
Feeds
Junichi Uekawa: Google docs has some tab feature.
Plasma Crash Course - DrKonqi
A while ago a colleague of mine asked about our crash infrastructure in Plasma and whether I could give some overview on it. This seems very useful to others as well, I thought. Here I am, telling you all about it!
Our crash infrastructure is comprised of a number of different components.
- KCrash: a KDE Framework performing crash interception and prepartion for handover to…
- coredumpd: a systemd component performing process core collection and handover to…
- DrKonqi: a GUI for crashes sending data to…
- Sentry: a web service and UI for tracing and presenting crashes for developers
We’ve already looked at KCrash and coredumpd. Now it is time to look at DrKonqi.
DrKonqiDrKonqi is the UI that comes up when a crash happens. We’ll explore how it integrates with coredumpd and Sentry.
Crash PickupWhen I outlined the functionality of coredumpd, I mentioned that it starts an instance of systemd-coredump@.service. This not only allows the core dumping itself to be controlled by systemd’s resource control and configuration systems, but it also means other systemd units can tie into the crash handling as well.
That is precisely what we do in DrKonqi. It installs drkonqi-coredump-processor@.service which, among other things, contains the rule:
WantedBy=systemd-coredump@.service…meaning systemd will not only start systemd-coredump@unique_identifier but also a corresponding drkonqi-coredump-processor@unique_identifier. This is similar to how services start as part of the system boot sequence: they all are “wanted by” or “want” some other service, and that is how systemd knows what to start and when (I am simplifying here 😉). Note that unique_identifier is actually a systemd feature called “instances” — one systemd unit can be instantiated multiple times this way.
drkonqi-coredump-processorWhen drkonqi-coredump-processor@unique_identifier runs, it first has some synchronization to do.
As a brief recap from the coredumpd post: coredumpd’s crash collection ends with writing a journald entry that contains all collected data. DrKonqi needs this data, so we wait for it to appear in the journal.
Once the journal entry has arrived, we are good to go and will systemd-socket-activate a helper in the relevant user.
The way this works is a bit tricky: drkonqi-coredump-processor runs as root, but DrKonqi needs to be started as the user the crash happened to. To bridge this gap a new service drkonqi-coredump-launcher comes into play.
drkonqi-coredump-launcherEvery user session has a drkonqi-coredump-launcher.socket systemd unit running that provides a socket. This socket gets connected to by the processor (remember: it is root so it can talk to the user socket). When that happens, an instance of drkonqi-coredump-launcher@.service is started (as the user) and the processor starts streaming the data from journald to the launcher.
The crash has now traveled from the user, through the kernel, to system-level systemd services, and has finally arrived back in the actual user session.
Having been started by systemd and initially received the crash data from the processor, drkonqi-coredump-launcher will now augment that data with the KCrash metadata originally saved to disk by KCrash. Once the crash data is complete, the launcher only needs to find a way to “pick up” the crash. This will usually be DrKonqi, but technically other types of crash pickup are also supported. Most notably, developers can set the environment variable KDE_COREDUMP_NOTIFY=1 to receive system notifications about crashes with an easy way to open gdb for debugging. I’ve already written about this a while ago.
When ready, the launcher will start DrKonqi itself and pass over the complete metadata.
the crashed application └── kernel └── systemd-coredumpd ├── systemd-coredumpd@unique_identifier.service └── drkonqi-coredump-processor@unique_identifier.service ├── drkonqi-coredump-launcher.socket └── drkonqi-coredump-launcher@unique_identifier.service └── drkonqiWhat a journey!
Crash ProcessingDrKonqi kicks off crash processing. This is hugely complicated and probably worth its own post. But let’s at least superficially explore what is going on.
The launcher has provided DrKonqi with a mountain of information so it can now utilize the CLI for systemd-coredump, called coredumpctl, to access the core dump and attach an instance of the debugger GDB to it.
GDB runs as a two step automated process:
Preamble StepAs part of this automation, we run a service called the preamble: a Python program that interfaces with the Python API of GDB. Its most important functionality is to create a well-structured backtrace that can be converted to a Sentry payload. Sentry, for the most part, doesn’t ingest platform specific core dumps or crash reports, but instead relies on an abstract payload format that is generated by so called Sentry SDKs. DrKonqi essentially acts as such an SDK for us. Once the preamble is done, the payload is transferred into DrKonqi and the next step can continue.
Trace StepAfter the preamble, DrKonqi executes an actual GDB trace (i.e. the literal backtrace command in gdb) to generate the developer output. This is also the trace that gets sent to KDE’s Bugzilla instance at bugs.kde.org if the user chooses to file a bug report. The reason this is separate from the already created backtrace is mostly for historic reasons. The trace is then routed through a text parser to figure out if it is of sufficient quality; only when that is the case will DrKonqi allow filing a report in Bugzilla.
TransmissionWith all the trace data assembled, we just need to send them off to Bugzilla or Sentry, depending on what the user chose to do.
BugzillaThe Bugzilla case is simply sending a very long string of the backtrace to the Bugzilla API (albeit surrounded by some JSON).
SentryThe Sentry case on the other hand requires more finesse. For starters, the Sentry code also works when offline. The trace and optional user message get converted into a Sentry envelope tagged with a receiver address — a Sentry-specific URL for ingestion so it knows under which project to file the crash. The envelope is then written to ~/.cache/drkonqi/sentry-envelopes/. At this point, DrKonqi’s job is done; The actual transmission happens in an auxiliary service.
Writing an envelope to disk triggers drkonqi-sentry-postman.service which will attempt to send all pending envelopes to Sentry using the URL inside the payload. It will try to do so every once in a while in case there are pending envelopes as well, thereby making sure crashes that were collected while offline still make it to Sentry eventually. Once sent successfully, the envelopes are archived in ~/.cache/drkonqi/sentry-sent-envelopes/.
This concludes DrKonqi’s activity. There’s much more detail going on behind the scenes but it’s largely inconsequential to the overall flow. Next time we will look at the final piece in the puzzle — Sentry itself.
Kanopi Studios: Default Content in Drupal
In Drupal 10.3, the DefaultContent API was added to Drupal core as part of the experimental Recipes APIs. These APIs allow Drupal to create content from files that are part of a recipe. This content that we programmatically create isn’t intended for deploying or migrating content, we have the Workspaces and other modules for that. […]
The post Default Content in Drupal appeared first on Kanopi Studios.
Members Newsletter – September 2024
It’s been a busy couple of months, and things are going to stay that way as we approach All Things Open in October. Version 0.0.9 of the Open Source AI Definition has been released after collecting months of community feedback.
We’re continuing our march towards a stable release by the end of October 2024, at All Things Open. Get involved by joining the discussion on the forum, finding OSI staff around the world, and online at the weekly town halls. The community continues iterating through drafts after meeting diverse stakeholders at the worldwide roadshow, collecting feedback and carefully looking for new arguments in dissenting opinions. All thanks to a grant by the Alfred P. Sloan Foundation. We also need to decide how to best address the reviews of new licenses for datasets, documentation and the agreements governing model parameters.
The lively conversations will continue at conferences, town halls, and online. The first two stops were at AI_dev and Open Source Congress. Other events are planned to take place in Africa, South America, Europe and North America.
On a separate delightful note, the Open Source community got some welcome news on August 29, as Elastic returned to the community by adding the AGPL licensing option for Elasticsearch and Kibana. This decision is confirmation that shipping software with licenses that comply with the Open Source Definition is valuable—to the maker, to the customer, and to the user. Elastic’s choice of a strong copyleft license signals the continuing importance of that license and its dual effect: one, it’s designed to preserve the user’s freedoms downstream, and two, it also grants strong control over the project by the single-vendor developers.
We’re encouraged to see Elastic return to the Open Source community. And who knows… maybe others will follow suit!
Stefano Maffulli
Executive Director, OSI
I hold weekly office hours on Fridays with OSI members: book time if you want to chat about OSI’s activities, if you want to volunteer or have suggestions.
News from the OSI Community input drives the new draft of the Open Source AI DefinitionFrom the Research and Advocacy program
The Open Source AI Definition v0.0.9 has been released and collaboration continues at in-person events and in the online forums. Read what changes have been made, what to do next and how to get involved. Read more.
Three things I learned at KubeCon + AI_Dev China 2024From the Research and Advocacy program
KubeCon China 2024 was a whirlwind of innovation, community and technical deep dives. As it often happens at these community events, I was blown away by the energy, enthusiasm and sheer amount of knowledge being shared. Read more.
Highlights from our participation at Open Source CongressFrom the Research and Advocacy program
The Open Source Initiative (OSI) proudly participated in the Open Source Congress 2024, held from August 25-27 in Beijing, China. This event was a pivotal gathering for key individuals in the Open Source nonprofit community, aiming to foster collaboration, innovation, and strategic development within the ecosystem. Read more.
OSI in the news Elasticsearch is open source, againOSI at elastic.co
“Being able to call Elasticsearch and Kibana Open Source again is pure joy.” — Shay Banon, Elastic Founder and CTO. Read more.
Meta is accused of bullying the open source communityOSI at The Economist
Purists are pushing back against Meta’s efforts to set its own standard on the definition of open-source AI. Stefano Maffulli, head of the OSI, says Mr Zuckerberg “is really bullying the industry to follow his lead”. Read more.
Debate over “open source AI” term brings new push to formalize definitionOSI at Ars Technica
The Open Source Initiative (OSI) recently unveiled its latest draft definition for “open source AI,” aiming to clarify the ambiguous use of the term in the fast-moving field. The move comes as some companies like Meta release trained AI language model weights and code with usage restrictions while using the “open source” label. This has sparked intense debates among free-software advocates about what truly constitutes “open source” in the context of AI. Read more.
Other Highlights- Open source AI now has a definition. This it what it means and why it’s still tricky (Euro News)
- We’re a big step closer to defining open source AI – but not everyone is happy (ZDNet)
- We finally have a definition for open-source AI (MIT Technology Review)
- We’re a long way from truly open-source AI (Financial Times)
- Like it or not, this open source AI definition take a giant step forward (ZDNet)
- Mozilla Foundation: Celebrating An Important Step Forward For Open Source AI
- Python Software Foundation: Python Developers Survey 2023 Results
- OpenJS Foundation: OpenJS Foundation’s Leader Details the Threats to Open Source
- Linux Foundation: How open source is steering AI down the high road
- ClearlyDefined at SAP: enhancing Open Source license compliance through Open Source data
- Open Source visibility hacks — No icky marketing needed
- So, You Have Your 20-Page Open Source Strategy Doc. Now What?
- Pajamas to profit: Launch your Open Source empire
- Demystifying Open Source as a Business
The Open Source Initiative (OSI) is running a series of stories about a few of the people involved in the Open Source AI Definition (OSAID) co-design process.
2024 Generative AI SurveyThis survey aims to understand the deployment, use, and challenges of generative AI technologies in organizations and the role of open source in this domain. Take survey here.
Events Upcoming events- India FOSS (September 7-8, 2024 – Bengaluru)
- Open Source Summit Europe (September 16-18, 2024 – Vienna)
- Nerdearla Argentina (September 24-28, 2024 – Buenos Aires)
- Hacktoberfest (October – Online)
- SOSS Fusion (October 22-23, 2024 – Atlanta)
- Open Community Experience (October 22-24, 2024 – Mainz)
- All Things Open (October 27-29 – Raleigh)
- Nerdearla Mexico (November 7-9, 2024 – Mexico City)
- OpenForum Academy Symposium (November, 13-14, 2024 – Boston)
- SCALE 22x (March 6-9, 2025 – Pasadena)
- Consul Conference (February, 4-6, 2025 – Las Palmas de Gran Canaria)
- Nerdearla Mexico (November 7-9, 2024 – Mexico City)
- Mercado Libre
Interested in sponsoring, or partnering with, the OSI? Please see our Sponsorship Prospectus and our Annual Report. We also have a dedicated prospectus for the Deep Dive: Defining Open Source AI. Please contact the OSI to find out more about how your company can promote open source development, communities and software.
Support OSI by becoming a member!Let’s build a world where knowledge is freely shared, ideas are nurtured, and innovation knows no bounds!
Highlights from our participation at Open Source Congress 2024
The Open Source Initiative (OSI) proudly participated in the Open Source Congress 2024, held from August 25-27 in Beijing, China. This event was a gathering for key individuals in the Open Source nonprofit community, aiming to foster collaboration, innovation, and strategic development within the ecosystem. Here are some highlights from OSI’s participation at the event.
Panel: Collaboration between Open Source OrganizationsStefano Maffulli, OSI’s Executive Director, played an important role in the panel on “Collaboration between Open Source Organizations.” This session, moderated by Daniel Goldscheider (Executive Director, OpenWallet Foundation) and Chris Xie (Board Advisor, Linux Foundation Research), brought together influential leaders, including Keith Bergelt (CEO, Open Invention Network), Bryan Che (Advisory Board Member, Software Heritage Foundation), Mike Milinkovich (Executive Director, Eclipse Foundation), Rebecca Rumbul (Executive Director, Rust Foundation), Xiaohua Xin (Deputy Secretary-General, OpenAtom Foundation), and Jim Zemlin (Executive Director, Linux Foundation). The panel discussed the importance of collaboration in addressing the challenges faced by the Open Source ecosystem and explored ways to strengthen inter-organizational ties.
Fireside Chat: Datasets, Privacy, and CopyrightStefano Maffulli also led a fireside chat on “Datasets, Privacy, and Copyright” in the context of Open Source AI along with Donnie Dong (Steering Committee Member, Digital Asia Hub; Senior Partner, Hylands Law Firm). This session was particularly relevant given the growing concerns around AI and the legal implications of creating and distributing large datasets. The discussion provided valuable insights into how these issues intersect with Open Source principles and what steps the community can take to address them responsibly. Some questions addressed included the use of copyrighted material in training datasets; fair use in the context of AI training and content generation; and China’s AI regulatory framework.
Talk: The Open Source AI DefinitionOSI’s involvement was further highlighted by Stefano Maffulli’s talk on “The Open Source AI Definition,” where he announced version 0.0.9 of the Open Source AI Definition (OSAID), a significant milestone resulting from a multi-year, global, and multi-stakeholder process. This version reflects the collective input of a diverse range of experts and community members who participated in extensive co-design workshops and public consultations, ensuring that the definition is robust, inclusive, and aligned with the principles of openness. Maffulli emphasized the importance of the “4 Freedoms of Open Source AI”—Use, Study, Modify, and Share—as foundational principles guiding the development of AI technologies. The session was particularly crucial for gathering feedback from the community in China, providing a platform for discussing the practical implications of the OSAID in different cultural and regulatory contexts.
Panel: The Future of Open Source CongressDeborah Bryant, OSI’s US Policy Director, moderated a pivotal panel discussion on “The Future of Open Source Congress: Converting Ideas to Shared Action.” This session focused on how the community can transform discussions into actionable strategies, ensuring the continued growth and impact of Open Source globally.
Other highlights from the eventThe “Unlocking Innovation: Open Strategies in Generative AI” panel led by Anni Lai (Chair of Generative AI Commons; Board member of LF AI & Data; Head of Open Source Operations, Futurewei) explored how openness is essential for advancing Generative AI innovation, democratizing access, and ensuring ethical AI practices. Panelists Richard Sikang Bian (Outreach Chair, LF AI & Data; Head of OSPO, Ant Group), Richard Lin (Member, OpenDigger Community; Head of Open Source, 01.ai), Ted Liu (Co-founder, KAIYUANSHE), and Zhenhua Sun (China Workgroup Chair, OpenChain; Open Source Legal Counsel, ByteDance) delved into the challenges of the Open Source generative AI landscape, such as “open washing,” inconsistent definitions, and the complexities of licensing. They highlighted the need for clear, standardized frameworks to define what truly constitutes Open Source AI, emphasizing that openness fosters transparency, accelerates learning, and mitigates biases. The panelists called for increased collaboration among stakeholders to address these challenges and further develop Open Source AI standards, ensuring that AI technologies are transparent, ethical, and widely adoptable.
In her closing keynote at the Open Source AI track, Amreen Taneja, Standards Lead at the Digital Public Goods Alliance (DPGA), emphasized the critical role of Open Source AI in advancing public good and supporting the Sustainable Development Goals (SDGs). She explained that Digital Public Goods (DPGs) are digital technologies made freely available to benefit society and highlighted the importance of OSAI in democratizing access to powerful AI technologies. Taneja outlined the DPGA’s efforts to align AI with public interests, including updating the DPG Standard to better accommodate AI, ensuring transparency in AI development, and promoting responsible AI practices that prioritize privacy and avoid harm. She stressed the need for rigorous evaluation, clear ownership, open licensing, and platform independence to drive the adoption of AI DPGs, ultimately aiming to create AI systems that are ethical, transparent, and beneficial for all.
Quotes from OSI Board and affiliatesAttending the Open Source Congress was really inspiring. Over two days, we participated in intensive discussions and exchanges with dozens of Open Source foundations and organizations worldwide, which was incredibly beneficial. I believe this will foster broader cross-community collaboration globally. I hope the conclusion of the second Open Source Congress marks the beginning of ongoing cooperation, allowing our “community of communities” to maintain regular communication and exchange.
Nadia Jiang – Board Chair of KAIYUANSHE
Open Source development experience is all about two words: consensus and antifragile decision-making process. The most valuable part of this event is seeing and listening to all the executive directors, open-source leaders in the room, and being very comfortable with the information density and the constructiveness of the discussions. Towards the end of the day, what people care about are not fundamentally different and there are indeed really difficult questions to resolve. I feel the world becomes slightly better after this OSC, and that means a lot to have an event like this.
Richard Bian – Head of Ant Group OSPO; Outreach Chair, Linux Foundation AI & Data
Open Source is the cornerstone of innovation, transparency, and collaboration, driving solutions that benefit everyone. The Open Source Congress 2024 represented a significant step forward in fostering alignment and building consensus within the open source community. By bringing together diverse voices and ideas, it amplified our collective efforts to create a more open, inclusive, and impactful digital ecosystem for the future.
Amreen Taneja – Standards Lead, Digital Public Goods Alliance
Stefano Maffulli with Board Directors of KAIYUANSHE: Emily Chen, Nadia Jiang (photo credits), and Ted Liu. ConclusionOSI’s active participation in the Open Source Congress 2024 reinforced its leadership role in the global Open Source community. By engaging in critical discussions, leading panels, and contributing to the future direction of Open Source initiatives, OSI continues to shape the landscape of Open Source development, ensuring that it remains inclusive, innovative, and aligned with the values of the global community.
This event marked another successful chapter in OSI’s ongoing efforts to drive collaboration and innovation in the Open Source world. We extend our sincere thanks to the organizers of OSC and the Open Source community in China for creating a platform that brought together a diverse and dynamic group of stakeholders, enabling meaningful discussions and progress. We look forward to continuing these conversations and turning ideas into action in the years to come.
Electric Citizen: Get Ready for Twin Cities Drupal Camp
This September, Minneapolis will once again host this annual gathering of the Drupal community.
If you are a Drupal developer, web designer, content strategist, site editor or anything connected to open-source and Drupal, you should consider attending!
Dominique De Cooman: Dreaming about Drupal its long term potential
Stefanie Molin: How to Create a Pre-Commit Hook
Real Python: Lists vs Tuples in Python
In Python, lists and tuples are versatile and useful data types that allow you to store data in a sequence. You’ll find them in virtually every nontrivial Python program. Learning about them is a core skill for you as a Python developer.
In this tutorial, you’ll:
- Get to know lists and tuples
- Explore the core characteristics of lists and tuples
- Learn how to define and manipulate lists and tuples
- Decide when to use lists or tuples in your code
To get the most out of this tutorial, you should know the basics of Python programming, including how to define variables.
Get Your Code: Click here to download the free sample code that shows you how to work with lists and tuples in Python.
Take the Quiz: Test your knowledge with our interactive “Lists vs Tuples in Python” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Lists vs Tuples in PythonChallenge yourself with this quiz to evaluate and deepen your understanding of Python lists and tuples. You'll explore key concepts, such as how to create, access, and manipulate these data types, while also learning best practices for using them efficiently in your code.
Getting Started With Python Lists and TuplesIn Python, a list is a collection of arbitrary objects, somewhat akin to an array in many other programming languages but more flexible. To define a list, you typically enclose a comma-separated sequence of objects in square brackets ([]), as shown below:
Python >>> colors = ["red", "green", "blue", "yellow"] >>> colors ['red', 'green', 'blue', 'yellow'] Copied!In this code snippet, you define a list of colors using string objects separated by commas and enclose them in square brackets.
Similarly, tuples are also collections of arbitrary objects. To define a tuple, you’ll enclose a comma-separated sequence of objects in parentheses (()), as shown below:
Python >>> person = ("Jane Doe", 25, "Python Developer", "Canada") >>> person ('Jane Doe', 25, 'Python Developer', 'Canada') Copied!In this example, you define a tuple with data for a given person, including their name, age, job, and base country.
Up to this point, it may seem that lists and tuples are mostly the same. However, there’s an important difference:
Feature List Tuple Is an ordered sequence ✅ ✅ Can contain arbitrary objects ✅ ✅ Can be indexed and sliced ✅ ✅ Can be nested ✅ ✅ Is mutable ✅ ❌Both lists and tuples are sequence data types, which means they can contain objects arranged in order. You can access those objects using an integer index that represents their position in the sequence.
Even though both data types can contain arbitrary and heterogeneous objects, you’ll commonly use lists to store homogeneous objects and tuples to store heterogeneous objects.
Note: In this tutorial, you’ll see the terms homogeneous and heterogeneous used to express the following ideas:
- Homogeneous: Objects of the same data type or the same semantic meaning, like a series of animals, fruits, colors, and so on.
- Heterogeneous: Objects of different data types or different semantic meanings, like the attributes of a car: model, color, make, year, fuel type, and so on.
You can perform indexing and slicing operations on both lists and tuples. You can also have nested lists and nested tuples or a combination of them, like a list of tuples.
The most notable difference between lists and tuples is that lists are mutable, while tuples are immutable. This feature distinguishes them and drives their specific use cases.
Essentially, a list doesn’t have a fixed length since it’s immutable. Therefore, it’s natural to use homogeneous elements to have some structure in the list. A tuple, on the other hand, has a fixed length so the position of elements can have meaning, supporting heterogeneous data.
Creating Lists in PythonIn many situations, you’ll define a list object using a literal. A list literal is a comma-separated sequence of objects enclosed in square brackets:
Python >>> countries = ["United States", "Canada", "Poland", "Germany", "Austria"] >>> countries ['United States', 'Canada', 'Poland', 'Germany', 'Austria'] Copied!In this example, you create a list of countries represented by string objects. Because lists are ordered sequences, the values retain the insertion order.
Read the full article at https://realpython.com/python-lists-tuples/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Tellico 4.0 Released
I’m excited to make Tellico 4.0 available as the first version to leverage the new Qt6 and KDE Frameworks 6 libraries. Tellico 4.0 also continues to build with Qt5/KF5 for those who haven’t yet transitioned to the newer versions.
Especially since this has many updates and changes in the underlying library code, please backup your data before switching to the new version. Creating a full backup file can be done by using the Export to Zip option which will create a file with all your images together with the main collection.
Please let me know of any compilation issues or bugs, particularly since I haven’t tested this on a wide range of Qt6/KF6 releases. The KDE builds are all working, which certainly helps my confidence, but one never knows.
Improvements and Fixes- Building with Qt6 is enabled by default, falling back to Qt5 for older versions of ECM or when the BUILD_WITH_QT6=off flag is used.
- Book and video collections can be imported from file metadata (Bug 214606).
- All entry templates were updated to include any loan information (Bug 411903).
- Creating and viewing the internal log file is supported through the --log and --logfile command-line options (Bug 426624).
- The DBUS interface can output to stdout using -- as the file name.
- Choice fields are now allowed to have multiple values (Bug 483831).
- The iTunes, Discogs, and MusicBrainz sources now separate multi-disc albums (Bug 479503).
- A configurable locale was added to the IMDb data source.
- The Allocine and AnimeNFO data sources were removed.
The Drop Times: Drupal GovCon 2024: LaunchDarkly and Drupal: A Solid Combo For A/B Testing
Reproducible Builds: Reproducible Builds in August 2024
Welcome to the August 2024 report from the Reproducible Builds project!
Our reports attempt to outline what we’ve been up to over the past month, highlighting news items from elsewhere in tech where they are related. As ever, if you are interested in contributing to the project, please visit our Contribute page on our website.
Table of contents:
- LWN: The history, status, and plans for reproducible builds
- Intermediate Autotools build artifacts removed from PostgreSQL distribution tarballs
- Distribution news
- Mailing list news
- diffoscope
- Website updates
- Upstream patches
- Reproducibility testing framework
The free software newspaper of record, Linux Weekly News, published an in-depth article based on Holger Levsen’s talk, Reproducible Builds: The First Eleven Years which was presented at the recent DebConf24 conference in Busan, South Korea.
Titled The history, status, and plans for reproducible builds and written by Jake Edge, LWN’s article not only summarises Holger’s talk and clarifies its message but it links to external information as well. Holger’s original talk can also be watched on the DebConf24 webpage (direct .webm link and his HTML slides are available also). There are also a significant number of comments on LWN’s page as well.
Holger Levsen also headed a scheduled discussion session at DebConf24 on Preserving *other* build artifacts addressing a topic where a number of Debian packages are (or would like to) produce results that are neither the .deb files, the build logs nor the logs of CI tests. This is an issue for reproducible builds as this “4th type” of build artifact are typically shipped within the binary .deb packages, and are invariably non-deterministic; thus making the .deb files unreproducible. (A direct .webm link and HTML slides are available).
Peter Eisentraut wrote a detailed blog post on the subject of “The new PostgreSQL 17 make dist”. Like many projects, the PostgreSQL database has previously pre-built parts of its GNU Autotools build system: “the reason for this is a mix of convenience and traditional practice”. Peter astutely notes that this arrangement in the build system is “quite tricky” as:
You need to carefully maintain the different states of “clean source code”, “partially built source code”, and “fully built source code”, and the commands to transition between them.
However, Peter goes on to mention that:
… a lot more attention is nowadays paid to the software supply chain. There are security and legal reasons for this. When users install software, they want to know where it came from, and they want to be sure that they got the right thing, not some fake version or some version of dubious legal provenance.
And cites the XZ Utils backdoor as a reason to care about transparent and reproducible ways of distributing and communicating a source tarball and provenance. Because of this, intermediate build artifacts are now henceforth essentially disallowed from PostgreSQL distribution tarballs.
Distribution newsIn Debian this month, 30 reviews of Debian packages were added, 17 were updated and 10 were removed this month adding to our knowledge about identified issues. One issue type was added by Chris Lamb, too. […]
In addition, an issue was filed to update the Salsa CI pipeline (used by 1,000s of Debian packages) to no longer test for reproducibility with reprotest’s build_path variation. Holger Levsen provided a rationale for this change in the issue, which has already been made to the tests being performed by tests.reproducible-builds.org.
In Arch Linux this month, Jelle van der Waa published a short blog post on the topic of Investigating creating reproducible images with mkosi, motivated by the desire to make it possible for anyone to “re-recreate the official Arch cloud image bit-by-bit identical on their own machine as per [the] reproducible builds definition.” In addition, Jelle filed a patch for pacman, the Arch Linux package manager, to respect the SOURCE_DATE_EPOCH environment variable when installing a package.
In openSUSE news, Bernhard M. Wiedemann published another report for that distribution.
In Android news, the IzzyOnDroid project added 49 new rebuilder recipes and now features 256 total reproducible applications representing 21% of the total offerings in the repository. IzzyOnDroid is “an F-Droid style repository for Android apps[:] applications in this repository are official binaries built by the original application developers, taken from their resp. repositories (mostly GitHub).”
From our mailing list this month:
-
Bernhard M. Wiedemann posted a brief message to the list with some helpful information regarding nondeterminism within Rust binaries, positing the use of the codegen-units = 16 default and resulting in a bug being filed in the Rust issue tracker. […]
-
Bernhard also wrote to the list, following up to a thread in November 2023, on attempts to make the LibreOffice suite of office applications build reproducibly. In the thread from this month, Bernhard could announce that the four patches previously mentioned have landed in LibreOffice upstream.
-
Fay Stegerman linked the mailing list to a thread she made on the Signal issue tracker regarding whether “device-specific binaries [can] ever be considered meaningfully reproducible”. In particular: “the whole part about ‘allow[ing] multiple third parties to come to a consensus on a “correct” result’ breaks down completely when ‘correct’ is device-specific and not something everyone can agree on.” […]
-
Developer kpcyrd posted an update for source code indexing project, whatsrc.org. Announcing that it now importing packages from live-bootstrap (“a usable Linux system [that is] created with only human-auditable, and wherever possible, human-written, source code”) into its database of provenance data.
-
Lastly, Mechtilde Stehmann posted an update to an earlier thread about how Java builds are not reproducible on the armhf architecture, enquiring how they might gain temporary access to such a machine in order to perform some deeper testing. […]
diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb released versions 274, 275, 276 and 277, uploaded these to Debian, and made the following changes as well:
-
New features:
- Strip ANSI escapes—usually colour codes—from the output of the Procyon Java decompiler. […]
- Factor out a method for stripping ANSI escapes. […]
- Append output from dumppdf(1) in more cases, avoiding situations where we fallback to a binary diff. […]
- Add support for versions of Perl’s IO::Compress::Zip version 2.212. […]
-
Bug fixes:
- Also catch RuntimeError exceptions when importing the PyPDF library so that it, or, crucially, its transitive dependencies, cannot not cause diffoscope to traceback at runtime and build time. […]
- Do not call marshal.load(…) of precompiled Python bytecode as it, alas, inherently unsafe. Replace for now with a brief summary of the code section of .pyc. […][…]
- Don’t include excessive debug output when calling dumppdf(1). […]
-
Testsuite-related changes:
- Don’t bother to check version number in test_python.py: the fixture for this test is fixed. […][…]
- Update test_zip text fixtures and definitions to support new changes to the Perl IO::Compress library. […]
In addition, Mattia Rizzolo updated the available architectures for a number of test dependencies […] and Sergei Trofimovich fixed an issue to avoid diffoscope crashing when hashing directory symlinks […] and Vagrant Cascadian proposed GNU Guix updates for diffoscope versions [275 and 276 and [277.
There were a rather substantial number of improvements made to our website this month, including:
-
Alba Herrerias:
- Substantially extend the guidance on the Contribute page. […]
-
Chris Lamb:
-
Fay Stegerman:
- Add IzzyOnDroid (IoD) to the Projects page. […]
-
hulkoba:
- Considerably overhaul the History page in the documentation, linking strip-nondeterminism and SOURCE_DATE_EPOCH […], fixing the test statistics link […], adjusting the Google Summer of Code application link […], a link to a Debian bug […], and removed a dead link to the debhelper utility […].
- Use the jekyll-sitemap plugin to create a sitemap for the website. […]
- Use raw HTML to avoid a literal { .lead } directive appearing in the page. […]
- Fix a number of issues on the Virtual machine drivers page, such as keeping the Gitian info, linking (and then removing) an issue on the Bitcoin issue tracker […] and fixing a link to the Bazel website […].
- Address a broken footnote link on the Timestamps page. […]
- Unify the style on the Commandments of Reproducible Builds page in order to match other documentation entries. […]
- Add a table of contents to the main Documentation page. […]
- Avoid a number of so-called “here” links on the Variations in the build environment page. […]
- Fix a link to the man2html patch on the SOURCE_DATE_EPOCH documentation page. […]
- Fix a link to sources.debian.org on the Randomness page. […]
-
kpcyrd:
- Fix a typo on the Variations in the build environment page. […]
-
Mattia Rizzolo:
-
Pol Dellaiera:
- Fix the DoI for their thesis on the Publications page. […]
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Bernhard M. Wiedemann:
- agama-integration-tests (uses a random TCP-port number in .lock file)
- ca-certificates-mozilla:ca-certificates-mozilla-prebuilt
- cosmic (hash order issue)
- openSUSE (meta-issue to test reproducibility in the openSUSE Build Service)
- pop-launcher (parallelism-related issue)
- post (toolchain-issue, avoiding Rust parallelism)
- rpm-config-SUSE (date-related issue)
- rust (Rust toolchain issue)
- weblate (build gets stuck)
-
Chris Lamb:
-
James Addison:
- #1064782 forwarded and merged in bind9-doc
- #1066083 forwarded and merged in gnome-maps
The Reproducible Builds project operates a comprehensive testing framework running primarily at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility. In August, a number of changes were made by Holger Levsen, including:
- Temporarily install the openssl-provider-legacy package for the Debian unstable environments for running diffoscope due to Debian bug #1078944. […][…][…][…]
- Mark Debian armhf architecture nodes as being down due to proxy down. […][…]
- Detect proxy failures. […][…][…]
- Run the index-buildinfo for the builtin-pho script with the -q switch. […]
- Disable all Arch Linux reproducible jobs. […]
In addition, Mattia Rizzolo updated the website configuration to install the ruby-jekyll-sitemap package as it is now used in the website […], Roland Clobus updated the script to build Debian ‘live’ images to treat openQA issues as warnings […], and Vagrant Cascadian marked the cbxi4b node as down […].
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC: #reproducible-builds on irc.oftc.net.
-
Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list: rb-general@lists.reproducible-builds.org
-
Twitter: @ReproBuilds
Real Python: Quiz: Lists vs Tuples in Python
Challenge yourself with this quiz to evaluate and deepen your understanding of Python lists and tuples. You’ll explore key concepts, such as how to create and manipulate these data types, while also learning best practices for using them efficiently in your code.
You can take this quiz after reading the Lists vs Tuples in Python tutorial.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
joshics.in: Why Drupal is the Ultimate CMS for Your Business: Flexibility, Security, and Scalability
When it comes to choosing a Content Management System (CMS) or framework, the options can be overwhelming. WordPress, Joomla, Squarespace, and many others each have their own strengths. However, there's one CMS that stands out among the rest for its power, flexibility, and scalability: Drupal. Here’s why Drupal should be at the top of your list.
Unmatched FlexibilityDrupal is known for its modular architecture, which allows developers to create highly customised solutions. Unlike WordPress and Squarespace that offer limited customisation out of the box, Drupal’s framework enables you to build virtually any type of website, from simple blogs to complex enterprise-level applications. Joomla also offers flexibility, but Drupal surpasses it with its extensive range of modules and themes.
Robust SecuritySecurity is a critical concern for any website owner. While WordPress is often targeted due to its vast user base, and Joomla has had its share of vulnerabilities, Drupal boasts one of the most secure CMS frameworks available. With a dedicated security team that actively works to identify and patch vulnerabilities, Drupal ensures that your site is well-protected against common cyber threats.
ScalabilityOne of the most compelling reasons to choose Drupal is its ability to scale. Whether you're running a small business website or a high-traffic enterprise portal, Drupal can handle your needs. Major websites like NASA trust Drupal to manage their vast amount of content and traffic demands. While WordPress can also scale, it may require significant customisation and optimisations, which come naturally to Drupal.
Active Community SupportDrupal has a large and active community of developers, designers, and contributors who constantly improve the platform. While WordPress boasts the largest community, Drupal’s community-driven approach means you benefit from a wide range of modules, themes, and plugins that can extend the functionality of your site. Joomla also has a strong community, but Drupal’s focus on high-quality, enterprise-level solutions sets it apart.
SEO-FriendlyHaving a website that ranks well on search engines is crucial. Drupal offers extensive SEO capabilities right out of the box, comparable to those of WordPress, which is often praised for its SEO plugins. From clean URLs to meta tags and mobile optimisation, Drupal provides the tools you need to ensure your site is easily discoverable by search engines. This built-in SEO functionality means you can focus more on your content and less on technical tweaks.
Cost-Effective in the Long RunWhile initial development costs for a Drupal site might be higher compared to simpler platforms like WordPress or Squarespace, the long-term benefits make it a cost-effective choice. Its robust architecture reduces the need for frequent redesigns or overhauls, ensuring you get a higher return on investment over time.
Integrated Digital EcosystemFor businesses looking to integrate their website with other digital tools and platforms, Drupal offers seamless integration capabilities. Whether it’s CRM systems, marketing automation tools, or e-commerce platforms, Drupal can easily connect with your existing digital ecosystem, streamlining your operations and enhancing user experience.
if you're looking for a CMS that offers unparalleled flexibility, robust security, scalability, active community support, SEO-friendliness, and long-term cost-effectiveness, Drupal is an excellent choice. Make the smart move and consider Drupal for your next project.
Drupal Drupal CMS Drupal Planet Add new commentHynek Schlawack: Production-ready Python Docker Containers with uv
Starting with 0.3.0, Astral’s uv brought many great features, including support for cross-platform lock files uv.lock. Together with subsequent fixes, it has become Python’s finest workflow tool for my (non-scientific) use cases. Here’s how I build production-ready containers, as fast as possible.
Jonathan Dowland: loading (unintended consequences?)
For their 30th anniversary (ish; the Covid pandemic pushed the date out a bit) British electronic music duo Orbital released the compilation 30 something. The track list mostly looks like a best hits list, which — given their prior compilation celebrating 20 years looks much the same — would appear superfluous. However, they’ve rearranged and re-recorded all their songs for 30, to reflect their live arrangements. The reworkings are sufficiently distinct from the original versions (in some cases I prefer them) and elevate the release. The couple of new tracks are also fun, and many of the remixes on the second disc are worth a listen too.
{kind=link}
But what I actually sat down to write about was the cover artwork. They often have designs which riff on the notion of a circle (given their name) and the 30-something art (both for the album and single takes from it) adapts a “loading” spinner-like device from computing (I suppose it mostly closely resembles the spinner from macOS).
A possibly unintended effect of the pattern occurs when you view it on a display which is adjusting its brightness, such as if you’re listening to it on a phone, the screen is off, and you pick it up. The brightest part of the spinner is visible first, and the rest fade into visibility in sequence. The first time you see this is unexpected and very cool. (I've tried to recreate it in the picture below, but I don't think it's worked.)
Although I've suffixed the titled of this post unintended consequences?, It's quite possible this was deliberate.
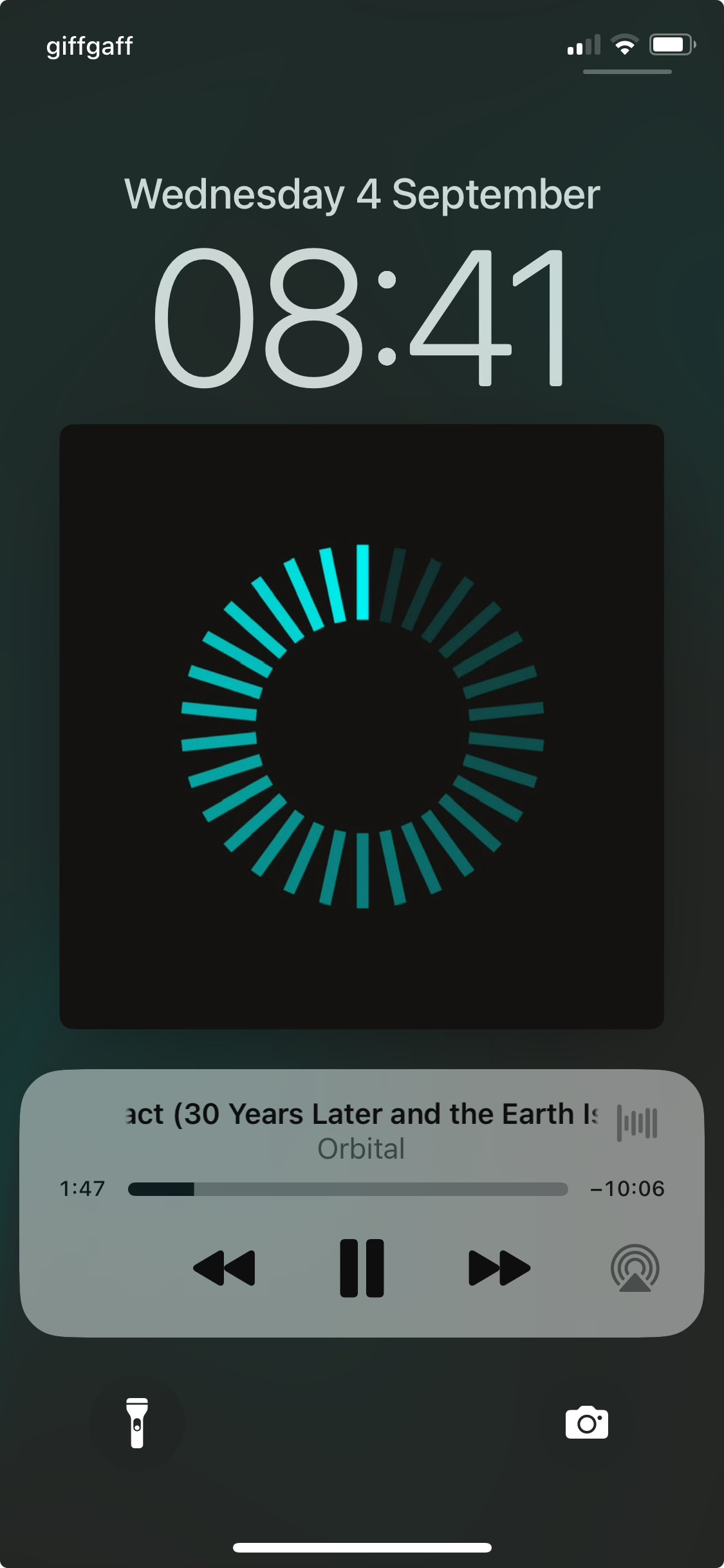{kind=link}
I’ve got the pattern on a t-shirt and my kids love to call out “Daddy’s loading!” In my convalescence it’s taken on a special sort of resonance because at times I’ve felt I’m in a holding state: waiting for an appointment to be made; waiting a polite interval before chasing an appointment; waiting for treatment to start after attending an appointment. Thankfully I’m at the end of that now, I hope.
Promet Source: DotNetNuke vs Drupal for Large Government Agencies
Talk Python to Me: #476: Unified Python packaging with uv
Dirk Eddelbuettel: RcppCNPy 0.2.13 on CRAN: Micro Bugfix
Another (again somewhat minor) maintenance release of the RcppCNPy package arrived on CRAN earlier today.
RcppCNPy provides R with read and write access to NumPy files thanks to the cnpy library by Carl Rogers along with Rcpp for the glue to R.
A change in the most recent Rcpp appears to cause void functions wrapper via Rcpp Modules to return NULL, as opposed to being silent. That tickles discrepancy between the current output and the saved (reference) output of one test file, leading CRAN to display a NOTE which we were asked to take care of. Done here in this release—and now that we know we will also look into restoring the prior Rcpp behaviour. Other small changes involved standard maintenance for continuous integration and updates to files README.md and DESCRIPTION. More details are below.
Changes in version 0.2.13 (2024-09-03)A test script was updated to account for the fact that it now returns a few instances of NULL under current Rcpp.
Small package maintenance updates have been made to the README and DESCRIPTION files as well as to the continuous integration setup.
CRANberries also provides a diffstat report for the latest release. As always, feedback is welcome and the best place to start a discussion may be the GitHub issue tickets page.
If you like this or other open-source work I do, you can now sponsor me at GitHub.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
Brightness controls for all your displays
Whoops, it's already been months since I last blogged. I've been actively involved with Plasma and especially its power management service PowerDevil for over a year now. I'm still learning about how everything fits together.
Turns out though that a little bit of involvement imbues you with just enough knowledge and confidence to review other people's changes as well, so that they can get merged into the next release without sitting in limbo forever. Your favorite weekly blogger for example, Nate Graham, is a force of nature when it comes to responding to proposed changes and finding a way to get them accepted in one form or another. But it doesn't have to take many years of KDE development experience to provide helpful feedback.
Otfen we simply need another pair of eyes trying to understand the inner workings of a proposed feature or fix. If two people think hard about an issue and agree on a solution, chances are good that things are indeed changing for the better. Three or more, even better. I do take pride in my own code, but just as much in pushing excellent improvements like these past the finish line:
- Fabian Arndt's support for Lenovo laptops' battery conservation mode (Plasma 6.1)
- Natalie Clarius's feature to block apps from inhibiting sleep and screen locking (6.2)
- Christoph Wolk's improvements to usability for the Power Management settings page (6.2, one among many of the sort)
- Nate's changes to show the current power profile in addition to the battery charge (6.2)
- Xaver Hugl's push to allow software brightness adjustments not just for HDR displays (6.1), but indeed for any display without hardware brightness controls (6.2)
In turn, responsible developers will review your own changes so we can merge them with confidence. Xaver, Natalie and Nate invested time into getting my big feature merged for Plasma 6.2, which you've already read about:
Per-display Brightness Controls
This was really just a follow-up project to the display support developments mentioned in the last blog post. I felt it had to be done, and it lined up nicely with what KWin's been up to recently.
So how hard could it be to add another slider to your applet? Turns out there are indeed a few challenges.
In KDE, we like to include new features early on and tweak them over time. As opposed to, say, the GNOME community, which tends to discuss them for a loooong time in an attempt to merge the perfect solution on the first try. Both approaches have advantages and drawbacks. Our main drawback is harder to change imperfect code, because it's easy to break functionality for users that already rely on them.
Every piece of code has a set of assumptions embedded into it. When those assumptions don't make sense for the next, improved, hopefully perfect solution (definitely perfect this time around!) then we have to find ways to change our thinking. The code is updated to reflect a more useful set of assumptions, ideally without breaking anyone's apps and desktop. This process is called "refactoring" in software development.
But let's be specific: What assumptions am I actually talking about?
There is one brightness slider for your only displayThis one's obvious. You can use more than just one display at a time. However, our previous code only used to let you read one brightness value, and set one brightness value. For which screen? Well... how about the code just picks something arbitrarily. If you have a laptop with an internal screen, we use that one. If you have no internal screen, but your external monitor supports DDC/CI for brightness controls, we use that one instead.
What's that, you have multiple external monitors that all support DDC/CI? We'll set the same value for all of them! Even if the first one counts from 0 to 100 and the second one from 0 to 10.000! Surely that will work.
No it won't. We only got lucky that most monitors count from 0 to 100.
The solution here is to require all software to treat each display differently. We'll start watching for monitors being connected and disconnected. We tell all the related software about it. Instead of a single set-brightness and a single get-brightness operation, we have one of these per display. When the lower layers require this extra information, software higher up in the stack (for example, a brightness applet) is forced to make better choices about the user experience in each particular case. For example, presenting multiple brightness sliders in the UI.
A popup indicator shows the new brightness when it changesSo this raises new questions. With only one display, we can indicate any brightness change by showing you the new brightness on a percentage bar:
Now you press the "Increase Brightness" key on your keyboard, and multiple monitors are connected. This OSD popup shows up on... your active screen? But did the brightness only change for your active screen, or for all of them? Which monitor is this one popup representing?
Ideally, we'd show a different popup on each screen, with the name of the respective monitor:
That's a good idea! But Plasma's OSD component doesn't have a notion of different popups being shown at the same time on different monitors. It may even take further changes to ask KWin, Plasma's compositor component, about that. What we did for Plasma 6.2 was to provide Plasma's OSD component with all the information it needs to do this eventually. But we haven't implemented our favorite UI yet, instead we hit the 6.2 deadline and pack multiple percentages into a single popup:
That's good enough for now, not the prettiest but always clear. If you only use or adjust one screen, you'll get the original fancy percentage bar you know and love.
The applet can do its own brightness adjustment calculationsYou can increase or decrease brightness by scrolling on the icon of the "Brightness and Color" applet with your mouse wheel or touchpad. Sounds easy to implement: read the brightness for each display, add or subtract a certain percentage, set the brightness again for the same display.
Nope, not that easy.
For starters, we handle brightness key presses in the background service. You'd expect the "Increase Brightness" key to behave the same as scrolling up with your mouse wheel, right? So let's not implement the same thing in two different places. The applet has to say goodbye to its own calculations, and instead we add an interface to background service that the applet can use.
Then again, the background service never had to deal with high-resolution touchpad scrolling. It's so high-resolution that each individual scroll event might be smaller than the number of brightness steps on your screen. The applet contained code to add up all of these tiny changes so that many scroll events taken together will at least make your screen change by one step.
Now the service provides this functionality instead, but it adds up the tiny changes for each screen separately. Not only that, it allows you to keep scrolling even if one of your displays has already hit maximum brightness. When you scroll back afterwards, both displays don't just count down from 100% equally, but the original brightness difference between both screens is preserved. Scroll up and down to your heart's content without messing up your preferred setup.
Dimming will turn down the brightness, then restore the original value laterSimple! Yes? No. As you may guess, we now need to store the original brightness for each display separately so we can restore it later.
But that's not enough: What if you unplug your external screen while it's dimmed? And then you move your mouse pointer again, so the dimming goes away. Your monitor, however, was not there for getting its brightness restored to the original value. Next time you plug it in, it starts out with the dimmed lower brightness as a new baseline, Plasma will gladly dim even further next time.
Full disclosure, this was already an issue in past releases of Plasma and is still an issue. Supporting multiple monitors just makes it more visible. More work is needed to make this scenario bullet-proof as well. We'll have to see if a small and safe enough fix can still be made for Plasma 6.2, or if we'll have to wait until later to address this more comprehensively.
Anyway, these kind of assumptions are what eat up a good amount of development time, as opposed to just adding new functionality. Hopefully users will find the new brightness controls worthwhile.
So let's get to the good newsYour donations allowed KDE e.V. to approve a travel cost subsidy in order to meet other KDE contributors in person and scheme the next steps toward world domination. You know what's coming, I'm going to:
Akademy is starting in just about two days from now! Thank you all for allowing events like this to happen, I'll try to make it count. And while not everyone can get to Germany in person, keep in mind that it's a hybrid conference and especially the weekend talks are always worth watching online. You can still sign up and join the live chat, or take a last-minute weekend trip to Würzburg if you're in the area, or just watch the videos shortly afterwards (I assume they'll go up on the PeerTube Akademy channel).
I'm particularly curious about the outcome of the KDE Goals vote for the upcoming two years, given that I co-drafted a goal proposal this time around. Whether or not it got elected, I haven't forgotten about my promise of working on mouse gesture support on Plasma/Wayland. Somewhat late due to the aforementioned display work taking longer. Other interesting things are starting to happen as well on my end. I'll have to be mindful not to stretch myself too thinly.
Thanks everyone for being kind. I'll be keeping an eye out for your bug reports when the Plasma 6.2 Beta gets released to adventurous testers in just over a week from today.
Discuss this post on KDE Discuss.
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects