
Feeds
Real Python: Working With JSON Data in Python
Python’s json module provides you with the tools you need to effectively handle JSON data. You can convert Python data types to a JSON-formatted string with json.dumps() or write them to files using json.dump(). Similarly, you can read JSON data from files with json.load() and parse JSON strings with json.loads().
JSON, or JavaScript Object Notation, is a widely-used text-based format for data interchange. Its syntax resembles Python dictionaries but with some differences, such as using only double quotes for strings and lowercase for Boolean values. With built-in tools for validating syntax and manipulating JSON files, Python makes it straightforward to work with JSON data.
By the end of this tutorial, you’ll understand that:
- JSON in Python is handled using the standard-library json module, which allows for data interchange between JSON and Python data types.
- JSON is a good data format to use with Python as it’s human-readable and straightforward to serialize and deserialize, which makes it ideal for use in APIs and data storage.
- You write JSON with Python using json.dump() to serialize data to a file.
- You can minify and prettify JSON using Python’s json.tool module.
Since its introduction, JSON has rapidly emerged as the predominant standard for the exchange of information. Whether you want to transfer data with an API or store information in a document database, it’s likely you’ll encounter JSON. Fortunately, Python provides robust tools to facilitate this process and help you manage JSON data efficiently.
While JSON is the most common format for data distribution, it’s not the only option for such tasks. Both XML and YAML serve similar purposes. If you’re interested in how the formats differ, then you can check out the tutorial on how to serialize your data with Python.
Free Bonus: Click here to download the free sample code that shows you how to work with JSON data in Python.
Take the Quiz: Test your knowledge with our interactive “Working With JSON Data in Python” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Working With JSON Data in PythonIn this quiz, you'll test your understanding of working with JSON in Python. By working through this quiz, you'll revisit key concepts related to JSON data manipulation and handling in Python.
Introducing JSONThe acronym JSON stands for JavaScript Object Notation. As the name suggests, JSON originated from JavaScript. However, JSON has transcended its origins to become language-agnostic and is now recognized as the standard for data interchange.
The popularity of JSON can be attributed to native support by the JavaScript language, resulting in excellent parsing performance in web browsers. On top of that, JSON’s straightforward syntax allows both humans and computers to read and write JSON data effortlessly.
To get a first impression of JSON, have a look at this example code:
JSON hello_world.json { "greeting": "Hello, world!" } Copied!You’ll learn more about the JSON syntax later in this tutorial. For now, recognize that the JSON format is text-based. In other words, you can create JSON files using the code editor of your choice. Once you set the file extension to .json, most code editors display your JSON data with syntax highlighting out of the box:
The screenshot above shows how VS Code displays JSON data using the Bearded color theme. You’ll have a closer look at the syntax of the JSON format next!
Examining JSON SyntaxIn the previous section, you got a first impression of how JSON data looks. And as a Python developer, the JSON structure probably reminds you of common Python data structures, like a dictionary that contains a string as a key and a value. If you understand the syntax of a dictionary in Python, you already know the general syntax of a JSON object.
Note: Later in this tutorial, you’ll learn that you’re free to use lists and other data types at the top level of a JSON document.
The similarity between Python dictionaries and JSON objects is no surprise. One idea behind establishing JSON as the go-to data interchange format was to make working with JSON as convenient as possible, independently of which programming language you use:
[A collection of key-value pairs and arrays] are universal data structures. Virtually all modern programming languages support them in one form or another. It makes sense that a data format that is interchangeable with programming languages is also based on these structures. (Source)
To explore the JSON syntax further, create a new file named hello_frieda.json and add a more complex JSON structure as the content of the file:
JSON hello_frieda.json 1{ 2 "name": "Frieda", 3 "isDog": true, 4 "hobbies": ["eating", "sleeping", "barking"], 5 "age": 8, 6 "address": { 7 "work": null, 8 "home": ["Berlin", "Germany"] 9 }, 10 "friends": [ 11 { 12 "name": "Philipp", 13 "hobbies": ["eating", "sleeping", "reading"] 14 }, 15 { 16 "name": "Mitch", 17 "hobbies": ["running", "snacking"] 18 } 19 ] 20} Copied!In the code above, you see data about a dog named Frieda, which is formatted as JSON. The top-level value is a JSON object. Just like Python dictionaries, you wrap JSON objects inside curly braces ({}).
In line 1, you start the JSON object with an opening curly brace ({), and then you close the object at the end of line 20 with a closing curly brace (}).
Read the full article at https://realpython.com/python-json/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Real Python: How to Flatten a List of Lists in Python
Flattening a list in Python involves converting a nested list structure into a single, one-dimensional list. A common approach to flatten a list of lists is to use a for loop to iterate through each sublist. Then, add each item to a new list with the .extend() method or the augmented concatenation operator (+=). This will “unlist” the list, resulting in a flattened list.
Alternatively, Python’s standard library offers tools like itertools.chain() and functools.reduce() to achieve similar results. You can also use a list comprehension for a concise one-liner solution. Each method has its own performance characteristics, with for loops and list comprehensions generally being more efficient.
By the end of this tutorial, you’ll understand that:
- Flattening a list involves converting nested lists into a single list.
- You can use a for loop and .extend() to flatten lists in Python.
- List comprehensions provide a concise syntax for list transformations.
- Standard-library functions like itertools.chain() and functools.reduce() can also flatten lists.
- The .flatten() method in NumPy efficiently flattens arrays for data science tasks.
- Unlisting a list means to flatten nested lists into one list.
To better illustrate what it means to flatten a list, say that you have the following matrix of numeric values:
Python >>> matrix = [ ... [9, 3, 8, 3], ... [4, 5, 2, 8], ... [6, 4, 3, 1], ... [1, 0, 4, 5], ... ] Copied!The matrix variable holds a Python list that contains four nested lists. Each nested list represents a row in the matrix. The rows store four items or numbers each. Now say that you want to turn this matrix into the following list:
Python [9, 3, 8, 3, 4, 5, 2, 8, 6, 4, 3, 1, 1, 0, 4, 5] Copied!How do you manage to flatten your matrix and get a one-dimensional list like the one above? In this tutorial, you’ll learn how to do that in Python.
Free Bonus: Click here to download the free sample code that showcases and compares several ways to flatten a list of lists in Python.
Take the Quiz: Test your knowledge with our interactive “How to Flatten a List of Lists in Python” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
How to Flatten a List of Lists in PythonIn this quiz, you'll test your understanding of how to flatten a list in Python. Flattening a list involves converting a multidimensional list, such as a matrix, into a one-dimensional list. This is a common operation when working with data stored as nested lists.
How to Flatten a List of Lists With a for LoopHow can you flatten a list of lists in Python? In general, to flatten a list of lists, you can run the following steps either explicitly or implicitly:
- Create a new empty list to store the flattened data.
- Iterate over each nested list or sublist in the original list.
- Add every item from the current sublist to the list of flattened data.
- Return the resulting list with the flattened data.
You can follow several paths and use multiple tools to run these steps in Python. Arguably, the most natural and readable way to do this is to use a for loop, which allows you to explicitly iterate over the sublists.
Then you need a way to add items to the new flattened list. For that, you have a couple of valid options. First, you’ll turn to the .extend() method from the list class itself, and then you’ll give the augmented concatenation operator (+=) a go.
To continue with the matrix example, here’s how you would translate these steps into Python code using a for loop and the .extend() method:
Python >>> def flatten_extend(matrix): ... flat_list = [] ... for row in matrix: ... flat_list.extend(row) ... return flat_list ... Copied!Inside flatten_extend(), you first create a new empty list called flat_list. You’ll use this list to store the flattened data when you extract it from matrix. Then you start a loop to iterate over the inner, or nested, lists from matrix. In this example, you use the name row to represent the current nested list.
In every iteration, you use .extend() to add the content of the current sublist to flat_list. This method takes an iterable as an argument and appends its items to the end of the target list.
Now go ahead and run the following code to check that your function does the job:
Python >>> flatten_extend(matrix) [9, 3, 8, 3, 4, 5, 2, 8, 6, 4, 3, 1, 1, 0, 4, 5] Copied!That’s neat! You’ve flattened your first list of lists. As a result, you have a one-dimensional list containing all the numeric values from matrix.
With .extend(), you’ve come up with a Pythonic and readable way to flatten your lists. You can get the same result using the augmented concatenation operator (+=) on your flat_list object. However, this alternative approach may not be as readable:
Python >>> def flatten_concatenation(matrix): ... flat_list = [] ... for row in matrix: ... flat_list += row ... return flat_list ... Copied! Read the full article at https://realpython.com/python-flatten-list/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
This Week in KDE Apps: Search in Merkuro Mail, Tokodon For Android, LabPlot new documentation and more
Welcome to a new issue of "This Week in KDE Apps"! Every week we cover as much as possible of what's happening in the world of KDE apps.
AudioTube YouTube Music appAudioTube now shows synchronized lyrics provided by LRCLIB. This automatically falls back to normal lyrics if synced lyrics are not available. (Kavinu Nethsara, 25.04.0. Link)
Dolphin Manage your filesQuickly renaming multiple files by switching between them with the keyboard arrow keys now correctly starts a renaming of the next file even if a sorting change moved it. (Ilia Kats, 25.04.0. Link)
Fixed a couple of regressions in the 24.12.0 release. (Akseli Lahtinen, 24.12.1. Link 1, link 2, link 3)
KDE Itinerary Digital travel assistantImproved the touch targets of the buttons in the bottom drawer which appears on mobile. (Carl Schwan, 24.05.0. Link)
Akonadi Background service for KDE PIM appsImprove the stability of changing tags. Now deleting a tag will properly remove it from all items. (Daniel Vrátil, 24.12.1. Link 1 and link 2)
KMail A feature-rich email applicationThe tooltip of your folder in KMail will now show the absolute space quota in bytes. (Fabian Vogt, 25.04.0. Link)
KMyMoney Personal finance manager based on double-entry bookkeepingAn initial port of KMyMoney for Qt6 was merged. (Ralf Habacker. Link)
Krita Digital Painting, Creative FreedomKrita has a new plugin for fast sketching. You can find more about this on their blog post.
KTorrent BitTorrent ClientAdded the support for getting IPv6 peers from peer exchange. (Jack Hill, 25.04.0. Link)
LabPlot Interactive Data Visualization and AnalysisWe now show more plot types in the "Add new plot" context menu. (Alexander Senke. Link)
LabPlot has announced a new dedicated user manual page.
Okular View and annotate documentsWe improved how we are displaying the signature and certificate details in the mobile version of Okular. (Carl Schwan, 25.04.0. Link)
When selecting a certificate to use when digitally signing a PDF with the GPG backend, the fingerprints are rendered more nicely. (Sune Vuorela, 25.04.0. Link)
It's now possible to choose a custom default zoom level in Okular. (Wladimir Leuschner, 25.04.0. Link)
Merkuro Mail Read your emails with speed and easeMerkuro Mail now lets you search across your emails with a full text search. (Carl Schwan, 25.04.0. Link)
Additionally, the Merkuro Mail sidebar will now remember which folders were collapsed or expanded as well as the last selected folder across application restarts. (Carl Schwan, 25.04.0. Link)
PowerPlant Keep your plants aliveWe started the "KDE Review" process for PowerPlant, so expect a release in the comming weeks.
We added support for Windows and Android. (Laurent Montel, 1.0.0. Link 1, link 2 and link 3)
Ruqola Rocket Chat ClientRuqola 2.4.0 is out. You can now mute/unmute other users, cleanup the room history and more. Read the full announcement.
Tokodon Browse the FediverseThis week, Joshua spent some time improving Tokodon for mobile and in particular for Android. This includes performance optimization, adding missing icons and some mobile specific user experience improvements. (Joshua Goins, 25.04.0. Link 1, link 2 and link 3). A few more improvements for Android, like proper push notifications via unified push, are in the work.
Joshua also improved the draft and scheduled post features, allowing now to discard scheduled posts and drafts and showing when a draft was created. (Joshua Goins, 25.04.0. Link)
We also added a keyboard shortcut configuration page in Tokodon settings. (Joshua Goins and Carl Schwan, 25.04.0. Link 1 and link 2)
Finally, we created a new server information page with the server rules and made the existing announcements page a subpage of it. Speaking of announcements, we added support for the announcement's emoji reactions. (Joshua Goins, 25.04.0. Link)
WashiPad Minimalist Sketchnoting ApplicationWashiPad was ported to Kirigami instead of using its own custom QtQuick components. (Carl Schwan. Link)
…And Everything ElseThis blog only covers the tip of the iceberg! If you’re hungry for more, check out Nate's blog about Plasma and be sure not to miss his This Week in Plasma series, where every Saturday he covers all the work being put into KDE's Plasma desktop environment.
For a complete overview of what's going on, visit KDE's Planet, where you can find all KDE news unfiltered directly from our contributors.
Get InvolvedThe KDE organization has become important in the world, and your time and contributions have helped us get there. As we grow, we're going to need your support for KDE to become sustainable.
You can help KDE by becoming an active community member and getting involved. Each contributor makes a huge difference in KDE — you are not a number or a cog in a machine! You don’t have to be a programmer either. There are many things you can do: you can help hunt and confirm bugs, even maybe solve them; contribute designs for wallpapers, web pages, icons and app interfaces; translate messages and menu items into your own language; promote KDE in your local community; and a ton more things.
You can also help us by donating. Any monetary contribution, however small, will help us cover operational costs, salaries, travel expenses for contributors and in general just keep KDE bringing Free Software to the world.
To get your application mentioned here, please ping us in invent or in Matrix.
LostCarPark Drupal Blog: Drupal Advent Calendar day 22 - Gin Admin Theme track
Once more, we welcome you back to the Drupal Advent Calendar, to see what’s behind door number twenty-two. Today we are welcoming back an old friend, the Gin Admin Theme which was covered all the way back in Door 1 of the 2023 Drupal Advent Calendar.
So why feature it again? Well back then, Gin was something of a rebel, for use on cutting edge Drupal sites, but perhaps a bit too “punk” for respectable production sites.
But a year later Gin is becoming respectable, and as part of that, it has been selected as the default admin theme for Drupal CMS.
Drupal CMS is focused on giving the easiest to…
TagsSteinar H. Gunderson: Kernel adventures: When two rights make a wrong
My 3D printer took me on another adventure recently. Or, well, actually someone else's 3D printer did: It turns out that building a realtime system (with high-speed motors controlling to a 300-degree metal rod) by cobbling together a bunch of Python and JavaScript on an anemic Arm SoC with zero resource isolation doesn't always meet those realtime guarantees. So in particular after installing a bunch of plugins, people would report the infamous “MCU timer too close” Klipper error, which essentially means that the microcontroller didn't get new commands in time from the Linux host and shut down as a failsafe. (Understandably, this sucks if it happens in the middle of an eight-hour print. Nobody really invented a way to reliably resume from these things yet.)
I was wondering whether it was possible to provoke this and then look at what was actually going on in the scheduler; perf sched lets you look at scheduling history on the host, so if I could reproduce the error while collecting data, I could go in afterwards and see what was the biggest CPU hog, or at least that was the theory.
However, to my surprise, perf sched record died with an error essentially saying that the kernel was compiled without ftrace support (which is needed for the scheduler hooks; it's somewhat possible to do without by just doing a regular profile, but that's a different story and much more annoying). Not very surprising, these things tend to run stone-age vendor kernels from some long-forgotten branch with zero security support and seemingly no ftrace.
Now, I did not actually run said vendor kernel; at some point, I upgraded to the latest stable kernel (6.6) from Armbian, which is still far from mainline (for one, it needs to carry out-of-tree drivers to make wireless work at all) but which I trust infinitely more to actually provide updated kernels over time. It doesn't support ftrace either, so I thought the logical step would be to upgrade to the latest “edge” kernel (aka 6.11) and then compile with the right stuff on.
After a couple of hours of compiling (almost nostalgic to have such slow kernel compiles; cross-compiling didn't work for me!), I could boot into the new kernel, and:
[ 23.775976] platform 5070400.thermal-sensor: deferred probe pending: platform: wait for supplierand then Klipper would refuse to start because it couldn't find the host thermal sensors. (I don't know exactly why it is a hard dependency, but seemingly, it is.) A bit of searching shows that this error message is doubly vexing; it should have said “wait for supplier /i2c@fdd40000/pmic@20/regulators/SWITCH_REG1” or something similar, but ends only in a space and then nothing.
So evidently this has to be something about the device tree (DT), and switching out the new DT for the old one didn't work. Bisecting was also pretty much out of the question (especially with 400+ patches that go on top of the git tree), but after a fair bit of printk debugging and some more reading, I figured out what had happened:
First, the sun8i-thermal driver, which had been carried out-of-tree in Armbian, had gone into mainline. But it was in a slightly different version; while the out-of-tree version used previously (in Armbian's 6.6 kernel) had relied on firmware (run as part of U-Boot, as I understand it) to set a special register bit, the mainline version would be stricter and take care to set it itself. I don't really know what the bit does, short of “if you don't set it, all the values you get back are really crazy”, so this is presumably a good change. So the driver would set a bit in a special memory address somewhere (sidenote: MMIO will always feel really weird to me; like, some part of the CPU has to check all memory accesses in case they're really not to RAM at all?), and for that, the thermal driver would need to take on a DT reference to the allwinner,sram (comma is evidently some sort of hierarchical separator) node so that it could get its address. Like, in case it was moved around in future SoCs or something.
Second, there was an Armbian patch that dealt with exactly these allwinner,sram nodes in another way; it would make sure that references to them would cause devlink references between the nodes. I don't know what those are either, but it seems the primary use case is for waiting: If you have a dependency from A to B, then A's initialization will wait until B is ready. The configuration bit in question is always ready, but I guess it's cleaner somehow, and you get a little symlink somewhere in /sys to explain the relationship, so perhaps it's good? But that's what the error message means; “A: deferred probe pending: wait for supplier B” means that we're not probing for A's existence yet, because it wants B to supply something and B isn't ready yet.
But why is the relationship broken? Well, for that, we need to look at how the code in the patch looks:
sram_node = of_parse_phandle(np, prop_name, 0); sram_node = of_get_parent(sram_node); sram_node = of_get_parent(sram_node); return sram_node;And how the device tree is set up in this case (lots of irrelevant stuff removed for clarity):
bus@1000000 { /* this works */ reg = <0x1000000 0x400000>; allwinner,sram = <&de3_sram 1>; }; ths: thermal-sensor@5070400 { /* this doesn't */ allwinner,sram = <&syscon>; }; syscon: syscon@3000000 { sram_c: sram@28000 { de3_sram: sram-section@0 { reg = <0x0000 0x1e000>; }; }; };So that explains it; the code expects that all DT references are to a child of a child of syscon to find the supplier, and just goes up two levels to find it. But for the thermal sensor, the reference is directly to the syscon itself, and it goes up past the root of the tree, which is, well, NULL. And then the error message doesn't have a node name to print out, and the dependency just fails forever.
So that's two presumably good changes that just interacted in a really bad way (in particular, due to too little flexibility in the second one). A small patch later, and the kernel boots with thermals again!
Oh, and those scheduling issues I wanted to debug? I never managed to reliably reproduce them; I have seen them, but they're very rare for me. I guess that upstream for the plugins in question just made things a bit less RAM-hungry in the meantime, or that having a newer kernel improves things enough in itself. Shrug. :-)
Junichi Uekawa: Looking at my private repositories for what language I wrote.
KDE @ 38C3
In less than a week from now KDE will again be present at the 38th Chaos Communication Congress (38C3) in Hamburg, Germany.
Chaos Communication CongressEven bigger than FOSDEM and much wider in scope many impactful collaborations during the past couple of years can be traced back to contacts made at Congress. Be it KDE Eco, joint projects with the Open Transport community, the weather and emergency alert aggregation server or indoor routing to just name a few.
KDE AssemblyAt last year’s edition, 37C3, we had a KDE assembly (think “stand” or “booth” at other events) for the first time. That not only helps people to find us, it’s also very useful anchor point for the growing KDE delegation.
This year we’ll further improve on that, by being there with even more people and by having the KDE assembly as part of the Bits & Bäume Habitat. That not only comes with some shared infrastructure like a workshop space but also puts us next to some of our friends, like OSM, FSFE and Wikimedia.
We’ll be in the foyer on floor level 1 next to the escalators (map).
More of our friends and partners have their own assemblies elsewhere as well, such as Matrix and Linux on Mobile.
A special thanks goes again to the nice people at CCC-P and WMDE who helped us get tickets!
Talks & WorkshopsWe’ll also have three talks by KDE people, all of them featuring collaborations beyond the classical KDE scope.
- Jonah will talk about the free and open public transport routing service Transitous on day 2 at 12:00 on stage YELL.
- Nucleus from FOSSWarn and I will present the joint work on emergency and weather alert aggregation and distribution infrastructure, on day 4 at 16:40 on stage HUFF.
- Joseph’s talk Opt Green: Coordinating a Windows 10-to-Linux upcycling campaign across Free Software communities worldwide will be on day 2 at 11:00 on stage YELL.
There will also be two workshops chaired by Jospeh on the latter subject:
- Upcycling old laptops with Linux for kids, on day 3 from 12:00 to 15:00 in Saal 5.
- A BoF on Coordinating a Windows 10-to-Linux upcycling campaign, on day 4 from 13:00 to 15:00 in the Bits & Bäume workshop area.
Make sure to monitor the schedule for last-minute changes though.
See you in Hamburg!Looking forward to many interesting discussions, if you are at 38C3 as well make sure to come by the KDE assembly!
Russ Allbery: Review: Beyond the Fringe
Review: Beyond the Fringe, by Miles Cameron
Series: Arcana Imperii #1.5 Publisher: Gollancz Copyright: 2023 ISBN: 1-3996-1537-8 Format: Kindle Pages: 173Beyond the Fringe is a military science fiction short story collection set in the same universe as Artifact Space. It is intended as a bridge between that novel and its sequel, Deep Black.
Originally I picked this up for exactly the reason it was published: I was eagerly awaiting Deep Black and thought I'd pass the time with some filler short fiction. Then, somewhat predictably, I didn't get around to reading it until after Deep Black was already out. I still read this collection first, partly because I'm stubborn about reading things in publication order but mostly to remind myself of what was going on in Artifact Space before jumping into the sequel.
My stubbornness was satisfied. My memory was not; there's little to no background information here, and I had to refresh my memory of the previous book anyway to figure out the connections between these stories and the novel.
My own poor decisions aside, these stories are... fine, I guess? They're competent military SF short fiction, mostly more explicitly military than Artifact Space. All of them were reasonably engaging. None of them were that memorable or would have gotten me to read the series on their own. They're series filler, in other words, offering a bit of setup for the next novel but not much in the way of memorable writing or plot.
If you really want more in this universe, this exists, but my guess (not having read Deep Black) is that it's entirely skippable.
"Getting Even": A DHC paratrooper lands on New Shenzen, a planet that New Texas is trying to absorb into the empire it is attempting to build. He gets captured by one group of irregulars and then runs into another force with an odd way of counting battle objectives.
I think this exists because Cameron wanted to tell a version of a World War II story he'd heard, but it's basically a vignette about a weird military unit with no real conclusion, and I am at a loss as to the point of the story. There isn't even much in the way of world-building. I'm probably missing something, but I thought it was a waste of time. (4)
"Partners": The DHC send a planetary exobiologist to New Texas as a negotiator. New Texas is aggressively, abusively capitalist and is breaking DHC regulations on fair treatment of labor. Why send a planetary exobiologist is unclear (although probably ties into the theme of this collection that the reader slowly pieces together); maybe it's because he's originally from New Texas, but more likely it's because of his partner. Regardless, the New Texas government are exploitative assholes with delusions of grandeur, so the negotiations don't go very smoothly.
This was my favorite story of the collection just because I enjoy people returning rudeness and arrogance to sender, but like a lot of stories in this collection it doesn't have much of an ending. I suspect it's mostly setup for Deep Black. (7)
"Dead Reckoning": This is the direct fallout of the previous story and probably has the least characterization of this collection. It covers a few hours of a merchant ship having to make some fast decisions in a changing political situation. The story is framed around a veteran spacer and his new apprentice, although even that frame is mostly dropped once the action starts. It was suspenseful and enjoyable enough while I was reading it, but it's the sort of story that you forget entirely after it's over. (6)
"Trade Craft": Back on a planet for this story, which follows an intelligence agent on a world near but not inside New Texas's area of influence. I thought this was one of the better stories of the collection even though it's mostly action. There are some good snippets of characterization, an interesting mix of characters, and some well-written tense scenes. Unfortunately, I did not enjoy the ending for reasons that would be spoilers. Otherwise, this was good but forgettable. (6)
"One Hour": This is the first story with a protagonist outside of the DHC and its associates. It instead follows a PTX officer (PTX is a competing civilization that features in Artifact Space) who has suspicions about what his captain is planning and recruits his superior officer to help him do something about it.
This is probably the best story in the collection, although I personally enjoyed "Partners" a smidgen more. Shunfu, the first astrogator who is recruited by the protagonist, is a thoroughly enjoyable character, and the story is tense and exciting all the way through. For series readers, it also adds some depth to events in Artifact Space (if the reader remembers them), and I suspect will lead directly into Deep Black. (7)
"The Gifts of the Magi": A kid and his mother, struggling asteroid miners with ancient and malfunctioning equipment, stumble across a DHC ship lurking in the New Texas system for a secret mission. This is a stroke of luck for the miners, since the DHC is happy to treat the serious medical problems of the mother without charging unaffordable fees the way that the hyper-capitalist New Texas doctors would. It also gives the reader a view into DHC's covert monitoring of the activities of New Texas that all the stories in this collection have traced.
As you can tell from the title, this is a Christmas story. The crew of the DHC ship is getting ready to celebrate Alliday, which they claim rolls all of the winter holidays into one. Just like every other effort to do this, no, it does not, it just subsumes them all into Christmas with some lip service to other related holidays. I am begging people to realize that other religions often do not have major holidays in December, and therefore you cannot include everyone by just declaring December to be religious holiday time and thinking that will cover it.
There is the bones of an interesting story here. The covert mission setup has potential, the kid and his mother are charming if cliched, there's a bit of world-building around xenoglas (the magical alien material at the center of the larger series plot), and there's a lot of foreshadowing for Deep Black. Unfortunately, this is too obviously a side story and a setup story: none of this goes anywhere satisfying, and along the way the reader has to endure endless rather gratuitous Christmas references, such as the captain working on a Nutcracker ballet performance for the ship talent show.
This isn't bad, exactly, but it rubbed me the wrong way. If you love Christmas stories, you may find it more agreeable. (5)
Rating: 6 out of 10
Michael Foord: New Article: Essential Python Web Security Part 1
The Open Source Initiative have published part one of an article of mine. The article is called “Essential Python Web Security” and it’s part one of a series called “The Absolute Minimum Every Python Web Application Developer Must Know About Security”. The subject is Full Stack Security for Python web applications, based on the Defence in Depth approach.
This series explores the critical security principles every Python web developer should know. Whilst hard and fast rules, like avoiding plaintext passwords and custom security algorithms, are essential - a deeper understanding of broader security principles is equally important. This first pots delves into fundamental security best practises, ranging from general principles to specific Python-related techniques.
Part 2, on Cryptographic Algorithms, will be published soon. When the series is complete it will probably also be available as an ebook. The full document, about fifty pages, can be read here:
Special thanks to Gigaclear Ltd who sponsored the creation of this article. Also thanks to Dr David Mertz and Daniel Roy Greenfeld for technical reviews of this article prior to publication.
Benjamin Mako Hill: Thug Life
My current playlist is this diorama of Lulu the Piggy channeling Tupac Shakur in a toy vending machine in the basement of New World Mall in Flushing Chinatown.
{kind=link}
Dirk Eddelbuettel: anytime 0.3.11 on CRAN: Maintenance
A follow-up release 0.3.11 to the recent 0.3.10 release release of the anytime package arrived on CRAN two days ago. The package is fairly feature-complete, and code and functionality remain mature and stable, of course.
anytime is a very focused package aiming to do just one thing really well: to convert anything in integer, numeric, character, factor, ordered, … input format to either POSIXct (when called as anytime) or Date objects (when called as anydate) – and to do so without requiring a format string as well as accomodating different formats in one input vector. See the anytime page, or the GitHub repo for a few examples, and the beautiful documentation site for all documentation.
This release simply skips one test file. CRAN labeled an error ‘M1mac’ yet it did not reproduce on any of the other M1 macOS I can access (macbuilder, GitHub Actions) as this appeared related to a local setting of timezone values I could not reproduce anywwhere. So the only way to get rid of the ‘fail’ is to … not to run the test. Needless to say the upload process was a little tedious as I got the passive-aggressive ‘not responding’ treatment on a first upload and the required email answer it lead to. Anyway, after a few days, and even more deep breaths, it is taken care of and now the package result standing is (at least currently) pristinely clean.
The short list of changes follows.
Changes in anytime version 0.3.11 (2024-12-18)- Skip a test file
Courtesy of my CRANberries, there is also a diffstat report of changes relative to the previous release. The issue tracker tracker off the GitHub repo can be use for questions and comments. More information about the package is at the package page, the GitHub repo and the documentation site.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. If you like this or other open-source work I do, you can now sponsor me at GitHub.
Dan Yeaw: A Big Job Change
I recently changed jobs, and now I am an Engineering Manager for OSS at Anaconda!
This is my second major career pivot, and I thought I would share why I decided to make the change. Even though being a Submarine Officer, a Functional Safety Lead, and working on OSS are very different, they share a common thread of leadership and deeply technical engineering. I’m excited to bring these skills into my new role.
Goodbye to FordI spent the last 11 years leading Functional Safety at Ford. It was incredibly rewarding to grow from an individual contributor to a manager and eventually to leading a global team dedicated to ensuring Ford vehicles were safe.
While this role let me support Functional Safety Engineers across the company, I started to miss getting hands-on with technical contributions since most of my time was focused on leading the team.
Looking back, there are a couple of things I wish had been different at Ford:
- A strong bias for external talent with executive leadership
- Too much bureaucracy, especially in approval processes
Having a good mix of new talent join an organization is so important because fresh ideas and perspectives can make a big difference. However, in Ford’s software engineering areas, about 90% of the executive leadership roles were filled by people from outside the company. While I wasn’t aiming for higher leadership roles, this clear preference for external hires made it feel like developing and retaining internal talent wasn’t a priority. As you might expect, it took new leaders a while to adapt, and there was a lot of turnover.
On top of that, the approval process for things like hiring and travel was overly complicated. Simple approvals could take months with no feedback. This culture of control slowed everything down. Delegating authority—like giving managers a budget and headcount to work with and holding them accountable—would have made things so much smoother and faster.
The thing I’ll miss most about Ford is the people. I loved collaborating with all the Functional Safety Engineers and everyone else I worked with. I wish them all the best in the future!
Hello AnacondaI am now an Engineering Manager for Open Source Software at Anaconda, where I lead a team of engineers working on amazing projects like:
...and more!
Over the last seven years, I’ve been contributing to open source projects, especially in Python. Getting the chance to lead a team that does this full-time feels like a dream come true.
One of the things I’m most excited about with these projects is how they help make programming more accessible. BeeWare, for example, makes it possible to create apps for mobile and desktop, and PyScript lets you write Python directly in your web browser. Both tools are fantastic for helping anyone pick up Python, build something useful, and share it with others. Meanwhile, Jupyter and fsspec are key tools for data science, making it easier to analyze diverse datasets and integrate different data sources.
I’m thrilled to have the opportunity to strengthen the open-source communities around these projects, encourage healthier collaboration, and create more value for Python users by connecting these tools with the broader PyData ecosystem.
Real Python: Basic Data Types in Python: A Quick Exploration
Python data types are fundamental to the language, enabling you to represent various kinds of data. You use basic data types like int, float, and complex for numbers, str for text, bytes and bytearray for binary data, and bool for Boolean values. These data types form the core of most Python programs, allowing you to handle numeric, textual, and logical data efficiently.
Understanding Python data types involves recognizing their roles and how to work with them. You can create and manipulate these data types using built-in functions and methods. You can also convert between them when necessary. This versatility helps you manage data effectively in your Python projects.
By the end of this tutorial, you’ll understand that:
- Python’s basic data types include int, float, complex, str, bytes, bytearray, and bool.
- You can check a variable’s type using the type() function in Python.
- You can convert data types in Python using functions like int(), float(), str(), and others.
- Despite being dynamically typed, Python does have data types.
- The most essential data types in Python can be categorized as numeric, sequence, binary, and Boolean.
In this tutorial, you’ll learn only the basics of each data type. To learn more about a specific data type, you’ll find useful resources in the corresponding section.
Get Your Code: Click here to download the free sample code that you’ll use to learn about basic data types in Python.
Take the Quiz: Test your knowledge with our interactive “Basic Data Types in Python: A Quick Exploration” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Basic Data Types in Python: A Quick ExplorationTake this quiz to test your understanding of the basic data types that are built into Python, like numbers, strings, bytes, and Booleans.
Python’s Basic Data TypesPython has several built-in data types that you can use out of the box because they’re built into the language. From all the built-in types available, you’ll find that a few of them represent basic objects, such as numbers, strings and characters, bytes, and Boolean values.
Note that the term basic refers to objects that can represent data you typically find in real life, such as numbers and text. It doesn’t include composite data types, such as lists, tuples, dictionaries, and others.
In Python, the built-in data types that you can consider basic are the following:
Class Basic Type int Integer numbers float Floating-point numbers complex Complex numbers str Strings and characters bytes, bytearray Bytes bool Boolean valuesIn the following sections, you’ll learn the basics of how to create, use, and work with all of these built-in data types in Python.
Integer NumbersInteger numbers are whole numbers with no decimal places. They can be positive or negative numbers. For example, 0, 1, 2, 3, -1, -2, and -3 are all integers. Usually, you’ll use positive integer numbers to count things.
In Python, the integer data type is represented by the int class:
Python >>> type(42) <class 'int'> Copied!In the following sections, you’ll learn the basics of how to create and work with integer numbers in Python.
Integer LiteralsWhen you need to use integer numbers in your code, you’ll often use integer literals directly. Literals are constant values of built-in types spelled out literally, such as integers. Python provides a few different ways to create integer literals. The most common way is to use base-ten literals that look the same as integers look in math:
Python >>> 42 42 >>> -84 -84 >>> 0 0 Copied!Here, you have three integer numbers: a positive one, a negative one, and zero. Note that to create negative integers, you need to prepend the minus sign (-) to the number.
Python has no limit to how long an integer value can be. The only constraint is the amount of memory your system has. Beyond that, an integer can be as long as you need:
Python >>> 123123123123123123123123123123123123123123123123 + 1 123123123123123123123123123123123123123123123124 Copied!For a really, really long integer, you can get a ValueError when converting it to a string:
Read the full article at https://realpython.com/python-data-types/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Real Python: A Practical Introduction to Web Scraping in Python
Python web scraping allows you to collect and parse data from websites programmatically. With powerful libraries like urllib, Beautiful Soup, and MechanicalSoup, you can fetch and manipulate HTML content effortlessly. By automating data collection tasks, Python makes web scraping both efficient and effective.
You can build a Python web scraping workflow using only the standard library by fetching a web page with urllib and extracting data using string methods or regular expressions. For more complex HTML or more robust workflows, you can use the third-party library Beautiful Soup, which simplifies HTML parsing. By adding MechanicalSoup to your toolkit, you can even enable interactions with HTML forms.
By the end of this tutorial, you’ll understand that:
- Python is well-suited for web scraping due to its extensive libraries, such as Beautiful Soup and MechanicalSoup.
- You can scrape websites with Python by fetching HTML content using urllib and extracting data using string methods or parsers like Beautiful Soup.
- Beautiful Soup is a great choice for parsing HTML documents with Python effectively.
- Data scraping may be illegal if it violates a website’s terms of use, so always review the website’s acceptable use policy.
This tutorial guides you through extracting data from websites using string methods, regular expressions, and HTML parsers.
Note: This tutorial is adapted from the chapter “Interacting With the Web” in Python Basics: A Practical Introduction to Python 3.
The book uses Python’s built-in IDLE editor to create and edit Python files and interact with the Python shell, so you’ll see occasional references to IDLE throughout this tutorial. However, you should have no problems running the example code from the editor and environment of your choice.
Source Code: Click here to download the free source code that you’ll use to collect and parse data from the Web.
Take the Quiz: Test your knowledge with our interactive “A Practical Introduction to Web Scraping in Python” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
A Practical Introduction to Web Scraping in PythonIn this quiz, you'll test your understanding of web scraping in Python. Web scraping is a powerful tool for data collection and analysis. By working through this quiz, you'll revisit how to parse website data using string methods, regular expressions, and HTML parsers, as well as how to interact with forms and other website components.
Scrape and Parse Text From WebsitesCollecting data from websites using an automated process is known as web scraping. Some websites explicitly forbid users from scraping their data with automated tools like the ones that you’ll create in this tutorial. Websites do this for two possible reasons:
- The site has a good reason to protect its data. For instance, Google Maps doesn’t let you request too many results too quickly.
- Making many repeated requests to a website’s server may use up bandwidth, slowing down the website for other users and potentially overloading the server such that the website stops responding entirely.
Before using your Python skills for web scraping, you should always check your target website’s acceptable use policy to see if accessing the website with automated tools is a violation of its terms of use. Legally, web scraping against the wishes of a website is very much a gray area.
Important: Please be aware that the following techniques may be illegal when used on websites that prohibit web scraping.
For this tutorial, you’ll use a page that’s hosted on Real Python’s server. The page that you’ll access has been set up for use with this tutorial.
Now that you’ve read the disclaimer, you can get to the fun stuff. In the next section, you’ll start grabbing all the HTML code from a single web page.
Build Your First Web ScraperOne useful package for web scraping that you can find in Python’s standard library is urllib, which contains tools for working with URLs. In particular, the urllib.request module contains a function called urlopen() that you can use to open a URL within a program.
In IDLE’s interactive window, type the following to import urlopen():
Python >>> from urllib.request import urlopen Copied!The web page that you’ll open is at the following URL:
Python >>> url = "http://olympus.realpython.org/profiles/aphrodite" Copied!To open the web page, pass url to urlopen():
Python >>> page = urlopen(url) Copied!urlopen() returns an HTTPResponse object:
Python >>> page <http.client.HTTPResponse object at 0x105fef820> Copied! Read the full article at https://realpython.com/python-web-scraping-practical-introduction/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Stack Abuse: Performance Optimization for Django-Powered Websites on Shared Hosting
Running a Django site on shared hosting can be really agonizing. It's budget-friendly, sure, but it comes with strings attached: sluggish response time and unexpected server hiccups. It kind of makes you want to give up.
Luckily, with a few fixes here and there, you can get your site running way smoother. It may not be perfect, but it gets the job done. Ready to level up your site? Let’s dive into these simple tricks that’ll make a huge difference.
Know Your Limits, Play Your StrengthsBut before we dive deeper, let's do a quick intro to Django. A website that is built on the Django web framework is called a Django-powered website.
Django is an open-source framework written in Python. It can easily handle spikes in traffic and large volumes of data. Platforms like Netflix, Spotify, and Instagram have a massive user base, and they have Django at their core.
Shared hosting is a popular choice among users when it comes to Django websites, mostly because it's affordable and easy to set up. But since you're sharing resources with other websites, you are likely to struggle with:
- Limited resources (CPU, storage, etc.)
- Noisy neighbor effect
However, that's not the end of the world. You can achieve a smoother run by–
- Reducing server load
- Regular monitoring
- Contacting your hosting provider
These tricks help a lot, but shared hosting can only handle so much. If your site is still slow, it might be time to think about cheap dedicated hosting plans.
But before you start looking for a new hosting plan, let's make sure your current setup doesn't have any loose ends.
Flip the Debug Switch (Off!)Once your Django site goes live, the first thing you should do is turn DEBUG off. This setting shows detailed error texts and makes troubleshooting a lot easier.
This tip is helpful for web development, but it backfires during production because it can reveal sensitive information to anyone who notices an error.
To turn DEBUG off, simply set it to False in your settings.py file.
DEBUG = FalseNext, don’t forget to configure ALLOWED_HOSTS. This setting controls which domains can access your Django site. Without it, your site might be vulnerable to unwanted traffic. Add your domain name to the list like this:
ALLOWED_HOSTS =['yourdomain.com', 'www.yourdomain.com']With DEBUG off and ALLOWED_HOSTS locked down, your Django site is already more secure and efficient. But there’s one more trick that can take your performance to the next level.
Cache! Cache! Cache!Imagine every time someone visits your site, Django processes the request and renders a response. What if you could save those results and serve them instantly instead? That’s where caching comes in.
Caching is like putting your site’s most frequently used data on the fast lane. You can use tools like Redis to keep your data in RAM. If it's just about API responses or database query results, in-memory caching can prove to be a game changer for you.
To be more specific, there's also Django's built-in caching:
- Queryset caching: if your system is repeatedly running database queries, keep the query results.
- Template fragment caching: This feature caches the parts of your page that almost always remain the same (headers, sidebars, etc.) to avoid unnecessary rendering.
Your database is the backbone of your Django site. Django makes database interactions easy with its ORM (Object-Relational Mapping). But if you’re not careful, those queries can become a bone in your kebab.
- Use .select_related() and .prefetch_related()
When querying related objects, Django can make multiple database calls without you even realizing it. These can pile up and slow your site.
Instead of this:
posts = Post.objects.all() for post in posts: print(post.author.name) # Multiple queries for each post's authorUse this:
posts = Post.objects.select_related('author') for post in posts: print(post.author.name) # One query for all authors- Avoid the N+1 Query Problem: The N+1 query problem happens when you unknowingly run one query for the initial data and an additional query for each related object. Always check your queries using tools like Django Debug Toolbar to spot and fix these inefficiencies.
- Index Your Database:
Indexes help your database find data faster. Identify frequently searched fields and ensure they’re indexed. In Django, you can add indexes like this:
- Query Only What You Need:
Fetching unnecessary data wastes time and memory. Use .only() or .values() to retrieve only the fields you actually need.
Static files (images, CSS, and JavaScript) can put a heavy load on your server. But have you ever thought of offloading them to a Content Delivery Network (CDN)? CDN is a dedicated storage service. The steps are as follows:
- Set Up a CDN (e.g., Cloudflare, AWS CloudFront):
A CDN will cache your static files and serve them from locations closest to your clients. - Use Dedicated Storage (e.g., AWS S3, Google Cloud Storage):
Store your files in a service designed for static content. Use Django’s storages library. - Compress and Optimize Files:
Minify your CSS and JavaScript files and compress images to reduce file sizes. Use tools like django-compressor to automate this process.
By offloading static files, you’ll free up server storage and improve your site’s speed. It’s one more thing off your plate!
Lightweight Middleware, Heavyweight ImpactMiddleware sits between your server and your application. It processes every request and response.
Check your MIDDLEWARE setting and remove anything you don’t need. Use Django’s built-in middleware whenever you can because it’s faster and more reliable. If you create custom middleware, make sure it’s simple and only does what’s really necessary. Keeping middleware lightweight reduces server strain and uses fewer resources.
Frontend First AidYour frontend is the first thing users see, so a slow, clunky interface can leave a bad impression. Using your frontend the right way can dramatically improve the user experience.
-
Minimize HTTP Requests: Combine CSS and JavaScript files to reduce the number of requests.
-
Optimize Images: Use tools like TinyPNG or ImageOptim to compress images without losing quality.
-
Lazy Load Content: Delay loading images or videos until they’re needed on the screen.
-
Enable Gzip Compression: Compress files sent to the browser to reduce load times.
In the end, the key to maintaining a Django site is constant monitoring. By using tools like Django Debug Toolbar or Sentry, you can quickly identify performance issues.
Once you have a clear picture of what’s happening under the radar, measure your site’s performance. Use tools like New Relic or Google Lighthouse. These tools will help you prioritize where to make improvements. With this knowledge, you can optimize your code, tweak settings, and ensure your site runs smoothly.
LostCarPark Drupal Blog: Drupal Advent Calendar day 21 - Search
Today is the twenty-first day of our Advent Calendar, and we are looking at how you will search your Drupal CMS site. We are joined by Baddý to summarise the work her team is doing…
The Search Track, led by Baddý Breidert, Dr. Christoph Breidert and Artem Dmitriiev from 1xINTERNET, has made substantial progress since DrupalCon Barcelona. A key achievement is the integration of the Search Recipe into the Drupal CMS project. This recipe provides a flexible framework for configuring search functionalities based on specific user needs.
To enhance advanced search capabilities, the team has…
TagsJoey Hess: aiming at December
I have been working all year on a solar upgrade aimed at December. Now here it is, midwinter, and my electric car is charging on a cloudy day from my offgrid solar fence.
I lived happily enough with 1 kilowatt of solar that I installed in 2017. Meanwhile, solar panel prices came down massively, incentives increased and everything came together: This was the year.
In the spring I started clearing forest trees that were leaning over the house, making both a firebreak and a solar field.
In June I picked up a pallet of panels in a box truck.
a porch with a a bunch of solar panels, stacked on edge leaning up against the wall. A black and white cat is sprawled in front of them.{kind=link}
In August I bought the EV and was able to charge it offgrid from my old solar system... a few miles per day on the most sunny days.
In September and October I built a solar fence, of my own design.
Me standing in front of the solar fence, which is 10 panels long{kind=link}
For the past several weeks I have been installing additional solar panels on ballasted ground mounts full of gravel. At this point I'm half way through installing my 30 panel upgrade.
The design goal of my 12 kilowatt system is to produce 1 kilowatt of power all day on a cloudy day in midwinter, which allows swapping between major loads (EV charger, hot water heater, etc) on a cloudy day and running everything on a sunny day. So the size of the battery bank doesn't matter much. Batteries are getting cheaper fast too, but they are a wear item, so it's better to oversize the solar system and minimize the battery.
A lot of this is nonstandard and experimental. And that makes sense with the price of solar panels. It costs more to mount solar panels now than the panels are worth. And non-ideal panel orientation isn't a problem when the system is massively overpaneled.
I'm hoping to finish up the install before the end of winter. I have more trees to clear, more ballasted ground mounts to install, and need to come up with something even more experimental for a half dozen or so panels. Using solar panels as mounts for solar panels? Hanging them from trees?
Soon the wan light will fade, time to head off to the solstice party to enjoy the long night, and a bonfire.
Solar fence with some ballasted ground mounts in front of it, late evening light. Old pole mounted solar panels in the foreground are from the 90's.{kind=link}
This Week in Plasma: end-of-year bug fixing
Lots of KDE folks are winding down for well-deserved end-of-year breaks, but that didn't stop a bunch of people from landing some awesome changes anyway! This will be a short one, and I may skip next week as many of us are going to be focusing on family time. But in the meantime, check out what we have here:
Notable UI ImprovementsWhen applying screen settings fails due to a graphics driver issue, the relevant page in System Settings now tells you about it, instead of failing silently. (Xaver Hugl, 6.3.0. Link)
Added a new Breeze open-link icon with the typical "arrow pointing out of the corner of a square" appearance, which should start showing up in places where web URLs are opened from things that don't clearly look like blue clickable links. (Carl Schwan, Frameworks 6.10. Link)
Notable Bug FixesFixed one of the most common recent Powerdevil crashes. (Jakob Petsovits, 6.2.5. Link)
Recording a specific window in Spectacle and OBS now produces a recording with the correct scale when using any screen scaling (Xaver Hugl, 6.2.5. Link)
When using a WireGuard VPN, the "Persistent keepalive" setting now works. (Adrian Thiele, 6.2.5. Link)
Implemented multiple fixes and improvements for screen brightness and dimming. (Jakob Petsovits, 6.3.0. Link 1, link 2, link 3, and link 4)
Auto-updates in Discover now work again! (Harald Sitter, 6.3.0. Link)
Vastly improved game controller joystick support in Plasma, fixing many weird and random-seeming bugs. (Arthur Kasimov, 6.3.0. Link)
For printers that report per-color ink levels, System Settings' Printers page now displays the ink level visualization in the actual ink colors again. (Kai Uwe Broulik, 6.3.0. Link)
Pager widgets on very thin floating panels are now clickable in all the places they're supposed to be clickable. (Niccolò Venerandi, 6.3.0. Link)
Wallpapers with very very special EXIF metadata can no longer generate text labels that escape from their intended boundaries on Plasma's various wallpaper chooser views. (Jonathan Riddell and Nate Graham, Frameworks 6.10. Link)
Fixed one of the most common Qt crashes affecting Plasma and KDE apps. (Fabian Kosmale, Qt 6.8.2. Link)
Other bug information of note:
- 2 Very high priority Plasma bugs (same as last week). Current list of bugs
- 34 15-minute Plasma bugs (up from 32 last week). Current list of bugs
- 125 KDE bugs of all kinds fixed over the last week. Full list of bugs
Significantly reduced the CPU usage of System Monitor during the time after you open the app but before you visit to the History page. More CPU usage fixes are in the pipeline, too! (Arjen Hiemstra, 6.2.5. Link)
Plasma Browser Integration now works for the Flatpak-packaged version of Firefox. (Harald Sitter, 6.3.0. Link)
How You Can HelpKDE has become important in the world, and your time and contributions have helped us get there. As we grow, we need your support to keep KDE sustainable.
You can help KDE by becoming an active community member and getting involved somehow. Each contributor makes a huge difference in KDE — you are not a number or a cog in a machine!
You don’t have to be a programmer, either. Many other opportunities exist:
- Triage and confirm bug reports, maybe even identify their root cause
- Contribute designs for wallpapers, icons, and app interfaces
- Design and maintain websites
- Translate user interface text items into your own language
- Promote KDE in your local community
- …And a ton more things!
You can also help us by donating to our yearly fundraiser! Any monetary contribution — however small — will help us cover operational costs, salaries, travel expenses for contributors, and in general just keep KDE bringing Free Software to the world.
To get a new Plasma feature or a bugfix mentioned here, feel free to push a commit to the relevant merge request on invent.kde.org.
Michael Prokop: Grml 2024.12 – codename Adventgrenze
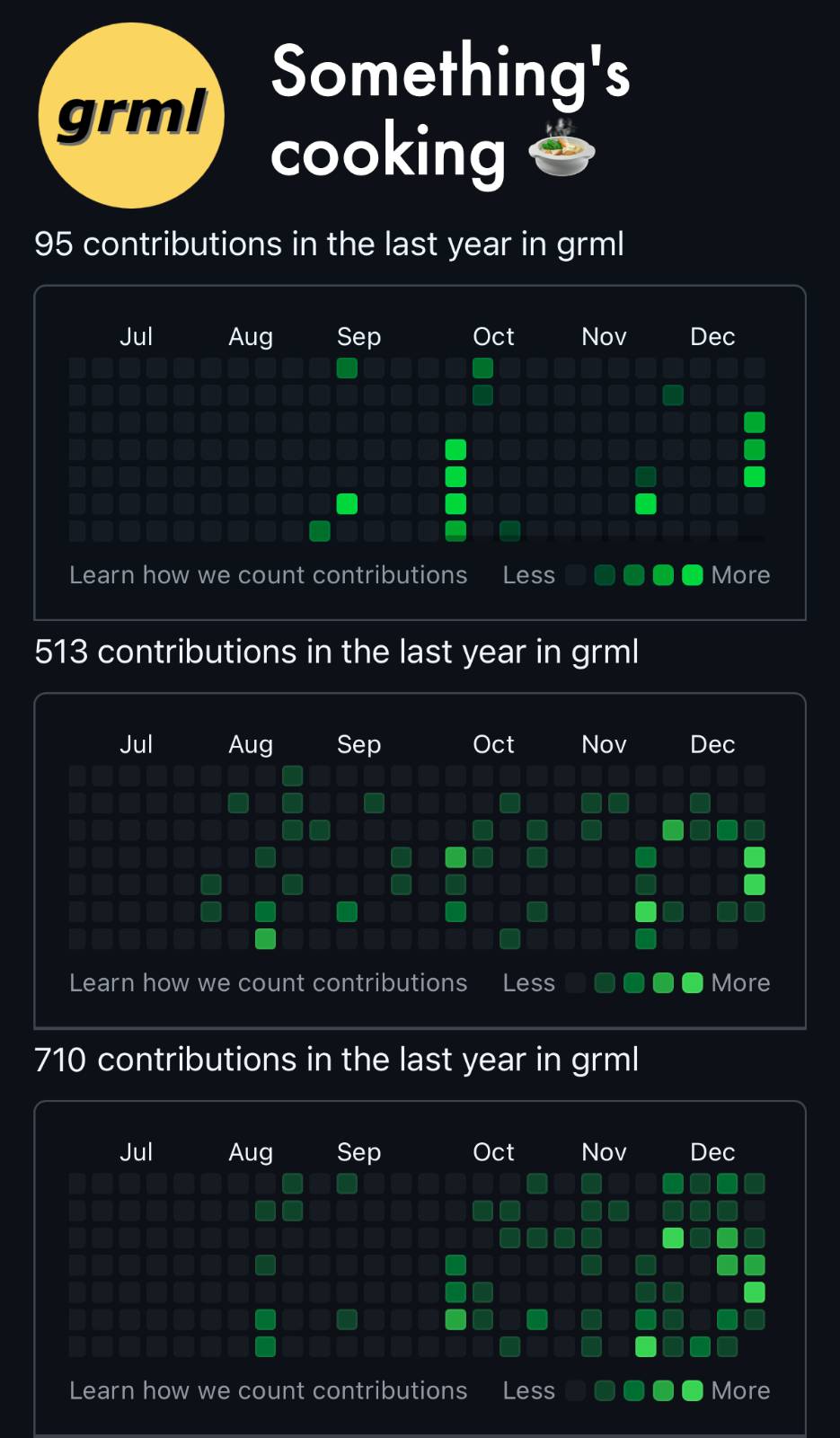{kind=link}
We did it again™! Just in time, we’re excited to announce the release of Grml stable version 2024.12, code-named ‘Adventgrenze’! (If you’re not familiar with Grml, it’s a Debian-based live system tailored for system administrators.)
This new release is built on Debian trixie, and for the first time, we’re introducing support for 64-bit ARM CPUs (arm64 architecture)!
I’m incredibly proud of the hard work that went into this release. A significant amount of behind-the-scenes effort went into reworking our infrastructure and redesigning the build process. Special thanks to Chris and Darsha – our Grml developer days in November and December were a blast!
For a detailed overview of the changes between releases 2024.02 and 2024.12, check out our official release announcement. And, as always, after a release comes the next one – exciting improvements are already in the works!
BTW: recently we also celebrated 20(!) years of Grml Releases. If you’re a Grml and or grml-zsh user, please join us in celebrating and send us a postcard!
ComputerMinds.co.uk: Views Data Export: Sprint 1 Summary
As explained in the previous article in the series I've started working on maintaining Views Data Export again.
I've decided to document my work in 2 week 'sprints'. And so this article is about what I did in Sprint 1.
Sprint progressAt the start of the sprint there in the Drupal.org issue queue there were:
- 204 open bugs
- 276 other open issues.
So that's a total of 480 open issues.
By the end it looked like this:
- 91 open bugs
- 17 fixed issues.
- 81 other open issues
So that's a total of 189 open issues, a 60% reduction from before!
Key goalsIn this sprint I wanted to:
- Tame the issue queues on Drupal.org and get a handle on what the common frustrations and missing features were.
- Read and understand all of the code in the Drupal 8.x-1.x branch.
Taming the issue queue
As mentioned in a previous article I decided to close down pretty much all the tickets for the Drupal 7 version of the module. This is the codebase that I'm most familiar with, but it's causing a lot of noise in the issue queue, so getting rid of that is a great first step, and pretty easy.
https://www.drupal.org/project/views_data_export/issues/3492246 was my ticket where I detailed what I was going to do, and then I went about doing that.
This felt immensely good! I went through each Drupal 7 ticket and gave it a quick scan and then pasted-in my prepared closing statement. It took just over an hour, and was like taking a trip down memory lane: seeing all those old issues come up and remembering when I triaged some of them originally.
After this initial round of work, I've also been working in the 8.x-1.x queue to close out duplicate and solved issues. I've been focussing on support requests which are usually super quick to evaluate and close out. However, this means that I've not really had a chance to look through all the feature requests and bugs, so I still don't really have a handle on what's needed/broken with the module.
Understanding the codeI had a good old read of the code. There's some really great stuff in there, and there's some obvious room for improvement.
But, at least I know what the code does now, and can see some obvious problems/issues. But also, the codebase is small, and there some automated tests, so we've got a great platform to get going with.
Giving directionThere were a few tickets for 8.x-1.x where there were contributors making great contributions and I was able to provide some guidance of how to implement a feature or resolve a bug. I feel like the issue queue has been lacking any kind of technical leadership and so many tickets are collections of patches where developers are fixing the problem they have in quite a specific way. I'm really looking forward to giving some direction to these contributions and then at some point committing and releasing the great work!
Future roadmap/goalsI'm not committing myself to doing these exactly, or any particular order, but this is my high-level list of hopes/dreams/desires, I'll copy and paste this to the next sprint summary article as I go and adjust as required.
- Get the project page updated with information relevant to Drupal 8.x-1.x version of the module
- Update the documentation on Drupal.org
- Not have any duplicate issues on Drupal.org
Pages
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects