
Feeds
Talking Drupal: Skills Upgrade #7
Welcome back to “Skills Upgrade” a Talking Drupal mini-series following the journey of a D7 developer learning D10. This is episode 7.
Topics-
Review Chad's goals for the previous week
- Test Example
- Set up phpunit.xml
- Start with FrontPageLinkTest.php
-
Review Chad's questions
- In the testing_example module, the file "src/Controller/TestingExampleController.php" has a function for simpletestDescription(). Is this an outdated artifact that should have been removed at some point? The module itself doesn't appear to use Simpletest elsewhere and appears to only rely on PHPUnit.
- What do you recommend for the minimal code structure to include for any given test type? Is the Testing Example module an ideal model or are there other resources I should review? The testing reference from Selwyn was helpful.
- In the "FrontPageLinkDependenciesTest.php" setUp() function, the createContentType() function is called without specifying the type. Is that set somewhere else? I may have overlooked it. Nevermind—it's set using randomMachineName() in the createContentType() function. Is there anything extra or standard to write in tests for drupal.org?
-
Tasks for the upcoming week
- Smart Date - Martin (maintainer) to review promptly, I've already chatted with him about it. Create a new functional test: "submit a range with an end time before the start and validate that an error is returned"
- Create an issue in the Smart Date queue and assign to yourself.
- Create an issue fork.
- Check out the issue fork locally.
- Write (and test) the test locally.
- Commit and push to the issue fork.
- Mark issue as "Needs review".
- Ask someone to review - if all looks good, the reviewer will mark as RBTC.
- Smart Date - Martin (maintainer) to review promptly, I've already chatted with him about it. Create a new functional test: "submit a range with an end time before the start and validate that an error is returned"
Chad's Drupal 10 Learning Curriclum & Journal Chad's Drupal 10 Learning Notes
The Linux Foundation is offering a discount of 30% off e-learning courses, certifications and bundles with the code, all uppercase DRUPAL24 and that is good until June 5th https://training.linuxfoundation.org/certification-catalog/
HostsAmyJune Hineline - @volkswagenchick
GuestsChad Hester - chadkhester.com @chadkhest Mike Anello - DrupalEasy.com @ultimike
The Drop Times: Mounting /Himalayas to /Enterprise Web: Gai Technologies' Ascetic Route
Dirk Eddelbuettel: RcppArmadillo 0.12.8.2.1 on CRAN: Micro Fix
Armadillo is a powerful and expressive C++ template library for linear algebra and scientific computing. It aims towards a good balance between speed and ease of use, has a syntax deliberately close to Matlab, and is useful for algorithm development directly in C++, or quick conversion of research code into production environments. RcppArmadillo integrates this library with the R environment and language–and is widely used by (currently) 1135 other packages on CRAN, downloaded 33.7 million times (per the partial logs from the cloud mirrors of CRAN), and the CSDA paper (preprint / vignette) by Conrad and myself has been cited 579 times according to Google Scholar.
Yesterday’s release accommodates reticulate by suspending a single test that now ‘croaks’ creating a reverse-dependency issue for that package. No other changes were made.
The set of changes since the last CRAN release follows.
Changes in RcppArmadillo version 0.12.8.2.1 (2024-04-15)- One-char bug fix release commenting out one test that upsets reticulate when accessing a scipy sparse matrix
Courtesy of my CRANberries, there is a diffstat report relative to previous release. More detailed information is on the RcppArmadillo page. Questions, comments etc should go to the rcpp-devel mailing list off the Rcpp R-Forge page.
If you like this or other open-source work I do, you can sponsor me at GitHub.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
Seth Michael Larson: Microsoft supports urllib3 with FOSS Fund 2024
Published 2024-04-17 by Seth Larson
Reading time: minutes
Back in January we announced that urllib3 would be fundraising to implement support for HTTP/2 in a backwards compatible way to urllib3 v2.x and to ensure the project's development remains sustainable in the long-term.
Microsoft has awarded urllib3 $5,000 USD as one of its FOSS Fund recipients for 2024 🥳 Thank you, Microsoft for supporting open source software!
Since announcing our fundraiser we have raised $7,275 USD in 3 months, many of the donations coming from individuals and long-time sponsors like Sourcegraph and Sentry.
Thanks Microsoft! ❤️ How to get started supporting your own dependencies?Contribute directly to projects you depend on. Many of them already have funding mechanisms documented like Open Collective, GitHub Sponsors, or similar.
Subscribe to an organization like Tidelift to handle discovery of dependencies and fundable projects and to get additional guarantees like security and long-term support.
Thanks.dev provides a lightweight option to throw money in open sources' direction.
Thanks for reading! ♡ Did you find this article helpful and want more content like it?
Get notified of new posts by subscribing to the RSS feed or the email newsletter.
This work is licensed under CC BY-SA 4.0
Python Engineering at Microsoft: Glow up! A new look for Python Reference documentation on Microsoft Learn
Today, we’re excited to announce a new, improved experience for Python library reference documentation on Microsoft Learn, formerly Microsoft Docs. The new experience is now available for all Microsoft Python libraries on Learn, such as the Azure SDK for Python. In this blog post, we take a closer look at the specific changes made and how they improve the overall experience and accessibility of Python reference documentation on Learn.
Change SummaryThe key changes made to Python reference documentation on Learn were improving the navigation experience with the table of contents (TOC), the organization of in-page content, and in-page navigation via the right rail. When combined, these three key changes greatly improve the experience of finding information in Python reference on Learn.
Table of Contents (TOC)If you’ve used reference documentation before, you’ll know that the TOC serves as a uniquely pivotal tool for navigation between pages. Reference documentation, unlike conceptual articles and tutorials, rarely links together in an easy-to-follow way. This means that the TOC is often the only way for cross-page navigation in reference documentation, making it a key priority for us to get right.
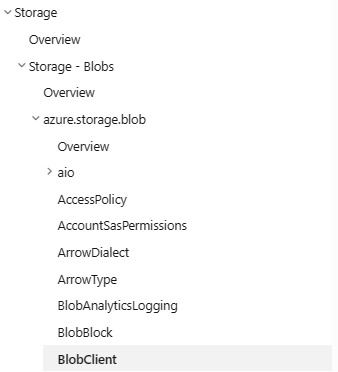
TOC – BeforePreviously, the table of contents for Python Reference documentation on Learn had a redundant layer of navigation for package names (in the screenshot below, the azure-storage-blob node), which added confusion for users looking to navigate deeper into the documentation. In addition, the table of contents had package prefixes attached to every item. This led to a cluttered experience, with some items in the TOC taking up two lines of space, further impacting readability and accessibility.
{kind=link}
TOC – After
The new TOC design removes the package name overview page and trims the package prefix from TOC items, making it easier to scan and navigate. If you’ve bookmarked a package name overview page, don’t worry, as you’ll be redirected to the package overview page automatically.
{kind=link}
In-Page Right Rail
The in-page right rail is a key part of reference documentation, allowing you to navigate in-page and quickly jump to different sections.
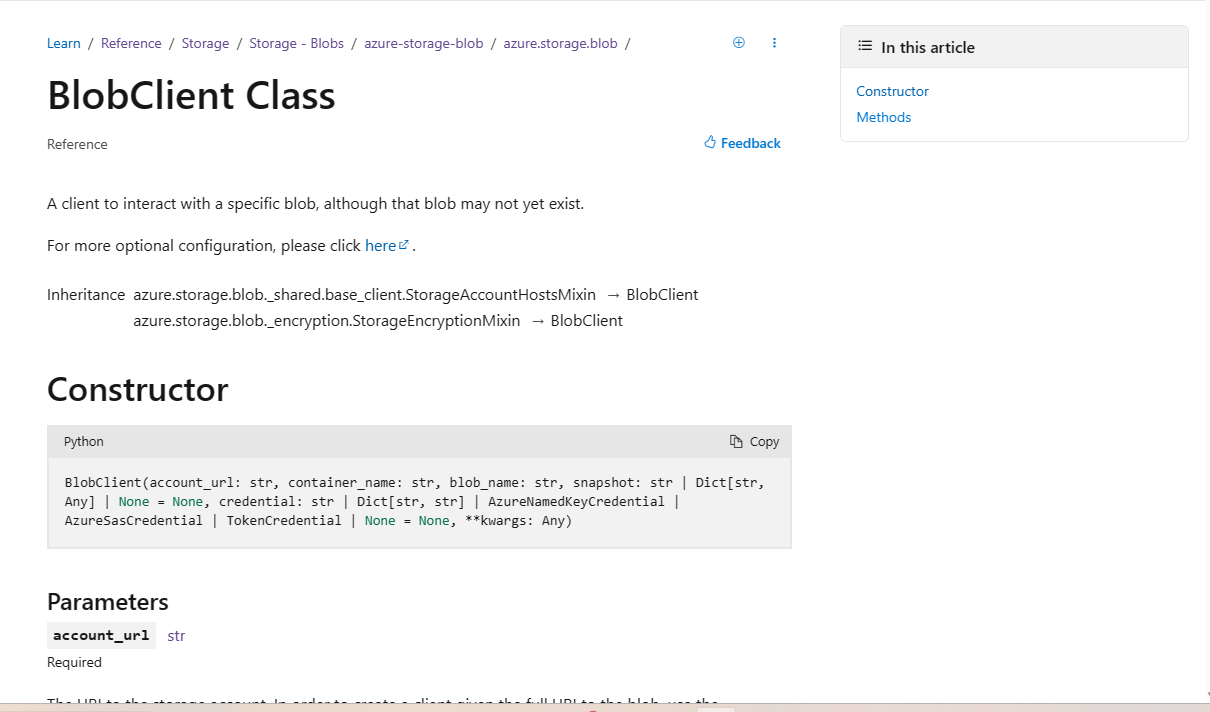
In-Page Right Rail – BeforeBefore, the right rail wasn’t “sticky”, meaning that once users scrolled on the page, the rail wouldn’t follow them, and the entire right side of the screen would be unused space. Additionally, the right rail links only covered H2 content on the page, resulting in a right rail that didn’t clarify any major details on the page. Finally, the right rail would be collapsed beyond four items, leading to extra effort from the user to see all of the H2 sections on the page. We recognize this design wasn’t consistent with the ways that other Python libraries design their documentation and made updates to better align with design patterns and expectations.
In-Page Right Rail – After
{kind=link}
The enhanced experience adds an individually scrollable, sticky right rail with details down to H3s, giving much more detail into what content the page has. The right rail additionally has active highlighting for the current item on the screen, making it easier for you to understand your current position relative to other content.
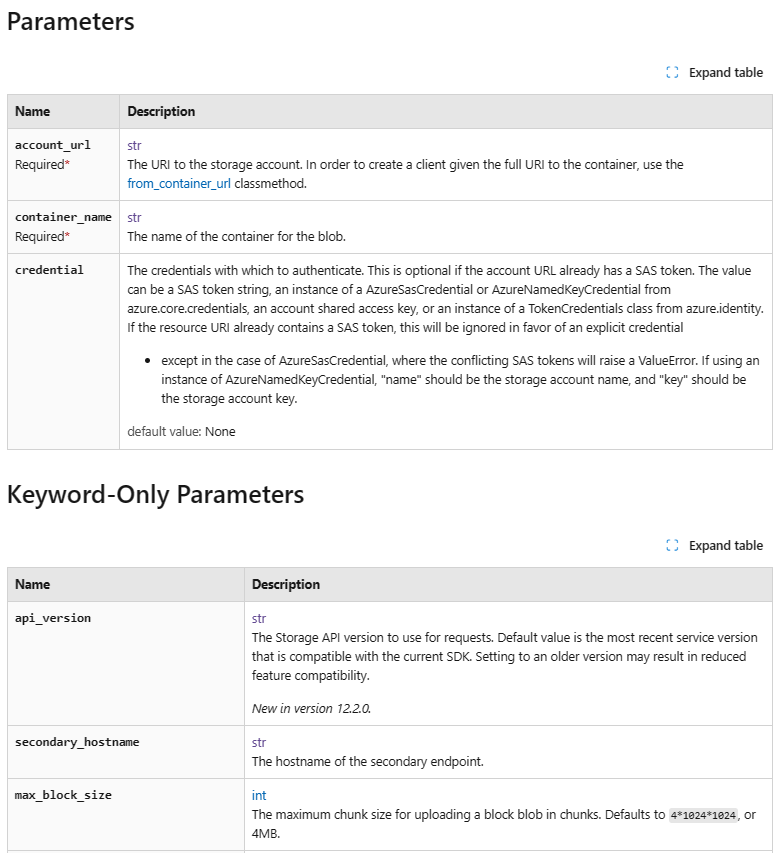
Parameter, Return, and Exception Organization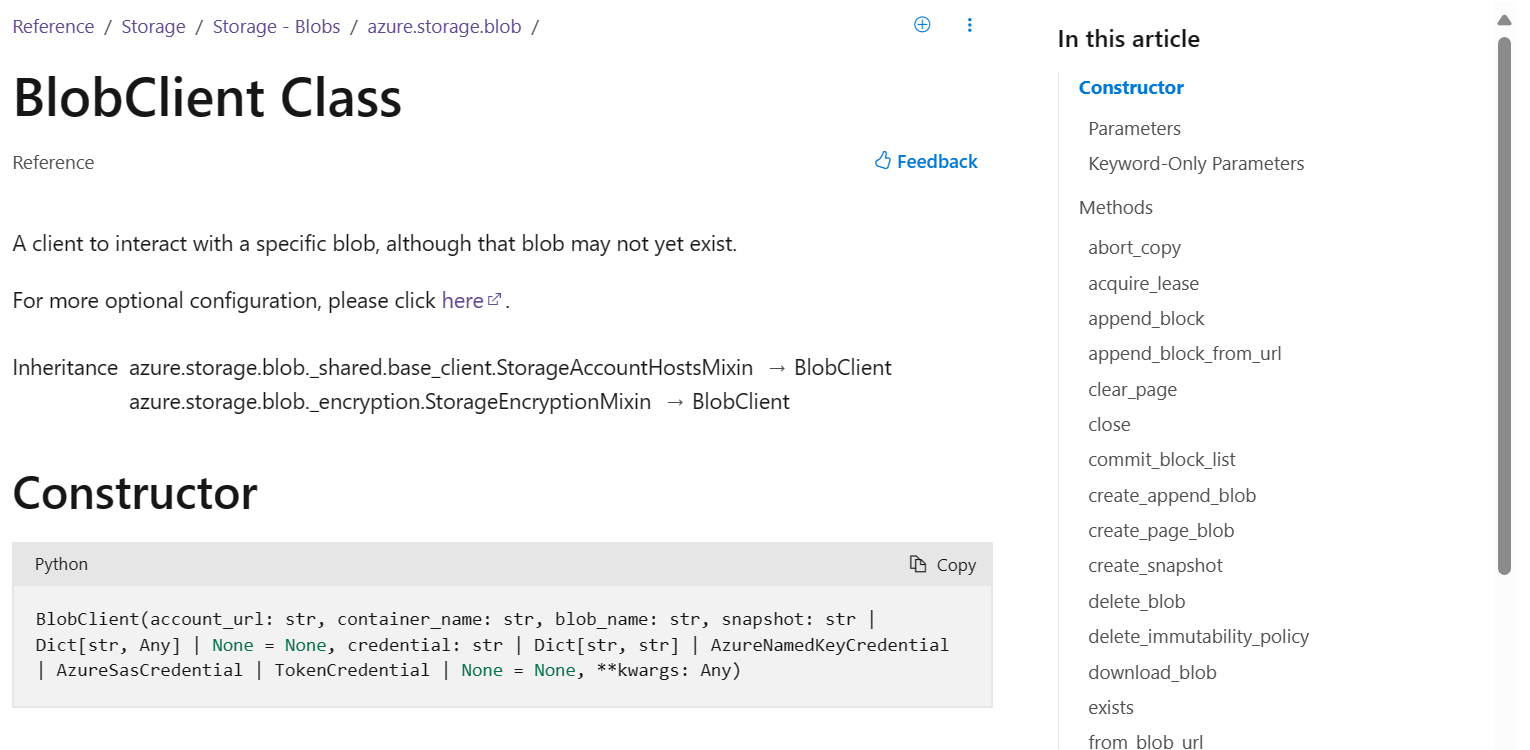{kind=link}
While the first two major feature changes focus on both overall and in-page navigation, we also identified an opportunity to improve in-page organization as well. When you’re looking at our reference documentation, being able to easily identify key information such as parameters, return values, and exceptions is crucial.
In-Page Organization – BeforeBefore the updates, these details were listed but not clearly separated between classes, leading to a confusing experience where it’s not clear where items started or ended. Additionally, as a result of the formatting of these values, a significant amount of vertical space was used, leading to a lot of scrolling to find the information needed. Lastly, required parameters, default values, and keyword-only parameters weren’t clearly highlighted to follow accessibility best practices, resulting in extra effort to find crucial information.
In-Page Organization – After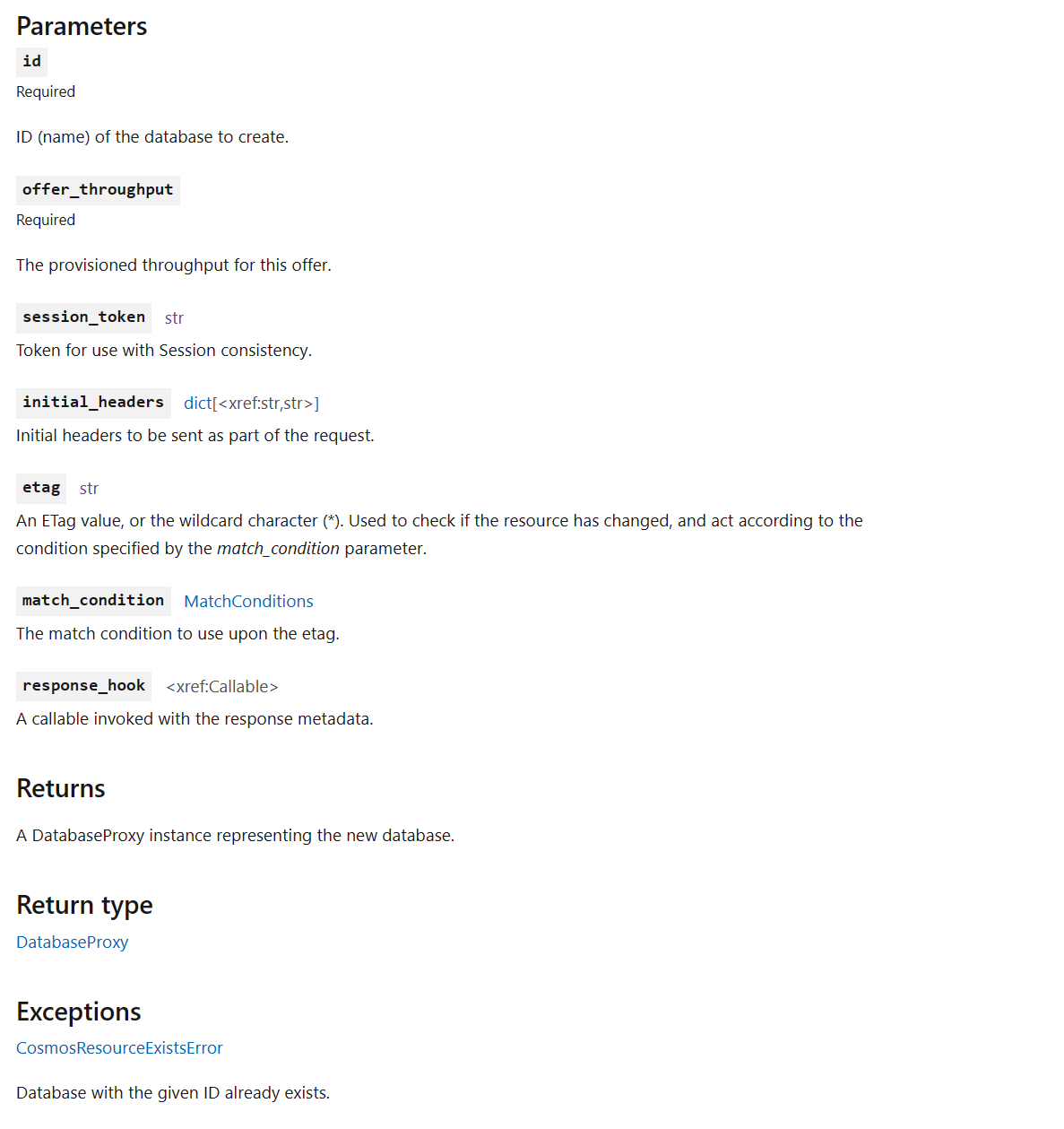{kind=link}
The new experience organizes parameters, return values, and exceptions into easy-to-scan tables. By using tables, default values, required tags, and types are clearly indicated. The end result is a cleaner and easier-to-use experience for all developers when scrolling through our documentation.
Conclusion
{kind=link}
In short, the new Python reference documentation experience on Learn is a major improvement for any developer using Microsoft’s Python libraries. The new TOC, in-page right rail, and in-page organization changes make finding information easier, with an added visual upgrade. We’re excited to continue optimizing the Python developer experience across all of our libraries and tools.
We hope you enjoy the changes! If you have any thoughts, you can leave feedback in the Azure SDK for Python GitHub repo.
The post Glow up! A new look for Python Reference documentation on Microsoft Learn appeared first on Python.
Philippe Normand: From WebKit/GStreamer to rust-av, a journey on our stack’s layers
In this post I’ll try to document the journey starting from a WebKit issue and ending up improving third-party projects that WebKitGTK and WPEWebKit depend on.
I’ve been working on WebKit’s GStreamer backends for a while. Usually some new feature needed on WebKit side would trigger work …
PyCoder’s Weekly: Issue #625 (April 16, 2024)
#625 – APRIL 16, 2024
View in Browser »
Discover the power of Pydantic, Python’s most popular data parsing, validation, and serialization library. In this hands-on tutorial, you’ll learn how to make your code more robust, trustworthy, and easier to debug with Pydantic.
REAL PYTHON
Coding on the web means you have to be more security conscious as everyone has access to your software. This article discusses key steps you can take to help make your code more secure.
ARJAN
With Sentry, you can trace issues from the frontend to the backend—detecting slow and broken code, to fix what’s broken faster. Installing the Python SDK is super easy and PyCoder’s Weekly subscribers get three full months of the team plan. Just use code “pycoder” on signup →
SENTRY sponsor
Michael of TalkPython fame gave this keynote at PyCon Philippines. He addresses topics such as Python trends in code, asyncio, Flask and Django, getting rid of the GIL and more.
MICHAEL KENNEDY video
“Django’s system check framework provides fantastic protection for configuration mishaps. It’s like a targeted linter that runs when you start Django commands.” It also can be a bit slow for large projects. As part of the Django 5.1 release many optimizations have been applied. This blog posts discusses the work involved.
ADAM JOHNSON
“When talking flippantly about programming languages, it’s sometimes useful to glob a bunch of them together based on characteristics, whether superficial or not. This started with jokes about common features of ‘P languages’ like Perl, PHP, Python, JavaScript and Ruby, but you can classify other languages too.”
BRYCE KERLEY
In this video course, you’ll learn how to use Python to generate QR codes, from your standard black-and-white QR codes to beautiful ones with your favorite colors. You’ll learn how to format QR codes, rotate them, and even replace the static background with moving images.
REAL PYTHON course
Sometimes teachers or mentors ask students to contribute to an open source project, without the context of what that entails. This opinion piece covers just how much noise that causes for the projects and why you shouldn’t do it unless you truly mean to contribute.
DAVID LORD
Ashlynn ran into a problem where her code was initializing a connection to the Google Cloud API before the credentials for it had been imported. This blog post covers the problem and how she got around it.
ASHLYNN ANTROBUS
For a year and a half, Rodrigo worked at Textualize the company behind the popular open source Python projects Rich and Textual. This blog post talks about what he learned while he was there.
RODRIGO GIRÃO SERRÃO
Like many of us, Pawel uses f-strings a lot. Even with frequent use, it can be hard to remember how the formatting syntax works. This post covers some of the more common formats around.
PAWEL JASTRZEBSKI
What’s it mean to write clean code? What is clean Python code, specifically? This article talks about how to write code that is easier to read and the tools you can use to get there.
NIK TOMAZIC
Were you in the path of the eclipse last week? Would you like to figure out if you’ll be in the next one? This article shows you how using the Astropy library.
ERIK BERNHARDSSON
This guide walks you through transcribing video using the OpenAI Whisper model and seamlessly adding subtitles with FFmpeg tool.
EDITFRAME
April 17, 2024
REALPYTHON.COM
April 18, 2024
MEETUP.COM
April 18, 2024
PYLADIES.COM
April 19 to April 22, 2024
PYTEXAS.ORG
April 19 to April 21, 2024
DJANGOGIRLS.ORG
April 19 to April 20, 2024
MEETUP.COM
April 22 to April 25, 2024
PYCON.DE
Happy Pythoning!
This was PyCoder’s Weekly Issue #625.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
Chapter Three: National Nurses United: Supporting a Large Website
Drupal Association blog: 5 Reasons to Join Us at DrupalCon Portland 2024
Discover Why DrupalCon Portland 2024 Is the Must-Attend Event of the Year
If you're part of the Drupal community or interested in Drupal, you won't want to miss DrupalCon Portland 2024! The conference is set to be the most exciting and informative event of the year, catering to developers, marketers, content editors, content publishers, and anyone else who interacts with their website. In this blog post, I'll outline the top five reasons why attending DrupalCon Portland in 2024 is a must.
Immerse Yourself in the Ultimate Drupal ExperienceDrupalCon Portland 2024 promises an entire week dedicated to Drupal and the vibrant Drupal Community. It's your chance to connect with some of the most brilliant minds in the industry, engage in discussions, build lasting friendships, and simply have a fantastic time. Key highlights of the event include:
-
Foster Community Through In-Person Connections: Experience the warmth and synergy of the Drupal community by connecting face-to-face with fellow Drupal enthusiasts. This is a unique chance to share your passion for Drupal with like-minded individuals in a vibrant, engaging setting.
-
Driesnote & Eminent Speakers: Gain insights from the Drupal founder during the much-anticipated Driesnote and learn from a lineup of distinguished speakers. These sessions promise to be thought-provoking, offering deep dives into various aspects of Drupal, its ecosystem, and future directions.
-
Contribution Opportunities: Participate in contribution sprints where you can tackle real-world problems, contribute to the project, and interact with key project contributors and maintainers. This is your chance to make a tangible impact and glean insights from the guardians of the Drupal codebase.
-
Social Gatherings and Welcome Party: DrupalCon isn't just about learning; it's also about having a great time. The Welcome Party and other social events provide perfect settings to unwind, celebrate, and build friendships in a more relaxed atmosphere. View the social events or submit yours now.
-
Birds of a Feather Sessions: Engage in "Birds of a Feather" (BoF) sessions, where small groups gather to discuss hot topics and share knowledge on specific areas of interest within Drupal and technology. These small gatherings encourage open dialogue and are a great way to dive deep into subjects you care about with peers.
After years of remote work and lockdowns, DrupalCon Portland 2024 provides a refreshing opportunity to step out of your home office and connect with passionate Drupal enthusiasts. Meet the faces behind your favorite modules and engage with like-minded individuals who share your love for Drupal.
Unparalleled Learning OpportunitiesDrupalCon offers unparalleled opportunities for learning and growth. From inspiring keynotes and informative sessions to hands-on training and contribution sprints, this event is the ultimate platform to expand your knowledge and expertise. Break out of your routine and explore the full potential of Drupal.
This year will be filled with broader topics to help you drive your digital experiences forward. Some of the new highlights this year include:
- A new marketing track dedicated to driving your business goals forward.
- Artificial Intelligence (AI) - Learning how AI is being incorporated into Drupal and how it can help you improve your day to day and achieve your goals.
- Birds of a Feather - More structure and planning going into our BOF sessions to drive higher levels of engagement and inform stronger conversations.
Witness the transformative power of Drupal and be inspired by the innovative and talented Drupal community. Attendees at DrupalCon Portland are focused on:
- Crafting cutting-edge content management systems.
- Delivering groundbreaking customer experiences.
- Mastering their craft and pushing boundaries.
DrupalCon Portland is the perfect environment to connect with individuals who share your passion for Drupal, open-source technology, and delivering top-notch digital experiences. Building relationships here can significantly impact your career, opening doors to exciting opportunities.
There are countless reasons to join us at DrupalCon Portland 2024, and we can't wait to welcome you! It's a unique opportunity to connect with the Drupal community, discover the incredible work happening within Drupal, and spend quality time with friends and colleagues from around the world who share your common passion. We look forward to seeing you there!
ImageX: Augment Your Drupal Content Management Workflows with the Augmentor AI Module
Authored by: Nadiia Nykolaichuk.
Python Morsels: Python Big O: the time complexities of different data structures in Python
The time complexity of common operations on Python's many data structures.
Table of contents
- Time Complexity ⏱️
- List 📋
- Double-Ended Queue ↔️
- Dictionary 🗝️
- Set 🎨
- Counter 🧮
- Heap / Priority Queue ⛰️
- Sorted List 🔤
- Traversal Techniques 🔍
- Other Data Structures? 📚
- Beware of Loops-in-Loops! 🤯
- Mind Your Data Structures 🗃️
Time complexity is one of those Computer Science concepts that's scary in its purest form, but often fairly practical as a rough "am I doing this right" measurement.
In the words of Ned Batchelder, time complexity is all about "how your code slows as your data grows".
Time complexity is usually discussed in terms of "Big O" notation. This is basically a way to discuss the order of magnitude for a given operation while ignoring the exact number of computations it needs. In "Big O" land, we don't care if something is twice as slow, but we do care whether it's n times slower where n is the length of our list/set/slice/etc.
Here's a graph of the common time complexity curves:
Remember that these lines are simply about orders of magnitude. If an operation is on the order of n, that means 100 times more data will slow things down about 100 times. If an operation is on the order of n² (that's n*n), that means 100 times more data will slow things down 100*100 times.
I usually think about those curves in terms of what would happen if we suddenly had 1,000 times more data to work with:
- O(1): no change in time (constant time!)
- O(log n): ~10 times slow down
- O(n): 1,000 times slow down
- O(n log n): 10,000 times slow down
- O(n²): 1,000,000 times slow down! 😲
With that very quick recap behind us, let's take a look at the relative speeds of all common operations on each of Python's data structures.
List 📋Python's lists are similar to …
Read the full article: https://www.pythonmorsels.com/time-complexities/Real Python: Using raise for Effective Exceptions
In your Python journey, you’ll come across situations where you need to signal that something is going wrong in your code. For example, maybe a file doesn’t exist, a network or database connection fails, or your code gets invalid input. A common approach to tackle these issues is to raise an exception, notifying the user that an error has occurred. That’s what Python’s raise statement is for.
Learning about the raise statement allows you to effectively handle errors and exceptional situations in your code. This way, you’ll develop more robust programs and higher-quality code.
In this video course, you’ll learn how to:
- Raise exceptions in Python using the raise statement
- Decide which exceptions to raise and when to raise them in your code
- Explore common use cases for raising exceptions in Python
- Apply best practices for raising exceptions in your Python code
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Matt Glaman: Writing tests first saves time and money later on
The TalkingDrupal podcast had Alexey Korepov on to talk about Test Driven Development. Alexey has written the Test Helpers module, a development package that provides many useful utility tools for writing unit tests for your Drupal code.
Balint Pekker: Enhancing Drupal with GitHub Actions
Talk Python to Me: #456: Building GPT Actions with FastAPI and Pydantic
Python Bytes: #379 Constable on the debugging case
Volker Krause - Secure HTTP Usage - Akademy 2019
For protecting the privacy of our users and the security and integrity of their systems, usage of transport encryption and authentication is crucial for any network communication. HTTP over TLS (HTTPS) is probably the most widespread set of protocols for that. What do we need to look out for when using this in our applications?
Akademy 2024: Registration Now Open
Akademy 2024 will be a hybrid event held simultaneously in Würzburg, Germany, and Online.
Hundreds of participants from the global KDE community, the wider free and open source software community, local organisations and software companies will gather at this year's Akademy 2024 conference. The event will take place in Würzburg and Online from Saturday 7th September to Thursday 12th September.
KDE developers, artists, designers, translators, users, writers, sponsors and supporters from around the world will meet face-to-face to discuss key technology issues, explore new ideas and strengthen KDE's innovative and dynamic culture.
Register now and join us for engaging talks, workshops, BoFs and coding sessions. Collaborate with your fellow KDE contributors to fix bugs, pioneer new features and immerse yourself in the world of open source.
For more information about the conference, visit the Akademy 2024 website.
Specbee: How to integrate Auth0 Single Sign-On (SSO) in Drupal
The Drop Times: Christoph Weber to Explore Private LLMs for Technical Documentation at LagoonCon 2024
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects