
Feeds
Real Python: Simulate a Text File in Python
Testing applications that read files from a disk can be challenging. Issues such as machine dependencies, special access requirements, and slow performance often arise when you need to read text from a file.
In this Code Conversation with instructor Martin Breuss, you’ll discover how to simplify this process by simulating text files with StringIO from the io module in Python’s standard library.
In this video course, you’ll learn how to:
- Use io.StringIO to simulate a text file on disk
- Perform file operations on a io.StringIO object
- Decide when to use io.StringIO and when to avoid it
- Understand possible alternatives
- Mock a file object using unittest.mock
Understanding how to simulate text file objects and mock file objects can help streamline your testing strategy and development process.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
The Drop Times: Thoughts on Drupal Starshot #2: A New Direction for Drupal
Matt Glaman: Trial experience for Starshot update
Earlier this month, I debuted a way to try out Drupal core and the Starshot prototype running in the browser using WebAssembly. It started as a passion project and fascination with new web technologies, something I had tried a year before but didn't find a fit for. Now, it's officially part of a Starshot initiative track.
Trial experience for Starshot trackI am the lead for the Trial experience for Starshot track. The track has three phases:
LabPlot funded through NGIO Core Fund
This year we applied to NLnet’s NGI Zero Core open call for proposals in February 2024. After a thorough review by the NLnet Foundation, LabPlot’s application was accepted and will be funded by the NGI0 Core Fund, a fund established by NLnet with financial support from the European Commission’s Next Generation Internet Program, under the aegis of DG Communications Networks, Content and Technology, under Grant Agreement No. 101092990.
NGI Zero Core is a grant program focused on free and open source projects that deliver free and open technologies to society with full transparency and user empowerment. See the full list of projects funded this year.
As part of this funding, the LabPlot team will mainly work on the following three features:
- Analysis on live data where we want to enable the already existing analysis functions (FFT, smooth, etc.) on live data
- Python Scripting which will allow users to leverage LabPlot’s C++ API via python bindings in external applications and also allow to control LabPlot from within the running instance of the application
- Statistical Analysis with the plan to implement the most relevant statistical hypothesis tests and correlation coefficients that are frequently used in the statistics community.
We’re not starting from scratch in these areas. For all of these topics, we have already received numerous requests and suggestions from users in the past, and there have already been discussions within the team. We have also defined some concrete tasks for what we want to achieve (see for example the planned roadmap for statistical analysis) and we have even done some proof-of-concept implementations. With the financial support, the team will now focus more on these issues, complete the development and release these important features to our users in the near future.
We would like to express our thanks to the NLnet Foundation and to the European Commission for their support!
Marcos Dione: Writing a tile server in python
Another dictated post111, but heavily edited. Buyer beware.
I developed a tileset based on OpenStreetMap data and style and elevation information, but I don't have a render server. What I have been doing is using my own version of an old script from the mapnik version of the OSM style. This script is called generate_tiles, and I made big modifications to it and now it's capable of doing many things, including spawning several processes for handling the rendering. You can define regions that you want to render, or you can just provide a bbox or a set of tiles or just coordinates. You can change the size of the meta tile, and it handles empty tiles. If you find a sea tile, most probably you will not need to render its children9, where children are the four tiles that are just under it in the next zoom level. For instance, in zoom level zero we have only one tile (0,0,0), and it's children are (1,0,0), (1,0,1), (1,1,0) and (1,1,1). 75% of the planet's surface is water, and with Mercator projection and the Antartic Ocean, the percent of tiles could be bigger, so this optimization cuts a lot of useless rendering time.
Another optimization is that it assumes that when you render zoom level N, you will be using at least the same data for zoom level N+1. Of course, I am not catching that data because mapnik does not allow this, but the operating system does the catching. So if you have enough RAM, then you should be able to reuse all the data that's already in buffers and cache, instead of having to fetch them again from disk. This in theory should accelerate rendering and probably it is10.
The script works very well, and I've been using it for years already for rendering tiles in batches for several zoom levels. Because my personal computer is way more powerful than my server (and younger; 2018 vs 2011), I render in my computer and rsync to my server.
So now I wanted to make a tile server based on this. Why do I want to make my own and not use renderd? I think my main issue with renderd is that it does not store the individual tiles, but keeps metatiles of 8x8 tiles and serve the individual tiles from there. This saves inode usage and internal fragmentation. Since my main usage so far has been (and probably will continue to be) rendering regions by hand, and since my current (static) tile server stores all the latest versions of the tiles I have rendered since I started doing this some 15 years ago, I want updating the server in a fast way. Most tile storage methods I know fail terribly at update time (see here); most of the time it means sending the whole file over the wire. Also, individual tiles are easier to convert to anything else, like creating a MBTiles file, push it to my phone, and have a offline tile service I can carry with me on treks where there is no signal. Also, serving the tiles can be as easy as python -m http.server from the tileset root directory. So renderd is not useful for me. Another reason is, well, I already have the rendering engine working. So how does it work?
The rendering engine consists of one main thread, which I call Master, and rendering threads3. These rendering threads load the style and wait for work to do. The current style file is 6MiB+ and takes mapnik 4s+ to load it and generate all its structures, which means these threads have to be created once per service lifetime. I have one queue that can send commands from the Master to the renderer pool asking for rendering a metatile, which is faster than rendering the individual tiles. Then one of the rendering threads picks the request from this queue, calls mapnik, generates the metatile, cuts it into the subtiles and saves them to disk. The rendering thread posts in another queue, telling the Master about the children metatiles that must be rendered, which due to emptiness can be between 0 and 4.
To implement the caching optimization I mentioned before, I use a third structure to maintain a stack. At the beginning I push into it the initial work; later I pop one element from it, and when a rendered returns the list of children to be rendered, I push them on top of the rest. This is what tries to guarantee that a metatile's children will be rendered before moving to another region that would trash the cache. And because the children can inspect the tiles being written, they can figure out when a child is all sea tiles and not returning it for rendering.
At the beginning I thought that, because the multiprocessing queues are implemented with pipes, I could use select()4 to see whether the queue was ready for writing or reading and use a typical non-blocking loop. When you're trying to write, these queues will block when the queue is full, and when you're trying to read, they will block when the queue is empty. But these two conditions, full and empty, are actually handled by semaphores, not by the size of the pipe. That means that selecting on those pipes, even if I could reach all the way down into the structures of the multiprocessing.Queue all the way down. and add them to a selector, yes, the read queue will not be selected if it's empty (nothing to read), but the write queue will not, since availability of space in the pipe does not mean the queue is not full.
So instead I'm peeking into these queues. For the work queue, I know that the Master thread8 is the only writer, so I can peek to see if it is full. If it is, I am not going to send any new work to be done, because it means that all the renders are busy, and the only work queued to be done has not been picked up yet. For the reading side it's the same, Master is the only reader. so, I can peek if it's empty, and if it is, I am not going to try to read any information from it. So, I have a loop, peeking first into the work queue and then into the info queue. If nothing has been done, I sleep a fraction of a second.
Now let's try to think about how to replace this main loop with a web frontend. What is the web frontend going to do? It's going to be getting queries by different clients. It could be just a slippy map in a web page, so we have a browser as a client, or it could be any of the applications that can also render slippy maps. For instance, on Linux, we have marble; on Android, I use MyTrails, and OsmAnd.
One of the things about these clients is that they have timeouts. Why am I mentioning this? Because rendering a metatile for me can take between 3 to 120 seconds, depending on the zoom level. There are zoom levels that are really, really expensive, like between 7 and 10. If a client is going to be asking directly a rendering service for a tile, and the tile takes too long to render, the client will timeout and close the connection. How do we handle this on the server side? Well, instead of the work stack, the server will have request queue, which will be collecting the requests from the clients, and the Master will be sending these requests to the render pool.
So if the client closes the connection, I want to be able to react to that, removing any lingering requests made by that client from the request queue. If I don't do that, the request queue will start piling up more and more requests, creating a denial of service. This is not possible in multiprocessing queues, you cannot remove an element. The only container that can do that is a dequeue5, which also is optimized for putting and popping things from both ends (it's probably implemented using a circular buffer), which is perfect for a queue. As for the info queue, I will not be caring anymore about children metatiles, because I will not be doing any work that the clients are not requesting.
What framework that would allow me to do this? Let's recap the requirements:
- Results are computed, and take several seconds.
- The library that generates the results is not async, nor thread safe, so I need to use subprocesses to achieve parallelization.
- A current batch implementation uses 2 queues to send and retrieve computations to a pool of subprocesses; my idea is to "just" add a web frontend to this.
- Each subprocess spends some seconds warming up, son I can't spawn a new process for each request.
- Since I will have a queue of requested computations, if a client dies, if its query is being processed, then I let it finish; if not, I should remove it from the waiting queue.
I started with FastAPI, but it doesn't have the support that I need. At first I just implemented a tile server; the idea was to grow from there6, but reading the docs it only allows doing long running async stuff after the response has been sent.
Next was Flask. Flask is not async unless you want to use sendfile(). sendfile() is a way to make the kernel read a file and write it directly on a socket without intervention from the process requesting that. The alternative is to to open the file, read a block, write it on the socket, repeat. This definitely makes your code more complex, you have to handle lots of cases. So sendfile() is very, very handy, but it's also faster because it's 0-copy. But Flask does not give control of what happens when the client suddenly closes the connection. I can instruct it to cancel the tasks in flight, but as per all the previous explanation, that's not what I want.
This same problem seems to affect all async frameworks I looked into. asyncio, aiohttp, tornado. Except, of course, twisted, but its API for that is with callbacks, and TBH, I was starting to get tired of all this, and the prospect of callback hell, even when all the rest of the system could be developed in a more async way, was too much. And this is not counting the fact that I need to hook into the main loop to step the Master. This could be implemented with timed callbacks, such as twisted's callLater(), but another thought started to form in my head.
Why did I go directly for frameworks? Because they're supposed to make our lives easier, but from the beginning I had the impression that this would not be a run of the mill service. The main issue came down to beign able to send things to render, return the rendered data to the right clients, associate several clients to a single job before it finished (more than one client might request the same tile or several tiles that belong to the same metatile), and handle client and job cancellation when clients disappear. The more frameworks' documentation I read, the more I started to fear that the only solution was to implement an non-blocking12 loop myself.
I gotta be honest, I dusted an old Unix Network Programming book, 2nd Ed., 1998 (!!!), read half a chapter, and I was ready to do it. And thanks to the simple selector API, it's a breeze:
- Create a listening socket.
- Register it for read events (connections).
- On connection, accept the client and wait for read events in that one too.
- We were not registering for write before because the client is always ready for write before we start sending anything, which lead to tight loops.
- On client read, read the request and send the job to Master. Unregister for read.
- But if there's nothing to read, the client disconnected. Send an empty.response, unregister for read and register for write.
- Step Master.
- If anything came back, generate the responses and queue them for sending. Register the right clients for write.
- On client write (almost always), send the response and the file with sendfile() if any.
- Then close the connection and unregister.
- Loop to #3.
Initially all this, including reimplementing fake Master and render threads, took less than 200 lines of code, some 11h of on-and-off work. Now that I have finished I have a better idea of how to implement this at least with twisted, which I think I will have to do, since step 4 assumes the whole query can be recv()'ed in one go and step 7 similarly for send()'ing; luckily I don't need to do any handholding for sendfile(), even when the socket is non blocking. A more production ready service needs to handle short reads and writes. Also, the HTTP/1.1 protocol all clients are using allows me to assume that once a query is received, the client will be waiting for an answer before trying anything else, and that I can close the connection once a response has been send and assume the client will open a new connection for more tiles. And even then, supporting keep alive should not be that hard (instead of closing the client, unregister for write, register for read, and only do the close dance when the response is empty). And because I can simply step Master in the main loop, I don't have to worry about blocking queues.
Of course, now it's more complex, because it's implementing support for multiple clients with different queries requiring rendering the same metatile. This is due that applications will open several clients for fetching tiles when showing a region, and unless it's only 4 and they fall in the corner of 4 adjacent metatiles, they will always mean more than one client per metatile. Also, I could have several clients looking at the same region. The current code is approaching the 500 lines, but all that should also be present in any other implementation.
I'm pretty happy about how fast I could make it work and how easy it was. Soon I'll be finishing integrating a real render thread with saving the tiles and implement the fact that if one metatile's tile is not present, we can assume it's OK, but if all are not present, I have to find out if they were all empty or never rendered. A last step would be how to make all this testable. And of course, the twisted port.
-
This is getting out of hand. The audio was 1h long, not sure how long it took to auto transcribe, and when editing and thinking I was getting to the end of it, the preview told me I still had like half the text to go through. ↩
-
No idea what I wanted to write here :) ↩
-
Because mapnik is not thread safe and because of the GIL, they're actually subprocesses via the multioprocessing module, but I'll keep calling them threads to simplify. ↩
-
Again, a simplification. Python provides the selector module that allows using abstract implementations that spare us from having to select the best implementation for the platform. ↩
-
I just found out it's pronounced like 'deck'. ↩
-
All the implementations I did followed the same pattern. In fact, right now, I hadn't implementing the rendering tile server: it's only blockingly sleep()'ing for some time (up to 75s, to trigger client timeouts), and then returning the tiles already present. What's currently missing is figuring out whether I should rerender or use the tiles already present7, and actually connecting the rendering part. ↩
-
Two reasons to rerender: the data is stale, or the style has changed. The latter requires reloading the styles, which will probably mean rebuilding the rendering threads. ↩
-
I keep calling this the Master thread, but at this point instead of having its own main loop, I'm just calling a function that implements the body of such loop. Following previous usage for such functions, it's called single_step(). ↩
-
Except when you start rendering ferry routes. ↩
-
I never measured it :( ↩
-
Seems like nikola renumbers the footnotes based on which order they are here at the bottom of the source. The first note was 0, but it renumbered it and all the rest to start counting from 1. ↩
-
Have in account that I'm explicitly making a difference between a non-blocking/select() loop from an async/await system, but have in account that the latter is actually implemented with the formet. ↩
Python Bytes: #394 Python is easy now?
drunomics: Green UX
Kay Hayen: Nuitka Release 2.4
This is to inform you about the new stable release of Nuitka. It is the extremely compatible Python compiler, “download now”.
This release largely contains bug fixes for the previous changes, but also finishes full compatibility with the match statements of 3.10, something that was long overdue since there were always some incompatible behaviors there.
In terms of bug fixes, it’s also huge. An upgrade is required, especially for new setuptools that made compiled programs segfault at startup.
Table of Contents
UI: Fix, we had reversed disable / force and wrong option name recommendation for --windows-console-mode when the user used old-style options.
Python3.10+: Fix, must not check for len greater or equal of 0 or for sequence match cases. That is unnecessary and incompatible and can raise exceptions with custom sequences not implementing __len__. Fixed in 2.3.1 already.
Python3.10+: Fix, match sequence with final star arguments failed in some cases to capture the rest. The assigned value then was empty.when it shouldn’t have been. Fixed in 2.3.1 already.
Python3.8+: Fix, calls to variable args functions now need to be done differently, or else they can crash, as was observed with 3.10 in PGO instrumentation, at least. Fixed in 2.3.1 already.
PGO: Fix, using nuitka-run did not execute the program created as expected. Fixed in 2.3.1 already.
Linux: Support extension modules used as DLLs by other DLLs or extension modules. That makes newer tensorflow and potentially more packages work again. Fixed in 2.3.1 already.
Python3.10+: Matches classes were not fully compatible.
We need to check against case-defined class __match_args__, not the matched value type __match_args that is not necessarily the same.
Also, properly annotating the exception exit of subscript matches; the subscript value can indeed raise an exception.
Collect keyword and positional match values in one go and detect duplicate attributes used, which we previously did not.
Scons: Fix, do not crash when clang is not reporting its version correctly. It happened if Clang usage was required with --clang option but not installed. Fixed in 2.3.2 already.
Debian: Fix, detecting the Debian flavor of Python was not working anymore, and as a result, the intended defaults were no longer applied by Nuitka, leading to incorrect suggestions that didn’t work. Fixed in 2.3.3 already.
Ubuntu: Fix, the static link library for Python 3.12 is not usable unless we provide parts of HACL for the sha2 module so as not to cause link errors. Fixed in 2.3.3 already.
Standalone: Fix, importing newer pkg_resources was crashing. Fixed in 2.3.3 already.
Python3.11+: Added support for newer Python with dill-compat. Fixed in 2.3.4 already.
Standalone: Support locating Windows icons for pywebview. Fixed in 2.3.4 already.
Standalone: Added support for spacy related packages. Fixed in 2.3.4 already.
Python3.12: Fix, our workaround for cv2 support cannot use the imp module anymore. Fixed in 2.3.4 already.
Compatibility: Added support for __init__ files that are extension modules. Architecture checks for macOS were false negatives for them, and the case insensitive import scan failed to find them on Windows. Fixed in 2.3.4 already.
Standalone: Added missing dependencies for standard library extension modules, mainly exhibited on macOS. Fixed in 2.3.4 already.
Windows: Fix build failures on mapped network drives. Fixed in 2.3.4 already.
Python3.12: Fix, need to set frame prev_inst or else f_lasti is random. Some packages; for example PySide6; use this to check what bytecode calls them or how they import them and it could crash when attempting it. Fixed in 2.3.6 already.
Fix, fork bomb in cpuinfo package no longer happens. Fixed in 2.3.8 already.
Nuitka-Python: Fix, cannot ask for shared library prefixes. Fixed in 2.3.8 already.
Standalone: Make sure keras package dependency for tensorflow is visible. Fixed in 2.3.10 already.
Linux: Fix, for static executables we should ignore errors setting a DLL load path. Fixed in 2.3.10 already.
Compatibility: Fix, nuitka resource readers also need to have .parent attribute. Fixed in 2.3.10 already.
Fix, need to force no-locale language outputs for tools outputs on non-Windows. Our previous methods were not forcing enough.
For non-Windows this makes Nuitka work on systems with locales active for message outputs only. Fixed in 2.3.10 already.
Fix, was not using proper result value for SET_ATTRIBUTE to check success in a few corner cases. Fixed in 2.3.10 already.
Windows: Retry deleting dist and build folders, allowing users to recognize still running programs and not crashing on Anti-Virus software still locking parts of them.
Fix, dict.fromkeys didn’t give compatible error messages for no args given.
Fix, output correct unsupported exception messages for in-place operations
For in-place **, it was also incompatible, since it must not mention the pow function.
Fix, included metadata could lead to instable code generation. We were using a dictionary for it, but that is not as stable order for the C compiler to fully benefit.
Fix, including data files for packages that are extension modules was not working yet.
macOS: Detect the DLL path of libpython (if used) by looking at dependencies of the running Python binary rather than encoding what CPython does. Doing that covers other Python flavors as well.
Fix, need to prefer extension modules over Python code for packages.
Fix, immutable constant values are not to be treated as very trusted.
Python3: Fix, the __loader__ attribute of a module should be an object and not only the class, otherwise only static methods can work.
Python3: Added .name and .path attributes to Nuitka loader objects for enhanced compatibility with code that expects source code loaders.
Fix, the sys.argv[0] needs to be absolute for best usability.
For dirname(sys.argv[0]) to be usable even if the program is launched via PATH environment by a shell, we cannot rely on how we are launched since that won’t be a good path, unlike with Python interpreter, where it always is.
Standalone: Fix, adding missing dependencies for some crypto packages.
Python3.12: Need to write to thread local variable during import. This however doesn’t work for Windows and non-static libpython flavors in general.
macOS: Enforce using system codesign as the Anaconda one is not working for us.
Fix, we need to read .pyi files as source code. Otherwise unicode characters can cause crashes.
Standalone: Fix, some packages query private values for distribution objects, so use the same attribute name for the path.
Multidist: Make sure to follow the multidist reformulation modules. Otherwise in accelerated mode, these could end up not being included.
Fix, need to hold a reference of the iterable while converting it to list.
Plugins: Fix, this wasn’t properly ignoring None values in load descriptions as intended.
macOS: Need to allow DLLs from all Homebrew paths.
Reports: Do not crash during report writing for very early errors.
Python3.11+: Fix, need to make sure we have split as a constant value when using exception groups.
Debian: More robust against problematic distribution folders with no metadata, these apparently can happen with OS upgrades.
Fix, was leaking exception in case of --python-flag=-m mode that could cause errors.
Compatibility: Close standard file handles on process forks as CPython does. This should enhance things for compilations using attach on Windows.
Standalone: Added data file for older bokeh version. Fixed in 2.3.1 already.
Standalone: Support older pandas versions as well.
Standalone: Added data files for panel package.
Standalone: Added support for the newer kivy version and added macOS support as well. Fixed in 2.3.4 already.
Standalone: Include all kivy.uix packages with kivy, so their typical config driven usage is not too hard.
Standalone: Added implicit dependencies of lxml.sax module. Fixed in 2.3.4 already.
Standalone: Added implicit dependencies for zeroconf package. Fixed in 2.3.4 already.
Standalone: Added support for numpy version 2. Fixed in 2.3.7 already.
Standalone: More complete support for tables package. Fixed in 2.3.8 already.
Standalone: Added implicit dependencies for scipy.signal package. Fixed in 2.3.8 already.
Standalone: Added support for moviepy and imageio_ffmeg packages. Fixed in 2.3.8 already.
Standalone: Added support for newer scipy. Fixed in 2.3.10 already.
Standalone: Added data files for bpy package. For full support more work will be needed.
Standalone: Added support for nes_py and gym_tetris packages.
Standalone: Added support for dash and plotly.
Standalone: Added support for usb1 package.
Standalone: Added support for azure.cognitiveservices.speech package.
Standalone: Added implicit dependencies for tinycudann package.
Standalone: Added support for newer win32com.server.register.
Standalone: Added support for jaxtyping package.
Standalone: Added support for open3d package.
Standalone: Added workaround for torch submodule import function.
Standalone: Added support for newer paddleocr.
Experimental support for Python 3.13 beta 3. We try to follow its release cycle closely and aim to support it at the time of CPython release. We also detect no-GIL Python and can make use of it. The GIL status is output in the --version format and the GIL usage is available as a new {GIL} variable for project options.
Scons: Added experimental option --experimental=force-system-scons to enforce system Scons to be used. That allows for the non-use of inline copy, which can be interesting for experiments with newer Scons releases. Added in 2.3.2 already.
Debugging: A new non-deployment handler helps when segmentation faults occurred. The crashing program then outputs a message pointing to a page with helpful information unless the deployment mode is active.
Begin merging changes for WASI support. Parts of the C changes were merged and for other parts, command line option --target=wasi was added, and we are starting to address cross platform compilation for it. More work will be necessary to fully merge it, right not it doesn’t work at all yet.
PGO: Added support for using it in standalone mode as well, so once we use it more, it will immediately be practical.
Make the --list-package-dlls use plugins as well, and make delvewheel and announce its DLL path internally, too. Listing DLLs for packages using plugins can use these paths for more complete outputs.
Plugins: The no-qt plugin was usable in accelerated mode.
Reports: Added included metadata and reasons for it.
Standalone: Added support for spacy with a new plugin.
Compatibility: Use existing source files as if they were .pyi files for extension modules. That gives us dependencies for code that installs source code and extension modules.
Plugins: Make version information, onefile mode, and onefile cached mode indication available in Nuitka Package Configuration, too.
Onefile: Warn about using tendo.singleton in non-cached onefile mode.
Tendo uses the running binary name for locking by default. So it’s not going to work if that changes for each execution, make the user aware of that, so they can use cached mode instead.
Reports: Include the micro pass counts and tracing merge statistics so we can see the impact of new optimization.
Plugins: Allow to specify modes in the Nuitka Package Configuration for annotations, doc_strings, and asserts. These overrule global configuration, which is often not practical. Some modules may require annotations, but for other packages, we will know they are fine without them. Simply disabling annotations globally barely works. For some modules, removing annotations can give a 30% compile-time speedup.
Standalone: Added module configuration for Django to find commands and load its engine.
Allow negative values for –jobs to be relative to the system core count so that you can tell Nuitka to use all but two cores with --jobs=-2 and need not hardcode your current code count.
Python3.12: Annotate libraries that are currently not supported
We will need to provide our own Python3.12 variant to make them work.
Python3.11+: Catch calls to uncompiled function objects with compiled code objects. We now raise a RuntimeError in the bytecode making it easier to catch them rather than segfaulting.
Statically optimize constant subscripts of variables with immutable constant values.
Forward propagate very trusted values for variable references enabling a lot more optimization.
Python3.8+: Calls of C functions are faster and more compact code using vector calls, too.
Python3.10+: Mark our compiled types as immutable.
Python3.12: Constant returning functions are dealing with immortal values only. Makes their usage slightly faster since no reference count handling is needed.
Python3.10+: Faster attribute descriptor lookups. Have our own replacement of PyDesc_IsData that had become an API call, making it very slow on Windows specifically.
Avoid using Python API function for determining sequence sizes when getting a length size for list creations.
Data Composer: More compact and portable Python3 int (Python2 long) value representation.
Rather than fixed native length 8 or 4 bytes, we use variable length encoding which for small values uses only a single byte.
This also avoids using struct.pack with C types, as we might be doing cross platform, so this makes part of the WASI changes unnecessary at the same time.
Large values are also more compact because middle 31-bit portions can be less than 4 bytes and save space on average.
Data Composer: Store bytecode blob size more efficient and portable, too.
Prepare having knowledge of __prepare__ result to be dictionaries per compile time decisions.
Added more hard trust for the typing module.
The typing.Text is a constant too. In debug mode, we now check all exports of typing for constant values. This will allow to find missing values sooner in the future.
Added the other types to be known to exist. That should help scalability for types intensive code somewhat by removing error handling for them.
macOS: Should use static libpython with Anaconda as it works there too, and reduces issues with Python3.12 and extension module imports.
Standalone: Statically optimize by OS in sysconfig.
Consequently, standalone distributions can exclude OS-specific packages such as _aix_support and _osx_support.
Avoid changing code names for complex call helpers
The numbering of complex call helper as normally applied to all functions are, caused this issue. When part of the code is used from the bytecode cache, they never come to exist and the C code of modules using them then didn’t match.
This avoids an extra C re-compilation for some modules that were using renumbered function the second time around a compilation happens. Added in 2.3.10 already.
Avoid using C-API when creating __path__ value.
Faster indentation of generated code.
Add new pydoc bloat mode to trigger warnings when using it.
Recognize usage of numpy.distutils as setuptools bloat for more direct reporting.
Avoid compiling large opcua modules that generate huge C files much like asyncua package. Added in 2.3.1 already.
Avoid shiboken2 and shiboken6 modules from matplotlib package when the no-qt plugin is used. Added in 2.3.6 already.
Changes for not using pydoc and distutils in numpy version 2. Added in 2.3.7 already.
Avoid numpy and packaging dependencies from PIL package.
Avoid using webbrowser module from pydoc.
Avoid using unittest in keras package. Added in 2.3.1 already.
Avoid distutils from _oxs_support (used by sysconfig) module on macOS.
Avoid using pydoc for werkzeug package. Fixed in 2.3.10 already.
Avoid using pydoc for site module. Fixed in 2.3.10 already.
Avoid pydoc from xmlrpc.server. Fixed in 2.3.10 already.
Added no_docstrings support for numpy2 as well. Fixed in 2.3.10 already.
Avoid pydoc in joblib.memory.
Avoid setuptools in gsplat package.
Avoid dask and jax in scipy package.
Avoid using matplotlib for networkx package.
Python3.12: Added annotations of official support for Nuitka PyPI package and test runner options that were still missing. Fixed in 2.3.1 already.
UI: Change runner scripts. The nuitka3 is no more. Instead, we have nuitka2 where it applies. Also, we now use CMD files rather than batch files.
UI: Check filenames for data files for illegal paths on the respective platforms. Some user errors with data file options become more apparent this way.
UI: Check spec paths more for illegal paths as well. Also do not accept system paths like {TEMP} and no path separator after it.
UI: Handle report writing interrupt with CTRL-C more gracefully. No need to present this this as a general problem, rather inform the user that he did it.
NoGIL: Warn if using a no-GIL Python version, as this mode is not yet officially supported by Nuitka.
Added badges to the README.rst of Nuitka to display package support and more. Added in 2.3.1 already.
UI: Use the retry decorator when removing directories in general. It will be more thorough with properly annotated retries on Windows. For the dist folder, mention the running program as a probable cause.
Quality: Check replacements and replacements_plain Nuitka package configuration values.
Quality: Catch backlashes in paths provided in Nuitka Package Configuration values for dest_path, relative_path, dirs, raw_dirs and empty_dirs.
Debugging: Disable pagination in gdb with the --debugger option.
PGO: Warn if the PGO binary does not run successfully.
UI: The new console mode option is a Windows-specific option now, move it to that group.
UI: Detect “rye python” on macOS. Added in 2.3.8 already.
UI: Be forgiving about release candidates; Ubuntu shipped one in a LTS release. Changed in 2.3.8 already.
Debugging: Allow fine-grained debug control for immortal checks
Can use --no-debug-immortal-assumptions to allow for corrupted immortal objects, which might be done by non-Nuitka code and then break the debug mode.
UI: Avoid leaking compile time Nuitka environment variables to the child processes.
They were primarily visible with --run, but we should avoid it for everything.
For non-Windows, we now recognize if we are the exact re-execution and otherwise, reject them.
Watch: Delete the existing virtualenv in case of errors updating or upgrading it.
Watch: Keep track of Nuitka compiled program exit code in newly added result files, too.
Watch: Redo compilations in case of previous errors when executing the compile program.
Quality: Wasn’t detecting files to ignore for PyLint on Windows properly, also detect crashes of PyLint.
Added test to cover the dill-compat plugin.
macOS: Make actual use of ctypes in its standalone test to ensure correctness on that OS, too.
Make compile extension module test work on macOS, too.
Avoid using 2to3 in our tests since newer Python no longer contains it by default, we split up tests with mixed contents into two tests instead.
Python3.11+: Make large constants test executable for as well. We no longer can easily create those values on the fly and output them due to security enhancements.
Python3.3: Remove support from the test runner as well.
Tests: Added construct-based tests for coroutines so we can compare their performance as well.
Make try/finally variable releases through common code. It will allow us to apply special exception value trace handling for only those for scalability improvements, while also making many re-formulations simpler.
Avoid using anti-bloat configuration values replacements where replacements_plain is good enough. A lot of config pre-date its addition.
Avoid Python3 and Python3.5+ specific Jinja2 modules on versions before that, and consequently, avoid warning about the SyntaxError given.
Moved code object extraction of dill-compat plugin from Python module template to C code helper for shared usage and better editing.
Also call va_end for standards compliance when using va_start. Some C compilers may need that, so we better do it even if what we have seen so far doesn’t need it.
Don’t pass main filename to the tree building anymore, and make nuitka.Options functions usage explicit when importing.
Change comments that still mentioned Python 3.3 as where a change in Python happened since we no longer support this version. Now, we consider what’s first seen in Python 3.4 is a Python3 change.
Cleanup, change Python 3.4 checks to 3.0 checks as Python3.3 is no longer supported. Cleans up version checks, as we now treat >=3.4 either as >=3 or can drop checks entirely.
The usual flow of spelling cleanups, this time for C codes.
This release cycle was a longer than usual, with much new optimization and package support requiring attention.
For optimization we got quite a few things going, esp. with more forward propagation, but the big ones for scalability are still all queued up and things are only prepared.
The 3.13 work was continuing smoothly and seems to be doing fine. We are still on track for supporting it right after release.
The parts where we try and address WASI prepare cross-compilation, but we will not aim at it generally immediately, and target our own Nuitka standalone backend Python that is supposed to be added in coming releases.
Russell Coker: Links July 2024
David Brin wrote an interesting article “Do We Really Want Immortality” [2]. I disagree with his conclusions about the politics though. Better manufacturing technology should allow decreasing the retirement age while funding schools well.
Scientific American has a surprising article about the differences between Chimp and Bonobo parenting [3]. I’d never have expected Chimp moms to be protective.
WorksInProgress has an insightful article about the world’s first around the world solo yacht race [5]. It has some interesting ideas about engineering.
Htwo has an interesting video about adverts for fake games [6]. It’s surprising how they apparently make money from advertising games that don’t exist.
Elena Hashman wrote an insightful blog post about Chronic Fatigue Syndrome [7]. I hope they make some progress on curing it soon. The fact that it seems similar to “long Covid” which is quite common suggests that a lot of research will be applied to that sort of thing.
Bruce Schneier wrote an insightful blog post about the risks of MS Copilot [8].
Bruce Schneier wrote an insightful blog post on How AI Will Change Democracy [10].
Bruce Schneier wrote an insightful blog post about seeing the world as a data structure [12].
Luke Miani has an informative YouTube video about eBay scammers selling overprices MacBooks [13].
- [1] https://tinyurl.com/ytwvpary
- [2] https://www.davidbrin.com/nonfiction/immortality.html
- [3] https://tinyurl.com/26czjpjl
- [4] https://sams-blog.com/?p=5615
- [5] https://worksinprogress.co/issue/the-maintenance-race/
- [6] https://www.youtube.com/watch?v=NhajAqI66nU
- [7] https://hashman.ca/me-cfs/
- [8] https://tinyurl.com/29b4h5oz
- [9] https://tinyurl.com/24sz7lwa
- [10] https://tinyurl.com/2c6dx8d4
- [11] https://tinyurl.com/26e3xxmn
- [12] https://tinyurl.com/26ykzgn4
- [13] https://www.youtube.com/watch?v=5V6Pez_Dbzs
- [14] https://tinyurl.com/27h5urv9
Related posts:
- Links March 2024 Bruce Schneier wrote an interesting blog post about his workshop...
- Links January 2024 Long Now has an insightful article about domestication that considers...
- Links April 2024 Ron Garret wrote an insightful refutation to 2nd amendment arguments...
Specbee: Integrating Single Directory Components (SDC) and Storybook in Drupal
Lukas Märdian: Creating a Netplan enabled system through Debian-Installer
With the work that has been done in the debian-installer/netcfg merge-proposal !9 it is possible to install a standard Debian system, using the normal Debian-Installer (d-i) mini.iso images, that will come pre-installed with Netplan and all network configuration structured in /etc/netplan/.
In this write-up, I’d like to run you through a list of commands for experiencing the Netplan enabled installation process first-hand. Let’s start with preparing a working directory and installing the software dependencies for our virtualized Debian system:
$ mkdir d-i_tmp && cd d-i_tmp $ apt install ovmf qemu-utils qemu-system-x86Now let’s download the official (daily) mini.iso, linux kernel image and initrd.gz containing the Netplan enablement changes:
$ wget https://d-i.debian.org/daily-images/amd64/daily/netboot/gtk/mini.iso $ wget https://d-i.debian.org/daily-images/amd64/daily/netboot/gtk/debian-installer/amd64/initrd.gz $ wget https://d-i.debian.org/daily-images/amd64/daily/netboot/gtk/debian-installer/amd64/linuxNext we’ll prepare a VM, by copying the EFI firmware files, preparing some persistent EFIVARs file, to boot from FS0:\EFI\debian\grubx64.efi, and create a virtual disk for our machine:
$ cp /usr/share/OVMF/OVMF_CODE_4M.fd . $ cp /usr/share/OVMF/OVMF_VARS_4M.fd . $ qemu-img create -f qcow2 ./data.qcow2 20GFinally, let’s launch the debian-installer using a preseed.cfg file, that will automatically install Netplan (netplan-generator) for us in the target system. A minimal preseed file could look like this:
# Install minimal Netplan generator binaryd-i preseed/late_command string in-target apt-get -y install netplan-generator
For this demo, we’re installing the full netplan.io package (incl. the interactive Python CLI), as well as the netplan-generator package and systemd-resolved, to show the full Netplan experience. You can choose the preseed file from a set of different variants to test the different configurations:
- Netplan minimal
- Netplan + systemd-resolved configuration
- Netplan + NetworkManager configuration
We’re using the linux kernel and initrd.gz here to be able to pass the preseed URL as a parameter to the kernel’s cmdline directly. Launching this VM should bring up the official debian-installer in its netboot/gtk form:
$ export U=https://people.ubuntu.com/~slyon/d-i/netplan-preseed+full.cfg $ qemu-system-x86_64 \ -M q35 -enable-kvm -cpu host -smp 4 -m 2G \ -drive if=pflash,format=raw,unit=0,file=OVMF_CODE_4M.fd,readonly=on \ -drive if=pflash,format=raw,unit=1,file=OVMF_VARS_4M.fd,readonly=off \ -device qemu-xhci -device usb-kbd -device usb-mouse \ -vga none -device virtio-gpu-pci \ -net nic,model=virtio -net user \ -kernel ./linux -initrd ./initrd.gz -append "url=$U" \ -hda ./data.qcow2 -cdrom ./mini.iso;Now you can click through the normal Debian-Installer process, using mostly default settings. Optionally, you could play around with the networking settings, to see how those get translated to /etc/netplan/ in the target system.
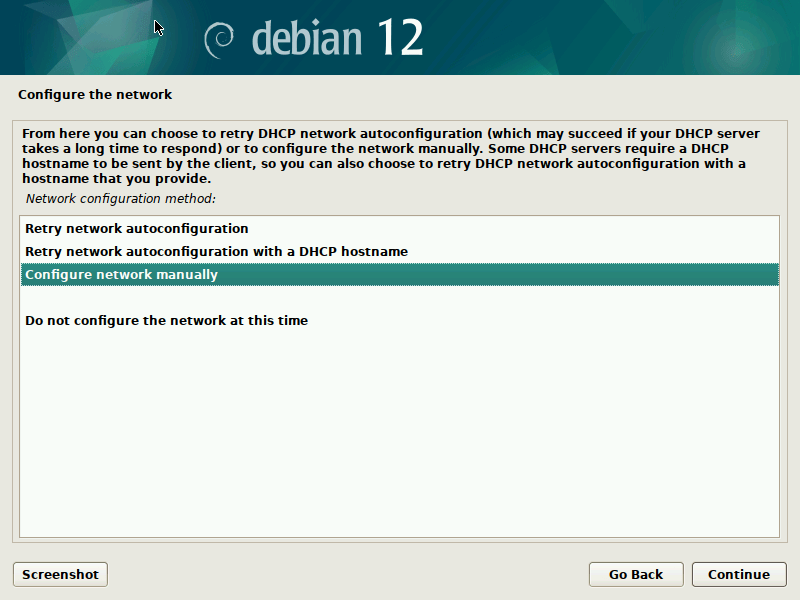{kind=link}
After you confirmed your partitioning changes, the base system gets installed. I suggest not to select any additional components, like desktop environments, to speed up the process.
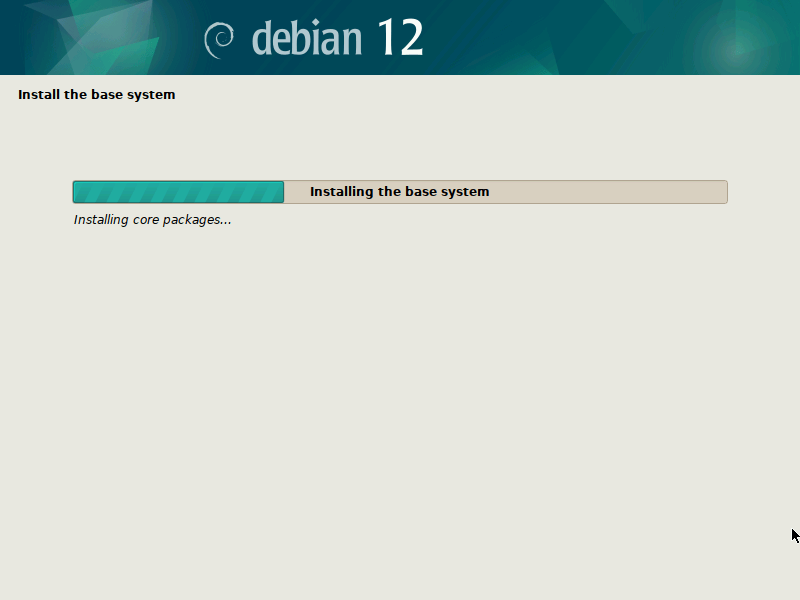{kind=link}
During the final step of the installation (finish-install.d/55netcfg-copy-config) d-i will detect that Netplan was installed in the target system (due to the preseed file provided) and opt to write its network configuration to /etc/netplan/ instead of /etc/network/interfaces or /etc/NetworkManager/system-connections/.
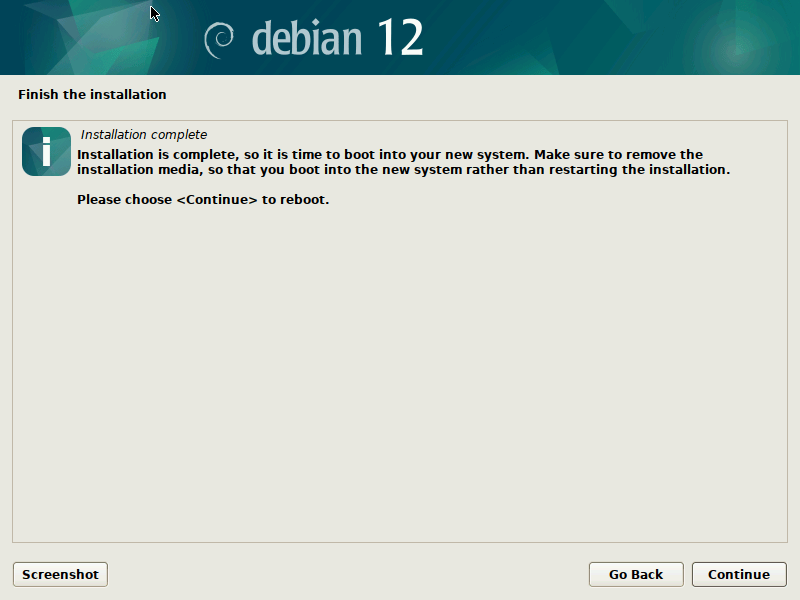{kind=link}
Done! After the installation finished, you can reboot into your virgin Debian Sid/Trixie system.
To do that, quit the current Qemu process, by pressing Ctrl+C and make sure to copy over the EFIVARS.fd file that was modified by grub during the installation, so Qemu can find the new system. Then reboot into the new system, not using the mini.iso image any more:
$ cp ./OVMF_VARS_4M.fd ./EFIVARS.fd $ qemu-system-x86_64 \ -M q35 -enable-kvm -cpu host -smp 4 -m 2G \ -drive if=pflash,format=raw,unit=0,file=OVMF_CODE_4M.fd,readonly=on \ -drive if=pflash,format=raw,unit=1,file=EFIVARS.fd,readonly=off \ -device qemu-xhci -device usb-kbd -device usb-mouse \ -vga none -device virtio-gpu-pci \ -net nic,model=virtio -net user \ -drive file=./data.qcow2,if=none,format=qcow2,id=disk0 \ -device virtio-blk-pci,drive=disk0,bootindex=1 -serial mon:stdioFinally, you can play around with your Netplan enabled Debian system! As you will find, /etc/network/interfaces exists but is empty, it could still be used (optionally/additionally). Netplan was configured in /etc/netplan/ according to the settings given during the d-i installation process.
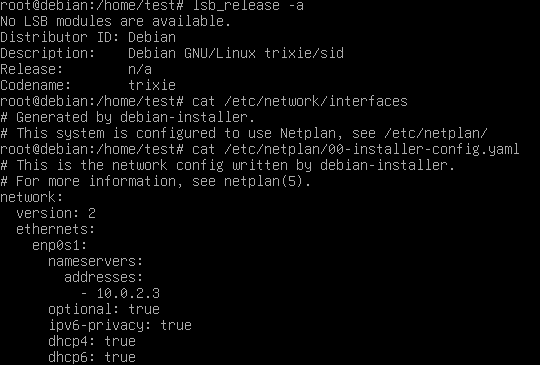{kind=link}
In our case, we also installed the Netplan CLI, so we can play around with some of its features, like netplan status:
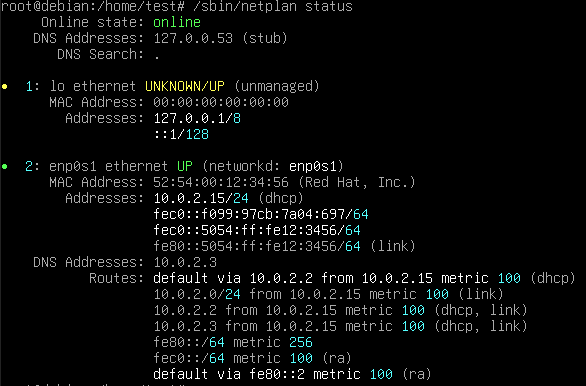{kind=link}
Thank you for following along the Netplan enabled Debian installation process and happy hacking! If you want to learn more, find us at GitHub:netplan.
The Drop Times: Drupal 11 is Around the Corner
Dear Readers,
In November 2023, the Drupal community outlined potential release windows for Drupal 11, contingent on meeting specific beta requirements. Today, it is exciting to anticipate that Drupal 11 is on the verge of being officially released, marking a significant milestone in the evolution of this widely used content management system. This release includes crucial updates to key dependencies such as Symfony 7, jQuery 4, and PHPUnit 10 or 11, promising enhanced performance and stability.
Initial challenges, particularly with the update to PHPUnit 10, made the first anticipated release window in June unfeasible. However, with the completion of beta requirements by April, the development team has positioned Drupal 11 for a scheduled release this week. The release candidate, Drupal 11.0.0-rc1, was made available in the week of July 11, 2024, paving the way for the stable release. This new version introduces several features designed to enhance the overall user experience, including more intuitive content management tools, enhanced site builder capabilities, and streamlined processes for upgrading and maintaining Drupal applications.
Noteworthy features in Drupal 11 include an improved administration backend with a faster toolbar and better permission management. The introduction of Single-Directory Components (SDC) simplifies the creation and management of UI components, making it easier for developers to work with the platform. These enhancements reflect Drupal's ongoing commitment to providing a powerful and user-friendly platform for web development.
With that, let's move on to the important stories from last week.
Last week, Janne Kalliola, the Chief Growth Officer and Founder of Exove delved into the origins and evolution of the Drupal Business Survey, which he co-initiated in 2016. The survey, which is in its ninth year, gathers information about the state of Drupal businesses and agencies worldwide. In his conversation with Alka Elizabeth, Janne emphasizes why agencies should respond to the Drupal Business Survey.
In an interview with Kazima Abbas, Brad Jones discusses his "JSON data and schemas FTW!" initiative, which aims to modernize Drupal's data management capabilities by integrating JSON data types and schemas. He highlights the initiative's potential to enhance Drupal's flexibility and interoperability, particularly in decoupled systems. The interview also explores Brad's journey with Drupal and the challenges of incorporating his project into Drupal's core.
In a recent article published on The DropTimes, Grzegorz Pietrzak, a Senior Drupal Developer at the European Commission, outlines five basic rules to keep website dependencies secure. His advice aims to help site maintainers manage and mitigate the risks associated with using third-party dependencies in Drupal projects.
The DropTimes highlighted the key moments from DrupalCamp Asheville 2024, emphasizing the event's engaging workshops, diverse sessions, and inclusive community atmosphere. Organizer April Sides shared insights on the camp's commitment to creating a welcoming environment and the challenges of organizing such events. The camp concluded with a scenic hike, underscoring the community's emphasis on well-being and connection. Read here.
DrupalCamp Colorado 2024, held at the Tivoli Center Ballroom in Denver, provided a unique blend of learning, networking, and community engagement for open-source technology enthusiasts. The event featured keynotes by Lynn Winter and Matthew Saunders, covering topics from digital strategy to diversity in tech. The camp offered workshops, community sessions, and networking activities, including a coffee exchange and an after-party, creating a comprehensive and enriching experience for attendees.
Presently in the Drupal world, Drupal GovCon scheduled for August 13-15, 2024 has opened volunteering opportunities for the event. The deadline for submissions to the 2024 Splash Awards Germany and Austria is rapidly approaching, with entries closing on July 31. The annual event, which recognizes outstanding Drupal projects, will take place on November 7 in Berlin.
The A11yTalks session titled "Empowering People with Disabilities Using GitHub Copilot" has been postponed from July 23 to July 31. Hosted by Carie Fisher and Jesse Dugas from the GitHub Accessibility team, this session aims to enhance coding practices through GitHub Copilot’s accessibility features.
This week, the Drupal community has organized several meetups and events, taking place from July 29th to August 4th, 2024. Find the full list here.
Drupal experts Kevin Quillen and Matt Glaman have announced the forthcoming release of their new book, "Drupal 11 Development Cookbook." It is designed as a comprehensive guide for site builders and developers, building on the success of their previous "Drupal 10 Development Cookbook." The new edition aims to help users navigate the latest features and updates in Drupal 11.
Provus® 2.1.12, developed by Promet Source, has been released, offering advanced features that continue to revolutionize the content management experience for non-technical editors. Provus® is a content management platform that enhances Drupal's capabilities, making it easier for users to create and manage website content.
Acquia has announced the availability of Drupal exams in French, marking a significant advancement for the French-speaking Drupal community. This initiative, in collaboration with Wide | Switzerland, a leading digital agency with a strong presence in several Francophone regions, aims to enhance accessibility and inclusivity.
We acknowledge that there are more stories to share. However, due to selection constraints, we must pause further exploration for now.
To get timely updates, follow us on LinkedIn, Twitter and Facebook. You can also, join us on Drupal Slack at #thedroptimes.
Thank you,
Sincerely
Alka Elizabeth
Sub-editor, The DropTimes.
Talking Drupal: Talking Drupal #461 - Distributions
Today we are talking about The Benefits of Distributions, If they have drawbacks, and what the future of distributions looks like with guest Rajab Natshah and Mohammed Razem. We’ll also cover Google Analytics Reports as our module of the week.
For show notes visit: www.talkingDrupal.com/461
Topics- What is a distribution
- How does this differ from profiles
- What does Varbase provide
- What types of users is Varbase geared towards
- Paragraphs or Layout Builder
- Vardoc
- How do you overcome fear of lock-in
- What do you think the future of distributions look like considering recipes
- Any plans to move Varbase to recipes
- Starshot
- Varbase Distribution
- Vardoc
- Google analytics counter
- United nations refugee agency
- George washington university
- City of Detroit
- Bootstrap Layout Builder
- Bootstrap Styles
- Visual Distribution Operator
- Profile inheritance issue
- Starshot work tracks
- Linux from Scratch
Rajab Natshah - rajab-natshah Mohammed Razem - mohammed-j-razem
HostsNic Laflin - nLighteneddevelopment.com nicxvan John Picozzi - epam.com johnpicozzi Josh Miller - joshmiller
MOTW CorrespondentMartin Anderson-Clutz - mandclu.com mandclu
- Brief description:
- Have you ever wanted to display Google Analytics charts directly within your Drupal website? There’s a module for that.
- Module name/project name:
- Brief history
- Created in Apr 2011 by raspberryman, but recent releases are by today’s guest Rajab Natshah
- Versions available include 7.x-3.2, 8.x-3.2, and 4.0.0, that last two of which support Drupal 10 and 11
- Maintainership
- Actively maintained, recent releases were less than a month ago
- Security coverage
- A documentation guide for older versions, and a README with detailed instructions to get it set up
- Number of open issues: 76 open issues, 9 of which are bugs against the current branch
- Usage stats:
- 4,272 sites
- Module features and usage
- To set up this module, you first need to set up the API connection in the Google Developers Console, and download the client secret JSON
- You’ll then upload that into the Google Analytics Report API submodule along with the property ID to enable the connection
- Next, you need to install the Charts module, and either the Google Charts or Highcharts sub-module to see graphical reports
- You will now have a new Google Analytics Summary in your site’s reports menu, and new "Google Analytics Reports Summary Block" and "Google Analytics Reports Page Block" blocks available
- I haven’t had a chance to try the 4.0 version of this module yet, but I have used older versions with a variety of dashboard solutions, including Moderation Dashboard and Homebox
- One of the many benefits of using a powerful, open source framework like Drupal to build your site is its ability to act as the “glass” for a variety of other systems, and this module is a perfect demonstration of that
FSF Events: Don't miss Craig Topham's talk at FOSSY 2024 in Portland, OR on August 2
The Drop Times: Streamlining Data Integration with Views CSV Source: Insights from Daniel Cothran
Week 9 recap
Real Python: Strings and Character Data in Python
In Python, string objects contain sequences of characters that allow you to manipulate textual data. It’s rare to find an application, program, or library that doesn’t need to manipulate strings to some extent. So, processing characters and strings is integral to programming and a fundamental skill for you as a Python programmer.
In this tutorial, you’ll learn how to:
- Create strings using literals and the str() function
- Use operators and built-in functions with strings
- Index and slice strings
- Do string interpolation and formatting
- Use string methods
To get the most out of this tutorial, you should have a good understanding of core Python concepts, including variables, functions, and operators and expressions.
Get Your Code: Click here to download the free sample code that shows you how to work with strings and character data in Python.
Take the Quiz: Test your knowledge with our interactive “Python Strings and Character Data” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Python Strings and Character DataThis quiz will evaluate your understanding of Python's string data type and your knowledge about manipulating textual data with string objects. You'll cover the basics of creating strings using literals and the `str()` function, applying string methods, using operators and built-in functions with strings, indexing and slicing strings, and more!
Getting to Know Strings and Characters in PythonPython provides the built-in string (str) data type to handle textual data. Other programming languages, such as Java, have a character data type for single characters. Python doesn’t have that. Single characters are strings of length one.
In practice, strings are immutable sequences of characters. This means you can’t change a string once you define it. Any operation that modifies a string will create a new string instead of modifying the original one.
A string is also a sequence, which means that the characters in a string have a consecutive order. This feature allows you to access characters using integer indices that start with 0. You’ll learn more about these concepts in the section about indexing strings. For now, you’ll learn about how to create strings in Python.
Creating Strings in PythonThere are different ways to create strings in Python. The most common practice is to use string literals. Because strings are everywhere and have many use cases, you’ll find a few different types of string literals. There are standard literals, raw literals, and formatted literals.
Additionally, you can use the built-in str() function to create new strings from other existing objects.
In the following sections, you’ll learn about the multiple ways to create strings in Python and when to use each of them.
Standard String LiteralsA standard string literal is just a piece of text or a sequence of characters that you enclose in quotes. To create single-line strings, you can use single ('') and double ("") quotes:
Python >>> 'A single-line string in single quotes' 'A single-line string in single quotes' >>> "A single-line string in double quotes" 'A single-line string in double quotes' Copied!In the first example, you use single quotes to delimit the string literal. In the second example, you use double quotes.
Note: Python’s standard REPL displays string objects using single quotes even though you create them using double quotes.
You can define empty strings using quotes without placing characters between them:
Python >>> "" '' >>> '' '' >>> len("") 0 Copied!An empty string doesn’t contain any characters, so when you use the built-in len() function with an empty string as an argument, you get 0 as a result.
To create multiline strings, you can use triple-quoted strings. In this case, you can use either single or double quotes:
Python >>> '''A triple-quoted string ... spanning across multiple ... lines using single quotes''' 'A triple-quoted string\nspanning across multiple\nlines using single quotes' >>> """A triple-quoted string ... spanning across multiple ... lines using double quotes""" 'A triple-quoted string\nspanning across multiple\nlines using double quotes' Copied!The primary use case for triple-quoted strings is to create multiline strings. You can also use them to define single-line strings, but this is a less common practice.
Read the full article at https://realpython.com/python-strings/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
PyCharm: Learning Resources for pytest
In this blog post, we’ll look at how PyCharm helps you when you’re working with pytest, and we will signpost you to a bunch of resources for learning pytest. While some of these resources were created by us here at JetBrains, others were crafted by the storytellers in the pytest community.
Using pytest in PyCharmPyCharm has extensive support for pytest, including a dedicated test pytest runner. PyCharm also gives you code completion for the test subject and pytest fixtures as detailed assert failure reports so you can get to the root of the problem quickly.
Resources for pytestIf you like reading blog posts, we have plenty of those. If videos are more your thing, we have some awesome content there, too. If you prefer a sequential course, we have some pointers for you, and if you prefer to snuggle down and read a book, we’ve got a great recommendation as well. There’s a little something here for everyone!
Although the majority of these resources don’t assume any prior knowledge of pytest, some delve deeper into the subject than others – so there’s plenty to explore when you’re ready.
First, let me point you to two important links:
- The pytest page on the JetBrains Guide serves as a starting point for all the pytest resources we’ve created.
- Brian Okken maintains a website for all his pytest resources (some of which are free, whereas others are paid).
We have a video tutorial series composed of nine videos on pytest that start from the beginning of pytest-time. You can check out the tutorials on YouTube.
If there’s something specific you want to take a look at, the individual video topics are:
- Background
- Setup
- First Test
- Test-Driven Development
- Finding and Fixing Errors
- Skipping Tests
- Using Fixtures
- Debugging Tests
- Testing for Exceptions
If you want a super-speedy refresher of pytest in PyCharm, you can watch PyCharm and pytest in Under 7 Minutes (beware – it’s fast!)
Tutorials about pytestIf you prefer learning by doing, we have some great pytest tutorials for you. First, the above video series is also available as a written tutorial in the JetBrains Guide.
Alternatively, Brian Okken has produced a detailed tutorial on everything pytest if you want to explore all areas. This tutorial is paid content, but it’s well worth it!
Books about pytestIf you prefer reading, we have lots of blog posts for you. Here are some of the pytest resources on the JetBrains Guide:
- An Interview with Brian Okken
- Three pytest Features You Will Love
- pytest vs. unittest: Which Is Better
- Do You Do Enough Testing? pytest to the Rescue!
Additionally, Brian has a blog that covers a diverse range of pytest subjects you can dive into.
While we’re on the subject of reading, Brian has also written an excellent book on pytest that you can purchase and curl up with if that’s your thing.
Official pytest documentationLast but not least, the official pytest documentation is another one to bookmark and keep close by as you go on your journey to pytest mastery.
ConclusionThe Python testing framework pytest is packed with helpful features such as fixtures, mocking, and parametrizing that make testing your applications easier, giving you confidence in the quality of your code. Go ahead and try pytest out and let us know what you learn on your path to Python testing excellence!
Zato Blog: Automating telecommunications networks with Python and SFTP
In telecommunications, the Secure File Transfer Protocol (SFTP) serves as a critical mechanism for secure and reliable file exchange between different network components devices, and systems, whether it is updating configurations, network monitoring, exchanging customer data, or facilitating software updates. Conversely, Python is an ideal tool for the automation of telecommunications networks thanks to its readability and versatility.
Let's dive into how to employ the two effectively and efficiently using the Zato integration and automation platform.
DashboardThe first step is to define a new SFTP connection in your Dashboard, as in the screenshots below.
The form lets you provide all the default options that apply to each SFTP connection - remote host, what protocol to use, whether file metadata should be preserved during transfer, logging level and other details that you would typically provide.
Simply fill it out with the same details that you would use if it were command line-based SFTP connections.
PingingThe next thing, right after the creation of a new connection, is to ping it to check if the server is responding.
Pinging opens a new SFTP connection and runs the ping command - in the screenshot above it was ls . - a practically no-op command whose sole purpose is to let the connection confirm that commands in fact can be executed, which proves the correctness of the configuration.
This will either returns details of why a connection could not be established or the response time if it was successful.
Cloud SFTP consoleHaving validated the configuration by pinging it, we can now execute SFTP commands straight in Dashboard from a command console:
Any SFTP command, or even a series of commands, can be sent and responses retrieved immediately. It is also possible to increase the logging level for additional SFTP protocol-level details.
This makes it possible to rapidly prototype file transfer functionality as a series of scripts that can be next moved as they are to Python-based services.
Python automationNow, in Python, your API automation services have access to an extensive array of capabilities - from executing transfer commands individually or in batches to the usage of SFTP scripts previously created in your Dashboard.
Here is how Python can be used in practice:
# -*- coding: utf-8 -*- # Zato from zato.server.service import Service class MySFTPService(Service): def handle(self): # Connection to use conn_name = 'My SFTP Connection' # Get a handle to the connection object conn = self.out.sftp[conn_name].conn # Execute an arbitrary script with one or more SFTP commands, like in web-admin my_script = 'ls -la /remote/path' conn.execute(my_script) # Ping a remote server to check if it responds conn.ping() # Download an entry, possibly recursively conn.download('/remote/path', '/local/path') # Like .download but remote path must point to a file (exception otherwise) conn.download_file('/remote/path', '/local/path') # Makes the contents of a remote file available on output out = conn.read('/remote/path') # Uploads a local file or directory to remote path conn.upload('/local/path', '/remote/path') # Writes input data out to a remote file data = 'My data' conn.write(data, '/remote/path') # Create a new directory conn.create_directory('/path/to/new/directory') # Create a new symlink conn.create_symlink('/path/to/new/symlink') # Create a new hard-link conn.create_hardlink('/path/to/new/hardlink') # Delete an entry, possibly recursively, no matter what kind it is conn.delete('/path/to/delete') # Like .delete but path must be a directory conn.delete_directory('/path/to/delete') # Like .delete but path must be a file conn.delete_file('/path/to/delete') # Like .delete but path must be a symlink conn.delete_symlink('/path/to/delete') # Get information about an entry, e.g. modification time, owner, size and more info = conn.get_info('/remote/path') self.logger.info(info.last_modified) self.logger.info(info.owner) self.logger.info(info.size) self.logger.info(info.size_human) self.logger.info(info.permissions_oct) # A boolean flag indicating if path is a directory result = conn.is_directory('/remote/path') # A boolean flag indicating if path is a file result = conn.is_file('/remote/path') # A boolean flag indicating if path is a symlink result = conn.is_symlink('/remote/path') # List contents of a directory - items are in the same format that .get_info uses items = conn.list('/remote/path') # Move (rename) remote files or directories conn.move('/from/path', '/to/path') # An alias to .move conn.rename('/from/path', '/to/path') # Change mode of entry at path conn.chmod('600', '/path/to/entry') # Change owner of entry at path conn.chown('myuser', '/path/to/entry') # Change group of entry at path conn.chgrp('mygroup', '/path/to/entry') SummaryGiven how important SFTP is in telecommunications, having a convenient and easy way to automate it using Python is an essential ability in a network engineer's skill-set.
Thanks to the SFTP connections in Zato, you can prototype SFTP scripts in Dashboard and employ them in API services right after that. To complement it, a full Python API is available for programmatic access to remote file servers.
Combined, the features make it possible to create scalable and reusable file transfer services in a quick and efficient manner using the most convenient programming language, Python.
More resources➤ Click here to read more about using Python and Zato in telecommunications
➤ What is a Network Packet Broker? How to automate networks in Python?
➤ What is an integration platform?
➤ Python Integration platform as a Service (iPaaS)
➤ What is an Enterprise Service Bus (ESB)? What is SOA?
Sahil Dhiman: Ola Maps and OpenStreetMap Data
Recently, Ola started rolling out Ola Maps in their main mobile app, replacing Google Maps, while also offering maps as a service to other organizations. The interesting part for me was the usage of OpenStreetMap data as base map with Ola’s proprietary data sources. I’ll mostly about talk about map data part here.
Screenshot of Ola App.OpenStreetMap attribution is shown after clicking the Ola Map icon.
OpenStreetMap (OSM) for staters, is a community owned and edited map data resource which gives freedom to use map data for any purpose. This includes the condition that attribution is given back to OSM which in turn ideally would encourage other users to contribute, correct and edit, helping everyone in turn. Due to this, OSM is also regarded as Wikipedia of maps. OSM data is not just used by Ola. Many others use it for various purposes like Wikipedia Maps, Strava Maps, Snapchat Map, bus tracking in GoIbibo/Redbus.
OSM India community has been following Ola map endeavor to use and contribute to OSM since they went public. As required by OSM for organized mapping efforts, Ola created wiki entry with information regarding their editors, usage, policy and mentions following as their data usage case:
OSM data is used for the road network, traffic signs and signals, buildings, natural features, landuse polygons and some POIs.
Creating a map product is a task in itself, an engineering hurdle creating the tech stack for collection, validation, import and serving the map and the map data part. Ola has done a good job describing the development of tech stack in their blog post. Ola holds an enormous corpus of live and constantly updated GPS trace data. Their drivers, users, and delivery partners generate those, which they harness to validate, correct and add missing map data. Ola employees now regularly contribute new or missing roads (including adding dual carriageway to existing ones), fix road geometry, classification, road access type and restrictions pan India. They have been active and engaging in OSM India community channels, though community members have raised some concerns on their OSM edit practices.
Ola’s venture into the map industry isn’t something out of the ordinary. Grab, a South East Asian company which has business interests in food deliveries, ride hailing and a bunch of other services too switched to their in-house map based on OpenStreetMap, followed by launching of their map product. Grab too contributed back data like Ola. Both Ola and Grab heavily rely on map for their business operations and seem to chose to go independent for it, bootstrapping the products on OSM.
In India too, a bunch of organizations contribute to OSM like Swiggy, Stackbox, Amazon, Apple. Microsoft, Meta/Facebook and many others. Everyone wants a better map (data), so everyone works together.
Ola could have gone their own route, bootstrapping map data from scratch, which would have been a gargantuan task when you’re competing against the likes of Google Maps and Bing Maps, which have been into this since many years. Deciding to use OSM and actively giving back to make data better for everyone deserves accolades. Now I’m waiting to for their second blog post, which they mention would be on map data.
If you’re an Ola map user through Ola Electric or Ola app, and find some road unmapped, you can always edit them in OSM. What I have heard from their employee, they import new OSM data weekly, which means your changes should start reflecting for you (and everyone else) by next week. If you’re new, follow Beginners’ guide and join OSM India community community.osm.be/resources/asia/india/ for any doubts and participating in various mapping events.
PS — You can see live OSM edits in India subcontinent here.
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
- #! code: Drupal 10: An Introduction To Batch Processing With The Batch API
- Mario Hernandez: SOLVED - Cannot crop based on original image after initial crop has been set
- Mario Hernandez: Migrating from Patternlab to Storybook
- Reproducible Builds (diffoscope): diffoscope 276 released
- GSoC 2024: Progress Update