
Feeds
Python Bytes: #405 Oh Really?
Zato Blog: What is an API gateway?
In this article, we are going to use Zato in its capacity as a multi-protocol Python API gateway - we will integrate a few popular technologies, accepting requests sent over protocols commonly used in frontend systems, enriching and passing them to backend systems and returning responses to the API clients using their preferred data formats. But first, let's define what an API gateway is.
Clearing up the terminologyAlthough we will be focusing on complex API integrations later on today, to understand the term API gateway we first need to give proper consideration to the very term gateway.
What comes to mind when we hear the word "gateway", and what is correct etymologically indeed, is an opening in an otherwise impermissible barrier. We use a gateway to access that which is in other circumstances inaccessible for various reasons. We use it to leave such a place too.
In fact, both "gate" and the verb "to go" stem from the same basic root and that, again, brings to mind a notion of passing through space specifically set aside for the purpose of granting access to what normally would be unavailable. And once more, when we depart from such an area, we use a gateway too.
From the perspective of its true intended purpose, a gateway letting everyone in and out as they are would amount to little more than a hole in a wall. In other words, a gateway without a gate is not the whole story.
Yes, there is undoubtedly an immense aesthetic gratification to be drawn from being close to marvels of architecture that virtually all medieval or Renaissance gates and gateways represent, but we know that, nowadays, they do not function to the fullest of their capacities as originally intended.
Rather, we can intuitively say that a gateway is in service as a means of entry and departure if it lets its operators achieve the following, though not necessarily all at the same time, depending on one's particular needs:
- Telling arrivals where they are, including projection of might and self-confidence
- Confirming that arrivals are who they say they are
- Checking if their port of origin is friendly or not
- Checking if they are allowed to enter that which is protected
- Directing them to specific areas behind the gateway
- Keeping a long term and short term log of arrivals
- Answering potential questions right by the gate, if answers are known to gatekeepers
- Cooperating with translators and coordinators that let arrivals make use of what is required during their stay
We can now recognize that a gateway operates on the border of what is internal and external and in itself, it is a relatively narrow, though possibly deep, piece of an architecture. It is narrow because it is only through the gateway that entry is possible but it may be deeper or not, depending on how much it should offer to arrivals.
We also keep in mind that there may very well be more than a single gateway in existence at a time, each potentially dedicated to different purposes, some overlapping, some not.
Finally, it is crucial to remember that gateways are structural, architectural elements - what a gateway should do and how it should do it is a decision left to architects.
With all of that in mind, it is easy to transfer our understanding of what a physical gateway is into what an API one should be.
- API clients should be presented with clear information that they are entering a restricted area
- Source IP addresses or their equivalents should be checked and requests rejected if an IP address or equivalent information is not among the allowed ones
- Usernames, passwords, API keys and similar representations of what they are should be checked by the gateway
- Permissions to access backend systems should be checked seeing as not every API client should have access to everything
- Requests should be dispatched to relevant backend systems
- Requests and responses should be logged in various formats, some meant to be read by programs and applications, some by human operators
- If applicable, responses can be served from the gateway's cache, taking the burden off the shoulders of the backend systems
- Requests and responses can be transformed or enriched which potentially means contacting multiple backend systems before an API caller receives a response
We can now define an API gateway as an element of a systems architecture that is certainly related to security, permissions and granting or rejecting access to backend systems, applications and data sources. On top of it, it may provide audit, data transformation and caching services. The definition will be always fluid to a degree, depending on an architect's vision, but this is what can be expected from it nevertheless.
Having defined what an API gateway is, let's create one in Zato and Python.
Clients and backend systemsIn this article, we will integrate two frontend systems and one backend application. Frontend ones will use REST and WebSockets whereas the backend one will use AMQP. Zato will act as an API gateway between them all.
Not granting frontend API clients direct access to backend systems is usually a good idea because the dynamics involved in creation of systems on either side are typically very different. But they still need to communicate and hence the usage of Zato as an API gateway.
Python codeFirst, let's show the Python code that is needed to integrate the systems in our architecture:
# -*- coding: utf-8 -*- # Zato from zato.server.service import Service class APIGateway(Service): """ Dispatches requests to backend systems, enriching them along the way. """ name = 'api.gateway' def handle(self): # Enrich incoming request with metadata .. self.request.payload['_receiver'] = self.name self.request.payload['_correlation_id'] = self.cid self.request.payload['_date_received'] = self.time.utcnow() # .. AMQP configuration .. outconn = 'My Backend' exchange = '/incoming' routing_key = 'api' # .. publish the message to an AMQP broker .. self.out.amqp.send(data, outconn, exchange, routing_key) # .. and return a response to our API client. self.response.payload = {'result': 'OK, data accepted'}There are a couple of points of interest:
-
The gateway service enriches incoming requests with metadata but it could very well enrich it with business data too, e.g. it could communicate with yet another system to obtain required information and only then pass the request to the final backend system(s)
-
In its current form we send all the information to AMQP brokers only but we could just as well send it to other systems, possibly modifying the requests along the way
-
The code is very abstract and all of its current configuration could be moved to a config file, Redis or another data source to make it even more high-level
-
Security configuration and other details are not declared directly in the body of the gateway service but they need to exist somewhere - we will describe it in the next section
In Zato, API clients access the platform's services using channels - let's create a channel for REST and WebSockets then.
First REST:
Now WebSockets:
We create a new outgoing AMQP connection in the same way:
Using the API gatewayAt this point, the gateway is ready - you can invoke it from REST or WebSockets and any JSON data it receives will be processed by the gateway service, the AMQP broker will receive it, and API clients will have replies from the gateway as JSON responses.
Let's use curl to invoke the REST channel with JSON payload on input:
$ curl http://api:<password-here>@localhost:11223/api/v1/user ; echo curl --data-binary @request.json http://localhost:11223/api/v1/user ; echo {"result": "OK, data accepted"} $Taken together, the channels and the service allowed us to achieve this:
- Multiple API clients can access the backend AMQP systems, each client using its own preferred technology
- Client credentials are checked on input, before the service starts to process requests (authentication)
- It is possible to assign RBAC roles to clients, in this way ensuring they have access only to selected parts of the backend API (authorization)
- Message logs keep track of data incoming and outgoing
- Responses from channels can be cached which lessens the burden put on the shoulders of backend systems
- Services accepting requests are free to modify, enrich and transform the data in any way required by business logic. E.g., in the code above we only add metadata but we could as well reach out to other applications before requests are sent to the intended recipients.
We can take it further. For instance, the gateway service is currently completely oblivious to the actual content of the requests.
But, since we just have a regular Python dict in self.request.payload, we can with no effort modify the service to dispatch requests to different backend systems, depending on what the request contains or possibly what other backend systems decide the destination should be.
Such additional logic is specific to each environment or project which is why it is not shown here, and this is also why we end the article at this point, but the central part of it all is already done, the rest is only a matter of customization and plugging in more channels for API clients or outgoing connections for backend systems.
Finally, it is perfectly fine to split access to systems among multiple gateways - each may handle requests from selected technologies on the one hand but on the other hand, each may use different caching or rate-limiting policies. If there is more than one, it may be easier to configure such details on a per-gateway basis.
Next steps:➤ Read about how to use Python to build and integrate enterprise APIs that your tests will cover
➤ Python API integration tutorial
➤ Python Integration platform as a Service (iPaaS)
➤ What is an Enterprise Service Bus (ESB)? What is SOA?
Trey Hunner: Django and the Python 3.13 REPL
Your new Django project uses Python 3.13.
You’re really looking forward to using the new REPL… but python manage.py shell just shows the same old Python REPL. What gives?
Well, Django’s management shell uses Python’s code module to launch a custom REPL, but the code module doesn’t (yet) use the new Python REPL.
So you’re out of luck… or are you?
How stable do you need your shell command to be?The new Python REPL’s code lives in a _pyrepl package. Surely there must be some way to launch the new REPL using that _pyrepl package!
First, note the _ before that package name. It’s _pyrepl, not pyrepl.
Any solution that relies on this module may break in future Python releases.
So… should we give up on looking for a solution, if we can’t get a “stable” one?
I don’t think so.
My shell command doesn’t usually need to be stable in more than one version of Python at a time. So I’m fine with a solution that attempts to use the new REPL and then falls back to the old REPL if it fails.
A working solutionSo, let’s look at a working solution.
Stick this code in a management/commands/shell.py file within one of your Django apps:
1 2 3 4 5 6 7 8 9 10 """Python 3.13 REPL support using the unsupported _pyrepl module.""" from django.core.management.commands.shell import Command as BaseShellCommand class Command(BaseShellCommand): shells = ["ipython", "bpython", "pyrepl", "python"] def pyrepl(self, options): from _pyrepl.main import interactive_console interactive_console() How it worksDjango’s shell command has made it very simple to add support for your favorite REPL of choice.
The code for the shell command loops through the shells list and attempts to run a method with that name on its own class. If an ImportError is raised then it attempts the next command, stopping once no exception occurs.
Our new command will try to use IPython and bpython if they’re installed and then it will try the new Python 3.13 REPL followed by the old Python REPL.
If Python 3.14 breaks our import by moving the interactive_console function, then an ImportError will be raised, causing us to fall back to the old REPL after we upgrade to Python 3.14 one day. If instead, the interactive_console function’s usage changes (maybe it will require arguments) then our shell command will completely break and we’ll need to manually fix it when we upgrade to Python 3.14.
What’s so great about the new REPL?If you’re already using IPython or BPython as your REPL and you’re enjoying them, I would stick with them.
Third-party libraries move faster than Python itself and they’re often more feature-rich. IPython has about 20 years worth of feature development and it has features that the built-in Python REPL will likely never have.
If you’re using the default Python REPL though, this new REPL is a huge upgrade. I’ve been using it as my default REPL since May and I love it. See my screencast on Python 3.13 for my favorite features in the new REPL.
Armin Ronacher: The Inevitability of Mixing Open Source and Money
This year, one of the projects I was involved in at Sentry was the launch of The Open Source Pledge. The idea behind it is simple: companies pledge an amount proportional to the number of developers they employ to fund the Open Source projects they depend on. I have written about this before.
Since then, I've had the chance to engage in many insightful discussions about Open Source funding and licensing. In the meantime we have officially launched the pledge, and almost simultaneously WordPress entered a crisis. At the heart of that crisis is a clash between Open Source ideals and financial interests by people other than the original creators.
You might have a lot of opinions on David Heinemeier Hansson, but I encourage you to read two of his recent posts on that very topic. In Automattic is doing open source dirty David is laying out the case that Automattic has no right to impose moral obligations on beyond the scope of the license. This has been followed by Open source royalty and mad kings in which he goes deeper into the fallout that Matt Mullenweg (the creator of WordPress) is causing with his fight.
I'm largely in agreement with the posts. However I want to talk a bit about some pretty significant difference between David's opinions on Open Source funding (on which these posts appear to be based): the money element. In 2013 David wrote the following about money and Open Source:
[…] it's tempting to cash in on goodwill earned. […] It's a cliché, but once you've sold out, the goodwill might well be spent for good.
[…] part of the reason much of open source is so good, and often so superior to closed-source commercial projects, is the natural boundary of constraints. If you are not being paid or otherwise compensated directly for your work, you're less likely to needlessly embellish it. […]
—David Heinemeier Hansson, The perils of mixing open source and money
At face value, this suggests that Open Source and money shouldn’t mix, and that the absence of monetary rewards fosters a unique creative process. There's certainly truth to this, but in reality, Open Source and money often mix quickly.
If you look under the cover of many successful Open Source projects you will find companies with their own commercial interests supporting them (eg: Linux via contributors), companies outright leading projects they are also commercializing (eg: MariaDB, redis) or companies funding Open Source projects primarily for marketing / up-sell purposes (uv, next.js, pydantic, …). Even when money doesn't directly fund an Open Source project, others may still profit from it, yet often those are not the original creators. These dynamics create stresses and moral dilemmas.
I’ve said this before, but it’s no coincidence that Rails has a foundation, large conferences, a strong core team, and a trademark, while Flask has none of it. There are barriers and it takes a lot of energy and determination to push a project to a level where it can sustain itself.
Rails pushed through this barrier. I never did with any of my projects and I'm at peace with that. I got to learn a lot through my Open Source work, I achieved a certain level of notoriety that I benefit from. I built a meaningful career by leveraging my work and I even met my wonderful wife that way. All are consequences of my Open Source contributions. There were clear and indisputable benefits to it and by all accounts I'm a happy and grateful person.
But every now and then doubts creep in and I wonder if I should have done something more commercial with Flask, or if I should have pushed Rye further. As much as I love listening to Charlie talking about uv, there is also an unavoidable doubt lingering there what could have been if I dared to build out Rye with funding on my own.
Over the years, I have seen too many of my colleagues and acquaintances struggle one way or another. Psychological, mentally and professionally. Midlife crises, burnout, health, and dealing with a strong feeling of dread and disappointment. Many of this as a indirect or even direct result of their Open Source work. While projects like Rails and Laravel are great examples of successful open source stewardship, they are also outliers. Many others don't survive or grow to that level.
And yet even some of those lighthouse projects can become fallen stars and face challenges. WordPress by all accounts is a massive success. WordPress is in the top 1% of open source projects in terms of impact, success, and financial return for its creator. Yet despite that — and it finding an actual business model to commercialize it — its creator suffers from the same fate as many small Open Source libraries: a feeling of being wronged.
This is where the lines between law and morality blur. Matt feels mistreated, especially by a private equity firm, but neither trademarks nor license terms can resolve the issue for him. It’s a moral question, and sadly, Matt’s actions have alienated many who would otherwise support him. He's turning into a “mad king” and behaving immoral in his own ways.
The reality is that we humans are messy and unpredictable. We don't quite know how we will behave until we have been throw into a particular situation. Open Source walks a very fine line, and anyone claiming to have all the answers probably doesn't. I certainly don't.
Is it a wise to mix Open Source and money? Maybe not. Yet I also believe it's something that is just a reality we need to navigate. Today there are some projects too small to get any funding (xz) and there are projects large enough to find some way to sustain by funneling money to it (Rails, WordPress).
We target with the Pledge small projects in particular. It's our suggestion of how to give to projects for which the barrier to attract funding is too high. At the same time I recognize all the open questions it leaves. There are questions about tax treatments, there are questions about sustainabilty and incentives, questions about distribution and governance.
I firmly believe that the current state of Open Source and money is inadequate, and we should strive for a better one. Will the Pledge help? I hope for some projects, but WordPress has shown that we need to drive forward that conversation of money and Open Source regardless of thes size of the project.
#! code: Drupal 11: Adding Operations To Running Batches
This is the fifth article in a series of articles about the Batch API in Drupal. The Batch API is a system in Drupal that allows data to be processed in small chunks in order to prevent timeout errors or memory problems.
So far in this series we have looked at creating a batch process using a form, followed by creating a batch class so that batches can be run through Drush, using the finished state to control batch processing and then processing CSV files through a batch process. All of these articles give a good grounding of how to use the Drupal Batch API.
In this article we will take a closer look at how the batch system processes items by creating a batch run inside an already running batch process. This will show how batch systems run and what happens when you try to add additional operations to a running batch.
Let's setup the initial batch operation.
Setting Up The BatchThe setup for this batch process is similar to the batch processes on the other articles. This will kick off a batch process that will process 1,000 items in chunks of 100 each.
Doug Hellmann: virtualenvwrapper 6.1.1
Andy Simpkins: The state of the art
A long time ago a computer was a woman (I think almost exclusively a women, not a man) who was employed to do a lot of repetitive mathematics – typically for accounting and stock / order processing.
Then along came Lyons, who deployed an artificial computer to perform the same task, only with fewer errors in less time. Modern day computing was born – we had entered the age of the Digital Computer.
These computers were large, consumed huge amounts of power but were precise, and gave repeatable, verifiable results.
Over time the huge mainframe digital computers have shrunk in size, increased in performance, and consume far less power – so much so that they often didn’t need the specialist CFC based, refrigerated liquid cooling systems of their bigger mainframe counterparts, only requiring forced air flow, and occasionally just convection cooling. They shrank so far and became cheep enough that the Personal Computer became to be, replacing the mainframe with its time shared resources with a machine per user. Desktop or even portable “laptop” computers were everywhere.
We networked them together, so now we can share information around the office, a few computers were given specialist tasks of being available all the time so we could share documents, or host databases these servers were basically PCs designed to operate 24×7, usually more powerful than their desktop counterparts (or at least with faster storage and networking).
Next we joined these networks together and the internet was born. The dream of a paperless office might actually become realised – we can now send email (and documents) from one organisation (or individual) to another via email. We can make our specialist computers applications available outside just the office and web servers / web apps come of age.
Fast forward a few years and all of a sudden we need huge data-halls filled with “Rack scale” machines augmented with exotic GPUs and NPUs again with refrigerated liquid cooling, all to do the same task that we were doing previously without the magical buzzword that has been named AI; because we all need another dot com bubble or block chain band waggon to jump aboard. Our AI enabled searches take slightly longer, consume magnitudes more power, and best of all the results we are given may or may not be correct….
Progress, less precise answers, taking longer, consuming more power, without any verification and often giving a different result if you repeat your question AND we still need a personal computing device to access this wondrous thing.
Remind me again why we are here?
(time lines and huge swaves of history simply ignored to make an attempted comic point – this is intended to make a point and not be scholarly work)
This Week in KDE Apps
Welcome to a new issue of "This Week in KDE Apps"! Every week we cover as much as possible of what's happening in the world of KDE apps.
This week we enhanced the accessibility of a bunch of our most popular apps; released new versions of KleverNotes, KPhotoAlbum; and improved the performance and usability of KDE Connect, Kate, Konqueror, and more.
Let's get started!
AccessibilityWe made the inline notifications that appear above the view in Dolphin, Gwenview, Okular, and many other applications fully accessible by keyboard and to screen readers. Applications will need to opt-in to actually have them announced though. (Felix Ernst, KDE Frameworks 6.8, Link, Dolphin 24.12.0, Link)
Dolphin Manage your filesAfter renaming a file, the renamed file is immediately selected. (Jin Liu, 24.12.0. Link)
Merkuro Contact Manage your contacts with speed and easeThe OpenPGP and S/MIME certificates of a contact are now displayed directly in Merkuro Contact. Clicking on them will open Kleopatra and show additional information. (Carl Schwan, 24.12.0. Link)
KAddressBook An address book managerFix a crash when editing a contact with a nonstandard phone type. (Jonathan Marten, 24.08.3. Link)
Kate Advanced Text EditorWe managed to reduce KDE's advanced text editor startup time by 250ms (Waqar Ahmed, 24.12.0. Link 1, link 2)
The Quick Open tool can now be used to search and browse the projects open in the current session (Akseli Lahtinen, 24.12.0. Link)
KDE Connect Seamless connection of your devicesThe list of devices you can connect to now shows the connected and remembered devices separately. (Albert Astals Cid, 24.12.0. Link)
KCron Task SchedulerImprove the clarity of the "Print Summary…" button. (Thomas Duckworth, 24.12.0. Link)
The printed output is now translated. (Carl Schwan, 24.12.0. Link)
KleverNotes Take and manage your notesKleverNotes 1.1.0 is out! KDE's note-taking app has a faster Markdown parser, a better toolbar and a WYSIWYG-like editor. Read the full announcement!.
KMail A feature-rich email applicationFix the dates in the message lists being stuck at 'Today' and 'Yesterday' even after the day has changed. (Christoph Erhardt, 24.08.3. Link)
Konqueror KDE File Manager & Web BrowserOur venerable file explorer/web browser comes with improved auto-filling of login information. (Stefano Crocco, 24.12.0. Link)
KPhotoAlbum KDE image management softwareKPhotoAlbum 5.13.0 is out. This is a small update that fixes numerous bugs and reworks timespan calculation. Read the full announcement
KStars Desktop PlanetariumKStars was ported to Qt6/KF6. (Jasem Mutlaq. Link)
KTorrent BitTorrent ClientIt is now possible to specify an https URL as webseeds in the "Create a Torrent" dialog. (Jack Hill, 24.12.0. Link)
NeoChat Chat with your friends on matrixKDE's homegrown Matrix instant messaging chat client comes with a redesigned general room settings dialog. (Carl Schwan, 24.12.0. Link)
Tokodon Browse the FediverseWe have added an "Open Server in Browser" button in the profile editor. This lets you configure some settings not exposed via the API that Tokodon uses. (Joshua Goins, 24.12.0. Link)
Tokodon now clarifies that a user's notes are private. (Joshua Goins, 24.12.0. Link)
Improve the names and descriptions of various profile options. (Joshua Goins, 24.12.0. Link)
Tokodon now lets you manage your followers and following users. Which means, it's now possible to forcibly remove users from your followers list. (Joshua Goins, 24.12.0. Link)
Added a new "Following" feed, to quickly page through your follows and their feed similar to the now discontinued Cohost social network.
Platforms AndroidVolker Krause posted a summary of all the improvements made to the Android platform on Android in October. This includes the retirement of Qt 5 Android CI, better translations lookup, dark mode support and more. Read the full blog post
SailfishOSThanks to Adam Pigg and rinigus, Qt6 and KF6 are now available on SailfishOS. This means Kirigami applications built with Qt6 can now be packaged on that platform. Read the announcement
...And Everything ElseThis blog only covers the tip of the iceberg! If you’re hungry for more, check out Nate's blog about Plasma and be sure not to miss his This Week in Plasma series, where every Saturday he covers all the work being put into KDE's Plasma desktop environment.
For a complete view of what's going on, visit KDE's Planet, where you can find all KDE news unfiltered directly from our contributors.
Get InvolvedThe KDE organization has become important in the world, and your time and contributions have helped us get there. As we grow, we're going to need your support for KDE to become sustainable.
You can help KDE by becoming an active community member and getting involved. Each contributor makes a huge difference in KDE — you are not a number or a cog in a machine! You don’t have to be a programmer either. There are many things you can do: you can help hunt and confirm bugs, even maybe solve them; contribute designs for wallpapers, web pages, icons and app interfaces; translate messages and menu items into your own language; promote KDE in your local community; and a ton more things.
You can also help us by donating. Any monetary contribution, however small, will help us cover operational costs, salaries, travel expenses for contributors and in general just keep KDE bringing Free Software to the world.
To get your application mentioned here, please ping us in invent or in Matrix.
Andrew Cater: Mini-DebConf Cambridge 20241013 1300
LATE NEWS
I haven't blogged until now: I should have done from Thursday onwards.
It's
a joy to be here in Cambridge at ARM HQ. Lots of people I recognise
from last year here: lots *not* here because this mini-conference is a
month before the next one in Toulouse and many people can't attend both.
Two
days worth of chatting, working on bits and pieces, chatting and
informal meetings was a very good and useful way to build relationships
and let teams find some space for themselves.
Lots of quiet hacking going on - a few loud conversations. A new ARM machine in mini-ITX format - see Steve's blog.
Two
days worth of talks for Saturday and Sunday. For some people, this is a
first time. Lightning talks are particularly good to break down
barriers - three slides and five minutes (and the chance for a bit of
gamesmanship to break the rules creatively).
Longer talks: a
couple from Steve Capper of ARM were particularly helpful to those
interested in upcoming development. A couple of the talks in the
schedule are traditional: if the release team are here, they tell us
what they are doing, for example.
ARM are main sponsors and have
been very generous in giving us conference and facilities space. Fast
network, coffee and interested people - what's not to like :)
Real Python: Quiz: Python Thread Safety: Using a Lock and Other Techniques
In this quiz, you’ll test your understanding of Python threading and thread safety. You’ll revisit concepts such as race conditions, thread safety issues, and synchronization primitives in the threading module. This knowledge is crucial when working with multithreaded code using Python’s threading module and ThreadPoolExecutor.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Taavi Väänänen: Bulk downloading Wikimedia Commons categories
Wikimedia Commons, the Wikimedia project for freely licensed media files, also contains a bunch of photos by me and photos of me at various events. While I don't think Commons is going away anytime soon, I would still like to have a local copy of those images available on my own storage hardware.
Obviously this requires some way to query for photos you want to download. I'm using Commons categories for this, since that's easy to implement and works for both use cases. The Commons community tends to come up with very specific categories that you can use, and if not, you can usually categorize the files yourself.
thankfully Commons has no such thing as a Conflict of interest (COI) policy
There is almost an existing tool for this: Sam Wilson's mwcli project has support for exporting images one has uploaded to Commons. However I couldn't use that to upload photos of me others have uploaded, plus it's written in PHP and I don't exactly want to deal with the problem of figuring out how to package it in a way I could neatly install it on my NAS.
So I wrote my own tool for it, called comload. It's written in Python because Python is easy to deploy (I can just throw it in a .deb and upload it to my internal repository), and because I did not find a Go library to handle Action API pagination for me. The basic usage is like this:
$ comload --subcats "Taavi Väänänen"This will download any files in Category:Taavi Väänänen and its sub-categories to the current directory. Former image versions, as well as the image description and SDC data, if any, is also included. And it's smart enough to not download any files that are already there on future runs, so you can just throw it in a systemd timer to get any future files. I'd still like it to handle moved files without creating a duplicate copy, but otherwise I'm really happy with the current state.
comload is available from PyPI and from my Git server directly, and is licensed under the GPLv3.
Jonathan Dowland: Code formatting in documents
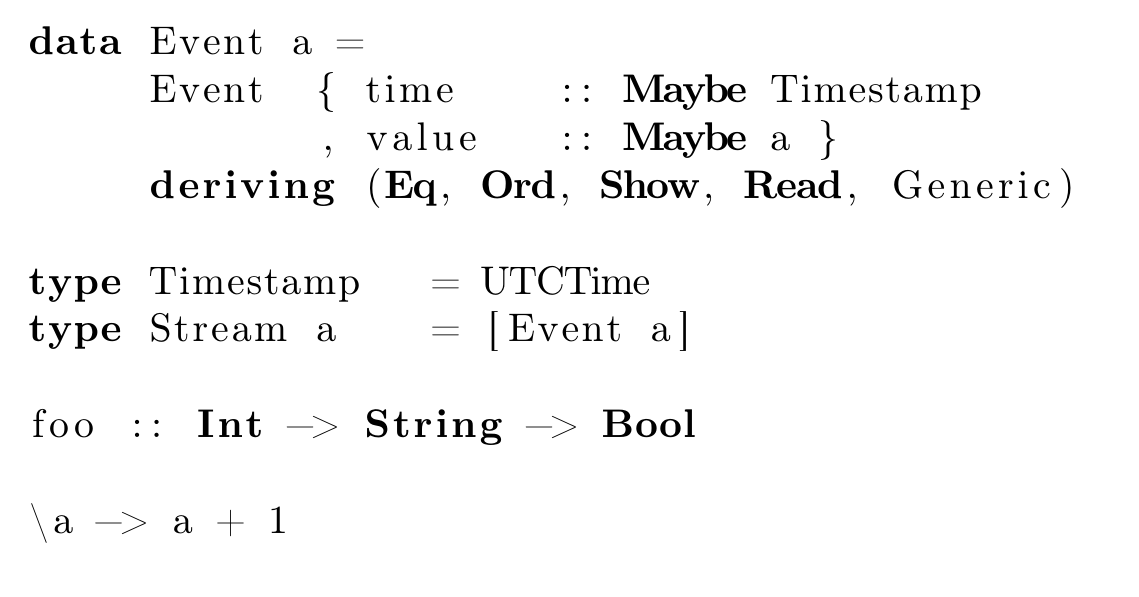
I've been exploring typesetting and formatting code within text documents such as papers, or my thesis. Up until now, I've been using the listings package without thinking much about it. By default, some sample Haskell code processed by listings looks like this (click any of the images to see larger, non-blurry versions):
{kind=link}
It's formatted with a monospaced font, with some keywords highlighted, but not syntactic symbols.
There are several other options for typesetting and formatting code in LaTeX documents. For Haskell in particular, there is the preprocessor lhs2tex, The default output of which looks like this:
{kind=link}
A proportional font, but it's taken pains to preserve vertical alignment, which is syntactically significant for Haskell. It looks a little cluttered to me, and I'm not a fan of nearly everything being italic. Again, symbols aren't differentiated, but it has substituted them for more typographically pleasing alternatives: -> has become →, and \ is now λ.
Another option is perhaps the newest, the LaTeX package minted, which leverages the Python Pygments program. Here's the same code again. It defaults to monospace (the choice of font seems a lot clearer to me than the default for listings), no symbolic substitution, and liberal use of colour:
{kind=link}
An informal survey of the samples so far showed that the minted output was the most popular.
All of these packages can be configured to varying degrees. Here are some examples of what I've achieved with a bit of tweaking
{kind=link}
listings adjusted with colour and some symbols substituted (but sadly not the two together)
{kind=link}
lhs2tex adjusted to be less italic, sans-serif and use some colour
All of this has got me wondering whether there are straightforward empirical answers to some of these questions of style.
Firstly, I'm pretty convinced that symbolic substitution is valuable. When writing Haskell, we write ->, \, /= etc. not because it's most legible, but because it's most practical to type those symbols on the most widely available keyboards and popular keyboard layouts.1 Of the three options listed here, symbolic substitution is possible with listings and lhs2tex, but I haven't figured out if minted can do it (which is really the question: can pygments do it?)
I'm unsure about proportional versus monospaced fonts. We typically use monospaced fonts for editing computer code, but that's at least partly for historical reasons. Vertical alignment is often very important in source code, and it can be easily achieved with monospaced text; it's also sometimes important to have individual characters (., etc.) not be de-emphasised by being smaller than any other character.
lhs2tex, at least, addresses vertical alignment whilst using proportional fonts. I guess the importance of identifying individual significant characters is just as true in a code sample within a larger document as it is within plain source code.
From a (brief) scan of research on this topic, it seems that proportional fonts result in marginally quicker reading times for regular prose. It's not clear whether those results carry over into reading computer code in particular, and the margin is slim in any case. The drawbacks of monospaced text mostly apply when the volume of text is large, which is not the case for the short code snippets I am working with.
I still have a few open questions:
- Is colour useful for formatting code in a PDF document?
- does this open up a can of accessibility worms?
- What should be emphasised (or de-emphasised)
- Why is the minted output most popular: Could the choice of font be key? Aspects of the font other than proportionality (serifs? Size of serifs? etc)
- The Haskell package Data.List.Unicode lets the programmer use a range of unicode symbols in place of ASCII approximations, such as ∈ instead of elem, ≠ instead of /=. Sadly, it's not possible to replace the denotation for an anonymous function, \, with λ this way.↩
KDE Android News (October 2024)
Here’s an overview of recent work around Android platform support for KDE Frameworks and KDE applications, most of which is a direct result of discussions and work at Akademy and the Matrix conference.
Notification permission fixesPorting Itinerary and NeoChat to use the KNotification permission API identified two issues around permission checks and callbacks on permission changes that resulted in the application seeing the wrong permission state. That’s fixed now.
Retirement of the Qt 5 CIWith the 24.08 KDE Gear release all our Android apps are based on Qt 6, including their stable release branches. We have therefore started with retiring the Android Qt 5 CI/CD infrastructure, which should save us both maintenance and computing resources.
As Qt 5 is meanwhile lagging behind several Android SDK versions it’s no longer a viable platform for producing APKs that work on up-to-date devices anymore anyway.
Android CI has meanwhile been removed from the KDE Frameworks 5 maintenance branches as well as from a few other libraries that still used it. The removal of Gitlab CI templates, Craft caches and container images will follow.
In particular this means the invent-registry.kde.org/sysadmin/ci-images/android-qt515 container image is deprecated and will be removed eventually. Please get in touch if you are still using this externally. Poppler’s CI was such a case for example.
QML file installationThe QML module macros in ECM used to install QML files to disk, besides bundling those via the Qt resource system as well. While that is still needed on most platforms due to some specific code in Kirigami, it’s unnecessary on Android where we rely solely on the bundled data.
This resulted in unnecessary content in the APKs, which has been fixed and makes all our APKs a bit smaller now.
Translation lookup orderThe probably most visible change is a fix for a long standing bug in KI18n’s multi-language fallback lookup order, which would result in applications showing a wild mix of languages under certain conditions.
This happened when the primary device language was set to English but the country to anything but the US or the UK and one or more secondary languages were also selected. While not strictly limited to Android, there’s two factors that made it particularly prone to happen there:
- Newer Android versions allow language and country to be set fully independently, while on many other systems only certain predefined combinations are available.
- The language setting doesn’t just impact application translations but also text input, so many more users have multiple languages configured.
KI18n first looks for a translation for the specific language/country pair and then just the language, before falling back to the next configured language/country pair. If no translation is found it’ll eventually use the English/US source text.
Conceptually this is not wrong, but the implementation missed the fact that there is no “country-less” English translation but only the English/US source text. A configuration of English/Canada and French/Canada therefore previously resulted in a French translation rather than an English one, as it does now.
This has been backported and should be available in all our APKs with 24.08.2 latest.
Runtime language changeThanks to input from Fabian during Akademy there’s also significant progress on having applications react to system language changes at runtime.
This basically consists of three parts:
- Propagate the native Android system configuration change to Qt, done in Qt CR 596175.
- Reset cached values inside KI18n on system language changes, done in KI18n MR 124.
- Trigger QML binding re-evaluation for i18n() calls on language changes, implemented in KI18n MR 127.
With those three changes applied and a few lines adjusted in the application code to make use of this large parts of the UI already follow system language changes automatically.
It’s far not perfect yet, as there’s more things that need to update in this case than just translated strings. Date/time formatting for example, as discussed in QTBUG-129727. But overall this is already much better than what I had expected and assumed to be feasible with realistic effort.
Dark mode supportAs reported previously we have working support for dark mode since 24.08.1, thanks to Julius’ work on icon recoloring.
So far this required minimal changes to applications to enable it though. That has also been fixed, dark mode support is now automatically enabled for all applications using the Breeze style.
OutlookThere’s still more to do regarding Android platform integration. I’d say the two probably most pressing issues are the following:
- On some devices the font size is unusably small, caused by the display scale factor being wrong. Based on some investigation during Akademy the current working theory is that this is a race condition in Qt’s code reading that information. I have no device/setup that reproduces this problem unfortunately.
- Selecting files in the platform file dialog that are located on a cloud storage such as Nextcloud silently fails. That is, to the application selecting such a file looks as if the user had canceled the dialog. Here we know exactly why this happens (it’s explicit code in Qt doing this, for valid reasons), the challenge is rather to find a proper solution.
If you are interested in Android integration for KDE applications, feel free to join us in the #kde-android Matrix channel!
Peoples Blog: Create a custom Drupal Service and Use as a Helper
Peoples Blog: Imagefield Slideshow module to render Slideshow on Drupal website
Peoples Blog: Unable to install Update Manager, update.settings already exists in active configuration
Peoples Blog: How to run PHPUnit test cases on your local machine for Drupal
Peoples Blog: API Docs, Drupal contributed module for your Developer Portal
Peoples Blog: How to improve drupal website performance
Peoples Blog: How to build the engaging digital experience via Drupal
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
- Bounteous.com: Upgrading to Drupal 10 (And Beyond) With Composer
- FSF Blogs: Free software is vital for the public and state-run infrastructure of a free society
- Free software is vital for the public and state-run infrastructure of a free society
- Kdenlive Café in December
- PyPodcats: Episode 7: With Anna Makarudze
FLOSS Research
- Celebrating 5 years at the Open Source Initiative: a journey of growth, challenges, and community engagement
- Highlights from the Digital Public Goods Alliance Annual Members Meeting 2024
- Give Your Input on the State of Open Source Survey
- Open Data and Open Source AI: Charting a course to get more of both
- The Open Source Initiative and the Eclipse Foundation to Collaborate on Shaping Open Source AI (OSAI) Public Policy