
FLOSS Project Planets
The Drop Times: Singapore Government Launches Purple A11y for Enhanced Web Accessibility
The Drop Times: Bryan Gruneberg to Highlight Open Source Hosting Benefits at LagoonCon Portland 2024
Test and Code: 218: Balancing test coverage with test costs - Nicole Tietz-Sokolskaya
Nicole is a software engineer and writer, and recently wrote about the trade-offs we make when deciding which tests to write and how much testing is enough.
We talk about:
- Balancing schedule vs testing
- How much testing is the right about of testing
- Should code coverage be measured and tracked
- Good refactoring can reduce code coverage
- Is it worth testing error conditions?
- Are rare error codes ok to just monitor?
- API drift and autospec
- Mitigating risk
- Deciding what to test and what not to test
- Focus testing on key money-making features
- If there's a bug in this part of the code, how much business impact is there?
- Performance testing needs to approximately match real world workloads
- Cost of a service breaking vs the cost of creating, maintaining, and running tests
- Keeping test suites quick to minimize getting distracted
Links:
- Too much of a good thing: the trade-off we make with tests
- Load testing is hard, and the tools are... not great. But why?
- Yet Another Rust Resource (YARR!)
- Goodhart's law - "When a measure becomes a target, it ceases to be a good measure"
Sponsored by Mailtrap.io
- An Email Delivery Platform that developers love.
- An email-sending solution with industry-best analytics, SMTP, and email API, SDKs for major programming languages, and 24/7 human support.
- Try for Free at MAILTRAP.IO
Sponsored by PyCharm Pro
- Use code PYTEST for 20% off PyCharm Professional at jetbrains.com/pycharm
- Now with Full Line Code Completion
- See how easy it is to run pytest from PyCharm at pythontest.com/pycharm
The Complete pytest Course
- For the fastest way to learn pytest, go to courses.pythontest.com
- Whether your new to testing or pytest, or just want to maximize your efficiency and effectiveness when testing.
Russ Allbery: Review: Unseen Academicals
Review: Unseen Academicals, by Terry Pratchett
Series: Discworld #37 Publisher: Harper Copyright: October 2009 Printing: November 2014 ISBN: 0-06-233500-6 Format: Mass market Pages: 517Unseen Academicals is the 37th Discworld novel and includes many of the long-standing Ankh-Morpork cast, but mostly as supporting characters. The main characters are a new (and delightful) bunch with their own concerns. You arguably could start reading here if you really wanted to, although you would risk spoiling several previous books (most notably Thud!) and will miss some references that depend on familiarity with the cast.
The Unseen University is, like most institutions of its sort, funded by an endowment that allows the wizards to focus on the pure life of the mind (or the stomach). Much to their dismay, they have just discovered that an endowment that amounts to most of their food budget requires that they field a football team.
Glenda runs the night kitchen at the Unseen University. Given the deep and abiding love that wizards have for food, there is both a main kitchen and a night kitchen. The main kitchen is more prestigious, but the night kitchen is responsible for making pies, something that Glenda is quietly but exceptionally good at.
Juliet is Glenda's new employee. She is exceptionally beautiful, not very bright, and a working class girl of the Ankh-Morpork streets down to her bones. Trevor Likely is a candle dribbler, responsible for assisting the Candle Knave in refreshing the endless university candles and ensuring that their wax is properly dribbled, although he pushes most of that work off onto the infallibly polite and oddly intelligent Mr. Nutt.
Glenda, Trev, and Juliet are the sort of people who populate the great city of Ankh-Morpork. While the people everyone has heard of have political crises, adventures, and book plots, they keep institutions like the Unseen University running. They read romance novels, go to the football games, and nurse long-standing rivalries. They do not expect the high mucky-mucks to enter their world, let alone mess with their game.
I approached Unseen Academicals with trepidation because I normally don't get along as well with the Discworld wizard books. I need not have worried; Pratchett realized that the wizards would work better as supporting characters and instead turns the main plot (or at least most of it; more on that later) over to the servants. This was a brilliant decision. The setup of this book is some of the best of Discworld up to this point.
Trev is a streetwise rogue with an uncanny knack for kicking around a can that he developed after being forbidden to play football by his dear old mum. He falls for Juliet even though their families support different football teams, so you may think that a Romeo and Juliet spoof is coming. There are a few gestures of one, but Pratchett deftly avoids the pitfalls and predictability and instead makes Juliet one of the best characters in the book by playing directly against type. She is one of the characters that Pratchett is so astonishingly good at, the ones that are so thoroughly themselves that they transcend the stories they're put into.
The heart of this book, though, is Glenda.
Glenda enjoyed her job. She didn't have a career; they were for people who could not hold down jobs.
She is the kind of person who knows where she fits in the world and likes what she does and is happy to stay there until she decides something isn't right, and then she changes the world through the power of common sense morality, righteous indignation, and sheer stubborn persistence. Discworld is full of complex and subtle characters fencing with each other, but there are few things I have enjoyed more than Glenda being a determinedly good person. Vetinari of course recognizes and respects (and uses) that inner core immediately.
Unfortunately, as great as the setup and characters are, Unseen Academicals falls apart a bit at the end. I was eagerly reading the story, wondering what Pratchett was going to weave out of the stories of these individuals, and then it partly turned into yet another wizard book. Pratchett pulled another of his deus ex machina tricks for the climax in a way that I found unsatisfying and contrary to the tone of the rest of the story, and while the characters do get reasonable endings, it lacked the oomph I was hoping for. Rincewind is as determinedly one-note as ever, the wizards do all the standard wizard things, and the plot just isn't that interesting.
I liked Mr. Nutt a great deal in the first part of the book, and I wish he could have kept that edge of enigmatic competence and unflappableness. Pratchett wanted to tell a different story that involved more angst and self-doubt, and while I appreciate that story, I found it less engaging and a bit more melodramatic than I was hoping for. Mr. Nutt's reactions in the last half of the book were believable and fit his background, but that was part of the problem: he slotted back into an archetype that I thought Pratchett was going to twist and upend.
Mr. Nutt does, at least, get a fantastic closing line, and as usual there are a lot of great asides and quotes along the way, including possibly the sharpest and most biting Vetinari speech of the entire series.
The Patrician took a sip of his beer. "I have told this to few people, gentlemen, and I suspect never will again, but one day when I was a young boy on holiday in Uberwald I was walking along the bank of a stream when I saw a mother otter with her cubs. A very endearing sight, I'm sure you will agree, and even as I watched, the mother otter dived into the water and came up with a plump salmon, which she subdued and dragged on to a half-submerged log. As she ate it, while of course it was still alive, the body split and I remember to this day the sweet pinkness of its roes as they spilled out, much to the delight of the baby otters who scrambled over themselves to feed on the delicacy. One of nature's wonders, gentlemen: mother and children dining on mother and children. And that's when I first learned about evil. It is built into the very nature of the universe. Every world spins in pain. If there is any kind of supreme being, I told myself, it is up to all of us to become his moral superior."
My dissatisfaction with the ending prevents Unseen Academicals from rising to the level of Night Watch, and it's a bit more uneven than the best books of the series. Still, though, this is great stuff; recommended to anyone who is reading the series.
Followed in publication order by I Shall Wear Midnight.
Rating: 8 out of 10
Breeze Icon Updates for April 2024 – with a Little Heart for You!
Hey everyone! Here is a new video explanation of the changes we have done. This time we tackled Labplot, maps, and media icons! Can you believe it? We are now officially past the mid-way for the icons. So exciting!
Samuel Henrique: Hello World
This is my very first post, just to make sure everything is working as expected.
Made with Zola and the Abridge theme.
www-zh-cn @ Savannah: It is easy to contribute to GNU
I will be delivering my talk, "It is easy to contribute to GNU," Saturday, May 4, 2024, 12:15--13:00 EDT (16:00 UTC), at the LibrePlanet 2024 conference, and I hope you’ll check it out!
LibrePlanet is a conference about software freedom, happening on May 4 & 5, 2024. The event is hosted by the Free Software Foundation (FSF), and brings together software developers, law and policy experts, activists, students, and computer users to learn skills, celebrate free software accomplishments, and face upcoming challenges. Newcomers are always welcome, and LibrePlanet 2024 will feature programming for all ages and experience levels.
*Please register in advance at <https://libreplanet.org/2024/>.*
wxie
Nonprofit Drupal posts: April Drupal for Nonprofits Chat: Getting Ready for DrupalCon
Join us THURSDAY, April 18 at 1pm ET / 10am PT, for our regularly scheduled call to chat about all things Drupal and nonprofits. (Convert to your local time zone.)
This month we'll be preparing for DrupalCon Portland, which features the return of the Nonprofit Summit!
And we'll of course also have time to discuss anything else that's on our minds at the intersection of Drupal and nonprofits. Got something specific you want to talk about? Feel free to share ahead of time in our collaborative Google doc: https://nten.org/drupal/notes!
All nonprofit Drupal devs and users, regardless of experience level, are always welcome on this call.
This free call is sponsored by NTEN.org and open to everyone.
-
Join the call: https://us02web.zoom.us/j/81817469653
-
Meeting ID: 818 1746 9653
Passcode: 551681 -
One tap mobile:
+16699006833,,81817469653# US (San Jose)
+13462487799,,81817469653# US (Houston) -
Dial by your location:
+1 669 900 6833 US (San Jose)
+1 346 248 7799 US (Houston)
+1 253 215 8782 US (Tacoma)
+1 929 205 6099 US (New York)
+1 301 715 8592 US (Washington DC)
+1 312 626 6799 US (Chicago) -
Find your local number: https://us02web.zoom.us/u/kpV1o65N
-
- Follow along on Google Docs: https://nten.org/drupal/notes
Tryton News: Security Release for issue #13142
Cédric Krier has found that trytond accepts compressed content from unauthenticated requests which makes it vulnerable to zip bomb attacks.
Impact- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Confidentiality: None
- Integrity: None
- Availability: Low
A proxy can be deployed in front of the trytond server to forbid this kind of request.
ResolutionAll affected users should upgrade trytond to the latest version.
Affected versions per series:
- trytond:
- 7.0: <= 7.0.9
- 6.8: <= 6.8.14
- 6.0: <= 6.0.44
Non affected versions per series:
- trytond:
- 7.0: >= 7.0.10
- 6.8: >= 6.8.15
- 6.0: >= 6.0.45
Any security concerns should be reported on the bug-tracker at https://bugs.tryton.org/ with the confidential checkbox checked.
1 post - 1 participant
The Drop Times: Tickets Now Available for DrupalCamping 2024 in Wolfsburg
The Drop Times: Drupal Developer Days Announces Featured Speakers Gábor Hojtsy and Cristina Chumillas
Petter Reinholdtsen: RAID status from LSI Megaraid controllers in Debian
I am happy to report that the megactl package, useful to fetch RAID status when using the LSI Megaraid controller, now is available in Debian. It passed NEW a few days ago, and is now available in unstable, and probably showing up in testing in a weeks time. The new version should provide Appstream hardware mapping and should integrate nicely with isenkram.
As usual, if you use Bitcoin and want to show your support of my activities, please send Bitcoin donations to my address 15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
Mike Driscoll: Announcing The Python Logging Book & Course Kickstarter
What does every new developer do when they are first learning to program? They print out strings to their terminal. It’s how we learn! But printing out to the terminal isn’t what you do with most professional applications.
In those cases, you log into files. Sometimes, you log into multiple locations at once. These logs may serve as an audit trail for compliance purposes or help the engineers debug what went wrong.
Python Logging teaches you how to log in the Python programming language. Python is one of the most popular programming languages in the world. Python comes with a logging module that makes logging easy.
What You’ll LearnIn this book, you will learn how about the following:
- Logger objects
- Log levels
- Log handlers
- Formatting your logs
- Log configuration
- Logging decorators
- Rotating logs
- Logging and concurrency
- and more!
The finished book will be made available in the following formats:
- paperback (at the appropriate reward level)
- epub
The paperback is a 6″ x 9″ book and is approximately 150 pages long.
You can support the book by clicking the button below:
The post Announcing The Python Logging Book & Course Kickstarter appeared first on Mouse Vs Python.
Real Python: How to Format Floats Within F-Strings in Python
You’ll often need to format and round a Python float to display the results of your calculations neatly within strings. In earlier versions of Python, this was a messy thing to do because you needed to round your numbers first and then use either string concatenation or the old string formatting technique to do this for you.
Since Python 3.6, the literal string interpolation, more commonly known as a formatted string literal or f-string, allows you to customize the content of your strings in a more readable way.
An f-string is a literal string prefixed with a lowercase or uppercase letter f and contains zero or more replacement fields enclosed within a pair of curly braces {...}. Each field contains an expression that produces a value. You can calculate the field’s content, but you can also use function calls or even variables.
While most strings have a constant value, f-strings are evaluated at runtime. This makes it possible for you to pass different data into the replacement fields of the same f-string and produce different output. This extensibility of f-strings makes them a great way to embed dynamic content neatly inside strings. However, even though f-strings have largely replaced the earlier methods, they do have their short-comings.
For example, one of the most common attacks performed on a relational database is a SQL injection attack. Often, users provide parameters to SQL queries, and if the query is formed within an f-string, it may be possible to damage a database by passing in rogue commands. F-strings can also be used in a denial-of-service attack by attacking Python’s logging module code.
In older versions of Python, f-strings had a number of other limitations that were only fixed with Python version 3.12. This version is used throughout this tutorial.
Take a look at the example below. It shows you how to embed the result of a calculation within an f-string:
Python >>> f"One third, expressed as a float is: {1 / 3}" 'One third, expressed as a float is: 0.3333333333333333' Copied!Without any explicit rounding, once an expression has produced its value it’ll be inserted into the string using a default number of decimal places. Here, the result is shown to sixteen decimal places, which, in most cases, is more precision than you’ll ever need. So you’ll likely want to round your final answer to a more practical number of digits.
In this tutorial, you’ll learn how to use a Python f-string to format floats to meet your requirements.
Get Your Code: Click here to download the free sample code and exercise solutions you’ll use for learning how to format floats within f-strings in Python.
Take the Quiz: Test your knowledge with our interactive “Format Floats Within F-Strings” quiz. Upon completion you will receive a score so you can track your learning progress over time:
Interactive Quiz
Format Floats Within F-StringsIn this quiz, you'll test your understanding of how to format floats within f-strings in Python. This knowledge will let you control the precision and appearance of floating-point numbers when you incorporate them into formatted strings.
How to Format and Round a Float Within a Python F-StringTo format a float for neat display within a Python f-string, you can use a format specifier. In its most basic form, this allows you to define the precision, or number of decimal places, the float will be displayed with.
The code below displays the same calculation as before, only it’s displayed more neatly:
Python >>> f"One third, rounded to two decimal places is: {1 / 3:.2f}" 'One third, rounded to two decimal places is: 0.33' Copied!To use Python’s format specifiers in a replacement field, you separate them from the expression with a colon (:). As you can see, your float has been rounded to two decimal places. You achieved this by adding the format specifier .2f into the replacement field. The 2 is the precision, while the lowercase f is an example of a presentation type. You’ll see more of these later.
Note: When you use a format specifier, you don’t actually change the underlying number. You only improve its display.
Python’s f-strings also have their own mini-language that allows you to format your output in a variety of different ways. Although this tutorial will focus on rounding, this is certainly not the only thing you can use them for. As you’ll see later, their mini-language is also used in other string formatting techniques.
In addition to displaying the result of calculations, the precision part of a format specifier can also be applied directly to variables and the return values of function calls:
Python >>> def total_price(cost): ... return cost * 1.2 ... >>> cost_price = 1000 >>> tax = 0.2 >>> f"£{1000:,.2f} + £{cost_price * tax:,.2f} = £{total_price(cost_price):,.2f}" '£1,000.00 + £200.00 = £1,200.00' Copied!This time, you’ve used multiple replacement fields in the same string. The first one formats a literal number, the second formats the result of a calculation, while the third formats the return value from a function call. Also, by inserting a comma (,) before the decimal point (.) in the format specifier, you add a thousands separator to your final output.
In everyday use, you display numbers with a fixed amount of decimals, but when performing scientific or engineering calculations, you may prefer to format them using significant figures. Your results are then assumed to be accurate to the number of significant figures you display them with.
If you want to round numbers to significant figures, you use the lowercase letter g in the format specifier. You can also use an uppercase G, but this automatically switches the format to scientific notation for large numbers.
Suppose you have a circle with a radius of 10.203 meters. To work out the area, you could use this code:
Read the full article at https://realpython.com/how-to-python-f-string-format-float/ »[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
PyBites: OpenStreetMaps, Overpass API and Python
OpenStreetMaps (OSM) is known for being an open source project that allows people to browse the world map and to plan routes. However it is more than that. Among others it provides a read-only API that allows users to query for very diverse map data: Overpass API
Data structure of OSMTo understand the structure of the queries, we first need to understand how OSM saves its data. OSM uses basic data structures: node, way, and relation. Each element can have multiple tags, which consist of a key-value pair and they help specify the features of each element.
Nodes also save a latitude and longitude, indicating where the node is located on the world. Ways contain a list of the nodes contained in the way. Finally, relations are groups of nodes, ways and relations defining a logical relationship for this elements, for example being part of the same street, neighbourhood, city, postal code area, etc.
If we go to https://www.openstreetmap.org/, right-click on some point of the map and then click on Query Features, we get a list of the elements of the area. By clicking on one of them, we can explore it’s characteristics. As an example, we can explore the node 1918872432, which we can see on the left picture. Looking at the data we can see that it is located at longitude 52.5024783 and latitude 13.4155630. On the tags we can see it has the name Oranienplatz and among others it contains a bench and a bin. The key highway contains the value bus_stop, which tells us it is a bus stop.
If we explore the way 1228261444 (right picture) we can see a list of all the nodes it contains. In addition on the key highway we can see it’s of the type footway, telling us it’s a way intended for pedestrians. In addition we can see that it is a lit way.
Many keywords like highway are normalized. As an example, we can find a list of standardized values for highway here.
Overpass Queries Querying a single elementWe can query the previous information using Overpass QL. For the query to get the information about the way 1228261444 we use way(1228261444). The default output format is in xml, so if we want to have it in json, we need to add [out:json] in front of it. Other possible formats are csv, for which we need to define the list of columns for it to work. We mark the end of the query with an out, so the complete query is:
[out:json]; way(1228261444); out;To execute the query we need to run it against an instance, thus the complete URL looks like this:
https://overpass-api.de/api/interpreter?data=[out:json];way(1228261444);out;We can copy the URL directly on the browser, or we can use wget to see the result:
wget -O my_file_name.osm "https://overpass-api.de/api/interpreter?data=[out:json];way(1228261444);out;"To query a single node or relation works in a parallel way.
Output format { "version": 0.6, "generator": "Overpass API 0.7.61.5 4133829e", "osm3s": { "timestamp_osm_base": "2024-03-06T20:54:14Z", "copyright": "The data included in this document is from www.openstreetmap.org. The data is made available under ODbL." }, "elements": [ { "type": "way", "id": 1228261444, "nodes": [ 9010521154, 9010521155, 11390038869, 11390038870, 9394918823, 9394918824, 4613855449, 11390038871, 11390038872, 11390038873, 9394918822 ], "tags": { "footway": "sidewalk", "highway": "footway", "lit": "yes", "surface": "paving_stones" } } ] }Here we can see two main blocks: the first with metadata like the version or the timestamp, and the second one with a list of the elements found with the query. Even if we queried for one specific element of type way, we still get it as a set formatted as list with length 1.
Querying many elementsIf we don’t want the information of one singe way, but the information of all ways in an area, we need to change the query a little bit:
[out:json]; way(52.49505089381484,13.401961459729343,52.509912981033516,13.411502705004548); out;Here, instead of requesting one single way, we put 4 coordinates in the parenthesis: boundaries in the south, west, north and east.
This returns a set of all the ways contained in the bounding box defined by the given coordinates.
It is not always needed to know the coordinates to get information for an area. With the query
[out:json]; area[name="Zürich"]; out;we get all areas called Zürich. In this example we can see that we can use special characters without problem. Most interestingly are both square parentheses behind area [name=”Zürich”]. This is a filter where we only get the areas that contain a tag with key name and value Zürich.
We can use more than one filter, for example to get only the element representing the city Zürich, in contrast to the canton Zürich. In that case we can just place them one after another like this:
[out:json]; area[name=”Zürich”][place=”city”]; out;We can filter by elements containing a certain tag independently from it’s value.
[out:json]; area[name=”Zürich”][place]; out;This returns a set of all areas containing the tag place, which in this case contains the same element as above.
SubqueriesWe can use the area we got in the previous query to get a set of certain elements inside said area. For example, if we want to get all public toilets in Zürich, we can use the following query:
[out:json]; area[name="Zürich"][place="city"]; node[amenity="toilets"](area); out;First we get the area corresponding to the city Zürich, and then we get all nodes whose tag key amenity contains the value toilets. By passing the area between the round parenthesis we limit the set of nodes to the previous area.
The tag amenity describes a large number of important facilities from cafés, public bookcases, benches, vending machines, ATMs, etc.
Other useful tag names to find interesting places are tourism and historic.
TIL: there is also a value for public baking ovens, baking_oven. Apparently there are 2 of those which Zürich, which looks to me like a good reason to visit that city again. Seriously, how awesome is that?
Using overpass in PythonThere are two ways to execute overpass queries with python that we will explore. One possibility is using the library and the other the library overpass-api-python-wrapper.
RequestsExample:
import requests overpass_url = 'https://overpass-api.de/api/interpreter' overpass_query = ''' [out:json]; area[name="Zürich"][place="city"]; node[amenity="toilets"](area); out; ''' response = requests.get(overpass_url, params={'data': overpass_query})This way we send to the overpass interpreter the query in overpass_query and save the result in the variable response. If no error happened, response.text contains the data as string so we can decode it with:
decoded_data =json.loads(response.text)If we had requested the information in xml or csv format, we would decode it accordingly.
Overpass-api-python-wrapperThe overpass-api-python-wrapper allows us to execute queries in a more concise and elegant way. First we need to initialize an overpass object.
import overpass api = overpass.API(endpoint="https://overpass.myserver/interpreter", timeout=25)All parameters are optional and the default values are the ones shown here.
query = 'area[name="Zürich"][place="city"];node[amenity="toilets"](area);' response = api.get(query, responseformat='json')By default, response contains a dictionary representing the returned json object, however we can define the output format with the parameter responseformat. With this query, the response is
{ "features": [ { "geometry": { "coordinates": [ 8.534562, 47.350221 ], "type": "Point" }, "id": 75743585, "properties": { "amenity": "toilets", "capacity": "4", "check_date:wheelchair": "2022-06-06", "fee": "no", "name": "Landiwiese", "opening_hours": "24/7", "operator": "Z\u00fcriWC", "unisex": "yes", "wheelchair": "no" }, "type": "Feature" }, etc }If we use xml as format, response will be a string, and with csv it will be a list.
Other Useful tools:We can find a complete manual on Overpass QL here, where we can read about more awesome possibilities that Overpass has to offer to us.
You can also try out queries with overpass-turbo. However it will only display the returned nodes on the map, but you can also get the returned response as text in the tab Data.
Finally, you can find another cool tutorial for using overpass with python here. In this case, the author shows us new possibilities with overpass, including how to plot the queried data in plots.
I hope you could awake your curiosity about the potential that OpenStreetMaps and Overpass offers. For me in meant not only to learn about a powerful tool, but while exploring it and playing with it it allowed me to learn more about the possibilities our cities and towns have to offer to us. Did you know that there are public showers, including in some train stations? Or that there are public ovens?
What I finally have to say is: keep calm and keep building cool stuff!
Talking Drupal: Skills Upgrade #7
Welcome back to “Skills Upgrade” a Talking Drupal mini-series following the journey of a D7 developer learning D10. This is episode 7.
Topics-
Review Chad's goals for the previous week
- Test Example
- Set up phpunit.xml
- Start with FrontPageLinkTest.php
-
Review Chad's questions
- In the testing_example module, the file "src/Controller/TestingExampleController.php" has a function for simpletestDescription(). Is this an outdated artifact that should have been removed at some point? The module itself doesn't appear to use Simpletest elsewhere and appears to only rely on PHPUnit.
- What do you recommend for the minimal code structure to include for any given test type? Is the Testing Example module an ideal model or are there other resources I should review? The testing reference from Selwyn was helpful.
- In the "FrontPageLinkDependenciesTest.php" setUp() function, the createContentType() function is called without specifying the type. Is that set somewhere else? I may have overlooked it. Nevermind—it's set using randomMachineName() in the createContentType() function. Is there anything extra or standard to write in tests for drupal.org?
-
Tasks for the upcoming week
- Smart Date - Martin (maintainer) to review promptly, I've already chatted with him about it. Create a new functional test: "submit a range with an end time before the start and validate that an error is returned"
- Create an issue in the Smart Date queue and assign to yourself.
- Create an issue fork.
- Check out the issue fork locally.
- Write (and test) the test locally.
- Commit and push to the issue fork.
- Mark issue as "Needs review".
- Ask someone to review - if all looks good, the reviewer will mark as RBTC.
- Smart Date - Martin (maintainer) to review promptly, I've already chatted with him about it. Create a new functional test: "submit a range with an end time before the start and validate that an error is returned"
Chad's Drupal 10 Learning Curriclum & Journal Chad's Drupal 10 Learning Notes
The Linux Foundation is offering a discount of 30% off e-learning courses, certifications and bundles with the code, all uppercase DRUPAL24 and that is good until June 5th https://training.linuxfoundation.org/certification-catalog/
HostsAmyJune Hineline - @volkswagenchick
GuestsChad Hester - chadkhester.com @chadkhest Mike Anello - DrupalEasy.com @ultimike
The Drop Times: Mounting /Himalayas to /Enterprise Web: Gai Technologies' Ascetic Route
Dirk Eddelbuettel: RcppArmadillo 0.12.8.2.1 on CRAN: Micro Fix
Armadillo is a powerful and expressive C++ template library for linear algebra and scientific computing. It aims towards a good balance between speed and ease of use, has a syntax deliberately close to Matlab, and is useful for algorithm development directly in C++, or quick conversion of research code into production environments. RcppArmadillo integrates this library with the R environment and language–and is widely used by (currently) 1135 other packages on CRAN, downloaded 33.7 million times (per the partial logs from the cloud mirrors of CRAN), and the CSDA paper (preprint / vignette) by Conrad and myself has been cited 579 times according to Google Scholar.
Yesterday’s release accommodates reticulate by suspending a single test that now ‘croaks’ creating a reverse-dependency issue for that package. No other changes were made.
The set of changes since the last CRAN release follows.
Changes in RcppArmadillo version 0.12.8.2.1 (2024-04-15)- One-char bug fix release commenting out one test that upsets reticulate when accessing a scipy sparse matrix
Courtesy of my CRANberries, there is a diffstat report relative to previous release. More detailed information is on the RcppArmadillo page. Questions, comments etc should go to the rcpp-devel mailing list off the Rcpp R-Forge page.
If you like this or other open-source work I do, you can sponsor me at GitHub.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
Seth Michael Larson: Microsoft supports urllib3 with FOSS Fund 2024
Published 2024-04-17 by Seth Larson
Reading time: minutes
Back in January we announced that urllib3 would be fundraising to implement support for HTTP/2 in a backwards compatible way to urllib3 v2.x and to ensure the project's development remains sustainable in the long-term.
Microsoft has awarded urllib3 $5,000 USD as one of its FOSS Fund recipients for 2024 🥳 Thank you, Microsoft for supporting open source software!
Since announcing our fundraiser we have raised $7,275 USD in 3 months, many of the donations coming from individuals and long-time sponsors like Sourcegraph and Sentry.
Thanks Microsoft! ❤️ How to get started supporting your own dependencies?Contribute directly to projects you depend on. Many of them already have funding mechanisms documented like Open Collective, GitHub Sponsors, or similar.
Subscribe to an organization like Tidelift to handle discovery of dependencies and fundable projects and to get additional guarantees like security and long-term support.
Thanks.dev provides a lightweight option to throw money in open sources' direction.
Thanks for reading! ♡ Did you find this article helpful and want more content like it?
Get notified of new posts by subscribing to the RSS feed or the email newsletter.
This work is licensed under CC BY-SA 4.0
Python Engineering at Microsoft: Glow up! A new look for Python Reference documentation on Microsoft Learn
Today, we’re excited to announce a new, improved experience for Python library reference documentation on Microsoft Learn, formerly Microsoft Docs. The new experience is now available for all Microsoft Python libraries on Learn, such as the Azure SDK for Python. In this blog post, we take a closer look at the specific changes made and how they improve the overall experience and accessibility of Python reference documentation on Learn.
Change SummaryThe key changes made to Python reference documentation on Learn were improving the navigation experience with the table of contents (TOC), the organization of in-page content, and in-page navigation via the right rail. When combined, these three key changes greatly improve the experience of finding information in Python reference on Learn.
Table of Contents (TOC)If you’ve used reference documentation before, you’ll know that the TOC serves as a uniquely pivotal tool for navigation between pages. Reference documentation, unlike conceptual articles and tutorials, rarely links together in an easy-to-follow way. This means that the TOC is often the only way for cross-page navigation in reference documentation, making it a key priority for us to get right.
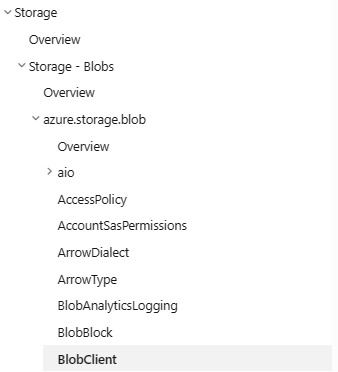
TOC – BeforePreviously, the table of contents for Python Reference documentation on Learn had a redundant layer of navigation for package names (in the screenshot below, the azure-storage-blob node), which added confusion for users looking to navigate deeper into the documentation. In addition, the table of contents had package prefixes attached to every item. This led to a cluttered experience, with some items in the TOC taking up two lines of space, further impacting readability and accessibility.
{kind=link}
TOC – After
The new TOC design removes the package name overview page and trims the package prefix from TOC items, making it easier to scan and navigate. If you’ve bookmarked a package name overview page, don’t worry, as you’ll be redirected to the package overview page automatically.
{kind=link}
In-Page Right Rail
The in-page right rail is a key part of reference documentation, allowing you to navigate in-page and quickly jump to different sections.
In-Page Right Rail – BeforeBefore, the right rail wasn’t “sticky”, meaning that once users scrolled on the page, the rail wouldn’t follow them, and the entire right side of the screen would be unused space. Additionally, the right rail links only covered H2 content on the page, resulting in a right rail that didn’t clarify any major details on the page. Finally, the right rail would be collapsed beyond four items, leading to extra effort from the user to see all of the H2 sections on the page. We recognize this design wasn’t consistent with the ways that other Python libraries design their documentation and made updates to better align with design patterns and expectations.
In-Page Right Rail – After
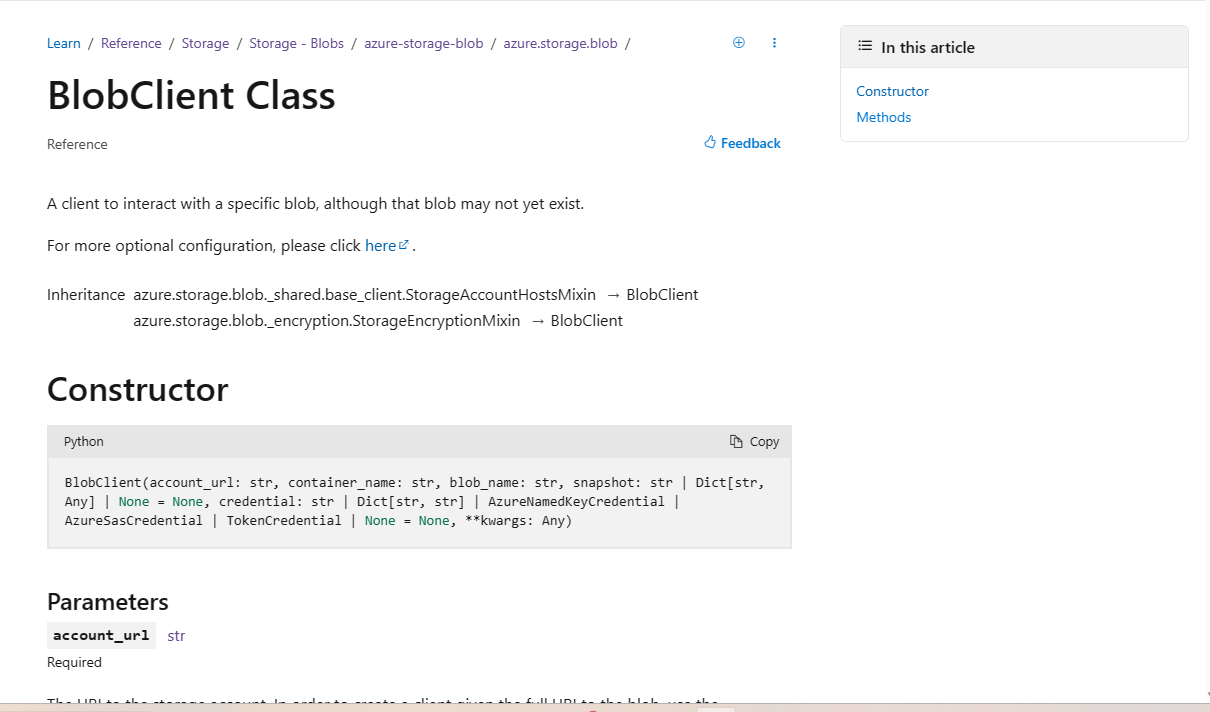{kind=link}
The enhanced experience adds an individually scrollable, sticky right rail with details down to H3s, giving much more detail into what content the page has. The right rail additionally has active highlighting for the current item on the screen, making it easier for you to understand your current position relative to other content.
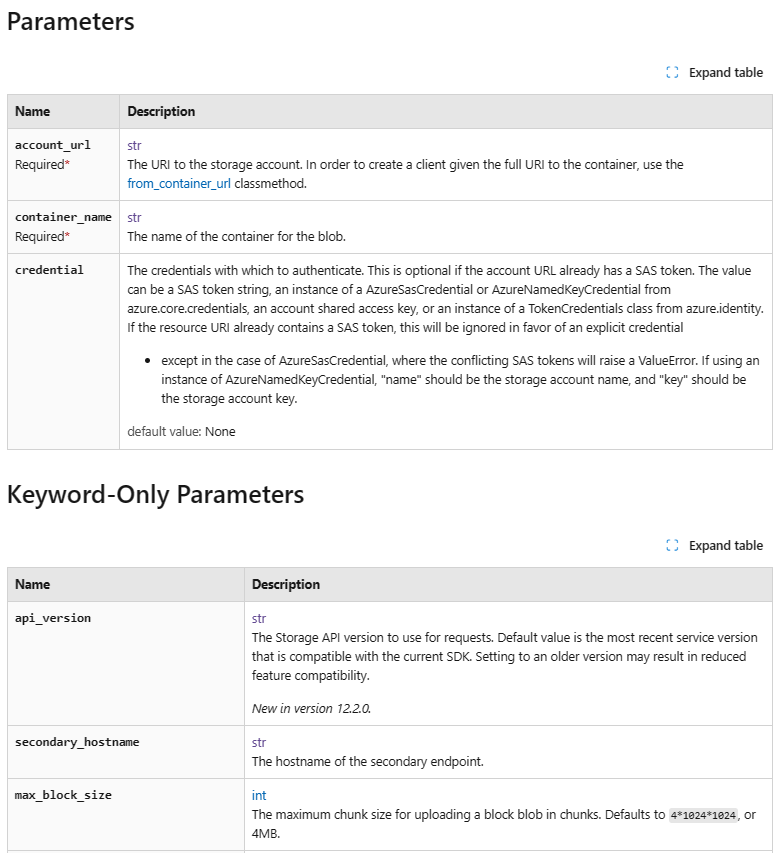
Parameter, Return, and Exception Organization{kind=link}
While the first two major feature changes focus on both overall and in-page navigation, we also identified an opportunity to improve in-page organization as well. When you’re looking at our reference documentation, being able to easily identify key information such as parameters, return values, and exceptions is crucial.
In-Page Organization – BeforeBefore the updates, these details were listed but not clearly separated between classes, leading to a confusing experience where it’s not clear where items started or ended. Additionally, as a result of the formatting of these values, a significant amount of vertical space was used, leading to a lot of scrolling to find the information needed. Lastly, required parameters, default values, and keyword-only parameters weren’t clearly highlighted to follow accessibility best practices, resulting in extra effort to find crucial information.
In-Page Organization – After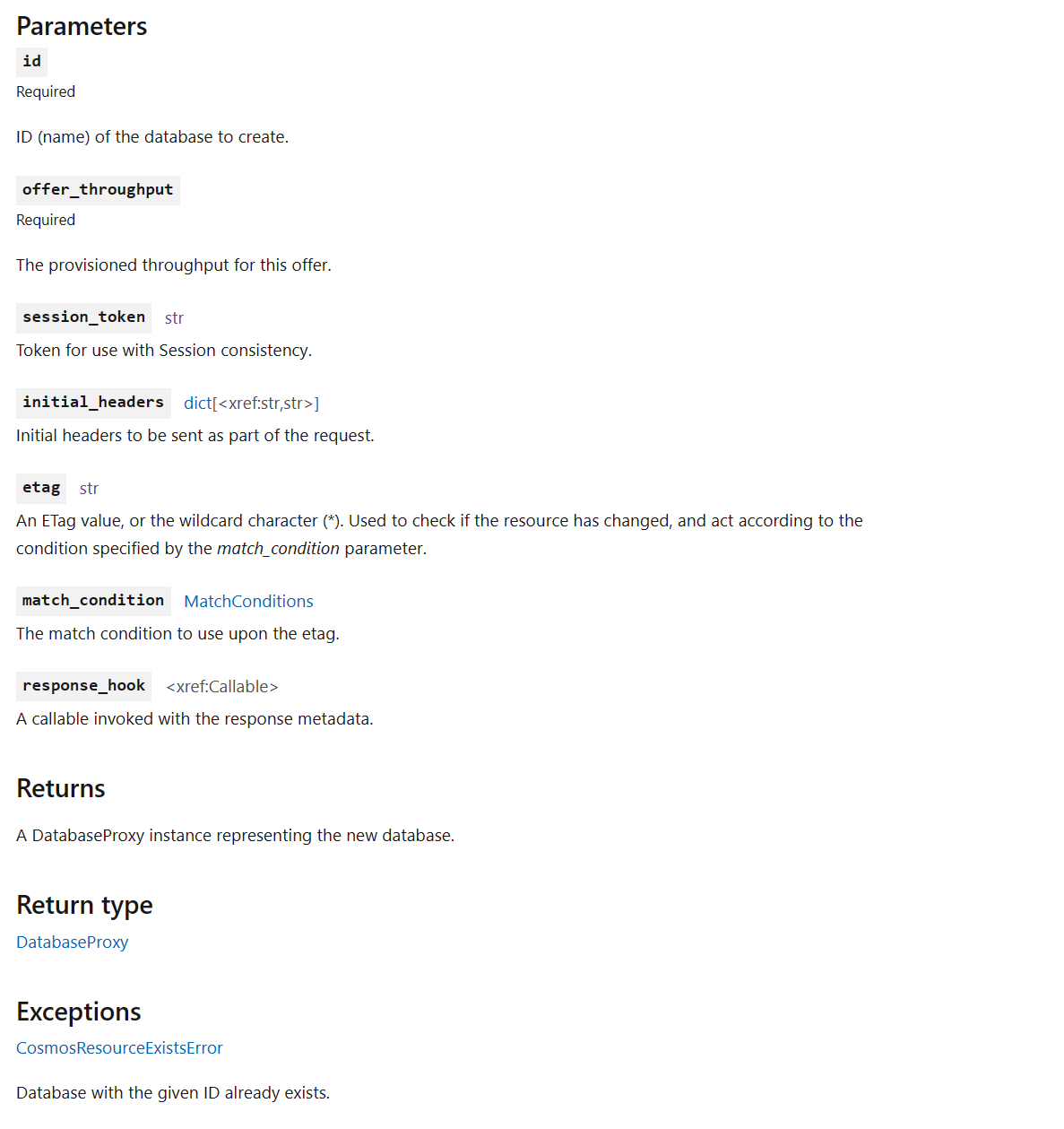{kind=link}
The new experience organizes parameters, return values, and exceptions into easy-to-scan tables. By using tables, default values, required tags, and types are clearly indicated. The end result is a cleaner and easier-to-use experience for all developers when scrolling through our documentation.
Conclusion
{kind=link}
In short, the new Python reference documentation experience on Learn is a major improvement for any developer using Microsoft’s Python libraries. The new TOC, in-page right rail, and in-page organization changes make finding information easier, with an added visual upgrade. We’re excited to continue optimizing the Python developer experience across all of our libraries and tools.
We hope you enjoy the changes! If you have any thoughts, you can leave feedback in the Azure SDK for Python GitHub repo.
The post Glow up! A new look for Python Reference documentation on Microsoft Learn appeared first on Python.
Pages
Recent Publications
- Managing Hidden Dependencies in OO Software: a Study Based on Open Source Projects
- Open Source Communities as Liminal Ecosystems
- Investigating developers' email discussions during decision-making in Python language evolution
- Developers, Quality Control and Download Volume in Open Source Software (OSS) Projects
FLOSS Project Planets
- Python Morsels: Multiline comments in Python
- The Drop Times: DrupalTO Meetup: Glimpses from the Event—Strategies for a Seamless Transition to Drupal 10
- Golems GABB: Boosting Productivity in Drupal with Composer 2
- Real Python: The Real Python Podcast – Episode #201: Decoupling Systems to Get Closer to the Data
- LN Webworks: Drupal Configuration Synchronization: A Simplified Guide
FLOSS Research
- Open Source AI Definition – Weekly update April 15
- Submit your proposal for All Things Open – Doing Business with Open Source
- Compelling responses to NTIA’s AI Open Model Weights RFC
- Open Source AI Definition – Weekly update April 8
- OSI participates in Columbia Convening on openness and AI; first readouts available