
Feeds
Dirk Eddelbuettel: Rblpapi 0.3.15: Updated and New BLP Library
Version 0.3.15 of the Rblpapi package arrived on CRAN today. Rblpapi provides a direct interface between R and the Bloomberg Terminal via the C++ API provided by Bloomberg (but note that a valid Bloomberg license and installation is required).
This is the fifteenth release since the package first appeared on CRAN in 2016. This release updates to the current version 3.24.6 of the Bloomberg API, and rounds out a few corners in the packaging from continuous integration to the vignette.
The detailed list of changes follow below.
Changes in Rblpapi version 0.3.15 (2024-09-18)A warning is now issued if more than 1000 results are returned (John in #377 addressing #375)
A few typos in the rblpapi-intro vignette were corrected (Michael Streatfield in #378)
The continuous integration setup was updated (Dirk in #388)
Deprecation warnings over char* where C++ class Name is now preferred have been addressed (Dirk in #391)
Several package files have been updated (Dirk in #392)
The request formation has been corrected, and an example was added (Dirk and John in #394 and #396)
The Bloomberg API has been upgraded to release 3.24.6.1 (Dirk in #397)
Courtesy of my CRANberries, there is also a diffstat report for the this release. As always, more detailed information is at the Rblpapi repo or the Rblpapi page. Questions, comments etc should go to the issue tickets system at the GitHub repo.
If you like this or other open-source work I do, you can sponsor me at GitHub.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
Wim Leers: XB week 17: drag and drop party
We matched last week’s record: again 26 MRs merged! :D
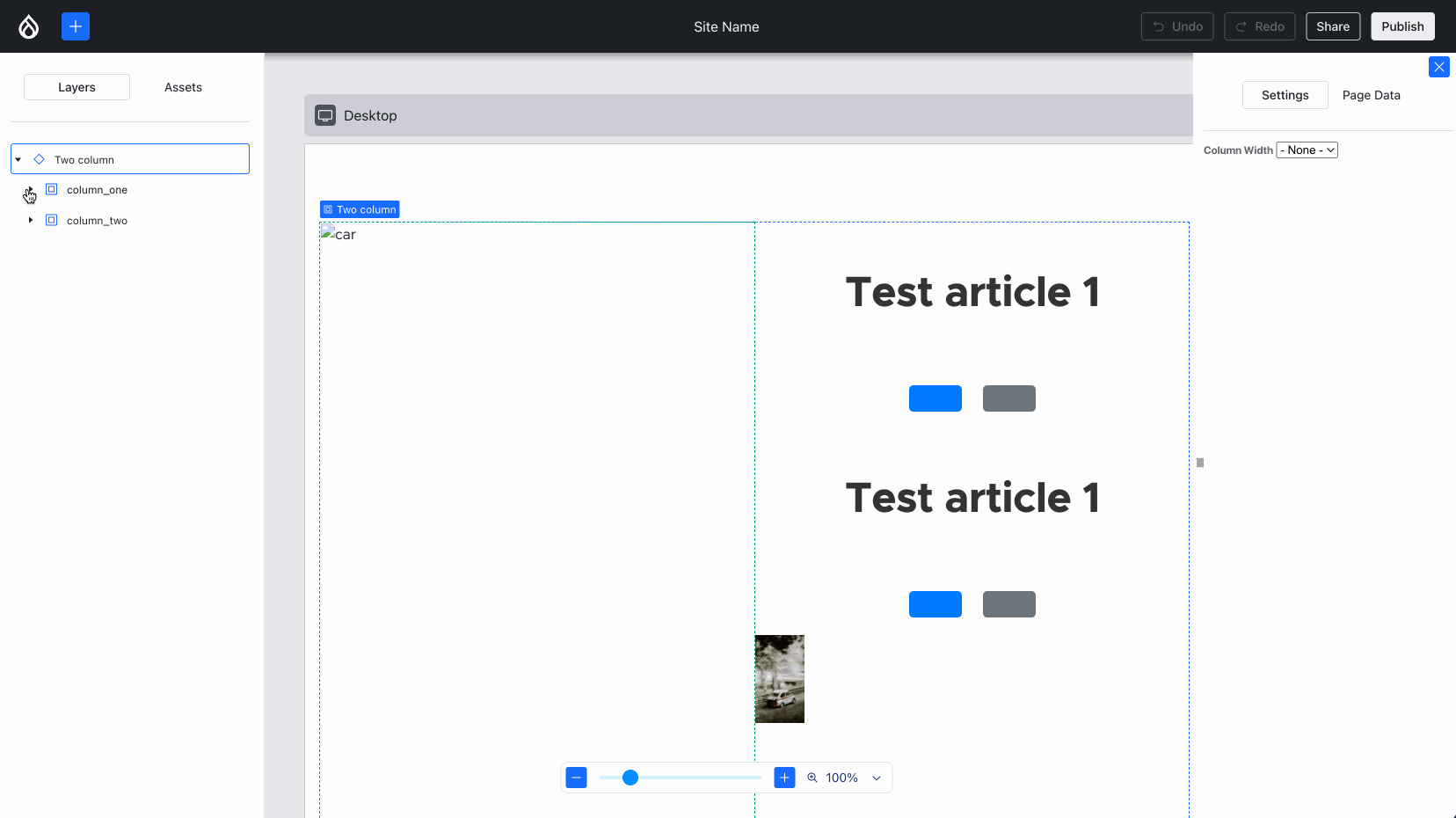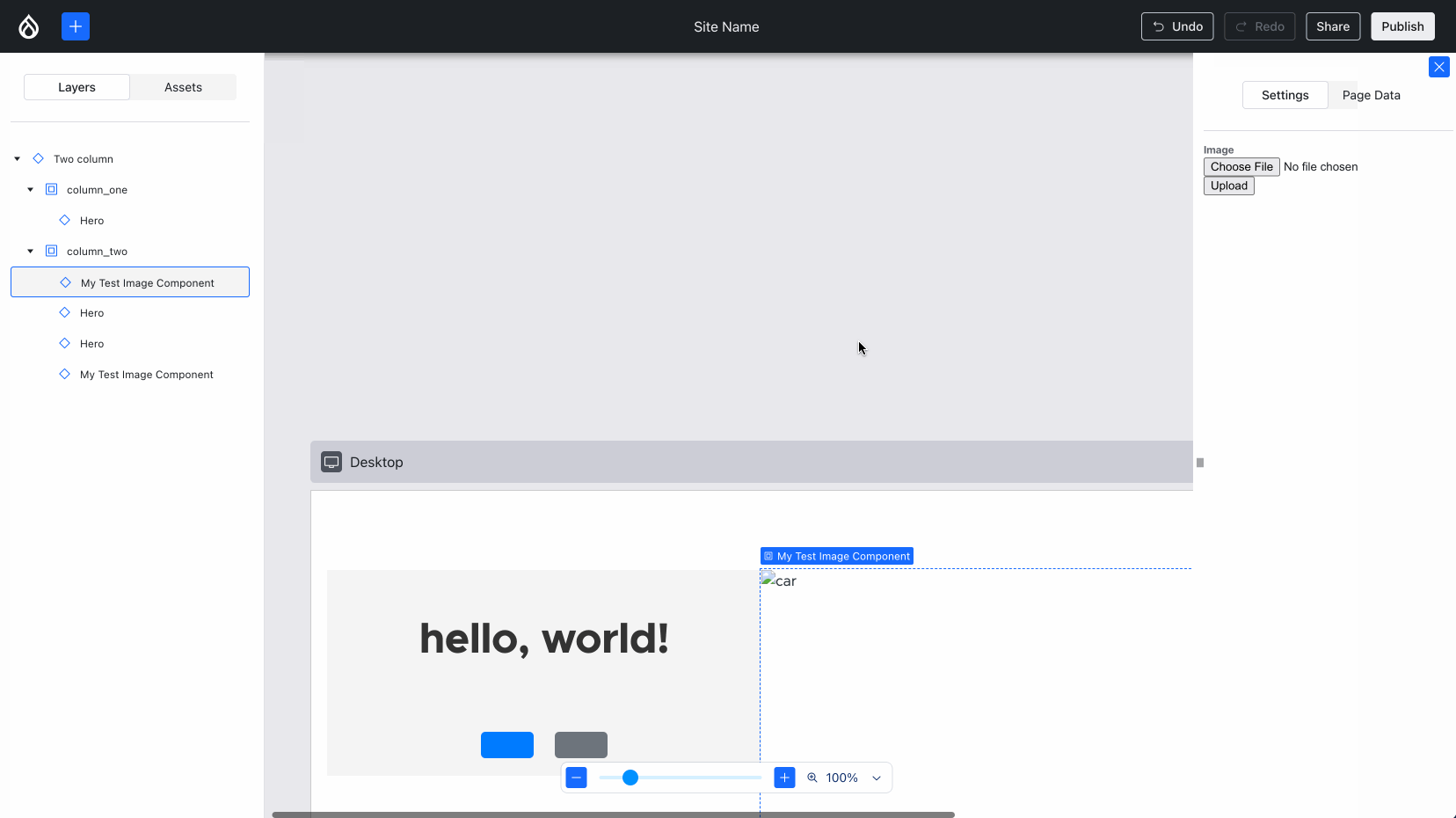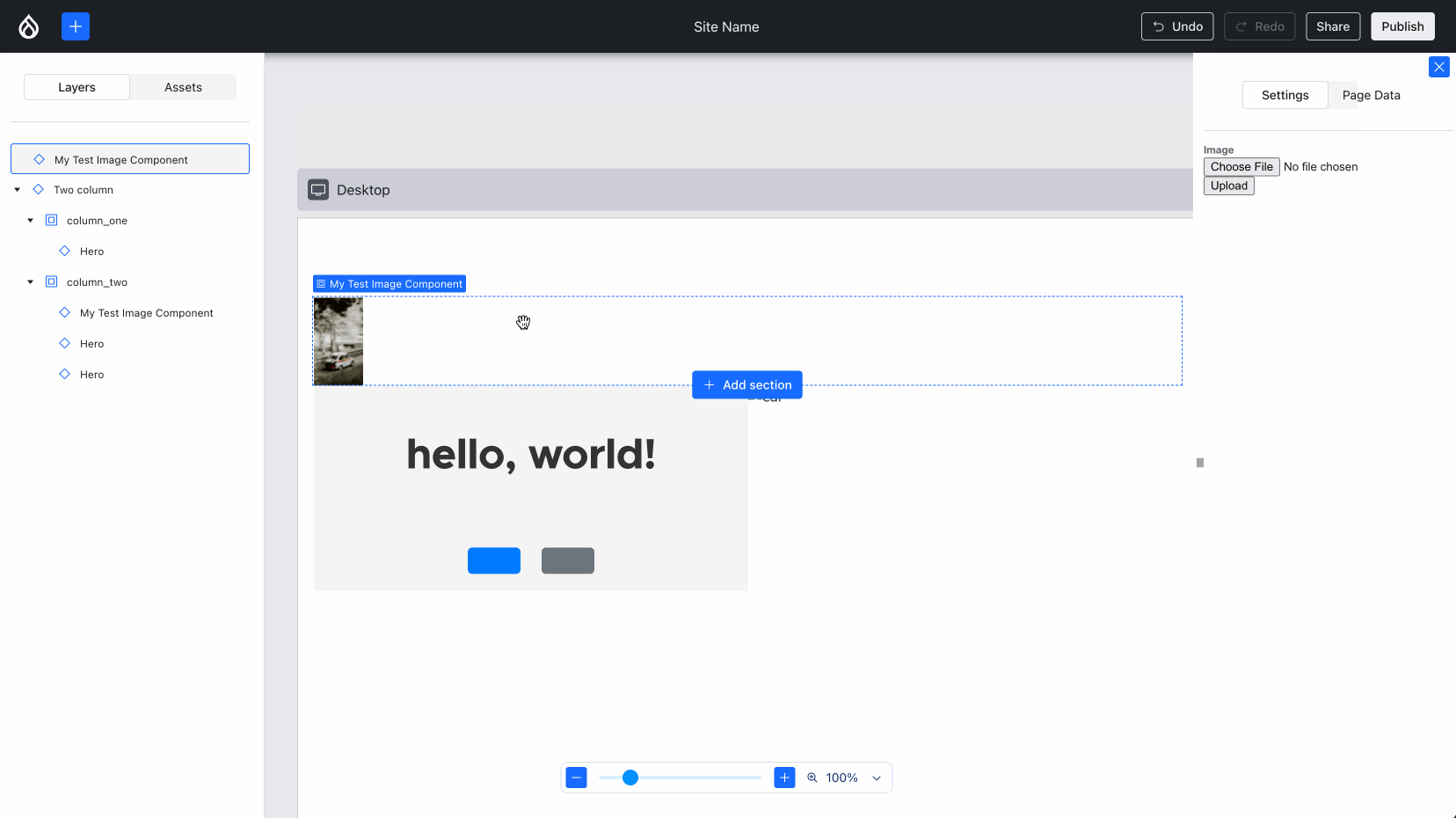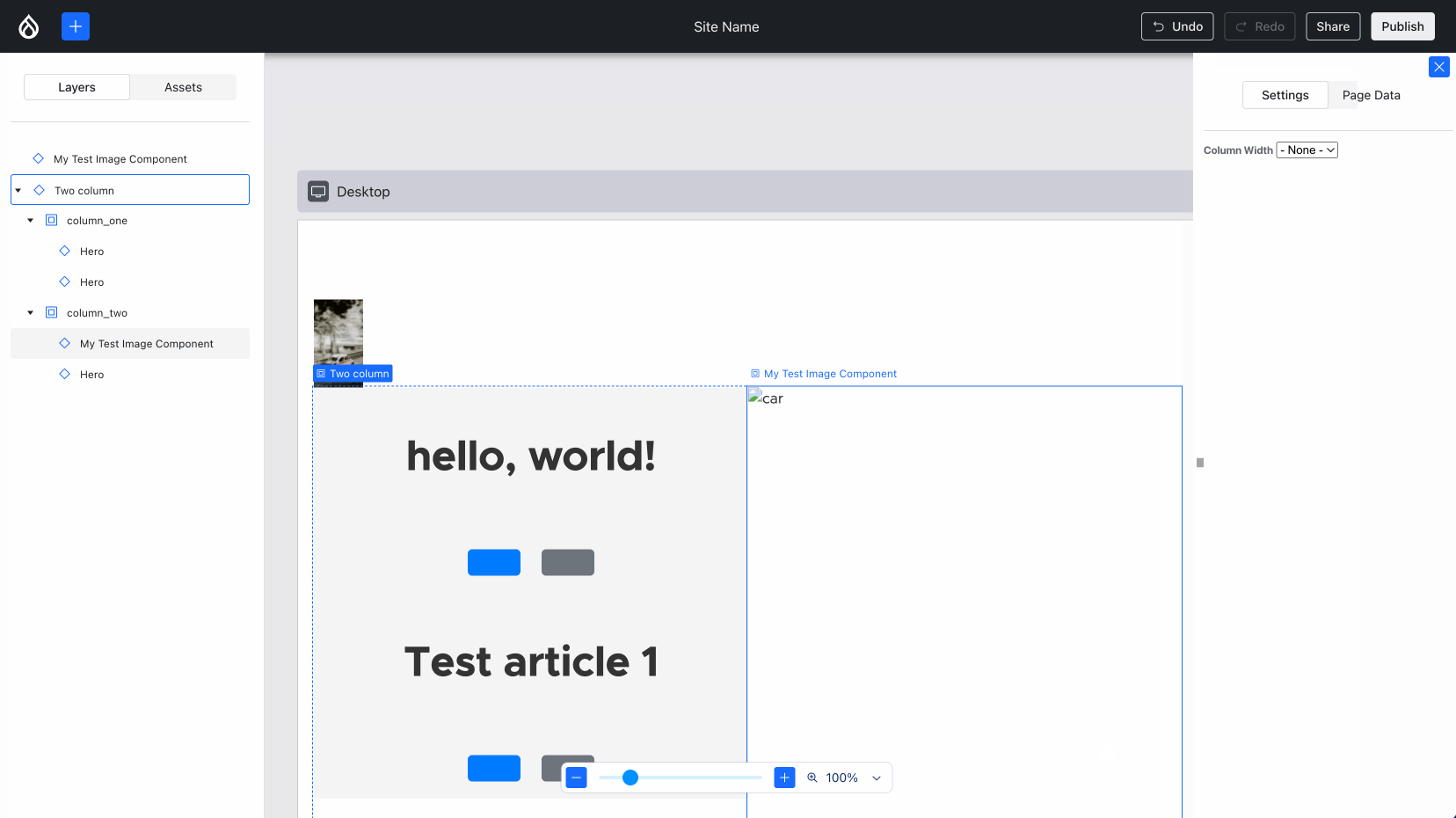
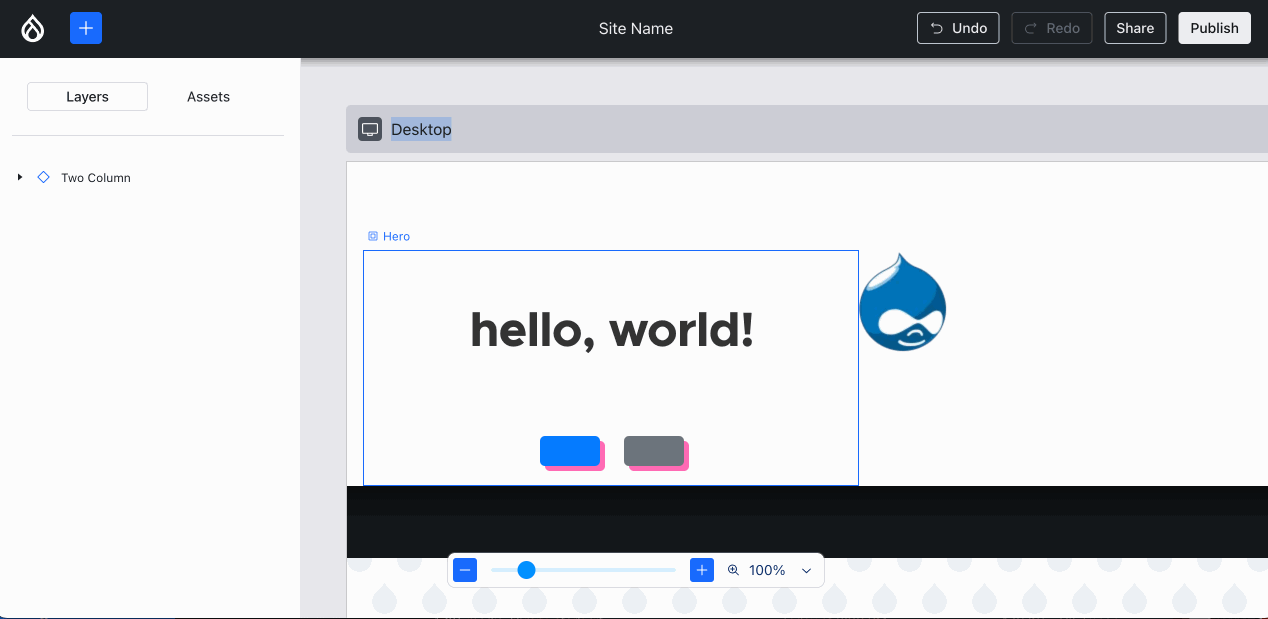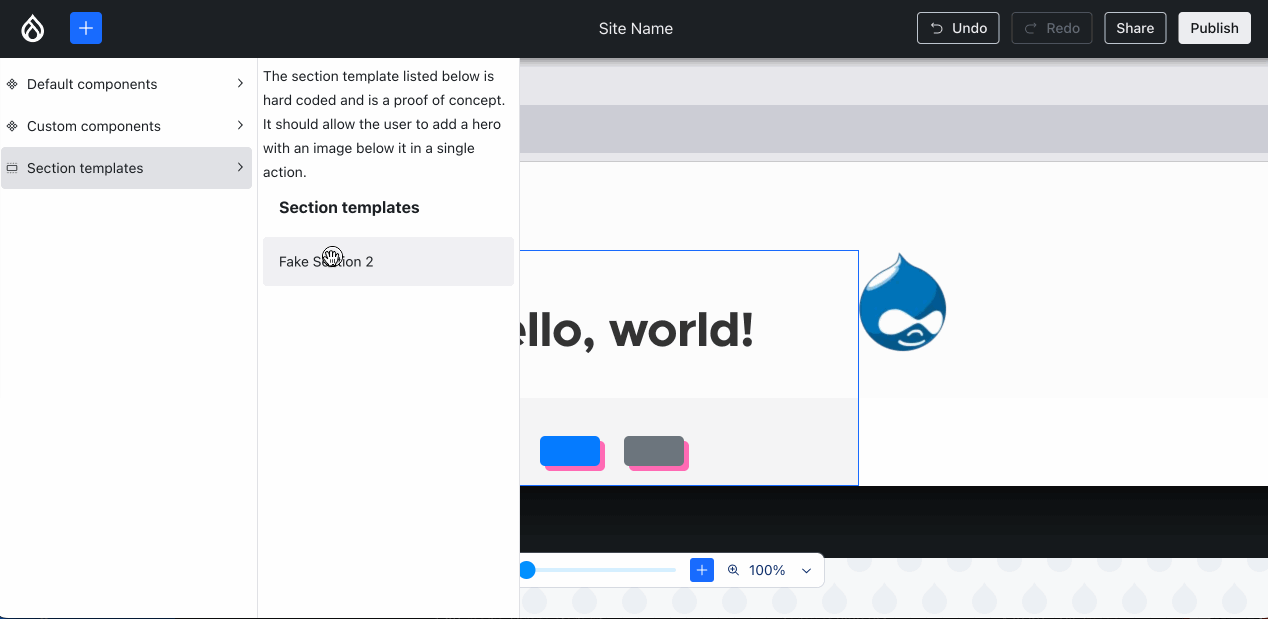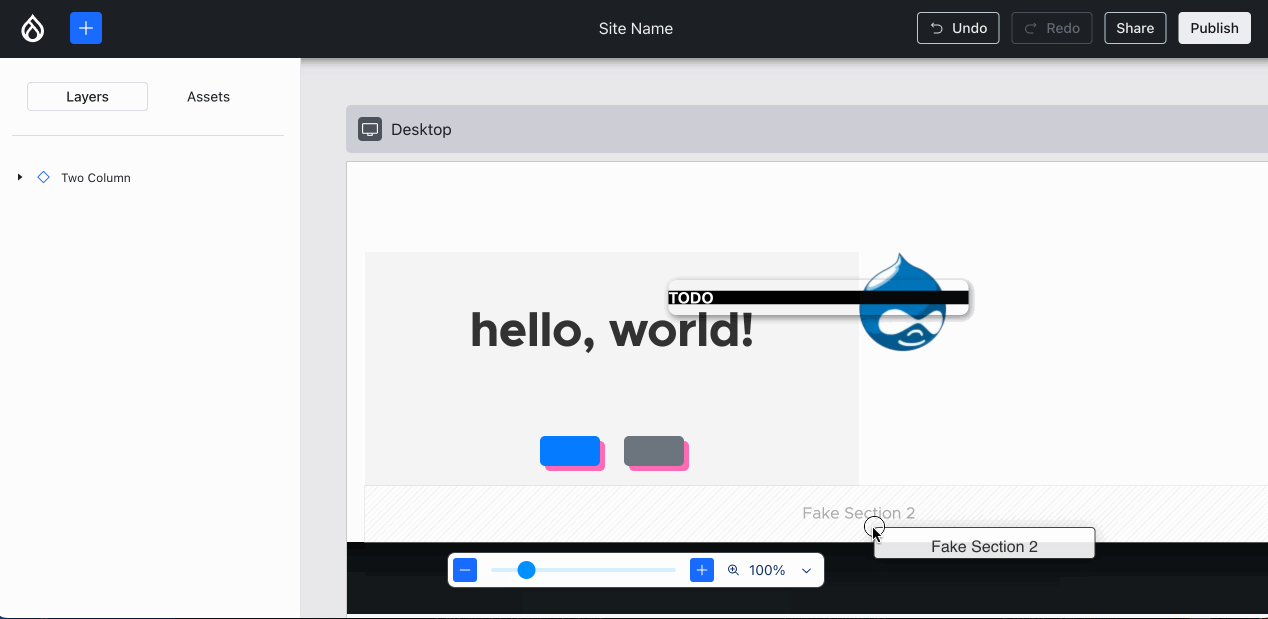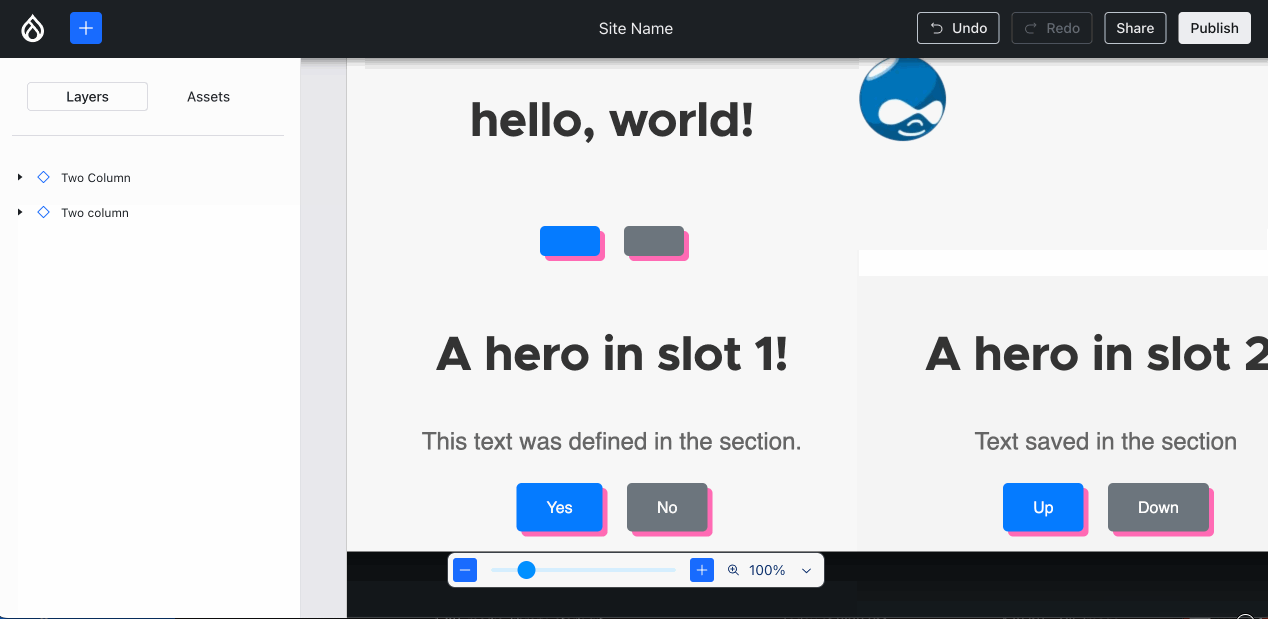
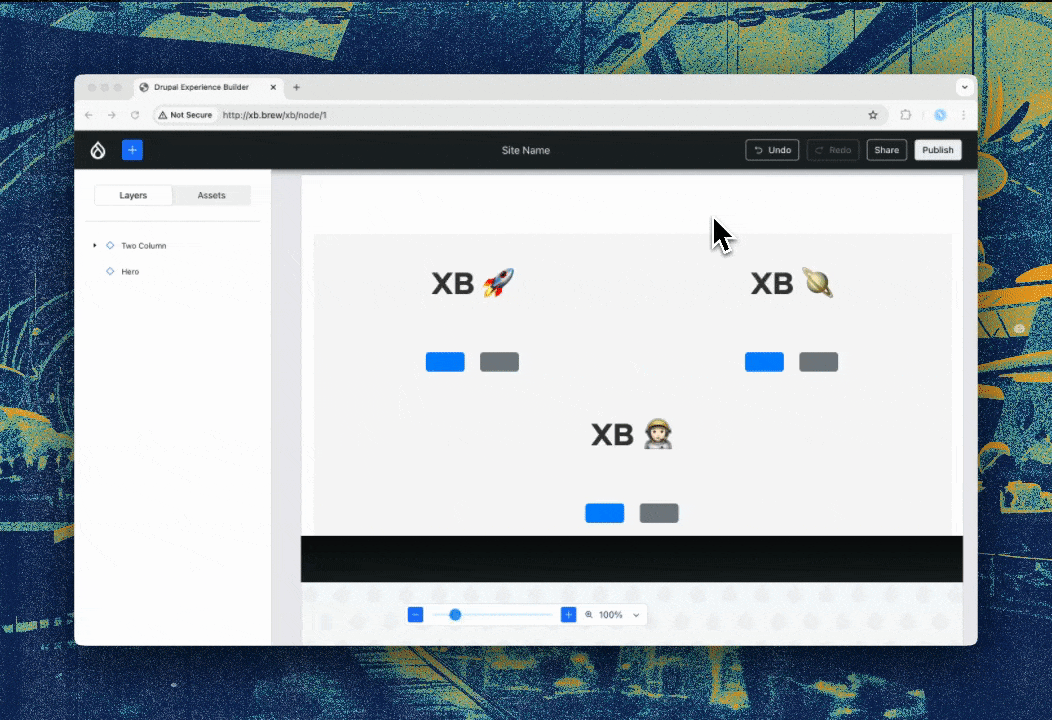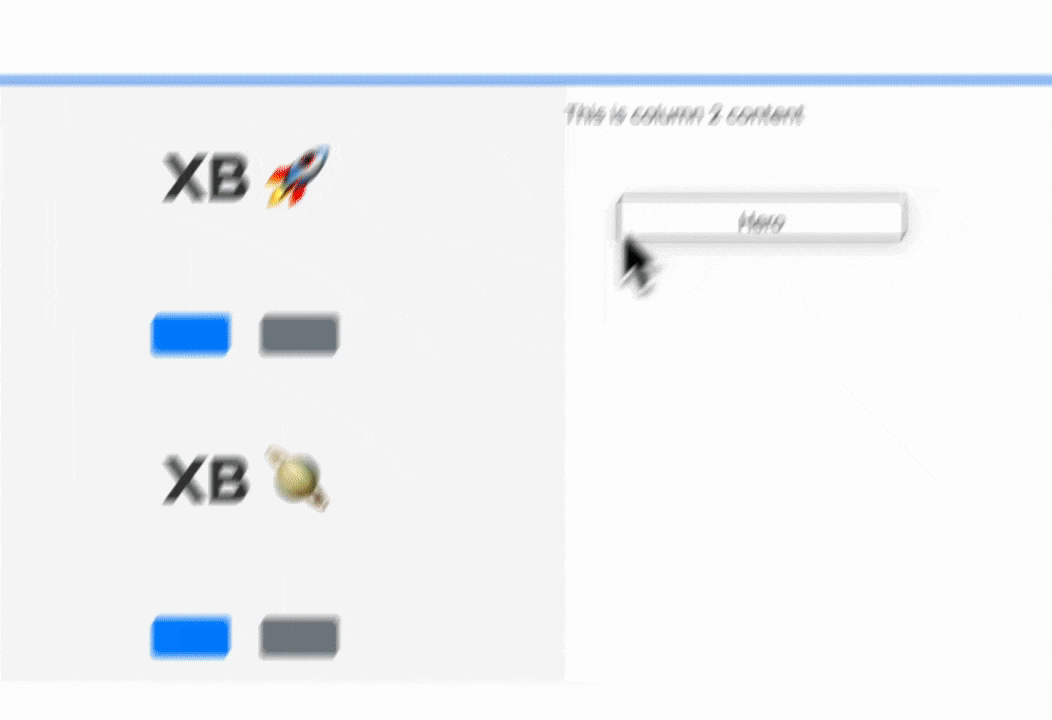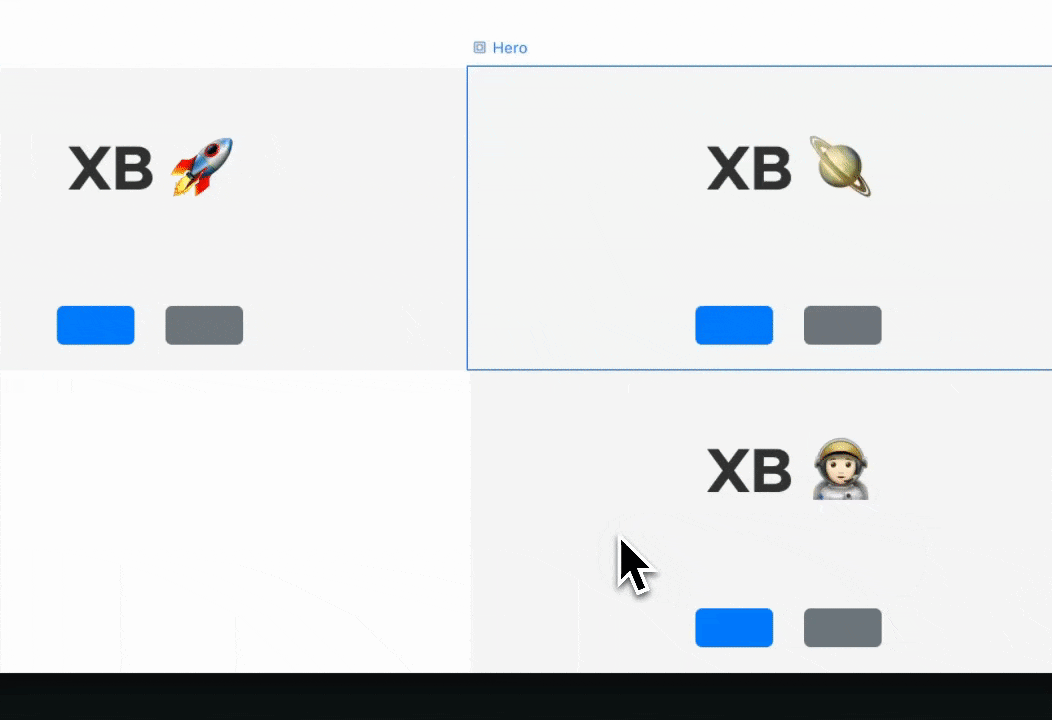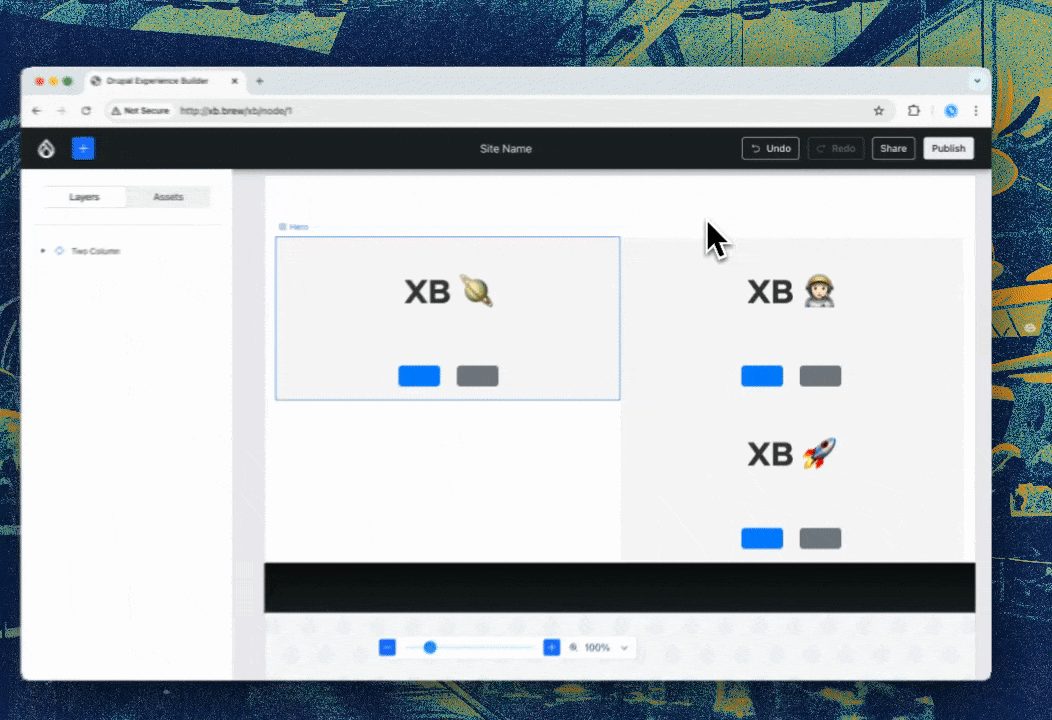
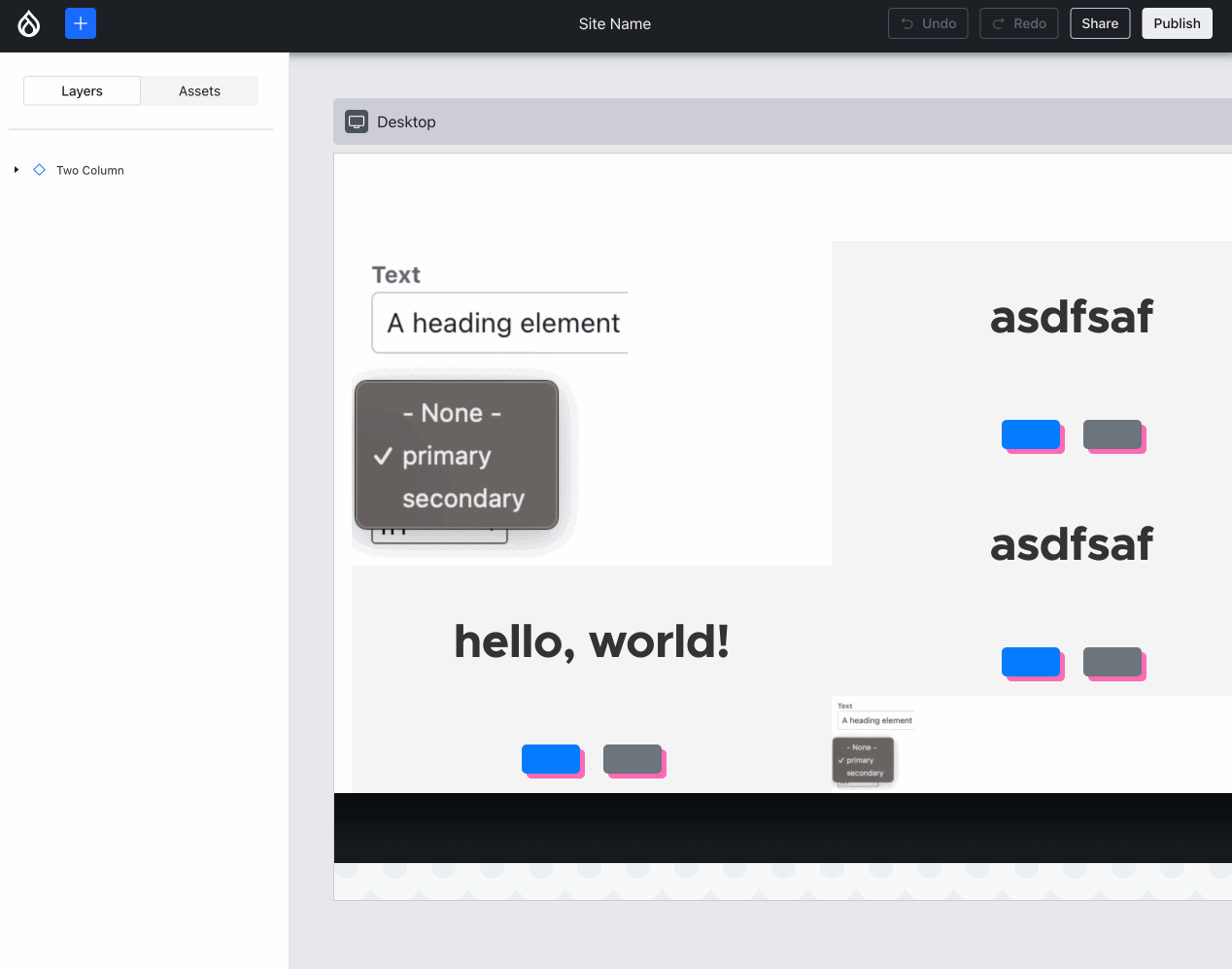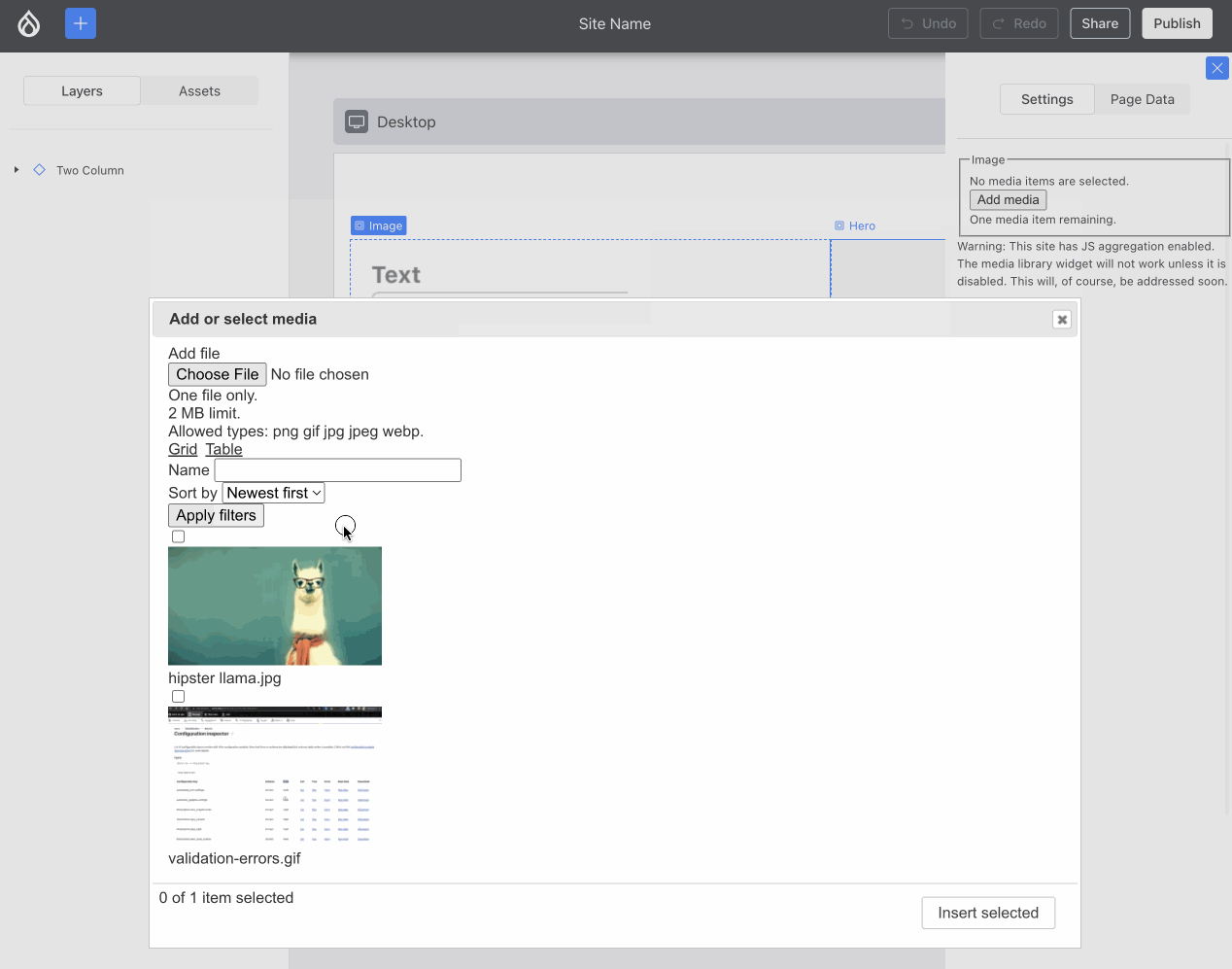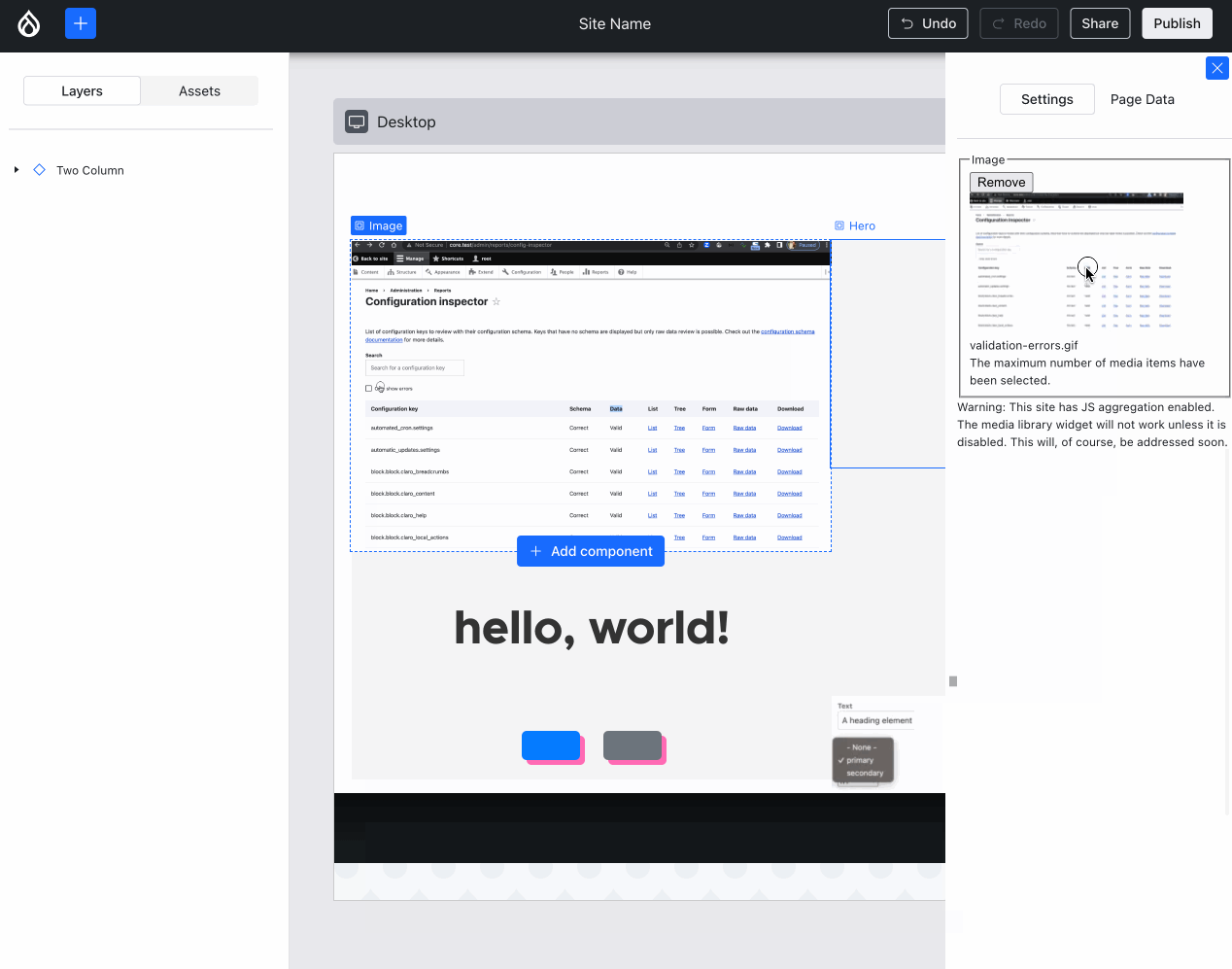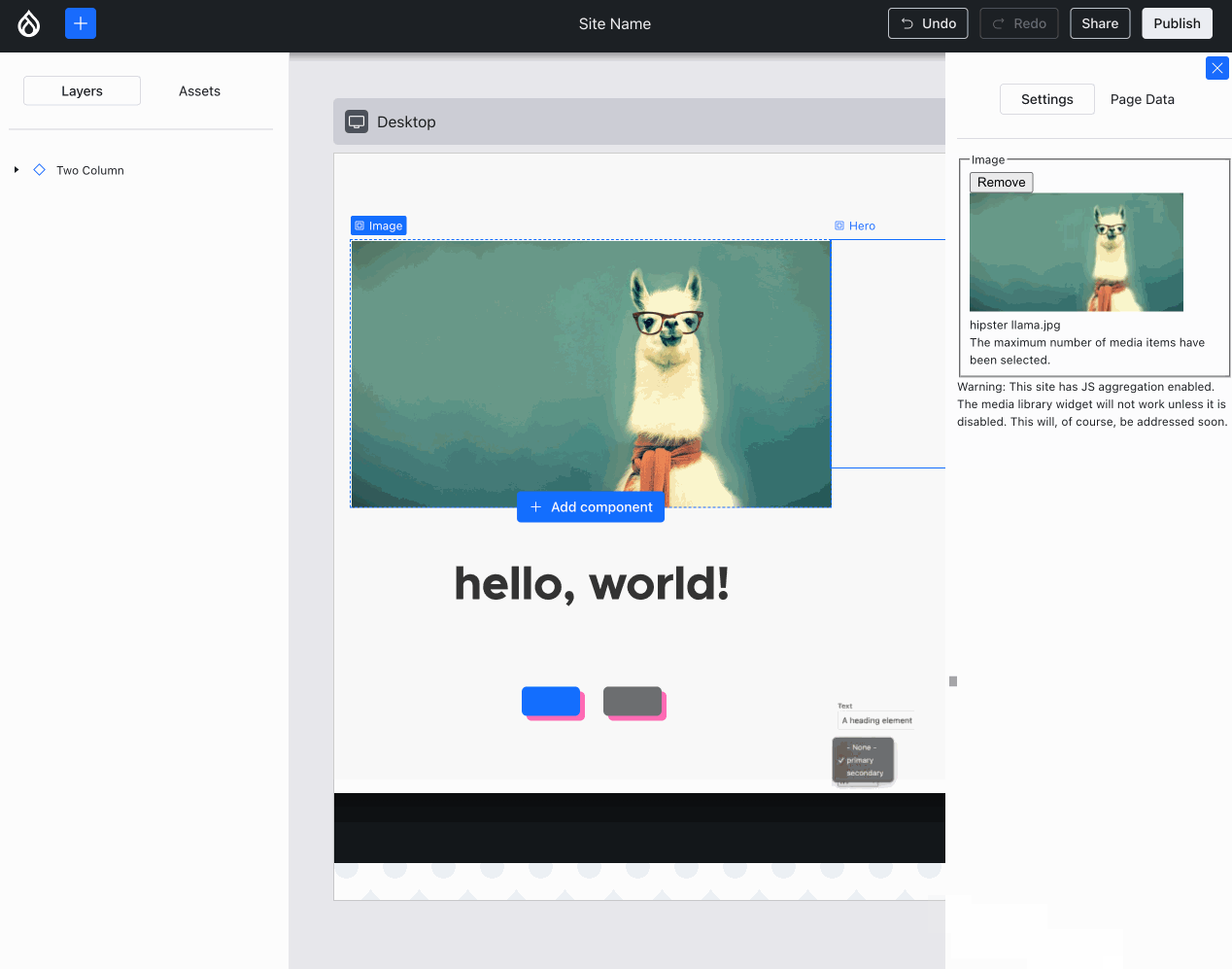
Experience Builder (XB) already had a hierarchy view for a while. Lauri worked with the Acquia UX team to change that to match the more common “layers” pattern (used in Photoshop and Figma). Harumi “hooroomoo” Jang made that a reality:
The new “layers” panel, which also allows moving components.{kind=link}
Issue #3458503, image by Harumi.
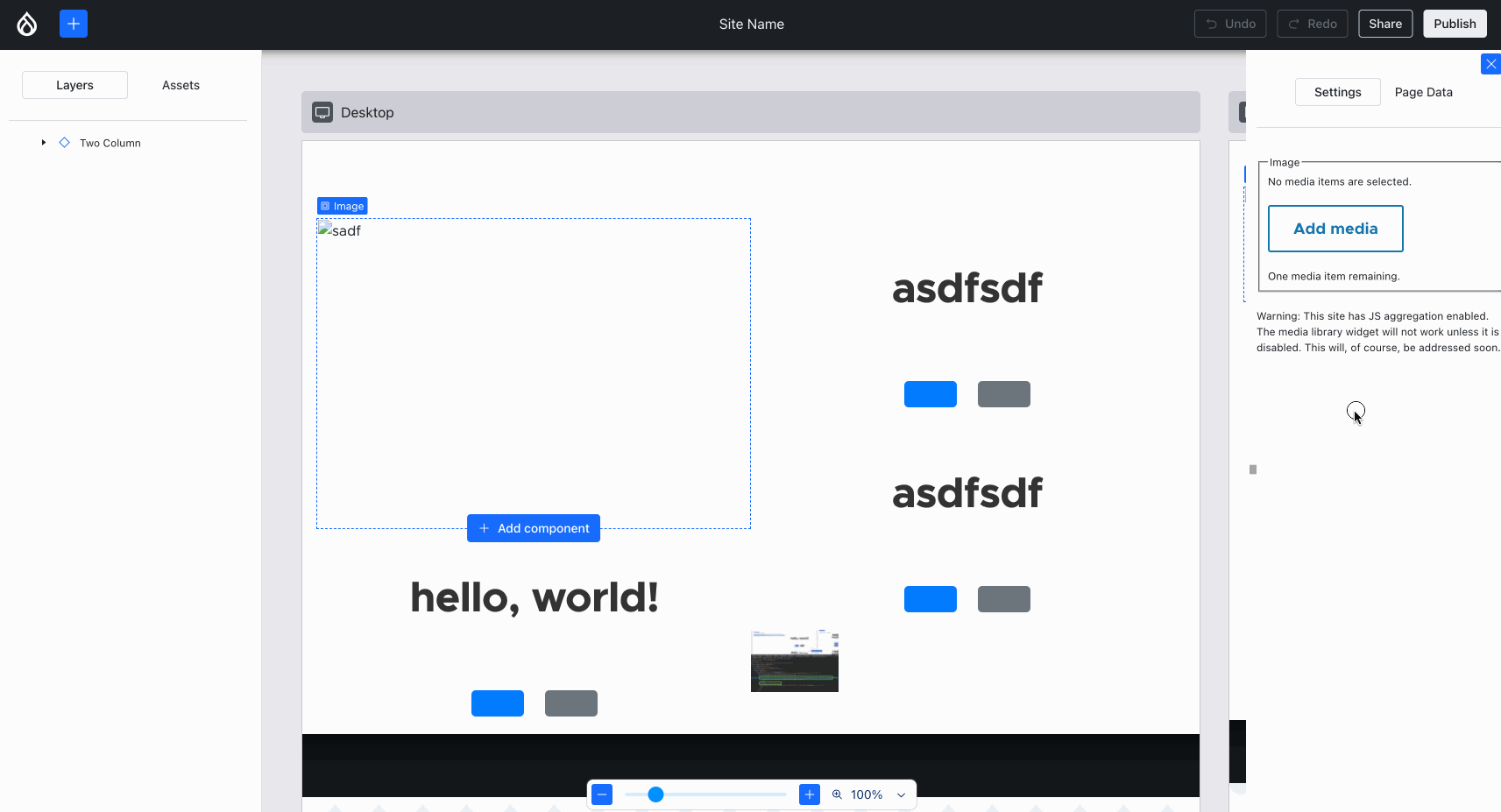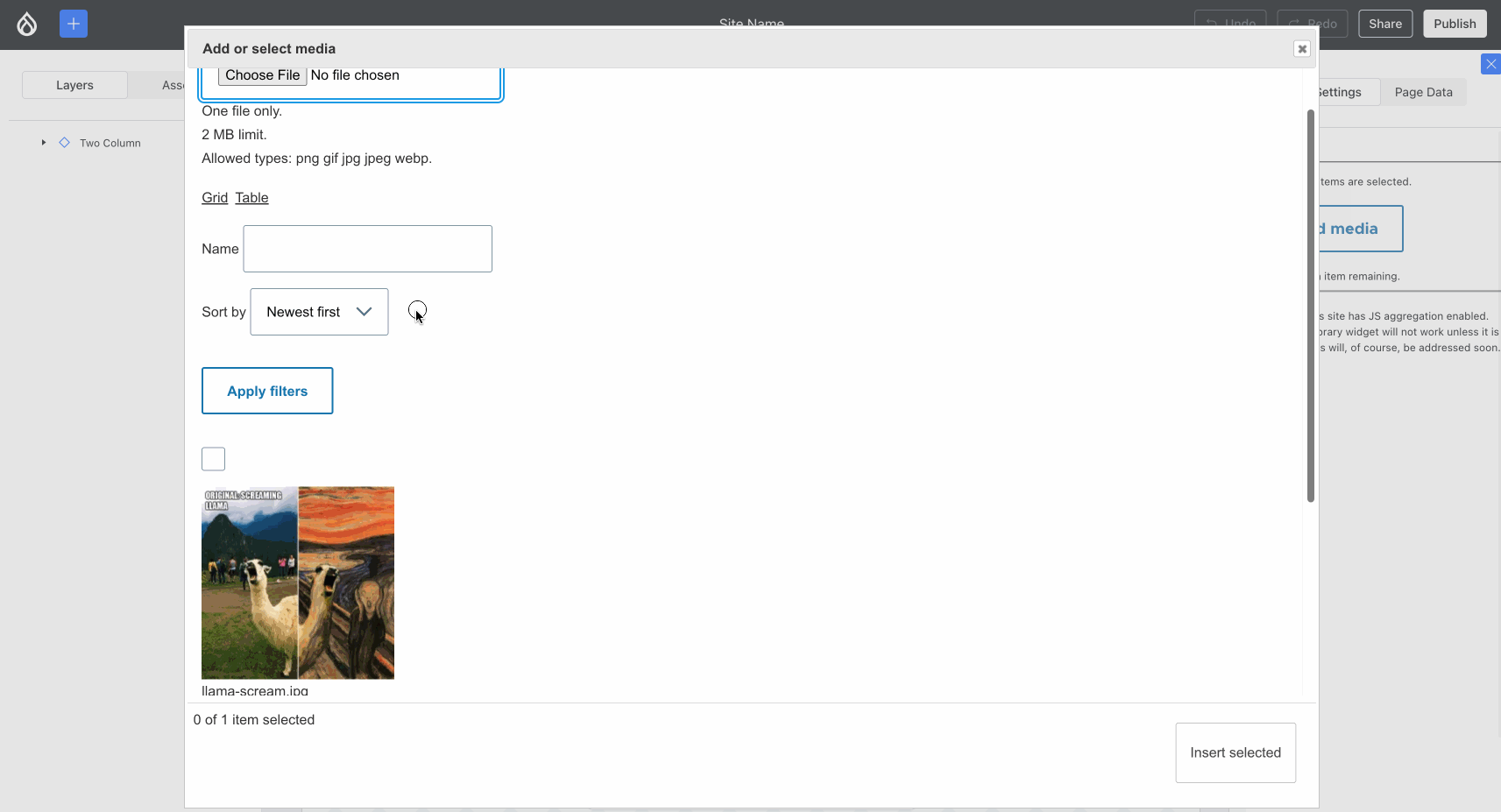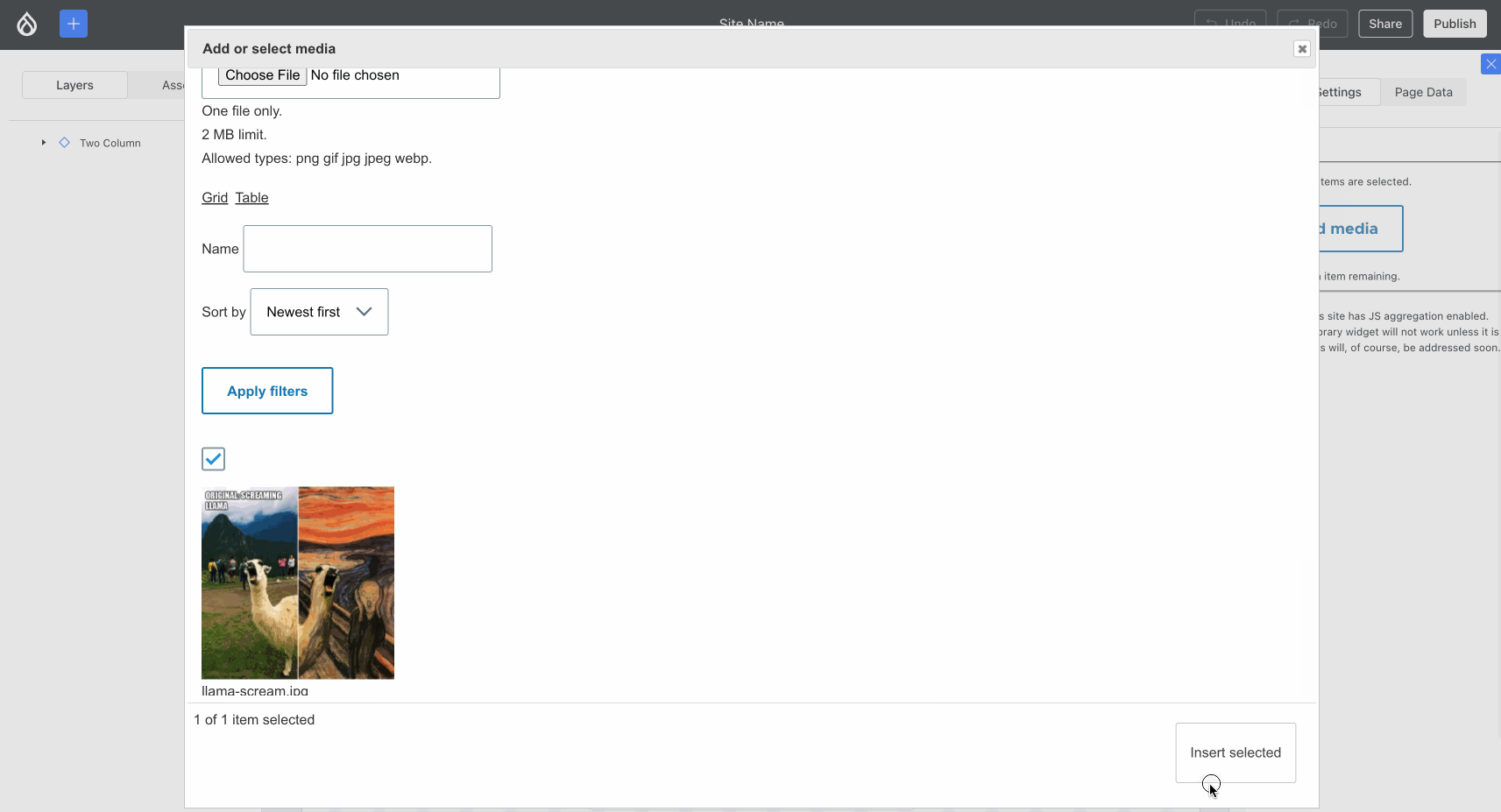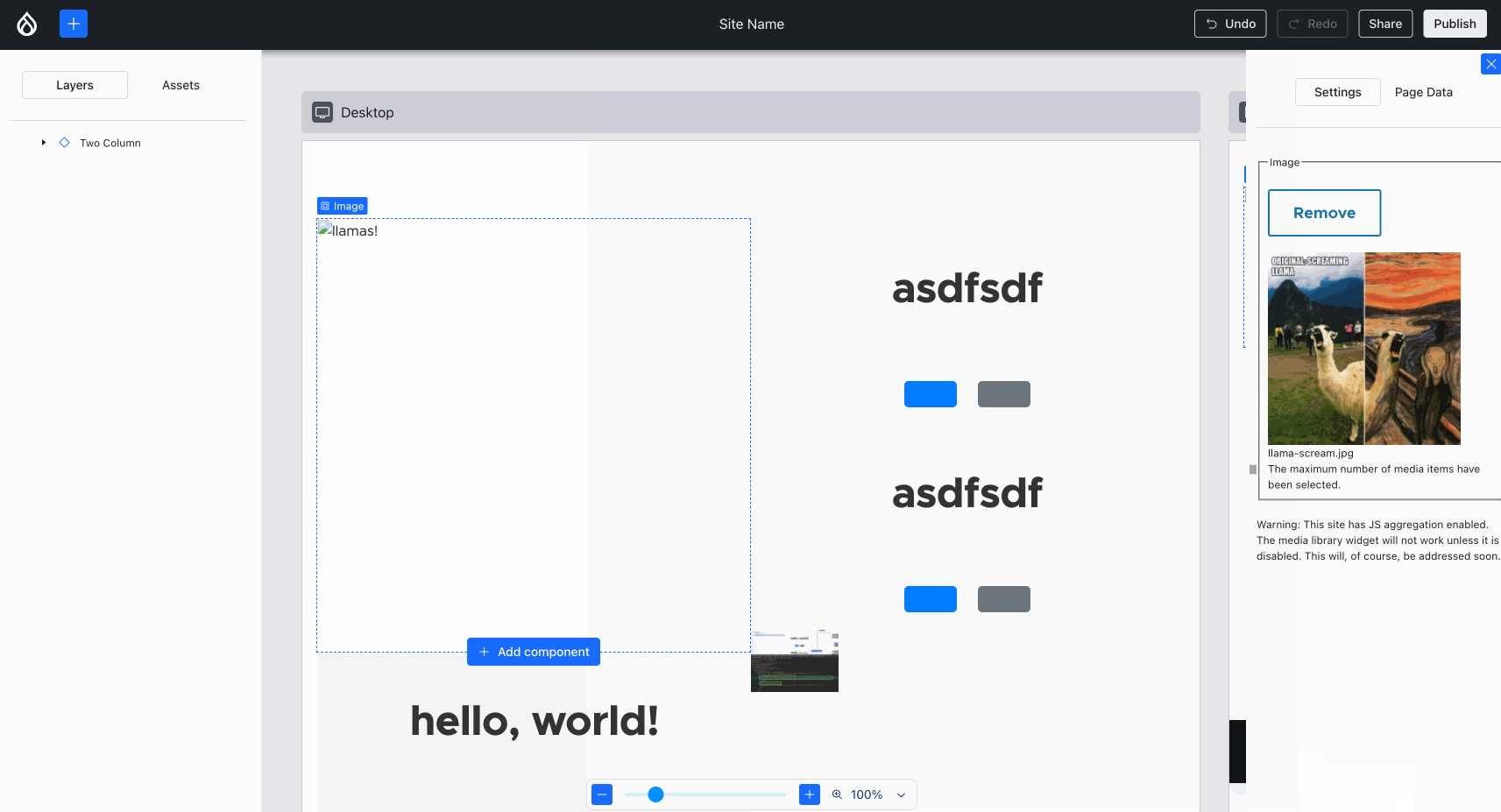
Ben “bnjmnm” Mullins and I (mostly Ben!) collaborated on integrating Media Library! This required expanding some of the lower-level XB infrastructure but most importantly, it means we proved Drupal core’s most complex field widget 1 can work, which is an important milestone:
Using an image from the Media Library. Note how the alt updates, but the image won’t load — more about that later in this post :){kind=link}
Issue #3454173, image by me.
During the product research phase, Lauri identified that it’s important for Content Creators’ productivity to not have to craft the same combinations of components over and over again. Lauri and the Acquia UX team have labeled such combinations “sections” — similar to Layout Builder’s sections. Creating new ones is out-of-scope for 0.1.0, but conveying what that UX would feel like is in scope. So, Jesse “jessebaker” Baker and Bálint “balintbrews” Kléri worked on a client-only implementation that hardcodes a single section (again: for now):
Using an image from the Media Library. Note how the alt updates, but the image won’t load — more about that later in this post :){kind=link}
Issue #3463300, image by me.
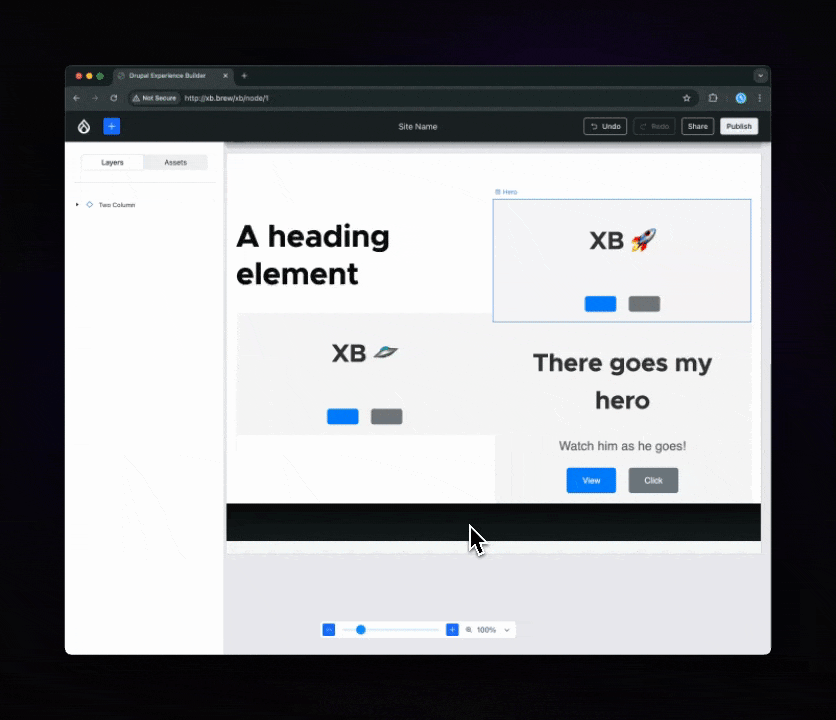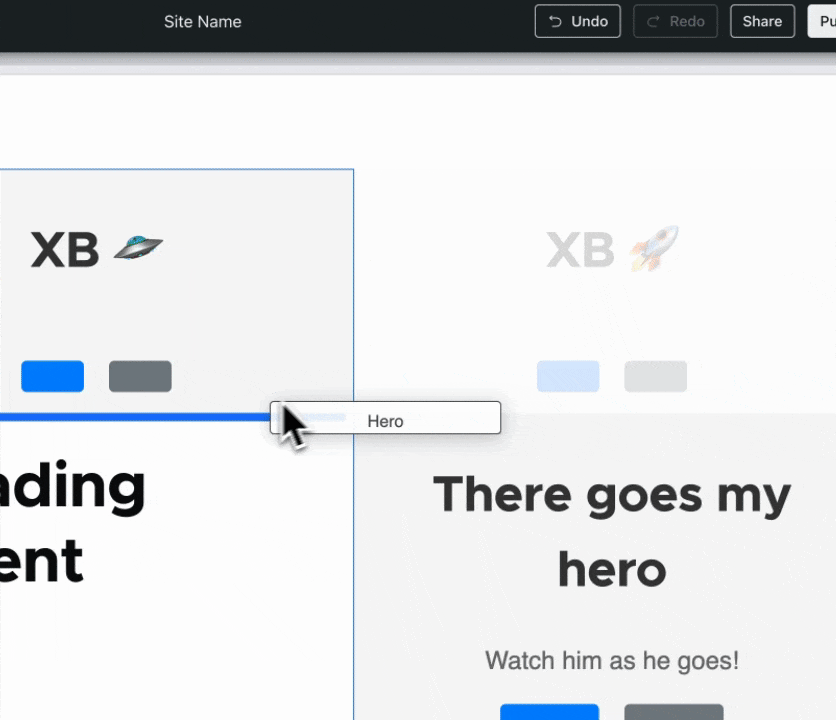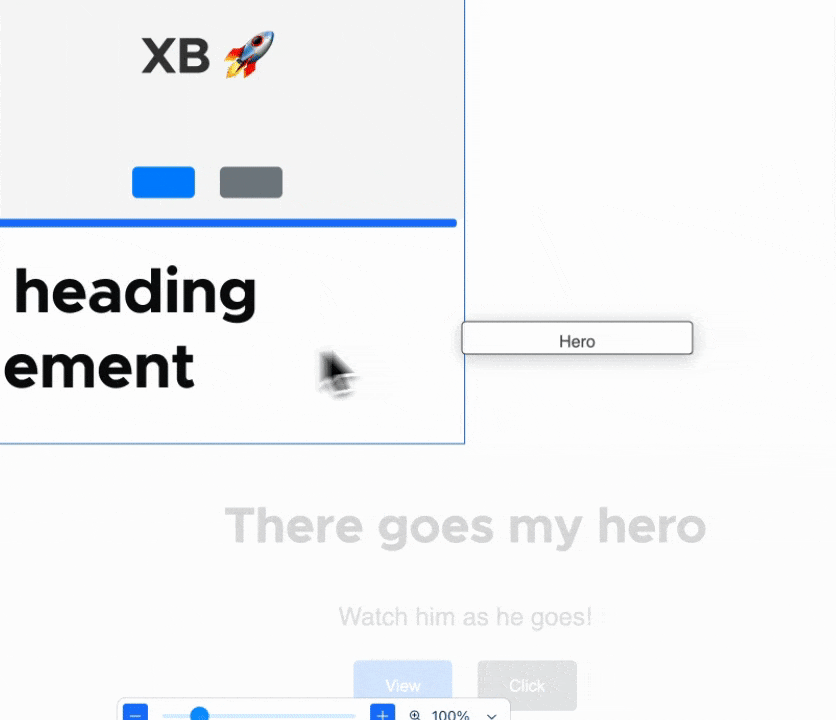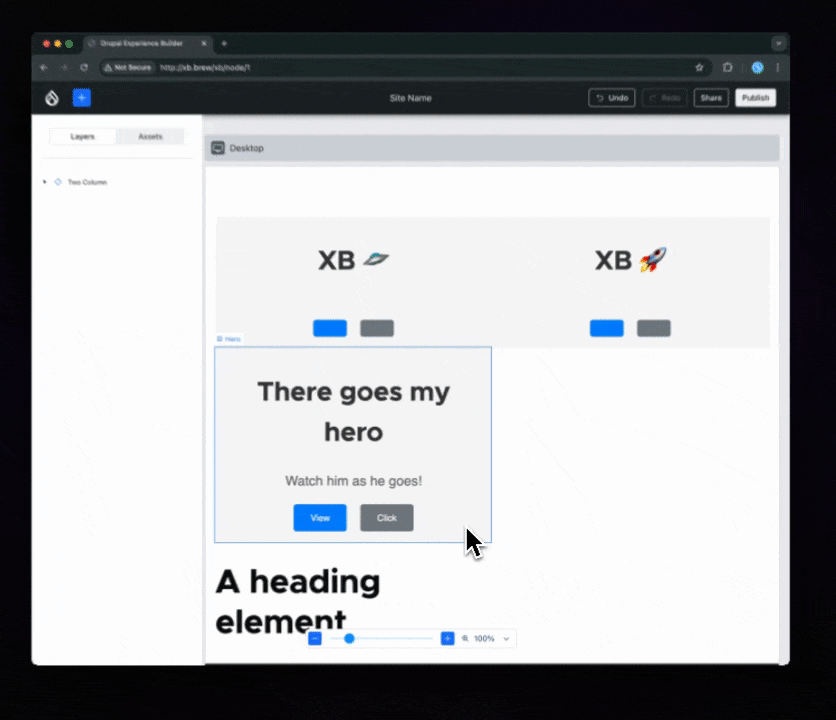
It takes no designer or expert user to observe that in the above images, the drag-and-drop UX and visualization can be improved. The Figma designs do not have an answer for this. But … we have Bálint! :D He thought, tinkered, experimented and gave the Drupal ecosystem this delightful UX:
A blue line now precedes the ghost while dragging, which conveys both the current position and the target position upon dropping.{kind=link}
Issue #3470973, image by Bálint.
… which subsequently enabled him together with danielveza and Jesse to also highlight the slot that a component is about to be placed in:
The precise destination of a component is has a thick blue line, the containing slot gets a thin outline.{kind=link}
Issue #3469822, image by Bálint.
If that isn’t an epic leap forward on the front end, then I don’t know what is! :D On so many fronts, dragging and dropping components became not only more usable, but also enjoyable.
It doesn’t end there, though:
- Utkarsh “utkarsh_33” updated the styling of text inputs, boolean toggle, etc to match the designs, by mapping more form elements to XB’s React components using the semi-coupled theme engine that Ben introduced in week 10
- Utkarsh, fazilitehreem and Jesse made deleting component instances more intuitive: you can delete the selected one using the keyboard now
- fazilitehreem, Utkarsh and Jesse added right-click support to the selected component
- Jesse fixed a crucial bug that prevented slots in freshly dropped components from working
Missed a prior week? See all posts tagged Experience Builder.
Goal: make it possible to follow high-level progress by reading ~5 minutes/week. I hope this empowers more people to contribute when their unique skills can best be put to use!
For more detail, join the #experience-builder Slack channel. Check out the pinned items at the top!
Back endComparatively, the back end progress this week was very non-visual… with one exception: Ted “tedbow” Bowman and I fixed the visually broken “image” components — this was caused by the buggy PoC code I wrote 14 weeks ago — finally this rose to the top of the priorities!
Images now render as expected in Experience Builder. Compare and contrast with the Media Library image above :){kind=link}
Issue #3469436, image by me.
Feliksas “f.mazeikis” Mazeikis and I discovered a critical bug in the auto-generated Component config entities for Single-Directory Components (SDCs) meeting the criteria: the field type and widget for optional props were missing. How could this happen? Because we’ve been racing ahead to make functionality exist, without the foundations being sufficiently thoroughly checked: the Component config entity’s schema is littered with @todos for adding more validation constraints. One of those would’ve prevented this problem … so we fixed not only the problem at hand, but also ensured that it could never reoccur, by introducing a KeyForEverySdcProp validation constraint first, and then fixing the auto-generation logic.
Dave “longwave” Long, Lee “larowlan” Rowlands and Deepak “deepakkm” Mishra updated XB to declare a runtime rather than development dependency on justinrainbow/json-schema — this is what the SDC subsystem uses to validate that the provided props values are considered acceptable by an SDC, and that’s why XB uses it to validate an XB field is valid (i.e. every SDC in the component tree must be renderable and hence trigger no exceptions for provided SDC props values). So that should’ve been marked as an explicit dependency months ago, but we didn’t spot that. Easy enough!
However … Lee pointed out that this is actually unacceptable for Drupal sites that use JSON:API in production, because it causes automatic validation for every JSON:API response against the JSON:API spec if assertions are enabled. That results in a significant performance regression. That being said, having assertions enabled is also a violation of Drupal best practices (and PHP best practices). Still, Drupal should help users even when they ignore/are unaware of best practices, so the XB module warns on the status report when best practices are violated. A core issue was created to improve this upstream: #3472008.
What a week! :D
Week 17 was September 2–8, 2024.
-
For now, that Media Library dialog looks rather stark, because it is, well … using the Stark theme. We plan to load the Claro/Gin styles, but to ensure style isolation, that requires some non-trivial <iframe> shenanigans in #3471978 to avoid loading that CSS/JS in the context of the XB React app. ↩︎
- The new "layers" panel, which also allows moving components.
- Using an image from the Media Library.
- The sole "section" available right now: one that contains two predefined hero components.
- A blue line now precedes the ghost while dragging, which conveys both the current position and the target position upon dropping
- The precise destination of a component is has a thick blue line, the containing slot gets a thin outline.
- Images now render as expected in Experience Builder.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Real Python: Python 3.13 Preview: Free Threading and a JIT Compiler
Although the final release of Python 3.13 is scheduled for October 2024, you can download and install a preview version today to explore the new features. Notably, the introduction of free threading and a just-in-time (JIT) compiler are among the most exciting enhancements, both designed to give your code a significant performance boost.
In this tutorial, you’ll:
- Compile a custom Python build from source using Docker
- Disable the Global Interpreter Lock (GIL) in Python
- Enable the Just-In-Time (JIT) compiler for Python code
- Determine the availability of new features at runtime
- Assess the performance improvements in Python 3.13
- Make a C extension module targeting Python’s new ABI
Check out what’s new in the Python changelog for a complete list of the upcoming features and improvements. This document contains a quick summary of the release highlights as well as a detailed breakdown of the planned changes.
To download the sample code and other resources accompanying this tutorial, click the link below:
Get Your Code: Click here to download the free sample code that shows you how to work with the experimental free threading and JIT compiler in Python 3.13.
Take the Quiz: Test your knowledge with our interactive “Python 3.13: Free-Threading and a JIT Compiler” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Python 3.13: Free-Threading and a JIT CompilerIn this quiz, you'll test your understanding of the new features in Python 3.13. You'll revisit how to compile a custom Python build, disable the Global Interpreter Lock (GIL), enable the Just-In-Time (JIT) compiler, and more.
Free Threading and JIT in Python 3.13: What’s the Fuss?Before going any further, it’s important to note that the majority of improvements in Python 3.13 will remain invisible to the average Joe. This includes free threading (PEP 703) and the JIT compiler (PEP 744), which have already sparked a lot of excitement in the Python community.
Keep in mind that they’re both experimental features aimed at power users, who must take extra steps to enable them at Python’s build time. None of the official channels will distribute Python 3.13 with these additional features enabled by default. This is to maintain backward compatibility and to prevent potential glitches, which should be expected.
Note: Don’t try to use Python 3.13 with the experimental features in a production environment! It may cause unexpected problems, and the Python Steering Council reserves the right to remove these features entirely from future Python releases if they prove to be unstable. Treat them as an experiment to gather real-world data.
In this section, you’ll get a birds-eye view of these experimental features so you can set the right expectations. You’ll find detailed explanations on how to enable them and evaluate their impact on Python’s performance in the remainder of this tutorial.
Free Threading Makes the GIL OptionalFree threading is an attempt to remove the Global Interpreter Lock (GIL) from CPython, which has traditionally been the biggest obstacle to achieving thread-based parallelism when performing CPU-bound tasks. In short, the GIL allows only one thread of execution to run at any given time, regardless of how many cores your CPU is equipped with. This prevents Python from leveraging the available computing power effectively.
There have been many attempts in the past to bypass the GIL in Python, each with varying levels of success. You can read about these attempts in the tutorial on bypassing the GIL. While previous attempts were made by third parties, this is the first time that the core Python development team has taken similar steps with the permission of the steering council, even if some reservations remain.
Note: Python 3.12 approached the GIL obstacle from a different angle by allowing the individual subinterpreters to have their independent GILs. This can improve Python’s concurrency by letting you run different tasks in parallel, but without the ability to share data cheaply between them due to isolated memory spaces. In Python 3.13, you’ll be able to combine subinterpreters with free threading.
The removal of the GIL would have significant implications for the Python interpreter itself and especially for the large body of third-party code that relies on it. Because free threading essentially breaks backward compatibility, the long-term plan for its implementation is as follows:
- Experimental: Free threading is introduced as an experimental feature and isn’t a part of the official Python distribution. You must make a custom Python build to disable the GIL.
- Enabled: The GIL becomes optional in the official Python distribution but remains enabled by default to allow for a transition period.
- Disabled: The GIL is disabled by default, but you can still enable it if needed for compatibility reasons.
There are no plans to completely remove the GIL from the official Python distribution at the moment, as that would cause significant disruption to legacy codebases and libraries. Note that the steps outlined above are just a proposal subject to change. Also, free threading may not pan out at all if it makes single-threaded Python run slower than without it.
Until the GIL becomes optional in the official Python distribution, which may take a few more years, the Python development team will maintain two incompatible interpreter versions. The vanilla Python build won’t support free threading, while the special free-threaded flavor will have a slightly different Application Binary Interface (ABI) tagged with the letter “t” for threading.
This means that C extension modules built for stock Python won’t be compatible with the free-threaded version and the other way around. Maintainers of those external modules will be expected to distribute two packages with each release. If you’re one of them, and you use the Python/C API, then you’ll learn how to target CPython’s new ABI in the final section of this tutorial.
JIT Compiles Python to Machine CodeAs an interpreted language, Python takes your high-level code and executes it on the fly without the need for prior compilation. This has both pros and cons. Some of the biggest advantages of interpreted languages include better portability across different hardware architectures and a quick development time due to the lack of a compilation step. At the same time, interpretation is much slower than directly executing code native to your machine.
Note: To be more precise, Python interprets bytecode instructions, an intermediate binary representation between pure Python and machine code. The Python interpreter compiles your code to bytecode when you import a module and stores the resulting bytecode in the __pycache__ folder. This doesn’t inherently make your Python scripts run faster, but loading a pre-processed bytecode can indeed speed up their startup time.
Languages like C and C++ leverage Ahead-of-Time (AOT) compilation to translate your high-level code into machine code before you ship your software. The benefit of this is faster execution since the code is already in the computer’s mother tongue. While you no longer need a separate program to interpret the code, you must compile it separately for all target platforms that you want supported. You should also handle platform-specific differences yourself.
Read the full article at https://realpython.com/python313-free-threading-jit/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Tag1 Consulting: Migrating Your Data from D7 to D10:Migrating view modes and field groups
Today, we're building on our previous work with field widget settings. We will cover migrating view modes, a prerequisite for migrating field groups and field formatter settings. We’ll then walk through migrating field groups. Field formatter settings will be addressed in our next article.
Read more mauricio Wed, 09/18/2024 - 05:36Jamie McClelland: Gmail vs Tor vs Privacy
A legit email went to spam. Here are the redacted, relevant headers:
[redacted] X-Spam-Flag: YES X-Spam-Level: ****** X-Spam-Status: Yes, score=6.3 required=5.0 tests=DKIM_SIGNED,DKIM_VALID, [redacted] * 1.0 RCVD_IN_XBL RBL: Received via a relay in Spamhaus XBL * [185.220.101.64 listed in xxxxxxxxxxxxx.zen.dq.spamhaus.net] * 3.0 RCVD_IN_SBL_CSS Received via a relay in Spamhaus SBL-CSS * 2.5 RCVD_IN_AUTHBL Received via a relay in Spamhaus AuthBL * 0.0 RCVD_IN_PBL Received via a relay in Spamhaus PBL [redacted] [very first received line follows...] Received: from [10.137.0.13] ([185.220.101.64]) by smtp.gmail.com with ESMTPSA id ffacd0b85a97d-378956d2ee6sm12487760f8f.83.2024.09.11.15.05.52 for <xxxxx@mayfirst.org> (version=TLS1_3 cipher=TLS_AES_128_GCM_SHA256 bits=128/128); Wed, 11 Sep 2024 15:05:53 -0700 (PDT)At first I though a Gmail IP address was listed in spamhaus - I even opened a ticket. But then I realized it wasn’t the last hop that Spamaus is complaining about, it’s the first hop, specifically the ip 185.220.101.64 which appears to be a Tor exit node.
The sender is using their own client to relay email directly to Gmail. Like any sane person, they don’t trust Gmail to protect their privacy, so they are sending via Tor. But WTF, Gmail is not stripping the sending IP address from the header.
I’m a big fan of harm reduction and have always considered using your own client to relay email with Gmail as a nice way to avoid some of the surveillance tax Google imposes.
However, it seems that if you pursue this option you have two unpleasant choices:
- Embed your IP address in every email message or
- Use Tor and have your email messages go to spam
I supposed you could also use a VPN, but I doubt the IP reputation of most VPN exit nodes are going to be more reliable than Tor.
Drupal Starshot blog: Drupal CMS Update for The Mid September 2024
We are in the middle of September and that means it’s time for our regular update on what’s going on with the Drupal CMS. Let’s check out what’s new!
Documentation
The Drupal Association is on a mission to bring world-class documentation and maintenance software for Drupal CMS launch and beyond. In order to achieve that, we teamed up with Drupalize.me. Our common goal is to make sure that by the time when Drupal CMS hits the market we have an easy to follow user guide suitable for our target audience. Also we prepared an announcement that will be revealed at DrupalCon Barcelona. Stay tuned for the details!
Contact Form
We are happy to announce that we found a track lead for the Contact form! J. Hogue from Oomph joined the team very recently but has already managed to show progress: he and his team are getting busy with the research and MVP mapping. It’s great to have you with us!
Blog
As per the most recent update from Laurens Van Damme and his team, The MVP version has been set up and now the team is busy with the research on how to align with Drupal CMS standards.
Events
While Martin Anderson-Clutz and his team are considering expanding functionality with the options that will not be applied by default, they are working on a different calendar solution that would have more community support, as well as UX improvement for the date widget. We can’t wait to see the result of their work!
Data Privacy / Compliance
Jürgen Haas tells us that information research and framing the scope of the track has been completed and the team agreed on the documentation. Therefore, the following 3 action items has been set as immediate next priorities:
-
continue documentation
-
break down existing feature list into deliverables/recipes and prioritise them
-
define components for the "Compliance Audit" module as an additional deliverable
Trial experience for Starshot
Some exciting news is coming from Matt Glaman: the trial now displays an interactive installer of Drupal CMS. Meanwhile, the work on styling so the trial would look like the Drupal CMS installer while it is being set up, is full steam on.
Dashboard
The team, lead by Christian López Espínola and Matthew Tift has got the wireframes they can rely on hence now it’s time to get things rolling! They are busy looking deeper into the Gin theme, in particular - config actions for adding blocks to the dashboards from other recipes. There is a decision to be made on whether the right sidebar should consist of shortcuts or individual blocks. At the same time, planning for the upcoming activities is in progress and we are waiting patiently to see more details on what’s ahead.
SEO
Great news from Jim Birch and John Doyle with the SEO track team: Basic and Advanced SEO Recipes have been committed to the repository. Next priority is to continue the iteration process on the recipes, documentation, and guidelines for other tracks.
Content Publishing Workflows
We are most excited to announce that we’ve got one more valuable addition to the team - Mohammed Razem from Vardot is joining the Drupal CMS crew as a track lead of the Content Publishing Workflows track. Welcome on board!
Advanced Search
The 1xINTERNET team has been busy finalising the first version of the concept. The next target for them is to get insights from the survey asking Drupalers what they prefer to use in order to confirm earlier findings from the specification.
Media Management
Tony Barker informs that the Media Track team is researching the features of content management systems identified in the Strategy document as well as working through the information and ideas from the earlier released questionnaire. They keep experimenting with modules and configuration to make necessary choices, with the focus on features that can make it into early recipes over the coming weeks.
Accessibility Tools
From Gareth Alexander we learn the following: as the discovery process and gathering insight on common practices has been finalised, the team has published a survey and is now busy reviewing the results. As review of the current module availability has been completed the list has been simmered down to the ones now being reviewed for feasibility.
This will lead to a proposal for the features and recipes for Accessibility Tools to be considered for inclusion in early versions of Drupal CMS.
Proposal creation is underway and the next steps are being generated.
Analytics
Dharizza Espinach meanwhile shares that the team has finished the market research, and is currently wrapping up the work on a comparison with other tools. The selected tools are to be included in the recipes. Another objective the track team is busy with is preparing the list of recommendations for features that should be included later in the project. The proposal document is underway and iterating over a first version of the basic recipe will be the next step.
AI
Jamie Abrahams is working on something very special that will be released during DrupalCon Barcelona. So I will keep the intrigue and will allow you to discover the details for yourself in just 1 week!
New Track Announcement!
As we make progress with the already defined deliverables, we keep discovering the missing parts of the puzzle. In order to close those gaps, we are excited to announce 2 new tracks we not only set up but managed to get staffed as well:
-
NavigationMatthew Oliveira, Pablo López Escobés from Lullabot. >
-
Gin admin theme track - Known by many, a long time maintainer of the Gin, Sascha Eggenberger became track lead for this milestone.
Our heartfelt welcome to all of the newly acquired Drupal CMS track leads - we are excited to have you and looking forward to all the expertise you are bringing along!
I truly hope you find the news outlined above as exciting as we do and look forward to sharing even more at DrupalCon Barcelona. So if you somehow didn’t get your ticket yet - better hurry up!
Django Weblog: Last call for DjangoCon US 2024 tickets!
DjangoCon US starts next week in Durham, NC on September 22nd!
If you aren't able to join in person, please consider purchasing an online ticket: https://ti.to/defna/djangocon-us-2024
The conference is full of a variety of talks with excellent keynote speakers! It's shaping up to be an event you'll want to experience live.
If you'd like to learn more about DjangoCon US visit them at their website or reach out to them at hello@djangocon.us.
Qt for MCUs 2.8.1 LTS released
Qt for MCUs 2.8.1 LTS (Long-Term Support) has been released and is available for download. This first patch release provides bug fixes and other improvements while maintaining source compatibility with Qt for MCUs 2.8. It does not add any new functionality.
LN Webworks: How To Render A Custom Form In Drupal Block
Blocks are basically content containers that are showcased in distinct sections of a website including social sharing buttons, “Who’s online” sections, recently viewed content, and social media feeds. Custom Blocks that are available through GUI operate similarly to node entities. In this guide, you will get a concise overview of their implementations, but primarily focusing on custom blocks developed through the creation of a custom module in Drupal development services.
Step-by-Step Guide To Displaying Custom Forms In Drupal Blocks Step 1: Create a Custom ModuleCreate a directory first by using the following command: =>
mkdir modules/custom/mymodule
Create the Necessary Files
Within the modules/custom/mymodule directory, create the following files:
mymodule.info.yml
src/Plugin/block/CistomBlock.php
src/Form/MyCustomForm.php
Ensure that these files are properly structured to fit the requirements of your module.
1. mymodule.info.yml
Oliver Davies' daily list: De-jargoning Drupal
This week, I learned there is a Drupalisms Working Group - a group focused on de-jargoning Drupal and making it easier for newcomers to Drupal by removing some of the Drupal-specific language.
From the introductory blog post:
If you’re familiar with Drupal, you will have learned its language. You will be familiar with words like Views, Blocks and Paragraphs, and you will appreciate their respective features and functions. But for those new to Drupal, getting to grips with what words mean can mean a steep learning curve.
Drupalisms is something I've discussed on a few episodes of Beyond Blocks, including the most recent episode and the seonc with Eirik Morland.
I didn't realise there were BoF sessions about this at DrupalCon Lille last year, so I'm hoping there will be more next week in Barcelona.
Anything that helps Drupal easier to use and adopt is a good thing.
Spyder IDE: Scientific IDE UX Birds of a Feather session at SciPy 2024
My First Akademy Adventure
This year was my first Akademy, and I was thrilled to be able to attend in person. Even better, some veterans said it was the best Akademy so far. It was great to see some people I had met in April and to meet new people. I arrived on Friday, 6th Sept and left the following Friday. I very much enjoyed staying in the lovely town of Würzburg and doing a day tour of Rothenberg. Now that I've caught up on sleep (the jet lag, it is real), it's time to write about it.
As described in the Akademy 2024 report, the focus this year was resetting priorities, refocusing goals and reorganizing projects. Since I had recently become a more active contributor to KDE, I was keen to learn about the direction things will take over the next year. It was also exciting to see the new design direction in Union and Plasma Next!
A Personal NoteSpeaking of goals, a personal one I've striven toward in my career is to contribute to something that improves the world, even if indirectly. It's not something I've always been able to do. It feels good to be able to work with a project that is open source, and is working to make the computing world more sustainable.
I'd also like to recognize all the wonderful, welcoming folks that make Akademy such a great conference. I've been to a few other tech conferences and events, with varying atmospheres and attitudes. I can say that people at Akademy are so helpful, and so nice - it made being among a lot of new faces in a foreign country a truly great experience.
The ConferenceThe keynote had powerful information about the impacts of improper tech disposal and what we can do to improve the situation. This highlighted the importance of the KDE Eco project, which aims to help to reduce e-waste and make our projects more sustainable. Their new Opt Green initiative is going to take concrete steps toward this.
Some of the talks I attended:
- KDE Goals - one talk about the last 2 years of goals and another revealing the new goals.
- "Adapt or Die" - how containerized packaging affects KDE projects.
- Union and styling in KDE's future.
- Banana OS KDE Linux - why it's being developed and some technical planning.
- Getting Them Early: Teaching Pupils About The Environmental Benefits Of FOSS
This strategy has been powerful for other projects (like Microsoft Windows,
Google Chromebooks, Java), so I'm glad to see it for KDE.
- Why and how to use KDE frameworks in non-KDE apps
- KDE Apps Initiative
- Cutting Gordian's "End-User Focus" vs. "Privacy" Knot - collecting useful user data while respecting privacy and security.
- Plasma Next - Visual Design Evolution for Plasma
- The Road to KDE Neon Core
Some of the BoF sessions I attended:
- Decentralizing KUserFeedback
- Streamlined Application Development Experience
- Organizing the Plasma team, Plasma goals
- Plasma "Next" initiative
- Union: The future of styling in KDE
- KWallet modern replacement
- Video tutorial for BoF best practice (Kieryn roped me into this one)
- Security Team BoF Notes
Thanks to everyone who made this year's Akademy such a wonderful experience. If anyone out there is thinking of attending next year, and can make it, I really recommend it. I'm hoping to be at Akademy 2025!
Power, input & people at Akademy 2024
Contrary to popular belief, Akademy 2024 was not my first Akademy. KDE seems to keep tagged faces from Akademy group photos around, so I stumbled over some vintage pictures of me in 2006 (Glasgow) and 2007 (Dublin). At the time, I was an utter greenhorn with big dreams, vague plans, and a fair bit of social anxiety.
And then I disappeared for 15 years, but now it's time for a new shot. This time around, I'm a little less green (rather starting to grey a little) and had a surprising amount of stuff to discuss with various KDE collaborators. Boy, is there no end of interesting people and discussion topics to be had at Akademy.
"Oh, you're the PowerDevil guy"You're not wrong, I've been contributing to that for the past year. As such, one highlight for me was to meet KDE's hardware integration contractor Natalie Clarius in person and sync up on all things power-related.
Natalie presented a short talk and hosted a BoF session ("Birds of a Feather", a.k.a. workshop) about power management topics. We had a good crowd of developers in attendance, clearing up the direction of several outstanding items.
Power management in Plasma desktops is in decent shape overall. One of the bigger remaining topics is (re)storing battery charge limits across reboots, for laptops whose firmware doesn't remember those settings. There is a way forward that involves making use of the cross-desktop UPower service and its new charge limit extensions. This will give us the restoring feature for free, but we have to add some extra functionality to make sure that charge threshold customization remains possible for Plasma users after switching over.
We also looked at ways to put systems back to sleep that weren't supposed to wake up yet. Unintended wake-ups can happen e.g. when the laptop in your backpack catches a key press from the screen when it's squeezed against the keyboard. Or when one of those (conceptually neat) "Modern Standby" implementations on recent laptops are buggy. This will need a little more investigation, but we've got some ideas.
I talked to Bhushan Shah about power saving optimizations in Plasma Mobile. He is investigating a Linux kernel feature designed for mobile devices that saves power more aggressively, but needs support from KDE's power management infrastructure to make sure the phone will indeed wake up when it's meant to. If this can be integrated with KDE's power management service, we could improve battery runtimes for mobile devices and perhaps even for some laptops.
The friendly people from Slimbook dropped by to show off their range of Linux laptops, and unveiled their new Slimbook VI with KDE neon right there at the conference. Compared to some of their older laptops, build quality is improved leaps and bounds. Natalie and I grilled their BIOS engineer on topics such as power profiles, power consumption, and how to get each of their function keys show the corresponding OSD popup.
"I'm excited that your input goal was chosen"
Every two years, the KDE community picks three "Goals" to rally around until the next vote happens. This time, contributors were asked to form teams of "goal champions" so that the work of educating and rallying people does not fall on the shoulders of a single poor soul per goal.
So now we have eight poor souls who pledge to advance a total of three focus areas over the next two years. Supported by KDE e.V.'s new Goals Coordinator, Farid. There's a common thread around attracting developers, with Nicolas Fella and Nate Graham pushing for a "Streamlined Application Development Experience" and the KDE Promo team with a systematic recruitment initiative titled "KDE Needs You". And then there's this other thing, with a strict end user focus, briefly introduced on stage by guess who?
Turns out a lot of people in KDE are passionate about support for input devices, virtual keyboards and input methods. Gernot Schiller (a.k.a. duha) realized this and assembled a team consisting of himself, Joshua Goins (a.k.a. redstrate) as well as Yours Truly to apply as champions. The goal proposed that "We care about your Input" and the community's response is Yes, Yes We Do.
As soon as the new goals were announced, Akademy 2024 turned into an Input Goal Akademy for me. In addition to presenting the new goal on stage briefly, we also gathered in a BoF session to discuss the current state, future plans and enthusiastic volunteering assignments related to all things input. I also sat down with a number of input experts to learn more about everything. There is still much more I need to learn.
It's a sprawling topic with numerous tasks that we want to get done, ranging from multi-month projects to fixing lots of low-hanging fruit. This calls for a series of dedicated blog posts, so I'll go into more detail later.
Join us at #kde-input:kde.org on Matrix or watch this space (and Planet KDE in general) for further posts on what's going on with input handling in KDE.
Look at the brightness sideKWin hacker extraordinaire Xaver Hugl (a.k.a. zamundaaa) demoed some of his color magic on a standard SDR laptop display. Future KWin can play bright HDR videos in front of regular SDR desktop content. Accurate color transformations for both parts without special HDR hardware, that's pretty impressive. I thought that HDR needs dedicated hardware support, turns out I'm wrong, although better contrast and more brightness can still improve the experience.
I also got to talk to Xaver about touchpad gestures, learned about stalled attempts to support DDC/CI in the Linux kernel directly, and pestered him for a review to improve Plasma's D-Bus API for the new per-monitor brightness features. Also the XDC conference in Montreal, is happening in less than a month, featuring more of Xaver as well as loads of low-level graphics topics. Perhaps even input-related stuff. It's only a train ride from Toronto, maybe I'll drop by. Maybe not. Here's a medieval German town selfie.
Thanks to the entire KWin gang for letting me crash their late-night hacking session and only throwing the last of us out at 2 AM after my D-Bus change got merged. Just in time for the Plasma 6.2 beta. I was dead tired on Thursday, totally worth it though.
Atomic KDE for users & developersPlasma undoubtedly has some challenges ahead in order to bring all of its power and flexibility to an image-based, atomic OS with sandboxed apps (i.e. Flatpak/Snap). David Edmundson's talk emphasized that traditional plugins are not compatible with this new reality. We'll need to look into other ways of extending apps.
The good news is that lots of work is indeed happening to prepare KDE for this future. Baloo making use of thumbnailer binaries in addition to thumbnailer plugins. KRunner allowing D-Bus plugins in addition to shared libraries. Arjen Hiemstra's work-in-progress Union style being customizable through configuration rather than code. Heck, we even learned about a project called KDE Neon Core trying to make a Snap out of each and every piece of KDE software.
Going forward, it seems that there will be a more distinct line between Plasma as a desktop platform and KDE apps, communicating with each other through standardized extension points.
All of this infrastructure will come in handy if Harald Sitter's experimental atomic OS, KDE Linux (working title), is to become a success. Personally, I've long been hoping for a KDE-based system that I can recommend to my less technical family members. KDE Linux could eventually be that. Yes, Fedora Kinoite is also great.
What took me by surprise about Harald's presentation was that it could be great even as a development platform for contributing to the Plasma desktop itself.
As a desktop developer, I simply can't run my Plasma development build in a container. Many functions interact with actual hardware so it needs to run right on the metal. On my current Arch system, I use a secondary user account with Plasma installed into that user's home directory. That way the system packages aren't getting modified - one does not want to mess with system packages.
But KDE Linux images contain the same system-wide build that I would make for myself. I can build an exact replacement with standard KDE tooling, perhaps a slight bit newer, and temporarily use it as system-wide replacement using systemd-sysext. I can revert whenever. KDE Linux includes all the development header files too, making it possible to build and replace just a single system component without building all the rest of KDE.
Different editions make it suitable for users anywhere between tested/stable (for family members) and bleeding edge (for myself as Plasma developer). Heck, perhaps we'll even be able to switch back and forth between different editions with little effort.
Needless to say, I'm really excited about the potential of KDE Linux. Even without considering how much work it can save for distro maintainers that won't have to combine outdated Ubuntu LTS packages with the latest KDE desktop.
ConclusionThere's so much else I've barely even touched on, like NLnet funding opportunities, quizzing Neal Gompa about KDE for Enterprise, Rust and Python binding efforts, Nicolas Fella being literally everywhere, Qt Contributor Summit, finding myself in a hostel room together with fellow KDE devs Carl & Kåre. But this blog post is already long enough. Read some of the other KDE blogs for more Akademy reports.
Getting home took all day and jet lag isn't fun, but I've reasonably recovered to give another shot at bringing KDE software to the masses. You can too! Get involved, donate to KDE, or simply enjoy the ride and discuss this post on KDE Discuss.
Or don't. It's all good :)
Benjamin Mako Hill: My Chair
I realize that because I have several chairs, the phrase “my chair” is ambiguous. To reduce confusion, I will refer to the head of my academic department as “my office chair” going forward.
Horizontal Digital Blog: Why you shouldn't upgrade from Drupal 7
PyCoder’s Weekly: Issue #647 (Sept. 17, 2024)
#647 – SEPTEMBER 17, 2024
View in Browser »
This tutorial teaches you how to use the where() function to select elements from your NumPy arrays based on a condition. You’ll learn how to perform various operations on those elements and even replace them with elements from a separate array or arrays.
REAL PYTHON
In data science you’ll sometimes hear a debate between R and Python. Cosima says ‘why not choose both?’ She outlines a data pipeline that uses the best tool for each job.
COSIMA MEYER
Build AI apps that understand speech with insanely accurate speech-to-text models. Sign up for a free account and get $50 in credits to try AssemblyAI’s speech recognition models →
ASSEMBLY AI sponsor
Learn about the differences between Requests, HTTPX, and AIOHTTP, and when to use each library for your Python projects.
GEORGES HAIDAR
In this quiz, you’ll test your understanding of generating images with DALL·E by OpenAI using Python. You’ll revisit concepts such as using the OpenAI Python library, making API calls for image generation, creating images from text prompts, and converting Base64 strings to PNG image files.
REAL PYTHON
In this quiz, you’ll test your understanding of the Python Walrus Operator. This operator was introduced in Python 3.8, and understanding it can help you write more concise and efficient code.
REAL PYTHON
Over the last few months there has been a lot of back and forth in the Python community, especially on the forums, around changes to bylaws and how the Code of Conduct is enforced. This article covers the history and context of the events.
JAKE EDGE
Django’s SECRET_KEY setting is used for cryptographic signing in various places, such as for session storage and password reset tokens. If you need to rotate it you can allow read-only use of the old key to smooth the transition.
ADAM JOHNSON
Tired of tediously send files and trying to use general-purpose collaboration tools? Posit Connect makes it easy to share, collaborate, and get feedback on your data science work including Jupyter notebooks, Plotly dashboards, Streamlit, Quarto, Shiny or other interactive analytics applications →
POSIT sponsor
Armin has played around with enabling multiple versions of a library to be installed for the same instance of Python in the past, and recent feature additions to uv are making it come closer to fruition.
ARMIN RONACHER
“When we received feedback our Notebooks UI was taking too long too load, our engineers dove into ways to improve the developer experience — bringing some load times from 30 seconds down to less than one.”
LUIS NEVES
In this video course, you’ll learn the difference between the string representations returned by .__repr__() vs .__str__() and understand how to use them effectively in classes that you define.
REAL PYTHON course
The Python Bytes podcast just delivered show #400. This is a huge accomplishment. This episode celebrates the achievement, and also covers: Python 3.13RC, Docker with uv, the humanize project, and more.
PYTHON BYTES podcast
The pretty print module (pprint) provides more readable output for complex data structures and this post shows you how to use the library and what you can get out of it.
JUHA-MATTI SANTALA
Make mastering Python your mission: This mix of online courses, books, exercises, and productivity tools is here to help you succeed—whether you’re a beginner or a skilled Python pro. Support Girls Who Code and get Python books, software, and video courses collectively valued at $1,882 for a pay-what-you-want price →
HUMBLEBUNDLE.COM sponsor
Will has recently switched from using a variety of packaging tools to just using uv. This post is a summary of what needed to change when going from pyenv to uv.
WILL KAHN-GREENE
There is a deep conversation going on about the longevity of uv on Mastodon and for those not on the platform, Simon has summarized it.
SIMON WILLISON
This post talks about why you might want to include information in your code comments about why you didn’t take a particular approach.
HILLEL WAYNE
This article describes how to build a secure, fast to build, and lightweight Docker image for your Poetry-based project
CODEMAGEDDON • Shared by Sergey
Glyph explains just what a Framework is on macOS and why CPython on macOS should be built that way.
GLYPH LEFKOWITZ
GITHUB.COM/MATTEOGUADRINI • Shared by Matteo Guadrini
pocketpy: Portable Python 3.x Interpreter in Modern C graphiti: Build Dynamic, Temporally-Aware Knowledge Graphs picows: Ultra-Fast Websocket Client and Server for Asyncio django-cotton: Component Based Design to Django Templates Events PyData Amsterdam 2024 September 18 to September 21, 2024
PYDATA.ORG
September 18, 2024
REALPYTHON.COM
September 20 to September 24, 2024
PYCON.ORG
September 21 to September 23, 2024
PYCON.ORG
September 22 to September 27, 2024
DJANGOCON.US
September 23 to September 24, 2024
PYBAY.ORG
September 24 to September 29, 2024
PYCON.ORG
September 25 to September 27, 2024
PYDATA.ORG
September 27 to September 30, 2024
PYCON.JP
September 27 to September 29, 2024
PYTHONNORTE.ORG
September 28 to September 30, 2024
PYCON.ORG
Happy Pythoning!
This was PyCoder’s Weekly Issue #647.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
David Manset: Voices of the Open Source AI Definition
The Open Source Initiative (OSI) is running a blog series to introduce some of the people who have been actively involved in the Open Source AI Definition (OSAID) co-design process. The co-design methodology allows for the integration of diverging perspectives into one just, cohesive and feasible standard. Support and contribution from a significant and broad group of stakeholders is imperative to the Open Source process and is proven to bring diverse issues to light, deliver swift outputs and garner community buy-in.
This series features the voices of the volunteers who have helped shape and are shaping the Definition.
Meet David MansetWhat’s your background related to Open Source and AI?
My background in Open Source and AI is shaped by my ongoing experience as the senior coordinator of the Open Source Ecosystem Enabler (OSEE) project at the United Nations International Telecommunication Union (ITU), a project developed in collaboration with the UN Development Program and under the funding of the EU’s Directorate-General for International Partnerships, to support countries developing digital public goods and services using Open Source. In this capacity, a significant part of my work involves driving initiatives related to Open Source for various types of use cases in the public sector.
Witnessing the birth of an Open Source AI definition during the DPGA Annual Members meeting in 2023, I have since then been contributing to the Open Source AI agenda, and more recently to various Open Source AI initiatives within the ITU Open Source Program Office (OSPO). Additionally, I co-lead the Open Source AI for Digital Public Goods (OSAI4DPG) track at AI for Good, focusing on creating AI-driven public goods that are both accessible and affordable.
One of my recent achievements includes co-organizing the AIntuition hackathon aimed at developing cost-effective Open Source AI solutions. This event focused on utilizing Retrieval Augmented Generation (RAG) and Large Language Models (LLMs) to create a basic yet understandable and adaptable prototype implementation for public administration. My efforts in this area highlight my commitment to practical and usable AI tools that meet public sector needs.
Prior to my role at ITU, I worked in the private sector, where I developed AI services that enhanced healthcare services and protected patients/citizens. This experience gives me a well-rounded perspective on implementing and scaling Open Source AI technologies for public benefit.
What motivated you to join this co-design process to define Open Source AI?
My motivation to participate in this co-design process for defining Open Source AI is deeply rooted in my former experiences in software development and as the coordinator of the OSEE project, where my focus lies in enhancing digital public services and developing digital public goods. Open Source AI indeed presents a unique opportunity, especially for the public sector, to adopt cost-effective and scalable solutions that can significantly improve public services. However, to harness these benefits, it is imperative to establish a clear, standardized and consensual definition of Open Source AI. This definition will serve as a foundational guideline, ensuring transparency and understanding of the specific types of AI technologies being developed and implemented.
Moreover, my involvement is driven by the critical work of the ITU OSPO, particularly in developing Open Source AI solutions tailored for low- and middle-income countries (LMICs). These regions often face challenges such as scarce resources and limited representation in global AI training processes. By contributing to the development of Open Source AI, I aim to support these countries in accessing affordable and effective AI technologies, thereby promoting greater equity in AI development and utilization. This effort is not just about technology but also about fostering global inclusivity and ensuring that the benefits of AI are accessible to all.
Why do you think AI should be Open Source?
AI should be Open Source for several compelling reasons, especially when considering its potential impact on global development and governance. First, transparency, traceability and explainability are crucial, particularly in digital public services. Open Source AI allows public scrutiny of the algorithms and models used, ensuring that decision-making processes are transparent and accountable. This is vital for building trust in AI systems, especially in sectors like healthcare, education and public administration, where decisions can significantly impact individuals and communities.
Second, accessibility and affordability are key benefits for LMICs. Open Source AI lowers the barriers to entry, enabling these countries to access cutting-edge technologies without the prohibitive costs associated with proprietary systems. This democratization of AI technology ensures that even resource-constrained nations can harness AI’s transformative potential. Moreover, Open Source AI fosters greater representation and competition for LMICs in the global AI landscape. By contributing to and benefiting from Open Source projects, these countries can influence AI development and ensure that their specific needs and contexts are considered.
Finally, as AI increasingly becomes a foundational technology, Open Source serves as a universal resource that can be adapted and improved by anyone, promoting innovation and inclusivity across the globe.
What new perspectives or ideas did you encounter while participating in the co-design process?
Participating in the co-design process introduced me to several new perspectives and ideas that have deepened my understanding of the role of Open Source AI, particularly in supporting global development. One key insight is the realization that LMICs would significantly benefit from having access to an Open Source AI reference implementation. This concept, which we are actively working on, would provide these countries with a practical, ready-to-use model for AI development, helping them overcome resource constraints and accelerate their AI initiatives.
Another important perspective is that Open Source AI requires solid foundational elements—an Open Source mindset, adherence to best practices, and generalized policies must be embedded across all organizations involved. This is not just about technology; it’s about fostering a culture and infrastructure that supports Open Source principles at every level. Notably, ITU is now coordinating the definition of a common policy framework for United Nations Open Source initiatives, which will be crucial in guiding future Open Source AI developments. This framework will ensure that Open Source AI projects are supported by robust Open Source policies, promoting sustainable and equitable technological advancement worldwide.
What do you think the primary benefit will be once there is a clear definition of Open Source AI?
The primary benefit of a clear definition of Open Source AI will be the establishment of a unified framework that ensures transparency, accessibility, and ethical standards in AI development. This clarity will enable broader adoption across various sectors, particularly in LMICs, by providing a reliable foundation for building and implementing AI technologies. It will also foster global collaboration, ensuring that AI advancements are inclusive and equitable, while promoting innovation through open contributions, ultimately leading to more trustworthy and widely beneficial AI solutions.
What do you think are the next steps for the community involved in Open Source AI?
Once a global standard definition of Open Source AI is established, the Open Source AI community should focus on several key steps to ensure its widespread adoption and effective implementation. These include developing comprehensive guidelines and best practices, creating reference implementations to help organizations, particularly in LMICs, adopt the standard, and enhancing global collaboration through international networks and partnerships. Additionally, launching education and awareness campaigns will be crucial for informing stakeholders about the benefits and practices of Open Source AI. Establishing a governance and compliance framework will help maintain the integrity of AI projects, while supporting policy development and advocacy will ensure alignment with national and international regulations. Finally, fostering innovation and research through funding, hackathons, and collaborative platforms will drive ongoing advancements in Open Source AI. These steps will help build a robust, inclusive, and impactful Open Source AI ecosystem that benefits societies globally.
How to get involvedThe OSAID co-design process is open to everyone interested in collaborating. There are many ways to get involved:
- Join the forum: share your comment on the drafts.
- Leave comment on the latest draft: provide precise feedback on the text of the latest draft.
- Follow the weekly recaps: subscribe to our monthly newsletter and blog to be kept up-to-date.
- Join the town hall meetings: we’re increasing the frequency to weekly meetings where you can learn more, ask questions and share your thoughts.
- Join the workshops and scheduled conferences: meet the OSI and other participants at in-person events around the world.
CTI Digital: Unlock Your Marketing Potential with Drupal 11: An In-Depth Guide
As businesses strive to succeed online, the need for an effective content management system (CMS) becomes paramount. Drupal 11, the latest version of this powerful CMS, is packed with new features and improvements designed to enhance your marketing strategy.
We’re excited to share how these advancements can elevate your marketing efforts and help create exceptional digital experiences for your audience.
The Drop Times: Reimagining the Limits of Possibilities
Dear Readers,
"Imagine a world where creating or cloning any application becomes as simple as issuing a command: "Build me that."
The capabilities of AI are evolving at a fast pace, and the developments that have been brought forth are unprecedented. The recent demonstration of the O1 model by Reuven Cohen is a striking testament to this progress. Imagine taking a complex content management system like Drupal, traditionally built on PHP, and seamlessly transforming it into a JavaScript-based platform—all within an hour. This is precisely what the O1 model has achieved. Reuven tested this revolutionary AI by converting the entire Drupal CMS into Node.js, and the results were nothing short of astounding. The model didn't just convert code; it reimagined and replicated the whole system in a new language, paving the way for revolutionary changes in software development.
By providing the O1 model with a detailed prompt, including Drupal's structure, API, and taxonomy, it generated a complete implementation plan in mere seconds.
"It seamlessly transformed the codebase from PHP to JavaScript,"
Reuven noted, emphasizing how the model made cross-language conversion appear effortless. Once the backend was replicated into what can be called 'Drupal.js,' the process moved on to the front end. Utilizing GPT-Engineer, a UI was designed, wrapping up the entire transformation process in just about an hour.
What makes the O1 model truly exceptional is not just its ability to replicate; it goes beyond to fully clone and transform. The AI didn’t stop at code conversion—it provided a clear specification, built the necessary folder and file structure, and even automated the setup process with a bash script. This is more than a mere glimpse into the future; it is a tangible demonstration of how software development could evolve.
As we stand on the brink of this new era, it's clear that these advancements will redefine our approach to software development and open-source projects like Drupal. With tools like the O1 model, the boundaries of what's possible are expanding, making this an exhilarating time for developers and tech enthusiasts alike.
With that, let's move on to the stories from last week.
In an interview with Kazima Abbas, a Sub-Editor of The DropTimes (TDT), Julian Chabrillon, a seasoned full-stack developer at ES IMAGINACION, shares his inspiration behind Noah's Page Builder and how he developed the tool. With the help of his wife and work partner, Sofía García de Blas, he shaped its visual identity, creating a cohesive and user-friendly experience.
Among other notable stories, The DropTimes conducted a video interview with Piyuesh Kumar, the Director of Technology at QED42. Starting as an intern and with almost 14 years with QED42, he watched Drupal evolve from a basic content management framework into a powerful digital experience platform. Piyuesh also shares excitement about his upcoming sessions at DrupalCon Barcelona, where he’ll explore topics like AI’s role in supporting Digital Experience Platforms (DXP) and the importance of designing with privacy in mind, particularly in the context of GDPR.
Last week, Drupal.org refreshed its website with new fonts, transitioning from the previous fonts, Ubuntu and Ubuntu Sans, to ZT Gatha and Noto Sans. This update improves the platform's visual appeal and usability, reflecting the ongoing effort to modernize its design and user experience.
DrupalCon Barcelona is just a week away, and The DropTimes has published several articles and lists to guide attendees through the event. DrupalCon Barcelona 2024, happening from September 24-27, will feature several sessions focused on the Drupal Starshot Initiative, a project aimed at simplifying Drupal while incorporating advanced technologies like AI, no-code tools, and browser-based development. Take a look at 10 key sessions that will provide valuable insights into Drupal’s next steps.
This year’s event also promises to be an exciting convergence of ideas and innovations, with AI taking center stage in a range of sessions. As AI technologies continue to transform the way we build and interact with digital experiences, DrupalCon Barcelona 2024 will feature 13 AI-focused sessions, offering attendees the chance to dive into the latest advancements and explore how AI can revolutionize the future of web development.
Building on the success of DrupalCon Lille 2023 and continuing the partnership with TerraVerde Sustainability, the DrupalCon Barcelona 2024 organizers remain committed to advancing sustainability initiatives and creating lasting positive change. As DrupalCon Barcelona 2024 embraces a greener future, five key sustainability initiatives highlight the event’s commitment to reducing its environmental impact.
While you are there, the Drupal Association invites attendees of DrupalCon Barcelona 2024 to visit its booth to engage with the team, learn more about their ongoing initiatives, and explore ways to contribute to the community.
Meanwhile, we have published a list of Drupal events happening this week for Drupal enthusiasts to attend. Find the content here.
The FOSSEPS and OSOR projects are conducting a survey to assess interest in forming a European Open Source User Group for public administrations. The initiative seeks input from IT professionals within EU public bodies on the current use and challenges of Free and Open Source Software (FOSS).
Darren Oh has introduced the business model behind Drupal Forge, focusing on sustaining Drupal’s software and infrastructure through vendor contributions. Under this model, vendors can partner with product owners, such as the Drupal Association, by offering product trials via launch buttons integrated into their hosting platforms.
Kevin Quillen has taken up maintainership of the Netlify module for Drupal, a key integration that ensures seamless syncing between Drupal and Netlify. This module enables automatic triggering of builds in Netlify whenever changes are made to Drupal’s content or configuration, allowing headless websites, particularly those built on frameworks like Next.js, to stay current without caching issues.
As a final update, Monarq has developed a new system called Sections & Components to simplify content management in Drupal, enhancing user experience by making the platform more intuitive and flexible. This system enables site administrators to build customized, responsive pages by combining predefined sections and components such as text blocks, images, carousels, and call-to-action buttons.
We acknowledge that there are more stories to share. However, due to selection constraints, we must pause further exploration for now.
To get timely updates, follow us on LinkedIn, Twitter and Facebook. You can also, join us on Drupal Slack at #thedroptimes.
Thank you,
Sincerely
Alka Elizabeth
Sub-editor, The DropTimes.
Python Morsels: Understanding help() in Python
When using Python's help function, have you ever wondered what the various symbols (/, *, [, and ]) mean? Understanding those symbols will help you better understand how to use the functions and classes you're working with.
Table of contents
- What do all the symbols mean in help output?
- Multiple function signatures
- Pay attention to the nouns
- The symbols of help
- Default values: the = symbol
- Unlimited arguments: the * symbol before an argument name
- Keyword-only arguments: a lone * symbol
- Positional-only arguments: a lone / symbol
- Arbitrary keyword arguments: the ** symbol
- Square brackets: optional arguments
- Ellipsis (...) and other weird things
- The conventions of Python's help function
We'll cover what the * and / symbols below mean:
>>> help(sorted) Help on built-in function sorted in module builtins: sorted(iterable, /, *, key=None, reverse=False) Return a new list containing all items from the iterable in ascending order. A custom key function can be supplied to customize the sort order, and the reverse flag can be set to request the result in descending order.We'll also talk about the different formats that help output comes in. For example, note the square brackets in [x] below and note that there are two different styles noted for calling int:
>>> help(int) Help on class int in module builtins: class int(object) | int([x]) -> integer | int(x, base=10) -> integerWe'll start by giving a name to that line which indicates how a function, method, or class is called.
Multiple function signaturesA function signature notes the …
Read the full article: https://www.pythonmorsels.com/understanding-help/Pages
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
- Bounteous.com: Upgrading to Drupal 10 (And Beyond) With Composer
- FSF Blogs: Free software is vital for the public and state-run infrastructure of a free society
- Free software is vital for the public and state-run infrastructure of a free society
- Kdenlive Café in December
- PyPodcats: Episode 7: With Anna Makarudze
FLOSS Research
- Celebrating 5 years at the Open Source Initiative: a journey of growth, challenges, and community engagement
- Highlights from the Digital Public Goods Alliance Annual Members Meeting 2024
- Give Your Input on the State of Open Source Survey
- Open Data and Open Source AI: Charting a course to get more of both
- The Open Source Initiative and the Eclipse Foundation to Collaborate on Shaping Open Source AI (OSAI) Public Policy