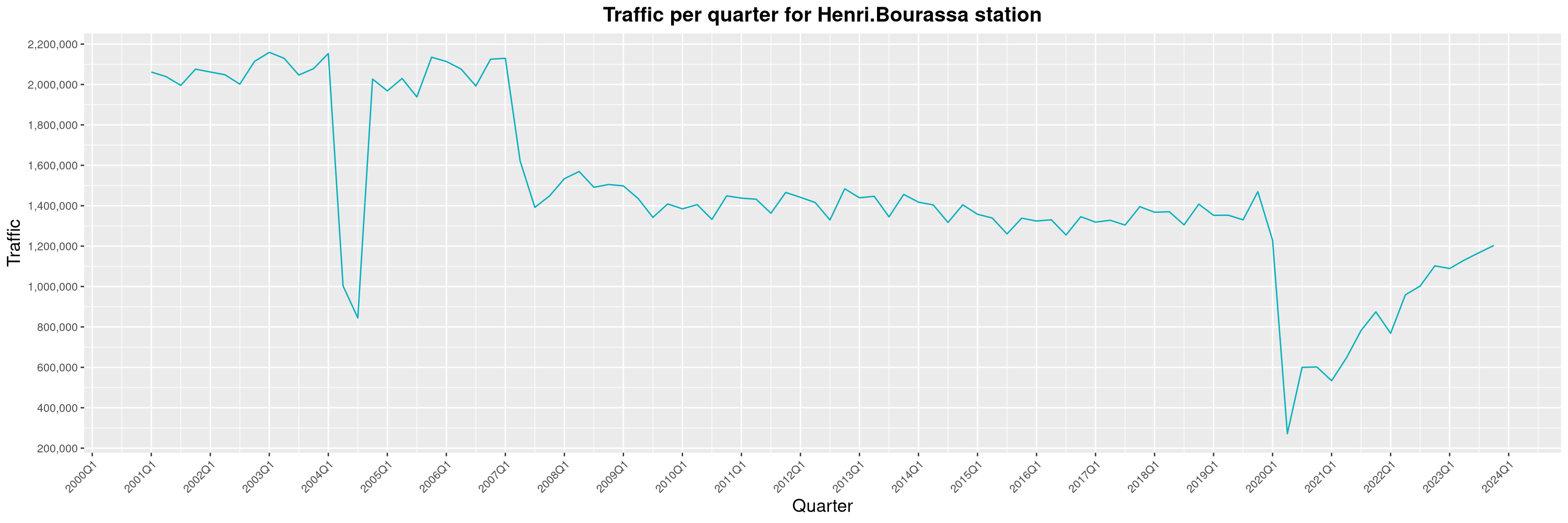
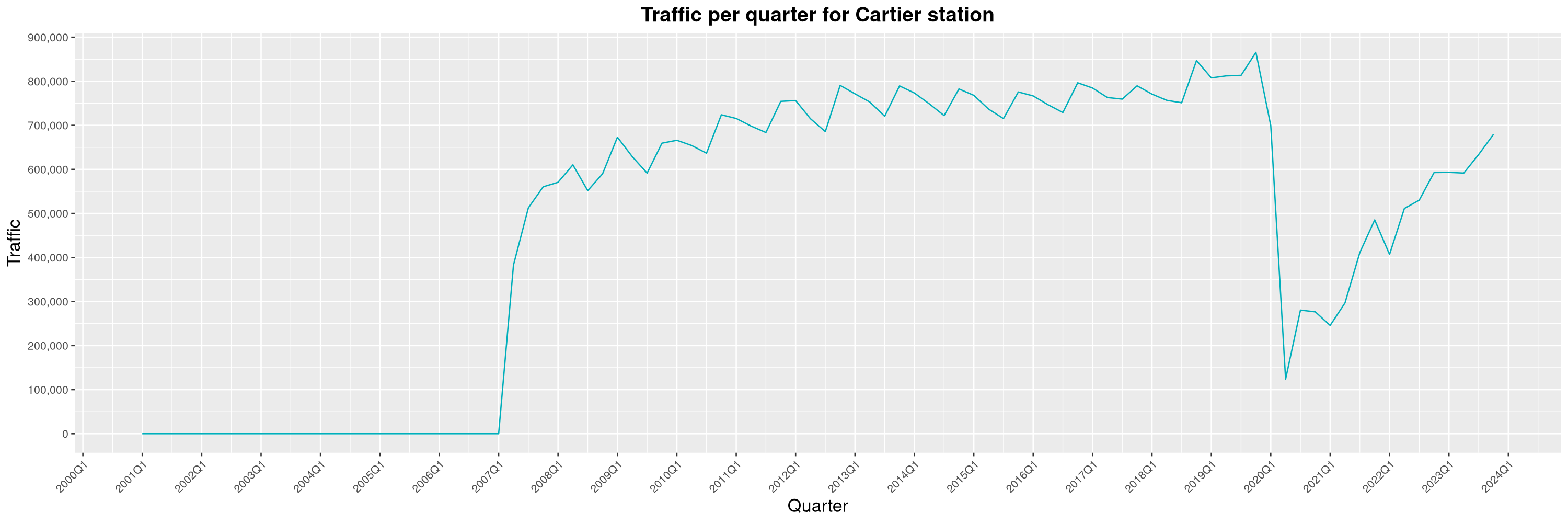
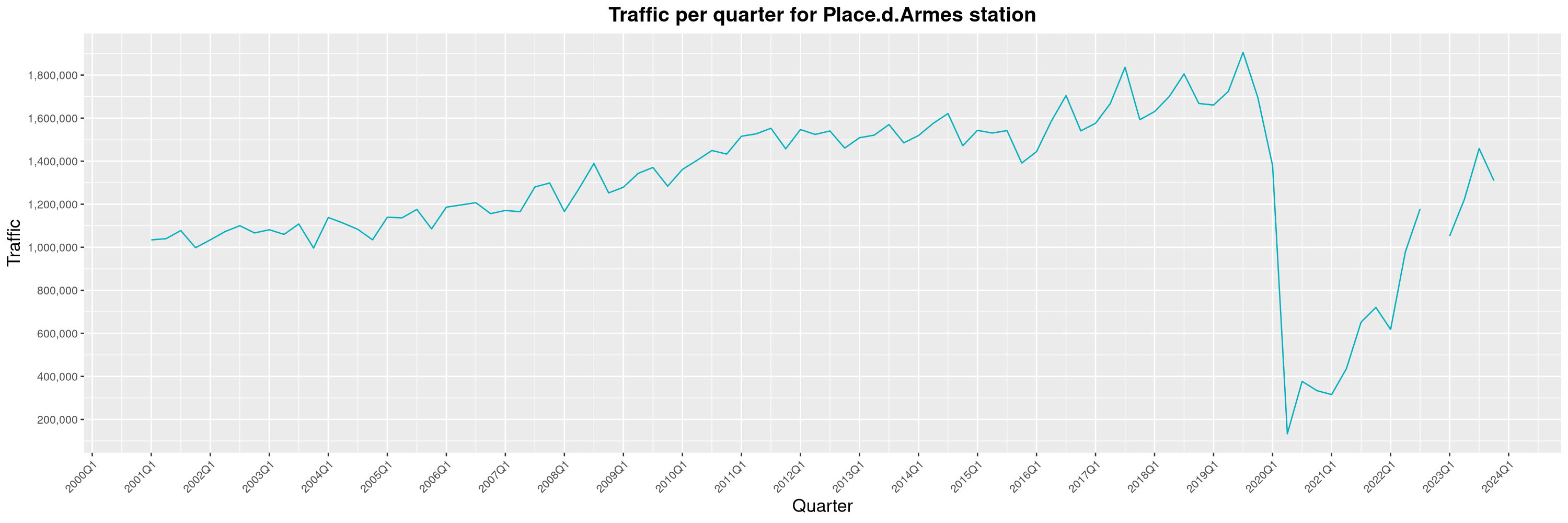
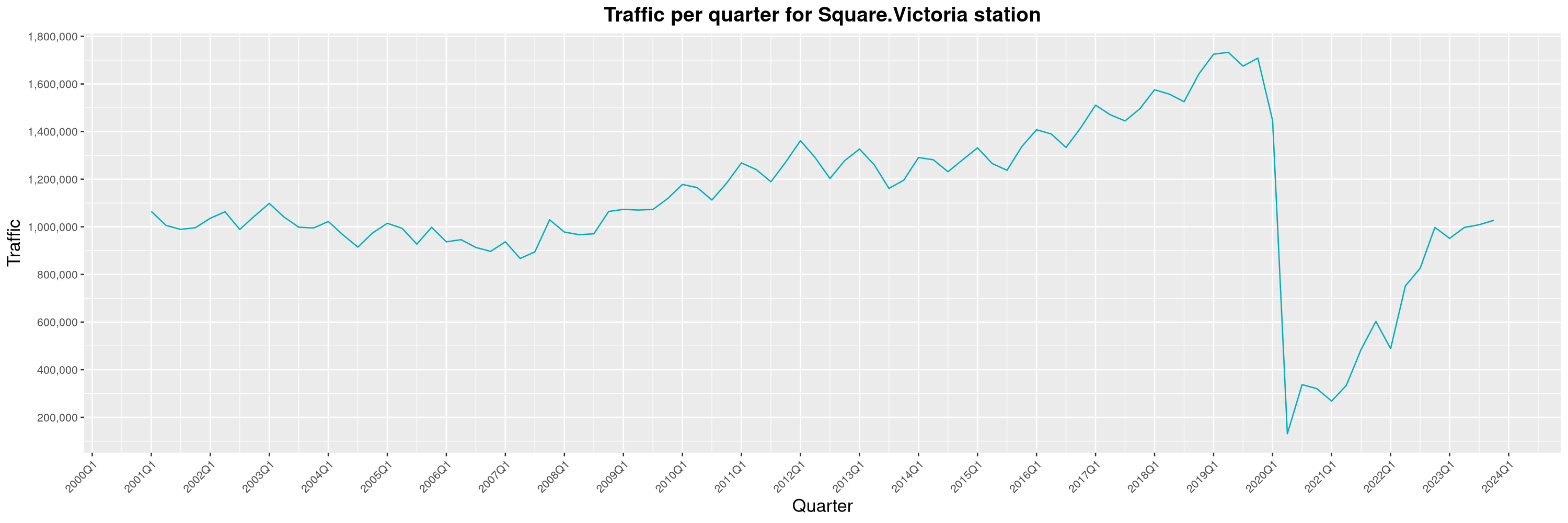
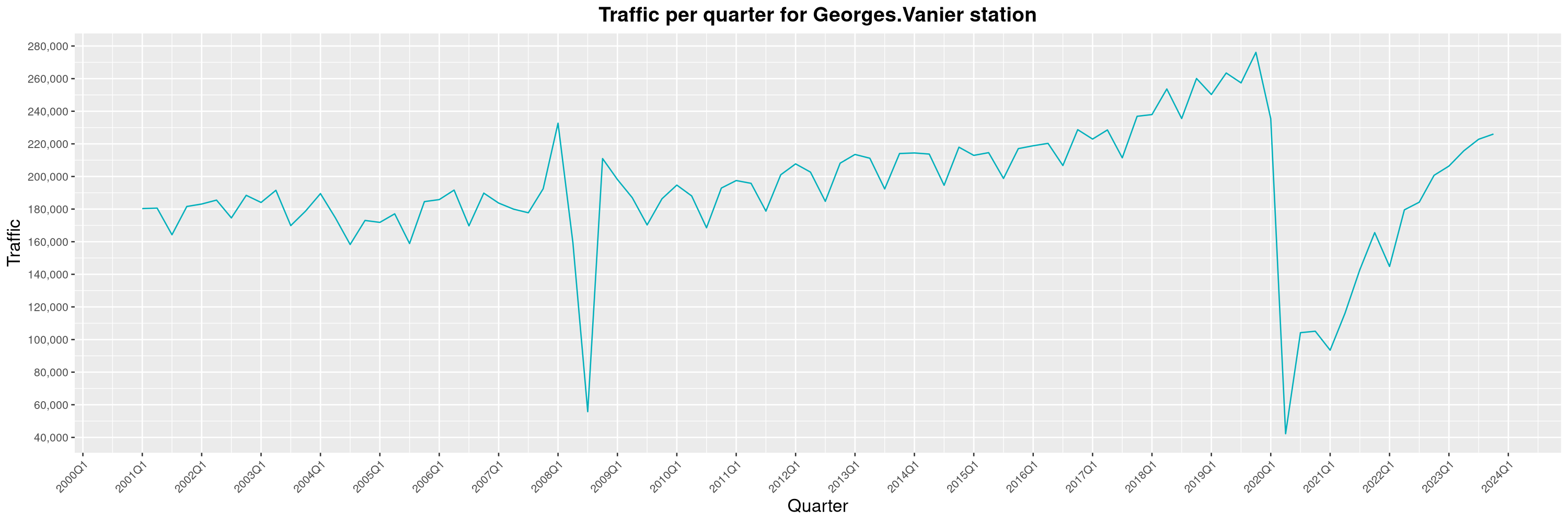
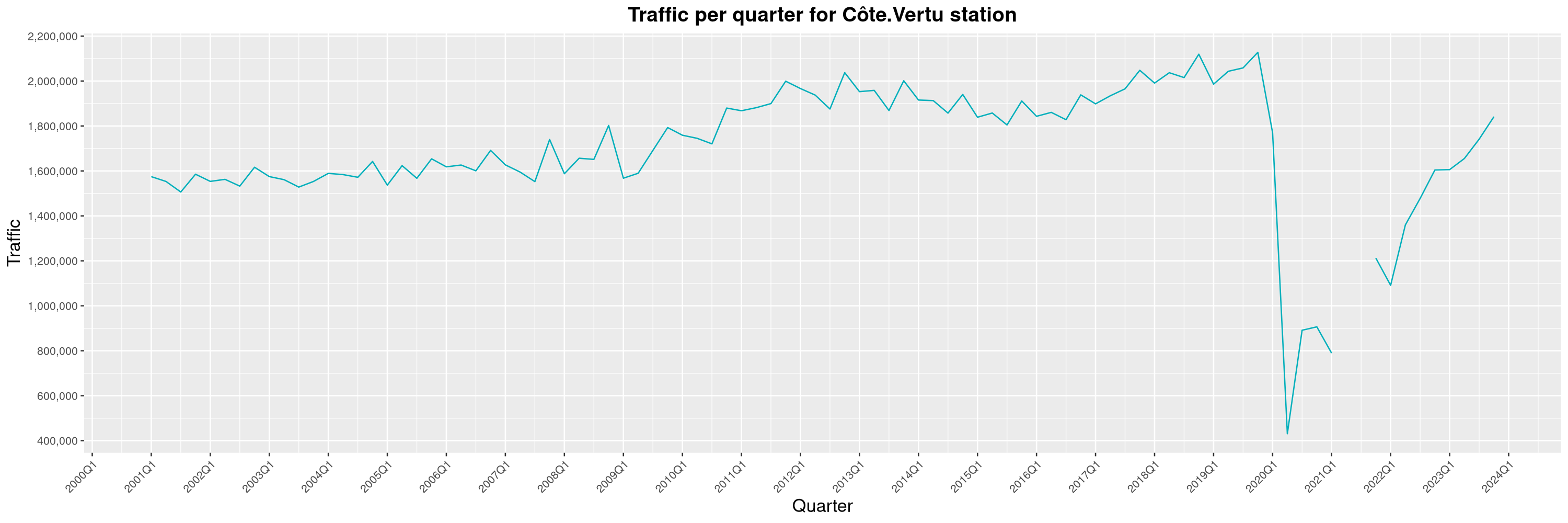
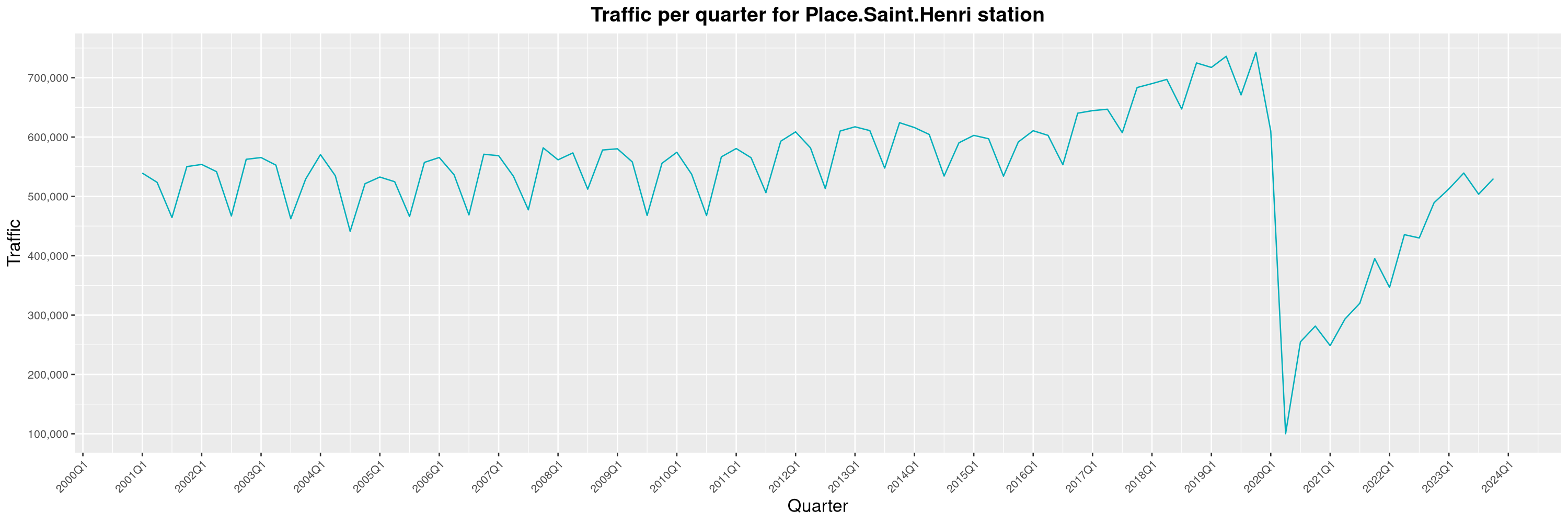
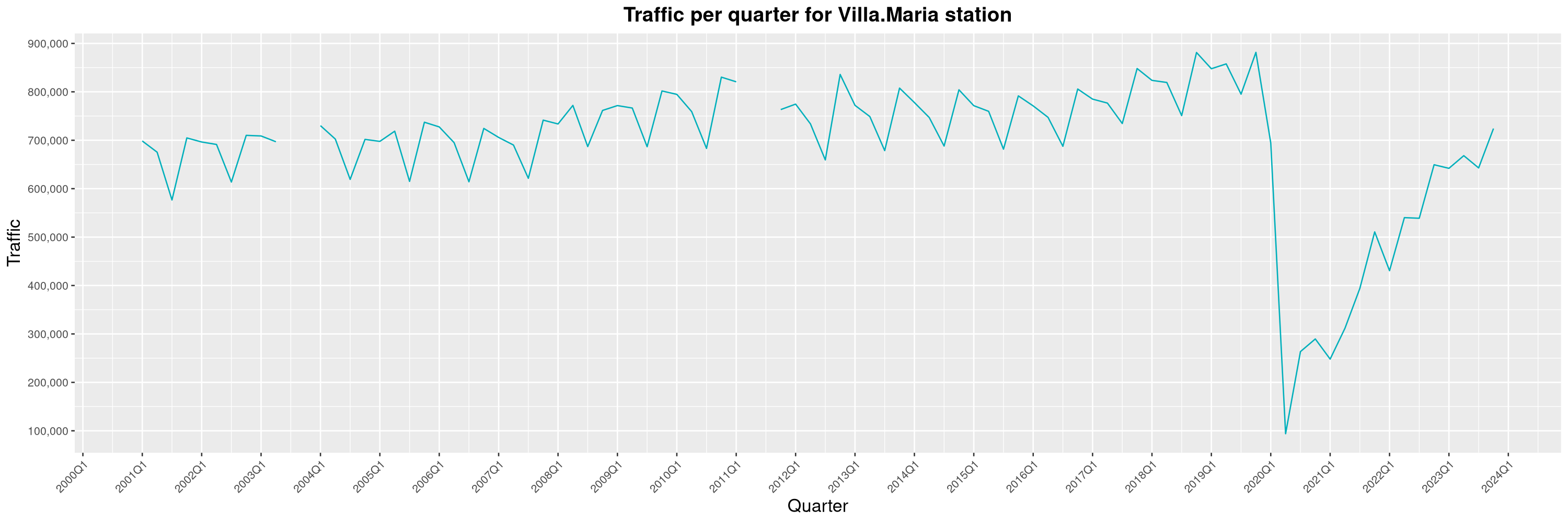
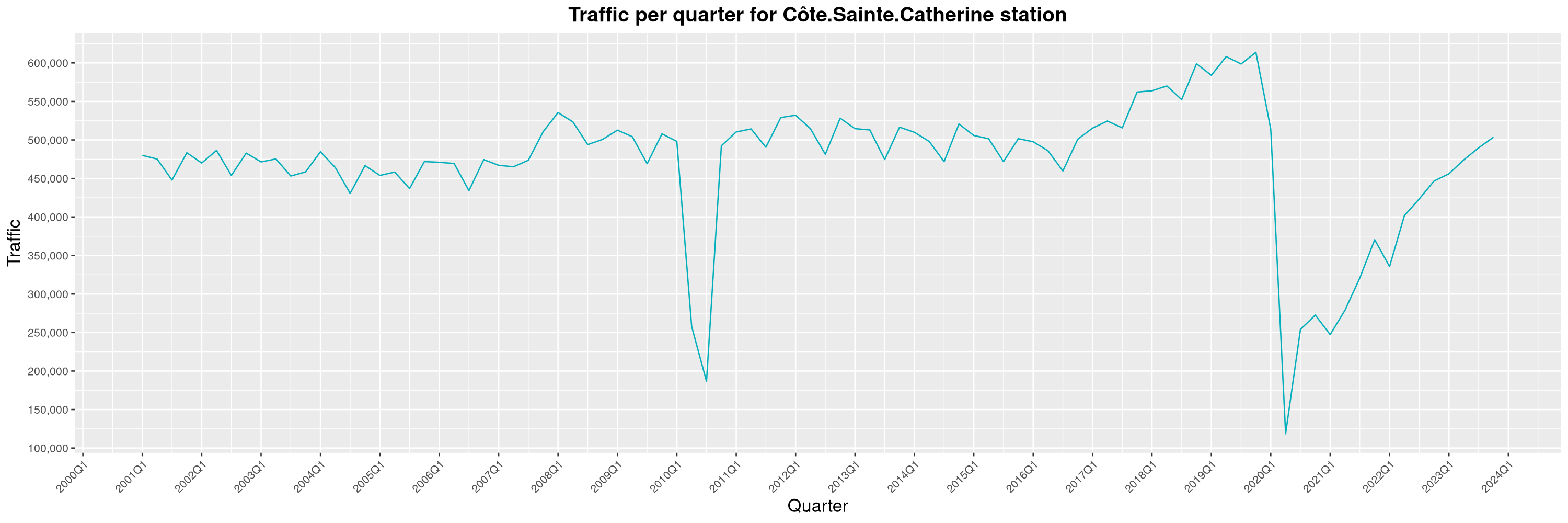
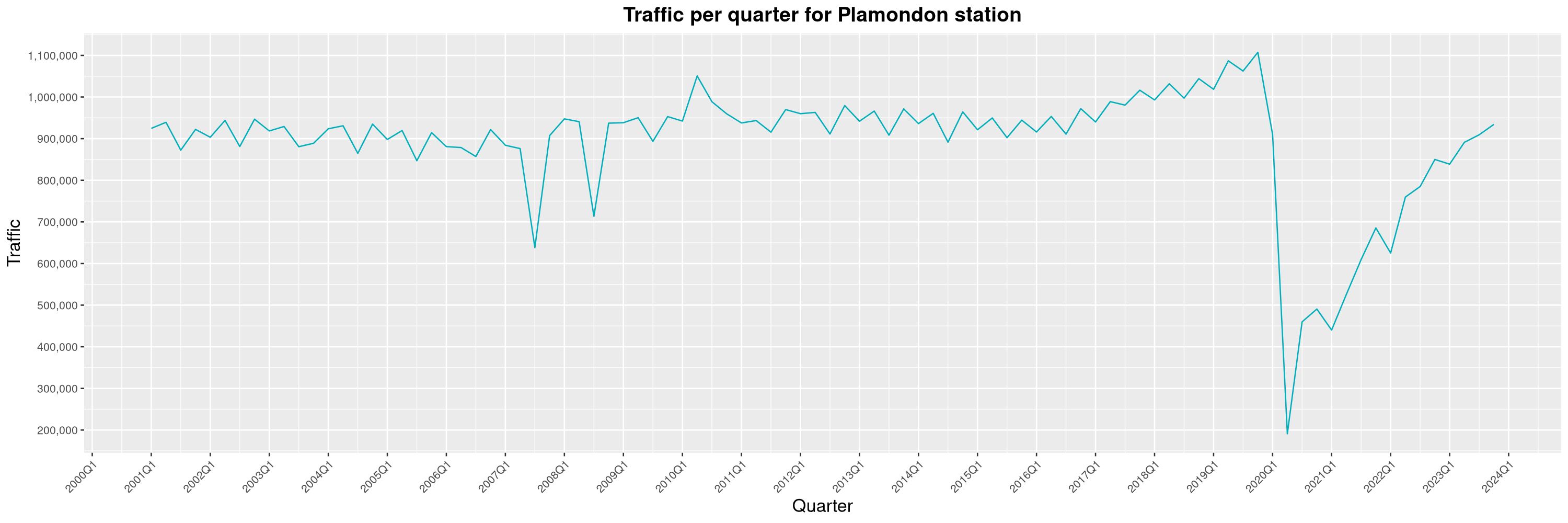
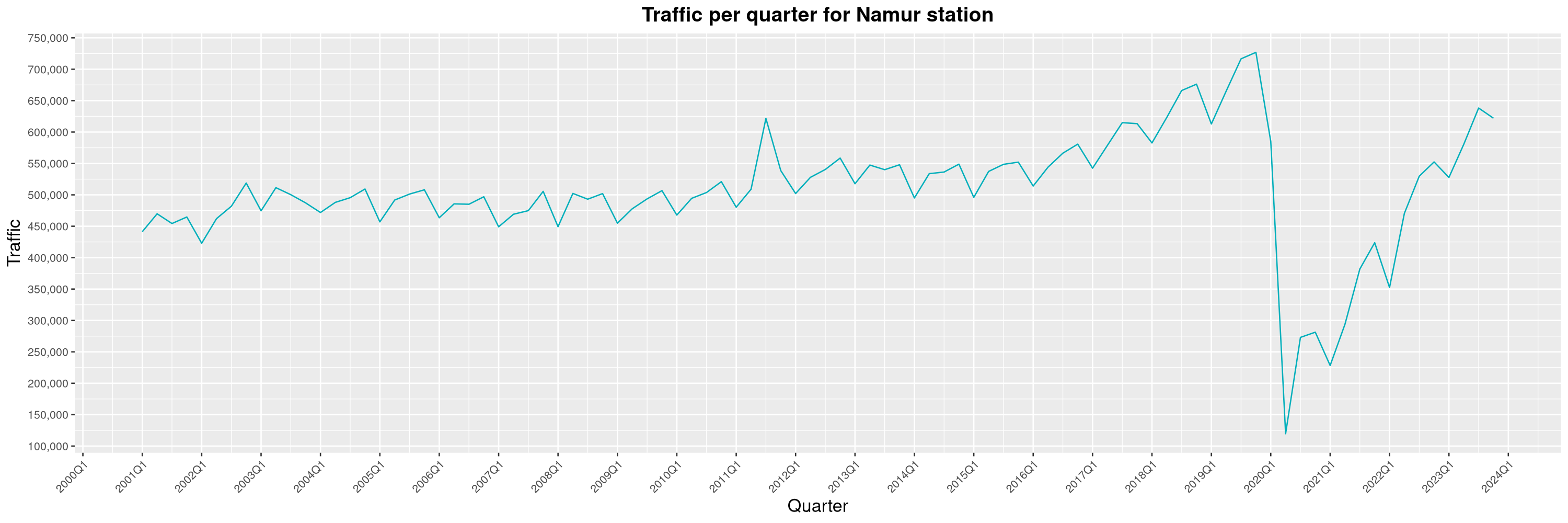
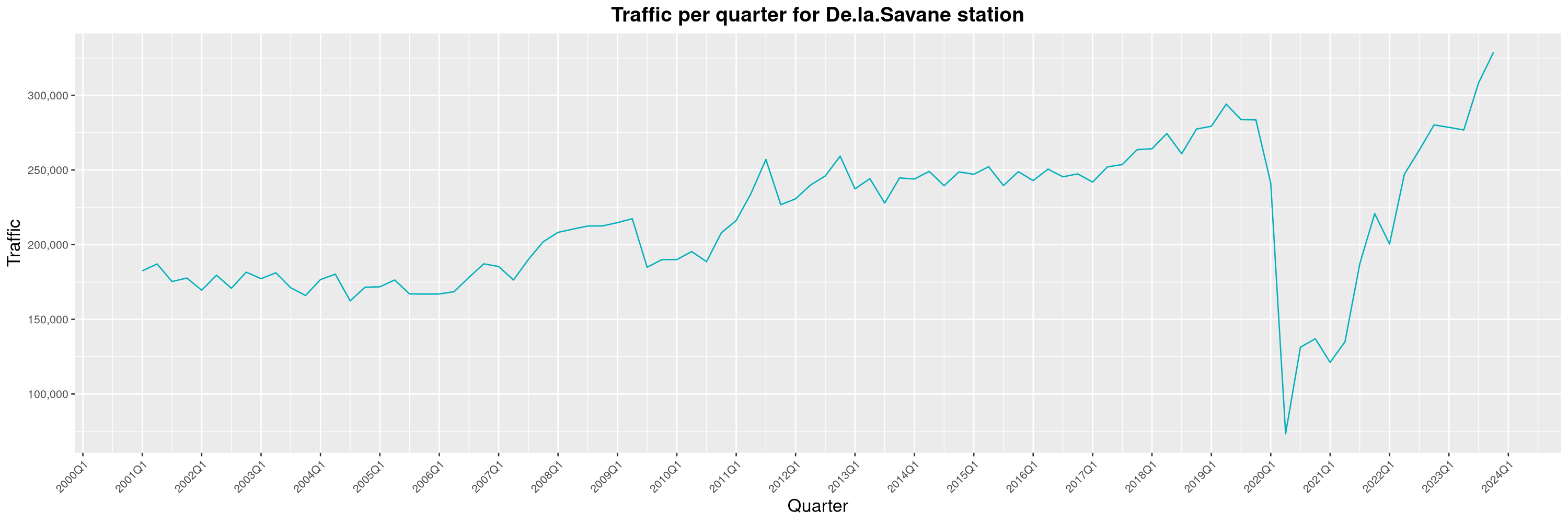
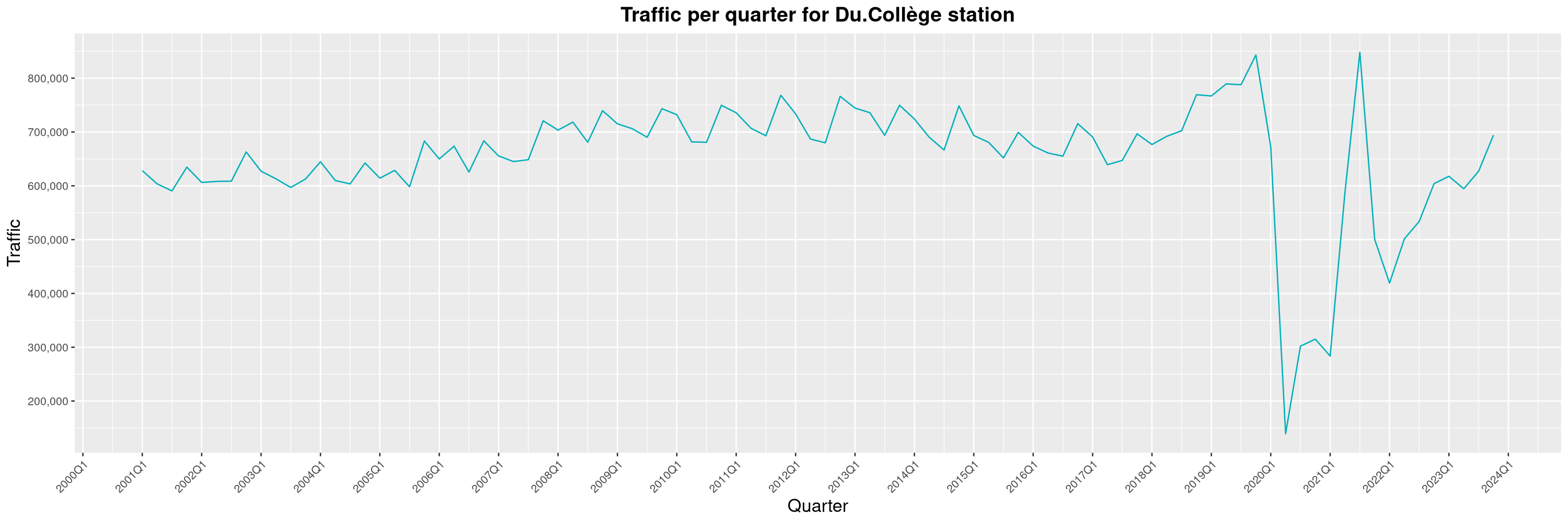
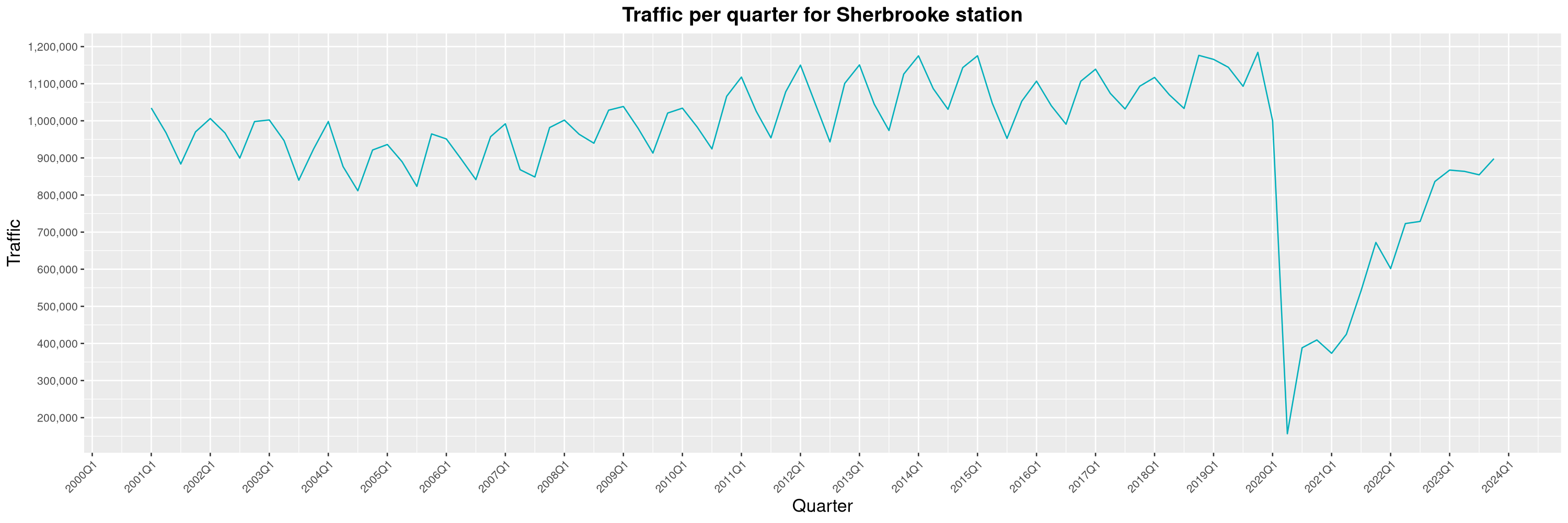
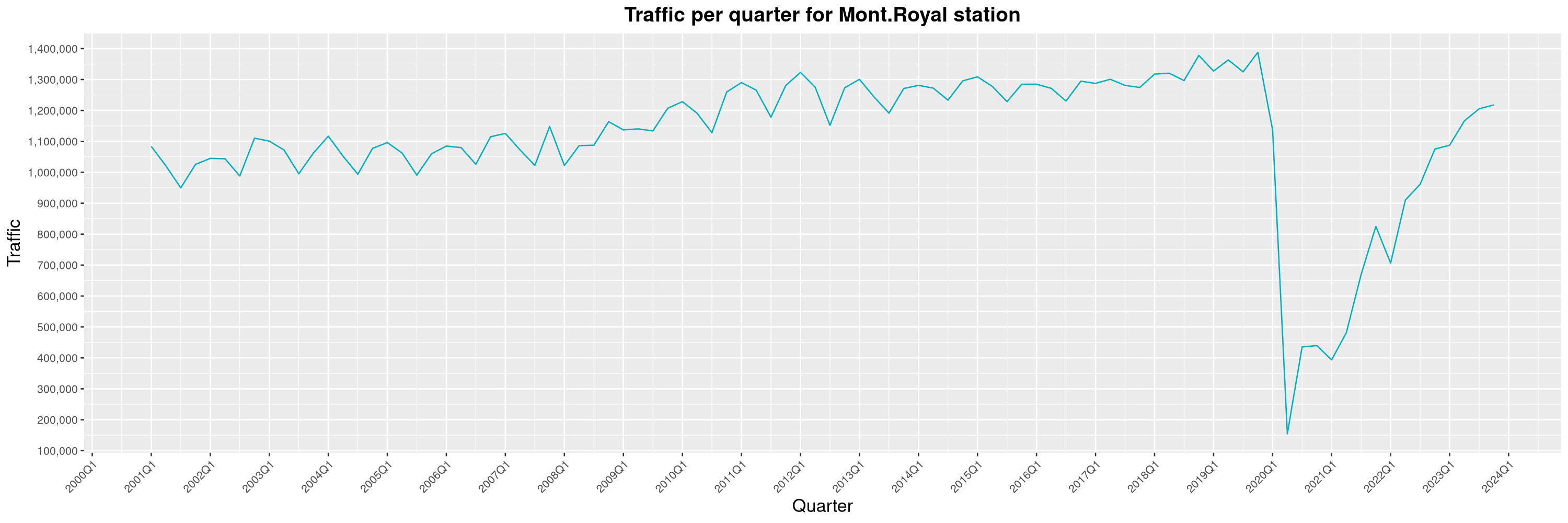
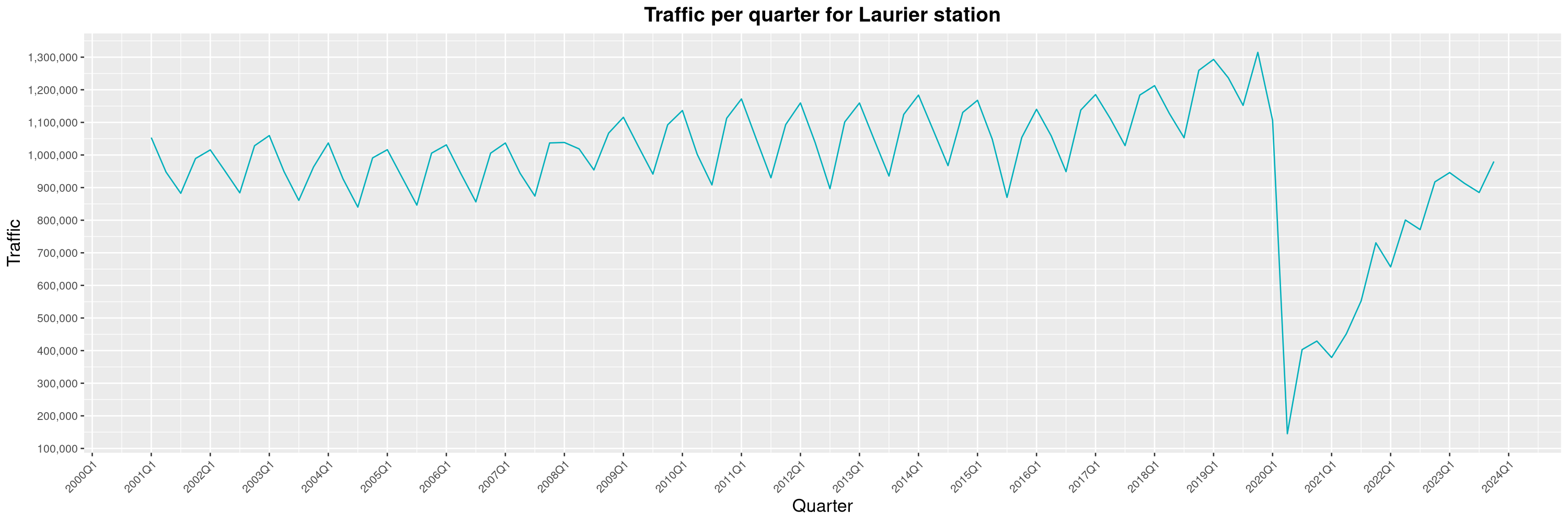
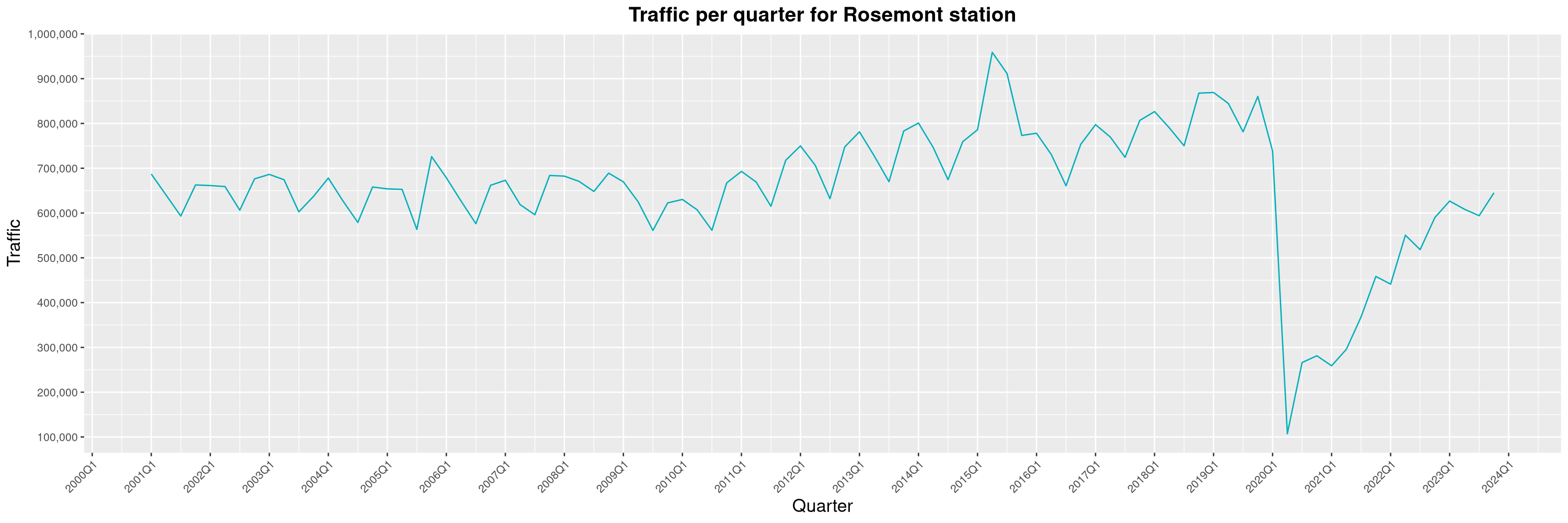
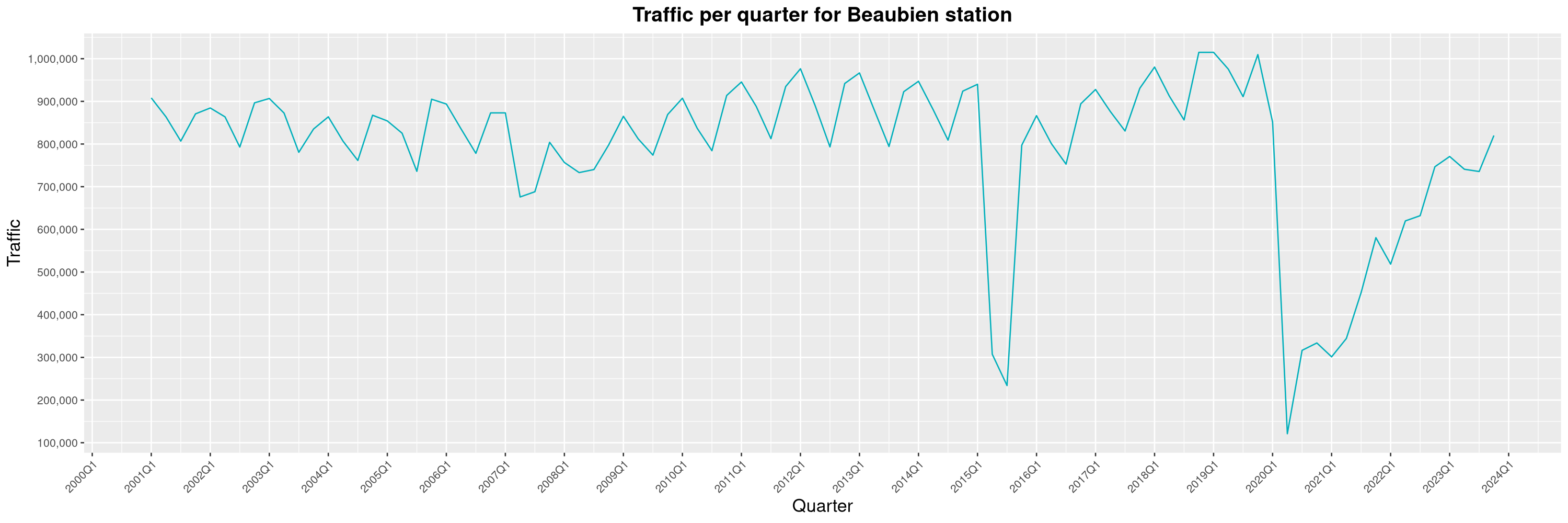
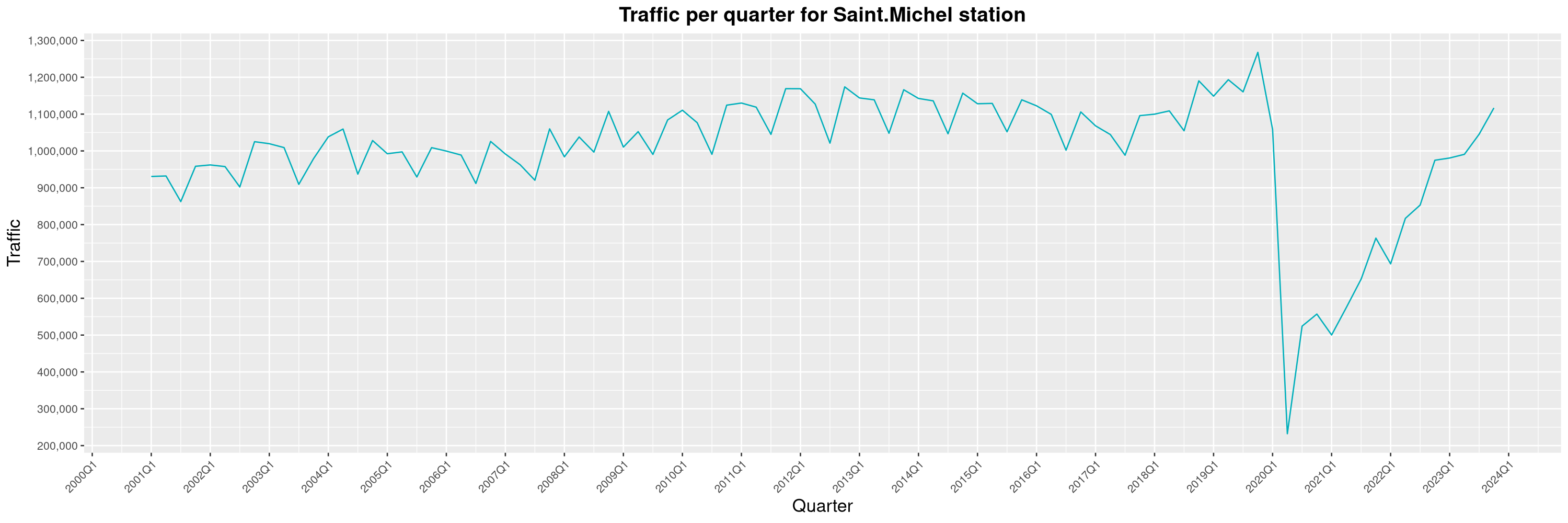
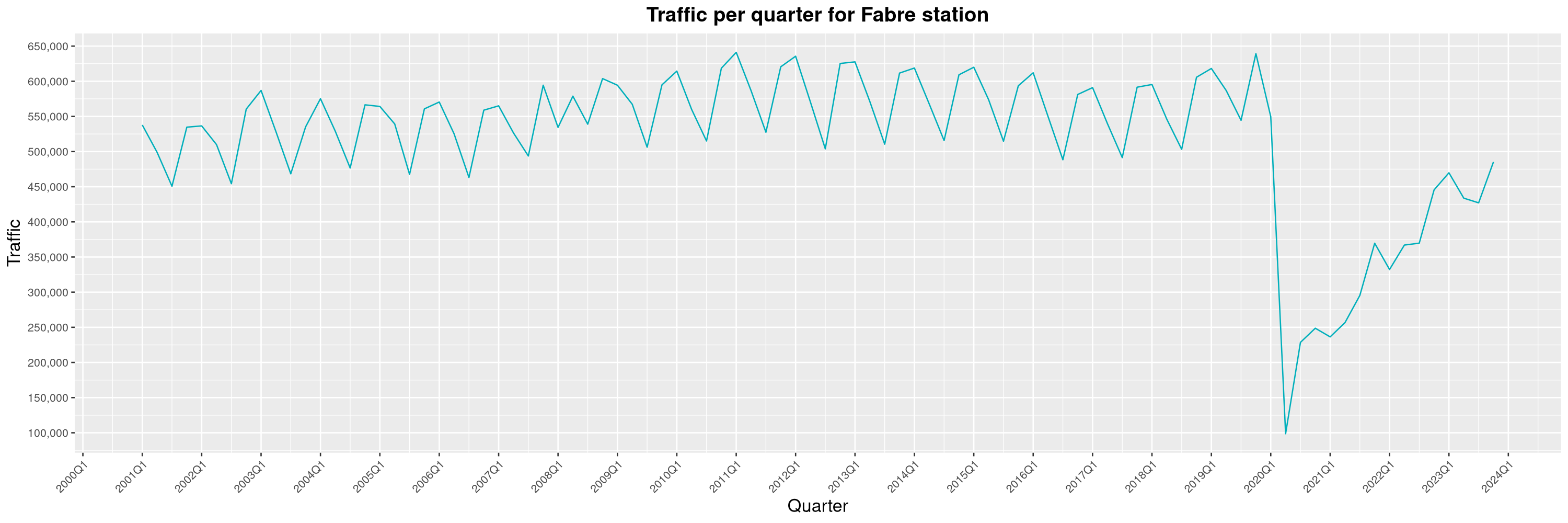
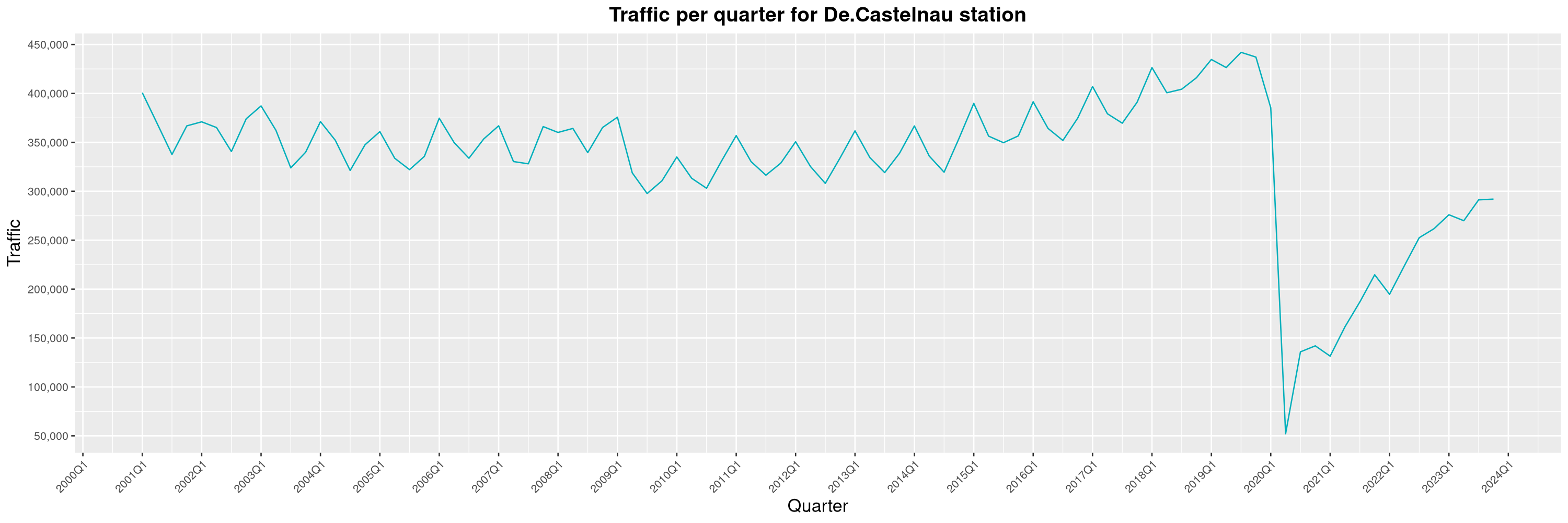
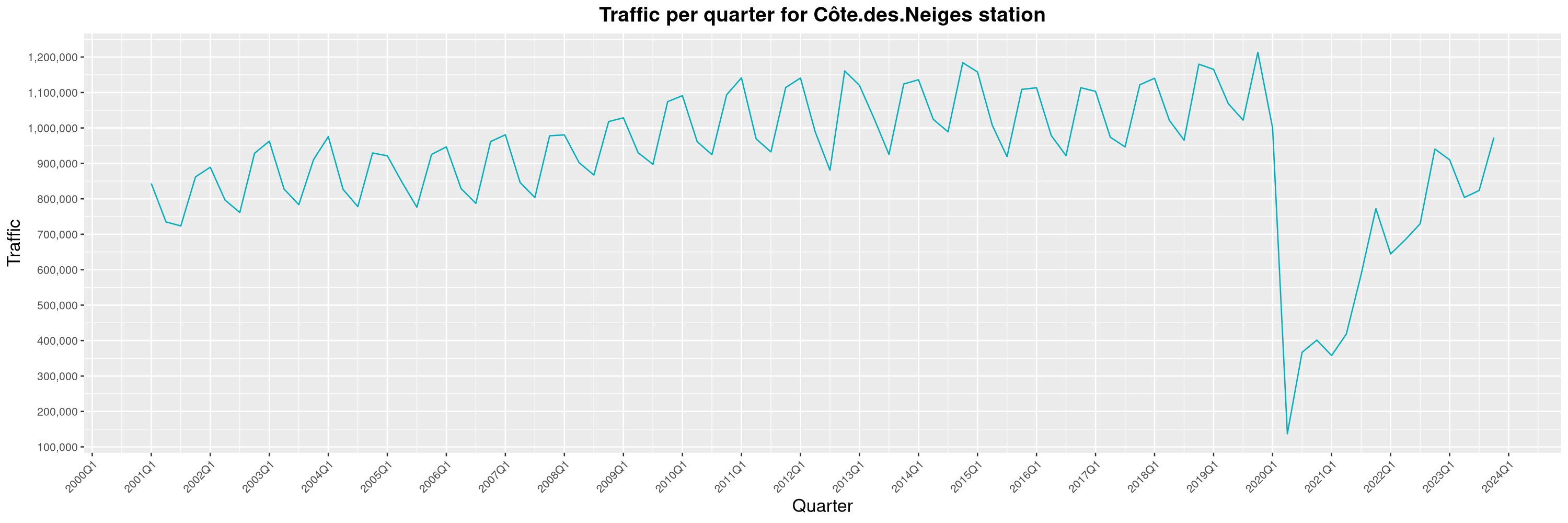
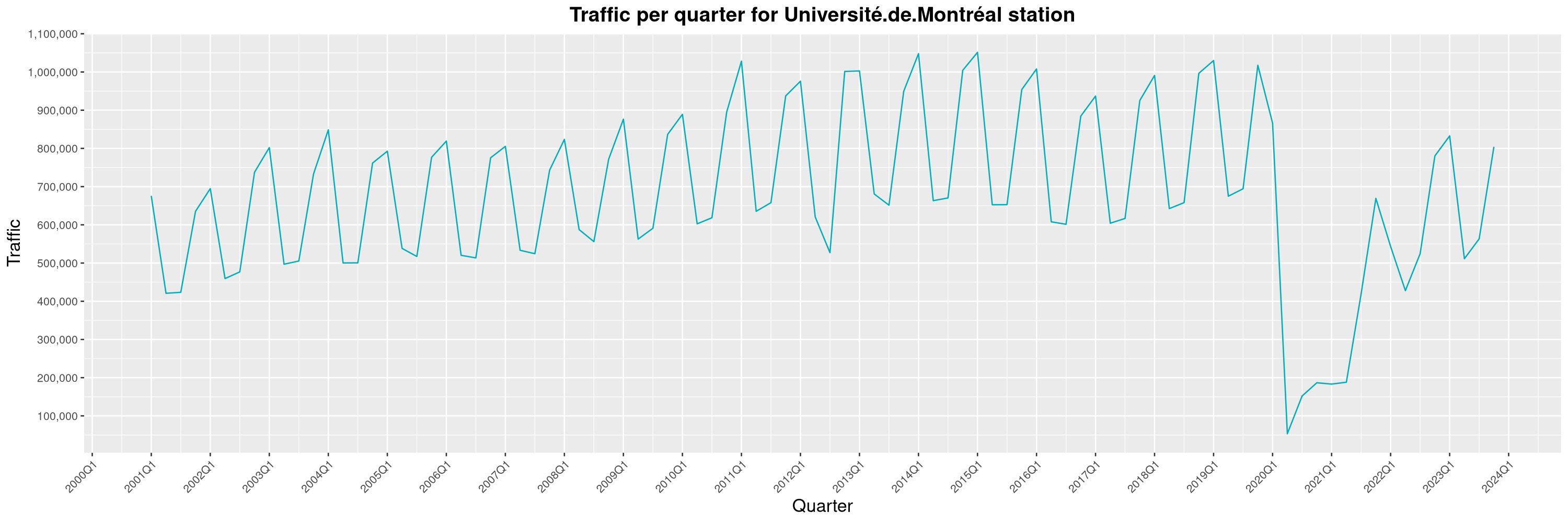
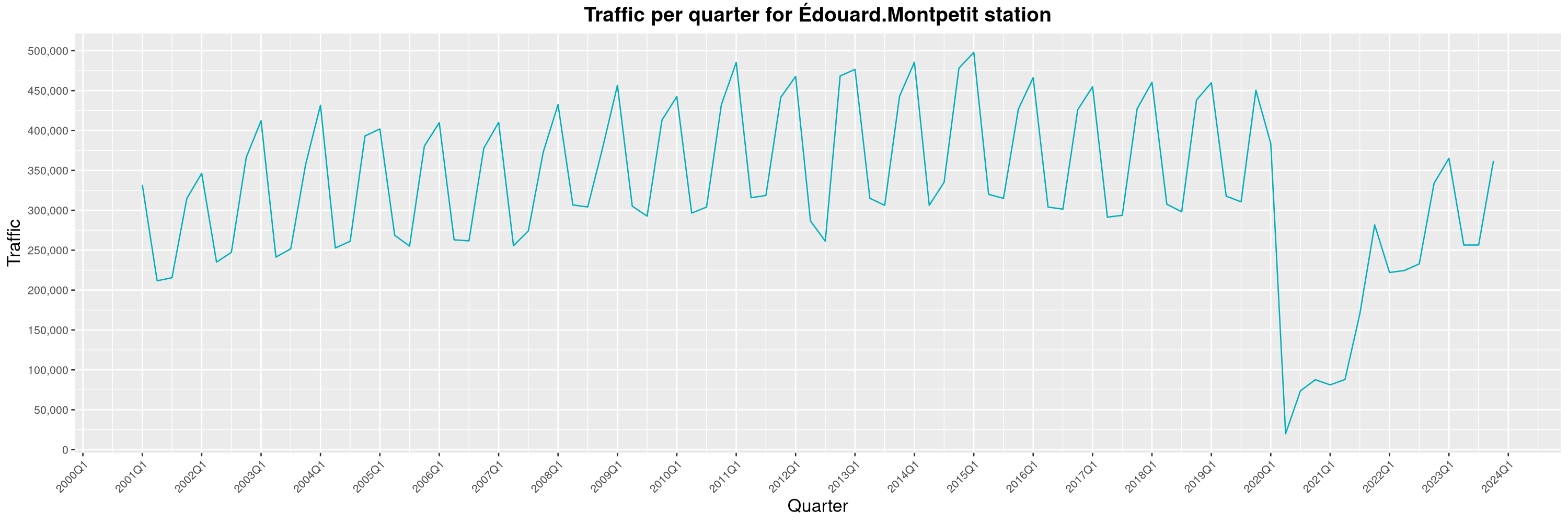
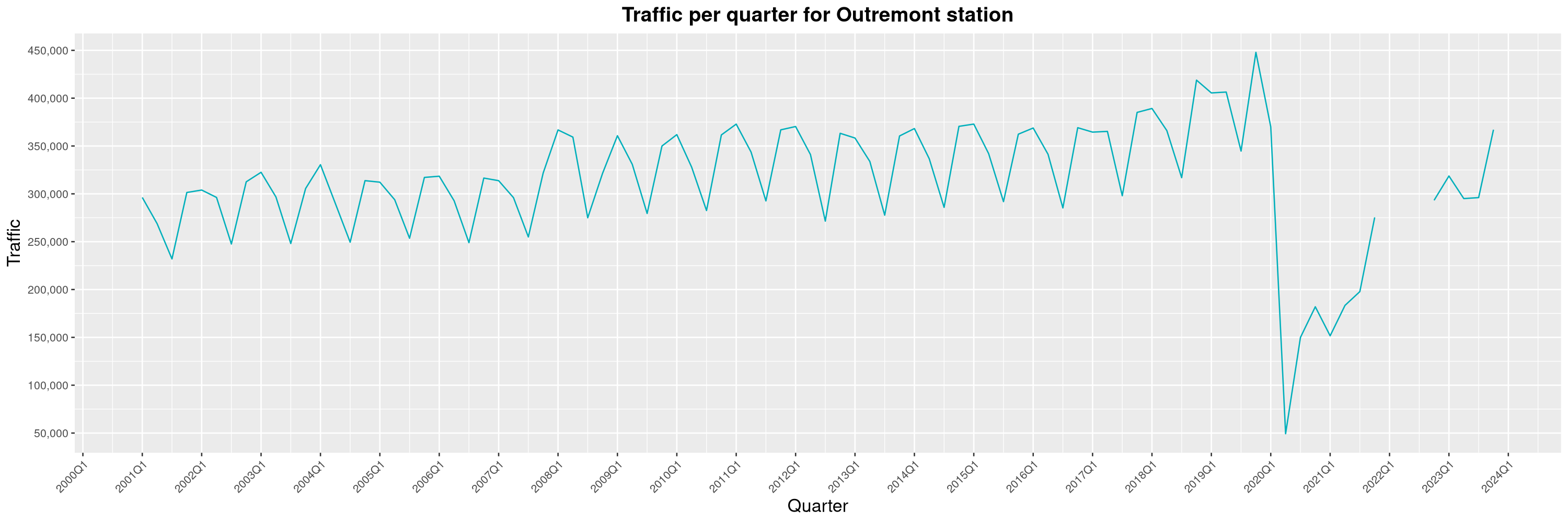
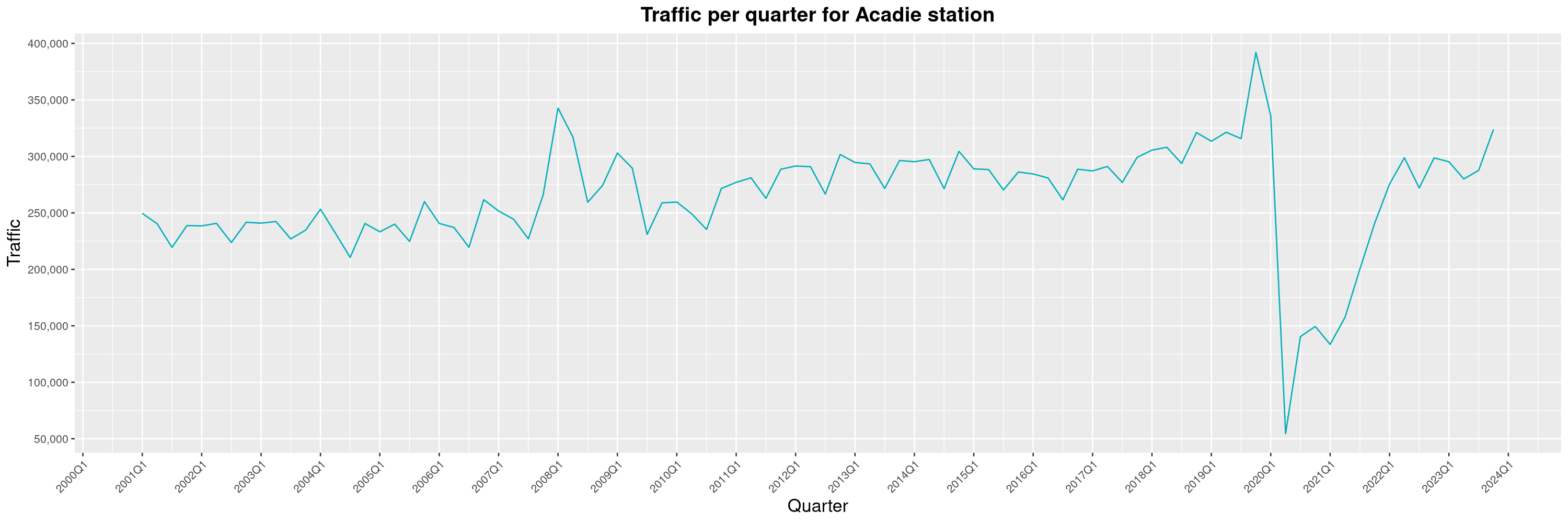
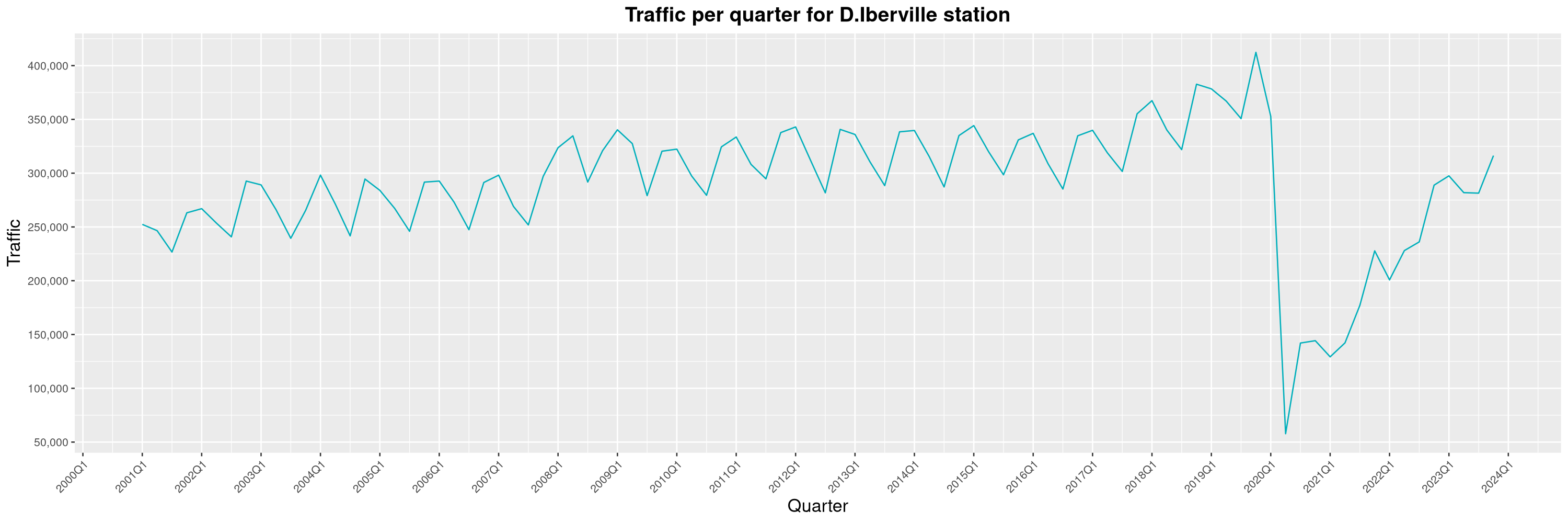
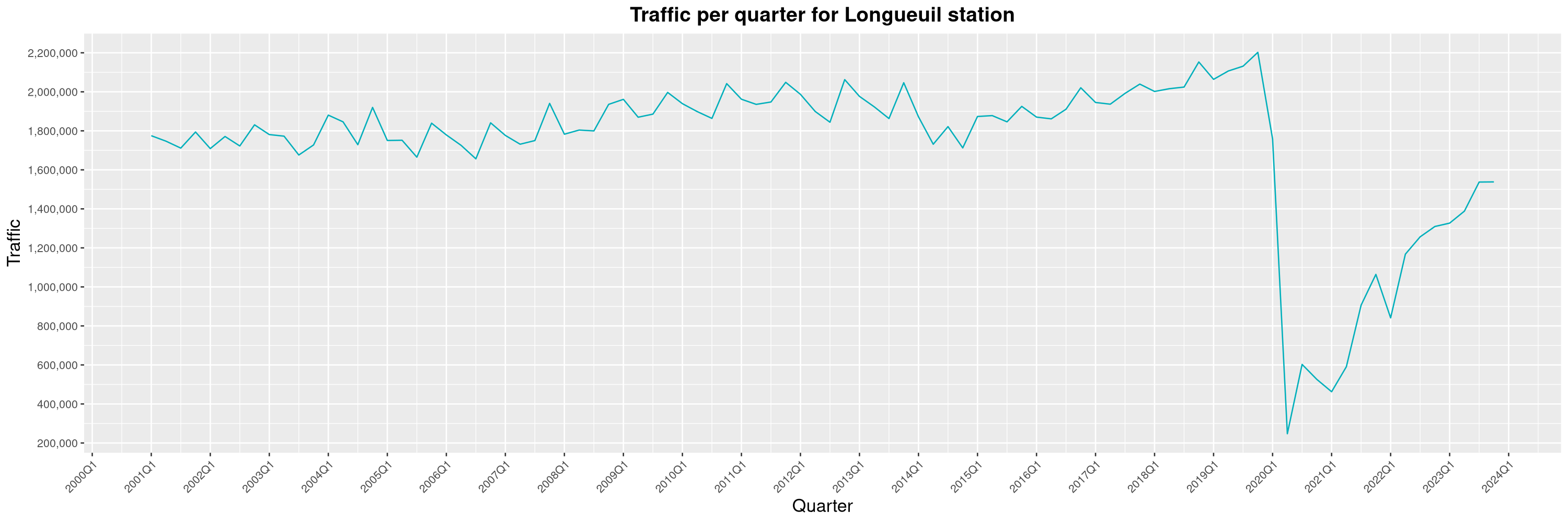
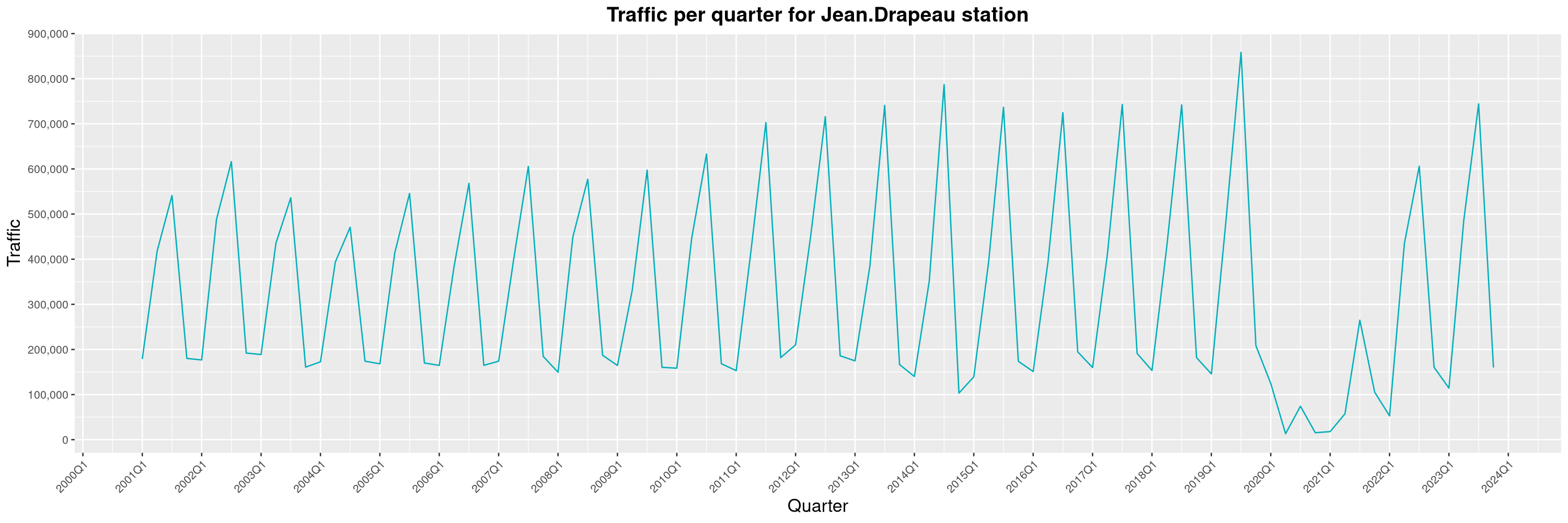
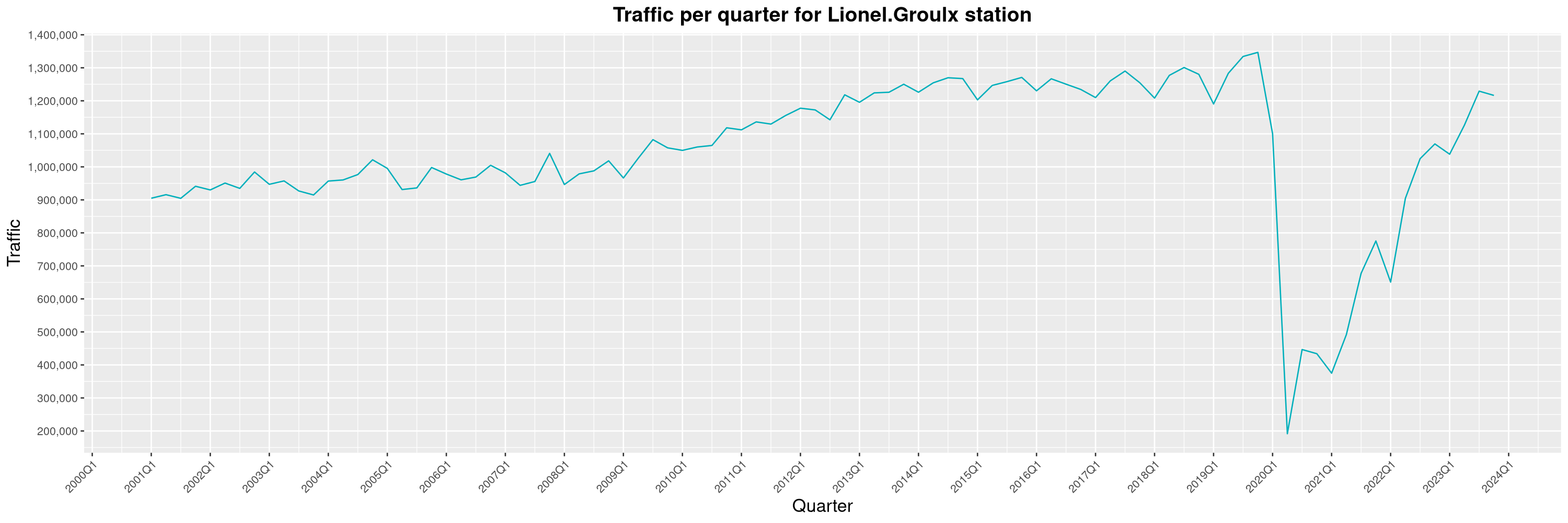
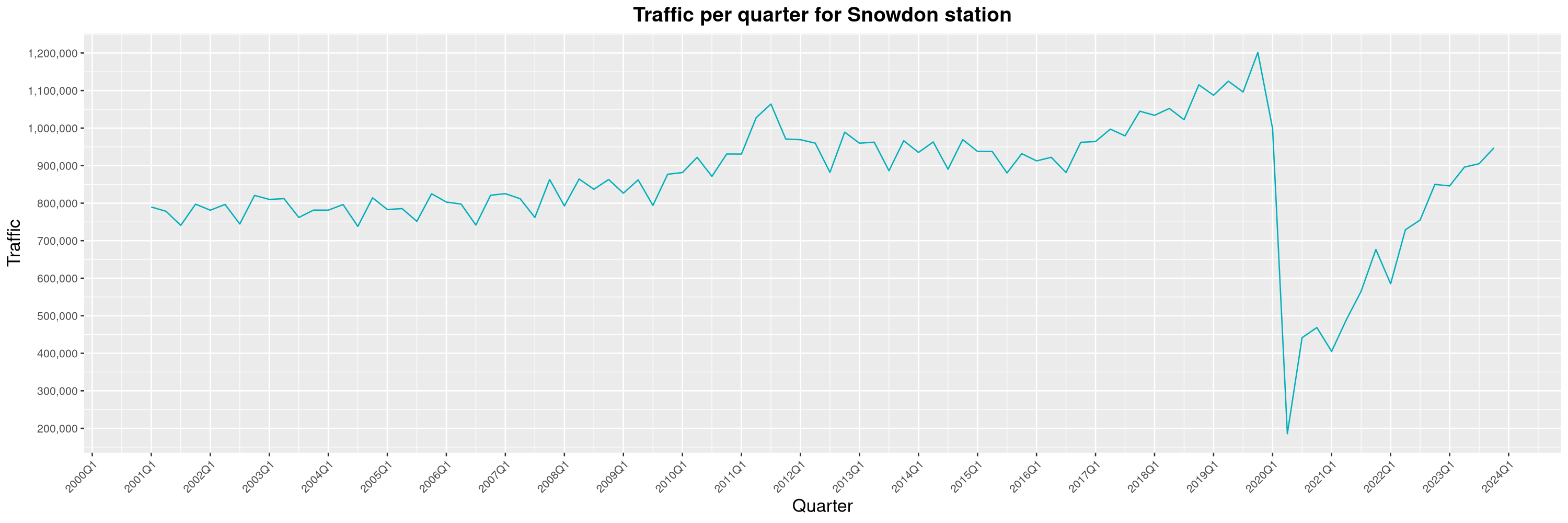
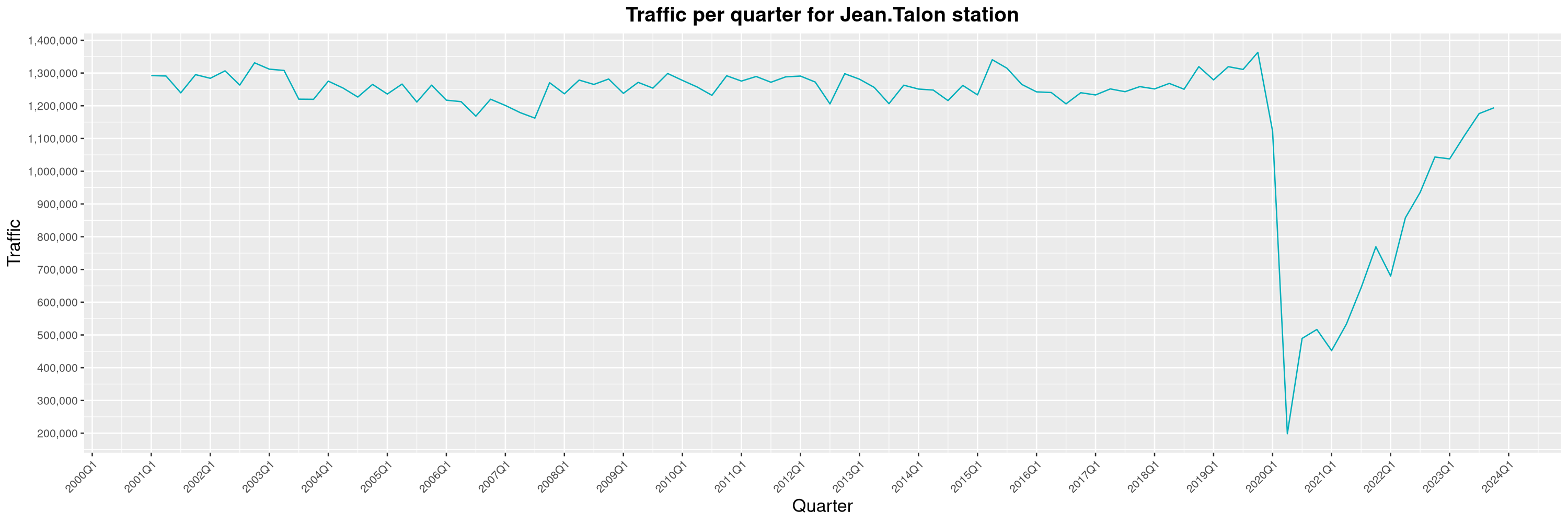
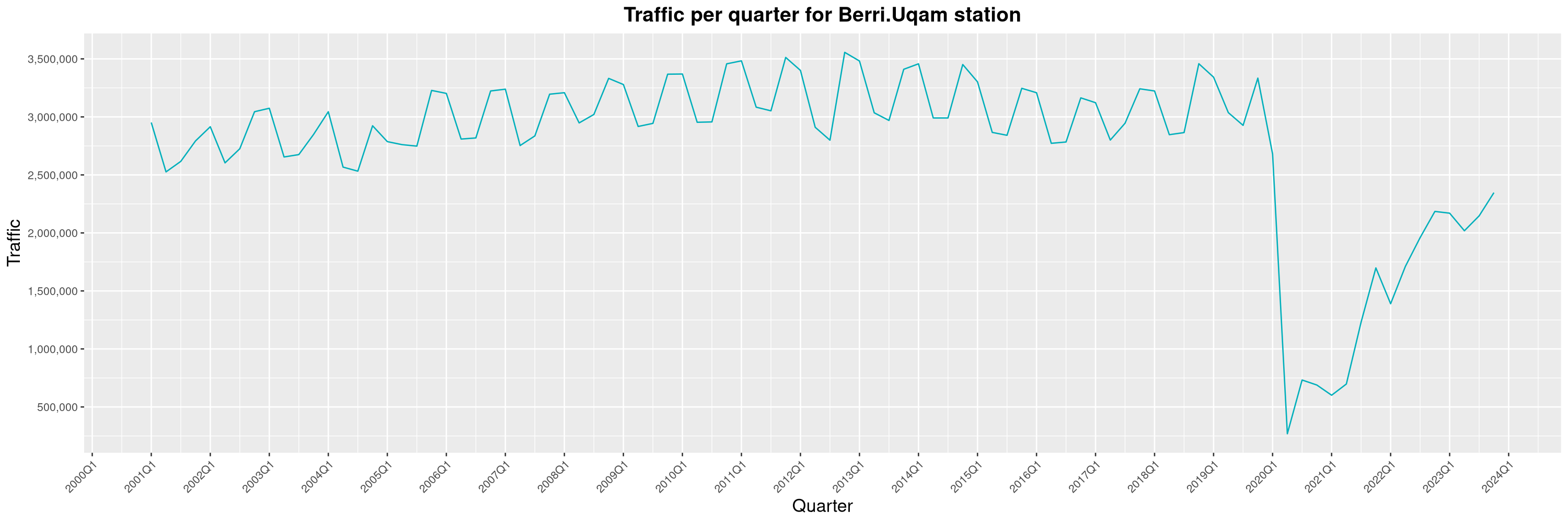
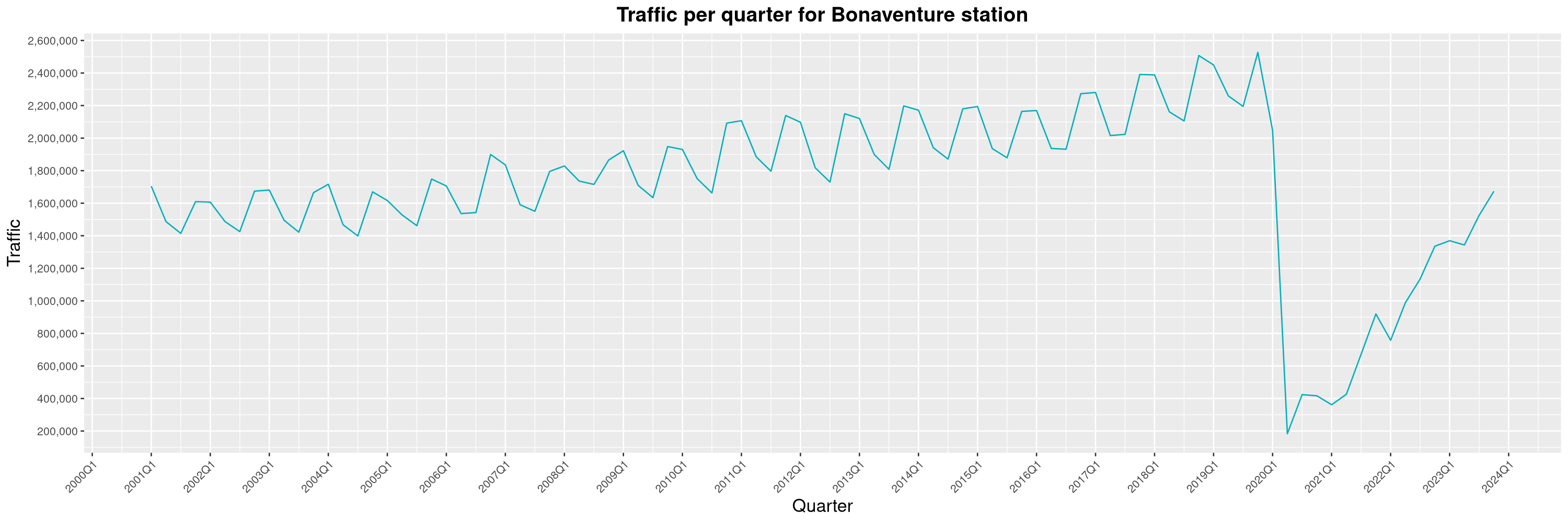
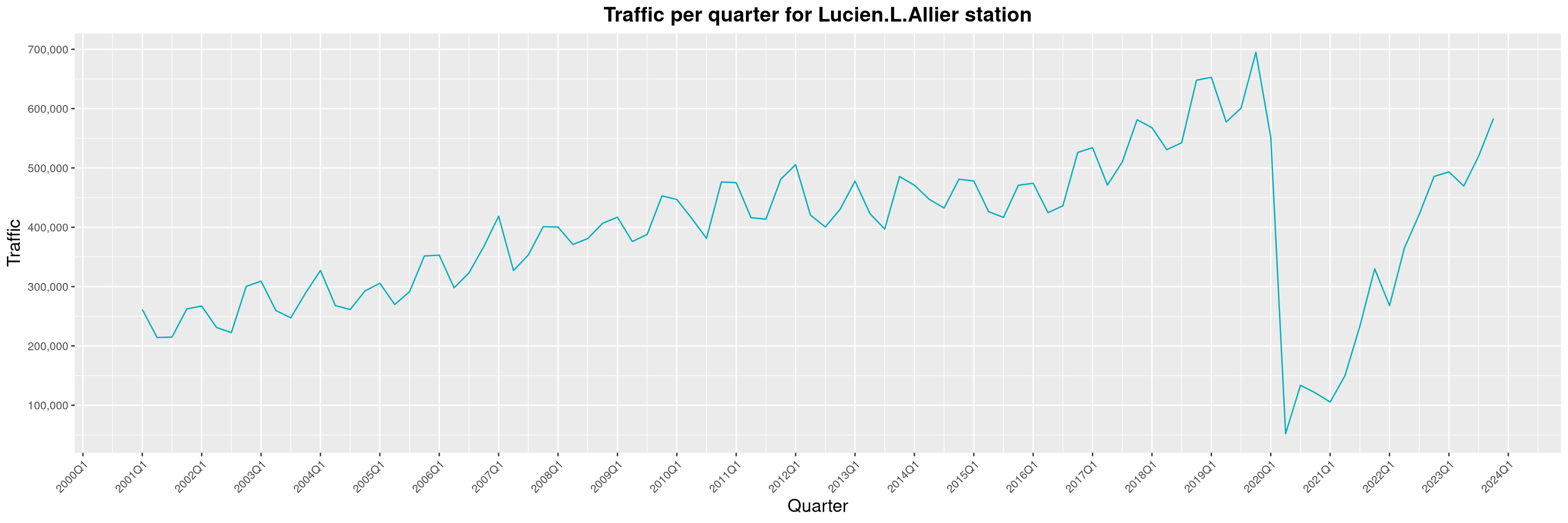
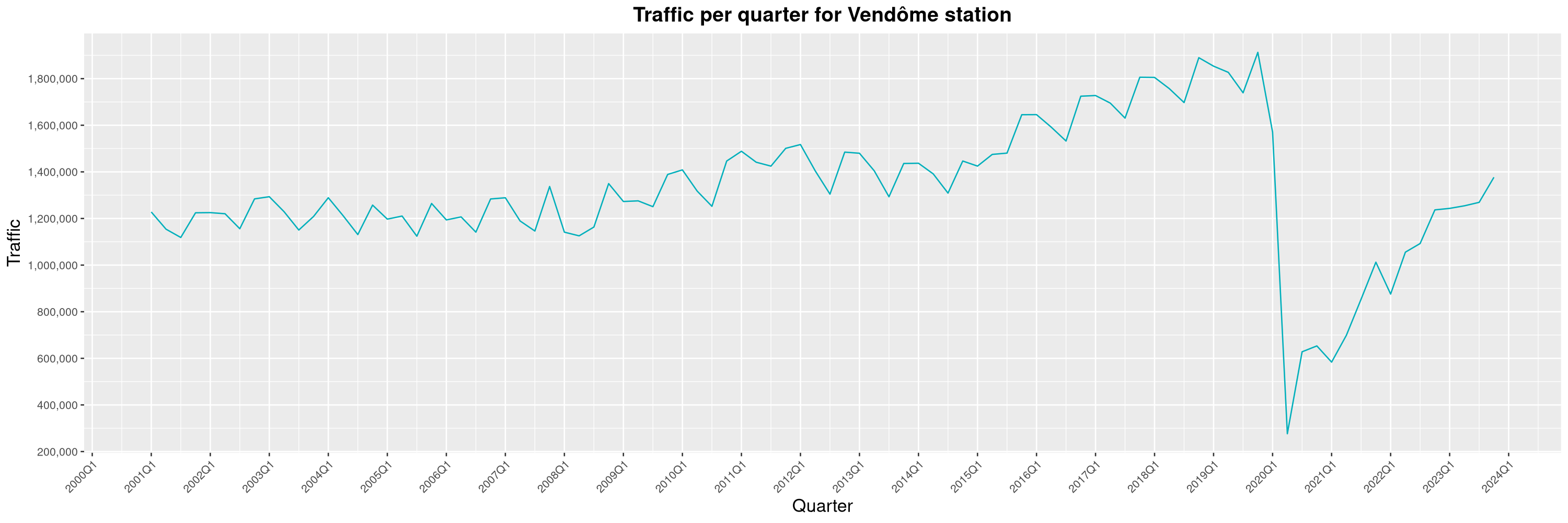
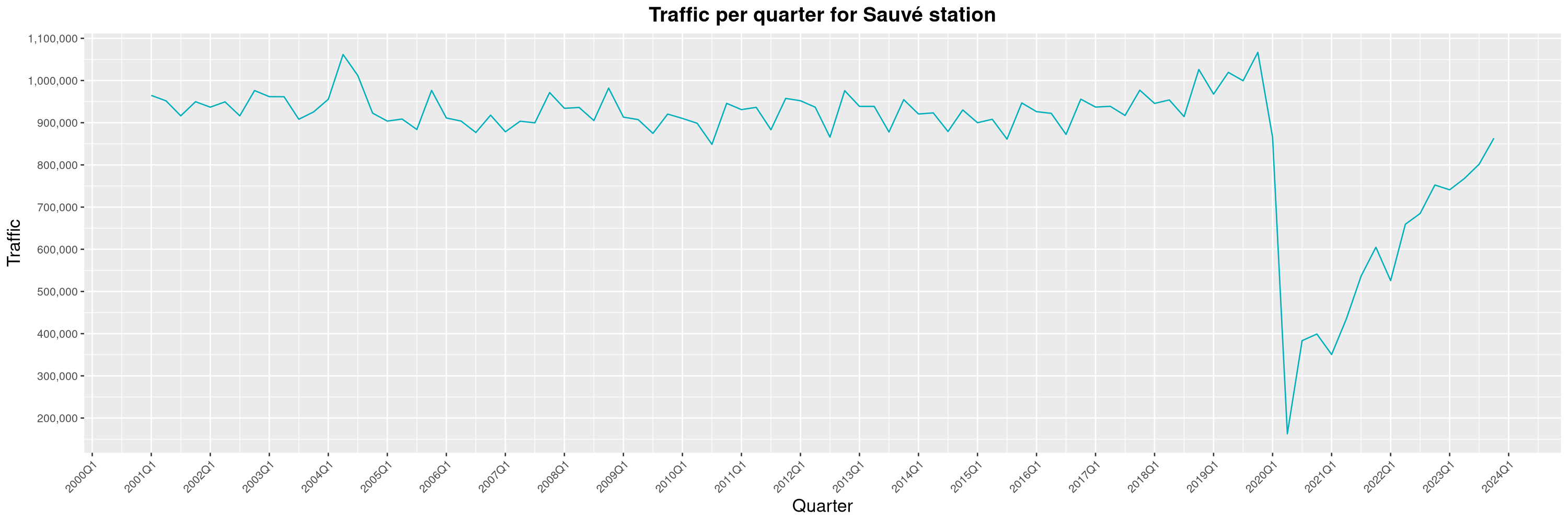
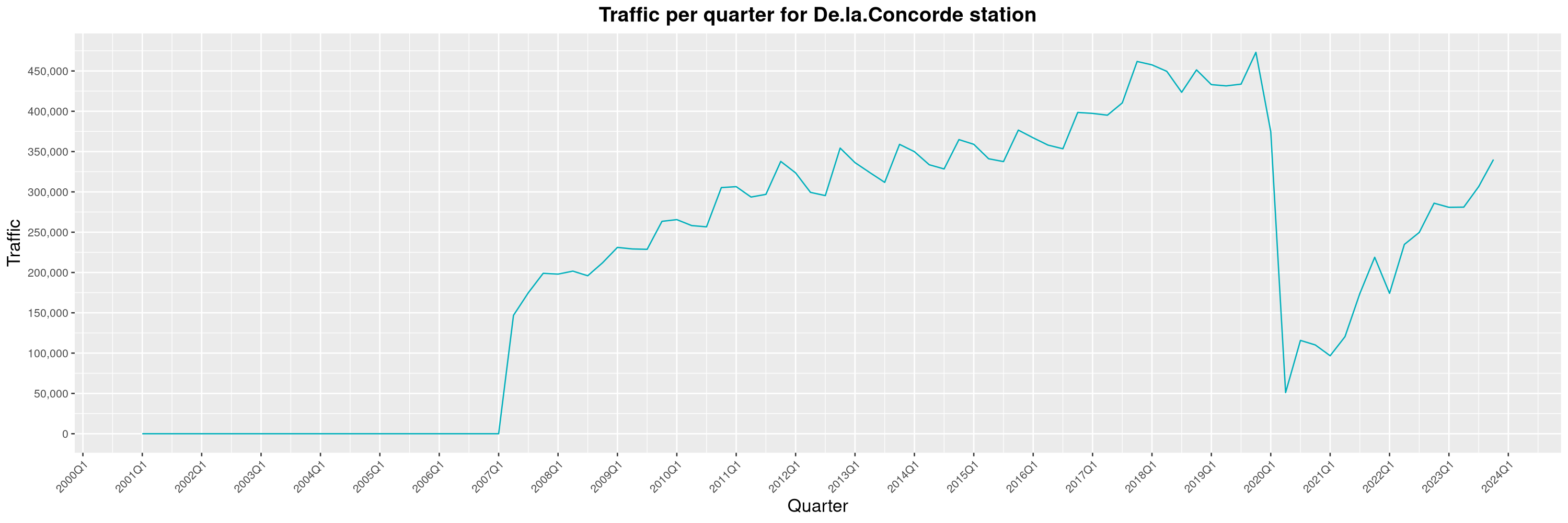
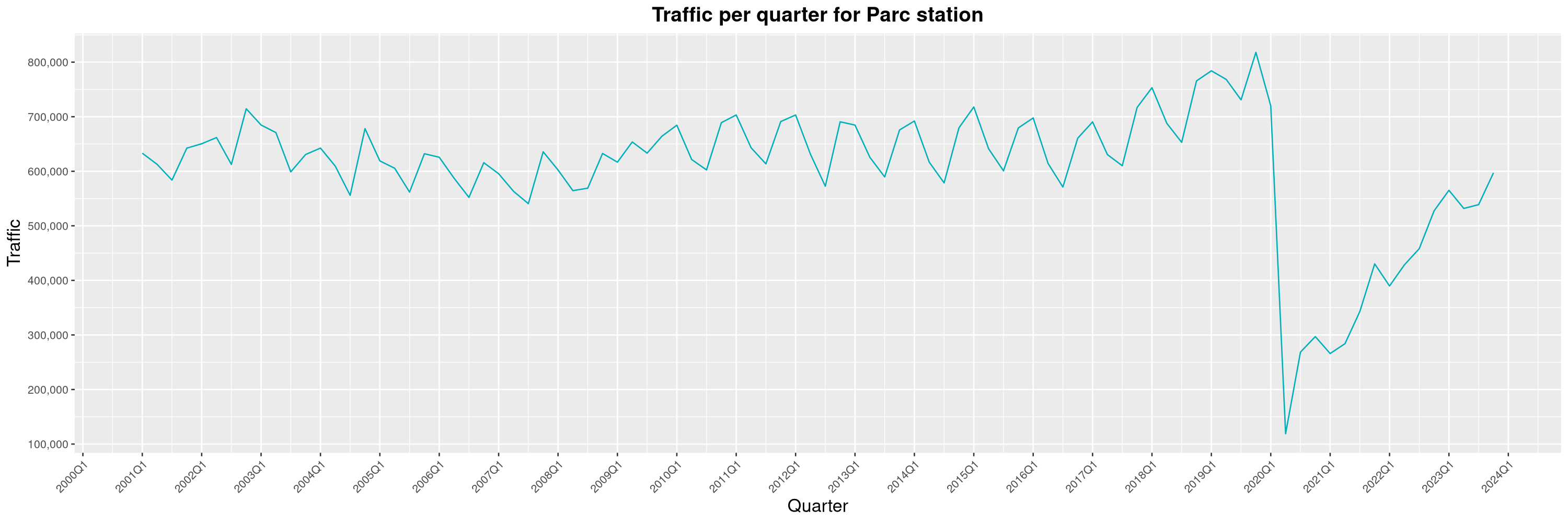
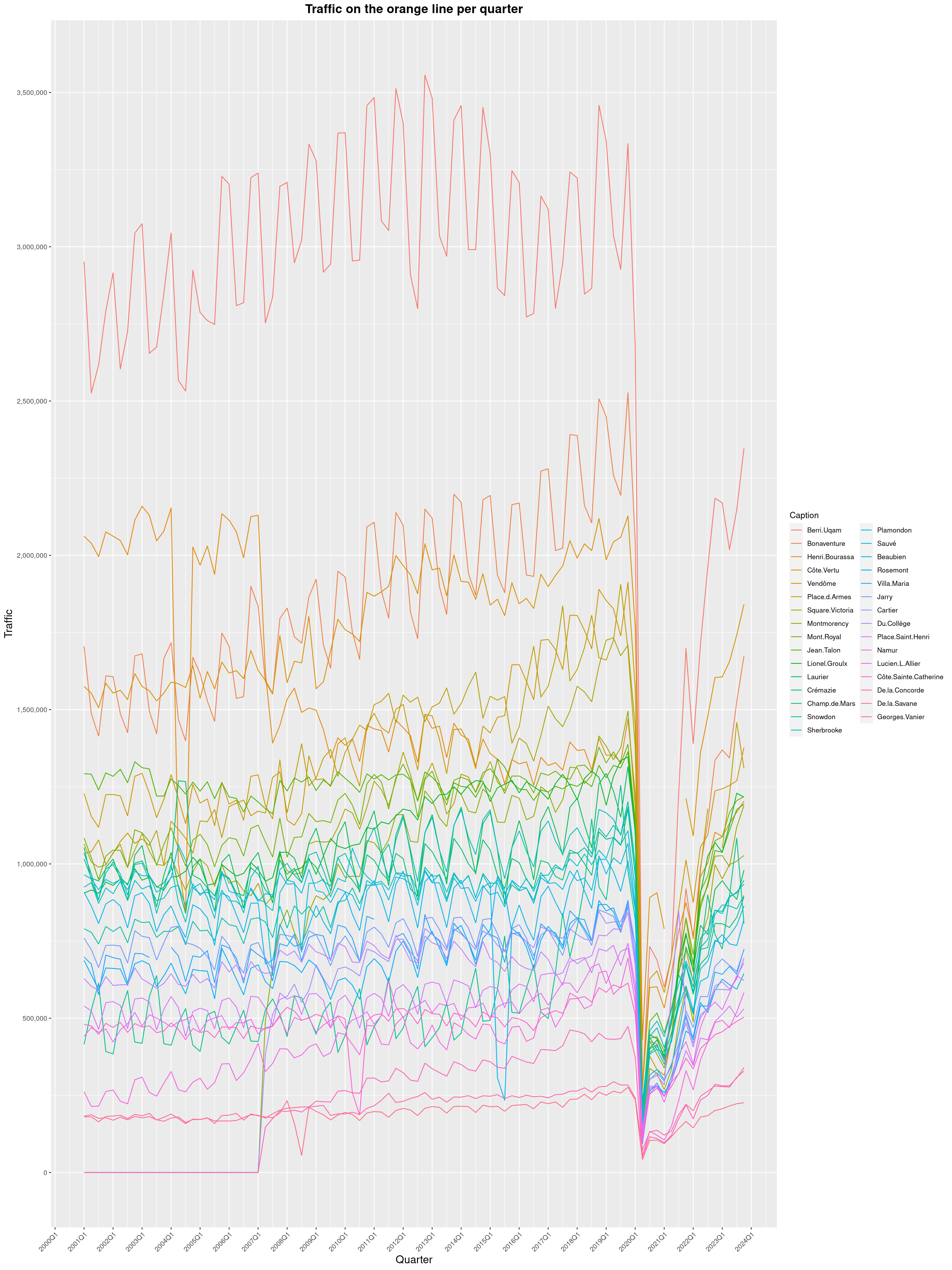
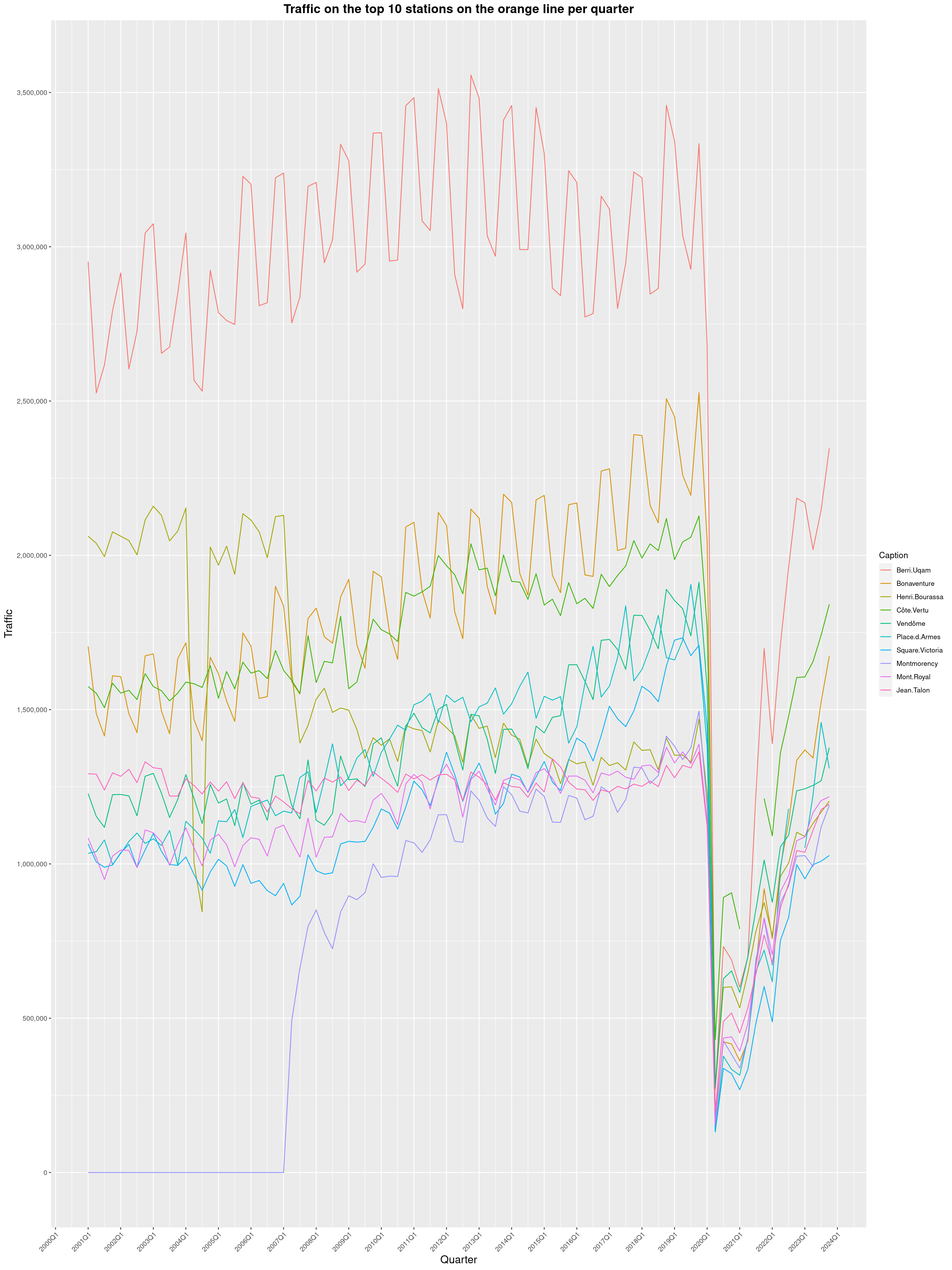
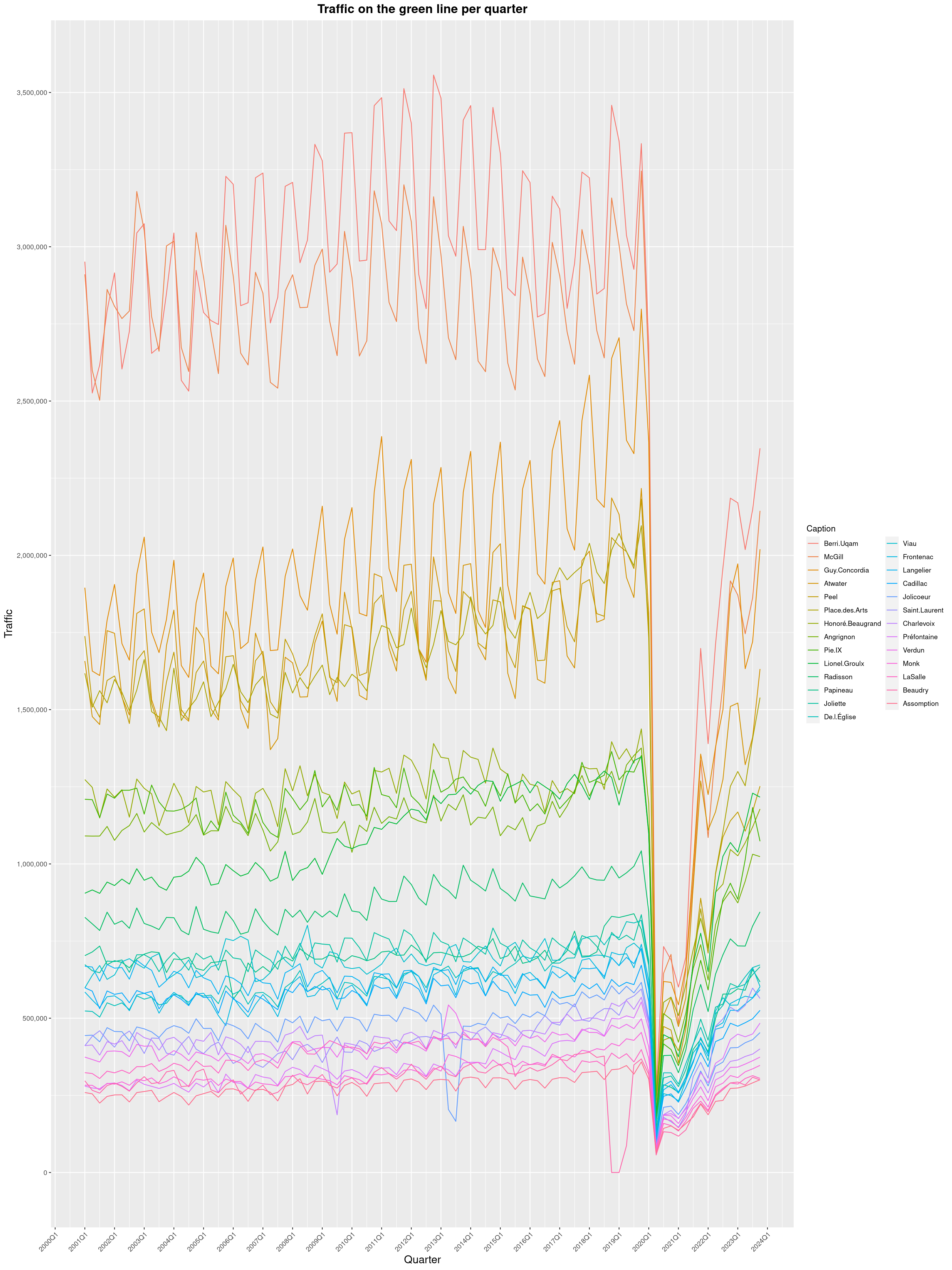
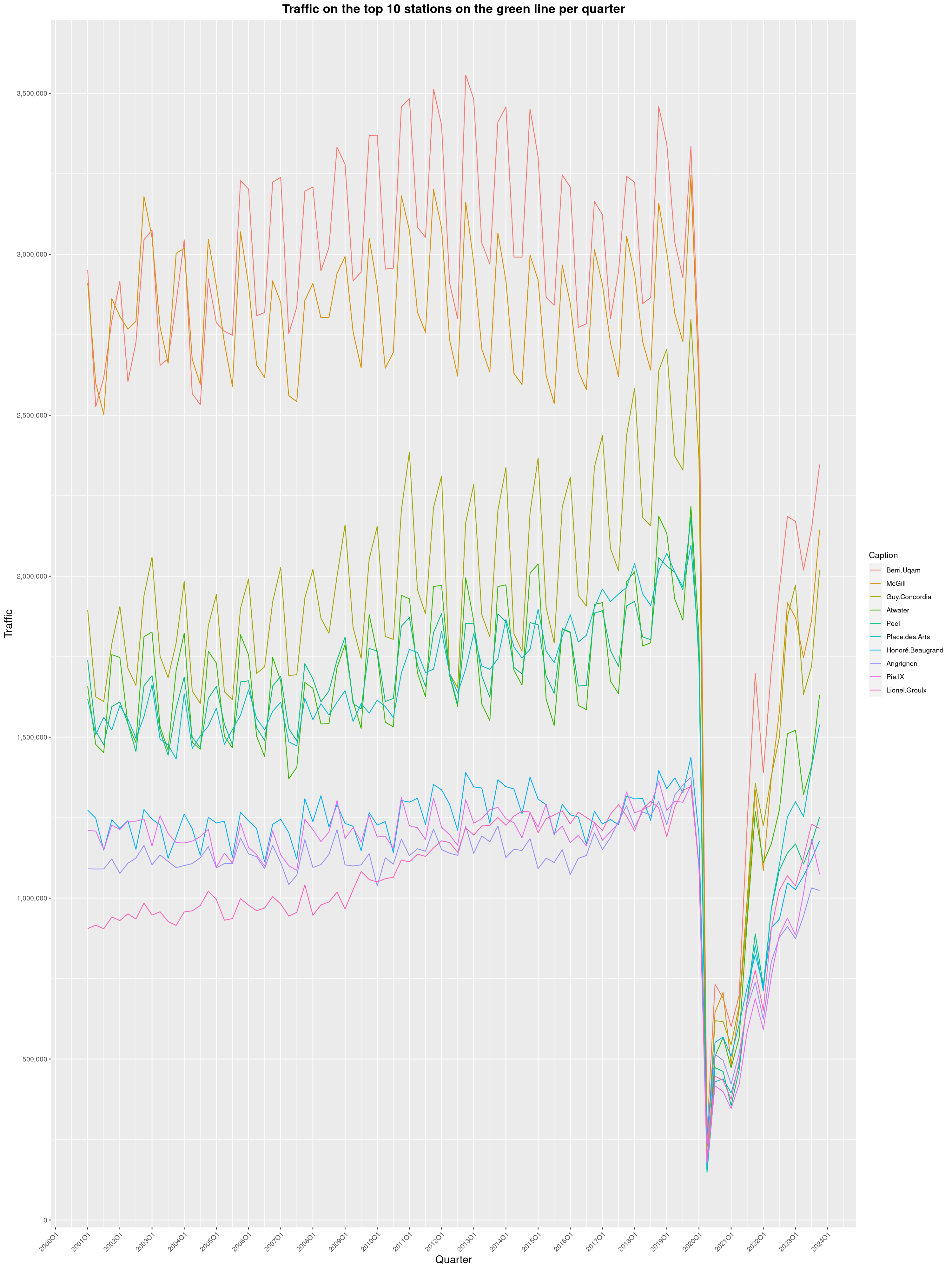
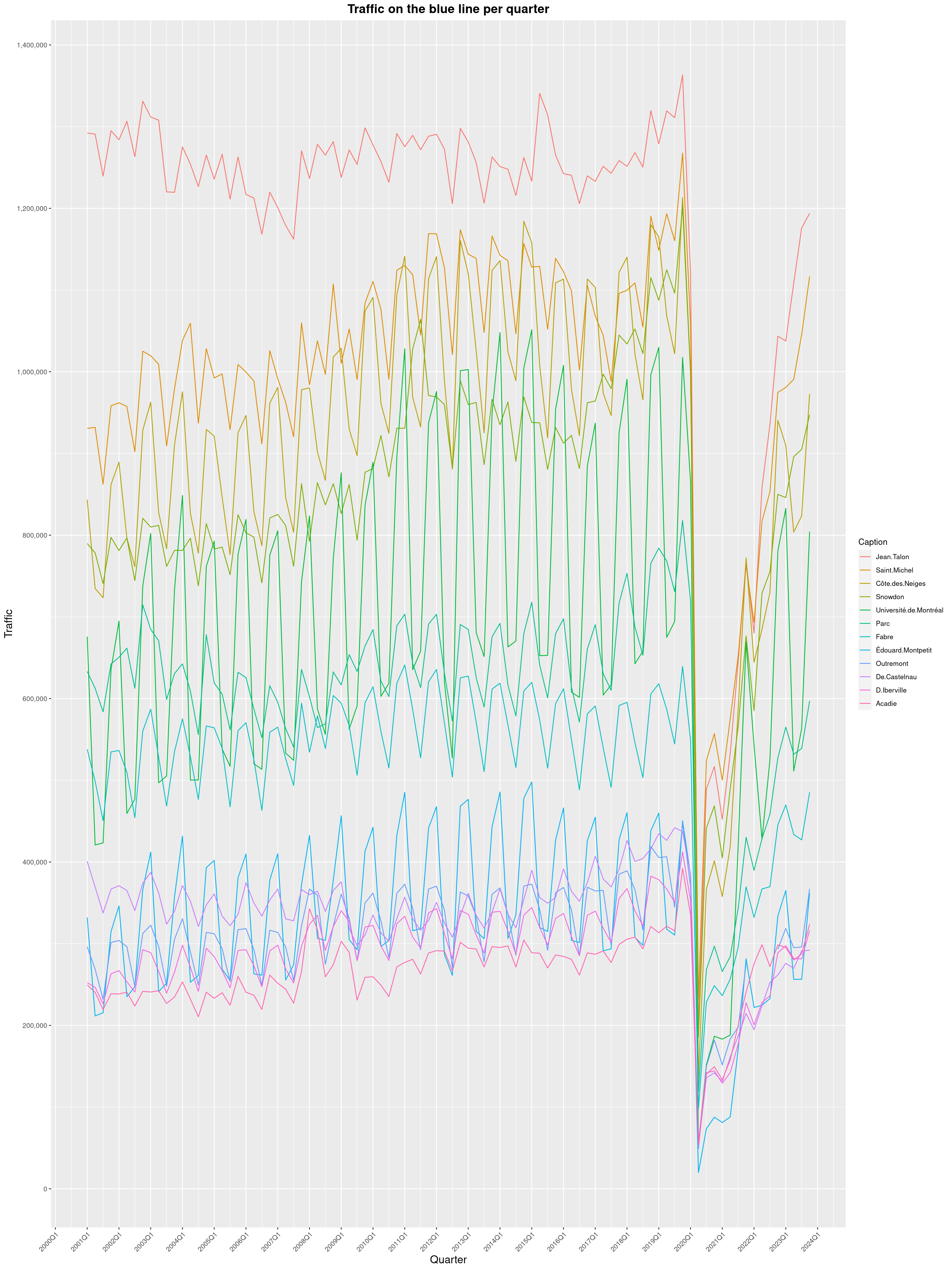
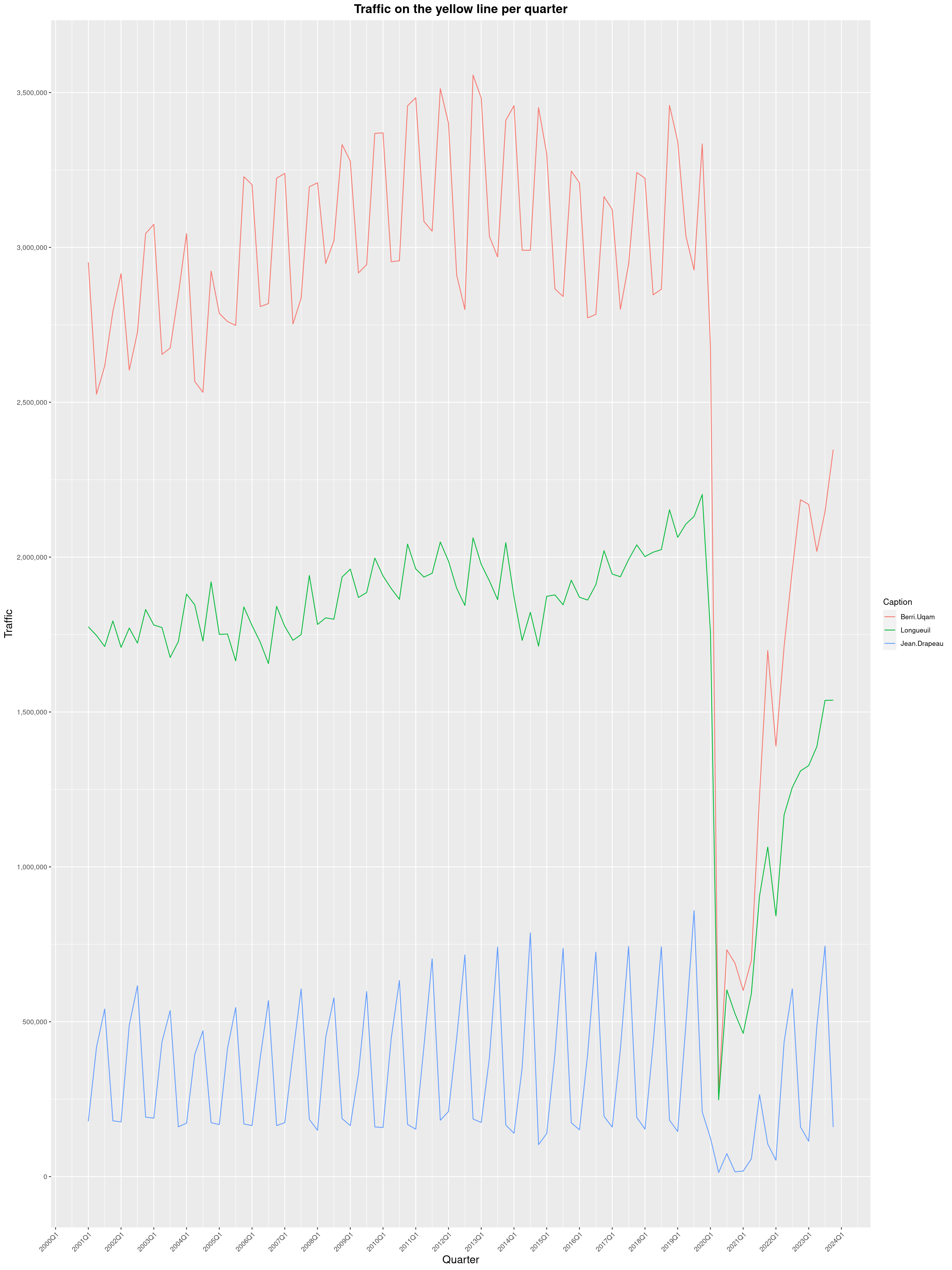
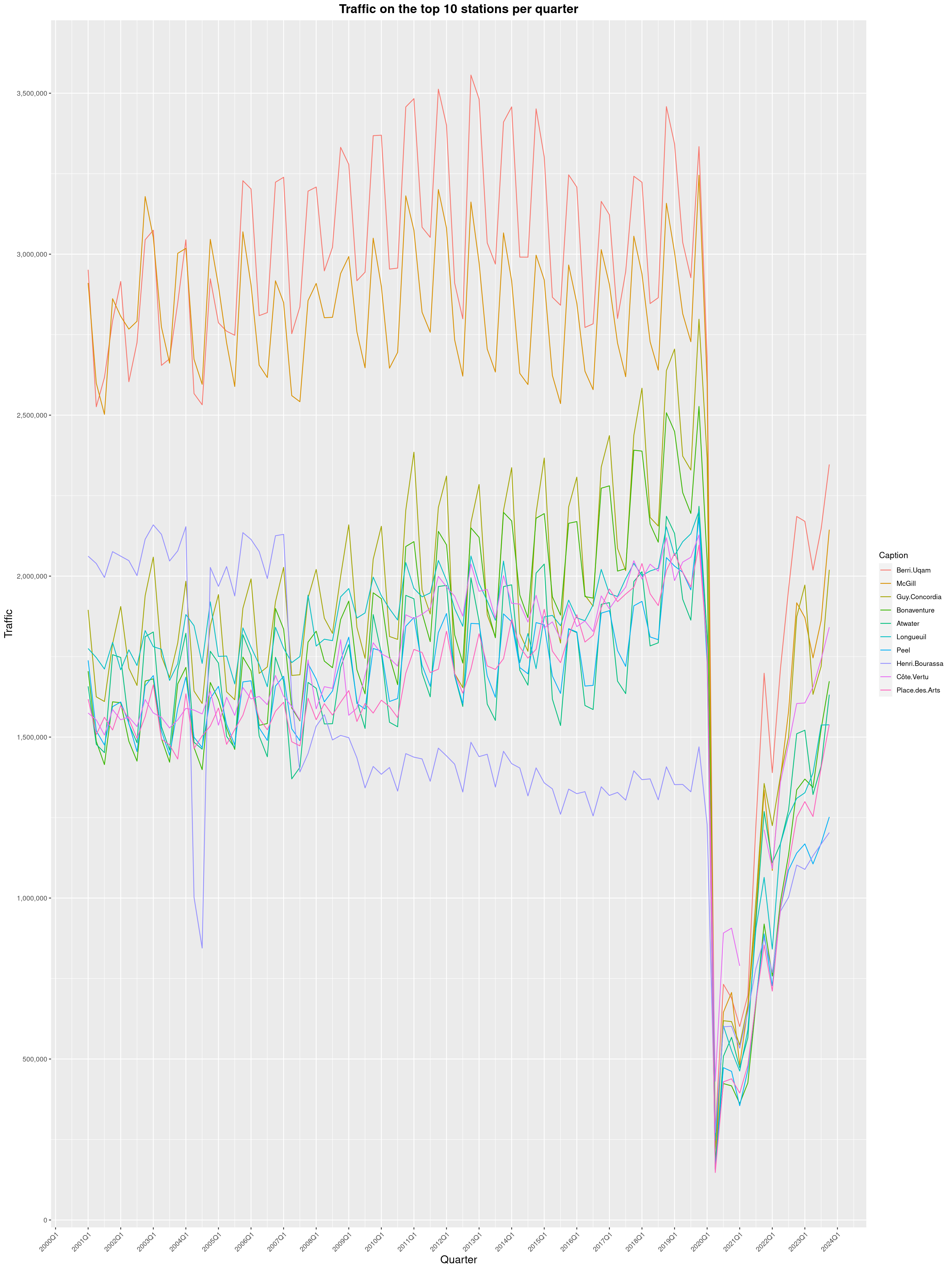
Louis-Philippe Véronneau: Montreal Subway Foot Traffic Data, 2023 edition
For the fifth year in a row, I've asked Société de Transport de Montréal, Montreal's transit agency, for the foot traffic data of Montreal's subway.
By clicking on a subway station, you'll be redirected to a graph of the station's foot traffic.
Licences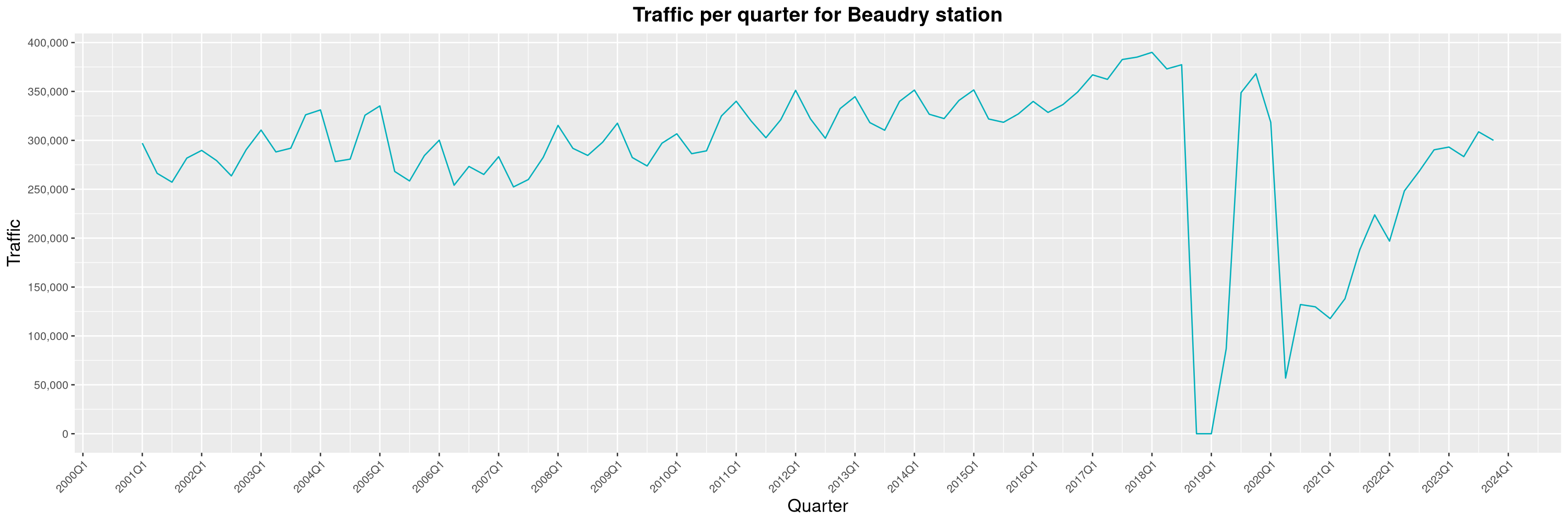{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
-
The subway map displayed on this page, the original dataset and my modified dataset are licenced under CCO 1.0: they are in the public domain.
-
The R code I wrote is licensed under the GPLv3+. It's pretty much the same code as last year. I tweaked last's year converter script and although I had to clean some of the data by hand, it worked pretty well.
parallel @ Savannah: GNU Parallel 20240122 ('Frederik X') released
GNU Parallel 20240122 ('Frederik X') has been released. It is available for download at: lbry://@GnuParallel:4
Quote of the month:
GNU Parallel alone provides more value than moreutils
-- Ferret7446@news.ycombinator.com
New in this release:
- --sshlogin supports ranges: server[01-12,15] 10.0.[1-10].[2-254]
- --plus enables {slot-1} and {seq-1} = {%}-1 and {#}-1 to count from 0.
- env_parallel.{sh,ash,dash,bash,ksh,zsh} are now the same script.
- Bug fixes and man page updates.
GNU Parallel - For people who live life in the parallel lane.
If you like GNU Parallel record a video testimonial: Say who you are, what you use GNU Parallel for, how it helps you, and what you like most about it. Include a command that uses GNU Parallel if you feel like it.
GNU Parallel is a shell tool for executing jobs in parallel using one or more computers. A job can be a single command or a small script that has to be run for each of the lines in the input. The typical input is a list of files, a list of hosts, a list of users, a list of URLs, or a list of tables. A job can also be a command that reads from a pipe. GNU Parallel can then split the input and pipe it into commands in parallel.
If you use xargs and tee today you will find GNU Parallel very easy to use as GNU Parallel is written to have the same options as xargs. If you write loops in shell, you will find GNU Parallel may be able to replace most of the loops and make them run faster by running several jobs in parallel. GNU Parallel can even replace nested loops.
GNU Parallel makes sure output from the commands is the same output as you would get had you run the commands sequentially. This makes it possible to use output from GNU Parallel as input for other programs.
For example you can run this to convert all jpeg files into png and gif files and have a progress bar:
parallel --bar convert {1} {1.}.{2} ::: *.jpg ::: png gif
Or you can generate big, medium, and small thumbnails of all jpeg files in sub dirs:
find . -name '*.jpg' |
parallel convert -geometry {2} {1} {1//}/thumb{2}_{1/} :::: - ::: 50 100 200
You can find more about GNU Parallel at: http://www.gnu.org/s/parallel/
You can install GNU Parallel in just 10 seconds with:
$ (wget -O - pi.dk/3 || lynx -source pi.dk/3 || curl pi.dk/3/ || \
fetch -o - http://pi.dk/3 ) > install.sh
$ sha1sum install.sh | grep 883c667e01eed62f975ad28b6d50e22a
12345678 883c667e 01eed62f 975ad28b 6d50e22a
$ md5sum install.sh | grep cc21b4c943fd03e93ae1ae49e28573c0
cc21b4c9 43fd03e9 3ae1ae49 e28573c0
$ sha512sum install.sh | grep ec113b49a54e705f86d51e784ebced224fdff3f52
79945d9d 250b42a4 2067bb00 99da012e c113b49a 54e705f8 6d51e784 ebced224
fdff3f52 ca588d64 e75f6033 61bd543f d631f592 2f87ceb2 ab034149 6df84a35
$ bash install.sh
Watch the intro video on http://www.youtube.com/playlist?list=PL284C9FF2488BC6D1
Walk through the tutorial (man parallel_tutorial). Your command line will love you for it.
When using programs that use GNU Parallel to process data for publication please cite:
O. Tange (2018): GNU Parallel 2018, March 2018, https://doi.org/10.5281/zenodo.1146014.
If you like GNU Parallel:
- Give a demo at your local user group/team/colleagues
- Post the intro videos on Reddit/Diaspora*/forums/blogs/ Identi.ca/Google+/Twitter/Facebook/Linkedin/mailing lists
- Get the merchandise https://gnuparallel.threadless.com/designs/gnu-parallel
- Request or write a review for your favourite blog or magazine
- Request or build a package for your favourite distribution (if it is not already there)
- Invite me for your next conference
If you use programs that use GNU Parallel for research:
- Please cite GNU Parallel in you publications (use --citation)
If GNU Parallel saves you money:
- (Have your company) donate to FSF https://my.fsf.org/donate/
GNU sql aims to give a simple, unified interface for accessing databases through all the different databases' command line clients. So far the focus has been on giving a common way to specify login information (protocol, username, password, hostname, and port number), size (database and table size), and running queries.
The database is addressed using a DBURL. If commands are left out you will get that database's interactive shell.
When using GNU SQL for a publication please cite:
O. Tange (2011): GNU SQL - A Command Line Tool for Accessing Different Databases Using DBURLs, ;login: The USENIX Magazine, April 2011:29-32.
GNU niceload slows down a program when the computer load average (or other system activity) is above a certain limit. When the limit is reached the program will be suspended for some time. If the limit is a soft limit the program will be allowed to run for short amounts of time before being suspended again. If the limit is a hard limit the program will only be allowed to run when the system is below the limit.
Wing Tips: AI Assisted Development in Wing Pro
This Wing Tip introduces Wing Pro's AI assisted software development capabilities. Starting with Wing Pro version 10, you can use generative AI to write new code at the current editor insertion point, or you can use the AI tool to refactor, redesign, or extend existing code.
Generative AI is astonishingly capable as a programmer's assistant. As long as you provide it with sufficient context and clear instructions, it can cleanly and correctly execute a wide variety of programming tasks.
AI Code Suggestion
Here is an example where Wing Pro's AI code suggestion capability is used to write a missing method for an existing class. The AI knows what to add because it can see what precedes and follows the insertion point in the editor. It infers from that context what code you would like it to produce:
Shown above: Typing 'def get_full_name' followed by Ctrl-? to initiate AI suggestion mode. The suggested code is accepted by pressing Enter.
AI Refactoring
AI refactoring is even more powerful. You can request changes to existing code according to written instructions. For example, you might ask it to "convert this threaded implementation to run asynchronously instead":
Shown above: Running the highlighted request in the AI tool to convert multithreaded code to run asynchronously instead.
Description-Driven Development
Wing Pro's AI refactoring tool can also be used to write new code at the current insertion point, according to written instructions. For example, you might ask it to "add client and server classes that expose all the public methods of FileManager to a client process using sockets and JSON":
Shown above: Using the AI tool to request implementation of client/server classes for remote access to an existing class.
Simpler and perhaps more common requests like "write documentation strings for these methods" and "create unit tests for class Person" of course also work. In general, Wing Pro's AI assistant can do any reasonably sized chunk of work for which you can clearly state instructions.
Used correctly, this capability will have a significant impact on your productivity as a programmer. Instead of typing out code manually, your role changes to one of directing an intelligent assistant capable of completing a wide range of programming tasks very quickly. You will still need to review and accept or reject the AI's work. Generative AI can't replace you, but it allows you to concentrate much more on higher-level design and much less on implementation details.
Getting Started
Wing Pro uses OpenAI as its AI provider, and you will need to create and pay for your own OpenAI account before you can use this feature. You may need to pay up to US $50 up front to be given computational rate limits that are high enough to use AI for your software development. However, individual requests often cost less than a US$ 0.01. More complex tasks may cost up to 30 cents, if you provide a lot of context with them. This is still far less than the paid programmer time the AI is replacing.
To use AI assisted development effectively, and you will need to learn how to create well-designed requests that provide the AI both with the necessary relevant context and clear and specific instructions. Please read all of the AI Assisted Development documentation for details on setup, framing requests, and monitoring costs. It takes a bit of time to get started, but it is well worth the effort incorporate generative AI into your tool chain.
That's it for now! We'll be back soon with more Wing Tips for Wing Python IDE.
As always, please don't hesitate to email support@wingware.com if you run into problems or have any questions.
Dirk Eddelbuettel: RcppAnnoy 0.0.22 on CRAN: Maintenance
A very minor maintenance release, now at version 0.0.22, of RcppAnnoy has arrived on CRAN.
RcppAnnoy is the Rcpp-based R integration of the nifty Annoy library by Erik Bernhardsson. Annoy is a small and lightweight C++ template header library for very fast approximate nearest neighbours—originally developed to drive the Spotify music discovery algorithm. It had all the buzzwords already a decade ago: it is one of the algorithms behind (drum roll …) vector search as it finds approximate matches very quickly and also allows to persist the data.
This release responds to a CRAN request to clean up empty macros and sections in Rd files.
Details of the release follow based on the NEWS file.
Changes in version 0.0.22 (2024-01-23)- Replace empty examples macro to satisfy CRAN request.
Courtesy of my CRANberries, there is also a diffstat report for this release.
If you like this or other open-source work I do, you can sponsor me at GitHub.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
The Russian Lullaby: How to set up a local development environment (LDE) for Drupal
You are probably interested in setting up a workign environment for Drupal-based projects or maybe you have new members in your development team, so the configuration of the correct development environment is a fundamental part of the process of working with Drupal, you are right. By reading this how-to guide, you will implement a complete and ready-to-go Drupal working environment ready for versions 8, 9, and 10 of our favorite CMS/framework. Do you want to start?…
Picture from Unsplash, user Mathyas Kurmann, @mathyaskurmann.
This content has been constructed as a …
Seth Michael Larson: Releases on the Python Package Index are never “done”
Published 2024-01-24 by Seth Larson
Reading time: minutes
PEP 740 is a proposal to add support for digital attestations to PyPI artifacts, for example publish provenance attestations, which can be verified and used by tooling.
William Woodruff has been working on PEP 740 which is in draft on GitHub, William addressed my feedback this week. During this work the open-endedness of PyPI releases came up during our discussion, specifically how it is a common gotcha for folks designing tools and policy for multiple software ecosystems difficult.
What does it mean for PyPI releases to be open-ended? It means that you can always upload new files to an existing release on PyPI even if the release has been created for years. This is because a PyPI “release” is only a thin layer aggregating a bunch of files on PyPI that happen to share the same version.
This discussion between us was opened up as a wider discussion on discuss.python.org about this property. Summarizing this discussion:
- New Python releases mean new wheels need to be built for non-ABI3 compatible projects. IMO this is the most compelling reason to keep this property.
- Draft releases seem semi-related, being able to put artifacts into a "queue" before making them public.
- Ordering of which wheel gets evaluated as an installation candidate isn't defined well. Up to installers, tends to be more specific -> less specific.
- PyPI doesn't allow single files to be yanked even though PEP 592 allows for yanking at the file level instead of only the release level.
- The "attack" vector is fairly small, this property would mostly only provide additional secrecy for attackers by blending into existing releases.
CPython 3.13.0a3 was released, this is the very first CPython release that contains any SBOM metadata at all, and thus we can create an initial draft SBOM document.
Much of the work on CPython's SBOMs was done to fix issues related to pip's vendored dependencies and issues found by downstream distributors of CPython builds like Red Hat. The issues were as follows:
- Don't require internet access to run the SBOM script. We use internet access to automatically generate metadata for pip, but if the internet isn't available we should continue using the metadata that we already have (assuming the file hasn't changed) and then rely on CI which should always have internet access (the script fails in CI) to verify the values.
- If pip wheel is removed, don't raise an unskippable error. Redistributors will typically remove the wheel in favor of their own distribution of pip for ensurepip.
- Enumerate pip's vendored dependencies in the SBOM. This requires parsing the vendor.txt script inside of pip's vendor directory.
All of these issues are mostly related and touch the same place in the codebase, so resulted in a medium-sized pull request to fix all the issues together.
On the release side, I've addressed feedback from the first round of reviews for generating SBOMs for source code artifacts and uploading them during the release. Once those SBOMs start being generated they'll automatically begin being added to python.org/downloads.
Other items- Two new Developer-in-Residence roles have been filled at the Python Software Foundation. Welcome, Petr Viktorin as the Deputy Developer-in-Residence and Serhiy Storchaka as the Supporting Developer-in-Residence. We've already gotten a chance to collaborate and I look forward to even more.
- scikit-learn is considering build reproducibility.
- Wrote my piece for the Python Software Foundation Annual Impact report.
- Submitted to the OpenSSF SOSS Community Day Call for Proposals (see you in Washington!)
- Reviewed a fix by Erlend Aasland for the SBOM generation script.
- I published a blog post which provides guidance on how to remove a maintainer from an open source project to reduce the attack surface of an open source project.
That's all for this week! 👋 If you're interested in more you can read last week's report.
Thanks for reading! ♡ Did you find this article helpful and want more content like it? Get notified of new posts by subscribing to the RSS feed or the email newsletter.
This work is licensed under CC BY-SA 4.0
Kay Hayen: Nuitka Package Configuration Part 3
This is the third part of a post series under the tag package_config that explains the Nuitka package configuration in more detail. To recap, Nuitka package configuration is the way Nuitka learns about hidden dependencies, needed DLLs, data files, and just generally avoids bloat in the compilation. The details are here on a dedicate page on the web site in Nuitka Package Configuration but reading on will be just fine.
Problem PackageEach post will feature one package that caused a particular problem. In this case, we are talking about the package toga.
Problems like with this package are typically encountered in standalone mode only, but they also affect accelerated mode, since it doesn’t compile all the things desired in that case. Some packages, and in this instance look at what OS they are running on, environment variables, etc. and then in a relatively static fashion, but one that Nuitka cannot see through, loads a what it calls “backend” module.
We are going to look at that in some detail, and will see a workaround applied with the anti-bloat engine doing code modification on the fly that make the choice determined at compile time, and visible to Nuitka is this way.
Initial SymptomThe initial symptom reported was that toga did suffer from broken version lookups and therefor did not work, and we encountered even two things, that prevented it, one was about the version number. It was trying to do int after resolving the version of toga by itself to None.
Traceback (most recent call last): File "C:\py\dist\toga1.py", line 1, in <module> File "<frozen importlib._bootstrap>", line 1176, in _find_and_load File "<frozen importlib._bootstrap>", line 1147, in _find_and_load_unlocked File "<frozen importlib._bootstrap>", line 690, in _load_unlocked File "C:\py\dist\toga\__init__.py", line 1, in <module toga> File "<frozen importlib._bootstrap>", line 1176, in _find_and_load File "<frozen importlib._bootstrap>", line 1147, in _find_and_load_unlocked File "<frozen importlib._bootstrap>", line 690, in _load_unlocked File "C:\py\dist\toga\app.py", line 20, in <module toga.app> File "<frozen importlib._bootstrap>", line 1176, in _find_and_load File "<frozen importlib._bootstrap>", line 1147, in _find_and_load_unlocked File "<frozen importlib._bootstrap>", line 690, in _load_unlocked File "C:\py\dist\toga\widgets\base.py", line 7, in <module toga.widgets.base> File "<frozen importlib._bootstrap>", line 1176, in _find_and_load File "<frozen importlib._bootstrap>", line 1147, in _find_and_load_unlocked File "<frozen importlib._bootstrap>", line 690, in _load_unlocked File "C:\py\dist\travertino\__init__.py", line 4, in <module travertino> File "<frozen importlib._bootstrap>", line 1176, in _find_and_load File "<frozen importlib._bootstrap>", line 1147, in _find_and_load_unlocked File "<frozen importlib._bootstrap>", line 690, in _load_unlocked File "C:\py\dist\setuptools_scm\__init__.py", line 7, in <module setuptools_scm> File "<frozen importlib._bootstrap>", line 1176, in _find_and_load File "<frozen importlib._bootstrap>", line 1147, in _find_and_load_unlocked File "<frozen importlib._bootstrap>", line 690, in _load_unlocked File "C:\py\dist\setuptools_scm\_config.py", line 15, in <module setuptools_scm._config> File "<frozen importlib._bootstrap>", line 1176, in _find_and_load File "<frozen importlib._bootstrap>", line 1147, in _find_and_load_unlocked File "<frozen importlib._bootstrap>", line 690, in _load_unlocked File "C:\py\dist\setuptools_scm\_integration\pyproject_reading.py", line 8, in <module setuptools_scm._integration.pyproject_reading> File "<frozen importlib._bootstrap>", line 1176, in _find_and_load File "<frozen importlib._bootstrap>", line 1147, in _find_and_load_unlocked File "<frozen importlib._bootstrap>", line 690, in _load_unlocked File "C:\py\dist\setuptools_scm\_integration\setuptools.py", line 62, in <module setuptools_scm._integration.setuptools> File "C:\py\dist\setuptools_scm\_integration\setuptools.py", line 29, in _warn_on_old_setuptools ValueError: invalid literal for int() with base 10: 'unknown'So, this is clearly something that we consider bloat in the first place, to runtime lookup your own version number. The use of setuptools_scm is implying the use of setuptools, for which the version cannot be determined, and that’s crashing.
Step 1 - Analysis of initial crashingSo first thing, we did was to repair setuptools, to know its version. It is doing it a bit different, because it cannot use itself. Our compile time optimization failed there, but also would be overkill. We never came across this, since we avoid setuptools very hard normally, but it’s not good to be incompatible.
- module-name: 'setuptools.version' anti-bloat: - description: 'workaround for metadata version of setuptools' replacements: "pkg_resources.get_distribution('setuptools').version": "repr(__import__('setuptools.version').version.__version__)"We do not have to include all metadata for setuptools here, just to get that one item, so we chose to make a simple string replacement here, that just looks the value up at compile time and puts it into the source code automatically. That removes the pkg_resources.get_distribution() call entirely.
With that, setuptools_scm was not crashing anymore. That’s good. But we don’t really want it to be included, since it’s good for dynamically detecting the version from git, and what not, but including the framework for building C extensions, not a good idea in the general case. Nuitka therefore said this:
Nuitka-Plugins:WARNING: anti-bloat: Undesirable import of 'setuptools_scm' (intending to Nuitka-Plugins:WARNING: avoid 'setuptools') in 'toga' (at Nuitka-Plugins:WARNING: 'c:\3\Lib\site-packages\toga\__init__.py:99') encountered. It may Nuitka-Plugins:WARNING: slow down compilation. Nuitka-Plugins:WARNING: Complex topic! More information can be found at Nuitka-Plugins:WARNING: https://nuitka.net/info/unwanted-module.htmlSo that’s informing the user to take action. And in the case of optional imports, i.e. ones where using code will handle the ImportError just fine and work without it, we can use do this.
- module-name: 'toga' anti-bloat: - description: 'remove setuptools usage' no-auto-follow: 'setuptools_scm': '' when: 'not use_setuptools'He we say, no not automatically follow setuptools_scm reports, unless there is other code that still does it. In that way, the import still happens if some other part of the code imports the module, but only then. We no longer enforce the non-usage of a module here, we just make that decision based on other uses being present.
With this the bloat warning, and the inclusion of setuptools_scm into the compilation is removed, and you always want to make as small as possible and remove those packages that do not contribute anything but overhead, aka bloat.
The next thing discovered was that toga needs the toga-core distribution to version check. For that, we use the common solution, and tell that we want to include the metadata of it, for when toga is part of a compilation.
- module-name: 'toga' data-files: include-metadata: - 'toga-core'So that moved the entire issue of version looks to resolved.
Step 2 - Dynamic Backend dependencyNow on to the backend issue. What remained was a need for including the platform specific backend. One that can even be overridden by an environment variable. For full compatibility, we invented something new. Typically what we would have done is to create a toga plugin for the following snippet.
- module-name: 'toga.platform' variables: setup_code: 'import toga.platform' declarations: 'toga_backend_module_name': 'toga.platform.get_platform_factory().__name__' anti-bloat: - change_function: 'get_platform_factory': "'importlib.import_module(%r)' % get_variable('toga_backend_module_name')"There is a whole new thing here, a new feature that was added specifically for this to be easy to do. And with the backend selection being complex and partially dynamic code, we didn’t want to hard code that. So we added support for variables and their use in Nuitka Package Configuration.
The first block variables defines a mapping of expressions in declarations that will be evaluated at compile time given the setup code under setup_code.
This then allows us to have a variable with the name of the backend that toga decides to use. We then change the very complex function get_platform_factory that we used used, for compilation, to be replacement that Nuitka will be able to statically optimize and see the backend as a dependency and use it directly at run time, which is what we want.
Final remarksI am hoping you will find this very helpful information and will join the effort to make packaging for Python work out of the box. Adding support for toga was a bit more complex, but with the new tool, once identified to be that kind of backend issue, it might have become a lot more easy.
Lessons learned. We should cover packages that we routinely remove from compilation, like setuptools, but e.g. also IPython. This will have to added, such that setuptools_scm cannot cloud the vision to actual issues.
Quansight Labs Blog: Captioning: A Newcomer’s Guide
The Drop Times: Technology and People Make Drupal Happen: Fran Garcia
PyCoder’s Weekly: Issue #613 (Jan. 23, 2024)
#613 – JANUARY 23, 2024
View in Browser »
This is a follow-on post to Chris’s article from last year called Fourteen tools at least twelve too many. “Are there still fourteen tools, or are there even more? Has Python packaging improved in a year?”
CHRIS WARRICK
This post describes running Python code on a “soft” air-gapped system, one without direct internet access. Installing packages in a clean environment and moving them to the air-gapped machine has challenges. Read Ibrahim’s take on how he solved the problem.
IBRAHIM AHMED
Get ready to elevate your web development process with the newly released Full Stack FastAPI App Generator by MongoDB, offering a simplified setup process for building modern full-stack web applications with FastAPI and MongoDB →
MONGODB sponsor
After you implement the main functionality of a web project, it’s good to understand how your users interact with your app and where they may run into errors. In this tutorial, you’ll enhance your Flask project by creating error pages and logging messages.
REAL PYTHON
How can you measure the quality of a large language model? What tools can measure bias, toxicity, and truthfulness levels in a model using Python? This week on the show, Jodie Burchell, developer advocate for data science at JetBrains, returns to discuss techniques and tools for evaluating LLMs With Python.
REAL PYTHON podcast
This article presents various aspects you need to consider when choosing a database for your project - querying, performance, ORMs, migrations, etc. It shows how things are approached differently for Postgres vs. DynamoDB and includes examples in Python.
JAN GIACOMELLI • Shared by Jan Giacomelli
Hear from our technical team on how we’ve built Temporal Cloud to deliver world-class latency, performance, and availability for the smallest and largest workloads. Whether you’re using Temporal Cloud or self-host, this series will be full of insights into how to optimize your Temporal Service →
TEMPORAL sponsor
“As with every technology stack, Python has its advantages and limitations. The key to success is to use Python at the right time and in the right place.” This guide talks about what a product owner needs to know to take on a Python project.
PAVLO PYLYPENKO • Shared by Alina
In this video course, you’ll explore how to make HTTP requests using Python’s handy built-in module, urllib.request. You’ll try out examples and go over common errors, all while learning more about HTTP requests and Python in general.
REAL PYTHON course
Nvidia has created GPU-based replacements for NumPy and other tools and promises significant speed-ups, but the comparison may not be accurate. Read on to learn if GPU replacements for CPU-based libraries are really that much faster.
ITAMAR TURNER-TRAURING
Your Django migrations are piling up in your repo? You want to clean them up without a hassle? Check out this new package django-migration-zero that helps make migration management a piece of cake!
RONNY VEDRILLA • Shared by Sarah Boyce
To understand NumPy, you need to understand the ndarray type. This article starts with Python’s native lists and shows you when you need to move to NumPy’s ndarray data type.
STEPHEN GRUPPETTA • Shared by Stephen Gruppetta
PyPy is an alternative implementation of Python, and its C API compatibility layer has some performance issues. This article describes on-going work to improve its performance.
MAX BERNSTEIN
It’s not uncommon to find yourself reading Excel in Python. This article compares several ways to read Excel from Python and how they perform.
HAKI BENITA
This article provides an in-depth walkthrough of how requests are processed in a Flask application.
TESTDRIVEN.IO • Shared by Michael Herman
GITHUB.COM/LEWOUDAR • Shared by Kevin Tewouda
Autometrics-py: Metrics to Debug in ProductionGITHUB.COM/AUTOMETRICS-DEV • Shared by Adelaide Telezhnikova
django-cte: Common Table Expressions (CTE) for Django Events Weekly Real Python Office Hours Q&A (Virtual) January 24, 2024
REALPYTHON.COM
January 25, 2024
MEETUP.COM
January 25, 2024
MEETUP.COM
January 27, 2024
MEETUP.COM
January 27, 2024
PYTHON.ORG.BR
Happy Pythoning!
This was PyCoder’s Weekly Issue #613.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
- KDE e.V. is looking for a web designer (Hugo) for environmental sustainability project
- Bastian Venthur: New python-debianbts in experimental
- The Drop Times: Which CMS Powers Your Country's Official Website? A Global CMS Usage Analysis
- Debian Brasil: MiniDebConf BH 2024 - vídeos e fotos
- Dries Buytaert: State of Drupal presentation (May 2024)