
Feeds
Python Morsels: Python's range() function
The range function can be used for counting upward, countdown downward, or performing an operation a number of times.
Table of contents
- Counting upwards in Python
- Using range with a step value
- Counting backwards in Python
- The arguments range accepts are similar to slicing
- Using range with for loops
How can you count from 1 to 10 in Python?
You could make a list of all those numbers and then loop over it:
>>> numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> for n in numbers: ... print(n) ... 1 2 3 4 5 6 7 8 9 10But that could get pretty tedious. Imagine if we were working with 100 numbers... or 1,000 numbers!
Instead, we could use one of Python's built-in functions: the range function.
The range function accepts a start integer and a stop integer:
>>> for n in range(1, 11): ... print(n) ... 1 2 3 4 5 6 7 8 9 10The range function counts upward starting from that start number, and it stops just before that stop number. So we're stopping at 10 here instead of going all the way to 11.
You can also call range with just one argument:
>>> for n in range(5): ... print(n) ... 0 1 2 3 4When range is given one argument, it starts at 0, and it stops just before that argument.
So range can accept one argument (the stop value) where it starts at 0, and it stops just before that number. And range can also accept two arguments: a start value and a stop value. But range also accepts a third argument!
Using range with a step valueThe range function can accept …
Read the full article: https://www.pythonmorsels.com/range/Tag1 Consulting: Performance Testing Leads To Major Improvements for Drupal CMS — and all of Drupal
When we added Gander performance tests to Drupal CMS, we uncovered several opportunities for improvements that benefit Drupal CMS users and the broader Drupal community. Our systematic approach to testing revealed optimization opportunities in both core and contributed modules.
catch Tue, 01/14/2025 - 15:07Daniel Roy Greenfeld: TIL: Using inspect and timeit together
Freelock Blog: 🕵️♂️ Privacy for website owners, and introducing 💧 Drupal CMS
Happy New Year!
This month we're doing a deep dive into privacy. Privacy for website owners, privacy for you, privacy for the world. To cap it all off, we have a special Privacy Tune-up offer to make sure your privacy policy is accurate and covering your assets...
And if that's not enough, it's a big week for Drupal -- see below for why!
Read MoreKdenlive 24.12.1 released
The first maintenance release of the 24.12 series is out packed with important fixes and enhancements. This update focuses on polishing the newly introduced built-in effects, resolving issues with bin effects and the effect stack, and addressing some recently introduced crashes. Other highlights include fixing an issue where hiding a track in a sequence could alter the length of the parent sequence, ensuring tags and markers are maintained when reloading proxy clips, fixing Whisper model downloads and installation of Python virtual environment (venv) issues on some Linux distributions.
Full changelog:
- Ensure sequence clips in timeline are not resized to smaller when hiding a track. Commit. Fixes bug #498178.
- Fix crash moving build-in effect with feature disabled. Commit.
- Fix crash saving effect stack. Commit. Fixes bug #498124.
- Fix layout order with > 9 layouts. Commit.
- Fix use after free from last commit. Commit.
- Fix reload or proxy clip losing tags, markers, force aspect ratio. Commit. Fixes bug #498014.
- Fix bin clips effects sometimes incorrectly applied to timeline instance. Commit.
- Fix typo. Commit. Fixes bug #497932.
- Fix title widget braking text shadow and typewriter settings. Commit. Fixes bug #476885.
- Math operators not supported in xml params. Commit. Fixes bug #497796.
- Fix track resizing. Commit.
- Fix bin effects cannot be removed from timeline instance. Commit.
- Fix crash trying to move bin effect before builtin effect. Commit.
- Fix venv packages install on some distros. Commit.
- Fix Whisper models download. Commit.
- Fix delta display when resizing clip, add duration info when resizing from start. Commit.
- Fix line return when pasting text with timecodes inside project notes. Commit.
- Fix transparent rendering ffv1 profile. Commit.
- Bring back presets to build in effects. Commit.
The post Kdenlive 24.12.1 released appeared first on Kdenlive.
Real Python: Building Dictionary Comprehensions in Python
Dictionary comprehensions are a concise and quick way to create, transform, and filter dictionaries in Python. They can significantly enhance your code’s conciseness and readability compared to using regular for loops to process your dictionaries.
Understanding dictionary comprehensions is crucial for you as a Python developer because they’re a Pythonic tool for dictionary manipulation and can be a valuable addition to your programming toolkit.
In this video course, you’ll learn how to:
- Create dictionaries using dictionary comprehensions
- Transform existing dictionaries with comprehensions
- Filter key-value pairs from dictionaries using conditionals
- Decide when to use dictionary comprehensions
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Django Weblog: Django security releases issued: 5.1.5, 5.0.11, and 4.2.18
In accordance with our security release policy, the Django team is issuing releases for Django 5.1.5, Django 5.0.11, and Django 4.2.18. These releases address the security issues detailed below. We encourage all users of Django to upgrade as soon as possible.
CVE-2024-56374: Potential denial-of-service vulnerability in IPv6 validationLack of upper bound limit enforcement in strings passed when performing IPv6 validation could lead to a potential denial-of-service attack. The undocumented and private functions clean_ipv6_address and is_valid_ipv6_address were vulnerable, as was the django.forms.GenericIPAddressField form field, which has now been updated to define a max_length of 39 characters.
The django.db.models.GenericIPAddressField model field was not affected.
Thanks to Saravana Kumar for the report.
This issue has severity "moderate" according to the Django security policy.
Affected supported versions- Django main
- Django 5.1
- Django 5.0
- Django 4.2
Patches to resolve the issue have been applied to Django's main, 5.1, 5.0, and 4.2 branches. The patches may be obtained from the following changesets.
CVE-2024-56374: Potential denial-of-service vulnerability in IPv6 validation- On the main branch
- On the 5.1 branch
- On the 5.0 branch
- On the 4.2 branch
- Django 5.1.5 (download Django 5.1.5 | 5.1.5 checksums)
- Django 5.0.11 (download Django 5.0.11 | 5.0.11 checksums)
- Django 4.2.18 (download Django 4.2.18 | 4.2.18 checksums)
The PGP key ID used for this release is Natalia Bidart: 2EE82A8D9470983E
General notes regarding security reportingAs always, we ask that potential security issues be reported via private email to security@djangoproject.com, and not via Django's Trac instance, nor via the Django Forum, nor via the django-developers list. Please see our security policies for further information.
Eli Bendersky: Reverse mode Automatic Differentiation
Automatic Differentiation (AD) is an important algorithm for calculating the derivatives of arbitrary functions that can be expressed by a computer program. One of my favorite CS papers is "Automatic differentiation in machine learning: a survey" by Baydin, Perlmutter, Radul and Siskind (ADIMLAS from here on). While this post attempts to be useful on its own, it serves best as a followup to the ADIMLAS paper - so I strongly encourage you to read that first.
The main idea of AD is to treat a computation as a nested sequence of function compositions, and then calculate the derivative of the outputs w.r.t. the inputs using repeated applications of the chain rule. There are two methods of AD:
- Forward mode: where derivatives are computed starting at the inputs
- Reverse mode: where derivatives are computed starting at the outputs
Reverse mode AD is a generalization of the backpropagation technique used in training neural networks. While backpropagation starts from a single scalar output, reverse mode AD works for any number of function outputs. In this post I'm going to be describing how reverse mode AD works in detail.
While reading the ADIMLAS paper is strongly recommended but not required, there is one mandatory pre-requisite for this post: a good understanding of the chain rule of calculus, including its multivariate formulation. Please read my earlier post on the subject first if you're not familiar with it.
Linear chain graphsLet's start with a simple example where the computation is a linear chain of primitive operations: the Sigmoid function.
This is a basic Python implementation:
def sigmoid(x): return 1 / (1 + math.exp(-x))To apply the chain rule, we'll break down the calculation of S(x) to a sequence of function compositions, as follows:
\[\begin{align*} f(x)&=-x\\ g(f)&=e^f\\ w(g)&=1+g\\ v(w)&=\frac{1}{w} \end{align*}\]Take a moment to convince yourself that S(x) is equivalent to the composition v\circ(w\circ(g\circ f))(x).
The same decomposition of sigmoid into primitives in Python would look as follows:
def sigmoid(x): f = -x g = math.exp(f) w = 1 + g v = 1 / w return vYet another representation is this computational graph:
Each box (graph node) represents a primitive operation, and the name assigned to it (the green rectangle on the right of each box). An arrows (graph edge) represent the flow of values between operations.
Our goal is to find the derivative of S w.r.t. x at some point , denoted as S'(x_0). The process starts by running the computational graph forward with our value of . As an example, we'll use x_0=0.5:
Since all the functions in this graph have a single input and a single output, it's sufficient to use the single-variable formulation of the chain rule.
\[(g \circ f)'(x_0)={g}'(f(x_0)){f}'(x_0)\]To avoid confusion, let's switch notation so we can explicitly see which derivatives are involved. For and g(f) as before, we can write the derivatives like this:
\[f'(x)=\frac{df}{dx}\quad g'(f)=\frac{dg}{df}\]Each of these is a function we can evaluate at some point; for example, we denote the evaluation of f'(x) at as \frac{df}{dx}(x_0). So we can rewrite the chain rule like this:
\[\frac{d(g \circ f)}{dx}(x_0)=\frac{dg}{df}(f(x_0))\frac{df}{dx}(x_0)\]Reverse mode AD means applying the chain rule to our computation graph, starting with the last operation and ending at the first. Remember that our final goal is to calculate:
\[\frac{dS}{dx}(x_0)\]Where S is a composition of multiple functions. The first composition we unravel is the last node in the graph, where v is calculated from w. This is the chain rule for it:
\[\frac{dS}{dw}=\frac{d(S \circ v)}{dw}(x_0)=\frac{dS}{dv}(v(x_0))\frac{dv}{dw}(x_0)\]The formula for S is S(v)=v, so its derivative is 1. The formula for v is v(w)=\frac{1}{w}, so its derivative is -\frac{1}{w^2}. Substituting the value of w computed in the forward pass, we get:
\[\frac{dS}{dw}(x_0)=1\cdot\frac{-1}{w^2}\bigg\rvert_{w=1.61}=-0.39\]Continuing backwards from v to w:
\[\frac{dS}{dg}(x_0)=\frac{dS}{dw}(x_0)\frac{dw}{dg}(x_0)\]We've already calculated \frac{dS}{dw}(x_0) in the previous step. Since w=1+g, we know that w'(g)=1, so:
\[\frac{dS}{dg}(x_0)=-0.39\cdot1=-0.39\]Continuing similarly down the chain, until we get to the input x:
\[\begin{align*} \frac{dS}{df}(x_0)&=\frac{dS}{dg}(x_0)\frac{dg}{df}(x_0)=-0.39\cdot e^f\bigg\rvert_{f=-0.5}=-0.24\\ \frac{dS}{dx}(x_0)&=\frac{dS}{df}(x_0)\frac{df}{dx}(x_0)=-0.24\cdot -1=0.24 \end{align*}\]We're done; the value of the derivative of the sigmoid function at x=0.5 is 0.24; this can be easily verified with a calculator using the analytical derivative of this function.
As you can see, this procedure is rather mechanical and it's not surprising that it can be automated. Before we get to automation, however, let's review the more common scenario where the computational graph is a DAG rather than a linear chain.
General DAGsThe sigmoid sample we worked though above has a very simple, linear computational graph. Each node has a single predecessor and a single successor; moreover, the function itself has a single input and single output. Therefore, the single-variable chain rule is sufficient here.
In the more general case, we'll encounter functions that have multiple inputs, may also have multiple outputs [1], and the internal nodes are connected in non-linear patterns. To compute their derivatives, we have to use the multivariate chain rule.
As a reminder, in the most general case we're dealing with a function that has n inputs, denoted a=a_1,a_2\cdots a_n, and m outputs, denoted f_1,f_2\cdots f_m. In other words, the function is mapping .
The partial derivative of output i w.r.t. input j at some point a is:
Assuming f is differentiable at a, then the complete derivative of f w.r.t. its inputs can be represented by the Jacobian matrix:
The multivariate chain rule then states that if we compose f\circ g (and assuming all the dimensions are correct), the derivative is:
This is the matrix multiplication of and .
Linear nodesAs a warmup, let's start with a linear node that has a single input and a single output:
In all these examples, we assume the full graph output is S, and its derivative by the node's outputs is \frac{\partial S}{\partial f}. We're then interested in finding \frac{\partial S}{\partial x}. Since since f:\mathbb{R}\to\mathbb{R}, the Jacobian is just a scalar:
\[Df=\frac{\partial f}{\partial x}\]And the chain rule is:
\[D(S\circ f)=DS(f)\cdot Df=\frac{\partial S}{\partial f}\frac{\partial f}{\partial x}\]No surprises so far - this is just the single variable chain rule!
Fan-inLet's move on to the next scenario, where f has two inputs:
Once again, we already have the derivative \frac{\partial S}{\partial f} available, and we're interested in finding the derivative of S w.r.t. the inputs.
In this case, f:\mathbb{R}^2\to\mathbb{R}, so the Jacobian is a 1x2 matrix:
\[Df=\left [ \frac{\partial f}{\partial x_1} \quad \frac{\partial f}{\partial x_2} \right ]\]And the chain rule here means multiplying a 1x1 matrix by a 1x2 matrix:
\[D(S\circ f)=DS(f)\cdot Df= \left [ \frac{\partial S}{\partial f} \right ] \left [ \frac{\partial f}{\partial x_1} \quad \frac{\partial f}{\partial x_2} \right ] = \left [ \frac{\partial S}{\partial f} \frac{\partial f}{\partial x_1} \quad \frac{\partial S}{\partial f} \frac{\partial f}{\partial x_2} \right ]\]Therefore, we see that the output derivative propagates to each input separately:
\[\begin{align*} \frac{\partial S}{\partial x_1}&=\frac{\partial S}{\partial f} \frac{\partial f}{\partial x_1}\\ \frac{\partial S}{\partial x_2}&=\frac{\partial S}{\partial f} \frac{\partial f}{\partial x_2} \end{align*}\] Fan-outIn the most general case, f may have multiple inputs but its output may also be used by more than one other node. As a concrete example, here's a node with three inputs and an output that's used in two places:
While we denote each output edge from f with a different name, f has a single output! This point is a bit subtle and important to dwell on: yes, f has a single output, so in the forward calculation both f_1 and f_2 will have the same value. However, we have to treat them differently for the derivative calculation, because it's very possible that \frac{\partial S}{\partial f_1} and \frac{\partial S}{\partial f_2} are different!
In other words, we're reusing the machinery of multi-output functions here. If f had multiple outputs (e.g. a vector function), everything would work exactly the same.
In this case, since we treat f as f:\mathbb{R}^3\to\mathbb{R}^2, its Jacobian is a 2x3 matrix:
\[Df= \begin{bmatrix} \frac{\partial f_1}{\partial x_1} & \frac{\partial f_1}{\partial x_2} & \frac{\partial f_1}{\partial x_3} \\ \\ \frac{\partial f_2}{\partial x_1} & \frac{\partial f_2}{\partial x_2} & \frac{\partial f_2}{\partial x_3} \\ \end{bmatrix}\]The Jacobian DS(f) is a 1x2 matrix:
\[DS(f)=\left [ \frac{\partial S}{\partial f_1} \quad \frac{\partial S}{\partial f_2} \right ]\]Applying the chain rule:
\[\begin{align*} D(S\circ f)=DS(f)\cdot Df&= \left [ \frac{\partial S}{\partial f_1} \quad \frac{\partial S}{\partial f_2} \right ] \begin{bmatrix} \frac{\partial f_1}{\partial x_1} & \frac{\partial f_1}{\partial x_2} & \frac{\partial f_1}{\partial x_3} \\ \\ \frac{\partial f_2}{\partial x_1} & \frac{\partial f_2}{\partial x_2} & \frac{\partial f_2}{\partial x_3} \\ \end{bmatrix}\\ &= \left [ \frac{\partial S}{\partial f_1}\frac{\partial f_1}{\partial x_1}+\frac{\partial S}{\partial f_2}\frac{\partial f_2}{\partial x_1}\qquad \frac{\partial S}{\partial f_1}\frac{\partial f_1}{\partial x_2}+\frac{\partial S}{\partial f_2}\frac{\partial f_2}{\partial x_2}\qquad \frac{\partial S}{\partial f_1}\frac{\partial f_1}{\partial x_3}+\frac{\partial S}{\partial f_2}\frac{\partial f_2}{\partial x_3} \right ] \end{align*}\]Therefore, we have:
\[\begin{align*} \frac{\partial S}{\partial x_1}&=\frac{\partial S}{\partial f_1}\frac{\partial f_1}{\partial x_1}+\frac{\partial S}{\partial f_2}\frac{\partial f_2}{\partial x_1}\\ \frac{\partial S}{\partial x_2}&=\frac{\partial S}{\partial f_1}\frac{\partial f_1}{\partial x_2}+\frac{\partial S}{\partial f_2}\frac{\partial f_2}{\partial x_2}\\ \frac{\partial S}{\partial x_3}&=\frac{\partial S}{\partial f_1}\frac{\partial f_1}{\partial x_3}+\frac{\partial S}{\partial f_2}\frac{\partial f_2}{\partial x_3} \end{align*}\]The key point here - which we haven't encountered before - is that the derivatives through f add up for each of its outputs (or for each copy of its output). Qualitatively, it means that the sensitivity of f's input to the output is the sum of its sensitivities across each output separately. This makes logical sense, and mathematically it's just the consequence of the dot product inherent in matrix multiplication.
Now that we understand how reverse mode AD works for the more general case of DAG nodes, let's work through a complete example.
General DAGs - full exampleConsider this function (a sample used in the ADIMLAS paper):
\[f(x_1, x_2)=ln(x_1)+x_1 x_2-sin(x_2)\]It has two inputs and a single output; once we decompose it to primitive operations, we can represent it with the following computational graph [2]:
As before, we begin by running the computation forward for the values of x_1,x_2 at which we're interested to find the derivative. Let's take x_1=2 and x_2=5:
Recall that our goal is to calculate \frac{\partial f}{\partial x_1} and \frac{\partial f}{\partial x_2}. Initially we know that \frac{\partial f}{\partial v_5}=1 [3].
Starting with the v_5 node, let's use the fan-in formulas developed earlier:
\[\begin{align*} \frac{\partial f}{\partial v_4}&=\frac{\partial f}{\partial v_5} \frac{\partial v_5}{\partial v_4}=1\cdot 1=1\\ \frac{\partial f}{\partial v_3}&=\frac{\partial f}{\partial v_5} \frac{\partial v_5}{\partial v_3}=1\cdot -1=-1 \end{align*}\]Next, let's tackle v_4. It also has a fan-in configuration, so we'll use similar formulas, plugging in the value of \frac{\partial f}{\partial v_4} we've just calculated:
\[\begin{align*} \frac{\partial f}{\partial v_1}&=\frac{\partial f}{\partial v_4} \frac{\partial v_4}{\partial v_1}=1\cdot 1=1\\ \frac{\partial f}{\partial v_2}&=\frac{\partial f}{\partial v_4} \frac{\partial v_4}{\partial v_2}=1\cdot 1=1 \end{align*}\]On to v_1. It's a simple linear node, so:
\[\frac{\partial f}{\partial x_1}^{(1)}=\frac{\partial f}{\partial v_1} \frac{\partial v_1}{\partial x_1}=1\cdot \frac{1}{x_1}=0.5\]Note the (1) superscript though! Since x_1 is a fan-out node, it will have more than one contribution to its derivative; we've just computed the one from v_1. Next, let's compute the one from v_2. That's another fan-in node:
\[\begin{align*} \frac{\partial f}{\partial x_1}^{(2)}&=\frac{\partial f}{\partial v_2} \frac{\partial v_2}{\partial x_1}=1\cdot x_2=5\\ \frac{\partial f}{\partial x_2}^{(1)}&=\frac{\partial f}{\partial v_2} \frac{\partial v_2}{\partial x_2}=1\cdot x_1=2 \end{align*}\]We've calculated the other contribution to the x_1 derivative, and the first out of two contributions for the x_2 derivative. Next, let's handle v_3:
\[\frac{\partial f}{\partial x_2}^{(2)}=\frac{\partial f}{\partial v_3} \frac{\partial v_3}{\partial x_2}=-1\cdot cos(x_2)=-0.28\]Finally, we're ready to add up the derivative contributions for the input arguments. x_1 is a "fan-out" node, with two outputs. Recall from the section above that we just sum their contributions:
\[\frac{\partial f}{\partial x_1}=\frac{\partial f}{\partial x_1}^{(1)}+\frac{\partial f}{\partial x_1}^{(2)}=0.5+5=5.5\]And:
\[\frac{\partial f}{\partial x_2}=\frac{\partial f}{\partial x_2}^{(1)}+\frac{\partial f}{\partial x_2}^{(2)}=2-0.28=1.72\]And we're done! Once again, it's easy to verify - using a calculator and the analytical derivatives of f(x_1,x_2) - that these are the right derivatives at the given points.
Backpropagation in ML, reverse mode AD and VJPsA quick note on reverse mode AD vs forward mode (please read the ADIMLAS paper for much more details):
Reverse mode AD is the approach commonly used for machine learning and neural networks, because these tend to have a scalar loss (or error) output that we want to minimize. In reverse mode, we have to run AD once per output, while in forward mode we'd have to run it once per input. Therefore, when the input size is much larger than the output size (as is the case in NNs), reverse mode is preferable.
There's another advantage, and it relates to the term vector-jacobian product (VJP) that you will definitely run into once you start digging deeper in this domain.
The VJP is basically a fancy way of saying "using the chain rule in reverse mode AD". Recall that in the most general case, the multivariate chain rule is:
However, in the case of reverse mode AD, we typically have a single output from the full graph, so is a row vector. The chain rule then means multiplying this row vector by a matrix representing the node's jacobian. This is the vector-jacobian product, and its output is another row vector. Scroll back to the Fan-out sample to see an example of this.
This may not seem very profound so far, but it carries an important meaning in terms of computational efficiency. For each node in the graph, we don't have to store its complete jacobian; all we need is a function that takes a row vector and produces the VJP. This is important because jacobians can be very large and very sparse [4]. In practice, this means that when AD libraries define the derivative of a computation node, they don't ask you to register a complete jacobian for each operation, but rather a VJP.
This also provides an additional way to think about the relative efficiency of reverse mode AD for ML applications; since a graph typically has many inputs (all the weights), and a single output (scalar loss), accumulating from the end going backwards means the intermediate products are VJPs that are row vectors; accumulating from the front would mean multiplying full jacobians together, and the intermediate results would be matrices [5].
A simple Python implementation of reverse mode ADEnough equations, let's see some code! The whole point of AD is that it's automatic, meaning that it's simple to implement in a program. What follows is the simplest implementation I could think of; it requires one to build expressions out of a special type, which can then calculate gradients automatically.
Let's start with some usage samples; here's the Sigmoid calculation presented earlier:
xx = Var(0.5) sigmoid = 1 / (1 + exp(-xx)) print(f"xx = {xx.v:.2}, sigmoid = {sigmoid.v:.2}") sigmoid.grad(1.0) print(f"dsigmoid/dxx = {xx.gv:.2}")We begin by building the Sigmoid expression using Var values (more on this later). We can then run the grad method on a Var, with an output gradient of 1.0 and see that the gradient for xx is 0.24, as calculated before.
Here's the expression we used for the DAG section:
x1 = Var(2.0) x2 = Var(5.0) f = log(x1) + x1 * x2 - sin(x2) print(f"x1 = {x1.v:.2}, x2 = {x2.v:.2}, f = {f.v:.2}") f.grad(1.0) print(f"df/dx1 = {x1.gv:.2}, df/dx2 = {x2.gv:.2}")Once again, we build up the expression, then call grad on the final value. It will populate the gv attributes of input Vars with the derivatives calculated w.r.t. these inputs.
Let's see how Var works. The high-level overview is:
- A Var represents a node in the computational graph we've been discussing in this post.
- Using operator overloading and custom math functions (like the exp, sin and log seen in the samples above), when an expression is constructed out of Var values, we also build the computational graph in the background. Each Var has links to its predecessors in the graph (the other Vars that feed into it).
- When the grad method is called, it runs reverse mode AD through the computational graph, using the chain rule.
Here's the Var class:
class Var: def __init__(self, v): self.v = v self.predecessors = [] self.gv = 0.0v is the value (forward calculation) of this Var. predecessors is the list of predecessors, each of this type:
@dataclass class Predecessor: multiplier: float var: "Var"Consider the v5 node in DAG sample, for example. It represents the calculation v4-v3. The Var representing v5 will have a list of two predecessors, one for v4 and one for v3. Each of these will have a "multiplier" associated with it:
- For v3, Predecessor.var points to the Var representing v3 and Predecessor.multiplier is -1, since this is the derivative of v5 w.r.t. v3
- Similarly, for v4, Predecessor.var points to the Var representing v4 and Predecessor.multiplier is 1.
Let's see some overloaded operators of Var [6]:
def __add__(self, other): other = ensure_var(other) out = Var(self.v + other.v) out.predecessors.append(Predecessor(1.0, self)) out.predecessors.append(Predecessor(1.0, other)) return out # ... def __mul__(self, other): other = ensure_var(other) out = Var(self.v * other.v) out.predecessors.append(Predecessor(other.v, self)) out.predecessors.append(Predecessor(self.v, other)) return outAnd some of the custom math functions:
def log(x): """log(x) - natural logarithm of x""" x = ensure_var(x) out = Var(math.log(x.v)) out.predecessors.append(Predecessor(1.0 / x.v, x)) return out def sin(x): """sin(x)""" x = ensure_var(x) out = Var(math.sin(x.v)) out.predecessors.append(Predecessor(math.cos(x.v), x)) return outNote how the multipliers for each node are exactly the derivatives of its output w.r.t. corresponding input. Notice also that in some cases we use the forward calculated value of a Var's inputs to calculate this derivative (e.g. in the case of sin(x), the derivative is cos(x), so we need the actual value of x).
Finally, this is the grad method:
def grad(self, gv): self.gv += gv for p in self.predecessors: p.var.grad(p.multiplier * gv)Some notes about this method:
- It has to be invoked on a Var node that represents the entire computation.
- Since this function walks the graph backwards (from the outputs to the inputs), this is the direction our graph edges are pointing (we keep track of the predecessors of each node, not the successors).
- Since we typically want the derivative of some output "loss" w.r.t. each Var, the computation will usually start with grad(1.0), because the output of the entire computation is the loss.
- For each node, grad adds the incoming gradient to its own, and propagates the incoming gradient to each of its predecessors, using the relevant multiplier.
- The addition self.gv += gv is key to managing nodes with fan-out. Recall our discussion from the DAG section - according to the multivariate chain rule, fan-out nodes' derivatives add up for each of their outputs.
- This implementation of grad is very simplistic and inefficient because it will process the same Var multiple times in complex graphs. A more efficient implementation would sort the graph topologically first and then would only have to visit each Var once.
- Since the gradient of each Var adds up, one shouldn't be reusing Vars between different computations. Once grad was run, the Var should not be used for other grad calculations.
The full code for this sample is available here.
ConclusionThe goal of this post is to serve as a supplement for the ADIMLAS paper; once again, if the topic of AD is interesting to you, I strongly encourage you to read the paper! I hope this post added something on top - please let me know if you have any questions.
Industrial strength implementations of AD, like autograd and JAX, have much better ergonomics and performance than the toy implementation shown above. That said, the underlying principles are similar - reverse mode AD on computational graphs.
I'll discuss an implementation of a more sophisticated AD system in a followup post.
[1]In this post we're only looking at single-output graphs, however, since these are typically sufficient in machine learning (the output is some scalar "loss" or "error" that we're trying to minimize). That said, for functions with multiple outputs the process is very similar - we just have to run the reverse mode AD process for each output variable separately. [2]Note that the notation here is a bit different from the one used for the sigmoid function. This notation is adopted from the ADIMLAS paper, which uses v_i for all temporary values within the graph. I'm keeping the notations different to emphasize they have absolutely no bearing on the math and the AD algorithm. They're just a naming convention. [3]For consistency, I'll be using the partial derivative notation throughout this example, even for nodes that have a single input and output. [4]For an example of gigantic, sparse jacobians see my older post on backpropagation through a fully connected layer. [5]There are a lot of additional nuances here to explain; I strongly recommend this excellent lecture by Matthew Johnson (of JAX and autograd fame) for a deeper overview. [6]These use the utility function ensure_var; all it does is wrap the its argument in a Var if it's not already a Var. This is needed to wrap constants in the expression, to ensure that the computational graph includes everything.The Drop Times: Drupal CMS Launch Party—Are You Game?
Hello Drupalista,
Drupal is turning 24! Happy Birthday, Drupal!
On January 15, 2025, the community will celebrate the 24th birthday of Drupal—and witness the birth of an exciting new addition: Drupal CMS!
What is Drupal CMS?Not familiar with Drupal CMS yet? We have you covered.
Python Software Foundation: Powering Python together in 2025, thanks to our community!
We are so very grateful for each of you who donated or became new members during our end-of-year fundraiser and membership drive. We raised $30,000 through the PyCharm promotion offered by JetBrains– WOW! Including individual donations, Supporting Memberships, donations to our Fiscal Sponsorees, and JetBrains’ generous partnership we raised around $99,000 for the PSF’s mission supporting Python and its community.
Your generous support means we can dive into 2025 ready to invest in our key goals for the year. Some of our goals include:
- Embrace the opportunities and tackle the challenges that come with scale
- Foster long term sustainable growth- for Python, the PSF, and the community
- Improve workflows through iterative improvement in collaboration with the community
Each bit of investment from the Python community—money, time, energy, ideas, and enthusiasm—helps us to reach these goals!
We want to specifically call out to our new members: welcome aboard, thank you for joining us, and we are so appreciative of you! We’re looking forward to having your voice take part in the PSF’s future. If you aren’t a member of the PSF yet, check out our Membership page, which includes details about our sliding scale memberships. We are happy to welcome new members any time of year!
As always, we want to thank those in the community who took the time to share our posts on social media and their local or project based networks. We’re excited about what 2025 has in store for Python and the PSF, and as always, we’d love to hear your ideas and feedback. Looking for how to keep in touch with us? You can find all the ways in our "Where to find the PSF?" blog post.
We wish you a perfectly Pythonic year ahead!
- The PSF Team
P.s. Want to continue to help us make an impact? Check out our “Do you know the PSF's next sponsor?” blog post and share with your employer!
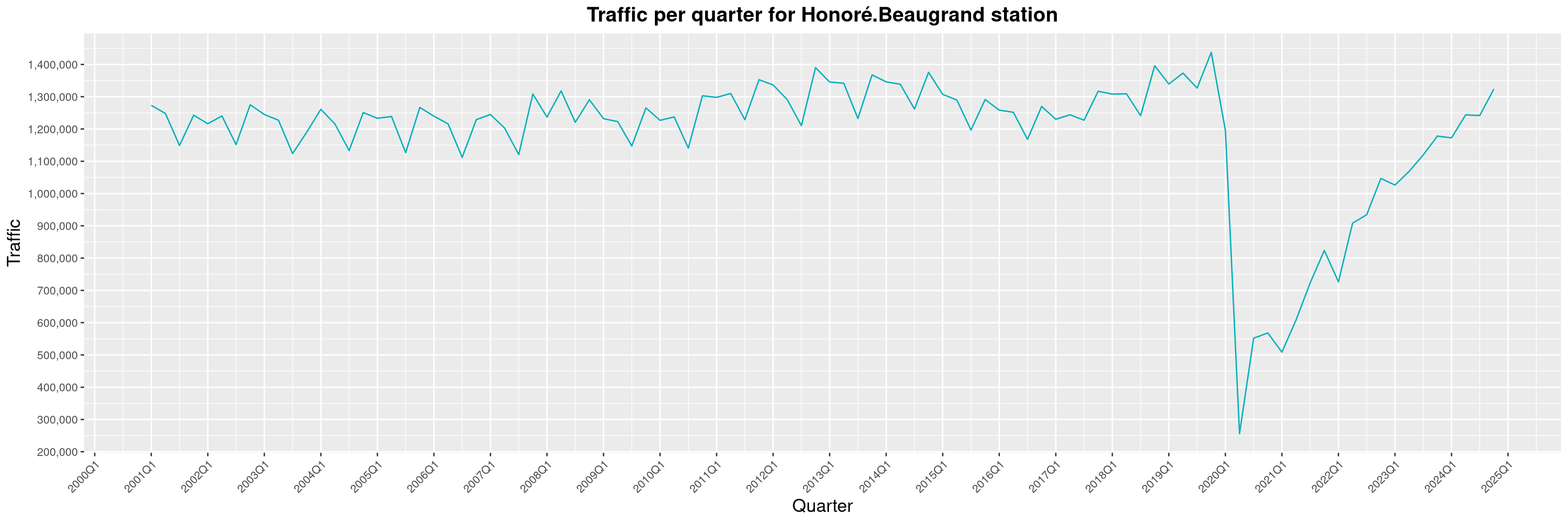
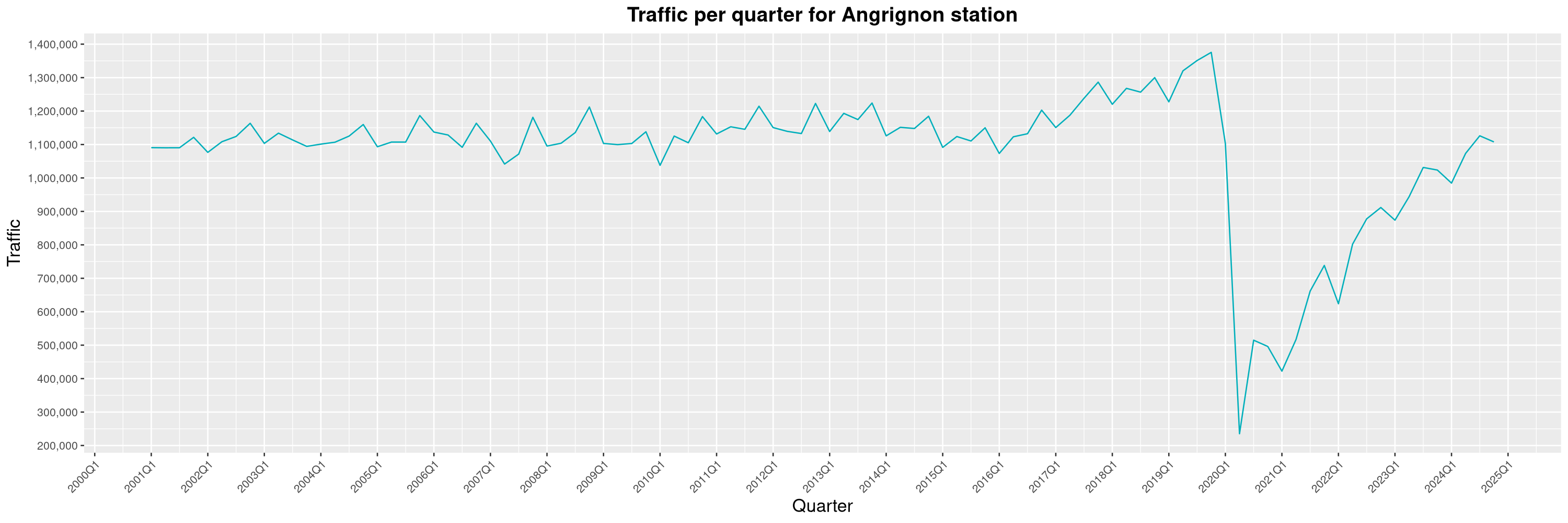
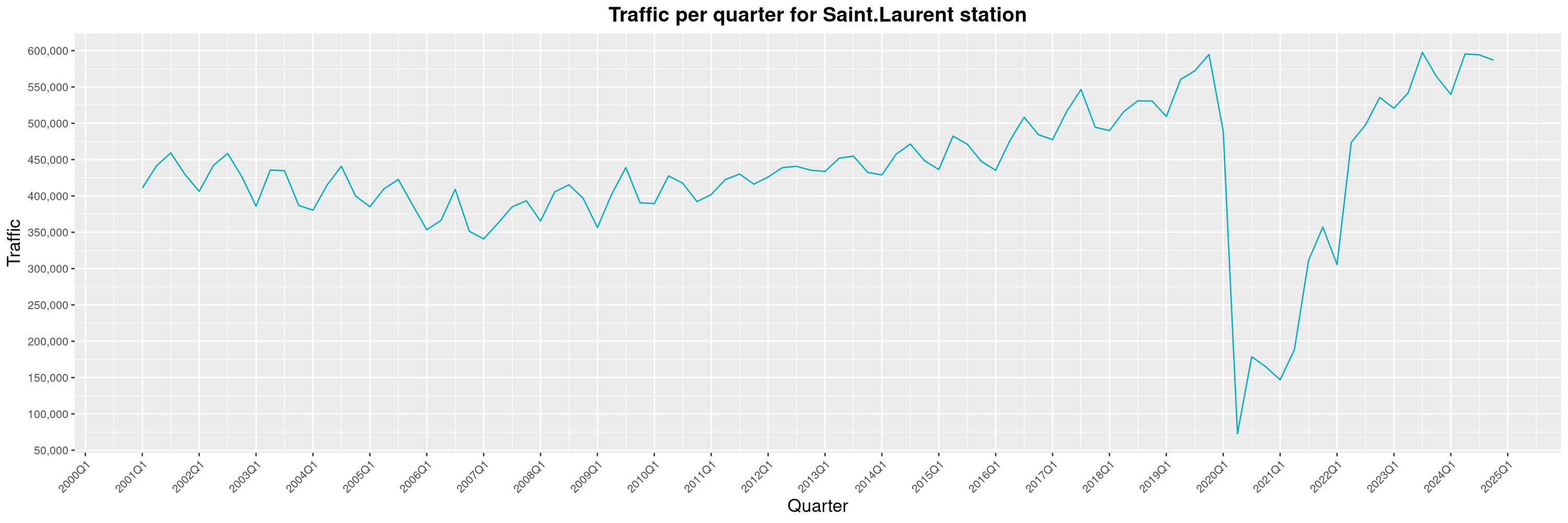
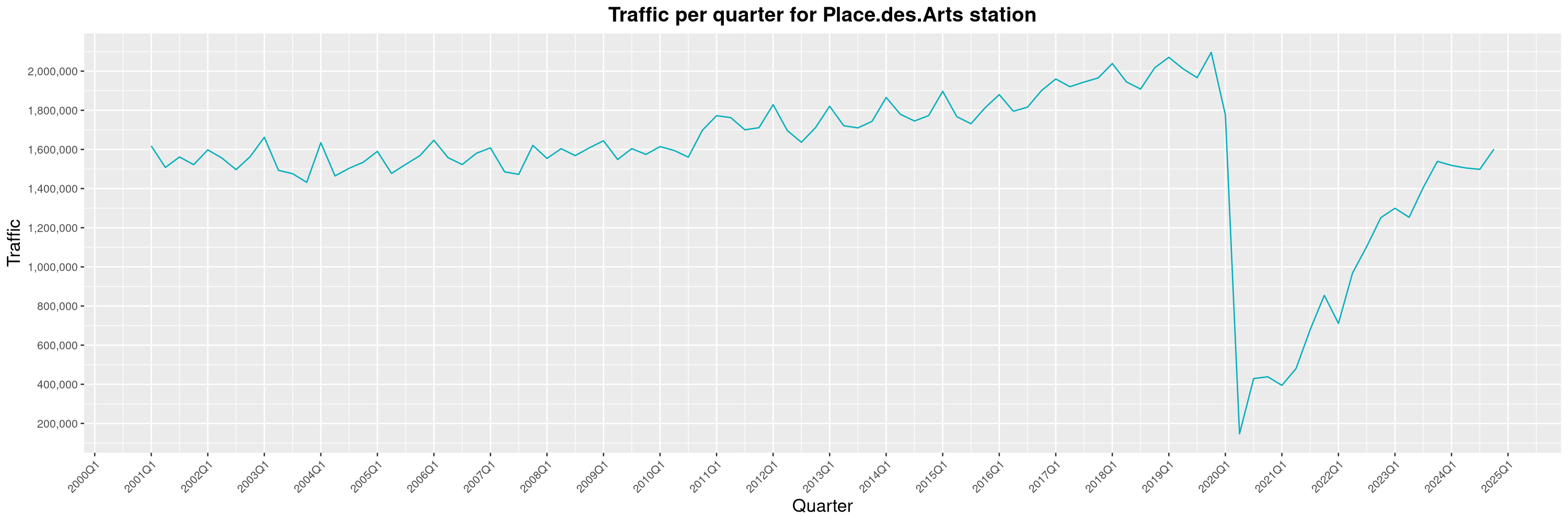
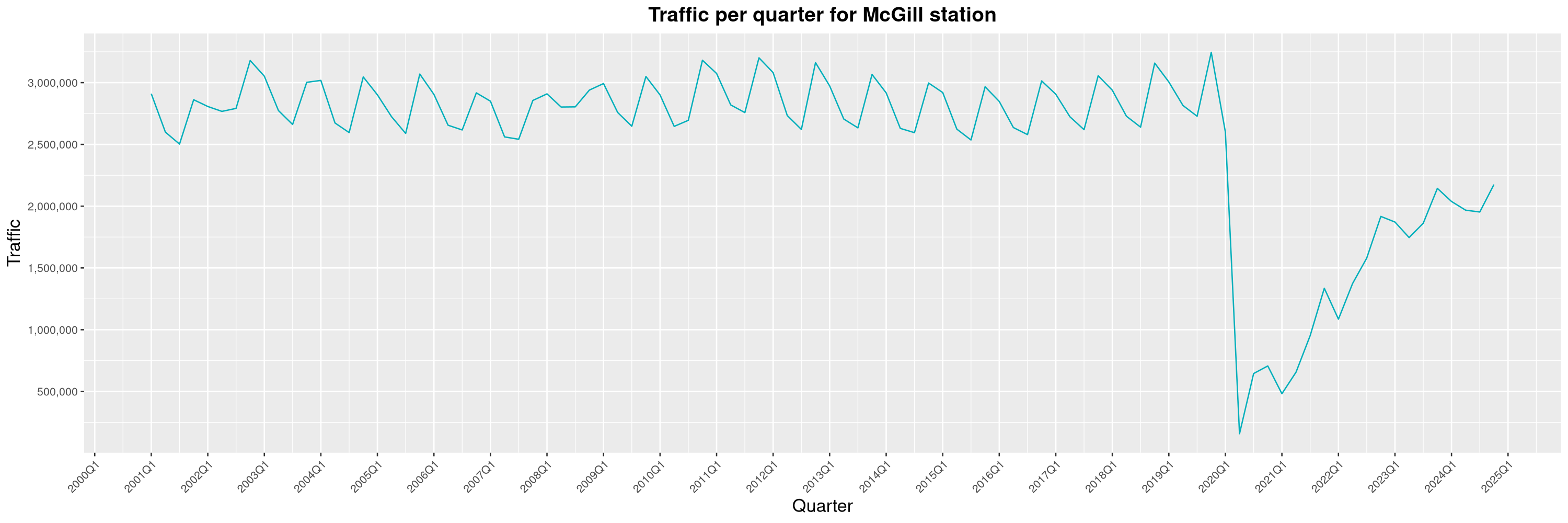
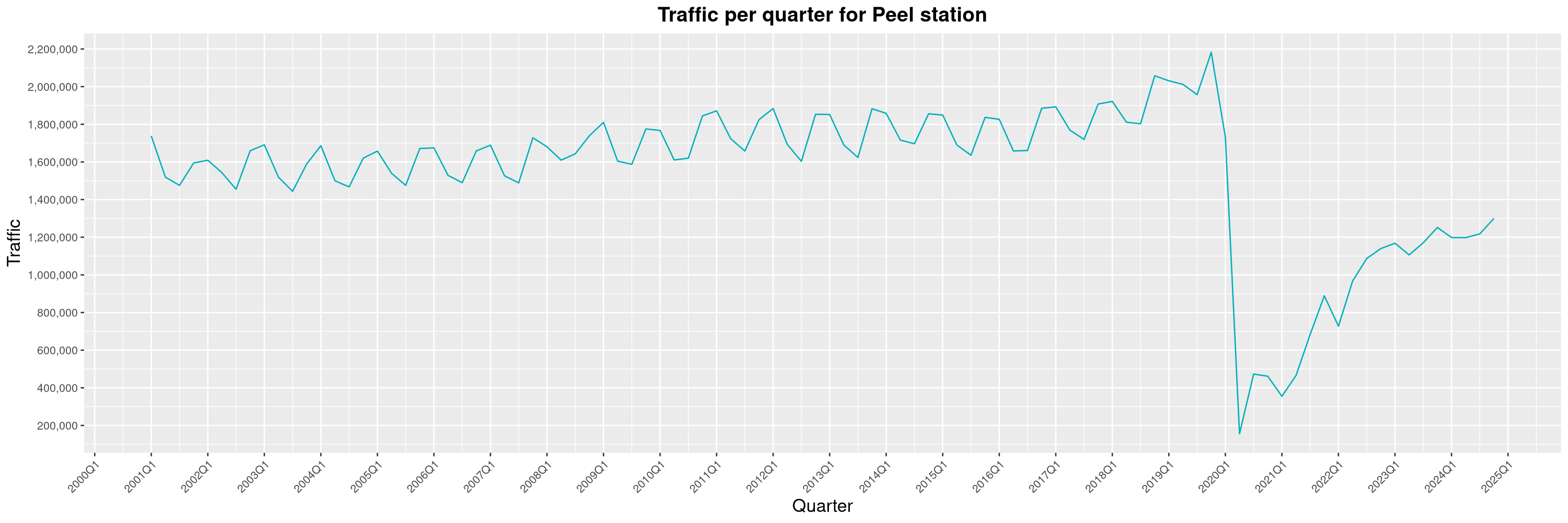
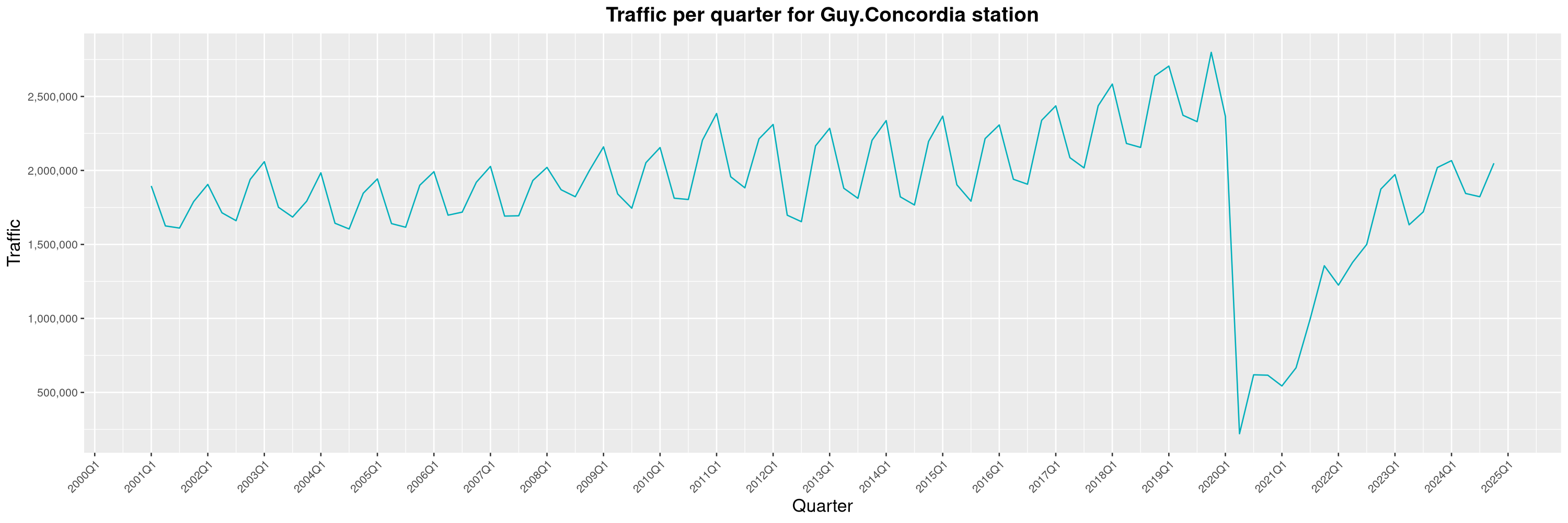
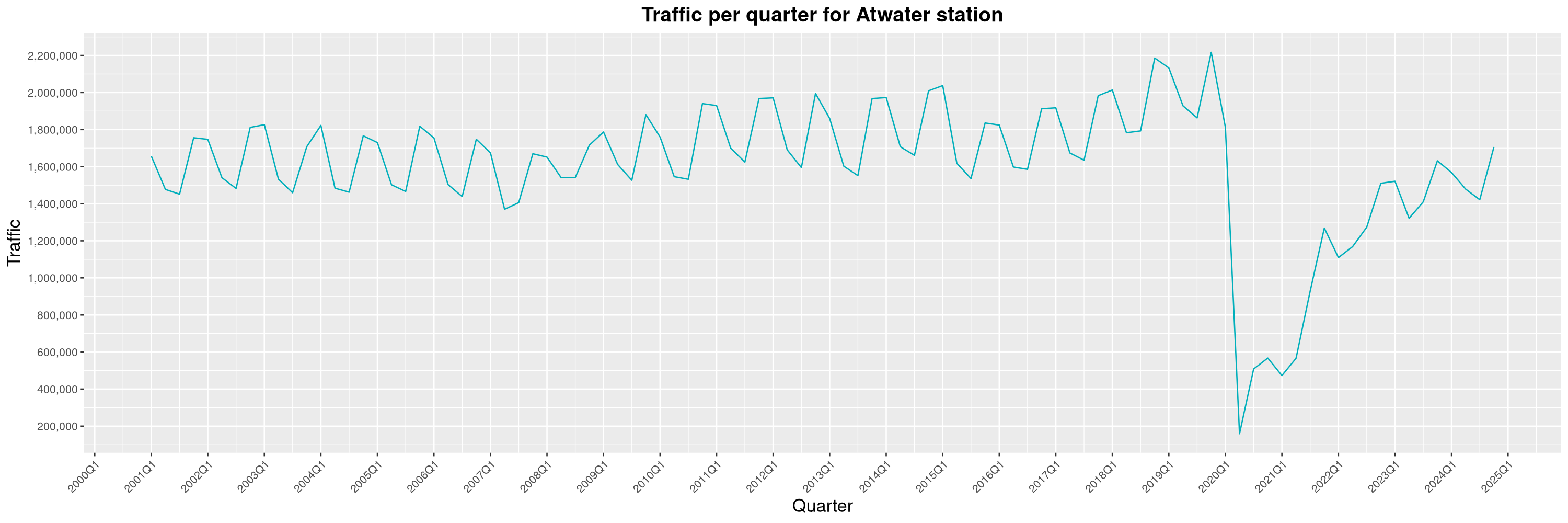
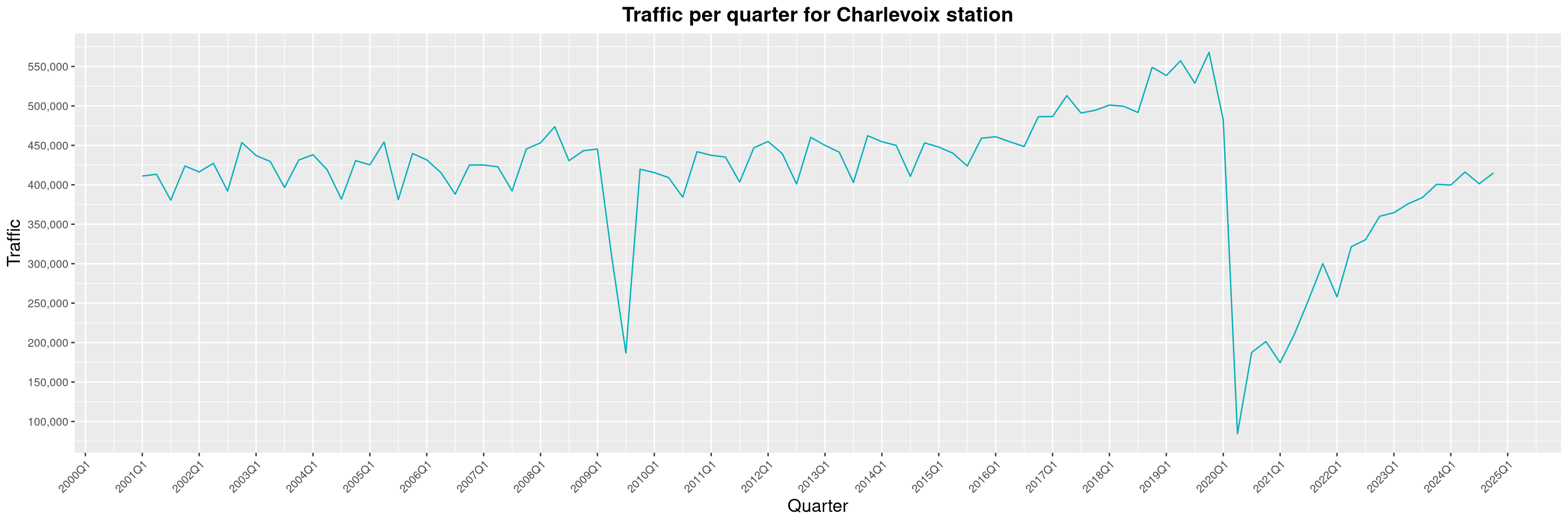
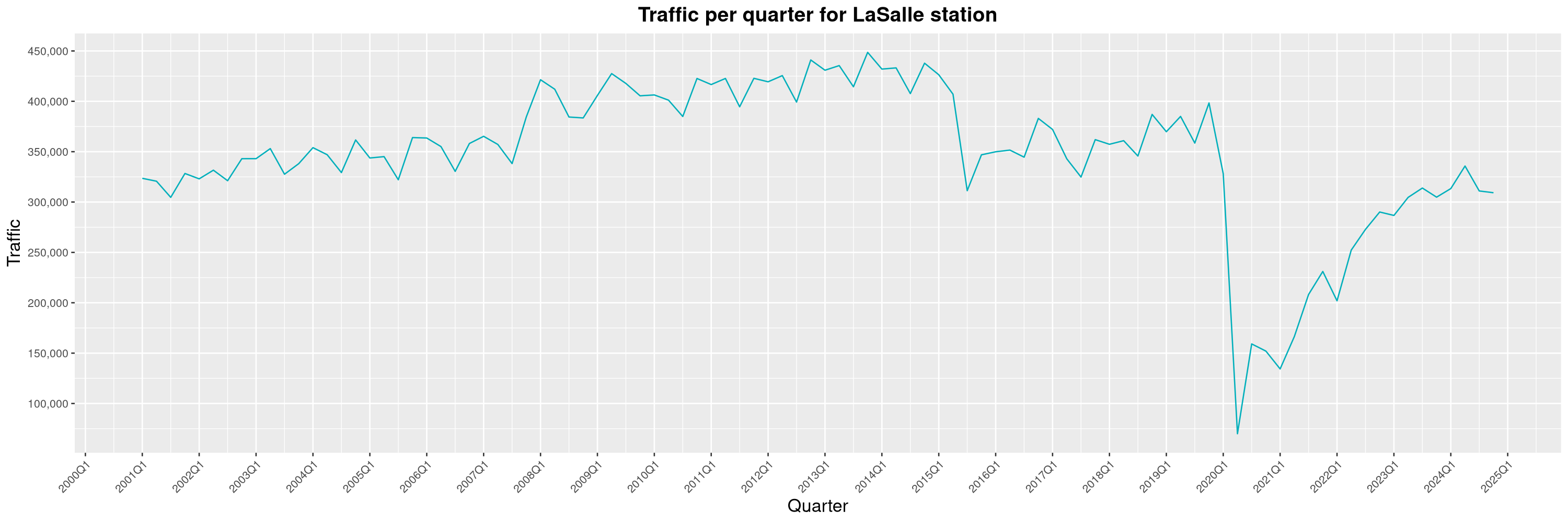
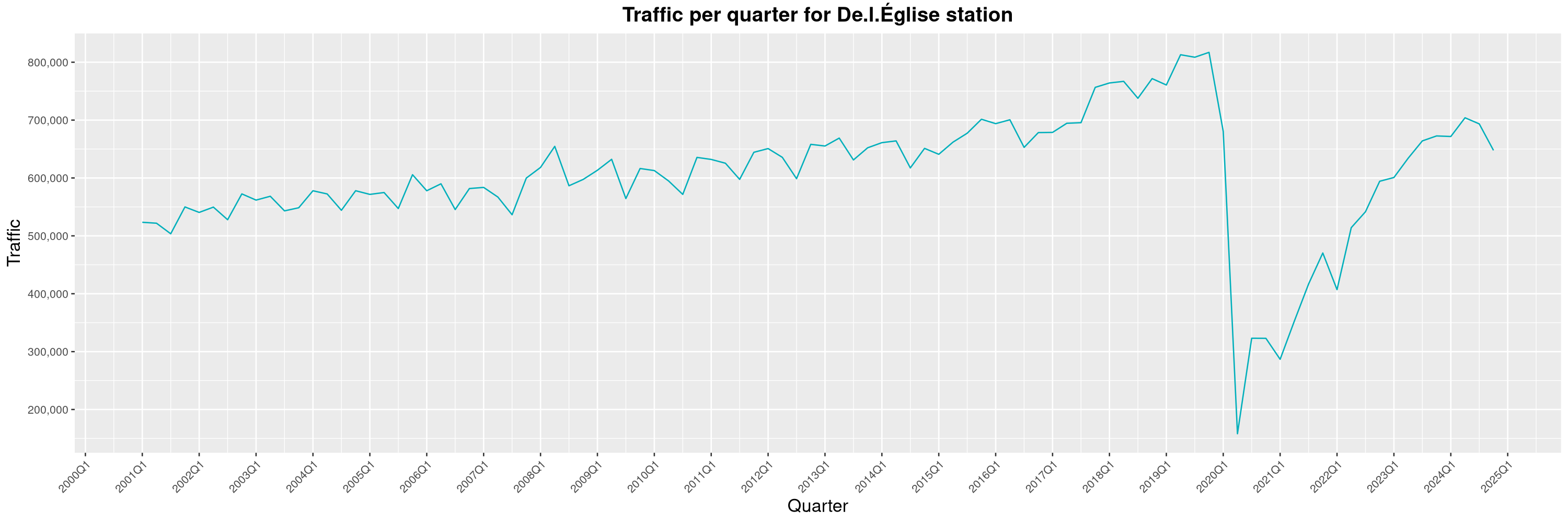
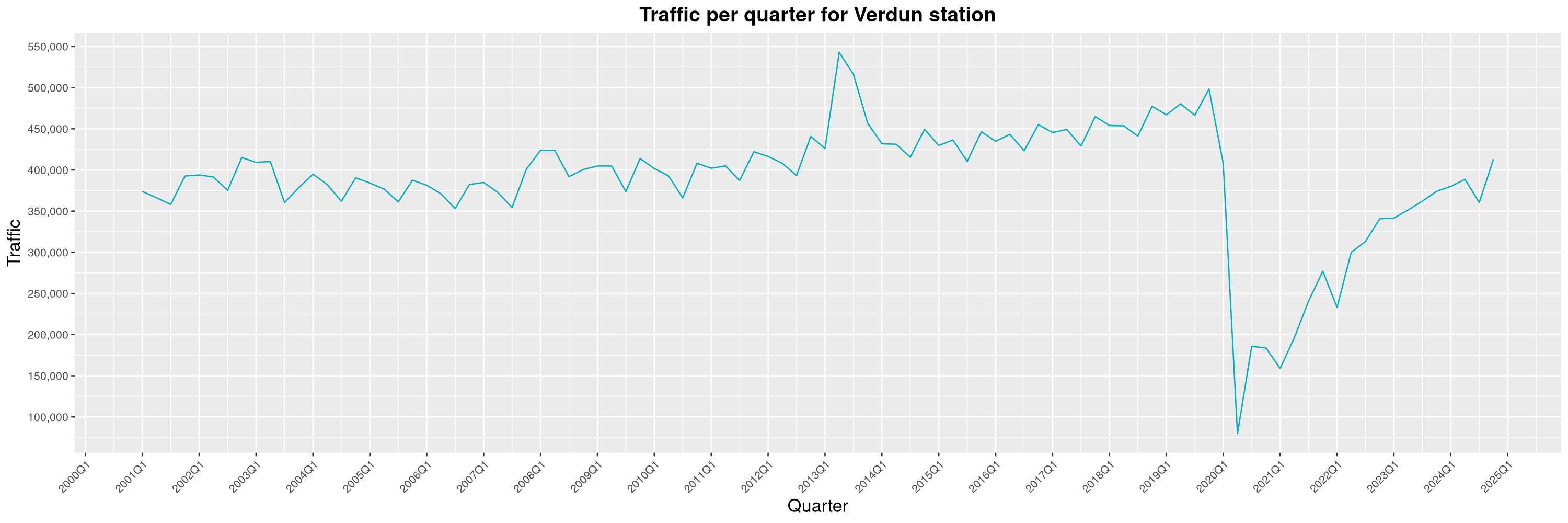
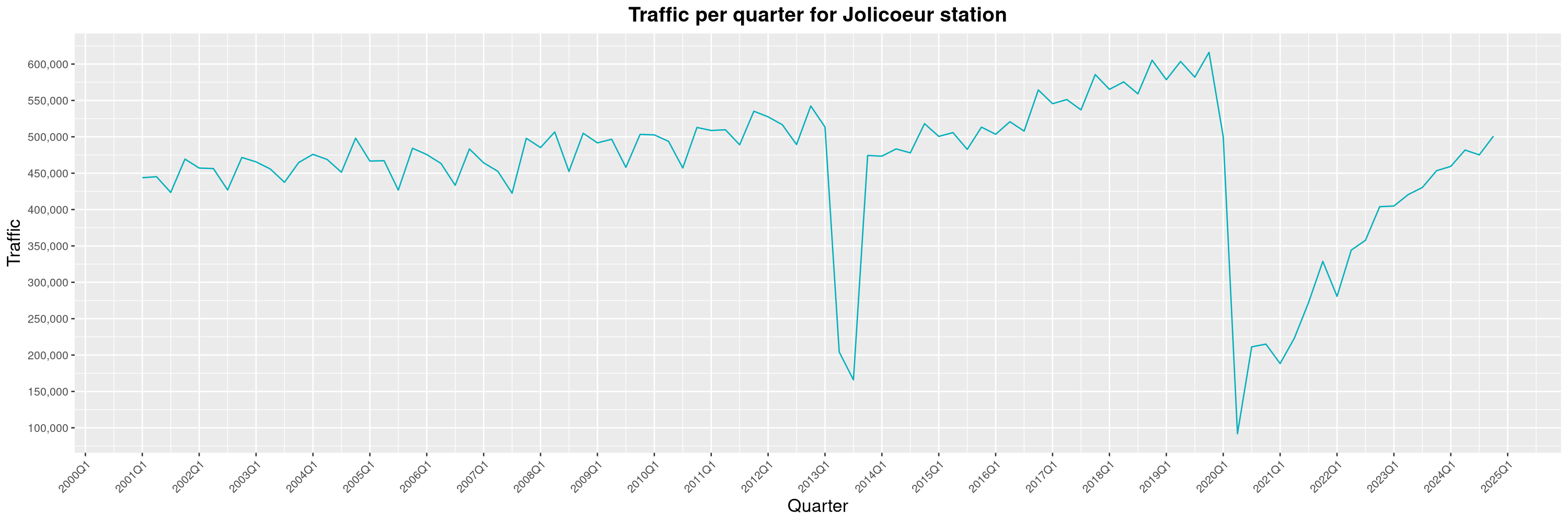
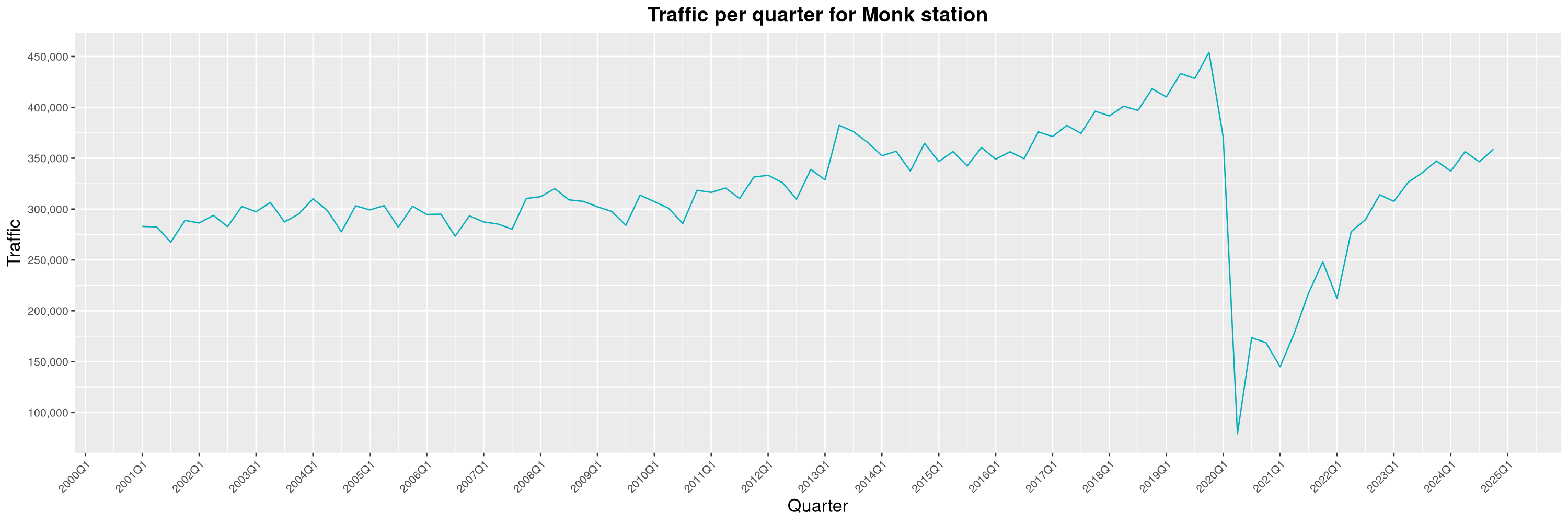
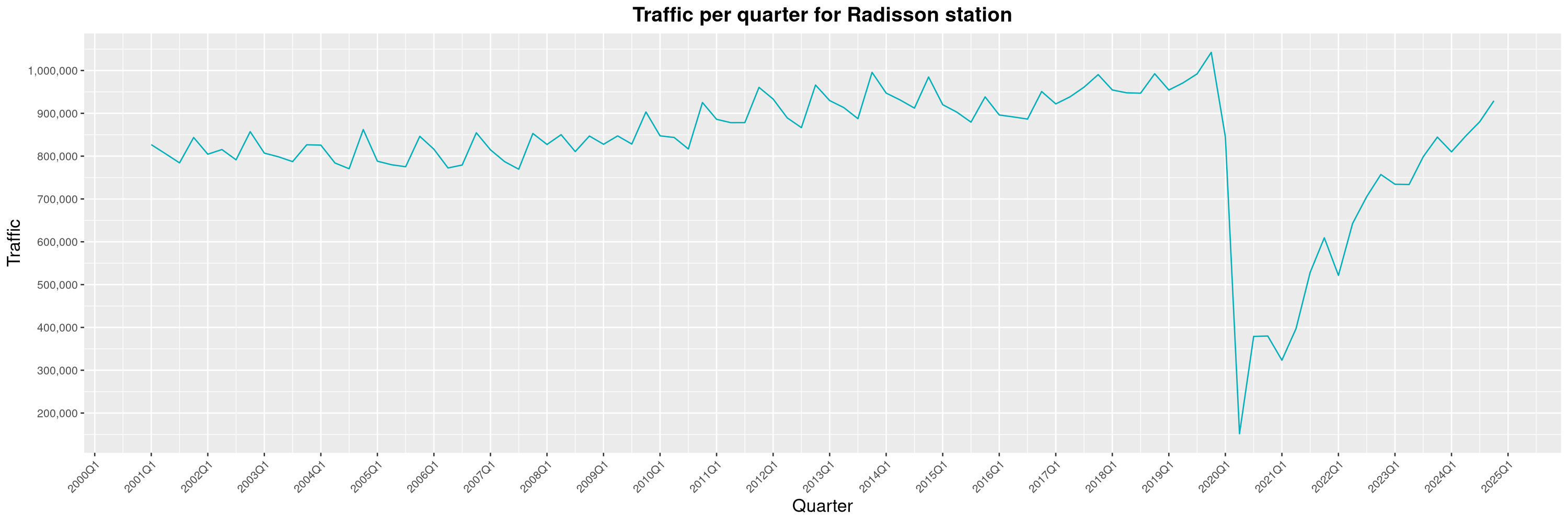
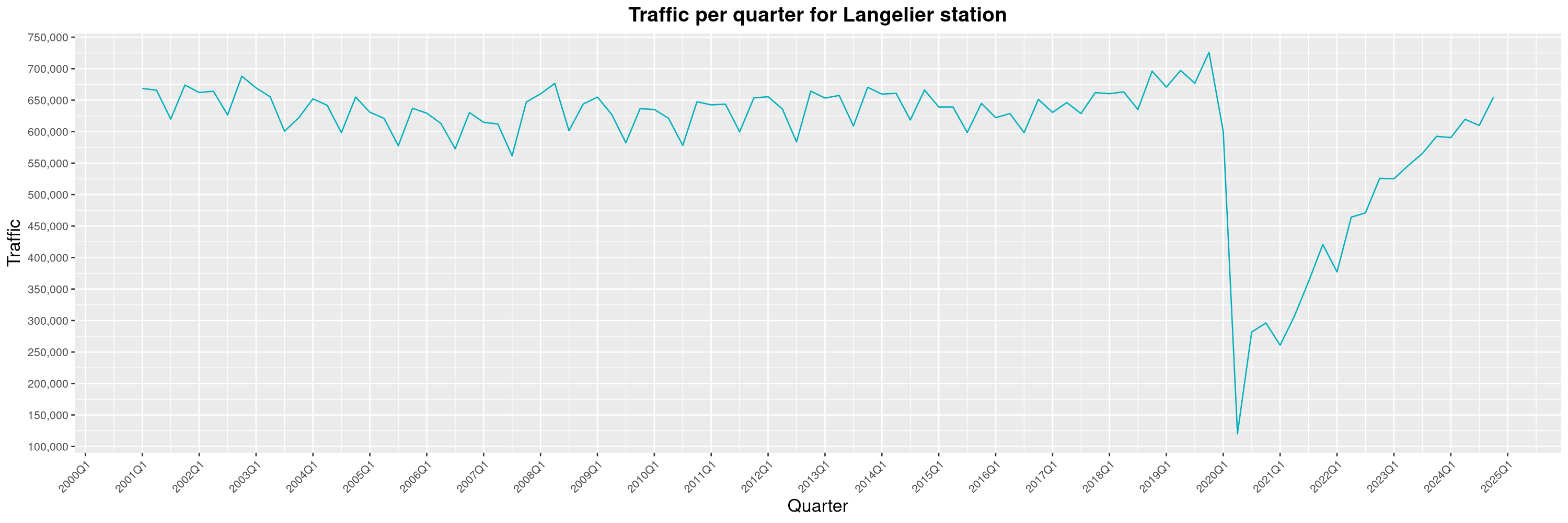
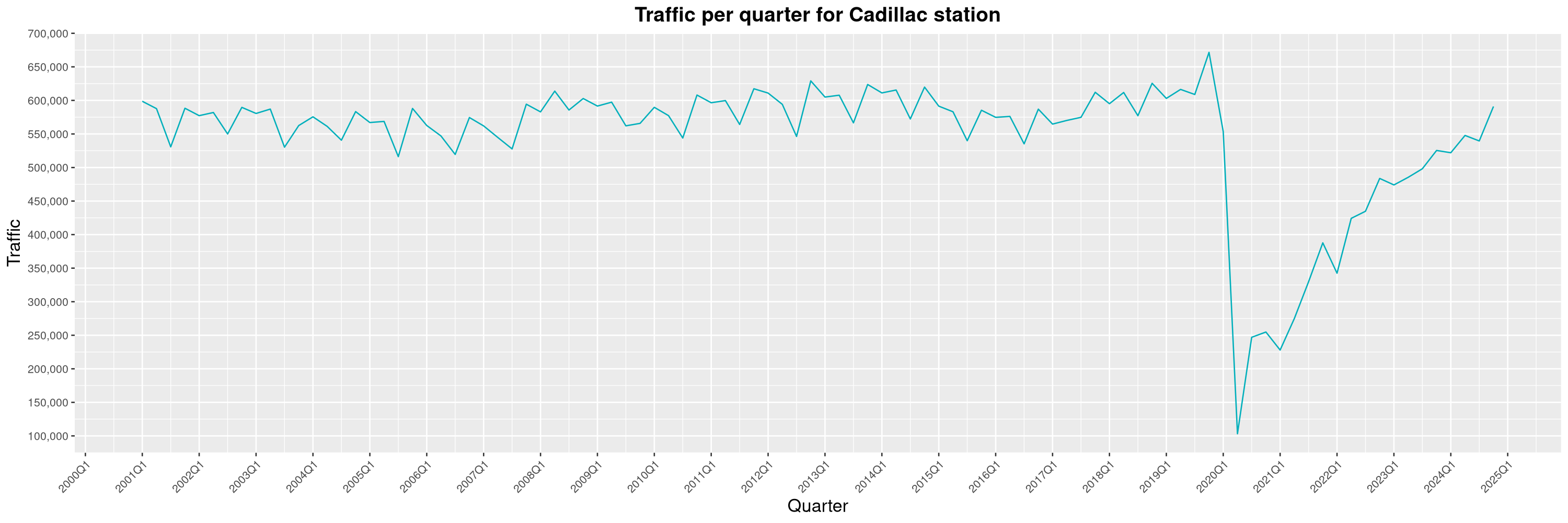
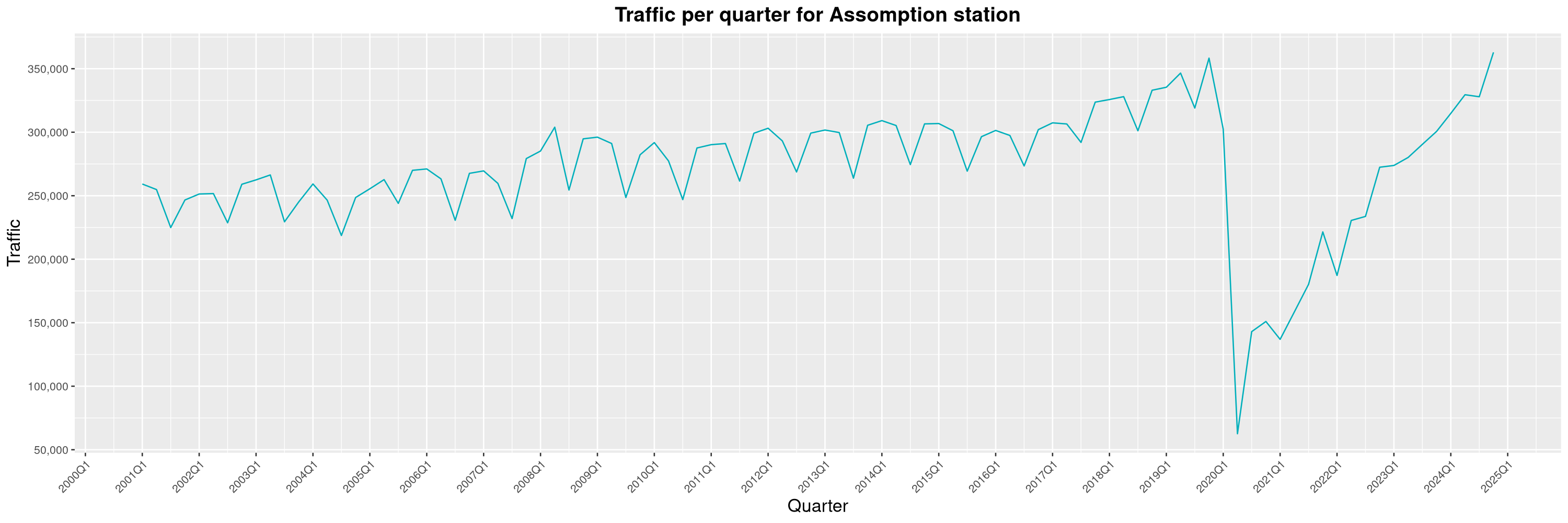
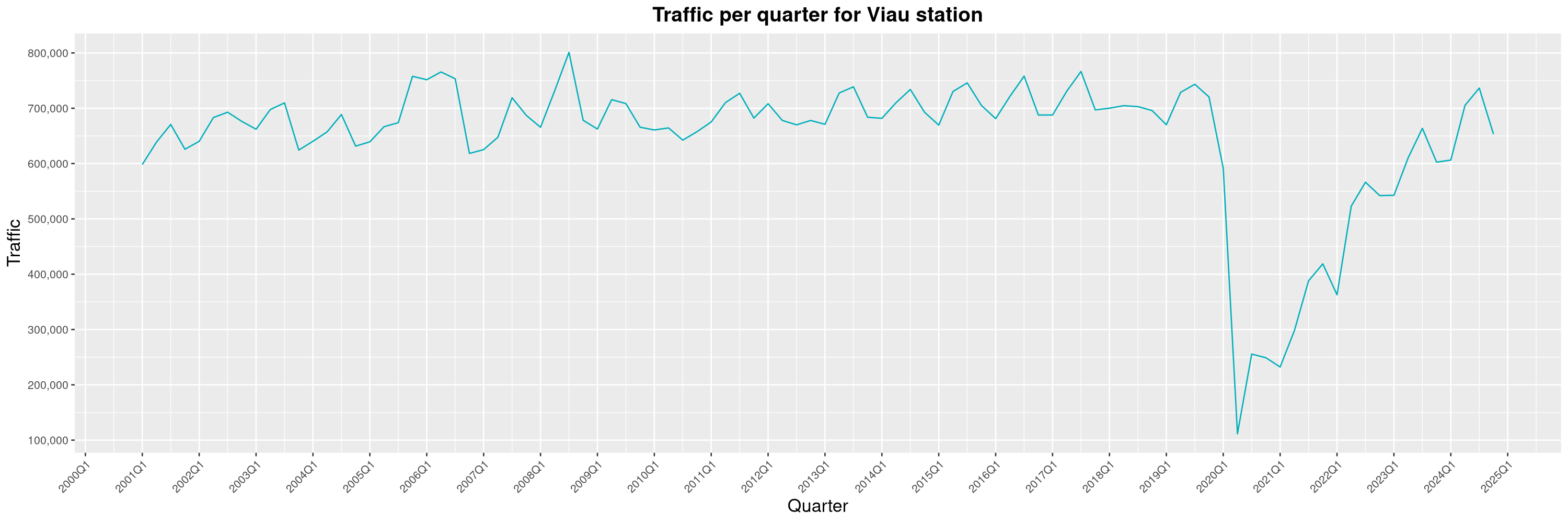
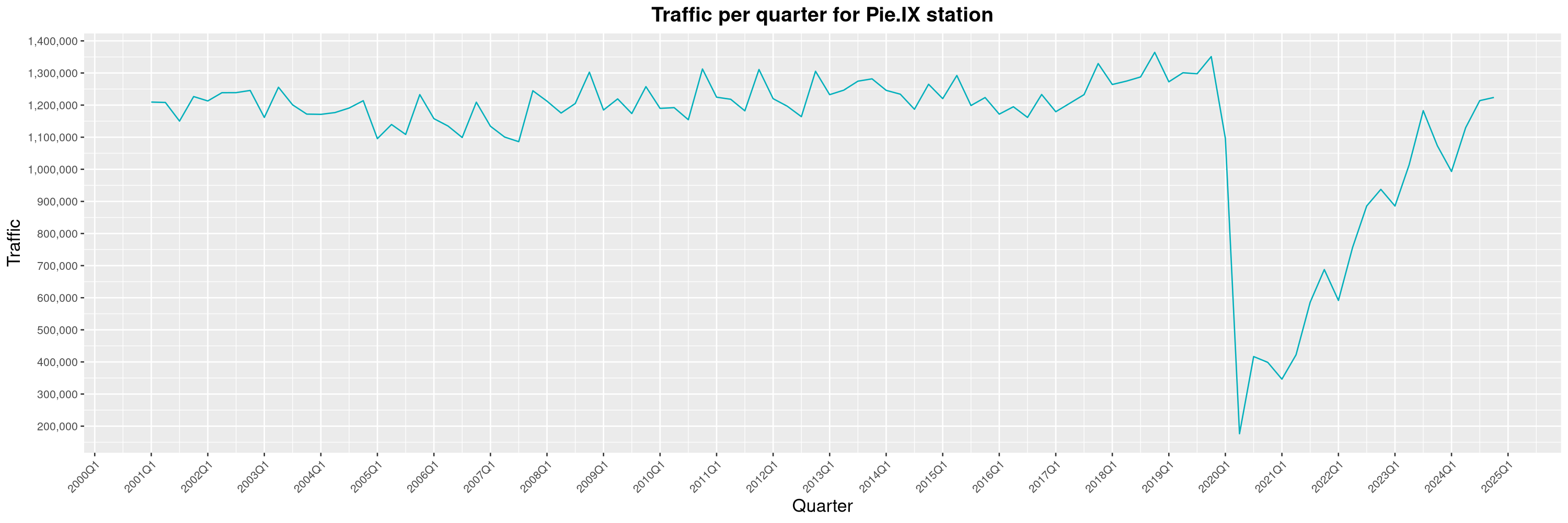
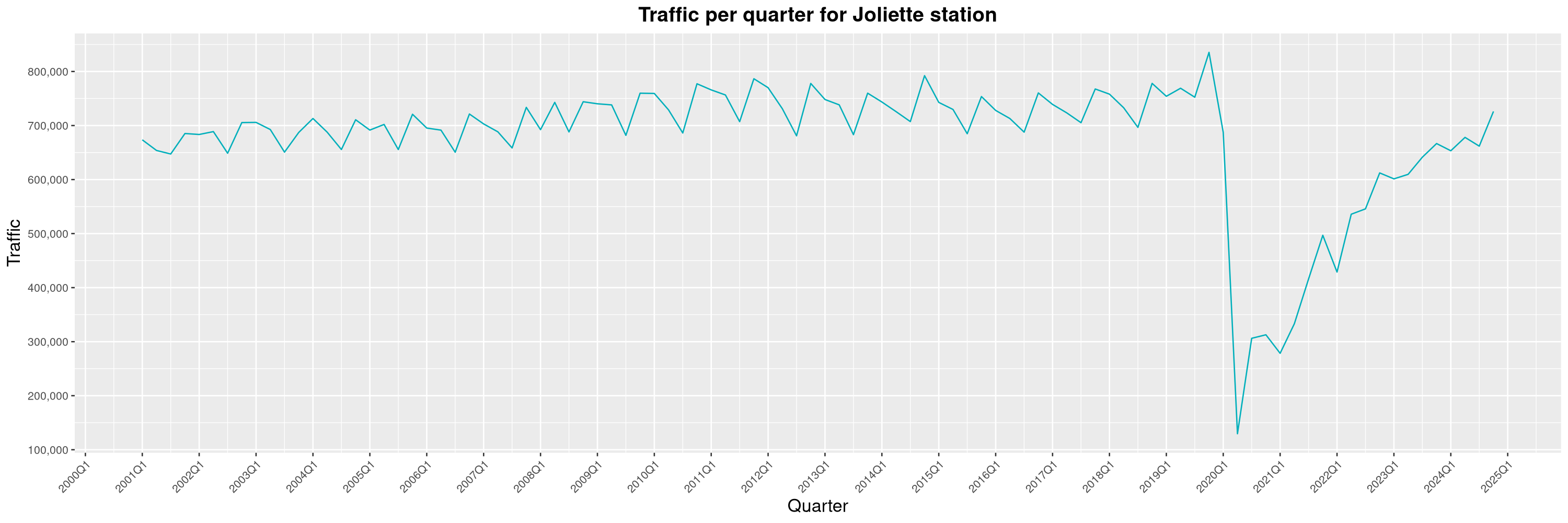
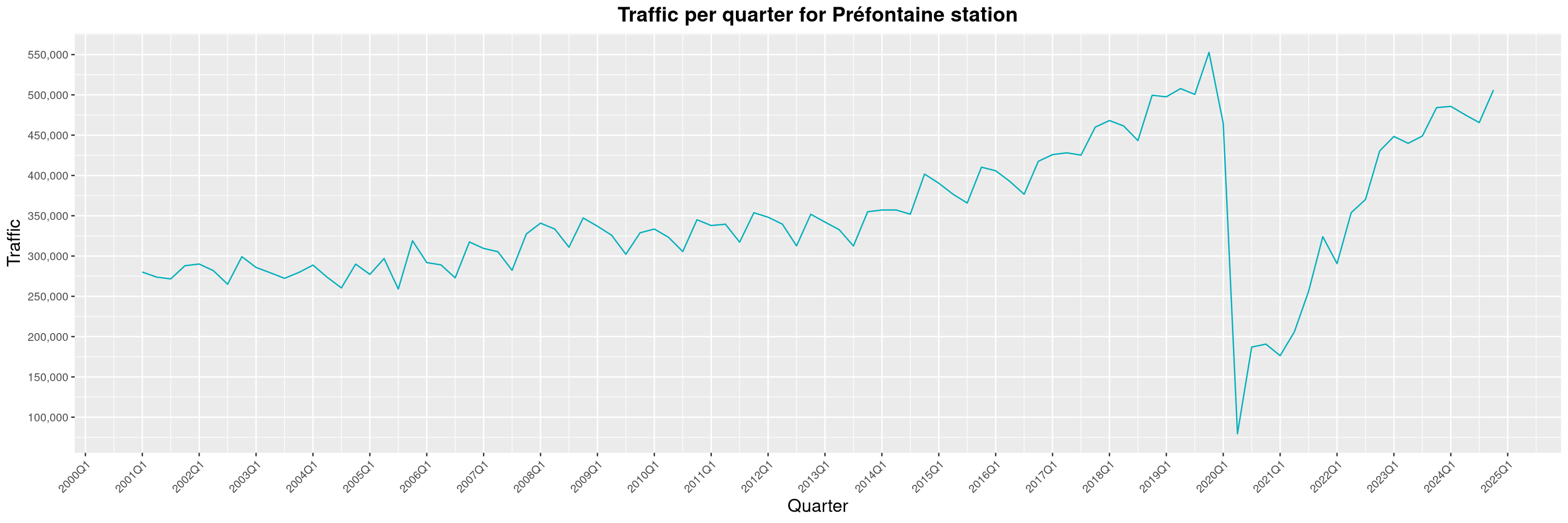
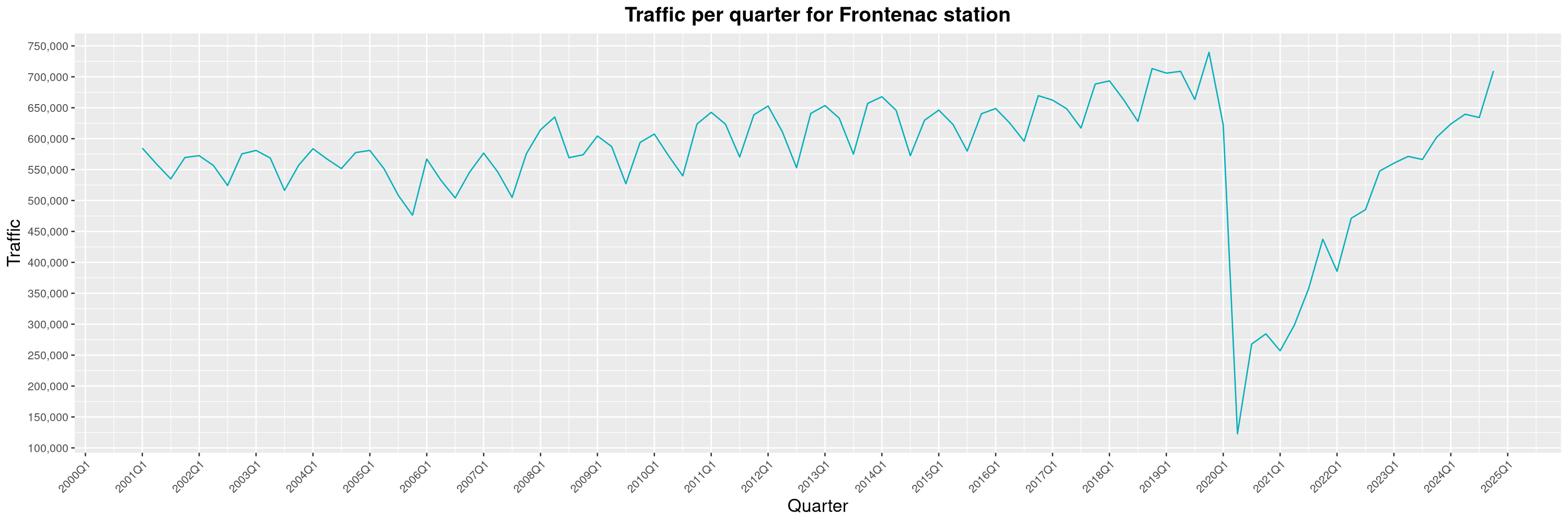
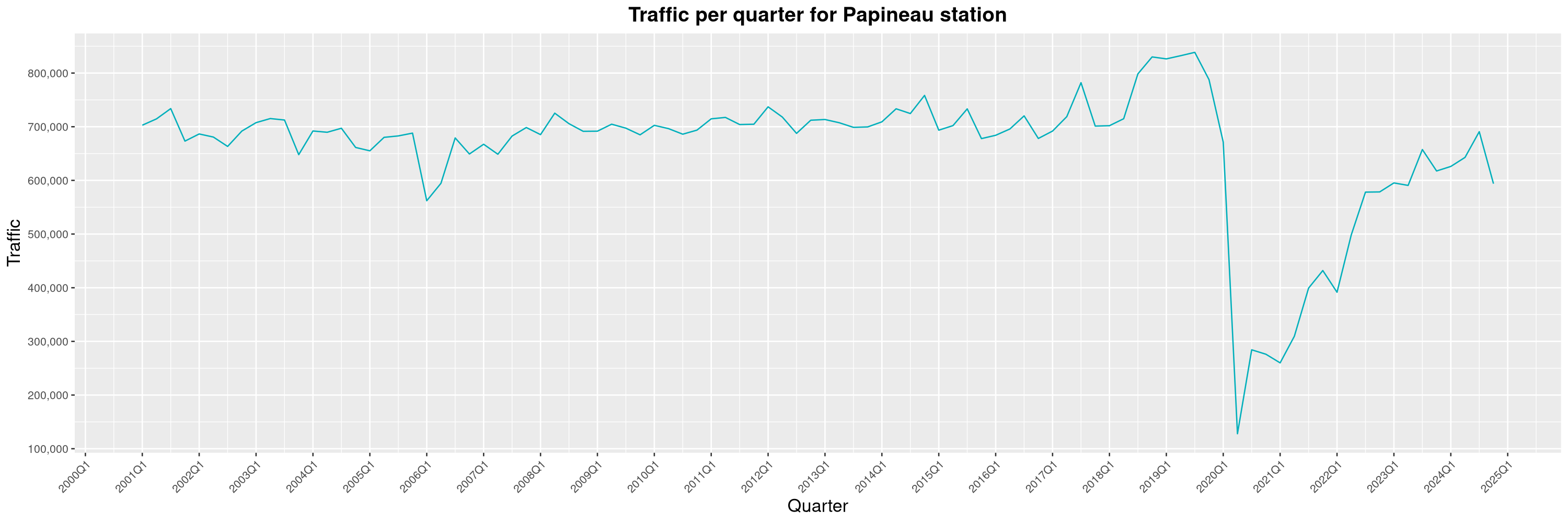
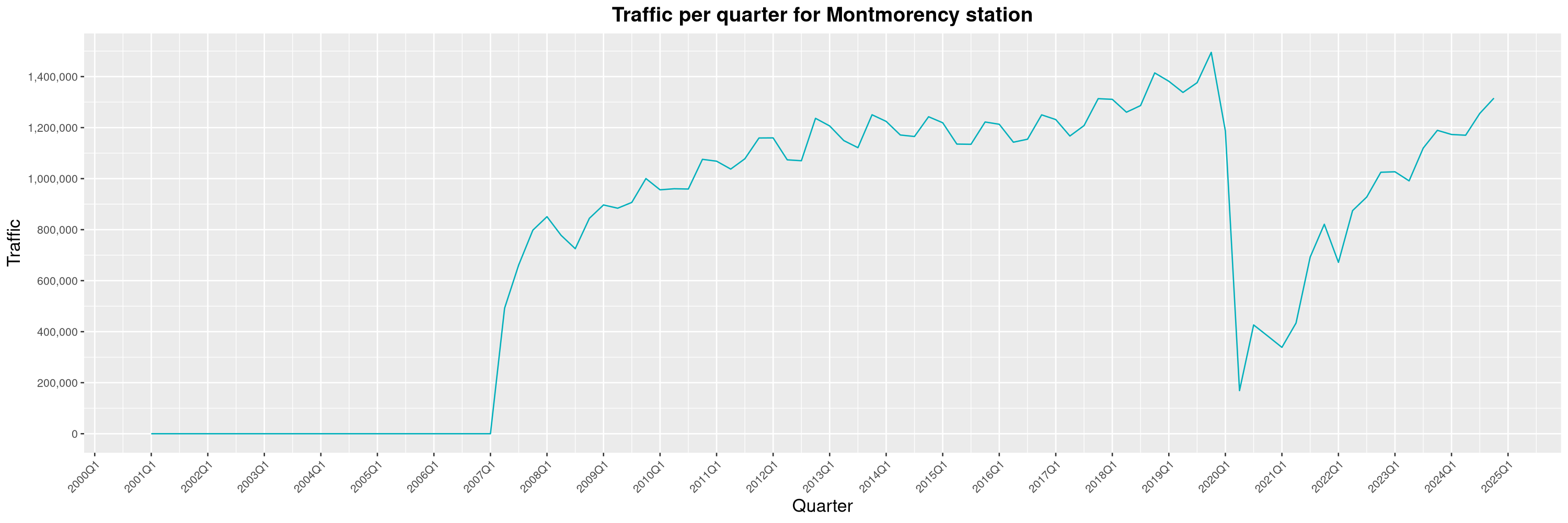
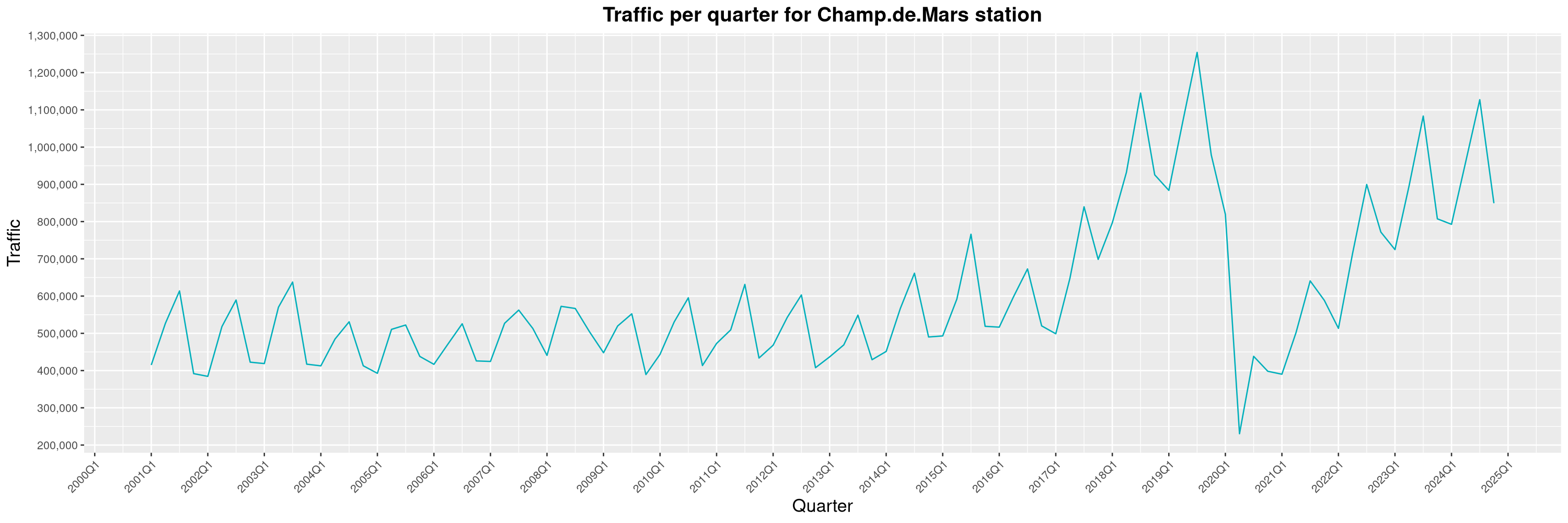
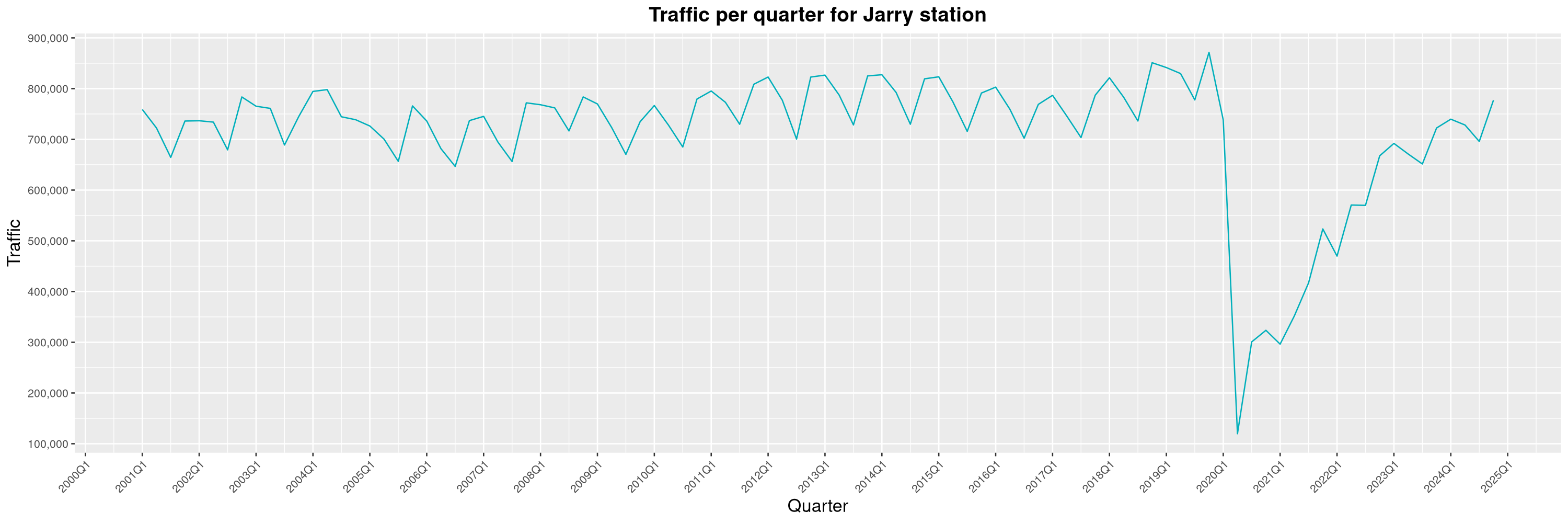
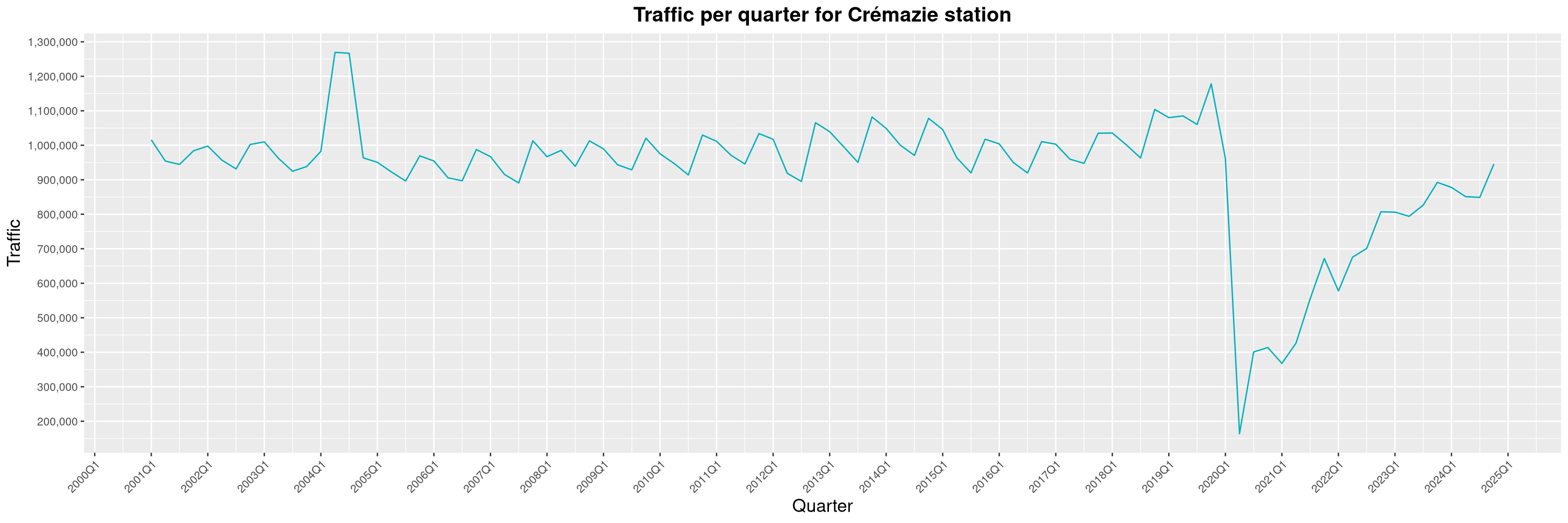
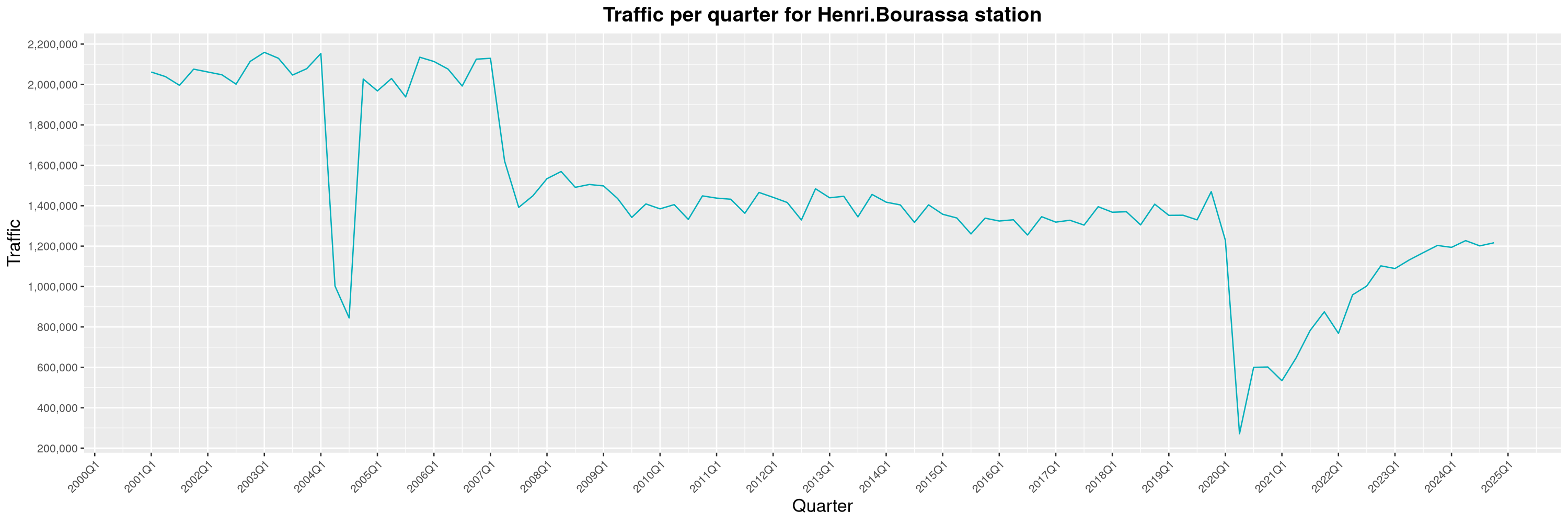
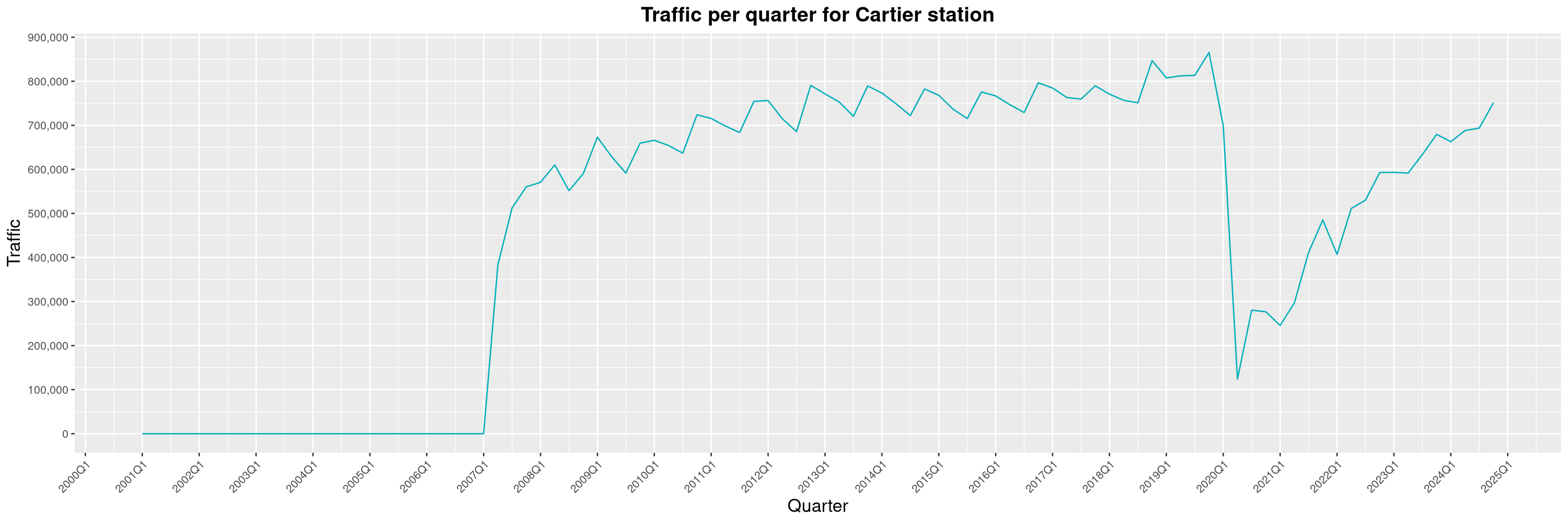
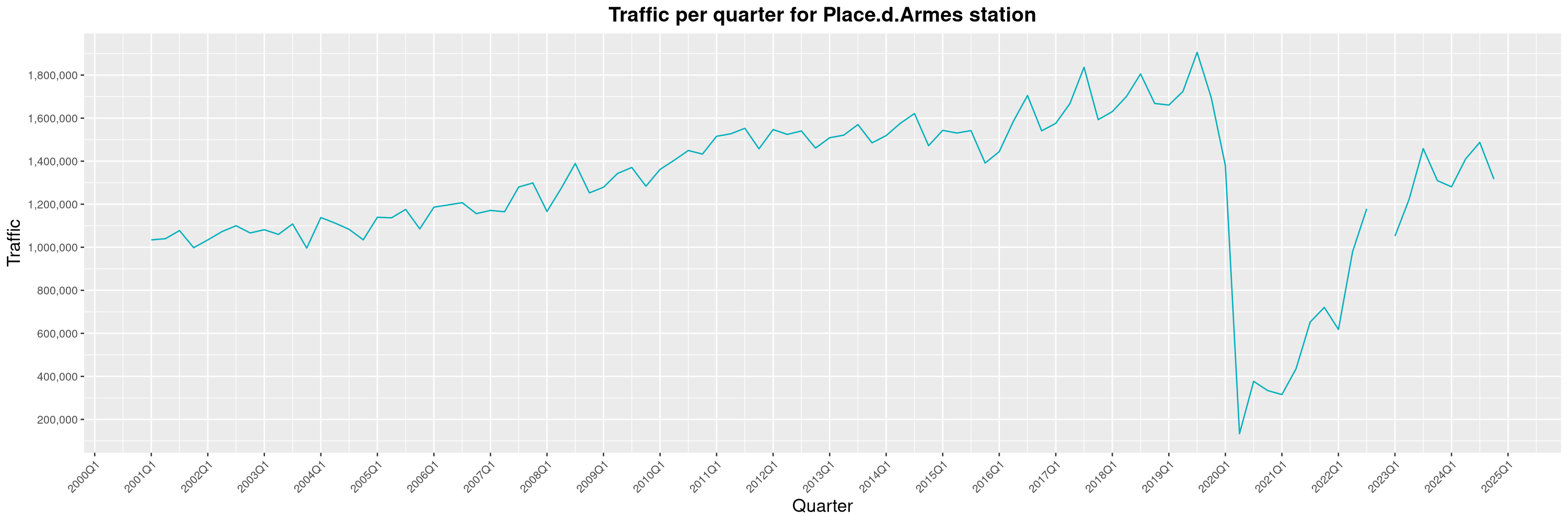
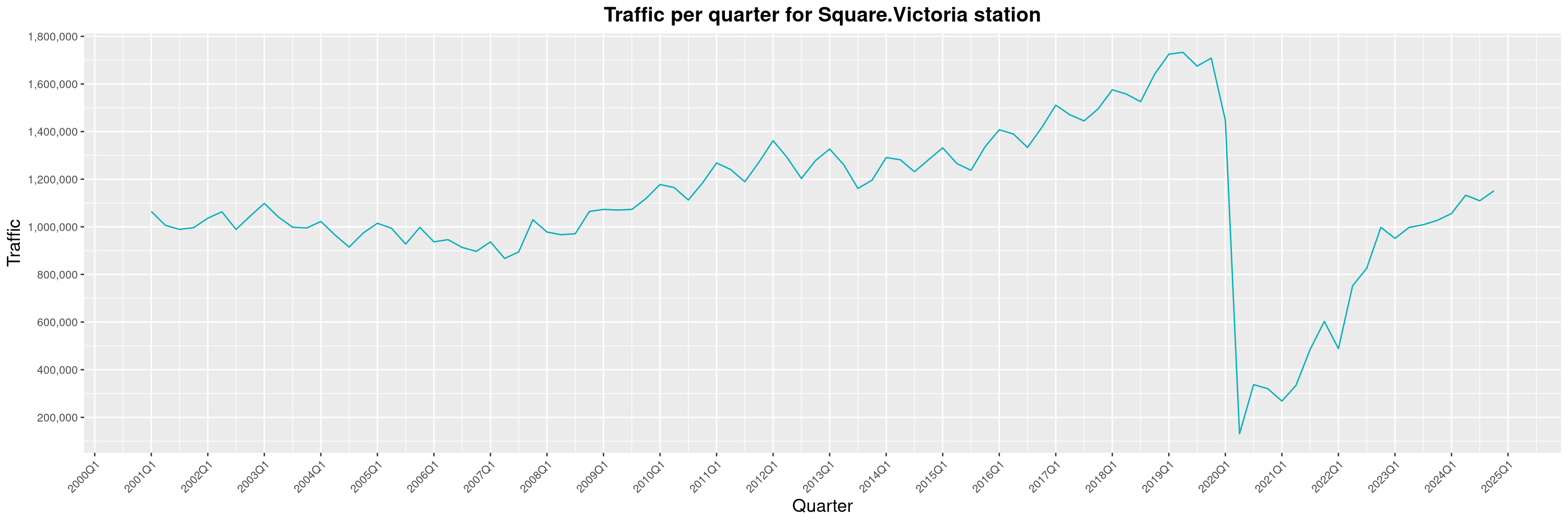
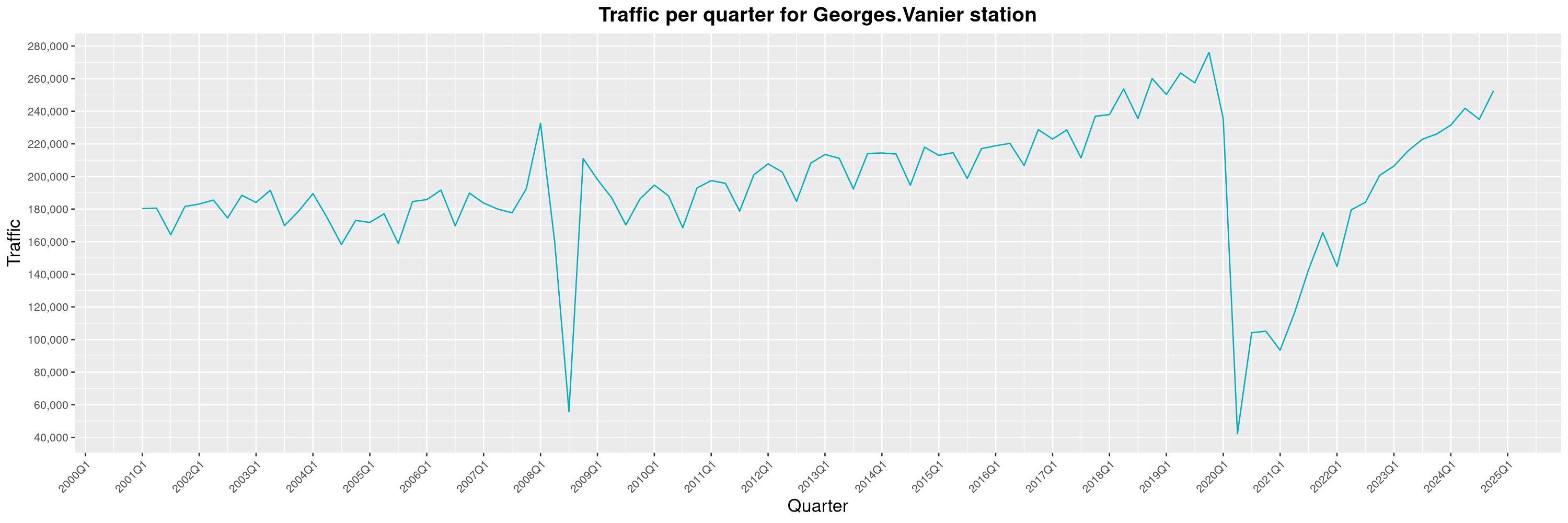
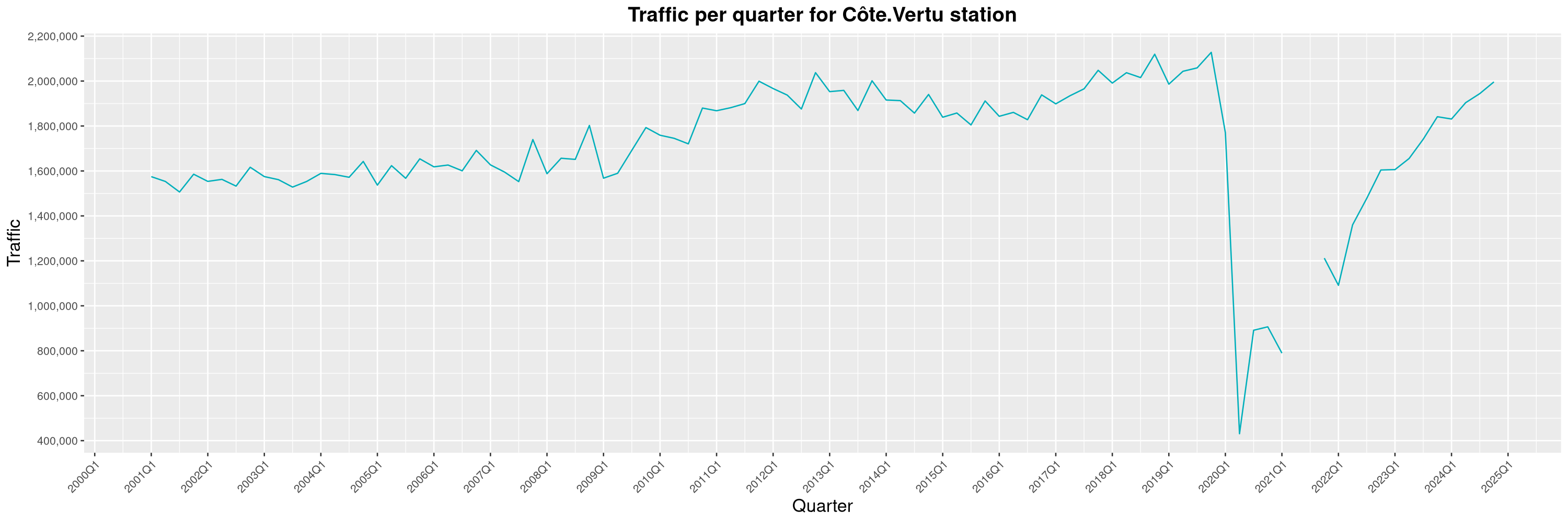
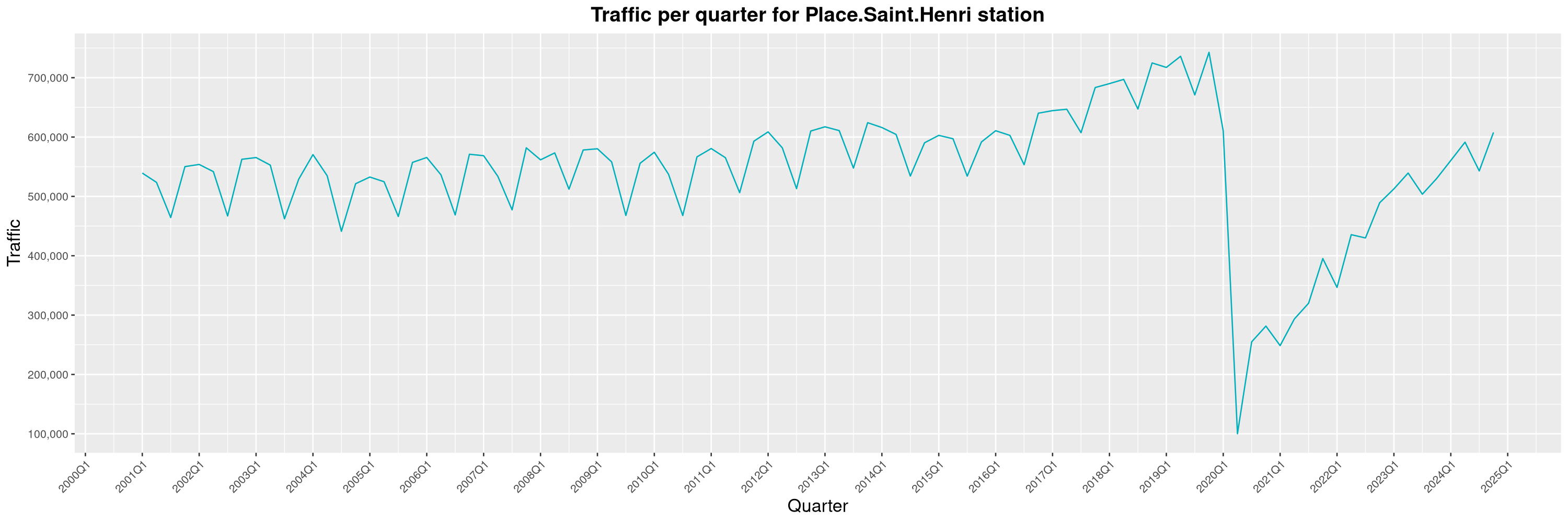
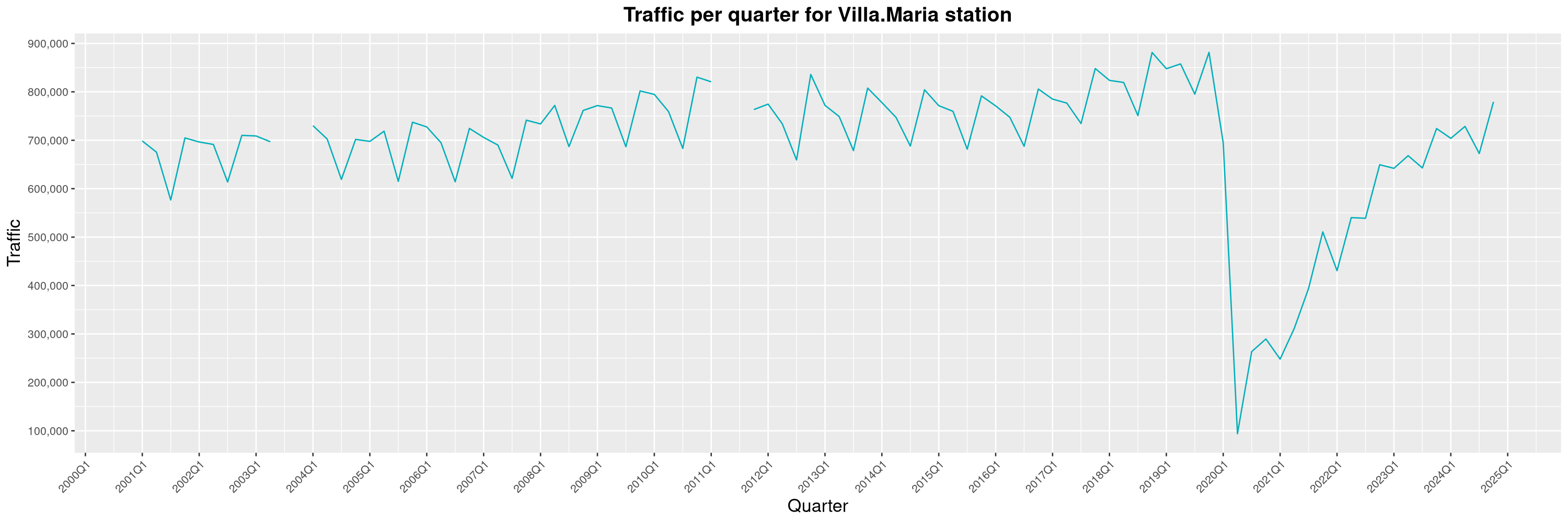
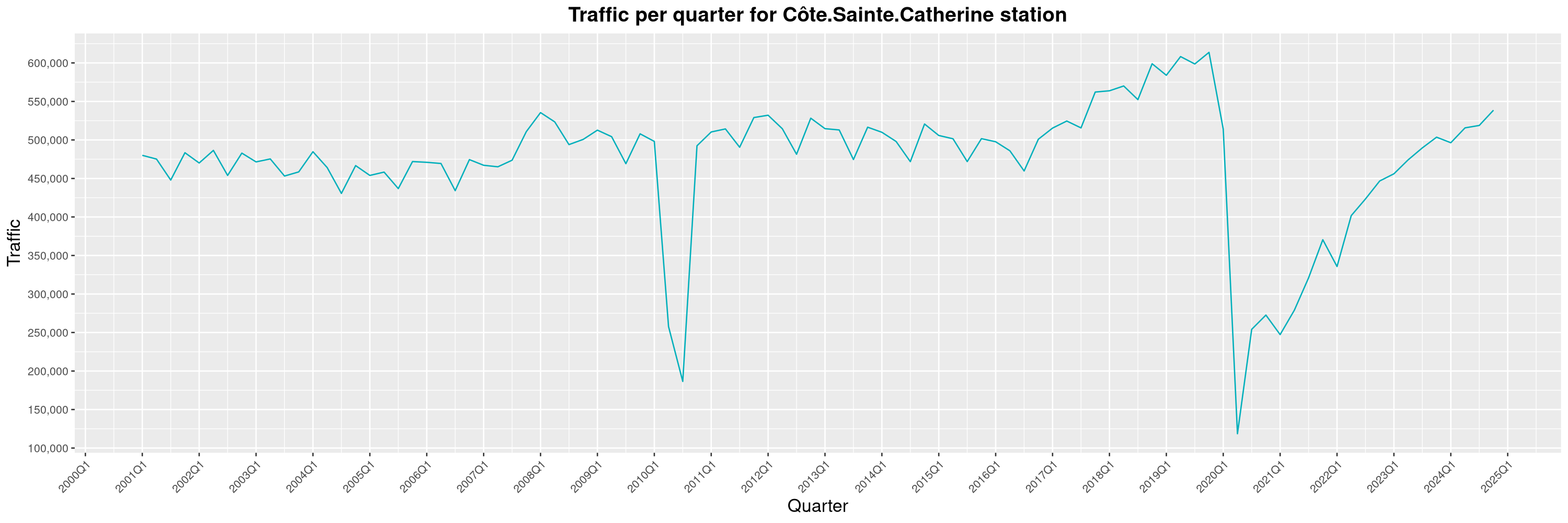
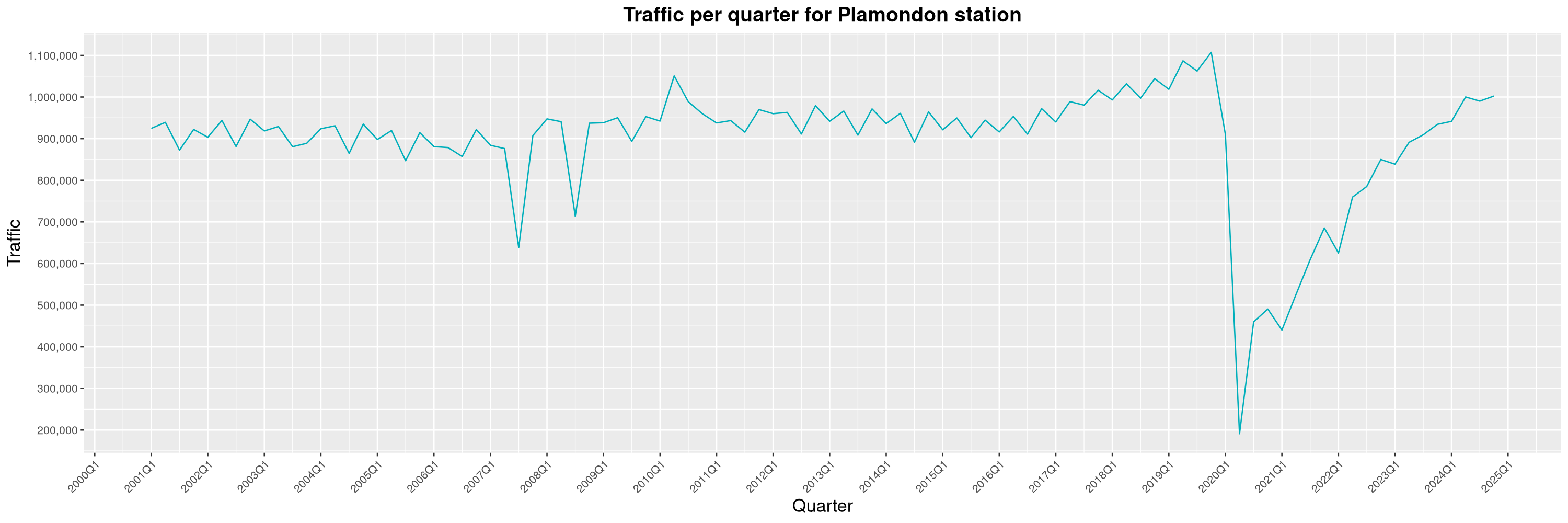
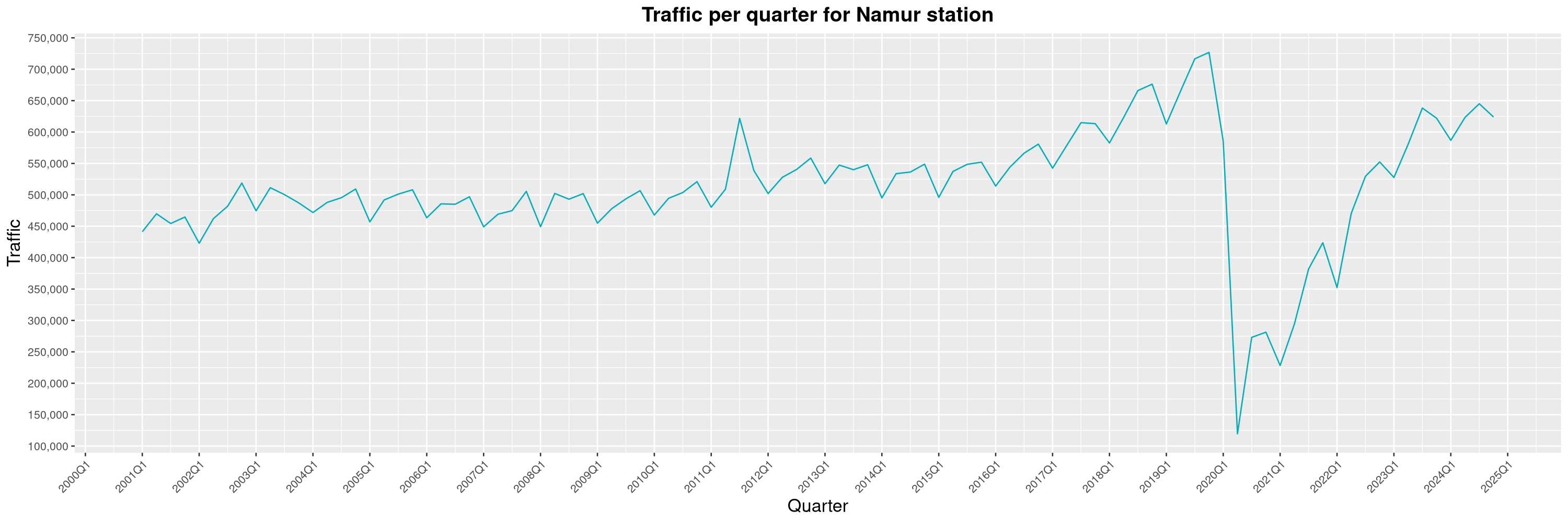
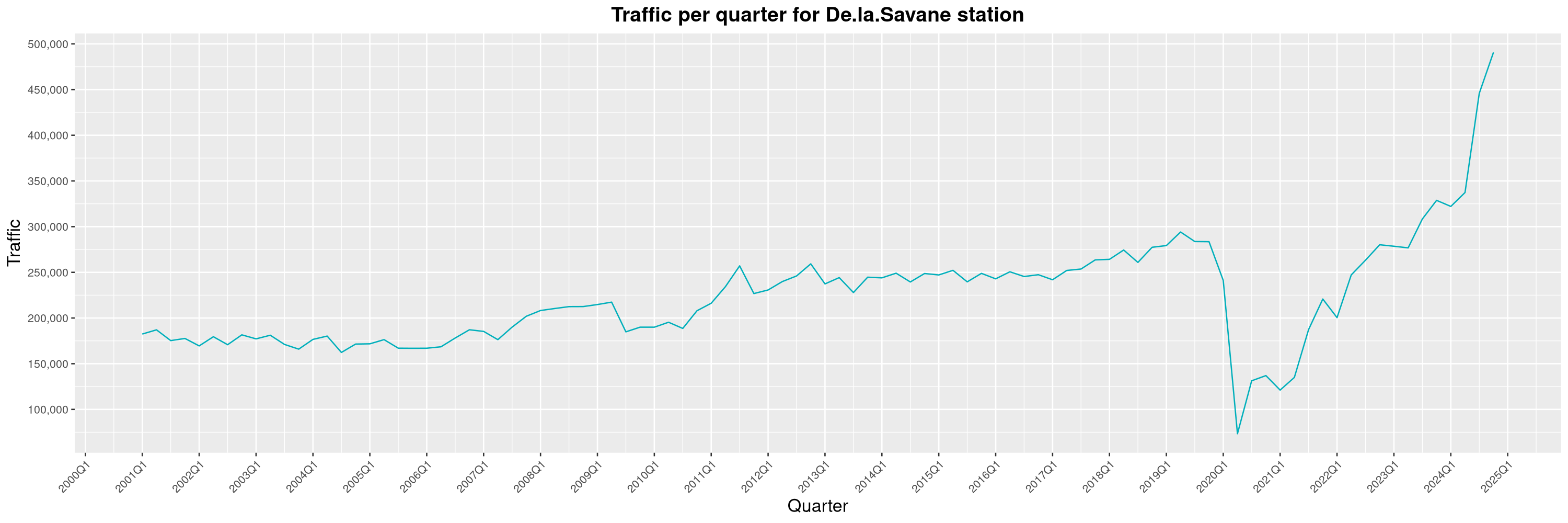
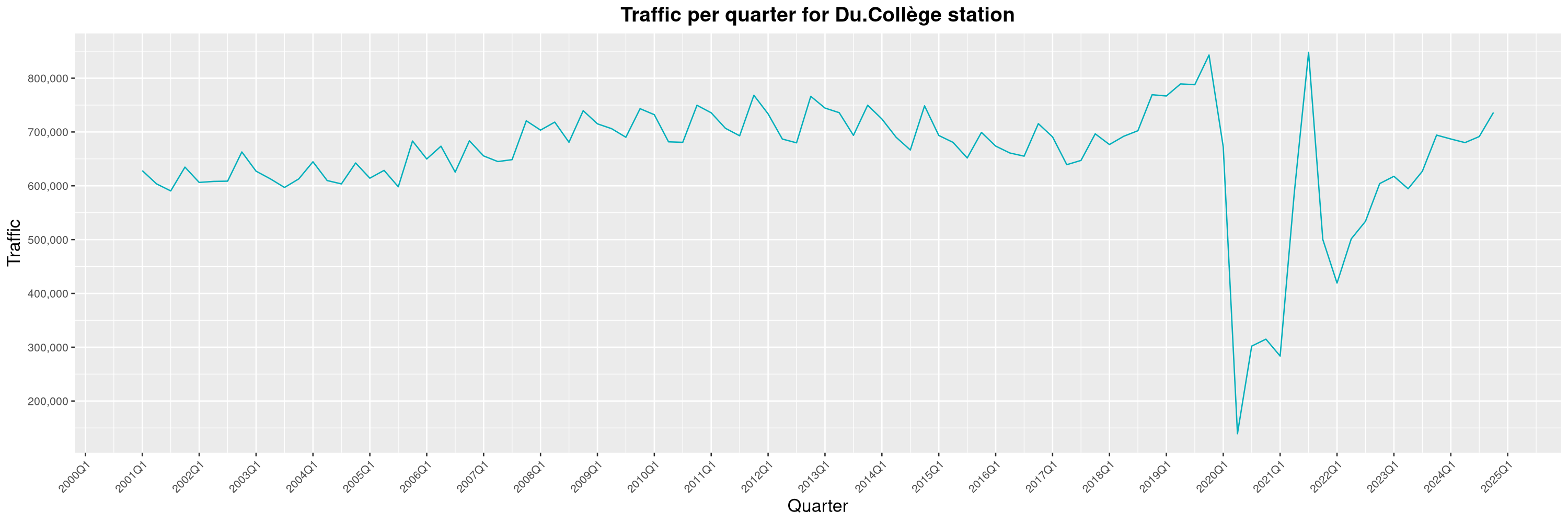
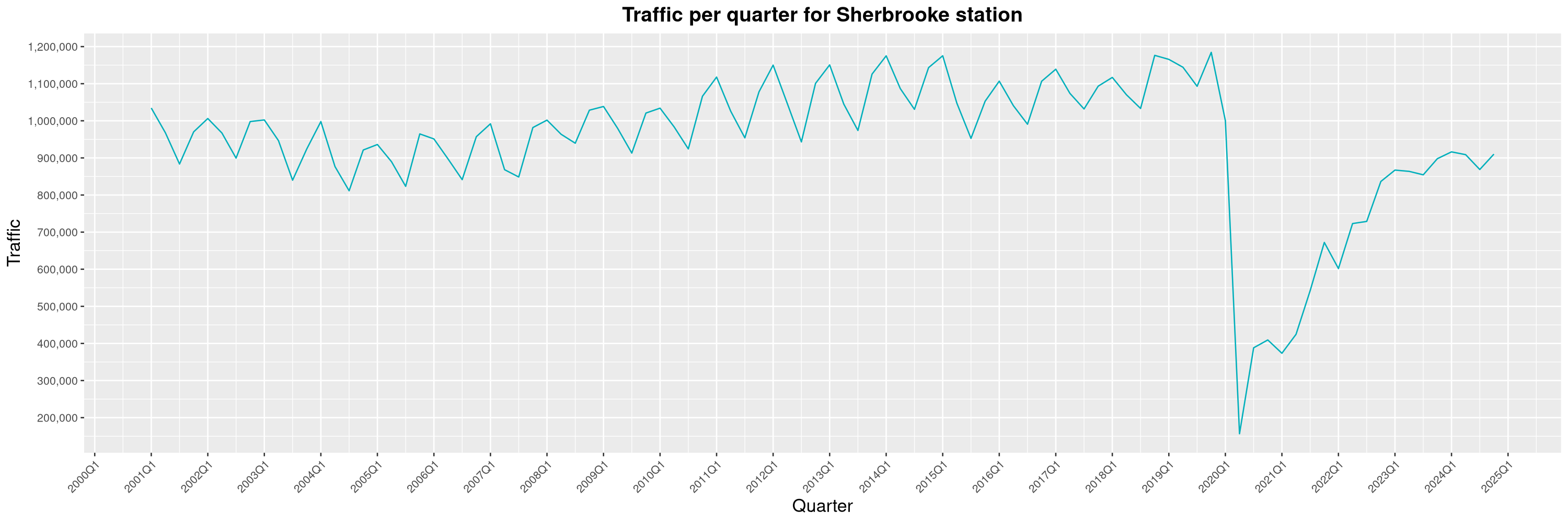
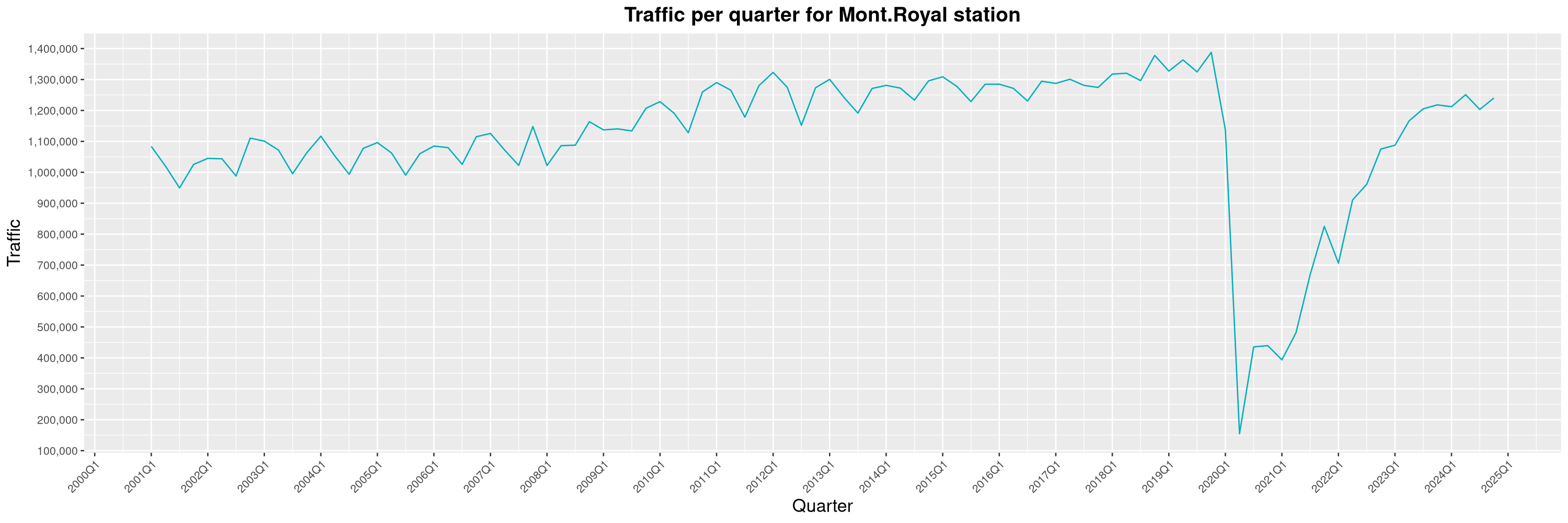
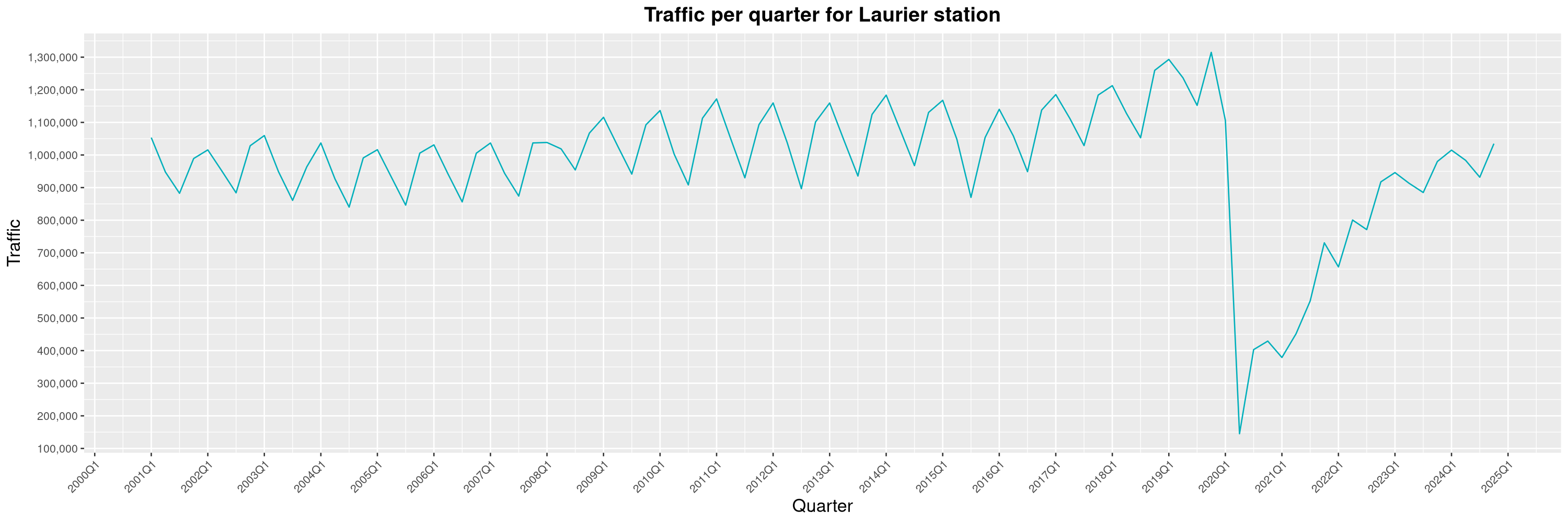
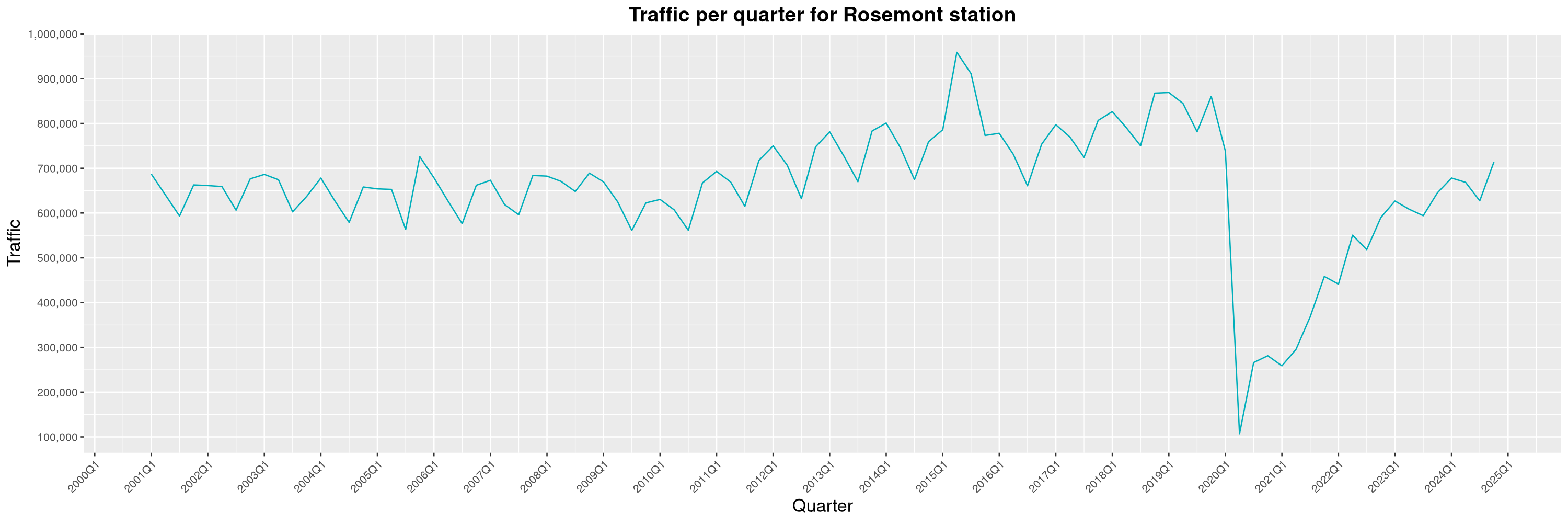
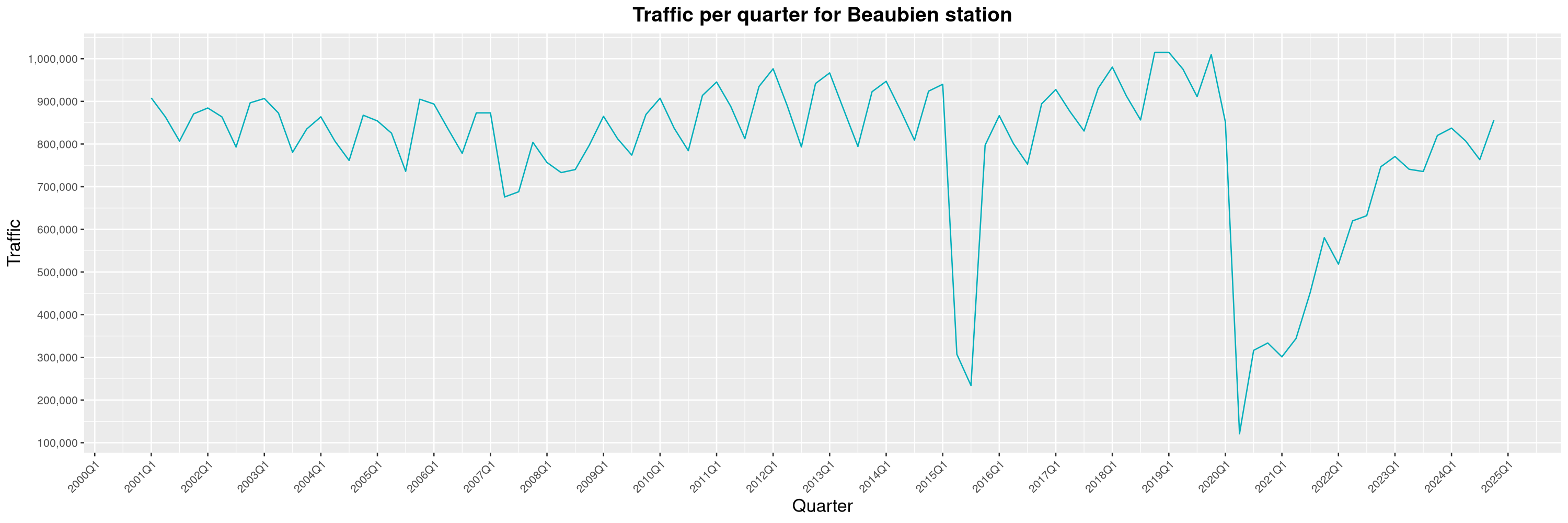
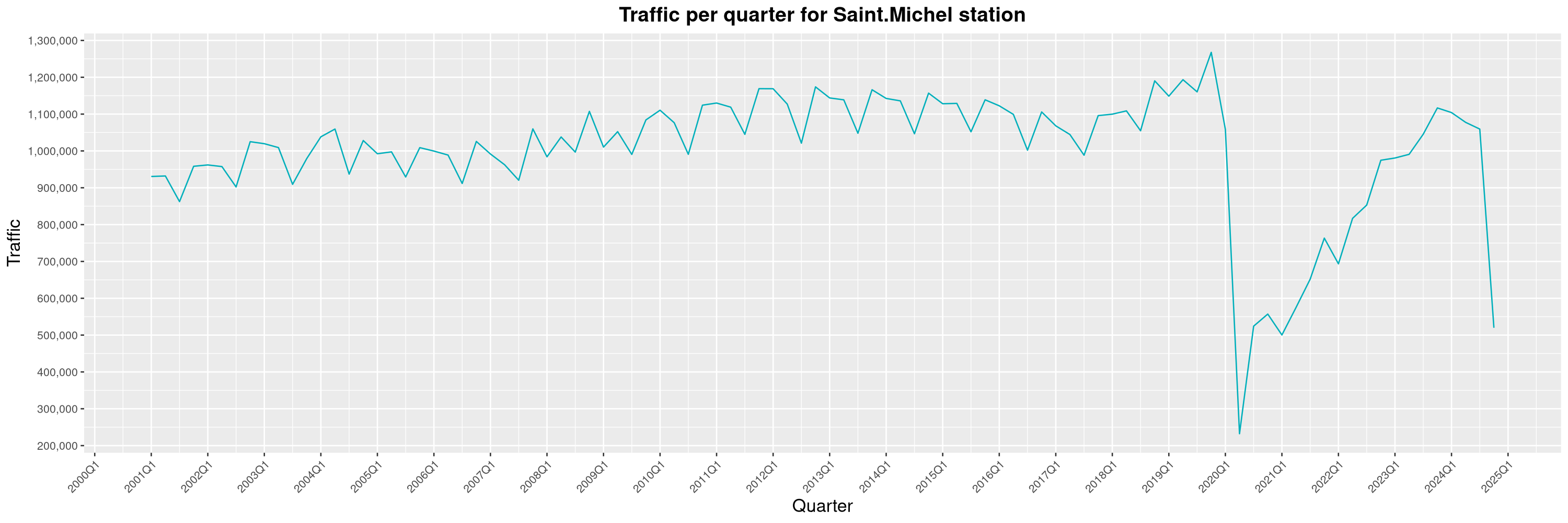
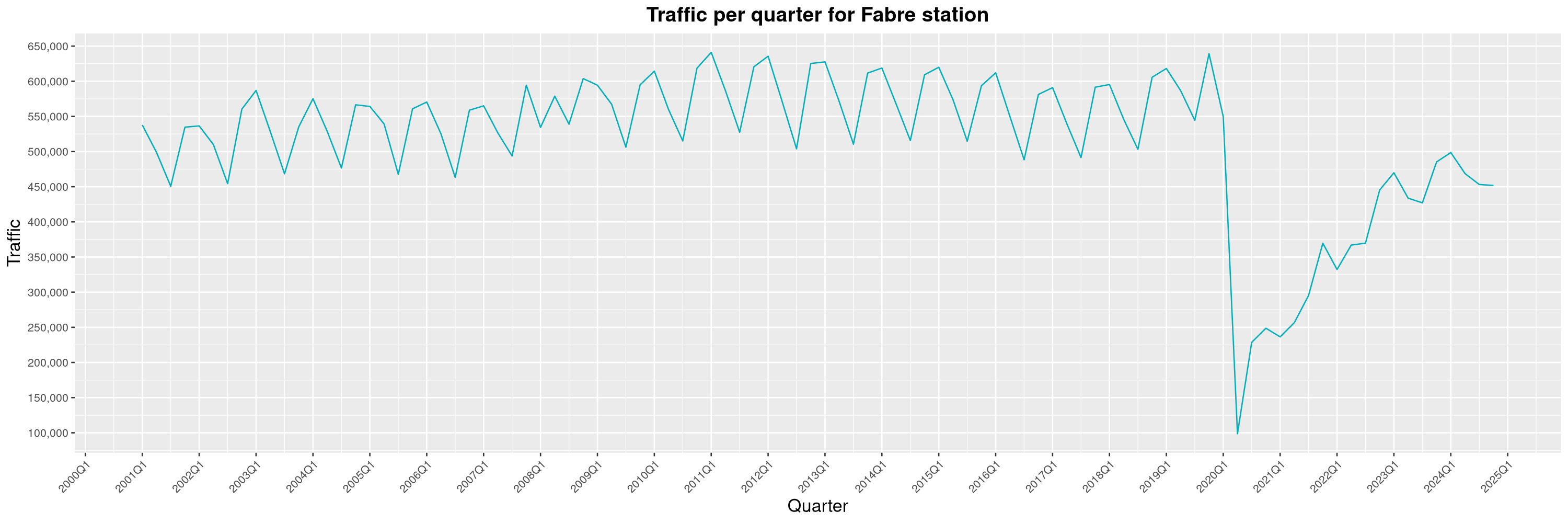
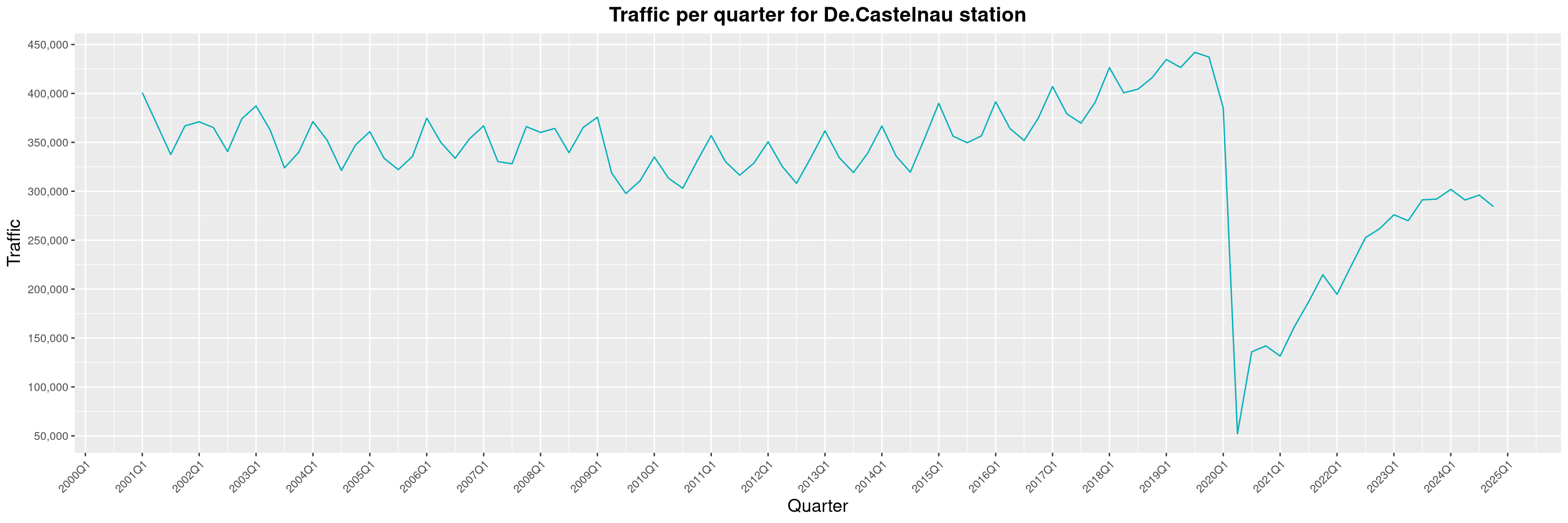
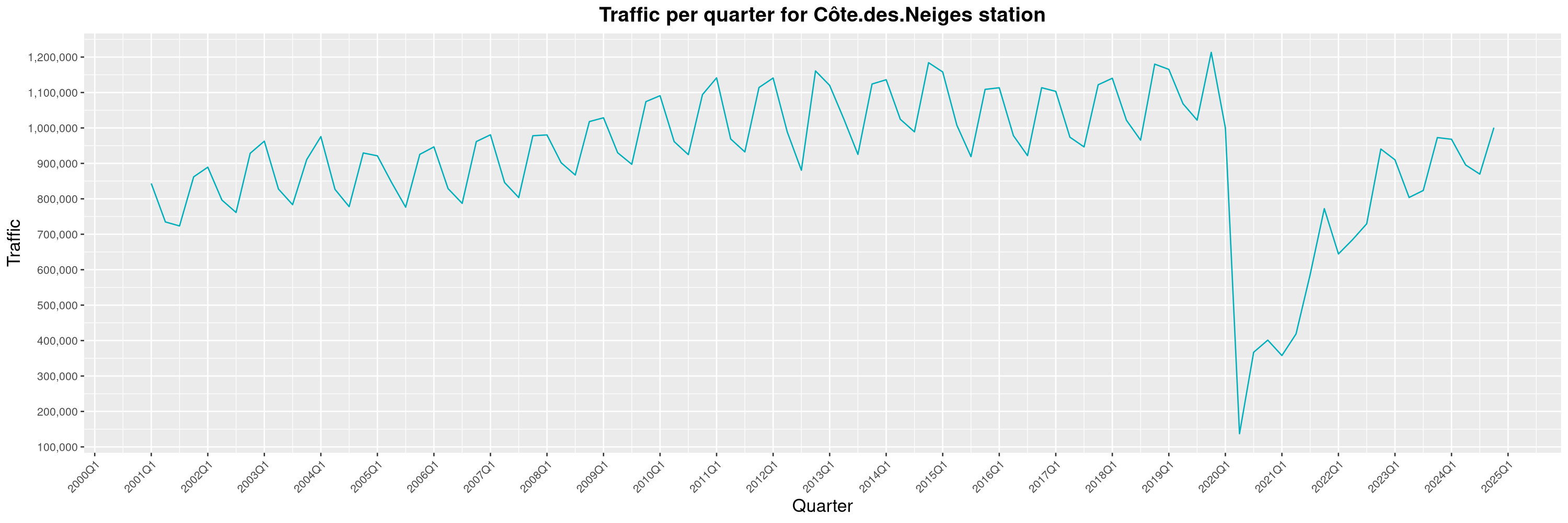
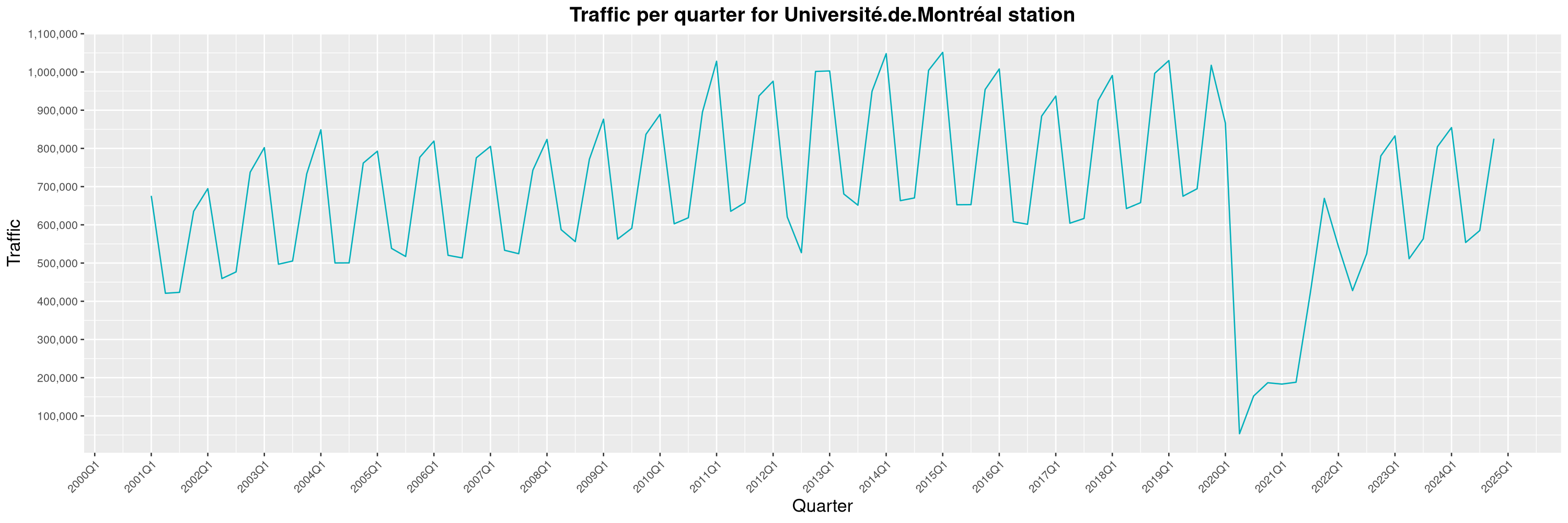
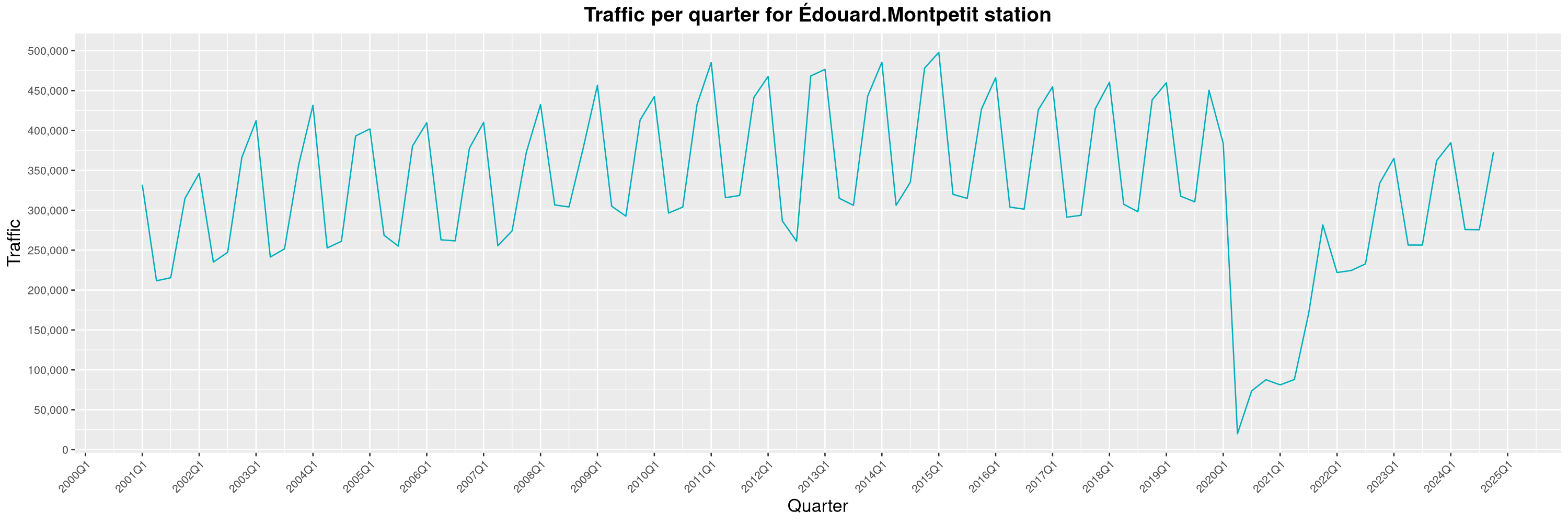
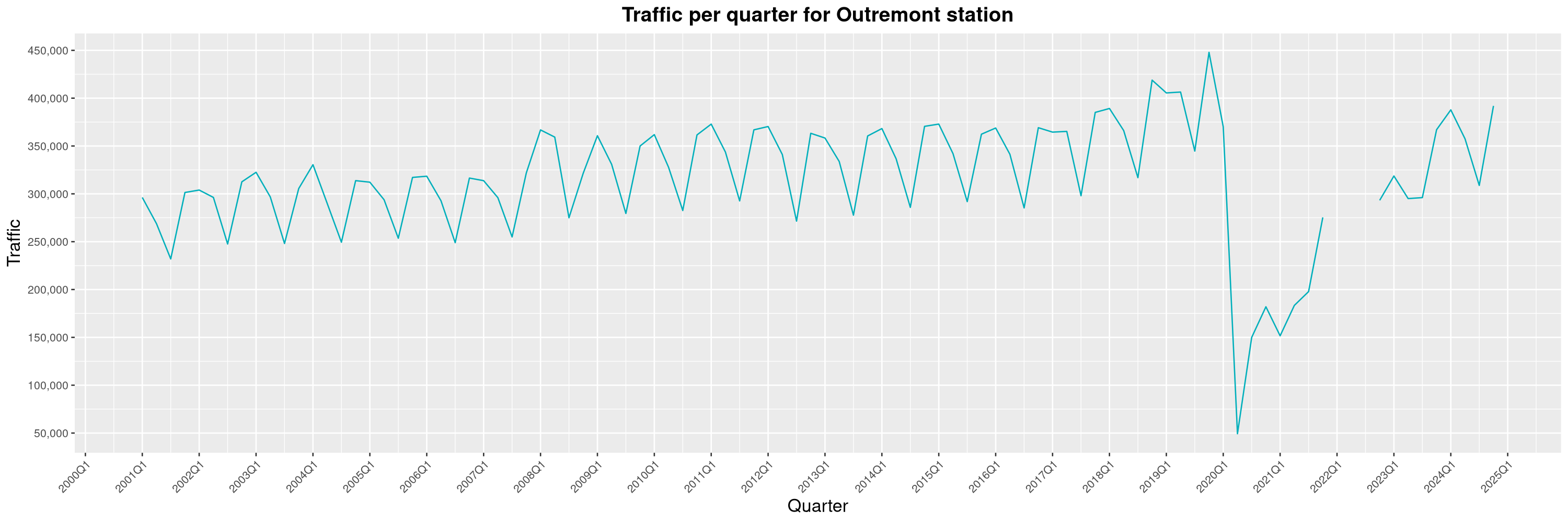
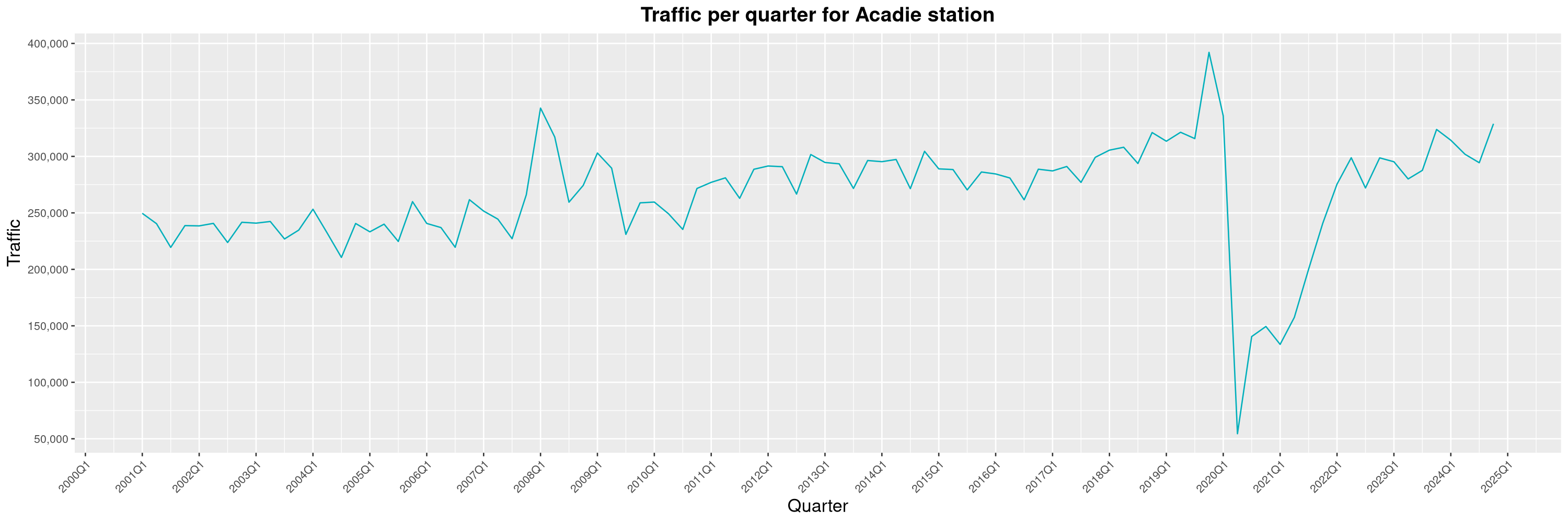
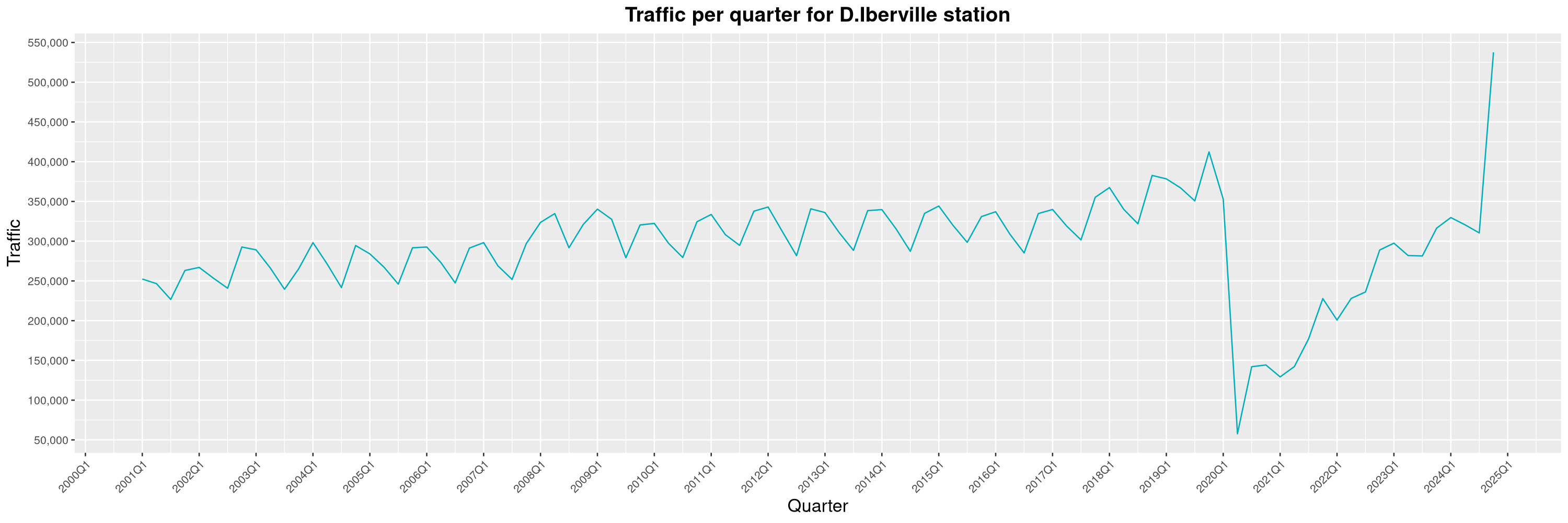
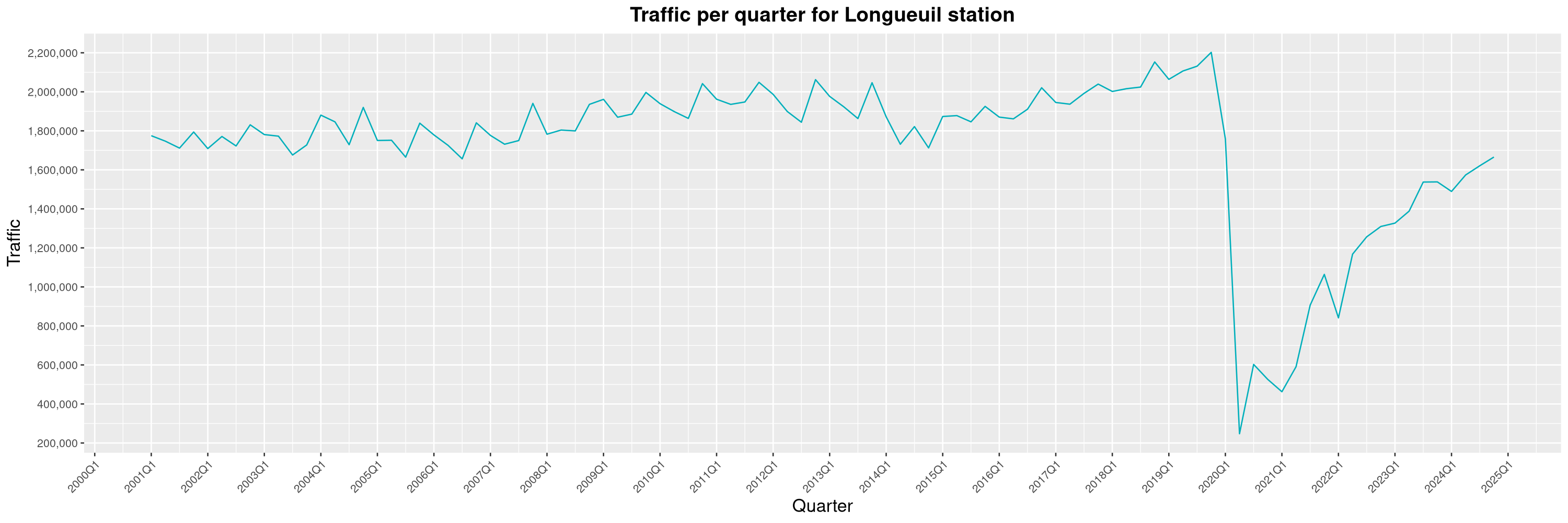
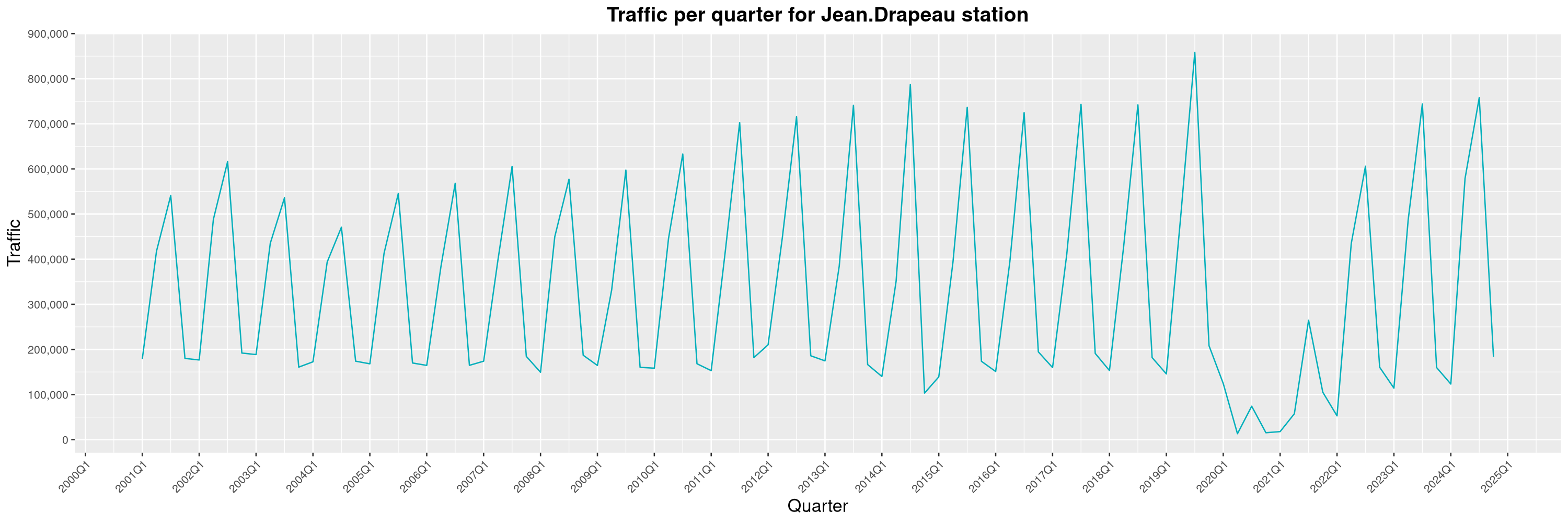
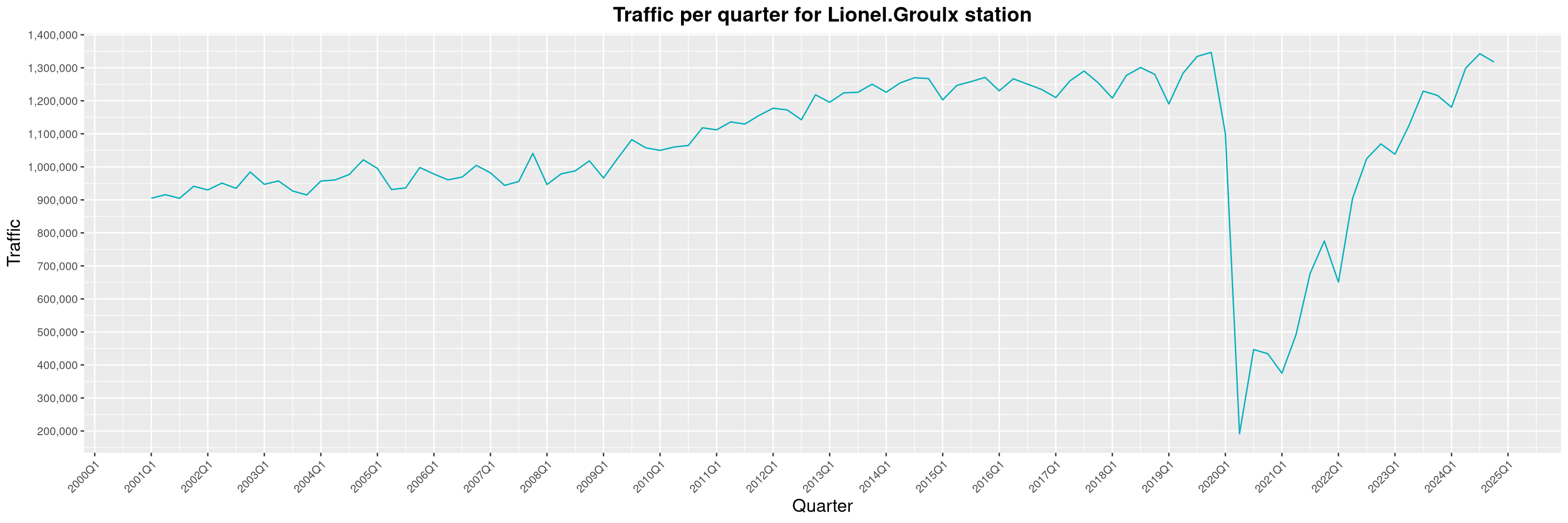
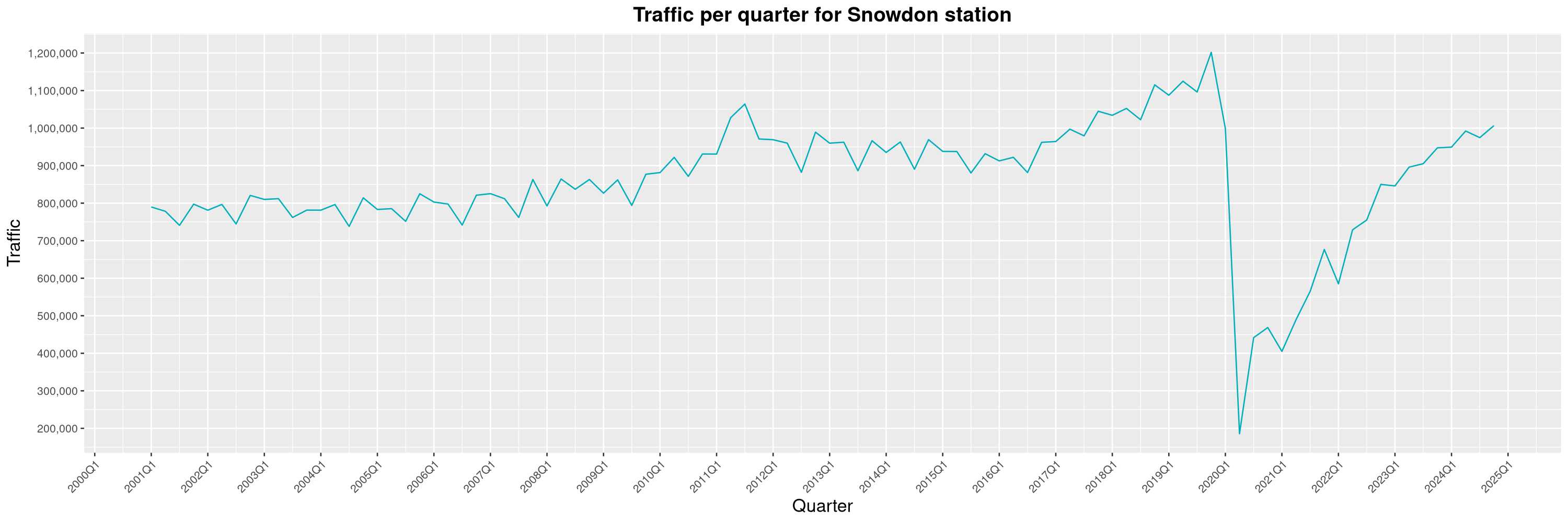
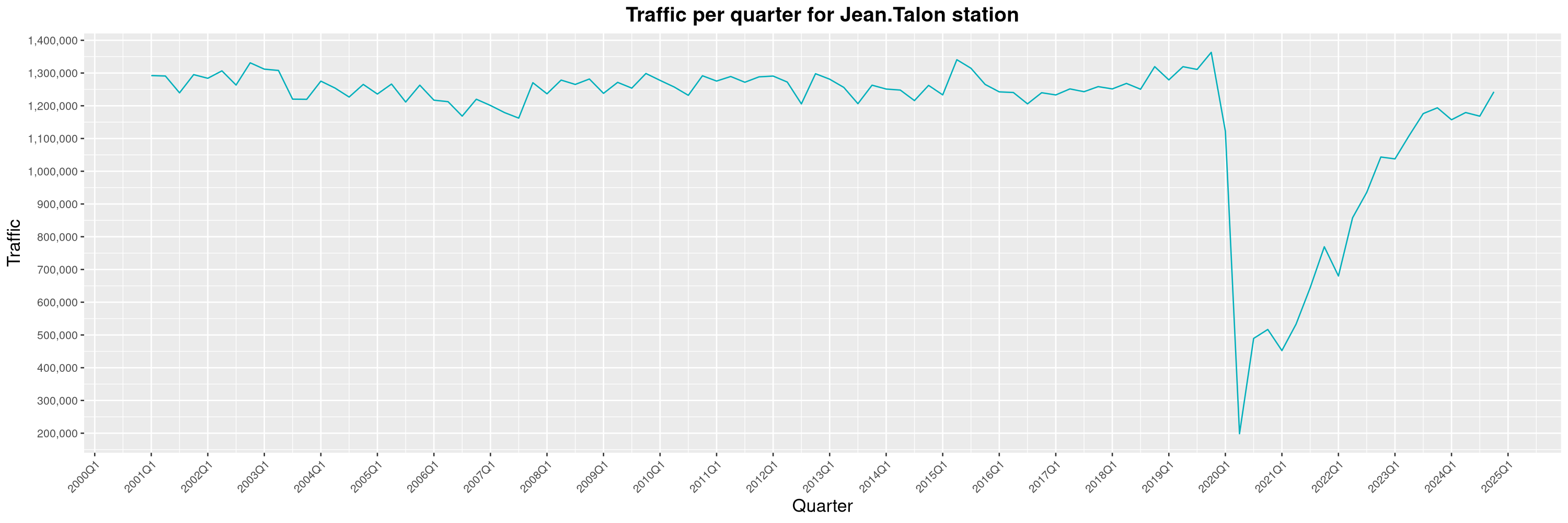
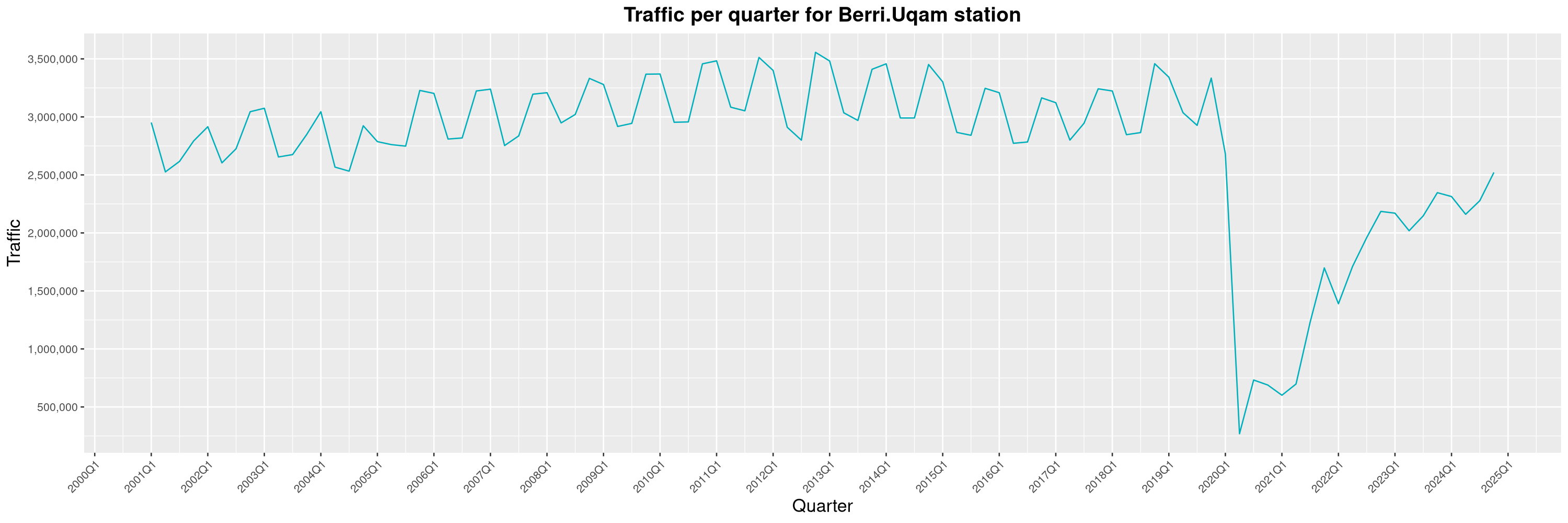
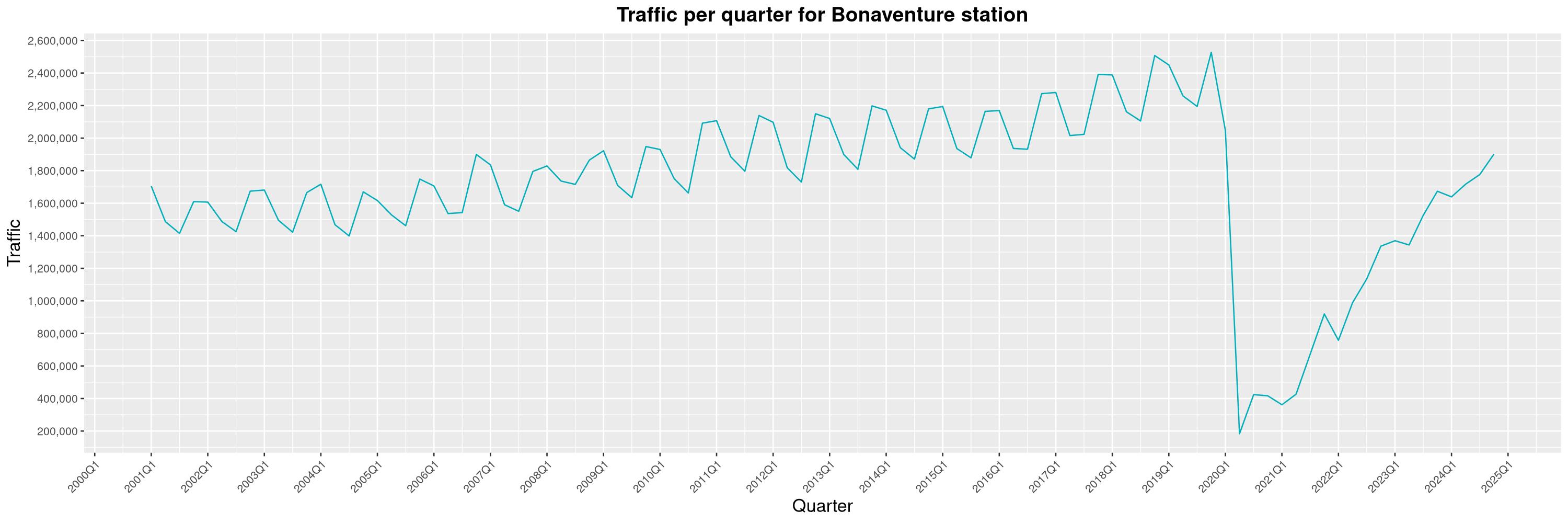
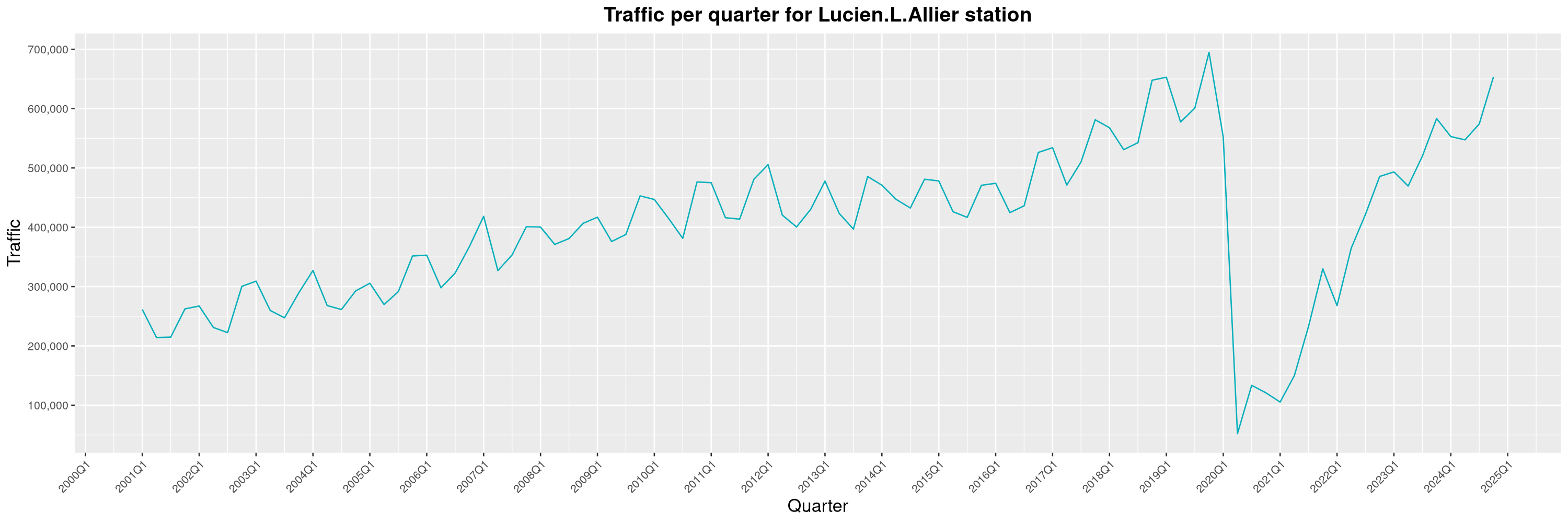
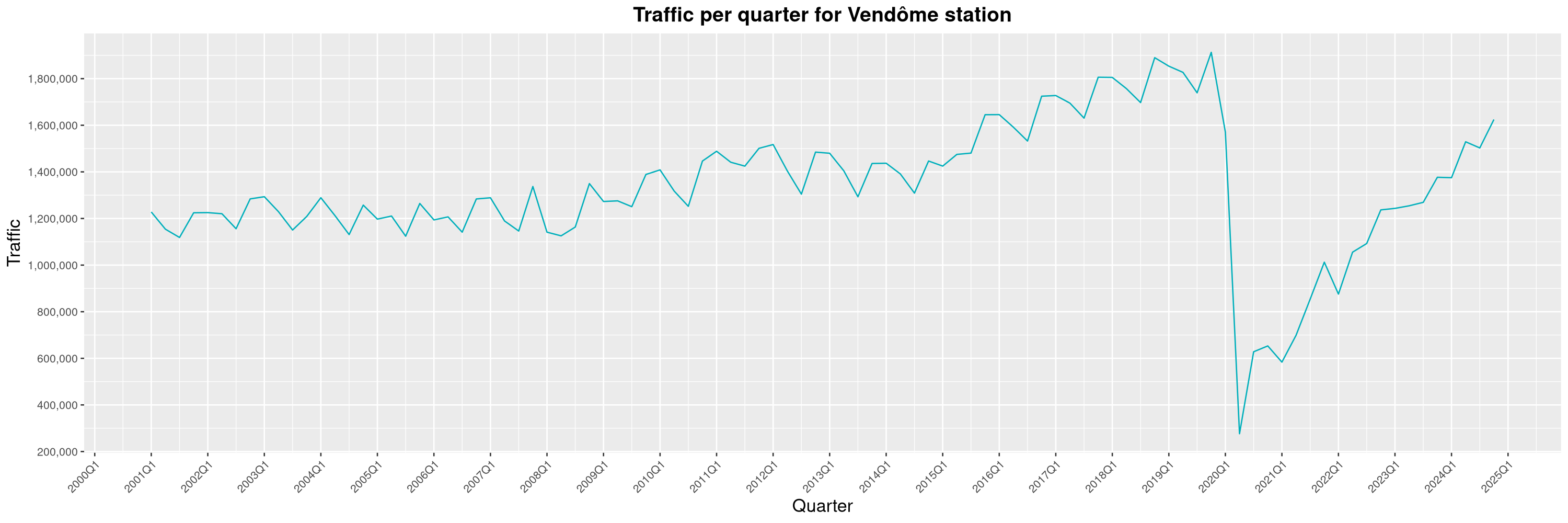
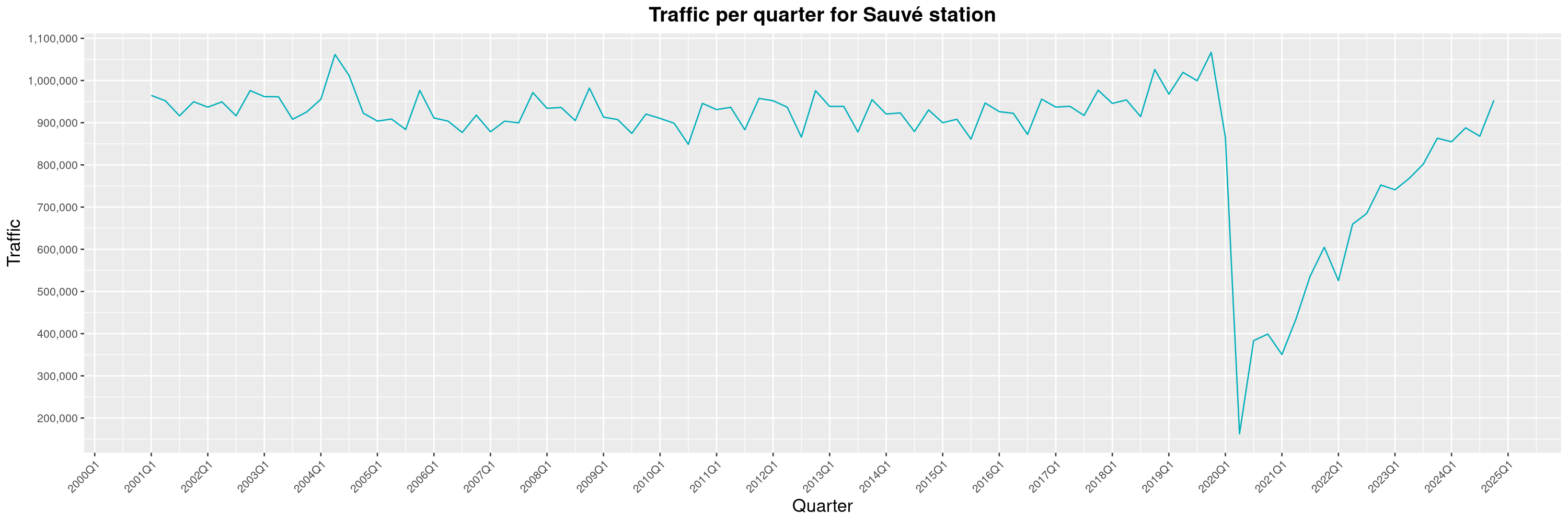
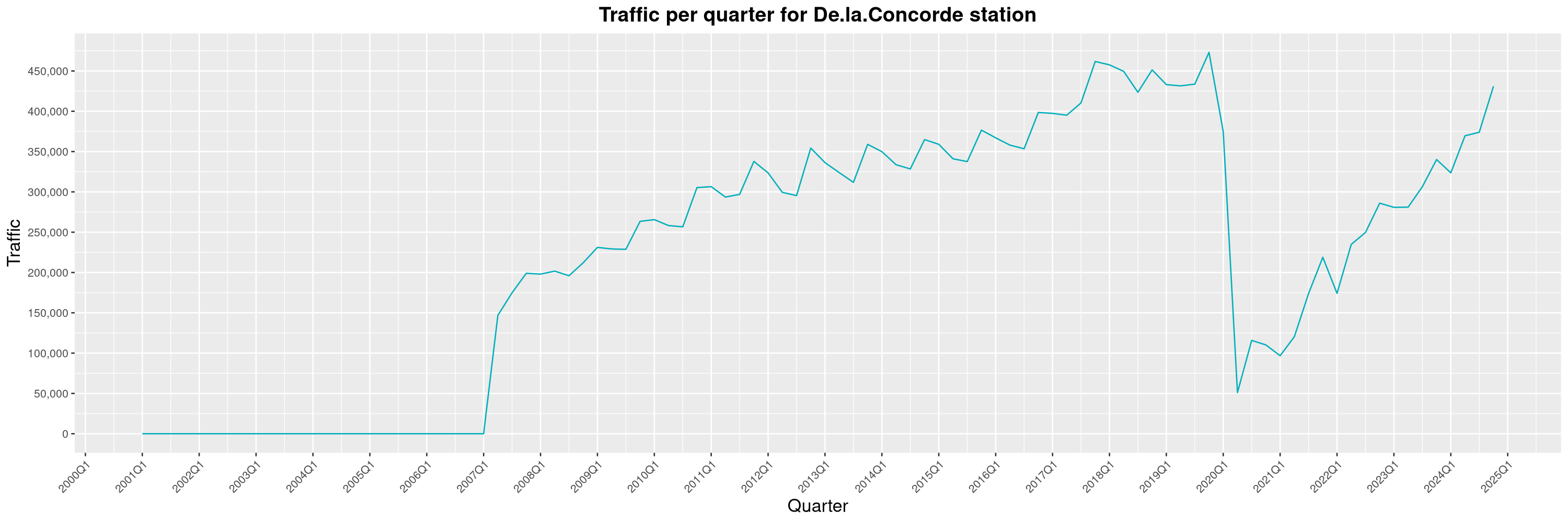
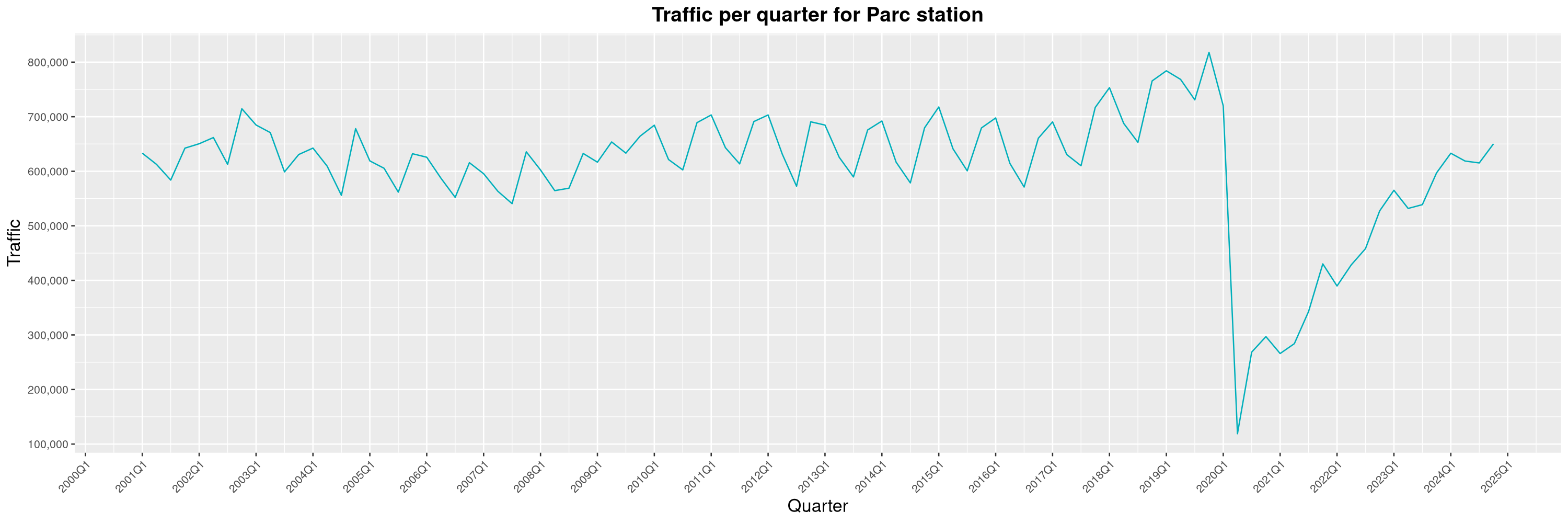
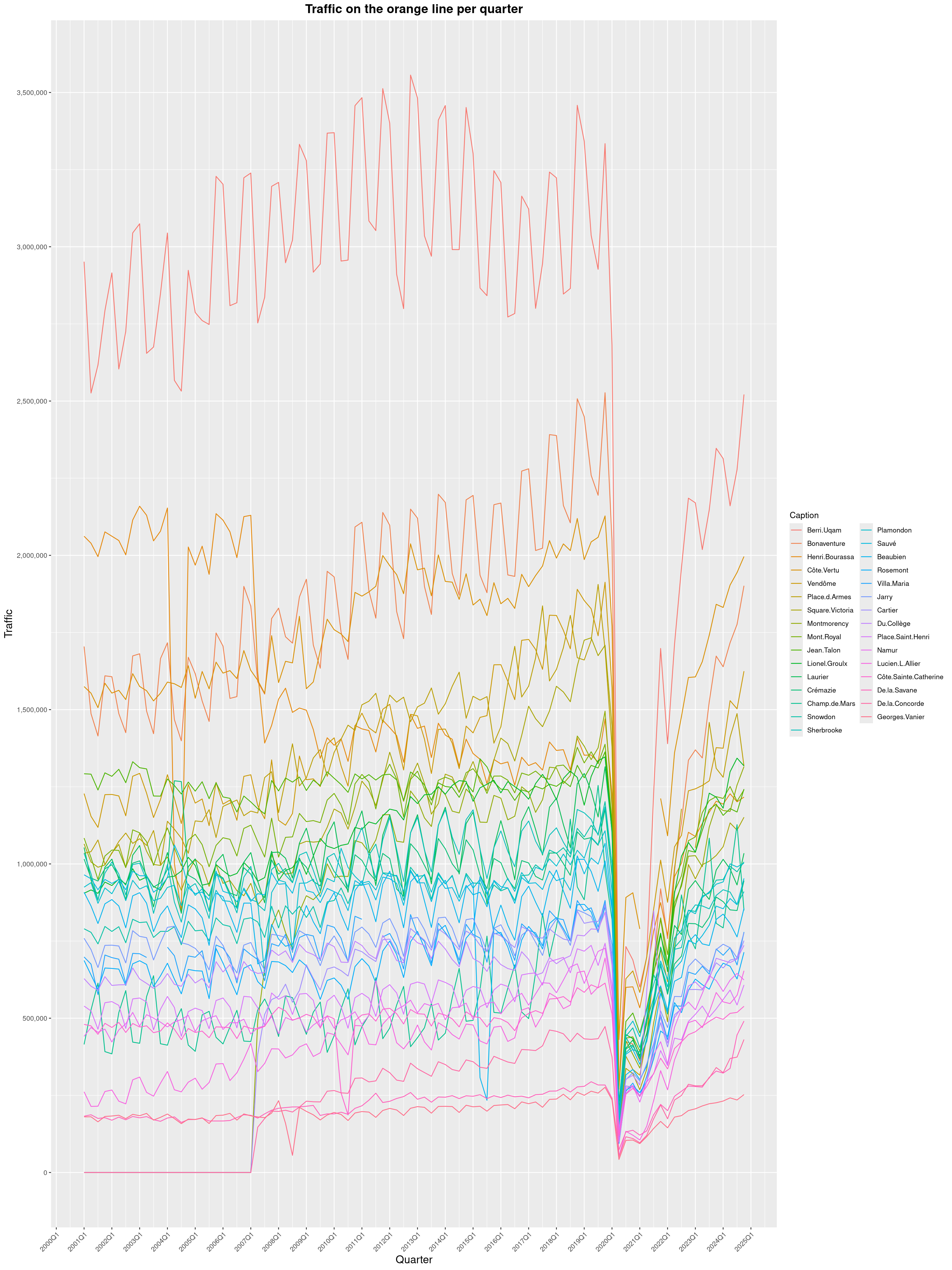
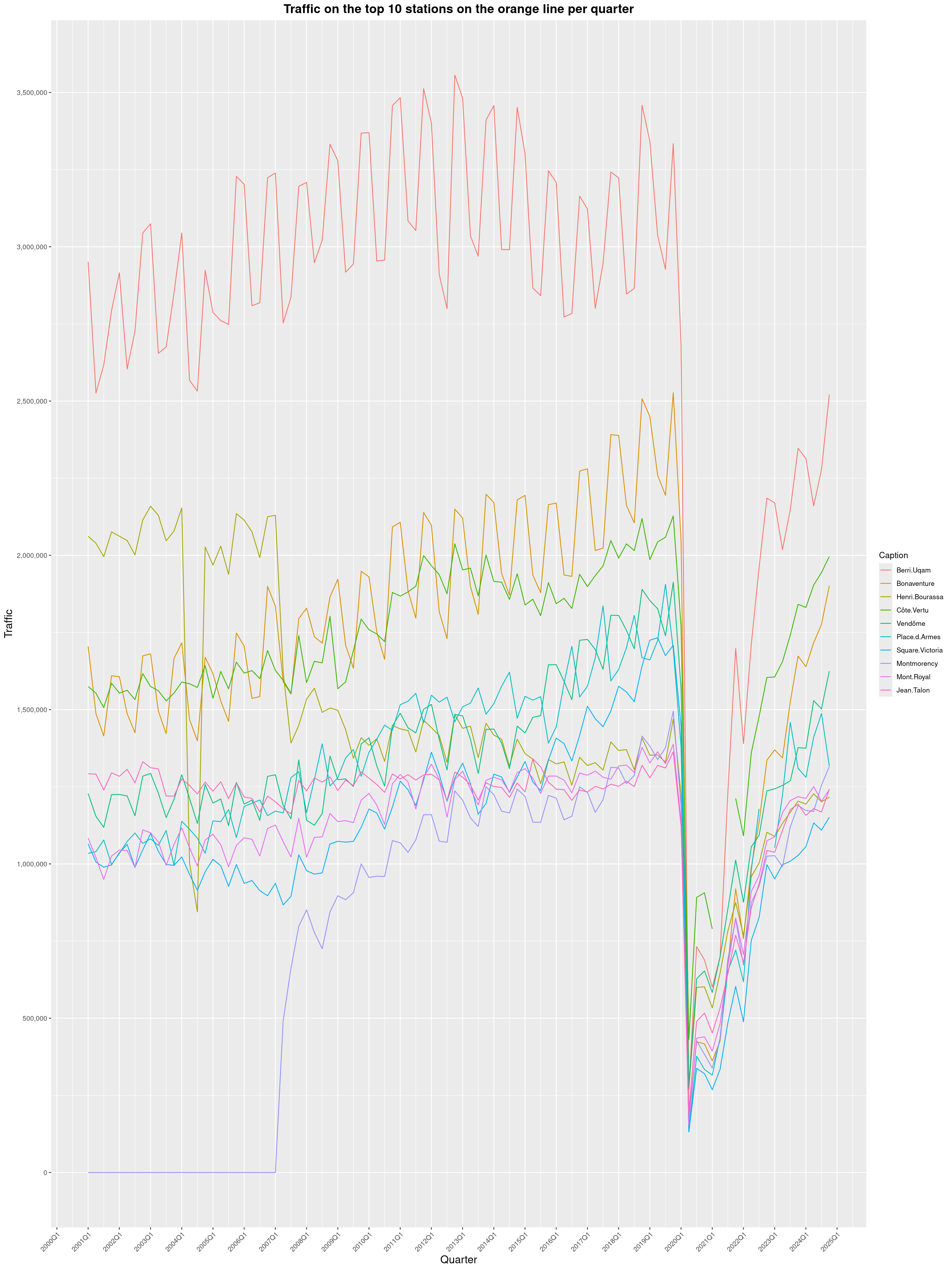
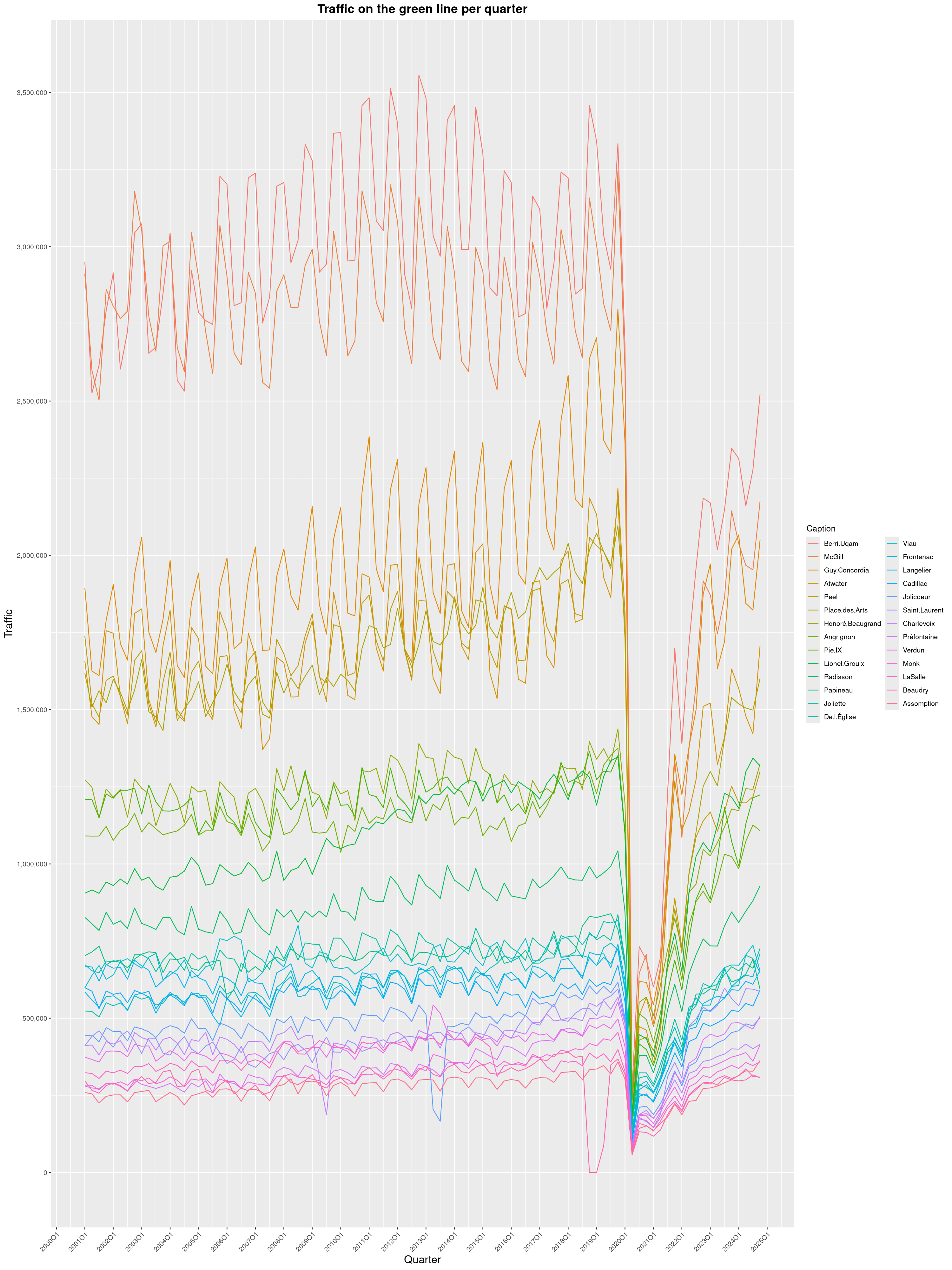
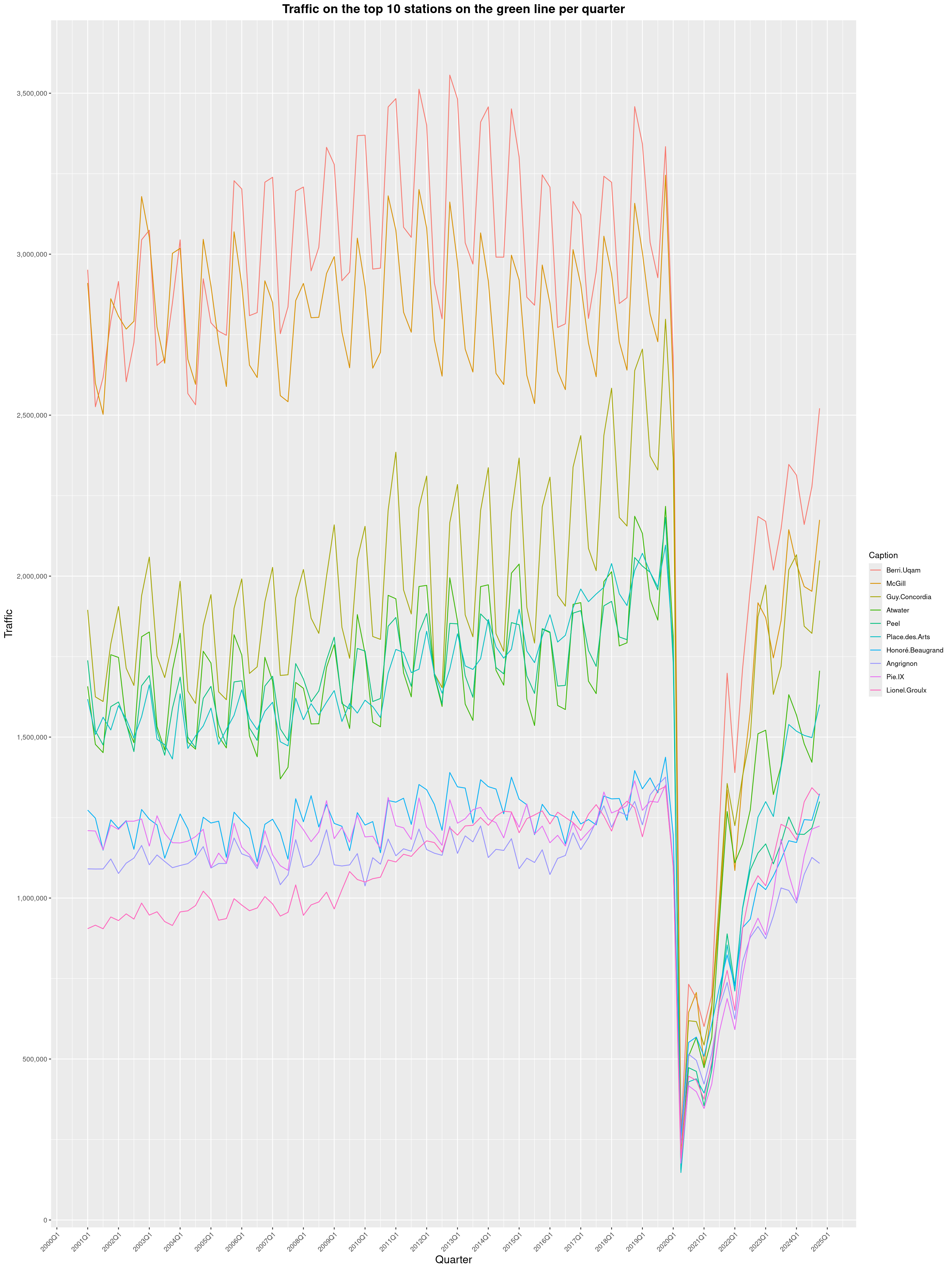
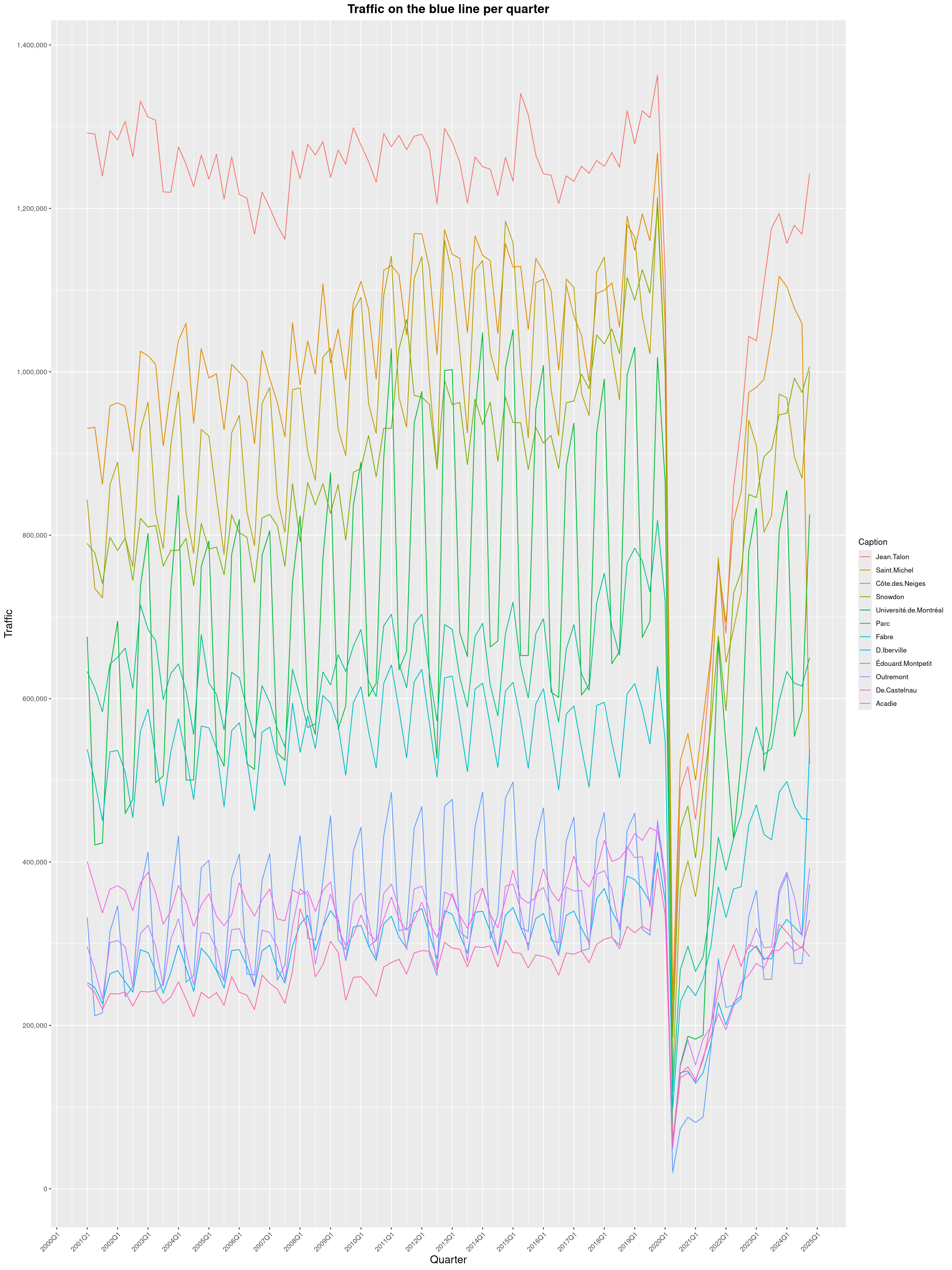
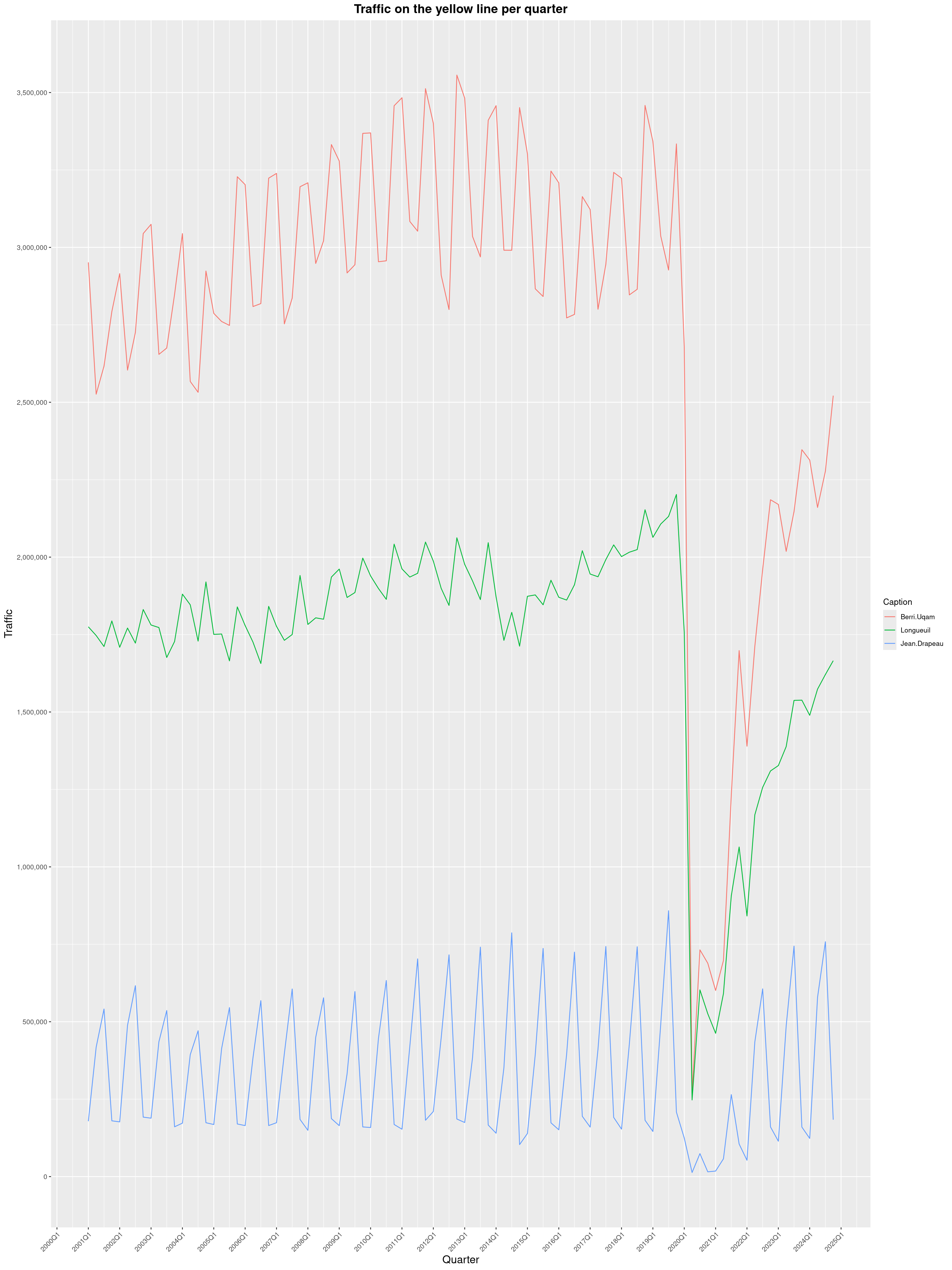
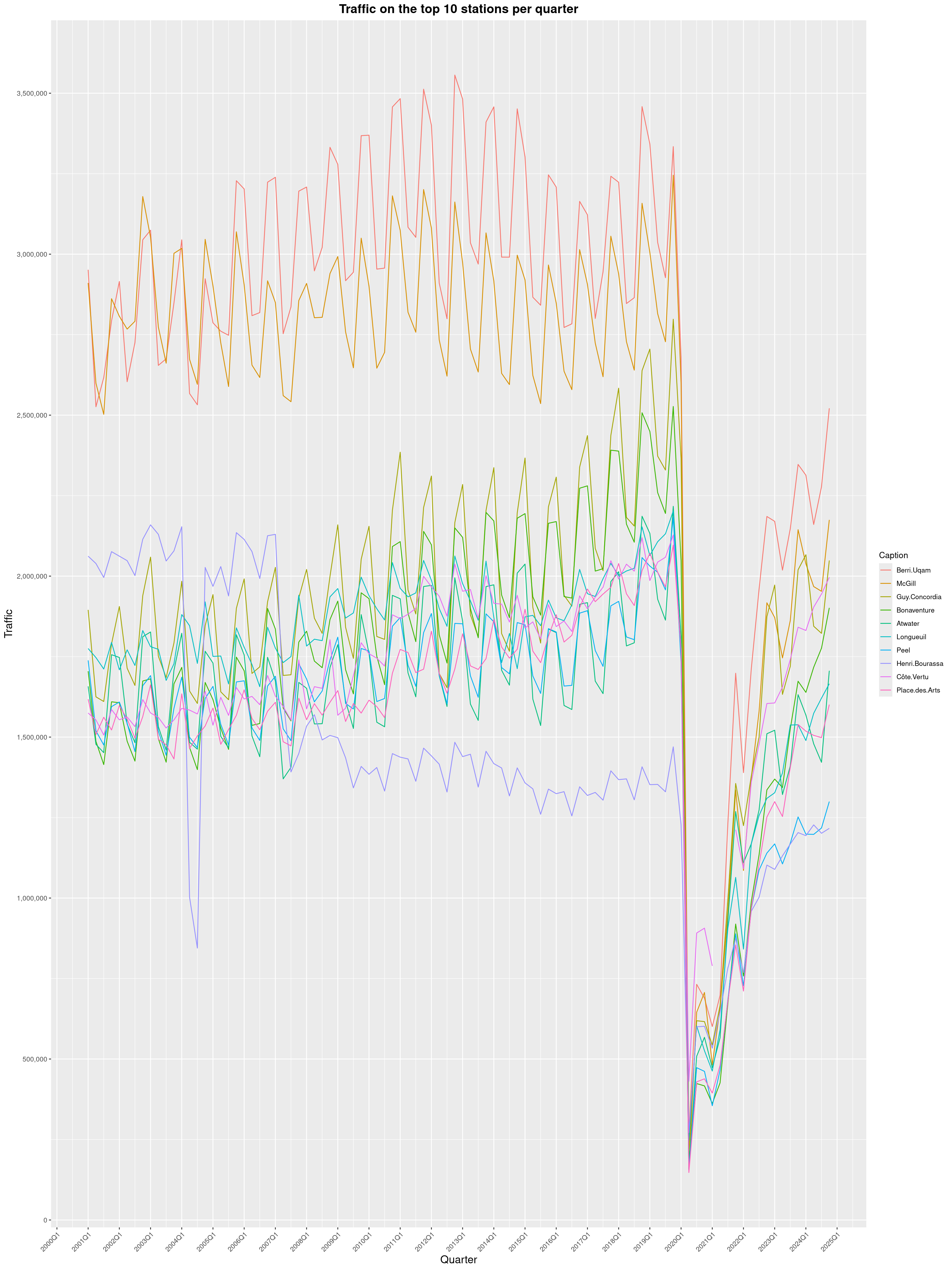
Louis-Philippe Véronneau: Montreal Subway Foot Traffic Data, 2024 edition
Another year of data from Société de Transport de Montréal, Montreal's transit agency!
A few highlights this year:
-
The closure of the Saint-Michel station had a drastic impact on D'Iberville, the station closest to it.
-
The opening of the Royalmount shopping center nearly doubled the traffic of the De La Savane station.
-
The Montreal subway continues to grow, but has not yet recovered from the pandemic. Berri-UQAM station (the largest one) is still below 1 million entries per quarter compared to its pre-pandemic record.
By clicking on a subway station, you'll be redirected to a graph of the station's foot traffic.
Licences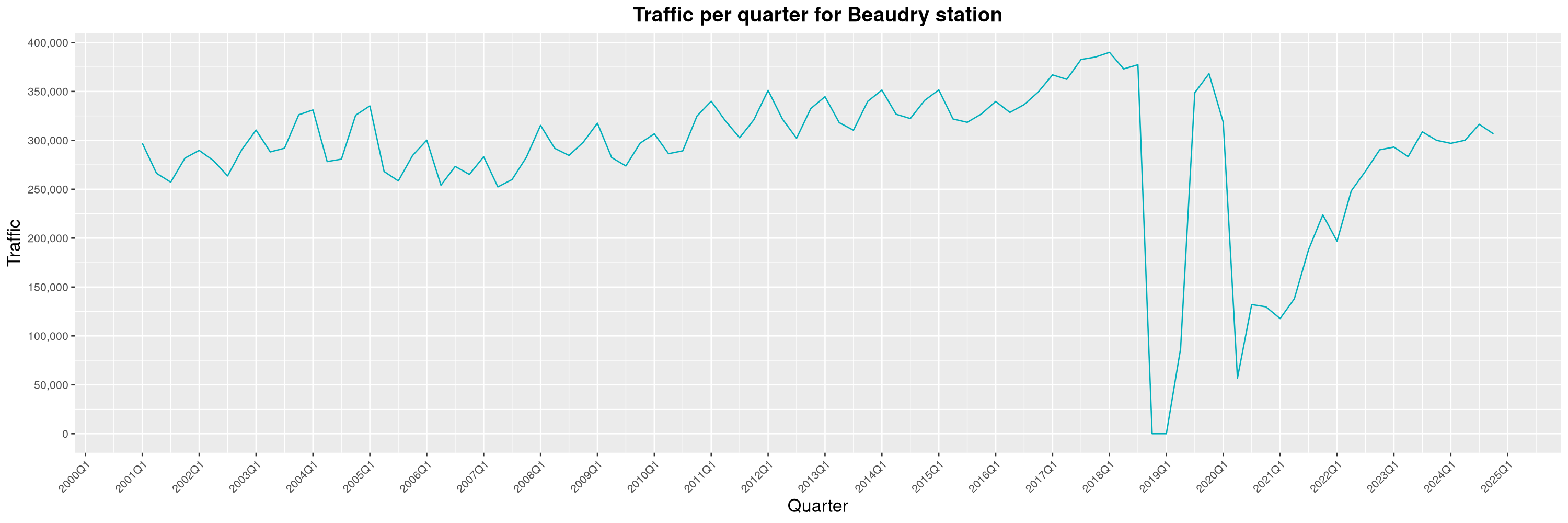{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
-
The subway map displayed on this page, the original dataset and my modified dataset are licenced under CCO 1.0: they are in the public domain.
-
The R code I wrote is licensed under the GPLv3+. It's pretty much the same code as last year. STM apparently changed (again!) the way they are exporting data, and since it's now somewhat sane, I didn't have to rely on a converter script.
Freelock Blog: What website owners need to know about Privacy
Owning a website in 2025 is not as freeform a thing as it was a couple decades ago. Much like the owner of a store or an amusement park ride has to pay some attention to safety hazards, now site owners can't simply neglect caring for the privacy of their visitors.
Sustainable/Open Business Read MoreNonprofit Drupal posts: January Drupal for Nonprofits Chat
Join us THURSDAY, January 16 at 1pm ET / 10am PT, for our regularly scheduled call to chat about all things Drupal and nonprofits. (Convert to your local time zone.)
We don't have anything specific on the agenda this month, so we'll have plenty of time to discuss anything that's on our minds at the intersection of Drupal and nonprofits. Got something specific you want to talk about? Feel free to share ahead of time in our collaborative Google doc: https://nten.org/drupal/notes!
All nonprofit Drupal devs and users, regardless of experience level, are always welcome on this call.
This free call is sponsored by NTEN.org and open to everyone.
-
Join the call: https://us02web.zoom.us/j/81817469653
-
Meeting ID: 818 1746 9653
Passcode: 551681 -
One tap mobile:
+16699006833,,81817469653# US (San Jose)
+13462487799,,81817469653# US (Houston) -
Dial by your location:
+1 669 900 6833 US (San Jose)
+1 346 248 7799 US (Houston)
+1 253 215 8782 US (Tacoma)
+1 929 205 6099 US (New York)
+1 301 715 8592 US (Washington DC)
+1 312 626 6799 US (Chicago) -
Find your local number: https://us02web.zoom.us/u/kpV1o65N
-
- Follow along on Google Docs: https://nten.org/drupal/notes
Bounteous.com: The Future of Experimentation: Acquia Convert
Bounteous.com: Discover the Power of Drupal for Enhanced Operational Efficiency and Security for Healthcare Systems
Bounteous.com: A New Age of Drupal: Drupal CMS
Bounteous.com: A Guide to the Latest Security Updates for Drupal 7 Users
Bounteous.com: Best Practices With Composable Drupal
Bounteous.com: The Evolution of Drupal: Discover the Features D7 Users Are Missing Out On
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
- Python Morsels: Python's range() function
- Tag1 Consulting: Performance Testing Leads To Major Improvements for Drupal CMS — and all of Drupal
- Daniel Roy Greenfeld: TIL: Using inspect and timeit together
- Freelock Blog: 🕵️♂️ Privacy for website owners, and introducing 💧 Drupal CMS
- Kdenlive 24.12.1 released