
FLOSS Project Planets
Talk Python to Me: #475: Python Language Summit 2024
Russell Coker: Wifi 6E Mesh
I am looking into getting a Wifi mesh network. The aim is to use it for providing access to devices through my home especially for devices on the congested 2.4GHz frequency. Ideally I want 6GHz Wifi6E for the communication between mesh nodes as well as for talking to the few devices that are new enough to support it (I like buying cheap second hand devices). 2.5Gbit ethernet connections on all mesh nodes would be good too.
Wifi 7 is semi-released, you can buy devices even though the specs aren’t entirely finalised. I expect that next year when Wifi 7 devices are more common the second hand prices of Wifi 6E will drop. Currently Wifi 6E devices are somewhat expensive.
One major problem at the moment is “cloud configuration”. Here is a 41 page forum thread of TP-Link customers asking in vain for non-cloud configuration [1]. The problems with cloud configuration are that it doesn’t allow configuration without Internet access (so no fixing things when internet breaks and no use for a private network without Internet), it relies on a proprietary phone app (so a problem with your phone breaks everything), and it adds a dependency on an unpaid service that TP-Link might decide to turn off at some future time. The TP -Link Deco X55 AX3000 looks like a good set of devices, it currently costs $328 for a set of three Wifi 6 (not 6E) devices is a good deal, pity that the poor software options let it down.
TP-Link also seems to be scanning web traffic and sending the analysis to an external site [2], it seems to be operating as malware. The TP-Link software seems to be most accurately described as malware.
There is the OpenWrt project for open firmware on Wifi APs which is a great project [3] but it doesn’t seem to support any Wifi 6 mesh systems yet. If most Wifi hardware requires malware for operation it seems that running a VPN over Wifi is the way to go. A hostile party being able to sniff your home network is much worse than a hostile party sniffing public Internet traffic.
The Google Nest mesh devices have good specs and price, $359 for a three node Wifi 6E mesh that has 2.5Gbit ethernet. But they can only be configured with a Google app for Android or iOS and require a Gmail account. Giving Google the ability to shut down all my stuff by deleting my gmail account is not acceptable. Also Google is well known for cancelling services [4]. A mitigating factor is that there should be enough of those devices sold to make them a good target for an OpenWRT port.
As an aside it looks like the TailScale mesh VPN system could be a solution to the security issues related to malware on Wifi APs problem [5]. There is also HeadScale which is the fully open source variant of that [6]. Even when the vendor isn’t overtly hostile they can make mistakes so encryption is good.
Kogan is selling an own-brand Wifi 6 mesh network package that comes with 1/2/3 devices for $70/$120/$140. It doesn’t do Wifi 6E but supports the better encoding methods of Wifi 6 over Wifi 5 and will be good for bridging a LAN in one part of a house to a Wifi 2.4GHz or Ethernet connected device in another part. They also support up to 7 nodes so you could buy two of the 3 device packages and run one network with 2 and another with 4. The pricing is very competitive and they support web based administration!
I’ve just ordered the $140 pack from Kogan. If it doesn’t do what I want then I can find someone else who will be happy with whatever functionality it gives and $140 is an amount I can risk without concern. If it works well then I might upgrade to Wifi 6E or Wifi 7 next year and deploy the Wifi 6 one for a relative.
- [1] https://community.tp-link.com/en/home/forum/topic/531350
- [2] https://tinyurl.com/y84skkdp
- [3] https://openwrt.org/supported_devices
- [4] https://killedbygoogle.com/
- [5] https://en.wikipedia.org/wiki/Tailscale
- [6] https://headscale.net/
Related posts:
- Wifi Performance on Linux Wifi usually just works. In the past I haven’t had...
- 2 node vs 3+ node clusters A comment on my post about the failure probability of...
- Ethernet bonding Bonding is one of the terms used to describe multiple...
Russell Coker: Is Secure Boot Worth Using?
With news like this one cited by Bruce Schneier [1] people are asking whether it’s worth using Secure Boot.
Regarding the specific news article, this is always a risk with distributed public key encryption systems. Lose control of one private key and attackers can do bad things. That doesn’t make it bad it just makes it less valuable. If you want to setup a system for a government agency, bank, or other high value target then it’s quite reasonable to expect an adversary to purchase systems of the same make and model to verify that their attacks will work. If you want to make your home PC a little harder to attack then you can expect that the likely adversaries won’t bother with such things. You don’t need security to be perfect, making a particular attack slightly more difficult than other potential attacks gives a large part of the benefit.
The purpose of Secure Boot is to verify the boot loader with a public key signature and then have the boot loader verify the kernel. Microsoft signs the “shim” that is used by each Linux distribution to load GRUB (or another boot loader). So when I configure a Debian system with Secure Boot enabled that doesn’t stop anyone from booting Ubuntu. From the signatures on the boot loader etc there is no difference from my Debian installation and a rescue image from Debian, Ubuntu, or another distribution booted by a hostile party to do things against my interests. The difference between the legitimate OS image and malware is a matter of who boots it and the reason for booting it.
It is possible to deconfigure Microsoft keys from UEFI to only boot from your own key, this document describes what is necessary to do that [2]. Basically if you boot without using any “option ROMs” (which among other things means the ROM from your video card) then you can disable the MS keys.
If it’s impossible to disable the MS keys that doesn’t make it impossible to gain a benefit from the Secure Boot process. You can use a block device decryption process that involves a signature of the kernel and the BIOS being used as part of the decryption for the device. So if a system is booted with the wrong kernel and the user doesn’t recognise it then they will find that they can’t unlock the device with the password. I think it’s possible on some systems to run the Secure Boot functionality in a non-enforcing mode such that it will use a bootloader without a valid signature but still use the hash for TPM calculations, that appears impossible on my Thinkpad Yoga Gen3 which only has enabled and disabled as options but should work on Dell laptops which have an option to run Secure Boot in permissive mode.
I believe that the way of the future is to use something like EFIStub [3] to create unified kernel images with a signed kernel, initrd, and command-line parameters in a single bundle which can be loaded directly by the UEFI BIOS. From the perspective of a distribution developer it’s good to have many people using the current standard functionality of shim and GRUB for EFI as a step towards that goal.
CloudFlare has a good blog post about Linux kernel hardening [4]. In that post they cover the benefits of a full secure boot setup (which is difficult at the current time) and the way that secure boot enables the lockdown module for kernel integrity. When Secure Boot is detected by the kernel it automatically enables lockdown=integrity functionality (see this blog post for an explanation of lockdown [5]). It is possible to enable this by putting “lockdown=integrity” on the kernel command line or “lockdown=confidentiality” if you want even more protection, but it happens by default with Secure Boot. Secure Boot is something you can set to get a selection of security features enabled and get a known minimum level of integrity even if the signatures aren’t used for anything useful, restricting a system to only boot kernels from MS, Debian, Ubuntu, Red Hat, etc is not useful.
For most users I think that Secure Boot is a small increase in security but testing it on a large number of systems allows increasing the overall security of operating systems which benefits the world. Also I think that having features like EFIStub usable for a large portion of the users (possibly the majority of users) is something that can be expected to happen in the lifetime of hardware being purchased now. So ensuring that Secure Boot works with GRUB now will facilitate using EFIStub etc in future years.
- [1] https://tinyurl.com/264thnky
- [2] https://github.com/Foxboron/sbctl/wiki/FAQ#option-rom
- [3] https://wiki.debian.org/EFIStub
- [4] https://blog.cloudflare.com/de-de/linux-kernel-hardening
- [5] https://mjg59.dreamwidth.org/55105.html
- [6] https://wiki.debian.org/SecureBoot
Related posts:
- Secure Boot and Protecting Against Root There has been a lot of discussion recently about the...
- Question about a “Secure Filesystem” I have just been asked for advice about “secure filesystem”...
- Designing a Secure Linux System The Threat Bruce Schneier’s blog post about the Mariposa Botnet...
This week in KDE: per-monitor brightness control and “update then shut down”
This week was all about the quality of life features! As we close in on Plasma 6.2 (the soft feature freeze is in four days, eek!), some great work that’s been in progress for a long time got merged.
Notable New FeaturesOkular now has a “speak text from current page” feature (Athul Raj Kollareth, Okular 24.12.0. Link)
Plasma’s Brightness widget now shows individual brightness sliders for every connected monitor that supports this, so you can control them separately! If you want to adjust all of them together, you can still do that via global shortcut/keyboard key or by scrolling over the widget (Jakob Petsovits, Plasma 6.2.0. Link):
When there’s a pending offline system update, you’ve already got the option to update and then reboot, or just reboot and skip the update. Now, there’s also an option to complete the update and then shut down the computer! This option is exposed both on the logout screen, and also in Discover (Thomas Duckworth, Plasma 6.2.0. Link 1, link 2, and link 3):
Long-pressing an empty area of a Plasma panel using a touchscreen now enters edit mode for that panel (Niccolò Venerandi, Plasma 6.2.0. Link)
Notable UI ImprovementsThe “Add Widgets” sidebar has received a UX overhaul with numerous usability focused changes, including:
- Appearing on the right side of the screen when opened from a right-screen-edge panel
- Using wider grid cells to permit longer text without elision or unnatural word-wrap behaviors
- Improved appearance of the filter button, so now it looks like it opens a drop-down menu — because it does
- Sorting is now locale-aware, taking into account, for example, accented characters
- You access it from buttons and menu items labeled “Add or Manage Widgets,” since it also acts as the place where you get new widgets or delete unwanted ones
- Spacer widgets can also be found there, no longer only from the panel settings dialog
- When installing manually-downloaded widgets, the open dialog now accept all valid file types
And believe it or not, that’s not all that’s planned! But the rest will have to wait until next week… (Niccolò Venerandi, Plasma 6.2.0. Link 1, link 2 3, link 4, link 5, link 6, link 7)
When your system is using a non-default power profile, it’s now shown as a badge on the battery icon, so you can see both the power profile and also the battery status at the same time (Louis Moureaux and me: Nate Graham, Plasma 6.2.0. Link 1 and link 2):
At the moment this only works with the Breeze icon theme, and 3rd-party icon themes will have to add some more icons to opt into it. Until then, users of those icon themes will get the old appearance when using a non-default power profileA panel popup opened from a widget on the end of a limited-width panel now tries its best to align its edge with that of the panel (Niccolò Venerandi, Plasma 6.2.0. Link):
Maybe I just really like clocks, ok?You can now give a custom display name to your custom command shortcuts (Yifan Zhu and Thenujan Sandramohan, Plasma 6.2.0. Link):
Discover is now more accurate about how it presents licenses, and communicates the subtle distinctions between “proprietary” and “non-free”, rather than branding everything that isn’t free software as proprietary (me: Nate Graham, Plasma 6.2.0. Link):
When you change keyboard layouts, the labels of the language codes that appear in the system tray no longer subtly change in size based on the shape of their letters (Sauf Lvc, Plasma 6.2.0. Link)
Added a Breeze icon for Applet Wallet bundle files (Kai Uwe Broulik, Frameworks 6.6. Link):
Notable Bug FixesWhen Spectacle is configured to save in a format other than PNG by default, pasting a just-copied screenshot now always works in every target app, with the caveat that some apps that don’t advertise support for non-PNG image pasting (like Firefox and Chromium, annoyingly) will get a PNG version anyway, rather than your preferred file format. This is better than it not working at all, at least! (Noah Davis, Spectacle 24.08.1. Link)
You can once again use the arrow keys to move focus out of Kickoff’s favorites grid view (Arjen Hiemstra, Plasma 6.1.5. Link)
Fixed a complex bug that could cause KWin to crash when X11 or XWayland-using apps monkeyed with the window stacking order in specific ways (Vlad Zahorodnii, Plasma 6.1.5. Link. And thanks to the reporter Peter Strick for being incredibly helpful in making the issue reproducible! All bug reports should be so good.)
Fixed an annoying bug that caused text copied from cells in LibreOffice Calc to never make it onto the clipboard unless you changed the clipboard’s settings to always store images (Fushan Wen, Plasma 6.1.5. Link)
Fixed a bug that caused tooltips to appear at the last location the mouse pointer was located at when interacting with the system using a stylus (David Redondo, Plasma 6.1.5. Link)
Fixed a funny bug that could make Plasma crash when you have a Media Player widget on your panel (not the System Tray, directly on a panel) and play certain specific songs whose titles are exactly the right length to trigger an obscure layout bug (Fushan Wen, Plasma 6.2.0. Link)
Fixed a weird issue that made modifier-only global shortcuts in the X11 session fail to switch keyboard layouts as expected while on the lock screen and other places (Yifan Zhu, Plasma 6.2.0. Link)
Exporting your shortcuts on System Settings’ Shortcuts page now includes any custom script shortcuts you’ve created, so that when you import them elsewhere, they work (Akseli Lahtinen and David Redondo, Plasma 6.2.0. Link)
Other bug information of note:
- 2 Very high priority Plasma bugs (down from 3 as last week). Current list of bugs
- 36 15-minute Plasma bugs (up from 30 last week; bug triage activities discovered some more old issues that seemed important to fix soon, which were added to the list). Current list of bugs
- 156 KDE bugs of all kinds fixed over the last week. Full list of bugs
Improved KWin’s HDR tone mapping, allowing it to do a better job of displaying colors in cases where HDR content specifies a brightness level higher than what the screen is capable of outputting. There’s even more that can be done, but it’s already a big improvement. (Xaver Hugl, Plasma 6.2.0. Link)
Even further optimized the system performance impact in KWin of using an ICC profile to change your screen’s color calibration (Xaver Hugl, Plasma 6.2.0. Link)
Improved KWin’s performance for some multi-GPU systems (Xaver Hugl, Plasma 6.2.0. Link)
Added a bunch of autotests for X11-specific behavior in KWin, since fewer people are exercising that code now that 80+% of Plasma 6 users are using Wayland (Vlad Zahorodnii, Plasma 6.2.0. Link)
…And Everything ElseThis blog only covers the tip of the iceberg! If you’re hungry for more, check out https://planet.kde.org, where you can find more news from other KDE contributors.
How You Can HelpOtherwise, visit https://community.kde.org/Get_Involved to discover other ways to be part of a project that really matters. Each contributor makes a huge difference in KDE; you are not a number or a cog in a machine! You don’t have to already be a programmer, either. I wasn’t when I got started. Try it, you’ll like it! We don’t bite! Or consider donating instead! That helps too.
Web Review, Week 2024-34
Let’s go for my web review for the week 2024-34.
Unbundling Profile: MIT Libraries - SPARCTags: research, copyright, open-access
It’s good to see major institutions like this get out of contracts with scientific publishing companies. Those unfortunately became mostly parasitic. Open access should be the norm for research.
https://sparcopen.org/our-work/big-deal-knowledge-base/unbundling-profiles/mit-libraries/
Tags: tech, mozilla, privacy
Since they unfortunately turned on private attribution by default (why? Mozilla, why?). Here is an easy automated way to turn it off.
https://make-firefox-private-again.com/
Tags: tech, web, semantic
With all those bots and scripts crawling the Web, some of the semantic web vision got silently implemented.
Tags: tech, ai, machine-learning, gpt, markov-chains, funny
Interesting musing. The predictability in tone doesn’t make for very funny content indeed. Also as a side-effect this might help people remember that Markov chain are a thing and much less expensive.
https://emnudge.dev/blog/markov-chains-are-funny/
Tags: tech, security
Scary thread… developers should know better than do this and ship it on devices around the world. Their data is now anyone for the taking and users’ privacy can’t be ensured.
https://digipres.club/@foone/112990331505043510
Tags: tech, networking, security, tools
Looks like a nice tool to monitor your network.
Tags: tech, book, ip, networking
Looks like an interesting resource to learn about IPv6.
Tags: tech, linux, kernel, memory
Funny musing about the OOM killer. With nice pointers if you want to dive further into the topic.
https://quuxplusone.github.io/blog/2024/08/22/overcommit/
Tags: tech, benchmarking
Be sure to pick the right behavior model when you make a benchmark. Otherwise you might just measure the wrong thing.
https://buttondown.com/jaffray/archive/the-closed-loop-benchmark-trap/
Tags: tech, c++
A little refresher about std::ref and std::cref. They come in handy sometimes, but also if you don’t realize you need them you’ll generate more copies than necessary.
https://www.sandordargo.com/blog/2024/08/21/std-ref
Tags: tech, cpu, simd, performance, physics, simulation
SIMD is hard to use, not all problems can apply to it. But when they can, the performance gain can be great.
https://box2d.org/posts/2024/08/simd-matters/
Tags: tech, python, tools
Looks like there’s another contender for package management for Python. This is sooo fragmented now… this one is compelling though.
https://astral.sh/blog/uv-unified-python-packaging
Tags: tech, javascript, memory, leak
There are many ways to create a memory leak in Javascript. Here is a good list of the things to pay attention to.
https://www.trevorlasn.com/blog/common-causes-of-memory-leaks-in-javascript
Tags: tech, web, frontend, ux
It’s better than no feedback. It’s a bit lazy and far from perfect though.
https://maxschmitt.me/posts/toasts-bad-ux
Tags: tech, web, frontend, ux, criticism
Interesting series about the rise of the javascript frontend framework, the bad practices which came with them and the very real impacts on the users. There are indeed better ways.
https://infrequently.org/series/reckoning/
Tags: tech, design, programming
This is a good point. The DRY principle has value but the trick is finding the right time to apply it.
https://jerf.org/iri/post/2024/dry_strong/
Tags: tech, codereview
Starts like a satire, but there’s a serious conclusion in the end. Indeed, mind the power dynamics in code reviews. Be nice, steer away from those antipatterns, especially since you might be on the receiving end the next time.
https://www.chiark.greenend.org.uk/~sgtatham/quasiblog/code-review-antipatterns/
Tags: tech, agile, history, criticism
Very nice interview. This is an interesting reflection on the past 20+ years of Agile Software Development.
https://ronjeffries.com/articles/-x024/-v04/8/
Tags: tech, product-management
Nice way to keep in check how and why behavior changes as the requests from various stakeholders come in.
https://buttondown.com/j2kun/archive/decision-logs/
Tags: tech, hr, interviews, debugging
This is indeed a nice way to approach technical interviews. Unfortunately it requires quite some effort to setup and maintain. You also have to find the right bugs to put in the interview and this is a rarity.
https://blog.jez.io/bugsquash/
Bye for now!
The Drop Times: For an Independent, Sustainable, Future-Proof DA: Alejandro Moreno
The Drop Times: Drupal Decoupled Simplifies Adoption with New Composer Project Template
Real Python: The Real Python Podcast – Episode #218: Exploring Robotics and Python Through Electronic Projects
Are you interested in learning robotics with Python? Can physical electronics-based projects grow a child's interest in coding? This week on the show, we speak with author Marwan Alsabbagh about his book "Build Your Own Robot - Using Python, CRICKIT, and Raspberry Pi."
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
mark.ie: My Drupal Core Contributions for week-ending August 23rd, 2024
I've been spending some time recently trying to get the Umami demo message from toolbar into the navigation module.
Metrics in KDE – Are they useful?
Since Plasma 5.18, nearly five years ago, Plasma has shipped with a "telemetry" system. It’s opt-in, allowing users to send a small amount of data back to us.
Was it useful or worth it? It's a question that comes up occasionally, and the answer is mixed. I believe it showed real potential, though the reality of our implementation was somewhat underwhelming and didn't really deliver. There are many lessons learned that are worth sharing with other projects that might face similar endeavours.
The good bitsWhere we had data available for topics being discussed it worked. To give two concrete examples from memory:
-
A developer claimed, "No one is using a screen smaller than 1024x768," while bumping the minimum size of a window. This was proved wrong; the number of users at 800x600 or even 640x480 is surprisingly high. Still low as an overall percentage, but higher than you would ever intuitively think. Presumably, it's the default for a lot of virtual machines.
-
Four years ago, a developer claimed, "No one still uses only OpenGL2; we can change the code to do XYZ." A check of our user base showed it would have affected nearly 5% of our users, so the change was abandoned.
Interestingly, this last topic came up again very recently, as it held back colour management improvements, but in a narrower Wayland-only path and with a fallback. After checking metrics again, the usage was below 1%, so we went ahead with that merge request.
So, are metrics worth it just to stop developers and designers from making nonsense claims out of thin air? Absolutely! 90% of stats are just made up on the spot. Metrics are just as much about preventing changes as it is about sparking changes.
Indirect impactThe other important part is having a more general sense of the landscape. Currently, we have a lot of hard conversations about how quickly we push the move to Wayland. We have voices wanting to maintain support, and we have voices wanting to push quicker. These decisions shouldn't be made just by who can be the loudest. For every individual topic that came up in those discussions, I would always have in mind our current adoption value at the time.
Should we care about Nvidia? Knowing they make up about 25% of our user base makes the decision for us. I ran with an Nvidia card in one machine because of this, implementing Nvidia context loss handling and doing what we could during the Wayland transition
We don't test BSD while developing Plasma, but we also let it hold us back. Should we care about it more or less? My opinion matches exactly what the metrics say.
Another role of metrics is being a conversation starter—people will fawn over a graph. More topics on Reddit will be about our Wayland usage rather than the topic I'm trying to discuss. I'll focus on Wayland examples beacuse that's a topic close to me.
Wayland adoption over timeI keep tabs on what our metrics show here. We can see the slow increase from under 20% to around 45% over time, showing the progress as both we and the Wayland ecosystem evolved. At Plasma 6, we switched the defaults a small bump in the graph can be seen. but 45% still seemed rather disappointing.
Filtering on just Plasma 6 reveals the true story:
There's still 20% of users switching away, or using a distro with a different default, or having carried over presets, but it's more promising. Interestingly, we can see that the GPU vendor distribution differs between X11 and Wayland.
Problems and lessons learnedUltimately, despite the positive parts it would be hard to call our telemetry a staggering success. For the handful of examples above, there are a hundreds of cases where we had no data to back anything up. The range of data points was pitiful and it wasn't often used
The viewing tool is really, really important!Data collection without viewing it is meaningless. As shown above, we often need to drill down and cross-reference filters to extract conclusions.
The original plan was to use the existing UI provided by kuserfeedback, which did not scale at all and quickly fell over. It was designed for high-fidelity data for a small number of users, not what we had.
In a rush, we pivoted to using Grafana because there was already a setup hosted.
It worked—ish, but it’s not designed for this, especially combined with our data structure, which was a manual NoSQL in normal SQL. Every graph needed to be written by hand, and it felt very much like fighting the system rather than working with it. Combined with the limited access permissions granted, it wasn't used by many people.
It being used is the number one indicator of its usefulness!
We need to find a tool specifically designed for visualization and querying datasets (maybe Apache Superset?).
Time-based data just makes noiseOur system sent updates every N days with basically the same data every time. This made writing queries way messier than it should have been. It never added any value; I would always be interested in what the current stats are. As described in the Wayland usage graphs above, if I'm making a Wayland decision, it doesn't matter what most people are using; it matters what people on the latest release are using. We always ended up having to add filters to focus on just the latest version.
The upgrade story needs planning in advanceThe amount of data we collected was tiny—some GPU information, screen information, language, and a few other fragments. The plan was to slowly add more and more stats over time, but we hit a wall. Our UX involved the user selecting to enable metrics and it being a fire-and-forget operation.
What do we do when we want to add more data? For example, whether you use an analog or digital clock. We would need to prompt the user and reset their settings in the meantime, which is at odds with it being a setting. The whole thing became such an ordeal that made it not worthwhile.
Wrap upThe project didn't fail, when we had data and it was used it worked, but overall our implementation falls short. I would like to open a discussion at Akademy on how we move forward with our current system potentially starting from scratch treating it more like a survey that we prompt to auto populate and submit each year.
Golems GABB: Using React in Drupal Themes
React can rightfully be called a game-changer JavaScript library for Drupal developers, as it can completely change the way interfaces are built. By integrating it into Drupal themes, we can enter a completely new world full of creativity and convenient functions, thus improving user experiences significantly.
With the help of React, interfaces of websites built on Drupal will no longer be static and boring: they become real, interactive, and fast. Less words, let's learn more details about how you can benefit from using React in Drupal themes.
Matt Layman: Golang Middleware and DBs - Building SaaS #199
GSoC 2024: Wrapping Up
Throughout this summer, I’ve developed a C++ library called MankalaEngine, implementing three opponents for the games of Bohnenspiel and Oware.
The current library is highly extensible. After implementing all the base classes and Bohnenspiel, adding Oware to the library was fairly fast and straightforward. This focus on extensibility has been a priority since the beginning of the project. Given that the Mancala family of games comprises numerous variants, designing the API with this in mind has proven valuable.
The three provided opponents use a random selection algorithm, Minimax, and MTD-f. The Minimax and MTD-f opponents were implemented with optimizations like alpha-beta pruning and transposition tables, making them both very capable, consistently outperforming the random opponent.
For a more detailed overview of what was accomplished, I wrote a work report on KDE’s wiki.
What I’ve learnedThe last few months have been a very enriching experience from a technical standpoint.
Contributing to a “real-world” project allowed me to learn about technologies I hadn’t used before. For example, I learned how to use CMake and how to set up a CI pipeline.
I also faced concerns that don’t typically arise when developing a school or personal project, such as adhering to an organization’s software standards. To this end, I learned about open-source licenses and new programming idioms.
Interacting With The CommunitySince MankalaEngine is a completely new library, my interaction with the community was limited, as there isn’t an existing group of contributors for this particular project.
I mainly interacted with my mentors, who were very helpful. Although less frequently, I also had the opportunity to communicate with other KDE contributors through mailing lists, from whom I also learned a great deal.
Thomas Goirand: Packaging Home Assistant
During Debconf, Edward Betts and myself started packaging Home Assistant for Debian. It consists of hundreds of Python packages. So far, we counted at least 675 packages. That’s a lot, though most packages are just libraries to talk with some IoT devices and some APIs. It’s fairly easy to create a new package: it takes me about 15 to 20 minutes, probably half that time to Edward. And it’s a lot of fun. So far in one month of time, we managed to package about 1 third of the list (probably 200+ Python packages already). Once we’ve done all the dependencies, we may start to have fun with the core of the application! At the current speed, hopefully we’ll be done before the end of the year. Edward and myself have swear to make at least one package a day, which I’ve been doing so far, and Edward did a way more… We also received contributions from Silton0506, Tianyu, piotr, EiPi Fun, sourabhtk37, and Count-Dracula, as per the very bottom of the TODO list in the wiki (see link below).
If you have a bit of free time, we’d love to have more contributors. Here’s were to get the needed information:
We created a team in Salsa: https://salsa.debian.org/homeassistant-team/
Our TODO list: https://wiki.debian.org/Python/HomeAssistant
Our DDPO Q/A page: https://qa.debian.org/developer.php?login=team%2Bhomeassistant%40tracker.debian.org
Feel free to join us on IRC: #debian-homeassistant
Discussing with a lot of people about it, I realized that A LOT of DDs are actually using Home Assistant. Wouldn’t you like it better if it was just a “apt install” away ? Any DD can simply take a package in the wiki, open an ITP, upload it’s debianized source on Salsa, and upload to the Debian archive. Most are very easy simple packages to make.
Twin Cities Drupal Camp: Interview With Keynote Speaker, Preston So
Talking to Preston So is easy.
I was nervous before our conversation simply because on paper there are things about the man that are frankly intimidating. Author of Content Strategy for Mobile Karen McGrane named Preston “the smartest guy in the field” in 2024. He was called “probably the smartest person working in this industry right now” by Deane Barker, author of Web Content Management.
But Preston So one-on-one is so personable, so engaging, that he instantly put me at ease. We talked about some aspects of his life and career, his experiences working in Drupal and other content management systems, what his keynote will be about, as well as his love of travel and learning languages.
Preston, you work at dotCMS. Can you talk a bit about what your job is and what it is you're doing?Many of the folks who know me from the Drupal world are probably a little surprised to see that I've gone over to a Java-based CMS. But I used to work at Oracle also, which was a Java-based CMS. I don't really have a lot of opinions about Java versus PHP, but I know there's some strong opinions on both sides.
But dotCMS is really interesting as a company. We're an open source CMS. You can see all of our code, all of what we do. You can contribute if you want to. So in that case, it's very similar to Drupal.
I joined dotCMS about five or six months ago as our new VP of product. And in that role, I basically oversee all of our sort of product or product-related functions. And that means our product team, our design team, our data function, our developer relations function. And also, I work on our analyst relations functions as well. So I wear a lot of hats at dotCMS.
And it's very similar to what I was doing before. I mean, my background has always been in software, in the actual engineering … in coding.
I read in your bio about your interest in voice interface and voice content. Can you talk a bit about your interest in non-traditional interfaces like voice?This ties into the writing I've done in the past around what I call the “channel explosion”…. These days, content needs to go to a lot of different places. One of the things that we often forget, especially those of us who have primarily worked with web content, is that content isn't just read, right? It's also spoken. It's also aural. It's visual. It's spatial. There are so many things about content that aren't really … tied to that rectangular box that we call the website or the screen or the web browser.
And a really good example of that is voice interfaces and voice bots or voice assistants. About seven or eight years ago, I was part of a really amazing team at Acquia, [that] worked on the first ever Alexa skill for the state of Georgia, building an Amazon Alexa skill that would allow people to ask questions: like, how do I register to vote or how do I enroll my child in pre-K?
Content needs to come from a single source of truth. You're seeing a lot of these new use cases emerge where people want to serve content to a mobile app, people want to serve content to a Roku device, people want to serve content to an AR overlay, for example, in your Vision Pro.
One of the reasons why I've been so interested in voice is because it really throws out a lot of the prescriptions and a lot of the ideas that we have about content, a lot of those biases that we have towards written, visual online content…. Web content is actually more abstracted away from natural human language and natural human biology than is speech-based interfaces or how we actually converse.
So I wrote a book about five years ago called Voice Content and Usability. In that book, I talk about voice content strategy, voice content design, how do you actually get content ready for a voice interface? And how do you actually implement an end-to- end voice interface that needs to consume content from a CMS?
When that book came out, there weren't a whole lot of Alexa content-driven implementations. It was basically just Capital One balance checking and Domino's Pizza ordering. And that was about it. No one had ever done a content-driven voice interface that was more informational rather than transactional.
Unfortunately, a lot of the things that have happened over the last few years with generative AI have really thrown those approaches out the window, because oftentimes with AI, you don't really feed it content. You're looking at content that is being reconstituted … by the AI as opposed to something that you're actually serving. But for governments, it's a much, much bigger concern for that content to stay up to date.
[You want] to help somebody learn how to get health insurance, or how to file a death certificate, [and that] cannot be mucked up by AI hallucinations or incorrectness. This is one of the reasons why voice content strategy and voice content still remains so relevant.
Your bio says that you're interested in “endangered and underserved languages”. Where else does your interest in learning languages come from?My biggest passion outside of work, outside of professional pursuits, is travel and languages. A lot of it comes from my background. I spent a good amount of time in Brazil when I was younger, so I'm fluent in Portuguese because I did an exchange program there. I taught English there in college as well. I also spent time in Wales.
Some of the richest interactions and some of the richest experiences I have when I travel are when I'm able to converse in a language that is a very seldom learned language, a very atypical language. It's a language that people don't really often take the time to learn or have much of an interest in learning. But [these languages are the way] in which you can get to know the culture, get to know the food, get to know just the way that people interact in these other environments and in these other languages.
Languages are entire universes unto themselves. Especially those languages that have that rich, rich tradition of oral language traditions or rich literature that stretches back for centuries. I love to focus on languages that I can speak right now with people today.
Right now, I'm focusing on three languages – two of them are incredibly difficult. The third is a little bit easier, and it's all towards a vacation I've got planned with a friend coming up in November. We're headed to South Africa, and so I'm learning Afrikaans, which is obviously at the center of Middle Dutch, the sort of colonial language in South Africa, but I'm also learning Xhosa and Zulu, which are two of the Nguni languages spoken in South Africa.
Can you say a little more about the keynote presentation that you're going to be giving at Twin Cities Drupal Camp?Over the past four to five years, I've been tracking sort of dissatisfaction on both sides of CMS.
I think one of the things that's really unique about the content management system is that it occupies a very unique ecological niche in the software world. Whereas a lot of other software products have a focus on individual personas, like Salesforce for salespeople. CRM tools tend to be for those kinds of folks.
The CMS has always been very unique in software because it brings together people with very different skills and very different priorities. Two of those personas that are probably the chief personas that the CMS deals with are, number one, the CMS developer. And then number two, the sort of content practitioner or content team or content architect or compliance reviewer or accessibility reviewer, everyone who has a stake in making sure that content is successful.
But we know based on just hearing from folks around the CMS industry that we're starting to see a bit of a schism right now, which is that there is, number one, a trend for developers to go towards headless CMSs, like Contentful, Sanity, some of those, and really go in that direction. But the problem with that is that it kind of leaves content teams with their hands tied behind their back. They can't really do drag and drop layout management anymore. They can't do preview of all of their different sites anymore. There's a lot of issues that come up with headless CMS.
But by the same token, developers today really don't want to work with the sort of monolithic or traditional CMS anymore. I love Twig. I love PHP template. There's a lot of folks who don't. There's a lot of folks, especially who are coming into front-end development nowadays, that really, really don't like to work with those paradigms.
One of the things that I think is really important is that as we contend with this huge influx of new JavaScript frameworks like Astro, SELT, so on and so forth, and also new delivery channels like we were talking about earlier, Blaine, around AR, VR, voice, AI, so on and so forth, it becomes a really big concern.
How do we actually collaborate effectively in a CMS that works for everybody and not just one half of the back office? One of the struggles that we see very often is that oftentimes headless CMSs will say, well, hey, content is just the data. Let us handle the presentation. Let us handle the front-end. Let us handle how things look.
But what that does is it severs all those linkages with how content authors want to preview, with how content editors want to be able to look at and review or schedule content or review things for compliance or review things for accessibility, so on and so forth. But developers also don't want to be held back.
The topic of my talk is really what I call the universal CMS, which is a new pair and I am really quickly getting a lot of traction. It really is about restoring the balance that characterized the early static web CMS era. Basically saying, hey, we could do all these really cool things with the website, but we had a handshake where we agreed that, hey, developers, if you hand over control over layout and control over all of these visual components, I will give you obviously control over how to code the whole thing.
But this unique grand compromise that we forged is something that is starting to come back. We are starting to see headless CMSs build in visual editing features which violate the peer headless architectural prescription. We are also seeing a lot of the old traditional CMSs or monolithic CMSs begin to build a lot more APIs and SDKs for JavaScript developers or mobile app developers to build on top of. And so I think what we are going to start to see here is a convergence between both the headless CMSs and the traditional CMSs towards a new equilibrium which I call universal CMS.
And here in just a few years, I think we are going to get rid of this full distinction between headless and monolithic and all of those tired terms that have a lot of baggage with them.
[Short bio]
Preston So (he/they) is a product executive with over 25 years in software, 17 years in content technologies, and 9 years leading product, design, engineering, and developer relations functions at organizations such as Oracle, Acquia, dotCMS, Time Inc., and Gatsby. He is Vice President, Product at dotCMS and the author of Immersive Content and Usability (A Book Apart, 2023), Gatsby: The Definitive Guide (O'Reilly, 2021), Voice Content and Usability (A Book Apart, 2021), and Decoupled Drupal in Practice (Apress, 2018).
Named “the smartest guy in the field” by Content Strategy for Mobile author Karen McGrane in 2024 and “probably the smartest person working in this industry right now” by Web Content Management author Deane Barker in 2020, Preston is a globally recognized authority on the intersections of content, design, and code. He is an editor at A List Apart and former top-read columnist at CMSWire. Preston is a frequent presenter with 17 years of speaking engagements spanning over 50 conferences, including SXSW Interactive (2017, 2017 encore, 2018) and An Event Apart (2020–22) and keynotes in three languages. He is based in New York City, where he can often be found immersing himself in languages that are endangered or underserved.
Posted In Drupal PlanetJonathan McDowell: Thoughts on Advent of Code + Rust
Diego wrote about his dislike for Advent of Code and that reminded me I hadn’t written up my experience from 2023. Mostly because, spoiler, I never actually completed it and always intended to do so and then write it up. I think it’s time to accept I’m not going to do that, and write down some thoughts before I forget all of them. These are somewhat vague, given the time that’s elapsed, but I think still relevant. You might also find Roger’s problem write up interesting.
I’ve tried AoC a couple of times before; I think I had a very brief attempt back in 2021, and I got 4 days in for 2022. For Advent of Code 2023 I tried much harder to actually complete the challenges, and got most of the way there. I didn’t allow myself to move on to the next day until fully completing the previous day, and didn’t end up doing the second half of December 24th, or any of December 25th.
RustFirst I want to talk about Rust, which is the language I chose to use for the problems. I’ve dabbled a little in it, but I’d like more familiarity with the basic language, and some programming problems seemed like a good way to get that. It’s a language I want to like; I’ve spent a lot of my career writing C, do more in Go these days, and generally think Rust promises a low level, run-time light environment like C but with the rough edges taken off.
I set myself the challenge of using just bare Rust; no external crates, no use of cargo. I was accused of playing on hard mode by doing this, but it really wasn’t the intention - I figured that I should be able to do what I needed without recourse to anything outside the core language, and didn’t want what seemed like the extra complexity of dealing with cargo.
That caused problems, however. I’m used to by-default generic error handling in Go through the error type, but Rust seems to have much more tightly typed errors. I was pointed at anyhow as the right way to do this in Rust. I still find this surprising; I ended up using unwrap() a lot when I think with more generic error handling I could have used ?.
The other thing I discovered is that by default rustc is heavy on the debug output. I got significantly better results on some of the solutions with rustc -O -C target-cpu=native source.rs. I probably shouldn’t be surprised by this, but worth noting.
Rust, to me, has a syntax only a C++ programmer could love. I am not a C++ programmer. Coming from C I found Go to be a nice, simple syntax to learn. Rust has not been the same. There’s a lot more punctuation, and it’s not always clear to me what it’s doing. This applies more when reading other people’s code than when writing it myself, obviously, but I see a lot of Rust code that could give Perl a run for its money in terms of looking like line noise.
The borrow checker didn’t bug me too much, but did add overhead to my thinking. The Rust compiler is generally very good at outputting helpful error messages when the programmer is an idiot. I ended up having to use a RefCell for one solution, and using .iter() for loops rather than explicit iterators (why, why is this different?). I also kept forgetting to explicitly mark variables as mutable when declaring them.
Things I liked? There’s a rich set of first class data types. Look, I’m a C programmer, I’m easily pleased. You give me some sort of hash array and I’ll be happy. Rust manages that, tuples, strings, all the standard bits any modern language can provide. The whole impl thing for adding methods to structures I like as a way of providing some abstraction, though I think Go has a nicer syntax for it. The compiler, as mentioned, is great at spitting out useful errors for the most part. Also although I wasn’t using external crates for AoC I do appreciate there’s a decent ecosystem there now (though that brings up another gripe: rust seems to still be a fairly fast moving target, to the extent I can no longer rely on the compiler in Debian stable to be able to compile random projects I find).
Advent of CodeLet’s talk about the advent of code bit now. Hopefully it’s long enough since it came out that this won’t be spoilers for anyone, but if you haven’t attempted the 2023 AoC and might, you might want to stop reading here.
First, a refresher on the format for those who might not be aware of it. Problems are posted daily from December 1st until the 25th. Each is in 2 parts; the second part is not viewable until you have provided the correct answer for the first part. There’s a whole leaderboard thing going on, but the puzzle opens at midnight UTC-5 so generally by the time I wake up and have time to look the problem has been solved many times over; no chance of getting listed.
Credit to AoC creator, Eric Wastl, for writing up the set of problems in an entertaining fashion. I quite enjoyed seeing how the puzzle would be phrased each day, and the whole thing obviously brings a lot of joy to folk I know.
I always start AoC thinking it’ll be a fun set of puzzles to solve. Then something happens and I miss a day or two, and all of a sudden I’ve a bunch of catching up to do and it’s all a bit more of a chore. I hit that at some points this time, but made a concerted effort to try and power through it.
That perseverance was required up front, because I found the second part of Day 1 to be ill specified, and had to iterate a few times to actually calculate the desired solution (IIRC, issues about whether sevenone at the end of a line ended up as 7 or 1 really tripped me up). I don’t recall any other problems that bit me as hard on the specification as this one, but it happening up front was unfortunate.
The short example input doesn’t always help with this either; either it’s not enough to be able to extrapolate patterns, or it doesn’t show all the variations you need to account for (that aren’t fully specified in the text), or in a few cases it turned out I needed to understand the shape of the actual data to produce a solution that could actually complete in a reasonable time.
Which brings me to another matter, sometimes brute force doesn’t actually work. This is fine, but the second part of the day’s problem can change the approach you’d take. So sometimes I got lucky in the way I handled the first half, and doing the second half was a simple 5 minute tweak, and sometimes I had to entirely change the way I was storing data.
You might claim that if I was a better programmer I’d have always produced a first half solution that was amenable to extension for the second half. First, I dispute that; I think there are always situations where the problem domain can change in enough directions that you can’t handle all of them without a lot of effort. Secondly, I didn’t find AoC an environment that encouraged me to optimise for generic solutions. Maybe some of the puzzles in isolation would allow for that, but a month of daily problems to solve while still engaging in regular life meant I hacked things up, took short cuts based on the knowledge I had of the input data, etc, etc.
Overall I can see the appeal, but the sheer quantity and the fact I write code as part of my day job just made it feel too much like a chore, rather than a fun mental exercise. I did wonder how they’d look as a set of interview puzzles (obviously a subset, rather than all of them), but I’m not sure how you’d actually use them for that - I wouldn’t want anyone to have to solve them in a live interview.
So, in case it’s not obvious, I’m not planning to engage in AoC again this yet. But I’m continuing to persevere with Rust (though most of my work stuff is thankfully still Go).
Python Engineering at Microsoft: Announcing the General Availability of the VS Code extension for Azure Machine Learning
Machine learning and artificial intelligence are transforming the world as we know it. With the power of data, you will have countless opportunities to create something new, unique, and exciting. Whether you are a seasoned data scientist or a curious beginner, you need a platform that can help you build, train, deploy, and manage your machine learning models with ease and efficiency. Azure Machine Learning has always been the backbone for machine learning tasks, and we want to further help you in your machine learning journey by improving the way you write code.
The VS Code extension for Azure Machine Learning has been in preview for a while and we are excited to announce the general availability of the VS Code extension for Azure Machine Learning. You can use your favorite VS Code setup, either desktop or web, to build, train, deploy, debug, and manage machine learning models with Azure Machine Learning from within VS Code. This means that the extension is stable, reliable, ready for production use, and comes with additional features, such as VNET support.
{kind=link}
“We have been using the VS Code extension for Azure Machine Learning since its preview release, and it has significantly streamlined our workflow. The ability to manage everything from building to deploying models directly within our preferred VS Code environment has been a game-changer. The seamless integration and robust features like interactive debugging and VNET support have enhanced our productivity and collaboration. We are thrilled about its general availability and look forward to leveraging its full potential in our AI projects.” – Ornaldo Ribas Fernandes: Co-founder and CEO, Fashable
Azure Machine LearningAzure Machine Learning (Azure ML) is a cloud-based service that enables you to build, train, deploy, and manage machine learning models.
With Azure Machine Learning service, you can:
- Build and train machine learning models faster, and easily deploy to the cloud or the edge.
- Use the latest open-source technologies such as TensorFlow, PyTorch, or Jupyter.
- Experiment locally and then quickly scale up or out with large GPU-enabled clusters in the cloud.
- Interactively debug experiments, pipelines, and deployments using the built-in VS Code debugger.
- Speed up data science with automated machine learning and hyper-parameter tuning.
- Track your experiments, manage models, and easily deploy with integrated CI/CD tooling.
With this extension installed, you can accomplish much of this workflow directly from Visual Studio Code. The VS Code extension provides a user interface to create and manage Azure ML resources, such as experiments, compute targets, environments, and deployments. It also supports the Azure ML 2.0 CLI, which is the new command-line tool that simplifies the specification and execution of machine learning tasks.
Get Started with Azure Machine Learning Extension One click Connect to VS Code from Azure ML StudioTo get started with VS Code, navigate to the compute section of your Azure Machine Learning Studio. Find the desired compute instance and click on the VS Code (Web) or VS Code (Desktop) links under the “Applications” section.
Don’t have an Azure ML workspace or compute instance? Check out the guide here: Tutorial: Create workspace resources – Azure Machine Learning | Microsoft Learn
VS Code Desktop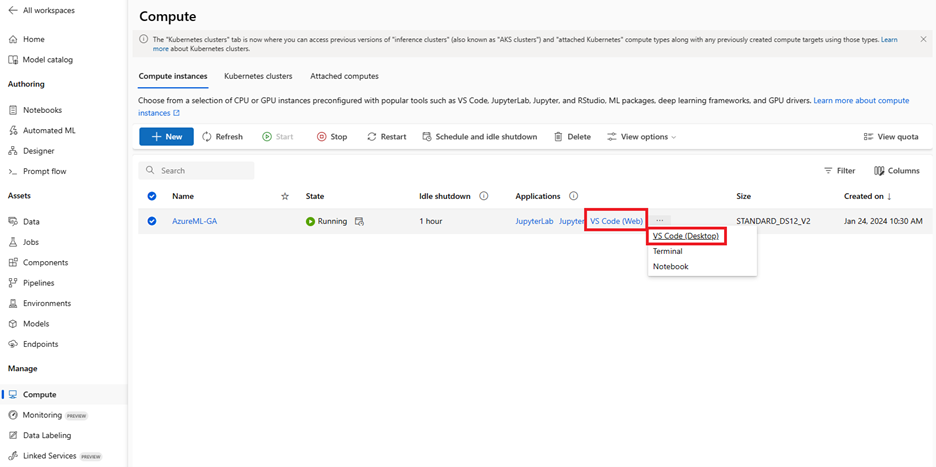{kind=link}
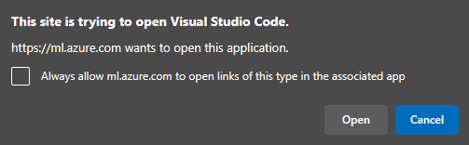
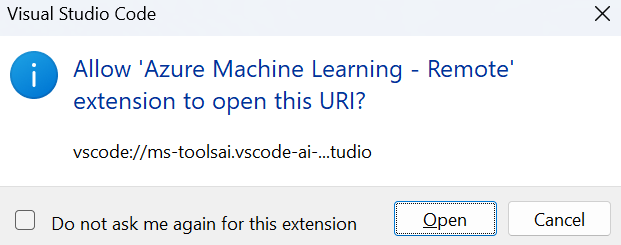
After clicking on the link for VS Code desktop, the browser will ask you for your permission to launch the VS Code Desktop application. VS Code desktop will ask you to sign in using your Microsoft/Azure account.
{kind=link}
{kind=link}
Follow the sign-in prompts, then you should be all set up to develop your own machine learning models using your favorite VS Code set up!
VS Code WebAfter clicking on the link, VS Code (Web) will open to a new tab on your browser. It may ask you to sign in using your Microsoft/Azure account, so VS Code will have permission to access your Azure subscription and workspace. Note the connection process may take a few minutes.
After signing in, you should now be connected to your Azure Machine Learning workspace inside of VS Code. Time to build your own machine learning model using the full power of VS Code!
Feedback{kind=link}
Give the Azure Machine Learning extension a try and let us know what you think. If you have any questions or feedback, please let us know your thoughts in this survey! You can also file an issue on our public GitHub repo with any questions or concerns you may have.
Need a guide to help you get started or documentation? Check out the tutorials here: Azure Machine Learning documentation | Microsoft Learn
The post Announcing the General Availability of the VS Code extension for Azure Machine Learning appeared first on Python.
mark.ie: My LocalGov Drupal contributions for week-ending August 23rd, 2024
This week I built a LocalGov Drupal dashboard, so we can better keep track of all our projects.
GSoC '24 Progress: Week 9 - 12
Hello everyone! Time flies and now we’re already in the final week of GSoC. In this blog post I’ll be sharing the progress I’ve made since my last update, focusing primarily on subtitle styling.
Subtitle EditorThe first thing I did was to enhance the existing subtitle editor. The updated editor now serves as an interface for editing ASS events, which include various components. With the new subtitle editor, we can easily modify elements such as the event’s layer, style, margins, and more. I’ve also simplified the effects section, allowing us to control subtitle scrolling by simply adjusting checkboxes and combo boxes for speed, direction, and range.
However, the most significant change is the text field and the buttons above it. To better understand these changes, it’s important to first introduce the relationship between ASS styles and events. In ASS files, each event must be assigned a valid style that applies to the entire event text. Additionally, ASS override tags are special text blocks within events that allow precise control over the styles of different parts of the text, rather than the entire text. (There are some exceptions, like “Set Position.”)
The text field has been enhanced to assist users in inputting ASS override tags using the provided buttons. For instance, when a user clicks the “Toggle Bold” button, tags are automatically inserted or adjusted to toggle the bold style for either the selected text or the text following the cursor if nothing is selected. Additionally, the text field features a highlighter that renders different parts of the tags in distinct styles, making them more distinguishable, and an auto-completer that lists all valid presets as we start typing a tag name.
For those who prefer the previous subtitle editor, which only displays the rendered text, a “Simple Editor” is also available. This editor syncs with the normal editor but displays only the text without tags while rendering some basic tag effects. However, due to the complexities of ASS tag rules, style editing in the Simple Editor can sometimes behave unpredictably. So it’s best suited for simpler use cases before or after editing styles.
Subtitle ManagerContinuing from the previous improvements, the Subtitle Manager is now integrated with style management and has been divided into four sections: File, Event, Style, and Info, which correspond to the four main components of ASS subtitles. Each section, except for the File section, includes a sidebar for switching between different subtitle files. Additionally, when in the Style section, we can drag and drop a style item onto a subtitle file name in the sidebar to efficiently move or copy styles between files. The same functionality is available in the Event section, where we can move or copy an entire layer to another file.
Misc Style EditorA new widget, the Style Editor, was created to edit styles and provide a preview.
Convert Old Global StyleOld styles will now be automatically converted to the “Default” style in the new project. Font size, outline, and shadow will be scaled to maintain the original effects.
Different Default Styles for LayersNow, we can assign different default styles to each layer, which will automatically be applied to a subtitle event when it’s created on the corresponding layer. This feature is especially useful for quickly building a subtitle file with multiple speakers, allowing each speaker to have a distinct style.
SummaryIt has been a wonderful summer getting involved in the KDE community and contributing to Kdenlive! I may not be the best at coding, but I’ve learned a lot throughout this journey. Thanks for everyone who has gave me guidence — Eugen Mohr, Farid Abdelnour, and especially my mentor, Jean-Baptiste Mardelle. While GSoC is coming to an end, my journey with KDE is just beginning. After these updates, I plan to continue improving subtitle functions, including making it easier for users to input more ASS override tags and refining the UI and user experience. See you in my next blog :)
The Drop Times: Connecting Drupal with the Next Generation of Makers: Albert Hughes
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Research
- Give Your Input on the State of Open Source Survey
- Open Data and Open Source AI: Charting a course to get more of both
- The Open Source Initiative and the Eclipse Foundation to Collaborate on Shaping Open Source AI (OSAI) Public Policy
- ClearlyDefined v2.0 adds support for LicenseRefs
- ClearlyDefined at SOSS Fusion 2024: a collaborative solution to Open Source license compliance