
Feeds
The Drop Times: Streamlining Local Development with DDEV, Docker, and NGROK
Debug Academy: How to create a partial date field in Drupal (i.e. Year & Month without Day)
One of Drupal's main strengths is its data modeling.
But sometimes choosing the appropriate field type comes with a form widget that isn't what we're looking for. For example, using a Date field results in the form displaying a date "widget" (form input) which includes a full date consisting of a day, month, and year, and optionally a time.
How to remove the time from a date field in DrupalBecause removing the time from date fields is such a common request, Drupal allows its removal without writing any custom code.
How to hide the time Drupal's frontendFortunately, the date field has a highly configurable display on the frontend. By visiting the "Manage Display" page (or configuring the field's block, if using layout builder), you will have the option of selecting (or creating) a date format.
Follow these steps to change the date's output for your frontend:
ashrafabed Fri, 04/26/2024Dirk Eddelbuettel: RQuantLib 0.4.22 on CRAN: Maintenance
A new minor release 0.4.22 of RQuantLib arrived at CRAN earlier today, and has been uploaded to Debian.
QuantLib is a rather comprehensice free/open-source library for quantitative finance. RQuantLib connects (some parts of) it to the R environment and language, and has been part of CRAN for more than twenty years (!!) as it was one of the first packages I uploaded there.
This release of RQuantLib updates to QuantLib version 1.34 which was just released yesterday, and deprecates use of an access point / type for price/yield conversion for bonds. We also made two minor earlier changes.
Changes in RQuantLib version 0.4.22 (2024-04-25)Small code cleanup removing duplicate R code
Small improvements to C++ compilation flags
Robustify internal version comparison to accommodate RC releases
Adjustments to two C++ files for QuantLib 1.34
Courtesy of my CRANberries, there is also a diffstat report for the this release. As always, more detailed information is on the RQuantLib page. Questions, comments etc should go to the rquantlib-devel mailing list. Issue tickets can be filed at the GitHub repo.
If you like this or other open-source work I do, you can now sponsor me at GitHub.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
Petter Reinholdtsen: 45 orphaned Debian packages moved to git, 391 to go
Nine days ago, I started migrating orphaned Debian packages with no version control system listed in debian/control of the source to git. At the time there were 438 such packages. Now there are 391, according to the UDD. In reality it is slightly less, as there is a delay between uploads and UDD updates. In the nine days since, I have thus been able to work my way through ten percent of the packages. I am starting to run out of steam, and hope someone else will also help brushing some dust of these packages. Here is a recipe how to do it. I start by picking a random package by querying the UDD for a list of 10 random packages from the set of remaining packages:
PGPASSWORD="udd-mirror" psql --port=5432 --host=udd-mirror.debian.net \ --username=udd-mirror udd -c "select source from sources \ where release = 'sid' and (vcs_url ilike '%anonscm.debian.org%' \ OR vcs_browser ilike '%anonscm.debian.org%' or vcs_url IS NULL \ OR vcs_browser IS NULL) AND maintainer ilike '%packages@qa.debian.org%' \ order by random() limit 10;"Next, I visit http://salsa.debian.org/debian and search for the package name, to ensure no git repository already exist. If it does, I clone it and try to get it to an uploadable state, and add the Vcs-* entries in d/control to make the repository more widely known. These packages are a minority, so I will not cover that use case here.
For packages without an existing git repository, I run the following script debian-snap-to-salsa to prepare a git repository with the existing packaging.
#!/bin/sh # # See also https://bugs.debian.org/804722#31 set -e # Move to this Standards-Version. SV_LATEST=4.7.0 PKG="$1" if [ -z "$PKG" ]; then echo "usage: $0 " exit 1 fi if [ -e "${PKG}-salsa" ]; then echo "error: ${PKG}-salsa already exist, aborting." exit 1 fi if [ -z "ALLOWFAILURE" ] ; then ALLOWFAILURE=false fi # Fetch every snapshotted source package. Manually loop until all # transfers succeed, as 'gbp import-dscs --debsnap' do not fail on # download failures. until debsnap --force -v $PKG || $ALLOWFAILURE ; do sleep 1; done mkdir ${PKG}-salsa; cd ${PKG}-salsa git init # Specify branches to override any debian/gbp.conf file present in the # source package. gbp import-dscs --debian-branch=master --upstream-branch=upstream \ --pristine-tar ../source-$PKG/*.dsc # Add Vcs pointing to Salsa Debian project (must be manually created # and pushed to). if ! grep -q ^Vcs- debian/control ; then awk "BEGIN { s=1 } /^\$/ { if (s==1) { print \"Vcs-Browser: https://salsa.debian.org/debian/$PKG\"; print \"Vcs-Git: https://salsa.debian.org/debian/$PKG.git\" }; s=0 } { print }" < debian/control > debian/control.new && mv debian/control.new debian/control git commit -m "Updated vcs in d/control to Salsa." debian/control fi # Tell gbp to enforce the use of pristine-tar. inifile +inifile debian/gbp.conf +create +section DEFAULT +key pristine-tar +value True git add debian/gbp.conf git commit -m "Added d/gbp.conf to enforce the use of pristine-tar." debian/gbp.conf # Update to latest Standards-Version. SV="$(grep ^Standards-Version: debian/control|awk '{print $2}')" if [ $SV_LATEST != $SV ]; then sed -i "s/\(Standards-Version: \)\(.*\)/\1$SV_LATEST/" debian/control git commit -m "Updated Standards-Version from $SV to $SV_LATEST." debian/control fi if grep -q pkg-config debian/control; then sed -i s/pkg-config/pkgconf/ debian/control git commit -m "Replaced obsolete pkg-config build dependency with pkgconf." debian/control fi if grep -q libncurses5-dev debian/control; then sed -i s/libncurses5-dev/libncurses-dev/ debian/control git commit -m "Replaced obsolete libncurses5-dev build dependency with libncurses-dev." debian/control fi Some times the debsnap script fail to download some of the versions. In those cases I investigate, and if I decide the failing versions will not be missed, I call it using ALLOWFAILURE=true to ignore the problem and create the git repository anyway.With the git repository in place, I do a test build (gbp buildpackage) to ensure the build is actually working. If it does not I pick a different package, or if the build failure is trivial to fix, I fix it before continuing. At this stage I revisit http://salsa.debian.org/debian and create the project under this group for the package. I then follow the instructions to publish the local git repository. Here is from a recent example:
git remote add origin git@salsa.debian.org:debian/perl-byacc.git git push --set-upstream origin master upstream pristine-tar git push --tagsWith a working build, I have a look at the build rules if I want to remove some more dust. I normally try to move to debhelper compat level 13, which involves removing debian/compat and modifying debian/control to build depend on debhelper-compat (=13). I also test with 'Rules-Requires-Root: no' in debian/control and verify in debian/rules that hardening is enabled, and include all of these if the package still build. If it fail to build with level 13, I try with 12, 11, 10 and so on until I find a level where it build, as I do not want to spend a lot of time fixing build issues.
Some times, when I feel inspired, I make sure debian/copyright is converted to the machine readable format, often by starting with 'debhelper -cc' and then cleaning up the autogenerated content until it matches realities. If I feel like it, I might also clean up non-dh-based debian/rules files to use the short style dh build rules.
Once I have removed all the dust I care to process for the package, I run 'gbp dch' to generate a debian/changelog entry based on the commits done so far, run 'dch -r' to switch from 'UNRELEASED' to 'unstable' and get an editor to make sure the 'QA upload' marker is in place and that all long commit descriptions are wrapped into sensible lengths, run 'debcommit --release -a' to commit and tag the new debian/changelog entry, run 'debuild -S' to build a source only package, and 'dput ../perl-byacc_2.0-10_source.changes' to do the upload. During the entire process, and many times per step, I run 'debuild' to verify the changes done still work. I also some times verify the set of built files using 'find debian' to see if I can spot any problems (like no file in usr/bin any more or empty package). I also try to fix all lintian issues reported at the end of each 'debuild' run.
If I find Debian specific patches, I try to ensure their metadata is fairly up to date and some times I even try to reach out to upstream, to make the upstream project aware of the patches. Most of my emails bounce, so the success rate is low. For projects with no Homepage entry in debian/control I try to track down one, and for packages with no debian/watch file I try to create one. But at least for some of the packages I have been unable to find a functioning upstream, and must skip both of these.
If I could handle ten percent in nine days, twenty people could complete the rest in less then five days. I use approximately twenty minutes per package, when I have twenty minutes spare time to spend. Perhaps you got twenty minutes to spare too?
As usual, if you use Bitcoin and want to show your support of my activities, please send Bitcoin donations to my address 15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
Drupal Association blog: Making the Most of Your Time at DrupalCon Portland
It’s less than two weeks to DrupalCon Portland 2024, and the excitement is building! If you’re gearing up for the biggest Drupal event of the year, we’re here to help you maximize your travel experience to Portland. Let’s dive right in!
Hotel Bookings at Great PricesYou still have a chance to book your DrupalCon Portland hotel within the official hotel block. By staying within the hotel block, you'll get the best proximity to the conference center as well as the chance to run into other Drupalists on your floor! Book now:
- Hyatt Regency Portland
- DoubleTree by Hilton - book by Sunday 28 April
DrupalCon North America 2024 will be held from 6th to 9th May 2024 at the Oregon Convention Center (yes, in-person!). Located right in the heart of the city, it is a perfect hub for exploration. You'll find hotels, restaurants, and shops just around the corner. It's also super easy to get to fun stuff like entertainment and hiking. With endless possibilities, you're sure to find something that suits your fancy.
Things you should NOT miss out on in PortlandMay is a delightful time to be in Portland, with spring in full bloom. Enjoy the sunny weather and mild temperatures, making it the perfect season to explore the city's vibrant outdoor scene. There are several must-visit places that capture the city's unique charm.
1. Governor Tom McCall Waterfront ParkThis is the perfect place to enjoy Portland's beauty while watching the river flow by. Visitors to the park can enjoy a variety of recreational activities, from leisurely strolls and picnics to jogging and biking along the paved pathways. The park also hosts numerous events throughout the year, including festivals, concerts, and outdoor markets, adding to its vibrant atmosphere.
One of the park's highlights is the Salmon Street Springs Fountain, where children and adults alike can cool off in the refreshing water jets during the warmer months. The park also features several monuments and public art installations, adding cultural and historical significance to its landscape.
Image Source: https://www.travelportland.com/attractions/governor-tom-mccall-waterfront-park/
Powell's City of Books is a literary wonderland located in downtown Portland, Oregon. As the world's largest independent bookstore, Powell's spans an entire city block and boasts multiple floors filled with books of every genre imaginable. One of Powell's most unique features is its rare book room, home to a collection of rare and out-of-print titles, first editions, and signed copies that will delight bibliophiles and collectors alike.
In addition to its vast selection of books, Powell's hosts author readings, book signings, and other literary events, fostering a sense of community among book lovers from near and far.
Image Source: https://www.travelportland.com/attractions/powells/
Founded in 1892, the Portland Art Museum is the oldest art museum on the West Coast and holds a rich and diverse collection of artworks spanning various time periods, cultures, and mediums. It is located in the heart of downtown Portland. One of the museum's highlights is its extensive collection of Native American art, which celebrates the rich artistic traditions of indigenous peoples from the Pacific Northwest and beyond.
In addition to its permanent collection, the Portland Art Museum hosts rotating exhibitions that showcase both established and emerging artists, offering visitors the opportunity to engage with cutting-edge contemporary art and explore new perspectives.
Image Source: https://www.travelportland.com/attractions/portland-art-museum/
Voodoo Doughnut is more than just a bakery; it's a Portland icon, a symbol of creativity, and a culinary experience like no other. It was founded in 2003 by friends Kenneth Pogson and Richard Shannon and has gained international fame for its wacky doughnut creations.
It is located in the heart of downtown Portland, Voodoo Doughnut draws long lines of locals and tourists, eager to sample its unique offerings. Some of the must-try snacks: Voodoo Doll doughnut, pretzel stake and raspberry filling, Bacon Maple Bar topped with crispy bacon strips. If this has got you drooling (like me), make sure you head to this place while you’re at Portland.
Image Source: https://www.travelportland.com/attractions/voodoo-doughnut/
The Oregon Museum of Science and Industry (OMSI) is a beloved institution in Portland, Oregon, dedicated to inspiring curiosity and fostering a love of science through engaging exhibits, interactive displays, and educational programs. Located on the east bank of the Willamette River, OMSI's sprawling campus encompasses a variety of attractions that cater to visitors of all ages.
OMSI's planetarium is a highlight, where visitors can explore the wonders of the night sky, learn about astronomy and astrophysics, and take virtual journeys through space. The museum also features a state-of-the-art IMAX theater, where visitors can experience immersive films on topics ranging from nature and wildlife to history and technology.
Image Source: https://www.travelportland.com/attractions/omsi/
Find more information to plan your trip here.
Jonathan McDowell: Sorting out backup internet #3: failover
With local recursive DNS and a 5G modem in place the next thing was to work on some sort of automatic failover when the primary FTTP connection failed. My wife works from home too and I sometimes travel so I wanted to make sure things didn’t require me to be around to kick them into switch the link in use.
First, let’s talk about what I didn’t do. One choice to try and ensure as seamless a failover as possible would be to get a VM somewhere out there. I’d then run Wireguard tunnels over both the FTTP + 5G links to the VM, and run some sort of routing protocol (RIP, OSPF?) over the links. Set preferences such that the FTTP is preferred, NAT v4 to the VM IP, and choose somewhere that gave me a v6 range I could just use directly.
This has the advantage that I’m actively checking link quality to the outside work, rather than just to the next hop. It also means, if the failover detection is fast enough, that existing sessions stay up rather than needing re-established.
The downsides are increased complexity, adding another point of potential failure (the VM + provider), the impact on connection quality (even with a decent endpoint it’s an extra hop and latency), and finally the increased cost involved.
I can cope with having to reconnect my SSH sessions in the event of a failure, and I’d rather be sure I can make full use of the FTTP connection, so I didn’t go this route. I chose to rely on local link failure detection to provide the signal for failover, and a set of policy routing on top of that to make things a bit more seamless.
Local link failure turns out to be fairly easy. My FTTP is a PPPoE configuration, so in /etc/ppp/peers/aquiss I have:
lcp-echo-interval 1 lcp-echo-failure 5 lcp-echo-adaptiveWhich gives me a failover of ~ 5s if the link goes down.
I’m operating the 5G modem in “bridge” rather than “router” mode, which means I get the actual IP from the 5G network via DHCP. The DHCP lease the modem hands out is under a minute, and in the event of a network failure it only hands out a 192.168.254.x IP to talk to its web interface. As the 5G modem is the last resort path I choose not to do anything special with this, but the information is at least there if I need it.
To allow both interfaces to be up and the FTTP to be preferred I’m simply using route metrics. For the PPP configuration that’s:
defaultroute-metric 100and for the 5G modem I have:
iface sfp.31 inet dhcp metric 1000 vlan-raw-device sfpThere’s a wrinkle in that pppd will not replace an existing default route, so I’ve created /etc/ppp/ip-up.d/default-route to ensure it’s added:
#!/bin/bash [ "$PPP_IFACE" = "pppoe-wan" ] || exit 0 # Ensure we add a default route; pppd will not do so if we have # a lower pref route out the 5G modem ip route add default dev pppoe-wan metric 100 || trueAdditionally, in /etc/dhcp/dhclient.conf I’ve disabled asking for any server details (DNS, NTP, etc) - I have internal setups for the servers I want, and don’t want to be trying to select things over the 5G link by default.
However, what I do want is to be able to access the 5G modem web interface and explicitly route some traffic out that link (e.g. so I can add it to my smokeping tests). For that I need some source based routing.
First step, add a 5g table to /etc/iproute2/rt_tables:
16 5gThen I ended up with the following in /etc/dhcp/dhclient-exit-hooks.d/modem-interface-route, which is more complex than I’d like but seems to do what I want:
#!/bin/sh case "$reason" in BOUND|RENEW|REBIND|REBOOT) # Check if we've actually changed IP address if [ -z "$old_ip_address" ] || [ "$old_ip_address" != "$new_ip_address" ] || [ "$reason" = "BOUND" ] || [ "$reason" = "REBOOT" ]; then if [ ! -z "$old_ip_address" ]; then ip rule del from $old_ip_address lookup 5g fi ip rule add from $new_ip_address lookup 5g ip route add default dev sfp.31 table 5g || true ip route add 192.168.254.1 dev sfp.31 2>/dev/null || true fi ;; EXPIRE) if [ ! -z "$old_ip_address" ]; then ip rule del from $old_ip_address lookup 5g fi ;; *) ;; esacWhat does all that aim to do? We want to ensure traffic directed to the 5G WAN address goes out the 5G modem, so I can SSH into it even when the main link is up. So we add a rule directing traffic from that IP to hit the 5g routing table, and a default route in that table which uses the 5G link. There’s no configuration for the FTTP connection in that table, so if the 5G link is down the traffic gets dropped, which is what we want. We also configure 192.168.254.1 to go out the link to the modem, as that’s where the web interface lives.
I also have a curl callout (curl --interface sfp.31 … to ensure it goes out the 5G link) after the routes are configured to set dynamic DNS with Mythic Beasts, which helps with knowing where to connect back to. I seem to see IP address changes on the 5G link every couple of days at least.
Additionally, I have an entry in the interfaces configuration carving out the top set of the netblock my smokeping server is in:
up ip rule add from 192.0.2.224/27 lookup 5gMy smokeping /etc/smokeping/config.d/Probes file then looks like:
*** Probes *** + FPing binary = /usr/bin/fping ++ FPingNormal ++ FPing5G sourceaddress = 192.0.2.225 + FPing6 binary = /usr/bin/fpingwhich allows me to use probe = FPing5G for targets to test them over the 5G link.
That mostly covers the functionality I want for a backup link. There’s one piece that isn’t quite solved, however, IPv6, which can wait for another post.
Drupalize.Me: Learning Drupal with the Help of an AI Tutor
TL; DR: Use this prompt and the text from a Drupalize.Me tutorial to experiment with using generative AI as a tutor for learning Drupal.
A while ago, I wrote an article and gave a presentation about why learning Drupal is so hard. One of the key challenges I identified is the “pit of despair”. It's that point in the learning journey where you can no longer rely on the hand holding of step-by-step tutorials. You need to step out into the chasm and come up with your own unique solutions to your specific problems. That point where you know just enough to realize the breadth of what you don’t yet know. And I had said, based on input from many peers, that the quickest way through the dip is real-world experience and drawing on the expertise of others. The advice could be summed up as: if you want to learn fast, get a tutor.
It can be hard to find a mentor. As much as we would love to be able to do so, our small team at Drupalize.Me can't scale personalized individual tutoring. So I've been thinking about how you might be able to use AI to help get at least some of the benefits of tutoring.
joe Thu, 04/25/2024 - 11:29Kubuntu 24.04 LTS Noble Numbat Released
The Kubuntu Team is happy to announce that Kubuntu 24.04 has been released, featuring the ‘beautiful’ KDE Plasma 5.27 simple by default, powerful when needed.
Codenamed “Noble Numbat”, Kubuntu 24.04 continues our tradition of giving you Friendly Computing by integrating the latest and greatest open source technologies into a high-quality, easy-to-use Linux distribution.
Under the hood, there have been updates to many core packages, including a new 6.8-based kernel, KDE Frameworks 5.115, KDE Plasma 5.27 and KDE Gear 23.08.
Kubuntu 24.04 with Plasma 5.27.11Kubuntu has seen many updates for other applications, both in our default install, and installable from the Ubuntu archive.
Haruna, Krita, Kdevelop, Yakuake, and many many more applications are updated.
Applications for core day-to-day usage are included and updated, such as Firefox, and LibreOffice.
For a list of other application updates, and known bugs be sure to read our release notes.
Download Kubuntu 24.04, or learn how to upgrade from 23.10 or 22.04 LTS.
Note: For upgrades from 23.10, there may a delay of a few hours to days between the official release announcements and the Ubuntu Release Team enabling upgrades.
Jonathan Dowland: Biosphere
I've been enjoying Biosphere as the soundtrack to my recent "concentrated work" spells.
Knives by BiosphereI remember seeing their name on playlists of yester-year: axioms, bluemars1, and (still a going concern) soma.fm's drone zone.
- Bluemars lives on, at echoes of bluemars↩
Data School: How to prevent data leakage in pandas & scikit-learn ☔
Let&aposs pretend you&aposre working on a supervised Machine Learning problem using Python&aposs scikit-learn library. Your training data is in a pandas DataFrame, and you discover missing values in a column that you were planning to use as a feature.
After considering your options, you decide to impute the missing values, which means that you&aposre going to fill in the missing values with reasonable values.
How should you perform the imputation?
- Option 1 is to fill in the missing values in pandas, and then pass the transformed data to scikit-learn.
- Option 2 is to pass the original data to scikit-learn, and then perform all data transformations (including missing value imputation) within scikit-learn.
Option 1 will cause data leakage, whereas option 2 will prevent data leakage.
Here are questions you might be asking:
- What is data leakage?
- Why is data leakage problematic?
- Why would data leakage result from missing value imputation in pandas?
- How can I prevent data leakage when using pandas and scikit-learn?
Answers below! 👇
What is data leakage?Data leakage occurs when you inadvertently include knowledge from testing data when training a Machine Learning model.
Why is data leakage problematic?Data leakage is problematic because it will cause your model evaluation scores to be less reliable. This may lead you to make bad decisions when tuning hyperparameters, and it will lead you to overestimate how well your model will perform on new data.
It&aposs hard to know whether data leakage will skew your evaluation scores by a negligible amount or a huge amount, so it&aposs best to just avoid data leakage entirely.
Why would data leakage result from missing value imputation in pandas?Your model evaluation procedure (such as cross-validation) is supposed to simulate the future, so that you can accurately estimate right now how well your model will perform on new data.
But if you impute missing values on your whole dataset in pandas and then pass your dataset to scikit-learn, your model evaluation procedure will no longer be an accurate simulation of reality. That&aposs because the imputation values will be based on your entire dataset (meaning both the training portion and the testing portion), whereas the imputation values should just be based on the training portion.
In other words, imputation based on the entire dataset is like peeking into the future and then using what you learned from the future during model training, which is definitely not allowed.
How can we avoid this in pandas?You might think that one way around this problem would be to split your dataset into training and testing sets and then impute missing values using pandas. (Specifically, you would need to learn the imputation value from the training set and then use it to fill in both the training and testing sets.)
That would work if you&aposre only ever planning to use train/test split for model evaluation, but it would not work if you&aposre planning to use cross-validation. That&aposs because during 5-fold cross-validation (for example), the rows contained in the training set will change 5 times, and thus it&aposs quite impractical to avoid data leakage if you use pandas for imputation while using cross-validation!
How else can data leakage arise?So far, I&aposve only mentioned data leakage in the context of missing value imputation. But there are other transformations that if done in pandas on the full dataset will also cause data leakage.
For example, feature scaling in pandas would lead to data leakage, and even one-hot encoding (or "dummy encoding") in pandas would lead to data leakage unless there&aposs a known, fixed set of categories.
More generally, any transformation which incorporates information about other rows when transforming a row will lead to data leakage if done in pandas.
How does scikit-learn prevent data leakage?Now that you&aposve learned how data transformations in pandas can cause data leakage, I&aposll briefly mention three ways in which scikit-learn prevents data leakage:
- First, scikit-learn transformers have separate fit and transform steps, which allow you to base your data transformations on the training set only, and then apply those transformations to both the training set and the testing set.
- Second, the fit and predict methods of a Pipeline encapsulate all calls to fit_transform and transform so that they&aposre called at the appropriate times.
- Third, cross_val_score splits the data prior to performing data transformations, which ensures that the transformers only learn from the temporary training sets that are created during cross-validation.
When working on a Machine Learning problem in Python, I recommend performing all of your data transformations in scikit-learn, rather than performing some of them in pandas and then passing the transformed data to scikit-learn.
Besides helping you to prevent data leakage, this enables you to tune the transformer and model hyperparameters simultaneously, which can lead to a better performing model!
One final note...This post is an excerpt from my upcoming video course, Master Machine Learning with scikit-learn.
Join the waitlist below to get free lessons from the course and a special launch discount 👇
The Drop Times: DrupalCollab: How big is the Drupal Community?
Lukas Märdian: Creating a Netplan enabled system through Debian-Installer
With the work that has been done in the debian-installer/netcfg merge-proposal !9 it is possible to install a standard Debian system, using the normal Debian-Installer (d-i) mini.iso images, that will come pre-installed with Netplan and all network configuration structured in /etc/netplan/.
In this write-up I’d like to run you through a list of commands for experiencing the Netplan enabled installation process first-hand. For now, we’ll be using a custom ISO image, while waiting for the above-mentioned merge-proposal to be landed. Furthermore, as the Debian archive is going through major transitions builds of the “unstable” branch of d-i don’t currently work. So I implemented a small backport, producing updated netcfg and netcfg-static for Bookworm, which can be used as localudebs/ during the d-i build.
Let’s start with preparing a working directory and installing the software dependencies for our virtualized Debian system:
$ mkdir d-i_bookworm && cd d-i_bookworm $ apt install ovmf qemu-utils qemu-system-x86Now let’s download the custom mini.iso, linux kernel image and initrd.gz containing the Netplan enablement changes, as mentioned above.
TODO: localudebs/
$ wget https://people.ubuntu.com/~slyon/d-i/bookworm/mini.iso $ wget https://people.ubuntu.com/~slyon/d-i/bookworm/linux $ wget https://people.ubuntu.com/~slyon/d-i/bookworm/initrd.gzNext we’ll prepare a VM, by copying the EFI firmware files, preparing some persistent EFIVARs file, to boot from FS0:\EFI\debian\grubx64.efi, and create a virtual disk for our machine:
$ cp /usr/share/OVMF/OVMF_CODE_4M.fd . $ cp /usr/share/OVMF/OVMF_VARS_4M.fd . $ qemu-img create -f qcow2 ./data.qcow2 5GFinally, let’s launch the installer using a custom preseed.cfg file, that will automatically install Netplan for us in the target system. A minimal preseed file could look like this:
# Install minimal Netplan generator binaryd-i preseed/late_command string in-target apt-get -y install netplan-generator
For this demo, we’re installing the full netplan.io package (incl. Python CLI), as the netplan-generator package was not yet split out as an independent binary in the Bookworm cycle. You can choose the preseed file from a set of different variants to test the different configurations:
- Netplan + systemd-resolved configuration
- Netplan + NetworkManager configuration
We’re using the custom linux kernel and initrd.gz here to be able to pass the PRESEED_URL as a parameter to the kernel’s cmdline directly. Launching this VM should bring up the normal debian-installer in its netboot/gtk form:
$ export U=https://people.ubuntu.com/~slyon/d-i/bookworm/netplan-preseed+networkd.cfg $ qemu-system-x86_64 \ -M q35 -enable-kvm -cpu host -smp 4 -m 2G \ -drive if=pflash,format=raw,unit=0,file=OVMF_CODE_4M.fd,readonly=on \ -drive if=pflash,format=raw,unit=1,file=OVMF_VARS_4M.fd,readonly=off \ -device qemu-xhci -device usb-kbd -device usb-mouse \ -vga none -device virtio-gpu-pci \ -net nic,model=virtio -net user \ -kernel ./linux -initrd ./initrd.gz -append "url=$U" \ -hda ./data.qcow2 -cdrom ./mini.iso;Now you can click through the normal Debian-Installer process, using mostly default settings. Optionally, you could play around with the networking settings, to see how those get translated to /etc/netplan/ in the target system.
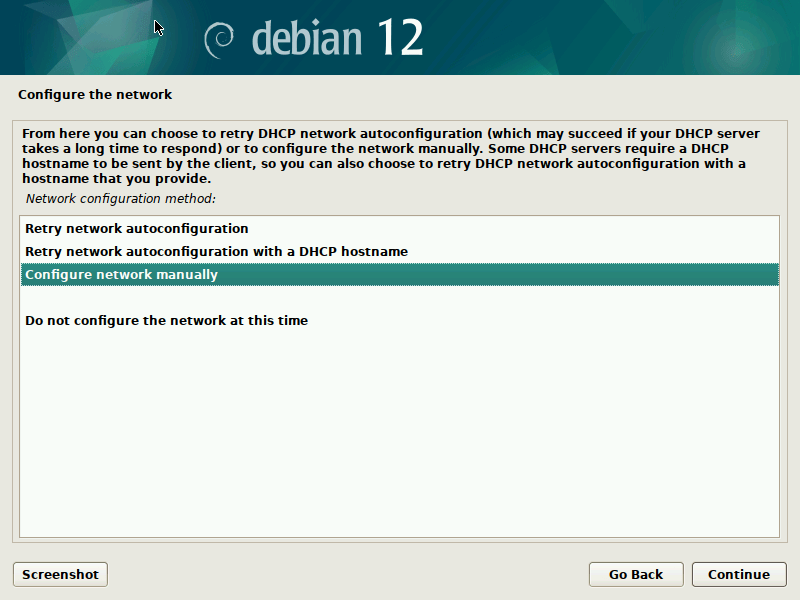{kind=link}
After you confirmed your partitioning changes, the base system gets installed. I suggest not to select any additional components, like desktop environments, to speed up the process.
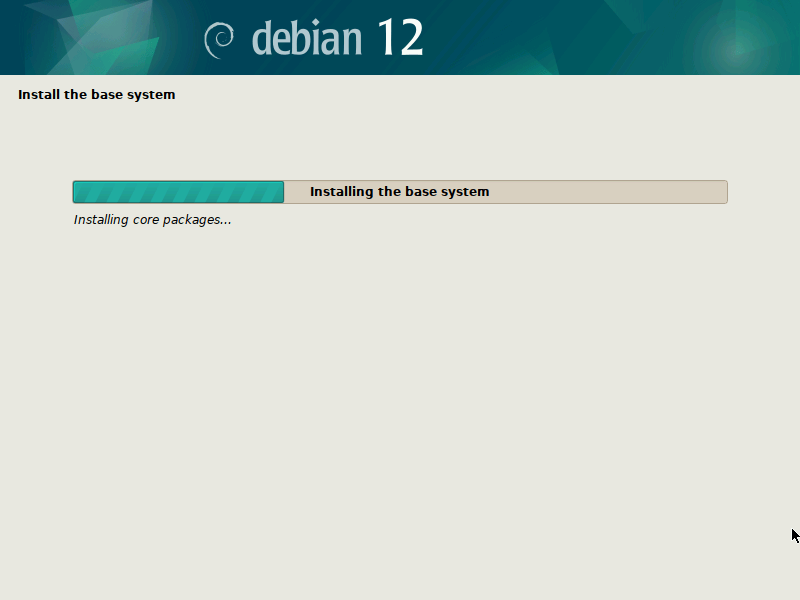{kind=link}
During the final step of the installation (finish-install.d/55netcfg-copy-config) d-i will detect that Netplan was installed in the target system (due to the preseed file provided) and opt to write its network configuration to /etc/netplan/ instead of /etc/network/interfaces or /etc/NetworkManager/system-connections/.
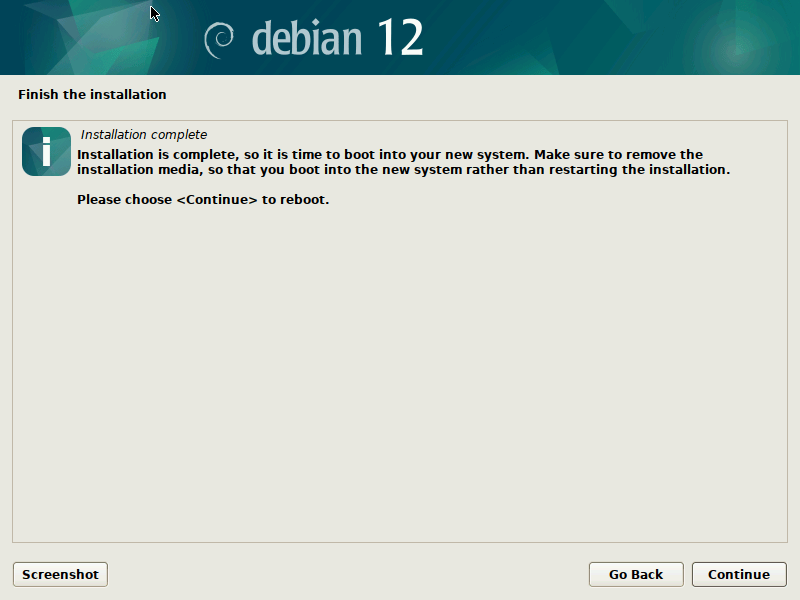{kind=link}
Done! After the installation finished you can reboot into your virgin Debian Bookworm system.
To do that, quit the current Qemu process, by pressing Ctrl+C and make sure to copy over the EFIVARS.fd file that was written by grub during the installation, so Qemu can find the new system. Then reboot into the new system, not using the mini.iso image any more:
$ cp ./OVMF_VARS_4M.fd ./EFIVARS.fd $ qemu-system-x86_64 \ -M q35 -enable-kvm -cpu host -smp 4 -m 2G \ -drive if=pflash,format=raw,unit=0,file=OVMF_CODE_4M.fd,readonly=on \ -drive if=pflash,format=raw,unit=1,file=EFIVARS.fd,readonly=off \ -device qemu-xhci -device usb-kbd -device usb-mouse \ -vga none -device virtio-gpu-pci \ -net nic,model=virtio -net user \ -drive file=./data.qcow2,if=none,format=qcow2,id=disk0 \ -device virtio-blk-pci,drive=disk0,bootindex=1 -serial mon:stdioFinally, you can play around with your Netplan enabled Debian system! As you will find, /etc/network/interfaces exists but is empty, it could still be used (optionally/additionally). Netplan was configured in /etc/netplan/ according to the settings given during the d-i installation process.
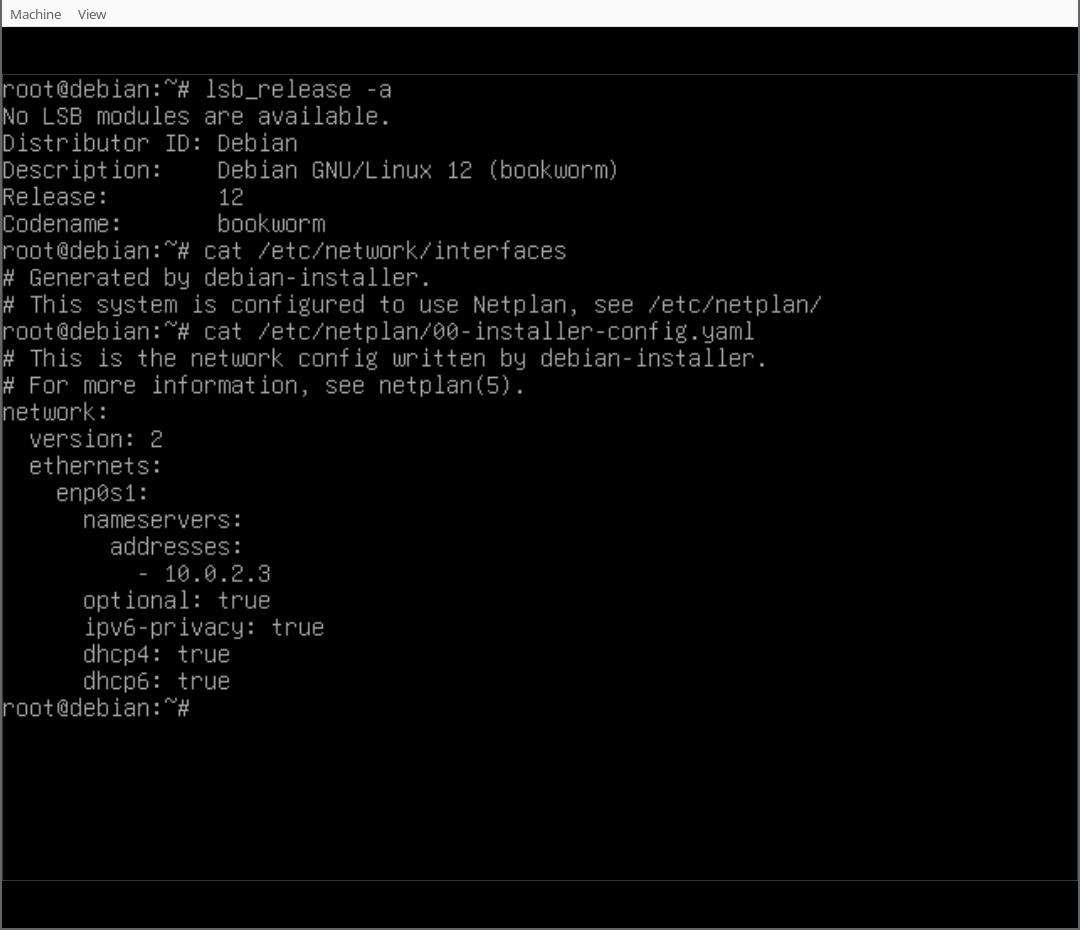{kind=link}
In our case we also installed the Netplan CLI, so we can play around with some of its features, like netplan status:
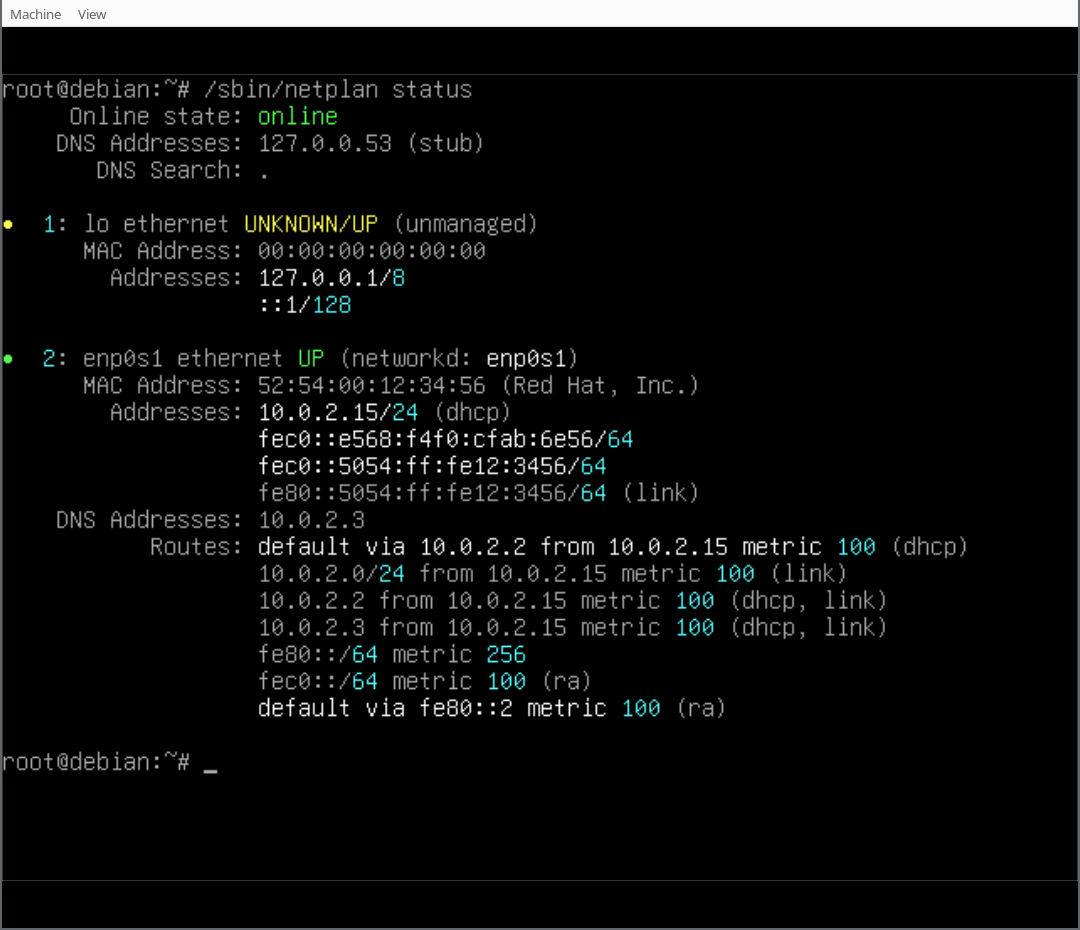{kind=link}
Thank you for following along the Netplan enabled Debian installation process and happy hacking! If you want to learn more join the discussion at Salsa:installer-team/netcfg and find us at GitHub:netplan.
Mixing C++ and Rust for Fun and Profit: Part 3
In the two previous posts (Part 1 and Part 2), we looked at how to build bindings between C++ and Rust from scratch. However, while building a binding generator from scratch is fun, it’s not necessarily an efficient way to integrate Rust into your C++ project. Let’s look at some existing technologies for mixing C++ and Rust that you can easily deploy today.
bindgenbindgen is an official tool of the Rust project that can create bindings around C headers. It can also wrap C++ headers, but there are limitations to its C++ support. For example, while you can wrap classes, they won’t have their constructors or destructors automatically called. You can read more about these limitations on the bindgen C++ support page. Another quirk of bindgen is that it only allows you to call C++ from Rust. If you want to go the other way around, you have to add cbindgen to generate C headers for your Rust code.
CXXCXX is a more powerful framework for integrating C++ and Rust. It’s used in some well-known projects, such as Chromium. It does an excellent job at integrating C++ and Rust, but it is not an actual binding generator. Instead, all of your bindings have to be manually created. You can read the tutorial to learn more about how CXX works.
autocxxSince CXX doesn’t generate bindings itself, if you want to use it in your project, you’ll need to find a generator that wraps C++ headers with CXX bindings. autocxx is a Google project that does just that, using bindgen to generate Rust bindings around C++ headers. However, it gets better—autocxx can also create C++ bindings for Rust functions.
CXX-QtWhile CXX is one of the best C++/Rust binding generators available, it fails to address Qt users. Since Qt depends so heavily on the moc to enable features like signals and slots, it’s almost impossible to use it with a general-purpose binding generator. That’s where CXX-Qt comes in. KDAB has created the CXX-Qt crate to allow you to integrate Rust into your C++/Qt application. It works by leveraging CXX to generate most of the bindings but then adds a Qt support layer. This allows you to easily use Rust on the backend of your Qt app, whether you’re using Qt Widgets or QML. CXX-Qt is available on Github and crates.io.
If you’re interested in integrating CXX-Qt into your C++ application, let us know. To learn more about CXX-Qt, you can check out this blog.
Other optionsThere are some other binding generators out there that aren’t necessarily going to work well for migrating your codebase, but you may want to read about them and keep an eye on them:
In addition, there are continuing efforts to improve C++/Rust interoperability. For example, Google recently announced that they are giving $1 million dollars to the Rust foundation to improve interoperability.
ConclusionIn the world of programming tools and frameworks, there is never a single solution that will work for everybody. However, CXX, CXX-Qt, and autocxx seem to be the best options for anyone who wants to port their C++ codebase to Rust. Even if you aren’t looking to completely remove C++ from your codebase, these binding generators may be a good option for you to promote memory safety in critical areas of your application.
Have you successfully integrated Rust in your C++ codebase with one of these tools? Have you used a different tool or perhaps a different programming language entirely? Leave a comment and let us know. Memory-safe programming languages like Rust are here to stay, and it’s always good to see programmers change with the times.
About KDAB
If you like this article and want to read similar material, consider subscribing via our RSS feed.
Subscribe to KDAB TV for similar informative short video content.
KDAB provides market leading software consulting and development services and training in Qt, C++ and 3D/OpenGL. Contact us.
The post Mixing C++ and Rust for Fun and Profit: Part 3 appeared first on KDAB.
Django Weblog: Livestream: Django Trends for 2024
Today at 3pm UTC – Discover the latest trends in the Django ecosystem, based on insights from 4,000 developers who participated in the Django Developers Survey. Join the livestream with Sarah Abdermane, a Django Software Foundation Board member, and Sarah Boyce, a Django Fellow, to reflect on insights from the Django community.
Russ Allbery: Review: Nation
Review: Nation, by Terry Pratchett
Publisher: Harper Copyright: 2008 Printing: 2009 ISBN: 0-06-143303-9 Format: Trade paperback Pages: 369Nation is a stand-alone young adult fantasy novel. It was published in the gap between Discworld novels Making Money and Unseen Academicals.
Nation starts with a plague. The Russian influenza has ravaged Britain, including the royal family. The next in line to the throne is off on a remote island and must be retrieved and crowned as soon as possible, or an obscure provision in Magna Carta will cause no end of trouble. The Cutty Wren is sent on this mission, carrying the Gentlemen of Last Resort.
Then comes the tsunami.
In the midst of fire raining from the sky and a wave like no one has ever seen, Captain Roberts tied himself to the wheel of the Sweet Judy and steered it as best he could, straight into an island. The sole survivor of the shipwreck: one Ermintrude Fanshaw, daughter of the governor of some British island possessions. Oh, and a parrot.
Mau was on the Boys' Island when the tsunami came, going through his rite of passage into manhood. He was to return to the Nation the next morning and receive his tattoos and his adult soul. He survived in a canoe. No one else in the Nation did.
Terry Pratchett considered Nation to be his best book. It is not his best book, at least in my opinion; it's firmly below the top tier of Discworld novels, let alone Night Watch. It is, however, an interesting and enjoyable book that tackles gods and religion with a sledgehammer rather than a knife.
It's also very, very dark and utterly depressing at the start, despite a few glimmers of Pratchett's humor. Mau is the main protagonist at first, and the book opens with everyone he cares about dying. This is the place where I thought Pratchett diverged the most from his Discworld style: in Discworld, I think most of that would have been off-screen, but here we follow Mau through the realization, the devastation, the disassociation, the burials at sea, the thoughts of suicide, and the complete upheaval of everything he thought he was or was about to become. I found the start of this book difficult to get through. The immediate transition into potentially tragic misunderstandings between Mau and Daphne (as Ermintrude names herself once there is no one to tell her not to) didn't help.
As I got farther into the book, though, I warmed to it. The best parts early on are Daphne's baffled but scientific attempts to understand Mau's culture and her place in it. More survivors arrive, and they start to assemble a community, anchored in large part by Mau's stubborn determination to do what's right even though he's lost all of his moorings. That community eventually re-establishes contact with the rest of the world and the opening plot about the British monarchy, but not before Daphne has been changed profoundly by being part of it.
I think Pratchett worked hard at keeping Mau's culture at the center of the story. It's notable that the community that reforms over the course of the book essentially follows the patterns of Mau's lost Nation and incorporates Daphne into it, rather than (as is so often the case) the other way around. The plot itself is fiercely anti-colonial in a way that mostly worked. Still, though, it's a quasi-Pacific-island culture written by a white British man, and I had some qualms.
Pratchett quite rightfully makes it clear in the afterward that this is an alternate world and Mau's culture is not a real Pacific island culture. However, that also means that its starkly gender-essentialist nature was a free choice, rather than one based on some specific culture, and I found that choice somewhat off-putting. The religious rituals are all gendered, the dwelling places are gendered, and one's entire life course in Mau's world seems based on binary classification as a man or a woman. Based on Pratchett's other books, I assume this was more an unfortunate default than a deliberate choice, but it's still a choice he could have avoided.
The end of this book wrestles directly with the relative worth of Mau's culture versus that of the British. I liked most of this, but the twists that Pratchett adds to avoid the colonialist results we saw in our world stumble partly into the trap of making Mau's culture valuable by British standards. (I'm being a bit vague here to avoid spoilers.) I think it is very hard to base this book on a different set of priorities and still bring the largely UK, US, and western European audience along, so I don't blame Pratchett for failing to do it, but I'm a bit sad that the world still revolved around a British axis.
This felt quite similar to Discworld to me in its overall sensibilities, but with the roles of moral philosophy and humor reversed. Discworld novels usually start with some larger-than-life characters and an absurd plot, and then the moral philosophy sneaks up behind you when you're not looking and hits you over the head. Nation starts with the moral philosophy: Mau wrestles with his gods and the problem of evil in a way that reminded me of Job, except with a far different pantheon and rather less tolerance for divine excuses on the part of the protagonist. It's the humor, instead, that sneaks up on you and makes you laugh when the plot is a bit too much. But the mix arrives at much the same place: the absurd hand-in-hand with the profound, and all seen from an angle that makes it a bit easier to understand.
I'm not sure I would recommend Nation as a good place to start with Pratchett. I felt like I benefited from having read a lot of Discworld to build up my willingness to trust where Pratchett was going. But it has the quality of writing of late Discworld without the (arguable) need to read 25 books to understand all of the backstory. Regardless, recommended, and you'll never hear Twinkle Twinkle Little Star in quite the same way again.
Rating: 8 out of 10
Capellic: How We Broke up Complex Drupal Webforms to Improve the User Experience
Berlin mega-sprint recap
For the past 8 days I’ve been in Berlin for what is technically four sprints: first a two-day KDE e.V. Board of Directors sprint, and then right afterwards, the KDE Goals mega-sprint for the Eco, Accessibility, and Automation/Systematization Goals! Both were hosted in the offices of KDE Patron MBition, a great partner to KDE which uses our software both internally and in some Mercedes cars. Thanks a lot, MBition! It’s been quite a week, but a productive one. So I thought I’d share what we did.
If you’re a KDE e.V. member, you’ve already received an email recap about the Board sprint’s discussion topics and decisions. Overall the organization is healthy and in great shape. Something substantive I can share publicly is that we posed for this wicked sick picture:
Moving onto the combined Goals sprint: this was in fact the first sprint for any of the KDE Goals, and having all three represented in one room attracted a unique cross-section of people from the KDE Eco crowd, usability-interested folks, and deeply technical core KDE developers.
Officially I’m the Goal Champion of the Automation & Systematization Goal, and a number of folks attended to work on those topics, ranging from adding and fixing tests to creating a code quality dashboards. Expect more blog posts from other participants regarding what they worked on!
Speaking personally, I changed the bug janitor bot to direct Debian users on old Plasma versions to Debian’s own Bug tracker—as in fact the Debian folks advise their own users to do. I added an autotest to validate the change, but regrettably it caused a regression anyway, which I corrected quickly. Further investigation into the reason why this went uncaught revealed that all the autotests for the version-based bug janitor actions are faulty. I worked on fixing them but unfortunately have not met with success yet. Further efforts are needed.
In the process of doing this work, I also found that the bug janitor operates on a hardcoded list of Plasma components, which has of course drifted out of sync with reality since it was originally authored. This causes the bot to miss many bugs at the moment.
Fellow sprint participant Tracey volunteered to address this, so I helped get her set up with a development environment for the bug janitor bot so she can auto-generate the list from GitLab and sysadmin repo metadata. This is in progress and proceeding nicely.
I also proposed a merge request template for the plasma-workspace git repo, modeled on the one we currently use in Elisa. The idea is to encourage people to write better merge request descriptions, and also nudge people in the direction of adding autotests for their merge requests, or at least mentioning reviewers can test the changes. If this ends up successful, I have high hopes about rolling it out more broadly.
But I was also there for the other goals too! Joseph delivered a wonderful presentation about KDE Eco topics, which introduced my new favorite cartoon, and it got me thinking about efficiency and performance. For a while I’d been experiencing high CPU usage in KDE’s NeoChat app, and with all the NeoChat developers there in the room, I took the opportunity to prod them with my pointy stick. This isn’t the first time I’d mentioned the performance issue to them, but in the past no one could reproduce it and we had to drop the investigation. Well, this time I think everyone else was also thinking eco thoughts, and they really moved heaven and earth to try to reproduce it. Eventually James was able to, and it wasn’t long before the issue was put six feet under. The result: NeoChat’s background CPU usage is now 0% for people using Intel GPUs, down from 30%. A big win for eco and laptop battery life, which I’m already appreciating as I write this blog post in an airport disconnected from AC power.
To verify the CPU usage, just for laughs I added the Catwalk widget to my panel. It’s so adorable that I haven’t had the heart to remove it, and now I notice things using CPU time when they should be idle much more than I did before. More visibility for performance issues should over time add up to more fixes for them!
Another interesting thing happens when you get a bunch of talented KDE contributors in a room: people can’t help but initiate discussions about pressing topics. The result was many conversations about release schedules, dependency policy, visual design vision, and product branding. One discussion very relevant to the sprint was the lack of systematicity in how we use units for spacing in the QtQuick-based UIs we build. This resulted in a proposal that’s already generating some spirited feedback.
All in all it was a happy and productive week, and after doing one of these I always feel super privileged to be able to work with as impressively talented and friendly a group of colleagues as this is:
Full disclosure: KDE e.V. paid for my travel and lodging expenses, but not my döner kebab expenses!
KDE e.V. board meeting
Last week was one of the regular KDE e.V. board meetings. We (the board of KDE e.V.) have a video call every week, but twice a year we try to get together and actually put in some full days, actually sit around and laugh, actually listen to Dad jokes and eat food and drink beer or Fritz cola together.
It’s a good addition to our usual workflow.
Berlin is just so much fun (for five days, anyway). I can hop on the train, walk along the Spree to a hotel, walk everywhere – Friday I did 15km – get amazing food for cheap – compared to the Netherlands anyway – and hang out with friends. Some of those friends are the board. The board is some of those friends.
The actual board work is not something to write about all that much. There were HR things and finances and projects and plans and .. you’ll see some of the results on the KDE e.V. website. We also played GeoGuesser and something with WikiData.
One of the HR things I should particularly mention: welcome to
Nicole,
our latest employee who is further involved with our
sustainable software efforts.
The regular board calls resume next week, and we will meet again in September at Akademy.
ImageX: Drupal 7 vs. Drupal 10: An Objective Visual Comparison of Some Popular Website Features
Authored by: Nadiia Nykolaichuk.
Drupal 7 was released 13 years ago, during the Jurassic period in the world of modern software. However, as of April 2024, there are 322,700+ websites officially listed on drupal.org as still running on Drupal 7, which sadly makes it the #1 installed Drupal major core version but, luckily, this number is steadily reducing.
Sumana Harihareswara - Cogito, Ergo Sumana: Model UX Research &amp; Design Docs for Command-Line Open Source
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects