
Planet Python
Julien Tayon: PySimpleGUI : surviving the rug pull of licence part I
The main advantage was about not having to remember in wich order to make the pack and having to do the mainloop call. It was not a revolution, just a simple, elegant evolution, hence I was still feeling in control.
However, the projet made a jerk move by relicensing in full proprietary license that requires a key to work functionnaly.
I will not discuss this since the point have been made clearly on python mailing list.
Luckily I want to raise 2 points :
- we have been numerous coders to fork the project for doing pull requests
- it higlights once more the danger of too much dependencies
If you have a working copy of the repository
Well, you can still install a past version of pysimpleGUI, but unless you can do pip install git+https://github.com/jul/PySimpleGUI#egg=pysimpleGUI
Pro: if that version suited you, your old code will work
Con: there will be no update for the bugs and it is pretty much a no-go.
Expect free alternative
One of the power of free software is the power to fork, and some coders already forked in a « free forever » version of pysimpleGUI.
One of this fork is : Free Simple GUI.
Pro: migration is as simple as : pip install FreeSimpleGUI and then in the source : - import PySimpleGUI as sg + import FreeSimpleGUI as sg
Con: a project is as useful as the capacity of the community to keep up with the job of solving issues and the strength of the community to follow up.
Migrating to tkinter
This will be covered in the week to come by translating some examples to real life migration by myself.
Since tkinter has improved a lot and his a pillar of python distribution when it is not broken by debian, it is fairly easy.
Pro: diminises the need for a dependency and empower you with the poweful concept of tk such as variables binded to a widget (an observer pattern).
Con: PySimpleGUI is a multi-target adaptor to not only tkinter but also remi (web), wx, Qt. If you were using the versatility of pysimpleGUI and its multi-platform features you really need to look at the « free forever » alternatives.
Python Engineering at Microsoft: Python in Visual Studio Code – October 2024 Release
We’re excited to announce the October 2024 release of the Python and Jupyter extensions for Visual Studio Code!
This release includes the following announcements:
- Run Python tests with coverage
- Default Python problem matcher
- Python language server mode
If you’re interested, you can check the full list of improvements in our changelogs for the Python, Jupyter and Pylance extensions.
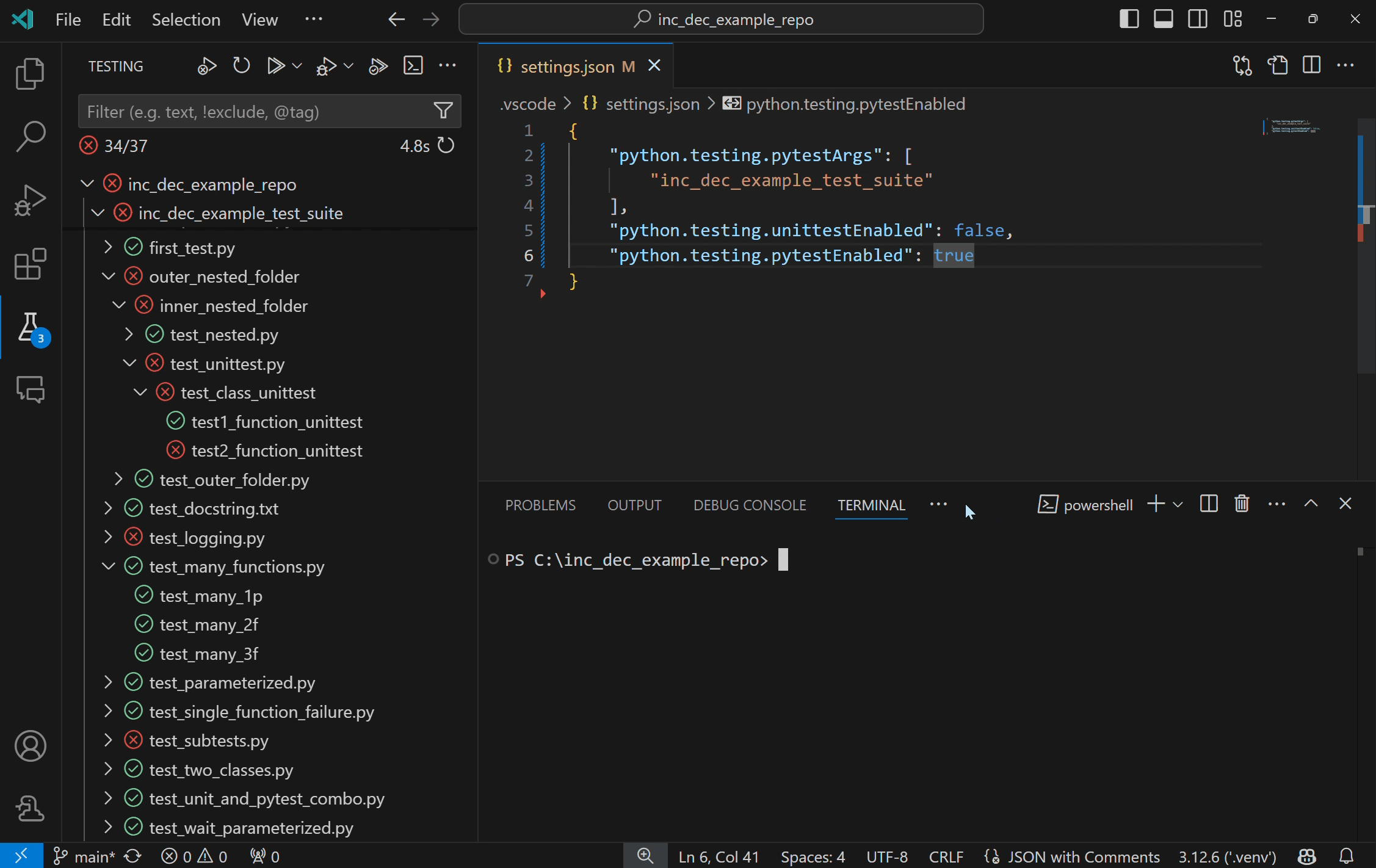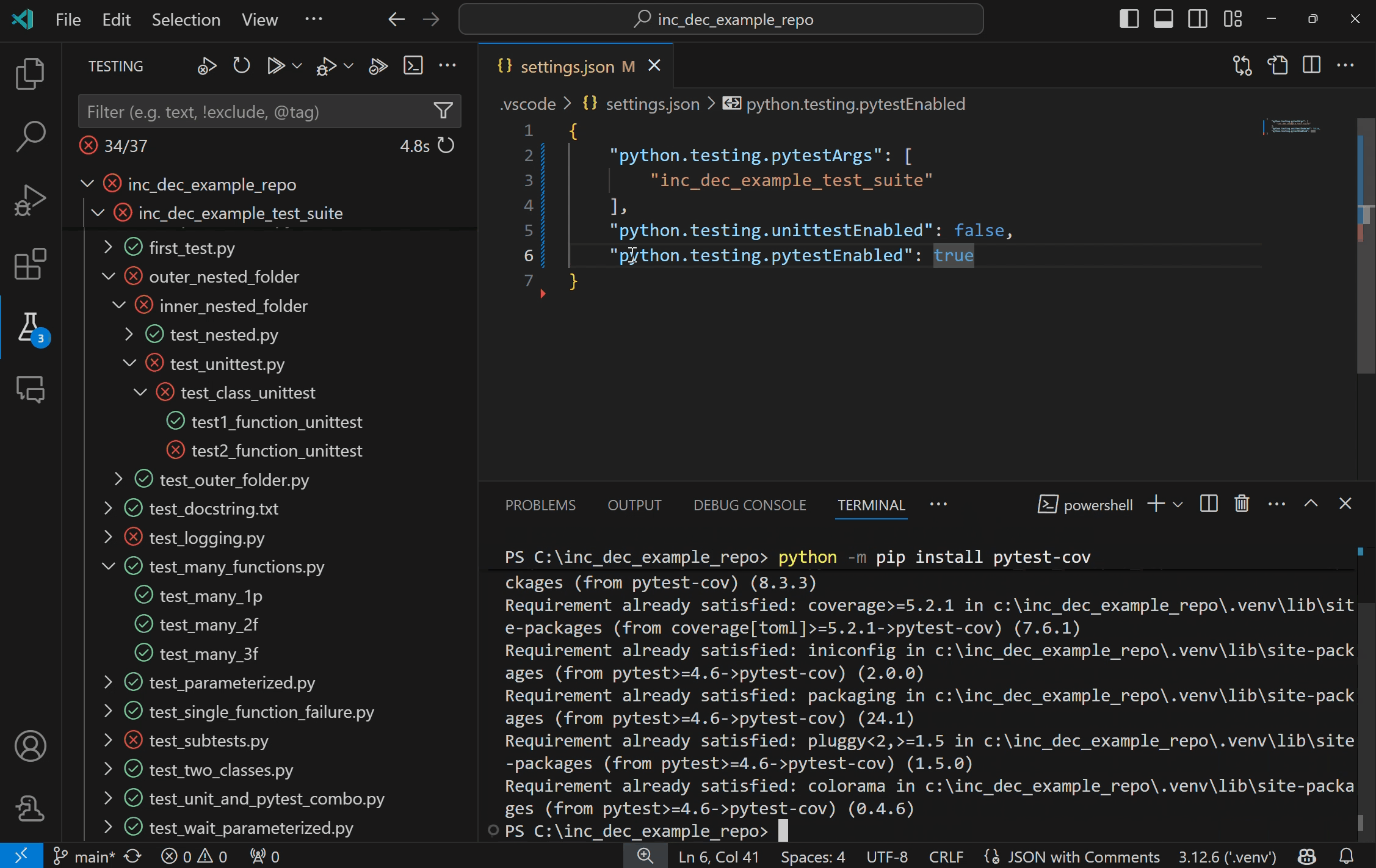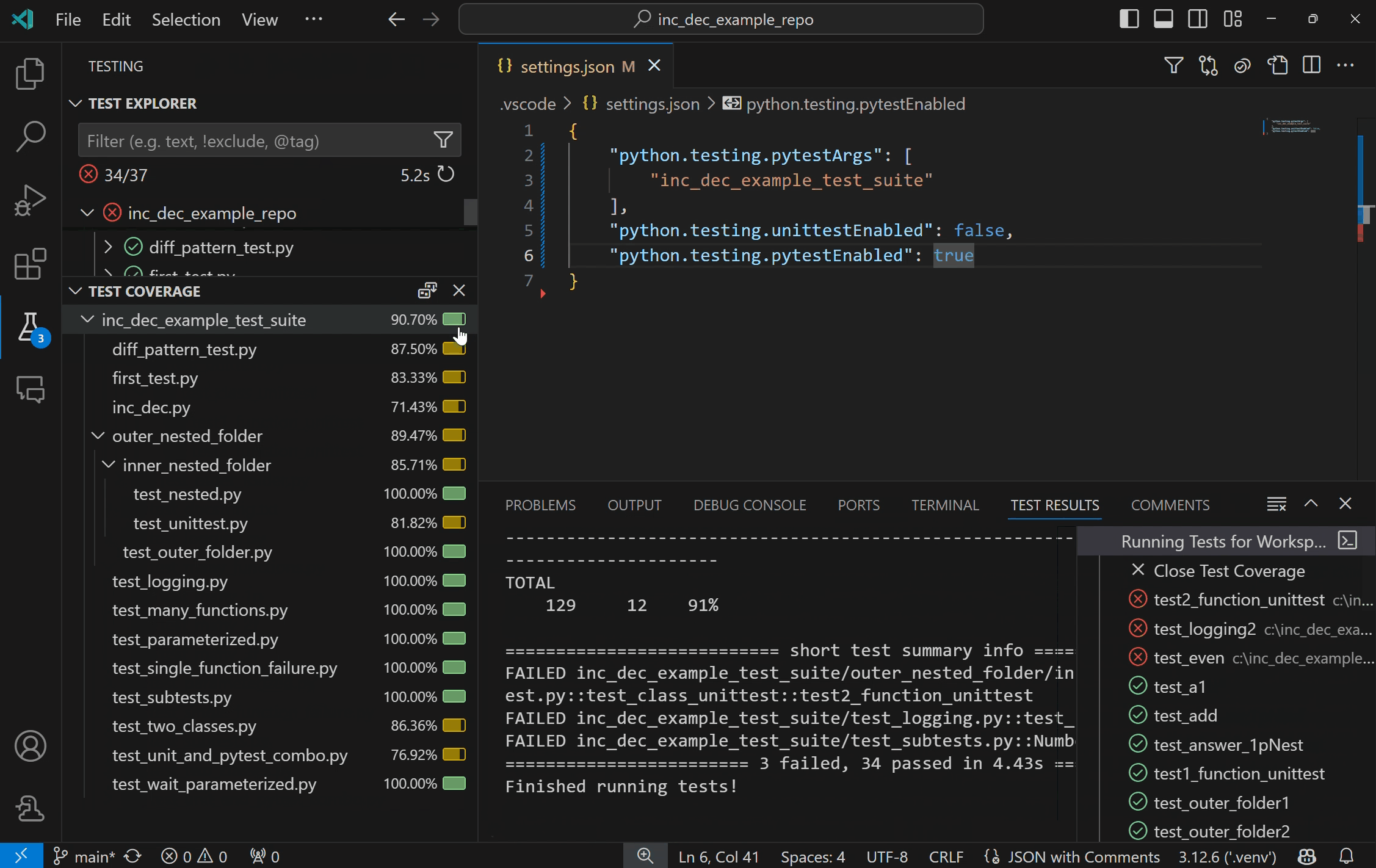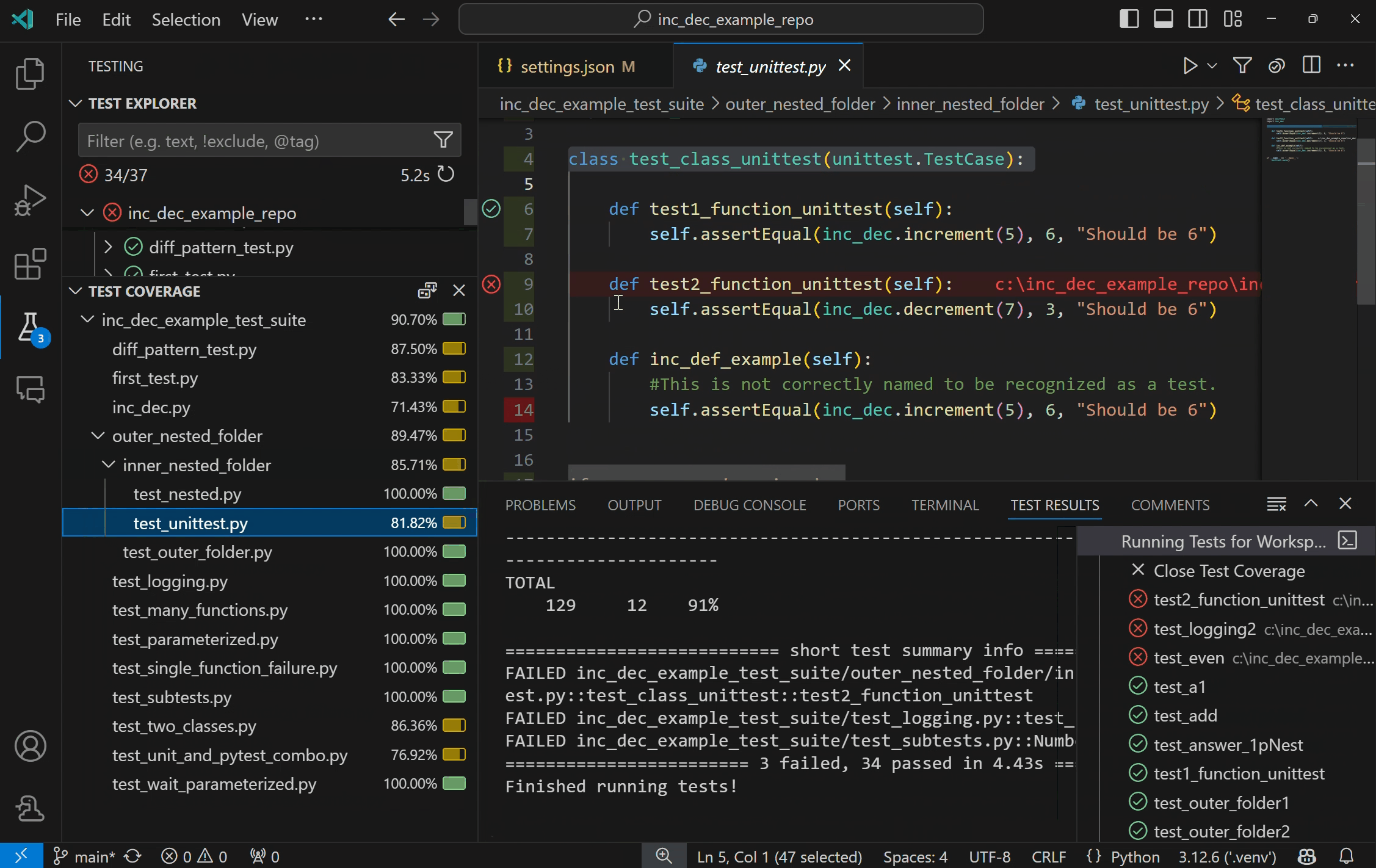
Run Python tests with coverageYou can now run Python tests with coverage in VS Code! Test coverage is a measure of how much of your code is covered by your tests, which can help you identify areas of your code that are not being fully tested.
To run tests with coverage enabled, select the coverage run icon in the Test Explorer or the “Run with coverage” option from any menu you normally trigger test runs from. The Python extension will run coverage using the pytest-cov plugin if you are using pytest, or with coverage.py for unittest.
Note: Before running tests with coverage, make sure to install the correct testing coverage package for your project.
Once the coverage run is complete, lines will be highlighted in the editor for line level coverage. Test coverage results will appear as a “Test Coverage” sub-tab in the Test Explorer, which you can also navigate to with Testing: Focus on Test Coverage View in Command Palette (F1)). On this panel you can view line coverage metrics for each file and folder in your workspace.
{kind=link}
For more information on running Python tests with coverage, see our Python test coverage documentation. For general information on test coverage, see VS Code’s Test Coverage documentation.
Default Python problem matcherWe are excited to announce support for one of our longest request features: there is now a default Python problem matcher! Aiming to simplifying issue tracking in your Python code and offering more contextual feedback, a problem matcher scans the task’s output for errors and warnings and displays them in the Problems panel, enhancing your development workflow. To integrate it, add "problemMatcher": "$python" to your tasks in task.json.
Below is an example of a task.json file that uses the default problem matcher for Python:
{ "version": "2.0.0", "tasks": [ { "label": "Run Python", "type": "shell", "command": "${command:python.interpreterPath}", "args": [ "${file}" ], "problemMatcher": "$python" } ] }For more information on tasks and problem matchers, visit VS Code’s Tasks documentation.
Pylance language server modeThere’s a new setting python.analysis.languageServerMode that enables you to choose between our current IntelliSense experience or a lightweight one that is optimized for performance. If you don’t require the full breadth of IntelliSense capabilities and prefer Pylance to be as resource-friendly as possible, you can set python.analysis.languageServerMode to light. Otherwise, to continue with the experience you have with Pylance today, you can leave out the setting entirely or explicitly set it to default .
This new functionality overrides the default values of the following settings:
Setting light mode default mode “python.analysis.exclude” [“**”] [] “python.analysis.useLibraryCodeForTypes” false true “python.analysis.enablePytestSupport” false true “python.analysis.indexing” false trueThe settings above can still be changed individually to override the default values.
Shell integration in Python terminal REPLThe Python extension now includes a python.terminal.shellIntegration.enabled setting to enable a better terminal experience on MacOS and Linux machines. When enabled, this setting runs a PYTHONSTARTUP script before you launch the Python REPL in the terminal (for example, by typing and entering python), allowing you to leverage terminal shell integrations such as command decorations, re-run command and run recent commands.
Other Changes and Enhancements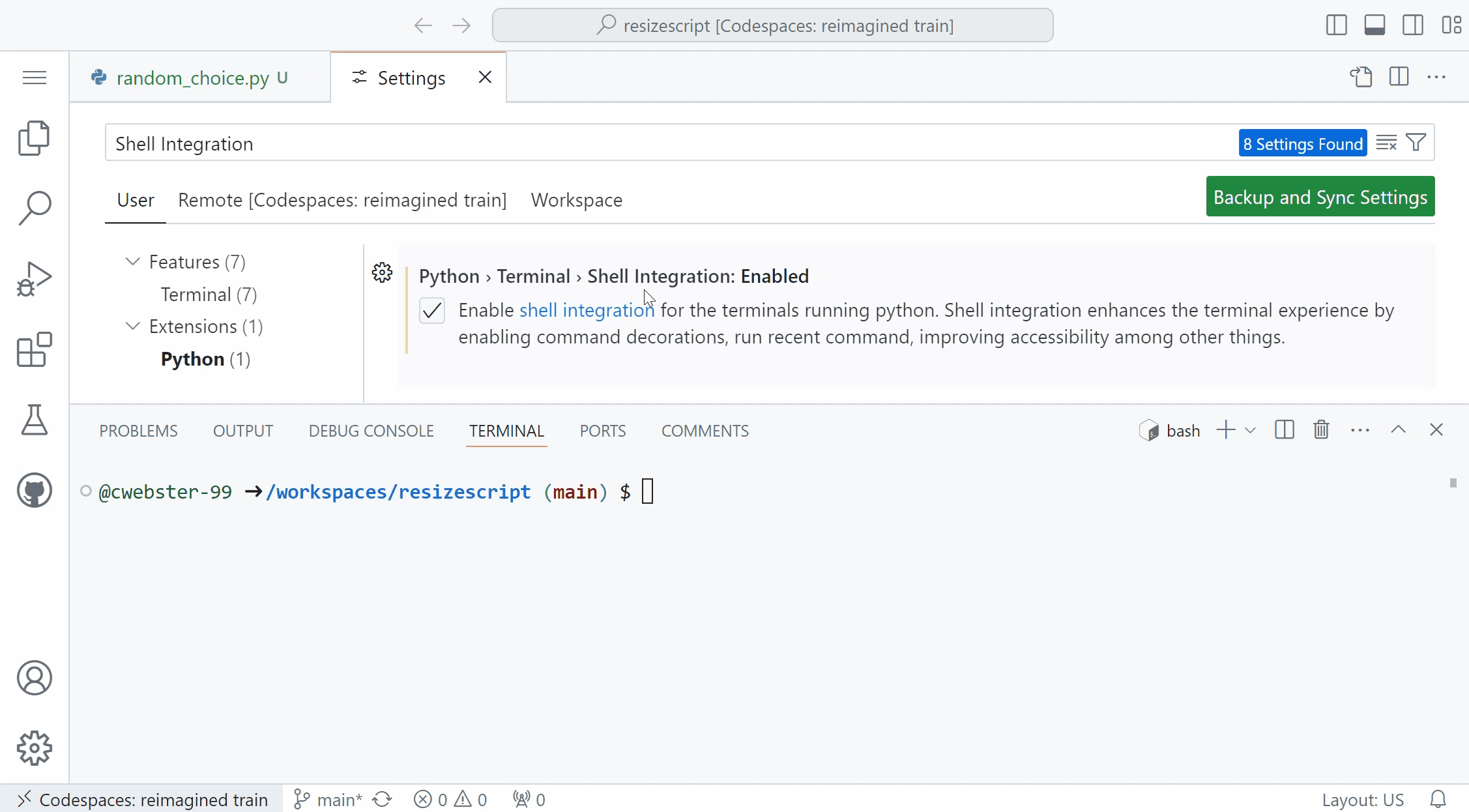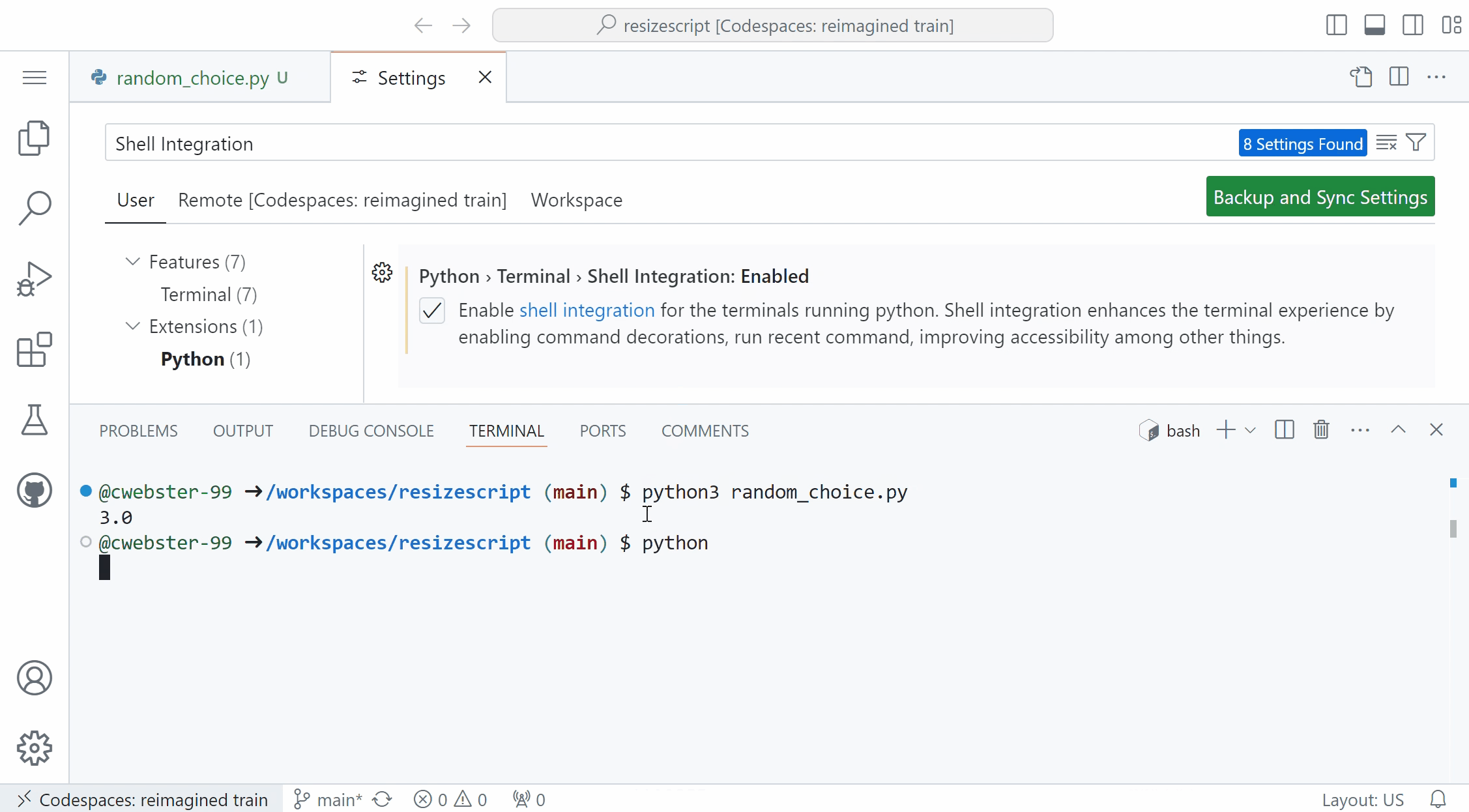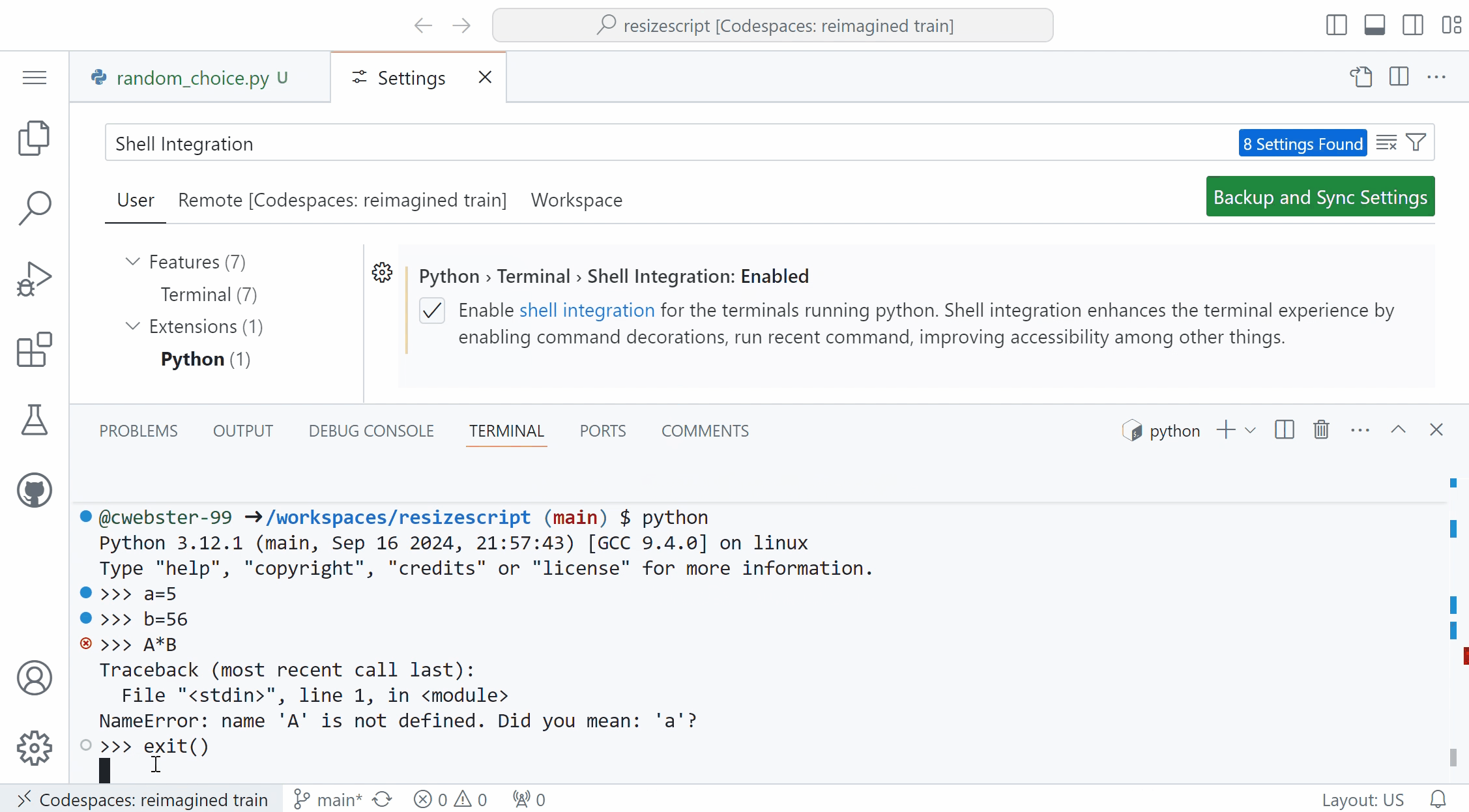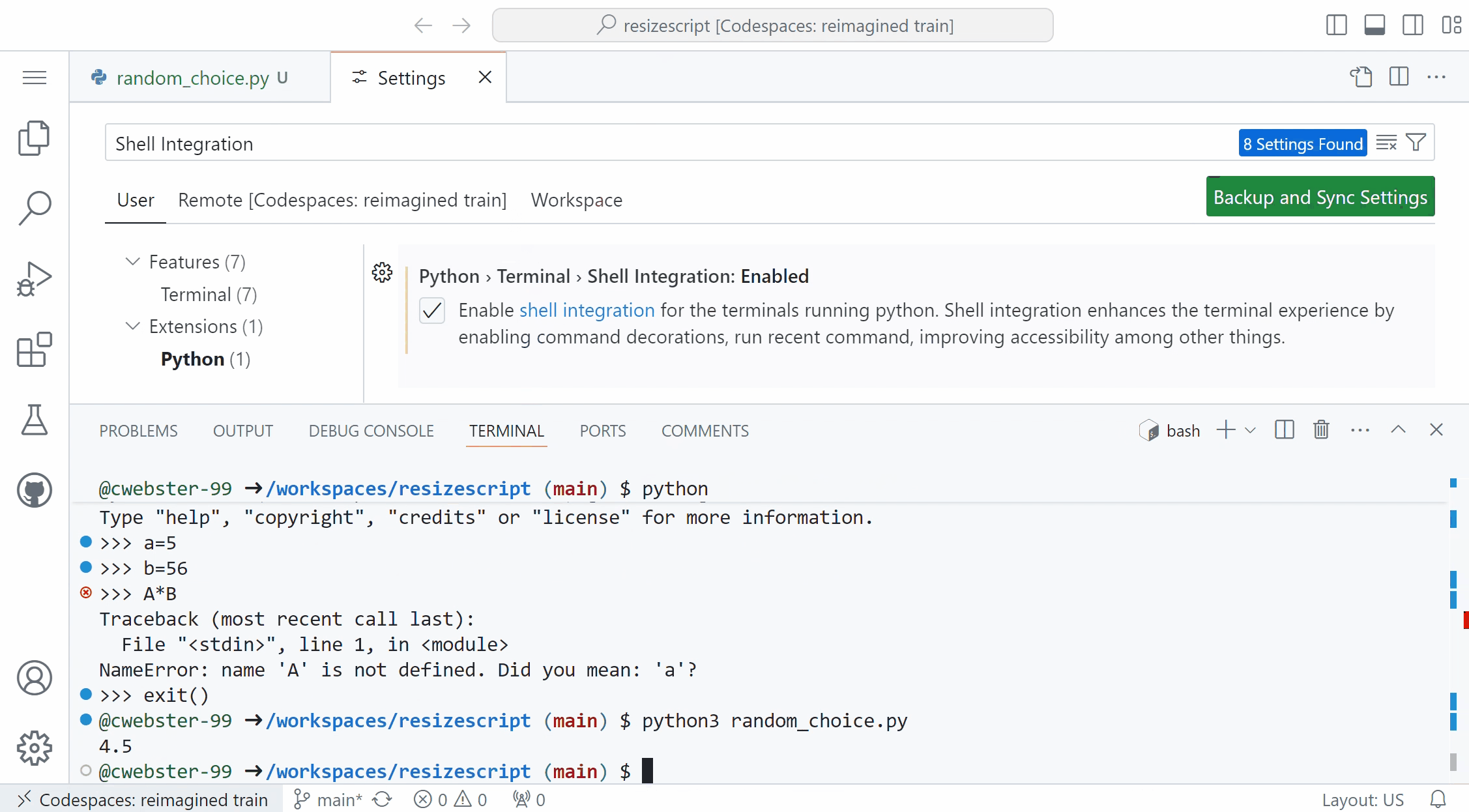{kind=link}
We have also added small enhancements and fixed issues requested by users that should improve your experience working with Python and Jupyter Notebooks in Visual Studio Code. Some notable changes include:
- Experimental Implement Abstract Classes with Copilot Code Action available for GitHub Copilot users using Pylance. Enable by adding "python.analysis.aiCodeActions": {"implementAbstractClasses": true} in your User settings.json
- Fixed duplicate Python executable code when sending code to the Terminal REPL by using executeCommand rather than sendText for the activation command in @vscode#23929
We would also like to extend special thanks to this month’s contributors:
- @edgarrmondragon Add uv.lock to file associations in vscode-python#23991
- @vishrutss Remove redundant @typescript-eslint/no-explicit-any suppression in vscode-python#24091
Try out these new improvements by downloading the Python extension and the Jupyter extension from the Marketplace, or install them directly from the extensions view in Visual Studio Code (Ctrl + Shift + X or ⌘ + ⇧ + X). You can learn more about Python support in Visual Studio Code in the documentation. If you run into any problems or have suggestions, please file an issue on the Python VS Code GitHub page.
The post Python in Visual Studio Code – October 2024 Release appeared first on Python.
Real Python: Quiz: Iterators and Iterables in Python: Run Efficient Iterations
In this quiz, you’ll test your understanding of Python’s Iterators and Iterables.
By working through this quiz, you’ll revisit how to create and work with iterators and iterables, understand the differences between them, and review how to use generator functions and the yield statement.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Seth Michael Larson: EuroPython 2024 talks about security
Published 2024-10-04 by Seth Larson
Reading time: minutes
EuroPython 2024 which occurred back in July 2024 has published the talk recordings to YouTube earlier this week. I've been under the weather for most of this week, but have had a chance to listen to a few of the security-related talks in-between resting.
Counting down for Cyber Resilience Act: Updates and expectationsThis talk was delivered by Python Software Foundation Executive Director Deb Nicholson and and Board Member Cheuk Ting Ho. The Cyber Resilience Act (CRA) is coming, and it'll affect more software than just the software written in the EU. Deb and Cheuk describe the recent developments in the CRA like the creation of a new entity called the "Open Source Steward" and how open source foundations and maintainers are preparing for the CRA.
For the rest of this year and next year I am focusing on getting the Python ecosystem ready for software security regulations like the CRA and SSDF from the United States.
Starting with improving the Software Bill-of-Materials (SBOM) story for Python, because this is required by both (and likely, future) regulations. Knowing what software you are running is an important first step towards being able to secure that same software.
To collaborate with other open source foundations and projects on this work, I've joined the Open Regulatory Compliance Working Group hosted by the Eclipse Foundation.
Towards licensing standardization in Python packagingThis talk was given by Karolina Surma and it detailed all the work that goes into researching, writing, and having a Python packaging standard accepted (spoiler: it's a lot!). Karolina is working on PEP 639 which is for adopting the SPDX licensing expression and identifier standards in Python as they are the current state of the art for modeling complex licensing situations accurately for machine (and human) consumption.
This work is very important for Software Bill-of-Materials, as they require accurate license information in this exact format. Thanks to Karolina, C.A.M. Gerlach, and many others for working for years on this PEP, it will be useful to so many uers once adopted!
The Update Framework (TUF) joins PyPIThis talk was given by Kairo de Araujo and Lukas Pühringer and it detailed the history and current status of The Update Framework (TUF) integration into the Python Package Index.
TUF provides better integrity guarantees for software repositories like PyPI like making it more difficult to "compel" the index to serve the incorrect artifacts and to make a compromise of PyPI easier to roll-back and be certain that files hadn't been modified. For a full history and latest status, you can view PEP 458 and the top-level GitHub issue for Warehouse.
I was around for the original key-signing ceremony for the PyPI TUF root keys which was live-streamed back in October 2020. Time flies, huh.
Writing Python like it's Rust: more robust code with type hintsThis talk was given by Jakub Beránek about using type hints for more robust Python code. Having written a case-study on urllib3's adoption of type hints to find defects that testing and other tooling missed I highly recommend type hints for Python code as well:
Accelerating Python with Rust: The PyO3 RevolutionThis talk was given by Roshan R Chandar about using PyO3 and Rust in Python modules.
Automatic Trusted Publishing with PyPIThis talk was given by Facundo Tuesca on using Trusted Publishing for authenticating with PyPI to publish packages.
Zero Trust APIs with PythonThis talk was given by Jose Haro Peralta on how to design and implement secure web APIs using Python, data validation with Pydantic, and testing your APIs using tooling for detecting common security defects.
Best practices for securely consuming open source in PythonThis talk was given by Cira Carey which highlights many of today's threats targetting open source consumers. Users should be aware of these when selecting projects to download and install.
Thanks for reading! ♡ Did you find this article helpful and want more content like it?
Get notified of new posts by subscribing to the RSS feed or the email newsletter.
This work is licensed under CC BY-SA 4.0
Trey Hunner: Switching from virtualenvwrapper to direnv, Starship, and uv
Earlier this week I considered whether I should finally switch away from virtualenvwrapper to using local .venv managed by direnv.
I’ve never seriously used direnv, but I’ve been hearing Jeff and Hynek talk about their use of direnv for a while.
After a few days, I’ve finally stumbled into a setup that works great for me. I’d like to note the basics of this setup as well as some fancy additions that are specific to my own use case.
My old virtualenvwrapper workflowFirst, I’d like to note my old workflow that I’m trying to roughly recreate:
- I type mkvenv3 <project_name> to create a new virtual environment for the current project directory and activate it
- I type workon <project_name> when I want to workon that project: this activates the correct virtual environment and changes to the project directory
The initial setup I thought of allows me to:
- Run echo layout python > .envrc && direnv allow to create a virtual environment for the current project and activate it
- Change directories into the project directory to automatically activate the virtual environment
The more complex setup I eventually settled on allows me to:
- Run venv <project_name> to create a virtual environment for the current project and activate it
- Run workon <project_name> to change directories into the project (which automatically activates the virtual environment)
First, I installed direnv and added this to my ~/.zshrc file:
1 eval "$(direnv hook zsh)"Then whenever I wanted to create a virtual environment for a new project I created a .envrc file in that directory, which looked like this:
1 layout pythonThen I ran direnv allow to allow, as direnv instructed me to, to allow the new virtual environment to be automatically created and activated.
That’s pretty much it.
Unfortunately, I did not like this initial setup.
No shell prompt?The first problem was that the virtual environment’s prompt didn’t show up in my shell prompt. This is due to a direnv not allowing modification of the PS1 shell prompt. That means I’d need to modify my shell configuration to show the correct virtual environment name myself.
So I added this to my ~/.zshrc file to show the virtual environment name at the beginning of my prompt:
1 2 3 4 5 6 7 # Add direnv-activated venv to prompt show_virtual_env() { if [[ -n "$VIRTUAL_ENV_PROMPT" && -n "$DIRENV_DIR" ]]; then echo "($(basename $VIRTUAL_ENV_PROMPT)) " fi } PS1='$(show_virtual_env)'$PS1 Wrong virtual environment directoryThe next problem was that the virtual environment was placed in .direnv/python3.12. I wanted each virtual environment to be in a .venv directory instead.
To do that, I made a .config/direnv/direnvrc file that customized the python layout:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 layout_python() { if [[ -d ".venv" ]]; then VIRTUAL_ENV="$(pwd)/.venv" fi if [[ -z $VIRTUAL_ENV || ! -d $VIRTUAL_ENV ]]; then log_status "No virtual environment exists. Executing \`python -m venv .venv\`." python -m venv .venv VIRTUAL_ENV="$(pwd)/.venv" fi # Activate the virtual environment . $VIRTUAL_ENV/bin/activate } Loading, unloading, loading, unloading…I also didn’t like the loading and unloading messages that showed up each time I changed directories. I removed those by clearing the DIRENV_LOG_FORMAT variable in my ~/.zshrc configuration:
1 export DIRENV_LOG_FORMAT= The more advanced setupI don’t like it when all my virtual environment prompts show up as .venv. I want ever prompt to be the name of the actual project… which is usually the directory name.
I also really wanted to be able to type venv to create a new virtual environment, activate it, and create the .envrc file for my automatically.
Additionally, I thought it would be really handy if I could type workon <project_name> to change directories to a specific project.
I made two aliases in my ~/.zshrc configuration for all of this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 venv() { local venv_name=${1:-$(basename "$PWD")} local projects_file="$HOME/.projects" # Check if .envrc already exists if [ -f .envrc ]; then echo "Error: .envrc already exists" >&2 return 1 fi # Create venv if ! python3 -m venv --prompt "$venv_name"; then echo "Error: Failed to create venv" >&2 return 1 fi # Create .envrc echo "layout python" > .envrc # Append project name and directory to projects file echo "${venv_name} = ${PWD}" >> $projects_file # Allow direnv to immediately activate the virtual environment direnv allow } workon() { local project_name="$1" local projects_file="$HOME/.projects" local project_dir # Check for projects config file if [[ ! -f "$projects_file" ]]; then echo "Error: $projects_file not found" >&2 return 1 fi # Get the project directory for the given project name project_dir=$(grep -E "^$project_name\s*=" "$projects_file" | sed 's/^[^=]*=\s*//') # Ensure a project directory was found if [[ -z "$project_dir" ]]; then echo "Error: Project '$project_name' not found in $projects_file" >&2 return 1 fi # Ensure the project directory exists if [[ ! -d "$project_dir" ]]; then echo "Error: Directory $project_dir does not exist" >&2 return 1 fi # Change directories cd "$project_dir" }Now I can type this to create a .venv virtual environment in my current directory, which has a prompt named after the current directory, activate it, and create a .envrc file which will automatically activate that virtual environment (thanks to that ~/.config/direnv/direnvrc file) whenever I change into that directory:
1 $ venvIf I wanted to customized the prompt name for the virtual environment, I could do this:
1 $ venv my_projectWhen I wanted to start working on that project later, I can either change into that directory or if I’m feeling lazy I can simply type:
1 $ workon my_projectThat reads from my ~/.projects file to look up the project directory to switch to.
Switching to uvI also decided to try using uv for all of this, since it’s faster at creating virtual environments. One benefit of uv is that it tries to select the correct Python version for the project, if it sees a version noted in a pyproject.toml file.
Another benefit of using uv, is that I should also be able to update the venv to use a specific version of Python with something like --python 3.12.
Here are the updated shell aliases for the ~/.zshrc for uv:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 venv() { local venv_name local dir_name=$(basename "$PWD") # If there are no arguments or the last argument starts with a dash, use dir_name if [ $# -eq 0 ] || [[ "${!#}" == -* ]]; then venv_name="$dir_name" else venv_name="${!#}" set -- "${@:1:$#-1}" fi # Check if .envrc already exists if [ -f .envrc ]; then echo "Error: .envrc already exists" >&2 return 1 fi # Create venv using uv with all passed arguments if ! uv venv --seed --prompt "$@" "$venv_name"; then echo "Error: Failed to create venv" >&2 return 1 fi # Create .envrc echo "layout python" > .envrc # Append to ~/.projects echo "${venv_name} = ${PWD}" >> ~/.projects # Allow direnv to immediately activate the virtual environment direnv allow } Switching to starshipI also decided to try out using Starship to customize my shell this week.
I added this to my ~/.zshrc:
1 eval "$(starship init zsh)"And removed this, which is no longer needed since Starship will be managing the shell for me:
1 2 3 4 5 6 7 # Add direnv-activated venv to prompt show_virtual_env() { if [[ -n "$VIRTUAL_ENV_PROMPT" && -n "$DIRENV_DIR" ]]; then echo "($(basename $VIRTUAL_ENV_PROMPT)) " fi } PS1='$(show_virtual_env)'$PS1I also switched my python layout for direnv to just set the $VIRTUAL_ENV variable and add the $VIRTUAL_ENV/bin directory to my PATH, since the $VIRTUAL_ENV_PROMPT variable isn’t needed for Starship to pick up the prompt:
1 2 3 4 5 layout_python() { VIRTUAL_ENV="$(pwd)/.venv" PATH_add "$VIRTUAL_ENV/bin" export VIRTUAL_ENV }I also made a very boring Starship configuration in ~/.config/starship.toml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 format = """ $python\ $directory\ $git_branch\ $git_state\ $character""" add_newline = false [python] format = '([(\($virtualenv\) )]($style))' style = "bright-black" [directory] style = "bright-blue" [character] success_symbol = "[\\$](black)" error_symbol = "[\\$](bright-red)" vimcmd_symbol = "[❮](green)" [git_branch] format = "[$symbol$branch]($style) " style = "bright-purple" [git_state] format = '\([$state( $progress_current/$progress_total)]($style)\) ' style = "purple" [cmd_duration.disabled]I setup such a boring configuration because when I’m teaching, I don’t want my students to be confused or distracted by a prompt that has considerably more information in it than their default prompt may have.
The biggest downside of switching to Starship has been my own earworm-oriented brain. As I update my Starship configuration files, I’ve repeatedly heard David Bowie singing “I’m a Starmaaan”. 🎶
Ground control to major TOMLAfter all of that, I realized that I could additionally use different Starship configurations for different directories by putting a STARSHIP_CONFIG variable in specific layouts. After that realization, I made my configuration even more vanilla and made some alternative configurations in my ~/.config/direnv/direnvrc file:
1 2 3 4 5 6 7 8 9 10 11 12 layout_python() { VIRTUAL_ENV="$(pwd)/.venv" PATH_add "$VIRTUAL_ENV/bin" export VIRTUAL_ENV export STARSHIP_CONFIG=/home/trey/.config/starship/python.toml } layout_git() { export STARSHIP_CONFIG=/home/trey/.config/starship/git.toml }Those other two configuration files are fancier, as I have no concern about them distracting my students since I’ll never be within those directories while teaching.
You can find those files in my dotfiles repository.
The necessary toolsSo I replaced virtualenvwrapper with direnv, uv, and Starship. Though direnv was is doing most of the important work here. The use of uv and Starship were just bonuses.
I am also hoping to eventually replace my pipx use with uv and once uv supports adding python3.x commands to my PATH, I may replace my use of pyenv with uv as well.
Thanks to all who participated in my Mastodon thread as I fumbled through discovering this setup.
Real Python: Quiz: Python import: Advanced Techniques and Tips
In this quiz, you’ll test your understanding of Python’s import statement and related topics.
By working through this quiz, you’ll revisit how to use modules in your scripts and import modules dynamically at runtime.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Real Python: A Guide to Modern Python String Formatting Tools
When working with strings in Python, you may need to interpolate values into your string and format these values to create new strings dynamically. In modern Python, you have f-strings and the .format() method to approach the tasks of interpolating and formatting strings.
In this tutorial, you’ll learn how to:
- Use f-strings and the .format() method for string interpolation
- Format the interpolated values using replacement fields
- Create custom format specifiers to format your strings
To get the most out of this tutorial, you should know the basics of Python programming and the string data type.
Get Your Code: Click here to download the free sample code that shows you how to use modern string formatting tools in Python.
Take the Quiz: Test your knowledge with our interactive “A Guide to Modern Python String Formatting Tools” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
A Guide to Modern Python String Formatting ToolsYou can take this quiz to test your understanding of modern tools for string formatting in Python. These tools include f-strings and the .format() method.
Getting to Know String Interpolation and Formatting in PythonPython has developed different string interpolation and formatting tools over the years. If you’re getting started with Python and looking for a quick way to format your strings, then you should use Python’s f-strings.
Note: To learn more about string interpolation, check out the String Interpolation in Python: Exploring Available Tools tutorial.
If you need to work with older versions of Python or legacy code, then it’s a good idea to learn about the other formatting tools, such as the .format() method.
In this tutorial, you’ll learn how to format your strings using f-strings and the .format() method. You’ll start with f-strings to kick things off, which are quite popular in modern Python code.
Using F-Strings for String InterpolationPython has a string formatting tool called f-strings, which stands for formatted string literals. F-strings are string literals that you can create by prepending an f or F to the literal. They allow you to do string interpolation and formatting by inserting variables or expressions directly into the literal.
Creating F-String LiteralsHere you’ll take a look at how you can create an f-string by prepending the string literal with an f or F:
Python 👇 >>> f"Hello, Pythonista!" 'Hello, Pythonista!' 👇 >>> F"Hello, Pythonista!" 'Hello, Pythonista!' Copied!Using either f or F has the same effect. However, it’s a more common practice to use a lowercase f to create f-strings.
Just like with regular string literals, you can use single, double, or triple quotes to define an f-string:
Python 👇 >>> f'Single-line f-string with single quotes' 'Single-line f-string with single quotes' 👇 >>> f"Single-line f-string with double quotes" 'Single-line f-string with single quotes' 👇 >>> f'''Multiline triple-quoted f-string ... with single quotes''' 'Multiline triple-quoted f-string\nwith single quotes' 👇 >>> f"""Multiline triple-quoted f-string ... with double quotes""" 'Multiline triple-quoted f-string\nwith double quotes' Copied!Up to this point, your f-strings look pretty much the same as regular strings. However, if you create f-strings like those in the examples above, you’ll get complaints from your code linter if you have one.
The remarkable feature of f-strings is that you can embed Python variables or expressions directly inside them. To insert the variable or expression, you must use a replacement field, which you create using a pair of curly braces.
Interpolating Variables Into F-StringsThe variable that you insert in a replacement field is evaluated and converted to its string representation. The result is interpolated into the original string at the replacement field’s location:
Python >>> site = "Real Python" 👇 >>> f"Welcome to {site}!" 'Welcome to Real Python!' Copied!In this example, you’ve interpolated the site variable into your string. Note that Python treats anything outside the curly braces as a regular string.
Read the full article at https://realpython.com/python-formatted-output/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Kushal Das: Thank you Gnome Nautilus scripts
As I upload photos to various services, I generally resize them as required based on portrait or landscape mode. I used to do that for all the photos in a directory and then pick which ones to use. But, I wanted to do it selectively, open the photos in Gnome Nautilus (Files) application and right click and resize the ones I want.
This week I noticed that I can do that with scripts. Those can be in any given language, the selected files will be passed as command line arguments, or full paths will be there in an environment variable NAUTILUS_SCRIPT_SELECTED_FILE_PATHS joined via newline character.
To add any script to the right click menu, you just need to place them in ~/.local/share/nautilus/scripts/ directory. They will show up in the right click menu for scripts.
Below is the script I am using to reduce image sizes:
#!/usr/bin/env python3 import os import sys import subprocess from PIL import Image # paths = os.environ.get("NAUTILUS_SCRIPT_SELECTED_FILE_PATHS", "").split("\n") paths = sys.argv[1:] for fpath in paths: if fpath.endswith(".jpg") or fpath.endswith(".jpeg"): # Assume that is a photo try: img = Image.open(fpath) # basename = os.path.basename(fpath) basename = fpath name, extension = os.path.splitext(basename) new_name = f"{name}_ac{extension}" w, h = img.size # If w > h then it is a landscape photo if w > h: subprocess.check_call(["/usr/bin/magick", basename, "-resize", "1024x686", new_name]) else: # It is a portrait photo subprocess.check_call(["/usr/bin/magick", basename, "-resize", "686x1024", new_name]) except: # Don't care, continue passYou can see it in action (I selected the photos and right clicked, but the recording missed that part):
Real Python: Quiz: A Guide to Modern Python String Formatting Tools
Test your understanding of Python’s tools for string formatting, including f-strings and the .format() method.
Take this quiz after reading our A Guide to Modern Python String Formatting Tools tutorial.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Python Software Foundation: Python 3.13 and the Latest Trends: A Developer's Guide to 2025 - Live Stream Event
Join Tania Allard, PSF Board Member, and Łukasz Langa, CPython Developer-in-Residence, for ‘Python 3.13 and the Latest Trends: A Developer’s Guide to 2025’, a live stream event hosted by Paul Everitt from JetBrains. Thank to JetBrains for partnering with us on the Python Developers Survey and this event to highlight the current state of Python!
The session will take place tomorrow, October 3, at 5:00 pm CEST (11:00 am EDT). Tania and Łukasz will be discussing the exciting new features in Python 3.13, plans for Python 3.15 and current Python trends gathered from the 2023 Annual Developers Survey. Don't miss this chance to hear directly from the experts behind Python’s development!
Watch the live stream event on YouTubeDon’t forget to enable YouTube notifications for the stream and mark your calendar.
Chris Rose: uv, direnv, and simple .envrc files
I have adopted uv for a lot of Python development. I'm also a heavy user of direnv, which I like as a tool for setting up project-specific environments.
Much like Hynek describes, I've found uv sync to be fast enough to put into the chdir path for new directories. Here's how I'm doing it.
Direnv LibrariesFirst, it turns out you can pretty easily define custom direnv functions like the built-in ones (layout python, etc...). You do this by adding functions to ~/.config/direnv/direnvrc or in ~/.config/direnv/lib/ as shell scripts. I use this extensively to make my .envrc files easier to maintain and smaller. Now that I'm using uv here is my default for python:
function use_standard-python() { source_up_if_exists dotenv_if_exists source_env_if_exists .envrc.local use venv uv sync } What does that even mean?Let me explain each of these commands and why they are there:
-
source_up_if_exists -- this direnv stdlib function is here because I often group my projects into directories with common configuration. For example, when working on Chicon 8, I had a top level .envrc that set up the AWS configuration to support deploying Wellington and the Chicon 8 website. This searches up til it finds a .envrc in a higher directory, and uses that. source_up is the noisier, less-adaptable sibling.
-
dotenv_if_exists -- this loads .env from the current working directory. 12-factor apps often have environment-driven configuration, and docker compose uses them relatively seamlessly as well. Doing this makes it easier to run commands from my shell that behave like my development environment.
-
source_env_if_exists .envrc.local -- sometimes you need more complex functionality in a project than just environment variables. Having this here lets me use .envrc.local for that. This comes after .env because sometimes you want to change those values.
-
use venv -- this is a function that activates the project .venv (creating it if needed); I'm old and set in my ways, and I prefer . .venv/bin/activate.fish in my shell to the more newfangled "prefix it with a runner" mode.
-
uv sync -- this is a super fast, "install my development and main dependencies" command. This was way, way too slow with pip, pip-tools, poetry, pdm, or hatch, but with uv, I don't mind having this in my .envrc
With this set up in direnv's configuration, all I need in my .envrc file is this:
use standard-pythonI've been using this pattern for a while now; it lets me upgrade how I do default Python setups, with project specific settings, easily.
PyCharm: Prompt AI Directly in the Editor
With PyCharm, you now have the support of AI Assistant at your fingertips. You can interact with it right where you do most of your work – in the editor.
Stuck with an error in your code? Need to add documentation or tests? Just start typing your request on a new line in the editor, just as if you were typing in the AI Assistant chat window. PyCharm will automatically recognize your natural language request and generate a response.
PyCharm leaves a purple mark in the gutter next to lines changed by AI Assistant so you can easily see what has been updated.
If you don’t like the initial suggestion, you can generate a new one by pressing Tab. You can also adjust the initial input by clicking on the purple block in the gutter or simply pressing Ctrl+/ or ⌘/.
Want to get assistance with a specific argument? You can narrow the context that AI Assistant uses for its response as much as you want. Just put the caret in the relevant context, type the $ or ? symbol, and start writing. PyCharm will recognize your prompt and take the current context into account for its suggestions.
The new inline AI assistance works for Python, JavaScript, TypeScript, JSON, and YAML file formats, while the option to narrow the context works only for Python so far.
This feature is available to all AI Assistant subscribers in the second PyCharm 2024.3 EAP build. You can get a free trial version of AI Assistant straight in the IDE: to enable AI Assistant, open a project in PyCharm, click the AI icon on the right-hand toolbar, and follow the instructions that appear.
Tryton News: Security Release for issue #93
Cédric Krier has found that python-sql does not escape non-Expression for unary operators (like And and Or) which makes any system exposing those vulnerable to an SQL injection attack.
Impact- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: Low
- User Interaction: None
- Scope: Changed
- Confidentiality: High
- Integrity: Low
- Availability: Low
There is no known workaround.
ResolutionAll affected users should upgrade python-sql to the latest version.
Affected versions: <= 1.5.1
Non affected versions: >= 1.5.2
Any security concerns should be reported on the bug-tracker at https://bugs.tryton.org/python-sql with the confidential checkbox checked.
2 posts - 2 participants
William Minchin: u202410012332
Microblogging v1.3.0 for Pelican released! Posts should now sort as expected. Thanks @ashwinvis. on PyPI #Microblogging #Pelican Plugins #Releases #Python
PyCoder’s Weekly: Issue #649 (Oct. 1, 2024)
#649 – OCTOBER 1, 2024
View in Browser »
In this tutorial, you’ll learn about the new features in Python 3.13. You’ll take a tour of the new REPL and error messages and see how you can try out the experimental free threading and JIT versions of Python 3.13 yourself.
REAL PYTHON
Some last minute performance considerations are delaying the release of Python 3.13 with one of the features being backed out. The new target is next week.
PYTHON.ORG
Python ships with a command-line based debugger called pdb. To set a breakpoint, you call the breakpoint() function in your code. This post introduces you to pdb and debugging from the command-line.
JUHA-MATTI SANTALA
Don’t miss out on your chance to register for DevSecCon 2024! From the exciting lineup of 20+ sessions, here’s one that you can’t skip: Ali Diamond, from Hak5: “I’m A Software Engineer, and I Have to Make Bad Security Decisions—why?” Save your spot →
SNYK.IO sponsor
Looking to experiment or build your portfolio? Discover creative Django project ideas for all skill levels, from beginner apps to advanced full-stack projects.
EVGENIA VERBINA
In this tutorial, you’ll explore one of Python 3.13’s new features: a new and modern interactive interpreter, also known as a REPL.
REAL PYTHON
This post talks about the pros and cons of upgrading to Python 3.13 and why you might do it immediately or wait for the first patch release in December.
ITAMAR TURNER-TRAURING
Jack was toying around with a refactor where he wanted to replace a variable name across a large number of files. His usual tools of grep and sed weren’t sufficient, so he tried tree-sitter instead. Associated HN Discussion.
JACK EVANS
Information retrieval often uses a two-stage pipeline, where the first stage does a quick pass and the second re-ranks the content. This post talks about re-ranking, the different methods out there, and introduces a Python library to help you out.
BENJAMIN CLAVIE
A code contract is a way of specifying how your code is supposed to perform. They can be useful for tests and to generally reduce the number of bugs in your code. This article introduces you to the concept and the dbc library.
LÉO GERMOND
Technical debt is the accumulation of design decisions that eventually slow teams down. This post talks about two ways to pay it down: using tech debt payments to get into the flow, and what you need before doing a big re-write.
GERGELY OROSZ
The asyncio.gather() method works as the meeting point for multiple co-routines, but it doesn’t have to be a synchronous call. This post teaches you how to use .gather() in the background.
JASON BROWNLEE
The Python import system is as powerful as it is useful. In this in-depth video course, you’ll learn how to harness this power to improve the structure and maintainability of your code.
REAL PYTHON course
Ryan just finished his second round mentoring with the Djangonaut.Space program. This post talks about both how you can help your mentor help you, and how to be a good mentor.
RYAN CHELEY
The dunder method __new__ is used to customise object creation and is a core stepping stone in understanding metaprogramming in Python.
RODRIGO GIRÃO SERRÃO
This short post shows you how to prompt your users for input with Python’s built-in input() function.
TREY HUNNER
Talk Python interviews Anna-Lena Popkes and they talk about how and when to teach coding to children.
TALK PYTHON podcast
October 2, 2024
REALPYTHON.COM
October 3 to October 5, 2024
PYCON.ORG
October 3, 2024
MEETUP.COM
October 3, 2024
SYPY.ORG
October 4 to October 6, 2024
PYCON.ORG
October 4 to October 5, 2024
DJANGODAY.DK
October 9 to October 14, 2024
PYCON.ORG
October 10 to October 11, 2024
PYCON.ORG
Happy Pythoning!
This was PyCoder’s Weekly Issue #649.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
PyCharm: Python 3.13 and the Latest Trends: A Developer’s Guide to 2025
We invite you to join us in just two days time, on October 3 at 5:00 pm CEST (11:00 am EDT), for a livestream shining a spotlight on Python 3.13 and the trends shaping its development.
Our speakers:
- Łukasz Langa, CPython Developer in Residence, release manager for Python 3.8–3.9, and creator of Black.
- Tania Allard, Vice-chair of the PSF board, PSF fellow, and Director at Quansight Labs.
They will discuss the most notable features of Python 3.13 and examine the industry trends likely to influence its future. This is a great opportunity to get ahead of the release and ask your questions directly to the experts.
Don’t forget to enable YouTube notifications and mark your calendar.
PyCharm: PyCharm’s Interactive Tables for Data Science
Data cleaning, exploration, and visualization are some of the most time-consuming tasks for data scientists. Nearly 50% of data specialists dedicate 30% or more of their time to data preparation. The pandas and Polars libraries are widely used for these purposes, each offering unique advantages. PyCharm supports both libraries, enabling users to efficiently explore, clean, and visualize data, even with large datasets.
In this blog post, you’ll discover how PyCharm’s interactive tables can enhance your productivity when working with either Polars or pandas. You will also learn how to perform many different data exploration tasks without writing any code and how to use JetBrains AI Assistant for data analysis.
Getting startedTo start using pandas for data analysis, import the library and load data from a file using pd.read_csv(“FileName”), or drag and drop a CSV file into a Jupyter notebook. If you’re using Polars, import the library and use pl.read_csv(“FileName/path to the file”) to load data into a DataFrame. Then, print the dataset just by using the name of the variable.
PyCharm’s interactive tables – key features and uses Browse, sort, and view datasetsInteractive tables offer a wide range of features that allow you to easily explore your data. For example, you can navigate through your data with infinite horizontal and vertical scrolling, use single and multiple column sorting, and many other features.
This feature allows you to sort columns alphabetically or maintain the existing column order. You can also find specific columns by typing the column name in the Column List menu. Through the context menu or Column List, you can selectively hide or display columns. For deeper analysis, you can hide all but the essential columns or use the Hide Other Columns option to focus on a single column.
Finally, you can open your dataframe in a separate window for even more in-depth analysis.
Explore your dataYou can easily understand data types directly from column headers. For example, is used for a data type object, while indicates numeric data.
Additionally, you can access descriptive statistics by hovering over column headers in Compact mode or view them directly in Detailed mode, where distribution histograms are also available.
Create code-free data visualizationsInteractive tables also offer several features available in the Chart view section.
- No-code chart creation, allowing you to visualize data effortlessly.
- Ability to compare graphs.
- Ability to save your charts with one click.
You can access the AI Assistant in the upper-left corner of the tables for the following purposes:
- To access insights about your data quickly with AI Assistant.
- Use AI Assistant to visualize your data.
Exploratory Data Analysis (EDA) is a crucial step in data science, as it allows data scientists to understand the underlying structure and patterns within a dataset before applying any modeling techniques. EDA helps you identify anomalies, detect outliers, and uncover relationships among variables – all of which are essential for making informed decisions.
Interactive tables offer many features that allow you to explore your data faster and get reliable results.
Spotting statistics, patterns, and outliers Viewing the dataset informationLet’s look at a real-life example of how the tables could boost the productivity of your EDA. For this example, we will use the Bengaluru House Dataset. Normally we start with an overview of our data. This includes just viewing it to understand the size of the dataset, data types of the columns, and so on. While you can certainly do this with the help of code, using interactive tables allows you to get this data without code. So, in our example, the size of the dataset is 13,320 rows and 9 columns, as you can see in the table header.
Our dataset also contains different data types, including numeric and string data. This means we can use different techniques for working with data, including correlation analysis and others.
And of course you can take a look at the data with the help of infinite scrolling and other features we mentioned above.
Performing statistical analysisAfter getting acquainted with the data, the next step might be more in-depth analysis of the statistics. PyCharm provides a lot of important information about the columns in the table headers, including missing data, mode, mean, median, and so on.
For example, here we see that many columns have missing data. In the “bath” column, we obviously have an outlier, as the max value significantly exceeds the 95th percentile.
Additionally, data type mismatches, such as “total_sqft” not being a float or integer, indicate inconsistencies that could impact data processing and analysis.
After sorting, we notice one possible reason for the problem: the use of text values in data and ranges instead of normal numerical values.
Analyzing the data using AIAdditionally, if our dataset doesn’t have hundreds of columns, we can use the help of AI Assistant and ask it to explain the DataFrame. From there, we can prompt it with any important questions, such as “What data problems in the dataset should be addressed and how?”
Visualizing data with built-in chartingIn some cases, data visualization can help you understand your data. PyCharm interactive tables provide two options for that. The first is Chart View and the second is Generate Visualizations in Chat.
Let’s say my hypothesis is that the price of a house should be correlated with its total floor area. In other words, the bigger a house is, the more expensive it should be. In this case, I can use a scatter plot in Chart View and discover that my hypothesis is likely correct.
Wrapping upPyCharm Professional’s interactive tables offer numerous benefits that significantly boost your productivity in data exploration and data cleaning. The tables allow you to work with the most popular data science library, pandas, and the fast-growing framework Polars, without writing any code. This is because the tables provide features like browsing, sorting, and viewing datasets; code-free visualizations; and AI-assisted insights.
Interactive tables in PyCharm not only save your time but also reduce the complexity of data manipulation tasks, allowing you to focus on deriving meaningful insights instead of writing boilerplate code for basic tasks.
Download PyCharm Professional and get an extended 60-day trial by using the promo code “PyCharmNotebooks”. The free subscription is available for individual users only.
Activate your 60-day trialFor more information on interactive tables in PyCharm, check out our related blogs, guides, and documentation:
Real Python: Differences Between Python's Mutable and Immutable Types
As a Python developer, you’ll have to deal with mutable and immutable objects sooner or later. Mutable objects are those that allow you to change their value or data in place without affecting the object’s identity. In contrast, immutable objects don’t allow this kind of operation. You’ll just have the option of creating new objects of the same type with different values.
In Python, mutability is a characteristic that may profoundly influence your decision when choosing which data type to use in solving a given programming problem. Therefore, you need to know how mutable and immutable objects work in Python.
In this video course, you’ll:
- Understand how mutability and immutability work under the hood in Python
- Explore immutable and mutable built-in data types in Python
- Identify and avoid some common mutability-related gotchas
- Understand and control how mutability affects your custom classes
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Robin Wilson: I won two British Cartographic Society awards!
It’s been a while since I posted here – I kind of lost momentum over the summer (which is a busy time with a school-aged child) and never really picked it up again.
Anyway, I wanted to write a quick post to tell people that I won two awards at the British Cartographic Society awards ceremony a few weeks ago.
They were both for my British Placename Mapper web app, which is described in more detail in this blog post. If you haven’t seen it already, I strongly recommend you check it out.
I won a Highly Commended certificate in the Avenza Award for Electronic Mapping, and the First Prize trophy for the Ordnance Survey Award (for any map using OS data).
The certificates came in a lovely frame, and the trophy is enormous – about 30cm high and weighing over 3kg!
{kind=link}
I was presented with the trophy at the BCS Annual Conference in London, but they very kindly offered to keep the trophy to save me carrying it across London on my wheelchair and back on the train, so they invited me to Ordnance Survey last week to be presented with it again. I had a lovely time at OS – including 30 minutes with their Director General/CEO and was formally presented with my trophy again (standing in front of the first ever Ordnance Survey map!):
{kind=link}
Full information on the BCS awards are available on their website and I strongly recommend submitting any appropriate maps you’ve made for next year’s awards. I need to get my thinking cap on for next year’s entry…
Python Insider: Python 3.12.7 released
I'm pleased to announce the release of Python 3.12.7:
https://www.python.org/downloads/release/python-3127/
Python 3.12 is the newest major release of the Python programming language, and it contains many new features and optimizations. 3.12.7 is the latest maintenance release, containing more than 100 bugfixes, build improvements and documentation changes since 3.12.6.
Major new features of the 3.12 series, compared to 3.11 New features- More flexible f-string parsing, allowing many things previously disallowed (PEP 701).
- Support for the buffer protocol in Python code (PEP 688).
- A new debugging/profiling API (PEP 669).
- Support for isolated subinterpreters with separate Global Interpreter Locks (PEP 684).
- Even more improved error messages. More exceptions potentially caused by typos now make suggestions to the user.
- Support for the Linux perf profiler to report Python function names in traces.
- Many large and small performance improvements (like PEP 709 and support for the BOLT binary optimizer), delivering an estimated 5% overall performance improvement.
- New type annotation syntax for generic classes (PEP 695).
- New override decorator for methods (PEP 698).
- The deprecated wstr and wstr_length members of the C implementation of unicode objects were removed, per PEP 623.
- In the unittest module, a number of long deprecated methods and classes were removed. (They had been deprecated since Python 3.1 or 3.2).
- The deprecated smtpd and distutils modules have been removed (see PEP 594 and PEP 632. The setuptools package continues to provide the distutils module.
- A number of other old, broken and deprecated functions, classes and methods have been removed.
- Invalid backslash escape sequences in strings now warn with SyntaxWarning instead of DeprecationWarning, making them more visible. (They will become syntax errors in the future.)
- The internal representation of integers has changed in preparation for performance enhancements. (This should not affect most users as it is an internal detail, but it may cause problems for Cython-generated code.)
For more details on the changes to Python 3.12, see What’s new in Python 3.12.
More resources- Online Documentation.
- PEP 693, the Python 3.12 Release Schedule.
- Report bugs via GitHub Issues.
- Help fund Python directly or via GitHub Sponsors, and support the Python community.
Thanks to all of the many volunteers who help make Python Development and these releases possible! Please consider supporting our efforts by volunteering yourself or through organization contributions to the Python Software Foundation.
Your release team,
Thomas Wouters
Łukasz Langa
Ned Deily
Steve Dower
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
- www-zh-cn @ Savannah: Welcome our new member - bingchuanjuzi
- Matt Glaman: Lenient Composer Plugin officially replaces lenient packages endpoint
- libtool @ Savannah: libtool-2.5.4 released [stable]
- Trey Hunner: Python Black Friday & Cyber Monday sales (2024)
- Security advisories: Drupal core - Moderately critical - Gadget chain - SA-CORE-2024-008
FLOSS Research
- Give Your Input on the State of Open Source Survey
- Open Data and Open Source AI: Charting a course to get more of both
- The Open Source Initiative and the Eclipse Foundation to Collaborate on Shaping Open Source AI (OSAI) Public Policy
- ClearlyDefined v2.0 adds support for LicenseRefs
- ClearlyDefined at SOSS Fusion 2024: a collaborative solution to Open Source license compliance