
Feeds
Michael Foord: Gigaclear One Touch Switch Service
For the last year I’ve been working as a team lead for backend API development with Gigaclear a UK rural ISP who own and run fibre internet to rural communities across the UK. This is alongside my training work.
This image shows the main project I’ve been working on since joining Gigaclear, One Touch Switch. A regulatory requirement for all ISPs to allow automated switching between ISPs. When you sign up with a new internet provider your account is automatically ceased with the old provider and VOIP numbers can be automatically ported.
Our OTS project is just part of the Gigaclear One Touch Switch system which interfaces with Salesforce and Netadmin and the website order flow (the Online Buying Journey) and represents an impressive engineering effort. We were one of the first ISPs with a system ready to take part in industry trials a few months ago, both OTS and our underlying systems passed pen testing with flying colours, and the switch on has been smooth.
Something I’m proud to have been part of. My current project is preparing security awareness training materials based on OWASP for our various engineering departments whilst we also undertake a systematic review of all of our systems and processes.
In the diagram I’m team lead for the Sphinx engineering team.
Michael Foord: Adventures with MicroPython
My first blog post in a few years! I have some articles I’d like to publish, and some adventures to share, so I thought it was time to fire up a blog engine again.
My nine year old son, Benjamin, is really into programming with Scratch and he’s keen to play with electronics and learn MicroPython. Which is awesome because there’s almost nothing I would love to do more with him.
MicroPython is an extremely impressive implementation of Python that will run on embedded devices and microcontrollers, as well as bigger tiny computers like the Raspberry Pi.
I’ve dug out an old MicroBit I had, purchased a Raspberry Pi Pico board/kit and also a ZumoBot 2040 robot which uses the same microcontroller as the Pico, to play with.
I’m now starting to get to grips with the basics, using the Thonny IDE.
I have a bunch of Neopixel LEDs, including a long light strip, I’d like to wire up in my living room controlled by a Pico board and an Android App using Kivy. That’s my goal number 1.
I’d like to program the ZumoBot to explore and map my flat. Goal 2.
Meanwhile Benjamin is enjoying playing with electronics (switches, LEDs, potentiometer and now a motor) with the Pico and on his own he’s programming the MicroBit with Scratch (or at least “blocks” which is the Microsoft equivalent). I’ve also done my first soldering in over a decade.
I have a github repository to track my tinkering, but I’d like to write up some recipes and post them on this blog as I go. (The biggest hurdle is I can’t easily create circuit diagrams. Time to explore.)
The github repository and ZumoBot links:
Brett Cannon: Don't return named tuples in new APIs
In my opinion, you should only introduce a named tuple to your code when you&aposre updating a preexisting API that was already returning a tuple or you are wrapping a tuple return value from another API.
Let&aposs start with when you should use named tuples. Usually an API that returns a tuple does so when you only have a couple of items in your tuple and the name of the function returning the tuple id enough to explain what each item in the tuple does. But sometimes your API expands and you find that your tuple is no longer self-documenting purely based on the name of the API (e.g., get_mouse_position() very likely has a two-item tuple of X and Y coordinates of the screen while app_state() could be a tuple of anything). When you find yourself in the situation of needing your return type to describe itself and a tuple isn&apost cutting it anymore, then that&aposs when you reach for a named tuple.
So why not start out that way? In a word: simplicity. Now, some of you might be saying to yourself, "but I use named tuples because they are so simple to define!" And that might be true for when you define your data structure (and I&aposll touch on this "simplicity of definition" angle later), but it actually makes your API more complex for both you and your users to use. For you, it doubles the data access API surface for your return type as you have to now support index-based and attribute-based data access forever (or until you choose to break your users and change your return type so it doesn&apost support both approaches). This leads to writing tests for both ways of accessing your data, not just one of them. And you shouldn&apost skimp on this because you don&apost know if your users will use indexes or attribute names to access the data structure, nor can you guarantee someone won&apost break your code in the future by dropping the named tuple and switching to some custom type (thanks to Python&aposs support of structural typing (aka duck typing), you can&apost assume people are using a type checker and thus the structure of your return type becomes your API contract). And so you need to test both ways of using your return type to exercise that contract you have with your users, which is more work than had you not used a named tuple and instead chose just a tuple or just a class.
Named tuples are also a bit more complex for users. If you&aposre reaching for a named tuple you&aposre essentially signalling upfront that the data structure is too big/complex for a tuple alone to work. And yet by using a named tuple means you are supporting the tuple approach even if you don&apost think it&aposs a good idea from the start. On top of that, the tuple API allows for things that you probably don&apost want people doing with your return type, like slicing, iterating over all the items as if they are homogeneous, etc. Basically my argument is the "flexibility" of having the index-based access to the data on top of the attribute-based access isn&apost flexible in a good way.
So why do people still reach for named tuples when defining return types for new APIs? I think it&aposs because people find them faster to define a new type than writing out a new class. Compare this:
Point = namedtuple(&aposPoint&apos, [&aposx&apos, &aposy&apos, z&apos])To this:
class Point: def __init__(self, x, y, z): self.x = x self.y = y self.z = zSo there is a clear difference in the amount of typing. But there are three more ways to do the same data structure that might not be so burdensome. One is dataclasses:
@dataclasses.dataclass class Point: x: int y: int z: intAnother is simply a dictionary, although I know some prefer attribute-based access to data so much that they won&apost use this option). Toss in a TypedDict and you also get editor support as well:
class Point(typing.TypedDict): x: int y: int z: int # Alternatively ... Point = typing.TypedDict("Point", {"x": int, "y": int, "z": int})A third option is types.SimpleNamespace if you really want attributes without defining a class:
Point = lambda x, y, z: types.SimpleNamespace(x=x, y=y, z=z)If none of these options work for you then you can always hope that somehow I convince enough people that my record/struct idea is a good one and get into the language. 😁
My key point in all of this is to prefer readability and ergonomics over brevity in your code. That means avoiding named tuples except where you are expanding to tweaking an existing API where the named tuple improves over the plain tuple that&aposs already being used.
Dirk Eddelbuettel: Rcpp 1.0.13-1 on CRAN: Hot Fix
A hot-fix release 1.0.13-1, consisting of two small PRs relative to the last regular CRAN release 1.0.13, just arrived on CRAN. When we prepared 1.0.13, we included a change related to the ‘tightening’ of the C API of R itself. Sadly, we pinned an expected change to ‘comes with next (minor) release 4.4.2’ rather than now ‘next (normal aka major) release 4.5.0’. And now that R 4.4.2 is out (as of two days ago) we accidentally broke building against the header file with that check. Whoops. Bugs happen, and we are truly sorry—but this is now addressed in 1.0.13-1.
The normal (bi-annual) release cycle will resume with 1.0.14 slated for January. As you can see from the NEWS file of the development branch, we have a number of changes coming. You can safely access that release candidate version, either off the default branch at github or via r-universe artifacts.
The list below details all changes, as usual. The only other change concerns the now-mandatory use of Authors@R.
Changes in Rcpp release version 1.0.13-1 (2024-11-01)Changes in Rcpp API:
Changes in Rcpp Deployment:
- Authors@R is now used in DESCRIPTION as mandated by CRAN
Thanks to my CRANberries, you can also look at a diff to the previous release Questions, comments etc should go to the rcpp-devel mailing list off the R-Forge page. Bugs reports are welcome at the GitHub issue tracker as well (where one can also search among open or closed issues).
If you like this or other open-source work I do, you can sponsor me at GitHub.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
Ned Batchelder: Coverage.py originally
Something many people don’t realize is that I didn’t write the original coverage.py. It was written by Gareth Rees in 2001. I’ve been extending and maintaining it since 2004. This ancient history came up this week, so I grabbed the 2001 version from archive.org to keep it here for posterity.
I already had a copy of Gareth’s original page about coverage.py, which now links to my local copy of coverage.py from 2001. BTW: that page is itself a historical artifact now, with the header from this site as it looked when I first copied the page.
The original coverage.py was a single file, so the “coverage.py” name was literal: it was the name of the file. It only had about 350 lines of code, including a few to deal with pre-2.0 Python! Some of those lines remain nearly unchanged to this day, but most of it has been heavily refactored and extended.
Coverage.py now has about 20k lines of Python in about 100 files. The project now has twice the amount of C code as the original file had Python. I guess in almost 20 years a lot can happen!
It’s interesting to see this code again, and to reflect on how far it’s come.
Hugo van Kemenade: Speed up CI with uv ⚡
We can use uv to make linting and testing on GitHub Actions around 1.5 times as fast.
LintingWhen using pre-commit for linting:
We can replace pre-commit/action with tox-dev/action-pre-commit-uv:
This means uv will create virtual environments and install packages for pre-commit, which is faster for the initial seed operation when there's no cache.
Lint comparisonFor example: python/blurb#32
Before After Times faster No cache 60s 37s 1.62 With cache 11s 11s 1.00 TestingWhen testing with tox:
We can replace tox with tox-uv:
tox-uv is tox plugin to replace virtualenv and pip with uv in your tox environments. We only need to install uv, and use uvx to both install tox-uv and run tox, for faster installs of tox, the virtual environment, and the dependencies within it.
Test comparisonFor example: python/blurb#32
Before After Times faster No cache 2m 0s 1m 26s 1.40 With cache 1m 58s 1m 22s 1.44 Bonus tipRun the new tool zizmor to find security issues in GitHub Actions.
Header photo: "Road cycling at the 1952 Helsinki Olympics" by Olympia-Kuva Oy & Helsinki City Museum, Public Domain.
This week in Plasma: moved to KDE infrastructure!
Surprise! This blog post series has now been moved to blogs.kde.org so it’s now open for others to participate and contribute! This week’s post can be found at https://blogs.kde.org/2024/11/02/this-week-in-plasma-spoooooky-ooooooooom-notifications
That’s probably where it should have been all along, as this work is much bigger than me. I’ll remain the editor-in-chief for now, but do welcome contributions to help lighten the load.
Unfortunately, due to GDPR restrictions, I’m unable to migrate existing email subscribers to the new email digest over there. So if you’d like to re-subscribe to “This week in Plasma.” head to https://newsletter.kde.org/subscription/form and re-subscribe.
I’ll still be blogging here about KDE topics of interest to me and hopefully you as well, just not the weekly Plasma news. So I do hope you’ll stick around.
Russell Coker: More About the Yoga Gen3
Two months ago I bought a Thinkpad X1 Yoga Gen3 [1]. I’m still very happy with it, the screen is a great improvement over the FullHD screen on my previous Thinkpad. I have yet to discover what’s the best resolution to have on a laptop if price isn’t an issue, but it’s at least 1440p for a 14″ display, that’s 210DPI. The latest Thinkpad X1 Yoga is the 7th gen and has up to 3840*2400 resolution on the internal display for 323DPI. Apple apparently uses the term “Retina Display” to mean something in the range of 250DPI to 300DPI, so my current laptop is below “Retina” while the most expensive new Thinkpads are above it.
I did some tests on external displays and found that this Thinkpad along with a Dell Latitude of the same form factor and about the same age can only handle one 4K display on a Thunderbolt dock and one on HDMI. On Reddit u/Carlioso1234 pointed out this specs page which says it supports a maximum of 3 displays including the built in TFT [2]. The Thunderbolt/USB-C connection has a maximum resolution of 5120*2880 and the HDMI port has a maximum of 4K. The latest Yoga can support four displays total which means 2*5K over Thunderbolt and one 4K over HDMI. It would be nice if someone made a 8000*2880 ultrawide display that looked like 2*5K displays when connected via Thunderbolt. It would also be nice if someone made a 32″ 5K display, currently they all seem to be 27″ and I’ve found that even for 4K resolution 32″ is better than 27″.
With the typical configuration of Linux and the BIOS the Yoga Gen3 will have it’s touch screen stop working after suspend. I have confirmed this for stylus use but as the finger-touch functionality is broken I couldn’t confirm that. On r/thinkpad u/p9k told me how to fix this problem [3]. I had to set the BIOS to Win 10 Sleep aka Hybrid sleep and then put the following in /etc/systemd/system/thinkpad-wakeup-config.service :
# https://www.reddit.com/r/thinkpad/comments/1blpy20/comment/kw7se2l/?context=3 [Unit] Description=Workarounds for sleep wakeup source for Thinkpad X1 Yoga 3 After=sysinit.target After=systemd-modules-load.service [Service] Type=oneshot ExecStart=/bin/sh -c "echo 'enabled' > /sys/devices/platform/i8042/serio0/power/wakeup" ExecStart=/bin/sh -c "echo 'enabled' > /sys/devices/platform/i8042/serio1/power/wakeup" ExecStart=/bin/sh -c "echo 'LID' > /proc/acpi/wakeup" [Install] WantedBy=multi-user.targetNow it works fine, for stylus at least. I still get kernel error messages like the following which don’t seem to cause problems:
wacom 0003:056A:5146.0005: wacom_idleprox_timeout: tool appears to be hung in-prox. forcing it out.When it wasn’t working I got the above but also kernel error messages like:
wacom 0003:056A:5146.0005: wacom_wac_queue_insert: kfifo has filled, starting to drop eventsThis change affected the way suspend etc operate. Now when I connect the laptop to power it will leave suspend mode. I’ve configured KDE to suspend when the lid is closed and there’s no monitor connected.
- [1] https://etbe.coker.com.au/2024/01/29/thinkpad-x1-yoga-gen3/
- [2] https://tinyurl.com/2cvq6qts
- [3] https://tinyurl.com/26ho6vxk
Related posts:
- Thinkpad X1 Yoga Gen3 I just bought myself a Thinkpad X1 Yoga Gen3 for...
- More About Kogan 5120*2160 Monitor On the 18th of May I blogged about my new...
- Thinkpad X1 Carbon Gen 6 In February I reviewed a Thinkpad X1 Carbon Gen 1...
Russell Coker: Moving Between Devices
I previously wrote about the possibility of transferring work between devices as an alternative to “convergence” (using a phone or tablet as a desktop) [1]. This idea has been implemented in some commercial products already.
MrWhosTheBoss made a good YouTube video reviewing recent Huawei products [2]. At 2:50 in that video he shows how you can link a phone and tablet, control one from the other, drag and drop of running apps and files between phone and tablet, mirror the screen between devices, etc. He describes playing a video on one device and having it appear on the other, I hope that it actually launches a new instance of the player app as the Google Chromecast failed in the market due to remote display being laggy. At 7:30 in that video he starts talking about the features that are available when you have multiple Huawei devices, starting with the ability to move a Bluetooth pairing for earphones to a different device.
At 16:25 he shows what Huawei is doing to get apps going including allowing apk files to be downloaded and creating what they call “Quick Apps” which are instances of a web browser configured to just use one web site and make it look like a discrete app, we need something like this for FOSS phone distributions – does anyone know of a browser that’s good for it?
Another thing that we need is to have an easy way of transferring open web pages between systems. Chrome allows sending pages between systems but it’s proprietary, limited to Chrome only, and also takes an unreasonable amount of time. KDEConnect allows sharing clipboard contents which can be used to send URLs that can then be pasted into a browser, but the process of copy URL, send via KDEConnect, and paste into other device is unreasonably slow. The design of Chrome with a “Send to your devices” menu option from the tab bar is OK. But ideally we need a “Send to device” for all tabs of a window as well, we need it to run from free software and support using your own server not someone else’s server (AKA “the cloud”). Some of the KDEConnect functionality but using a server rather than direct connection over the same Wifi network (or LAN if bridged to Wifi) would be good.
What else do we need?
- [1] https://etbe.coker.com.au/2024/04/26/convergence-vs-transference/
- [2] https://www.youtube.com/watch?v=IhYDtLzmRQI
Related posts:
- Convergence vs Transference I previously wrote a blog post titled Considering Convergence [1]...
- Moving from a Laptop to a Cloud Lifestyle My Laptop History In 1998 I bought my first laptop,...
- Cheap NAS Devices Suck There are some really good Network Attached Storage (NAS) devices...
Russell Coker: What is a Workstation?
I recently had someone describe a Mac Mini as a “workstation”, which I strongly disagree with. The Wikipedia page for Workstation [1] says that it’s a type of computer designed for scientific or technical use, for a single user, and would commonly run a multi-user OS.
The Mac Mini runs a multi-user OS and is designed for a single user. The issue is whether it is for “scientific or technical use”. A Mac Mini is a nice little graphical system which could be used for CAD and other engineering work. But I believe that the low capabilities of the system and lack of expansion options make it less of a workstation.
The latest versions of the Mac Mini (to be officially launched next week) have up to 64G of RAM and up to 8T of storage. That is quite decent compute power for a small device. For comparison the HP ML 110 Gen9 workstation I’m currently using was released in 2021 and has 256G of RAM and has 4 * 3.5″ SAS bays so I could easily put a few 4TB NVMe devices and some hard drives larger than 10TB. The HP Z640 workstation I have was released in 2014 and has 128G of RAM and 4*2.5″ SATA drive bays and 2*3.5″ SATA drive bays. Previously I had a Dell PowerEdge T320 which was released in 2012 and had 96G of RAM and 8*3.5″ SAS bays.
In CPU and GPU power the recent Mac Minis will compare well to my latest workstations. But they compare poorly to workstations from as much as 12 years ago for RAM and storage. Which is more important depends on the task, if you have to do calculations on 80G of data with lots of scans through the entire data set then a system with 64G of RAM will perform very poorly and a system with 96G and a CPU less than half as fast will perform better. A Dell PowerEdge T320 from 2012 fully loaded with 192G of RAM will outperform a modern Mac Mini on many tasks due to this and the T420 supported up to 384G.
Another issue is generic expansion options. I expect a workstation to have a number of PCIe slots free for GPUs and other devices. The T320 I used to use had a PCIe power cable for a power hungry GPU and I think all the T320 and T420 models with high power PSUs supported that.
I think that a usable definition of a “workstation” is a system having a feature set that is typical of servers (ECC RAM, lots of storage for RAID, maybe hot-swap storage devices, maybe redundant PSUs, and lots of expansion options) while also being suitable for running on a desktop or under a desk. The Mac Mini is nice for running on a desk but that’s the only workstation criteria it fits. I think that ECC RAM should be a mandatory criteria and any system without it isn’t a workstation. That excludes most Apple hardware. The Mac Mini is more of a thin-client than a workstation.
My main workstation with ECC RAM could run 3 VMs that each have more RAM than the largest Mac Mini that will be sold next week.
If 32G of non-ECC RAM is considered enough for a “workstation” then you could get an Android phone that counts as a workstation – and it will probably cost less than a Mac Mini.
Related posts:
- BTRFS Rebuild Time In February I replaced a Dell T320 server with a...
- SSD for a Workstation SSDs have been dropping in price recently so I just...
- T320 iDRAC Failure and new HP Z640 The Dell T320 Almost 2 years ago I made a...
This Week in Plasma: spoooooky ooooooooom notifications!
Welcome to the new home of "This Week in Plasma"! No longer is it a private personal thing on my (Nate Graham's) blog, but now it's a weekly series hosted here on KDE's infrastructure, open to anyone's participation and contribution! I'll remain the editor-in-chief for now, and welcome contributions via direct push to the relevant merge request on invent.kde.org. And after a post is published, if you find a typo or broken link, feel free to just fix it.
Anyway, this week we added a useful service to detect out-of-memory (OOM) conditions, did some UI polishing, and also a lot of bug-fixing! Check it out:
Notable New FeaturesWhen the system has run out of memory (OOM) and the kernel terminated an app, there's now a little service to detect this and show you a system notification explaining what happened, plus suggestions for what you can do about it in the future. (Harald Sitter, 6.3.0. Link)
Notable UI ImprovementsThe Emoji Selector app now does sub-string matching from the middle of words too, so you can find emojis more easily. (Eren Karakas, 6.2.3. Link)
The grouping indicator in the Task Manager widget (which looks like a little plus sign) is no longer always green; now it follows the current accent color! (Tem PQD, 6.3.0. Link)
Appropriate symbolic icons from will now be automatically substituted for apps' system tray icons — when they exist in the icon theme. If you'd like to extend this to more apps, figure out what icon name the app asks for, then create a symbolic version of it, append -symbolic to the name, and submit it to the Breeze Icons repo! (Marco Martin, 6.3.0. Link)
Notable Bug FixesFixed a way that misbehaving XWayland-using apps could make KWin freeze. (Vlad Zahorodnii, 6.2.3. Link)
Fixed a bug causing notifications about modifier key changes (if you've turned them on) to not actually appear. (Nicolas Fella, 6.2.3. Link)
Fixed a bug in the Bluetooth pairing wizard that caused it to be annoying to enter digits. (Daniil-Viktor Ratkin, 6.2.3. Link)
Reviews on Discover's app pages now load properly when the app is accessed from the Home page, as opposed to after browsing or searching. (Aleix Pol Gonzalez, 6.2.3. Link)
Fixed the Task Manager widget's setting to reverse the direction that new tasks appear in so that it works as originally designed, and not only halfway there. (Michael Rivnak, 6.2.3. Link)
Fixed a bug that caused customized user avatars for other currently-logged-in users to not be displayed in the User Switcher widget. (Blazer Silving, 6.2.3. Link)
Fixed a bug causing the "Show Logout Screen" item in the desktop context menu to not show enough items if you had customized the "default logout option" in the past, back when we offered that as a user-facing setting. (Nate Graham, 6.2.3 Link)
With global animations set to "instant", window thumbnails in KWin's Desktop Grid effect are no longer too small. (Niccolò Venerandi, 6.2.3. Link)
When you've got the Application Dashboard widget set up with an icon naming style that causes the text to be long and get elided, hovering over the icon now shows a tooltip with the correct full text in it. (Tomislav Pap, 6.2.3. Link)
Fixed a case where KWin could crash when moving certain drawing tablet pens to the surface of the pad. (Vlad Zahorodnii, 6.3.0. Link)
Fixed an issue that caused XWayland-using apps to resize in a janky and jumpy manner. (Vlad Zahorodnii, 6.3.0. Link, see detailed blog post)
How You Can HelpKDE has become important in the world, and your time and contributions have helped us get there. As we grow, we need your support to keep KDE sustainable.
You can help KDE by becoming an active community member and getting involved somehow. Each contributor makes a huge difference in KDE — you are not a number or a cog in a machine!
You don’t have to be a programmer, either. Many other opportunities exist:
- Filter and confirm bug reports, maybe even identify their root cause
- Contribute designs for wallpapers, icons, and app interfaces
- Design and maintain websites
- Translate user interface text items into your own language
- Promote KDE in your local community
- …And a ton more things!
You can also help us by donating to our yearly fundraiser! Any monetary contribution — however small — will help us cover operational costs, salaries, travel expenses for contributors, and in general just keep KDE bringing Free Software to the world.
To get a new Plasma feature or a bugfix mentioned here, feel free to push a commit to the relevant merge request on invent.kde.org.
HDR and color management in KWin, part 4: nonlinear blending
In Plasma 6.2, KWin switched from doing linear blending with HDR to blending in a gamma 2.2 space. Let’s take a look at what that means, and why it was done.
What is blending?When KWin composites, it paints window by window, going by the order of how the windows are stacked - the bottom-most window first, the topmost window last. When a window is opaque, you just overwrite the pixels in the framebuffer with the ones from the window. When a window is semi-transparent though, we need to additionally do blending.
To do blending, the GPU calculates the value that the framebuffer should have with some equation that gets the pixel from the window and the existing value in the framebuffer, and outputs some appropriate value. Usually that equation is1
framebuffer = framebuffer.rgb * (1 - window.alpha) + window.rgb * window.alphawhere window.alpha is a per-pixel value that describes how opaque the pixel is.
Blending with color managementIn Plasma 5, compositing happened in the display color space. As displays could be assumed to be roughly the same, with brightness levels encoded in sRGB, that resulted in blending looking very similar everywhere.
With HDR in Plasma 6 however, that assumption was no longer true, so we had to do something else. As it was considered the most “correct” thing and allows us to ensure the exact same blending result even with displays that have wildly different colorspaces, linear blending was chosen for Plasma 6.0. The result of linear blending would look different from sRGB, but it would at least be consistent everywhere.
With linear blending, instead of just taking the rgb values as is, you first convert them into light-linear values, for example with sRGB you’d just do
rgb_linear = pow(rgb_sRGB, 2.2)then apply the blending equation, and at the end convert it back to whatever encoding the screen needs.
Because of limitations in KWin’s renderer and the ancient OpenGL versions KWin supports, the only way to do this was to render first into a so-called shadow buffer2 with linear values, and after compositing a second shader pass would run, taking that shadow buffer as the input and outputting a buffer with non-linear values that’s suitable for sending to the screen.
The caveats of linear blendingIt’ll be pretty obvious to most that doing a fullscreen copy each frame is not ideal for performance or battery life, but there was even a second problem: If you use only 8 or 10 bits per color (bpc) to store linear brightness values, you get visible banding in the dark areas of the image, as human vision is very non-linear. So on top of doing fullscreen copies, KWin also had to use a floating point buffer with 16 bpc, which uses twice the memory bandwidth vs. 8 bpc and makes performance and power usage even worse.
With that performance hit, we couldn’t enable this on all hardware, but had to restrict linear blending to those displays where HDR or an ICC profile is enabled. This threw the whole consistency benefit out of the window, because now a semi-transparent surface would look a lot more transparent just because you enabled HDR… causing the very problem we wanted to avoid!
SDR HDRWe had to do something when blending in HDR though, so a different approach had to be taken.
Custom transfer functionsWhen storing colors in buffers, usually we use non-linear encodings with transfer functions like sRGB or PQ. All the transfer functions have some sort of luminance levels attached to them, for example an sRGB value of 1.0 is defined to result in a luminance of 80 nits in its reference viewing environment3.
There’s no reason to be restricted to those definitions though - we can make transfer functions that mean whatever we want or need. In KWin’s case, we switched the shadow buffer from using a linear encoding to a gamma 2.2 encoding, in which 1.0 means the maximum luminance of your monitor. This means we do blending in a very similar way as on SDR screens4, and translucent surfaces on the screen look pretty much the same again, no matter what display settings you have.
As the gamma 2.2 encoding allocates more numbers to darker parts of the image, we can also avoid banding with fewer bits per color. Whenever HDR is enabled and the driver supports buffers with 10 bpc, KWin now prefers to use that instead of 16 bpc, alleviating some of the performance issues. There was still more that could be done though…
KMS offloadingOn most graphics cards, the scanout hardware that takes care of sending the image to the display has some fixed function blocks to change the colors in various ways - the most common being a simple look up table (LUT) per color channel.
Through the DRM/KMS API, the compositor can set this LUT, so we can use it to change the encoding from whatever we did blending in to the one the display needs. With HDR screens, this means we
- convert from our shadow buffer encoding with gamma 2.2 and the maximum luminance of the screen to linear
- possibly apply rgb factors for night light
- convert from linear to the PQ encoding the screen needs
With that LUT in place, we don’t have to run a shader pass to convert from the shadow buffer encoding to the screen anymore, so the whole fullscreen copy falls away.
Except for a few additional instructions in the shaders used for compositing, enabling HDR in Plasma 6.2 thus has no performance impact anymore on the vast majority of hardware!
-
in practice, window.rgb is already “pre-multiplied” with window.alpha, but that doesn’t really matter here ↩
-
it’s called that because it’s never actually shown on the screen ↩
-
the viewing environment basically defines a standardized room, in which the content can be viewed as intended without doing any brightness adjustments ↩
-
it’s not exactly the same though. If you need some exactly specific blending behavior in your application, it’s best if you do it yourself ↩
FSF Blogs: Free Software Supporter -- Issue 199, November 2024
Free Software Supporter -- Issue 199, November 2024
FSF Blogs: October GNU Spotlight with Amin Bandali: Seven new GNU releases!
October GNU Spotlight with Amin Bandali: Seven new GNU releases!
Web Review, Week 2024-44
Let’s go for my web review for the week 2024-44.
What You Can Learn from Just Seven Pages by Hannah ArendtTags: tech, philosophy, history, politics
A very precious philosopher from the 20th century. Her texts are still very precious and resonate today. In this piece it’s focusing about tech relevant excerpts, she had plenty to say about today’s politics as well.
https://www.honest-broker.com/p/what-you-can-learn-from-just-seven
Tags: tech, foss, ai, machine-learning
Nice initiative from the OSI. It is timely, such a definition was surely needed. The data information part seems fairly weak though… for sure you could make a system which doesn’t respect the four freedoms that way.
https://opensource.org/ai/open-source-ai-definition
Tags: tech, foss, ai, machine-learning
Like me, you find the Open Source AI Definition weak on the training data information side? You’d be right and there’s a reason for it… it’s probably hiding quite some open washing for the larger models. This is a good explanation of the motives and consequences.
https://tante.cc/2024/10/16/does-open-source-ai-really-exist/
Tags: tech, web, mobile, react, framework, criticism
This is definitely true. As long as web frontends are dominated by large frameworks, the web will always have subpar experience on mobile. And the solution isn’t going to come from the mobile providers too happy to gatekeep their app store.
https://infrequently.org/2024/10/platforms-are-competitions/#fn-failure-on-repeat-2
Tags: tech, matrix, protocols
This is definitely getting there in terms of performance and usability. The mobile clients seem mature enough, just need the desktop clients to catch up before this becomes really something I’d feel confident enough to recommend and push for.
https://matrix.org/blog/2024/10/29/matrix-2.0-is-here/
Tags: tech, unix, posix
It’s nice to see the standard still moves. Some of the additions are definitely welcome.
https://blog.toast.cafe/posix2024-xcu
Tags: tech, time, culture, internationalization
Time management and timezones are definitely complicated. In a way it’s culture colliding with computers and localisation… it can’t be simple.
https://ssoready.com/blog/engineering/truths-programmers-timezones/
Tags: tech, tools, ssh, dns, security
Nice technique for automating the verification of SSH host keys. It’d be nice to see wider adoption.
https://blog.apnic.net/2022/12/02/improving-sshs-security-with-sshfp-dns-records/
Tags: tech, github, ci, security, tools
Definitely an interesting tool. GitHub Actions workflow aren’t easy to setup while ensuring they’re secure, having a tool analyzing them for issues can only help.
https://blog.yossarian.net/2024/10/27/Now-you-can-have-beautiful-clean-workflows
Tags: tech, rust, type-systems, memory
Interesting progress on safe type casting in Rust. This should bring nice zero copy parsing of binary data in some cases.
https://lwn.net/SubscriberLink/994334/5e1f97f08916b494/
Tags: tech, c++, rust, legacy
This is a good view of what you’re getting into with the “rewrite it in Rust” knee-jerk reaction.
https://gaultier.github.io/blog/lessons_learned_from_a_successful_rust_rewrite.html
Tags: tech, postgresql, databases, ai, machine-learning, language
I definitely like the approach of having vectorisation in the RDBMS directly. This is one less moving part, less complexity at the application level to synchronize everything together. In this case it’s a Postgres extension.
https://www.timescale.com/blog/vector-databases-are-the-wrong-abstraction/
Tags: tech, sqlite, databases, tools
Interesting, there’s now an official tool to replicate sqlite databases. It’s still early days, we’ll see which features it’ll get.
Tags: tech, java, spring, profiling
A quick tour of the available tools to profile Spring Boot applications.
https://foojay.io/today/how-to-profile-a-performance-issue-using-spring-boot-profiling-tools/
Tags: tech, git, tools
Yet another Git option I missed. This is definitely useful, I’ll try it out.
https://andrewlock.net/working-with-stacked-branches-in-git-is-easier-with-update-refs/
Tags: tech, python, 3d, webgpu, data-visualization
Looks like a very interesting Python library to build interactive 3d visualizations.
https://docs.pygfx.org/stable/index.html
Tags: tech, 2d, 3d, graphics, mathematics
Ever wondered how to simulate 3D from 2D based primitives? Here is a nice experiment explaining how to approach it.
https://www.charlespetzold.com/blog/2024/09/Rudimentary-3D-on-the-2D-HTML-Canvas.html
Tags: tests, 3d, graphics
A nice list of the techniques used to render shadows in games.
https://30fps.net/pages/videogame-shadows/
Tags: tech, 3d, graphics, shader
Very nice deep dive into a post-processing shader to create a painted scene effect.
https://blog.maximeheckel.com/posts/on-crafting-painterly-shaders/?ck_subscriber_id=2669647738
Tags: tech, craftsmanship, learning, career
Indeed, those are fundamental traits to make sure you learn and make progress on your journey.
https://registerspill.thorstenball.com/p/the-basics
Tags: tech, learning, career, craftsmanship
Another excellent piece from Kent Beck, he’s right that the real differentiator in our profession is about digging deep on topics, seeing them through even if that’s on the side. Curiosity is a key trait.
https://tidyfirst.substack.com/p/background-work
Tags: tech, agile, architecture, history
Good explanation on how the agile movement scaled down about design over time in its literature. It’s probably its biggest failure. The good thing is that the pendulum is starting to swing in the other direction a bit (that’s probably why Beck is now working on a book series on software design).
https://explaining.software/archive/the-death-of-the-architect/
Tags: tech, quality, product-management, project-management
This is accurate in my opinion. Engineering and product teams need to properly negotiate, otherwise quality will suffer.
Tags: tech, project-management, product-management, decision-making
Interesting guidelines idea to help teams manage the priorities themselves. It’s written in the context of a product manager but I think it is lightweight and generic enough to apply in other contexts.
https://productmanagers.substack.com/p/how-to-not-be-a-prioritization-machine
Tags: science, complexity
It’s sometimes extremely difficult to get to the original source of a scientific claim. Our corpus of science is so large and complex now that finding where a claim comes from can be a daunting task.
https://www.youtube.com/watch?v=bgo7rm5Maqg
Tags: science, neuroscience
This is an amazing example of the brain plasticity. It’s also great to have a patch for increased quality of life with a training of only a few weeks.
https://academic.oup.com/cercor/article/34/6/bhae239/7696241?login=false
Bye for now!
Python Engineering at Microsoft: Python in Visual Studio Code – November 2024 Release
We’re excited to announce the November 2024 release of the Python, Pylance and Jupyter extensions for Visual Studio Code!
This release includes the following announcements:
- Generate docstrings with Pylance
- New fold and unfold all docstrings commands
- Import suggestions can now include aliases from user files
- Experimental AI Code Action for implementing abstract classes
- Native REPL variables view
If you’re interested, you can check the full list of improvements in our changelogs for the Python, Jupyter and Pylance extensions.
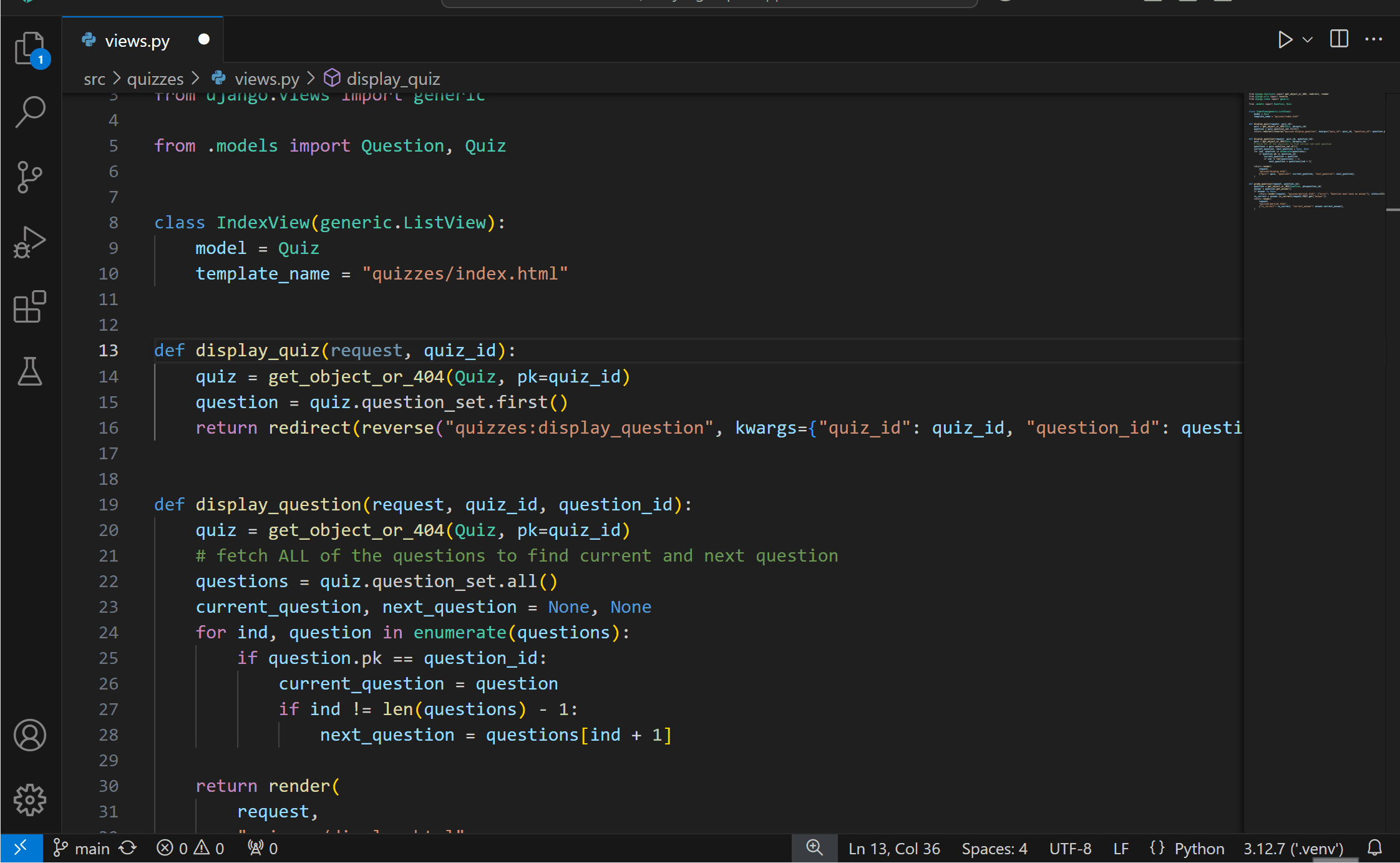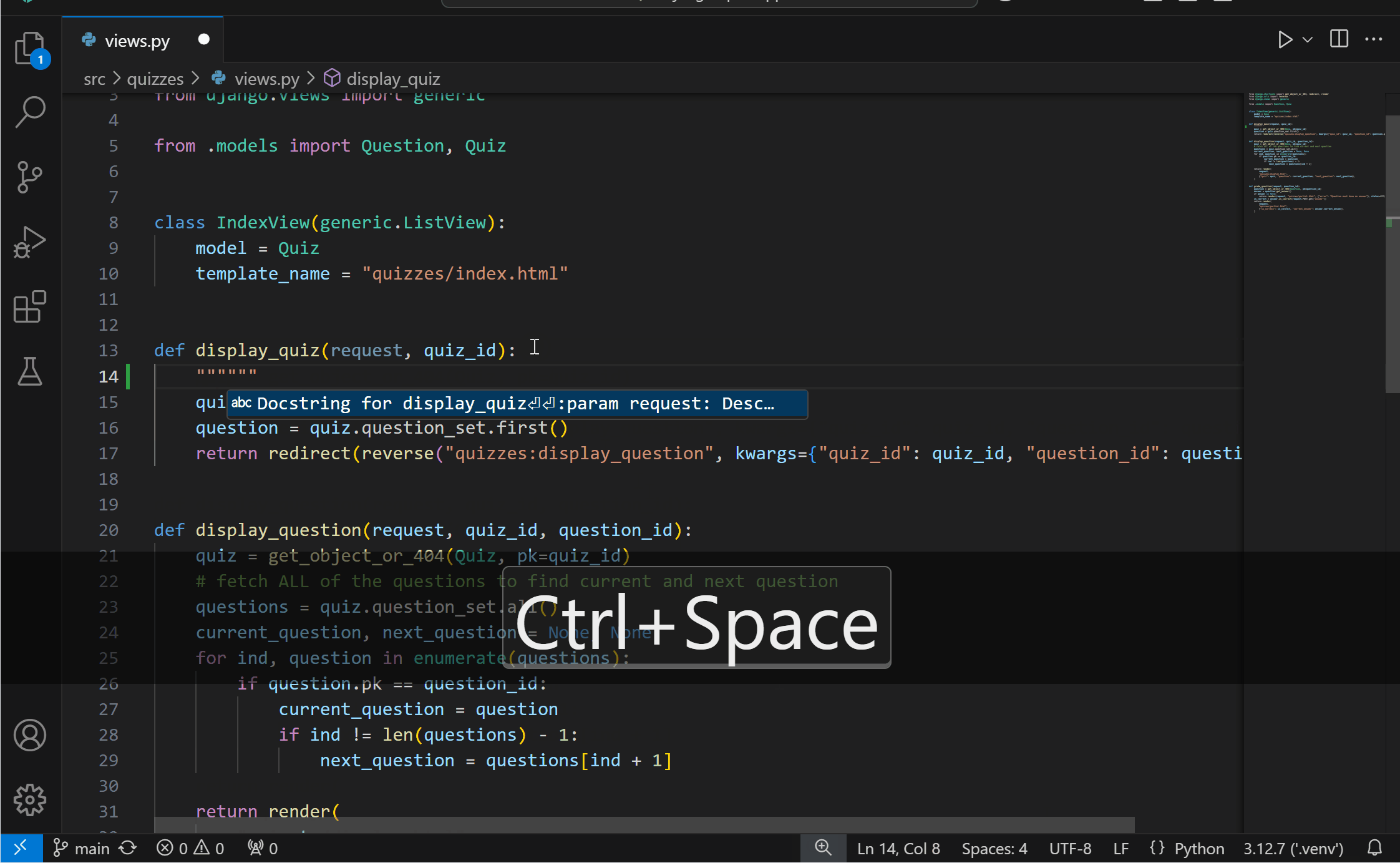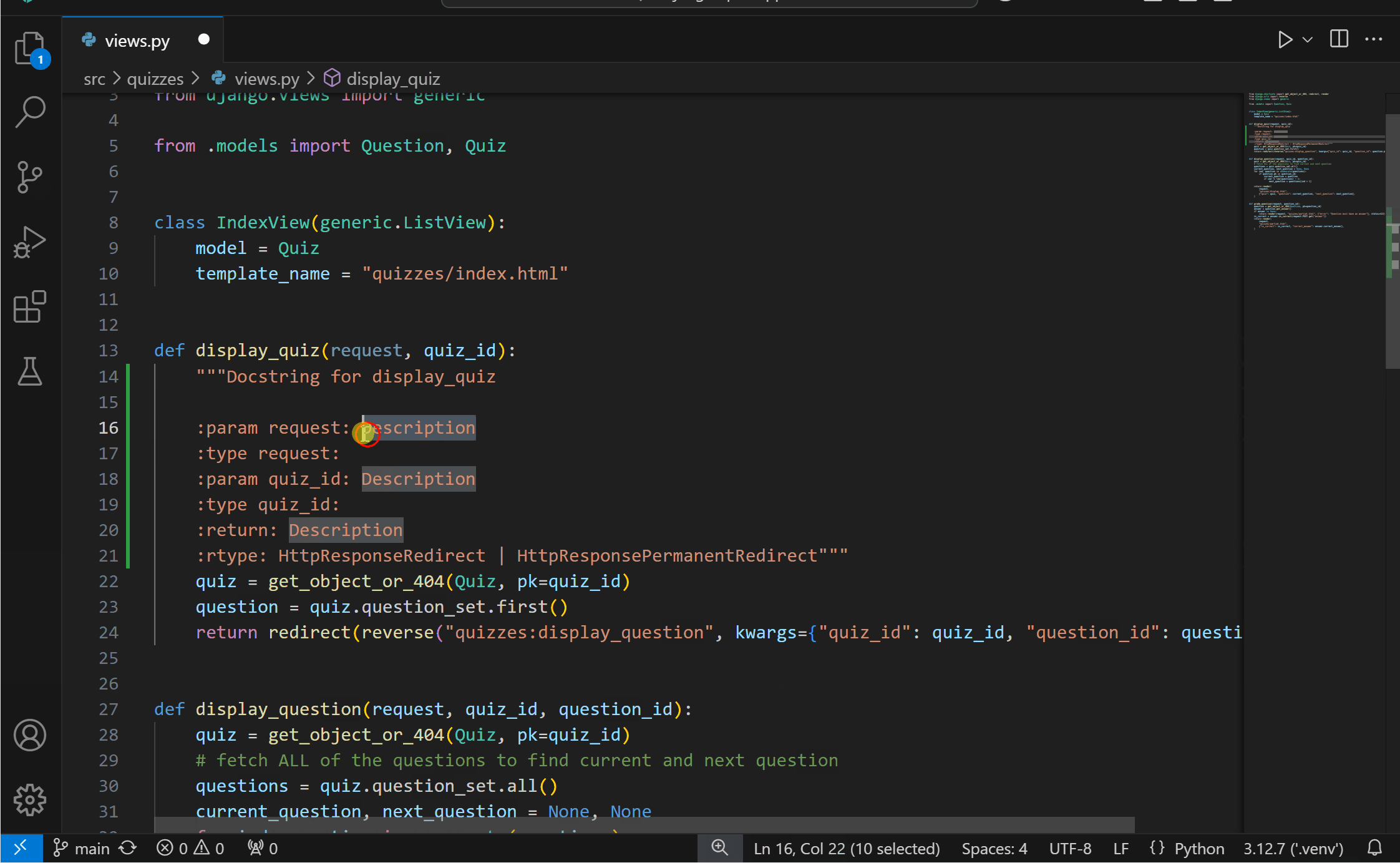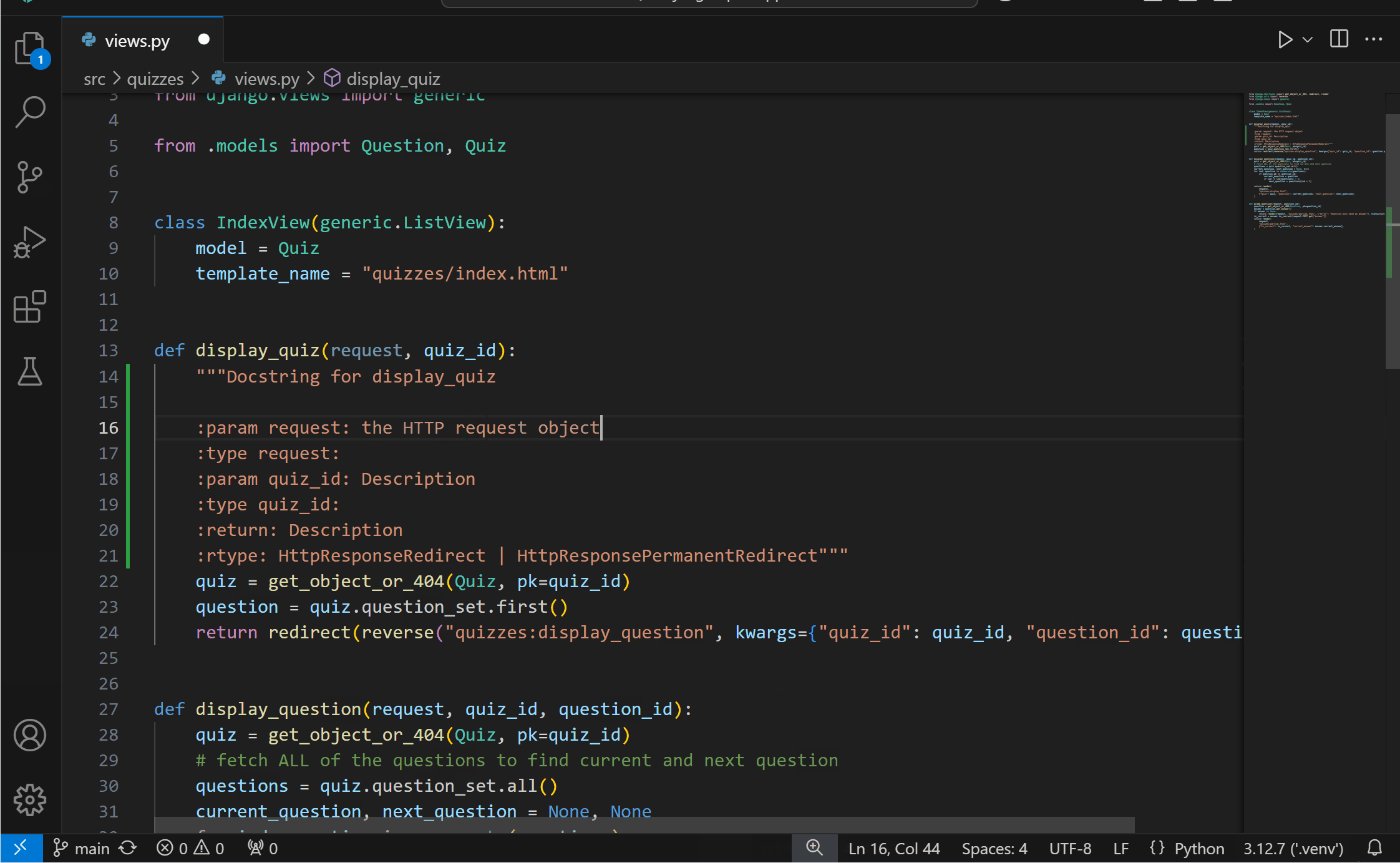
Generate docstrings with PylanceYou can now more conveniently generate documentation for your Python code with Pylance‘s docstrings template generation feature! You can generate a docstring template for classes or methods by typing """ or ''', pressing kbstyle(Ctrl+Space), or selecting the lightbulb to invoke the Generate Docstring Code Action. The generated docstring includes fields for the function’s description, parameter descriptions, parameter types, return value description, and return type.
{kind=link}
This feature is currently behind an experimental setting, but we look forward to making it the default experience soon. You can try it out today by enabling the python.analysis.supportDocstringTemplate setting.
New fold and unfold all docstrings commandsDocstrings are great for providing context and explanations for your code, but sometimes you might want to fold them to focus on the code itself. You can now more easily do so by folding docstrings with the new Pylance: Fold All Docstrings command, which can also be bound to a keybinding of your choice. To unfold them, use the Pylance: Unfold All Docstrings command.
Import suggestions with aliases from user files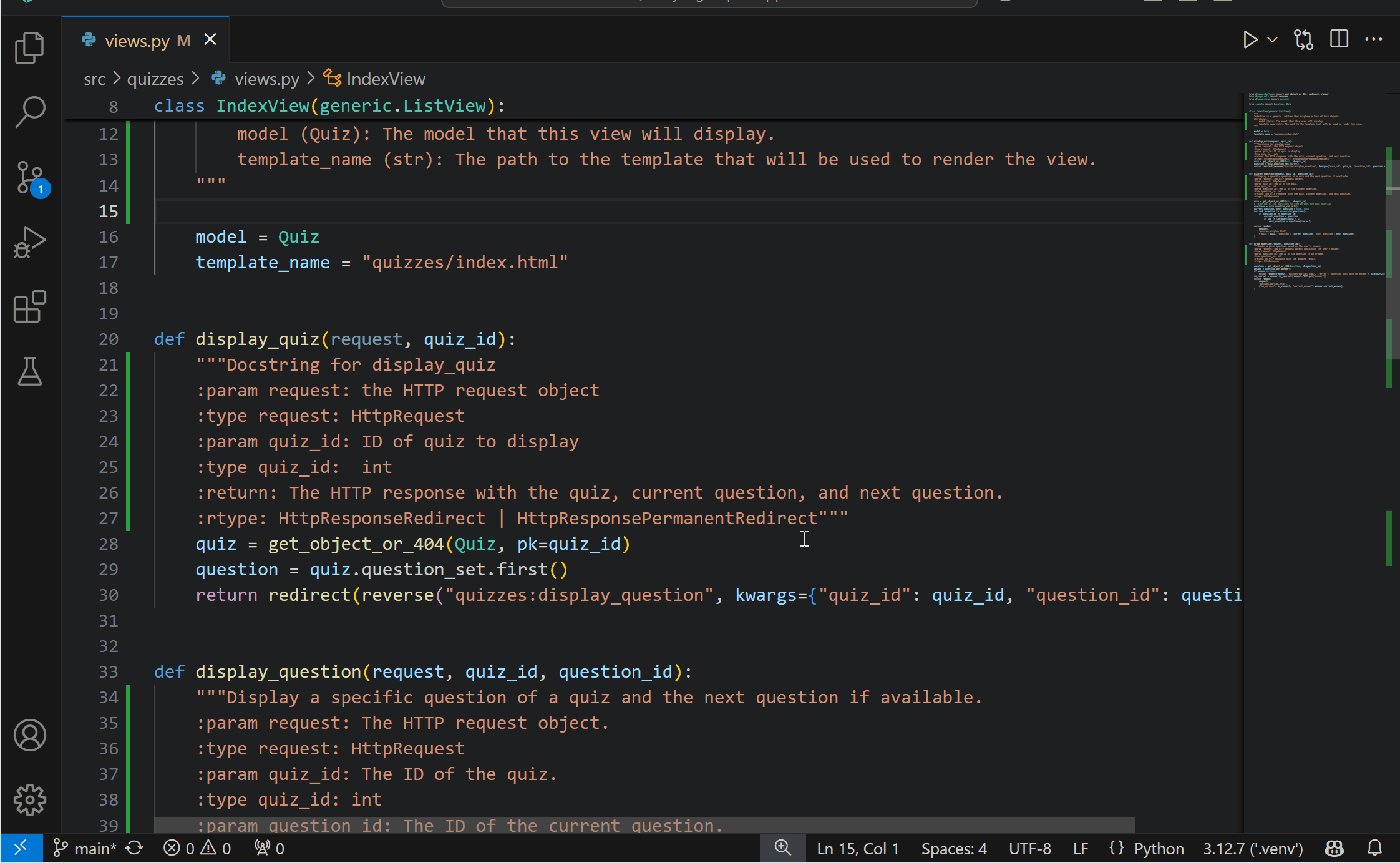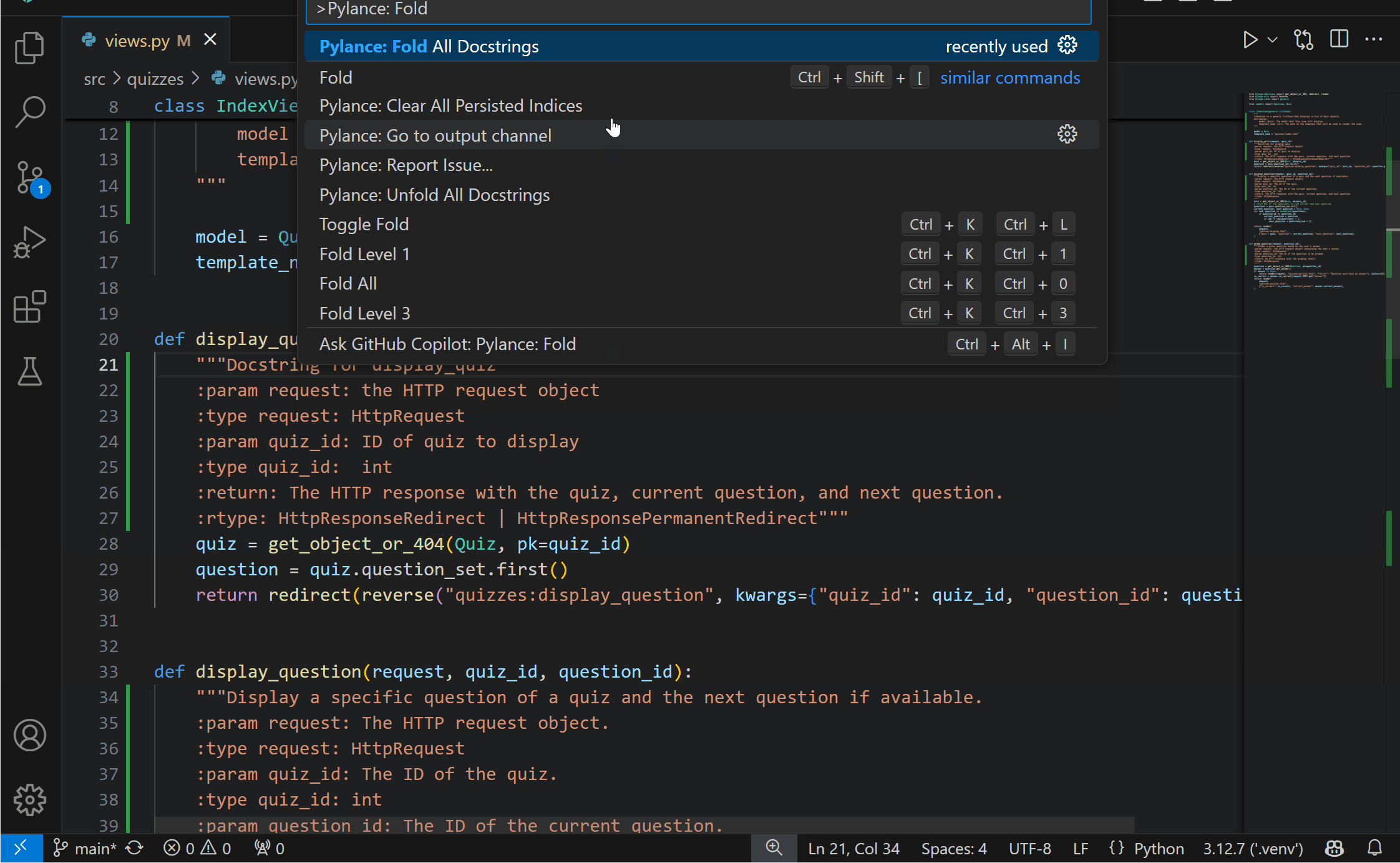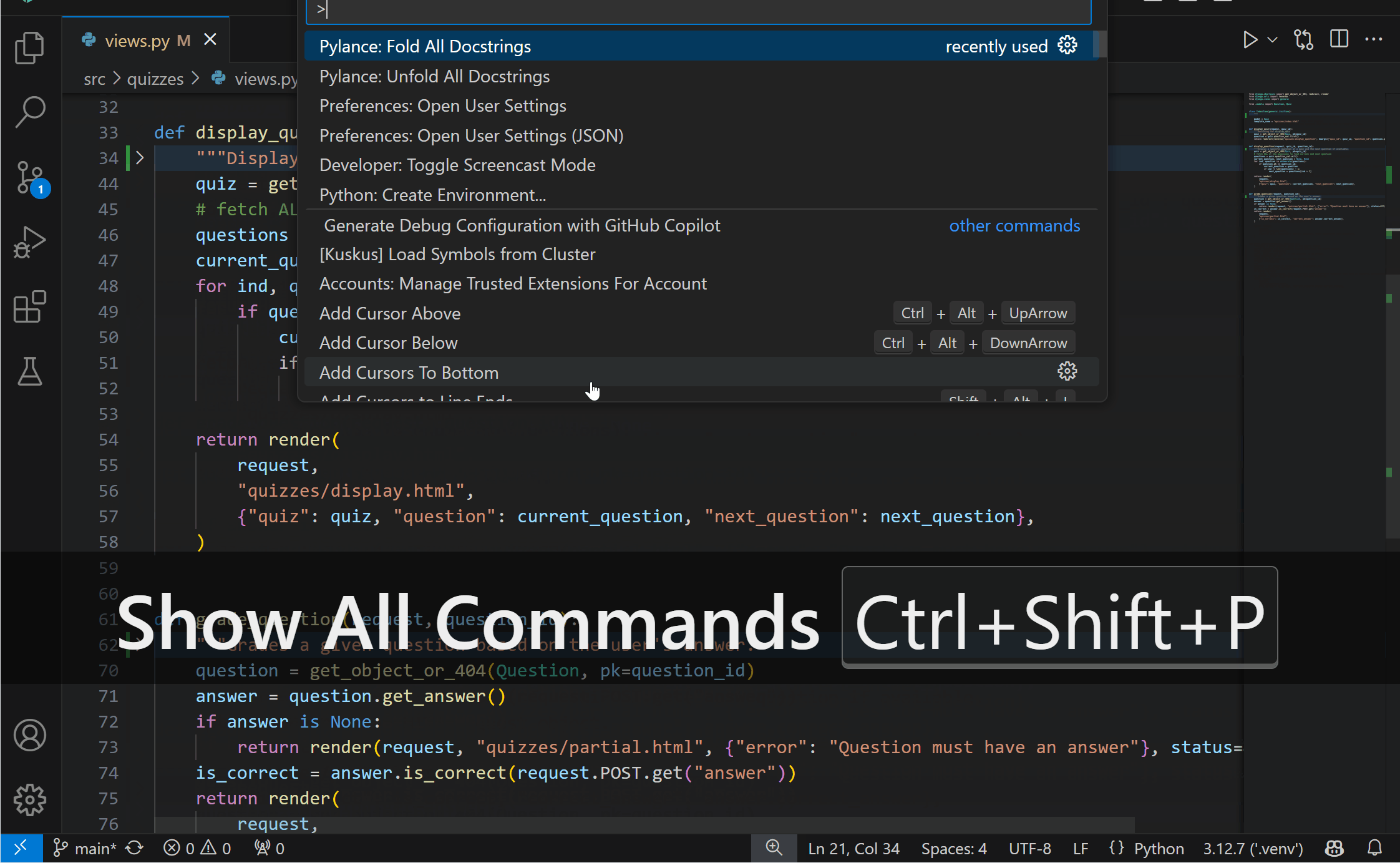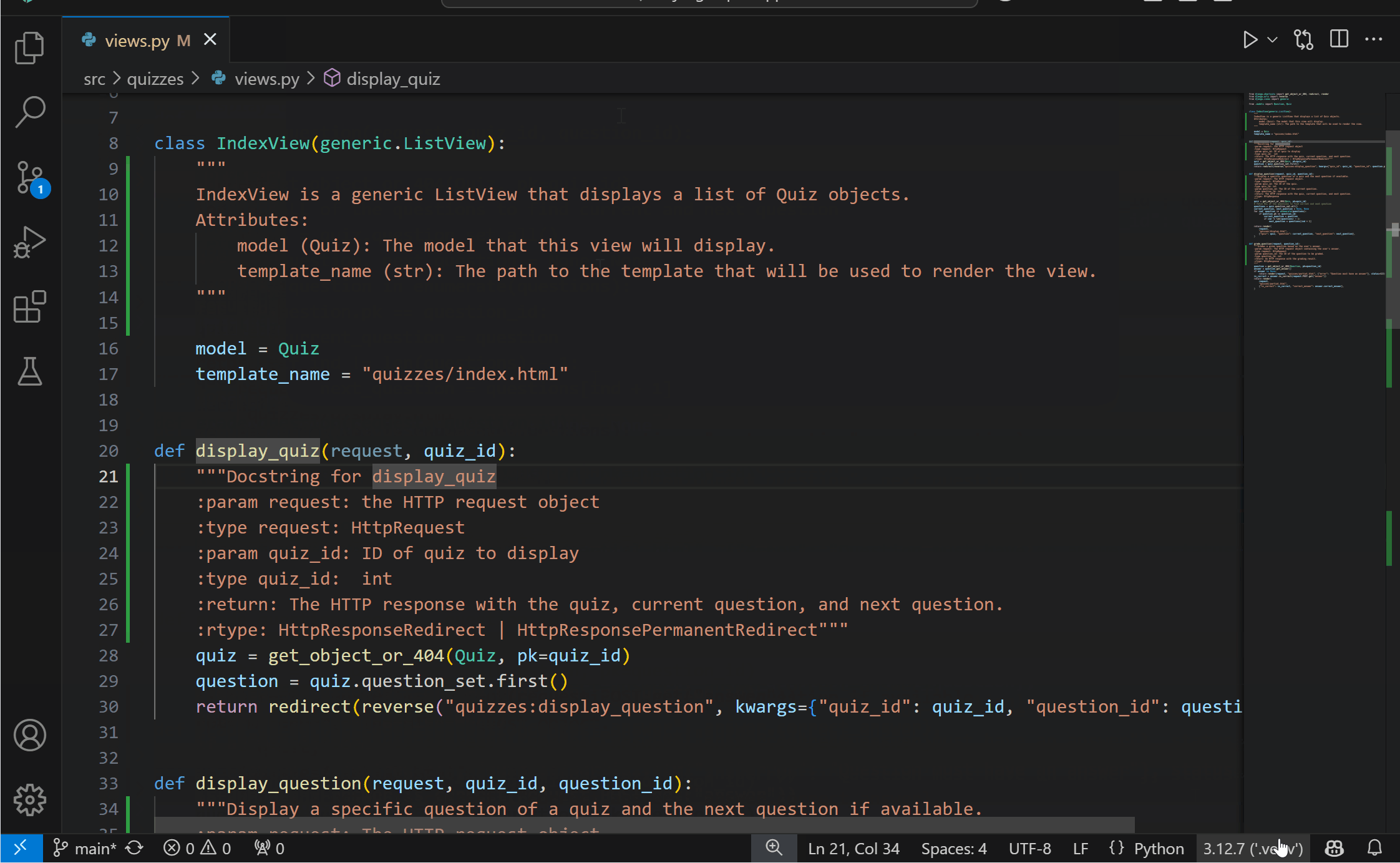{kind=link}
One of Pylance’s most powerful features is its ability to provide auto-import suggestions. By default, Pylance offers the import suggestion from where the symbol is defined, but you might want it to import from a file where the symbol is imported (i.e. aliased). With the new python.analysis.includeAliasesFromUserFiles setting, you can now control whether Pylance includes alias symbols from user files in its auto-import suggestions and in the add import Quick Fix.
Note: Enabling this setting can negatively impact performance, especially in large codebases, as Pylance may need to index more symbols and monitor more files for changes, which can increase resource usage.
Experimental AI Code Action: Implement Abstract ClassesYou can now get the best of both worlds with AI and static analysis with the new experimental Code Action to implement abstract classes! This feature requires both the Pylance and the GitHub Copilot extensions. To try it out, you can select the Implement all inherited abstract classes with Copilot Code Action when defining a class that inherits from an abstract one.
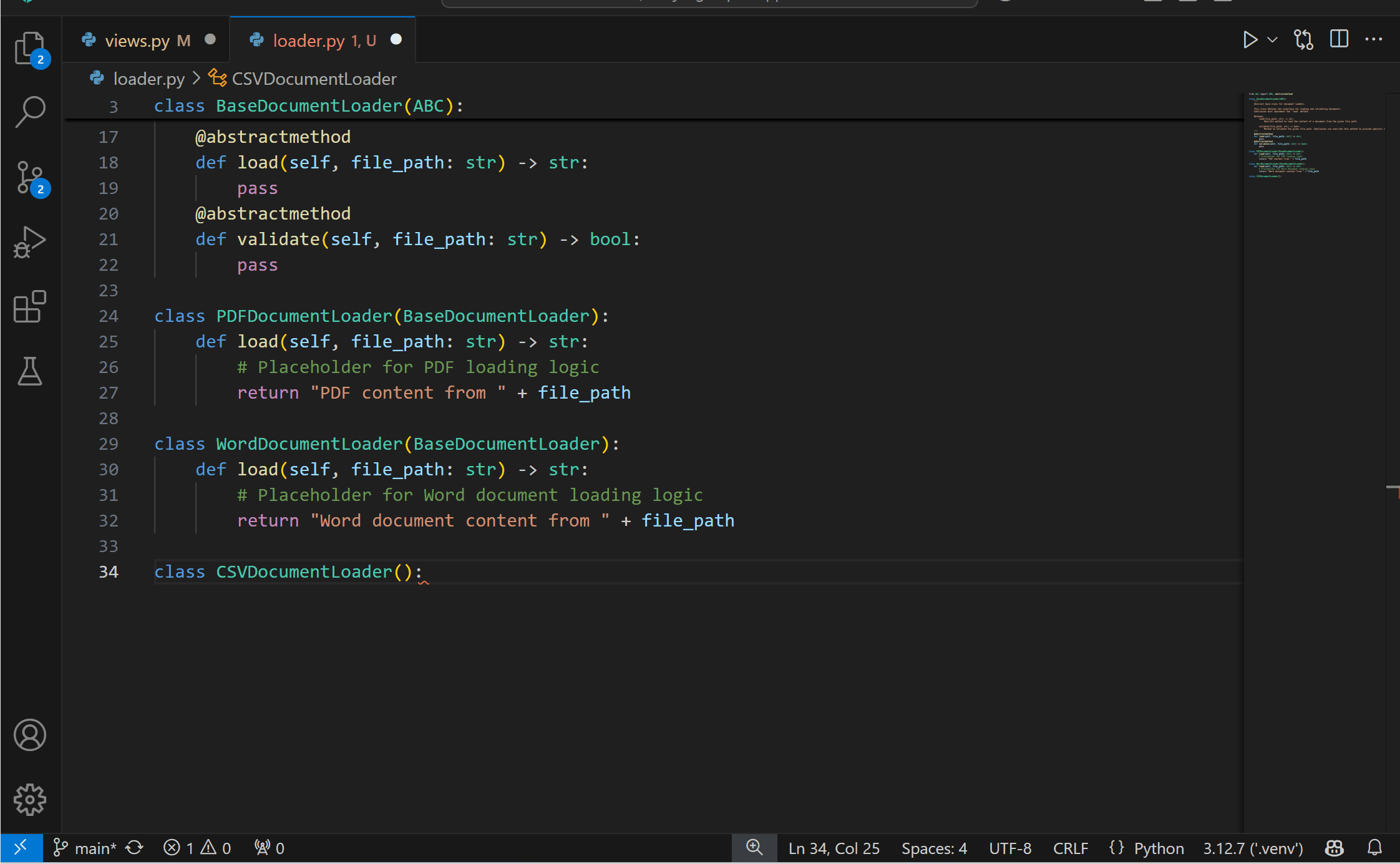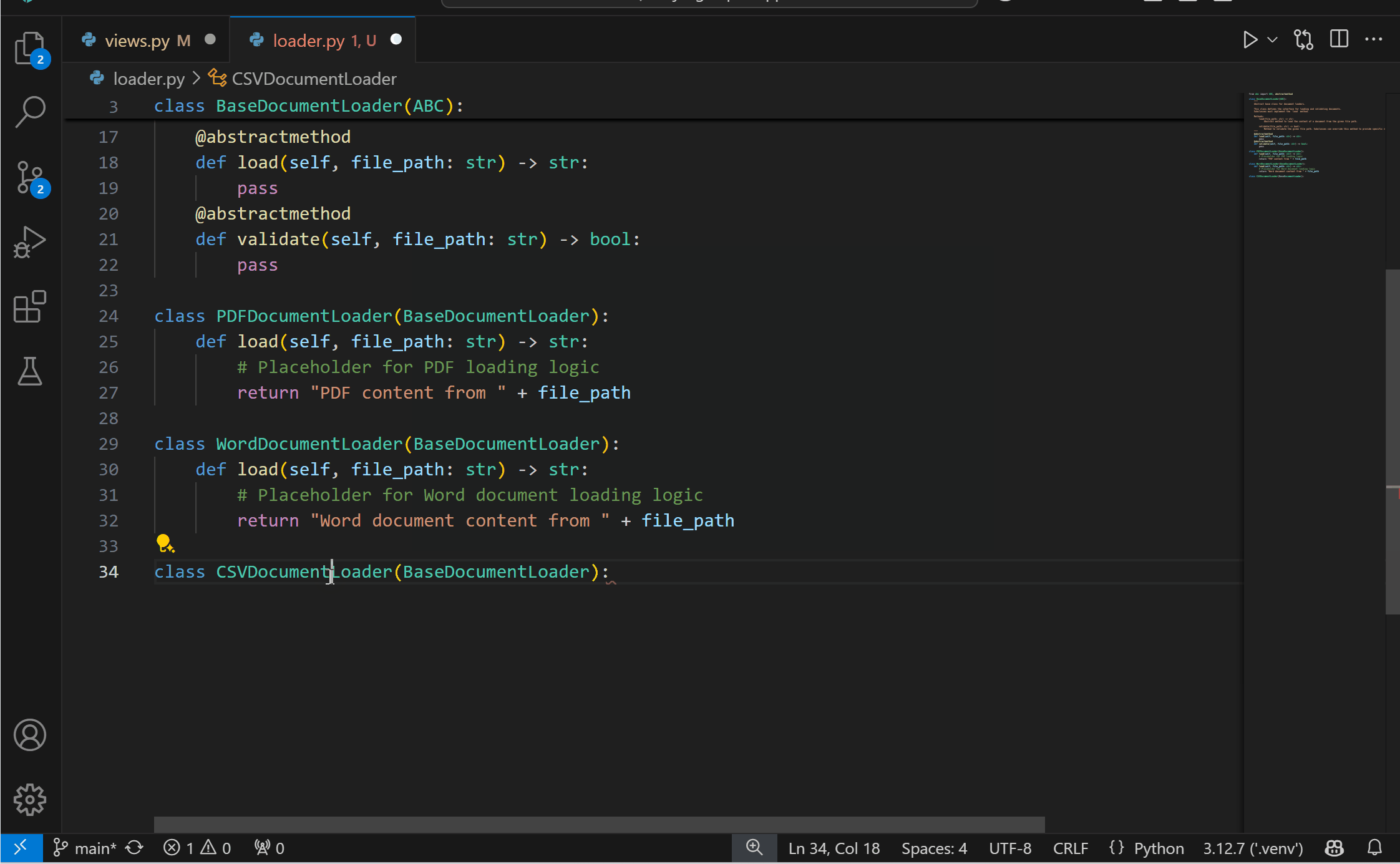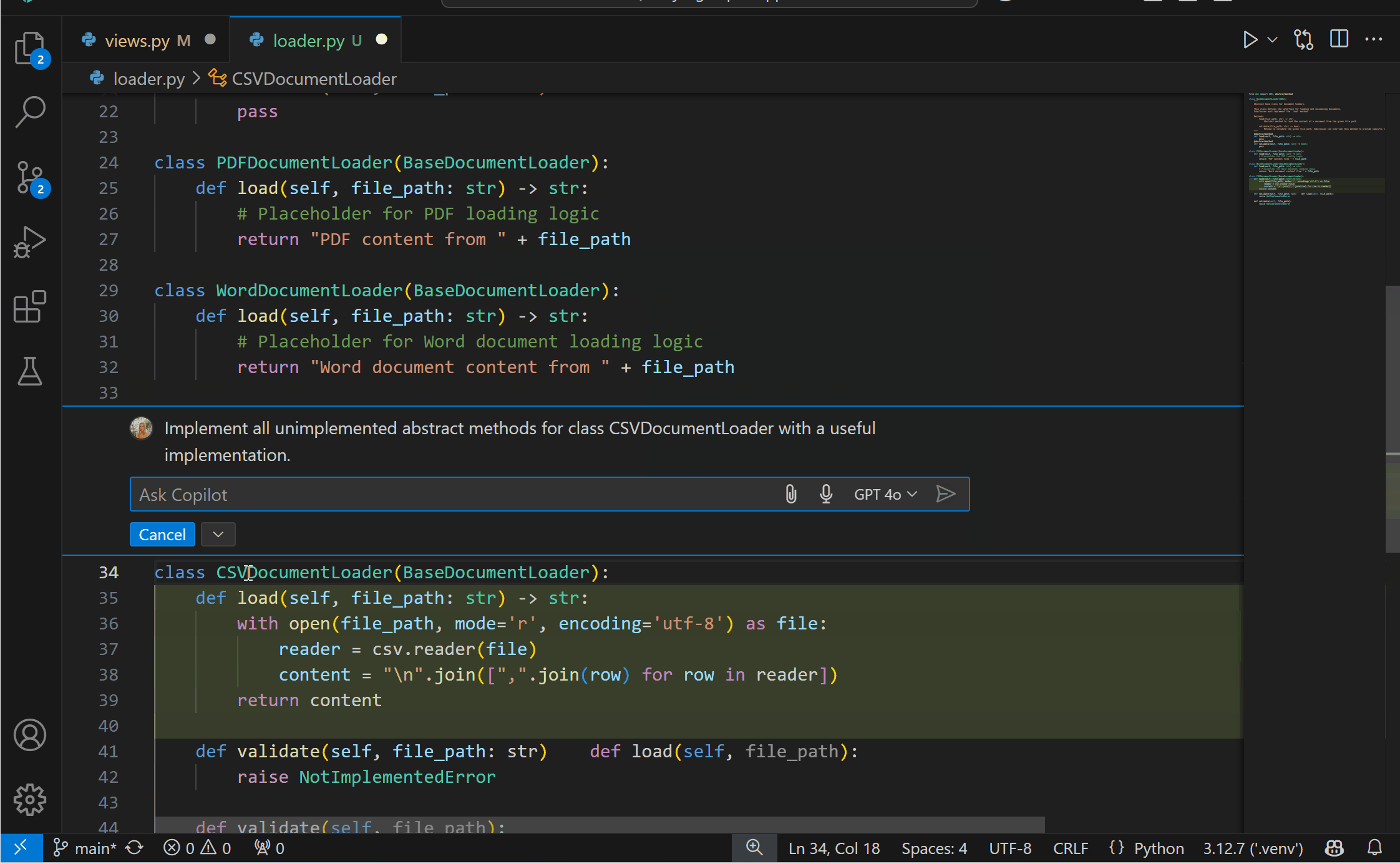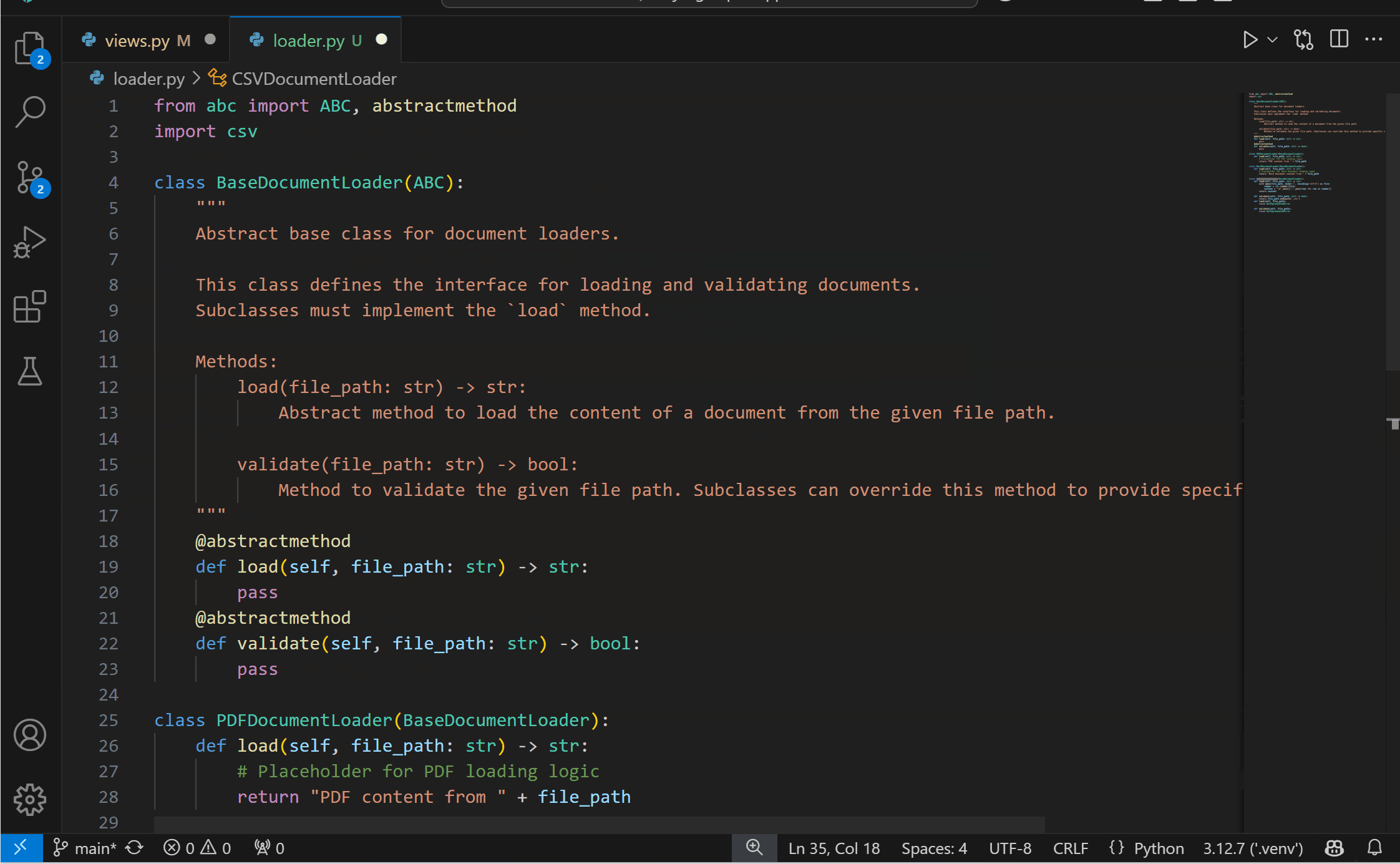{kind=link}
You can disable this feature by setting "python.analysis.aiCodeActions": {"implementAbstractClasses": false} in your User settings.
Native REPL Variables ViewThe Native Python REPL now provides up-to-date variables for the built-in Variables view. This lets you dig into the state of the interpreter as you execute code from files or through the REPL input box.
Upcoming deprecation of Python 3.8 support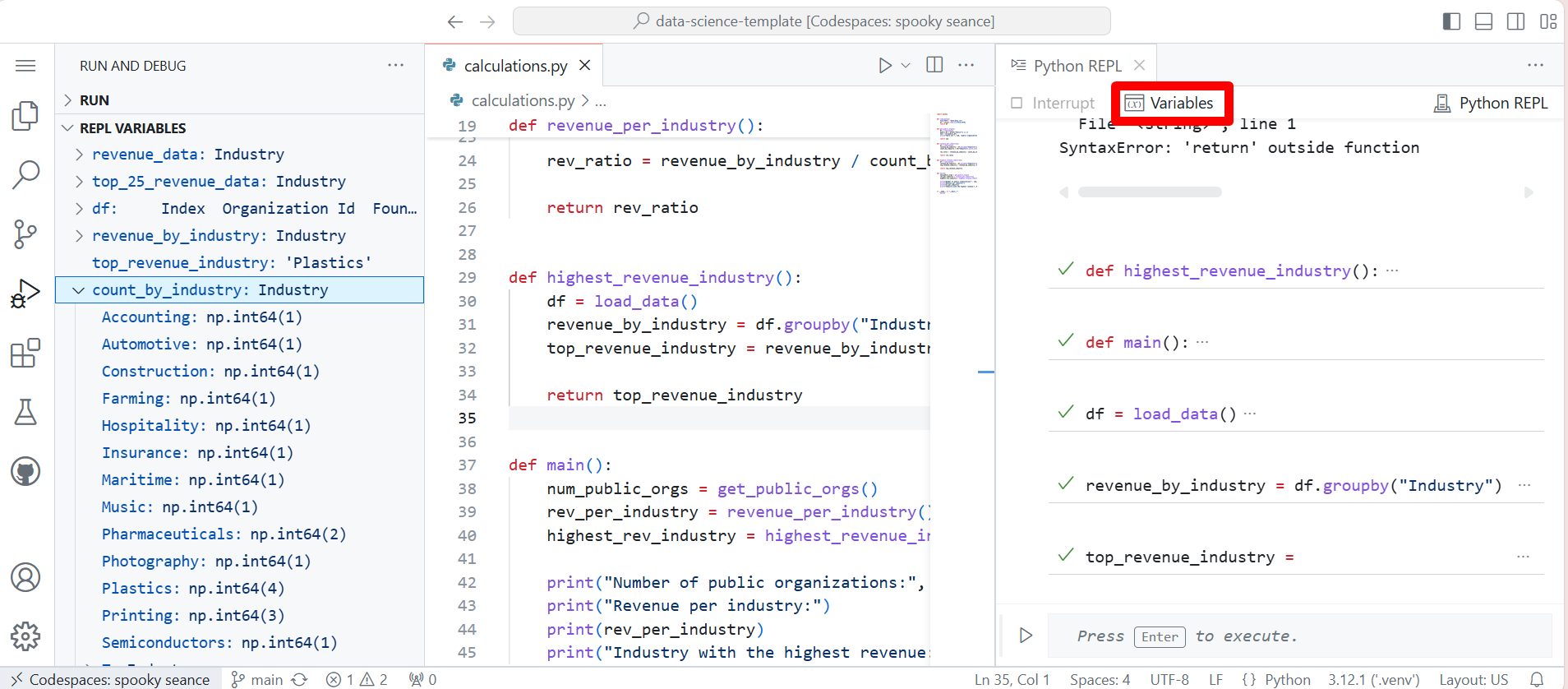{kind=link}
Python 3.8 reached end-of-life (EOL) on 2024-10-07. As such, official support for Python 3.8 in the Python extension will stop in three months, in the February 2025 release of the Python extension. There are no plans to actively remove support for Python 3.8, and so we expect the extension will continue to work unofficially with Python 3.8 for the foreseeable future.
Other Changes and EnhancementsWe have also added small enhancements and fixed issues requested by users that should improve your experience working with Python and Jupyter Notebooks in Visual Studio Code. Some notable changes include:
- There’s a new documentation page on the various ways to run Python code in VS Code.
- Pixi functionality has been restored only when Pixi is available (vscode-python#24310).
- You can now change the type checking mode to strict or standard from the Language Status menu (pylance-release#6080)
We would also like to extend special thanks to this month’s contributors:
- @mnoah1 Add customizable interpreter discovery timeout in vscode-python#24227
- @brokoli777 Refactor code to remove unused JSDoc types in vscode-python#24300
- @T-256 Make python_server.py compatible to Python 3.7 in vscode-python#24252
Note: This doesn’t guarantee full compatibility nor support for Python 3.7 in other parts of the Python extension. The minimum Python version we support is still Python 3.8 until February 2025, when the minimum officially supported version will be Python 3.9.
Try out these new improvements by downloading the Python extension and the Jupyter extension from the Marketplace, or install them directly from the extensions view in Visual Studio Code (Ctrl + Shift + X or ⌘ + ⇧ + X). You can learn more about Python support in Visual Studio Code in the documentation. If you run into any problems or have suggestions, please file an issue on the Python VS Code GitHub page.
The post Python in Visual Studio Code – November 2024 Release appeared first on Python.
mark.ie: Why Your Council Should Consider LocalGov Drupal for Your Website’s CMS
Let’s explore why it’s the CMS of choice for councils across the UK!
Python Software Foundation: PyCon US 2025 Kicks Off: Website, CfP, and Sponsorship Now Open!
Exciting news: the PyCon US 2025 conference website, Call for Proposals, and sponsorship program are open!
To learn more about the location, deadlines, and other details, check out the links below:
- PyCon US 2025 Launch Blog Post
- PyCon US 2025 Website
- Submit Your PyCon US 2025 Proposal on Pretalx
- Sponsorship Application
- PyCon US 2025 Changes Blog Post
We’re very happy to answer any questions you have about PSF sponsorship or PyCon US 2025– please feel free to reach out to us at sponsors@python.org.
On behalf of the PSF and the PyCon US 2025 Team, we look forward to receiving your proposals and seeing you in Pittsburgh next year 🥳 🐍
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
- Bounteous.com: Upgrading to Drupal 10 (And Beyond) With Composer
- FSF Blogs: Free software is vital for the public and state-run infrastructure of a free society
- Free software is vital for the public and state-run infrastructure of a free society
- Kdenlive Café in December
- PyPodcats: Episode 7: With Anna Makarudze
FLOSS Research
- Celebrating 5 years at the Open Source Initiative: a journey of growth, challenges, and community engagement
- Highlights from the Digital Public Goods Alliance Annual Members Meeting 2024
- Give Your Input on the State of Open Source Survey
- Open Data and Open Source AI: Charting a course to get more of both
- The Open Source Initiative and the Eclipse Foundation to Collaborate on Shaping Open Source AI (OSAI) Public Policy