
Feeds
Aten Design Group: New Configuration Storage Options with Backdrop CMS
If you haven’t heard of it already, Backdrop CMS has a direct upgrade path from Drupal 7 - making it a viable and affordable option for sites lingering on Drupal 7. Backdrop’s recent 1.28.0 release brought a number of new features, including the ability to choose where your configuration is stored: in the file system or in the database. This can be very helpful, depending on where you are hosting your site. If you are hosting on a server with a writable directory on a solid-state drive (SSD), the default of storing active configuration files on the filesystem can be a very fast and efficient option. On some more specialized hosting where writable directories are on a distributed filesystem in which repeated reading and writing is slower than a SSD (Pantheon, for example), it can now be more efficient to keep the active configuration in the database. This is more in line with the way that modern Drupal handles configuration (with some notable exceptions between the two, such as the format that configuration is imported and exported in – JSON in Backdrop, YAML in Drupal).
Active and Staging Configuration StatesWhen discussing a Backdrop site’s configuration, there are generally two configuration states under discussion: active and staging. The active configuration is the collection of configuration settings that are currently in use for the site, and the staging configuration is composed of any new changes that you are preparing to synchronize with the active settings.
When you run the configuration synchronization process, the staging configuration overwrites the active configuration and any necessary database modifications (e.g. new database schemas for new fields) will be run so that the database state matches what the configuration is describing.
Backdrop will by default store both active and staging configuration files as JSON files directly in the filesystem, in directories that are defined in your settings.php file. Directories that are known to be writable are selected by default, but often these will be adjusted during the site creation process – to allow the staging directory to be kept in your version controlled repository for example. (Note that if you are going to keep your staging configuration in your repository, there is an additional setting in the settings.php file to tell Backdrop not to empty the staging folder after a synchronization action occurs.)
Configuration Storage on PantheonPreviously, in order to run a Backdrop site on Pantheon, the active configuration would typically be in the writable files directory, which, as was mentioned, can run slowly when reading or writing multiple times in succession. One other strategy for Pantheon was to keep the active configuration in the repository itself, in a non-writable directory. This provided the benefit of extremely fast loading of the configuration files, but had a significant downside in that you could not do any actions that required saving configuration. In fact, if you tried, you would get an error and run the risk of having a database that was out of sync with the configuration settings.
With the new config storage option, you can define where in the repository your staging folder will be, and keep the active configuration in the database. Periodically when you’re making changes locally, you’ll want to export the configuration from the live site into your staging folder and commit those changes to make sure you have saved the most recent configuration. As you make changes locally and commit changes into the configuration staging folder, you’ll be able to synchronize the configuration with each deployment to get the latest configuration changes added to your current database content.
Database Configuration Storage for Developing LocallyWhen developing locally, it can also be beneficial to store active configuration in the database because it makes it very easy to save snapshots of the site’s content and configuration in one step. This means you can do a “save game” at various points, test out various things to see if they work, and simply reload the saved database snapshot if you want to go back to the earlier version, without needing to worry about multiple moving parts – database plus active configuration files. (If you use DDEV, look into the built-in “snapshot” functionality.)
Typically the configuration storage setting will not be changed regularly, but a new module is in development that can make it much easier to switch between the two. If you are using storage on the file system in one environment and in the database on another (e.g. hosted vs. local installations), the Config Mover module could be a useful development tool.
Config Mover module Backdrop's FlexibilityThis is another case where Backdrop shines with its flexibility: you pick which configuration storage option works best for your current hosting environment.
Read more about this change in the official change record and let us know what you think in the comments below.
Laryn Kragt Bakkermark.ie: My LocalGov Drupal contributions for week-ending August 2nd, 2024
Here's what I've been working on for my LocalGov Drupal contributions this week. Thanks to Big Blue Door for sponsoring the time to work on these.
The Drop Times: DrupalCamp Ottawa 2024: A Convergence of Web Development Expertise and Community Spirit
Guido Günther: Free Software Activities July 2024
A short status update on what happened on my side last month. Looking at unified push support for Chatty prompted some libcmatrix fixes and Chatty improvements (benefiting other protocols like SMS/MMS as well).
The Bluetooth status page in Phosh was a slightly larger change code wise as we also enhanced our common widgets for building status pages, simplifying the Wi-Fi status page and making future status pages simpler. But as usual investigating bugs, reviewing patches (thanks!) and keeping up with the changing world around us is what ate most of the time.
PhoshA Wayland Shell for mobile devices
- Update to latest gvc (MR)
- Mark more strings as translatable (MR)
- Improve Bluetooth support by adding a StatusPage (MR)
- Improve vertical space usage for status pages (MR)
- Fix build with newer GObject introspection, we can now finally enable --fatal-warnings (MR)
- Fix empty system modal dialog on keyring lookups: (MR)
- Send logind locked hint: (MR)
- Small cleanups (MR, MR)
A Wayland compositor for mobile devices
libphosh-rsPhosh Rust bindings
phosh-osk-stubA on screen keyboard for Phosh
- Allow for up to five key rows and add more keyboard layouts: (MR)
Wallpapers, Sounds and other artwork
- Add Phone hangup event: (MR)
Suite to help with Debian packages in Git repositories
- Fix tests with Python 3.12 and upload 0.9.34
Tool to find processes mapping shared objects
- Fix build with python 3.12 and release 0.0.14
The universal operating system
- Upload whatmaps 0.0.14
- Package libssc (MR) for upcoming sensor support on some Qualcomm based phones
- Fix iio-sensor-proxy RC bug and cleanup a bit: (MR)
- Update wlroots to 0.17.4 (MR)
- Update calls to 46.3 (MR)
- Prepare 0.18.0 (MR
- meta-phosh: Switch default font and recommend iio-sensor-proxy: (MR)
A Debian derivative for mobile devices
CallsPSTN and SIP calls for GNOME
- Emit phone-hangup event when a call ended (MR). Together with the sound theme changes this gives a audible sound when the other side hung up.
- Debug and document Freeswitch sofia-sip failure (it's TLS validation).
Minimalistic video player targeting mobile devices
- Export stream position and duration via MPRIS (MR)
- Slightly improve duration display (MR)
- Improve docs a bit: (MR)
Common user interface parts for call handling in GNOME and Phosh.
feedbackdDBus service for haptic/visual/audio feedback
- Fix test failures on recent Fedora due to more strict json-glib: (MR)
Messaging application for mobile and desktop
- Continue work on push notifications: (MR)
- Allow to delete push server
- Hook into DBus connector class
- Parse push notifications
- Avoid duplicate lib build and fix warnings (MR)
- Let F10 enable the primary menu: (MR)
- Focus search when activating it (MR)
- Fix search keybinding: (MR)
- Fix keybinding to open help overlay (MR)
- Don't hit assertions in libsoup by iterating the wrong context: (MR)
- Matrix: Fix unread count getting out of sync: (MR)
- Allow to disable purple via build profile (MR)
- Fix critical during key verification (MR)
- ChatInfo: Use AdwDialog and show Matrix room topic (MR)
- Fix crash on account creation: (MR)
A matrix client client library
- Fix gir annotations, make gir and doc warnings fatal: (MR)
- Cleanup README: (MR)
- Some more minor cleanups and docs: (MR, (MR, (MR)
- Generate enum types to make them usable by library consumers (MR)
- Don't blindly iterate the default context (MR)
- Allow to fetch a single event (useful for handling push notifications) (MR)
- Make CmCallback behave like other callbacks (MR)
- Allow to add/remove/fetch pushers sync (MR)
- Add sync variant for fetching past events (MR)
- Make a self contained library, test that in CI and make all public classes show up in the docs (MR)
- Track unread count (MR)
- Release libcmatrix 0.0.1
- Add support for querying room topics (MR)
- Allow to disable running the tests so superprojects have some choice (MR)
- Fix crashes, use after free, … (MR, MR, MR)
A libcmatrix test client
- New project to ease testing libcmatrix changes: https://github.com/agx/eigenvalue
- Add support for /room-details: (MR)
- Add support for /room-load-past-events: (MR)
If you want to support my work see donations. This includes list of hardware we want to improve support for.
mark.ie: How to use the LocalGov Drupal KeyNav Module
Here's a short video outlining the features of the LocalGov Drupal KeyNav module.
More Ways to Rust
In our earlier blog, The Smarter Way to Rust, we discuss why a blend of C++ and Rust is sometimes the best solution to building robust applications. But when you’re merging these two languages, it’s critical to keep in mind that the transition from C++ to Rust isn’t about syntax, it’s about philosophy.
Adapting to Rust’s world viewIf you’re an experienced C++ developer who is new to Rust, it’s only natural to use the same patterns and approaches that have served you well before. But problem-solving in Rust requires a solid understanding of strict ownership rules, a new concurrency model, and differences in the meaning of “undefined” code. To prevent errors arising from an overconfident application of instinctual C++ solutions that don’t align with Rust’s idioms, it’s a good idea to start by tackling non-critical areas of code. This can give you room to explore Rust’s features without the pressure of potentially bringing critical systems crashing down.
Maximizing performance in a hybrid applicationPerformance is often a concern when adopting a new language. Luckily, Rust holds its own against C++ in terms of runtime efficiency. Both languages compile to machine code, have comparable runtime checks, don’t use run-time garbage collection, and share similar back-ends like GCC and LLVM. That means that in most real-world applications, the performance differences are negligible.
However, when Rust is interfaced with C++ via a foreign function interface (FFI), there may be a noticeable overhead. The FFI disrupts the optimizer’s ability to streamline code execution on both sides of the interface. Keep this in mind when structuring your hybrid applications, particularly in performance-critical sections. You could use link-time optimization (LTO) in LLVM to help with this, but the additional complexity of maintaining this solution makes it a consideration only if profiling/benchmarking points to FFI being a main source of overhead.
Embracing ‘unsafe’ RustThe normal approach for Rust is to eliminate code marked as ‘unsafe’ as much as possible. While both C++ and ‘unsafe’ Rust allow for pointer dereferencing that can potentially crash, the advantage in Rust is that this keyword makes issues easier to spot. ‘Unsafe’ Rust pinpoints where safety compromises are made, highlighting manageable risk areas. This in turn streamlines code reviews and simplifies the hunt for elusive bugs.
Bridging Rust with C/C++Connecting Rust and C/C++ is clearly required when building hybrid applications. Thankfully, there’s a rich ecosystem of tools to support this:
- Rust’s built-in extern “C” for straightforward C FFI needs
- bindgen and cbindgen for generating bindings between Rust and C/C++
- CXX and AutoCXX for robust, safe interoperability between the two environments
- CXX-Qt for mixing Rust and Qt C++
Each tool serves a distinct purpose and choosing the right one can make the difference between a seamless integration and a complicated ball of compromises. (We provide more detailed guidance on this topic in our Hybrid Rust and C++ best practice guide, and my colleague Loren has a three part blog series that talks about this topic too: part 1, part 2, part 3.)
Adopting the microservice modelIn complex applications with interwoven parts, it’s probably best to keep Rust and C++ worlds distinct. Taking a cue from the microservices design pattern, you can isolate functionalities into separate service loops on each side, passing data between them through well-defined FFI calls. This approach circumvents issues of thread blocking and data ownership, shifting focus from direct code calls to service requests.
Navigating Rust ABI dynamicsRust does not guarantee a stable ABI between releases, which influences how you must design and compile your applications. To prevent breaking the build, create statically linked executables or use C FFIs for shared libraries and plugins, ensure that your entire project sticks to a consistent Rust version, and encapsulate all dependencies behind a C FFI.
Choosing the right build systemBuilding hybrid applications requires a thoughtful approach to choose a build system that will work well for the code you have and adapt easily as your program evolves.
- Start with Cargo (provided by the Rust environment) for Rust-centric projects with minimal C++ code.
- Switch to CMake if C++ takes on a more significant role.
- Consider Bazel or Buck2 build systems for handling complex, language-agnostic build processes.
If you’re considering a custom build system, closely examine the available options first. With the breadth of today’s build tool landscape, it’s usually overkill to invent your own solution.
SummaryBy understanding the challenges and employing the right strategies, C++ developers can smoothly transition to Rust, leveraging the strengths of both languages to build robust and efficient applications. For more information on this trending topic, you’ll want to consult our Hybrid Rust and C++ best practice guide, which was created in collaboration with Ferrous Systems co-founder Florian Gilcher.
About KDAB
If you like this article and want to read similar material, consider subscribing via our RSS feed.
Subscribe to KDAB TV for similar informative short video content.
KDAB provides market leading software consulting and development services and training in Qt, C++ and 3D/OpenGL. Contact us.
The post More Ways to Rust appeared first on KDAB.
Tryton News: Newsletter July 2024
{kind=link}
During the last month we focused on fixing bugs, improving the behaviour of things, speeding-up performance issues - building on the changes from our last release. We also added some new features which we would like to introduce to you in this newsletter.
For an in depth overview of the Tryton issues please take a look at our issue tracker or see the issues and merge requests filtered by label.
Changes for the User Sales, Purchases and ProjectsWe’ve now added optional reference and warehouse fields to the purchase_request_quotation list view.
Accounting, Invoicing and PaymentsWe now allow users in the account admin group to update the invoice line descriptions in a revised invoice.
Until now a direct debit was created for each unpaid line. However, this may not be wanted when there are many payable lines. In these cases the company may want to have a single direct debit for the total amount of the payable lines. So, we’ve now introduced an option to define if a recept of a direct debit should be based on the lines or the balance.
Stock, Production and ShipmentsNow we’ve extend the lot trace information by moves generated from an inventory. This way we are able to show the origin of a lot.
We removed the default planned date on supplier shipments.
User InterfaceIt is now possible for the users to resize the preview panel of attachments.
Now users are able to type search filters immediately after opening a screen with a search entry.
System Data and ConfigurationWe’ve added the following party identifiers:
- Taiwanese Tax Number
- Turkish tax identification number
- El Salvador Tax Number
- Singapore’s Unique Entity Number
- Montenegro Tax Number
- Kenya Tax Number
The documentations for the following modules has been improved:
- account_be
- account_asset
- account_eu
- account_deposit
- account_de_skr03
- account_fr
- notification_email module
- stock_lot
We’ve added a warning that because the database is modified in place it is important to make a backup before running an update.
We’ve migrated what were previously links to the configuration section to config-anchors like this :ref:trytond:topics-configuration.
New ReleasesWe released bug fixes for the currently maintained long term support series
7.0 and 6.0, and for the current series 7.2.
Now when running trytond-admin with the --indexes argument but without any modules to update, the indexes of all models are updated.
Changes for Implementers and DevelopersWe are now able to run tests with PYTHONWARNINGS="error" to catch future issues earlier. Warnings from third-party-libraries can be ignored by the filters defined in the TEST_PYTHONWARNINGS environment variable.
1 post - 1 participant
Python Insider: Python 3.13.0 release candidate 1 released
I'm pleased to announce the release of Python 3.13 release candidate 1.
https://www.python.org/downloads/release/python-3130rc1/
This is the first release candidate of Python 3.13.0
This release, 3.13.0rc1, is the penultimate release preview. Entering the release candidate phase, only reviewed code changes which are clear bug fixes are allowed between this release candidate and the final release. The second candidate (and the last planned release preview) is scheduled for Tuesday, 2024-09-03, while the official release of 3.13.0 is scheduled for Tuesday, 2024-10-01.
There will be no ABI changes from this point forward in the 3.13 series, and the goal is that there will be as few code changes as possible.
Call to actionWe strongly encourage maintainers of third-party Python projects to prepare their projects for 3.13 compatibilities during this phase, and where necessary publish Python 3.13 wheels on PyPI to be ready for the final release of 3.13.0. Any binary wheels built against Python 3.13.0rc1 will work with future versions of Python 3.13. As always, report any issues to the Python bug tracker.
Please keep in mind that this is a preview release and while it’s as close to the final release as we can get it, its use is not recommended for production environments.
Core developers: time to work on documentation now- Are all your changes properly documented?
- Are they mentioned in What’s New?
- Did you notice other changes you know of to have insufficient documentation?
Some of the new major new features and changes in Python 3.13 are:
New features- A new and improved interactive interpreter, based on PyPy’s, featuring multi-line editing and color support, as well as colorized exception tracebacks.
- An experimental free-threaded build mode, which disables the Global Interpreter Lock, allowing threads to run more concurrently. The build mode is available as an experimental feature in the Windows and macOS installers as well.
- A preliminary, experimental JIT, providing the ground work for significant performance improvements.
- The locals() builtin function (and its C equivalent) now has well-defined semantics when mutating the returned mapping, which allows debuggers to operate more consistently.
- The (cyclic) garbage collector is now incremental, which should mean shorter pauses for collection in programs with a lot of objects.
- A modified version of mimalloc is now included, optional but enabled by default if supported by the platform, and required for the free-threaded build mode.
- Docstrings now have their leading indentation stripped, reducing memory use and the size of .pyc files. (Most tools handling docstrings already strip leading indentation.)
- The dbm module has a new dbm.sqlite3 backend that is used by default when creating new files.
- The minimum supported macOS version was changed from 10.9 to 10.13 (High Sierra). Older macOS versions will not be supported going forward.
- WASI is now a Tier 2 supported platform. Emscripten is no longer an officially supported platform (but Pyodide continues to support Emscripten).
- iOS is now a Tier 3 supported platform, with Android on the way as well.
- Support for type defaults in type parameters.
- A new type narrowing annotation, typing.TypeIs.
- A new annotation for read-only items in TypeDicts.
- A new annotation for marking deprecations in the type system.
- PEP 594 (Removing dead batteries from the standard library) scheduled removals of many deprecated modules: aifc, audioop, chunk, cgi, cgitb, crypt, imghdr, mailcap, msilib, nis, nntplib, ossaudiodev, pipes, sndhdr, spwd, sunau, telnetlib, uu, xdrlib, lib2to3.
- Many other removals of deprecated classes, functions and methods in various standard library modules.
- C API removals and deprecations. (Some removals present in alpha 1 were reverted in alpha 2, as the removals were deemed too disruptive at this time.)
- New deprecations, most of which are scheduled for removal from Python 3.15 or 3.16.
(Hey, fellow core developer, if a feature you find important is missing from this list, let Thomas know.)
For more details on the changes to Python 3.13, see What’s new in Python 3.13. The next pre-release of Python 3.13 will be 3.13.0rc2, the final release candidate, currently scheduled for 2024-09-03.
More resources- Online Documentation
- PEP 719, 3.13 Release Schedule
- Report bugs at Issues · python/cpython · GitHub.
- Help fund Python directly (or via GitHub Sponsors), and support the Python community.
Thanks to all of the many volunteers who help make Python Development and these releases possible! Please consider supporting our efforts by volunteering yourself or through organization contributions to the Python Software Foundation.
Whatevs,
Your release team,
Thomas Wouters
Łukasz Langa
Ned Deily
Steve Dower
Sitback Solutions: Good Design for Housing – NSW Gov digital map case study
Dirk Eddelbuettel: RQuantLib 0.4.24 on CRAN: Robustification
A new minor release 0.4.24 of RQuantLib arrived on CRAN this afternoon (just before the CRAN summer break starting tomorrow), and has been uploaded to Debian too.
QuantLib is a rather comprehensice free/open-source library for quantitative finance. RQuantLib connects (some parts of) it to the R environment and language, and has been part of CRAN for more than twenty-one years (!!) as it was one of the first packages I uploaded.
This release of RQuantLib follows the recent release from last week which updated to QuantLib version 1.35 released that week, and solidifies conditional code for older QuantLib versions in one source file. We also updated and extended the configure source file, and increased the mininum version of QuantLib to 1.25.
Changes in RQuantLib version 0.4.24 (2024-07-31)Updated detection of QuantLib libraries in configure
The minimum version has been increased to QuantLib 1.25, and DESCRIPTION has been updated to state it too
The dividend case for vanilla options still accommodates deprecated older QuantLib versions if needed (up to QuantLib 1.25)
The configure script now uses PKG_CXXFLAGS and PKG_LIBS internally, and shows the values it sets
Courtesy of my CRANberries, there is also a diffstat report for the this release. As always, more detailed information is on the RQuantLib page. Questions, comments etc should go to the rquantlib-devel mailing list. Issue tickets can be filed at the GitHub repo.
If you like this or other open-source work I do, you can now sponsor me at GitHub.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
Junichi Uekawa: I've tried Android Element app for matrix first time during Debconf.
Junichi Uekawa: Joining Debconf, it's been 16 years.
Balint Pekker: Drupal 11 is at the doorstep
Ned Batchelder: Pushing back on sys.monitoring
I’ve been continuing to work on adapting coverage.py to the new sys.monitoring facility. Getting efficient branch coverage has been difficult even with the new API. The latest idea was to compile the code under measurement to insert phantom lines that could trigger line monitoring events that would track branch execution. But I’ve come to the opinion that this is not the right approach. It’s a complex work-around for a gap in the sys.monitoring API.
Update: Mark Shannon is working on new events: Add BRANCH_TAKEN and BRANCH_NOT_TAKEN events to sys.monitoring.
To re-cap: sys.monitoring let you subscribe to events for code execution. A line event lets you know when lines are executed. You can disable a line event, and you will never again be notified about that particular line being executed.
The gap is in the branch events: when one is fired, it tells you the bytecode offset of the source and destination. The problem is that disabling a branch event disables the source offset. You never hear about that source offset again, even when the destination offset is different. The central idea of a branch is that one source has two different destinations, so this disabling behavior is awkward.
If we leave the branch event enabled, then we might be repeatedly told about the same source/destination pair, slowing down execution. We could disable the event once we saw both possible destinations, but that means implementing our own bookkeeping, and we still have the overhead of repeated first-destination events. If we disable the branch event immediately, we’ll never hear about the other possible destination and the coverage data will be incomplete.
The clever idea from SlipCover is to insert do-nothing lines at each branch destination, then only subscribe to line events. This works in theory, but adds complexity to coverage.py. It also limits how it can be used: you can’t start coverage measurement in a process after code has already been imported because the line insertion happens during compilation via an import hook. To make matters worse, there’s a tricky interaction between the coverage.py import hook and the pytest import hook that rewrites assertions.
Over the years I’ve done plenty of clever work-arounds for limitations in systems I build on top of. They can be interesting puzzles and proud achievements. They can also be maintenance headaches and fragile sources of bugs.
My progress on adapting coverage.py to sys.monitoring has be slow, even glacial. I think it will be faster overall to work on improving sys.monitoring instead, even though it means the improvements wouldn’t be available until 3.14. It will keep coverage.py simpler and more flexible, and will make the improved branch events available to everyone. I can’t see how the current behavior is useful, so let’s change it.
I’ve proposed that we fix the sys.monitoring API. Of course other participation is welcome in that discussion.
I remember years ago working at Lotus, using the Lotus Notes API. I accepted it as a finished thing. Later I joined the organization that built Lotus Notes. We had a discussion about something we were building and a difficulty we were encountering. One of the longer-tenured engineers said, “Let’s extend the API.” It was a revelation that we didn’t have to limit ourselves to the current capabilities of our foundation, we could change the foundation.
The same is true of Python, especially because it is open source. But it can be hard to remember that and to advocate for it where necessary.
BTW, I still believe that coverage.py’s internal focus on “arcs” is misguided, and will be working to remove that idea in favor of true branches.
As I mentioned last time, there’s now a dedicated #coverage-py channel in the Python Discord if you are interested in discussing any of this.
Python Engineering at Microsoft: Python in Visual Studio Code – August 2024 Release
We’re excited to announce the August 2024 release of the Python and Jupyter extensions for Visual Studio Code!
This release includes the following announcements:
- Improved Python discovery using python-environment-tools
- Inline variable values shown in source code
- Improvements to the VS Code Native REPL for Python
If you’re interested, you can check the full list of improvements in our changelogs for the Python, Jupyter and Pylance extensions.
Improved Python discovery using python-environment-toolsIn the last release, we announced the Python environment tools, which redesigned the Python discovery infrastructure focused on performance. This new approach reduces the need for executing python binaries to probe for information and thus improving performance.
Starting in this release, we are rolling out this enhancement as part of an experiment. If you are interested in trying this out, you can set "python.locator" to "native" in your User settings.json and reload your VS Code window. Visit the python-environment-tools repo to learn more about this feature, ongoing work, and provide feedback.
Inline variable values shown in source codeThe Python Debugger extension introduced an Inline Values feature to enhance your Python debugging experience making it easier to track variable values during a debug session. This feature enables the display of variable values directly in the editor, next to the corresponding line of code during a debugging session. This helps you to quickly understand the state of your program without needing to hover over variables or check the variables pane. To enable this feature, set the configuration value debugpy.showPythonInlineValues to true in your User settings.
Note: This feature is currently in exploration state and improvements are actively being made. Please try out this feature and provide feedback in the vscode-python-debugger repo!
Improvements to the VS Code Native REPL for Python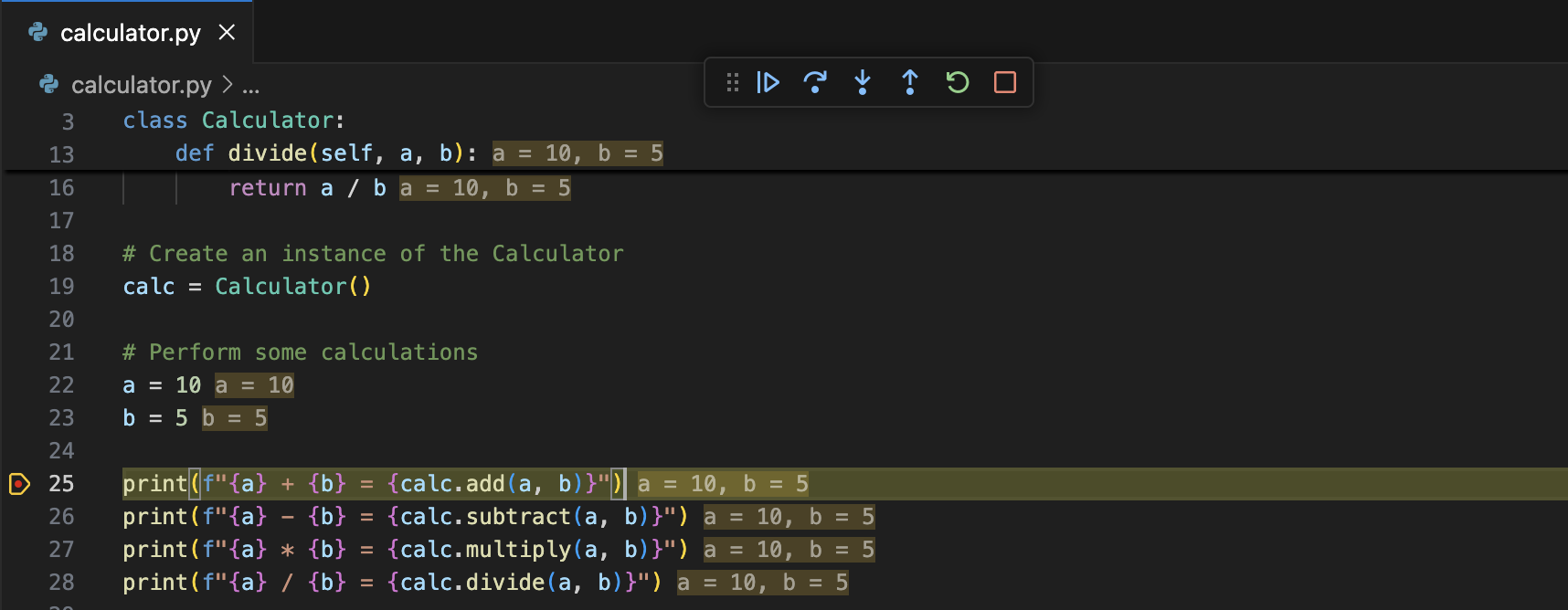{kind=link}
The experimental native REPL ("python.REPL.sendToNativeREPL": true) will now display success/failure UI, similar to that in a Jupyter cell, depending on the outcome of execution. Furthermore, we have made improvements so that we no longer display an empty line on cells that generate no output.
Other Changes and EnhancementsWe have also added small enhancements and fixed issues requested by users that should improve your experience working with Python and Jupyter Notebooks in Visual Studio Code. Some notable changes include:
- Pylance now provides a way to disable unreachability hints in @pylance-release#6106
- The Debug Welcome view now includes a button for quick access to automatic Python configurations when a Python file is open in the editor
As we are planning and prioritizing future work, we value your feedback! Below are a few issues we would love feedback on:
- In a joint effort from various parts of the Python community, we are collecting responses about usage of type annotations in Python. Please take a few minutes to share your experience in the Type Annotation in Python survey! The survey will close at the end of August 2024.
- Design proposal for test coverage in (@vscode-python#22827)
Try out these new improvements by downloading the Python extension and the Jupyter extension from the Marketplace, or install them directly from the extensions view in Visual Studio Code (Ctrl + Shift + X or ⌘ + ⇧ + X). You can learn more about Python support in Visual Studio Code in the documentation. If you run into any problems or have suggestions, please file an issue on the Python VS Code GitHub page.
The post Python in Visual Studio Code – August 2024 Release appeared first on Python.
Jonathan McDowell: Using QEmu for UEFI/TPM testing
This is one of those posts that’s more for my own reference than likely to be helpful for others. If you’re unlucky it’ll have some useful tips for you. If I’m lucky then I’ll get a bunch of folk pointing out some optimisations.
First, what I’m trying to achieve. I want a virtual machine environment where I can manually do tests on random kernels, and also various TPM related experiments. So I don’t want something as fixed as a libvirt setup. I’d like the following:
- It to be fairly lightweight, so I can run it on a laptop while usefully doing other things
- I need a TPM 2.0 device to appear to the guest OS, but it doesn’t need to be a real TPM
- Block device discard should work, so I can back it with a qcow2 image and use fstrim to keep the actual on disk size small, without constraining my potential for file system expansion should I need it
- I’ve no need for graphics, in fact a serial console would be better as it eases copy & paste, especially when I screw up kernel changes
That turns out to be possible, but it took a bunch of trial and error to get there. So I’m writing it down. I generally do this on a Fedora based host system (FC40 at present, but this all worked with FC38 + FC39 too), and I run Debian 12 (bookworm) as the guest. At present I’m using qemu 8.2.2 and swtpm 0.9.0, both from the FC40 packages.
One other issue I spent too long tracking down is that the version of grub 2.06 in bookworm does not manage to pass the TPMEventLog through to the guest kernel properly. The events get measured and the PCRs updated just fine, but /sys/kernel/security/tpm0/binary_bios_measurements doesn’t even get created. Using either grub 2.06 from FC40, or the 2.12 backport in bookworm-backports, makes this work just fine.
Anyway, for reference, the following is the script I use to start the swtpm, and then qemu. The debugcon line can be dropped if you’re not interested in OVMF debug logging. This needs the guest OS to be configured up for a serial console, but avoids the overhead of graphics emulation.
As I said at the start, I’m open to any hints about other options I should be passing; as long as I get acceptable performance in the guest I care more about reducing host load than optimising for the guest.
#!/bin/sh BASEDIR=/home/noodles/debian-qemu if [ ! -S ${BASEDIR}/swtpm/swtpm-sock ]; then echo Starting swtpm: swtpm socket --tpmstate dir=${BASEDIR}/swtpm \ --tpm2 \ --ctrl type=unixio,path=${BASEDIR}/swtpm/swtpm-sock & fi echo Starting QEMU: qemu-system-x86_64 -enable-kvm -m 2048 \ -machine type=q35 \ -smbios type=1,serial=N00DL35,uuid=fd225315-f72a-4d66-9b16-55363c6c938b \ -drive if=pflash,format=qcow2,readonly=on,file=/usr/share/edk2/ovmf/OVMF_CODE_4M.qcow2 \ -drive if=pflash,format=raw,file=${BASEDIR}/OVMF_VARS.fd \ -global isa-debugcon.iobase=0x402 -debugcon file:${BASEDIR}/debian.ovmf.log \ -device virtio-blk-pci,drive=drive0,id=virblk0 \ -drive file=${BASEDIR}/debian-12-efi.qcow2,if=none,id=drive0,discard=on \ -net nic,model=virtio -net user \ -chardev socket,id=chrtpm,path=${BASEDIR}/swtpm/swtpm-sock \ -tpmdev emulator,id=tpm0,chardev=chrtpm \ -device tpm-tis,tpmdev=tpm0 \ -display none \ -nographic \ -boot menu=onSumana Harihareswara - Cogito, Ergo Sumana: Middle Age and Absences
Ruslan Spivak: Up Your Game: Fundamental Skills for Software Engineers
“Fundamentals are the foundation of excellence. Without a strong base, you cannot reach your full potential.” – John Wooden
Hey there!
Let’s talk fundamentals today. Why are they important? John Wooden’s quote sums it up nicely, but let’s unpack it a bit more:
Strong foundation:
A solid grasp of fundamental concepts provides a strong foundation for building advanced skills. Just like a house needs a sturdy base, your knowledge in software engineering needs a solid groundwork. It may sound cliché, but it’s still true.
Continuous learning: fundamentals serve as a launchpad for continuous learning. Once you have a solid base, you can explore more advanced topics and specializations, keeping your skills sharp and relevant.
Confidence: mastering the fundamentals boosts your confidence. Remember, competence breeds confidence.
Shelf-life: technology evolves at a breakneck pace. Remember when new JavaScript frameworks seemed to pop up before your morning coffee? Or just look at how quickly the AI space is advancing these days. While frameworks come and go, fundamentals like data structures, algorithms, math, software design, OS internals, and soft skills have enduring value. Investing in these fundamentals offers a much better return on investment compared to the often fleeting value of the latest frameworks.
Understanding the fundamentals is essential for software engineers at all levels; they’re not just for beginners.
Which specific fundamentals are important for software engineers?
Well, everyone loves a good list, so here you go - an opinionated list of essential fundamentals for software engineers at all levels, from entry-level to senior IC, staff, and beyond:
Programming languages: this one’s super obvious. The main question is which languages? Python, JavaScript, Go, and some C are the usual suspects. Bonus points if you dive into how interpreters and compilers work.
Software design and architecture
Data structures and algorithms (DSA)
Operating systems: this also includes basic computer architecture and networking.
Databases: design and internals
Distributed systems: nowadays, systems run on multiple machines and instances, so understanding the basics of distributed systems is important.
Math: this might be controversial, but it can also be the secret sauce, especially statistics and math for AI.
Soft skills: fundamental to any engineer’s career unless you’re living in a cave alone. The truth is, soft skills are actually hard to master.
Consider this a teaser! I’ll be doing deep dives into these fundamentals in upcoming posts, along with other key essentials for software engineers.
Spotlight
In today’s spotlight: “The Pragmatic Programmer: Your Journey to Mastery”
Andy Hunt and Dave Thomas offer a wealth of practical advice, timeless tips, and real-world examples. Every software engineer needs “The Pragmatic Programmer” on their shelf. Now in its second (20th anniversary) edition, this book is a must-read. I fondly remember the original edition titled “From Journeyman to Master.” My copy is well-worn from many reads - truly good books are worth revisiting.
Sneak Peak
In the next post, I’ll talk about essential fundamentals for engineering managers.
Stay curious,
Ruslan
FSF Blogs: Let's not celebrate CrowdStrike -- let's point to a better way
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects