
Feeds
Real Python: The Real Python Podcast – Episode #205: Considering Accessibility & Assistive Tech as a Python Developer
What's it like to learn Python as a visually impaired or blind developer? How can you improve the accessibility of your Python web applications and learn current guidelines? This week on the show, Real Python community member Audrey van Breederode discusses her programming journey, web accessibility, and assistive technology.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
The Drop Times: DrupalCamp Poland 2024 Kicks Off Tomorrow in Warsaw!
Web Review, Week 2024-20
Let’s go for my web review for the week 2024-20.
Password cracking: past, present, futureTags: tech, security
Ever wondered about the state of the art in password cracking? This is not an easy read but a good reference.
https://www.openwall.com/presentations/OffensiveCon2024-Password-Cracking/
Tags: tech, cryptography
There are other cryptography schemes out there with interesting properties. Too bad they’re not very much used.
https://blog.cryptographyengineering.com/2017/07/02/beyond-public-key-encryption/
Tags: tech, system, hardware, failure
Strange things do happen when the hardware fails… indeed the systemd open question at the end is mysterious.
https://rachelbythebay.com/w/2024/05/15/ro/
Tags: tech, debian, packaging
Interesting work. This is nice to see improvements and experiments in dependency solvers for package managers.
https://blog.jak-linux.org/2024/05/14/solver3/
Tags: tech, tools, make
Looks like nice extensions to use GNU Make to run simple tasks.
https://github.com/mitjafelicijan/makext
Tags: tech, system, filesystem
You expect joining file paths to be a simple operation? Think again, it’s definitely error prone and can change between stacks.
https://lukas-prokop.at/articles/2024-05-03-filepath-join-behavior
Tags: tech, processes, system, linux
Definitely a recent and lesser known to interact with other processes. Could be useful in some cases.
https://www.corsix.org/content/what-is-a-pidfd
Tags: tech, c++, performance, memory
Interesting quick comparison, this shows the design tradeoffs quite well.
https://devblogs.microsoft.com/oldnewthing/20240510-00/?p=109742
Tags: tech, gpu, hardware, ai, machine-learning, neural-networks, performance
Interesting how much extra performance you can shave off the GPU by going back to how the hardware works.
https://hazyresearch.stanford.edu/blog/2024-05-12-tk
Tags: tech, graphics, mathematics, funny
Funny experiment playing with the frequency domain and the spatial domain of an image. This gives unintuitive results for sure.
https://lcamtuf.substack.com/p/sir-theres-a-cat-in-your-mirror-dimension
Tags: tech, tests, snapshots
This is a technique which is definitely underestimated. There are plenty of libraries out there allowing to use them.
https://tigerbeetle.com/blog/2024-05-14-snapshot-testing-for-the-masses
Tags: tech, programming, software, craftsmanship, engineering
Good food for thought. Explains quite well the factors which impact software development.
https://tratt.net/laurie/blog/2024/what_factors_explain_the_nature_of_software.html
Bye for now!
PyCharm: PyCharm 2024.2 EAP Is Open!
This blog post marks the start of the Early Access Program for PyCharm 2024.2. The PyCharm 2024.2 EAP 1 build is now accessible for download, providing an early glimpse into the exciting updates on the horizon.
You can download the new version from our website, update directly from inside the IDE or via the free Toolbox App, or use snap packs for Ubuntu.
If you’re new to the EAP process, we encourage you to read our introductory blog post. It offers valuable insights into the program and explains why your participation is integral.
Join us in the coming weeks to explore the new features in PyCharm, test them out, and provide feedback on the new additions. Your engagement is what helps us shape the evolution of PyCharm.
VCS New Graph Options: First Parent and No MergesGit has a useful option for viewing the history of changes in a branch: –first-parent. Use it with the git log command. This option simplifies the log by hiding individual commits that came with the merge, making it easier to track changes.
We’ve also added filtering with the –no merges command, which displays the history without any merge commits.
Both options can be selected under the Graph Options button in the Git tool window.
And that wraps up the first week! To see all the changes in this EAP build, check out the full release notes.
Keep an eye on our blog for weekly updates leading up to the major release. Your feedback is incredibly important to us, so please share your thoughts on the new features. You can leave a comment under his blog post or contact our team on X (formerly Twitter). If you encounter any bugs in this build, please report them through our issue tracker.
Promet Source: 9 Ways Drupal Keeps Government Sites Ahead of the Curve
Reproducible Builds (diffoscope): diffoscope 267 released
The diffoscope maintainers are pleased to announce the release of diffoscope version 267. This version includes the following changes:
[ Chris Lamb ] * Include "xz --verbose --verbose" (ie. double --verbose) output, not just the single --verbose. (Closes: #1069329) * Only include "xz --list" output if the xz has no other differences.You find out more by visiting the project homepage.
ImageX: Save Time, Maintain Consistency: Bulk-Update Drupal Content Instantly with the Field Defaults Module
Authored by Nadiia Nykolaichuk and Bryan Sharpe.
Smart approaches and tools are shaping the future of content management and website administration, leaving behind the days of tedious manual work. With a click of a button, you can instantly make consistent changes to multiple pages, almost as if wielding a magical wand.
John Goerzen: Review of Reputable, Functional, and Secure Email Service
I last reviewed email services in 2019. That review focused a lot of attention on privacy. At the time, I selected mailbox.org as my provider, and have been using them for these 5 years since. However, both their service and their support have gone significantly downhill since, so it is time for me to look at other options.
Here I am focusing strongly on email. Some of the providers mentioned here provide other services (IM, video calls, groupware, etc.), and to the extent they do, I am ignoring them.
What Matters in 2024I want to start off by acknowledging that what you need in email probably depends on your circumstances and the country in which you live. For me, I begin by naming that the largest threat most of us face isn’t from state actors but from criminals: hackers, ransomware gangs, etc. It is important to take as many steps as possible to secure one’s account against that. Privacy and security are both part of the mix. I still value privacy but I am acknowledging, as Migadu does, that “Email as we know it and encryption are incompatible.” Although some of these services strongly protect parts of the conversation, the reality is that most people will be emailing people using plain old email services which don’t. For stronger security, something like Signal would be needed. (I wrote about Signal in 2021 also.)
Interestingly, OpenPGP support seems to be something of a standard feature in the providers I reviewed by this point. All or almost all of them provide integration with browser-based encryption as well as server-side encryption if you prefer that.
Although mailbox.org can automatically PGP-encrypt every message that arrives in plaintext, for general use, this is unwieldy; there isn’t good tooling for searching mailboxes where every message is encrypted, etc. So I never enabled that feature at Mailbox. I still value security and privacy, but a pragmatic approach addresses the most pressing threats first.
My criteriaThe basic requirements for an email service include:
- Ability to use my own domains
- Strong privacy policy
- Ability for me to use my own IMAP and SMTP clients on both desktop and mobile
- It must be extremely reliable
- It must not be free
- It must have excellent support for those rare occasions when it is needed
- Support for basic aliases
Why do I say it must not be free? Because if someone is providing a service with the quality I’m talking about here, and not charging for it, it implies something is fishy: either they are unscrupulous, are financially unstable, or the product is something else like ads. I am not aware of any provider that matches the other criteria with a free account anyhow. These providers range from about $30 to $90 per year, so cheaper than a Netflix subscription.
Immediately, this rules out several options:
- Proton doesn’t let me use my own clients on mobile (their bridge is desktop-only)
- Tuta also doesn’t let me use my own clients
- Posteo doesn’t let me use my own domain
- mxroute.com lacks a strong privacy policy, and its policy has numerous causes for concern (for instance, “If you repeatedly send email to invalid/unroutable recipients, they may be published on our GitHub”)
I will have a bit more to say about a couple of these providers below.
There are some additional criteria that are strongly desired but not absolutely required:
- Ability to set individual access passwords for every device/app
- Support for two-factor authentication (2FA/TFA/TOTP) for web-based access
- Support for basics in filtering: ability to filter on envelope recipient (so if I get BCC’d, I can still filter), and ability to execute more than one action on filter match (eg, deliver to two folders, or deliver to a folder and forward to someone else)
IMAP and SMTP don’t really support 2FA, so by setting individual passwords for every device, you can at least limit the blast radius and cut off a specific device if something is (or might be) compromised.
The candidatesI considered these providers: Startmail, Mailfence, Runbox, Fastmail, Kolab, Mailbox.org, and Migadu. I’ll review each, and highlight the pricing of the plan I would most likely use.
I set up trials with each of these (except Mailbox.org, with which I already had a paid account). It so happend that I had actual questions for support for each one, which gave me an opportunity to see how support responded. I did not fabricate questions, and would not have contacted support if I didn’t have real ones. (This means that I asked different questions of each provider, because they were the REAL questions I had.) I’ll jump to the spoiler right now: I eventually chose Migadu, with Fastmail and Mailfence as close seconds.
I looked for providers myself, and also solicited recommendations in a Mastodon thread.
Mailbox.orgI begin with Mailbox, as it was my top choice in 2019 and the incumbent.
Until this year, I had been quite happy with it. I had cause to reach their support less than once a year on average, and each time they replied the same day or next day. Now, however, they are failing on reliability and on support.
Their spam filter has become overly aggressive. It has blocked quite a bit of legitimate mail. When contacting their support about a prior issue earlier this year, they initially took 4 days to reply, and then 6 days to reply after that. Ouch. They had me disable some spam settings.
It didn’t really help. I continue to lose mail. I don’t know how much, because they block a lot of it before it even hits the spam folder. One of my friends texted to say mail was dropping. I raised a new ticket with mailbox, which took them 5 days to reply to. Their reply was unhelpful. “As the Internet is not a static system, unforeseen events can always occur.” Well yes, that’s true, and I get it, false positives exist with email. But this was from an ISP’s mail system with an address that had been established for years, and it was part of a larger pattern of rejecting quite a bit of legit mail. And every interaction with them recently hasn’t resulted in them actually doing anything to resolve anything. It’s just a paragraph or two of reply that does nothing and helps nothing.
When I complained that it took 5 days to reply, they said “We have not been able to reply sooner as we are currently experiencing a high volume of customer enquiries.” Even though their SLA for my account is a not-great “48 business hour” turnaround, they still missed it and their reason is “we’re busy.” I finally asked what RBL had caught the blocked email, since when I checked, the sender wasn’t on any RBL. Mailbox’s reply: they only keep their logs for 7 days, so next time I contact them within 7 days. Which, of course, I DID; it was them that kept delaying. Ugh! It’s like they’ve become a cable company.
Even worse is how they have been blocking mail from GrapheneOS’s discussion form. See their thread about it. In short, Graphene’s mail server has a clean reputation and Mailbox has no problem with it. But because one of Graphene’s IPv6 webservers has an IPv6 allocation of a size Mailbox doesn’t like, they drop mail. It’s ridiculous, and Mailbox was dismissive of this well-known and well-regarded Open Source project. So if the likes of GrapheneOS can’t get good faith effort to deliver their mail, what chance does an individual like me have?
I’m sorry, but I’m literally paying you to deliver email for me and provide good support. If you can’t do either of those, you don’t get to push that problem down onto me. Hire appropriate staff.
On the technical side, they support aliases, my own clients, and have a reasonable privacy policy. Their 2FA support exists for the web interface (though weirdly not the support site), though it is somewhat weird. They do not support app passwords.
A somewhat unique feature is the @secure.mailbox.org domain. If you try to receive mail at that address, mailbox.org will block it unless it uses TLS. Same for sending. This isn’t E2EE, but it does at least require things not be in plaintext for the last hop to Mailbox.
Verdict: not recommended due to poor reliability and support.
Mailbox.Org summary:
- Website: https://mailbox.org/en/
- Reliability: iffy due to over-aggressive spam filtering
- Support: Poor; takes 4-6 days for a reply and replies are unhelpful
- Individual access passwords: No
- 2FA: Yes, but with a PIN instead of a password as the other factor
- Filtering: Full SIEVE feature set and GUI editor
- Spam settings: greylisting on/off, reject some/all spam, etc. But they’re insufficient to address Mailbox’s overzealousness, which support says I cannot workaround within the interface.
- Server storage location: Germany
- Plan as reviewed: standard [pricing link]
- Cost per year: EUR 30 (about $33)
- Mail storage included: 10GB
- Limits on send/receive volume: none
- Aliases: 50 on your domain name, 25 on mailbox.org
- Additional mailboxes: Available; each one at the same fee as the primary mailbox
I really wanted to like Startmail. Its “vault” is an interesting idea and should contribute to the security and privacy of an account. They clearly care about privacy.
It falls down in filtering. They have no way to filter on envelope recipient (BCC or similar). Their support confirmed this to me and that’s a showstopper.
Startmail support was also as slow as Mailbox, taking 5 days to respond to me.
Two showstoppers right there.
Verdict: Not recommended due to slow support responsiveness and weak filtering.
Startmail summary:
- Website: https://www.startmail.com/
- Reliability: Seems to be fine
- Support: Mediocre; Took 5 days for a reply, but the reply was helpful
- Individual app access passwords: Yes
- 2FA: Yes
- Filtering: Poor; cannot filter on envelope recipient, and can’t build filters with multiple actions
- Spam settings: None
- Server storage location: The Netherlands
- Plan as reviewed: Custom domain (trial was Personal), [pricing link]
- Cost per year: $70
- Mail storage included: 20GB
- Limits on send/receive volume: none
- Aliases: unlimited, with lots of features: can set expiration, etc.
- Additional mailboxes: not available
Kolab Now is mainly positioned as a full groupware service, but they do have a email-only option which I investigated. There isn’t much documentation about it compared to other providers, and also not much in the way of settings. You can turn greylisting on or off. And…. that’s it.
It has a full suite of filtering options. They set an X-Envelope-To header which you can use with the arbitrary header match to do the right thing even for BCC situations. Filters can have multiple conditions and multiple actions. It is SIEVE-based and you can download your SIEVE definitions.
If you enable 2FA, you disable IMAP and SMTP; not great.
Verdict: Not an impressive enough email featureset to justify going with it.
Kolab Now summary:
- Website: https://kolabnow.com/
- Reliability: Seems to be fine
- Support: Fine responsiveness (next day)
- Invidiaul app passwords: no
- 2FA: Yes, but if you enable it, they disable IMAP and SMTP
- Filtering: Excellent
- Spam settings: Only greylisting on/off
- Server storage location: Switzerland; they have lots of details on their setup
- Plan as reviewed: “Just email” [pricing link]
- Cost per year: CHF 60, about $66
- Mail storage included: 5GB
- Limitations on send/receive volume: None
- Aliases: Yes. Not sure if there are limits.
- Additional mailboxes: Yes if you set up a group account. “Flexible pricing based on user count” is not documented anywhere I could find.
Mailfence is another option, somewhat similar to Startmail but without the unique vault. I had some questions about filters, and support was quite responsive, responding in a couple of hours.
Some of their copy on their website is a bit misleading, but support clarified when I asked them. They do not offer encryption at rest (like most of the entries here).
Mailfence’s filtering system is the kind I’d like to see. It allows multiple conditions and multiple actions for each rule, and has some unique actions as well (notify by SMS or XMPP). Support says that “Recipients” matches envelope recipients. However, one ommission is that I can’t match on arbitrary headers; only the canned list of headers they provide.
They have only two spam settings:
- spam filter on/off
- whitelist
Given some recent complaints about their spam filter being overly aggressive, I find this lack of control somewhat concerning. (However, I discount complaints about people begging for more features in free accounts; free won’t provide the kind of service I’m looking for with any provider.) There are generally just very few settings for email as well.
Verdict: Response and helpful support, filtering has the right structure but lacks arbitrary header match. Could be a good option.
Mailfence summary:
- Website: https://mailfence.com/
- Reliability: Seems to be fine
- Support: Excellent responsiveness and helpful replies (after some initial confusion about my question of greylisting)
- Individual app access passwords: No. You can set a per-service password (eg, an IMAP password), but those will be shared with all devices speaking that protocol.
- 2FA: Yes
- Filtering: Good; only misses the ability to filter on arbitrary headers
- Spam settings: Very few
- Server storage location: Belgium
- Plan as reviewed: Entry [pricing link]
- Cost per year: $42
- Mail storage included: 10GB, with a maximum of 50,000 messages
- Limits on send/receive volume: none
- Aliases: 50. Aliases can’t be deleted once created (there may be an exeption to this for aliases on your own domain rather than mailfence.com)
- Additional mailboxes: Their page on this is a bit confusing, and the pricing page lacks the information promised. It looks like you can pay the same $42/year for additional mailboxes, with a limit of up to 2 additional paid mailboxes and 2 additional free mailboxes tied to the account.
This one came recommended in a Mastodon thread. I had some questions about it, and support response was fantastic – I heard from two people that were co-founders of the company! Even within hours, on a weekend. Incredible! This kind of response was only surpassed by Migadu.
I initially wrote to Runbox with questions about the incoming and outgoing message limits, which I hadn’t seen elsewhere, as well as the bandwidth limit. They said the bandwidth limit is no longer enforced on paid accounts. The incoming and outgoing limits are enforced, and all email (even spam) counts towards the limit. Notably the outgoing limit is per recipient, so if you send 10 messages to your 50-recipient family group, that’s the limit. However, they also indicated a willingness to reset the limit if something happens. Unfortunately, hitting the limit results in a hard bounce (SMTP 5xx) rather than a temporary failure (SMTP 4xx) so it can result in lost mail. This means I’d be worried about some attack or other weirdness causing me to lose mail.
Their filter is a pain point. Here are the challenges:
- You can’t directly match on a BCC recipient. Support advised to use a “headers” match, which will search for something anywhere in the headers. This works and is probably “good enough” since this data is in the Received: headers, but it is a little more imprecise.
- They only have a “contains”, not an “equals” operator. So, for instance, a pattern searching for “test@example.com” would also match “newtest@example.com”. Support advised to put the email address in angle brackets to avoid this. That will work… mostly. Angle brackets aren’t always required in headers.
- There is no way to have multiple actions on the filter (there is just no way to file an incoming message into two folders). This was the ultimate showstopper for me.
Support advised they are planning to upgrade the filter system in the future, but these are the limitations today.
Verdict: A good option if you don’t need much from the filtering system. Lots of privacy emphasis.
Runbox summary:
- Website: https://runbox.com/
- Reliability: Seems to be fine, except returning 5xx codes if per-day limits are exceeded
- Support: Excellent responsiveness and replies from founders
- Individual app passwords: Yes
- 2FA: Yes
- Filtering: Poor
- Spam settings: Very few
- Server storage location: Norway
- Plan as reviewed: Mini [pricing link]
- Cost per year: $35
- Mail storage included: 10GB
- Limited on send/receive volume: Receive 5000 messages/day, Send 500 recipients/day
- Aliases: 100 on runbox.com; unlimited on your own domain
- Additional mailboxes: $15/yr each, also with 10GB non-shared storage per mailbox
Fastmail came recommended to me by a friend I’ve known for decades.
Here’s the thing about Fastmail, compared to all the services listed above: It all just works. Everything. Filtering, spam prevention, it is all there, all feature-complete, and all just does the right thing as you’d hope. Their filtering system has a canned dropdown for “To/Cc/Bcc”, it supports multiple conditions and multiple actions, and just does the right thing. (Delivering to multiple folders is a little cumbersome but possible.) It has a particularly strong feature set around administering multiple accounts, including things like whether users can prevent admins from reading their mail.
The not-so-great part of the picture is around privacy. Fastmail is based in Australia, where the government has extensive power around spying on data, even to the point of forcing companies to add wiretap capabilities. Fastmail’s privacy policy states user data may be hold in Australia, USA, India, and Netherlands. By default, they share data with unidentified “spam companies”, though you can disable this in settings. On the other hand, they do make a good effort towards privacy.
I contacted support with some questions and got back a helpful response in three hours. However, one of the questions was about in which countries my particular data would be stored, and the support response said they would have to get back to me on that. It’s been several days and no word back.
Verdict: A featureful option that “just works”, with a lot of features for managing family accounts and the like, but lacking in the privacy area.
Fastmail summary:
- Website: https://www.fastmail.com/
- Reliability: Seems to be fine
- Support: Good response time on most questions; dropped the ball on one tha trequired research
- Individual app access passwords: Yes
- 2FA: Yes
- Filtering: Excellent
- Spam settings: Can set filter aggressiveness, decide whether to share spam data with “spam-fighting companies”, configure how to handle backscatter spam, and evaluate the personal learning filter.
- Server storage locations: Australia, USA, India, and The Netherlands. Legal jurisdiction is Australia.
- Plan as reviewed: Individual [pricing link]
- Cost per year: $60
- Mail storage included: 50GB
- Limits on send/receive volume: 300/hour
- Aliases: Unlimited from what I can see
- Additional mailboxes: No; requires a different plan for that
Migadu was a service I’d never heard of, but came recommended to me on Mastodon.
I listed Migadu last because it is a class of its own compared to all the other options. Every other service is basically a webmail interface with a few extra settings tacked on.
Migadu has a full-featured email admin console in addition. By that I mean you can:
- View usage graphs (incoming, outgoing, storage) over time
- Manage DNS (if you want Migadu to run your nameservers)
- Manage multiple domains, and cross-domain relationships with mailboxes
- View a limited set of logs
- Configure accounts, reset their passwords if needed/authorized, etc.
- Configure email address rewrite rules with wildcards and so forth
Basically, if you were the sort of person that ran your own mail servers back in the day, here is Migadu giving you most of that functionality. Effectively you have a web interface to do all the useful stuff, and they handle the boring and annoying bits. This is a really attractive model.
Migadu support has been fantastic. They are quick to respond, and went above and beyond. I pointed out that their X-Envelope-To header, which is needed for filtering by BCC, wasn’t being added on emails I sent myself. They replied 5 hours later indicating they had added the feature to add X-Envelope-To even for internal mails! Wow! I am impressed.
With Migadu, you buy a pool of resources: storage space and incoming/outgoing traffic. What you do within that pool is up to you. You can set up users (“mailboxes”), aliases, domains, whatever you like. It all just shares the pool. You can restrict users further so that an individual user has access to only a subset of the pool resources.
I was initially concerned about Migadu’s daily send/receive message count limits, but in visiting with support and reading the documentation, what really comes out is that Migadu is a service with a personal touch. Hitting the incoming traffic limit will cause a SMTP temporary fail (4xx) response so you won’t lose legit mail – and support will work with you if it’s a problem for legit uses. In other words, restrictions are “soft” and they are interpreted reasonably.
One interesting thing about Migadu is that they do not offer accounts under their domain. That is, you MUST bring your own domain. That’s pretty easy and cheap, of course. It also puts you in a position of power, because it is easy to migrate email from one provider to another if you own the domain.
Filtering is done via SIEVE. There is a GUI editor which lets you accomplish most things, though it has an odd blind spot where you can’t file a message into multiple folders. However, you can edit a SIEVE ruleset directly and you get the full SIEVE featureset, which is extensive (and does support filing a message into multiple folders). I note that the SIEVE :envelope match doesn’t work, but Migadu adds an X-Envelope-To header which is just as good.
I particularly love a company that tells you all the reasons you might not want to use them. Migadu’s pro/con list is an honest drawbacks list (of course, their homepage highlights all the features!).
Verdict: Fantastically powerful, excellent support, and good privacy. I chose this one.
Migadu summary:
- Website: https://migadu.com/
- Reliability: Excellent
- Support: Fantastic. Good response times and they added a feature (or fixed a bug?) a few hours after I requested it.
- Individual access passwords: Yes. Create “identities” to support them.
- 2FA: Yes, on both the admin interface and the webmail interface
- Filtering: Excellent, based on SIEVE. GUI editor doesn’t support multiple actions when filing into a folder, but full SIEVE functionality is exposed.
- Spam settings:
- On the domain level, filter aggressiveness, Greylisting on/off, black and white lists
- On the mailbox level, filter aggressiveness, black and whitelists, action to take with spam; compatible with filters.
- Server storage location: France; legal jurisdiction Switzerland
- Plan as reviewed: mini [pricing link]
- Cost per year: $90
- Mail storage included: 30GB (“soft” quota)
- Limits on send/receive volume: 1000 messgaes in/day, 100 messages out/day (“soft” quotas)
- Aliases: Unlimited on an unlimited number of domains
- Additional mailboxes: Unlimited and free; uses pooled quotas, but individual quotas can be set
Here are a few others that I didn’t think worthy of getting a trial:
- mxroute was recommended by several. Lots of concerning things in their policy, such as:
- if you repeatedly send mail to unroutable recipients, they may publish the addresses on Github
- they will terminate your account if they think you are “rude” or want to contest a charge
- they reserve the right to cancel your service at any time for any (or no) reason.
- Proton keeps coming up, and I will not consider it so long as I am locked into their client on mobile.
- Skiff comes up sometimes, but they were acquired by Norton.
- Disroot comes up; this discussion highlights a number of reasons why I avoid them. Their Terms of Service (ToS) is inconsistent with a general-purpose email account (I guess for targeting nonprofits and activists, that could make sense). Particularly laughable is that they claim to be friends of Open Source, but then would take down your account if you upload “copyrighted” material. News flash: in order for an Open Source license to be meaningful, the underlying work is copyrighted. It is perfectly legal to upload copyrighted material when you wrote it or have the license to do so!
There are a lot of good options for email hosting today, and in particular I appreciate the excellent personal support from companies like Migadu and Runbox. Support small businesses!
Unveiling ClearlyDefined: this free SBOM service gets cleared for takeoff
With all the buzz around SBOMs and Open Source supply chain compliance and security, a new revolution is igniting at ClearlyDefined. This amazing project has been flying under the radar since its inception six years ago, but now this free service and open source project from the Open Source Initiative (OSI) gets cleared for takeoff with the launch of a new website focused on stellar documentation, excellent engineering, and healthy community growth.
Generating SBOMs at scale for each stage on the supply chain, for every build or release, has proven to be a real challenge for organizations. And fixing the same missing or wrongly identified licensing metadata over and over again has been a redundant pain for everyone. This is where ClearlyDefined shines, as it makes it really easy for organizations to fetch a cached copy of licensing metadata for each component through a simple API, which is always up-to-date thanks to its crowdsourced database.
The all-new ClearlyDefined website was completely revamped to welcome community members and foster collaboration united by a shared vision of Open Source excellence. The website is divided into three sections: Docs, Resources, and Community.
Under Docs, both new and existing community members will find several comprehensive guides and tutorials. The main guide is “Getting involved,” where members will embark on a journey to learn how to use the data, curate the data, contribute data, contribute code, add a harvest and adopt practices. The “Roles” guide provides a detailed description of how different roles can master ClearlyDefined, from data consumer and data curator to data contributor and code contributor. Other guides that will expand in the coming months include the “Curation” and “Harvest” guides. Curation is the process of fixing or identifying missing licensing metadata and sharing that with the community, while harvest is the process of fetching licensing metadata directly from the source (package managers like npm and PyPi), processing the license definitions, and making them available through an API.
Under Resources, members will find a rich collection of content: Blog, FAQ, Glossary, Providers, Architecture and Roadmap. The roadmap was created in collaboration with members of the community, who provided input into what they would like to see in 2024 and how they would be able to contribute towards these goals.
Under Community, members will find links to various channels where they can engage with others online or in-person: GitHub, Forum, Events and Meetings. They’ll also find a list of other community members with whom they can forge connections, as well as the Code of Conduct and the project Charter.
We would like to extend a heartfelt thank you to our existing community members who have been instrumental with the launch of the new website and welcome new ones who are learning about the project. Besides expanding the “Curation” and “Harvest” guides, next steps include enhancing the user experience by implementing sitewide search and adding case studies filled with rich media. Come and join the ClearlyDefined community here and get ready to take off together with us. Let’s define the future of Open Source, one definition at a time!
Robin Wilson: Some matplotlib tips – a reblog
I was looking through my past blog posts recently, and thought a few of them were worth ‘reblogging’ so that more people could see them (now that my blog posts are getting more readers). So, here are a few posts on matplotlib tips.
Matplotlib titles have configurable locations – and you can have more than one at once!
This post explains how to create matplotlib titles in various locations.
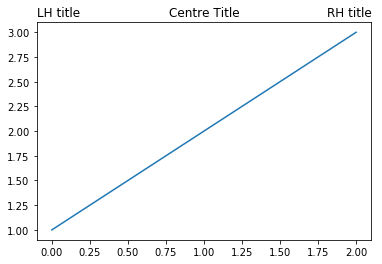{kind=link}
This post explains how to easily hide items from the legend in matplotlib.
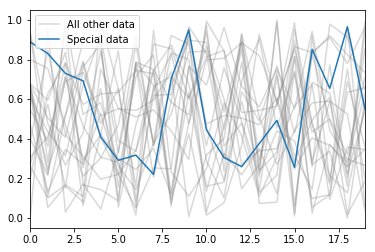{kind=link}
This post shows how to specify colours from the default colour cycle – ranging from a very simple way to more complex methods that might work in other situations.
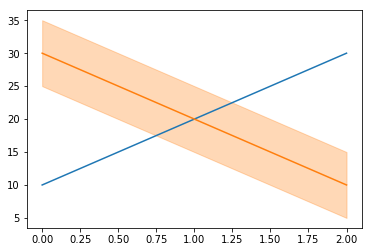{kind=link}
Matt Layman: Settings and Billing Portal - Building SaaS with Python and Django #190
Armin Ronacher: Using Rust Macros for Custom VTables
Given that building programming languages and interpreters is the developer's most favorite hobby, I will never stop writing templating engines. About three years ago I first wanted to see if I can make an implementation of my Jinja2 template engine for Rust. It's called MiniJinja and very close in behavior to Jinja2. Close enought that I have seen people pick it up more than I thought they would. For instance the Hugging Face Text Generation Inference uses it for chat templates.
I wrote it primarily just to see how you would introduce dynamic things into a language that doesn't have much of a dynamic runtime. A few weeks ago I released a major new version of the engine that has a very different internal object model for values and in this post I want to share a bit how it works, and what you can learn from it. At the heart of it is a type_erase! macro originally contributed by Sergio Benitez. This post goes into the need and usefulness of that macro.
Runtime ValuesTo understand the problem you first need to understand that a template engine like Jinja2 has requirements for runtime types that are a bit different from how Rust likes to think about data. The runtime is entirely dynamic and requires a form of garbage collection for those values. In case of a simple templating engine like Jinja2 you can largely get away with reference counting. The way this works in practice is that MiniJinja has a type called Value which can be cloned to increment the refcount, and when it's dropped the refcount is decremented. The value is the basic type that can hold all kinds of things (integers, strings, functions, sequences, etc.). In MiniJinja you can thus do something like this:
use minijinja::Value; // primitives let int_val = Value::from(42); let str_val = Value::from("Maximilian"); let bool_val = Value::from(true); // complex objects let vec_val = Value::from(vec![1, 2, 3]); // reference counting let vec_val2 = vec_val.clone(); // refcount = 2 drop(vec_val); // refcount = 1 drop(vec_val2); // refcount = 0 -> goneInside the engine these objects have all kinds of behaviors to make templates like this work:
{{ int_val }} 42 {{ str_val|upper }} MAXIMILIAN {{ not bool_val }} false {{ vec_val }} [1, 2, 3] {{ vec_val|reverse }} [3, 2, 1]Some of that functionality is also exposed via Rust APIs. So for instance you can iterate over values if they contain sequences:
let vec_val = Value::from(vec![1, 2, 3]); for value in vec_val.try_iter()? { println!("{} ({})", value, value.kind()); }If you run this, this will print the following:
1 (number) 2 (number) 3 (number)So each value in this object has itself been “boxed” in a value. As far as the engine is concerned, everything is a value.
ObjectsBut how do you get something interesting into these values that is not just a basic type that could be hardcoded (such as a vector)? Imagine you have a custom object that you want to efficently expose to the engine. This is in fact even something the engine itself needs to do internally. For instance Jinja has first class functions in the form of macros so it needs to expose that into the engine as well. Additionally Rust functions passed to the engine also need to be represented.
This is why a Value type can hold objects internally. These objects also support downcasting:
// box a vector in a value let value = Value::from_object(vec![1i32, 2, 3]); println!("{} ({})", value, value.kind()); // downcast it back into a reference of the original object let v: &Vec<i32> = value.downcast_object_ref().unwrap(); println!("{:?}", value);In order to do this, MiniJinja provides a trait called Object which if a type implements can be boxed into a value. All the dynamic operations of the value are forwarded into the internal Object. These operations are the following:
- repr(): returns the “representation” of the object. The representation define is how the object is represented (serialized) and how it behaves. Valid representations are Seq (the object is a list or sequence), Map (the object is a struct or map), Iterable (the object can be iterated over but not indexed), Plain (the object is just a plain object, for instance used for functions)
- get_value(key): looks up a key in the object
- enumerate(): returns the contents of the object if there are any
Additionally there is quite a few extra API (to render them to strings, to make them callable etc.) but we can ignore this for now. In addition there are a few more but some of them just have default implementations. For instance the “length” of an object by default comes from the length of the enumerator returned by enumerate().
So how would one design a trait like this? For sake of keeping this post brief let's pretend there is only repr, get_value and enumerate. Remember that we need to reference count, so we might be encouraged to make a trait like the following:
pub trait Object: Debug + Send + Sync { fn repr(self: &Arc<Self>) -> ObjectRepr { ObjectRepr::Map } fn get_value(self: &Arc<Self>, key: &Value) -> Option<Value> { None } fn enumerate(self: &Arc<Self>) -> Enumerator { Enumerator::NonEnumerable } }This trait looks pretty appealing. The self receiver type is reference counted (thanks to &Arc<Self>) and the interface is pretty minimal. Enumerator maybe needs a bit of explanation before we go further. In Rust usually when you iterate over an object you have something called an Iterator. Iterators usually borrow and you use traits to give the iterator additional functionality. For instance a DoubleEndedIterator can be reversed. In a template engine like Jinja we however need to do everything dynamically and we also need to ensure that we do not end up borrowing with lifetimes from the object. The engine needs to be able to hold on to the iterator independent of the object that you iterate. To simplify this process the engine uses this Enumerator type internally. It looks a bit like the following:
#[non_exhaustive] pub enum Enumerator { // object cannot be enumerated NonEnumerable, // object is empty Empty, // iterate over static strings Str(&'static [&'static str]), // iterate over an actual dynamic iterator Iter(Box<dyn Iterator<Item = Value> + Send + Sync>), // iterate by calling `get_value` in senquence from 0 to `usize` Seq(usize), }There are many more versions (for instance for DoubleEndedIterators and a few more) but again, let's keep it simple.
Why Arc Receiver?So why do you need an &Arc<Self> as receiver? Because in a lot of cases you really need to bump your own refcount to do something useful. For instance here is how the iteration of an object is implemented for sequences:
fn try_iter(self: &Arc<Self>) -> Option<Box<dyn Iterator<Item = Value> + Send + Sync>> where Self: 'static, { match self.enumerate() { Enumerator::Seq(l) => { let self_clone = self.clone(); Some(Box::new((0..l).map(move |idx| { self_clone.get_value(&Value::from(idx)).unwrap_or_default() }))) } // ... } }If we did not have a way to bump our own refcount, we could not implement something like this.
Boxing Up ObjectsWe can now use this to implement a custom struct for instance (say a 2D point with two attributes: x and y):
#[derive(Debug)] struct Point(f32, f32); impl Object for Point { fn repr(self: &Arc<Self>) -> ObjectRepr { ObjectRepr::Map } fn get_value(self: &Arc<Self>, key: &Value) -> Option<Value> { match key.as_str()? { "x" => Some(Value::from(self.0)), "y" => Some(Value::from(self.1)), _ => None, } } fn enumerate(self: &Arc<Self>) -> Enumerator { Enumerator::Str(&["x", "y"]) } }Or alternatively as a custom sequence:
#[derive(Debug)] struct Point(f32, f32); impl Object for Point { fn repr(self: &Arc<Self>) -> ObjectRepr { ObjectRepr::Seq } fn get_value(self: &Arc<Self>, key: &Value) -> Option<Value> { match key.as_usize()? { 0 => Some(Value::from(self.0)), 1 => Some(Value::from(self.1)), _ => None, } } fn enumerate(self: &Arc<Self>) -> Enumerator { Enumerator::Seq(2) } }Now that we have the object, we need to box it up into an Arc. Unfortunatley this is where we hit a hurdle:
error[E0038]: the trait `Object` cannot be made into an object --> src/main.rs:29:15 | 29 | let val = Arc::new(Point(1.0, 2.5)) as Arc<dyn Object>; | ^^^^^^^^^^^^^^^^^^^^^^^^^ `Object` cannot be made into an object | note: for a trait to be "object safe" it needs to allow building a vtable to allow the call to be resolvable dynamicallyThe reason it cannot be made into an object is because we declare the receiver as &Arc<Self> instead of &Self. This is a limitation because Rust is not capable of building a vtable for us. A vtable is nothing more than a struct that holds a field with a function pointer for each method on the trait. So our plan of using Arc<dyn Object> won't work, but we can in fact build out own version of this. To accomplish this we just need to build something like a DynObject which internally implements trampolines to call into the original methods and to manage the refcounting for us.
Macro MagicSince this requires a lot of unsafe code, and we want to generate all the necessary trampolines to put into the vtable automatically, we will use a macro. The invocation of that macro which generates the final type looks like this:
type_erase! { pub trait Object => DynObject { fn repr(&self) -> ObjectRepr; fn get_value(&self, key: &Value) -> Option<Value>; fn enumerate(&self) -> Enumerator; } }You can read this as “map trait Object into a DynObject smart pointer”. The actual macro has a few extra things (it also supports building the necessary vtable entries for fmt::Debug and other traits) but let's focus on the simple pieces. This macro generates some pretty wild output.
I cleaned it up and added some comments about what it does. Later I will show you the macro that generates it. First let's start with the definition of the fat pointer:
use std::sync::Arc; use std::any::{type_name, TypeId}; pub struct DynObject { /// ptr points to the payload of the Arc<T> ptr: *const (), /// this points to our vtable. The actual type is hidden /// (`VTable`) in a local scope. vtable: *const (), }And this is the implementation of the vtable and the type:
// this is a trick that is useful for generated macros to hide a type // at a local scope const _: () = { /// This is the actual vtable. struct VTable { // regular trampolines repr: fn(*const ()) -> ObjectRepr, get_value: fn(*const (), key: &Value) -> Option<Value>, enumerate: fn(*const ()) -> Enumerator, // method to return the type ID of the internal type for casts __type_id: fn() -> TypeId, // method to return the type name of the internal type __type_name: fn() -> &'static str, // method used to drop the refcount by one __drop: fn(*const ()), } /// Utility function to return a reference to the real vtable. fn vt(e: &DynObject) -> &VTable { unsafe { &*(e.vtable as *const VTable) } } impl DynObject { /// Takes ownership of an Arc<T> and boxes it up. pub fn new<T: Object + 'static>(v: Arc<T>) -> Self { // "shrinks" an Arc into a raw pointer. This returns the // address of the payload it carries, just behind the // refcount. let ptr = Arc::into_raw(v) as *const T as *const (); let vtable = &VTable { // example trampoline that is generated for each method repr: |ptr| unsafe { // before we reconstruct the Arc<T>, first ensure // we have incremented the refcount for panic // safety. If `repr()` panics, we will decref the // arc on unwind. Arc::<T>::increment_strong_count(ptr as *const T); // now take ownership of the ptr let arc = Arc::<T>::from_raw(ptr as *const T); // and invoke the original method via the arc <T as Object>::repr(&arc) }, get_value: |ptr, key| unsafe { Arc::<T>::increment_strong_count(ptr as *const T); let arc = Arc::<T>::from_raw(ptr as *const T); <T as Object>::get_value(&arc, key) }, enumerate: |ptr| unsafe { Arc::<T>::increment_strong_count(ptr as *const T); let arc = Arc::<T>::from_raw(ptr as *const T); <T as Object>::enumerate(&arc) }, // these are pretty trivial, they are modelled after // rust's `Any` type. __type_id: || TypeId::of::<T>(), __type_name: || type_name::<T>(), // on drop take ownership of the pointer (decrements // refcount by one) __drop: |ptr| unsafe { Arc::from_raw(ptr as *const T); }, }; Self { ptr, vtable: vtable as *const VTable as *const (), } } /// DynObject::repr() just calls via the vtable into the /// original type. pub fn repr(&self) -> ObjectRepr { (vt(self).repr)(self.ptr) } pub fn get_value(&self, key: &Value) -> Option<Value> { (vt(self).get_value)(self.ptr, key) } pub fn enumerate(&self) -> Enumerator { (vt(self).enumerate)(self.ptr) } } };At this point the object is functional, but it's kind of problematic because it does not yet have memory management so we would just leak memory. So we need to add that:
Memory management:
/// Clone just increments the strong refcount of the Arc. impl Clone for DynObject { fn clone(&self) -> Self { unsafe { Arc::increment_strong_count(self.ptr); } Self { ptr: self.ptr, vtable: self.vtable } } } /// Drop decrements the refcount via a method in the vtable. impl Drop for DynObject { fn drop(&mut self) { (vt(self).__drop)(self.ptr); } }Additionally to make the object useful, we need to add support for downcasting which is surprisingly easy at this point. If the type ID matches we're good to cast:
impl DynObject { pub fn downcast_ref<T: 'static>(&self) -> Option<&T> { if (vt(self).__type_id)() == TypeId::of::<T>() { unsafe { return Some(&*(self.ptr as *const T)); } } None } pub fn downcast<T: 'static>(&self) -> Option<Arc<T>> { if (vt(self).__type_id)() == TypeId::of::<T>() { unsafe { Arc::<T>::increment_strong_count(self.ptr as *const T); return Some(Arc::<T>::from_raw(self.ptr as *const T)); } } None } pub fn type_name(&self) -> &'static str { (vt(self).__type_name)() } } The MacroSo now that we know what we want, we can actually use a Rust macro to generate this stuff for us. I will leave most of this undocumented given that you know now what it expands to. Here just some notes to better understand what is going on:
- The const _:() = { ... } trick is useful as macros today cannot generate custom identifiers. Unlike with C macros where you can concatenate identifiers to create temporary names, that is unavailable in Rust. But you can use that to hide a type in a local scope as we are doing with the VTable struct.
- Since we cannot prefix identifiers, there is a potential conflict with the names in the struct for the methods and the internal names (__type_id etc.) To reduce the likelihood of collision the internal names are prefixed with two underscores.
- All names are fully canonicalized (eg: std::sync::Arc instead of Arc) to make the macro work without having to bring types into scope.
The macro is surprisingly only a bit awful:
macro_rules! type_erase { ($v:vis trait $t:ident => $erased_t:ident { $(fn $f:ident(&self $(, $p:ident: $t:ty $(,)?)*) $(-> $r:ty)?;)* }) => { $v struct $erased_t { ptr: *const (), vtable: *const (), } const _: () = { struct VTable { $($f: fn(*const (), $($p: $t),*) $(-> $r)?,)* $($($f_impl: fn(*const (), $($p_impl: $t_impl),*) $(-> $r_impl)?,)*)* __type_id: fn() -> std::any::TypeId, __type_name: fn() -> &'static str, __drop: fn(*const ()), } fn vt(e: &$erased_t) -> &VTable { unsafe { &*(e.vtable as *const VTable) } } impl $erased_t { $v fn new<T: $t + 'static>(v: std::sync::Arc<T>) -> Self { let ptr = std::sync::Arc::into_raw(v) as *const T as *const (); let vtable = &VTable { $( $f: |ptr, $($p),*| unsafe { std::sync::Arc::<T>::increment_strong_count(ptr as *const T); let arc = std::sync::Arc::<T>::from_raw(ptr as *const T); <T as $t>::$f(&arc, $($p),*) }, )* __type_id: || std::any::TypeId::of::<T>(), __type_name: || std::any::type_name::<T>(), __drop: |ptr| unsafe { std::sync::Arc::from_raw(ptr as *const T); }, }; Self { ptr, vtable: vtable as *const VTable as *const () } } $( $v fn $f(&self, $($p: $t),*) $(-> $r)? { (vt(self).$f)(self.ptr, $($p),*) } )* $v fn type_name(&self) -> &'static str { (vt(self).__type_name)() } $v fn downcast_ref<T: 'static>(&self) -> Option<&T> { if (vt(self).__type_id)() == std::any::TypeId::of::<T>() { unsafe { return Some(&*(self.ptr as *const T)); } } None } $v fn downcast<T: 'static>(&self) -> Option<Arc<T>> { if (vt(self).__type_id)() == std::any::TypeId::of::<T>() { unsafe { std::sync::Arc::<T>::increment_strong_count(self.ptr as *const T); return Some(std::sync::Arc::<T>::from_raw(self.ptr as *const T)); } } None } } impl Clone for $erased_t { fn clone(&self) -> Self { unsafe { std::sync::Arc::increment_strong_count(self.ptr); } Self { ptr: self.ptr, vtable: self.vtable, } } } impl Drop for $erased_t { fn drop(&mut self) { (vt(self).__drop)(self.ptr); } } }; }; }The full macro that is in MiniJinja is a bit more feature rich. It also generates documentation and implementations for other traits. If you want to see the full one look here: type_erase.rs.
Putting it TogetherSo now that we have this DynObject internally it's trivially possible to use it in the internals of our value type:
#[derive(Clone)] pub(crate) enum ValueRepr { Undefined, Bool(bool), U64(u64), I64(i64), F64(f64), None, String(Arc<str>, StringType), Bytes(Arc<Vec<u8>>), Object(DynObject), } #[derive(Clone)] pub struct Value(pub(crate) ValueRepr);And make the downcasting and construction of such types directly available:
impl Value { pub fn from_object<T: Object + Send + Sync + 'static>(value: T) -> Value { Value::from(ValueRepr::Object(DynObject::new(Arc::new(value)))) } pub fn downcast_object_ref<T: 'static>(&self) -> Option<&T> { match self.0 { ValueRepr::Object(ref o) => o.downcast_ref(), _ => None, } } pub fn downcast_object<T: 'static>(&self) -> Option<Arc<T>> { match self.0 { ValueRepr::Object(ref o) => o.downcast(), _ => None, } } }What do we learn from this? Not sure. I at least learned that just because Rust tells you that you cannot make something into an object does not mean that you actually can't. It just requires some creativity and the willingness to actually use unsafe code. Another thing is that this yet again makes a pretty good argument in favor of compile time introspection. Zig programmers will laugh / cry about this since comptime is a much more powerful system to make something like this work compared to the ridiculous macro abuse necessary in Rust.
Anyways. Maybe this is useful to you.
PreviousNext: Starshot and Experience Builder
Last week, I attended DrupalCon Portland 2024, and, like many others, I was swept up in the excitement of the Starshot announcement. The PreviousNext team is ready to support this initiative, focusing our efforts on the Experience Builder project for maximum impact.
by kim.pepper / 16 May 2024StarshotStarshot is a new concept that accelerates Drupal innovation by providing recipes or templates of best-practice features and configurations when creating a new Drupal site. It’s a separate product built on top of Drupal Core and has the working title “Drupal CMS”.
For years, we’ve pondered the question, “Is Drupal a product or a framework?” The answer has always been “both.” However, we can now clearly distinguish between the two.
We’re fully committed to the vision of bringing Drupal to new audiences by offering a straightforward way to create new Drupal sites using best-practice contributed modules and configuration. Combining Recipes with Project Browser, Automated Updates, and the new Experience Builder initiative will demonstrate Drupal’s full potential for product evaluators.
Releases for Drupal CMS will not be tied to Drupal Core, allowing it to innovate rapidly and evolve as contributed module updates and new best practices emerge. Drupal Core can simultaneously focus on maintaining quality and stability.
Experience BuilderExperience Builder is an ambitious initiative to reinvent how we build pages (experiences) in Drupal. Core committer Lauri Eskola undertook an extensive review of our own tools (Layout Builder, Paragraphs) and research into competing products to find a model that would best combine innovative user interface design with Drupal’s strengths in structured data.
Our team is in a strong and unique position to meaningfully contribute to the Experience Builder initiative. We have successfully delivered the Pitchburgh competition winner Decoupled Layout Builder prototype. We also provided numerous contributions to Layout Builder in core and contributed modules.
Experience Builder will become our primary contribution focus for the short and medium term, so watch this space.
We hope you are as excited as we are about the future of Drupal. We’re just getting started!
Five Jars: Drupal Starshot: Reflections on DrupalCon Portland 2024
Five Jars: The Driesnote 2024 at DrupalCon Portland
Mike Driscoll: An Intro to Logging with Python and Loguru
Python’s logging module isn’t the only way to create logs. There are several third-party packages you can use, too. One of the most popular is Loguru. Loguru intends to remove all the boilerplate you get with the Python logging API.
You will find that Loguru greatly simplifies creating logs in Python.
This chapter has the following sections:
- Installation
- Logging made simple
- Handlers and formatting
- Catching exceptions
- Terminal logging with color
- Easy log rotation
Let’s find out how much easier Loguru makes logging in Python!
InstallationBefore you can start with Loguru, you will need to install it. After all, the Loguru package doesn’t come with Python.
Fortunately, installing Loguru is easy with pip. Open up your terminal and run the following command:
python -m pip install loguruPip will install Loguru and any dependencies it might have for you. You will have a working package installed if you see no errors.
Now let’s start logging!
Logging Made SimpleLogging with Loguru can be done in two lines of code. Loguru is really that simple!
Don’t believe it? Then open up your Python IDE or REPL and add the following code:
# hello.py from loguru import logger logger.debug("Hello from loguru!") logger.info("Informed from loguru!")One import is all you need. Then, you can immediately start logging! By default, the log will go to stdout.
Here’s what the output looks like in the terminal:
2024-05-07 14:34:28.663 | DEBUG | __main__:<module>:5 - Hello from loguru! 2024-05-07 14:34:28.664 | INFO | __main__:<module>:6 - Informed from loguru!Pretty neat! Now, let’s find out how to change the handler and add formatting to your output.
Handlers and FormattingLoguru doesn’t think of handlers the way the Python logging module does. Instead, you use the concept of sinks. The sink tells Loguru how to handle an incoming log message and write it somewhere.
Sinks can take lots of different forms:
- A file-like object, such as sys.stderr or a file handle
- A file path as a string or pathlib.Path
- A callable, such as a simple function
- An asynchronous coroutine function that you define using async def
- A built-in logging.Handler. If you use these, the Loguru records convert to logging records automatically
To see how this works, create a new file called file_formatting.py in your Python IDE. Then add the following code:
# file_formatting.py from loguru import logger fmt = "{time} - {name} - {level} - {message}" logger.add("formatted.log", format=fmt, level="INFO") logger.debug("This is a debug message") logger.info("This is an informational message")If you want to change where the logs go, use the add() method. Note that this adds a new sink, which, in this case, is a file. The logger will still log to stdout, too, as that is the default, and you are adding to the handler list. If you want to remove the default sink, add logger.remove() before you call add().
When you call add(), you can pass in several different arguments:
- sink – Where to send the log messages
- level – The logging level
- format – How to format the log messages
- filter – A logging filter
There are several more, but those are the ones you would use the most. If you want to know more about add(), you should check out the documentation.
You might have noticed that the formatting of the log records is a little different than what you saw in Python’s own logging module.
Here is a listing of the formatting directives you can use for Loguru:
- elapsed – The time elapsed since the app started
- exception – The formatted exception, if there was one
- extra – The dict of attributes that the user bound
- file – The name of the file where the logging call came from
- function – The function where the logging call came from
- level – The logging level
- line – The line number in the source code
- message – The unformatted logged message
- module – The module that the logging call was made from
- name – The __name__ where the logging call came from
- process – The process in which the logging call was made
- thread – The thread in which the logging call was made
- time – The aware local time when the logging call was made
You can also change the time formatting in the logs. In this case, you would use a subset of the formatting from the Pendulum package. For example, if you wanted to make the time exclude the date, you would use this: {time:HH:mm:ss} rather than simply {time}, which you see in the code example above.
See the documentation for details on formating time and messages.
When you run the code example, you will see something similar to the following in your log file:
2024-05-07T14:35:06.553342-0500 - __main__ - INFO - This is an informational messageYou will also see log messages sent to your terminal in the same format as you saw in the first code example.
Now, you’re ready to move on and learn about catching exceptions with Loguru.
Catching ExceptionsCatching exceptions with Loguru is done by using a decorator. You may remember that when you use Python’s own logging module, you use logger.exception in the except portion of a try/except statement to record the exception’s traceback to your log file.
When you use Loguru, you use the @logger.catch decorator on the function that contains code that may raise an exception.
Open up your Python IDE and create a new file named catching_exceptions.py. Then enter the following code:
# catching_exceptions.py from loguru import logger @logger.catch def silly_function(x, y, z): return 1 / (x + y + z) def main(): fmt = "{time:HH:mm:ss} - {name} - {level} - {message}" logger.add("exception.log", format=fmt, level="INFO") logger.info("Application starting") silly_function(0, 0, 0) logger.info("Finished!") if __name__ == "__main__": main()According to Loguru’s documentation, the’ @logger.catch` decorator will catch regular exceptions and also work with applications with multiple threads. Add another file handler on top of the stream handler and start logging for this example.
Then you call silly_function() with a bunch of zeroes, which causes a ZeroDivisionError exception.
Here’s the output from the terminal:
If you open up the exception.log, you will see that the contents are a little different because you formatted the timestamp and also because logging those funny lines that show what arguments were passed to the silly_function() don’t translate that well:
14:38:30 - __main__ - INFO - Application starting 14:38:30 - __main__ - ERROR - An error has been caught in function 'main', process 'MainProcess' (8920), thread 'MainThread' (22316): Traceback (most recent call last): File "C:\books\11_loguru\catching_exceptions.py", line 17, in <module> main() └ <function main at 0x00000253B01AB7E0> > File "C:\books\11_loguru\catching_exceptions.py", line 13, in main silly_function(0, 0, 0) └ <function silly_function at 0x00000253ADE6D440> File "C:\books\11_loguru\catching_exceptions.py", line 7, in silly_function return 1 / (x + y + z) │ │ └ 0 │ └ 0 └ 0 ZeroDivisionError: division by zero 14:38:30 - __main__ - INFO - Finished!On the whole, using the @logger.catch is a nice way to catch exceptions.
Now, you’re ready to move on and learn about changing the color of your logs in the terminal.
Terminal Logging with ColorLoguru will print out logs in color in the terminal by default if the terminal supports color. Colorful logs can make reading through the logs easier as you can highlight warnings and exceptions with unique colors.
You can use markup tags to add specific colors to any formatter string. You can also apply bold and underline to the tags.
Open up your Python IDE and create a new file called terminal_formatting.py. After saving the file, enter the following code into it:
# terminal_formatting.py import sys from loguru import logger fmt = ("<red>{time}</red> - " "<yellow>{name}</yellow> - " "{level} - {message}") logger.add(sys.stdout, format=fmt, level="DEBUG") logger.debug("This is a debug message") logger.info("This is an informational message")You create a special format that sets the “time” portion to red and the “name” to yellow. Then, you add() that format to the logger. You will now have two sinks: the default root handler, which logs to stderr, and the new sink, which logs to stdout. You do formatting to compare the default colors to your custom ones.
Go ahead and run the code. You should see something like this:
Neat! It would be best if you now spent a few moments studying the documentation and trying out some of the other colors. For example, you can use hex and RGB colors and a handful of named colors.
The last section you will look at is how to do log rotation with Loguru!
Easy Log RotationLoguru makes log rotation easy. You don’t need to import any special handlers. Instead, you only need to specify the rotation argument when you call add().
Here are a few examples:
- logger.add("file.log", rotation="100 MB")
- logger.add("file.log", rotation="12:00")
- logger.add("file.log", rotation="1 week")
These demonstrate that you can set the rotation at 100 megabytes at noon daily or even rotate weekly.
Open up your Python IDE so you can create a full-fledged example. Name the file log_rotation.py and add the following code:
# log_rotation.py from loguru import logger fmt = "{time} - {name} - {level} - {message}" logger.add("rotated.log", format=fmt, level="DEBUG", rotation="50 B") logger.debug("This is a debug message") logger.info("This is an informational message")Here, you set up a log format, set the level to DEBUG, and set the rotation to every 50 bytes. When you run this code, you will get a couple of log files. Loguru will add a timestamp to the file’s name when it rotates the log.
What if you want to add compression? You don’t need to override the rotator like you did with Python’s logging module. Instead, you can turn on compression using the compression argument.
Create a new Python script called log_rotation_compression.py and add this code for a fully working example:
# log_rotation_compression.py from loguru import logger fmt = "{time} - {name} - {level} - {message}" logger.add("compressed.log", format=fmt, level="DEBUG", rotation="50 B", compression="zip") logger.debug("This is a debug message") logger.info("This is an informational message") for i in range(10): logger.info(f"Log message {i}")The new file is automatically compressed in the zip format when the log rotates. There is also a retention argument that you can use with add() to tell Loguru to clean the logs after so many days:
logger.add("file.log", rotation="100 MB", retention="5 days")If you were to add this code, the logs that were more than five days old would get cleaned up automatically by Loguru!
Wrapping UpThe Loguru package makes logging much easier than Python’s logging library. It removes the boilerplate needed to create and format logs.
In this chapter, you learned about the following:
- Installation
- Logging made simple
- Handlers and formatting
- Catching exceptions
- Terminal logging with color
- Easy log rotation
Loguru can do much more than what is covered here, though. You can serialize your logs to JSON or contextualize your logger messages. Loguru also allows you to add lazy evaluation to your logs to prevent them from affecting performance in production. Loguru also makes adding custom log levels very easy. For full details about all the things Loguru can do, you should consult Loguru’s website.
The post An Intro to Logging with Python and Loguru appeared first on Mouse Vs Python.
Real Python: Python's Built-in Exceptions: A Walkthrough With Examples
Python has a complete set of built-in exceptions that provide a quick and efficient way to handle errors and exceptional situations that may happen in your code. Knowing the most commonly used built-in exceptions is key for you as a Python developer. This knowledge will help you debug code because each exception has a specific meaning that can shed light on your debugging process.
You’ll also be able to handle and raise most of the built-in exceptions in your Python code, which is a great way to deal with errors and exceptional situations without having to create your own custom exceptions.
In this tutorial, you’ll:
- Learn what errors and exceptions are in Python
- Understand how Python organizes the built-in exceptions in a class hierarchy
- Explore the most commonly used built-in exceptions
- Learn how to handle and raise built-in exceptions in your code
To smoothly walk through this tutorial, you should be familiar with some core concepts in Python. These concepts include Python classes, class hierarchies, exceptions, try … except blocks, and the raise statement.
Get Your Code: Click here to download the free sample code that you’ll use to learn about Python’s built-in exceptions.
Errors and Exceptions in PythonErrors and exceptions are important concepts in programming, and you’ll probably spend a considerable amount of time dealing with them in your programming career. Errors are concrete conditions, such as syntax and logical errors, that make your code work incorrectly or even crash.
Often, you can fix errors by updating or modifying the code, installing a new version of a dependency, checking the code’s logic, and so on.
For example, say you need to make sure that a given string has a certain number of characters. In this case, you can use the built-in len() function:
Python >>> len("Pythonista") = 10 File "<input>", line 1 ... SyntaxError: cannot assign to function call here. Maybe you meant '==' instead of '='? Copied!In this example, you use the wrong operator. Instead of using the equality comparison operator, you use the assignment operator. This code raises a SyntaxError, which represents a syntax error as its name describes.
Note: In the above code, you’ll note how nicely the error message suggests a possible solution for correcting the code. Starting in version 3.10, the Python core developers have put a lot of effort into improving the error messages to make them more friendly and useful for debugging.
To fix the error, you need to localize the affected code and correct the syntax. This action will remove the error:
Python >>> len("Pythonista") == 10 True Copied!Now the code works correctly, and the SyntaxError is gone. So, your code won’t break, and your program will continue its normal execution.
There’s something to learn from the above example. You can fix errors, but you can’t handle them. In other words, if you have a syntax error like the one in the example, then you won’t be able to handle that error and make the code run. You need to correct the syntax.
On the other hand, exceptions are events that interrupt the execution of a program. As their name suggests, exceptions occur in exceptional situations that should or shouldn’t happen. So, to prevent your program from crashing after an exception, you must handle the exception with the appropriate exception-handling mechanism.
To better understand exceptions, say that you have a Python expression like a + b. This expression will work if a and b are both strings or numbers:
Python >>> a = 4 >>> b = 3 >>> a + b 7 Copied!In this example, the code works correctly because a and b are both numbers. However, the expression raises an exception if a and b are of types that can’t be added together:
Python >>> a = "4" >>> b = 3 >>> a + b Traceback (most recent call last): File "<input>", line 1, in <module> a + b ~~^~~ TypeError: can only concatenate str (not "int") to str Copied!Because a is a string and b is a number, your code fails with a TypeError exception. Since there is no way to add text and numbers, your code has faced an exceptional situation.
Python uses classes to represent exceptions and errors. These classes are generically known as exceptions, regardless of what a concrete class represents, an exception or an error. Exception classes give us information about an exceptional situation and also errors detected during the program’s execution.
The first example in this section shows a syntax error in action. The SyntaxError class represents an error but it’s implemented as a Python exception. This could be confusing, but Python uses exception classes for both errors and exceptions.
Read the full article at https://realpython.com/python-built-in-exceptions/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Real Python: How to Get the Most Out of PyCon US
Congratulations! You’re going to PyCon US!
Whether this is your first time or not, going to a conference full of people who love the same thing as you is always a fun experience. There’s so much more to PyCon than just a bunch of people talking about the Python language, and that can be intimidating for first-time attendees. This guide will help you navigate all there is to see and do at PyCon.
PyCon US is the biggest conference centered around the Python language. Originally launched in 2003, this conference has grown exponentially and has even spawned several other PyCons and workshops around the world.
Everyone who attends PyCon will have a different experience, and that’s what makes the conference truly unique. This guide is meant to help you, but you don’t need to follow it strictly.
By the end of this article, you’ll know:
- How PyCon consists of tutorials, conference, and sprints
- What to do before you go
- What to do during PyCon
- What to do after the event
- How to have a great PyCon
This guide will have links that are specific to PyCon 2024, but it should be useful for future PyCons as well.
Free Download: Get a sample chapter from Python Tricks: The Book that shows you Python’s best practices with simple examples you can apply instantly to write more beautiful + Pythonic code.
What PyCon InvolvesBefore considering how to get the most out of PyCon, it’s important to first understand what PyCon involves.
PyCon is broken up into three stages:
-
Tutorials: PyCon starts with two days of three-hour workshops, during which you get to learn in depth with instructors. These are great to go to since the class sizes are small, and you can ask questions of the instructors. You should consider going to at least one of these if you can, but they do have an additional cost of $150 per tutorial.
-
Conference: Next, PyCon offers three days of talks. Each presentation lasts for thirty to forty-five minutes, and there are about five talks going on at a time, including a Spanish language charlas track. But that’s not all: there are also open spaces, sponsors, posters, lightning talks, dinners, and so much more.
-
Sprints: During this stage, you can take what you’ve learned and apply it! This is a four-day exercise where people group up to work on various open-source projects related to Python. If you’ve got the time, going to one or more sprint days is a great way to practice what you’ve learned, become associated with an open-source project, and network with other smart and talented people. Learn more about sprints in this blog post from an earlier year.
Since most PyCon attendees go to the conference part, that’ll be the focus of this article. However, don’t let that deter you from attending the tutorials or sprints if you can!
You may even learn more technical skills by attending the tutorials rather than listening to the talks. The sprints are great for networking and applying the skills that you’ve already got, as well as learning new ones from the people you’ll be working with.
What to Do Before You GoIn general, the more prepared you are for something, the better your experience will be. The same applies to PyCon.
It’s really helpful to plan and prepare ahead of time, which you’re already doing just by reading this article!
Look through the talk schedule and see which talks sound most interesting to you. This doesn’t mean you need to plan out all of the talks that you’re going to see, in every slot possible. But it helps to get an idea of which topics are going to be presented so that you can decide what you’re most interested in.
Getting the PyCon US mobile app will help you plan your schedule. This app lets you view the schedule for the talks and add reminders for the ones that you want to attend. If you’re having a hard time picking which talks to go to, you can come prepared with a question or problem that you need to solve. Doing this can help you focus on the topics that are important to you.
If you can, come a day early to check in and attend the opening reception. The line to check in on the first day is always long, so you’ll save time if you check in the day before. There’s also an opening reception that evening, so you can meet other attendees and speakers, as well as get a chance to check out the various sponsors and their booths.
If you’re brand-new to PyCon, the Newcomer Orientation can help you get caught up on what the conference involves and how you can participate.
Read the full article at https://realpython.com/pycon-guide/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
The Open Source AI Definition gets closer to reality with a global workshop series
The OSI community is traveling to five continents seeking diverse input on how to guarantee the freedoms to use, study, share and modify Open Source AI systems.
SAN FRANCISCO – May 14, 2024 – Open Source Initiative (OSI), globally recognized by individuals, companies and public institutions as the authority that defines Open Source, is driving a global multi-stakeholder process to define “Open Source AI.” This definition will provide a framework to help AI developers and users determine if an AI system is Open Source or not, meaning that it’s available under terms that allow unrestricted rights to use, study, modify and share. There are currently no accepted means by which openness can be validated for AI, yet many organizations are claiming their AI to be “Open Source.” Just as the Open Source Definition serves as the globally accepted standard for Open Source software, so will the Open Source AI Definition act as a standard for openness in AI systems and their components.
In 2022 the OSI started an in-depth global initiative to engage key players, including corporations, academia, the legal community and organizations and nonprofits representing wider civil society, in a collaborative effort to draft a definition of Open Source AI that ensures that society at large can retain agency and control over the technology. The project has increased in importance as legislators around the world started regulating AI, asking for feedback as guardrails are defined.
This open process has resulted in a massive body of work including podcasts, panel discussions, webinars, published reports, and a plethora of town halls, workshops and conference sessions around the world. A big emphasis was given to make the process as inclusive and representative as possible: 53% of the working groups were composed of people of color. Women and femmes, including transgender women, accounted for 28% of the total and 63% of those individuals are women of color.
After months of weekly town hall meetings, draft releases and reviews the OSI is nearing a stable version of the Open Source AI Definition. Now, the OSI is embarking on a roadshow of workshops to be held on five continents to solicit input from diverse stakeholders on the draft definition. The goal is to present a stable version of the definition in October at the All Things Open event in Raleigh, North Carolina. This “Open Source AI Definition Roadshow” is sponsored by the Alfred P. Sloan Foundation, and OSI’s sponsors and donors.
“AI is different from regular software and forces all stakeholders to review how the Open Source principles apply to this space,” said Stefano Maffulli, executive director of the OSI. “OSI believes that everybody deserves to maintain agency and control of the technology. We also recognize that markets flourish when clear definitions promote transparency, collaboration and permissionless innovation. After spending almost two years gathering voices from all over the world to identify the principles of Open Source suitable for AI systems, we’re embarking on a worldwide roadshow to refine and validate the release candidate version of the Open Source AI Definition.”
The schedule of workshops is as follows:
- North America
- USA, Pittsburgh, PyCon US (May 17)
- USA, NYC, OSPOs for Good (July 9 – 11)
- USA, Raleigh, All Things Open (October 27 – 29)
- Europe
- France, Paris, OW2 (June 11 – 12)
- Spain, Madrid, OpenExpo Europe (June 13)
- Africa
- Nigeria, Lagos, August tentative
- Asia Pacific
- Hong Kong, AI_Dev (August 23)
- Asia – details TBD, DPGA members meeting (November 12 – 14)
- Latin America
- Argentina, Buenos Aires, Nerdearla (September 24 – 28)
For weekly updates, town hall recordings and access to all the previously published material, visit opensource.org/deepdive.
Supporters of the Open Source AI Definition ProcessThe Deep Dive: Defining Open Source AI co-design process is made possible thanks to grant 2024-22486 from Alfred P. Sloan Foundation, donations from Google Open Source, Cisco, Amazon and others, and donations by individual members. The media partner is OpenSource.net.
Others interested in offering support can contact OSI at sponsors@opensource.org.
Real Python: Quiz: What Are CRUD Operations?
In this quiz, you’ll test your understanding of CRUD Operations.
By working through this quiz, you’ll revisit the key concepts and techniques related to CRUD operations. Good luck!
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
- Behind the Scenes of Embedded Updates
- Dries Buytaert: Join the Drupal Starshot team as a track lead
- Dirk Eddelbuettel: Rcpp 1.0.13 on CRAN: Some Updates
- roose.digital: This is how you redirect all visitors to the HTTPS version of your Drupal website with or without WWW
- Lullabot: The Easy Guide to Resolving composer.lock Conflicts
FLOSS Research
- The Open Source Initiative joins CMU in launching Open Forum for AI: A human-centered approach to AI development
- Open Source AI Definition – Weekly update July 15
- Mer Joyce: voices of the Open Source AI Definition
- Beyond SPDX: expanding licenses identified by ClearlyDefined
- Highlights from AI_dev Paris