
FLOSS Project Planets
Chris Lamb: Increasing the Integrity of Software Supply Chains awarded IEEE ‘Best Paper’ award
IEEE Software recently announced that a paper that I co-authored with Dr. Stefano Zacchiroli has recently been awarded their ‘Best Paper’ award:
Titled Reproducible Builds: Increasing the Integrity of Software Supply Chains, the abstract reads as follows:
Although it is possible to increase confidence in Free and Open Source Software (FOSS) by reviewing its source code, trusting code is not the same as trusting its executable counterparts. These are typically built and distributed by third-party vendors with severe security consequences if their supply chains are compromised.
In this paper, we present reproducible builds, an approach that can determine whether generated binaries correspond with their original source code. We first define the problem and then provide insight into the challenges of making real-world software build in a "reproducible" manner — that is, when every build generates bit-for-bit identical results. Through the experience of the Reproducible Builds project making the Debian Linux distribution reproducible, we also describe the affinity between reproducibility and quality assurance (QA).
According to Google Scholar, the paper has accumulated almost 40 citations since publication. The full text of the paper can be found in PDF format.
The Drop Times: The DropTimes Carousels and Exciting Events
Have you ever wondered what a media partnership means to us? Simply put, it's like teaming up with some of the most remarkable events to bring their incredible stories directly to the readers through multiple channels, including our social media handles. We are humbled to acknowledge that The DropTimes (TDT) got the opportunity to be a media partner for several upcoming events, such as Florida Drupal Camp, Drupal Mountain Camp, and NERD Summit. We're already in friendly talks with events happening in 2024 for web coverage! We're planning to bring you even more fantastic stories.
Now, let's take a trip down memory lane with captivating carousels. Think of them like visual stories capturing the most exciting moments from events. It's our way of sharing each event's fun, happiness, and success. These carousels are like time machines, taking you back to the best parts of our media partnerships and the lively Drupal community.
The first features highlights from last year's events, including DrupalCon Pittsburgh and DrupalCon Lille 2023. Plus, get an exclusive sneak peek into what's coming up at DrupalCon Portland 2024 and DrupalCon Barcelona 2024.
But that's not all! Brace yourselves for a visual feast as we proudly present a collection of the best moments from Splash Awards (Germany and Austria), Drupal Developers Day Vienna, and DrupalCamp Costa Rica in 2023.
Moreover, we've compiled The Drop Times 2023 Carousel, a journey back to revisit the year's most noteworthy moments and achievements.
A big shout-out to the fantastic Drupal community for all the support in 2023. Your love and encouragement mean the world to us!
These moments are just the beginning. We're eager to build more partnerships in the future and share even more exciting stories with you. Now, let's shift our focus to the present. Explore some of the latest news stories and articles we covered last week. We've got a mix of engaging content waiting for you.
Elma John conducted a captivating interview with Nneka Hector, the Director of Web Development at DSFederal and a co-lead for Drupal GovCon. Nneka reflected on the community's eagerness for in-person interaction and valuable lessons learned.
Lukas Fischer, Founder of NETNODE AG and one of the developers behind the Content Planner module, shared a customised Dashboard for Drupal websites. Covered by Alka Elizabeth, the latest enhancements promise to make your Drupal experience even more delightful and user-friendly.
The Event Organizers Working Group (EOWG) election has wrapped up, and we're eagerly awaiting the results. Alka Elizabeth shared insights into the candidates' unique contributions. Stay tuned for the big reveal!
Meet Drupal Droid, a specially crafted AI model designed exclusively for the Drupal Community. Offering assistance with Drupal 9+ site building, development, and coding standards, this innovative tool was introduced by Michael Miles. Alka Elizabeth, sub-editor of The Drop Times, connected with Michael to glean insights into the creation and potential of Drupal Droid.
Now, let's explore what's been happening on the event front: Get a chance to showcase your talent and win a ticket to DrupalCon by submitting your design for the official DrupalCon Portland t-shirt. Enter before February 12! Volunteer as a Trivia Night Coordinator and embrace the opportunity to contribute to the organization of the iconic DrupalCon Trivia Night at Portland 2024.
Drupal Mountain Camp is leading the charge for diversity and inclusion in the Drupal community with a new initiative. They actively encourage underrepresented voices to participate, promoting a more diverse and enriched community. For more information, click here.
Explore exclusive sponsorship opportunities for NERD Summit 2024, a prominent mini-conference in web development and technology. Today is the last day for the NERD Summit 2024 for session submission. Make sure to propose your sessions or ideas before midnight. Get more details here.
Discover the upcoming Drupal Iberia 2024 event, set to convene in Evora on May 10th and 11th.
The largest Drupal Conference in Poland, DrupalCamp Poland 2024, calls for session submissions until April 16, 2024.
Secure your spot at Drupalcamp Rennes 2024! Ticket reservations are now available for the three-day event featuring insightful conferences and contribution opportunities.
Join the Drupal Delhi Meetup Group as they bring back the joy of in-person gatherings on February 24, 2024. Get more information here.
Missed LocalGov Drupal Week 2023? Don't worry! Dive into the virtual experience on their YouTube channel. Explore 14 sessions over five days, where 530+ participants shared experiences, best practices, and innovative code.
Join the GitLab Innovation Pitch Competition to showcase your software innovation skills. Compete for a $30,000 prize pool and the opportunity to collaborate with GitLab, focusing on DevOps, Machine Learning/AI, and Social Good projects. Deadline: Feb 27, 2024.
Here is a noteworthy update from the past week: Drupal pioneers innovation with its new credit bounty program, encouraging contributors to align with impactful projects and fostering a purpose-driven community for lasting impact.
There are more stories available out there. But the compulsion to limit the selection of stories is forcing us to put a hard break on further exploration.
As always, stay tuned for more exciting stories and updates. follow us on LinkedIn, Twitter and Facebook.
Thank you,
Sincerely
Kazima Abbas
Sub-editor, TheDropTimes
Drupal Association blog: Drupal Innovation in 2024: the Contribution Health Dashboards
2023 has been an eventful year, full of ideas, discussions and plans regarding innovation, where Drupal is heading, and, in our case, how the Drupal Association can best support. On top of that, you may have already heard, but innovation is a key goal for the Drupal Association.
Drupal is nothing but a big, decentralized, community. And before we can even think of how we can innovate, we need to understand how contribution actually happens and evolves in our ecosystem. And one of the things we agreed early on was that, without numbers, we don’t even know where we are going.
For that reason in 2024 we want to introduce you to part of the work we’ve been doing during the last part of 2023 to make sure that we know where we are coming from, we understand where we are going and how the changes we are doing are affecting (or not) the whole contribution ecosystem. I want to introduce you to the Contribution Health Dashboards (CHD).
The CH dashboards should help identify what stops or blocks people from contributing, uncover any friction, and if any problems are found, help to investigate and apply adequate remedies while we can as well measure those changes.
One thing to note is that the numbers we are showing next are based on the contribution credit system. The credit system has been very successful in standardizing and measuring contributions to Drupal. It also provides incentives to contribute to Drupal, and has raised interest from individuals and organizations.
Using the credit system to evaluate the contribution is not 100% perfect, and it could show some flaws and imperfections, but we are committed to review and improve those indicators regularly, and we think it’s the most accurate way to measure the way contribution happens in Drupal.
It must be noted as well that the data is hidden, deep, in the Drupal.org database. Extracting that data has proved a tedious task, and there are numbers and statistics that we would love to extract in the near future to validate further the steps we are taking. Again, future reviews of the work will happen during the next months while we continue helping contributors to continue innovating.
You can find the dashboards here, in the Contribution Health Dashboards, but keep reading next to understand the numbers better.
Unique individuals and organisationsJumping to what matters here, the numbers, one of the most important metrics to understand in the Drupal ecosystem is the number of contributions of both individuals and organisations.
As you can see, the number of individuals has stayed relatively stable, while their contribution has been more and more significant over the years (except for a slide in the first year of the pandemic). In a way this is telling us that once a user becomes a contributor, they stay for the long run. And, in my opinion, the numbers say that they stay actually very committed.
The number of organisations on the other hand displays a growing healthy trend. This shows that organisations are an important partner for Drupal and the Drupal Association, bringing a lot of value in the form of (but not just) contributors.
It definitely means that we need to continue supporting and listening to them. It’s actually a symbiotic relationship. These companies support and help moving forward, not just Drupal, but the whole concept of the Open Web. And their involvement doesn’t end up there, as their daily role in expanding the reach, the number of instances and customers of every size using Drupal is as well key.
In practical terms in 2023 we have been meeting different companies and organisations, and the plan is to continue listening and finding new ways to help their needs in 2024 and beyond. One of the things we are releasing soon is the list of priorities and strategic initiatives where your contributions, as individuals as well as organisations, are most meaningful. This is something I have been consistently asked for when meeting with those individuals and organisations, and I think it’s going to make a big difference unleashing innovation in Drupal. I recommend you to have a look at the blog post about the bounty program.
First year contributorsThe next value we should be tracking is how first time users are interacting with our ecosystem.
While the previous numbers are encouraging, we have a healthy ecosystem of companies and a crowd of loyal individuals contributing to the project, making sure that we onboard and we make it easier and attractive for new generations to contribute to the project is the only possible way to ensure that this continues to be the case for many years to come.
That’s why we are looking at first time contributions, or said differently, how many users make a first contribution in their first 12 months from joining the project. During 2024 I would like to look deeper into this data, reveal contribution data further on time, like after 24 and 36 months. For now this will be a good lighthouse that we can use to improve the contribution process.
Although last year's numbers give us a nice feeling of success, we want to be cautious about them, and try to make sure that the trend of previous years of a slight decline does not continue.
That is the reason why my first priority during the first months of 2024 is to review the registration process and the next step for new users on their contribution journey. From the form they are presented, to the documentation we are facilitating, to the messages we are sending them in the weeks and months after.
The changes we make should be guided as well by the next important graph, which is the Time To First Contribution. In other words, the amount of time a new user has taken to make their first contribution to Drupal.
You’ll see that the Contribution Health Dashboards includes other data that I have not mentioned in this post. It does not mean that it is not equally important, but given the Drupal Association has a finite amount of resources, we consider that this is the data that we need to track closely to get a grasp of the health of our contribution system.
For now, have a look at the Contribution Health Dashboards to get a grasp of the rest of the information that we have collected. If you are curious about the numbers and maybe would like to give us a hand, please do not hesitate to send me a message at alex.moreno@association.drupal.org
PyCon: Applications For Booth Space on Startup Row Are Now Open!
Applications For Booth Space on Startup Row Are Now Open
To all the startup founders out there, PyCon US organizers have some awesome news for you! The application window for Startup Row at PyCon US is now open.
You’ve got until March 15th to apply, but don’t delay. (And if you want to skip all this reading and go straight to the application, here’s a link for ya.)
That’s right! Your startup could get the best of what PyCon US has to offer:
- Coveted Expo Hall booth space
- Exclusive placement on the PyCon US website
- Access to the PyCon Jobs Fair (since, after all, there’s no better place to meet and recruit Python professionals)
- A unique in-person platform to access a fantastically diverse crowd of thousands of engineers, data wranglers, academic researchers, students, and enthusiasts who come to PyCon US.
Corporate sponsors pay thousands of dollars for this level of access, but to support the entrepreneurial community PyCon US organizers are excited to give the PyCon experience to up-and-coming startup companies for free. (Submitting a Startup Row application is completely free. To discourage no-shows at the conference itself, we do require a fully-refundable $400 deposit from companies who are selected for and accept a spot on Startup Row. If you show up, you’ll get your deposit back after the conference.)
Does My Startup Qualify?The goal of Startup Row is to give seed and early-stage companies access to the Python community. Here are the qualification criteria:
- Somewhat obviously: Python is used somewhere in your tech or business stack, the more of it the better!
- Your startup is roughly 2.5 years or less at the time of applying. (If you had a major pivot or took awhile to get a product in the market, measure from there.)
- You have 25 or fewer folks on the team, including founders, employees, and contractors.
- You or your company will fund travel and accommodation to PyCon US 2024 in Pittsburgh, Pennsylvania. (There’s a helpful page on the PyCon US website with venue and hotel information.)
- You haven’t already presented on Startup Row or sponsored a previous PyCon US. (If you applied before but weren’t accepted, please do apply again!)
There is a little bit of wiggle room. If your startup is more of a fuzzy rather than an exact match for these criteria, still consider applying.
How Do I Apply?Assuming you’ve already created a user account on the PyCon US website, applying for Startup Row is easy.
- Make sure you’re logged in.
- Go to the Startup Row application page and submit your application by March 15th. (Note: It might be helpful to draft your answers in a separate document.)
- Wait to hear back! Our goal is to notify folks about their application decision toward the end of March.
Again, the application deadline is March 15, 2024 at 11:59 PM Eastern. Applications submitted after that deadline may not be considered.
Can I learn more about Startup Row?You bet! Check out the Startup Row page for more details and testimonials from prior Startup Row participants. (There’s a link to the application there, too!)
Who do I contact with questions about Startup Row?First off, if you have questions about PyCon US in general, you can send an email to the PyCon US organizing team at pycon-reg@python.org. We’re always happy to help.
For specific Startup Row-related questions, reach out to co-chair Jason D. Rowley via email at jdr [at] omg [dot] lol, or find some time in his calendar at calendly [dot] com [slash] jdr.
Wait, What’s The Deadline Again?Again, the application deadline is March 15, 2024 at 11:59PM Eastern.
Good luck! We look forward to reviewing your application!
Paul Tagliamonte: Writing a simulator to check phased array beamforming 🌀
If you're on the Fediverse, I'd very much appreciate boosts on my toot!
While working on hz.tools, I started to move my beamforming code from 2-D (meaning, beamforming to some specific angle on the X-Y plane for waves on the X-Y plane) to 3-D. I’ll have more to say about that once I get around to publishing the code as soon as I’m sure it’s not completely wrong, but in the meantime I decided to write a simple simulator to visually check the beamformer against the textbooks. The results were pretty rad, so I figured I’d throw together a post since it’s interesting all on its own outside of beamforming as a general topic.
I figured I’d write this in Rust, since I’ve been using Rust as my primary language over at zoo, and it’s a good chance to learn the language better.
⚠️ This post has some large GIFsIt make take a little bit to load depending on your internet connection. Sorry about that, I'm not clever enough to do better without doing tons of complex engineering work. They may be choppy while they load or something. I tried to compress an ensmall them, so if they're loaded but fuzzy, click on them to load a slightly larger version.
This post won’t cover the basics of how phased arrays work or the specifics of calculating the phase offsets for each antenna, but I’ll dig into how I wrote a simple “simulator” and how I wound up checking my phase offsets to generate the renders below.
AssumptionsI didn’t want to build a general purpose RF simulator, anything particularly generic, or something that would solve for any more than the things right in front of me. To do this as simply (and quickly – all this code took about a day to write, including the beamforming math) – I had to reduce the amount of work in front of me.
Given that I was concerend with visualizing what the antenna pattern would look like in 3-D given some antenna geometry, operating frequency and configured beam, I made the following assumptions:
All anetnnas are perfectly isotropic – they receive a signal that is exactly the same strength no matter what direction the signal originates from.
There’s a single point-source isotropic emitter in the far-field (I modeled this as being 1 million meters away – 1000 kilometers) of the antenna system.
There is no noise, multipath, loss or distortion in the signal as it travels through space.
Antennas will never interfere with each other.
2-D Polar PlotsThe last time I wrote something like this, I generated 2-D GIFs which show a radiation pattern, not unlike the polar plots you’d see on a microphone.
These are handy because it lets you visualize what the directionality of the antenna looks like, as well as in what direction emissions are captured, and in what directions emissions are nulled out. You can see these plots on spec sheets for antennas in both 2-D and 3-D form.
Now, let’s port the 2-D approach to 3-D and see how well it works out.
Writing the 3-D simulatorAs an EM wave travels through free space, the place at which you sample the wave controls that phase you observe at each time-step. This means, assuming perfectly synchronized clocks, a transmitter and receiver exactly one RF wavelength apart will observe a signal in-phase, but a transmitter and receiver a half wavelength apart will observe a signal 180 degrees out of phase.
This means that if we take the distance between our point-source and antenna element, divide it by the wavelength, we can use the fractional part of the resulting number to determine the phase observed. If we multiply that number (in the range of 0 to just under 1) by tau, we can generate a complex number by taking the cos and sin of the multiplied phase (in the range of 0 to tau), assuming the transmitter is emitting a carrier wave at a static amplitude and all clocks are in perfect sync.
let observed_phases: Vec<Complex> = antennas .iter() .map(|antenna| { let distance = (antenna - tx).magnitude(); let distance = distance - (distance as i64 as f64); ((distance / wavelength) * TAU) }) .map(|phase| Complex(phase.cos(), phase.sin())) .collect();At this point, given some synthetic transmission point and each antenna, we know what the expected complex sample would be at each antenna. At this point, we can adjust the phase of each antenna according to the beamforming phase offset configuration, and add up every sample in order to determine what the entire system would collectively produce a sample as.
let beamformed_phases: Vec<Complex> = ...; let magnitude = beamformed_phases .iter() .zip(observed_phases.iter()) .map(|(beamformed, observed)| observed * beamformed) .reduce(|acc, el| acc + el) .unwrap() .abs();Armed with this information, it’s straight forward to generate some number of (Azimuth, Elevation) points to sample, generate a transmission point far away in that direction, resolve what the resulting Complex sample would be, take its magnitude, and use that to create an (x, y, z) point at (azimuth, elevation, magnitude). The color attached two that point is based on its distance from (0, 0, 0). I opted to use the Life Aquatic table for this one.
After this process is complete, I have a point cloud of ((x, y, z), (r, g, b)) points. I wrote a small program using kiss3d to render point cloud using tons of small spheres, and write out the frames to a set of PNGs, which get compiled into a GIF.
Now for the fun part, let’s take a look at some radiation patterns!
1x4 Phased ArrayThe first configuration is a phased array where all the elements are in perfect alignment on the y and z axis, and separated by some offset in the x axis. This configuration can sweep 180 degrees (not the full 360), but can’t be steared in elevation at all.
Let’s take a look at what this looks like for a well constructed 1x4 phased array:
And now let’s take a look at the renders as we play with the configuration of this array and make sure things look right. Our initial quarter-wavelength spacing is very effective and has some outstanding performance characteristics. Let’s check to see that everything looks right as a first test.
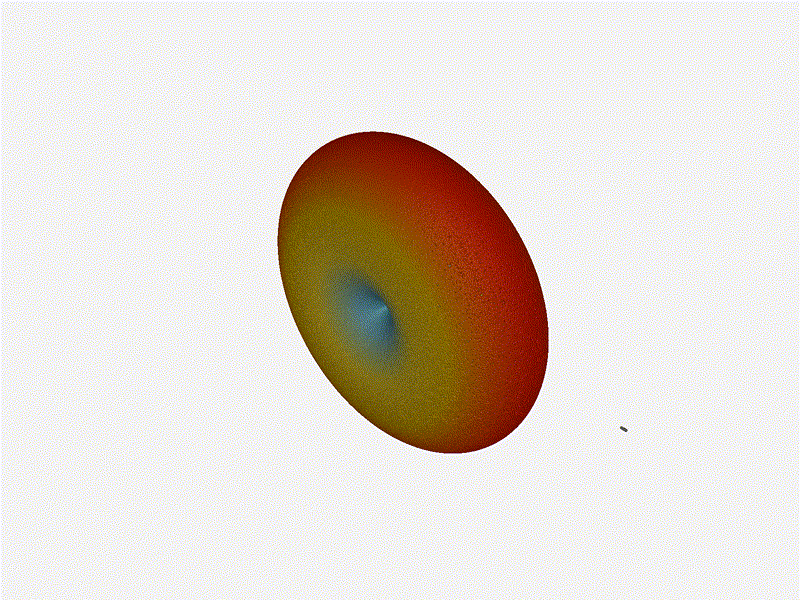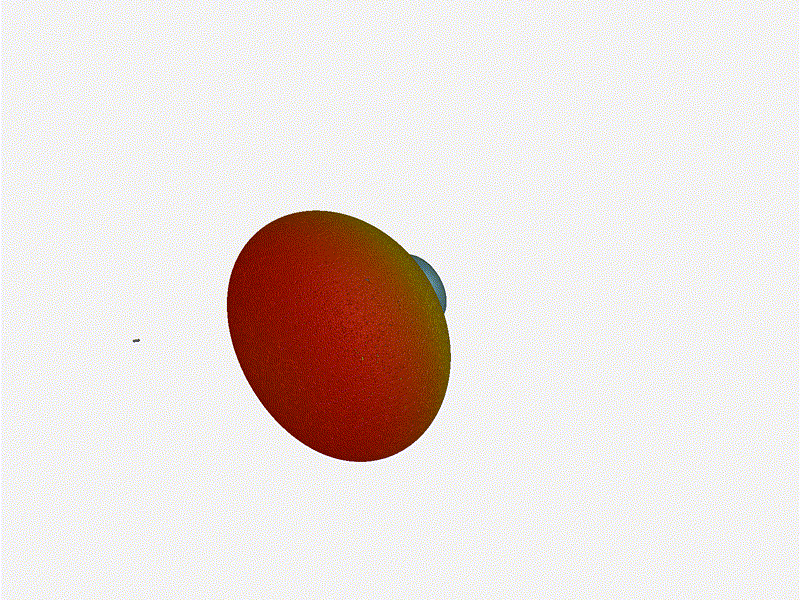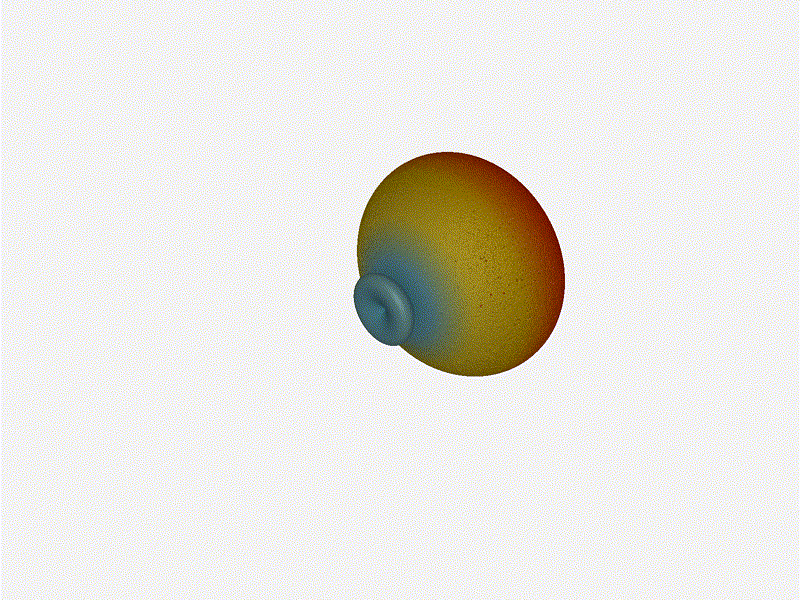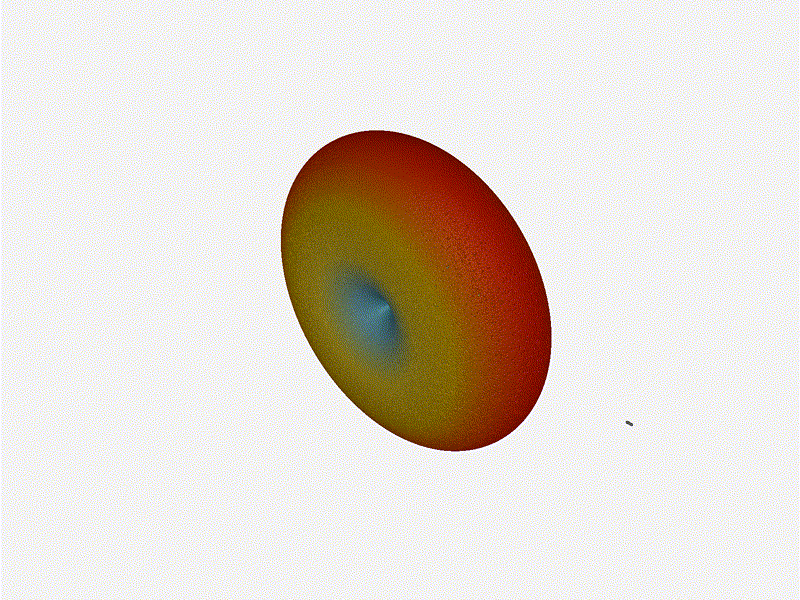{kind=link}
Nice. Looks perfect. When pointing forward at (0, 0), we’d expect to see a torus, which we do. As we sweep between 0 and 360, astute observers will notice the pattern is mirrored along the axis of the antennas, when the beam is facing forward to 0 degrees, it’ll also receive at 180 degrees just as strong. There’s a small sidelobe that forms when it’s configured along the array, but it also becomes the most directional, and the sidelobes remain fairly small.
Long compared to the wavelength (1¼ λ)Let’s try again, but rather than spacing each antenna ¼ of a wavelength apart, let’s see about spacing each antenna 1¼ of a wavelength apart instead.
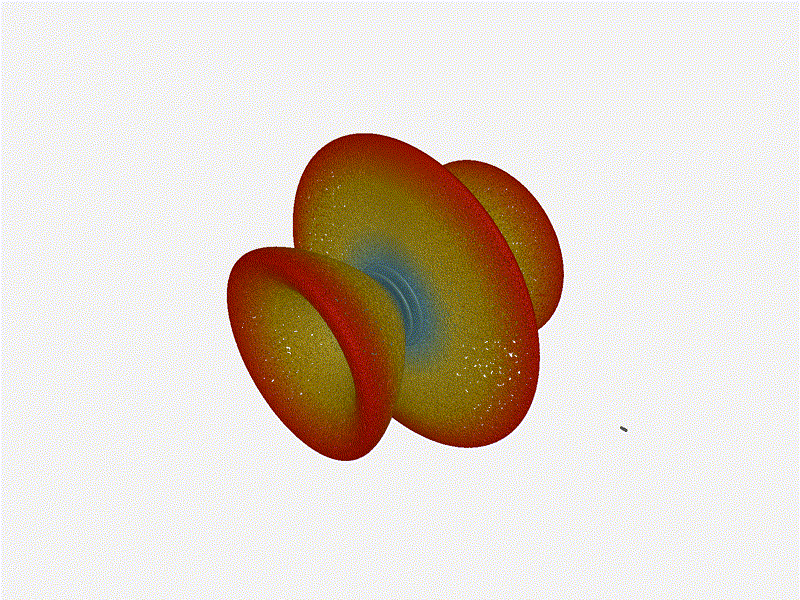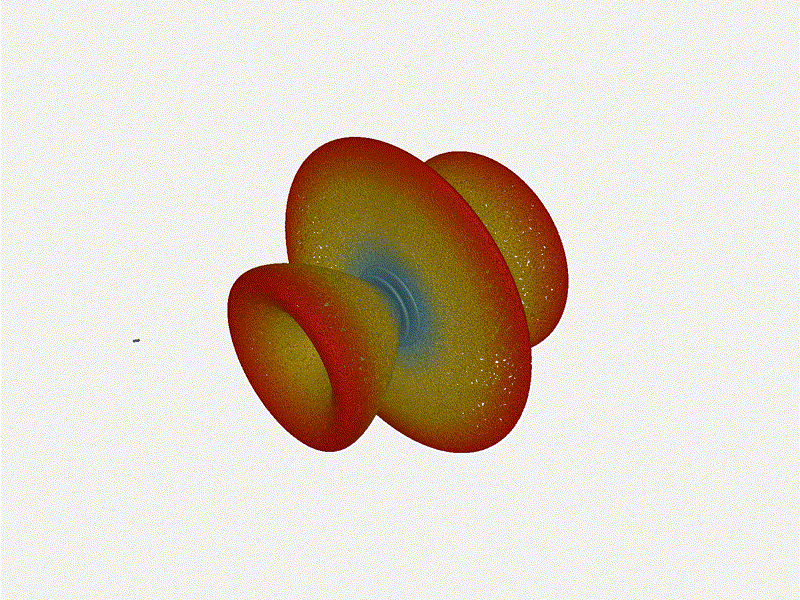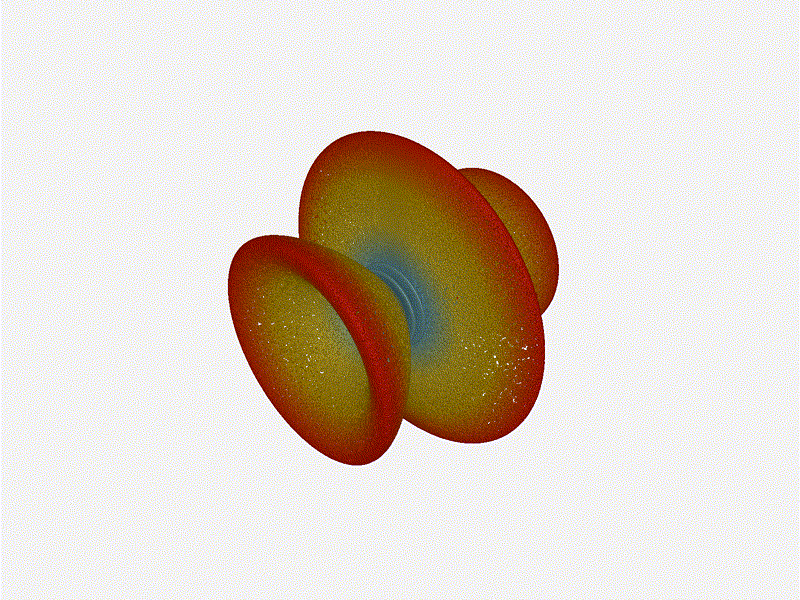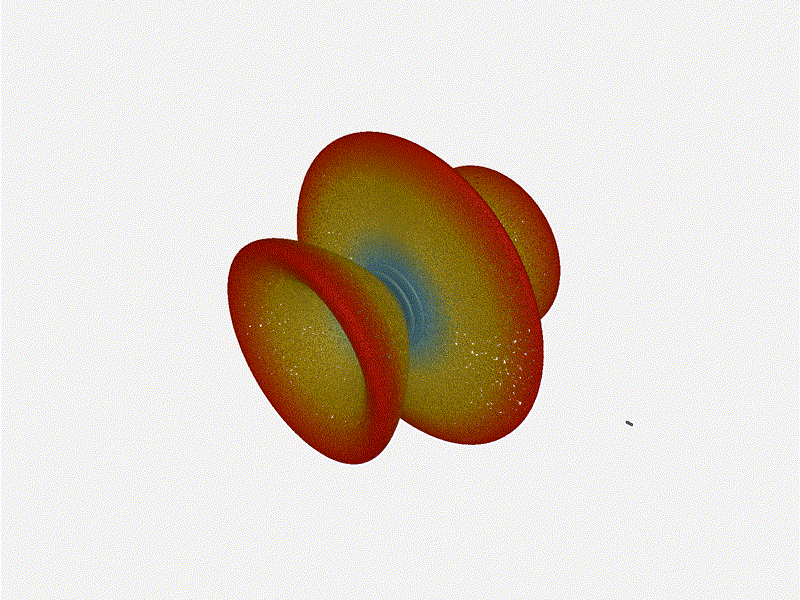{kind=link}
The main lobe is a lot more narrow (not a bad thing!), but some significant sidelobes have formed (not ideal). This can cause a lot of confusion when doing things that require a lot of directional resolution unless they’re compensated for.
Going from (¼ to 5¼ λ)The last model begs the question - what do things look like when you separate the antennas from each other but without moving the beam? Let’s simulate moving our antennas but not adjusting the configured beam or operating frequency.
{kind=link}
Very cool. As the spacing becomes longer in relation to the operating frequency, we can see the sidelobes start to form out of the end of the antenna system.
2x2 Phased ArrayThe second configuration I want to try is a phased array where the elements are in perfect alignment on the z axis, and separated by a fixed offset in either the x or y axis by their neighbor, forming a square when viewed along the x/y axis.
Let’s take a look at what this looks like for a well constructed 2x2 phased array:
Let’s do the same as above and take a look at the renders as we play with the configuration of this array and see what things look like. This configuration should suppress the sidelobes and give us good performance, and even give us some amount of control in elevation while we’re at it.
{kind=link}
Sweet. Heck yeah. The array is quite directional in the configured direction, and can even sweep a little bit in elevation, a definite improvement from the 1x4 above.
Long compared to the wavelength (1¼ λ)Let’s do the same thing as the 1x4 and take a look at what happens when the distance between elements is long compared to the frequency of operation – say, 1¼ of a wavelength apart? What happens to the sidelobes given this spacing when the frequency of operation is much different than the physical geometry?
{kind=link}
Mesmerising. This is my favorate render. The sidelobes are very fun to watch come in and out of existence. It looks absolutely other-worldly.
Going from (¼ to 5¼ λ)Finally, for completeness' sake, what do things look like when you separate the antennas from each other just as we did with the 1x4? Let’s simulate moving our antennas but not adjusting the configured beam or operating frequency.
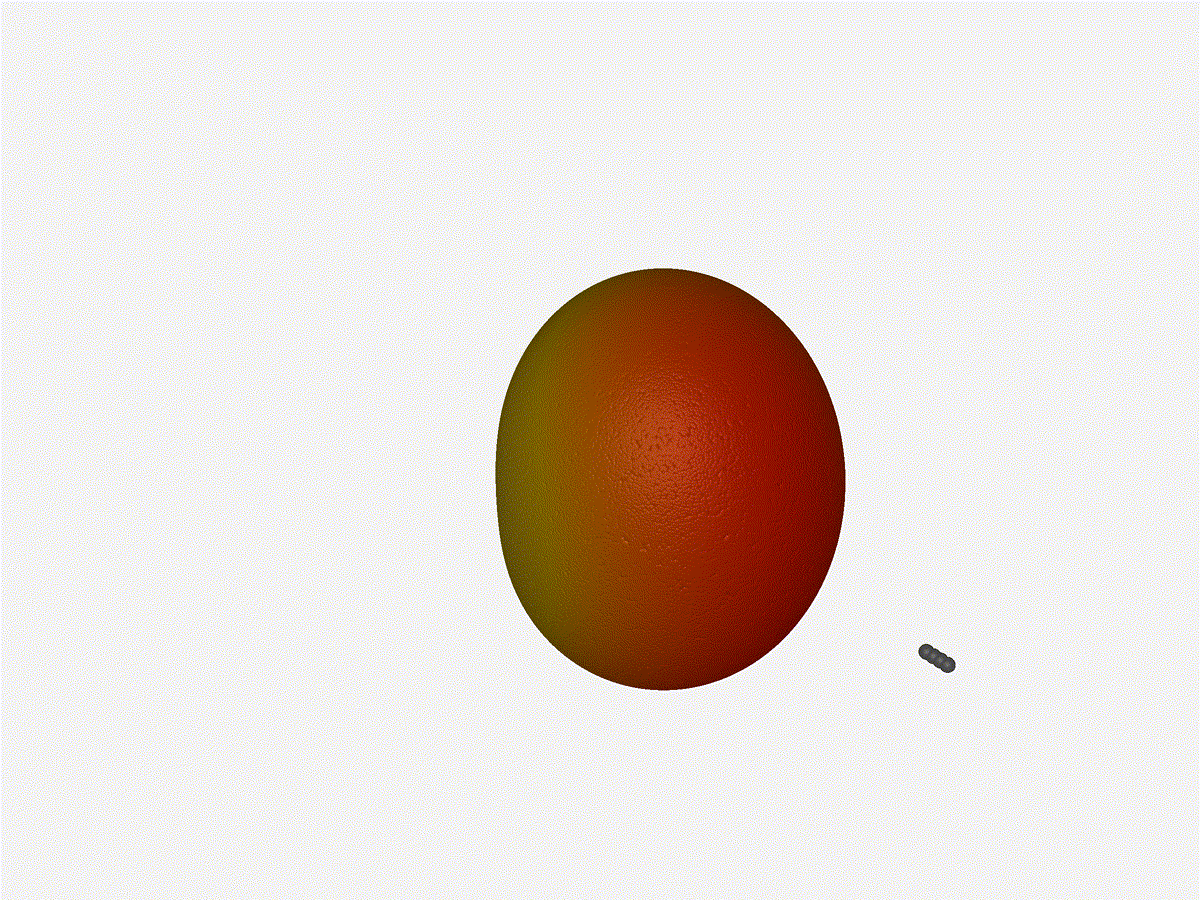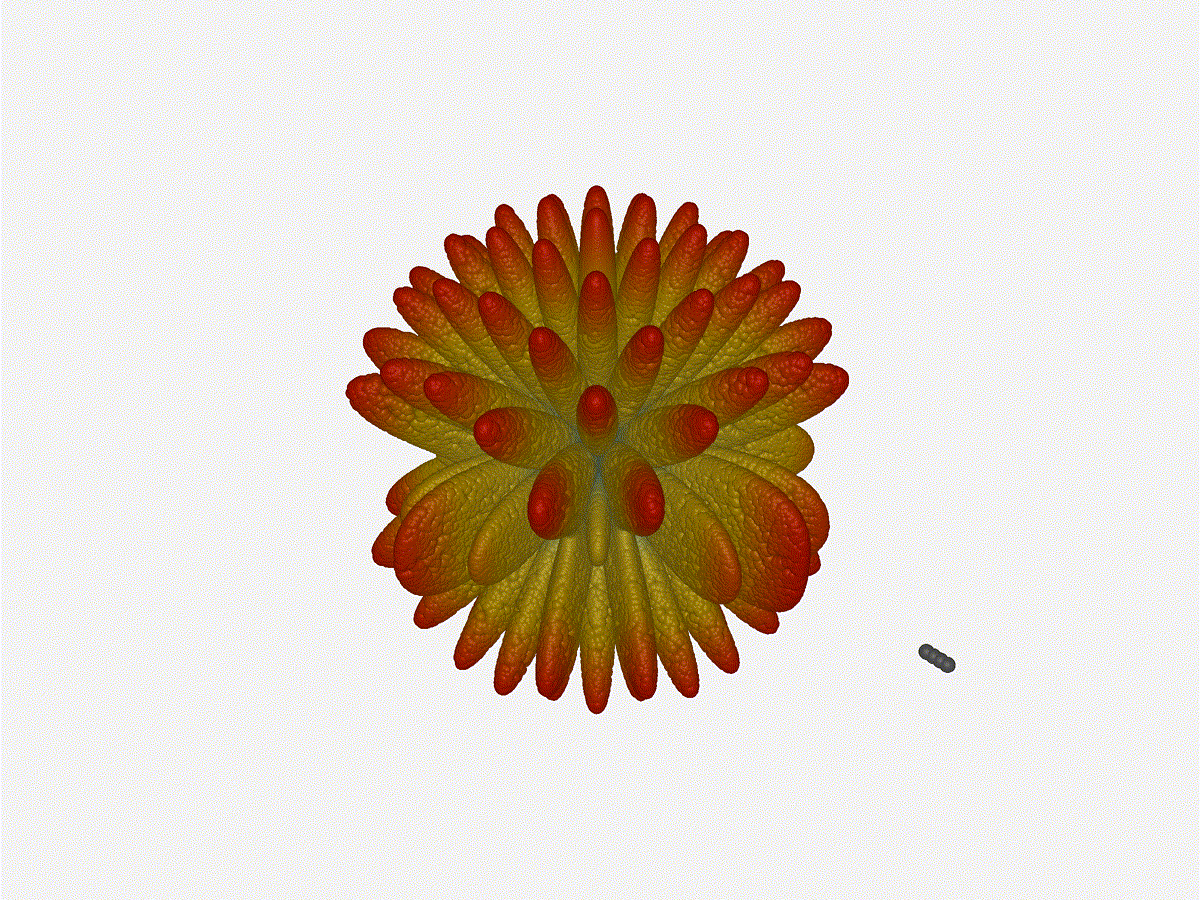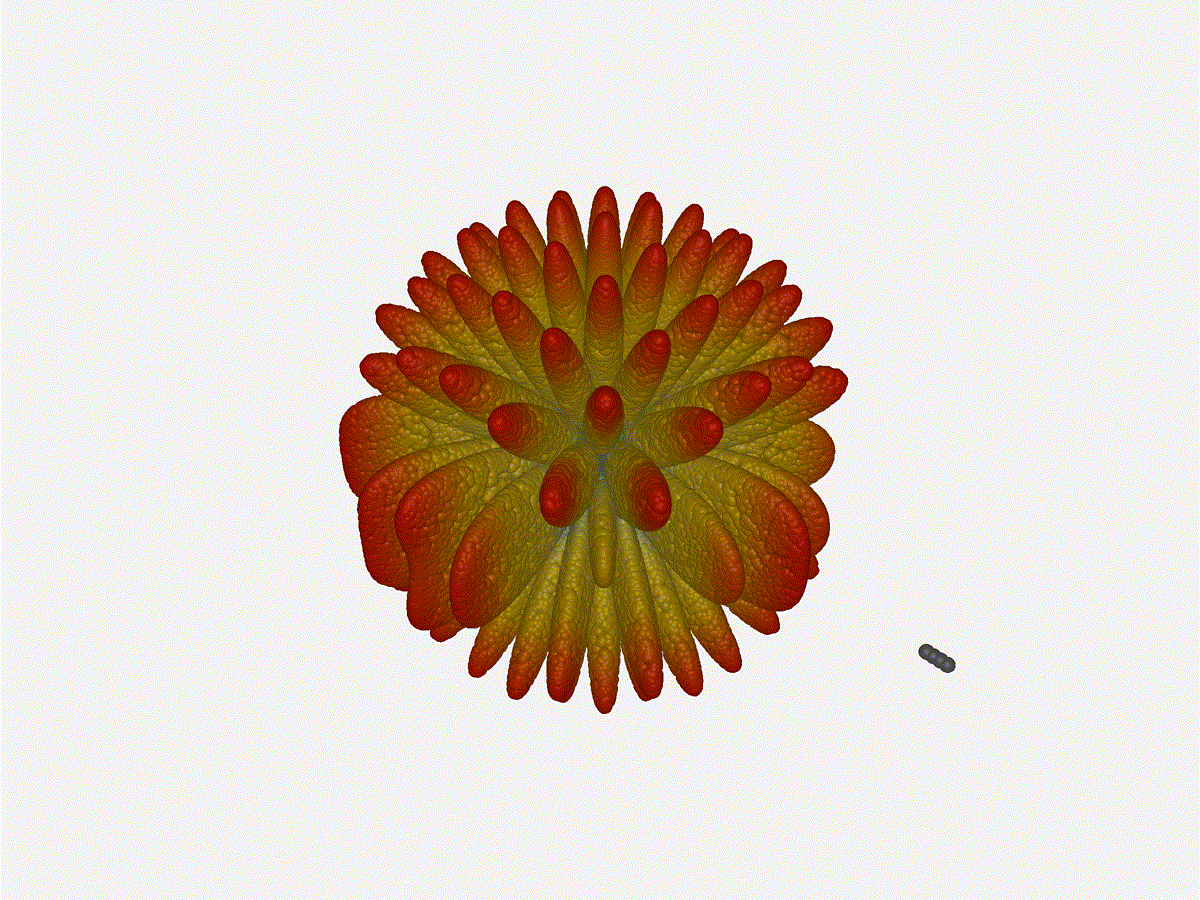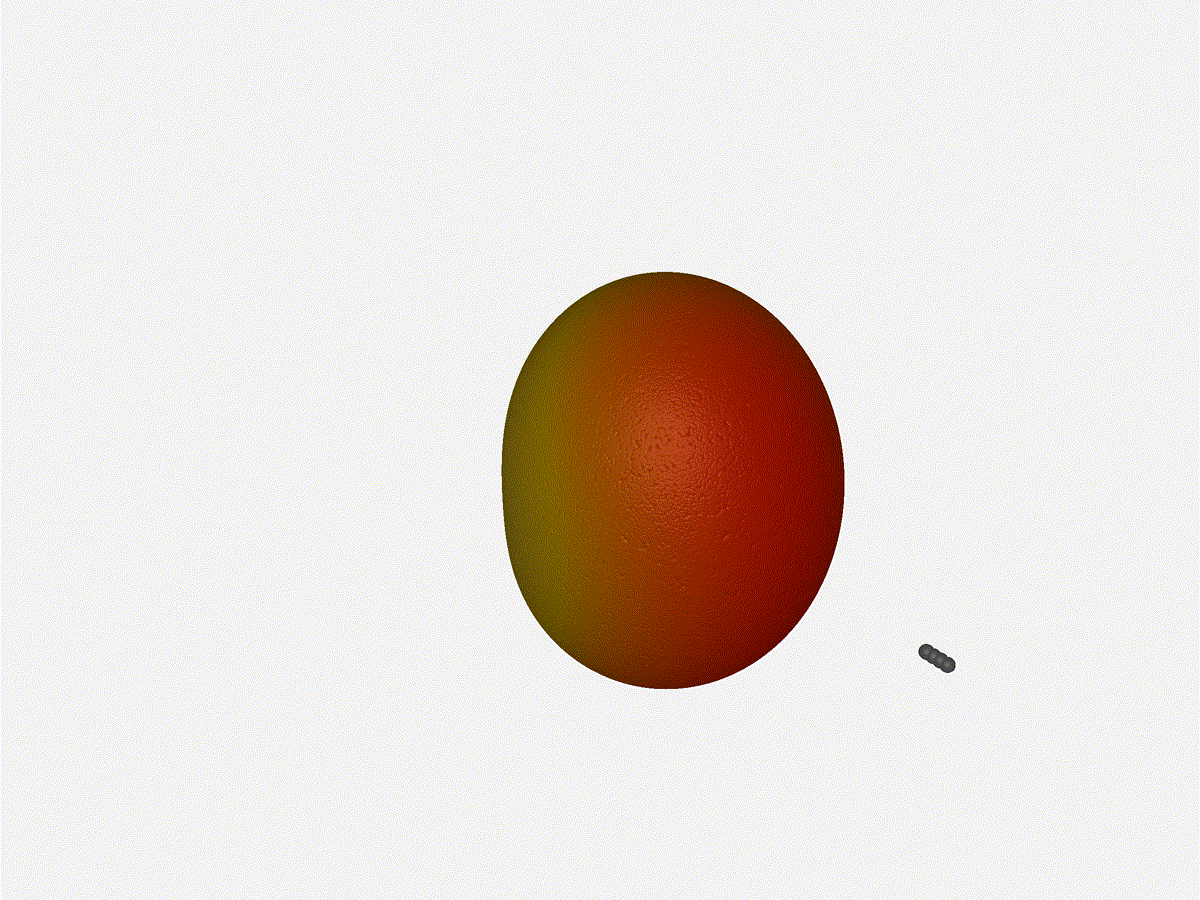{kind=link}
Very very cool. The sidelobes wind up turning the very blobby cardioid into an electromagnetic dog toy. I think we’ve proven to ourselves that using a phased array much outside its designed frequency of operation seems like a real bad idea.
Future WorkNow that I have a system to test things out, I’m a bit more confident that my beamforming code is close to right! I’d love to push that code over the line and blog about it, since it’s a really interesting topic on its own. Once I’m sure the code involved isn’t full of lies, I’ll put it up on the hztools org, and post about it here and on mastodon.
Real Python: When to Use a List Comprehension in Python
One of Python’s most distinctive features is the list comprehension, which you can use to create powerful functionality within a single line of code. However, many developers struggle to fully leverage the more advanced features of list comprehensions in Python. Some programmers even use them too much, which can lead to code that’s less efficient and harder to read.
By the end of this tutorial, you’ll understand the full power of Python list comprehensions and know how to use their features comfortably. You’ll also gain an understanding of the trade-offs that come with using them so that you can determine when other approaches are preferable.
In this tutorial, you’ll learn how to:
- Rewrite loops and map() calls as list comprehensions in Python
- Choose between comprehensions, loops, and map() calls
- Supercharge your comprehensions with conditional logic
- Use comprehensions to replace filter()
- Profile your code to resolve performance questions
Get Your Code: Click here to download the free code that shows you how and when to use list comprehensions in Python.
Transforming Lists in PythonThere are a few different ways to create and add items to a lists in Python. In this section, you’ll explore for loops and the map() function to perform these tasks. Then, you’ll move on to learn about how to use list comprehensions and when list comprehensions can benefit your Python program.
Use for LoopsThe most common type of loop is the for loop. You can use a for loop to create a list of elements in three steps:
- Instantiate an empty list.
- Loop over an iterable or range of elements.
- Append each element to the end of the list.
If you want to create a list containing the first ten perfect squares, then you can complete these steps in three lines of code:
Python >>> squares = [] >>> for number in range(10): ... squares.append(number * number) ... >>> squares [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] Copied!Here, you instantiate an empty list, squares. Then, you use a for loop to iterate over range(10). Finally, you multiply each number by itself and append the result to the end of the list.
Work With map ObjectsFor an alternative approach that’s based in functional programming, you can use map(). You pass in a function and an iterable, and map() will create an object. This object contains the result that you’d get from running each iterable element through the supplied function.
As an example, consider a situation in which you need to calculate the price after tax for a list of transactions:
Python >>> prices = [1.09, 23.56, 57.84, 4.56, 6.78] >>> TAX_RATE = .08 >>> def get_price_with_tax(price): ... return price * (1 + TAX_RATE) ... >>> final_prices = map(get_price_with_tax, prices) >>> final_prices <map object at 0x7f34da341f90> >>> list(final_prices) [1.1772000000000002, 25.4448, 62.467200000000005, 4.9248, 7.322400000000001] Copied!Here, you have an iterable, prices, and a function, get_price_with_tax(). You pass both of these arguments to map() and store the resulting map object in final_prices. Finally, you convert final_prices into a list using list().
Leverage List ComprehensionsList comprehensions are a third way of making or transforming lists. With this elegant approach, you could rewrite the for loop from the first example in just a single line of code:
Python >>> squares = [number * number for number in range(10)] >>> squares [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] Copied!Rather than creating an empty list and adding each element to the end, you simply define the list and its contents at the same time by following this format:
new_list = [expression for member in iterable]Every list comprehension in Python includes three elements:
- expression is the member itself, a call to a method, or any other valid expression that returns a value. In the example above, the expression number * number is the square of the member value.
- member is the object or value in the list or iterable. In the example above, the member value is number.
- iterable is a list, set, sequence, generator, or any other object that can return its elements one at a time. In the example above, the iterable is range(10).
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Russell Coker: Storage Trends 2024
It has been less than a year since my last post about storage trends [1] and enough has changed to make it worth writing again. My previous analysis was that for <2TB only SSD made sense, for 4TB SSD made sense for business use while hard drives were still a good option for home use, and for 8TB+ hard drives were clearly the best choice for most uses. I will start by looking at MSY prices, they aren't the cheapest (you can get cheaper online) but they are competitive and they make it easy to compare the different options. I'll also compare the cheapest options in each size, there are more expensive options but usually if you want to pay more then the performance benefits of SSD (both SATA and NVMe) are even more appealing. All prices are in Australian dollars and of parts that are readily available in Australia, but the relative prices of the parts are probably similar in most countries. The main issue here is when to use SSD and when to use hard disks, and then if SSD is chosen which variety to use.
Small StorageFor my last post the cheapest storage devices from MSY were $19 for a 128G SSD, now it’s $24 for a 128G SSD or NVMe device. I don’t think the Australian dollar has dropped much against foreign currencies, so I guess this is partly companies wanting more profits and partly due to the demand for more storage. Items that can’t sell in quantity need higher profit margins if they are to have them in stock. 500G SSDs are around $33 and 500G NVMe devices for $36 so for most use cases it wouldn’t make sense to buy anything smaller than 500G.
The cheapest hard drive is $45 for a 1TB disk. A 1TB SATA SSD costs $61 and a 1TB NVMe costs $79. So 1TB disks aren’t a good option for any use case.
A 2TB hard drive is $89. A 2TB SATA SSD is $118 and a 2TB NVMe is $145. I don’t think the small savings you can get from using hard drives makes them worth using for 2TB.
For most people if you have a system that’s important to you then $145 on storage isn’t a lot to spend. It seems hardly worth buying less than 2TB of storage, even for a laptop. Even if you don’t use all the space larger storage devices tend to support more writes before wearing out so you still gain from it. A 2TB NVMe device you buy for a laptop now could be used in every replacement laptop for the next 10 years. I only have 512G of storage in my laptop because I have a collection of SSD/NVMe devices that have been replaced in larger systems, so the 512G is essentially free for my laptop as I bought a larger device for a server.
For small business use it doesn’t make sense to buy anything smaller than 2TB for any system other than a router. If you buy smaller devices then you will sometimes have to pay people to install bigger ones and when the price is $145 it’s best to just pay that up front and be done with it.
Medium StorageA 4TB hard drive is $135. A 4TB SATA SSD is $319 and a 4TB NVMe is $299. The prices haven’t changed a lot since last year, but a small increase in hard drive prices and a small decrease in SSD prices makes SSD more appealing for this market segment.
A common size range for home servers and small business servers is 4TB or 8TB of storage. To do that on SSD means about $600 for 4TB of RAID-1 or $900 for 8TB of RAID-5/RAID-Z. That’s quite affordable for that use.
For 8TB of less important storage a 8TB hard drive costs $239 and a 8TB SATA SSD costs $899 so a hard drive clearly wins for the specific case of non-RAID single device storage. Note that the U.2 devices are more competitive for 8TB than SATA but I included them in the next section because they are more difficult to install.
Serious StorageWith 8TB being an uncommon and expensive option for consumer SSDs the cheapest price is for multiple 4TB devices. To have multiple NVMe devices in one PCIe slot you need PCIe bifurcation (treating the PCIe slot as multiple slots). Most of the machines I use don’t support bifurcation and most affordable systems with ECC RAM don’t have it. For cheap NVMe type storage there are U.2 devices (the “enterprise” form of NVMe). Until recently they were too expensive to use for desktop systems but now there are PCIe cards for internal U.2 devices, $14 for a card that takes a single U.2 is a common price on AliExpress and prices below $600 for a 7.68TB U.2 device are common – that’s cheaper on a per-TB basis than SATA SSD and NVMe! There are PCIe cards that take up to 4*U.2 devices (which probably require bifurcation) which means you could have 8+ U.2 devices in one not particularly high end PC for 56TB of RAID-Z NVMe storage. Admittedly $4200 for 56TB is moderately expensive, but it’s in the price range for a small business server or a high end home server. A more common configuration might be 2*7.68TB U.2 on a single PCIe card (or 2 cards if you don’t have bifurcation) for 7.68TB of RAID-1 storage.
For SATA SSD AliExpress has a 6*2.5″ hot-swap device that fits in a 5.25″ bay for $63, so if you have 2*5.25″ bays you could have 12*4TB SSDs for 44TB of RAID-Z storage. That wouldn’t be much cheaper than 8*7.68TB U.2 devices and would be slower and have less space. But it would be a good option if PCIe bifurcation isn’t possible.
16TB SATA hard drives cost $559 which is almost exactly half the price per TB of U.2 storage. That doesn’t seem like a good deal. If you want 16TB of RAID storage then 3*7.68TB U.2 devices only costs about 50% more than 2*16TB SATA disks. In most cases paying 50% more to get NVMe instead of hard disks is a good option. As sizes go above 16TB prices go up in a more than linear manner, I guess they don’t sell much volume of larger drives.
15.36TB U.2 devices are on sale for about $1300, slightly more than twice the price of a 16TB disk. It’s within the price range of small businesses and serious home users. Also it should be noted that the U.2 devices are designed for “enterprise” levels of reliability and the hard disk prices I’m comparing to are the cheapest available. If “NAS” hard disks were compared then the price benefit of hard disks would be smaller.
Probably the biggest problem with U.2 for most people is that it’s an uncommon technology that few people have much experience with or spare parts for testing. Also you can’t buy U.2 gear at your local computer store which might mean that you want to have spare parts on hand which is an extra expense.
For enterprise use I’ve recently been involved in discussions with a vendor that sells multiple petabyte arrays of NVMe. Apparently NVMe is cheap enough that there’s no need to use anything else if you want a well performing file server.
Do Hard Disks Make Sense?There are specific cases like comparing a 8TB hard disk to a 8TB SATA SSD or a 16TB hard disk to a 15.36TB U.2 device where hard disks have an apparent advantage. But when comparing RAID storage and counting the performance benefits of SSD the savings of using hard disks don’t seem to be that great.
Is now the time that hard disks are going to die in the market? If they can’t get volume sales then prices will go up due to lack of economy of scale in manufacture and increased stock time for retailers. 8TB hard drives are now more expensive than they were 9 months ago when I wrote my previous post, has a hard drive price death spiral already started?
SSDs are cheaper than hard disks at the smallest sizes, faster (apart from some corner cases with contiguous IO), take less space in a computer, and make less noise. At worst they are a bit over twice the cost per TB. But the most common requirements for storage are small enough and cheap enough that being twice as expensive as hard drives isn’t a problem for most people.
I predict that hard disks will become less popular in future and offer less of a price advantage. The vendors are talking about 50TB hard disks being available in future but right now you can fit more than 50TB of NVMe or U.2 devices in a volume less than that of a 3.5″ hard disk so for storage density SSD can clearly win. Maybe in future hard disks will be used in arrays of 100TB devices for large scale enterprise storage. But for home users and small businesses the current sizes of SSD cover most uses.
At the moment it seems that the one case where hard disks can really compare well is for backup devices. For backups you want large storage, good contiguous write speeds, and low prices so you can buy plenty of them.
Further IssuesThe prices I’ve compared for SATA SSD and NVMe devices are all based on the cheapest devices available. I think it’s a bit of a market for lemons [2] as devices often don’t perform as well as expected and the incidence of fake products purporting to be from reputable companies is high on the cheaper sites. So you might as well buy the cheaper devices. An advantage of the U.2 devices is that you know that they will be reliable and perform well.
One thing that concerns me about SSDs is the lack of knowledge of their failure cases. Filesystems like ZFS were specifically designed to cope with common failure cases of hard disks and I don’t think we have that much knowledge about how SSDs fail. But with 3 copies of metadata BTFS or ZFS should survive unexpected SSD failure modes.
I still have some hard drives in my home server, they keep working well enough and the prices on SSDs keep dropping. But if I was buying new storage for such a server now I’d get U.2.
I wonder if tape will make a comeback for backup.
Does anyone know of other good storage options that I missed?
- [1] https://etbe.coker.com.au/2023/04/09/storage-trends-2023/
- [2] https://en.wikipedia.org/wiki/The_Market_for_Lemons
Related posts:
- Storage Trends 2023 It’s been 2 years since my last blog post about...
- Storage Trends 2021 The Viability of Small Disks Less than a year ago...
- Storage Trends In considering storage trends for the consumer side I’m looking...
LN Webworks: AWS S3 Bucket File Upload In Drupal
- Log in to AWS Console: Go to the AWS Management Console and log in to your account.
- Navigate to S3: In the AWS Console, find and click on the "S3" service.
- Create a Bucket: Click the "Create bucket" button, provide a unique and meaningful name for your bucket, and choose the region where you want to create the bucket.
- Configure Options: Set the desired configuration options, such as versioning, logging, and tags. Click through the configuration steps, review your settings, and create the bucket.
$settings['s3fs.access_key'] = "YOUR_ACCESS_KEY";
$settings['s3fs.secret_key'] = "YOUR_SECRET_KEY";
$settings['s3fs.region'] = "us-east-1";
$settings['s3fs.upload_as_public'] = TRUE;
ADCI Solutions: How to Upgrade Drupal 7 and 8 to Drupal 10: Step-by-Step Guide
Developers of the ADCI Solutions Studio explain why you need to upgrade your Drupal 7 and 8 websites to Drupal 10 and what makes the migration process different from a routine CMS update.
Zato Blog: How to correctly integrate APIs in Python
Understanding how to effectively integrate various systems and APIs is crucial. Yet, without a dedicated integration platform, the result will be brittle point-to-point integrations that never lead to good outcomes.
➤ Read this article about Zato, an open-source integration platform in Python, for an overview of what to avoid and how to do it correctly instead.
More blog posts➤Dirk Eddelbuettel: RProtoBuf 0.4.22 on CRAN: Updated Windows Support!
A new maintenance release 0.4.22 of RProtoBuf arrived on CRAN earlier today. RProtoBuf provides R with bindings for the Google Protocol Buffers (“ProtoBuf”) data encoding and serialization library used and released by Google, and deployed very widely in numerous projects as a language and operating-system agnostic protocol.
This release matches the recent 0.4.21 release which enabled use of the package with newer ProtoBuf releases. Tomas has been updating the Windows / rtools side of things, and supplied us with simple PR that will enable building with those updated versions once finalised.
The following section from the NEWS.Rd file has full details.
Changes in RProtoBuf version 0.4.22 (2022-12-13)- Apply patch by Tomas Kalibera to support updated rtools to build with newer ProtoBuf releases on windows
Thanks to my CRANberries, there is a diff to the previous release. The RProtoBuf page has copies of the (older) package vignette, the ‘quick’ overview vignette, and the pre-print of our JSS paper. Questions, comments etc should go to the GitHub issue tracker off the GitHub repo.
If you like this or other open-source work I do, you can sponsor me at GitHub.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
Luke Plant: Python packaging must be getting better - a datapoint
I’m developing some Python software for a client, which in its current early state is desktop software that will need to run on Windows.
So far, however, I have done all development on my normal comfortable Linux machine. I haven’t really used Windows in earnest for more than 15 years – to the point where my wife happily installs Linux on her own machine, knowing that I’ll be hopeless at helping her fix issues if the OS is Windows – and certainly not for development work in that time. So I was expecting a fair amount of pain.
There was certainly a lot of friction getting a development environment set up. RealPython.com have a great guide which got me a long way, but even that had some holes and a lot of inconvenience, mostly due to the fact that, on the machine I needed to use, my main login and my admin login are separate. (I’m very lucky to be granted an admin login at all, so I’m not complaining). And there are lots of ways that Windows just seems to be broken, but that’s another blog post.
When it came to getting my app running, however, I was very pleasantly surprised.
At this stage in development, I just have a rough requirements.txt that I add Python deps to manually. This might be a good thing, as I avoid the pain of some the additional layers people have added.
So after installing Python and creating a virtual environment on Windows, I ran pip install -r requirements.txt, expecting a world of pain, especially as I already had complex non-Python dependencies, including Qt5 and VTK. I had specified both of these as simple Python deps via the wrappers pyqt5 and vtk in my requirements.txt, and nothing else, with the attitude of “well I may as well dream this is going to work”.
And in fact, it did! Everything just downloaded as binary wheels – rather large ones, but that’s fine. I didn’t need compilers or QMake or header files or anything.
And when I ran my app, apart from a dependency that I’d forgotten to add to requirements.txt, everything worked perfectly first time. This was even more surprising as I had put zero conscious effort into Windows compatibility. In retrospect I realise that use of pathlib, which is automatic for me these days, had helped me because it smooths over some Windows/Unix differences with path handling.
Of course, this is a single datapoint. From other people’s reports there are many, many ways that this experience may not be typical. But that it is possible at all suggests that a lot of progress has been made and we are very much going in the right direction. A lot of people have put a lot of work in to achieve that, for which I’m very grateful!
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
- Introducing the Enhanced KubuQA: Revolutionising ISO Testing Across Ubuntu Flavors
- Steinar H. Gunderson: Wikimedia jumps on the AI bandwagon
- Elana Hashman: I am very sick
- Daniel Lange: htop and PCP have a new home at Hack Club
- Freexian Collaborators: Debian Contributions: Salsa CI updates, OpenSSH option review, and more! (by Utkarsh Gupta)