
Feeds
Dirk Eddelbuettel: BH 1.84.0-1 on CRAN: New Upstream
Boost is a very large and comprehensive set of (peer-reviewed) libraries for the C++ programming language, containing well over one hundred individual libraries. The BH package provides a sizeable subset of header-only libraries for (easier, no linking required) use by R. It is fairly widely used: the (partial) CRAN mirror logs (aggregated from the cloud mirrors) show over 35.7 million package downloads.
Version 1.84.0 of Boost was released in December following the regular Boost release schedule of April, August and December releases. As the commits and changelog show, we packaged it almost immediately and started testing following our annual update cycle which strives to balance being close enough to upstream and not stressing CRAN and the user base too much. The reverse depends check revealed five packages requiring changes or adjustments which is a pretty good outcome given the over three hundred direct reverse dependencies. So we opened issue #100 to coordinate the issue over the winter break during which CRAN also closes (just as we did in previous years). Our sincere thanks to the two packages that already updated before, and to the one that updated today within hours (!!) of the BH uploaded it needed.
There are very few actual changes. We honoured one request (in issue #97) to add Boost QVM bringing quarternion support to R. No other new changes needed to be made. A number of changes I have to make each time in BH, and it is worth mentioning them. Because CRAN cares about backwards compatibility and the ability to be used on minimal or older systems, we still adjust the filenames of a few files to fit a jurassic constraints of just over a 100 characters per filepath present in some long-outdated versions of tar. Not a big deal. We also, and that is more controversial, silence a number of #pragma diagnostic messages for g++ and clang++ because CRAN insists on it. I have no choice in that matter. One warning we suppressed last year, but no longer do, concerns the C++14 standard that some Boost libraries now default to. Packages setting C++11 explicitly will likely get a note from CRAN changing this; in most cases that should be trivial to remove as we only had to opt into (then) newer standards under old compilers. These days newer defaults help; R itself now defaults to C++17.
Changes in version 1.84.0-0 (2024-01-09)Via my CRANberries, there is a diffstat report relative to the previous release. Comments and suggestions about BH are welcome via the issue tracker at the GitHub repo.
If you like this or other open-source work I do, you can now sponsor me at GitHub.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
Gabriel-Cezarin Popovici helps the campaigns team to spread the message that we need to fight for our digital freedom
FSF Blogs: Gabriel-Cezarin Popovici helps the campaigns team to spread the message that we need to fight for our digital freedom
TestDriven.io: Django vs. Flask in 2024: Which Framework to Choose
Nikola: Nikola v8.3.0 is out!
On behalf of the Nikola team, I am pleased to announce the immediate availability of Nikola v8.3.0. This release adds support for Python 3.12, with some other features and bugfixes.
Note that Nikola v8.3.0 no longer uses the Yapsy plugin manager, which has been replaced by a custom, minimal manager. The new Nikola Plugin Manager was tested with some typical plugins, but there might be issues if your plugins have an unusual structure or are outdated. Please update your plugins and report any bugs you may encounter.
The Nikola developers would also like to express discontent with Python’s efforts to remove features from the standard library, causing breakage without a solid reason, other than “it’s old”.
What is Nikola?Nikola is a static site and blog generator, written in Python. It can use Mako and Jinja2 templates, and input in many popular markup formats, such as reStructuredText and Markdown — and can even turn Jupyter Notebooks into blog posts! It also supports image galleries, and is multilingual. Nikola is flexible, and page builds are extremely fast, courtesy of doit (which is rebuilding only what has been changed).
Find out more at the website: https://getnikola.com/
DownloadsInstall using pip install Nikola.
Changes FeaturesImplement a new plugin manager from scratch to replace Yapsy, which does not work on Python 3.12 due to Python 3.12 carelessly removing parts of the standard library (Issue #3719)
Support for Discourse as comment system (Issue #3689)
Fix loading of templates from plugins with __init__.py files (Issue #3725)
Fix margins of paragraphs at the end of sections (Issue #3704)
Ignore .DS_Store files in listing indexes (Issue #3698)
Fix baguetteBox.js invoking in the base theme (Issue #3687)
Fix development (preview) server nikola auto for non-root SITE_URL, in particular when URL_TYPE is full_path. (Issue #3715)
Nikola now requires the .plugin file to contain a [Nikola] section with a PluginCategory entry set to the name of the plugin category class. This was already required by plugins.getnikola.com, but you may have custom plugins that don’t have this set.
PreviousNext: Real-time: Symfony Messenger Consume command and prioritised messages
The greatest advantage of Symfony Messenger is arguably the ability to send and process messages in a different thread almost immediately. This post covers the worker that powers this functionality.
by daniel.phin / 11 January 2024This post is part 3 in a series about Symfony Messenger.
- Introducing Symfony Messenger integrations with Drupal
- Symfony Messenger’ message and message handlers, and comparison with @QueueWorker
- Real-time: Symfony Messenger’ Consume command and prioritised messages
- Automatic message scheduling and replacing hook_cron
- Adding real-time processing to QueueWorker plugins
- Making Symfony Mailer asynchronous: integration with Symfony Messenger
- Displaying notifications when Symfony Messenger messages are processed
- Future of Symfony Messenger in Drupal
The Symfony Messenger integration, including the worker, is provided by the SM project. The worker is tasked with listening for messages ready to be dispatched from an asynchronous transport, such as the Doctrine database transport. The worker then re-dispatches the message onto the bus.
Some messages may be added to a bus with no particular execution time, in which case they are serialised by the original thread. Then unserialised almost immediately by the consume command in a different thread.
Since Messenger has the concept of delaying messages until a particular date, the DelayStamp can be utilised. The consume command respects this stamp and will not redispatch a message until the time is right.
The worker is found in the sm console application, rather than Drush. When SM is installed, Composer makes the application available in your bin directory. Typically at /vendor/bin/sm
The command takes one or more transports as the argument. For example if you’re using the Doctrine transport, the command would be:
sm messenger:consume doctrine
Multiple instances of the worker may be run simultaneously to improve throughput.
The worker. Messages output to stdout for demonstration purposes.Prioritised messagesThe worker allows you to prioritise the processing of messages by which transport a message was dispatched to. Transport prioritisation is achieved by adding a space separated list of transports as the command argument.
For example, given transports defined in a site-level services.yml file:
parameters: sm.transports: doctrine: dsn: 'doctrine://default?table_name=messenger_messages' highpriority: dsn: 'doctrine://default?table_name=messenger_messages_high' lowpriority: dsn: 'doctrine://default?table_name=messenger_messages_low'In this case, the command would be sm messenger:consume highpriority doctrine lowpriority
Routing from messages to transports must also be configured appropriately. For example, you may decide Email messages are the highest priority. \Symfony\Component\Mailer\Messenger\SendEmailMessage would be mapped to highpriority:
parameters: sm.routing: Symfony\Component\Mailer\Messenger\SendEmailMessage: highpriority Drupal\my_module\LessImportantMessage: lowpriority '*': doctrineMore information on routing can be found in the previous post.
The transport a message is sent to may also be overridden on an individual message basis by utilising the Symfony\Component\Messenger\Stamp\TransportNamesStamp stamp. Though for simplicity I’d recommend sticking to standard routing.
Running the CLI applicationThe sm worker listens and processes messages, and is designed to run forever. A variety of built in flags are included, with the ability to quit when a memory or time limit is reached, or when a certain number of messages are processed or fail. Flags can be combined to process available messages and quit, much like drush queue:run.
Further information on how to use the worker in production can be found in the Consuming Messages (Running the Worker) documentation.
The next post covers Cron and Scheduled messages, a viable replacement to hook_cron.
Tagged Symfony, Symfony Messenger, Symfony Console, CLIThe Drop Times: Essential Drupal Modules that Help you Prevent Spam
Drupal Association blog: DrupalCon 2024 - How to Convince Your Boss (Sample Letter Enclosed)
DrupalCon 2024 is approaching soon, and you can’t wait to head to vibrant Portland. If this is you, you also must be stressed about persuading your boss to invest in your attendance at the Drupal event of the year. But don’t worry, we’ve got you covered! This article is your go-to resource, where you’ll find all the ammo you need to make your case. Let’s get started!
But First, Are You Convinced About Attending DrupalCon?Naturally, your organization has various factors to weigh, with the primary concern being whether sending you to DrupalCon Portland is worth their investment. But the pivotal question is the value you see in it. Explore our list of strong reasons to attend DrupalCon 2024.
- For everyone - DrupalCon, the biggest open-source event in North America, offers a unique experience for all Drupal enthusiasts—whether you're diving into Drupal for the first time or have been a community member for years. The benefits of attending are vast.
- Training - Learn specific skills relevant to your role through targeted training at DrupalCon. Develop a deep knowledge of Drupal directly relevant to your career, ensuring a direct and positive return on investment. (Can we mention some of the Training sessions lined-up for DCON 2024?)
- Sessions - Dive into sessions led by the Drupal experts at DrupalCon. These are not just classes; they're conversations with the thought leaders who know their Drupal inside out. It's not just learning; it's getting hands-on wisdom from the best in the biz. (Can we mention some of the sessions lined-up for DCON 2024?)
- Keynotes - Want a front-row seat to the State of Drupal and the future of the web? Then you cannot miss out on DriesNote. Plus, there are other keynotes that'll fire up your imagination about what's possible in the digital world.
- Networking - Imagine being in a room with thousands of Drupal enthusiasts at DrupalCon. It's a community buzzing with passion. Got Drupal questions? Tap into a wealth of knowledge and enthusiasm at one of the largest open-source communities. Hallway Tracks and Exhibition areas are the heart of networking at DrupalCon. Who knows, you might just score a selfie with Dries on your stroll!
- Industry Summits - It's not just about networking—it's about conversing with peers who've been there, done that. Learn the nitty-gritty of industry best practices at industry summits like Higher Education Summit, Nonprofit Summit, Government Summit, and Community Summit. Discover how to tackle business challenges head-on with Drupal solutions, giving your job skills a serious boost.
- Peer Connection - It’s a chance to connect with folks who share the same passion as you. Swap stories, share insights, and stay in the loop about the latest in Drupal. Learn firsthand from those who get your role and challenges.
- Contribution Sprint - If you’re new to Drupal contributions, get hands-on guidance and sprint mentoring by experts. Whether you’re a coder or a non-coder, they are ways for everyone to participate in community contribution sprints to amplify the power of Drupal together.
Here’s a sample letter to help you convince your boss about attending DrupalCon 2024. We guarantee they'll see the light!
Dear [Boss’s Name],
I am writing to express my strong interest in attending DrupalCon 2024 in Portland, Oregon, and to request your approval for participation in this significant event. I believe that attending DrupalCon will not only benefit my professional development but also contribute to the success of our team and the company as a whole.
Here are several compelling reasons why my attendance at DrupalCon is beneficial for us:
-
Industry Insights: Networking at Industry Summits will keep us updated on best practices and innovative solutions.
-
Strategic Vision: Keynotes, especially DriesNote, offer strategic insights vital for our long-term planning.
-
Community Engagement: Networking with thousands of community members ensures immediate answers and collaborations.
-
Role-Specific Learning: Connecting with peers in our specific roles provides insights into the latest in Drupal.
-
Contribution Sprint: Active participation contributes to Drupal's strength, enhancing our company's reputation.
I am seeking approval for the associated expenditures, which include:
EXPENSE
AMOUNT
Airfare
Visa Fees (if required)
Ground Transportation
Hotel
Meals
Conference Ticket
TOTAL EXPENSE
[Add this line if you’re traveling from overseas] The Drupal Association can issue an official letter of invitation to obtain a visa for my travel to the United States.
The Drupal Association can also issue a Certificate of Attendance for the conference if required for our records.
Please accept this proposal to attend, as I'm confident in the significant return we will receive for the small investment. For more information on the event, please visit the conference website: https://events.drupal.org/portland2024.
I'm available to discuss this further at your earliest convenience.
Sincerely,
[Your Full Name]
[Your Position]
[Your Contact Information]
A historic view of the practice to delay releasing Open Source software: OSI’s report
The Open Source Initiative published today a new report that looks at the history of the business practice to delay releasing their code under freedom-respecting licenses. Since the early days of the Open Source movement, companies have experimented with finding a balance between granting their users the basic freedoms guaranteed by Open Source licenses while also capitalizing on their investments in software development. One common approach, albeit with many different flavors, is what this report calls “Delayed Open Source Publication” (DOSP) — “the practice of distributing or publicly deploying software under a proprietary license at first, then subsequently and in a planned fashion publishing that software’s source code under an Open Source license.”
The new report titled “Delayed Open Source Publication: A Survey of Historical and Current Practices” was authored by the team of Open Tech Strategies (Seth Schoen, James Vasile and Karl Fogel) based on crowdsourced interviews. Their research was made possible through a donation by Sentry and the financial contributions of OSI individual members.
Like the authors, I found that the historical survey revealed numerous surprises, and what I found even more intriguing are the new questions raised (see Section 7) that beg for more dedicated research.
I encourage you to give it a read and share it with others. We encourage feedback from the community: I hold office hours for OSI members and you can discuss this on Mastodon or LinkedIn.
The post <span class='p-name'>A historic view of the practice to delay releasing Open Source software: OSI’s report</span> appeared first on Voices of Open Source.
Real Python: Python range(): Represent Numerical Ranges
A range is a Python object that represents an interval of integers. Usually, the numbers are consecutive, but you can also specify that you want to space them out. You can create ranges by calling range() with one, two, or three arguments, as the following examples show:
Python >>> list(range(5)) [0, 1, 2, 3, 4] >>> list(range(1, 7)) [1, 2, 3, 4, 5, 6] >>> list(range(1, 20, 2)) [1, 3, 5, 7, 9, 11, 13, 15, 17, 19] Copied!In each example, you use list() to explicitly list the individual elements of each range. You’ll study these examples in more detail soon.
In this tutorial, you’ll learn how you can:
- Create range objects that represent ranges of consecutive integers
- Represent ranges of spaced-out numbers with a fixed step
- Decide when range is a good solution for your use case
- Avoid range in most loops
A range can sometimes be a powerful tool. However, throughout this tutorial, you’ll also explore alternatives that may work better in some situations. You can click the link below to download the code that you’ll see in this tutorial:
Get Your Code: Click here to download the free sample code that shows you how to represent numerical ranges in Python.
Construct Numerical RangesIn Python, range() is built in. This means that you can always call range() without doing any preparations first. Calling range() constructs a range object that you can put to use. Later, you’ll see practical examples of how to use range objects.
You can provide range() with one, two, or three integer arguments. This corresponds to three different use cases:
- Ranges counting from zero
- Ranges of consecutive numbers
- Ranges stepping over numbers
You’ll learn how to use each of these next.
Count From ZeroWhen you call range() with one argument, you create a range that counts from zero and up to, but not including, the number you provided:
Python >>> range(5) range(0, 5) Copied!Here, you’ve created a range from zero to five. To see the individual elements in the range, you can use list() to convert the range to a list:
Python >>> list(range(5)) [0, 1, 2, 3, 4] Copied!Inspecting range(5) shows that it contains the numbers zero, one, two, three, and four. Five itself is not a part of the range. One nice property of these ranges is that the argument, 5 in this case, is the same as the number of elements in the range.
Count From Start to StopYou can call range() with two arguments. The first value will be the start of the range. As before, the range will count up to, but not include, the second value:
Python >>> range(1, 7) range(1, 7) Copied!The representation of a range object just shows you the arguments that you provided, so it’s not super helpful in this case. You can use list() to inspect the individual elements:
Python >>> list(range(1, 7)) [1, 2, 3, 4, 5, 6] Copied!Observe that range(1, 7) starts at one and includes the consecutive numbers up to six. Seven is the limit of the range and isn’t included. You can calculate the number of elements in a range by subtracting the start value from the end value. In this example, there are 7 - 1 = 6 elements.
Count From Start to Stop While Stepping Over Numbers Read the full article at https://realpython.com/python-range/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Django Weblog: DSF membership now recognizes a much broader range of contributions to Django
Recently, the DSF made some changes to our bylaws to change the definition of DSF Membership. You can read the legalese of the new language in the meeting minutes for the October 12 board meeting, but here’s the short version: previously, individual membership required contribution of intellectual property (e.g. code or documentation) we’ve changed it so that individual membership now recognizes broader contributions to the DSF’s mission. That still includes code and docs, but now also includes many more activities: organizing a Django event, serving on a Working Group, maintaining a third-party app, moderating Django community spaces, and much more. (Corporate membership hasn’t changed; this just applies to individual membership.)
The DSF’s mission, as described in our bylaws, is:
The Foundation's purposes shall include, but not be limited to, developing and promoting the Django framework for free and open public use among the worldwide web development community, protecting the framework's long-term viability, and advancing the state of the art in web development.
Membership, then, recognizes material contributions to that mission. This is deliberately broad and inclusive: we want to allow as broad a definition of “contribution” as possible – including, critically, contributions to the community as well as code contributions. But we do want those contributions to be “material”: we want to recognize substantial or sustained contributions, not one-offs or “drive-by” contributions.
Because this definition of “material” is somewhat deliberately vague, we’ve prepared an FAQ that outlines several examples of things we believe do and do not qualify someone for membership. Ultimately, though, if you’re not sure: please apply anyway! We generally try to err on the side of saying “yes”.
To join the DSF under these new, more inclusive rules, fill out the application form here. The Board approves new members at its monthly meeting, so you can expect to hear back within about a month.
Colin Watson: Going freelance
I’ve mentioned this in a couple of other places, but I realized I never got round to posting about it on my own blog rather than on other people’s services. How remiss of me.
Anyway: after much soul-searching, I decided a few months ago that it was time for me to move on from Canonical and the Launchpad team there. Nearly 20 years is a long time to spend at any company, and although there are a bunch of people I’ll miss, Launchpad is in a reasonable state where I can let other people have a turn.
I’m now in business for myself as a freelance developer! My new company is Columbiform, and I’m focusing on Debian packaging and custom Python development. My services page has some self-promotion on the sorts of things I can do.
My first gig, and the one that made it viable to make this jump, is at Freexian where I’m helping with an exciting infrastructure project that we hope will start making Debian developers’ lives easier in the near future. This is likely to take up most of my time at least through to the end of 2024, but I may have some spare cycles. Drop me a line if you have something where you think I could be a good fit, and we can have a talk about it.
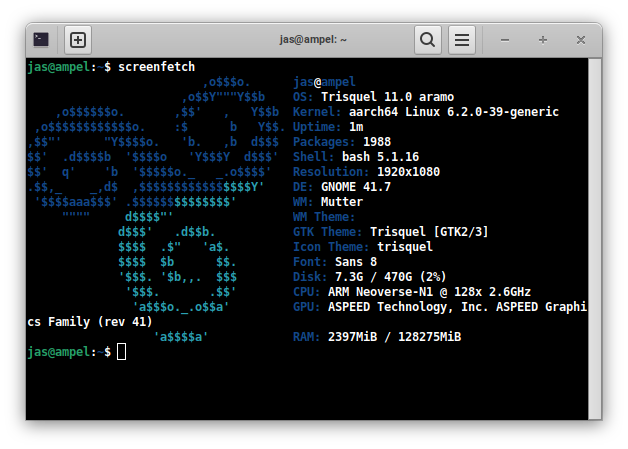
Simon Josefsson: Trisquel on arm64: Ampere Altra
Having had success running Trisquel on the ppc64 Talos II, I felt ready to get an arm64 machine running Trisquel. I have a Ampere Altra Developer Platform from ADLINK, which is a fairly powerful desktop machine. While there were some issues during installation, I’m happy to say the machine is stable and everything appears to work fine.
{kind=link}
{kind=link}
ISO images for non-amd64 platforms are unfortunately still hidden from the main Trisquel download area, so you will have to use the following procedure to download and extract a netinst ISO image (using debian-installer) and write it to a USB memory device. Another unfortunate problem is that there are no OpenPGP signatures or hash checksums, but below I publish one checksum.
wget -q http://builds.trisquel.org/debian-installer-images/debian-installer-images_20210731+deb11u9+11.0trisquel15_arm64.tar.gz tar xfa debian-installer-images_20210731+deb11u9+11.0trisquel15_arm64.tar.gz ./installer-arm64/20210731+deb11u9+11/images/netboot/mini.iso echo '311732519cc8c7c1bb2fe873f134fdafb211ef3bcb5b0d2ecdc6ea4e3b336357 installer-arm64/20210731+deb11u9+11/images/netboot/mini.iso' | sha256sum -c sudo wipefs -a /dev/sdX sudo dd if=installer-arm64/20210731+deb11u9+11/images/netboot/mini.iso of=/dev/sdX conv=sync status=progressInsert the USB stick in a USB slot in the machine, and power up. Press ESCAPE at the BIOS prompt and select the USB device as the boot device. The first problem that hit me was that translations didn’t work, I selected Swedish but the strings were garbled. Rebooting and selecting the default English worked fine. For installation, you need Internet connectivity and I use the RJ45 port closest to VGA/serial which is available as enP5p1s0 in the installer. I wouldn’t connect the BMC RJ45 port to anything unless you understand the security implications.
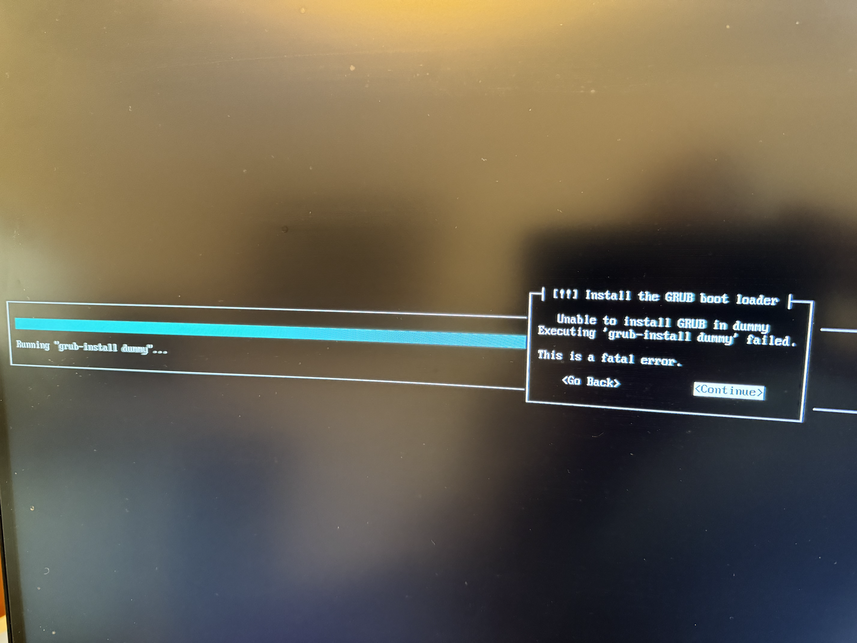
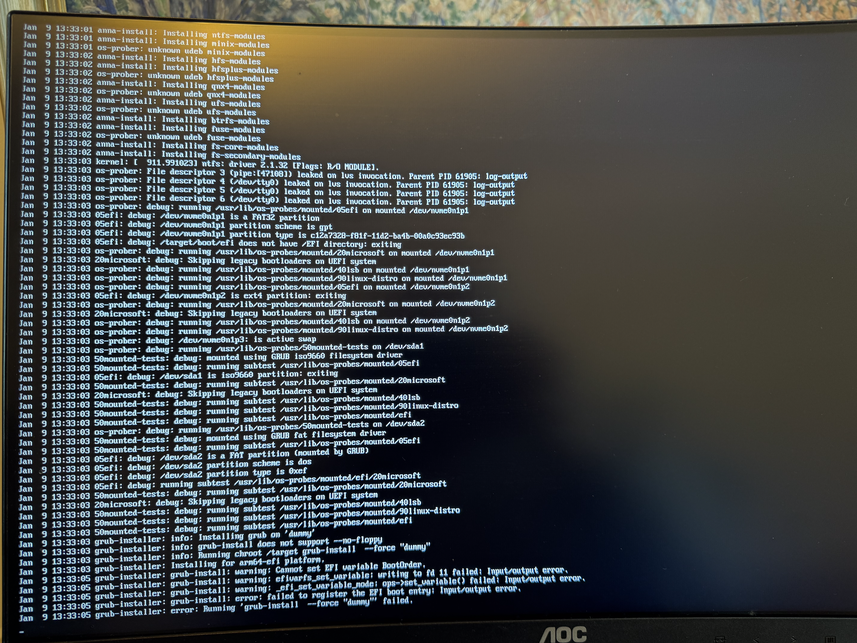
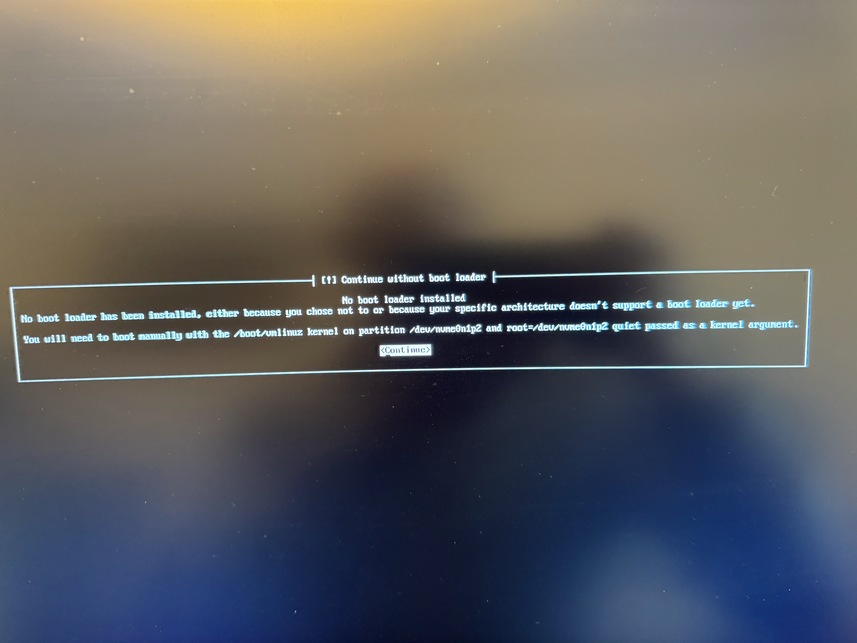
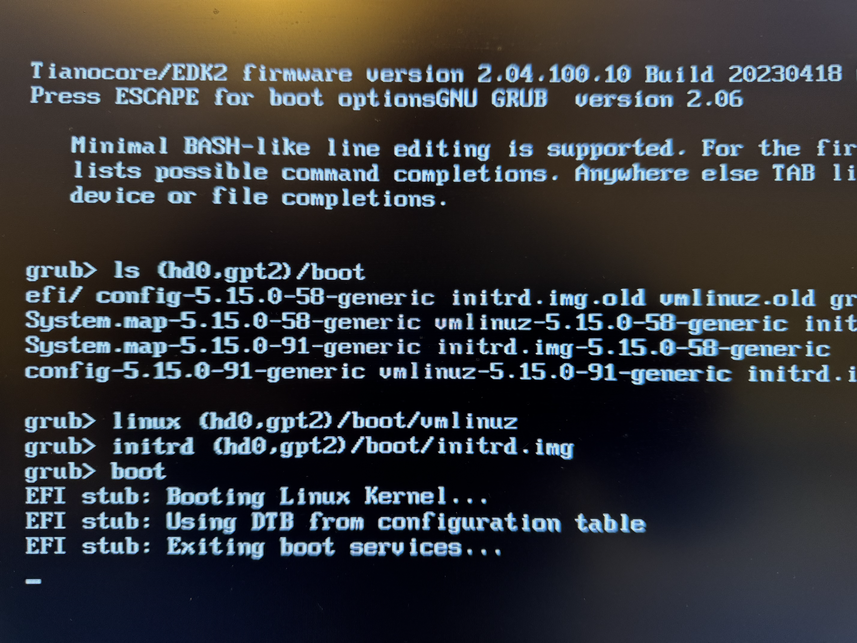
During installation you have to create a EFI partition for booting, and I ended up with one 1GB EFI partition, one 512GB ext4 partition for / with discard/noatime options, and a 32GB swap partition. The installer did not know about any Trisquel mirrors, but only had the default archive.trisquel.org, so if you need to use a mirror, take a note of the necessary details. The installation asks me about which kernel to install, and I went with the default linux-generic which results in a 5.15 linux-libre kernel. At the end of installation, unfortunately grub failed with a mysterious error message: Unable to install GRUB in dummy. Executing 'grub-install dummy' failed. On another console there is a better error message: failed to register the EFI boot entry. There are some references to file descriptor issues. Perhaps I partitioned the disk in a bad way, or this is a real bug in the installer for this platform. I continued installation, and it appears the installer was able to write GRUB to the device, but not add the right boot menu. So I was able to finish the installation properly, and then reboot and manually type the following GRUB commands: linux (hd0,gpt2)/boot/vmlinuz initrd (hd0,gpt2)/boot/initrd.img boot. Use the GRUB ls command to find the right device. See images below for more information.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Booting and installing GRUB again manually works fine:
root@ampel:~# update-grub Sourcing file `/etc/default/grub' Sourcing file `/etc/default/grub.d/background.cfg' Sourcing file `/etc/default/grub.d/init-select.cfg' Generating grub configuration file ... Found linux image: /boot/vmlinuz-5.15.0-91-generic Found initrd image: /boot/initrd.img-5.15.0-91-generic Found linux image: /boot/vmlinuz-5.15.0-58-generic Found initrd image: /boot/initrd.img-5.15.0-58-generic Warning: os-prober will not be executed to detect other bootable partitions. Systems on them will not be added to the GRUB boot configuration. Check GRUB_DISABLE_OS_PROBER documentation entry. Adding boot menu entry for UEFI Firmware Settings ... done root@ampel:~#During installation I tend to avoid selecting any tasksel components, in part because it didn’t use a local mirror to gain network speed, and in part because I don’t want to generate OpenSSH keys in a possibly outdated environment that is harder to audit and reproducible rebuild than the finally installed system. When I selected the OpenSSH and GNOME tasksel, I get an error, but fortunately using apt get directly is simple.
root@ampel:~# tasksel Tasksel GNOME failed: tasksel: apt-get failed (100) root@ampel:~# apt-get install trisquel-gnome sshGraphics in GNOME was slow using the built-in ASPEED AST2500 VGA controller with linux-libre 5.15. There are kernels labeled 64k but I haven’t tested them, and I’m not sure they would bring any significant advantage. I simply upgraded to a more recent linux-libre 6.2 kernel via the linux-image-generic-hwe-11.0 virtual package. After a reboot, graphics in GNOME is usable.
root@ampel:~# apt-get install linux-image-generic-hwe-11.0There seems to be some issue with power-saving inside GNOME, since the machine becomes unresponsive after 20 minutes, and I’m unable to make it resume via keyboard or power button. Disabling the inactivity power setting in GNOME works fine to resolve this.
I will now put this machine to some more heavy use and see how it handles it. I hope to find more suitable arm64-based servers to complement my ppc64el-based servers in the future, as this ADLINK Ampere Altra Developer Platform with liquid-cooling is more of a toy than a serious server for use in a datacentre.
Happy Trisquel-on-arm64 Hacking!
Russell Coker: SAS vs SATA and Recovery
SAS and SATA are electrically compatible to a degree that allows connecting a SATA storage device to a SAS controller. The SAS controller understands the SATA protocol so this works. A SAS device can’t be physically connected to a SATA controller and if you did manage to connect it then it wouldn’t work.
Some SAS RAID controllers don’t permit mixing SAS and SATA devices in the same array, this is a software issue and could be changed. I know that the PERC controllers used by Dell (at least the older versions) do this and it might affect many/most MegaRAID controllers (which is what PERC is).
If you have a hardware RAID array of SAS disks and one fails then you need a spare SAS disk and as the local computer store won’t have any you need some on hand.
The Linux kernel has support for the MegaRAID/PERC superblocks so for at least some of the RAID types supported by MegaRAID/PERC you can just connect the disks to a Linux system and have it work (I’ve only tested on JBOD AKA a single-disk RAID-0). So if you have a server from Dell or IBM or any other company that uses MegaRAID which fails you can probably just put the disks into a non-RAID SAS controller and have them work. As Linux doesn’t care about the difference between SAS and SATA at the RAID level you could then add a SATA disk to an array of SAS disks. If you want to move an array from a dead Dell to a working IBM server or the other way around then you need it to be all SATA or all SAS. You can use a Linux system to mount an array used by Windows or any other OS and then migrate the data to a different array.
If you have an old array of SAS disks and one fails then it might be a reasonable option to just migrate the data to a new array of SATA SSDs. EG if you had 6*600G SAS disks you could move to 2*4TB SATA SSDs and get more storage, much higher performance, less power use, and less noise for a cost of $800 or so (you can spend more to get better performance) and some migration time.
Having a spare SAS controller for data recovery is convenient. Having a spare SAS disk for any RAID-5/RAID-6 is a good thing. Having lots of spare SAS disks probably isn’t useful as migrating to SATA is a better choice. SATA SSDs are bigger and faster than most SAS disks that are in production. I’m sure that someone uses SAS SSDs but I haven’t yet seen them in production, if you have a SAS system and need the performance that SSDs can give then a new server with U.2 (the SAS equivalent of NVMe) is the way to go). SATA hard drives are also the solution for seriously large storage, 16TB SATA hard drives are cheap and work in all the 3.5″ SAS systems.
It’s hard to sell old SAS disks as there isn’t much use for them.
Related posts:
- Cheap SATA Disks in a Dell PowerEdge T410 A non-profit organisation I support has just bought a Dell...
- HP ML350P Gen8 I’m playing with a HP Proliant ML350P Gen8 server (part...
- Dell PowerEdge T320 and Linux I recently bought a couple of PowerEdge T320 servers, so...
Dirk Eddelbuettel: Rcpp 1.0.12 on CRAN: New Maintenance / Update Release
The Rcpp Core Team is once again thrilled to announce a new release 1.0.12 of the Rcpp package. It arrived on CRAN early today, and has since been uploaded to Debian as well. Windows and macOS builds should appear at CRAN in the next few days, as will builds in different Linux distribution–and of course at r2u should catch up tomorrow. The release was uploaded yesterday, and run its reverse dependencies overnight. Rcpp always gets flagged nomatter what because the grandfathered .Call(symbol) but … we had not single ‘change to worse’ among over 2700 reverse dependencies!
This release continues with the six-months January-July cycle started with release 1.0.5 in July 2020. As a reminder, we do of course make interim snapshot ‘dev’ or ‘rc’ releases available via the Rcpp drat repo and strongly encourage their use and testing—I run my systems with these versions which tend to work just as well, and are also fully tested against all reverse-dependencies.
Rcpp has long established itself as the most popular way of enhancing R with C or C++ code. Right now, 2791 packages on CRAN depend on Rcpp for making analytical code go faster and further, along with 254 in BioConductor. On CRAN, 13.8% of all packages depend (directly) on Rcpp, and 59.9% of all compiled packages do. From the cloud mirror of CRAN (which is but a subset of all CRAN downloads), Rcpp has been downloaded 78.1 million times. The two published papers (also included in the package as preprint vignettes) have, respectively, 1766 (JSS, 2011) and 292 (TAS, 2018) citations, while the the book (Springer useR!, 2013) has another 617.
This release is incremental as usual, generally preserving existing capabilities faithfully while smoothing our corners and / or extending slightly, sometimes in response to changing and tightened demands from CRAN or R standards.
The full list below details all changes, their respective PRs and, if applicable, issue tickets. Big thanks from all of us to all contributors!
Changes in Rcpp release version 1.0.12 (2024-01-08)Changes in Rcpp API:
Missing header includes as spotted by some recent tools were added in two places (Michael Chirico in #1272 closing #1271).
Casts to avoid integer overflow in matrix row/col selections have neem added (Aaron Lun #1281).
Three print format correction uncovered by R-devel were applied with thanks to Tomas Kalibera (Dirk in #1285).
Correct a print format correction in the RcppExports glue code (Dirk in #1288 fixing #1287).
The upcoming OBJSXP addition to R 4.4.0 is supported in the type2name mapper (Dirk and Iñaki in #1293).
Changes in Rcpp Attributes:
- Generated interface code from base R that fails under LTO is now corrected (Iñaki in #1274 fixing a StackOverflow issue).
Changes in Rcpp Documentation:
The caption for third figure in the introductory vignette has been corrected (Dirk in #1277 fixing #1276).
A small formatting issue was correct in an Rd file as noticed by R-devel (Dirk in #1282).
The Rcpp FAQ vignette has been updated (Dirk in #1284).
The Rcpp.bib file has been refreshed to current package versions.
Changes in Rcpp Deployment:
- The RcppExports file for an included test package has been updated (Dirk in #1289).
Thanks to my CRANberries, you can also look at a diff to the previous release Questions, comments etc should go to the rcpp-devel mailing list off the R-Forge page. Bugs reports are welcome at the GitHub issue tracker as well (where one can also search among open or closed issues).
If you like this or other open-source work I do, you can sponsor me at GitHub.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
TypeThePipe: Plot your GIS data with GeoPandas and Plotnine. A single glance insightful visualization
Working with geographical data can often be a bit tricky for the uninitiated. This post aims to shed some light for those who are encountering geo data for the first time and want an easy way to perform initial manipulations and plot it to gain their first insights.
We’re about to dive into a sea of coordinates, shapes, and a whole lot of mapping magic!
First of all, we want to make a summary about the most used data formats for geo data. These are the unsung heroes in the world of mapping and spatial analysis. Imagine trying to describe the vastness of our planet without them – it’s like trying to paint a masterpiece with just one color. Not happening, right?
First up in our parade of geo data superstars are formats like Shapefile (SHP), the old faithful of the geo world. But you’ll need a complete set of three files that are mandatory to make up a shapefile. The three required files are: .SHP for geometry, .SHX is the shape index position and .DBF is the attribute data.
Developed by ESRI, it’s like the trusty old pickup truck – not the flashiest but gets the job done. Then there’s GeoJSON, the cool kid on the block. It’s all about simplicity and web-friendliness, perfect for those who love to mingle with JavaScript and web mapping.
And let’s not forget about KML (Keyhole Markup Language), the go-to for Google Earth enthusiasts. It’s like having a GPS in your pocket – straightforward and ready to guide you through those virtual globetrotting adventures. Each of these formats has its own quirks and charms, kind of like different types of pasta – some are better suited for hearty meaty sauces, while others are perfect for a light seafood affair.
In short, the world of geo data formats is as diverse and colorful as the world it represents. Whether you’re a GIS guru or a casual map enthusiast, getting to know these formats is like getting the keys to a whole new world of spatial wonders
Yuo can check more info here!
Let’s kick things off by accessing the geo data and geometries. Imagine we are a company with central stations spread across the Spanish territory, responsible for the alerts in their vicinity. Each station acts as a sentinel, vigilantly monitoring and responding to the events unfolding around it. So we will begin with defining the country over which we’re planning to plot the stations and event coordinates.
Now, here comes the fun part: we load the Shape data using GeoPandas. It’s like unlocking a treasure chest of geographical wonders! GeoPandas makes it a breeze, turning what could be a complex task into a walk in the park. Imagine GeoPandas as your trusty GPS, guiding you through the intricate world of geo data with ease and precision. So, grab your data, let’s fire up GeoPandas, and watch as those lines of code magically transform into a map full of possibilities!
import geopandas as gp import pandas as pd def filter_shp_peninsular_data(df: pd.DataFrame) -> pd.DataFrame: return df[df["acom_name"] != "Canarias"] spain_gis_map = gp.read_file('./data/georef-spain-provincia/georef-spain-provincia-millesime.shp') peninsular_gis_map = filter_shp_peninsular_data(spain_gis_map)We can filter out any layer in the GeoPandas read_file function with the bbox and mask parameters. But let’s keep it simple for the moment and just load and filter out it.
For ease of use, we are going to load and filter also the alerts peninsular data. You can easily apply coordinates filters in order to focus in one specific geography. We will transform our internal data read with Polars to GeoPandas dataframe to show how it could be do, but it is not strictly necessary.
from shapely.geometry import Point import polars as pl def filter_df_peninsular_data(df: pd.DataFrame) -> pd.DataFrame: peninsular_bounds_min = peninsular_gis_map["geometry"].bounds.min() peninsular_bounds_max = peninsular_gis_map["geometry"].bounds.max() return df.filter( ( pl.col("x")>=peninsular_bounds_min["minx"] ) & ( pl.col("x")<=peninsular_bounds_max["maxx"] ) & ( pl.col("y")>=peninsular_bounds_min["miny"] ) & ( pl.col("y")<=peninsular_bounds_max["maxy"] ) ) alerts_geo_df = pl.read_csv("alers_data.csv") alerts_geo_df = gp.GeoDataFrame({ "geometry": alerts_geo_df["coord"].map_elements(lambda x: Point(x)), "alert_solved": alerts_geo_df["alert_solved"].is_not_null(), "x": alerts_geo_df["x"], "y": alerts_geo_df["y"], }) stations_geo_df = pl.read_csv("stations_data.csv") stations_geo_df = gp.GeoDataFrame({ "geometry": stations_geo_df["coord"].map_elements(lambda x: Point(x)), "x": stations_geo_df["x"], "y": stations_geo_df["y"], })Let’s start with our mission to plot a map sprinkled with stations (in cheerful yellow) and events (in bold red and blue).
Once we have the data both country layers and our project datapoints properly formated as GeoPandas DataFrames
The geom_map function is our stroke of genius, turning geographical data into visual narratives.
( ggplot() + geom_map(peninsular_gis_map, fill=None) + geom_map(alerts_geo_df, aes(fill="alert_solved"), size=2) + geom_map(stations_geo_df, colour="yellow", size=3) + labs( title="Alerts solved y/n, by location + Stations (yellow)", caption = "Data from 2023-01-01 to 2023-02-01", ) )Now, we’re not just mapping points; we’re painting a picture of the most representative category by location. Think of it as a data detective story, where each clue (or data point) reveals a part of the bigger picture.
Here’s how we crack the case:
( ggplot() + geom_bin2d(alerts_geo_df, aes(x="x", y="y", fill="alert_solved"), bins = 30) + geom_map(stations_geo_df, colour="yellow", size=3) + labs( title="Alerts solved y/n, by location + Stations (yellow)", caption = "Data from 2023-01-01 to 2023-02-01", ) )With geom_bin2d, we’re transforming our map into a vibrant tapestry, showcasing the most contacted categories in a kaleidoscope of colors. Each square on this grid is like a pixel, together weaving the story of our data’s journey across the Spanish landscape. And, of course, our stations, marked in sunny yellow, stand out as beacons in this sea of information.
Hopefully, this post has helped familiarize you with GeoPandas, GIS data nd Plotnine in Python.
If you want to stay updated…
#mc_embed_signup{background:#fff; clear:left; font:14px Helvetica,Arial,sans-serif; width:100%;} #mc_embed_signup .button { background-color: #0294A5; /* Green */ color: white; transition-duration: 0.4s; } #mc_embed_signup .button:hover { background-color: #379392 !important; } Suscribe for more Python posts! p { word-spacing: 3px; text-indent: 20px; text-align: justify; } .page-subtitle { text-align: left !important; text-indent: 0px !important; } .card-text { text-align: left !important; text-indent: 0px !important; } .hljs-keyword,.hljs-selector-tag,.hljs-subst{color:#2e8516;font-weight:bold}.hljs-comment, .hljs-quote { color: #0e847b; font-style: italic; }.hljs-number, .hljs-literal, .hljs-variable, .hljs-template-variable, .hljs-tag .hljs-attr { color: #008021; }Read the Docs: Read the Docs newsletter - January 2024
We have shipped New improvements to redirects, making our redirects much more powerful and flexible.
We have shipped an updated approach to notifications. Currently there isn’t much UX difference, but as we move forward with this project we will be able to provide more context and control to users.
We continue to work on improving Addons, our new approach to documentation integrations. New documentation and bug fixing continues to happen.
We shipped version 2.0 of our Read the Docs Sphinx Theme, which adds support for new Sphinx releases and drops support for many old versions of Sphinx and Python.
You can always see the latest changes to our platforms in our Read the Docs Changelog.
Upcoming changesAddons will be made more configurable in our new beta dashboard, starting a trend of moving away from the old dashboard for new features.
Our beta dashboard continues to be tested in public beta, and new functionality for Addons configuration will only be available in that new interface.
We continue to work on some business model changes enabled by the new redirects work, including allowing access to Forced Redirects for more users.
Want to follow along with our development progress? View our full roadmap 📍️
Possible issuesUsers need to update their webhooks before January 31, 2024 if they are configured without a secret. All users who need to take action should have received email and site notifications about this.
We are discussing removing support for all VCS systems except Git, as our userbase is heavily biased towards Git users and it will simplify maintenance and development of features. We stopped developing features for Mercurial, Subversion, and Bazaar years ago, and we are considering removing support for them entirely. We will be reaching out to these users to get feedback on this change.
Questions? Comments? Ideas for the next newsletter? Contact us!
KDE's 6th Megarelease - Release Candidate 1
Every few years we port the key components of our software to a new version of Qt, taking the opportunity to remove cruft and leverage the updated features the most recent version of Qt has to offer us.
KDE's megarelease is less than 50 days away. At the end of February 2024 we will publish Plasma 6, Frameworks 6, and a whole new set of applications in a special edition of KDE Gear all in one go.
If you have been following the updates here, here and here, you will know we are making our way through the testing phase and gradually reaching stability. KDE is making available today the first Release Candidate version of all the software we will include in the megarelease.
As with the Alpha and Beta versions, this is a preview intended for developers and testers. The software provided is nearing stability, but is still not 100% safe to use in a production environment. We still recommend you continue using stable versions of Plasma, Frameworks and apps for your everyday work. But if you do use this, watch out for bugs and report them promptly, so we can solve them.
Read on to find out more about KDE's 6th Megarelease, what it covers, and how you can help make the new versions of Plasma, KDE's apps and Frameworks a success now.
PlasmaPlasma is KDE's flagship desktop environment. Plasma is like Windows or macOS, but is renowned for being flexible, powerful, lightweight and configurable. It can be used at home, at work, for schools and research.
Plasma 6 is the upcoming version of Plasma that integrates the latest version of Qt, Qt 6, the framework upon which Plasma is built.
Plasma 6 incorporates new technologies from Qt and other constantly evolving tools, providing new features, better support for the latest hardware, and supports for the hardware and software technologies to come.
You can be part of the new Plasma. Download and install a Plasma 6-powered distribution (like Neon Unstable) to a test machine and start trying all its features. Check the Contributing section below to find out how you can deliver reports of what you find to the developers.
KDE GearKDE Gear is a collection of applications produced by the KDE community. Gear includes file explorers, music and video players, text and video-editors, apps to manage social media and chats, email and calendaring applications, travel assistants, and much more.
Developers of these apps also rely on the Qt toolbox, so most of the software will also be adapted to use the new Qt6 toolset and we need you to help us test them too.
- KDE Gear 24.02 RC 1 Source Code Info Page
- KDE Gear 24.02 RC 1 Full Changelog
- KDE Gear 24.02 packagers' release notes
KDE's Frameworks add tools created by the KDE community on top of those provided by the Qt toolbox. These tools give developers more and easier ways of developing interfaces and functionality that work on more platforms.
Among many other things, KDE Frameworks provide
- widgets (buttons, text boxes, etc.) that make building your apps easier and their looks more consistent across platforms, including Windows, Linux, Android and macOS
- libraries that facilitate storing and retrieving configuration settings
- icon sets, or technologies that make the integration of the translation workflow of applications easier
KDE's Frameworks also rely heavily on Qt and will also be upgraded to adapt them to the new version 6. This change will add more features and tools, enable your applications to work on more devices, and give them a longer shelf life.
- KDE Frameworks 6 RC 1 Source Code Info Page
- KDE Frameworks 6 RC 1 Full Changelog
- KDE Frameworks 6 packagers release notes
Contributing
KDE relies on volunteers to create, test and maintain its software. You can help too by...
- Reporting bugs -- When you come across a bug when testing the software included in this Alpha Megarelease, you can report it so developers can work on it and remove it. When reporting a bug
- make sure you understand when the bug is triggered so you can give developers a guide on how to check it for themselves
- check you are using the latest version of the software you are testing, just in case the bug has been solved in the meantime
- go to KDE's bug-tracker and search for your bug to make sure it does not get reported twice
- if no-one has reported the bug yet, fill in the bug report, giving all the details you think are significant.
- keep tabs on the report, just in case developers need more details.
- Solving bugs -- Many bugs are easy to solve. Some just require changing a version number or tweaking the name of a library to its new name. If you have some basic programming knowledge of C++ and Qt, you too can help carry the weight of debugging KDE's software for the grand release in February.
- Joining the development effort -- You may have a deeper knowledge development, and would like to contribute to KDE with your own solutions. This is the perfect moment to get involved in KDE and contribute with your own code.
- Donating to KDE -- Creating, debugging and maintaining the large catalogue of software KDE distributes to users requires a lot of resources, many of which cost money. Donating to KDE helps keep the day-to-day operation of KDE running smoothly and allows developers to concentrate on creating great software. KDE is currently running a drive to encourage more people to become contributing supporters, but you can also give one-time donations if you want.
Pre-release software is only suited for developers and testers. Alpha/Beta/RC software is unfinished, will be unstable and will contain bugs. It is published so volunteers can trial-run it, identify its problems, and report them so they can be solved before the publication of the final product.
The risks of running pre-release software are many. Apart from the hit to productivity produced by instability and the lack of features, using pre-release software can lead to data loss, and, in extreme cases, damage to hardware. That said, the latter is highly unlikely in the case of KDE software.
The version of the software included in KDE's 6th Megarelease is beta software. We strongly recommend you do not use it as your daily driver.
If, despite the above, you want to try the software distributed in KDE's 6th Megarelease, you do so under your sole responsibility, and in the understanding that the main aim, as a tester, you help us by providing feedback and your know-how regarding the software. Please see the Contributing section above.
Only six days left to support the FSF through the Combined Federal Campaign
FSF Blogs: Only six days left to support the FSF through the Combined Federal Campaign
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects